
Abstract
Modern supercomputers feature an ever-increasing degree of parallelism, particularly in the number of cores per node. These high core counts are considered in our flexible implementation of allreduce, which was implemented specifically with shared-memory communication in mind. At a high level, our algorithm consists of a reduce_scatter stage followed by an allgather stage, or a reduce stage followed by a broadcast stage, and allows for different factors (aka multi-radix) to be applied at each. The reduce and broadcast operations are also considered as standalone functions. Where barriers are required, they are integrated into the algorithm using counters to track progress. To accommodate the complexity of this approach, our implementation is split into a setup phase and an execution phase. The setup phase occurs only once for a given set of parameters, and is responsible for determining the algorithm that will be run each time the allreduce is called within the execution phase. We present two interfaces: a persistent collective interface (an MPI 4.0 feature), which inherently aligns with our setup and execution phases, and a blocking interface, where the setup is performed the first time a specific algorithm is required. Using these methods, we achieve speedups of half an order of magnitude compared to the persistent and blocking allreduce implementations of MPICH and Open MPI on a dual-socket node with AMD EPYC processors, and almost an order of magnitude on a four-socket node with NVIDIA Grace-Hopper processors. Reductions on vectors residing on both CPU and GPU memory are performed. Our implementation also achieves good performance on multiple nodes. A standard benchmark of the application CP2K is sped up by 2.5%. Notably, for long messages, our implementation achieves the same performance as NCCL.
1. Introduction
As core counts per node continue to grow on both modern supercomputing architectures and personal computer architectures, intra-node collective communication plays an increasing role in enabling efficient use of available resources. In this contribution, the essential operations reduce, broadcast, reduce_scatter, allgather, and allreduce are optimised both for standalone application and incorporation into allreduce inter-node communication. We describe a performant intra-node (shared memory) implementation of these operations, building upon our previous work on inter-node allreduce (Jocksch et al., 2021).
For the intra-node implementation, three algorithms are improved (cyclic shift, recursive exchange, and tree), and one is introduced: cyclic copy-in reduction. We utilise the first three with flexible factors (multi-radix) 1 instead of the classical constant radix of two. Further, technical improvements to these three algorithms are done in our study. Algorithmic schemes and benchmarks are presented. The latter cyclic copy-in algorithm is presented without benchmarks for completeness. We discuss and benchmark these algorithms mostly for the complex allreduce collective communication. The reduce_scatter and allgather collectives are part of the allreduce, and are therefore not evaluated individually. The on-node reduce and broadcast are also considered as standalone operations.
The inter-node communication we present is also an extension of our previous work (Jocksch et al., 2021). In contrast to our earlier work which primarily elaborates on the cyclic shift algorithm, the focus of this contribution is the recursive exchange. An algorithmic scheme for non-trivial factors is presented. Again, only the complex allreduce algorithm itself is benchmarked, not its components.
The optimisations considered here are well suited for applications where communication patterns with exactly the same parameters are repeated often. Particularly, repeated calls of allreduce are a part of many applications, such as Neko (Karp et al., 2022) and distributed training for artificial intelligence. This suggests that there may be an advantage in performing a complex algorithmic setup once in the initialisation phase of the communication; the optimised algorithm may then be run as many times as needed, amortising the initial overhead. This approach is called persistent collective communication (Holmes et al., 2021); it became a feature of the Message Passing Interface (MPI) standard in version 4.0, and implementations are available in libraries such as MPICH (Gropp et al., 1999), Open MPI (Gabriel et al., 2004), and MPC (Bouhrour et al., 2022).
Alternatively, for applications such as CP2K (Kühne et al., 2020), classical blocking collective communication is supported. When using this interface, the initialisation phase of the algorithms is deferred until the first call to the collectives, known as lazy initialisation. Successive calls upon the blocking collectives executes the algorithms with minor modifications. The setup of the algorithms in memory is discarded when the MPI communicator is released. For further speedups, the initialised algorithms are cached in ‘wisdom’ files for future reuse.
Key features of our intra-node communication algorithms include the use of shared memory, a combination of reduction operations and synchronisation barriers (Mohamed El Maarouf et al., 2023), and the ability to use flexible factors as already mentioned. From the four algorithms discussed for the shared memory implementation: recursive exchange, cyclic shift, tree, and cyclic copy-in reduction, the recursive exchange and tree algorithms support non-commutative operations (i.e., operations for which order of operands affects the result), while the cyclic shift and cyclic copy-in reduction are only used for commutative operations. Allreduce based on recursive exchange and cyclic shift consist of a reduce_scatter phase followed by an allgather phase. There is also the option to apply recursive exchange and cyclic shift to allreduce recursively. When using this option, the recursive allreduce is performed after the reduce_scatter phase and before the allgather phase. In CPU memory, our approach to MPI parallelism is to use shared send and receive buffers made available through the Cross Partition Memory (XPMEM) library (Hashmi et al., 2018) for reductions. GPU memory is shared analogously using CUDA inter-process communication.
Our inter-node allreduce recursive exchange algorithm is implemented in three phases: reduce_scatter followed by recursive allreduce and allgather, as in the cyclic shift version originally introduced by Bruck and Ho (1993). In principle, the inter-node allreduce can be executed on top of reduce_scatter and allgather intra-node communication. Then the execution is: (1) intra-node reduce_scatter, (2) inter-node allreduce, and (3) intra-node allgather. For performance reasons, the inter-node allreduce is implemented alternatively on top of reduce and broadcast intra-node communication by using the tree algorithm for intra-node communication: (1) intra-node reduce, (2) inter-node allreduce, and (3) intra-node broadcast. Many modern architectures have multiple sockets per node or other non-uniform memory access (NUMA). This has been taken into account for communication algorithms in the literature and is also considered in this contribution, enabling our intra-node communication algorithms to work with multiple sockets without modification.
In the following, we describe the recursive exchange algorithm for both intra-node communication and inter-node communication, as well as cyclic shift and tree algorithms for intra-node communication. We also discuss the interplay between intra-node and inter-node communication and parametrisation of these algorithms. Finally, we explore our implementations on multiple platforms, including both multi-core CPU- and GPU- based architectures, and analyse their performance. This includes single- and multi-node benchmarks with comparisons to MPICH, Open MPI, and NCCL (NVIDIA, 2025), as well as an evaluation of our algorithms’ performance with the application CP2K using our optimised allreduce and reduce_scatter_block. For a description of the allreduce algorithms based on reduce_scatter and allgather demonstrated with pure CPU benchmarks, see our contribution Jocksch et al. (2024).
2. Newly optimised algorithms
This section introduces four algorithms designed to optimise collective communication operations, particularly for modern high-performance computing (HPC) architectures with high core counts and multi-socket nodes. The algorithms presented are tailored to leverage shared-memory communication, flexible factorisations, and synchronisation barriers for efficiency in both intra-node and inter-node communications.
2.1. Recursive exchange
The recursive exchange algorithm is a kind of butterfly algorithm suited for non-commutative operators with flexible factors as a generalisation of the radix of two. It maps naturally onto multi-socket nodes if placed on the nodes such that a minimum data transfer is performed between sockets. Figure 1 shows the data flow between the processes for eight MPI tasks. The order of the tasks is chosen for an optimal performance for a possible application on a two-socket node, with tasks t0–t3 and t4–t7 on socket zero and one, respectively. Our recursive exchange algorithm for allreduce consists of a reduce_scatter stage and an allgather stage. In our example the reduce_scatter stage of our algorithm in step one a factor of four is applied in step two a factor of two. The allgather stage is described with steps three and four, which have the factors two and four, respectively. Recursive exchange on a node with eight tasks (t0–t7).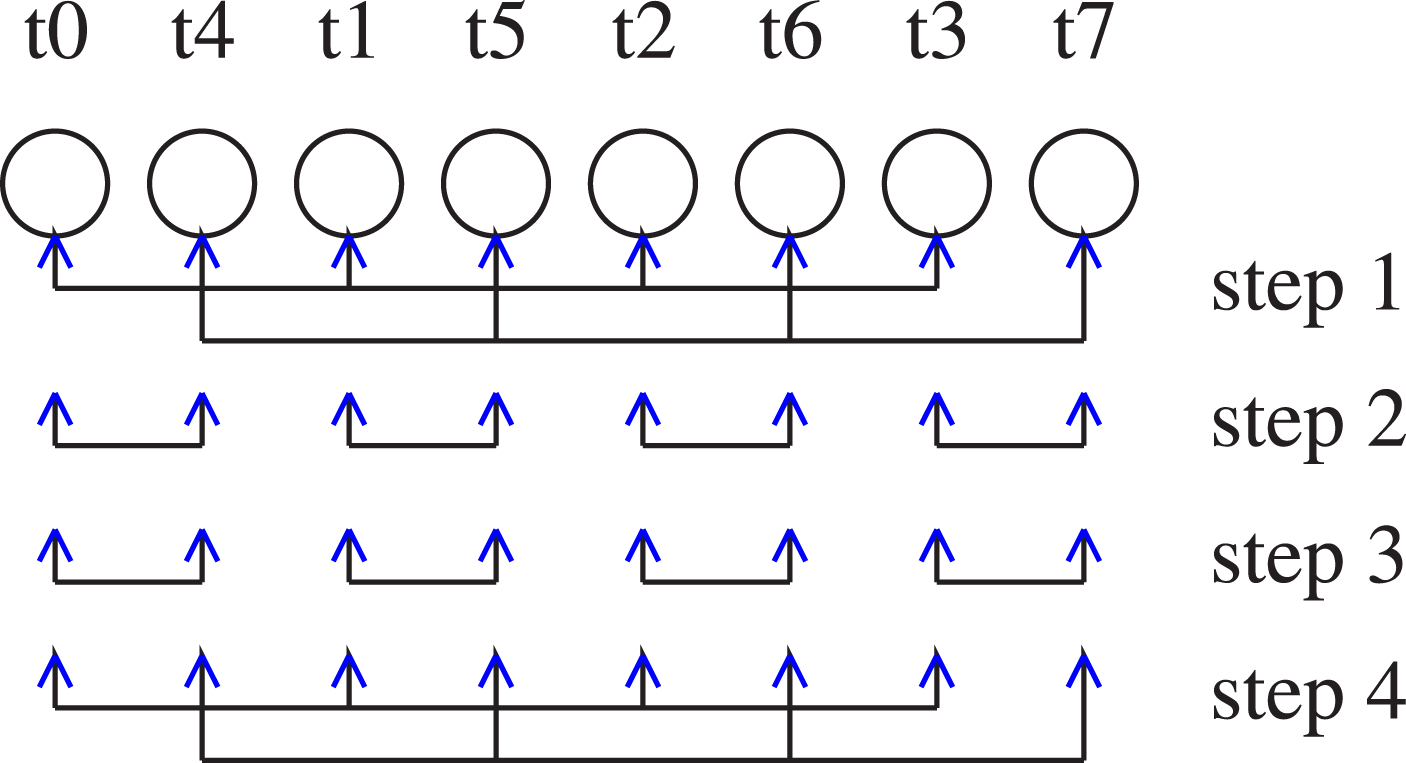
2.1.1. Intra-node communication
The recursive exchange algorithm consists of a reduce_scatter stage and an allgather stage, both of which are repeated for each factor in the factorisation of the number of tasks in the exchange. The optional allreduce stage between reduce_scatter and allgather we found not to be advantageous for intra-node communication. As in our inter-node allreduce implemented in Jocksch et al. (2021), the factors are also flexible. Barriers are integrated as counters into the algorithm, as demonstrated for OpenMP in Mohamed El Maarouf et al. (2023), meaning that flags are set and read individually in a way that the data needed by the different steps of the algorithm is guaranteed to be valid when processed. For an example of a standalone barrier see Section 3.1.
Figure 2 shows the recursive exchange algorithm for the same parameters as chosen in Figure 1. The messages are first reduced (reduce_scatter) with a factor of four (meaning four tasks cooperate) and then with a factor of two, before being redistributed (via allgather) with factors of two and four. Recursive exchange on a node with eight tasks. (a) the initial state (b) after reduce_scatter with a factor of four (c) after reduce_scatter with a factor of two (d) after allgather with a factor of two (e) the final state, after allgather with a factor of four.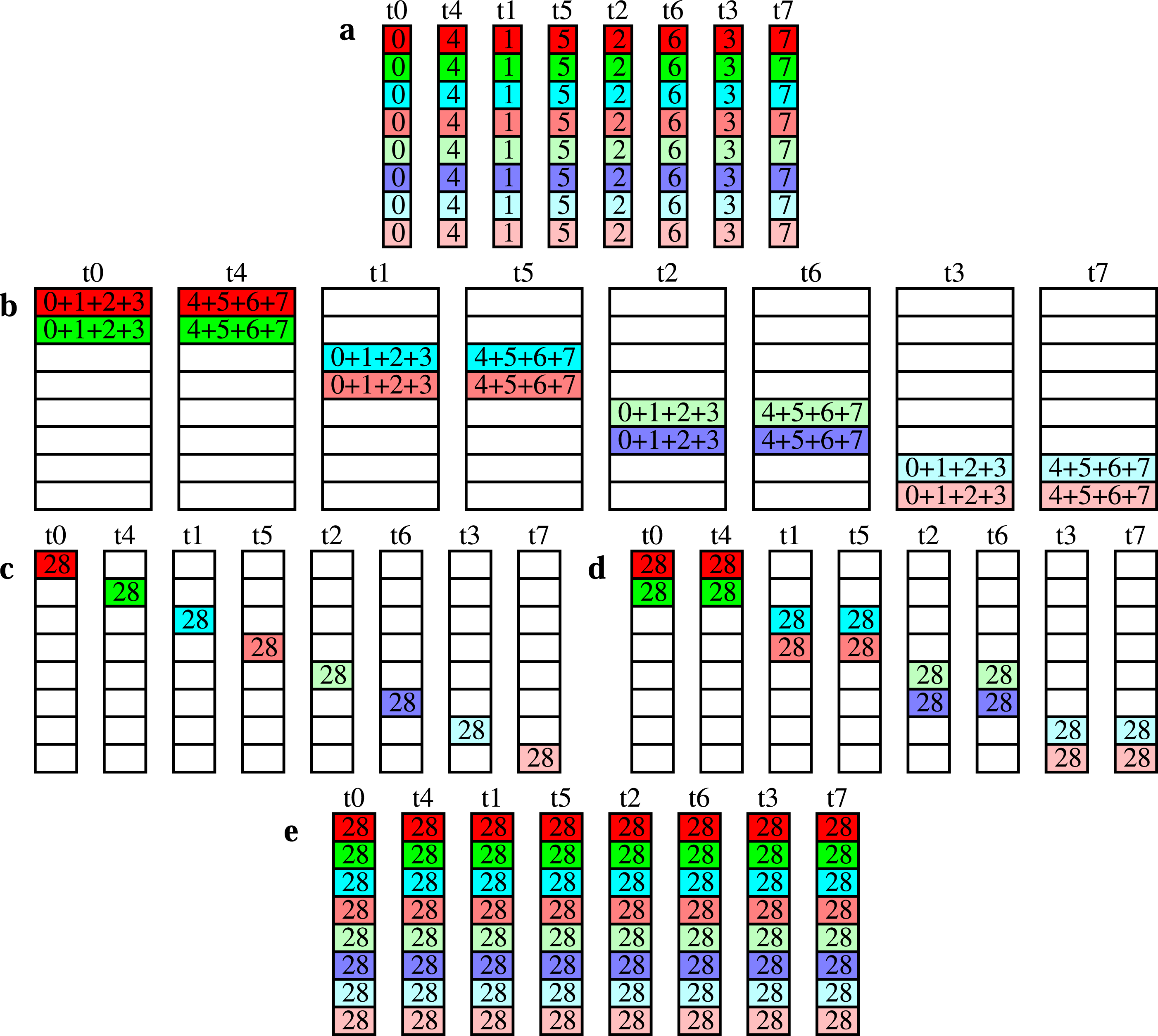
The vector of the messages to be reduced is split into separate parts, as indicated in Figure 2 as different rows with different colours. The parts do not need to have the same size. Currently, two message partitioning heuristics have been implemented: splitting the message into smaller messages of as equal size as possible, and using a fixed size (typically the cache line size) for the parts of the split message, except the last pieces. For the latter, one part being non-zero and all other parts being zero is a possible solution. In this case, our algorithm becomes identical to a tree reduce and broadcast with a flexible number of leaves.
