
Abstract
Sparse matrix-vector products (SpMVs) are a bottleneck in many scientific codes. Due to the heavy strain on the main memory interface from loading the sparse matrix and the possibly irregular memory access pattern, SpMV typically exhibits low arithmetic intensity. Repeating these products multiple times with the same matrix is required in many algorithms. This so-called matrix power kernel (MPK) provides an opportunity for data reuse since the same matrix data is loaded from main memory multiple times, an opportunity that has only recently been exploited successfully with the Recursive Algebraic Coloring Engine (RACE). Using RACE, one considers a graph based formulation of the SpMV and employs a level-based implementation of SpMV for the reuse of relevant matrix data. However, the underlying data dependencies have restricted the use of this concept to shared memory parallelization and thus to single compute nodes. Enabling cache blocking for distributed-memory parallelization of MPK is challenging due to the need for explicit communication and synchronization of data in neighboring levels. In this work, we propose and implement a flexible method that interleaves the cache-blocking capabilities of RACE with an MPI communication scheme that fulfills all data dependencies among processes. Compared to a “traditional” distributed-memory parallel MPK, our new distributed level-blocked MPK yields substantial speed-ups on modern Intel and AMD architectures across a wide range of sparse matrices from various scientific applications. Finally, we address a modern quantum physics problem to demonstrate the applicability of our method, achieving a speed-up of up to 4× on 832 cores of an Intel Sapphire Rapids cluster.
1. Introduction and related work
Parallel solvers for linear systems or eigenvalue problems involving large sparse matrices have been widely used for decades in traditional research fields using high-performance computing (HPC) such as quantum physics, quantum chemistry, and engineering. In recent years, new applications relying on powerful and efficient sparse matrix solvers have been developed, ranging from social graph analysis as shown by Simpson et al. (2018) to spectral clustering in the context of learning algorithms, as shown by Luxburg (2004); McQueen et al. (2016). Typically these solvers use iterative subspace methods, which may include advanced preconditioning techniques and rely on an efficient parallel implementation of the sparse-matrix vector (SpMV) kernel y ← Ax, where A is a sparse matrix and x, y are dense vectors. Scalable and efficient SpMV implementations have thus been an active field of investigation for a long time, as shown by Vuduc and Demmel (2003) and more recently by Gao et al. (2024). Its low computational intensity makes SpMV strongly memory bound on all modern compute devices, and much research focuses on efficient sparse matrix data layouts or matrix bandwidth reduction to improve access locality in the dense vectors involved in the SpMV. Kreutzer et al. (2014) showed that this was particularly relevant on GPGPUs and wide-SIMD many-core CPUs.
However, these efforts do not exploit the data reuse opportunities presented by successive SpMV invocations with the same matrix.
Certain algorithms can be reformulated to group SpMV invocations with the same matrix together, as shown by Demmel et al. (2008) for CA-Krylov and by Loe et al. (2020) for preconditioners based on matrix polynomials. These back-to-back SpMVs constitute what we call the traditional Matrix Power Kernel (MPK) implementation. This kernel computes all vectors y p ← A p x for each power p = 1, …, p m , where the sparse (and necessarily square) matrix A is loaded from main memory each time SpMV is called. This scenario presents an immense opportunity for raising the computational intensity through cache blocking, keeping relevant matrix data in the cache across successive SpMV invocations.

The Recursive Algebraic Coloring Engine (RACE), as introduced by Alappat et al. (2020a), can be used to construct an efficient, cache-blocked shared-memory MPK by taking advantage of the level-based formulation of SpMV. Alappat et al. (2022) describe the resulting Level-Blocked Matrix Power Kernel (LB-MPK), with applications of LB-MPK to contemporary sparse iterative solvers shown by Alappat et al. (2023). While successful, this work is restricted to shared-memory compute nodes. No concept or implementation to parallelize RACE for distributed-memory parallel systems using the Message Passing Interface (MPI) has been proposed until now. Satisfying the data dependencies of the level-based formulation among parallel processes by message passing is a non-trivial task.
The main contribution of this work is an MPI adaptation of LB-MPK. Other works on distributed-memory parallel MPK, such as those developed by Yamazaki et al. (2014a,b), are focused on reducing the MPI communication overhead. At the time of writing, there is surprisingly little work found in the direction of cache-blocking techniques for the distributed-memory parallel MPK. There exists an analysis of a similar diamond tiling strategy by Vatai et al. (2020), but it is purely theoretical. The closest work is likely from Mohiyuddin et al. (2009), but there are clear differences between this approach and ours. Besides being MPI-only whereas ours is a hybrid (MPI + OpenMP) approach, their MPK requires redundant computations and/or indirect accesses to matrix elements with bookkeeping to fulfill data dependencies. We will revisit this comparison in Section 5.
When compared to the traditional “back-to-back” SpMV implementation of MPK, our novel distributed level-blocked MPK algorithm shows speed-ups of up to 2.7× across various architectures for a wide variety of matrices from the SuiteSparse Matrix Collection by Davis and Hu (2011).
Note that there will only be notable benefits of cache blocking if the working set does not fit into the aggregate caches of all CPUs involved. With in-cache datasets, communication and synchronization overheads would likely dominate the runtime.
2. Overview and contributions
The Distributed Level-Blocked Matrix Power Kernel (DLB-MPK) algorithm extends the LB-MPK algorithm to the distributed-memory setting with MPI. Our implementation is efficient in that it does not increase the MPI overhead when compared to the traditional MPK implementation, and it does not require any redundant computations.
This paper is organized as follows. In Section 3, we begin with a brief summary of shared-memory SpMV and MPK. Then, by exploring the graph-matrix correspondence, we are able to understand the broad strokes of how RACE performs LB-MPK. In order to generalize LB-MPK, we must first understand distributed-memory parallel SpMV and MPK without cache blocking, which we explore in Section 4. We close this section with a motivation of our method by comparing it against the distributed-memory parallel MPK implemented by Mohiyuddin et al. (2009). Section 5 details our DLB-MPK method and implementation. In Section 6 we investigate the relevant hardware characteristics of three modern multicore CPU systems and their influence on the performance of DLB-MPK. Performance predictions based on the roofline model by Williams et al. (2009) are derived, and we investigate the influence of various parameters with RACE in the distributed-memory setting. We close the section with a strong scaling analysis of DLB-MPK. In Section 7 we examine the weak scaling characteristics of DLB-MPK used in Chebyshev time propagation, which has applications in quantum physics.
In this work, we make the following contributions: • We extend the level-based concepts in RACE to the distributed-memory setting. • We detail the trapezoidal-like tiling strategy which enables our DLB-MPK to fulfill the data dependencies inherent in repeated SpMV invocations, and present an efficient implementation of the DLB-MPK. • For a wide array of sparse matrices, we present a performance and scaling benefit summary of DLB-MPK on three modern CPUs from Intel and AMD. • We investigate the weak scaling behavior of DLB-MPK when applied to the Chebyshev method for the time evolution of quantum states for the Anderson model of localization, and show the favorable scaling qualities as compared to the traditional MPK.
3. RACE applied to the matrix power kernel
For a given square sparse matrix A and dense vector x, MPK computes all vectors y p ← A p x for each power p = 1, …, p m , and stores the result into p m dense vectors. As mentioned before, this is traditionally implemented as a series of back-to-back SpMVs, using the output vector from the previous iteration as the input vector x; for example, at the kth SpMV invocation, y k ← Ax where x = yk−1. SpMV is the central kernel of MPK, whose traditional implementation will be limited by the same bottleneck as SpMV. For matrices A that do not fit into the cache on modern CPUs (so-called “memory-resident” matrices), the limiting performance bottleneck is the main memory load bandwidth.
The key observation when cache blocking the MPK is that we can compute A p x on a subset of rows without waiting for the entire Ap−1x computation to finish first for all rows of A. The only data dependency for “promoting” a row v from Ap−1x to A p x, that is, executing the pth SpMV operation on it, is that the rows that correspond to the column indices of the non-zero elements in row v have already been promoted to Ap−1x. When using LB-MPK, cache blocking is achieved by detecting the dependencies between successive SpMV invocations using the level-based SpMV formation within RACE. The degree to which this fact can be exploited strongly depends on the sparsity pattern of the matrix. To understand the cache-blocking scheme in the shared memory setting, we describe this level-based formulation here.
Given a matrix A, there exists a correspondence with a graph G (V, E). The set of vertices V represents the rows of A, and the set of edges E represents the non-zero elements. If row v in A has a non-zero element at column j, then there exists a corresponding edge from vertex j to vertex v in G (V, E). In order to make the correspondence more immediate, we use G(A) to denote the graph which has A as its adjacency matrix. For this work, the values of the non-zero entries of the corresponding matrix A are not considered in the graph. An example of such a correspondence is given by the sparse matrix representing a modified 5pt stencil in Figure 1(b) and the associated graph in Figure 1(a). If vertex v is in the set of “neighbors” of u, Graph (a) and sparsity pattern (b) of the matrix associated with a modified five-point stencil. Graph (c) shows the permuted graph and (d) the sparsity pattern of the matrix after applying Breadth First Search (BFS) reordering. The vertices (rows) of the graph (matrix) that belong to a level are represented with the same color.
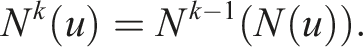
RACE will start a Breadth-First Search (BFS) at some “root vertex,” typically at row index 0. In the next step, all vertices that have an edge connected to this root vertex (i.e., its neighbors) are collected into a structure that we call a “level.” In general, for a graph G (V, E), we can define the ith level as: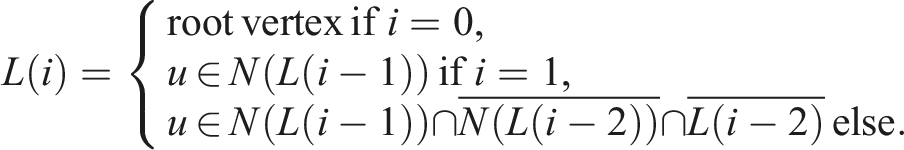
At each successive step in the search, all vertices in the current level are scanned, and all neighbors of these vertices that have not yet been touched are collected into the next level. The process continues until the graph is fully traversed, at which point every vertex is collected into a mutually exclusive level. 4 Once the graph is fully traversed and each vertex is assigned to a level, RACE then symmetrically permutes the matrix A (rows and columns) based on the levels collected. The symmetric permutation, referred to as “BFS reordering,” improves the temporal locality on the RHS x-vector and avoids irregular accesses to matrix elements. 5 An example of this reordering is given for our 5pt stencil matrix in Figure 1(d) and the associated graph in Figure 1(c).
