
Abstract
The direct solution of batches of band linear systems in parallel is important for many applications. In this paper, we elaborate on three new GPU algorithms for the data-parallel direct solution of linear system batches, sharing a band structure. We develop algorithms for three matrix types: tridiagonal, small bandwidth, and wide bandwidth. We exploit the band structure of the matrix, and store it in an efficient fashion (LAPACK band matrix format) and ensure that the SIMD parallelism of the GPUs are maximized. We develop a panel-based factorization for wide-band matrices to ensure coalesced access (with column-major storage) while minimizing main memory traffic. For the tridiagonal solvers, to ensure a high level of concurrency, we adapt a divide-and-conquer approach and utilize co-operative group functionality to efficiently communicate between compute units (in registers) on GPUs. We implement these algorithms for NVIDIA GPUs and study the performance for varying matrix sizes (16 to 1024) and across a range of batch items (upto 1 × 106). We compare the performance of our implementations with the corresponding optimized vendor implementations (cuSPARSE and MKL), with the state-of-the-art GPU library MAGMA, and with the optimized LAPACK implementation provided by Intel MKL on Intel Skylake CPUs. We also showcase the effectiveness of our batched band solvers for matrices originating from XGC, a gyrokinetic Particle-In-Cell (PIC) application optimized for modeling the edge region plasma within a plasma physics application. We show that our implementations are on average ∼ 2× (for batched banded solvers, compared to MAGMA and MKL) to ∼ 3× (for batched tridiagonal solvers, compared to cuSPARSE) faster than the state-of-the-art and the vendor provided implementations.
Keywords
1. Introduction
Many computational science applications such as plasma physics and combustion simulations use Ordinary Differential Equations (ODEs) for modeling the physics and the chemical processes in a grid of cells covering the simulation domain. The solution of the ODEs for the distinct cells results in many linear systems of small size that all share the same sparsity pattern. Often, the discretization is based on finite difference schemes, based on stencils of varying width. The stencil width on a grid defines the band-structure of the assembled matrix. When multiple independent quantities need to be computed on the same grid, a finite difference discretization leads to the assembled matrices sharing a sparsity pattern (with a band structure). To evolve the physics in space-time (Hindmarsh (2002)), a non-linear solver is required. For robustness and stability, implicit methods are usually preferred, and a linearization step necessitates the solution of a sequence of linear systems.
For applications that need to solve for non-coupled variables such as concentration of chemical species, the linear systems for the distinct cells are independent. Therefore, in each non-linear solve, there is a need for solver functionality that can efficiently handle a large number of (relatively small) independent linear systems. For the efficient solution of these independent linear systems, batched methods have been developed (Dongarra et al. (2016)).
Batched methods are well-suited for the hierarchical parallelism provided by many-core architectures such as GPUs. Mapping the independent linear system solutions to a coarser level enables synchronization-free computing, while the finer level of parallelism can still be utilized to accelerate the solution of the individual linear systems (Nayak (2023)).
Direct solvers for linear systems consist of two steps: A factorization-step such as LU factorization, that factorizes the matrix into upper and lower triangular factors (A = LU), and a solve step, which involves two triangular solves. For numerical stability, partial pivoting is usually necessary (Davis (2006)), which involves exchanging the rows of the matrix to ensure that the diagonal is not close to zero. Band matrices have a uniform sparsity pattern. We can therefore use a special storage format (based on LAPACK (Blackford and Dongarra (1991))), with only minimal additional storage required for fill-in due to partial pivoting.
With GPUs providing most of the computing power in the latest supercomputers, it is important to deploy algorithms that harness the massive parallelism provided by these architectures. Maximizing performance on the GPU can be challenging due to its massive fine-grained level of parallelism. Batched methods can take advantage of this massive fine-grained parallelism due to their embarrassingly parallel nature, but ensuring efficient mapping of data to the GPU is still challenging. Efficient solution of batched band matrices requires the implementation to ensure that within the fine-grained level, parallel workers have a balanced workload. Additionally, maximizing the cache utilization with efficient storage formats and access patterns for different sub-classes of band matrices (narrow bands, wide bands, tridiagonal etc.) is non-trivial (Abdelfattah et al. (2023)).
In this paper, we showcase our batched band solver algorithms, and their high performance implementations for arbitrary band sizes, and specializations for wide bands and tridiagonal matrices. The novel contributions of this paper are listed below: (1) General batched band matrix solver algorithms for GPUs that outperform existing state-of-the-art CPU and GPU solvers, with a column-based LU factorization and fused triangular solves. (2) A new variant of a blocked band solver algorithm that enables the efficient solution for wide bandwidth matrices, with adaptable panel sizes to maximize cache utilization and enable coalesced memory accesses. (3) A batched tridiagonal solver algorithm that outperforms the vendor libraries, using a divide-and-conquer approach to maximize concurrency. (4) A detailed performance evaluation of the GPU band solvers for randomly generated matrices and an analysis investigating the performance impact of partial pivoting. Additionally, we consider matrices originating from a plasma physics application, XGC, to showcase the performance of our batched band solver in real-world applications.
In Section 2, we provide a background of band matrices, their storage formats and on direct solvers, including their relevance in scientific computing applications. We consider some related work in Section 3. In Section 4, we provide details of our band and tridiagonal solver algorithms, including implementation and optimization details that enable efficient computation on GPUs. We evaluate the performance of our band solvers and benchmark them against state-of-the-art band solvers in Section 5. We conclude with a brief summary in Section 6.
2. Background
Direct methods for the solution of linear systems compute the solution via a fixed and pre-defined sequence of operations. Direct solvers typically factorize the coefficient matrix in the first step and then solve the linear system with forward and backward substitutions. For a general matrix of size n, the factorization step has a computational cost of
Algorithms for the factorization and subsequent solution can account for the sparsity pattern and symmetry of the matrix. While for small matrices, using a dense storage format is acceptable, storing large matrices in the dense format can be inefficient or even impossible if the memory requirements exceed the hardware resources. Efficient algorithms have been developed for these cases that handle the coefficient matrix and the factorization in sparse matrix formats such as CSR (Duff et al. (2017); Li and Demmel (2003)). When using sparse data formats, the factorization step is typically split into two stages, a symbolic phase where the row dependencies and fill-in are determined, and a numeric phase where the actual factorization and the numeric values are computed.
The sparsity pattern of the generated matrix depends on the application. Many applications require the solution of linear systems whose matrices have a band structure, for example, those that arise from a stencil discretization. Band matrices are characterized by two main parameters: the lower bandwidth, β
L
, and the upper bandwidth, β
U
, as shown in Figure 1 with (β
L
, β
U
) = (3, 1). Band matrix 
2.1. Ginkgo
Batched iterative solvers and preconditioners have been added recently to accelerate science applications such as combustion simulations (Aggarwal et al. (2021)) and plasma physics (Kashi et al. (2023)).