If between reduce_scatter and allgather allreduce is called the algorithm is applied recursively. Since recursive exchange is recursive by itself there seems to be no new algorithmic option. However, in our implementation, at different recursion levels, different message partitioning heuristics can be applied.
The recursive exchange algorithm is straightforward to apply: the number of tasks is factorised into all of its prime factors, and then these prime factors (or combinations of them) determine the size of the exchange at each step of the algorithm. If these factorisations do not deliver an efficient variant of the algorithm (i.e., the number of tasks is a large prime number), and the cyclic shift algorithm (Section 2.2) cannot be applied, the MPICH / Open MPI implementation is called instead. Internally, both of these libraries follow the building blocks algorithm of Rabenseifner (Thakur et al., 2005) which arranges the reductions to groups of tasks of size 2 n .
The speedup compared to the libraries mentioned is not only due to the integrated barriers but also to the optimal cache usage for optimal factors (Section 2.1.3). As an example we take the allgather step where the data originally owned by one process is distributed by this process to the memory of the other processes in multiple steps. When distributed to the first other processes memory, the data read is present in the cache and reused when written to further processes. This is contrary to a popular simpler implementation known from the literature where every process collects all data from the other processes memory. Cached values cannot be reused then.
2.1.2. Inter-node communication
For our implementation of inter-node communication, we assume a fully connected network with potentially multiple communication ports per node, or a network which behaves in approximately the same manner. Similar to our intra-node communication algorithms, our inter-node allreduce is implemented in three phases: a reduce_scatter, followed by a call to a nested allreduce, and then an allgather, as shown in Jocksch and Piccinali (2023a). Although we only evaluate benchmarks with multiple MPI processes per node (Section 5), we demonstrate recursive exchange with only one process per node for illustration purposes.
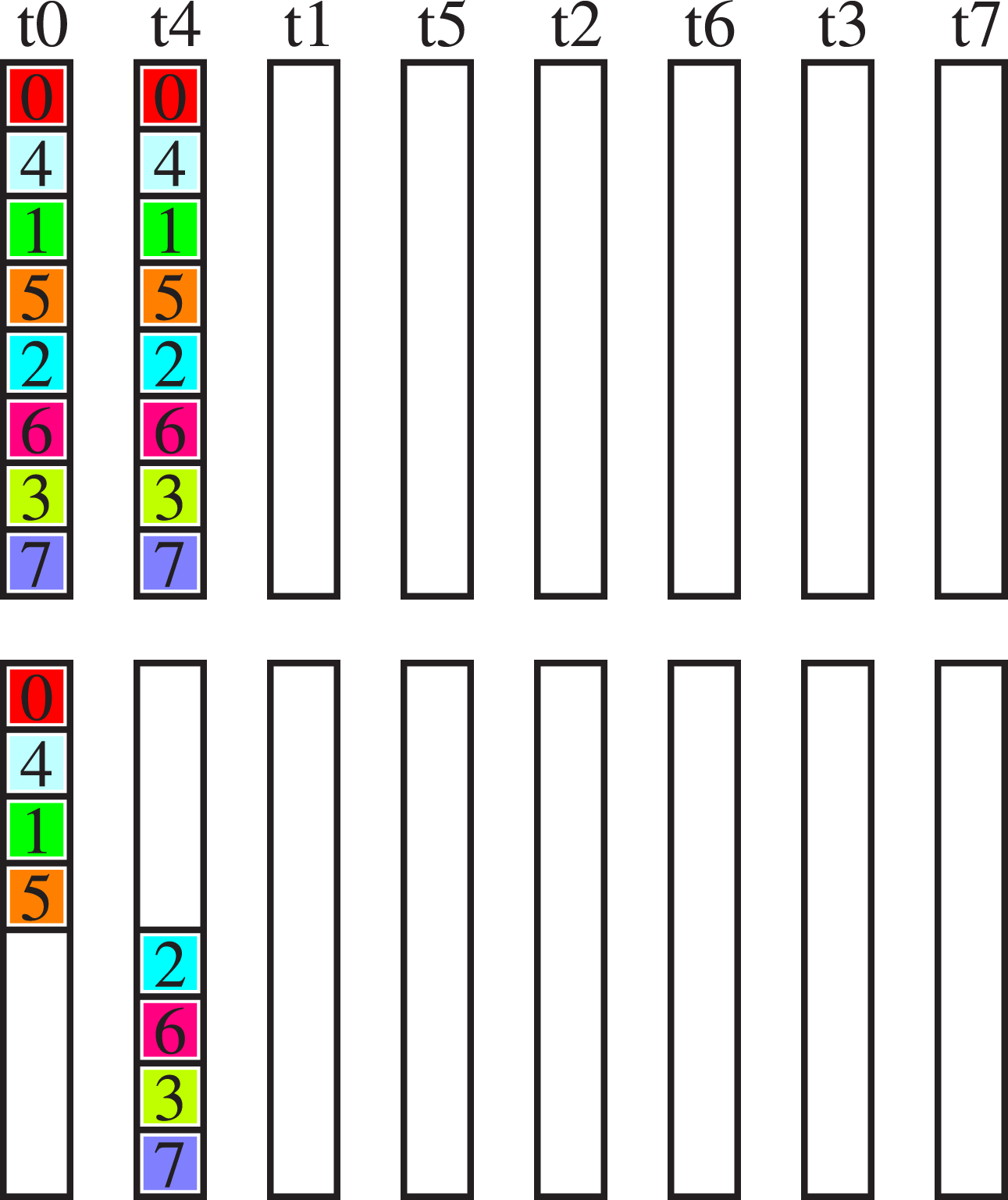
Figure 3 shows the recursive exchange’s algorithmic scheme for four nodes with one task per node, using a factorisation of {−2, 2, 2}. Algorithmic scheme depicting allreduce on four nodes with one MPI task per node; left: buffers, middle: nodes n0 to n3, right: script for node n0.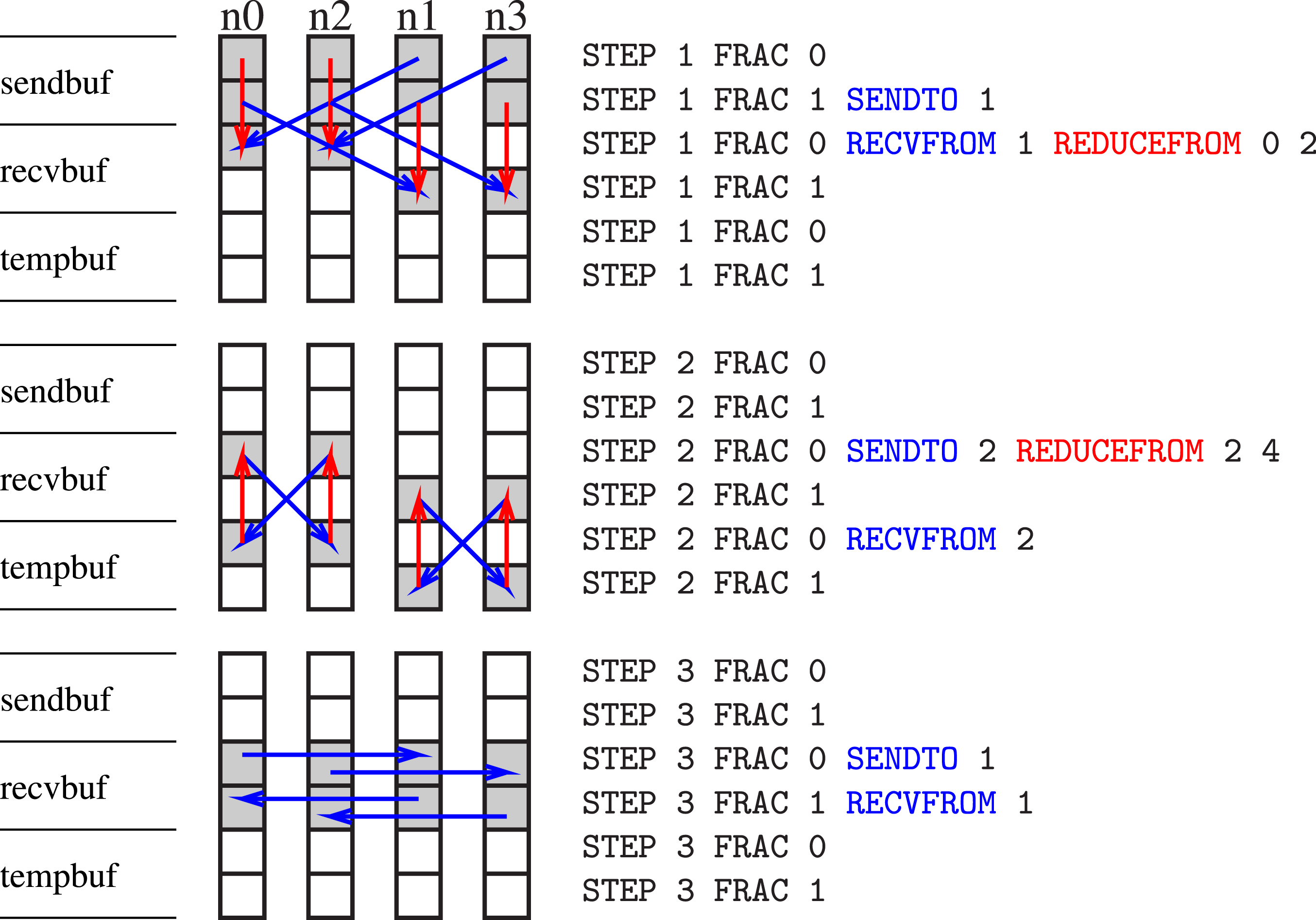
In Figure 3, each message is two boxes in length. In each column, the top two boxes represent each task’s send buffer (sendbuf), the middle two boxes the receive buffer (recvbuf), and the bottom two boxes a temporary buffer (tempbuf). On the right of the figure, the scheme is shown as a script for node zero, which is very similar to the script generated internally by our implementation in the algorithm setup phase. Each line corresponds to its box in the n0 column (left). There are three steps in the inter-node exchange, each indicated by the keyword STEP. The keyword FRAC describes the memory chunk, which is processed as follows: the first two lines 0–1 correspond to the send buffer, the second two lines 0–1 to the receive buffer, and the third two lines 0–1 to a temporary buffer. The keywords RECVFROM and SENDTO describe a non-blocking receive and send operation, respectively, with the number following being the partner’s MPI rank. For every step, sends and receives are scheduled and followed by a waitall. The step is finalised with a possible reduction operation, keyword REDUCEFROM. The numbers after the keyword specify from which lines the data is read, where the first number is the line of the data before the reduction operand and the second one is the line of the data after the reduction operand. The lines are counted from zero to five within the data vector (box).
We reiterate the three steps of our algorithm, while we discuss the message length for a data vector, assuming the overall size split into two equal-sized parts. The incomplete reduce_scatter step reduces the portion of the message managed by each process by a factor of two, corresponding to the factor of {−2} chosen in the setup phase of the algorithm. The following allreduce step (factor {2}) is implemented as allgather with reduction. The messages sent have the unmodified portion, and are reduced with redundant computation on the nodes. The final allgather step (factor {2}) then restores the message to its full size. Our implementation calls MPI_Irecv, MPI_Isend, and MPI_Waitall of the underlying MPI library.
For multiple tasks per node, the algorithm is split between the intra- and inter-node algorithms. The resulting algorithm has the following steps: a shared memory reduce_scatter step (Section 2.1.1), followed by a reduce_scatter step between nodes, an allgather step between nodes, and finally an allgather step in shared memory. The buffers we indicated as sendbuf and recvbuf in Figure 3 become temporary buffers between intra- and inter-node steps, as the memory layout between shared memory steps and inter-node steps differs and requires the data to be rearranged. As a consequence, the cyclic shift of the message vector for each task for the cyclic shift algorithm elaborated in Bruck and Ho (1993); Jocksch et al. (2021) can be done at the same time, and the recursive exchange has no preference over cyclic shift. If a node has multiple sockets or non-uniform memory, inter-node communication is done in parallel between sockets of the node, and shared memory portions of the algorithm allocate one shared memory segment per socket.
2.1.3. Parametrisation
Combinatorial number of factorisations for reduce_scatter / allgather algorithm.
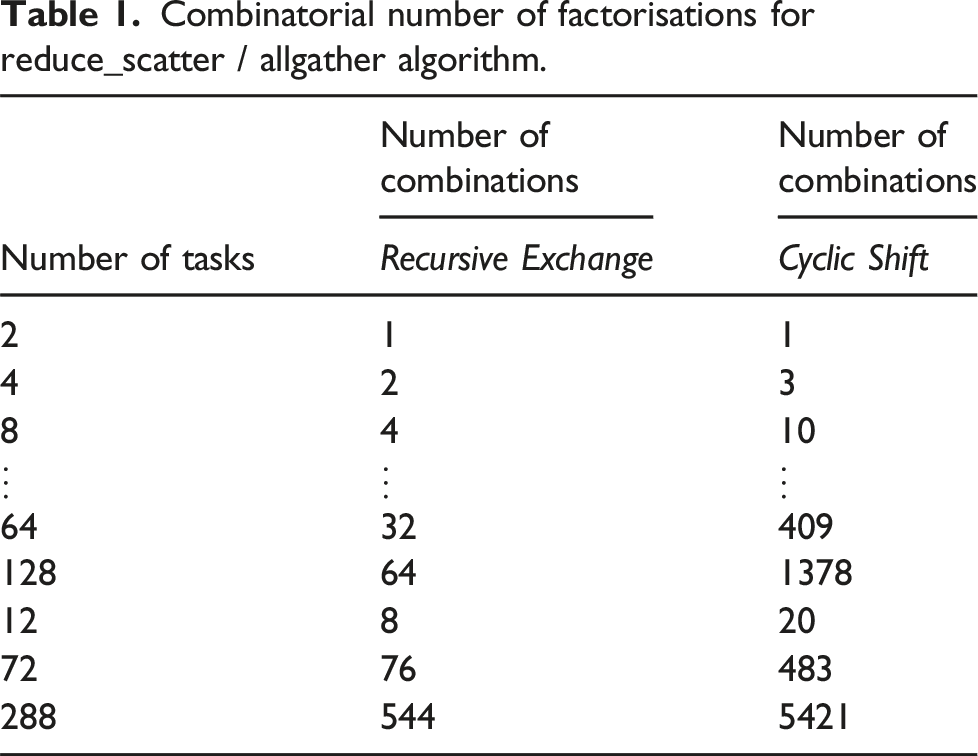
When trying to find optimal factor sets, additional restrictions apply. For intra-node communication, short messages should not be split into pieces smaller than the cache line size, as this would lead to cache devalidation when different tasks are writing into the buffers. Additionally, the size of the message produced at each step of the algorithm should not exceed the cache size to avoid cache misses. The algorithmic complexity of the integrated barriers should also be considered (Section 2.1.1).