We can visualize the dependencies and traversal order of LB-MPK with an “Lp diagram” given in Figure 2. The x-axis is the index of the level L, and the y-axis is the power p in A
p
x. An important property of levels is that neighbors of L(i) are contained in {L(i − 1), L(i), L(i + 1)}. This means in order to compute Ax on L(i), x has to be known only on {L(i − 1), L(i), L(i + 1)}. More generally, to compute A
p
x = AAp−1x on the vertices of L(i), Ap−1x computations on the vertices of L(i − 1), L(i), and L(i + 1) must have already been completed. One particular example is featured in Figure 2 for the computation of A4x at L(6), where the dependencies lie on p = 3 at {L(5), L(6), L(7)}. Lp diagram with 10 levels (L(0), …, L(9)) and a maximum power of p
m
= 5. Level colors are the same as in Figure 1(c). Each node in the Lp diagram is numbered according to the execution order. For p = 4 and level L(6), the explicit dependencies to levels at p = 3 are indicated with red arrows. The nodes highlighted in orange fulfill i + p = 6 (“diagonal”).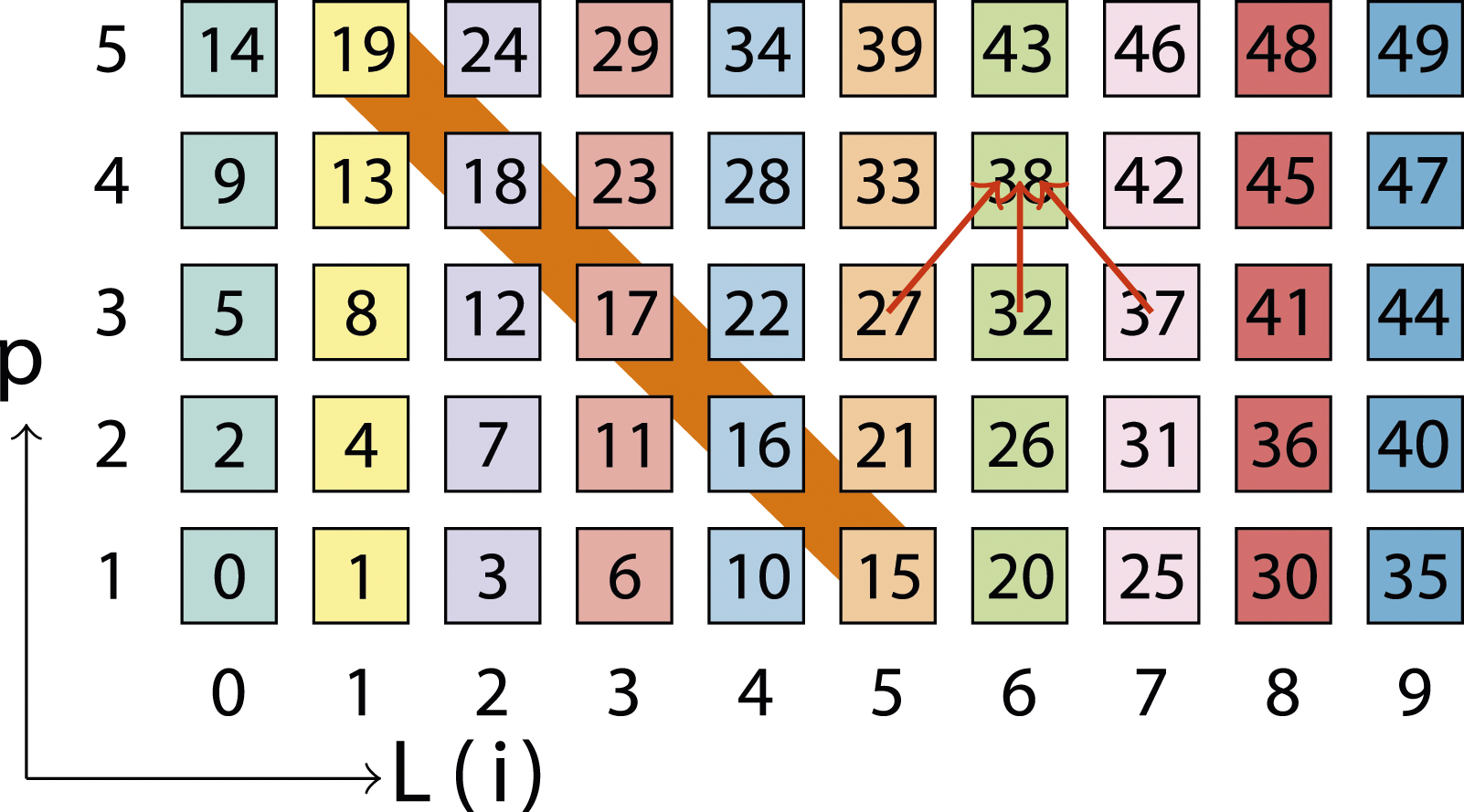
One way to ensure these dependencies are fulfilled at any point in time is to traverse the Lp diagram such that each diagonal defined by i + p≔const carries out computations in a “bottom-right to top-left” fashion for increasing values of “const” (i.e., i + p = 1, i + p = 2, … ). This execution order is given by the numbered boxes in Figure 2, and emphasized by the highlighted diagonal for i + p = 6.
With the aid of the Lp diagram, the idea behind level-based cache blocking can now be briefly introduced. As LB-MPK diagonally traverses the levels as described above, levels (and therefore matrix entries) are reused after p m + 1 execution steps (after the wind-up phase on the left end, and before the wind-down phase at the right end of the Lp diagram). If all the non-zero matrix entries associated with these p m + 1 levels accessed between two computations of the same L(i) can be held in cache, then all matrix data for the following computation with L(i) will be accessed from cache (with the exception of p = 1, which has a compulsory cache miss and must come from main memory). As an explicit example, see the level L(5) which is used in the 15th step in the execution of LB-MPK. If all the matrix data corresponding to the six levels L(1)–L(6) can be held in cache, then the vertices of L(5) are reused in the 21st step in the execution of LB-MPK when computing p = 2.
4. Challenges in the distributed-memory setting
Distributing MPK for level-based cache blocking across multiple MPI processes is not as easy as just executing LB-MPK locally on each MPI process. To understand this non-triviality, we first investigate the dependencies that arise from the “traditional” distributed-memory parallel MPK (TRAD). Just as in the shared memory setting, a distributed-memory parallel MPK is traditionally constructed from back-to-back SpMV invocations.

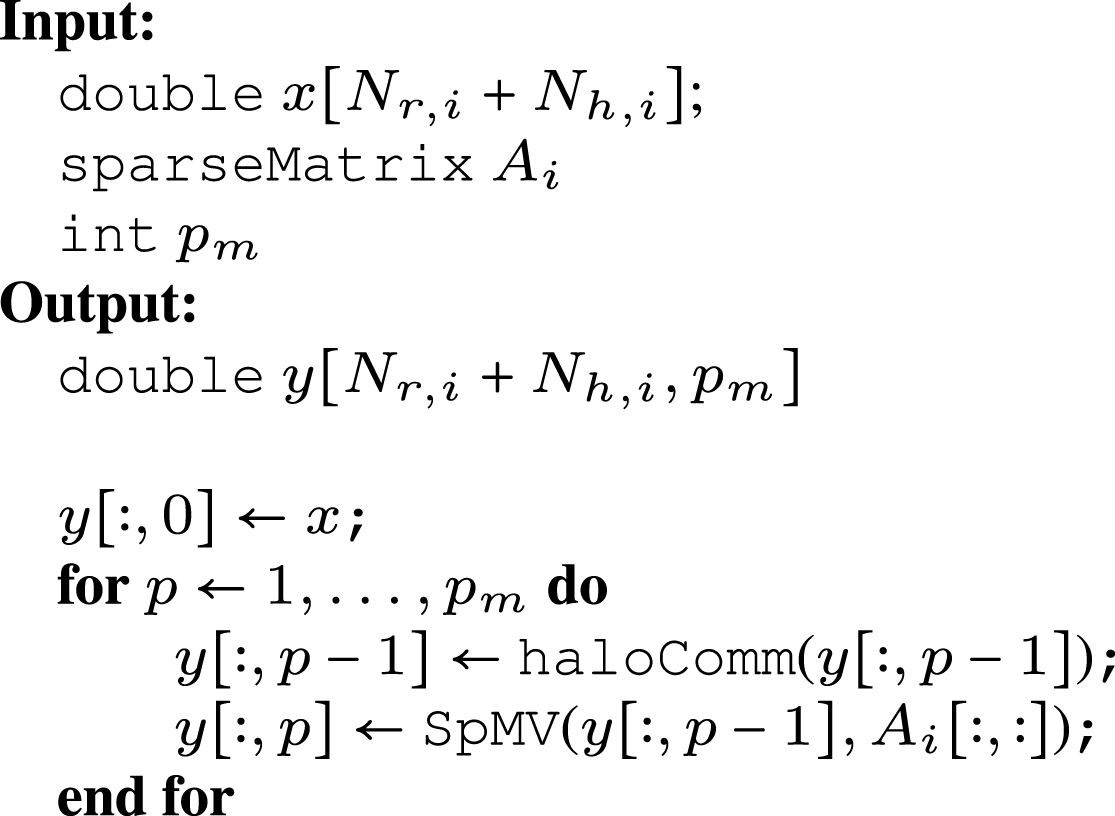
The global matrix A from Figure 1(b) and some RHS vector x are partitioned in a row-wise manner over two MPI processes in (a). The gray boxed-out regions show, on each MPI process, which elements are “local” (inside the gray region). The edge corresponding to the remote data dependency, that is, the edge crossing the MPI boundary, is highlighted in blue in (b). The rows at global indices 8 and 12 are highlighted as examples of rows that contain remote data dependencies for the SpMV. To fulfill these data dependencies, another MPI process must supply the appropriate “halo elements.” Shown in (c) is the process of data exchange on the x-vector for our two example rows, where incoming halo elements are received into an appropriately resized buffer.
