
Abstract
Tensor networks are a class of algorithms aimed at reducing the computational complexity of high-dimensional problems. They are used in an increasing number of applications, from quantum simulations to machine learning. Exploiting data parallelism in these algorithms is key to using modern hardware. However, there are several ways to map required tensor operations onto linear algebra routines (“building blocks”). Optimizing this mapping impacts the numerical behavior, so computational and numerical aspects must be considered hand-in-hand. In this paper we discuss the performance of solvers for low-rank linear systems in the tensor-train format (also known as matrix-product states). We consider three popular algorithms: TT-GMRES, MALS, and AMEn. We illustrate their computational complexity based on the example of discretizing a simple high-dimensional PDE in, for example, 5010 grid points. This shows that the projection to smaller sub-problems for MALS and AMEn reduces the number of floating-point operations by orders of magnitude. We suggest optimizations regarding orthogonalization steps, singular value decompositions, and tensor contractions. In addition, we propose a generic preconditioner based on a TT-rank-1 approximation of the linear operator. Overall, we obtain roughly a 5× speedup over the reference algorithm for the fastest method (AMEn) on a current multicore CPU.
Keywords
1. Introduction
Low-rank tensor methods provide a way to approximately solve problems that would otherwise require huge amounts of memory and computing time. Many ideas in this field arise from quantum physics. For example, the global state of a quantum system with N two-state particles can be expressed as a tensor of dimension 2 N . In this setting, interesting states are for example given by the eigenvectors of the smallest eigenvalues of the Hamiltonian of the system–a Hermitian linear operator that describes the energy of the system. Therefore, most work focuses on solving eigenvalue problems for Hermitian/symmetric operators using the DMRG method (Schollwöck, 2005; White, 1992; Wilson, 1983). However, linear systems in low-rank tensor formats also arise in interesting applications for example for solving high-dimensional or parameterized partial differential equations, see, for example, Kressner and Tobler (2011); Dahmen et al. (2015); Dolgov and Pearson (2019). In addition, linear solvers and eigenvalue solvers are closely related and many successful methods for finding eigenvalues are based on successive linear solves. This paper addresses iterative methods for solving linear systems (symmetric and non-symmetric) in the tensor-train (TT) format for the case where the individual dimensions are not tiny, that is, for systems of dimension n d × n d with n ≫ 2. We employ the TT format (called matrix-product states in physics) as it is a simple and common low-rank tensor format. Most of the ideas are transferable to other low-rank tensor formats (at least to loop-free tensor networks). Our work considers the TT-GMRES algorithm (Ballani and Grasedyck, 2012; Dolgov, 2013), the modified alternating least-squares (MALS) algorithm (DMRG for linear systems) (Holtz et al., 2012; Oseledets and Dolgov, 2012), and the Alternating Minimal Energy (AMEn) algorithm (Dolgov and Savostyanov, 2014). We show numerical improvements and performance improvements of the underlying operations and focus on a single CPU node. These improvements are orthogonal to the parallelization for distributed memory systems presented in Daas et al. (2022), so the suggestions from both Daas et al. (2022) and this paper could be combined in the future. As the resulting complete linear solver requires a tight interplay of different algorithmic components, we discuss the behavior of the different numerical methods involved for the TT format. An alternative class of methods to solve linear systems in TT format consists of Riemannian optimization on the manifold of fixed-rank tensor-trains, see Kressner et al. (2016). This results in a nonlinear optimization problem and is therefore not in the scope of this paper. However, it partly requires similar underlying operations.
The paper is organized as follows: First, we start with required numerical background in Section 2 and also introduce relevant performance metrics for today’s multicore computers. Then in Section 3, we discuss the involved high-level numerical algorithms TT-GMRES, MALS, and AMEn. Based on an example, we illustrate the numerical behavior of these algorithms and compare their complexity in Section 4. Afterwards, in Section 5, we analyze and optimize the underlying building blocks. We conclude in Section 6 with a short summary and open points for future work.
2. Background and notation
In this section, we provide the required background concerning numerics and performance.
2.1. Numerical background
We first introduce required matrix decompositions and a notation for the considered algorithms.
