
Abstract
We propose PoCL-R, a novel computing runtime that makes remote compute devices available to the client via the cross-vendor heterogeneous Open Computing Language (OpenCL) API standard. For robustness in mobile use cases, intermittent connection loss is handled gracefully even if the device’s IP address changes on the way. A major benefit in comparison to the previous state-of-the-art OpenCL distribution layers is that PoCL-R minimizes network-induced latency by transferring data and signaling command completions between remote devices in a peer-to-peer fashion, outperforming the state-of-the-art baseline by a factor of up to 50x in synthetic benchmarks. PoCL-R’s streamlined TCP-based protocol has a command latency of only 60 microseconds on top of network round-trip latency in synthetic benchmarks. The application of PoCL-R to porting of compute-heavy applications to mobile devices is demonstrated with a smartphone-based Augmented Reality (AR) rendering case study where we measure up to 19x improvements to frame rate and 17x improvements to local energy consumption when using the proposed runtime to remote-offload a part of the AR rendering workload. Scalability across multiple GPU server nodes in real-world applications is shown using a computational fluid dynamics simulation, which scales with the number of servers at roughly 80% efficiency which is comparable to a Message-Passing Interface (MPI) port of the same simulation, but with the benefit of not needing a separate API for cross-server distribution.
1. Introduction
Developing HPC applications poses a number of unique challenges that are not typically problems in software development workflows. Adhianto et al. point out problems specifically with getting application code distributed to compute nodes at scale, especially in heterogeneous environments with hardware from multiple vendors. Adhianto et al. (2024) Distributing files via networked storage is commonplace, but in the case of application binaries it quickly becomes brittle if all involved machines aren’t identical. Hardware from different vendors is usually incompatible with each other and requires completely different code paths and runtime environments. As a result it is often necessary to recompile the whole application for each configuration in the cluster. Communication between cluster nodes and partitioning work between nodes and compute accelerators usually requires manual work on the application side and makes applications very awkward to debug.
To address these problems we propose PoCL-R, a computing runtime that acts as a scalable low-latency hardware abstraction layer for distributed heterogeneous compute devices and aims to answer these unique challenges. As another feature, our solution also allows scaling down the device that runs the main control logic of the application to the level of a mid-range smartphone.
The key benefit of PoCL-R for heterogeneous offloading is its API which is solely based on the Open Computing Language (OpenCL) Khronos OpenCL Working Group, (2020). Since OpenCL is an open cross-vendor adopted heterogeneous computing standard, it helps accelerator code portability across various local and remote devices. PoCL-R is targeted for use by application developers directly or as a backend for a number of higher-level APIs like SYCL Khronos SYCL Working Group, (2020) or CUDA/HIP CHIP-SPV (2022). Compared to traditional solutions to multi-node computation, PoCL-R simplifies the development process by unifying single-node multi-device and multi-node code paths. Thanks to the vendor agnostic nature of OpenCL kernels and the server process not needing any application-specific knowledge, PoCL-R sidesteps this problem - albeit at the cost of requiring a compilation step in the compute accelerator driver on each node.
In comparison to prior work, the runtime has the following novel features: • Transparent utilization of multiple compute nodes with peer-to-peer (P2P) communication and synchronization between compute nodes for improved scalability. To application developers multi-node code becomes identical to single-node multi-device code. • Capability to support applications with both high performance and low latency demands. • Graceful handling of connection loss and restoration on unreliable networks and while roaming. • A minimal (optional) OpenCL API extension that can improve transfer times of dynamic-size buffers dramatically. This is particularly useful for taking advantage of buffers with variable length compressed data. • It is the first distributed OpenCL runtime that is integrated to a long-maintained widely used open source OpenCL implementation framework PoCL Jääskeläinen et al. (2015) available in https://code.portablecl.org/ and thus will be usable and extensible for anyone freely in the future.
This article is an extension of a conference publication where we presented an early version of PoCL-R Solanti et al. (2022). For this article, we extended the runtime to better solve the challenges posed by multi-node use cases while simultaneously enabling downsizing of the device in charge of the main thread of execution down to a mid-range smartphone. Of the various optimizations and enhancements the most important ones were the Remote Direct Memory Access (RDMA) support for server-side buffer migrations which bring up to 5x speedups compared to simple TCP socket communication and graceful handling for connection loss between the client device and compute server to account for roaming and unreliable wireless networks. The evaluation continues with a multi-server performance scaling case study that runs the Computational Fluid Dynamics (CFD) simulation FluidX3D Lehmann (2022) on multiple GPU server nodes, which demonstrates that PoCL-R works well for distributing unmodified High Performance Computing (HPC) applications that are written to use multiple GPU devices. Finally, we added extra synthetic and real-world benchmarks highlighting the importance of peer-to-peer (P2P) communication support when scaling to multi-node systems.
This article is organized as follows. Section 2 briefly introduces OpenCL and outlines the key API concepts that are relavant to this work. Section 3 provides an overview of the previous options for offloading at the compute API level. Section 4 describes the PoCL-R software architecture on a high level. Section 5 covers the most relevant techniques in the proposed runtime to achieve the low latency while retaining server-side scalability. Section 6 lays out the synthetic latency and throughput benchmark results, and Section 7 demonstrates real-world performance with two case studies. Finally, Section 8 concludes the article and outlines future research plans.
2. Background
2.1. Open Computing Language
OpenCL is an open cross-vendor standard for heterogeneous compute Khronos OpenCL Working Group (2020). Thanks to being officially supported by multiple hardware vendors, OpenCL is a convenient option for applications and libraries that require massively parallel computation while also wanting to remain portable.
OpenCL divides the application logic to two parts: The host program running in the host processor and compute “kernels” running on the accelerator. Kernels can be specified in a target-specific binary representation or using a target-independent intermediate representation (SPIR-V Kessenich et al. (2023)). There is also an option to invoke so called “built-in kernels” which can be used to abstract fixed hardware functions.
The OpenCL memory model states that memory buffers created in a single OpenCL context are transparently available on all devices that are part of the same context. Applications are reponsible for declaring data dependencies between the commands they issue, either with explicit event dependencies or implicitly by submitting them to an in-order command queue. In return, the OpenCL runtime is responsible for migrating buffer contents from device to device behind the scenes to guarantee that all dependency writes have become visible before dependent commands run. PoCL — which PoCL-R is building on — does this by injecting migration commands before commands that try to access a buffer on a different device than it was previously written to. Migrations always copy the entire buffer.
A command queue is associated with a single device. The decision of how work is partitioned across devices and which buffers are resident on which devices (implicitly based on accesses) is left to the application.
OpenCL was originally intended to be utilized for driving local single node computation and compute distribution is typically delegated to other APIs, such as a Message Passing Interface (MPI). Being able to utilize a single compute API greatly simplifies the client application logic, since local and remote execution can be done with identical API calls. The capability of OpenCL to describe both the host and the accelerator program in a single software description helps in the goal of having all the program logic in the client side.
3. Previous work
Offloading and distributing heterogeneous compute workloads has been attempted in the past by multiple projects Liang and Lin (2013); Xiao et al. (2012); Reynolds et al. (2011); Kegel et al. (2012) but they have not been maintained or their implementations are no longer available for comparison nor for further development. A great number of these projects Alves et al. (2012); Barak and Shiloh (2011); Diop et al. (2013); Kegel et al. (2012) mainly focus on HPC clusters and the existing ecosystems and libraries. Their focus is primarily on throughput, and latency is frequently ignored. Our proposed runtime can harness high performance compute clusters in a scalable manner while also supporting low latency requirements posed by real-time applications. Furthermore, none of the previous works have considered the use case of wireless mobile clients where intermittent connection loss is expected, making PoCL-R is the first to explicitly address this.
Out of the related projects we found, the one closest to PoCL-R is SnuCL Kim et al. (2012). Like PoCL-R, it implements the OpenCL standard API and provides facilities for offloading OpenCL commands to remote servers. However, like most pre-existing projects, SnuCL primarily targets HPC clusters and is mainly concerned with throughput. Instead of plain sockets, it uses the MPI framework to handle communication. Some peer-to-peer data transfer functionality exists in SnuCL as well, but the authors report that it has problems with scaling in some tasks, such as a matrix multiplication benchmark that is similar to the one used in this paper. By contrast, PoCL-R uses plain TCP sockets with their parameters tuned to reduce latency. The wire representation of commands is kept identical to the in-memory one to avoid a translation step. PoCL-R also performs command scheduling independently on the remote servers to the extent possible, whereas SnuCL relies on the client application for this.
There is also a continuation of the SnuCL work, named SNUCL-D Kim et al. (2016), which duplicates the control flow of the entire client application to each remote server. This should improve scalability, but adds a requirement for the host application to be fully replicable on all remote servers, which can involve additional host program development work and is obviously not always feasible e.g., with graphical applications targeting mobile devices or if the application accesses local file system resources. PoCL-R enables performant offloading capabilities to any OpenCL application with no code changes.
In terms of the general concept, rCUDA Peña et al. (2014) was very similar to PoCL-R. It also supported RDMA via GPUDirect. Silla et al. (2017) Unfortunately the rCUDA project had been retired by the time of writing this article and the files are no longer available, which precludes any benchmark comparisons. As the most notable difference PoCL-R has the benefit of being portable across a variety of vendors whereas rCUDA was limited to hardware supporting the proprietary CUDA API, and even there constrained by the CUDA SDK EULA.
RemoteCL is another OpenCL-based project with a similar approach to PoCL-R in that it uses plain TCP sockets for communication. The author of RemoteCL is however not interested in generalizing the library for full OpenCL standard conformance as stated in the project’s README fileFerreira (2023). RemoteCL also seems to be limited to using one remote server at a time, whereas PoCL-R can use multiple.
The newest similar work is rOpenCL Alves and Rufino (2020). Its design is rather similar to PoCL-R, but as a crucial difference it does not support migrating buffers between servers, requiring applications to download buffers manually from the source device and upload them to the destination device. In practice a lot of applications either do not support simultaneous use of multiple compute devices at all, or perform migrations manually via host memory for implementation convenience or in order to use separate OpenCL platforms simultaneously. PoCL-R exposes remote devices within a single OpenCL platform and performs buffer migrations transparently, as if all the devices were on the same machine. The same OpenCL platform can also contain a variety of local devices backed by other driver modules of PoCL if these are configured in the user environment. PoCL-R also optimizes buffer migrations and event completion notifications between servers by performing them in a P2P fashion rather than circulating them through the client connection. If the server supports RDMA, PoCL-R can use that to further speed up server-to-server (S2S) migrations.
4. PoCL-remote architecture
PoCL-R is inspired in great part by mobile applications that offload parts of their computational workload across a low-latency wireless link to one or more clusters comprised of a variety of compute accelerators such as GPUs and FPGAs. This kind of low power device with a wireless connection to a powerful compute cluster is the main reference scenario for the design of PoCL-R. This turns out to also be a convenient model for streamlining application development, as developer machines themselves do not necessarily need several heavy duty compute accelerators in order to debug multi-device compute workloads.