Transferring remote elements on-demand is feasible but would result in significant performance overhead due to the high latency of MPI communications. Consequently, a common strategy involves bulk transfer of all required remote elements before executing SpMV operations. These elements are then stored consecutively, typically at the end of the x-vector, forming what is commonly known as the “halo region/buffer.” Figure 3(c) illustrates this halo region and the process of populating it with remote elements. Algorithm 1 presents pseudocode for the traditional distributed-memory parallel MPK computing 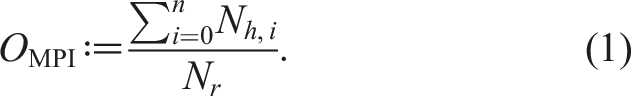
Figure 4(a) illustrates the distributed TRAD MPK approach and shows the required halo communication. The number on each vertex represents the execution order for computing SpMV on the particular vertex x
i
. The TRAD approach necessitates a complete SpMV operation to be carried out before initiating the subsequent halo communication routine. This poses a challenge to cache blocking, particularly when dealing with large in-memory matrices, as the cache may not be able to accommodate all matrix elements loaded during the entire SpMV computation. In Section 3, we have seen that caching can be realized by the LB-MPK approach on shared memory. This necessitates that all the p
m
SpMV computations required to raise the local matrix A
i
to power p
m
be carried out consecutively in one kernel. This requirement renders the basic halo communication scheme explained above inadequate for distributed-memory parallelization since only the halos necessary for a single SpMV are communicated in this step. However, for each halo element, we now require the values of all p
m
− 1 powers, that is, A
p
x for all p in the range [0, p
m
− 1]. Complicating matters further, these values (for p ≥ 1) are not yet available at this stage because SpMV computations have not been performed. Comparison of three MPK implementations for the computation of A3x on a 1D tri-diagonal stencil matrix, distributed across two MPI processes, where the execution order is written in each node. The traditional MPK implementation of back-to-back SpMVs is shown in (a) the “Communication Avoiding” MPK with redundant SpMVs in (b) and our implementation of DLB-MPK is shown in (c). Each dot represents an index of 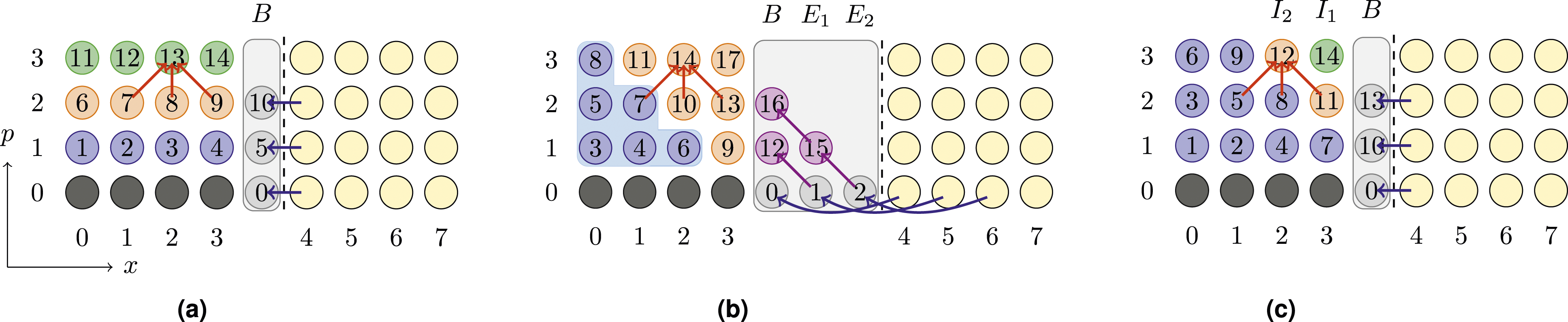
For example, consider Figure 3: employing a
One potential solution to this problem, as explained by Mohiyuddin et al. (2009), is known as communication-avoiding MPK (CA-MPK). In this approach, all the necessary values of halo elements, A p x for all p in the range [1, p m − 1], are computed locally on each MPI process. To achieve this, each MPI process conducts additional SpMVs on the halo elements. However, as discussed in Section 3, computing A p x by an SpMV operation necessitates updating its neighbors to the Ap−1x value, which in turn requires updating its neighbors to Ap−2x, and so on until it reaches the input vector A0x = x. Consequently, to raise boundary halos B to the p m − 1 power, all its distance-(p m − 1) neighbors must also be updated. Given that these neighbors often reside on different MPI processes, remote elements must be brought into the current MPI process, thereby requiring additional halo elements. Figure 4(b) illustrates the additional halos required by the CA-MPK approach on a 1D tri-diagonal stencil example. Additional SpMVs take place within the halo buffer, that is, vertices that are “external” to the process-local data. In our example, these redundant SpMVs occur at execution stages 12, 15, and 16. To compute A p x, CA-MPK requires p − 1 groups of these external vertices. In general, the halos are organized based on their distance from the boundary B, where E k represents the set of external vertices that are at a distance of k from B. The boundary halo elements B = E0 are elevated to power p m − 1, while the remaining halo elements E k are elevated to power p m − 1 − k to fulfill the dependencies.
To facilitate cache blocking, a diagonal-style execution order, similar to that in LB-MPK (see Section 3), can be employed. The name “communication-avoiding” stems from the ability of the CA-MPK approach to overlap communication and computations. In Figure 4(b) the purely local part (outlined in blue boundary) can be overlapped with the communication of the remote elements. Although the CA-MPK approach enables cache blocking, the overheads resulting from additional halo communication and SpMV computations escalate with the power p m and the number of MPI processes n. It is important to note that these extra SpMV computations on halos are redundant, as the MPI process possessing the element locally also conducts SpMVs on these elements. Particularly with irregular sparse matrices, these overheads can be substantial and may lead to limited speedups as shown in Yamazaki et al. (2014a).
One way to eliminate redundant computations involves a fine-grained synchronization mechanism, wherein the other process transmits the Ax value of halo elements once computations are completed, and the other process waits to receive this data. However, this entails significant synchronization overhead and the transmission of small MPI messages, ultimately resulting in substantial performance degradation due to the high latency of MPI communications. In the following section, we will introduce a savvy new approach to mitigate these performance pitfalls.
5. DLB-MPK methodology
The DLB-MPK approach enables cache blocking while mitigating the drawbacks associated with CA-MPK, namely the need for additional communication and computations. DLB-MPK achieves this by utilizing the same halo communication routine as in the traditional approach (TRAD), but with a reordering of computation and communication to facilitate cache blocking.
In our algorithm, following the initial halo communication, LB-MPK is executed on the local vertices. However, not all local vertices can be elevated to power p m immediately due to dependencies with the halo elements in B, which contain only the input value x. Internal vertices that are distance-1 neighbors to B can only be promoted to Ax (p = 1), while their neighbors can only be promoted up to A2x, and so forth. In general, internal vertices at a distance of k from the boundary B, denoted as I k , can only be elevated up to A k x. This implies that, at this stage of DLB-MPK, computations are incomplete on internal vertices I k where 1 ≤ k < p m . The final step of the DLB-MPK method is an iterative process ensuring the completion of SpMV computations on the incomplete internal vertices. The iterative post-cache-blocking computation phase begins with synchronization followed by a call to the halo communication routine to update halo boundaries B with the next power value (Ax in the first iteration). This enables all incomplete internal vertices I k to perform SpMVs, advancing their power computations by one step. This remainder phase is repeated for a total of p m − 1 times to ensure all internal vertices reach power p m . Figure 4(c) illustrates the DLB-MPK approach using a 1D tri-diagonal stencil example.
As shown in Figure 4, DLB-MPK requires the same halos as TRAD while benefiting from cache-blocking advantages similar to CA-MPK due to its diagonal-style execution; refer to Section 3 for details. Figure 5 quantifies the advantages of reduced halo elements and zero redundant computations for DLB-MPK for an irregular sparse matrix ( Overheads in CA-MPK associated with the 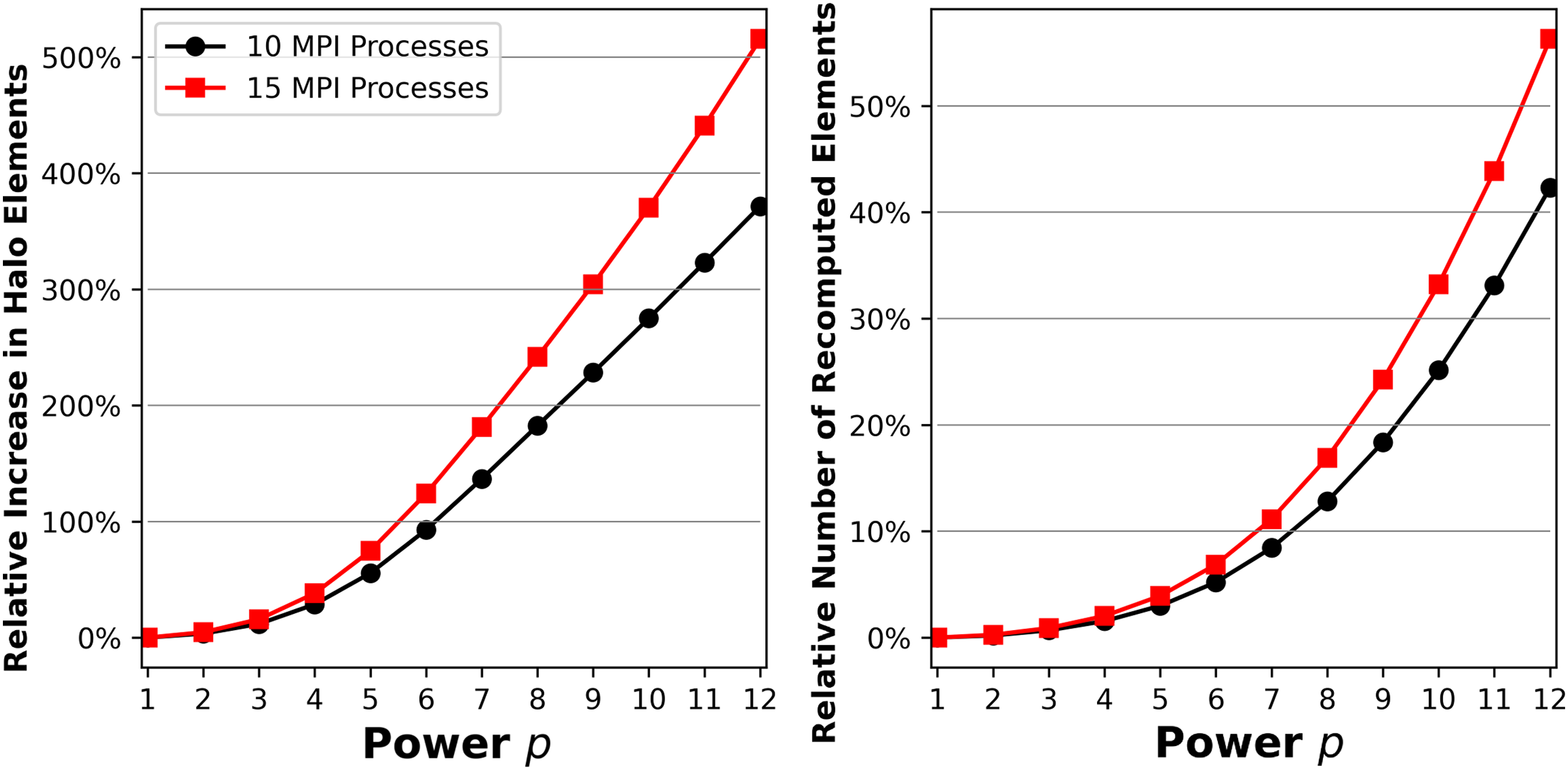
The implementation of DLB-MPK can be straightforwardly derived from the execution order illustrated in Figure 4(c) for a 1D tri-diagonal example. However, when dealing with a general sparse matrix, the internal boundary vertices I k for k < p m may not be ordered consecutively. Therefore, an efficient implementation will require gathering these boundary vertices and reordering the matrix during preprocessing to ensure that these vertices (rows in the matrix) appear consecutively. All vertices which are a distance of p m or greater from the boundary, i.e. all vertices in I k for k ≥ p m , are collected into a single main “bulk structure” M, which is large in practice.