2.2. Batched band matrix storage format
Unlike general sparse matrices, the fill-in for band-structure matrices is limited to within the band if no pivoting is used, and the fill-in with partial pivoting is also well-defined, with given lower and upper bandwidths. Storing these band matrices in a tailored format and using their structure to compute the factorization can be advantageous. LAPACK (Anderson (1999)) introduced an efficient storage format for band-structure matrices and a customized solver operating on the band matrix storage format in the LU factorization and the subsequent triangular solves. We visualize the band matrix storage format in Figure 2. As partial pivoting is necessary to ensure stability for a general linear system solver, the storage format allocates additional memory for possible fill-in during the factorization. In Figure 2, we see these locations marked by “+”. The extra padding (elements only stored to ensure uniform strided accesses) is marked with “∗”. The total number of bands stored, each of size n, is equal to β
st
= 2β
L
+ β
U
+ 1. This includes the extra storage required for possible fill-in introduced by pivoting. Band storage 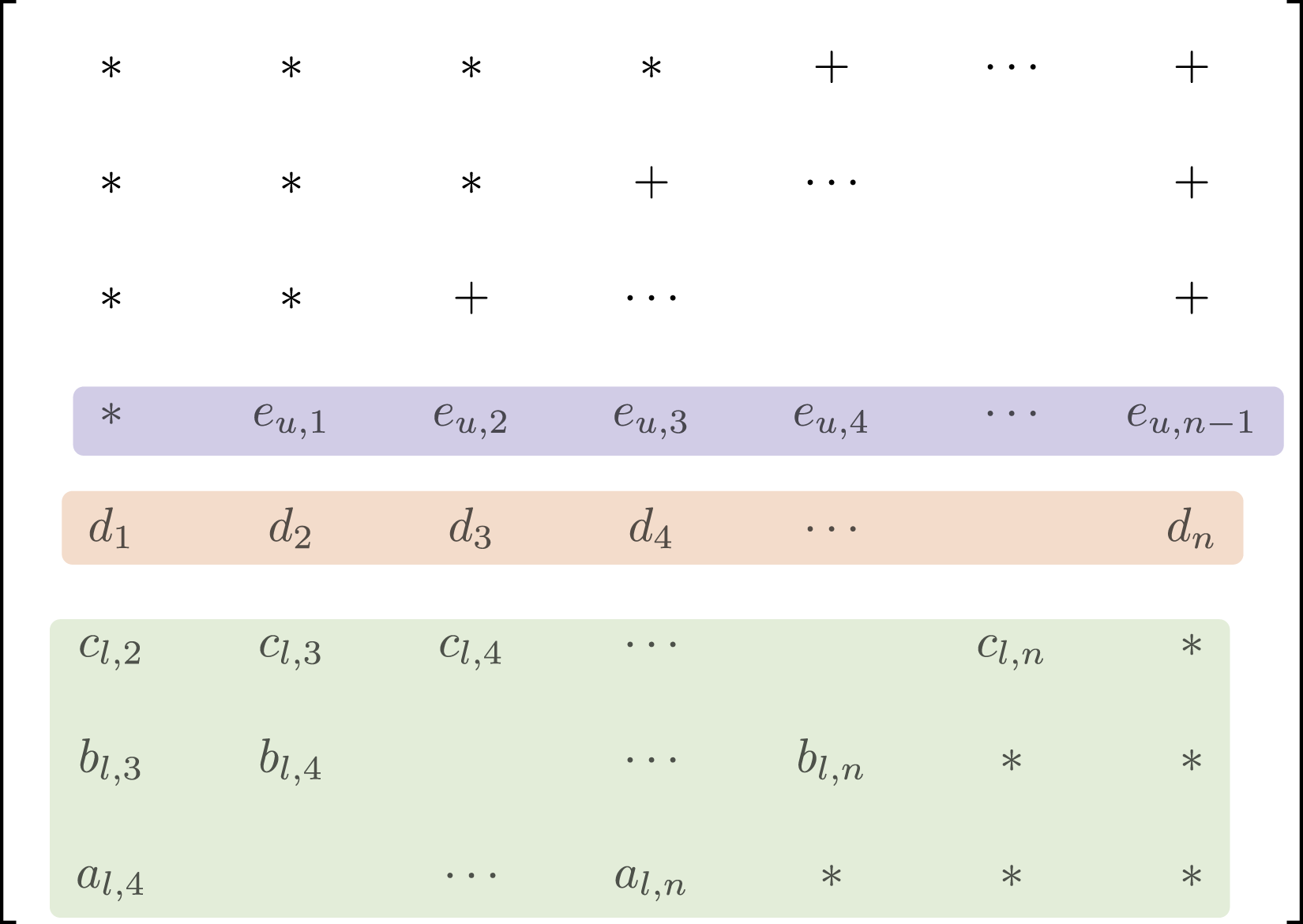
2.3. Batched direct solves for band matrices
With the band matrix stored as shown in Figure 2, the batched band direct solver consists of two steps: An LU factorization that decomposes a band matrix of the batch into triangular factors, and the subsequent triangular solves using the generated triangular band factors. The batched band direct solver is shown in Algorithm 1.

3. Related work
There have been efforts in developing algorithms for data-parallel basic linear algebra functionality (BLAS) and advanced solver algorithms (LAPACK). The data-parallel versions of the functionality are generally called “batched” to indicate the data-parallel processing of a batch of linear algebra objects. A batched BLAS interface has also been recently proposed (Dongarra et al. (2016; 2017)) to standardize the interface to batched basic linear algebra functionality across hardware architectures and software stacks. This standardization effort for batched functionality has also been expanded to LAPACK, providing direct solvers for dense linear systems (Abdelfattah et al. (2021)).
In terms of batched direct solvers for sparse problems, there has been some work on tridiagonal and penta-diagonal systems (Valero-Lara et al. (2018); Carroll et al. (2021); Gloster et al. (2019)), and the NVIDIA cuSPARSE library provides the
These methods aim to solve tridiagonal and penta-diagonal systems and rely on Thomas’ algorithm or cyclic reduction (Valero-Lara et al. (2018)). These implementations are not fine-grain parallel, but each GPU thread solves an entire linear system. The performance benefits, therefore, primarily come from storing the problem data in an interleaved fashion to enable coalesced data access. Coalesced accesses ensure concurrent threads can compute efficiently in a SIMD (single instruction multiple data) fashion, improving throughput. This is suitable for GPUs whose threads have limited co-operative functionality. For modern GPUs, utilizing the co-operative functionality between threads in addition to the SIMD functionality is necessary to provide better performance (NVIDIA (2020)).
In the context of the Human Brain Project (Valero-Lara et al. (2017)), methods similar to cuThomasBatch (Valero-Lara et al. (2018)) have been developed to accelerate the solution of batched Hines systems on NVIDIA GPUs. There also exists some work on the efficient solution of batched penta-diagonal systems (Gloster et al. (2019); Carroll et al. (2021)), however, in these attempts, the factorization step is performed on the CPU, necessitating data transfer for the triangular solves, which are performed on the GPU. Within a non-batched setting, GPU-based tridiagonal solvers have also received some attention (Klein and Strzodka (2021); Pérez Diéguez et al. (2018)).
The development of direct solvers for band matrices with an arbitrary number of sub- and super- diagonals, (β
L
, β
U
) has received very little attention due to the challenging nature of its implementation. The only implementation that performs a GPU-resident factorization and solve for band matrices that the authors could find at the time of writing this paper is the implementation available in the MAGMA library (Abdelfattah et al. (2023)). For the CPU, LAPACK provides efficient routines (
4. Batched band solvers in Ginkgo
In this paper, we extend the batched solver functionality in
As our focus is on small problems and the goal is to solve thousands to hundreds of thousands of small problems in parallel, we map one linear system solve (factorization + triangular solves) to one workgroup (thread block) of the GPU. As workgroups have no data dependencies, this allows for the parallel and independent processing of the problems, and global memory reads and writes are conflict-free, thereby reducing the global memory contention.
Due to the reduced amount of parallelism available in the band solver, large work-group sizes would lead to warp-stalling (A warp is similar to a SIMD unit in CUDA, consisting of 32 threads that execute the same instruction). We therefore tune our workgroup sizes based on the problem size and the matrix bandwidth. An additional advantage of small workgroup sizes is that more batch items can be processed concurrently, allowing for higher throughput.
For the efficient solution of batched band linear systems, we perform the triangular solves for each system immediately after the factorization. i.e., once a band matrix is loaded into the multiprocessor memory, we first perform in-place factorization and then the forward and backward triangular solves in shared memory without writing intermediate results to the GPU main memory. While this requires consolidating both functionalities into a single GPU kernel it radically reduces the main memory access. In the end, we launch a single kernel handling the solution of all linear systems in the batch.
Next, we provide more details on our generic band solver implementation. Afterward, we present the implementations tailored towards matrix batches with wide bands and batches composed of tridiagonal matrices.
4.1. Batched LU factorization for band matrices
The LU factorization of a band matrix batch is shown in Algorithm 2. For each batch item, we process each column individually. First, we identify the pivot and process the row swaps. We then proceed by scaling the columns and finish by updating the trailing matrix. After completion, we have an in-place factorization of the input band-matrix. We note that as a result of the storage scheme shown in Figure 2, we do not need to perform a structural analysis or allocate additional memory to account for fill-in.
Templating each kernel on a compile-time subwarp size, we can maximize SIMD parallelism and ensure that accesses to the band matrix are coalesced.

4.2. Batched triangular solves
After computing a factorization, we need to perform two triangular solves.