For inter-node communication, the number of communication ports must be taken into account in the factorisation of the number of tasks, where each factor is the number of ports plus one. The network might behave in a way that the number of communication ports efficiently used is message size dependent. In general the order of tasks matters for the overall execution time of the algorithm, if the network is inhomogeneous with respect to bandwidth or latency.
2.1.4. In-place versus out-of-place algorithms
For intra-node communication, we utilise the same algorithms for out-of-place reductions as for the in-place versions described. The only difference is that the very first reduction operation copies the message from the send to the receive buffer; otherwise, all read operations are done for the send buffer and all write operations for the receive buffer. If the intra-node allreduce algorithms are used in combination with inter-node communication, the intra-node reduce_scatter and allgather phases remain the same as for the pure intra-node communication. The distinction is just that the data of the receive buffer is copied to the temporary buffer for inter-node communication, rearranged, and copied back after the inter-node communication. For performance reasons another algorithm might be used for inter-node communication (Section 2.3).
2.2. Cyclic shift
The cyclic shift algorithm only works for commutative operators, due to its cyclical movement of data between tasks. It has been implemented by Bruck and Ho (1993) for inter-node communication, and by Li et al. for intra-node communication in a variant called the dissemination algorithm (Li et al., 2014). Our existing inter-node cyclic shift is described in Jocksch et al. (2021). We note that the recursive exchange algorithm for one MPI task per socket (node) requires less memory copies than the cyclic shift algorithm.
Figure 4 shows the data flow between the processes for the cyclic shift algorithm and seven MPI tasks. Cyclic shift on a node with seven tasks (t0–t6).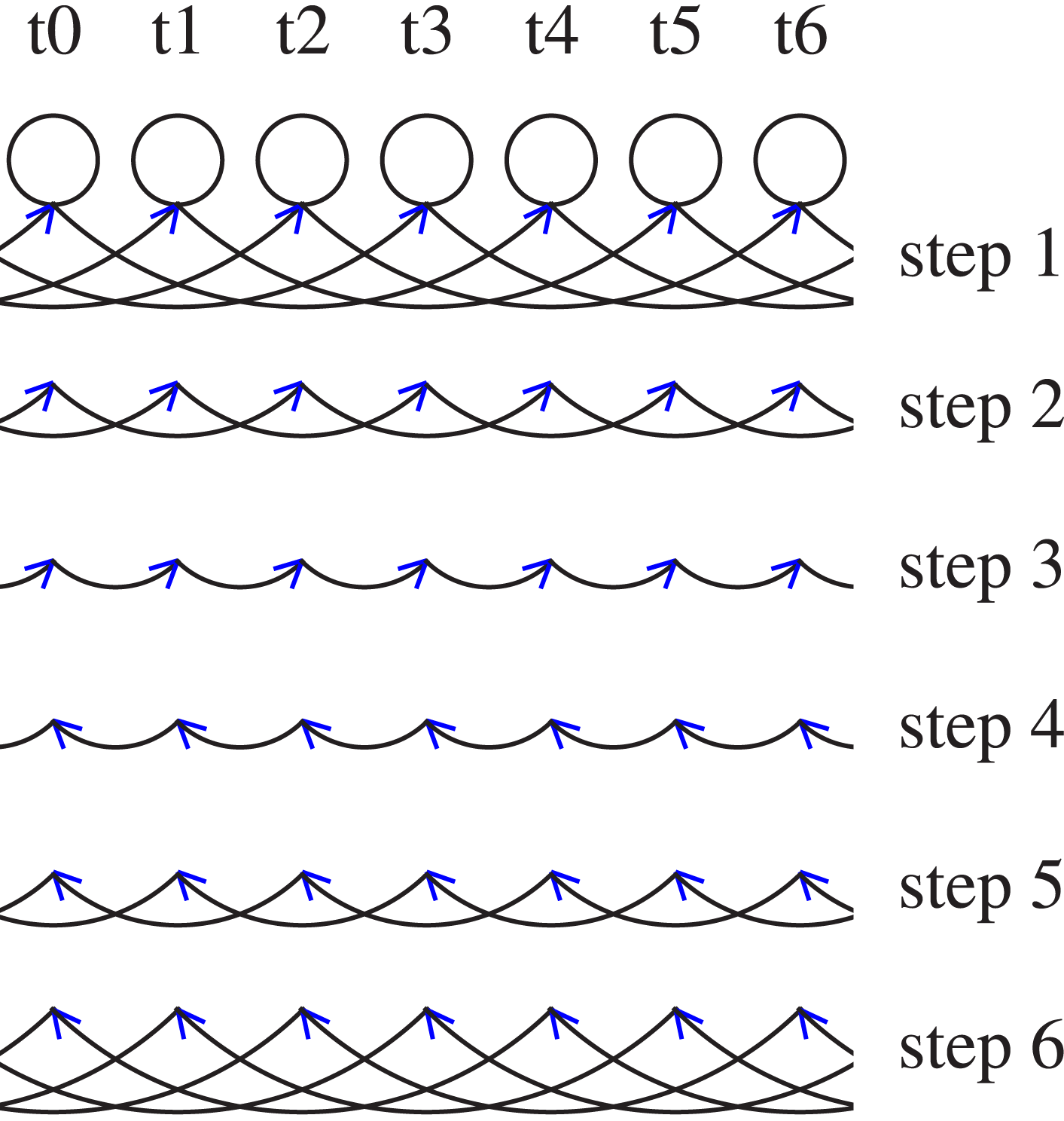
2.2.1. Intra-node communication
Figure 5 shows the algorithmic scheme of our cyclic shift algorithm for intra-node communication. In contrast to the implementation of Bruck and Ho (1993) for inter-node communication, we do not apply any cyclic shift of the message vectors before and after the actual communication. This is possible since there is no strong need to coalesce messages. For transfer in memory, messages can be split in many pieces, as long as no pieces are smaller than the cache line size. The key feature of the algorithm is that the product of factors for reduce_scatter or allgather can be larger than the number of tasks, such as {2, 2, 2} for 7 tasks as is represented in Figure 5. As a consequence, the number of rows is not halved or doubled in the first reduce_scatter step (a → b) or the last allgather step (f → g), respectively. Cyclic shift on a node with seven tasks, all with factors of two: (a) the initial state (b) 4-way reduce_scatter (c) 2-way reduce_scatter (d) after reduce_scatter steps (e) 2-way allgather (f) 4-way allgather (g) the final state, after allgather steps.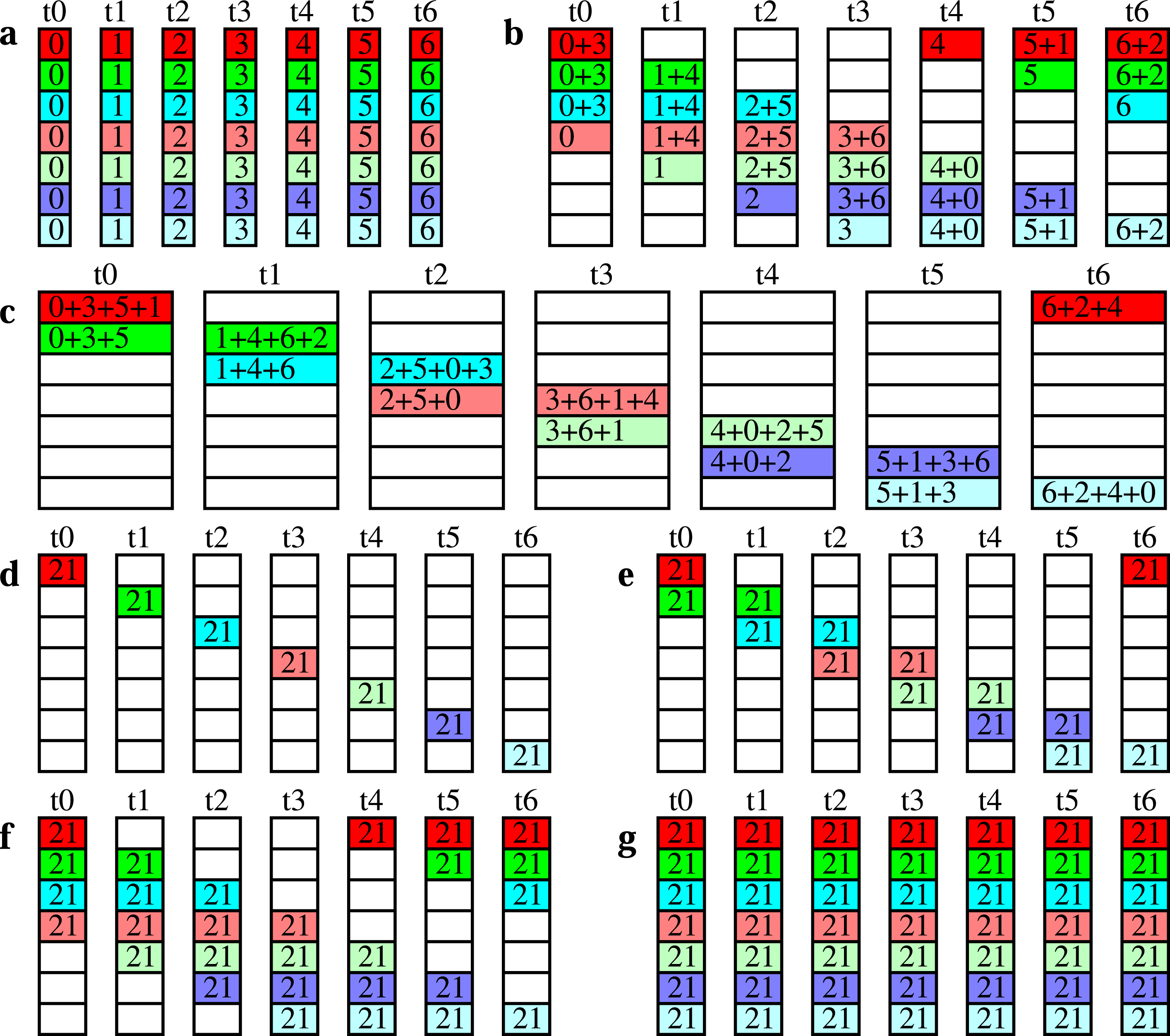
To reiterate, the algorithm is implemented here as a reduce_scatter step followed by an allgather step, allowing for the factors to be flexible and the barriers integrated. When there is no data to reduce, our reduce_scatter or allgather operation becomes a dissemination barrier (Hoefler et al., 2006; Nanjegowda et al., 2009). Thus, the reduction operation is implemented similarly to its OpenMP counterpart (Mohamed El Maarouf et al., 2023; Speziale et al., 2011) or any shared memory reduction (Lubachevsky, 1990). The allgather operation is implemented as the reversal of the reduce_scatter operation, where each task distributes its message to all other tasks.
The recursive application feature of our allreduce implementation is applied for multi-socket nodes and small messages. For multi-socket nodes, cyclic reduce_scatter operations are performed independently on the sockets first, and then the reduce_scatter is executed cyclically between sockets. Allgather operations are then applied between sockets and on-socket as the third and fourth steps, respectively. For short messages, the outer cyclic shift uses fractions of the message size which have at least the size of a cache line. The inner cyclic shift is applied to the smallest messages and resolved before continuing on to the outer part of the algorithm.
2.2.2. Parametrisation
The cyclic shift algorithm can be set up with many different factorisations. For eight tasks there are ten options: {2, 2, 2}, {2, 3, 2}, {2, 4}, {3, 2, 2}, {3, 3}, {4, 2}, {5, 2}, {6, 2}, {7, 2}, and {8}. They include the options for recursive exchange. For cyclic shift, the original order of the factor sets have to be reversed for the reduce_scatter step, but are used in forward order for allgather. For more examples of cyclic shift factors, see Table 1.
In contrast to recursive exchange, we do not see any obvious correlation between number of tasks and the combinatorial number of algorithmic options. If we consider the allreduce operation being constructed from reduce_scatter and allgather without any allreduce part in the middle, the total number of options for the complete allreduce is the square of the numbers in Table 1, since reduce_scatter and allgather can be executed with different factors. The allreduce version (with a possible incomplete reduce_scatter, allreduce and allgather), discussed for inter-node communication (Section 2.1.2), provides additional options.