4.1. Client-server organization
At the high level, the PoCL-R runtime is built on a client-server architecture, as is common for networked applications. The client side of the runtime is implemented as a remote driver in the Portable Computing Language (PoCL) Jääskeläinen et al. (2015). PoCL is an open-source implementation of the OpenCL API and has a lot of flexibility for implementing custom backends for diverse hardware and underlying software stacks. The remote driver exposes the compute devices on a given compute server through the OpenCL platform API, making them appear identically to local devices. Figure 1 shows the relations of the various frameworks and drivers on both the client device and compute servers. Overview of the software stack for an application using PoCL-R. The OpenCL API can be used directly for maximum efficiency, but also as a middleware for improved productivity APIs on top of it. PoCL is an OpenCL API implementation, a drop-in alternative to the other OpenCL implementations, with the special remote driver interfacing to the remote OpenCL-supported devices with distributed communication.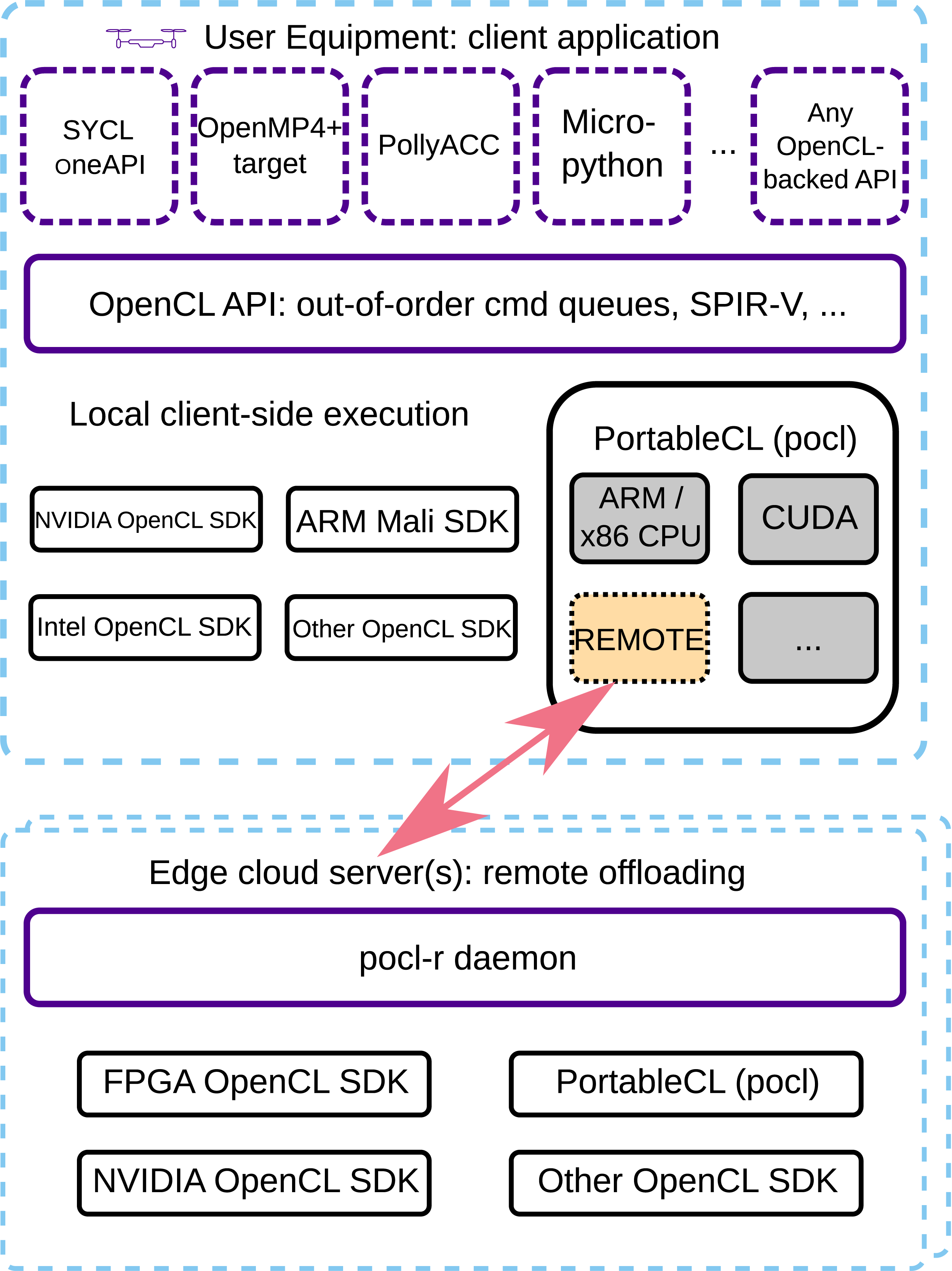
The host application using the OpenCL API can use PoCL-R as a drop-in implementation without recompilation. When using PoCL-R, the OpenCL calls are made to the PoCL-R client driver library, which in turn connects to one or multiple remote servers, each providing one or more remote compute devices. The remote servers can form interconnected clusters visible and controlled by PoCL-R as peers to avoid round-trips back to the client whenever synchronization or data transfers are needed between the remote devices.
The server side is a daemon, called pocld, that runs on the remote servers and receives commands from the client driver, and dispatches them to the OpenCL driver of the server’s devices accompanied by proper event dependencies. The OpenCL devices can be controlled via a device-specific proprietary OpenCL driver by the daemon, or through, e.g., the open source drivers provided by PoCL. Traffic encryption and authentication of new clients are currently not handled as they are outside of the scope of this research. However, in order to safely provide compute services involving potentially confidential data on the open internet, addressing this is a hard requirement. Multiple clients can connect simultaneously and they are all assigned their own command queues which get scheduled in parallel by the server’s OpenCL runtime. Expanding this to a more sophisticated Quality-of-Service (QoS) multi-client scheduling scheme to guarantee fairness when accelerators are shared between several concurrent users is a possible topic of future research.
The daemon is structured around network sockets for the client and peer connections. Each socket has a reader thread and a writer thread. The readers do blocking reads on the socket until they manage to read a new command, which they then dispatch to the underlying OpenCL runtime, store its associated OpenCL event in a queue and signal the corresponding writer thread. The server writer thread iterates through events in the queue and when it finds one that the underlying OpenCL runtime reports as complete, writes its result to the socket representing the host connection. Peer writers have separate queues, but are otherwise similar to the server writer. The server writer adds events that peers need to be notified of to these queues and signals the peer writers. Figure 2 illustrates this architecture and the flow of commands through it. Distributed command scheduling between servers: 1. The client sends command V (iolet) to Server A. 2. The client sends command T (eal) with a dependency on command V to Server B. Due to the unfulfilled dependency, Server B buffers the command instead of immediately executing it. 3. Server A executes command V. 4. Server A signals completion of command V to client. 5. Server A signals completion of command V to Server B. 6. With the dependency satisfied, Server B now executes command T. 7. Server B signals completion of command T.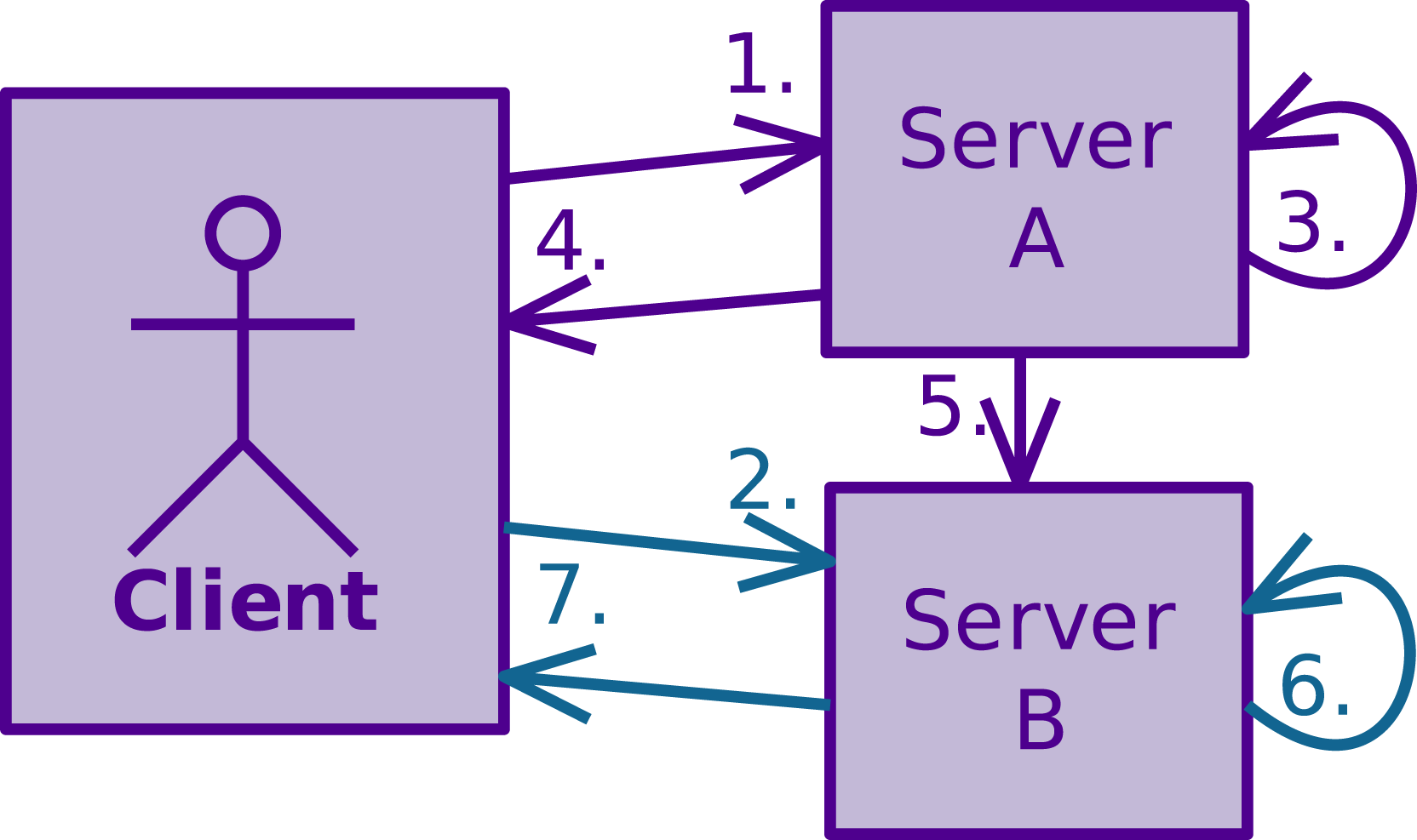
4.2. Handling connection loss
Wireless connections are prone to interference and limited in range, making it necessary to gracefully handle intermittent loss of connection. Handling this well requires designing the networking logic around the assumption that the connection can be lost at any point, even mid-command.
When PoCL-R detects that the connection to a remote server is lost, it marks all OpenCL devices associated with that server as unavailable yielding a ”device unavailable” error status from all OpenCL calls that attempt to access such a device after this point. It then attempts to reconnect to the server and once successful, marks the devices as available again and resumes command submissions for that server.
In the event of a sudden connection loss, it is possible that some commands are partially sent and can’t be processed by the server. PoCL-R will attempt to re-send such interrupted commands once a connection is established again. Commands are identified by a running number and the server ignores commands it has already processed. Higher software layers can make use of the device availability information and manually fall back to performing computations locally, as illustrated in Figure 3. Depending on the application it can make sense to wait for PoCL-R to reconnect and resume transparently or to have it mark unfinished commands as failed. Per the OpenCL specification, failures cascade to all dependents of the relevant command, meaning the application has to resubmit the commands either to the same device (once it is reconnected) or to a different one. Reconnecting with fallback to local computation. Applications can be designed to primarily use remote devices for computation in order to leverage the latest and most accurate algorithms. When connectivity to the remote compute servers is lost due to network conditions or the client device moving out of the wireless access point’s range, applications can fall back to a simpler, less accurate model that is feasible to compute on the mobile SoC. Once remote servers are reachable again, the application can switch back to the full accuracy computations.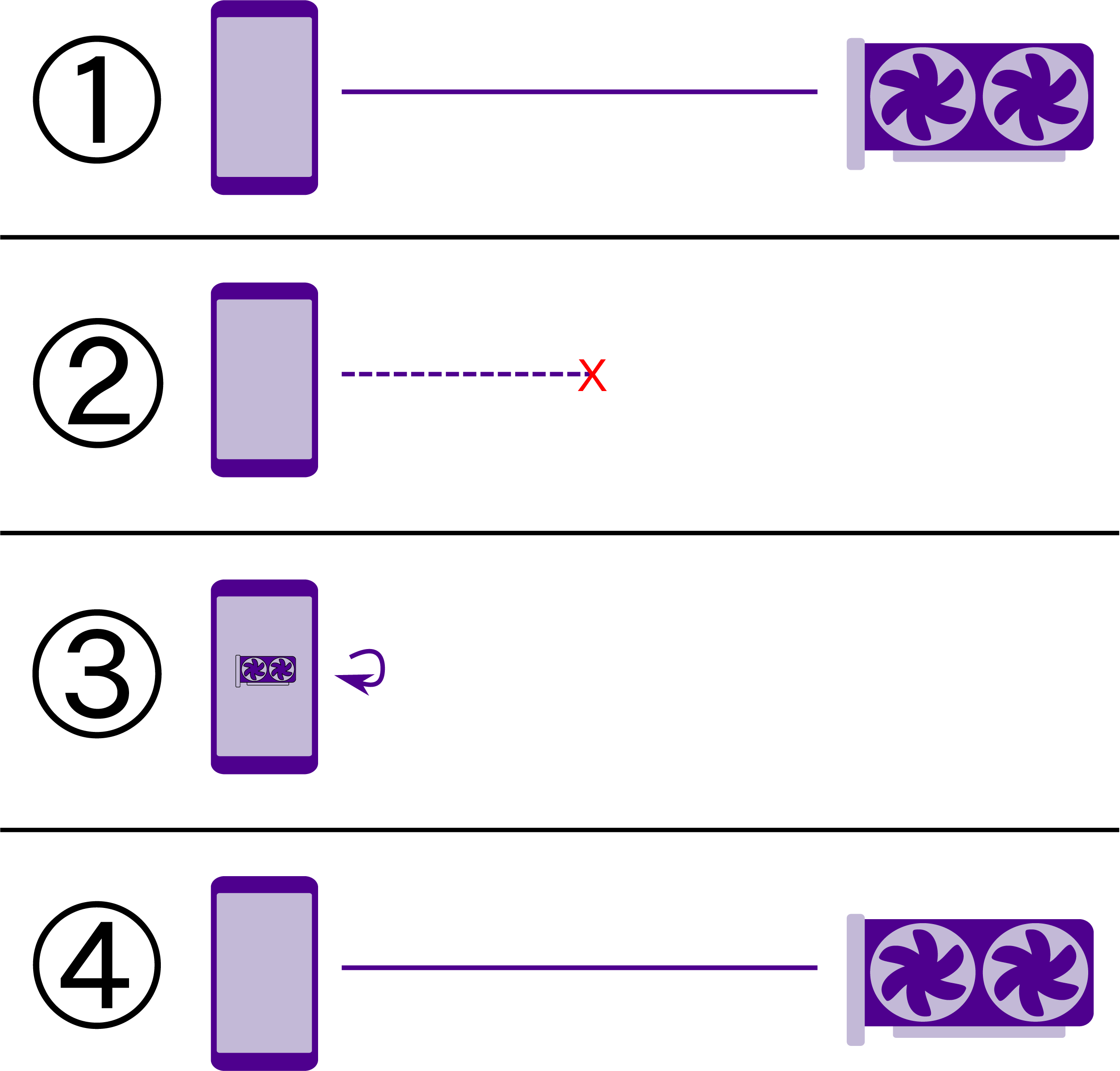
In order to facilitate reliable reconnecting without having to retransmit unchanged data, a 16-byte session ID is introduced. When a client initially connects to a server, it sends a handshake packet containing an all-zeroes session ID. The server generates a random ID and sends it as part of its handshake reply. When reconnecting, the client instead sends the ID it originally received from the server it is reconnecting to. The server keeps track of IDs it has handed out and uses them to attach incoming connections to the correct contexts. Servers retain the latest known state of all buffers and OpenCL programs when a client disconnects (unless configured to disallow reconnecting).