2.1.1. Matrix decompositions
As matrix decompositions are heavily used as steps in tensor-train algorithms, we repeat some basic properties of QR and SVD decompositions from the literature, see for example, Golub and Van Loan (2013); Higham (2002).
A QR-decomposition is a factorization of a matrix
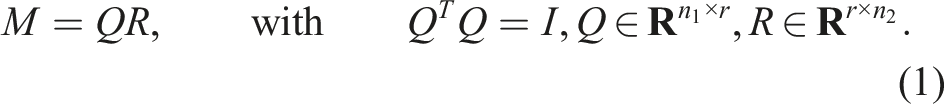
For (numerically) rank-deficient M, one can employ a pivoted QR-decomposition
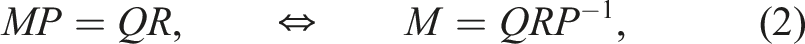
The singular value decomposition (SVD) in contrast provides the best approximation of lower rank:
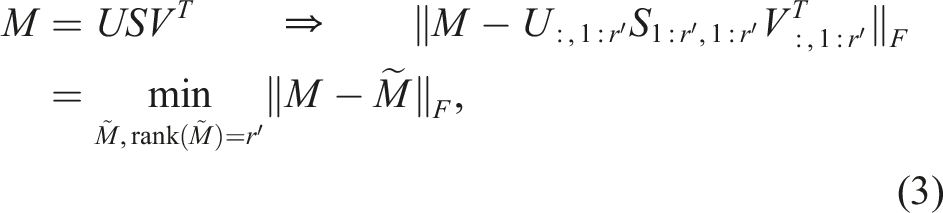
2.1.2. Tensor-train decomposition
In higher dimensions, there is no unique way to decompose a tensor into factors and to define its rank(s) (variants are e.g., the Tucker and the CANDECOMP/PARAFAC (CP) decompositions, see the review Kolda and Bader, 2009). We focus on the tensor-train format which decomposes a tensor
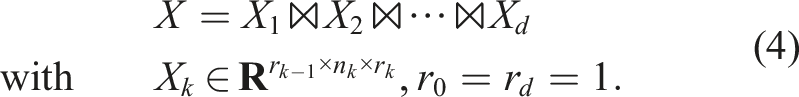
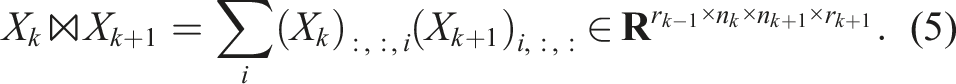
The TT decomposition of a given tensor is not unique: it is invariant with respect to multiplying one sub-tensor by a matrix and the next with its inverse. More precisely, for
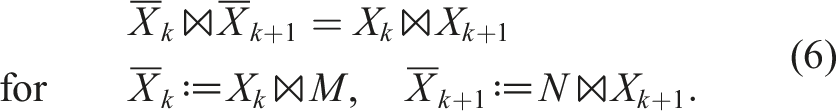
The smallest possible dimensions (r1, …rd−1) that allow to represent X denote the TT ranks of X with the maximal rank r≔rank (X) = max (r1, …, rd−1). If X has rank-1 in the TT format, we can also write it as a generalized dyadic product of a set of vectors:
2.1.3. Tensor unfolding and orthogonalities
We define a general reshape operation to reinterpret the entries of a tensor as a tensor of different dimensions:
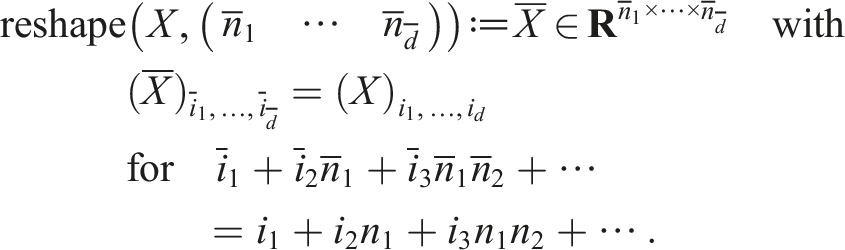
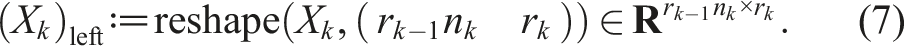