2.3. Tree algorithm
The recursive exchange algorithm with the data layout shown is good for intra-node communication, but necessitates an additional memory copy step before and after any inter-node communication. Therefore, we consider the on-node allreduce operation as a sequence of reduce and broadcast operations. The shared memory algorithm has the same number of computational operations. Figure 6 shows the alternative data layout which sacrifices data locality, but avoids the additional memory copy steps. Tree reduction in shared memory, colours (and numbers 0–7) indicate the different MPI tasks, vertical data vectors of tasks t0–t7; a → b represents the first step, c → d represents the second step. Last step of tree reduction in shared memory on two sockets per node, colours (and numbers 0–7) indicate the different MPI tasks, vertical data vectors of tasks t0–t7; for first step see Figure 6.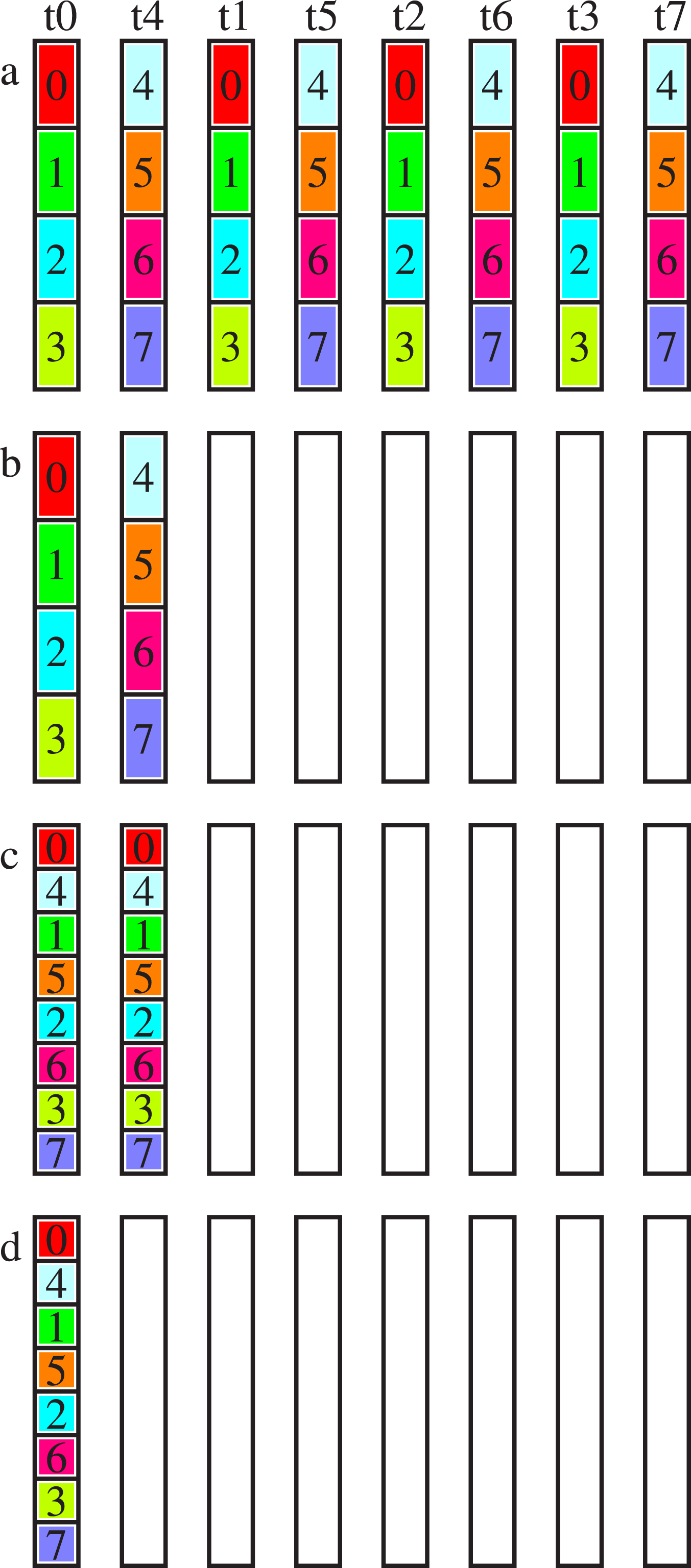
2.4. Cyclic copy-in reduction
If a copy-in phase is required and the message size is large, a combined copy-in and reduction is efficient (Figure 8). Copy in (top) and reduction operations (middle and bottom), + equals reduction operator, colours (and numbers 0–3) indicate the different MPI tasks, horizontal data vectors, adapted from Jocksch and Piccinali, 2023b.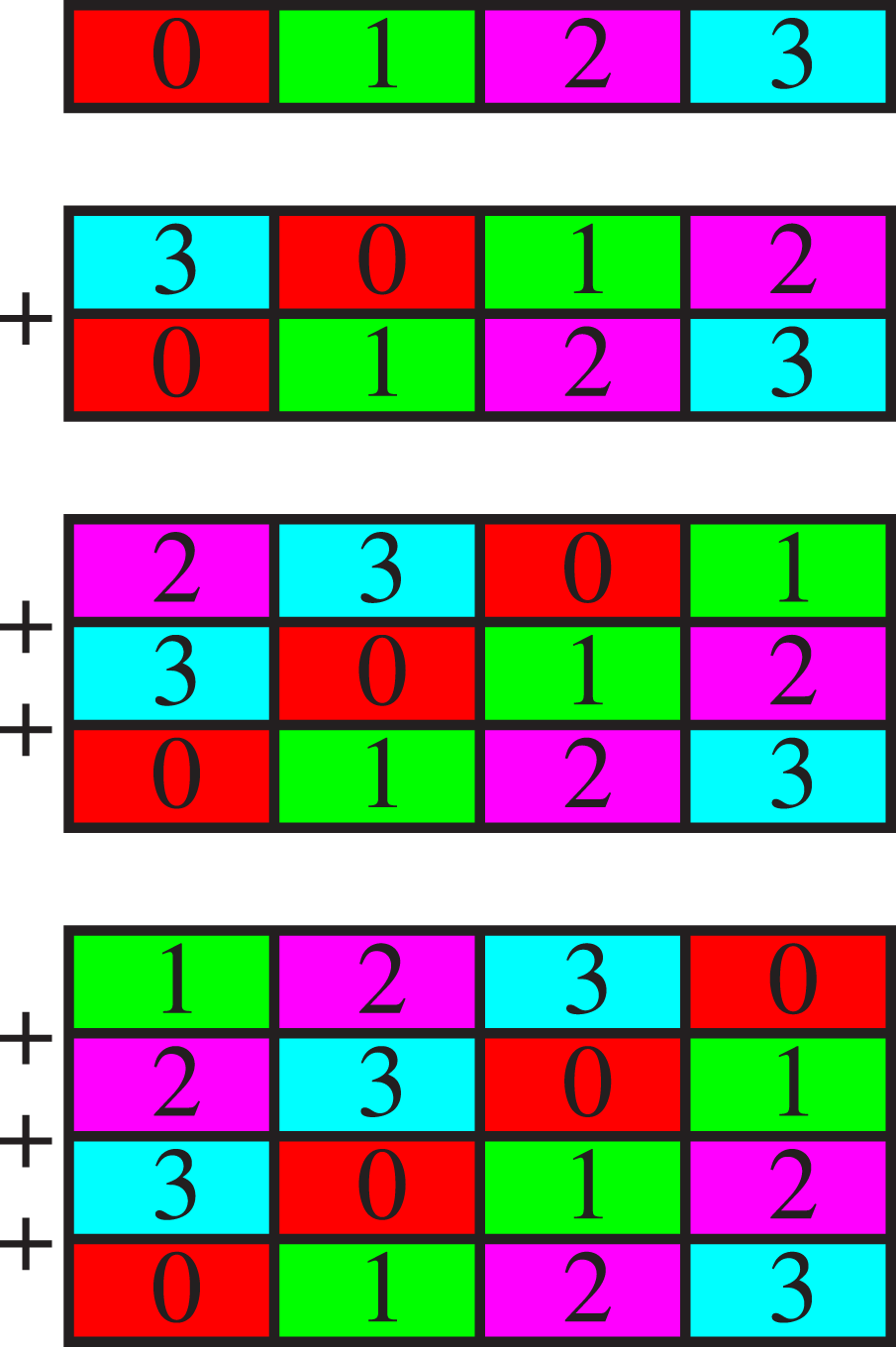
2.5. Other collective operations
The shared memory allreduce algorithms can be applied straightforwardly to other collective communications, such as reduce_scatter and allgatherv (the different phases of the allreduce algorithm). The banded structure of the data in Figures 2 and 5 requires a data copy operation to and from the reduce_scatter’s and allgatherv’s receive and send buffers, respectively. Furthermore, for the reduce_scatter operation, a temporary buffer of the size of the send buffer is required. In the special case of a radix equal to the number of tasks, the reduce_scatter algorithm does not require this temporary buffer. Instead, all data is copied and reduced in the receive buffer of every task directly. The broadcast and reduce collective communications can be obtained by replacing the reduce_scatter step with a scatter operation, and the allgather step with a gather operation, respectively. An alternative is the tree allreduce algorithm (Section 2.3) which consists of a reduce and a broadcast phase already.
3. Hardware mapping
The algorithmic schemes are mapped onto (potentially hierarchical) multi-socket hardware with the aim of facilitating maximum data locality. If required, reductions are performed on GPU memory, where the number of kernel invocations on the GPU is considered and minimised.
3.1. Barrier implementation
Every task’s shared memory segment is utilised to store the barrier flag counters, to better coordinate and facilitate synchronisation. The implementation details of the dissemination barrier are highlighted below in Listing 1.

The array shmem contains pointers to the flags of the different tasks, where indices are assigned cyclically, and thus index 0 is always the own flag. This flag is incremented in every step of the barrier, and is then compared with the flags of the other processes. The instruction memory_fence_store(); and memory_fence_load(); are memory barriers if necessary for the parallel architecture.
3.2. Translation of the algorithm
Colour code of assembler listings.
For illustration, we have chosen {−2, −2, 2, 2} as factors for the on-node allreduce and the reduce_scatter - allgather approach. Between nodes, the factors are also {−2, −2, 2, 2}. For our example, 1024 elements with a size of eight bytes were selected; more performant factorisations with more complicated code exist. The assembler code is written for task zero (i.e. node zero and task on the node zero). The instructions MEMORY_FENCE_STORE and MEMORY_FENCE_LOAD are memory fences for parallel execution on multi-core nodes.
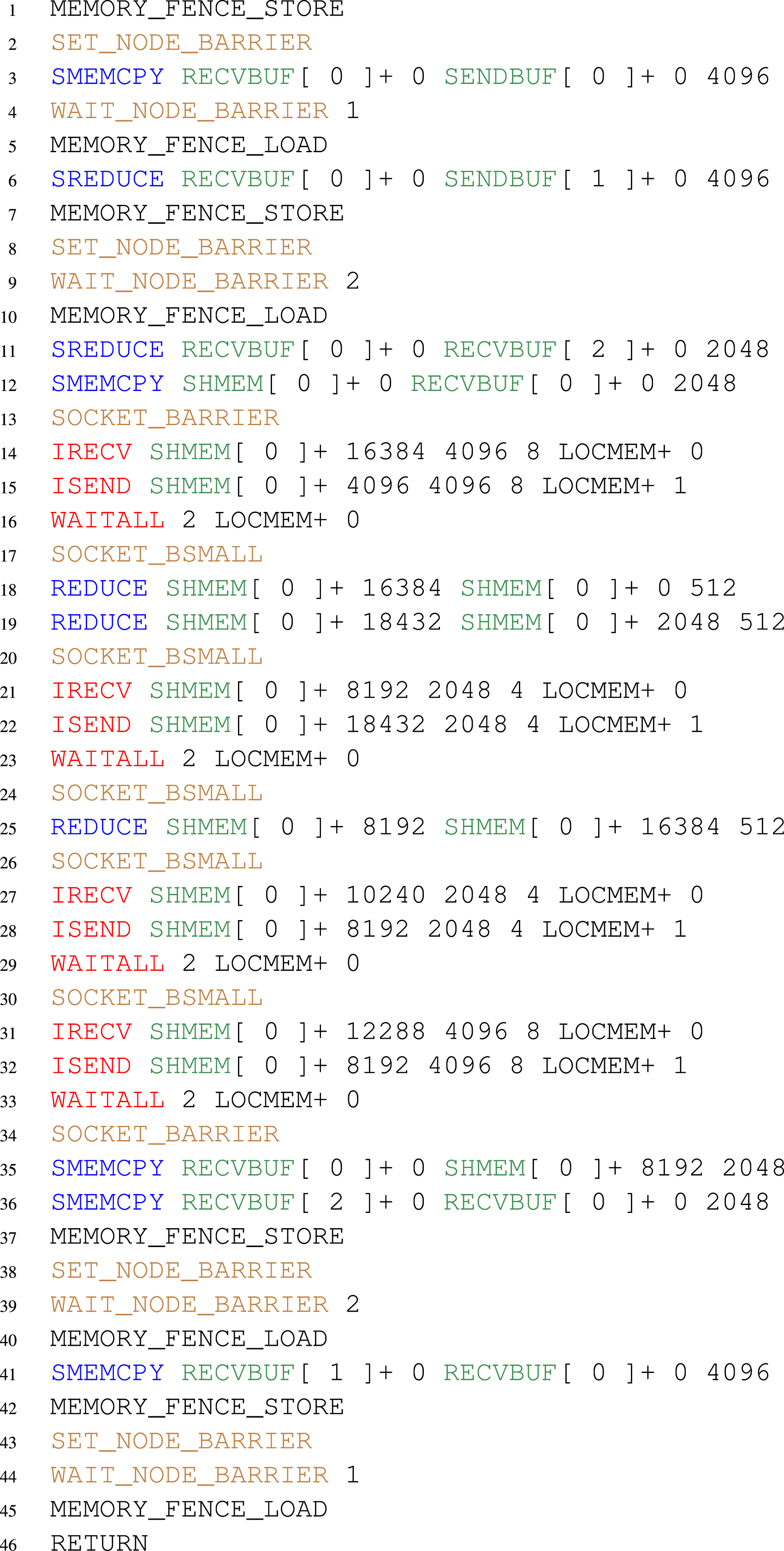
Memory copies and reductions in a serial way are specified with SREDUCE and SMEMCPY, respectively, where SENDBUF, RECVBUF, and SHMEM are the send buffers, receive buffers and temporary shared buffers of the node, respectively, the numbers in brackets are the task numbers of the memory, the numbers added are the offset in the buffer, and the last number is the size of the memory operation. The barrier flag of the task itself is incremented with SET_NODE_BARRIER, while the test for the barrier flags of other tasks of the node is done with WAIT_NODE_BARRIER 1, “1” stands for tasks one. MPI point-to-point communication with MPI_Isend, MPI_Irecv, and MPI_Waitall is represented with ISEND, IRECV, and WAITALL, where LOCMEM represents a local memory buffer used for the MPI ‘request’ handle. The REDUCE operations are reduction operations executed in parallel. The keyword indicates that at the same time other tasks on the node execute reduction operations on neighbouring memory chunks. Therefore, explicit memory barriers SOCKET_BARRIER and SOCKET_BSMALL are required. In our case both do the same thing: a dissemination barrier on the whole node. Typically the former acts between all tasks on the socket, and the latter on all tasks on the sockets which participate in parallel memory copies or reductions. The end of the execution is indicated with a RETURN statement. The assembler code is translated into bytecode, which is later executed.
Part of this bytecode reflects memory copy and reduction operations, incrementing and reading of barrier flags, MPI point-to-point communication with MPI_Isend, MPI_Irecv, and MPI_Waitall, as well as CUDA kernel calls. For the kernel calls, the parameters are stored in GPU memory and passed as a pointer to the kernel, which is one single copy / reduce kernel in the whole implementation. Consecutive operations are fused to a batch of GPU operations for a single kernel invocation. Any barrier, send, or receive operation limits the fusion of copy and reduce operations.
Thus, the assembler code for maximum performance on CPU or GPU differs not only in the factors for the algorithm and possible recursion or pipelining, but also has device-specific considerations for barrier flag handling. For the CPU, the check for barrier flags is done immediately before the corresponding memory copy or reduction operations. For the GPU, all flags are checked together (and possibly with a dissemination algorithm) before a batch of operations is executed on the GPU. Listing 3 shows the assembler code of an on-node allreduce for task 0 for factors {−4, 4}. All memory copy and reduction operations are executed within one CUDA kernel. Memory fence operations are not necessary for the GPU allreduce.

3.3. Mapping on the GPU
In a typical application in an MPI library, the send and receive buffers of the different tasks are not visible to the other tasks by default. This can be done with libraries (e.g., XPMEM for the CPU) or the CUDA runtime for the GPU. However, the execution of these library functions introduces certain time overheads. It is therefore more efficient to copy the data to / from a temporary buffer for small messages.
The memory copy, reduce, and send / receive operations can be executed on either the CPU or the GPU. The architecture supports CPU access to GPU memory and GPU access to CPU memory. We do not discuss this feature in depth here since it is particular to Grace-Hopper architecture Fusco et al. (2024). Both CPU and GPU executions have advantages: The CPU code has lower latency, while the GPU code has higher bandwidth. The CPU and GPU may be more physically separated or closely integrated, depending on the architecture.
The translator tries to put consecutive memory copies and reductions into a single kernel call. If this is not possible, since our kernels need to be embarrassingly parallel with respect to CUDA threads, the fallback translation is separate kernels. Send and receive operations utilise the GPU aware point-to-point communication of the underlying MPI library.
4. Persistent versus blocking interface
Our algorithms are part of a library on top of any MPI 4.0 library which overwrites functions using the MPI profiler hook. Thus, for the persistent interface the standard MPI_Allreduce_init call is overwritten with our fast implementation where the original routine is used as fallback for unimplemented features. The initialisation of our persistent collective communication is relatively expensive (Section 5). To reduce the number of initialisation calls, an alternative blocking interface is provided.