One notable shortcoming of the current implementation is that buffer migrations require the source server to be accessible to the client at the time of migration. If the client loses connectivity to a server and decides to switch, buffers can be migrated once connectivity is restored. However if the connection problems are persistent, migrations involving the lost server can not be done.
5. Latency and scalability optimizations
The following subsections describe the latency and scalability enhancing techniques applied in PoCL-R.
5.1. Peer-to-peer communication
Rather than routing all buffer transfers through the client device, PoCL-R supports a number of shorter paths when available, as illustrated in Figure 4. Devices on the same server typically support migrating OpenCL buffers directly between them, which pocld, the PoCL-R server daemon will make use of. Data center environments frequently have high-speed interconnects in the form of internal InfiniBand and Ethernet networks, reaching speeds in the order of hundreds of gigabits per second between servers, sometimes via separate interfaces than the one that connects them to the public internet. PoCL-R can make use of these connections by transferring buffers and signaling command completions directly between servers in a peer-to-peer (P2P) fashion. These P2P inter-server communication is referred to as S2S throughout this paper. If the fast inter-cluster communication channel uses a different interface than the public one, this is also possible to specify in the server configuration. This should alleviate the congestion on the often much slower public connection that is likely shared with all other external traffic and lead to overall better performance. Different paths for buffer transfers supported in PoCL-R: P2P network transfers between remote servers in red, direct transfers between devices within a server in yellow. Black arrows denote transfers between the client device and the remote servers.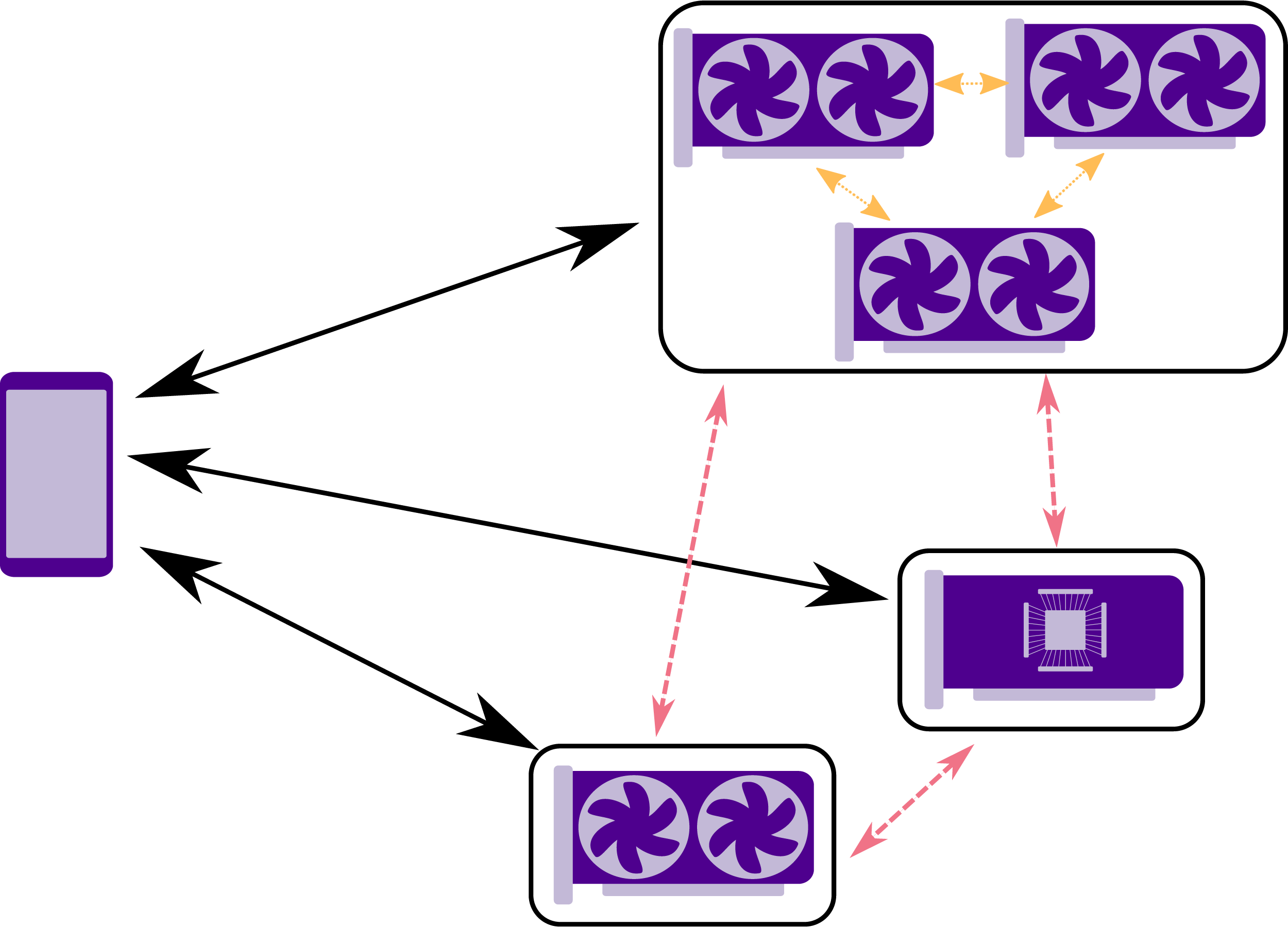
On the other hand, there is heavy demand to run applications on mobile devices, which are limited to wireless connections with limited bandwidth and a nontrivial amount of network congestion or other inference. As a result, network roundtrips to and from the client device ought to be considered relatively expensive and client bandwidth should be used sparingly. To this end, PoCL-R only sends a request to the source server when migrating buffers between servers. The source server then pushes the data directly to the destination, and only the destination server notifies the client of the migration’s completion. Compared to the naive solution of downloading the buffer from the source to the client and then uploading it to the destination, this completely eliminates transferring the contents of the potentially very large buffer across the slowest link in the system. One command roundtrip from the client and the wait for a reply from the server is also eliminated.
5.2. Decentralized command scheduling
When the client application makes an OpenCL API call, the respective command is pushed to the compute server immediately. If the command has a data dependency to prior commands, this is communicated by the application with OpenCL events. The runtime maps the events of the client application to local events of the native context in the remote daemon. Events of commands that are executed on a different server or on the client are mapped to OpenCL user events instead. This way, the task graph defined by the application-specified event dependencies stays intact and can be relied on to perform run time optimizations using the dependency rules presented in Jääskeläinen et al. (2019).
Besides the two connections each server has to the client, servers are directly connected to each other, forming a mesh of peers. These peer-to-peer connections are used for buffer migrations. Additionally, the completion of commands is reported to other servers using these direct connections, as to avoid an unnecessary client roundtrip. Figure 2 illustrates the flow of information and control for a command requiring buffer migration and one that does not require migration but sends a completion notification to the other servers: The client sends a command to the server that has the most up-to-date contents of the needed buffer. This server then directly pushes the buffer to the target server, which in turn sends a command completion to the client and the other servers. If no migration is needed the client simply sends the command to the target server, which replies to the client and notifies other servers once the command has finished. Any server that has received a command depending on a command executing on a different server can begin executing such blocked commands immediately when it receives completion notifications for each command being depended on.
5.3. Dynamic buffer content size extension
Device memory in OpenCL contexts is managed in the form of buffers whose size is fixed at creation time. Applications may however work with very varying amounts of data, especially when varying rate compression is involved. In such cases, the buffers allocated need to be sized conservatively, or the application needs to be able to split work into multiple chunks in order to fit a small buffer size. The latter is not necessarily very practical, and as a result a lot of memory can get wasted in preparation for a worst-case scenario. If buffers need to be migrated between devices, this further translates to wasted bandwidth. Network transfers are often orders of magnitude slower than interconnects within a single machine, which greatly emphasizes the overhead of transferring unneeded data.
As a performance improvement for transferring dynamic data sizes, we propose an OpenCL extension named cl_pocl_content_size. This extension allows applications to convey to the OpenCL runtime how much of any given buffer is actually used for meaningful data that has to be copied when migrating the buffer. This is done by designating a separate buffer holding exactly one unsigned integer as a “content size buffer”. The PoCL-R runtime reads this content size buffer and only sends the necessary parts of buffers across the wire when migrating buffers between remotes.
The extension does not alter the way the runtime behaves when an application does not specify a content size buffer. The extension is discussed more thoroughly in Solanti et al. (2022) and its implementation has been integrated to the PoCL open source repository.
5.4. RDMA-based server-side buffer transfers
PoCL-R can use RDMA to reduce the overhead of buffer migrations between server nodes compared to the original peer-to-peer communication via plain TCP streams.
RDMA is an API with associated networking protocols intended for transferring the contents of memory buffers across a network without CPU involvement and without making extra copies of the data to be sent. In stark contrast to the raw stream of bytes that a TCP socket offers, the RDMA API is designed around the concept of discrete messages managed via InfiniBand verbs. Recio et al. (2007); Shah et al. (2007)
The TCP stream communication scheme relies on a union of C structs defining the different commands that can be sent. The in-memory layout is kept consistent by attribute annotations forcing specific packing and alignment rules. However, the command structs vary in size from tens of bytes to multiple kilobytes and unions are always sized based on their largest field, which means every command would take up multiple kilobytes. In memory this is not a big problem, but it becomes a noticeable overhead when transferring commands over the TCP socket.
In order to avoid sending meaningless data alongside commands, the basic communication scheme first sends a standalone size field indicating the size of the specific command being sent, followed by that many bytes of the command union. The unused bytes of the union are left in an undefined state. For commands that require additional data such as buffer contents or OpenCL program build logs, the sizes of these are contained in the command struct and the buffers themselves are sent immediately after the struct.