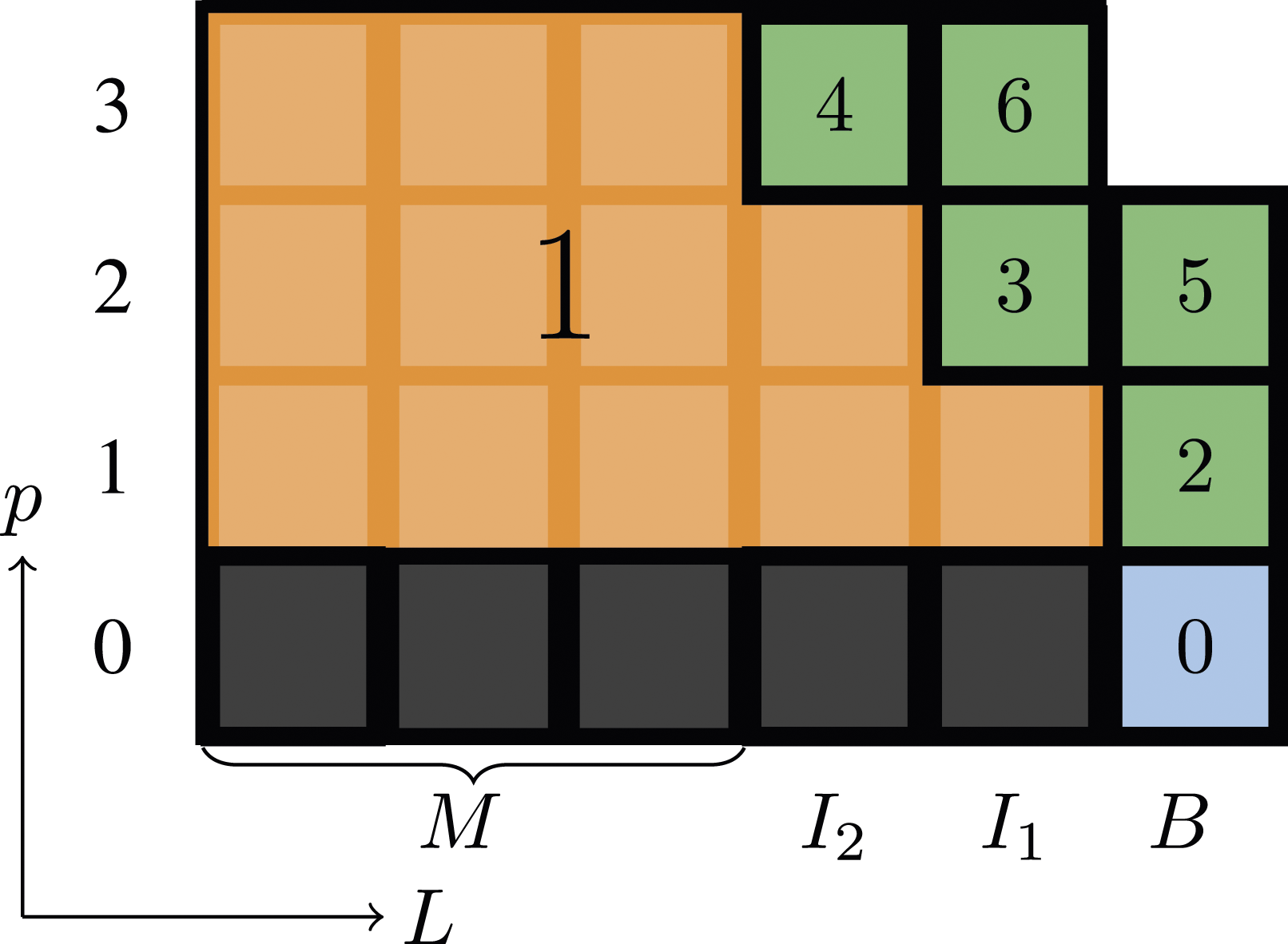
An adapted Lp diagram for DLB-MPK executing
A benefit of DLB-MPK is that we can use the same MPI routines as for TRAD. Hence, can easily integrate our algorithm into external libraries with existing SpMV and halo communication routines. This is shown in Algorithm 2, which gives a high-level overview of DLB-MPK. The call-back functions
The percentage of vertices that fall outside of the bulk structure is considered as the “local overhead” ODLB-MPK,i of DLB-MPK. While not an “overhead” per se, it is a useful quantity for our investigation as it expresses the efficiency of cache blocking. With M
i
denoting the bulk structure level on MPI process i, we can define this overhead as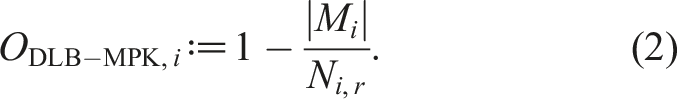
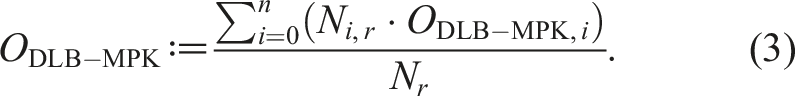
6. Results
In this section, we investigate the performance and scaling characteristics of DLB-MPK and how they compare to TRAD in a variety of scenarios on a selection of modern multicore CPUs. To gain a deeper understanding of the performance of our level-based cache-blocked MPK, we first establish a theoretical roofline-based upper performance prediction for the SpMV kernel, the main kernel used in MPK.
It is well known that SpMV (and by extension traditional MPK) is usually a memory-bound kernel on modern hardware for sparse matrices from science and engineering, as described by Kreutzer et al. (2014). According to the roofline model, in the memory bound regime with the CRS matrix storage format5 using 8 bytes for the matrix values, 4 bytes for the column indices, and 4 bytes for the row pointer, performance is limited by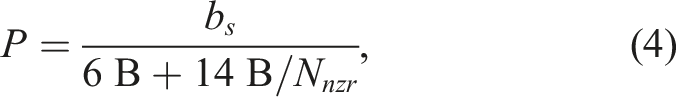
6.1. Experimental setup
The relevant hardware and software environment used for the measurements is explained in the following.
6.1.1. Hardware
Single-socket hardware Configurations.
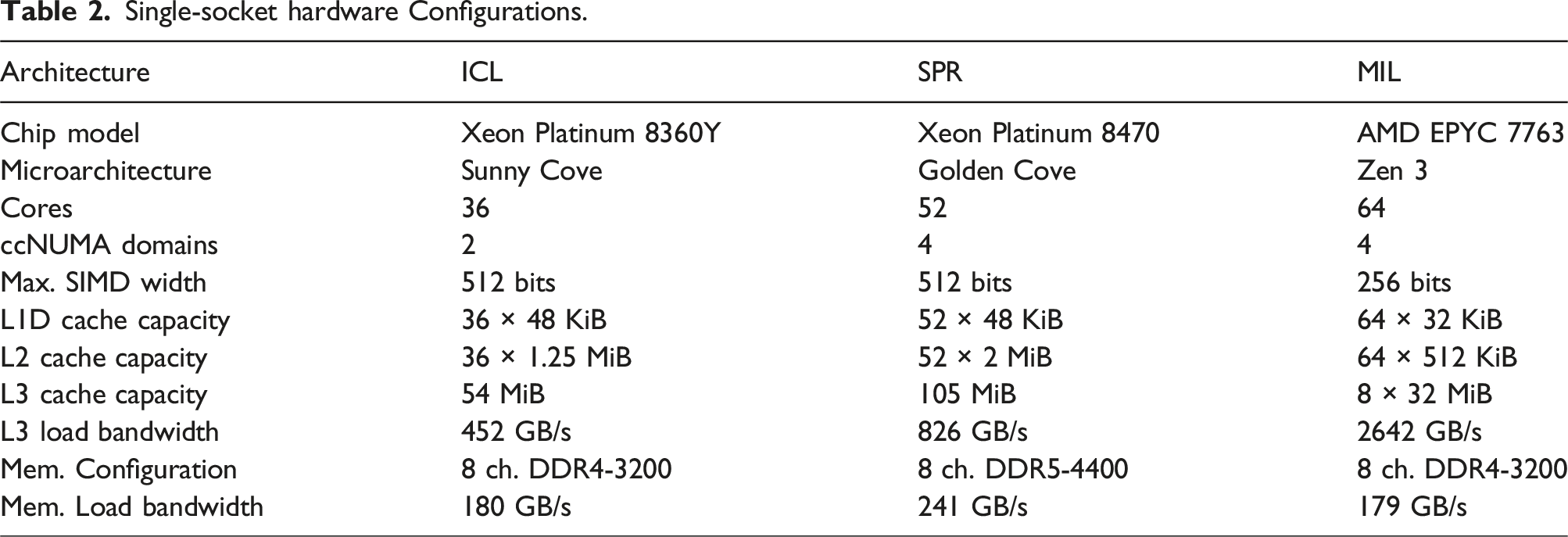
In order to reflect practical use case scenarios, turbo mode was enabled for all experiments.