The blocking interface is most suitable for applications which require different message sizes in every allreduce call, but still always use the same processes. The algorithms are lazily initialised in their first call for their best fit parameters, and are slightly adapted before execution within the MPI_Allreduce call. The message size is just the multiple of the one of the algorithmic set up, plus padding. After the algorithms initialisation and usage they are freed with communicator destruction. In order to avoid part of the expensive set up when a simulation is restarted, we store all bytecodes to disc and read them in upon re-initialisation of the algorithm.
For the intra-node communication algorithms introduced, the blocking interface is limited to message sizes without the need of padding only, or an additional memory copy is required if incorporated into inter-node communication, since padding is, in general, not possible for send and receive buffers passed to the MPI_Allreduce function. For intra-node communication, send and receive buffers of the different processes need to be made accessible for other processes on the node. This is done with the XPMEM library. In order to be efficient, the pointers are cached using a tree data structure, as in the MPICH library.
5. Benchmarks
Benchmarks were performed on a HPE Cray EX system with dual-socket nodes with 64-core AMD EPYC 7003 processors, and on a HPE EX system with nodes equipped with four NVIDIA Grace-Hopper chips (72 CPU cores each). On both architectures, the MPI libraries MPICH 4.2.0 and Open MPI 5.0.2 were used for comparison. In all tests, algorithm parameters were chosen empirically.
We perform one node allreduce measurements for potential best and worst case numbers of MPI tasks per node. The best case corresponds to the number of tasks being equal to all cores per CPU or node, while the worst case is represented by the largest prime number fitting the number of cores. The choice of the prime number is also motivated by the case that one or more cores are occupied for other purposes.