Having a separate command size at the start of each command means that for each command there will be a minimum of two write calls to the TCP socket, and a minimum of three write calls for a buffer transfer command. When transferring large additional buffers, the socket API sometimes requires splitting the writes up into multiple smaller ones, further increasing the number of system calls (Figure 5). Control flow of transferring a buffer between servers via TCP sockets. Commands are prefixed with a size field in order to avoid wasting bandwidth, as the size of command metadata varies a lot. For commands that require additional data, e.g., buffer contents, the size of this data is part of the command metadata and the data itself is simply written as-is immediately after the command metadata. If any of these parts is larger than the socket’s internal buffer, it has to be split into multiple writes/reads, which translates to multiple system calls.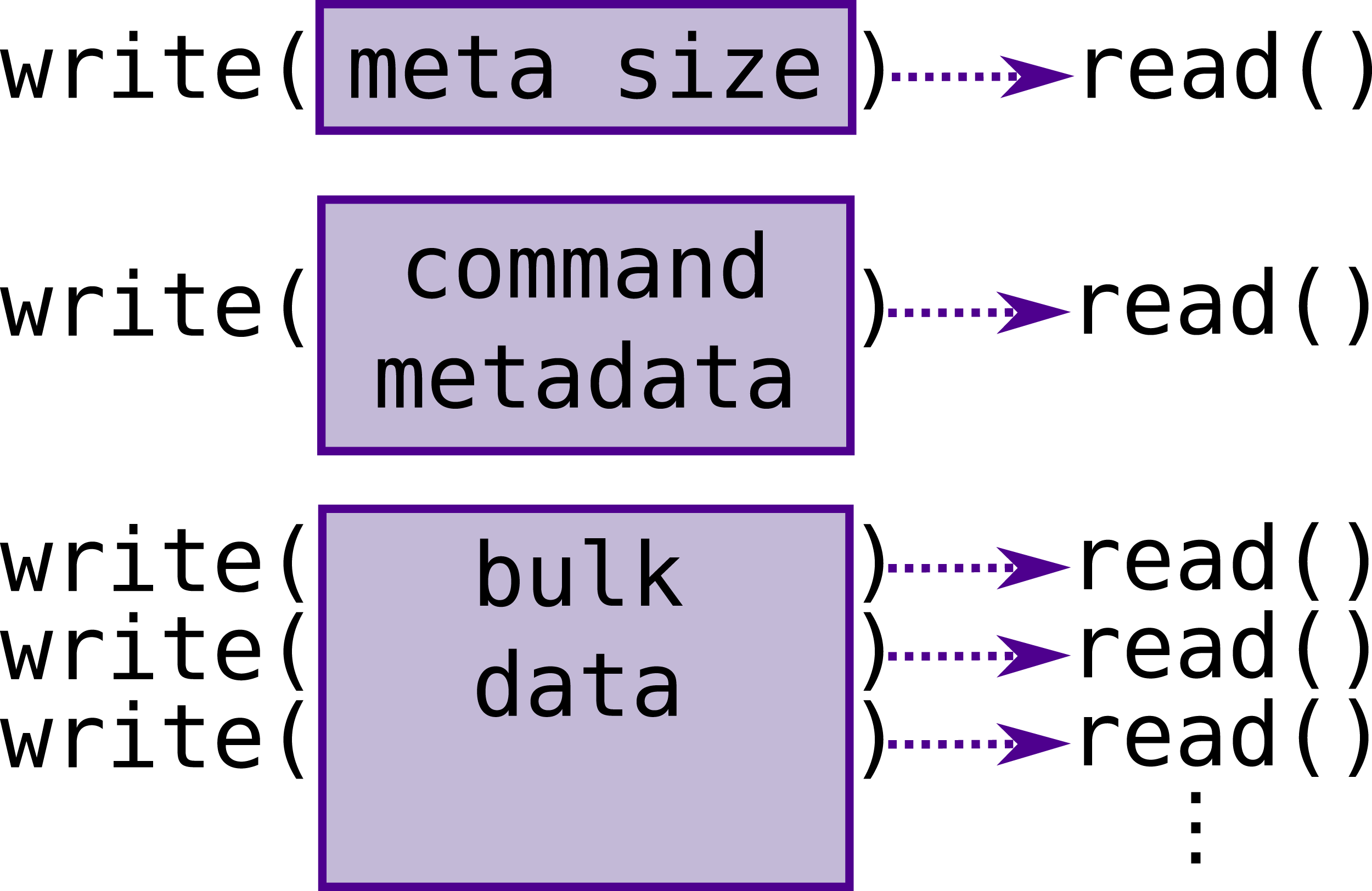
With RDMA, transfers simply involve defining the source and, depending on the specific command, the destination address and the size to be transferred. Additionally, multiple transfers can be chained via the next field of the transfer definition. These are then handled internally by the driver and the Host Channel Adapter (HCA, RDMA terminology for the network interface) and do not require further involvement from the kernel or the application (Figure 6). Control flow of transferring a buffer between servers via RDMA. Compared to Figure 5 no in band size fields are needed since RDMA is message-based and handles message size internally. RDMA messages can also be chained in order to submit multiple work requests with a single function call. The RDMA driver and hardware handle the multiple messages and potential message fragmenting internally without the need for additional syscalls.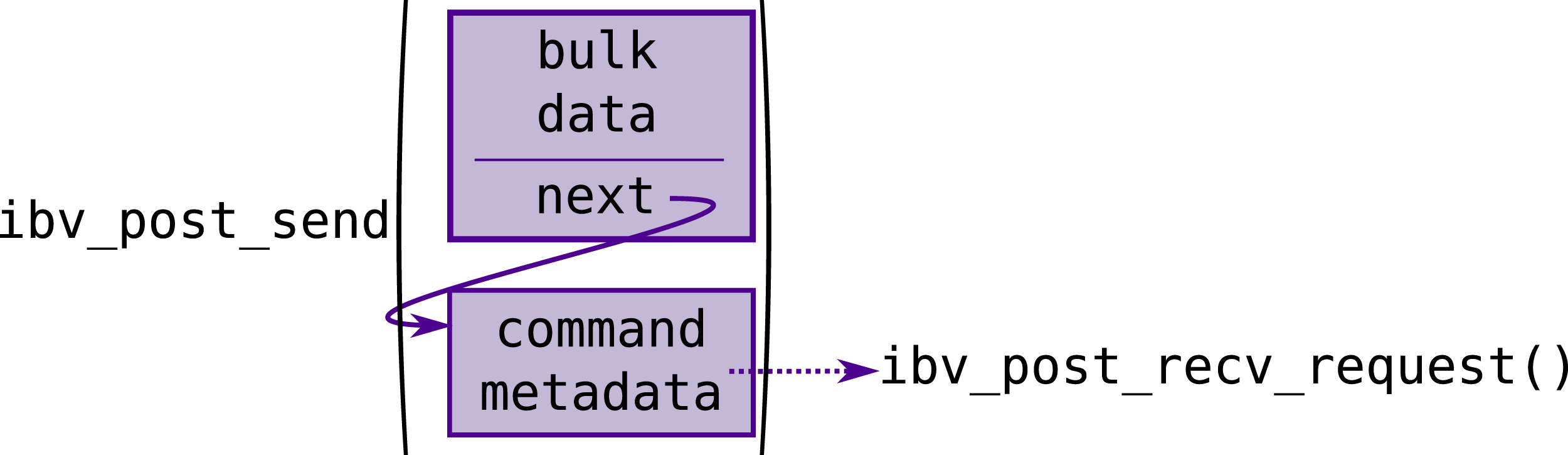
PoCL-R makes use of this chaining feature by having a dedicated fixed-size memory region for the command struct on both the sending and receiving side. As RDMA is currently only used for buffer transfers, the sending side sets up an
The receiving side has a fixed buffer of command structs allocated and registered as an RDMA memory region. For each command struct in the region, a receive request is posted to the RDMA driver. Once a buffer migration is issued from the sender, the
Unlike integrated GPUs, discrete GPUs typically have their dedicated global memory that might not be directly addressable by the CPU. Such GPU memory cannot trivially be registered for RDMA use, and graphics APIs usually have separate functionality for uploading data from system RAM to GPU memory.
There is increasing support for presenting a unified virtual memory space to applications. In OpenCL, such capabilities are utilized via the Shared Virtual Memory model (SVM). However, the level and maturity of SVM support varies heavily. Therefore, PoCL-R keeps a ”scratch” or ”shadow” buffer that is registered for both incoming and outgoing RDMA transfers. Upon receiving a transfer completion notification, the shadow buffer’s contents are then uploaded to the right OpenCL buffer internally. Similarly, on the sending side, buffer contents are copied into the shadow buffer when a migration command is received, before issuing the RDMA transfer request.
A shadow copy of each buffer is not needed if the server’s native OpenCL runtime supports allocating SVM buffers. Those get associated with proper addresses in the virtual address space of the application process and can thus be registered directly as RDMA memory regions. In PoCL-R this mode of operation can be enabled with a compile-time option and in principle it should yield noticeable improvements to performance and memory usage. For the time being, since support for SVM, while increasing, is still relatively niche and often unstable, the benchmarks performed in this article use the shadow buffer solution instead.
In the future, as SVM and related technologies get wider support, it is interesting to expand the cross-node DMA to support direct transfers also between GPU memories. There are APIs specifically for registering GPU memory directly as RDMA regions, such as NVIDIA GPUDirect® Li et al. (2020) and VK_NV_external_memory_rdma Khronos Vulkan Working Group (2022), which could be utilized internally.
6. Evaluation
The following subsections describe the latency and scalability benchmarks used to evaluate PoCL-R and their measurement results. The system configuration for the benchmarks resembles a contemporary edge compute environment: the benchmark application has a 1 gigabit ethernet (GbE) connection to a compute cluster which internally has 100GbE connectivity between its nodes.
The commonly used OpenCL benchmarks mainly focus on raw single-device compute performance or memory bandwidth within a single kernel invocation and completely omit overheads from API implementation, synchronisation between commands and cross-device buffer migrations. However, the latter aspects are of main interest in distributed and remote runtimes. Both the latest prior work, rOpenCL, and PoCL-R delegate the actual computation work to the vendor-provided OpenCL runtime, so raw TFLOPS and in-kernel memory bandwidth are bound to be effectively identical. To appropriately evaluate the overhead of the offloading API implementation, we instead rely on a set of custom synthetic benchmarks specifically crafted to also include the runtime’s internal communication overheads.
6.1. Reconnection delay
Reconnection latency is naturally dependent on the actual network conditions. In order to establish a good base line, a synthetic test was conducted on a PC with a wired ethernet connection. The test shuts down the sockets out of band and waits for the device availability query to first return an unavailable status and then again an available status. This way, latencies in the range of 0.7 − 1.3 ms across 1000 iterations were observed while an average ping for the same route measured 0.3 ms. If the server address was given as a DNS host name rather than a numeric IP address, the latency was slightly higher, 2.2 − 3.6 ms with occasional spikes into the dozen millisecond range, presumably caused by the client’s cached DNS records expiring and getting re-fetched behind the scenes. A trivial kernel and buffer read command are enqueued afterwards to confirm that the device is indeed working, but these are not timed since the connection is already re-established at that point.
6.2. Command overhead
With low latency being a high priority for PoCL-R, a synthetic benchmark was created that measures the duration of invocations of practically empty kernels. The benchmark starts a timer and dispatches a kernel that increments a single integer and immediately returns. Then the benchmark awaits the completion of this kernel and stops the timer. Since the kernel is almost a no-op, this gives a good idea of how much overhead is associated with dispatching kernels in the first place. This overhead consists of network traffic and bookkeeping in the runtime itself. The results of the benchmark are compared against the network round trip time measured with the ping utility, which is commonly used for measuring network latency.
In order to even out fluctuations caused by buffering, drivers and unrelated processes running on the devices, the kernel invocation was repeated 1000 times and the results are averaged. The client application for this benchmark was running on a desktop PC with an AMD Ryzen 5 1600 CPU and a wired 1 gigabit ethernet (GbE) connection. The server had an AMD Epyc 7643 CPU, 8 NVIDIA RTX A6000 GPUs and a 100 GbE connection. Client connection speed was thus limited to 1Gbps.