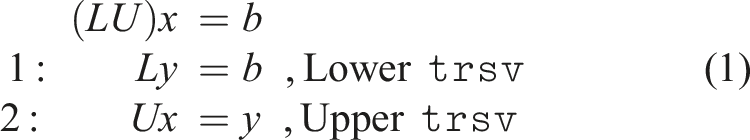
With partial pivoting (only row interchanges), the lower triangular solver uses the pivoting array computed in the factorization step, while pivoting is not required for the upper triangular solve.
Both triangular solves are processed row-by-row: the upper triangular solve uses backward substitution, and the lower triangular solve uses forward substitution.
4.3. Efficient solution of wide-band matrices
For matrices with small to medium bandwidths ((β L + β U ) < 32, with all elements of a row fitting inside a warp), processing each column is efficient, as it enables coalesced access when performing the scaling and the trailing matrix updates. For matrices with a wide band, due to the larger number of elements that need to be updated in each row, performing a blocked factorization and processing ϕ columns at once, where ϕ is the panel size, can be advantageous.
For wide-band matrices, processing more columns in a paneled fashion provides better overall concurrency as a result of reduced stalls for executing warps. In this case, the dependencies restricted to within one warp, thereby removing the need for cross-warp synchronizations. If we were to process one column per thread, then we would need more than one warp per row (
A schematic of our panel-based factorization is shown in Figure 3 for a panel size of 2. We partition the matrix into block-diagonal Panel factorization for band matrix (
The panel LU factorization algorithm, shown in Algorithm 3, proceeds by first factorizing the column panel
We proceed in this fashion recursively for the trailing block diagonal matrix until the entire matrix has been factorized. As the factors replace the original matrix in memory, we consider it an in-place factorization.
To ensure coalesced accesses when processing ϕ columns at a time, we utilize a workspace array to copy the matrix blocks that tend to have non-coalesced accesses, namely A02 and A20. We omit this implementation detail from Algorithm 3 for simplicity.

4.4. Efficient solution of tridiagonal matrices
Tridiagonal matrices are a special case of band matrices with (β L , β U ) = (1, 1). For these systems, it is not necessary to compute an LU factorization, but we can directly use the Thomas algorithm to solve the linear system (Valero-Lara et al. (2018)). A recursive divide-and-conquer approach allows for a high level of concurrency (Wang and Mou (1991)). We use this approach for the batched tridiagonal solver and show that our implementation is faster than both the vendor-provided tridiagonal solver implementation and the general band solver implementation.
The algorithm we use (shown in Algorithm 4) is a variant of the standard parallel Gaussian Elimination (GE) for tridiagonal matrices (Wang and Mou (1991)). The idea is to first merge adjacent rows into groups, with a partial GE, removing dependencies between the adjacent groups. We then obtain groups that can be eliminated in parallel with a full GE step. Once all groups have been eliminated with a forward GE, we can perform a backward substitution to obtain the final solution. A schematic of this process is shown in Figure 4 for ρ = 2 where ρ is the number of merge steps that is performed on the initial matrix and for a tile size, t = 16. Divide and conquer parallel Gauss-Elimination algorithm for tridiagonal matrices with number of merge steps, ρ = 2 and tile size, t = 16. (a) Initial matrix (b) Merge groups (c) Eliminate group 1 (d) Eliminate group 2 (e) All groups eliminated (f) Final solution.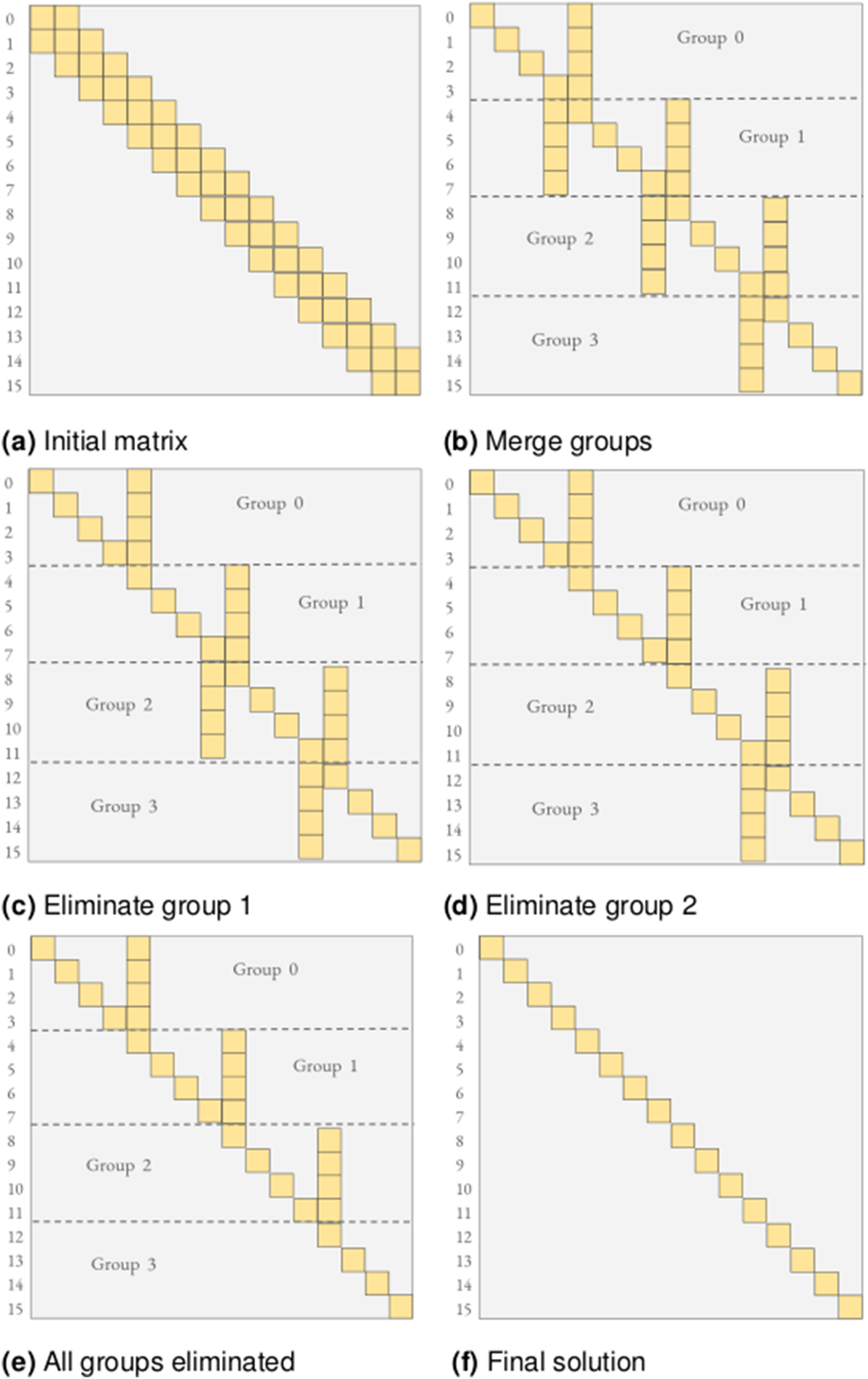
To optimize performance, we expose two control knobs to the user. The tile size, t, defines the size of the matrix tile to be handled by each subwarp, and the number of merge steps, ρ, defines the total number of groups that are created and forward-eliminated in parallel. Additionally, the user can choose one of two strategies: Each thread in a subwarp handles one row of the matrix (
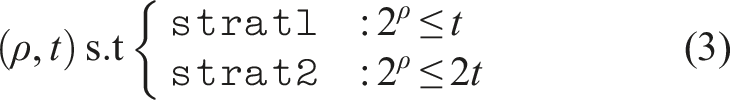
As the choice of ρ defines the subwarp size to be used, and the value of ρ depends on the problem size (n rows ), we instantiate kernels for all major subwarp sizes (1, 2, 4, 8, 16, 32: powers of 2, upto the warp size of 32) during compile time. The optimal subwarp size is selected at runtime, depending on the problem size (n rows ). As each subwarp handles one matrix tile of size t, we can utilize co-operative group functionality such as warp-shuffles and broadcasts (Tsai et al. (2021)) for efficient in-register and local memory operations (involved in the GE steps), which reduces the overall global memory traffic.

5. Benchmarking and performance evaluation
Hardware characteristics (NVIDIA (2020)).