We measure the performance of allreduce, reduce, and broadcast on one node, and of allreduce between nodes. Benchmarks on the GPU are also included for comparison with NCCL 2.20.3-1 with the AWS plugin. The benchmarks are concluded with an evaluation of our algorithms on the CP2K application.
5.1. Standalone communication
For all benchmarks, the messages were split inside the algorithm into equal parts, but with a minimum size of 64 bytes (cache line size). For messages less or equal than 64 bytes in length, the whole message was treated as one segment (Section 2.1.1). The pipelining and recursive call features are not exploited here for a more direct comparison with other implementations. For maximum performance, a suitable and possibly expensive individual parameter selection step in the initialisation phase would be necessary.
Parameters of the allreduce algorithm for different hardware configurations.
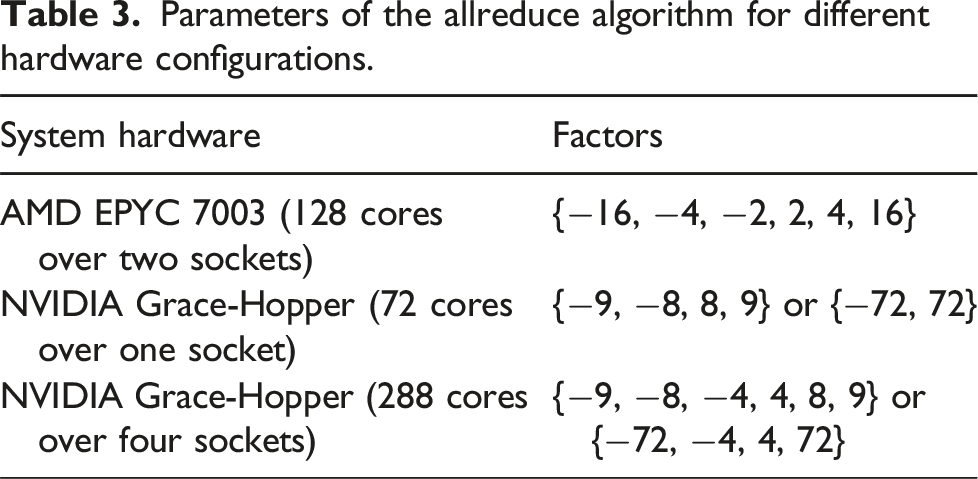
Figure 9 shows the the performance on the AMD EPYC processor. Allreduce on 1 node with 128 MPI tasks per node (top) and 127 MPI tasks per node (bottom), AMD EPYC.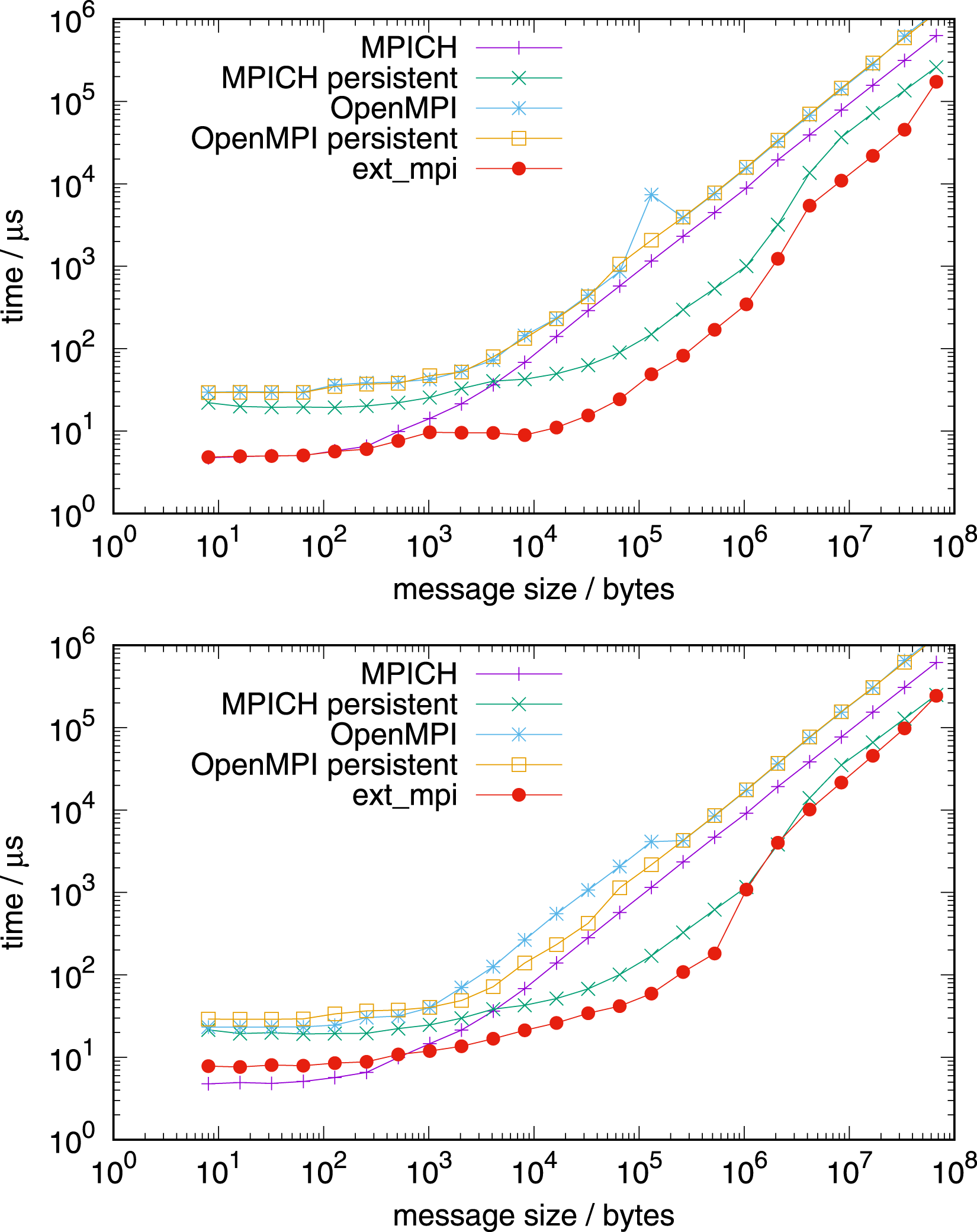
NVIDIA Grace CPU benchmarks are done on a single CPU (Figure 10), a single node (Figures 11 and 12), and on multiple nodes (Figure 13). Allreduce on 1 NVIDIA Grace CPU 72 tasks (top) and 71 tasks (bottom). Allreduce on 1 node with 4 NVIDIA Grace CPUs 288 tasks (top) and 283 tasks (bottom). Allreduce on 1 node with 4 NVIDIA Grace CPUs, in-place operation, 288 tasks. Allreduce on 4 nodes, top: with 128 MPI tasks per node, AMD EPYC, bottom: with 288 MPI tasks per node, NVIDIA Grace.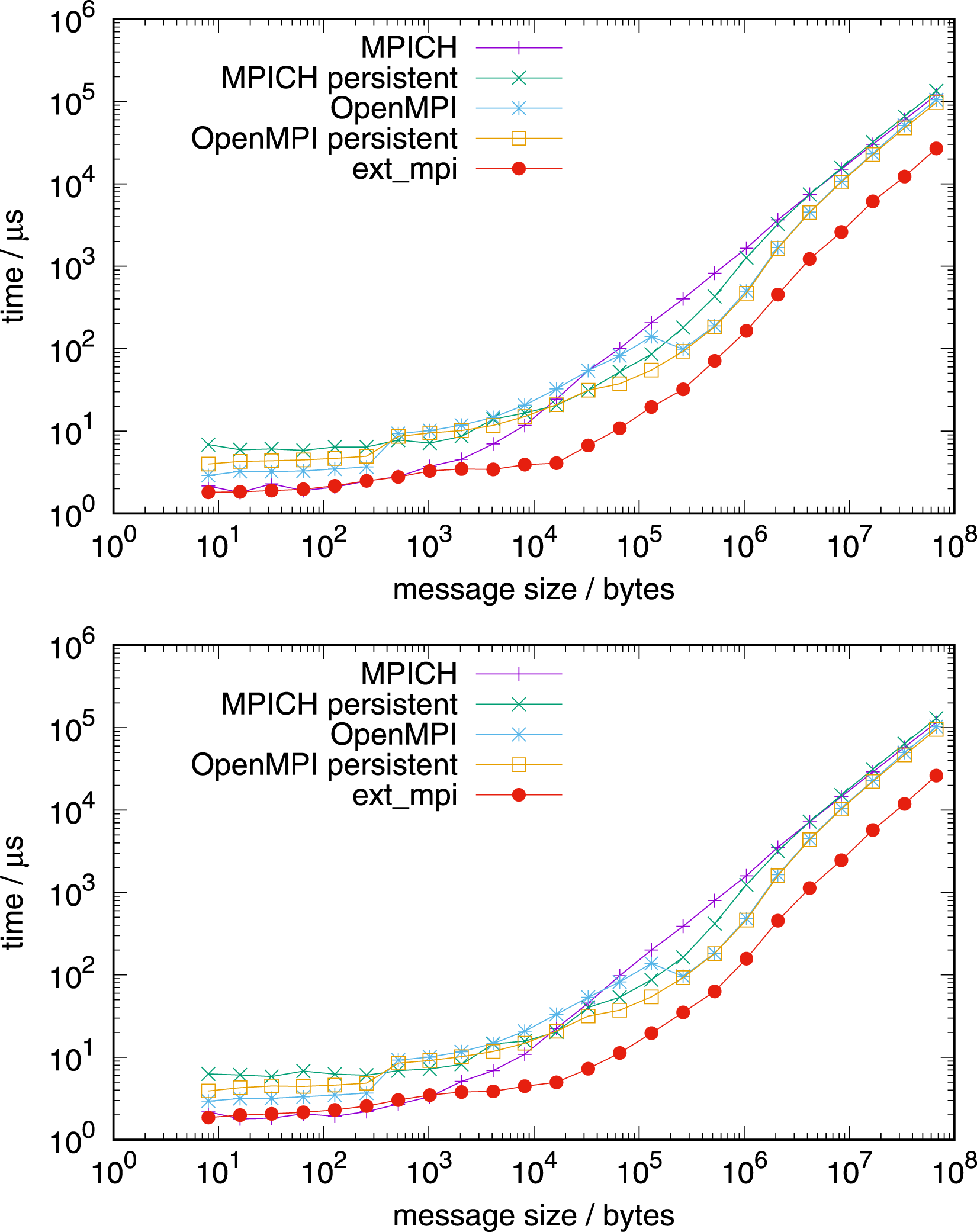
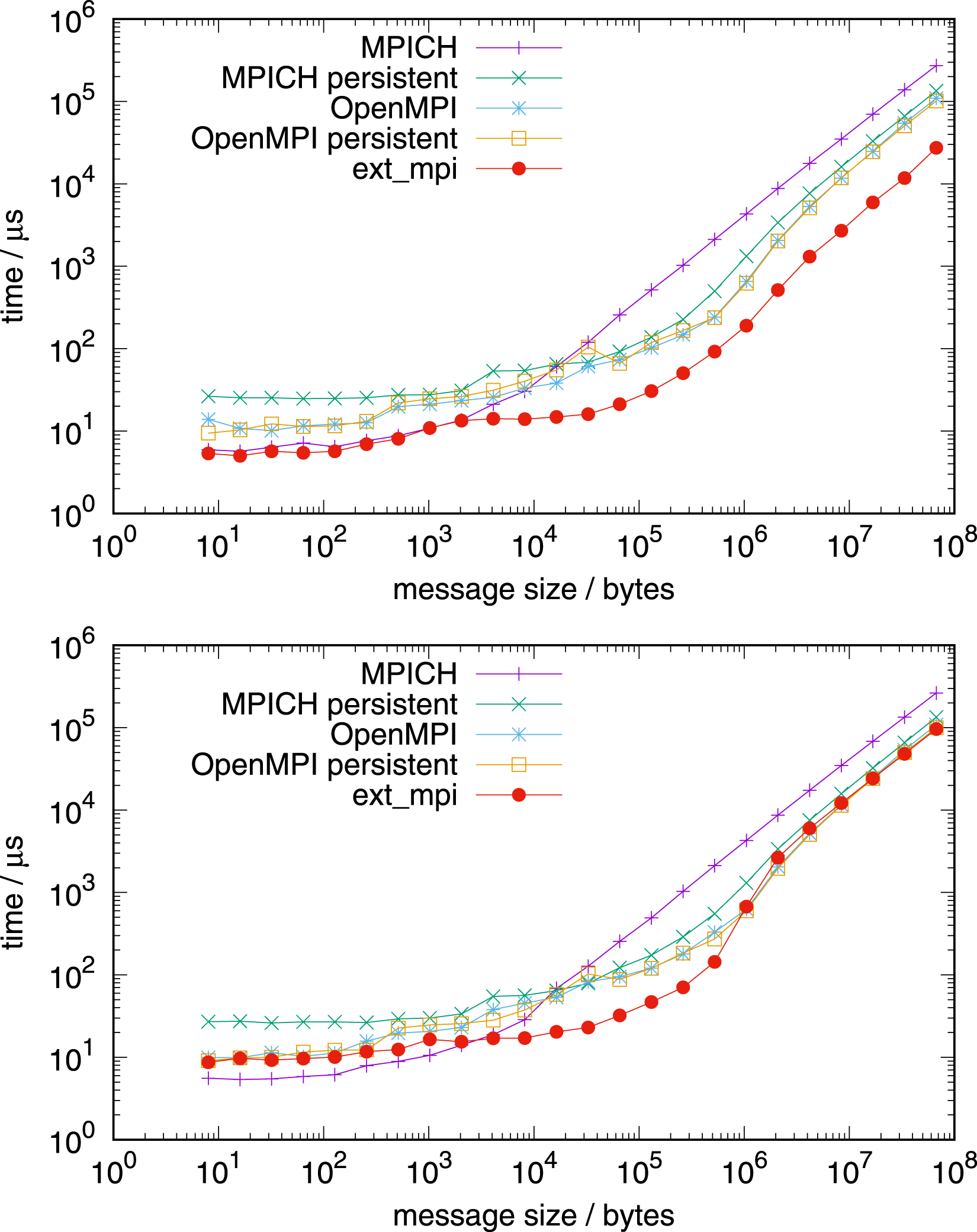
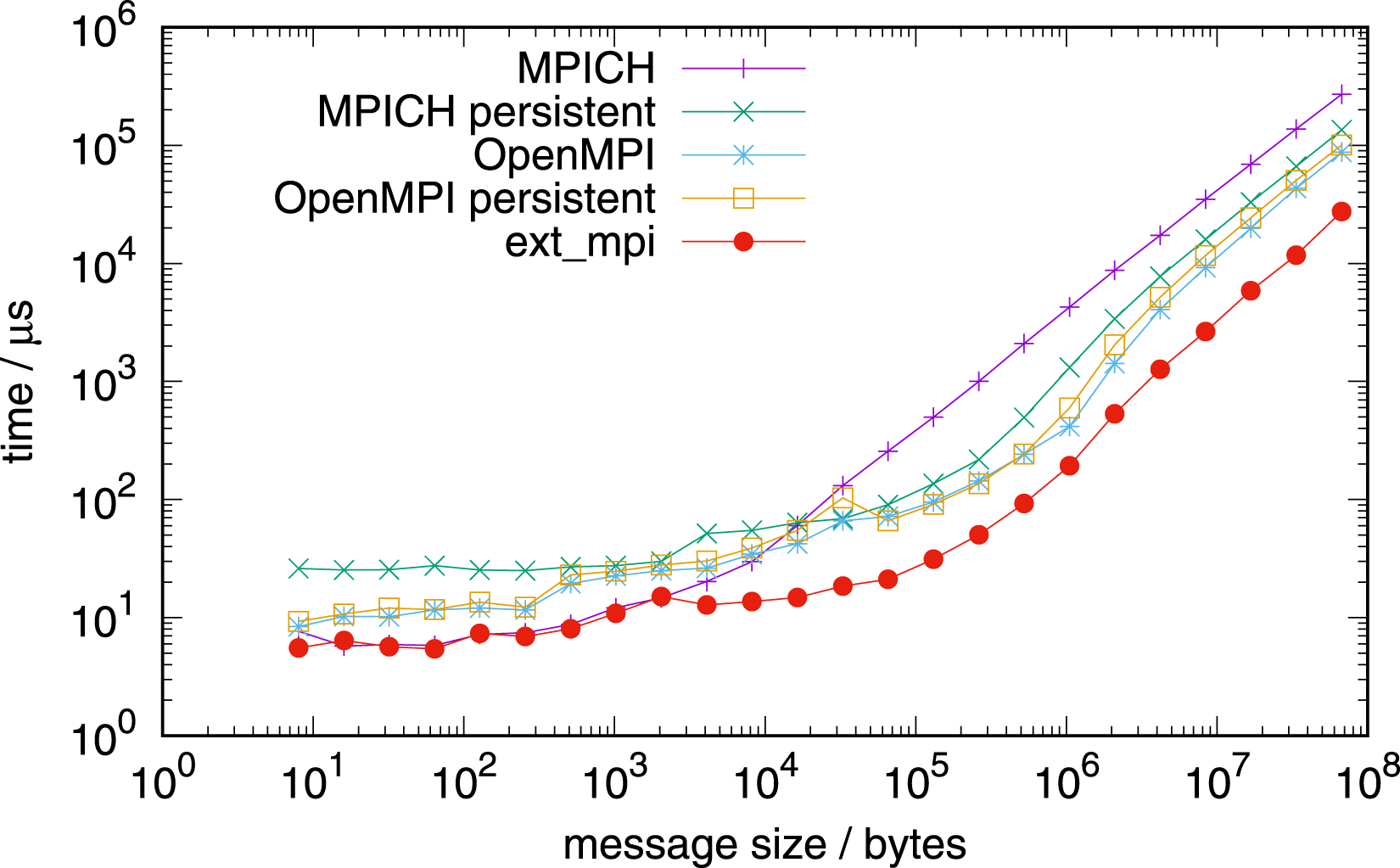
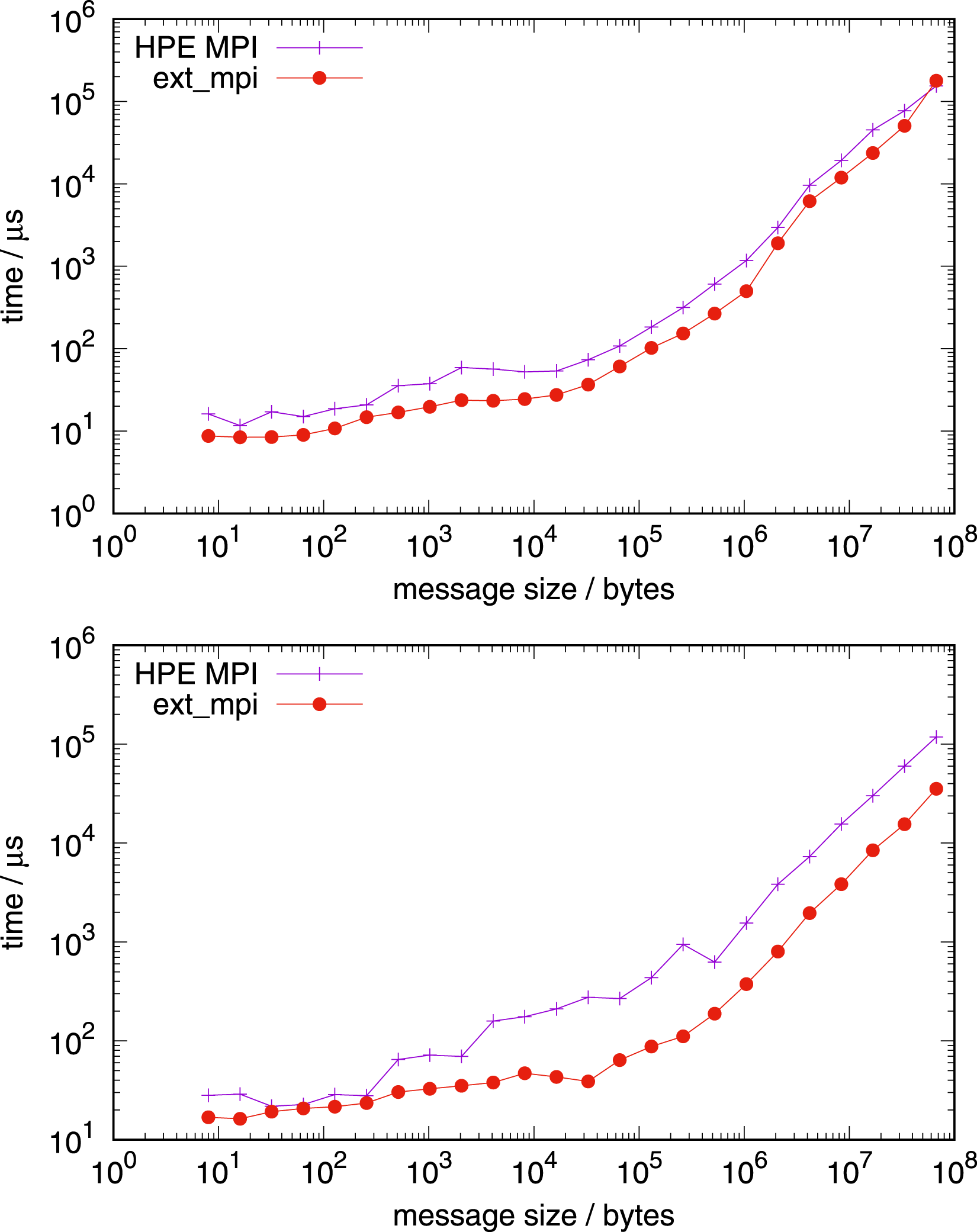
Figure 13 shows the performance comparison for communication for four nodes on both architectures, with 128 tasks per node on the AMD EPYC processor and with 288 MPI tasks per node on the NVIDIA Grace processor. For both tests in Figure 13, the network used is Slingshot with libfabric 1.15.2.0. Additionally, we use the vendor communication library, HPE MPI (based on MPICH), instead of Open MPI and MPICH from earlier tests. The factorisation of the intra-node part of allreduce is identical to those of the one node benchmarks, however the inter-node part uses parameters for latency optimal communication: allreduce based on allgather with a reduction following.
