
Abstract
Transformers, particularly large language models (LLMs), are revolutionizing applications in natural language processing and computer vision but at a high cost in memory, energy, and computational resources. Quantization has emerged as an effective compression method to alleviate these demands, reducing the bitwidth of model data and arithmetic precision to enable efficient inference on resource-constrained devices. This paper focuses on optimizing inference with transformer encoders on low-power general-purpose CPUs, as those often found in edge devices. Our key contributions include exposing the critical role of linear layers within transformer encoders on CPUs with a limited number of cores; developing mixed integer precision matrix multiplication on ARM and RISC-V CPUs; and evaluating performance impact and energy savings of quantized inference. In summary, this work highlights the advantages of applying quantization to transformer encoders on current single-core and multi-core low power CPUs, offering insights for efficient LLM deployment on edge platforms.
1. Introduction
Large language models (LLMs) are driving dramatic advancements across a wide range of scientific and industrial applications, impacting many tasks related to natural language processing (NLP) as well as computer vision. Unfortunately, the underlying transformer technology Vaswani et al. (2017) significantly increases the memory usage, energy consumption, and computational requirements for both training and inference Zhao et al. (2023); Shankar and Reuther (2022), showcasing the critical balance between innovation and the rising resource requirements.
In response to this scenario, quantization is a compression technique designed to shrink the cost of deep learning (DL) models in general and LLMs in particular, enabling inference on resource-constrained platforms such as smartphones and edge devices Hubara et al. (2017). To achieve this goal, quantization reduces the bitwidth of the model’s data, specifically weights and/or activations, as well as the precision of the arithmetic, primarily multiplications and additions.
A transformer can function as an encoder only (e.g., BERT), a decoder only (e.g., GPT-2) or both, depending on the target application. In this paper, we focus on transformer encoders due to their key role in text classification, question answering, information retrieval, speech recognition, document classification and language translation, among others. Furthermore, while most efforts on optimizing LLMs are directed toward training these models on graphics processing units (GPUs) and large-scale facilities, our paper targets transformer encoder inference on a variety of low power general-purpose processors, or CPUs, as those that are common on edge scenarios. In doing so, we make the following contributions: • We expose the critical role of the linear layers on the overall performance of the encoder block when executed on a low-power CPU. While some other components are also important when the encoder block is run on a many-core CPU, we argue that, at least for CPUs equipped with a small number of cores, their contribution varies between negligible and low. Moreover, the cost of these other components can be significantly reduced by employing inexpensive yet accurate approximations (in the case of the • We evaluate the impact of exploiting mixed precision kernels, with integer arithmetic, for the linear layers of the encoder block on state-of-the-art CPUs with ARM and RISC-V architectures. For all these platforms, we develop and tune our own version of the general matrix multiplication ( • For systems equipped with power counters, specifically the ARM-based designs in the NVIDIA Jetson boards, we also report the energy benefits that can be obtained from quantization.
Overall, our work provides a comprehensive analysis of the performance and energy gains that can be obtained from applying quantization to transformer encoders on a representative number of single-core and multi-core low-power CPUs.
The rest of the paper is structured as follows. In Section Related Work we offer a brief review of related papers. In Section Characterization of the Transformer Encoder we conduct an initial analysis of the theoretical and experimental costs of a transformer encoder on an ARM-based CPU. In Section
2. Related work
Much of the research on optimizing transformer encoders has focused on training these models using hardware accelerators. In contrast, the efforts discussed in this section specifically relate to the optimization of transformers on CPUs. This scenario is common in embedded systems, where the use of accelerators may be impractical due to integration challenges, or constraints related to cost, silicon area, or power consumption.
In Dice and Kogan (2021), the authors identify three main inefficiencies in executing oneDNN on Intel Skylake processors: matrix multiplications with transposed operands, dispatcher overhead, and suboptimal partitioning of matrix operands. The work in Kim et al. (2023) explores encoder inference, examining aspects such as model-to-hardware mapping and operation scheduling. The authors of Chitty-Venkata et al. (2023) survey various high-level software optimization techniques, including pruning, knowledge distillation, and quantization, alongside low-level hardware optimizations on application-specific circuits. The study in Jiang et al. (2023) focuses on optimizing encoder inference on ARM many-core CPUs with multiple NUMA (Non-Uniform Memory Access) domains, proposing the skipping of packing procedures for small matrix operands and the use of a specialized micro-kernel for such cases at the core level. In Martínez et al. (2024), we investigate the optimization of encoders on two low power CPUs, with ARM and RISC-V architecture. Lastly, in Wu et al. (2024) the authors present a library optimized for a wide range of ARM processors: from edge devices to HPC-grade CPUs.
All the previous works consider only the standard 32-bit floating point data/arithmetic and, therefore, miss the challenges and opportunities that quantized inference brings in combination with transformer encoders. We close this review by noting that our contributions are orthogonal and/or complementary to other model-related optimizations such as pruning, distillation, etc.
3. Characterization of the transformer encoder
In this section, we expose the anatomy of the transformer encoder, detailing the arithmetic cost of its main components together with an experimental analysis of the model’s inference efficiency.
3.1. Anatomy of the transformer encoder
A transformer encoder typically consists of an input embedding layer, multiple intermediate encoder blocks (ranging from a couple to several dozens), and an output classification layer. As the initial and final components contribute minimally to the global computational cost, we next focus on the intermediate blocks.
Internally, each encoder block is composed of a multi-head attention ( Architecture of the Dimensions of BERT models.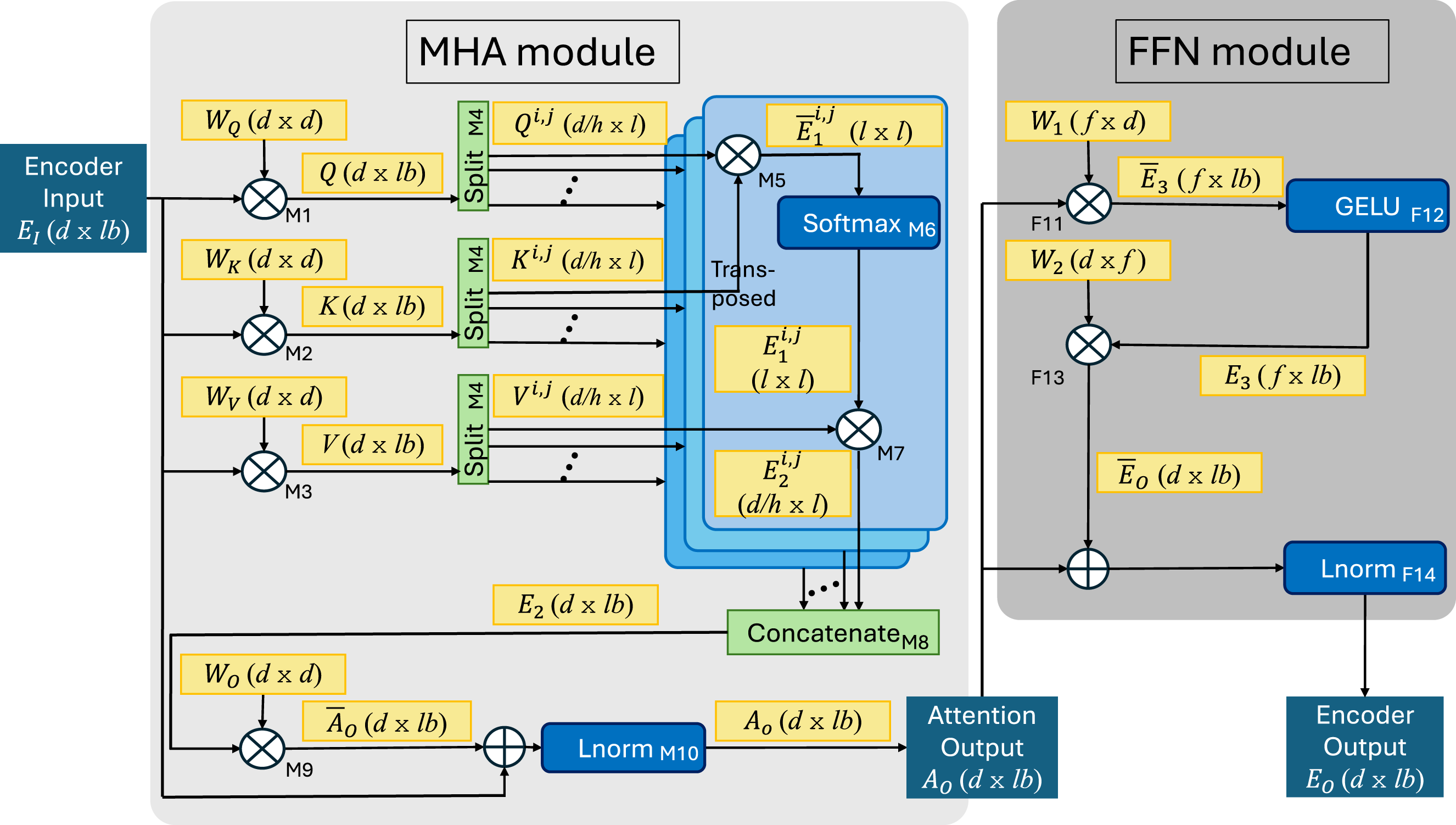

Consider the
Operations in the

3.2. Inference with FP32 data/arithmetic
We next characterize the inference costs of a transformer encoder, using the large instance of BERT (
For this particular experiment, the model weights and input/output activations are stored as IEEE single precision floating point (FP32) numbers, and all arithmetic is performed in FP32. For brevity, we only employ the NVIDIA Jetson AGX Xavier board, a system that is equipped with an 8-core NVIDIA Carmel processor and 32 GB of LPDDR4x (low power DDR4x) RAM.