Figure 7 shows the results of this benchmark. On average rOpenCL comes decently close to ping latency, however it does have a noticeably long maximum latency across the measured iterations. A likely reason for this is that rOpenCL appears to open a new TCP connection for each command and close it once the command finishes. PoCL-R manages to have a worst-case latency equal to only the average ping latency. This turns out to be related to the frequency of messages on the TCP connection: By default the ping utility sends out one ICMP packet per second. When instructing ping to send out packets at 2 millisecond intervals instead, average ping latency ends up a lot lower than with the default, and lower than PoCL-R. The exact reason for this is unclear but it is likely a combination of the TCP driver stack being put to sleep by the OS when there is no traffic and by the network hardware along the path prioritising the steadiness of consistent data streams over the latency of short bursts. Duration of a trivial NDRange kernel command with rOpenCL and PoCL-R OpenCL runtimes. ICMP ping latency and duration of the command using the native NVIDIA driver directly are shown for comparison.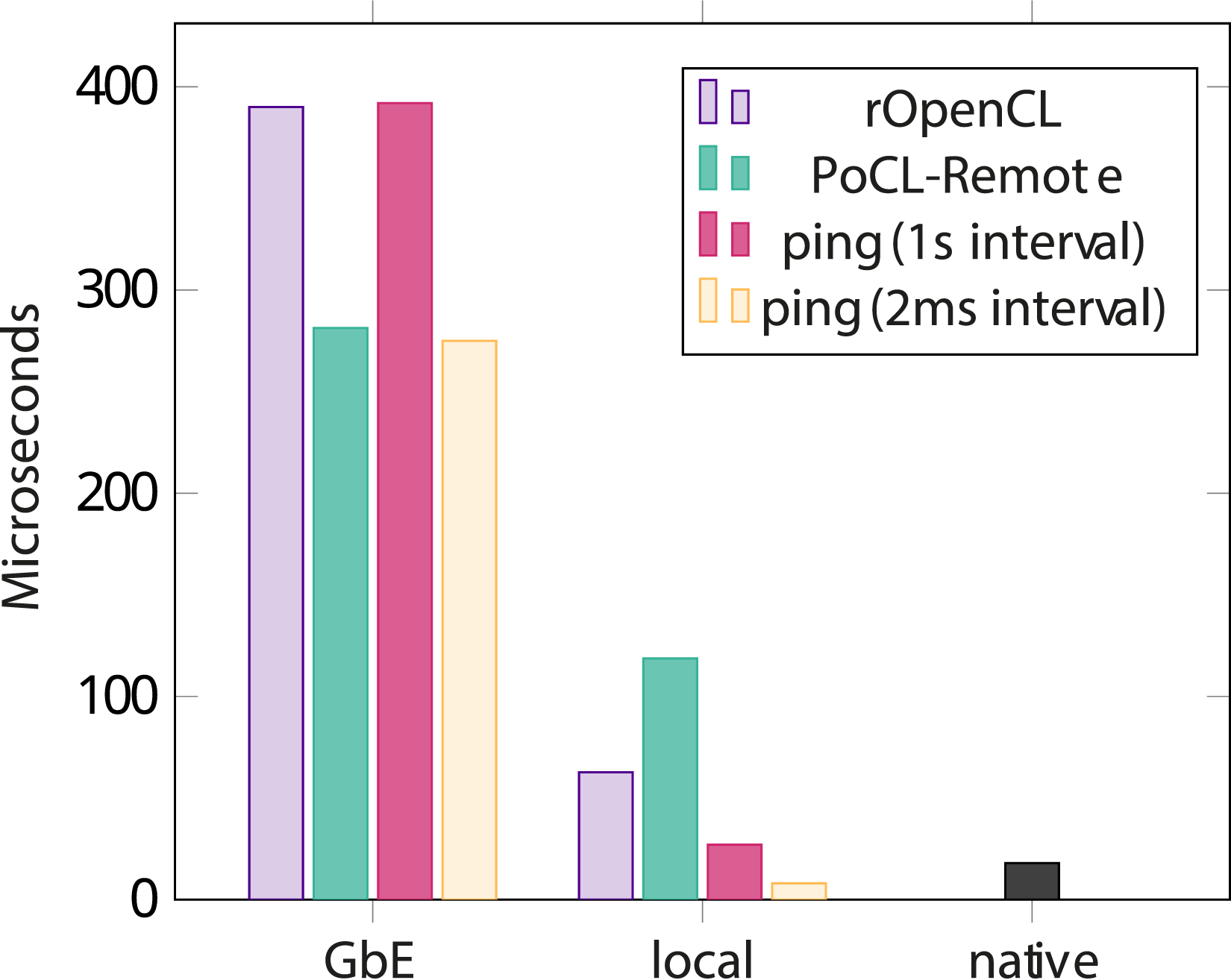
Running the same benchmark over the loopback network interface with client and server on the same machine flips the latency numbers of rOpenCL and PoCL-R around. This is a result of not doing any bookkeeping of OpenCL resources whatsoever in rOpenCL and instead leaving it up to the underlying runtime on the remote. This makes for very simple code in rOpenCL but comes at the cost of not being able to synchronize buffers and event completions between remotes. The overhead of opening and closing TCP connections on the loopback interface may also be optimized away by the driver stack since things such as TCP handshakes can likely be omitted entirely in this case, making rOpenCL a lot more efficient in comparison. When using an actual network connection this advantage is lost, however, and the persistent TCP connections used by PoCL-R end up being more efficient even with the overhead of remapping resources to facilitate coordination between multiple remotes.
6.3. Data migration performance
The authors of SnuCL report that moving data around is the main bottleneck in some of their benchmarks Kim et al. (2012). With other frameworks such as rOpenCL not supporting buffer migration at the API level at allAlves and Rufino (2020), it is interesting to measure the benefits of the runtime-optimized buffer migrations implemented by PoCL-R.
To this end, a synthetic buffer migration benchmark was devised. The benchmark migrates a buffer of a given size to a device and measures the time until the migration command’s completion has been registered with the host application. Then the application launches a simple kernel that increments a single integer in the buffer in order to force the runtime to consider the buffer contents as changed and waits again until the command is confirmed complete. The same sequence is then performed again, this time migrating back to the original device. This migration pair is repeated 100 times and the durations of the migration commands are aggregated at the end. Figure 8 shows the relative performance of various system configurations compared to manually performing buffer migrations via host memory. Since the obvious solution to data transfer bottlenecks is to simply increase the available bandwidth, a data series with the client running on one of the cluster nodes with 100GbE connectivity is also included. Relative duration of a buffer migration between two devices in different system configurations compared to a 1GbE client connection and no direct server-to-server communication (S2S). Simply improving client bandwidth is an obvious answer to the data migration bottleneck, so a 100GbE client is included as a forward-looking data point.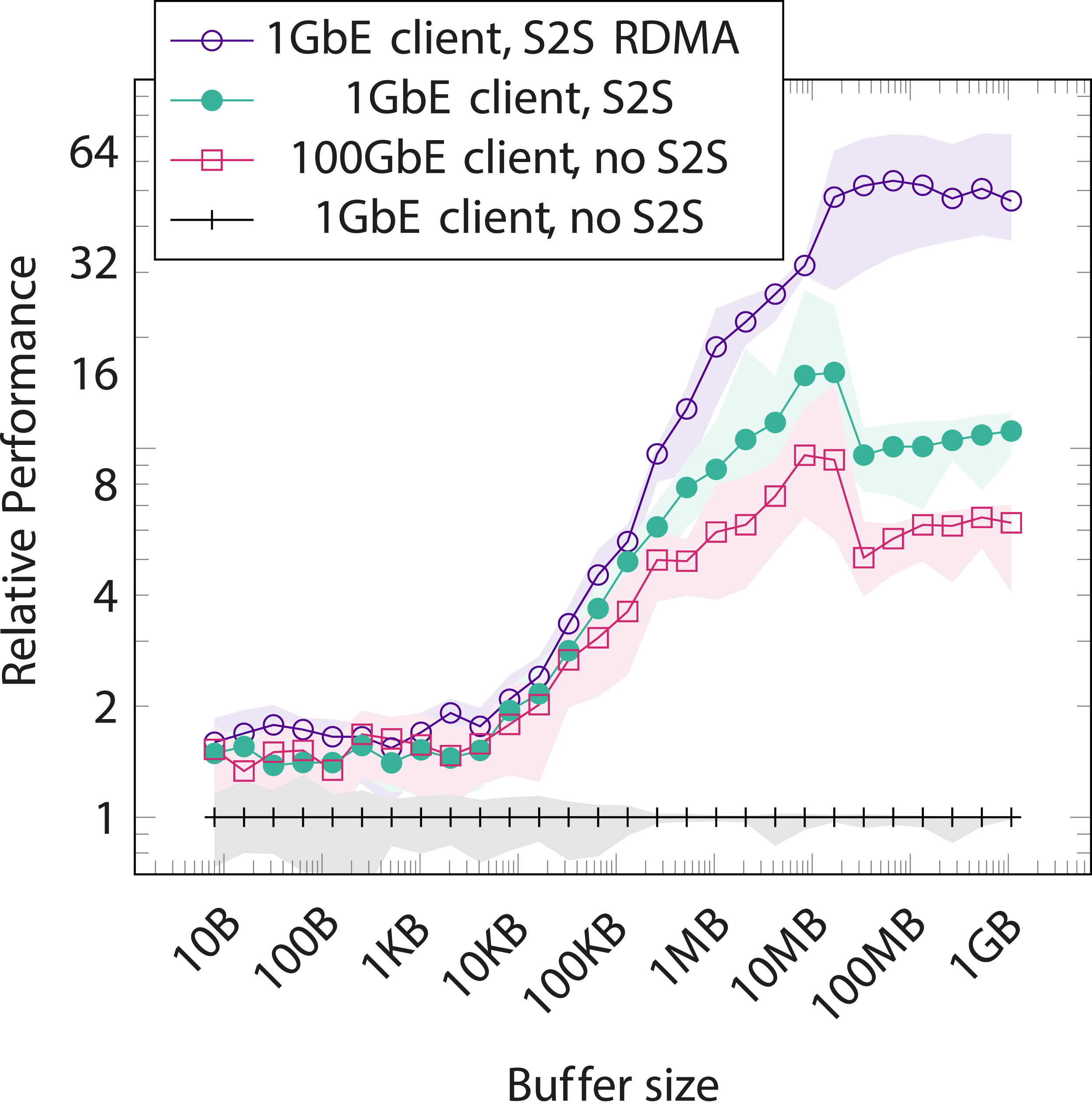
Increasing bandwidth does naturally improve performance, however in practice 100GbE connectivity for clients is expensive to set up. Additionally, compute-heavy applications are increasingly used in the field, where communication is limited to cellular networks that are far behind typical intra-cluster connections in terms of bandwidth. For example commercially available 5G connections only achieve up to 3Gbps throughput in optimal conditions, and are frequently limited to some hundreds of Mbps Narayanan et al. (2021). Migrations directly server to server (S2S) easily outperforms the ”fast client” scenario. The client connection being 100GbE or 1GbE turns out to have a relatively small effect. This makes sense intuitively: the migration command itself is very small, thus the client connection speed has negligible effect on performance here, and the total amount of bulk data transferred across the 100GbE in-cluster connection is effectively halved when migrating server → server rather than server → client → server.
Using RDMA for the the S2S transfers yields up to a 5x improvement over the base S2S migration performance, for a total of roughly 50x the performance of our baseline of manually migrating buffers via host memory on a 1GbE client connection and up to 10x improvement over simply improving client bandwidth. However with small buffers (
We also attempted a comparison against SnuCL, but calls to clEnqueueMigrateMemObjects consistently caused SnuCL to segfault, so an accurate comparison was not possible. Upon contacting the authors we were informed that their research had since shifted away from OpenCL and no newer version of SnuCL was available. Since rOpenCL does not support buffer migrations at all, it was also omitted from this comparison. Instead measurements without S2S were performed by marking direct migrations as unsupported within PoCL-R, causing the PoCL runtime to perform migrations via host memory instead. This is essentially how rOpenCL requires applications to be written in order to take advantage of multiple GPUs so we consider it a reasonable approximation of the state of the art.
6.4. Distributed large matrix multiplication
Scalability under non-trivial workloads was measured with a distributed matrix multiplication test. This benchmark multiplies two N × N matrices using all the available devices in the OpenCL context. The full input data is uploaded to each device, and each device computes a roughly equal number of rows of the result matrix. The actual computation is embarrassingly parallel, but the intermediate results from each device have to be collected into a single buffer to form the final result, which makes scaling this workload as a whole non-trivial.
The benchmark is broadly the same as the matrix multiplication used by SnuCL authors Kim et al. (2012), except that combining the partial results into a final output matrix is included in the host timings here. The example code by NVIDIA that Kim et al. (2012) mentions as the source for their benchmark only measures the duration of the multiplication kernels themselves, effectively only measuring the raw float multiply-add performance of the used devices. However the partial results themselves are generally not very meaningful, so the combining step has to be performed before the result can actually be used. Combining requires synchronizing and transferring a significant amount of data between devices after the partial results have been computed. Whether the SnuCL benchmark accounts for combining the intermediate results is unknown, but considering the reported scalability problems, it stands to assume that combining the results was indeed part of what was measured. Similarly to the migration benchmark, rOpenCL was not tested since it does not support buffer migrations. Instead a modified PoCL-R with S2S disabled was used for comparison.