All of these machines have three levels of cache: private, inclusive L1 and L2, and a victim-style L3 cache. This means that we can consider the sum of L2 and L3 cache as the total size for which we can use RACE to cache block. RACE excels when blocking for outer level caches, as shown by Alappat et al. (2022).
Since the achievable bandwidth of the hardware plays a vital role in determining the performance of SpMV-like kernels (see Equation (4)), we investigate the bandwidths on each of the machines in Figure 7. The load-only kernel from Full-node measured load bandwidths in GB/s (y-axis) versus data set size for the CPUs under consideration. The higher solid horizontal line represents the estimated L3 cache bandwidths and the lower one represents the estimated bandwidth from main memory. The dashed red line marks the overall L2 cache size for the entire node, while the dotted blue line represents the aggregate L2 + L3 cache size for the entire node. The widest SIMD registers are used on each machine for the load instructions.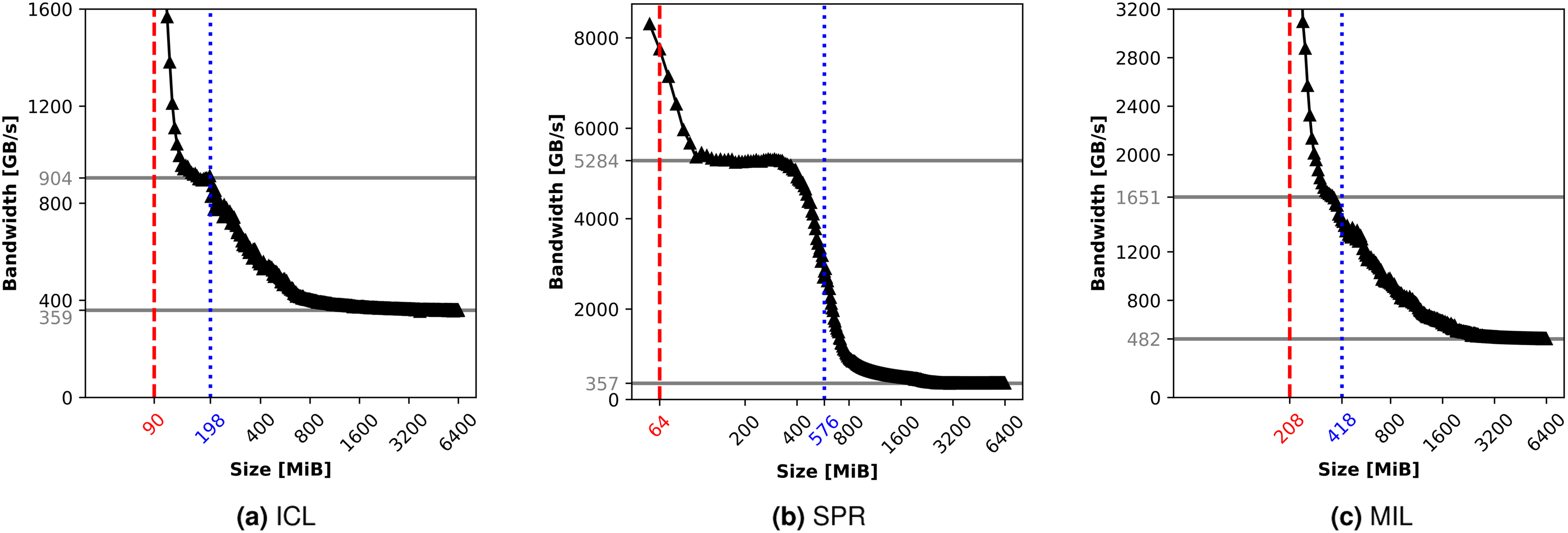
Software Configurations and compiler flags.
6.1.2. Software
Benchmark matrices.
Our selection of benchmark matrices is commonly used in the literature for performance investigations. They show the performance of DLB-MPK compared to TRAD across a wide variety of sparsity patterns while keeping data sets generally large enough to not be completely cache resident (thus, eliminating the need for cache blocking). Most matrices are freely available from the Suite Sparse matrix collection, with the exception of the
Measures had to be taken against the patch for the “Downfall” security bug as explained by Moghimi (2023), incurring a penalty for gather instructions on the architectures under consideration. The latest LLVM-based Intel compiler was required, with special compilation flags to avoid the expensive gather instructions. In Table 3, these flags are given under “Downfall fix.” To ensure vectorization of the SpMV kernel,
The same affinity is used for benchmarking on each architecture. Each MPI process is pinned to one ccNUMA domain, process i + 1 is mapped physically as close as possible to process i, and OpenMP threads are also pinned compactly to the physical cores. Simultaneous Multithreading (SMT) was disabled across all the systems.
While not a primary focus of this work, RACE allows users to specify a maximum recursion stage s
m
which enables the breaking down of “bulky” levels for increasing cache blocking efficiency. This maximum recursion stage is set to s
m
= 50 for all matrices except
We aim to understand the performance gained from cache blocking, not from improved data accesses on the RHS x-vector through the local symmetric BFS permutations (see Section 3). In an effort to not conflate the two, TRAD is executed with and without local symmetric BFS permutations and the representative performance metric is taken as the maximum of the two. Similarly, we take the maximum performance of DLB-MPK with and without recursion as the representative performance metric.
All numerical results are validated against Intel’s Math Kernel Library. 6 Benchmarks are repeated several times, and the median performance is taken as the representative performance metric. Error bars are excluded from our plots as run-to-run deviations are less than 5%.
6.2. Parameter study
RACE provides tuning parameters to optimize performance for the specific hardware under consideration. In this section, we perform a parameter study on ICL with the matrix
We focus here only on the parameters p and C since we have fixed the recursion depth s
m
as described before. In Figure 8, we scan various powers p and cache sizes C when performing DLB-MPK on Parameter study with 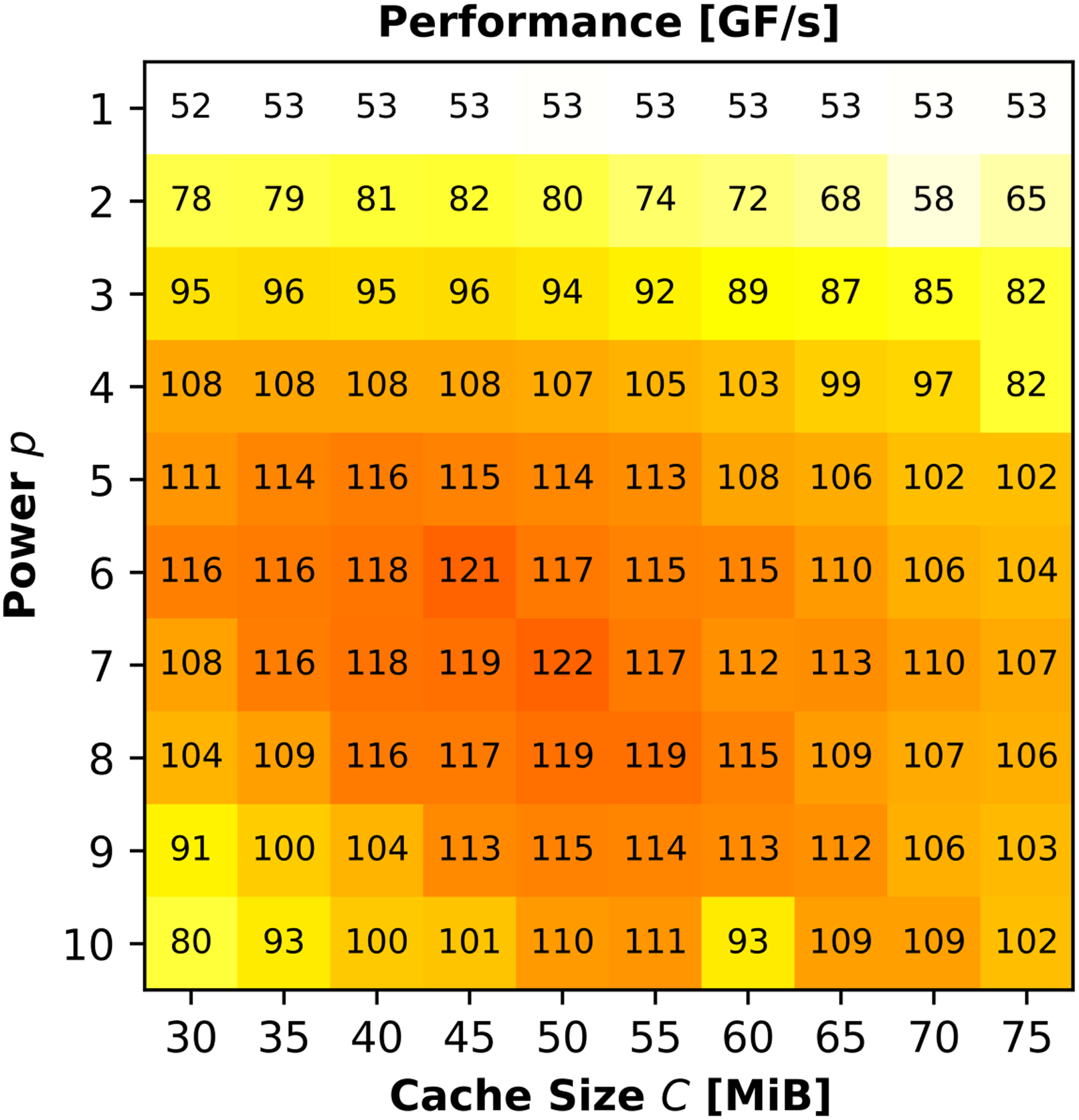
From Table 2, we know that one ccNUMA domain on ICL has 49 MiB L2 + L3 aggregate cache, so we would expect an optimal value for the parameter C to be around this range. The optimal C does not always correspond directly with the amount of available cache per process, due to a safety factor internal to RACE. A user of DLB-MPK would manually tune these two parameters to achieve the best possible performance for their use case 7 . Notice that the DLB-MPK performance for p = 1 stays roughly constant as cache size grows. This corroborates our claim from Section 3 that computing y ← A p x for p = 1 can not make use of cache blocking.