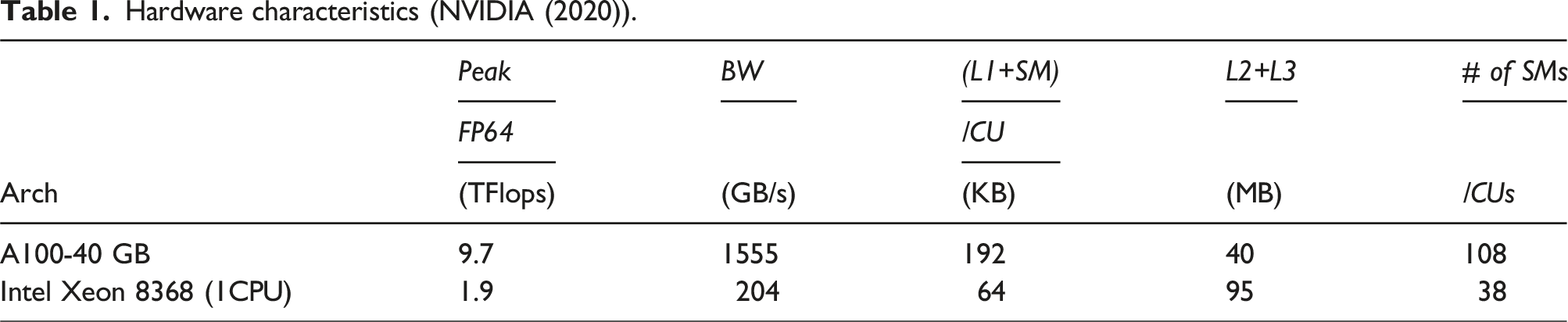
5.1. Dataset and evaluation metrics
Our dataset consists of artificially generated band matrices with random values (from a normal distribution) that are different along three main characteristics: the lower bandwidth β L , the upper bandwidth β U , and the diagonal dominance. For each of the experiments 2 , we run 2 warmup iterations to minimize the effects of startup artifacts such as library and symbol loading, data transfer, etc., and gather average timings over 5 kernel executions. We verified (post-solve) that all variants of the solvers (our solvers and the ones compared with) converged to machine precision (10−16).
To ensure a fair comparison of the solvers, we exclude the setup and analysis timings and only report the timings for the solution process (factorization and solve).
We present the performance of
We use MAGMA’s asynchronous batched strided interface. As mentioned previously, we do not include the timings for allocation and deallocation of MAGMA’s workspace. Both the MAGMA and MKL interfaces perform an in-place factorization, while
The number of batch items in the experiments varies with the number of nonzeros in each of the batch items. To minimize effects of the CUDA runtime, we set the number of batch items to a sufficiently high enough count that fills the GPU memory and is reflective of the application use-case.
5.2. Batched band solvers on GPUs
We first present the performance of Ginkgo band solver runtime (in seconds) with increasing matrix size (n
rows
) on a A100 GPU versus MKL + OpenMP on Intel Icelake (76 cores) and MAGMA (on A100 GPU), with 104 batch items. For matrices with narrow bands (left), 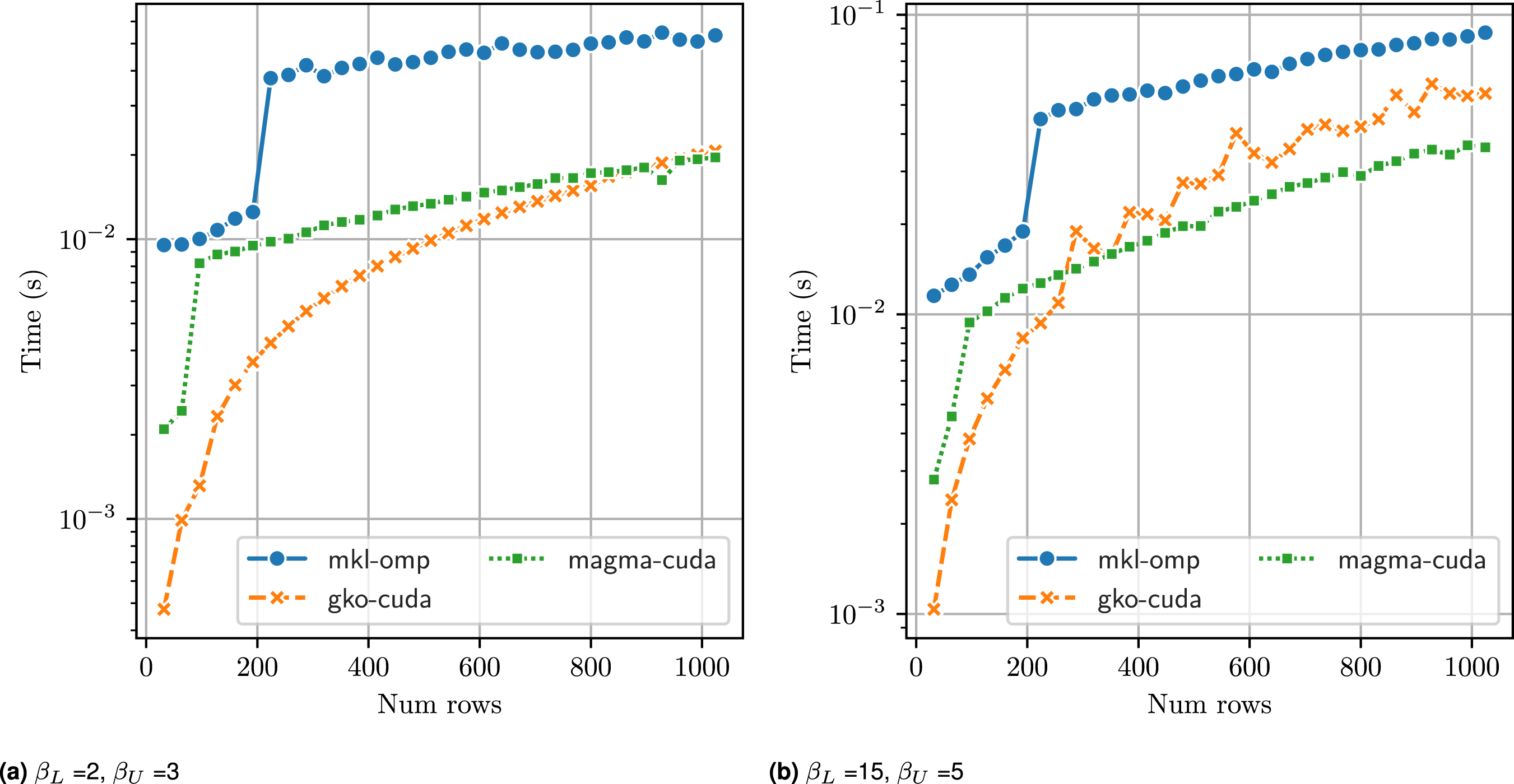
Due to the limited amount of parallelism available in the band LU factorization, large thread block sizes are inefficient as they leave most warps unutilized. For the non-blocked factorization,
Increasing the sizes of the bands of the matrices, as shown in Figure 5(b), with (β L , β U ) = (15, 5), we see a similar behavior: MAGMA’s batched band solvers perform the best, particularly for matrix sizes larger than (256 × 256). There, in addition to increased shared memory usage, it is beneficial to increase the amount of fine-grained parallelism available.