Similarly, we define the right-unfolding:
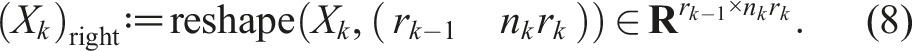
We denote a 3d tensor X
k
as left-orthogonal if the columns of the left-unfolding are orthonormal
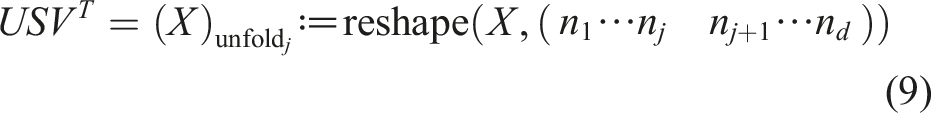
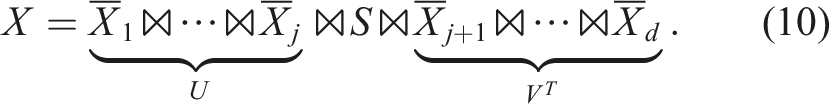
2.1.4. Tensor-train vectors and operators
A tensor-train operator is a tensor in TT format where we combine pairs of dimensions (n
i
× m
i
) with the form
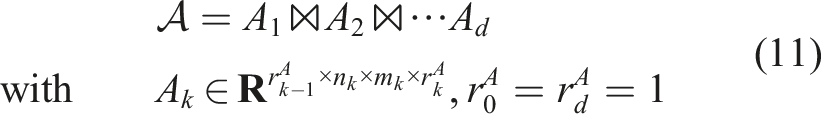
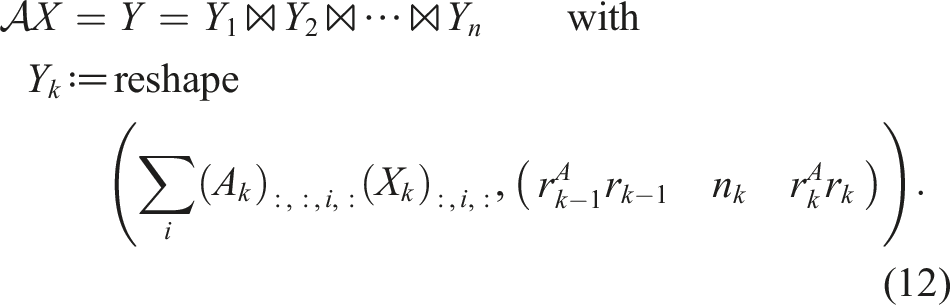
The resulting TT decomposition has ranks
With all these definitions at hand, we can specify the main problem considered in this paper: Given a low-rank linear operator in TT format
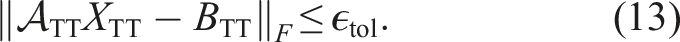
2.2. Performance characteristics on today’s multicore CPU systems
Today’s hardware features multiple levels of parallelism and memory that we need to exploit to efficiently use the available compute capacity: A supercomputer is composed of a number of nodes connected by a network (distributed memory parallelism). Each node contains one or more multicore CPUs with access to a main memory (shared memory parallelism). However, the different CPUs access different memory domains with different speed (NUMA architecture): Usually the access to the memory banks directly connected to one CPU is faster. Each CPU “socket” consists of multiple cores (≲ 100 in 2023) with a hierarchy of caches. Inside one core, SIMD units perform identical calculations on a small vector of floating-point numbers. We focus on the performance on a single multicore CPU, but the algorithms considered can also run in parallel on a cluster (see Daas et al., 2022). Many supercomputers nowadays use GPUs which is not discussed further in this paper.