6.3. Performance results summary
In this section, we give a concise high-level single-node performance summary of DLB-MPK and TRAD on our benchmark matrices.
Figure 9 shows the node-level performance of DLB-MPK (red, right bars) as compared to TRAD (blue, left bars) for optimally tuned parameters C and p. The matrices are ordered according to their size, and the vertical dashed line indicates the L2 + L3 aggregate cache size of the architecture. On MIL some matrices fit in the cache, that is, lie to the left of the dashed vertical line. In this regime, DLB-MPK has no benefit compared to TRAD since the matrices already fit in the cache, and cache blocking is pointless. The behavior is very similar with cache-resident matrices on ICL and SPR, although for this work, we chose large in-memory matrices to elucidate the situations in which DLB-MPK is advantageous to use. Node-level performance summary for benchmark matrices in Table 4, ordered by CRS size, on the CPUs under consideration. For each matrix, the numbers above the bars denote the optimal power p for which DLB-MPK was tuned. The horizontal black lines are the roofline predictions for TRAD according to Equation (4). The vertical dashed line represents the aggregate L2 + L3 cache size.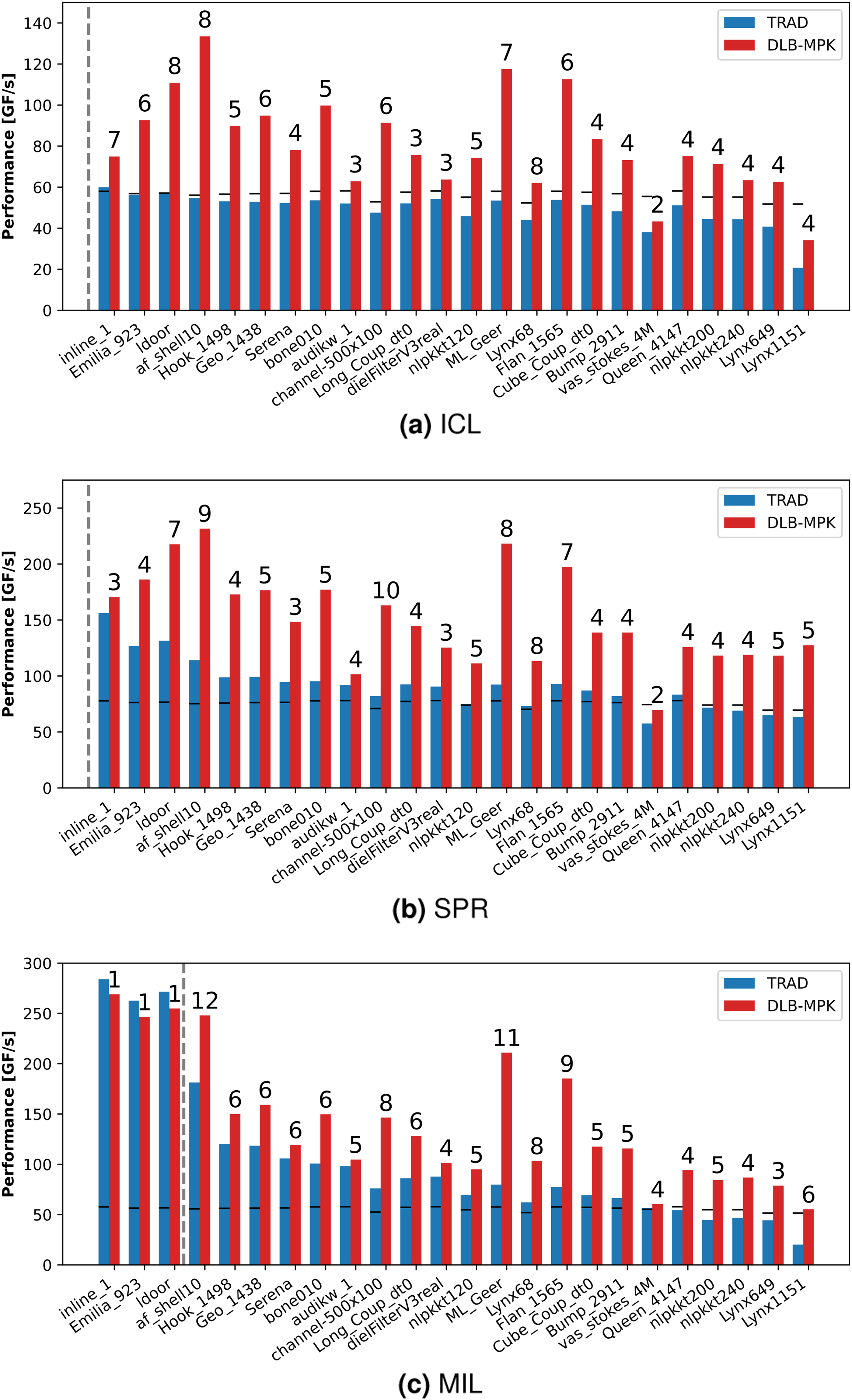
The short black line in or above each TRAD bar is the memory-bound roofline performance limit of SpMV for the given matrix and hardware computed using Equation (4). As TRAD performs back-to-back SpMVs, ideally one would expect the performance of TRAD for large in-memory matrices to be below the roofline limit. However, in many cases, close to the cache boundary (just to the right of the dashed vertical line), TRAD’s performance exceeds the roofline limit by a small margin. This is due to the residual caching effects as also observed in Figure 7 for the load-only benchmark. As predicted for SPR and MIL, TRAD exhibits these residual caching effects until the matrix size is up to 2400 MiB, that is, until
In general, towards the right of the dashed vertical line (the in-memory matrices), DLB-MPK has a significant advantage over TRAD. The performance of DLB-MPK is much higher than the roofline prediction and TRAD, due to cache blocking resulting in lower main memory traffic. We observe an average (maximum) speedup of 1.6× (2.5×), 1.7× (2.4×), and 1.6× (2.7×) for large in-memory datasets on ICL, SPR, and MIL, respectively. The numbers annotated above DLB-MPK bars show the optimal power value tuned in the range of p ∈ {1, 2, …, 12}. On ICL and MIL, both TRAD and DLB-MPK perform poorly with the
As shown by Alappat et al. (2022), the preprocessing costs associated with RACE to collect the level structure are typically equivalent to 5 to 50 SpMVs (increasing with the recursion stage s m ). The preprocessing costs associated with the introduction of MPI are minimal since the only additional steps are the identification and collection of the boundary vertices. As this is equivalent to each MPI process scanning its local rows once, this overhead is equivalent to roughly one additional SpMV.
6.4. Strong scaling
It is frequently more important to understand the scaling characteristics of performance rather than taking a snapshot for a single parameter configuration and input. We now investigate how the performance of DLB-MPK grows with an increasing number of ccNUMA domains. The experiment is conducted on eight nodes of SPR. As in the previous section, the power p is tuned in the range p ∈ {1, 2, …, 12}.
Figure 10(a) shows the performance of TRAD versus DLB-MPK for both p = 4 and p = 6 on Single- (left) and multi-node (right) strong scaling performance and overhead results for 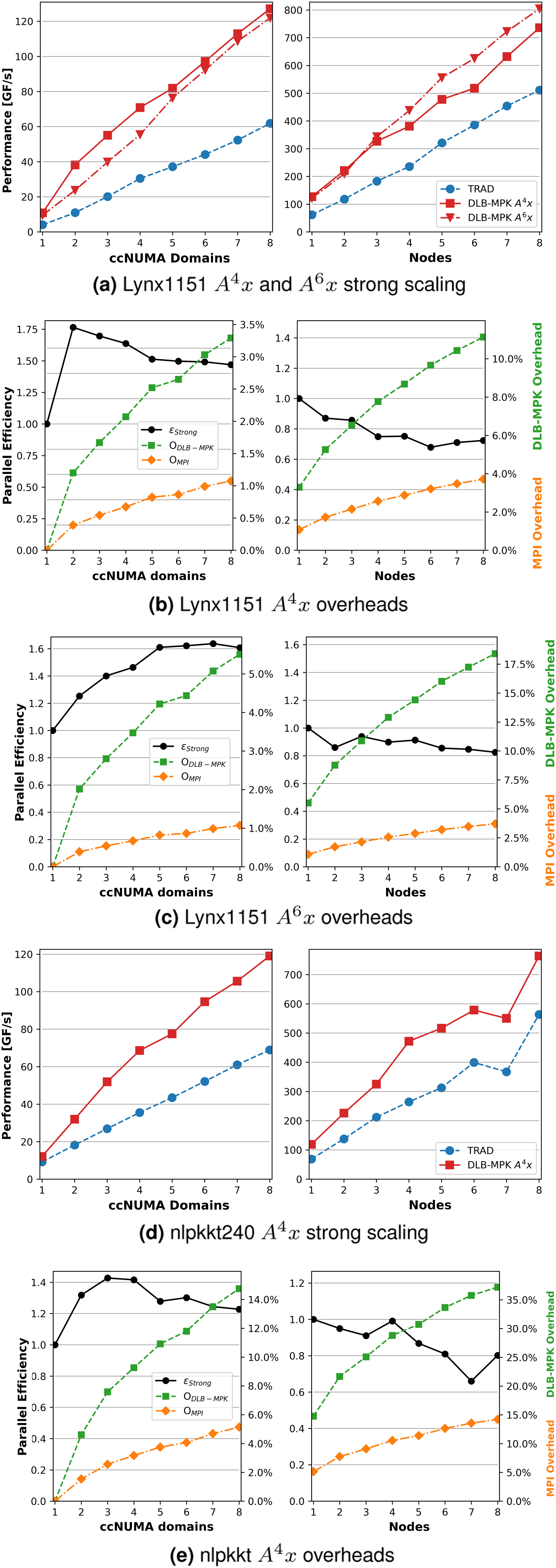
Figures 10(b) and 10(c) show on the right y-axis how the two overheads introduced in Sections 4 and 5 – MPI overhead (OMPI from Equation (1)) and DLB-MPK overhead (ODLB-MPK from Equation (3)) – scale for
Since we are blocking for a higher power in Figure 10(c), it makes sense that ODLB-MPK will be higher than in Figure 10(b), since there will be fewer vertices contained in the bulk structure M as described in Section 5. MPI overhead will be the same for both p = 4 and p = 6 since OMPI depends only on the matrix structure and number of MPI processes.