Figure 6 shows the solver runtime for Runtime comparison of 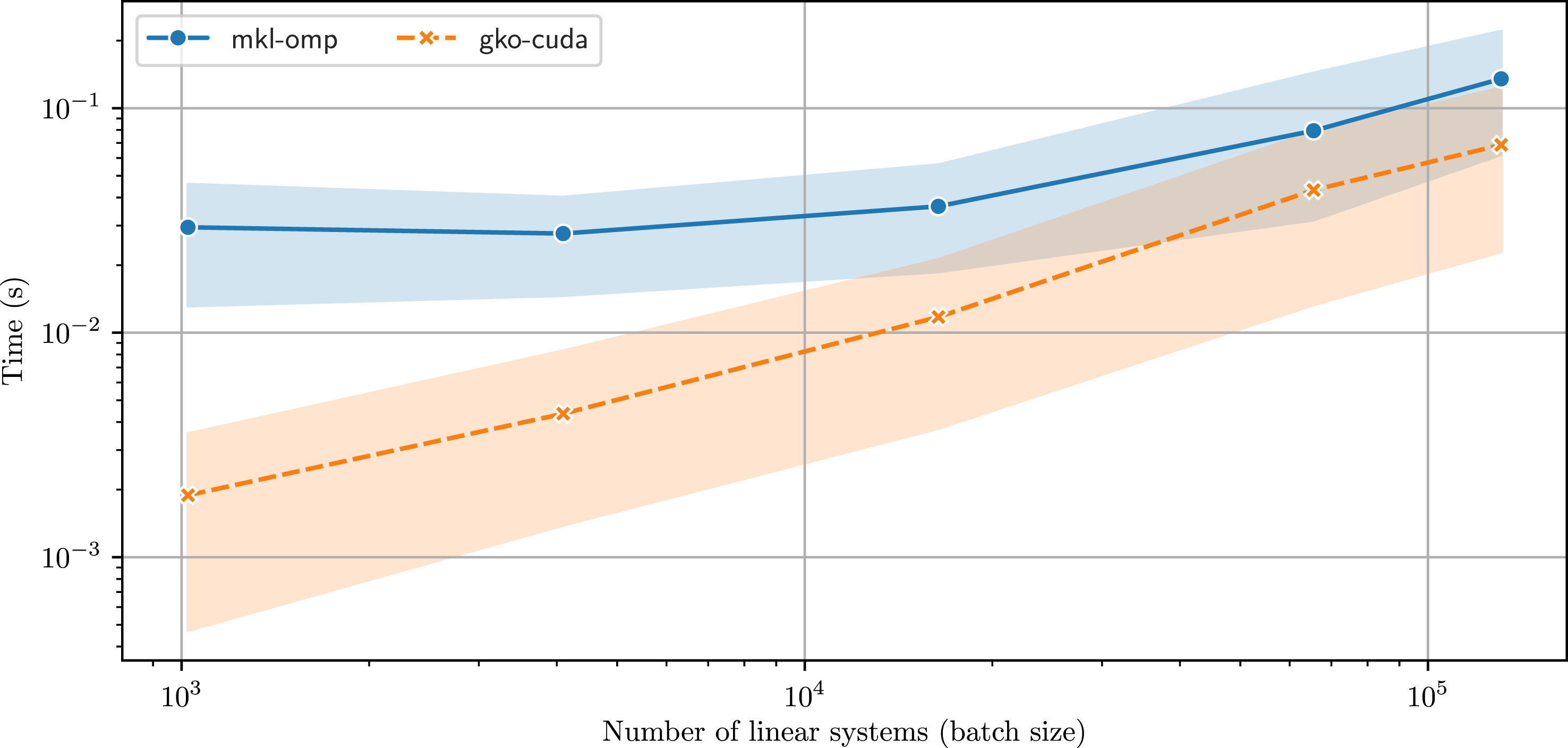
5.3. Wide band matrix optimizations
In Figure 7, we run the batched band solvers for matrices with a large bandwidth, (β
L
, β
U
) = (32, 32). These wide bands can occur in applications such as the XGC plasma simulations (Ku et al. (2009)). As noted before, using a non-blocked version of the factorization does not allow for harnessing the parallelism available, and we see in Figure 7 that the non-blocked version on the GPU achieves lower performance than CPU-based MKL solver. With a blocked version, Runtime comparison of 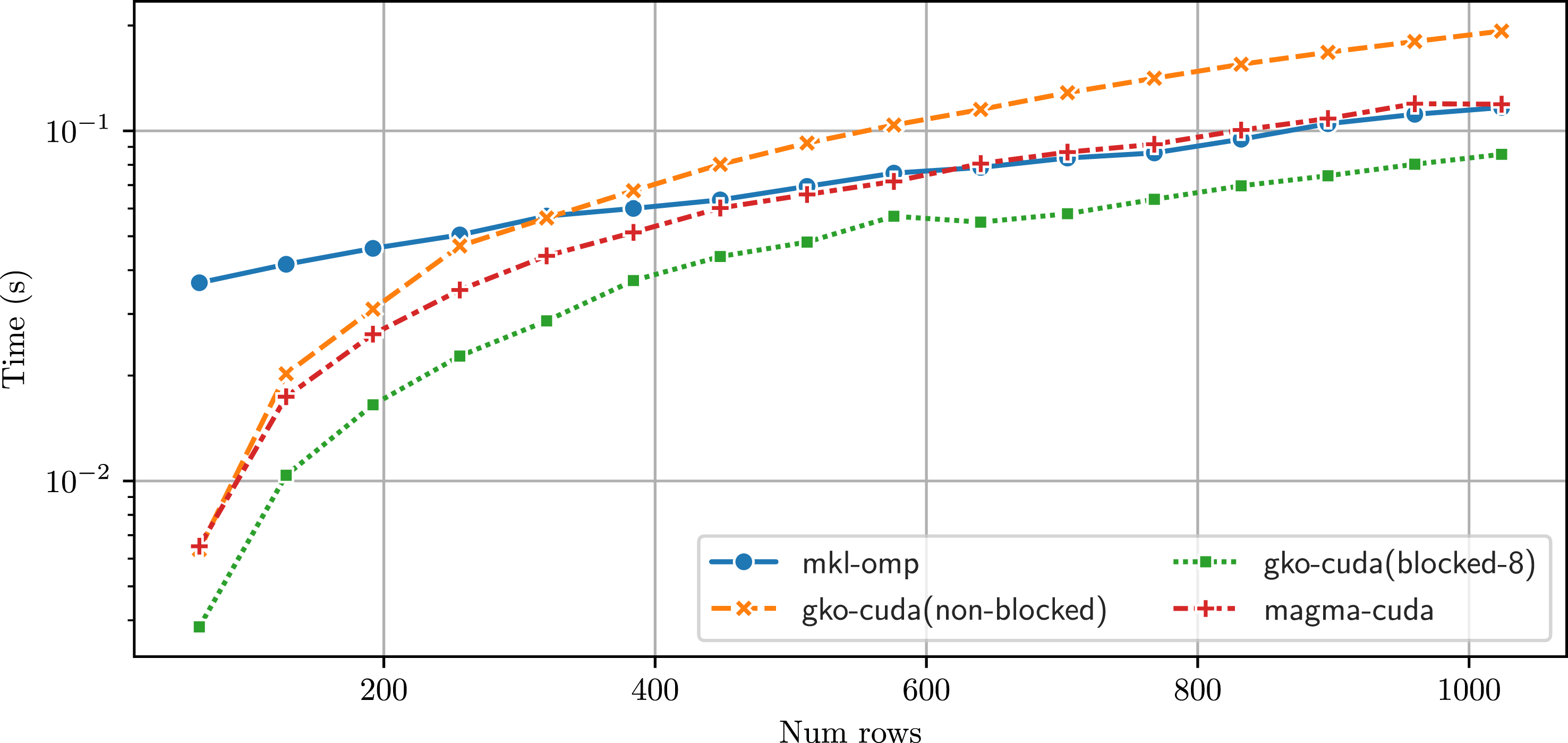
5.4. Tridiagonal matrix optimizations
A pathological case for the band solvers is a tridiagonal matrix. With only one sub- and super- diagonal, it does not offer enough parallelism to be solved with a general band solver algorithm like in LAPACK. We therefore implement a specialized tridiagonal solver as explained in Section 4, based on the parallel divide-and-conquer approach (Wang and Mou (1991)). Figure 8(a) shows the runtimes of Runtime (in seconds) of 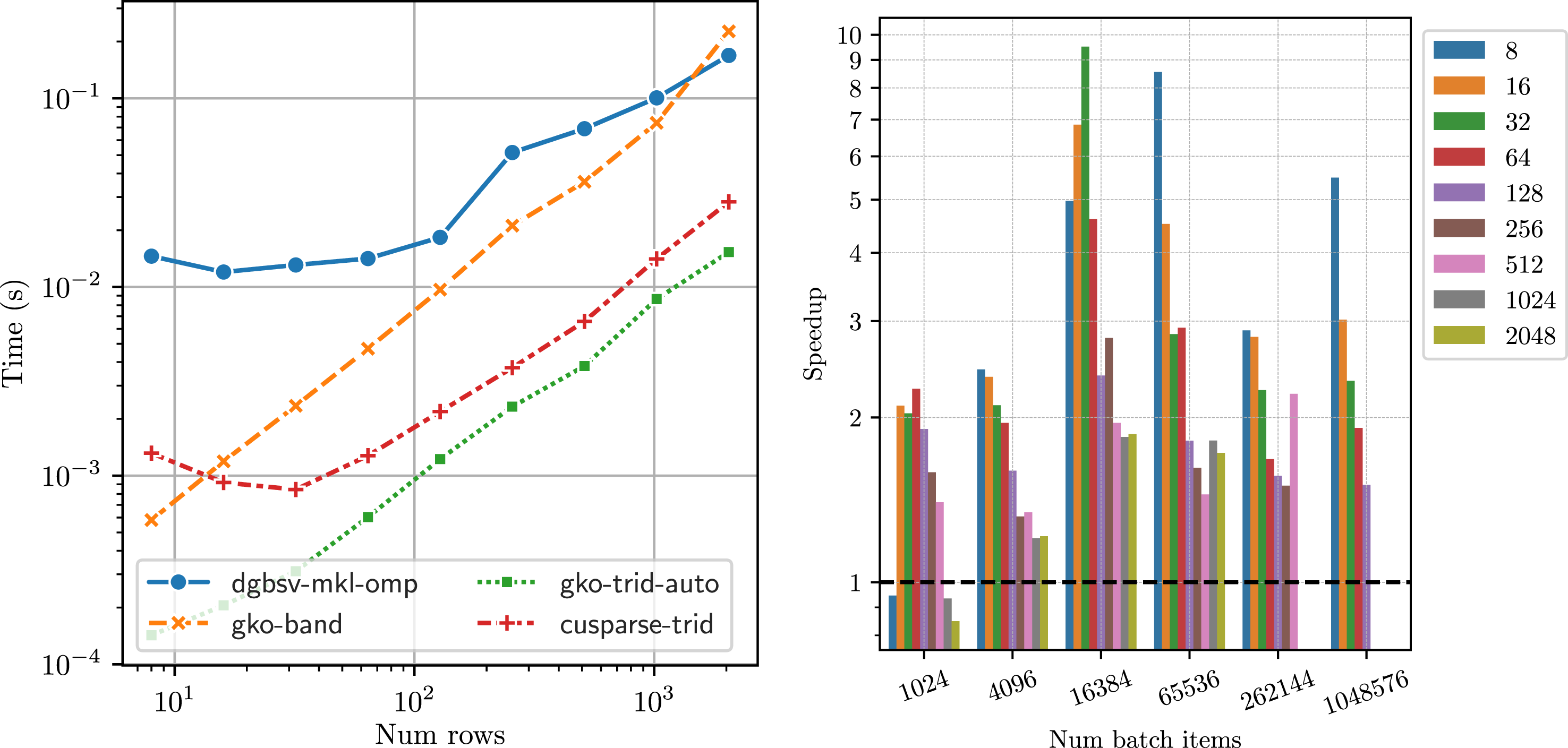
Figure 8(b) shows the speedup obtained by
5.5. Effects of pivoting
To ensure the robustness of the LU factorization, pivoting is usually necessary. For almost all cases, partial pivoting (row interchanges) is sufficient to ensure the stability of the factorization (Duff et al. (2017)). The state-of-the-art banded solvers such as MKL and MAGMA also implement only partial pivoting.
While pivoting is necessarry for stability of the algorithm, it can adversely affect performance. Partial pivoting, for instance consists of row interchanges to ensure that the largest element in a row is the diagonal element. This can have adverse effects, particularly increasing cache misses between subsequent operations before and after pivoting. It is therefore of interest to understand the effect of pivoting on the algorithm runtime.
Our dataset consists of matrices with all elements sampled from a normal distribution with variance of 0.1. All band solver implementations are equipped with partial pivoting. In Figure 9(a), we consider four experiment runs of the band solver and measure the number of row interchanges in each of the batch items for two matrix sizes. We see that with a random matrix generation approach, with approximately equal elements sampled from a normal distribution, all batch items need to perform partial pivoting and the number of row interchanges across the batch items ranges from Effect of pivoting on performance: (a) variation in number of row interchanges in a batch, (b) Comparing runtime (in seconds) of the band solvers (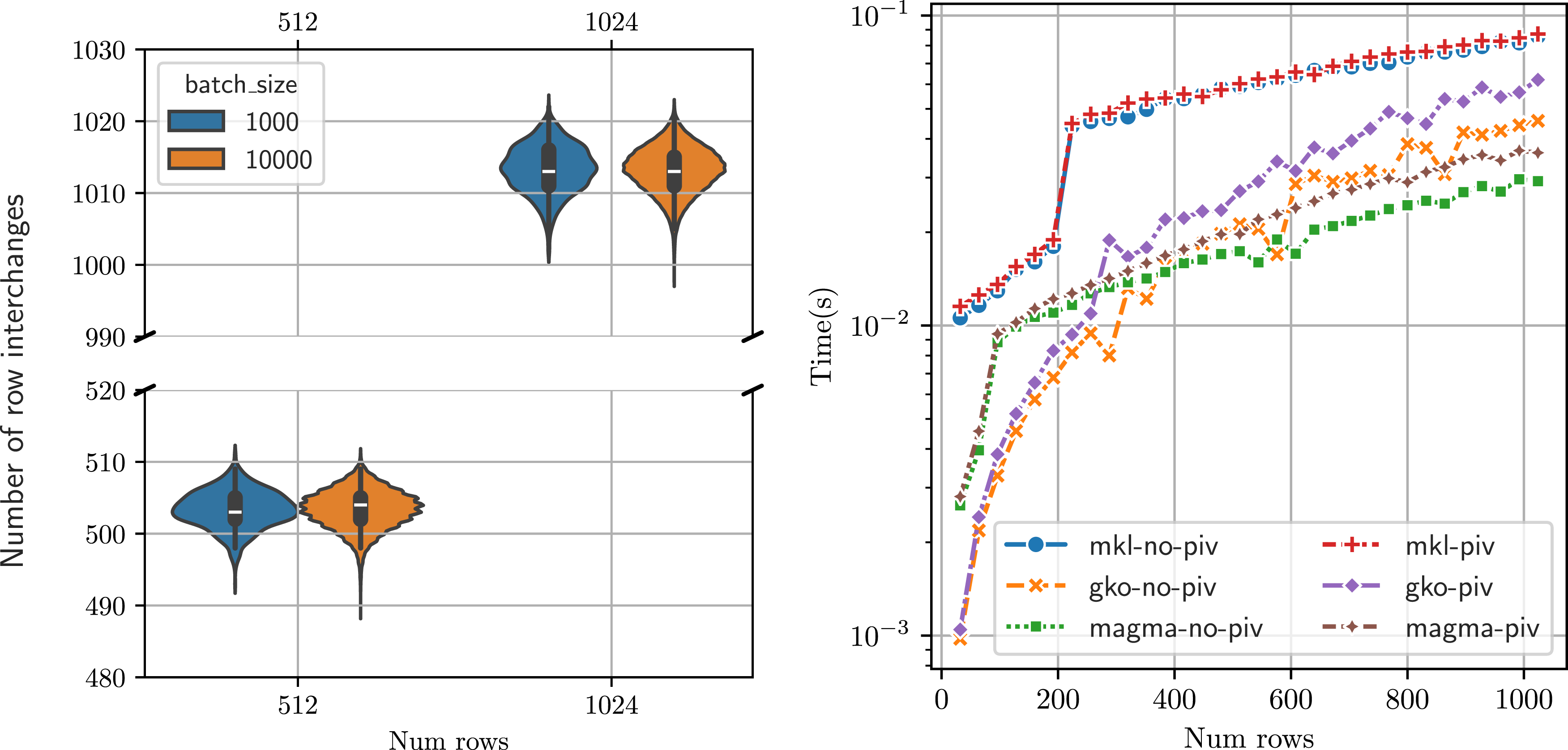