2.2.1. Roofline performance model
To obtain a simpler abstraction of the hardware, we employ the Roofline (Williams et al., 2009) performance model. The Roofline model distinguishes between computations (floating-point operations) and data transfers: The maximal performance one can achieve on a given hardware is Ppeak [GFlop/s]. The bandwidth of data transfers from main memory is b
s
[GByte/s]. If all data fits into some cache level, the appropriate cache bandwidth is used instead. These are the required hardware characteristics. The considered characteristics of one building block of an algorithm (e.g., one nested loop) are the number of required floating-point operations nflops and the volume of the data transfers Vread/write. Their ratio is called computational intensity I
c
≔nflops/Vread/write [Flop/Byte]. Assuming that the data transfers and operations overlap perfectly, this results in the following performance:
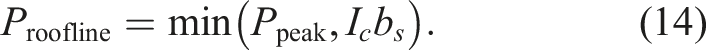
If the compute intensity is low (I c ≪ Ppeak/b s ), the building block is memory bound. If in contrast the compute intensity is high (I c ≫ Ppeak/b s ), the building block is compute bound. We specifically split the algorithms considered in this paper into smaller parts (“building blocks”) because they feature not one dominating operation but are composed of multiple different blocks with different performance characteristics.
2.2.2. Memory and cache performance
In addition to the model above, some details of the memory hierarchy play a crucial role for the algorithms at hand (see Hager and Wellein (2010) for more details): First, modifying memory is often slower than reading it. In order to write to main memory, the memory region is usually first transferred to the cache, modified there and written back (write-allocate). A special CPU instruction allows to avoid this and directly stream to memory (non-temporal store). A common technique to improve the performance of data transfers is to avoid writing large (temporary) data when the algorithm can be reformulated accordingly (write-avoiding), see Carson et al. (2016). Second, the CPU caches are organized in cache lines: This means that, e.g., 8 double precision values are transferred together, always starting from a memory address divisible by the cache line size. So the data locality–e.g., which index is stored contiguously–is important.
In addition, today’s CPUs use set-associative caches that allow the mapping of one memory address to a fixed set of cache lines. Due to this, memory addresses with a specific distance (e.g., 1024 double numbers) are mapped to the same cache set and the cache effectiveness is dramatically reduced when data is accessed with specific “bad” strides (cache thrashing). This easily occurs for tensor operations if the product of some dimensions is close to a power of two. A common solution for operations on 2d arrays is padding: adding a few ignored zero rows in a matrix such that the stride is at least a few cache lines bigger than some power of two. This becomes more complicated in higher dimensions as one either obtains a complex indexing scheme or one needs to perform calculations with zeros. This is discussed in more detail in Section 5.3.
3. Numerical algorithms
In this section, we discuss three different methods to approximately solve a linear system in TT format as in equation (13). We start with a general purpose (“global”) approach based on Krylov subspace methods, TT-GMRES (Dolgov, 2013), and present some improvements for the TT format. Then, we consider the more specialized (“local”) MALS (Holtz et al., 2012; Oseledets and Dolgov, 2012), which optimizes pairs of sub-tensors similar to DMRG. Afterwards, we discuss the (“more local”) AMEn (Dolgov and Savostyanov, 2014) method, which iterates on one sub-tensor after another. Finally, we present a simple yet effective preconditioner in TT format to accelerate convergence of TT-GMRES.