3.2.1. Experimental setup
Target systems evaluated in the experimental study.
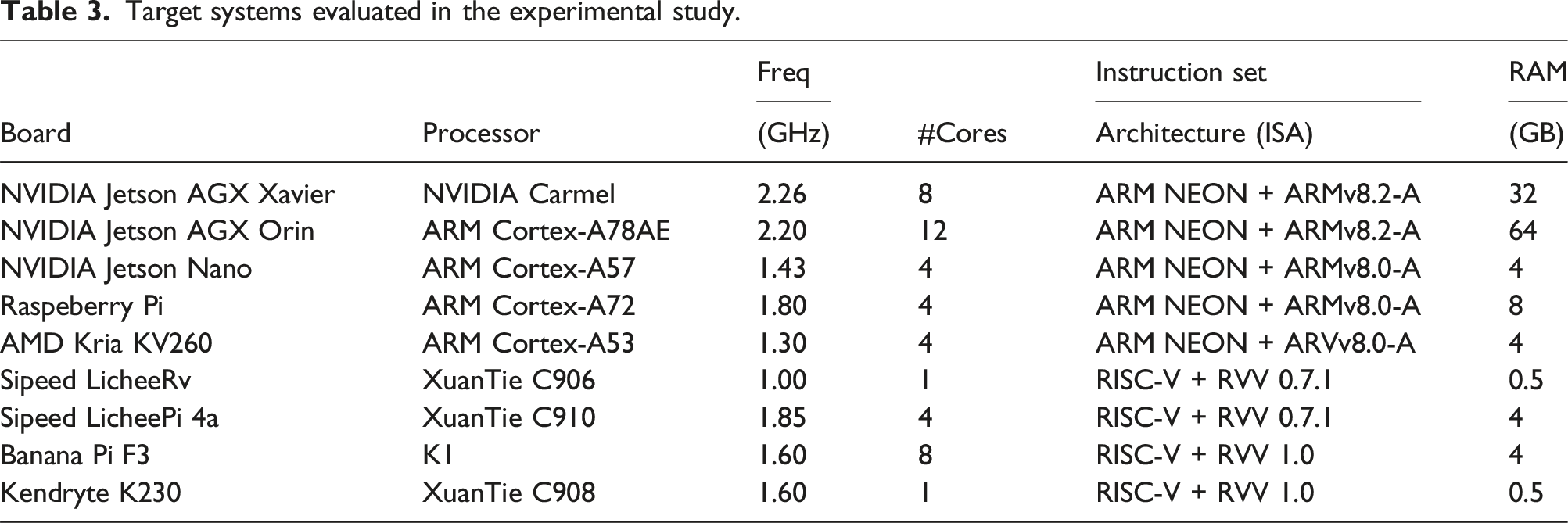
In all our experiments in this paper, the processor frequency is fixed; we execute the transformer using all cores of the target platform, with one thread per core; and the execution of each test is repeated for at least 5 seconds, with the reported results corresponding to average values.
Measured CPU-related power rails for each system platform.
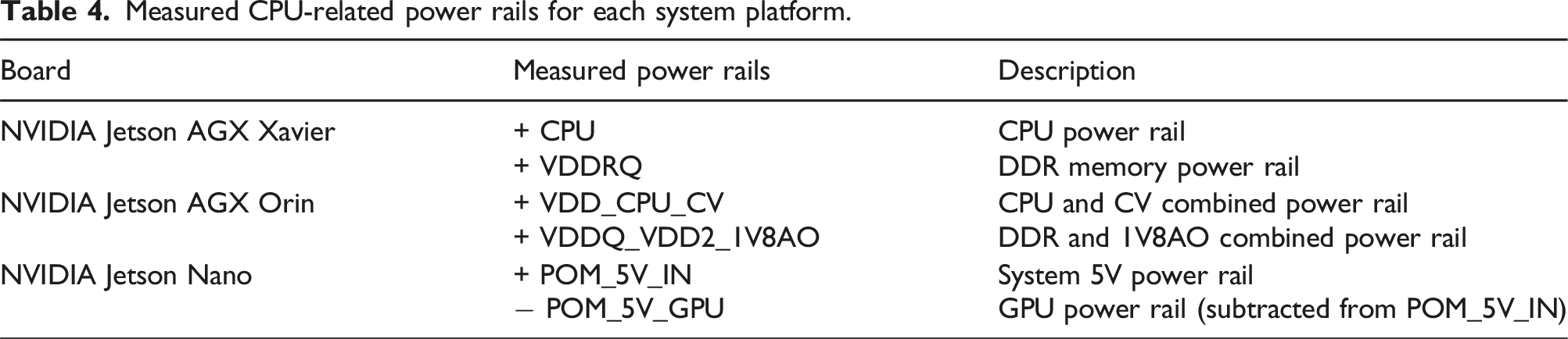
The peak performance for the NVIDIA Carmel processor with FP32 arithmetic, when operating all eight cores at 2.3 GHz, is 2.3 GHz × 16 FP32 floating point operations (flops) per cycle and core × 8 cores = 294.4 FP32 GFLOPS (billions of flops per second).