Figure 9(b) shows the runtime of the solvers with and without partial pivoting. To ensure that the band solvers do not apply row exchanges, we explicitly make the matrices strictly diagonally dominant by increasing the weight of the diagonal to be such that Band solver speedup without pivoting (ratio of solver runtimes with and without pivoting), β
L
= 15, β
U
= 5, with 104 batch items. The GPU solvers (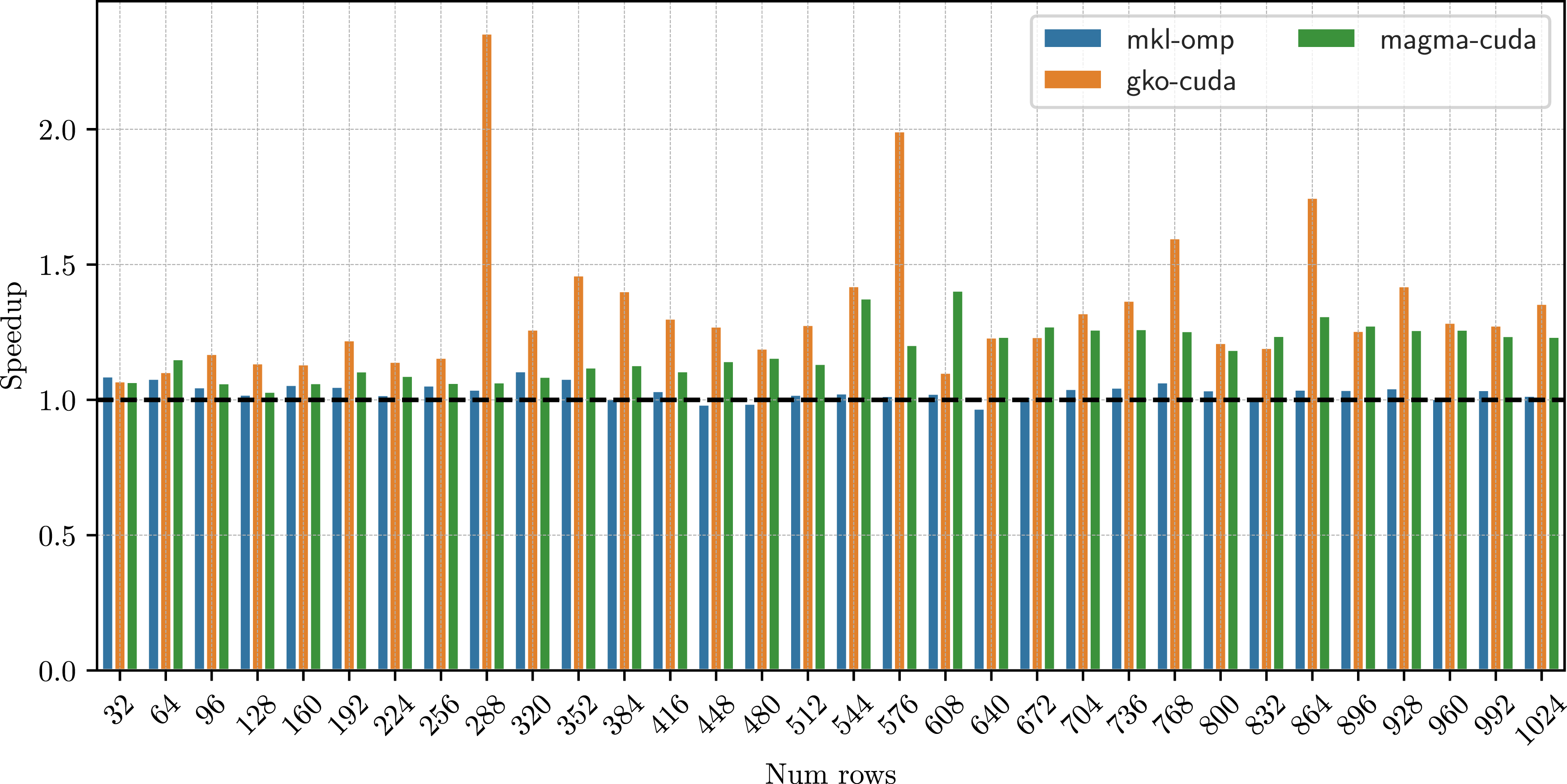
We note that the code for the two experiments is identical. The only difference is in the input data: the matrices are generated such that pivoting is not necessary. Therefore, the end-user automatically gets improved performance when the matrix does not require any pivoting.
5.6. Linear systems from a plasma physics application
Finally, we study the performance of
Each time-step therefore requires multiple non-linear steps and each non-linear step requires multiple independent linear solves, giving us a batched linear system for each species. XGC currently uses the band solver from vendor-provided LAPACK, mapping one linear system to one CPU core using Kokkos (Carter Edwards et al. (2014)).
The size and characteristics of the band matrix are dependent on the velocity grid used. For example, using a velocity grid of size (31 × 32) gives a matrix of size (992 × 992). Additionally, if multiple species are involved, we need to solve a linear system for each of these species. For our purposes, we use a velocity grid of size (31 × 32) and two species: ions and electrons. The characteristics of our test matrices (obtained from the XGC application) are shown in Figure 11. We note that the matrix is derived from a 9-point stencil, therefore the upper and lower bandwidths are given by (β
L
, β
U
) = (33, 33), dictated by the number of points in the x-direction of the velocity grid. The matrix therefore has a moderately large bandwidth. The number of batch items varies with the number of species, and can depend on the available GPU memory. In a typical run of XGC (on A100-40 GB), it can vary from 256 to 1024. It is expected that for newer GPUs with larger memory capacities, this can be significantly larger. XGC example matrix characteristics for the two species, ion and electron (Kashi et al. (2022)). Both species have the same sparsity pattern, but values stored are different. The figure on the right shows the eigenvalues for one such system matrix, for the ion and the electron species. (a) Sparsity pattern (b) Eigenvalues.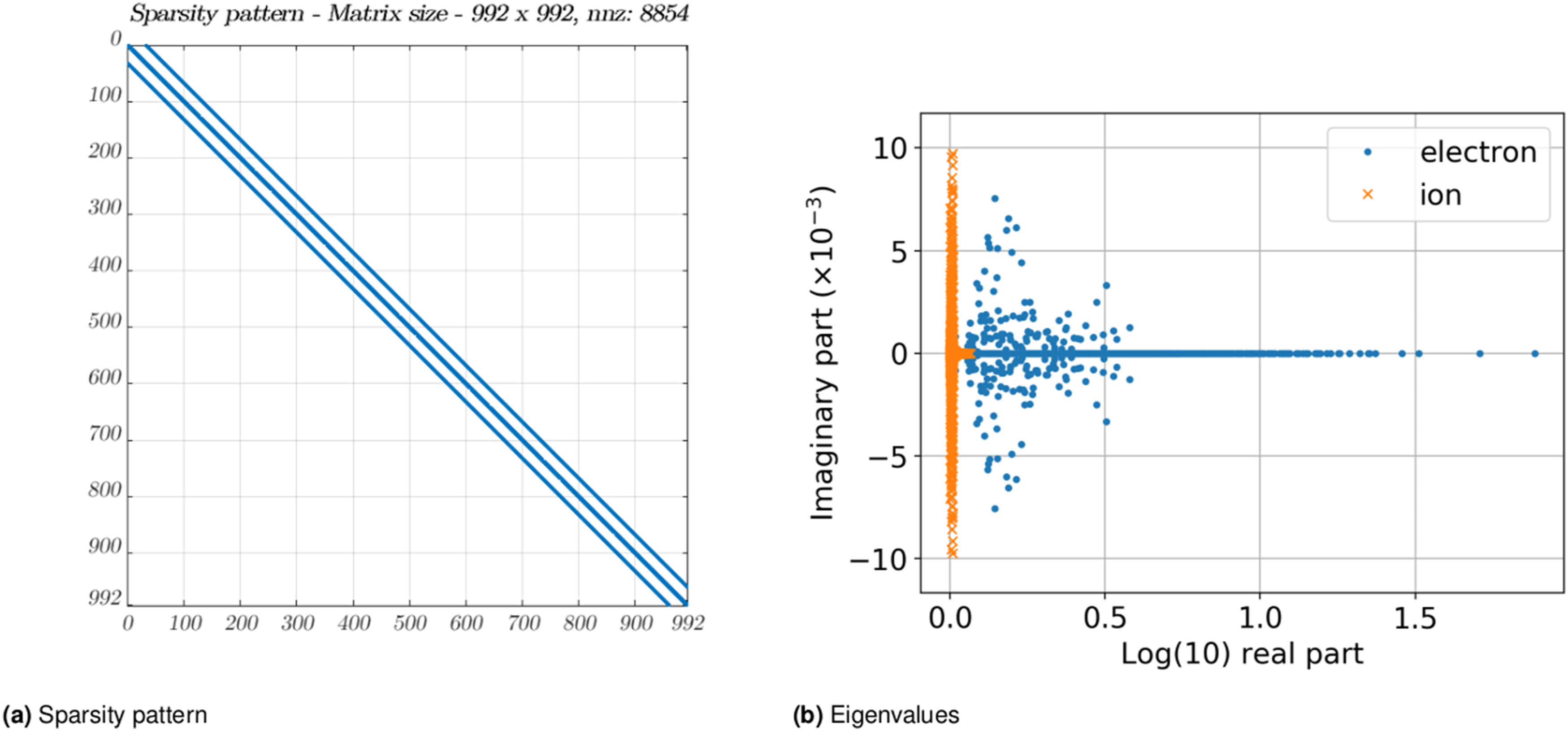