3.1. Krylov methods: TT-GMRES
All methods that apply the linear operator
3.1.1. Arithmetic operations in tensor-train format
Krylov methods require the following operations which can be performed directly in the TT format (all introduced in Oseledets, 2011): Applying the operator to a vector
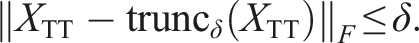
With these operations, we can perform a variant of the GMRES algorithm with additional truncation operations, see Alg. 1. This idea was first discussed in Ballani and Grasedyck (2012) for the more general H-Tucker format with a slightly different projection. We employ a variant based on Dolgov (2013). The numerical stability of TT-GMRES is analyzed in more detail in Coulaud et al. (2022). We remark that we use a more strict truncation tolerance than suggested in Dolgov (2013) based on the analysis of inexact Krylov methods in Simoncini and Szyld (2003). However, in Simoncini and Szyld (2003) only inaccurate applications of the linear operator are considered (as in line 5 of Alg. 1). We also truncate in each step of the orthogonalization (line 8) and once afterwards (line 10). We can still express the error as an error in the operator of the form (see eq. (2.2) in Simoncini and Szyld, 2003):
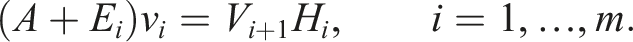
We denote the errors of all truncation operations in one Arnoldi iteration with Δw(0) (line 5), Δw(j) (line 8) and Δw(i+1). Then, we obtain for the error:
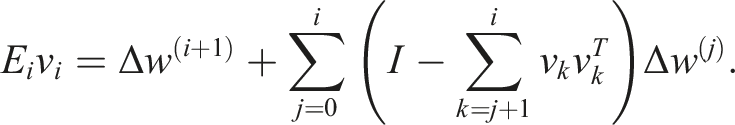
For orthogonal basis vectors v
k
of the Krylov subspace, the error of the Arnoldi iteration is bounded by:
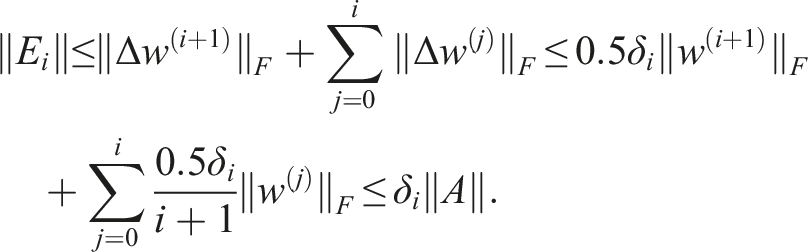
Of course, due to the truncations, one easily looses the orthogonality of the basis vectors v
k
, see discussion in Section 3.1.2 below. Suitable tolerances δ
i
require the condition number c = κ (H
m
) that we estimate using the parameter c ≈ κ (A) as suggested in Simoncini and Szyld (2003). So we obtain the following bound for the difference between the true residual vector r∗ and the inexact residual vector
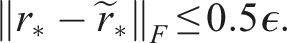
The factor 0.5 ensures that the true residual norm is smaller than the desired tolerance:
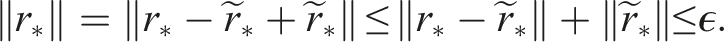
In our experiments, we use an optimized variant (see Section 5.1) of the standard TT truncation algorithm. An alternative randomized truncation algorithm is presented in Daas et al. (2022) for truncating sums of multiple tensor-trains (e.g., only truncating in line 10 of Alg. 1 and not in line 8).
3.1.2. Improved Gram-Schmidt orthogonalization
Above, we assumed that the resulting Krylov basis vectors are orthogonal. However, as the modified Gram-Schmidt orthogonalization is only applied approximately (truncations in line 8 and 10), this assumption is usually violated. As a result, the true residual norm might not be smaller than the prescribed tolerance ϵ even though the approximate residuals converge. To compensate for the inaccurate orthogonalization, one can prescribe a more strict truncation tolerance as discussed in Section 6 of Simoncini and Szyld (2003). Another common approach consists in re-orthogonalization: We employ the following specialized variant of a modified Gram-Schmidt iteration.
In the TT format calculating a scalar product is much faster than a truncated scaled addition (axpby) as discussed in more detail in Section 5. So we can perform additional scalar products to reorder Gram-Schmidt iterations and perform selective re-orthogonalization as shown in Alg. 2 to increase the robustness. This omits subtracting directions that are already almost orthogonal in order to avoid growing the TT-ranks. See Leon et al. (2012) and the references therein for a detailed discussion on different Gram-Schmidt orthogonalization schemes. Here, we again need to use sufficiently small truncation tolerances to fulfill the requirements of the outer inexact GMRES method. The factor 2i is an estimate for the number of inner iterations (line 9) as usually orthogonalizing “twice is enough” (Giraud et al., 2005; Parlett, 1998). And we choose kmax = 4 in all our experiments as this was sufficient for the cases we investigated.