3.2.2. Observations
Figure 2 reports the time, energy consumption and distribution of time for the execution of a single encoder block of Characterization of the execution time (and energy consumption) for an encoder block of 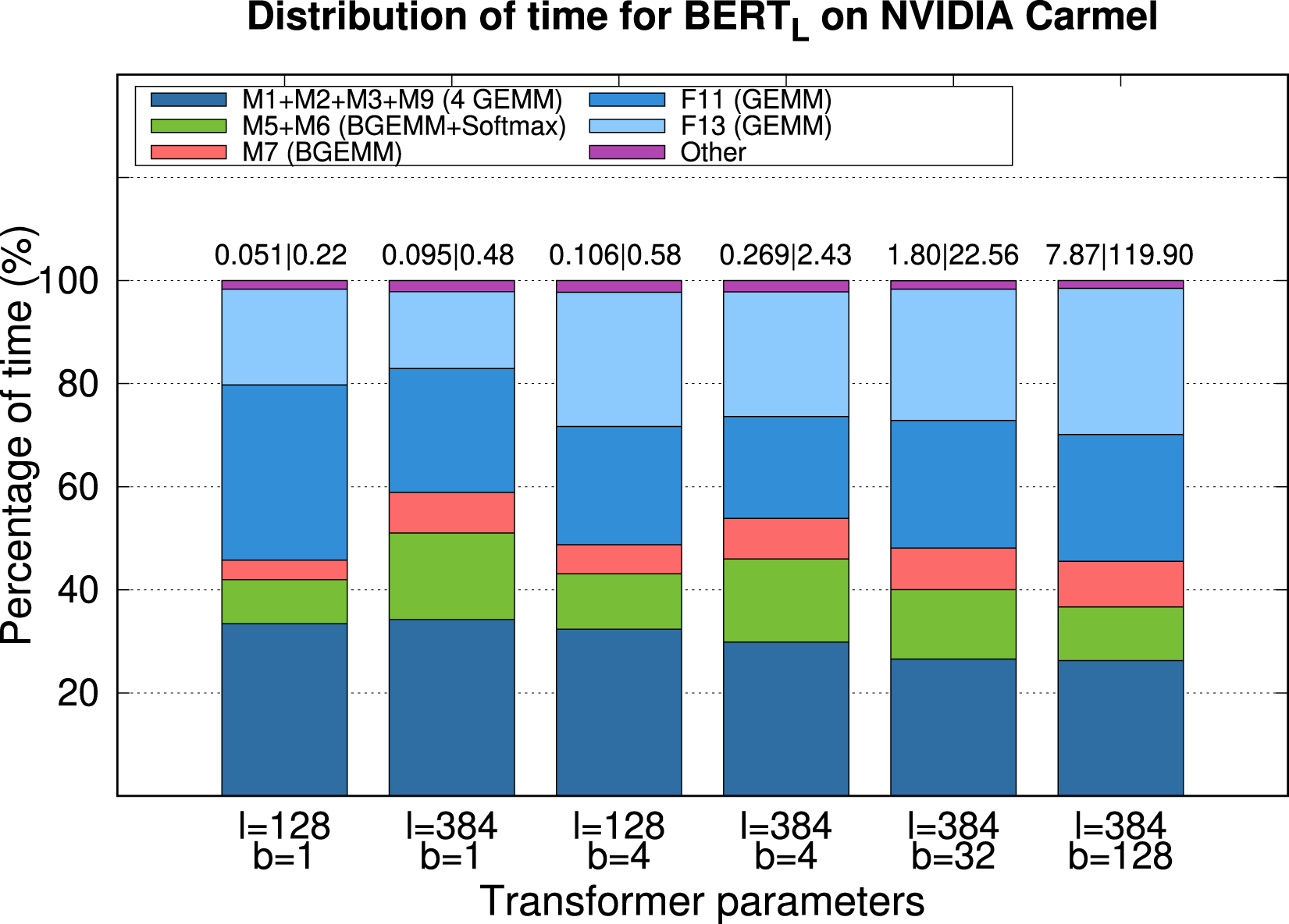
The results in Figure 2 offer the following observations: • In general, about 75%–80% of the time is due to the linear layers ( • The theoretical arithmetic costs in Table 2 estimate that the execution time should be linear on b. In practice, this is the case only for large b: From 1.80 s for b = 32 to 7.68 s for b = 128. For the practical cases of interest, with small b, the increase is sublinear. This shows the benefits, when b is small, of aggregating multiple samples (i.e., sentences) into a single batch, to be processed concurrently. When applicable, such strategy (1) reduces the cost of the memory accesses; and (2) increases the workload, helping to expose more parallelism. • In theory, the cost for • The difference between the bars for • Considering the execution time, depending on the value of l, b the cost varies between 0.40 ms/token and 0.15 ms/token, while the total energy consumption varies between 1.13 mJ/token and 2.31 mJ/token. • Our parallel implementation of the transformer encoder evaluated in this experiment attains around 76% of the peak for • When moving to a platform with a larger number of cores (e.g., the ARM Cortex-A78AE in the NVIDIA Jetson AGX Orin), the contribution of • In case that adapting the linear layers to operate with MIP results in a decrease of the cost for this type of operations,
In addition, we can also comment on the results that can be expected on other platforms:
4. GEMM in linear algebra libraries for scientific computing
In this section we revisit the conventional, high performance implementation of
4.1. Optimizing GEMM on multicore CPUs
High-performance instances of Reference algorithm for 
Optimizing • Design a micro-kernel that exploits the SIMD arithmetic units of the target architecture. • Select the loop strides m
c
, n
c
, k
c
for the reference algorithm in order to ensure an efficient use of the layered memory hierarchy Goto and Van de Geijn (2008b); Low et al. (2016). • Distribute the iteration space of the loops to expose enough parallelism for all the processor cores; achieve a balanced workload distribution; and favor an efficient use of the shared/private cache levels Van Zee and Van de Geijn (2016); Smith et al. (2014).
In the next subsection we focus on the first task, that is, the efficient implementation of the micro-kernel, as this component needs to be carefully adapted to transform the standard, floating point-oriented
4.2. High performance micro-kernel for GEMM
The generic micro-kernel in Figure 3 (top-right) updates an m
r
× n
r
micro-tile of C with the product of an m
r
× k
c
micro-panel of A and a k
c
× n
r
micro-panel of B: say C
r
+ = A
r
B
r
. For a micro-kernel of fixed dimensions m
r
× n
r
, provided the loop strides m
c
, n
c
, k
c
are chosen with care, during the execution of the micro-kernel A
r
resides in the L2 cache and B
r
in the L1 cache Goto and Van de Geijn (2008a); Van Zee and Van de Geijn (2015). Prior to the micro-kernel loop
Attaining high performance with a practical realization of the micro-kernel requires taking into consideration the following aspects: • Cast all the arithmetic (for the update of C
r
) as well as most/all the data movements (for loading A
r
, B
r
and loading/storing C
r
) as vector instructions that efficiently utilize the SIMD units. Figure 4 illustrates this for a simple m
r
× n
r
= 4 × 4 micro-kernel that employs ARM NEON v8.2 vector intrinsics. All the elements of A
r
, B
r
, C
r
are transferred between memory and the processor vector registers using the following two vector intrinsics: AXPY-oriented micro-kernel for ARM NEON that operates with a 4 × 4 micro-tile C
r
. All input matrices and arithmetic is FP32.


In the following, we will refer to this type of design as an AXPY (
α
times
x
plus
y
)-oriented micro-kernel.
• Increase the arithmetic intensity (AI) of the micro-kernel by setting m
r
≈ n
r
as large as possible without incurring into register spilling. Specifically, we note that the micro-kernel performs 2m
r
n
r
k
c
arithmetic operations while loading/storing m
r
n
r
elements from main memory for C
r
; loading m
r
k
c
elements from L2 cache for A
r
; and loading k
c
n
r
elements from L1 cache for B
r
. In consequence, the arithmetic intensity in arithmetic operations per element is AI = 2m
r
n
r
k
c
/(2m
r
n
r
+ m
r
k
c
+ k
c
n
r
). For example, for large k
c
and FP32, AI = 1.0, 1.6 and 2.4 floating point operations (or flops)/byte for m
r
× n
r
= 4 × 4, 16 × 4 and 12 × 8, respectively. A 12 × 12 micro-kernel offers = 3.0 flops/byte; however it requires 36 vector register for storing C
r
only. Therefore, it incurs into register spilling during its execution for all ARM and RISC-V platforms considered in this work. • Avoid write-after-write (WAW) hazards due to the updates of C
r
in consecutive iterations of the micro-kernel loop • In some cases encode the micro-kernel directly in assembly instead of vector intrinsics in order to avoid compiler decisions leading to suboptimal performance. For example, this is the case of the NVIDIA Jetson AGX Orin when targeting FP16 arithmetic. • There are some additional advanced optimizations that can contribute to further increase the performance of the micro-kernel. Concretely, some micro-kernels benefit from including instructions for software prefetching, modifying the code to exploit software pipelining and/or loop unrolling, etc. Dowd and Severance (1998).