In Figure 12, we compare the performance of our batched band solvers with that of the state-of-the-art CPU-based band solver from MKL on Intel CPUs and with the GPU batched band solvers from MAGMA. Given the wide bandwidth of this matrix, we observe that the non-blocked strategy is inefficient and each subwarp gets assigned too much work, and hence it is slower than both the MKL version and MAGMA. Using a blocked version, with a panel size ϕ = 2, we can improve our performance significantly, outperforming MKL solver on average by 1.5 × . The matrix has lower and upper bandwidths of 33, and we observe that a panel size of 8 gives the best performance, providing a good balance between the amount of work assigned to each subwarp while providing enough parallelism to have enough concurrent warps resident on the compute unit. On average, with a panel size of 8, we get a speedup of 2.5× over the MKL solver. We did not observe any performance benefits beyond a panel size of 8. Performance of the batched band solvers with matrices and right hand sides from the plasma physics application, XGC. The left figure shows the runtime (in seconds) for the different batched band solvers for increasing batch sizes. As the matrices have a wide band (33), the blocked version of the 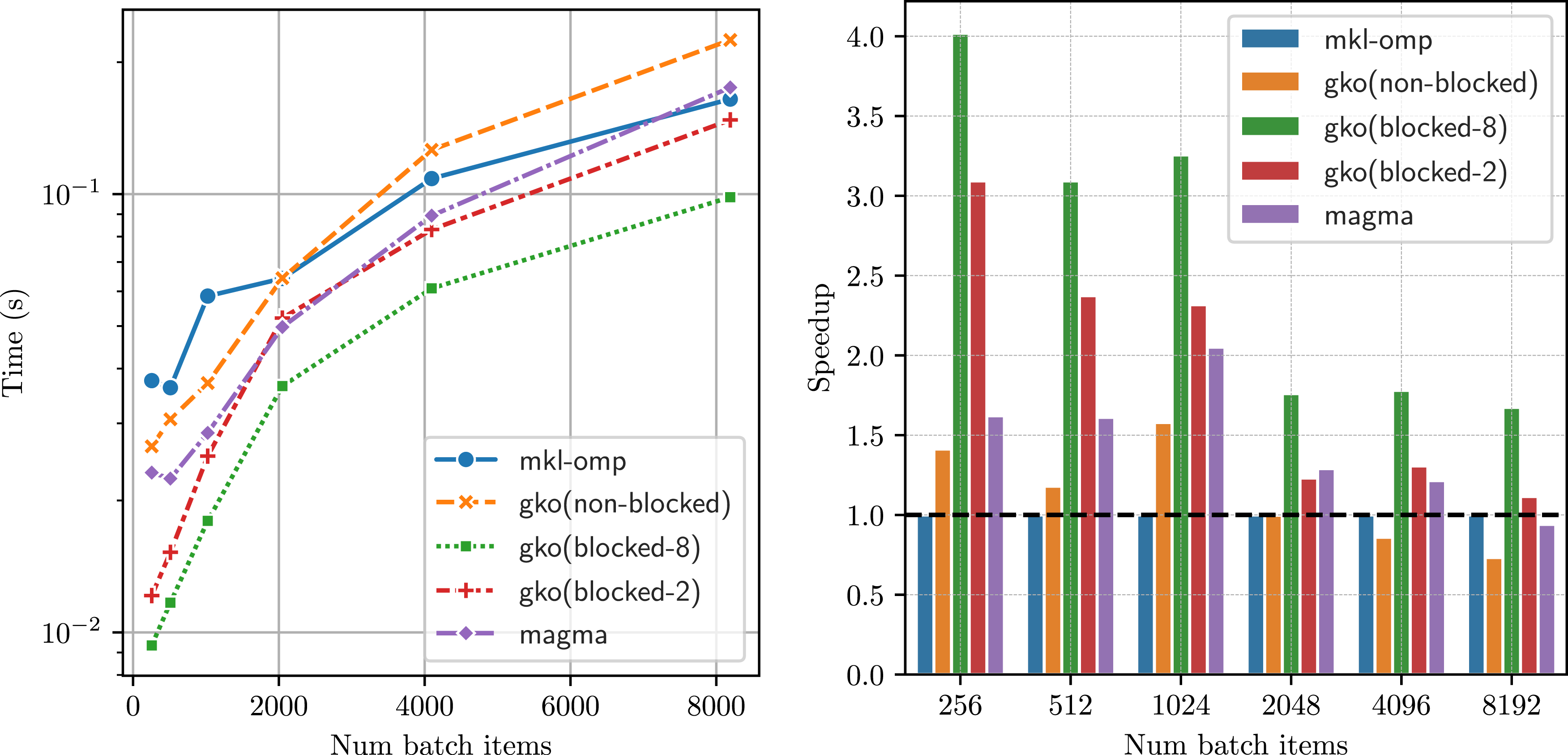
6. Conclusion
In this paper, we have presented
The third algorithm we presented employed a divide-and-conquer approach for the solution of batched tridiagonal systems. This strategy proved to be significantly faster than implementations available in the software stack provided by hardware vendors.
Finally, we investigated the performance of the developed batched band solvers when applied to linear systems originating from the XGC plasma physics application. We demonstrated attractive runtime savings over the solvers available in MKL and the GPU library MAGMA.
Footnotes
Acknowledgements