We see ɛstrong ≥ 1 in the intra-node regime in the left subfigure in Figure 10(b) where we normalize ɛstrong against the time taken by DLB-MPK on one ccNUMA domain. The sharp increase in ɛstrong from one to two processes is due to the additional cache available with the second ccNUMA domain. As the number of processes increases, we gain access to more cache, yet the MPI costs grow as we communicate with other processes that are physically farther away. Alternatively, in the right subfigure in Figure 10(b) ɛstrong ≤ 1 for the inter-node regime, where we normalize ɛstrong against the time taken by DLB-MPK on one entire node. We see the impact of MPI on a larger scale here, as inter-node communication latency is much higher than within a single node. Parallel efficiency reaches a higher maximum with p = 4 for the intra-node case as shown in Figure 10(b), but is sustained for larger MPI process for the inter-node case with p = 6 as shown in Figure 10(c).
Figures 10(d) and 10(e) show how the performance and overheads of DLB-MPK scale for
First, the matrix structure is much “worse,” i.e., the sparsity pattern is not banded, and there are many non-zero elements that are far from the diagonal. This will not only increase DLB-MPK overhead as there are fewer levels (i.e., fewer vertices inside the bulk structure M), but it will also increase the MPI overhead as there are more halo elements on each process. The second reason is that we recognize residual caching effects after around 4–5 nodes by the sharp jumps in the performance of both TRAD and DLB-MPK. From Table 2, we can compute that if
This is not uncommon and poses a difficulty when performing scaling studies with DLB-MPK. Most matrices from Suite Sparse are simply not large enough to fully take advantage of DLB-MPK.
7. Application: Chebyshev time propagation
A common application that can benefit from the DLB-MPK is the Chebyshev method for the time evolution of quantum states as shown by Tal-Ezer and Kosloff (1984); Fehske et al. (2009). In this section, we demonstrate the advantage of cache blocking in the context of this application and investigate the weak scaling characteristics of DLB-MPK.
Given a Hamiltonian 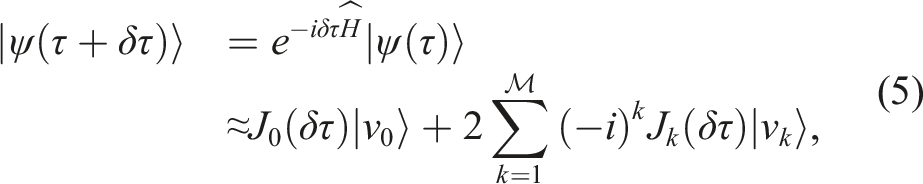
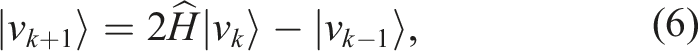
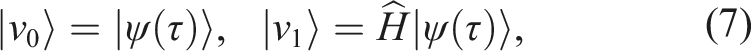
We demonstrate the Chebyshev time propagation for the 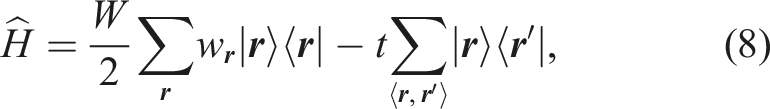
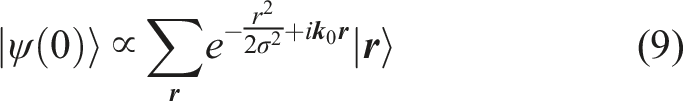
Prat et al. (2019); Janarek et al. (2020, 2022) have numerically investigated this “quantum boomerang effect” for various models using the Chebyshev time-propagation method. Here, we consider a variant of the Anderson model in which the hopping parameter t along the y and z axis is replaced by t⊥ < t, that is, a system of weakly coupled chains. By tuning t⊥, a localization transition can be induced at fixed disorder W, as shown by Zambetaki et al. (1997). Figure 11 displays results for the time evolution of a wave packet moving in the x direction with Time evolution of a wave packet (Equation (9)) with width σ = 20 and momentum 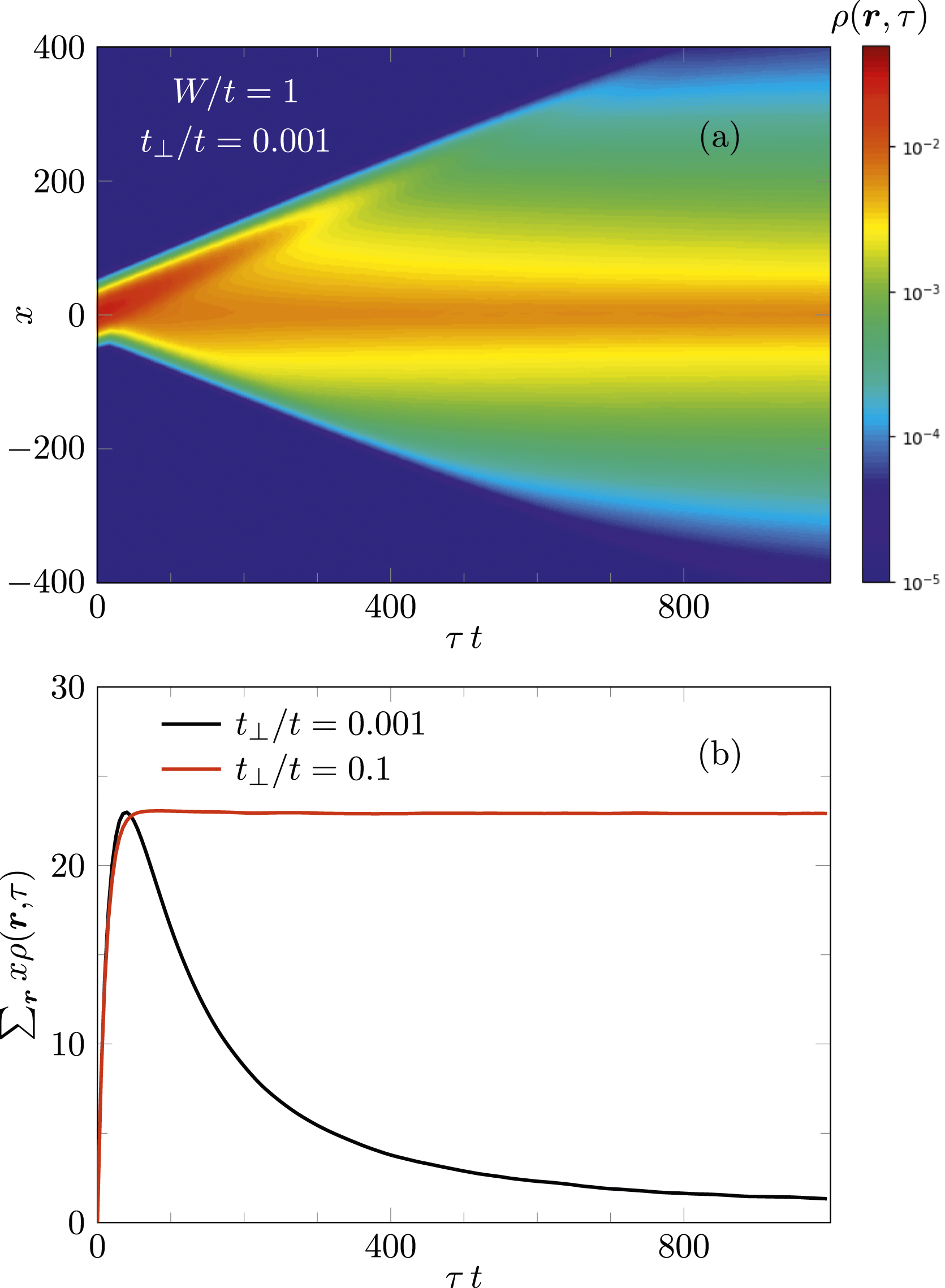
To demonstrate the effectiveness of DLB-MPK on a real-world application, we now perform a weak scaling study on the above-described Chebyshev time propagation method on SPR nodes. The
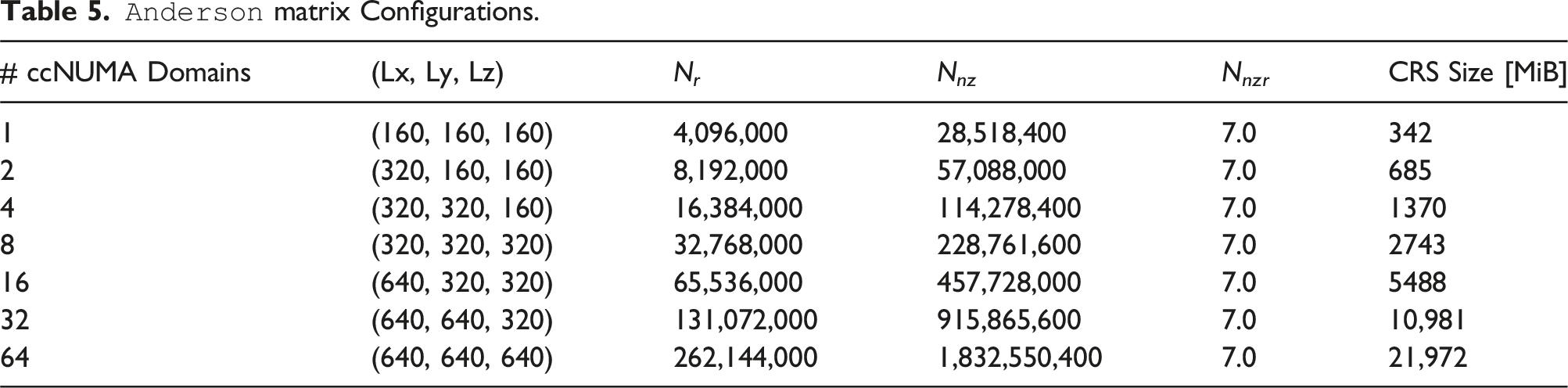
As previously mentioned, Equation (6) represents a series of
In the same manner described in Section 6.2, we first tune p m and the cache size C to obtain optimal node-wide performance. After such an investigation, DLB-MPK yields the highest performance on SPR at p m = 8, C = 35 MiB. Note that C is much smaller than the available L2 + L3 aggregate cache given for SPR in Table 4. This is expected since there are other data structures in the application that will also occupy space in the cache. We define parallel efficiency in the weak scaling case as ɛweak≔T1/T n . Since our workload now increases with the number of processes, we choose T1 = 1/P1 and T n = n/P n , where P n is still the performance of DLB-MPK on n ccNUMA domains.