3.1.3. Tensor-train ranks for problems with a displacement structure
Even with truncations after each tensor-train addition, the tensor-train ranks can grow exponentially in the worst case:
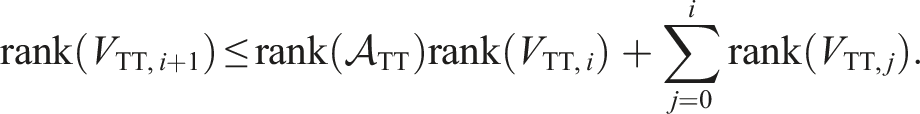
We observe only a much smaller growth for some special linear operators
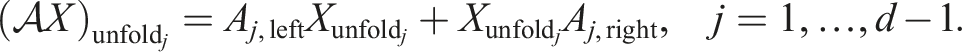
For those operators, the rank of the solution is bounded if the right-hand side also has small rank as discussed for several tensor formats in Shi and Townsend (2021). We obtain the following expression for applying the operator k times:
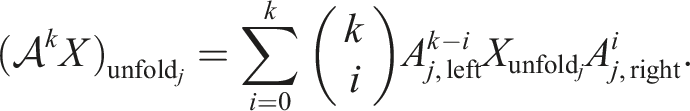
Similarly, for any matrix polynomial p
k
of degree k, we get
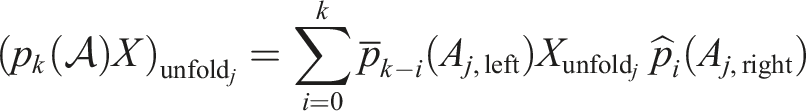
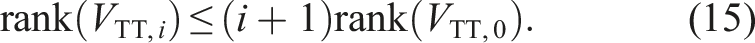
3.2. Modified alternating least-squares (MALS)
Krylov methods like TT-GMRES consider the linear operator as a black box. However, we can also exploit the tensor-train structure of the problem and project it onto the subspace of one or several sub-tensors. This is the idea of the ALS and MALS methods discussed in Holtz et al. (2012). In principle, MALS is identical to the famous DMRG method (Schollwöck, 2005; White, 1992) for eigenvalue problems from quantum physics. Here, we describe it from the point of view of numerical linear algebra. Using all but two sub-tensors of the current approximate solution, we define the operator:
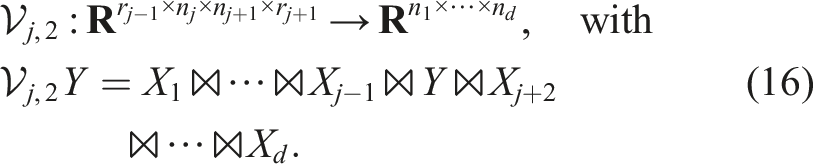
If sub-tensors (X1, …Xj−1) are left-orthogonal and sub-tensors (Xj+2, …X
d
) are right-orthogonal, the operator
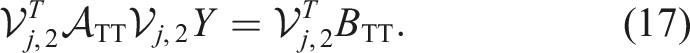
For s.p.d. operators ATT, this much smaller problem typically has a better condition number
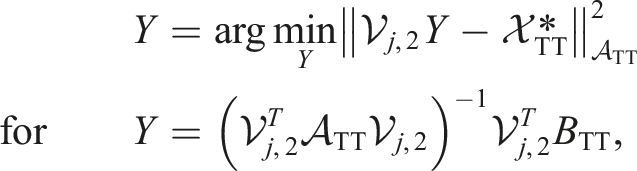
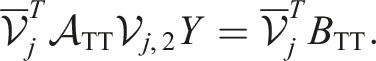
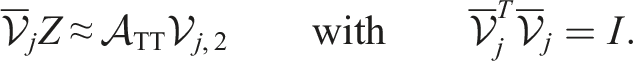
This is only possible approximately if

To solve the global problem, the MALS algorithm sweeps from the first two to the last two dimensions and back, see Alg. 3. This can be interpreted as a moving subspace correction as discussed in Oseledets et al. (2018). In contrast, the ALS algorithm only projects the problem onto the subspace of all but one sub-tensor. This yields smaller local problems but provides no mechanism to increase the TT-rank of the approximate solution. So in the simplest form, it can only converge for special initial guesses that already have the same TT-rank as the desired approximate solution. In Section 3.3, we discuss a possible way to avoid this problem.