Figure 5 shows the implications of the micro-kernel dimensions m
r
× n
r
on the practical performance of Cache-aware roofline for 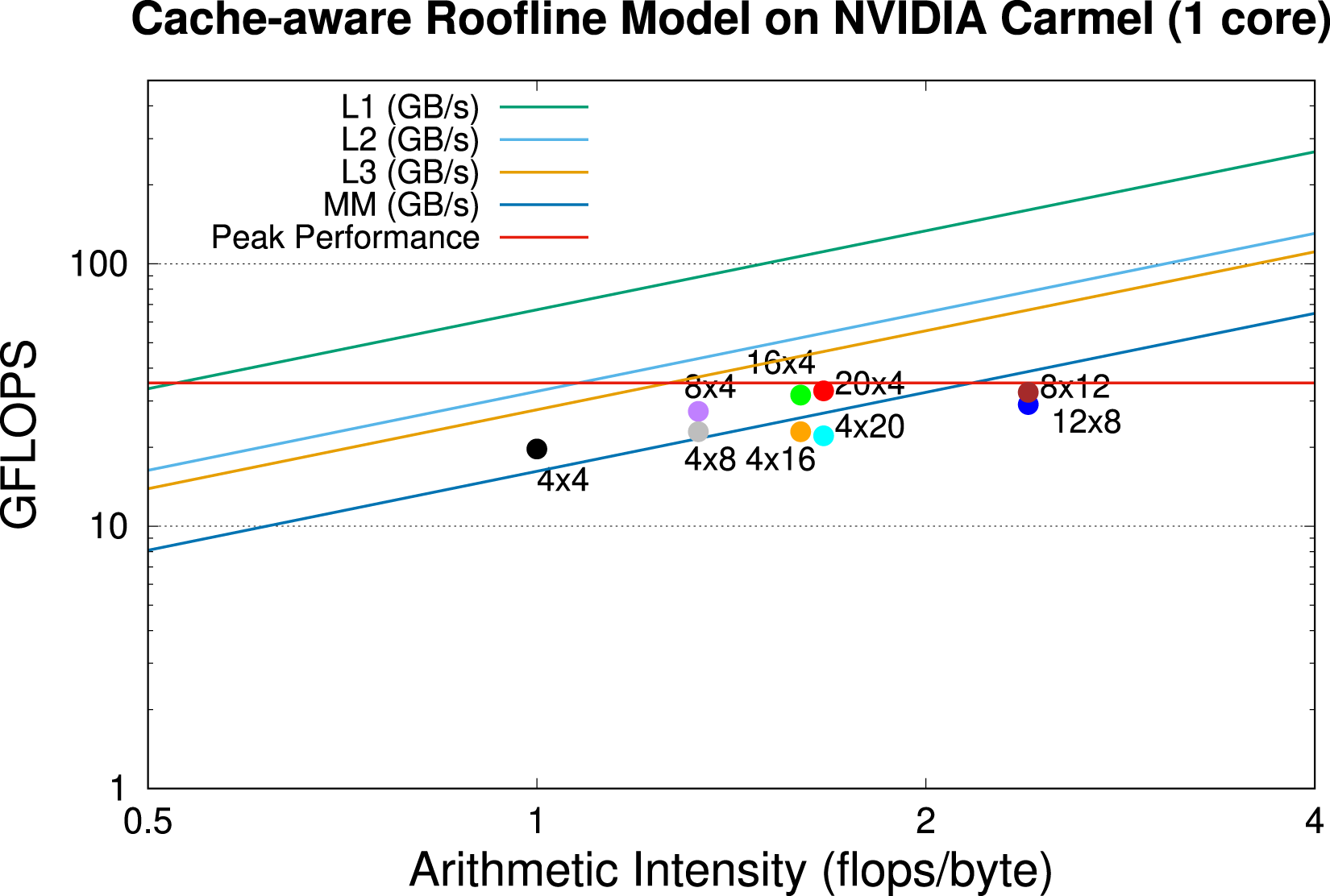
4.3. From ARM to RISC-V GEMM micro-kernels
Like many other ISA, RISC-V also offers a set of intrinsic functions to ease the use of vector operations without recurring to low-level, assembly code. We next revisit the simple 4 × 4 example in Figure 4 for ARM NEON to discuss its adaptation to RISC-V.

The first one loads

The intrinsic broadcasts (i.e., replicates) the scalar

which performs an element-wise vector fused-multiply-add combining the three input vector registers
5. Quantized GEMM
As mentioned earlier, most high performance linear algebra libraries are oriented toward solving scientific computing applications and, therefore, only implement
5.1. Quantization and GEMM
We recognize that there exist many strategies to apply quantization to
Symmetric quantization maps a real (i.e., floating point) value x ∈ [α, β] to an integer
Consider next the
Following the general trend for transformers, we apply quantization only to the linear layers (i.e.,
5.2. Reference implementations
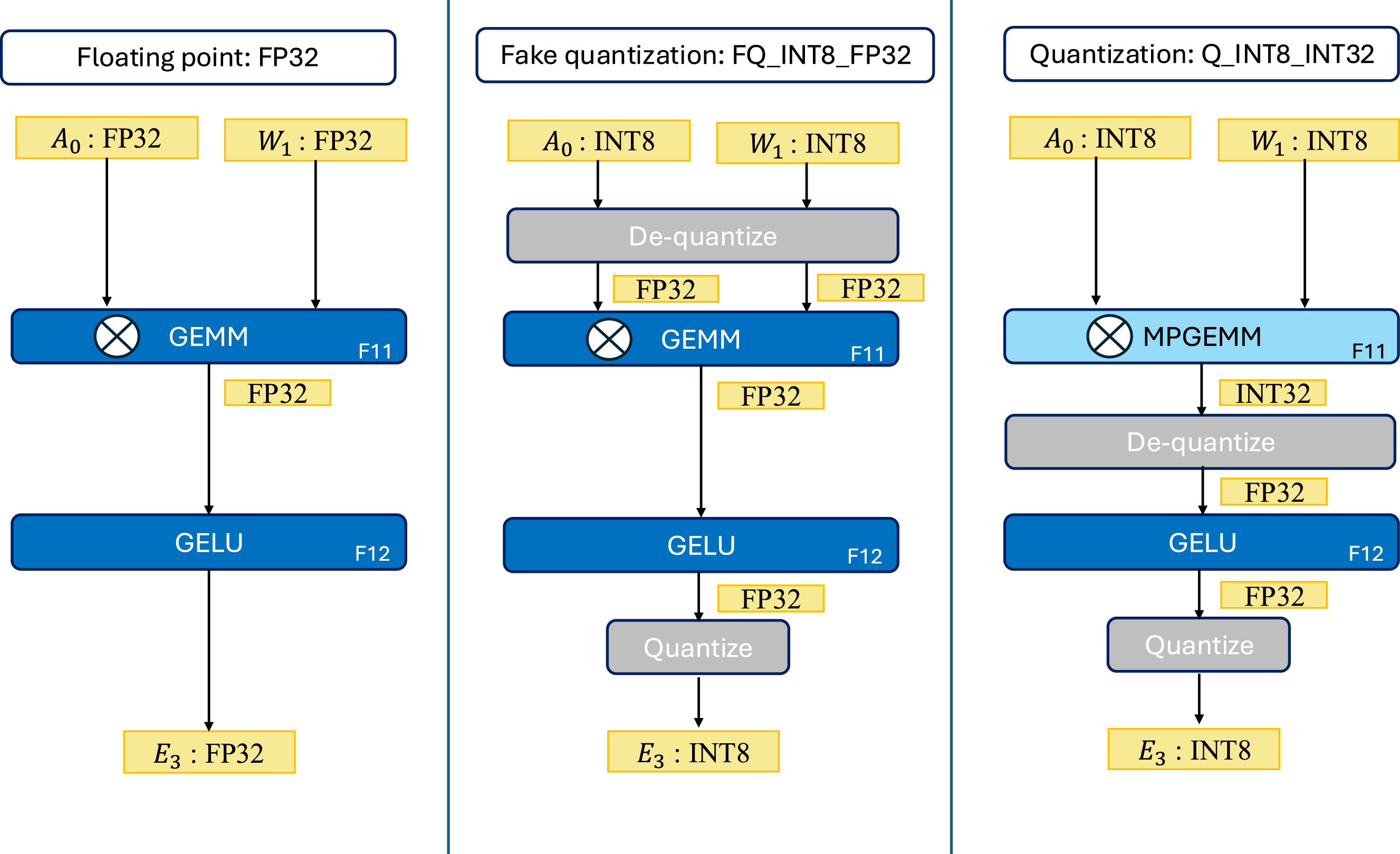
For reference, in the subsequent experiments we include the following optimized implementations of • F • FP • FQ
Figure 6 graphically displays the differences between our alternative schemes: • Floa • Fak • Qua Differences between operand data types/arithmetic for alternative schemes, illustrated via the operations
5.3. High level overview
In addition to the tiling loops (
In the following subsections we describe how to adapt this formulation of (1) RVV 0.7.1 (XuanTie C906, C910): These platforms provide no support for MIP arithmetic so we rely on fake quantization by transforming the INT8 data in A, B to INT32 precision as part of the packing routines. The arithmetic is then performed in INT32 precision, using a slightly modified variant of the conventional FP32 micro-kernel that decomposes each update round of the micro-tile C
r