Figure 12 shows the weak scaling performance per MPI process and the overheads of DLB-MPK applied to the Chebyshev time propagation method using various sizes of the Weak scaling investigation using the 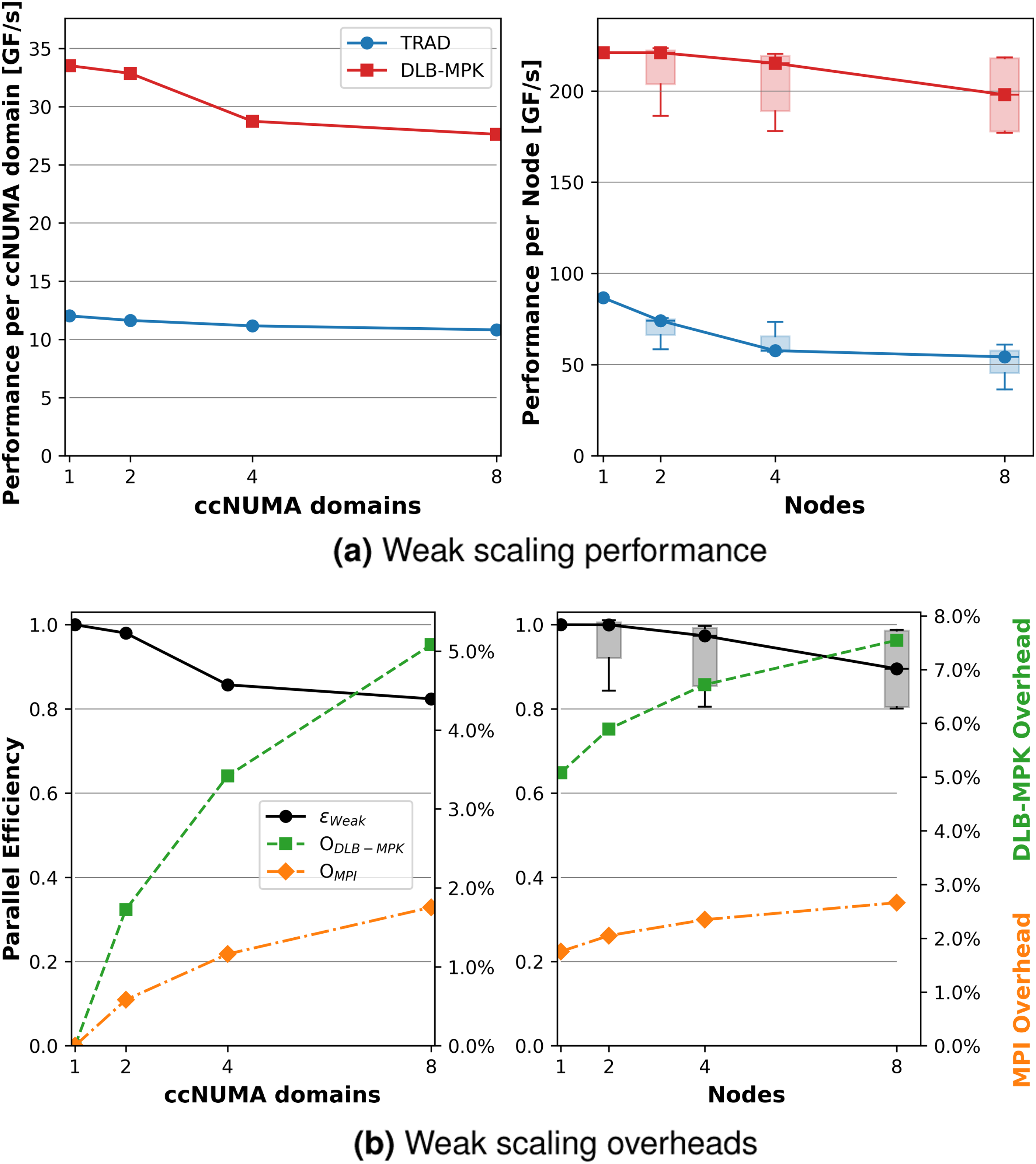
DLB-MPK maintains a speed-up of about 2.8× as compared against TRAD for one and two ccNUMA domains. When moving from 2 to 4, and then to 8 ccNUMA domains, speed-up drops to about 2.5×. In the multi-node regime (i.e., past eight ccNUMA domains) we maintain a speed-up of 2× to 3.3× for the worst performing DLB-MPK executions, and 2.5× to 4× for the best.
8. Summary
We have motivated and developed a novel cache-blocked MPI-parallel matrix power kernel based on the level-blocking capabilities of RACE. The resulting algorithm extends the ideas developed by Alappat et al. (2022) by first organizing local vertices on each MPI process by their distance k from the halo buffer into levels I k , and then interleaving a local cache blocking MPK with communication steps to fulfill data dependencies. Our algorithm, DLB-MPK, has been shown to be efficient in that it does not increase MPI overhead when compared to the traditional MPK implementation. This is because these collections of vertices I k grow inwards, keeping the number of halo elements constant while slightly reducing the efficiency of cache blocking. Furthermore, DLB-MPK has the advantage that it uses the same computation and halo communication routines as a traditional distributed-memory parallel MPK. Therefore, it can be easily integrated into existing libraries and can be used as a drop-in replacement for traditional distributed-memory parallel MPK.
We used the roofline model to explain expected performance behavior using key metrics extracted from our selection of test hardware platforms. After that, we gave an example of how one may tune DLB-MPK for optimal performance. To evaluate the performance of DLB-MPK, we first gave a snapshot summary of the optimally tuned performance as compared to the traditional MPK on modern multicore CPUs. We observed a node-wide average (maximum) speedup of 1.6× (2.5×), 1.7× (2.4×), and 1.6× (2.7×) for large in-memory datasets on ICL, SPR, and MIL, respectively
Then, strong scaling characteristics of DLB-MPK were studied, where we observed the influence of caches and communication on performance. Finally, DLB-MPK was integrated into an application using a Chebyshev method for the time evolution of quantum states for the Anderson model of localization. This enabled us to perform weak scaling investigations on up to eight Sapphire Rapids nodes, in which we observed a speed-up of up to 4× when compared to the traditional MPK implementation. Future work will be directed towards the integration of GPGPU support for DLB-MPK.
Footnotes
Acknowledgements
The authors gratefully acknowledge the computing time provided to them on the high-performance computer Noctua two at the NHR Center PC2. These are funded by the German Federal Ministry of Education and Research and the state governments participating on the basis of the resolutions of the GWK for the national high-performance computing at universities (![]() ). We would also like to thank Johannes Langguth at Simula Research Laboratory for the thought provoking discussions, as well as his assistance in generating the
). We would also like to thank Johannes Langguth at Simula Research Laboratory for the thought provoking discussions, as well as his assistance in generating the
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Bundesministerium für Bildung und Forschung 16ME0708.
Notes
Author biographies
Dane Lacey received a bachelor's degree in Applied Mathematics from the University of Utah and a master's degree in Computational and Applied Mathematics from Friedrich-Alexander-Universität Erlangen-Nürnberg. He is currently pursuing a Ph.D. under the supervision of Prof. Gerhard Wellein. His research focuses on hardware-aware building blocks for sparse linear algebra, with an emphasis on performance engineering for distributed-memory algorithms and iterative linear solvers.
Christie Alappat holds a master’s degree with honors from the Bavarian Graduate School of Computational Engineering, Friedrich-Alexander-Universität Erlangen-Nürnberg. He is currently in the final stages of completing his doctoral studies under the supervision of Professor Gerhard Wellein while simultaneously being employed as a math algorithm engineer at Intel. His research interests encompass performance engineering, sparse matrix and graph algorithms, iterative linear solvers, and eigenvalue computation. He is the author of the RACE open-source software framework, which facilitates the acceleration of computationally demanding sparse linear algebra operations on modern compute devices.
Florian Lange holds a master's degree and a Ph.D. in Theoretical Physics from the University of Greifswald. He is currently working at Erlangen National High Performance Computing Center (NHR@FAU) as a domain expert for physics in the Training & Support Division. His research interests are low-dimensional condensed matter systems, tensor network methods, and quantum computing.
Georg Hager holds a Ph.D. and a Habilitation degree in Computational Physics from the University of Greifswald. He heads the Training and Support Division at Erlangen National High Performance Computing Center (NHR@FAU) and is an associate lecturer at the Institute of Physics of the University of Greifswald. Recent research includes architecture-specific optimization strategies for current microprocessors, performance engineering of scientific codes on chip and system levels, and structure formation in large-scale parallel codes.
Holger Fehske received a Ph.D. in physics from the University of Leipzig, and a Habilitation degree and Venia Legendi in theoretical physics from the University of Bayreuth. In 2002, he became a full professor at the University of Greifswald. There the held the chair for Complex Quantum Systems and worked in the fields of solid-state theory, quantum statistical physics, light-matter interaction, quantum informatics, plasma physics, and computational physics. He is co-author of more than 400 scientific publications. Dr. Fehske is a member of the steering committee the Erlangen National High-Performance Computing Center.
Gerhard Wellein is a Professor for High Performance Computing at the Department for Computer Science of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and holds a Ph.D. in theoretical physics from the University of Bayreuth. From 2015 to 2017, he was also a guest lecturer at the Faculty of Informatics at the Università della Svizzera italiana (USI) in Lugano. Since 2024, he has been a Visiting Professor for HPC at the Delft Institute of Applied Mathematics at the Delft University of Technology. He is the director of the Erlangen National Center for High Performance Computing (NHR@FAU) and a member of the board of directors of the German NHR Alliance, which coordinates the national HPC Tier-2 infrastructure at German universities.