On AMD EPYC and NVIDIA Grace, two and four sockets were considered, respectively. For each socket, the inter-node communication algorithm is set up with the factor of four. The blocking version of HPE MPI allreduce (a persistent one is not present in this version) underperforms relative to our implementation on both architectures. An exception is very small messages, where our implementation is equally fast. In principle, we achieve even higher performance for long messages for bandwidth optimal intra-node communication, using a complete reduce_scatter followed by allgather, but the difference is marginal (not shown). Please note that on NVIDIA Grace, the vendor’s MPI was used with CMA, not XPMEM, due to current limitations.
Figure 14 shows the cost for the allreduce initialisation on the Grace-Hopper system. Allreduce initialisation on 1 socket (72 tasks) and 1 node (288 tasks), NVIDIA Grace.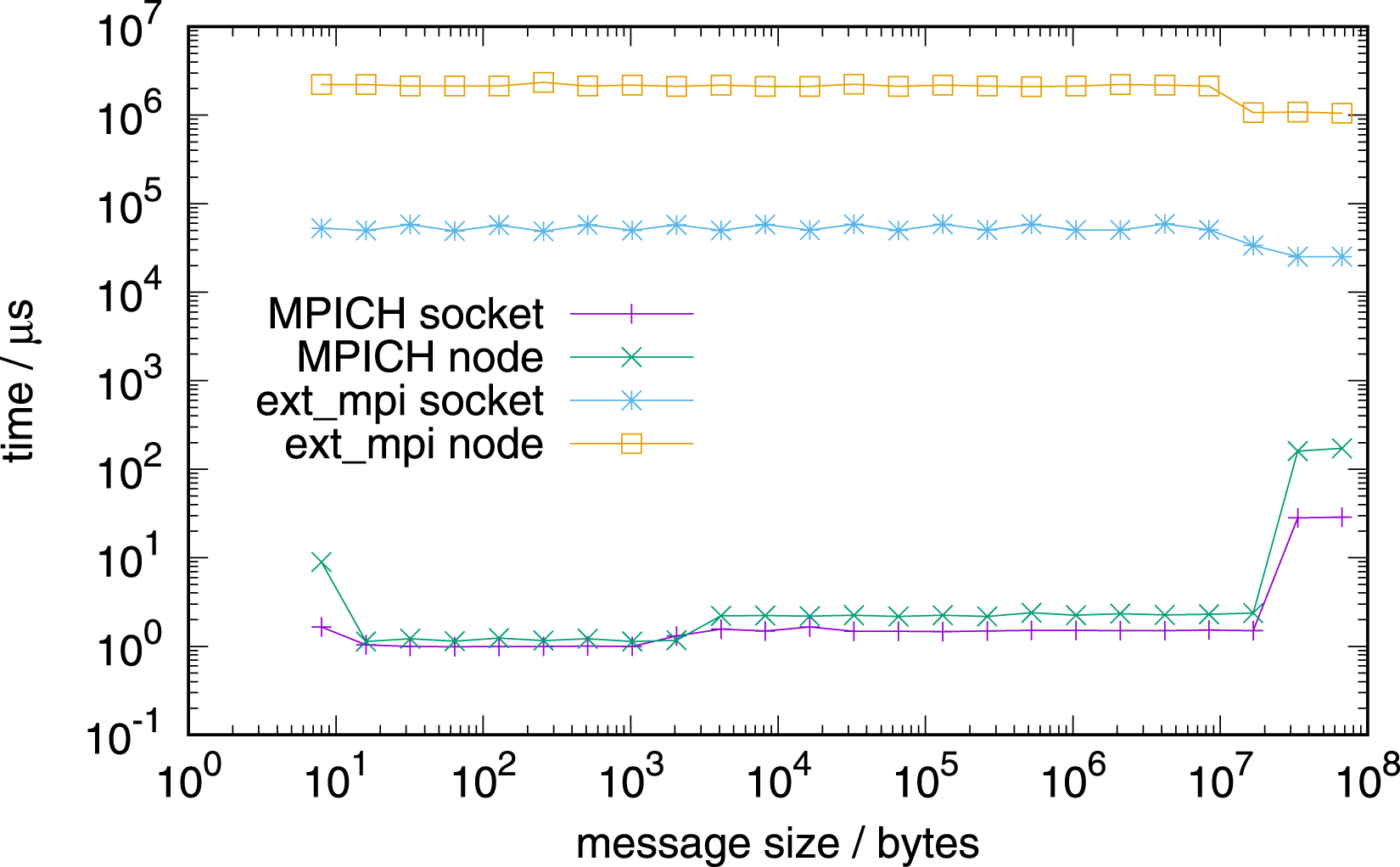
Figures 15–17 show benchmarks for reduce and broadcast on the different architectures. Reduce (top) and bcast (bottom) on 1 node with 2 AMD EPYC CPUs, 128 tasks. Reduce (top) and bcast (bottom) on 1 node with 4 Grace CPUs, 288 tasks. Reduce (top) and bcast (bottom) on 1 socket with 1 Grace CPU, 72 tasks.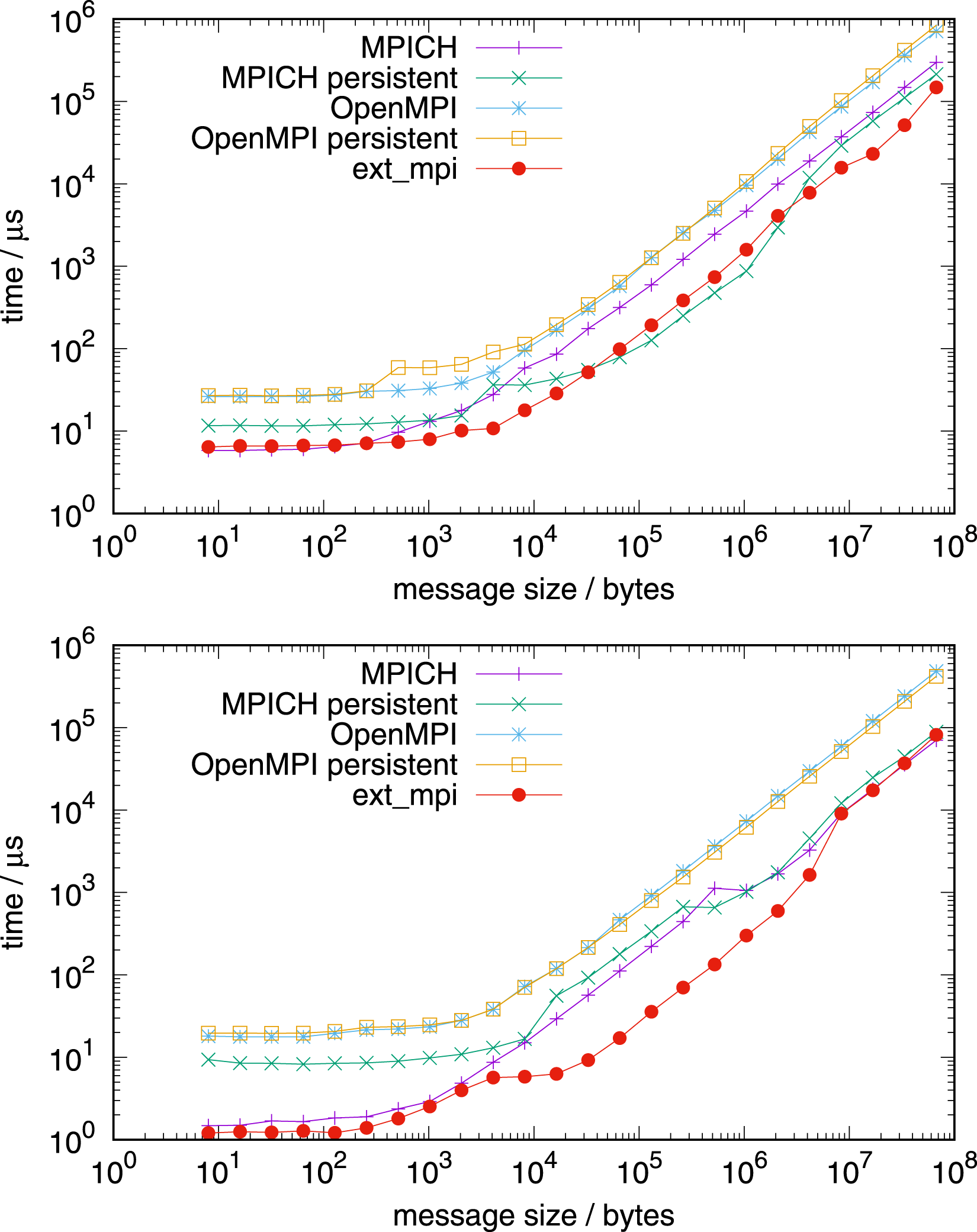
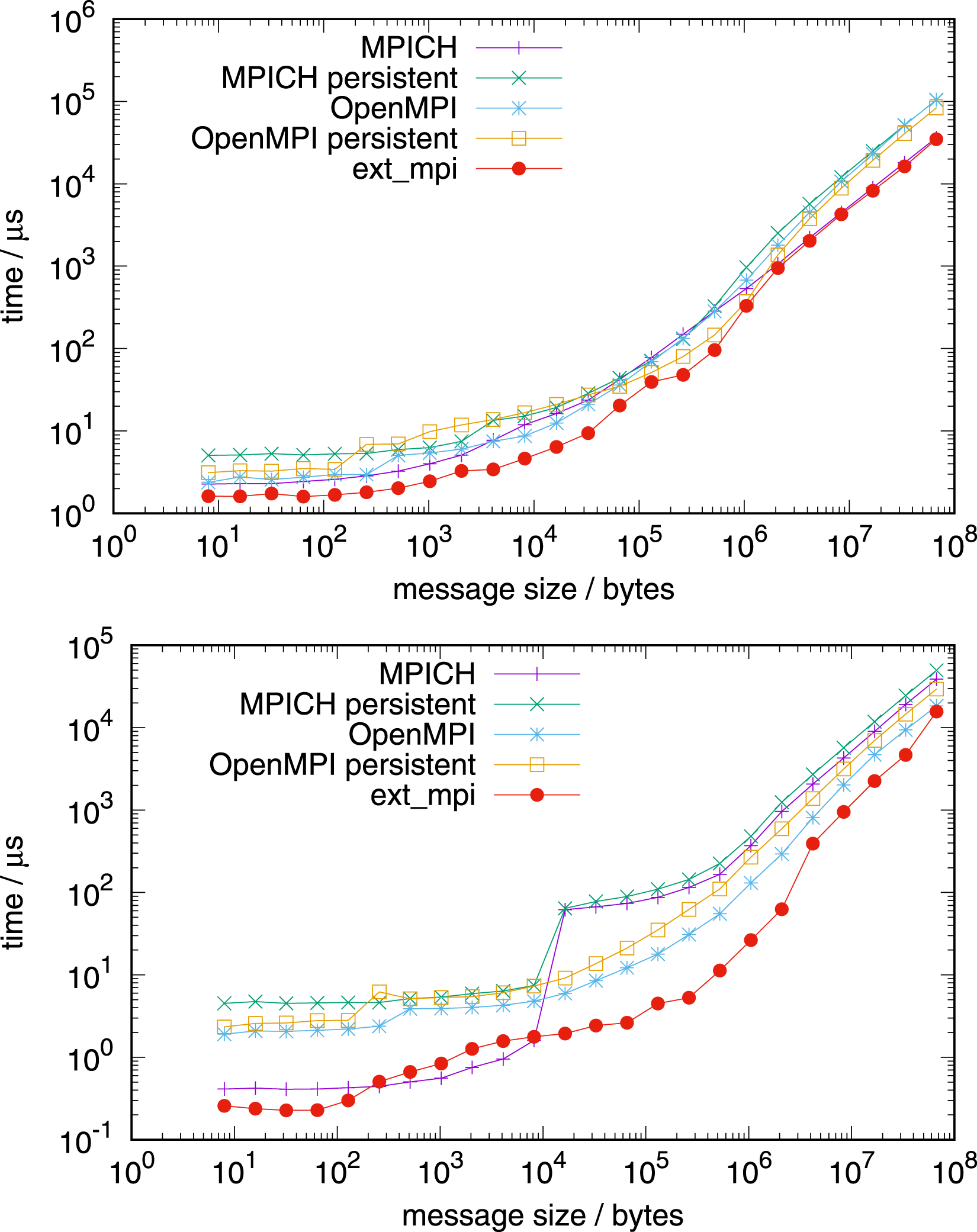
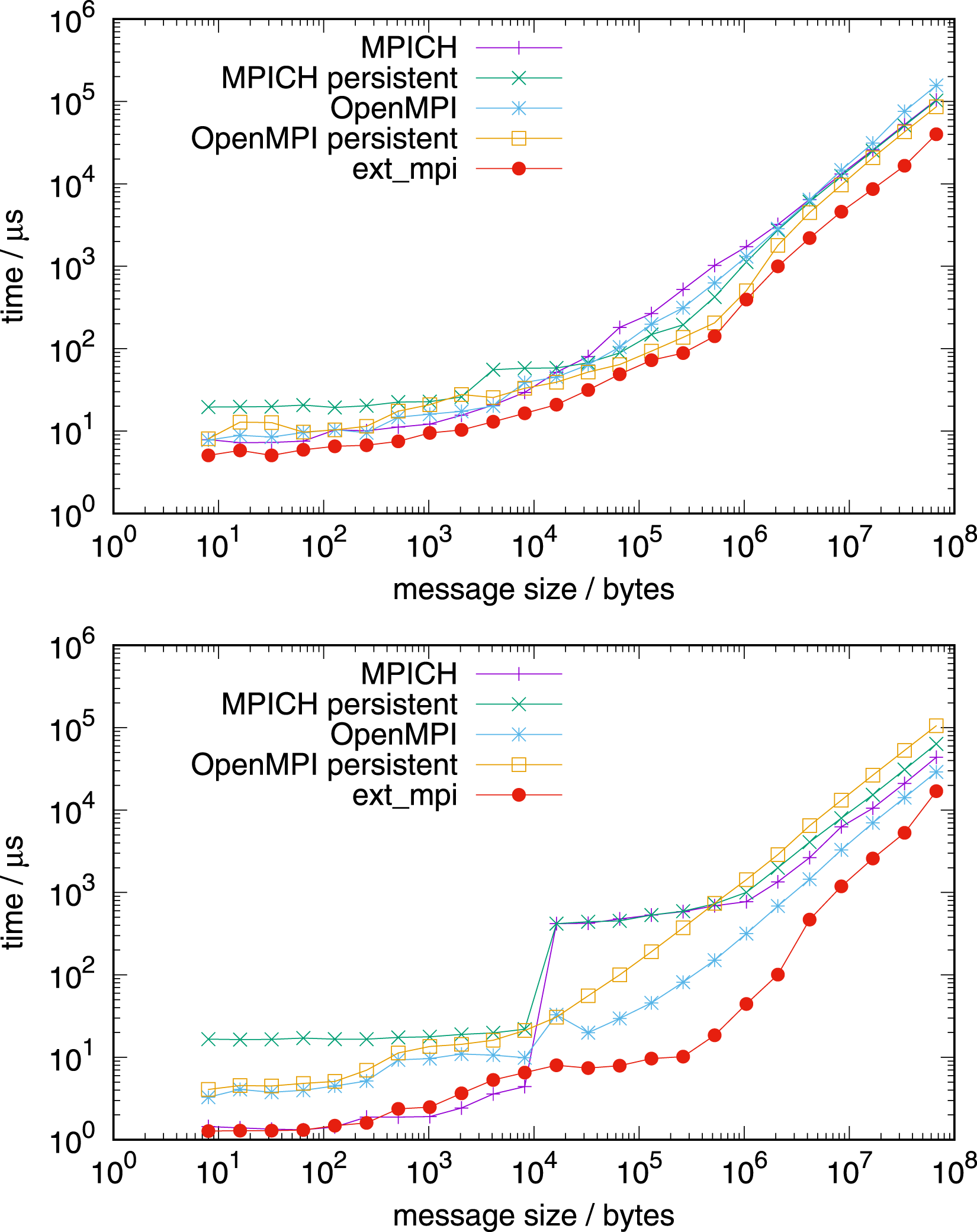
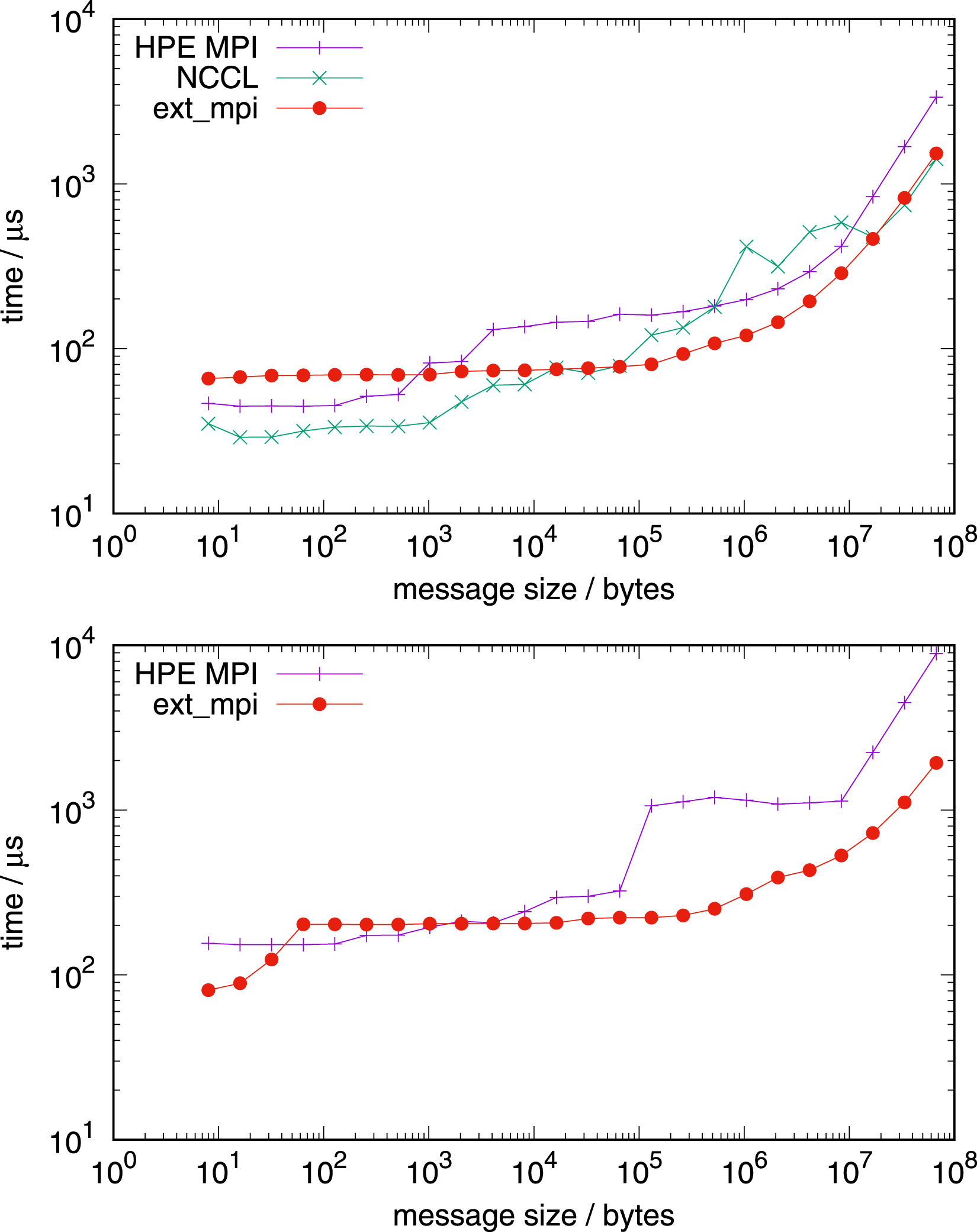
Figure 18 (top) shows the timings on the GPU part of a single Grace-Hopper node using one MPI task for each of the four GPUs. Allreduce 1 node, 4 Hopper GPUs, 4 tasks (top) and 16 tasks (bottom). Allreduce 4 nodes, 4 Hopper GPUs per node, 4 tasks per node (top) and 16 tasks per node (bottom); high uncertainty in the timings of NCCL for message sizes from 103 bytes to 107 bytes.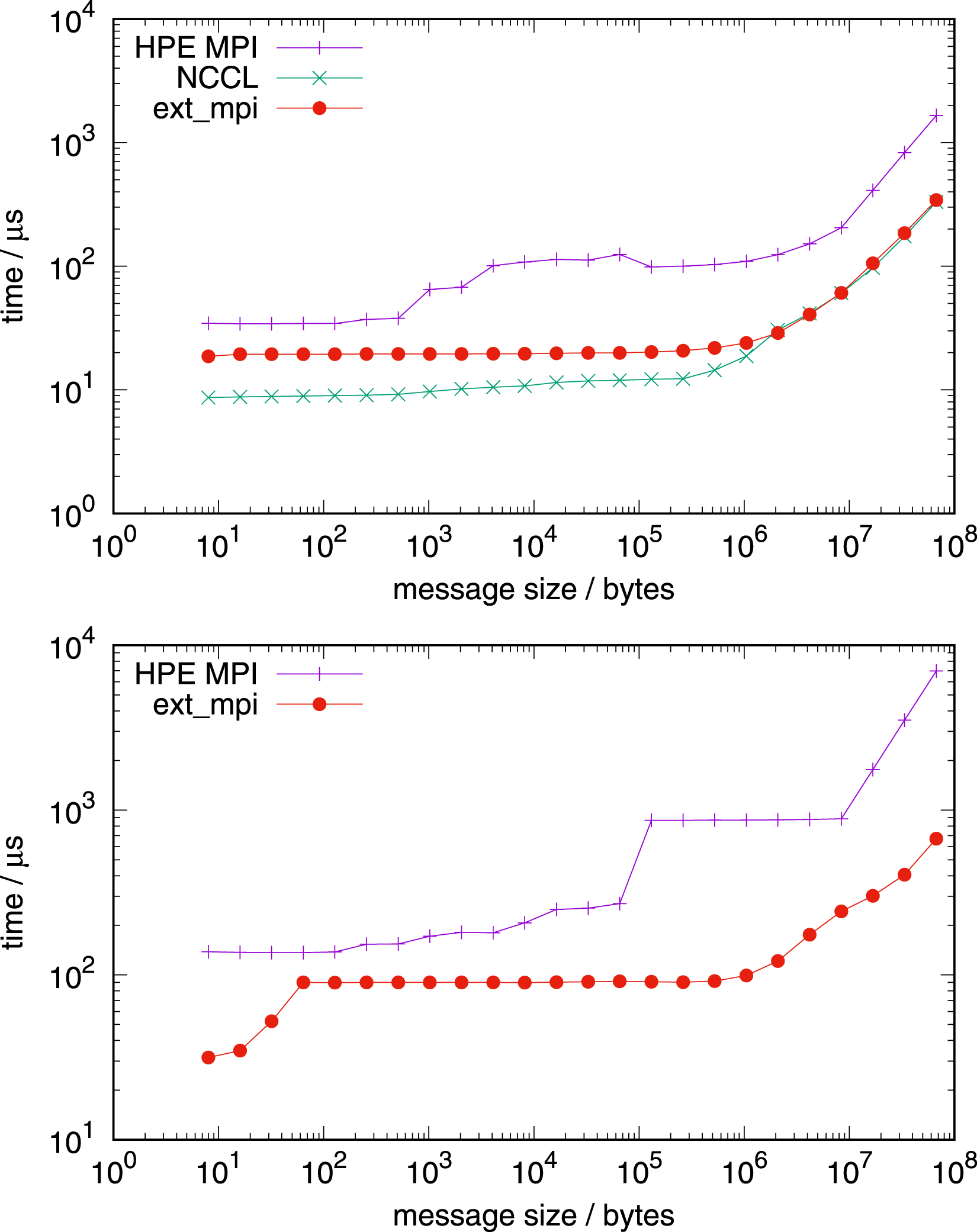
5.2. Application
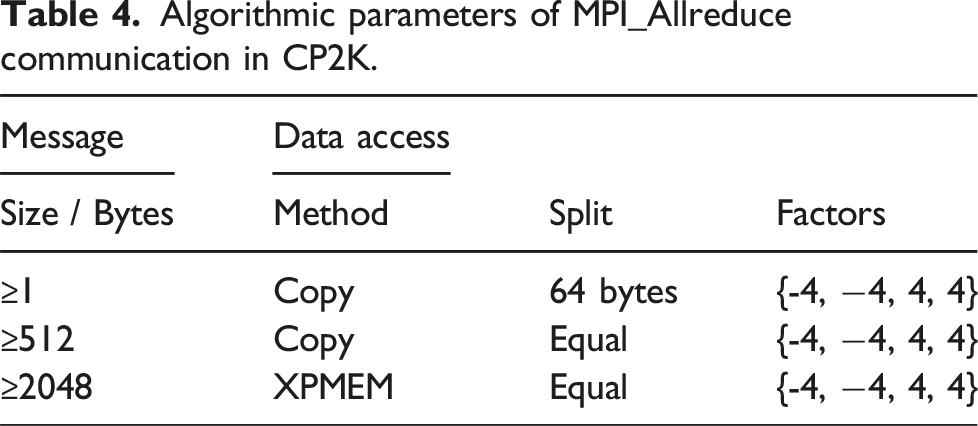
Algorithmic parameters of MPI_Allreduce communication in CP2K.