Two separate sets of measurements were conducted for this. The first set, the results of which are shown in Figure 9 were run on a compute cluster consisting of three servers with an IntelTM XeonTM E5-2640 v4 CPU and four NVIDIA Tesla P100 GPUs. The number of GPUs was padded to a total of 16 by adding one more server, with an IntelTM XeonTM Silver 4214 CPU and four NVIDIA Tesla V100 GPUs. All servers, as well as the machine running the client application, were connected to a 56 Gbps LAN. Multiplication of two 8192 × 8192 matrices using 1 to 16 remote devices in servers with 4 GPUs each, averaged across five runs that were executed in parallel. Displayed is the speedup compared to using a single GPU.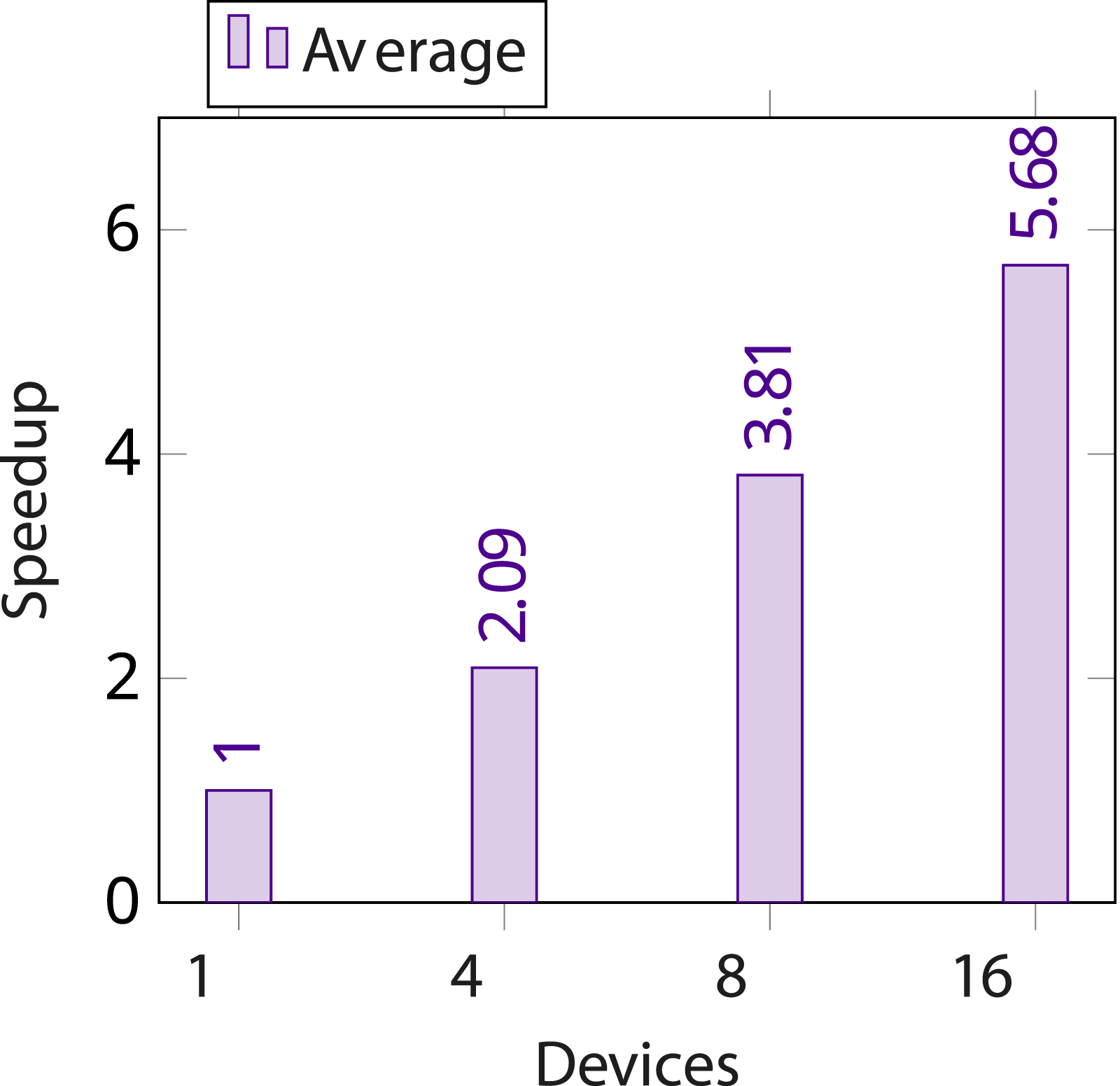
The performance increase appears to follow a logarithmic curve as more GPUs are added, ending up at slightly less than 6x when using all 16 GPUs. This is comparable to the results reported by Kim et al. (2012) when the proposed MPI collective communication extensions are used. PoCL-R does, however, not exhibit the performance regression when using more than 8 devices that the SnuCL authors report.
A more detailed analysis on the effects of S2S communication was performed with the cluster introduced in Section 6. The results are shown in Figure 10. With matrix sizes below 2048 × 2048 distributing the task is a net negative. At exactly 2048 × 2048 there is a large dip in baseline performance, which explains the massive peak in relative performance with multiple GPUs and the relative dip afterwards, as the per-GPU workload again exceeds this size. The three GPU case with 2048 × 2048 and 3072 × 3072 matrices has the RDMA implementation losing out to the plain TCP one. This likely stems from the benchmark not splitting the work optimally with 3 devices and with 4 devices RDMA would probably perform similarly or better than TCP, as it can be seen consistently doing in the two GPU case. Another contributor to this loss is the suboptimal implementation of RDMA in the PoCL-R server, since directly accessing GPU memory is not yet implemented. As matrix size goes past 8192 × 8192, the computation starts to outweigh the communication overhead by a big enough margin that even the non-S2S setup starts outperforming the single-GPU setup. Relative performance of a naively distributed dense matrix multiplication in different system configurations compared to a 1GbE client connection and no direct S2S communication. Numbers are averaged across 10 repeated iterations. Error bands show the full range of measured values.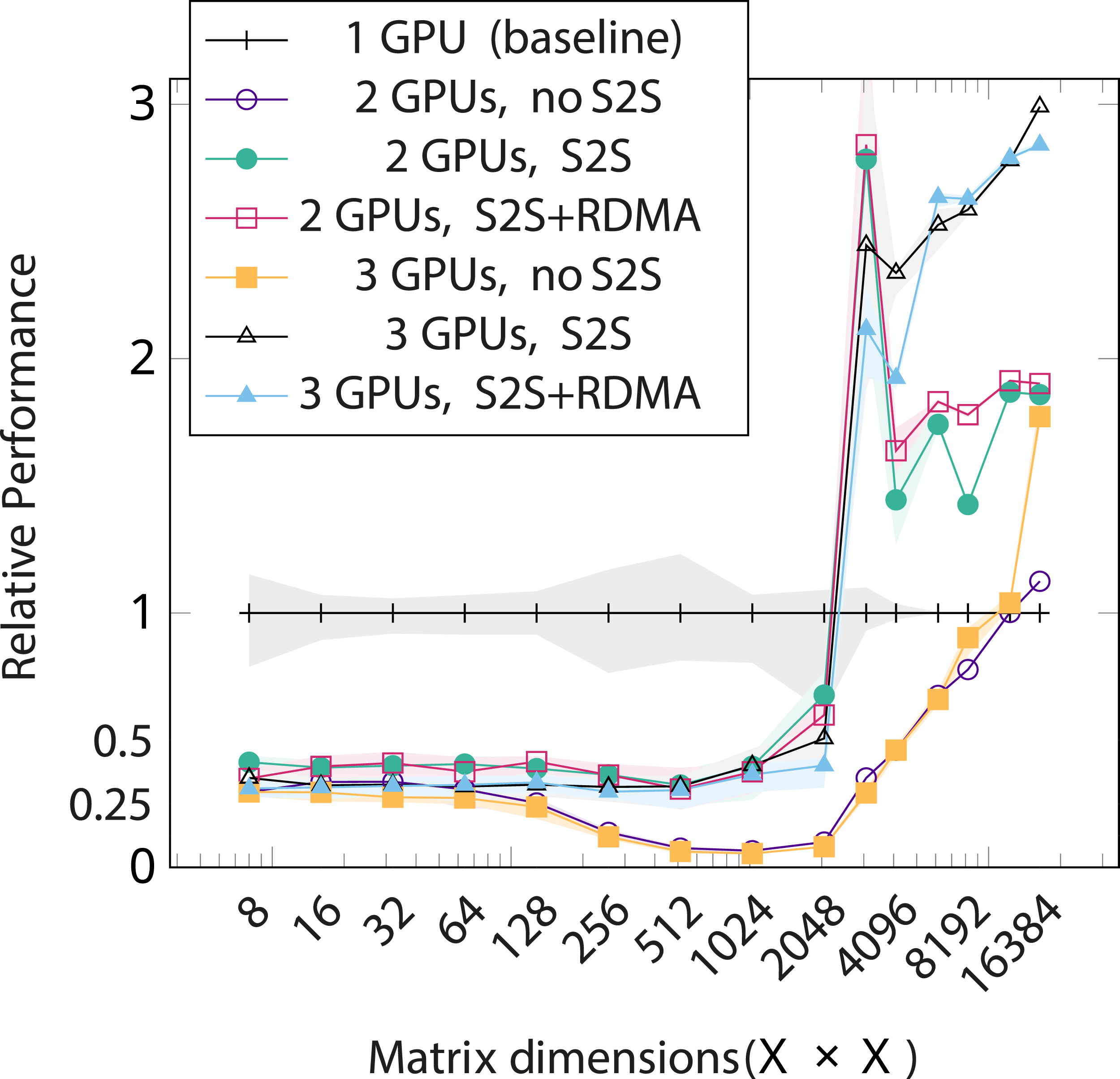
7. Application case studies
The following subsections describe a set of full application case studies performed with PoCL-R in real-world applications. The first case study is an augmented reality application where rendering quality was enhanced by optionally offloading computation to a compute server using PoCL-R. The second case demonstrates the scalability of the runtime at server-side in order to support applications with high performance requirements.
7.1. Real-time point cloud augmented reality rendering
For this case study, we implemented an Android-based smartphone application with real-time AR rendering. A sample screenshot of the application is shown in Figure 11. Screenshot of the AR application used to measure the effect of offloading heavy computation. A streamed animated point cloud of a person holding a small tablet device is displayed in augmented reality on top of a real-world chair.
The point cloud is received as a Video-based Point Cloud Compression (VPCC) stream encoded with High Efficiency Video Coding (HEVC) ITU-T Study Group 21 (2013); Sullivan et al. (2012). The video data is decompressed with a hardware HEVC decoder present in the smartphone SoC. The point cloud is then reconstructed from the data with OpenGL The Khronos Group Inc (2023) shaders Simpson et al. (2023). A more thorough explanation of the reconstruction process is given in Schwarz and Pesonen (2019).
The points of the received point cloud are sorted by their distance from the viewer in order to enable the use of alpha blending when rendering the points. Alpha blending produces less pixelated results than simply drawing the points as squares, yielding a much more visually pleasing end result.
Compared to reconstructing the individual point positions, sorting the points by distance to an arbitrary point is a very computationally heavy task, so it is a prime candidate for offloading to a high-powered compute server. When offloading is not in use, the steps from decoding the VPCC stream, to reconstructing and reordering the points, to the final render are all ran on the smartphone SoC. When offloading is enabled, however, the compressed VPCC stream is sent to both the smartphone and the compute server. Both devices decode and reconstruct the points, but only the remote server computes the sorted order of the points. The server then sends a sorted list of point indices to the smartphone to be used for rendering the point cloud. This way, the mobile SoC is free to perform other tasks such as pose estimation for tracking the position of its own viewpoint based on the live image from the smartphone’s built-in camera.