(one per iteration of loop (2) ARMV8.2-A and RVV 1.0 (NVIDIA Carmel, XuanTie C908, K1): This option loads the INT8 elements from A
c
, B
c
into vector registers to inmediately cast them as INT16 numbers using the same vector registers. A special vector FMA that combines the INT16 elements of these input vector registers is then used to update the contents of the INT32 micro-tile C
r
. (3) ARMV8.2-A with fast MIP DOT products (ARM Cortex-A78AE): This architecture provides a highly efficient support for MIP but enforces us to replace the vector FMAs with a vector DOT product. In addition, this change asks for a reformulation of the packing routines that enables the use of vector instructions in order to load of the elements of A
c
, B
c
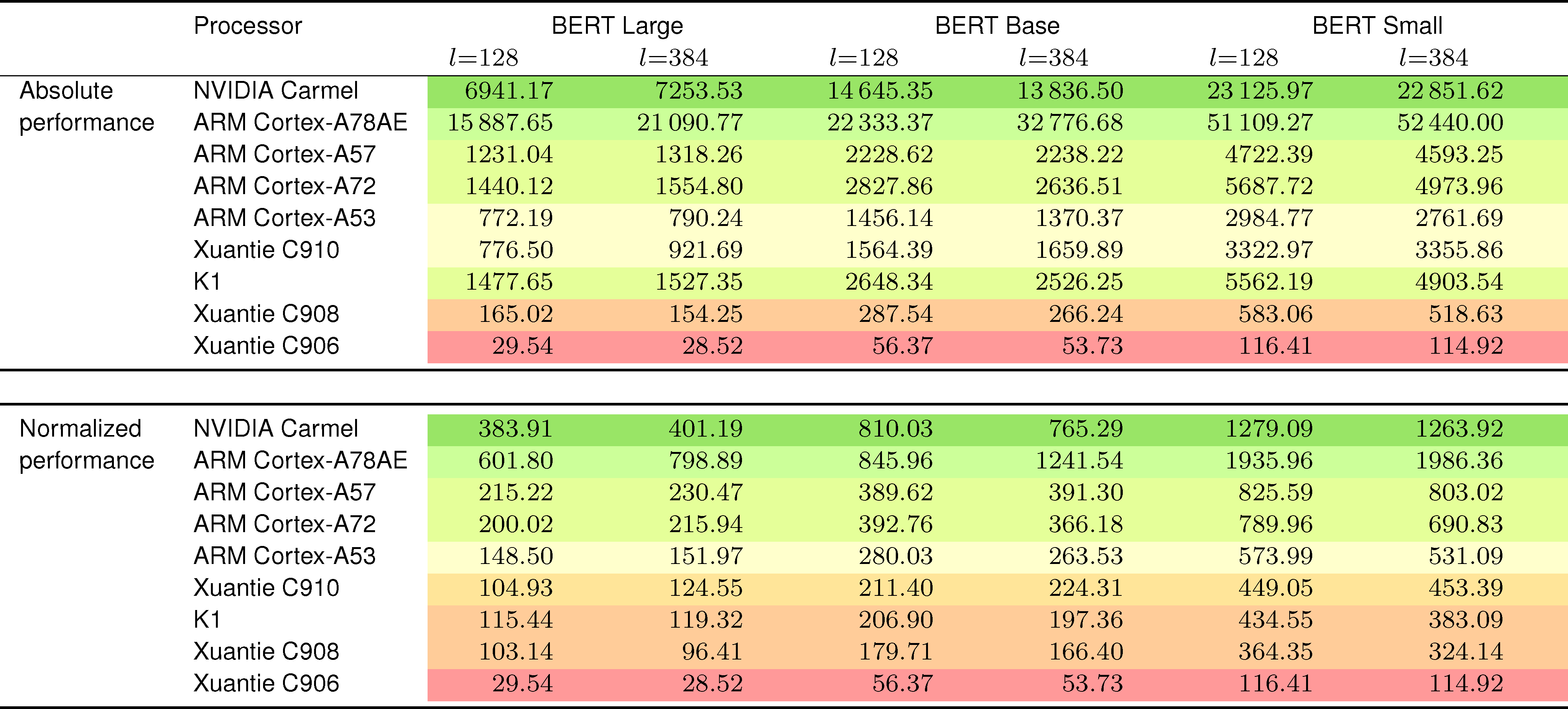
into vector registers as well as a direct utilization of the MIP vector DOT products. (4) ARMv8.0-A (ARM Cortex-A57, A72, A53): This architecture involves a sophisticated MIP micro-kernel that combines vector multiplications of INT8 input elements producing INT16 results; vector FMAs of INT16 elements with the result accumulated into an INT32 output vector; and vector reductions. Performance (in tokens per second) for the different architectures using three instances of the BERT family and two values of the sequence length l. The batch size is fixed in all cases to b = 4. The results in the top table are absolute values while in the bottom table they are normalized (i.e., divided) by the respective processor frequency and number of cores.
The remaining three groups in the list maintain the input matrices A, B as INT8 numbers, pack them into buffers A
c
, B
c
with INT8 entries and, when necessary, transform these data into extended precision inside the micro-kernel, prior to the arithmetic.
In the following the provide a detailed description of the vector intrinsics utilized to implement the micro-kernels for each target architecture. A reader that is only interested in the performance impact may want to skip these details and refer directly to the performance results in Figures 7, 8 and 9, Table 5, and the accompanying comments.