We would like to thank Paul Lin and Dhruva Kulkarni from LBNL for providing us with the matrices from the plasma physics application, XGC. This research was supported by the Exascale Computing Project (17-SC-20-SC), a collaborative effort of the U.S. Department of Energy Office of Science and the National Nuclear Security Administration. This work was performed on the HoreKa supercomputer funded by the Ministry of Science, Research and the Arts Baden-Württemberg and by the Federal Ministry of Education and Research, Germany.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Basic Energy Sciences (17-SC-20-SC), Bundesministerium für Bildung und Forschung.
Notes
Author biographies
Pratik Nayak is a research scientist at Technical University of Munich. He obtained his PhD from Karlsruhe Institute of Technology in the Computer Science and Applied Mathematics. His research interests include numerical linear algebra, algorithms and data structures for large scale distributed computing, and sustainable software development. In his efforts to further sustainable software, he contributes to many open-source scientific software libraries and he is also a core developer of the Ginkgo linear algebra library.
Isha Aggarwal was a research assistant at Karlsruhe Institute of Technology, Germany. She is currently pursing MBA in the Paris area. She obtained her Bachelors in Computer Science from the Indian Institute of Information Technology, Sri City, India and worked as a researcher in HPC and numerical linear algebra for 1 year at KIT.
Hartwig Anzt is the Chair of Computational Mathematics at the TUM School of Computation, Information and Technology of the Technical University of Munich (TUM) Campus Heilbronn. He also holds a Research Associate Professor position at the Innovative Computing Lab (ICL) at the University of Tennessee (UTK). Hartwig Anzt holds a PhD in applied mathematics from the Karlsruhe Institute of Technology (KIT) and specializes in iterative methods and preconditioning techniques for the next generation hardware architectures. He also has a long track record of high-quality development. He is author of the MAGMA-sparse open source software package and managing lead of the Ginkgo math software library. Hartwig Anzt had served as a PI in the Software Technology (ST) pillar of the US Exascale Computing Project (ECP), including a coordinated effort aiming at integrating low-precision functionality into high-accuracy simulation codes. He also is a PI in the EuroHPC project MICROCARD. Hartwig Anzt serves as Editor for ACM TOPC and SIAM SISC. He also is elected program manager of the SIAM Activity Group on Supercomputing.