OpenCL classifies compute devices as CPU, GPU, or Accelerator. With OpenCL 1.2, a new type was added, called
Figure 12 displays the frame rate achieved by the demo application in various configurations. The first two bars represent performance when using only the GPU integrated in the device’s SoC for reconstructing the points of the point cloud, sorting them and computing the camera position for AR rendering. For the next two numbers, sorting of the points was performed on a PoCL-R remote server, both with buffer migrations performed in P2P fashion and with a host round-trip. Compared to performing all operations on the mobile device, this already yields a 2.3x speedup. Finally, the effect dynamic buffer size extension is introduced to the application, drastically reducing the amount of data that needs to be transferred over the network and improving the frame rate almost 19x compared to performing all work on the mobile device. Frame rate and energy consumption (normalized to frame rate, Energy Per Frame) of the AR demo application in various offloading configurations. The lGPU and rGPU identifiers refer to the mobile device’s GPU and the remote GPU exposed via PoCL-R respectively. AR indicates that AR position tracking is being used. P2P refers to the peer-to-peer buffer migration feature in PoCL-R being used, and DYN indicates that the buffer content size extension is used to reduce network traffic.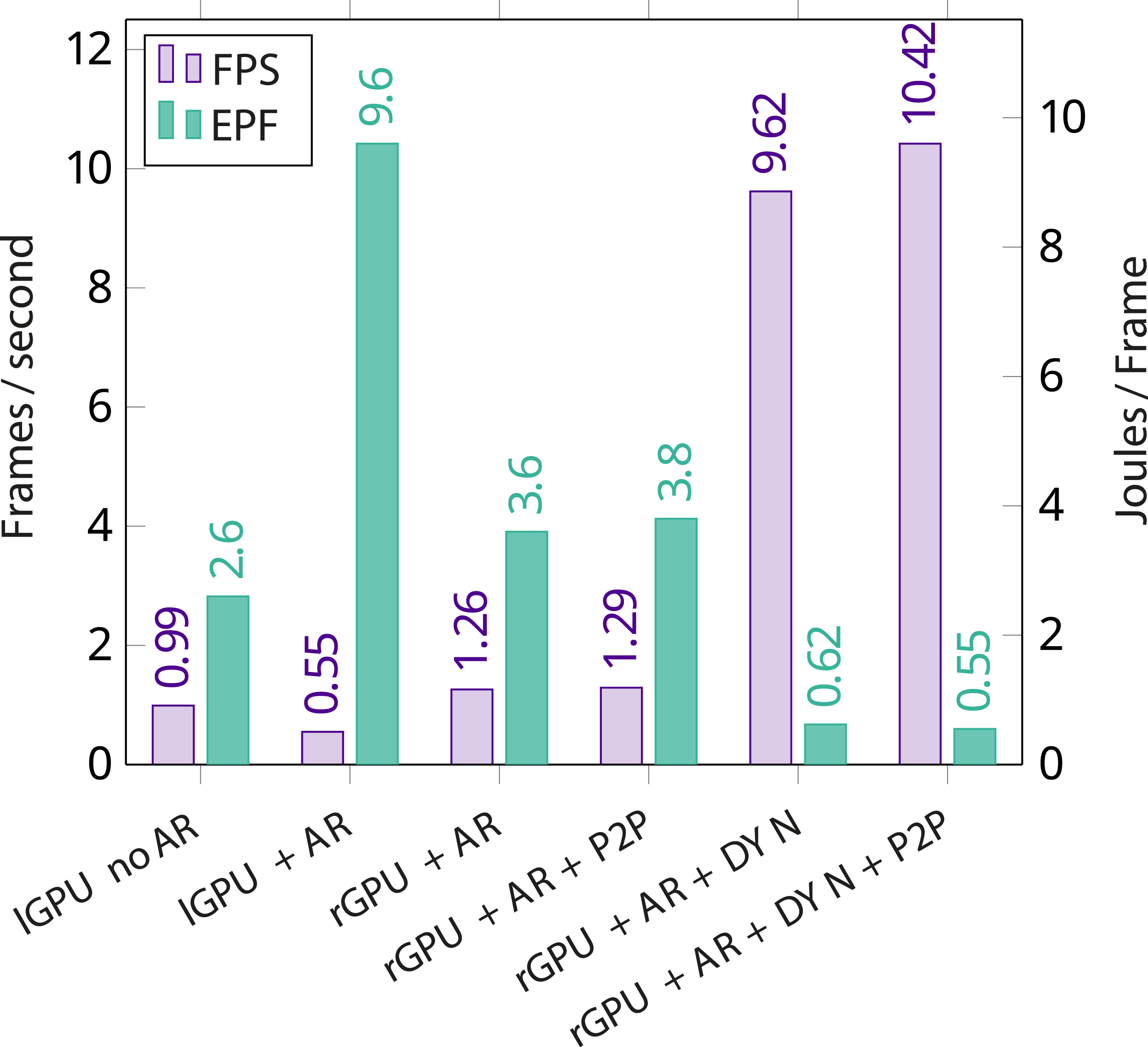
The energy consumption on the smartphone was measured using the Android Power Stats HAL interface. The results are shown in Figure 12. Since simply offloading the sorting step to a server almost entirely offsets the huge spike in power consumption caused by adding AR tracking, it suggests that the SoC was switching itself to a high power state to compensate for the increased load, while offloading the sorting step allowed it to stay at a lower power state while maintaining similar performance. Peer-to-peer buffer migrations appear to have a minor impact here, but the buffer content size extension helps bring energy consumption on the smartphone down to only around 20% of that of sorting the points locally and rendering them without AR tracking.
While the compute performance of the local GPU is sufficient for tracking AR camera movement and rendering static objects, when doing the same with animated objects of reasonable detail the frame rate is lackluster. Here, PoCL-R serves as an enabler technology, bringing the frame rate into a much more usable range and reducing power consumption per frame by a factor of 2.5x in the worst case to 17x in the optimized case. The reduced energy consumption per frame creates the possibility of deliberately reducing the frame rate in order to improve battery life on handheld devices.
Hardware used in this test: • Remote GPU: GeForce 1060 3 GB, Intel Core i7-6700 • Remote custom device: a virtual device implemented as a PoCL device driver simulating a point cloud camera by reading the stream from a file. Acts as the data source for the application. • Mobile device: Samsung Galaxy S10 SM-G973U1, Qualcomm® SnapdragonTM 855, connected via Wi-Fi 6 • Wi-Fi router: ASUS ROG Rapture GT-AX11000 • Wi-Fi router to remote server connection: 1Gbit wired Ethernet
7.2. Multi-node computational fluid dynamics
Server side multi-node scalability in real-world scenarios was measured using the FluidX3D Lehmann (2022) tool. FluidX3D simulates dynamic fluid behavior using the lattice Boltzmann method and a number of optional extensions for various specialized scenarios Lehmann (2023).
HPC applications are generally run in large compute clusters, where multi-node distribution is implemented using an MPI. Also, FluidX3D has been scaled to multi-node using MPI in the past Häusl (2019). Using MPI, however, might require changes to the application code and is generally not available outside HPC clusters, which causes a bit of a split between HPC and non-HPC applications. In contrast, PoCL-R works with any OpenCL application without changes to application code. However, running applications with PoCL-R can greatly magnify inefficiencies stemming from certain inadvisable (although still valid) API usage patterns, such as the following:
FluidX3D supports splitting up the simulation into multiple domains in order to spread computation across multiple compute devices. However, the boundaries of domains have to be synchronized across devices after each simulation time step. The basic implementation does this by manually downloading the boundary region from each device into RAM and uploading it to the destination device. This allows it to work across devices that are not part of the same OpenCL platform (e.g., because they are from different vendors) but is not “idiomatic OpenCL” and prevents OpenCL implementations from optimizing data transfers. To fix this, a new mode was added where the buffers that hold the boundary region data are implicitly migrated to the destination device, allowing the OpenCL implementation to perform the transfers in the most optimal way it is capable of. For PoCL-R, this means using the peer-to-peer connections between servers or, if both devices reside on the same server, deferring the task to the server’s native OpenCL driver.
The test setup for this benchmark is the same as in Section 6 FluidX3D itself was run in benchmark mode which runs only the basic lattice Boltzmann simulation without extensions and visualization. For the TCP and RDMA benchmarks, the application was run on the desktop PC. For benchmarks on localhost (i.e., client and server on the same machine) and native (using the NVIDIA OpenCL driver directly, without PoCL-R) the application was run on one of the servers. Comparing the numbers in Figures 13 and 14 shows that performance with PoCL-R scales with the number of server nodes almost as well as the NVIDIA driver scales with the number of local GPUs. Performance of FluidX3D using 1-24 remote devices spread across 3 servers on a 100GbE LAN with the client on a wired 1GbE connection. Measured is the peak value of millions of lattice updates per second during a 100-step simulation with a 338 × 338 × 338 sub-lattice for each GPU (around 2GiB when compressed to an FP16S format). Without S2S, the slow client network eliminates any gains from adding more nodes. With S2S performance is clearly much better, but in a memory-bound application like this the speed gains from adding more GPUs diminish quickly. Performance of FluidX3D using 1-8 local GPUs using two different drivers and FP16S compression. Measured is peak number of millions of lattice updates per second during the 1000-step simulation.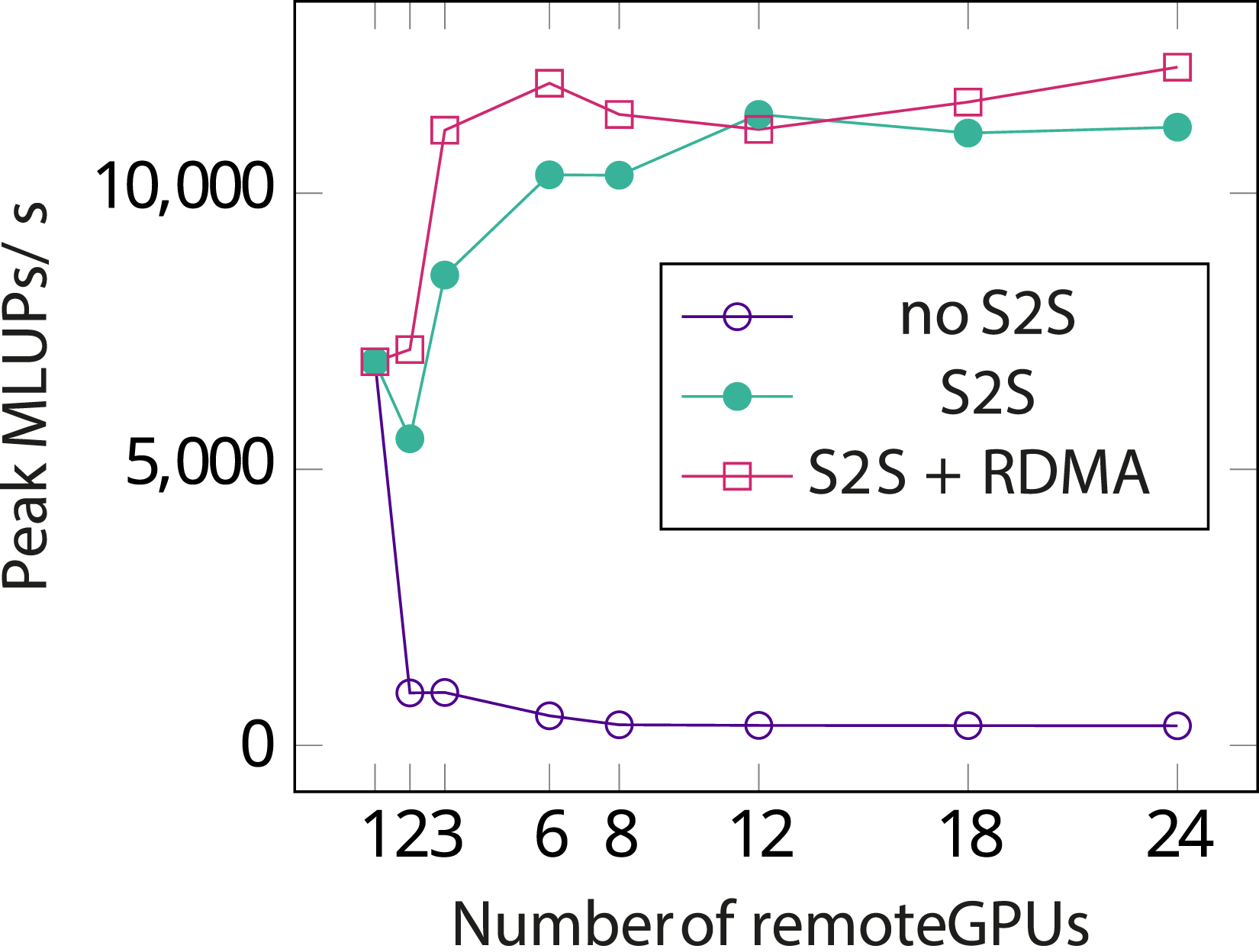
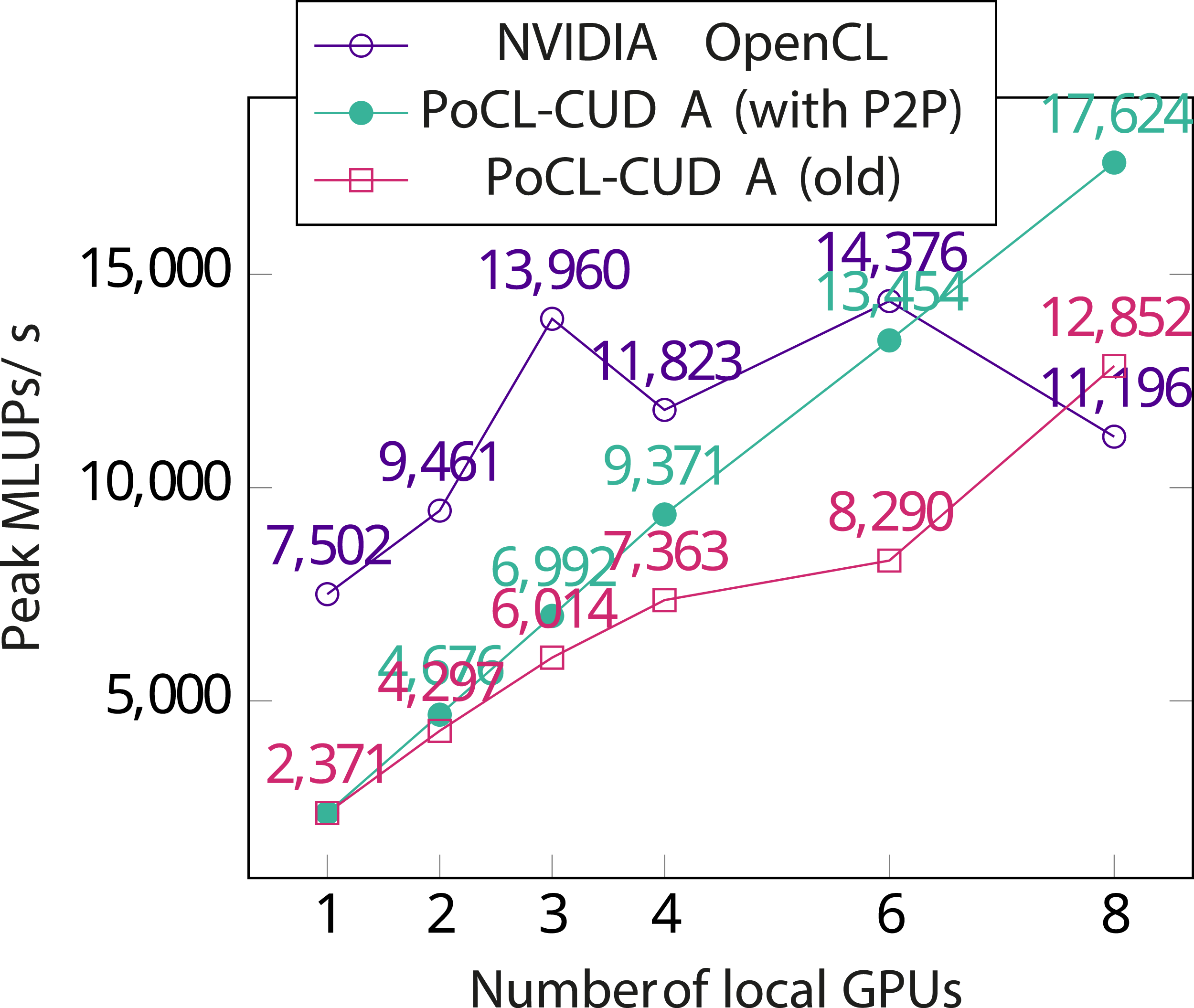
RDMA turns out to not benefit this benchmark much since even with the largest grid that the NVIDIA driver allows allocating in one chunk without memory compressionLehmann et al. (2022) (538 × 538 × 538 per used GPU), the boundary buffers are only around 5.4 MB in size. This means that the entire buffer fits in the kernel-side send and receive buffers of the TCP stack (configured to 9 MB for buffer transfers). Some improvement might be visible by eliminating the CPU altogether by performing RDMA transfers directly from GPU memory to GPU memory instead of going through the CPU. It also appears that the NVIDIA driver performs device to device copies by circulating them through the main memory instead of utilizing PCIe peer-to-peer copies. The lack of PCIe peer-to-peer copies also hides the aforementioned inefficiency of manually circulating buffer data through the CPU in the application.