5.4. Optimization of MIP GEMM for ARM NEON v8-A
The ARMv8-A architecture has several variants and extensions that cater to different application domains, ranging from general-purpose computing to specialized workloads arising from real-time processing and security. The ARMv8.0-A, released in 2011, was the initial initial version of the ARMv8-A architecture. Among its main features, it provided support for AArch64 (64-bit execution mode) and AArch32 (32-bit execution mode); introduced NEON and FPU (Floating Point Unit) as optional features; and supported Advanced SIMD (NEON) instructions. In 2016, ARM released ARMv8.2-A, providing FP16 support in the NEON and FPU units; and offering the optional scalable Vector Extension (SVE), for 128-bit to 2048-bit, which targeted high-performance computing (HPC) applications.




The MIP, AXPY-oriented micro-kernel for the NVIDIA Carmel that results is illustrated in Figure 7 for m
r
× n
r
= 8 × 8. Lines 33–38 load the INT8 elements of A
r
, B
r
, expanding them into INT16 values together with the unfolding. The arithmetic update of C
r
is in lines 41–48. AXPY-oriented micro-kernel that operates with a 8 × 8 micro-tile C
r
. Matrices A, B contain INT8 numbers, C contains INT32 values, and the arithmetic is MIP INT16-INT32.
Let us now discuss the theoretical advantages of reducing the arithmetic precision of the micro-kernel. Consider, for example, the case with m r × n r = 12 × 8. On the one hand, for FP32, this micro-kernel yields an AI = 2.4 FP32 flops/byte so that, by moving all data types and arithmetic to FP16, this ratio is doubled to AI = 4.8 FP16 flops/byte. However, the peak performance per core for the NVIDIA Carmel (at 2.26 GHz) is also doubled: From 36.18 FP32 GFLOPS to 72.36 FP16 GFLOPS. On the other hand, reducing the data type bitwidth allows to design larger non-spilling micro-kernels, because a vector register can now contain twice as many FP16 numbers compared to FP32. As a consequence, the number of micro-kernels that remain in the compute-bound part of the cache-aware roofline model becomes larger. For example, a micro-kernel of dimensions m r × n r = 24 × 8 that operates with FP16 requires 29 vector registers (the same as its 12 × 8 FP32 counterpart), but yields an AI = 6 FP16 flops/byte (instead of 2.4 FP32 flops/byte for FP32).
Consider next the MIP micro-kernel, which transfers all data for A
r
, B
r
as INT8 numbers, further reducing the bitwidth of the data. In this case we can double the m
r
dimension of the micro-kernel, without exhausting the capacity of the vector register file, to design for example an 48 × 8 micro-kernel, with an AI = 13.71 INT32 operations/byte. The number of MIP micro-kernels that remain compute-bound is thus very large. Unfortunately, the NVIDIA Carmel processor features a deficient hardware support for integer arithmetic. In particular, this processor can issue only one INT32 arithmetic instruction per cycle and core compared to two FP32 arithmetic instructions per cycle and core. As a result, the peak arithmetic rate for INT32 is only 18.08 INT32 OPS. The previous discussion exposes that we should not expect any significant performance gain when using the MIP
The practical implications of the different hardware support provided by the NVIDIA Carmel processor for floating-point version(s) versus integer arithmetic are reported for the encoder block in the top row of plots in Figure 8. These results lead to the following observations: • The clear winner is the • The quantized encoder block, configured to use the MIP micro-kernel • Finally, the reduction of the data transfer costs intrinsic to the approach that exploits fake quantization ( Execution time (left) and energy consumption (right) for an encoder block of
We close this analysis with two additional comments: (1) While our focus is on latency-oriented scenarios, corresponding to those experiments with small values of b, we also include result for a LLM “server” case (b = 128). The results for that problem instance illustrate the remaining margin for improvement in case we could work with larger batches. (2) We remind that only the linear layers (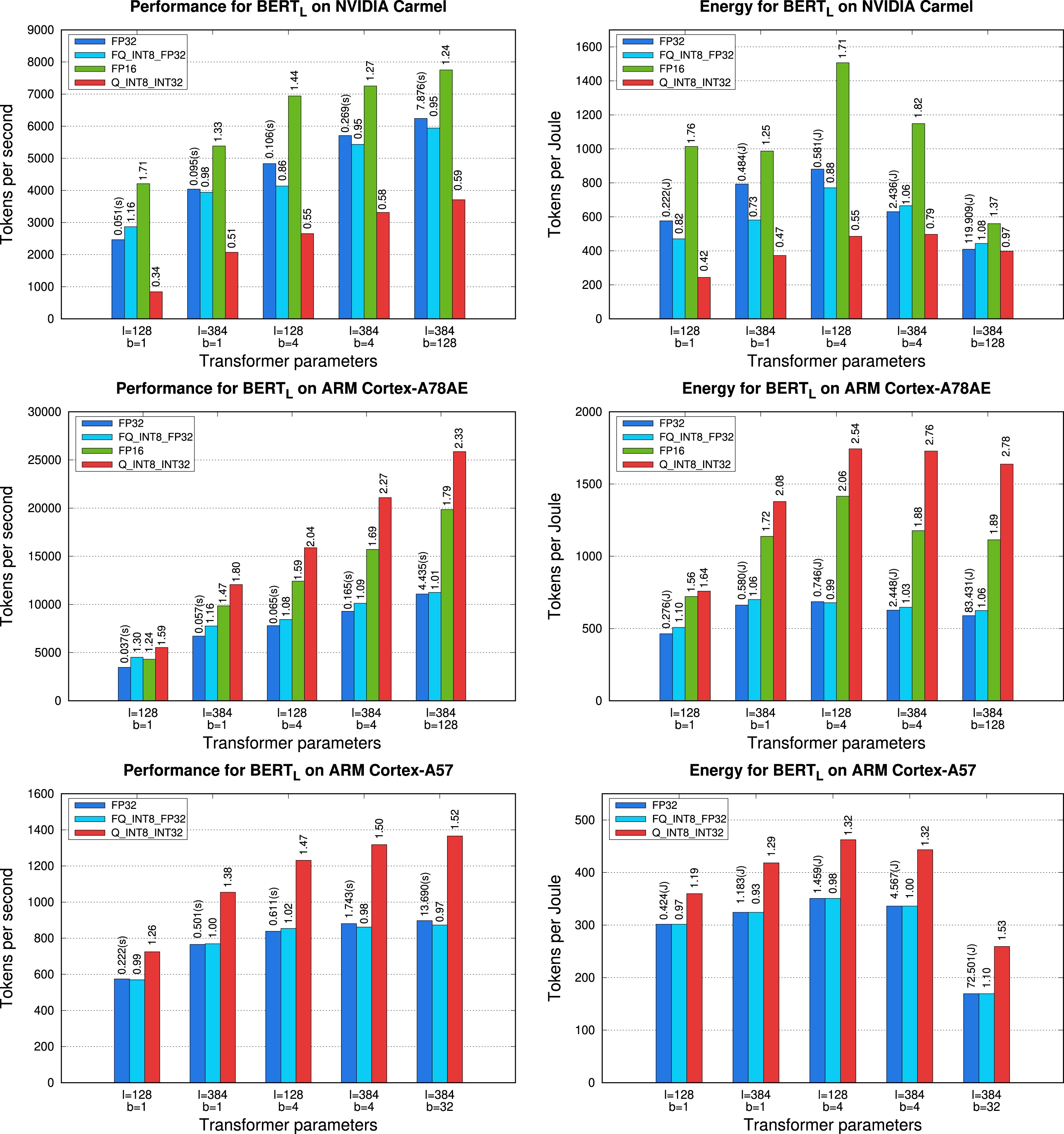


Unfortunately, the performance advantage of the DOT product vector intrinsic

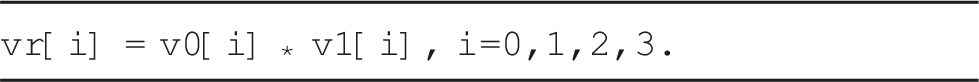
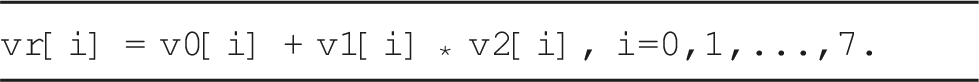
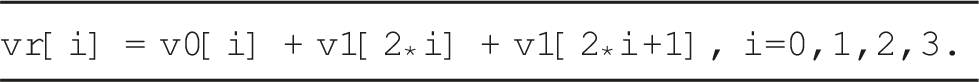


As in the case of the MIP micro-kernel for the ARM Cortex-A78AE, the use of this specialized vector intrinsics requires a complete rewrite of the micro-kernel and packing routines. For simplicity, we omit the details here and focus on the impact of this type of precision on the performance and energy consumption next.