Algorithmic parameters of MPI_Reduce_scatter_block communication in CP2K.
Average performance of MPI collective communication in CP2K and overall runtime, ±values indicate the corrected sample standard deviation s for 15 samples.
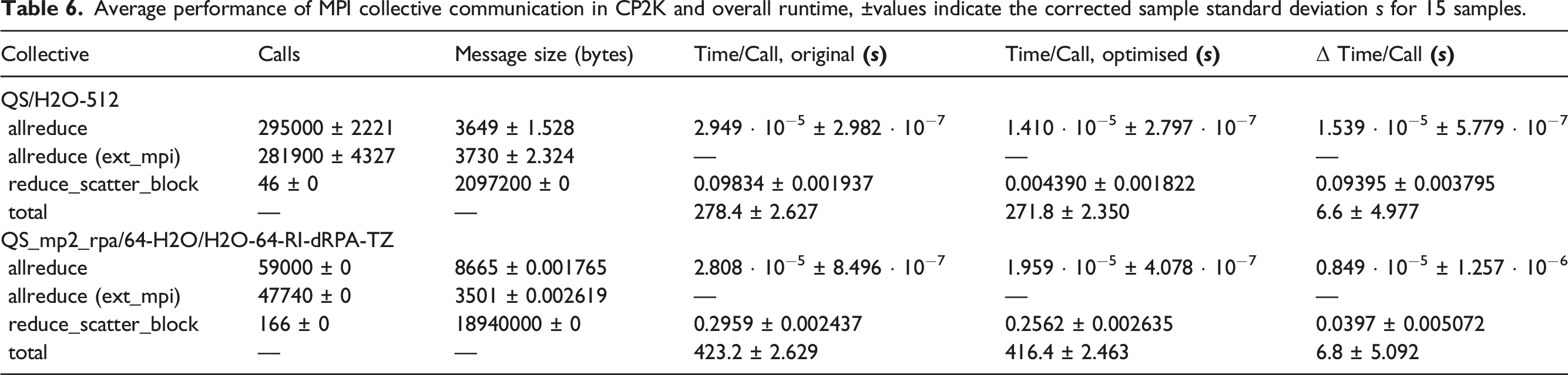
Real applications will execute far more time steps than the short benchmark runs. Therefore, the relative time spent in the initialisation of the collective communication will be smaller, and moderately higher speedups can be expected. We note, that the timings in Table 6 were measured for a restart run, using the wisdom files aforementioned. However, in this particular case with only 16 MPI tasks per node, the generation of wisdom files contributes only marginally to the timings.
6. Related work
A state-of-the-art summary and uniformation of collective communication algorithms is given by Träff et al. (2023). This work introduces a uniform framework for designing and analysing collective operations, with a particular focus on reductions. The authors derive these algorithms from a uniform, circulant graph communication pattern.
One possible approach to MPI parallelism is to use shared memory segments allocated with shmget (Peng et al., 2023). This has the advantage that send and receive buffers do not need to be shared, but an additional copy operation is required to bring the data into a shared memory segment. Other approaches include providing shared memory buffers from the application (Li et al., 2014), or using Cross Memory Attach (CMA) (Vienne, 2014) to access the memory of other processes directly. A prototype of shared memory collectives has been implemented by Li et al. (2014). The established MPI libraries MPICH, MVAPICH and Open MPI follow this implementation for intra-node communication based on shared memory utilising XPMEM.
Collective communication algorithms with a radix higher than two have been utilised recently (Fan et al., 2024; Wilkins et al., 2023), demonstrating their potential to reduce the number of communication steps and improve scalability in HPC systems. Earlier works have discussed algorithms with non-constant radix (Jocksch et al., 2021; Rüfenacht et al., 2017); that is, where the radix may vary dynamically based on message size, network topology, or hardware configuration.
Special cases of our generalised recursive exchange are the algorithms of Rüfenacht et al. (2017) for short messages and Thakur et al. (2005) for long messages. The former introduces a method for recursive multiplying that achieves a reduced execution time when compared to recursive doubling. The latter reference discusses optimisation techniques tailored specifically to long messages and situations with a number of processes not equal to a power of two.
We optimise allreduce with high data locality in a similar manner to Loch and Koslovski (2021). The referenced work introduces the Stripe Parallel Binomial Trees (Sparbit) algorithm. Sparbit achieves reduced latency and improved bandwidth utilisation by maintaining a more localised communication pattern.
An implementation of intra-node allreduce on GPUs has been implemented by Faraji and Afsahi (2014). The authors made use of CUDA inter-process communication for efficient data exchange. They propose two design approaches: a GPU-aware binomial reduce-broadcast algorithm, and a GPU shared-buffer aware design.
The idea to autotune MPI collectives has been present in the literature. For an automated selection of MPI algorithms, see the contribution of Hunold and Carpen-Amarie (2018) and references therein. In this contribution, machine learning techniques were used in order to find the best algorithmic solution, and the default configurations of Intel MPI and Open MPI were outperformed.
Today’s supercomputer architectures allow for alternative implementations of collective reductions. For short message allreduce performed on the network routers, see De Sensi et al. (2021). Their approach has the advantage of shorter ways from the compute node to the network router and back only, instead of from compute node to compute node and back.
In the context of distributed deep learning, sparse data vectors to be reduced are a common occurrence. Several authors, such as Li and Hoefler (2022), developed allreduce algorithms combined with data compression to exploit the sparsity. In the particular contribution from Li and Hoefler (2022), the performance of established dense allreduce is achieved with favourable speedups, as compared to known algorithms for sparse data. An alternative approach to the significant use case of sparse data, including sparse matrices, is described in Geyko et al. (2024), which introduces algorithms for dynamic, locality-aware data exchange via an MPI extension library. Their results demonstrate strong scalability and high performance.
There are preexisting solutions to allreduce with flexible parameters. A hierarchical application of reduction algorithms has been investigated by Hasanov and Lastovetsky (2017), which can be interpreted as flexibilisation of algorithmic parameters. They obtained relevant speedups for short and medium sized messages, even for two hierarchy levels of known reduction algorithms only.
While in our contribution only the frequently used inner-group communication is discussed, other relevant communication patterns exist. The general case of inter-group allgather communication has been considered by Kang et al. (2019). Data from m MPI tasks is redistributed to n tasks, with the algorithms introduced.
The case of multiple sockets per node is included in this contribution. From a more theoretical point of view, these multiple sockets are multiple parallel network lanes. These multiple lanes also exist in hardware on some computer architectures. An algorithmic development for different collective communication patterns on multiple parallel lanes of the network has been done by Träff and Hunold (2020) and Tran et al. (2024).
There are other communication libraries outside of the MPI standard, such as NCCL. NCCL is a commercial non-MPI communication library for allreduce and related collective patterns on the GPU. This library utilises the ring algorithm, and is therefore particularly suitable for long message sizes.
7. Conclusions
We have introduced an implementation of persistent allreduce that utilises the persistent interface’s design to effectively separate derivation of complex factorisations required for efficient allreduce from the allreduce operation itself. It allows for the application of more complex algorithms than those employed in pure execution without initialisation, such as that found in many implementations of the blocking communication programming interface. This can be highly performant when used in applications which use the same allreduce repeatedly. We also provide a blocking communication programming interface with partial initialisation of the algorithms. At execution time the algorithms are only modified slightly. Our contribution not only demonstrates the benefits of these approaches, partially known from the literature for inter-node communication, but also shows the usefulness of this approach for shared-memory communication. For the algorithm selection at initialisation, it is desirable to know the number of subsequent calls, since the initialisation time may not be negligible and can differ significantly for different algorithms.
Additionally, the recursive exchange and cyclic shift algorithms previously introduced for inter-node communication in the literature were extended to shared memory intra-node communication and mixed intra- and inter-node communication, including support for multi-socket nodes. The tree algorithm has been utilised for the on-node component of inter-node allreduce, and additionally for intra-node broadcast and reduce. The pure intra-node implementation outperforms the recent versions of MPICH and Open MPI up to almost an order of magnitude for medium-size messages and large messages on AMD EPYC and NVIDIA Grace-Hopper processors, for both CPU and GPU. For combined intra-node and inter-node communication, we obtain similar speedups.
The comparison of the GPU timings with the commercial NCCL library shows comparable performance. It should be noted that the inter-node communication algorithms of the libraries do not coincide, at least not in their formal descriptions. The NCCL library uses the ring algorithm while our implementation does not.
The reduce_scatter_block collective is covered by the algorithms for allreduce, and applied together with allreduce to the application CP2K. When our blocking interface is applied to CP2K, it shows an overall speedup for a standard benchmark of 2.5%.
8. Future work and Opportunities
The current heuristic relies on empirical parameter selection. Continuing research efforts seek to replicate or improve upon the results of this parameter selection with a machine-learning-guided heuristic to aid in extensibility and performance portability, complementing the compiled approach of the algorithms presented here.
This work may be meaningfully extended to optimise for sparse data, which is common in many deep learning applications. This may be accomplished, for instance, by utilising data compression, such as that found within the contribution from Li and Hoefler (2022), or with novel locality-aware algorithms, such as those found in Geyko et al. (2024).
Footnotes
Acknowledgements
Benchmarks were performed on the Alps supercomputer of CSCS. The authors would like to thank Jean-Guillaume Piccinali, Augustin Bussy, and Sebastian Keller (CSCS) for helpful discussions. This contribution is a throughout expanded version of the autors article “Flexible algorithms for persistent MPI allreduce communication” first published in Lecture Notes in Computer Science (LNCS). Vol. 15579, 273–286, 2024 by Springer Nature.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was performed with partial support from the National Science Foundation under Grants Nos. 2405142 and 2412182. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. Partial support from the Tennessee Technological University’s Department of Computer Science, CEROC, and the College of Engineering is acknowledged.
Notes
Author biographies
Andreas Jocksch is a senior research software engineer at the Swiss National Supercomputing Centre (CSCS). His past areas of activity include parallel computing and fluid dynamics.
C. Nicole Avans is a research assistant at Tennessee Technological University and an intern at Sandia National Laboratories.
Riley Shipley is a HPC researcher and lecturer at Tennessee Tech whose work includes multiple MPI profiling tools and methods as well as in-depth study on accelerator-centred communication models.
Anthony Skjellum Dr. Anthony (Tony) Skjellum studied at Caltech (BS, MS, PhD). His PhD work emphasised portable, parallel software for large-scale dynamic simulation, with a specific emphasis on message-passing systems, parallel nonlinear and linear solvers, and massive parallelism. From 1990-93, he was a computer scientist at LLNL focusing on performance-portable message passing and portable parallel math libraries. From 1993 to 2003, he was on faculty in Computer Science at Mississippi State University, where his group co-invented the MPICH implementation of the Message Passing Interface (MPI) together with colleagues at Argonne National Laboratory. He has also been active in the MPI Forum since its inception in 1992. From 2003 to 2013, he was professor and chair at the University of Alabama at Birmingham, Dept. of Computer and Information Sciences. In 2014, he joined Auburn University as Lead Cyber Scientist and led R&D in cyber and High-Performance Computing for over 3 years. From August 2017 to March 2023, he was at the University of Tennessee at Chattanooga as Professor of Computer Science, Chair of Excellence, and Director, SimCenter, where he continues work in HPC (emphasising MPI, scalable libraries, and heterogeneous computing). In August, 2023 he joined the Dept. of Computer Science at Tennessee Technological University, and is the prospective director of the soon to be approved ASCEND Center for High Performance Computing, Extreme Networks & Data at TN Tech He is also co-PI of the DOE/NNSA PSAAP III Center ”Center for Understandable, Performant Exascale Communication Systems” led by the University of New Mexico. He is a senior member of ACM and IEEE; and a member of ASEE and AIChE. He has over 17,200 citations on Google scholar, with an H-index of 40, and an I-10 Index of 140.