Peer-to-peer buffer migrations turn out to be of great importance even between local devices. Figure 14 shows the peak Millions of Lattice Updates per second (MLUPs/s) achieved during a 1000-step simulation using the NVIDIA OpenCL driver with a varying number of GPUs. Performance stops improving when using more than 3 GPUs. In order to analyze this behavior, the same test was run with PoCL-CUDA, a driver backend to PoCL that translates OpenCL kernels to NVIDIA PTX and executes them on local GPUs using the CUDA API. This driver shows a similar performance regression, although less dramatic. To address the regression, direct P2P migration support was added to PoCL-CUDA by using
During the initialization phase, the application is heavily bottle necked by the desktop’s gigabit connection, as that was fully saturated for the majority of that phase. During the simulation itself client traffic was a steady 7 KiB/s per used GPU and the p2p traffic between servers measured at 231 MiB/s (slightly under 2 Gbps) RX/TX on each server, summing up to a combined bandwidth of around 12 Gbps passing through the switch with 3 server nodes.
As shown in Figure 15, multi-node GPU utilization is in the order of 80%. This is comparable to the scaling results of the MPI port Häusl (2019), suggesting that PoCL-R is a viable alternative to MPI as a cluster distribution layer for some applications as far as performance is concerned. Additionally, the PoCL-R client having light requirements on the system opens up entirely new application scenarios, such as running unmodified HPC applications like FluidX3D on handheld devices while transparently offloading the bulk of the actual computation in a compute cluster. FluidX3D GPU utilization, with 1 GPU per server node, without memory compression. NVIDIA represents using the vendor driver directly and Localhost running server and client on the same machine. In these two cases, all GPUs are on the same server node.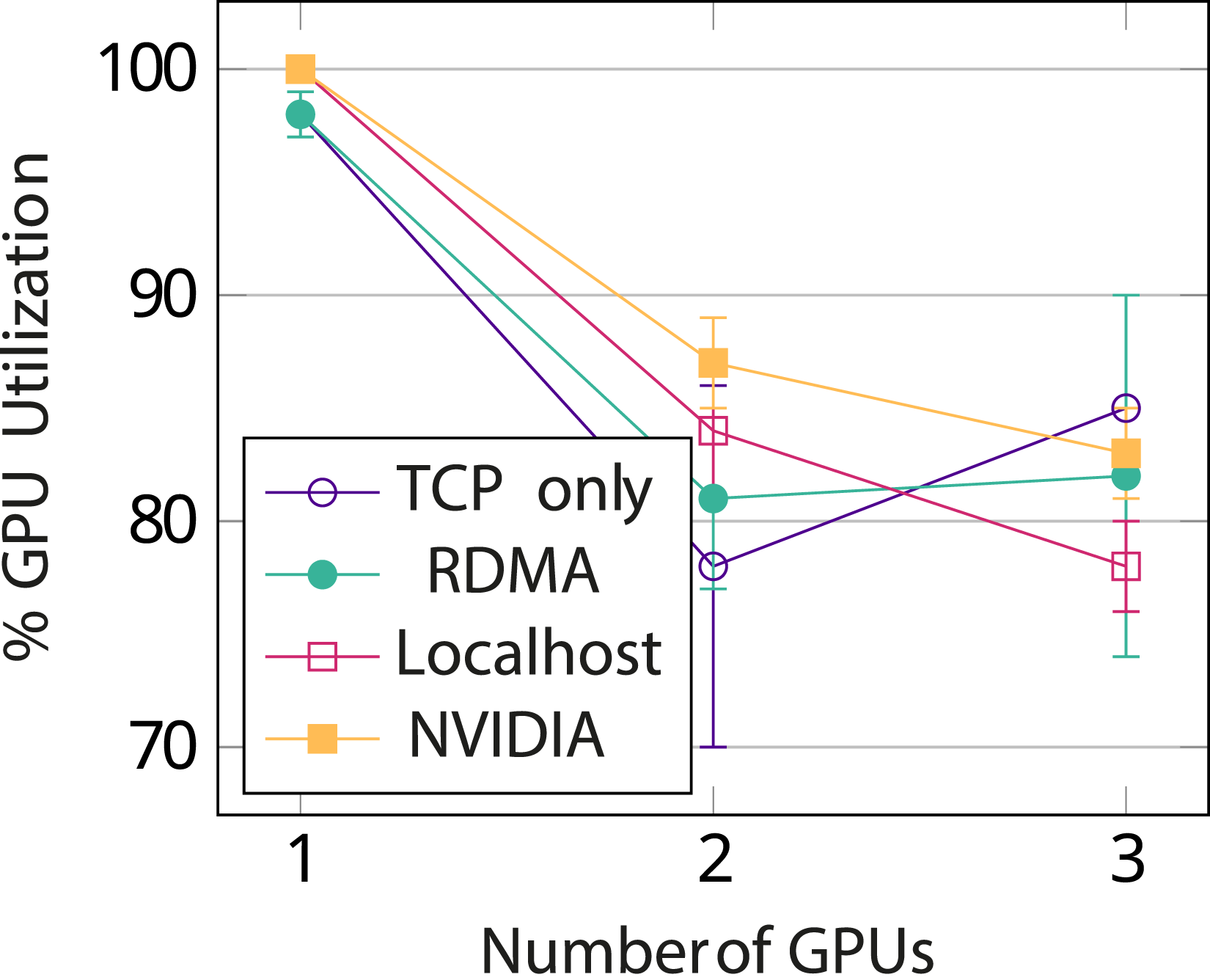
8. Conclusions
In this paper, we proposed PoCL-R, a distributed OpenCL-based heterogeneous computing runtime which both minimizes response latency and optimizes multi-node scalability on the server side that can cope with connection loss. The OpenCL programming model sidesteps common HPC application development and debugging problems by having a central thread of control that can be easily stepped through in a local debugger and vendor-independent compute kernel functions. With a PoCL-specific environment variable or a small tweak to the application’s device choosing logic is also easy to temporarily switch to the local CPU as a compute accelerator instead of a remote device, in which case the debugger can even step inside the compute kernel. Performance enhancing features of PoCL-R include RDMA accelerated peer-to-peer buffer transfers between remote computers participating in the execution and server-side orchestration of multi-device execution across nodes.
The suitability of PoCL-R for offloading of heavy real-time compute tasks was evaluated with an AR point cloud renderer running on a smartphone. Offloading is shown to yield up to 19x better frame rates at around 5.7% of the energy consumption when the optimizations outlined in this article were applied.
Performance scalability to support HPC workloads was demonstrated with a computational fluid dynamics simulation, where a multi-node efficiency of around 80% was observed. This was found to be comparable to the performance scaling of an MPI port of the same application Häusl (2019), suggesting that PoCL-R can also remove the need for MPI in some multi-node scaling cases. Measurements both in synthetic benchmarks and the fluid dynamics simulation also strongly support our hypothesis of the importance of direct P2P communication both locally between devices and in the case of network offloading, between servers.
The results show that the proposed compute offloading layer is an unique in its capabilities to support applications which have both high performance and low latency requirements. Since OpenCL is increasingly used as a cross-vendor portable computing layer below application-programmer-facing high-level programming models such as OpenVX Khronos OpenVX Working Group (2022), SYCL Khronos SYCL Working Group (2020) and CUDA/HIP Babej and Jääskeläinen (2020); CHIP-SPV (2022), we believe the open source PoCL-R runtime will have great utility in bringing high performance heterogeneous compute to wider and more varied environments. We outlined some shortcomings — namely the lack of confidentiality and QoS measures — that need to be addressed by future work in order to improve PoCL-R for a wider variety of cloud computing use cases.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: European Union’s Horizon 2020 research and innovation programme under Grant Agreement No. 871738 (CPSoSaware); Business Finland’s “AI for Situational Awareness (AISA)” programme.
Author biographies
Jan Solanti has been programming since the mid 2000s. He has worked professionally on graphics and HPC programming since the mid 2010s. In his free time, he contributes to various open source projects and enjoys making the pieces to fall into place so that a complex system springs to life, like is the case with PoCL-R. His research interests are on graphics rendering and on fast networked systems that do not depend on centralized resources.
Michal Babej has been working with open-source software since 2007 and with OpenCL since 2013. He is a leading contributor to the open source PoCL project, with interests in HPC and heterogeneous computing software stacks.
Julius Ikkala received the master’s degree in information technology from Tampere University in 2021 and is now pursuing a doctoral degree. Julius is a long-time contributor to computationally challenging open source projects whose research interests include photorealistic real-time rendering, especially ray tracing.
Pekka Jääskeläinen (Professor) has worked on parallel heterogeneous platform design and programming topics since the early 2000s. In addition to his publication activities, he leads the open source development of heterogeneous computing related open source projects such as PoCL and OpenASIP. He is interested in implementation challenges of applications with both low latency and high-performance requirements, and, on the other hand, the smallest scale of computing use cases with extreme energy efficiency requirements.