The two plots in the bottom row in Figure 8 compare the performance and energy consumption of different realizations of Execution time for an encoder block of 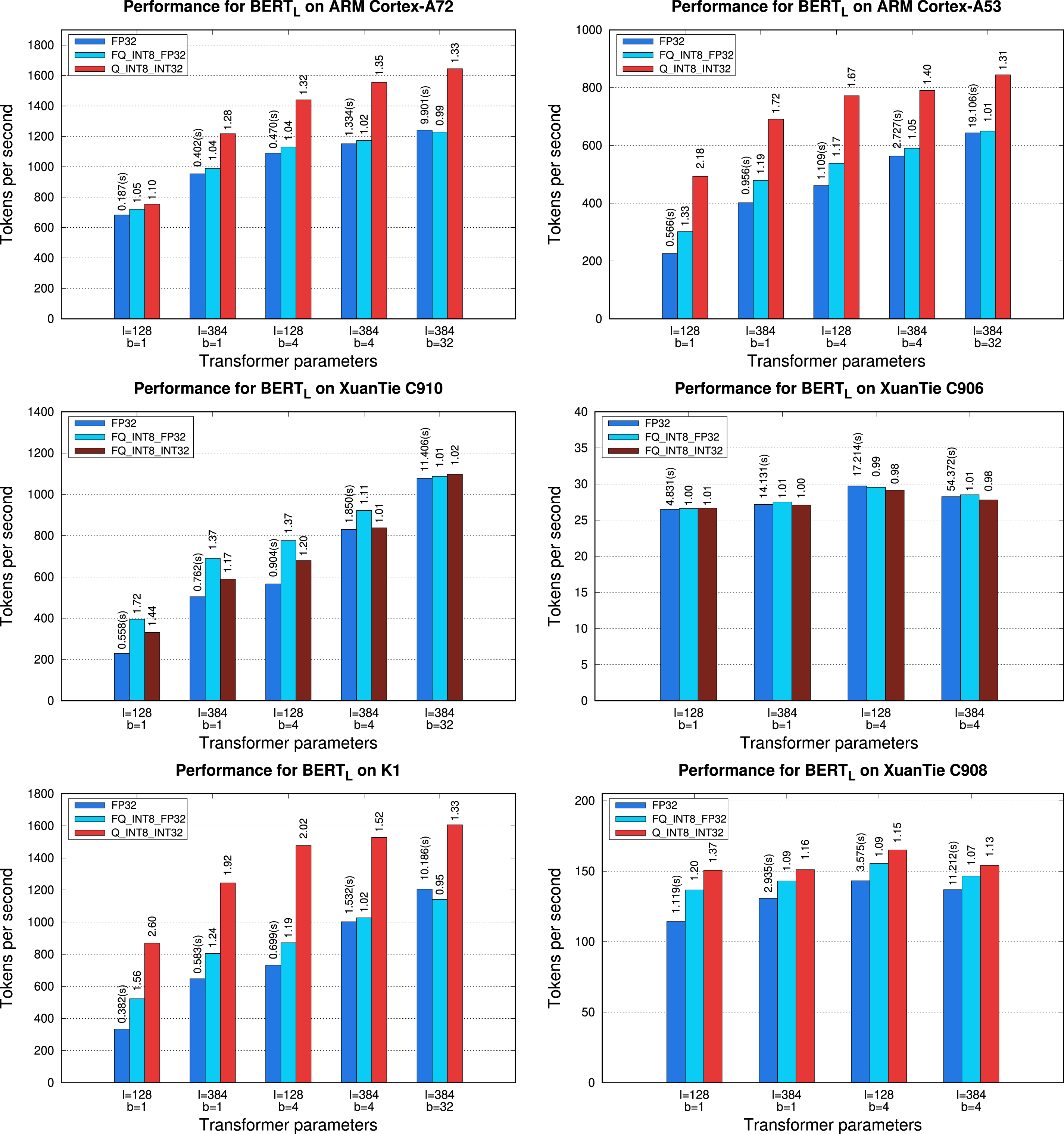
5.5. Optimization of MIP GEMM for RVV
Despite all RISC-V architectures targeted in this work support vector integer arithmetic, those that implement RVV 0.7.1 (Xuantie C906 and C010) do not offer vector instructions that combine integer operands of different data types (i.e., mixed arithmetic). Conversely, the RVV 1.0 CPUs (K1 and Xuantie C908) do support this possibility.
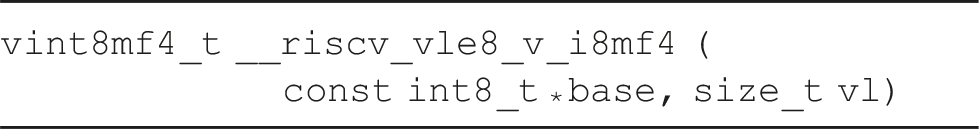
which loads eight INT8 elements into the vector register.
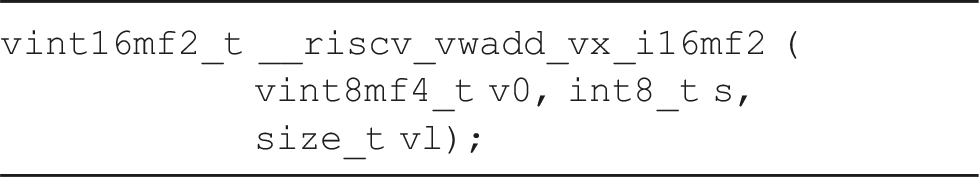
This intrinsic expands the data in the vector register

This instruction transforms the entries of
The two plots in the bottom row of Figure 9 report the execution time of the encoder block built upon the three variants of
5.6. Global comparison
To close the experiments, we compare the performance of all the CPUs included in our study. For this purpose we select a latency-oriented scenario with b = 4 and the best implementation of the transformer block in each platform. Furthermore, we offer two sets of results, corresponding to absolute performance in tokens per second; and values normalized by the respective processor frequency and cores, to isolate the effect of the differences in these two factors.
Table 5 reports the results from this final experiment. In terms of absolute performance (top part of the table), as could be expected, the ARM Cortex-A78AE is the clear winner. This processor benefits from its superior number of cores (12) and high frequency (2.20 GHz) compared to the rest of competitors. Only the NVIDIA Carmel is close in cores (8) and slightly superior in frequency (2.26 GHz). However, the processor in the NVIDIA Jetson AGX Orin still outperforms that in the NVIDIA Jetson AGX Xavier due to the efficient hardware support for MIP arithmetic, which allows to leverage a quantized version of
Looking at the normalized values next, we can observe that the two most powerful ARM-based CPUs still stand out, but the differences between the rest are much narrower for the largest problems.
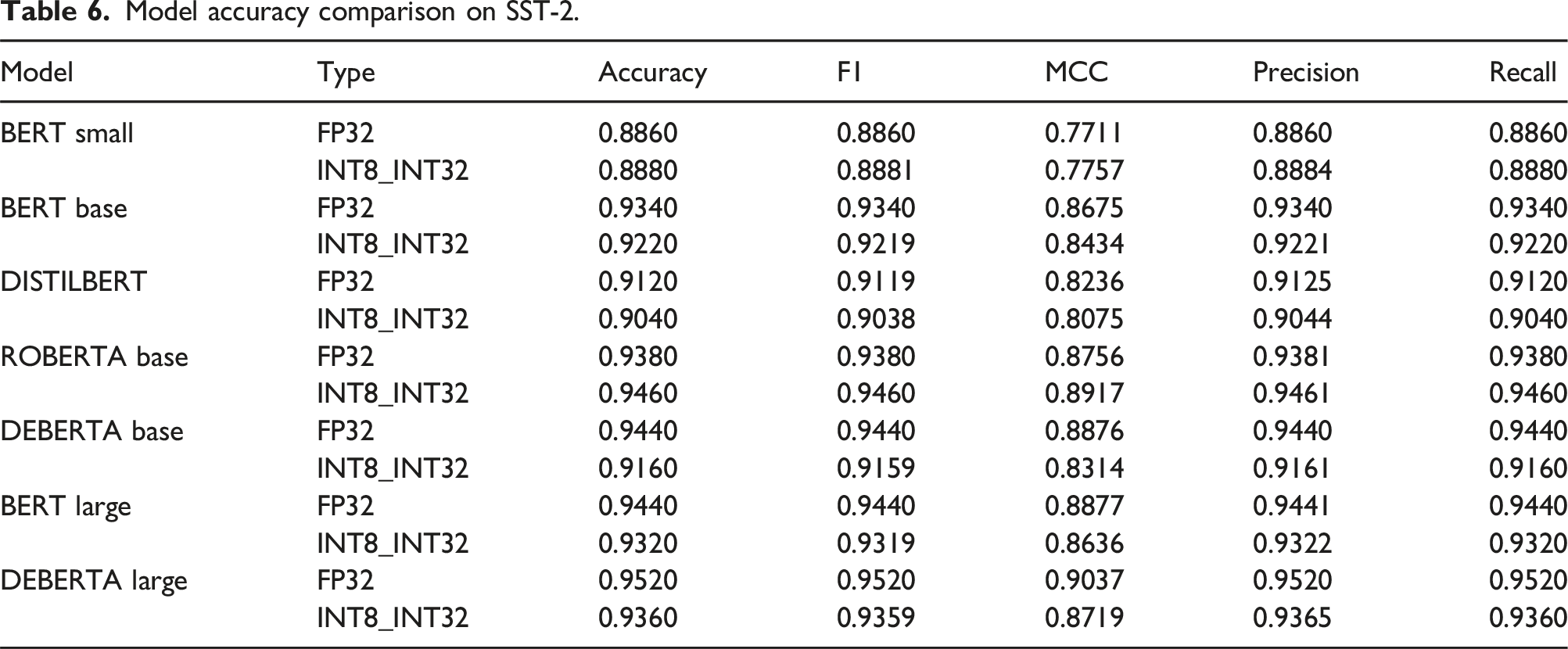
Model accuracy comparison on SST-2.
6. Concluding remarks
This paper focuses on optimizing transformer encoders, which play a vital role in tasks like text classification, speech recognition, and language translation. Unlike most LLM optimization efforts that target training on GPUs, this work emphasizes inference on low-power, general-purpose CPUs. The key contributions of our work include: (1) Performance Analysis: We identify the significant impact of linear layers on transformer encoder performance when executed on low-power CPUs. (2) Mixed-Precision Kernels: We develop and tune integer arithmetic-based mixed-precision kernels for linear layers on ARM and RISC-V CPUs, tailored to improve efficiency. (3) Energy Impact: We report the energy savings achievable via quantization on CPUs with power counters, particularly on ARM-based CPUs in the NVIDIA Jetson boards.
In summary, our study delivers a detailed evaluation of performance and energy gains from quantization, targeting transformer encoder inference on both single-core and multi-core low-power CPUs.
In addition, the paper offers the following list of conclusions: (1) Significance of Linear Layers: Linear layers dominate the computational workload in transformer encoders on low-power CPUs. Optimizing these layers is critical for enhancing performance. (2) Role of Quantization: Quantization effectively reduces the computational and energy demands of transformer encoder inference on resource-constrained CPUs, in principle with minimal trade-offs in accuracy. (3) Mixed-Precision Success: Custom mixed-precision implementations of general matrix multiplication significantly boost efficiency on ARM and RISC-V architectures. (4) Energy Efficiency Gains: Quantization offers measurable energy savings, as demonstrated on platforms with accessible power counters, exposing its suitability for edge computing scenarios. (5) General Applicability: The methodologies and findings provide actionable insights for deploying transformer-based NLP applications on low-power CPUs, promoting resource-efficient DL adoption.
Footnotes
Acknowledgements
This work was supported by the research projects PID2023-146569NB-C2 and PID2020-113656RB-C22 of MCIN/AEI/10.13039/501100011033 and ERDF/UE. H. Martínez is a POSTDOC_21_00025 fellow supported by Junta de Andalucía. S. Catalán is supported by the grant RYC2021-033973-I, funded by MCIN/AEI/10.13039/501100011033 and the “NextGenerationEU”/PRTR, and UJI-2023-04, funded by Universitat Jaume I. A. Castelló is supported by the CIAPOS/2023/431 grant, and Fondo Social Europeo Plus 2021-2027 from the Generalitat Valenciana.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: PID2023-146569NB-C2 and PID2020-113656RB-C22 of MCIN/AEI/10.13039/501100011033 and ERDF/UE, POSTDOC_21_00025 of Junta de Andalucía, RYC2021-033973-I of MCIN/AEI/10.13039/501100011033 and the “NextGenerationEU”/PRTR, UJI-2023-04 of Universitat Jaume I, and CIAPOS/2023/431 of Fondo Social Europeo Plus 2021-2027 from the Generalitat Valenciana.
Héctor Martínez received his bachelor and PhD degrees in Computer Science from Universitat Jaume I in 2010 and 2020, respectively. He is a postdoctoral researcher under the Junta de Andalucía program at Universidad de Córdoba and his research interests include high-performance computing, IoT, deep neural networks, and programming models.
Sandra Catalán received her Bachelor’s, M. Sc., and PhD degrees in Computer Science from Universitat Jaume I in 2012, 2013, and 2018, respectively. She is a postdoctoral researcher under the Ramón y Cajal program at Universitat Jaume I. Her research interests include high-performance computing, linear algebra, deep learning, and programming models.
Adrián Castelló received his Bachelor’s, M. Sc., and PhD degrees in Computer Science from Universitat Jaume I in 2011, 2013, and 2018, respectively. He is a Postdoc researcher under the APOSTD program of the Generalitat Valenciana at the Universitat Politècnica de València. His research interests include high-performance computing, code auto-generation, deep neural networks, and programming models.
Enrique S. Quintana-Ortí received bachelor and PhD degrees in Computer Science from Universitat Politècnica de València (UPV), Spain, in 1992 and 1996, respectively. After more than 20 years at Universitat Jaume I, he is currently Professor in Computer Architecture at UPV. His current research interests include parallel programming, linear algebra, energy consumption, transprecision computing and deep learning as well as advanced architectures and hardware accelerators.