3.2.1. Inner solver: TT-GMRES
The projected problem (17) again has a structure similar to (13) but with just two dimensions. More specifically, after some contractions, the projected operator has the form

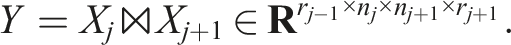
Using tensor contractions, we can also express the projected right-hand side as:
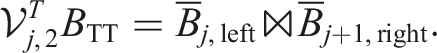
As long as the rank of Y during the iteration is much smaller than rj−1n j , respectively nj+1rj+1, it is usually beneficial to use the factorized form for Y. This results in an inner-outer scheme with an outer MALS and an inner TT-GMRES algorithm. From our observation, this also yields slightly smaller ranks in the outer MALS than using standard GMRES with the dense form of Y and a subsequent factorization.
In the first MALS sweeps, it is not necessary to solve the inner problem very accurately. So one can use a larger relative tolerance for the inner iteration than for the outer iteration. The same yields in the last MALS sweeps (close to the solution). Combining both aspects, we employ a relative tolerance of:
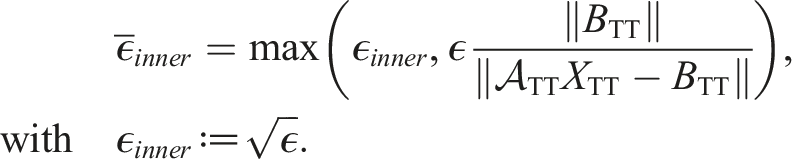
One might wonder if an inner-outer iteration scheme with outer (flexible) TT-GMRES and inner MALS (as preconditioner) might also work. In our experiments, this results in super-linear (up to exponential) growth of the TT-ranks in the Arnoldi iteration. This can be explained by the fact that the displacement structure of the linear operator is not retained through this form of a varying preconditioner. For symmetric problems, our implementation switches to TT-MINRES and for positive definite problems, one can also employ a tensor-train variant of the CG algorithm.
3.3. AMEn method
For the MALS method above, always two sub-tensors are considered at once in the inner problem. One can also consider only one sub-tensor (ALS) at a time using the projection operator
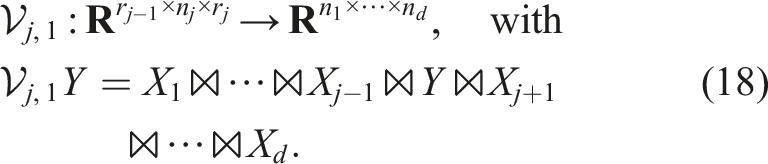
This results in a smaller local operator. By contracting sub-tensors of 
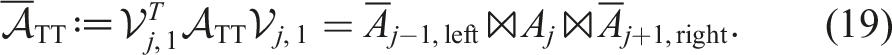
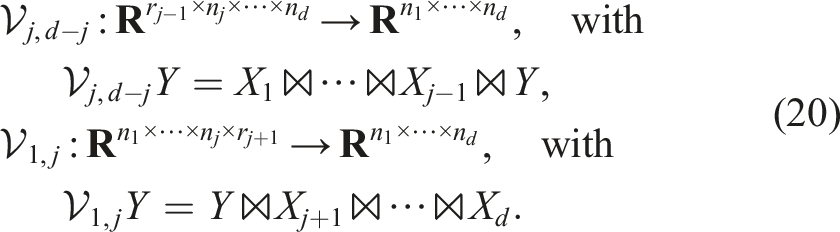
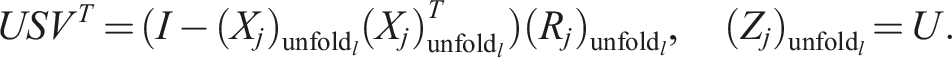
This results in the method AMEn + SVD from Dolgov and Savostyanov (2014). To append the directions (line 16), we concatenate the tensors, such that
As can be seen from Alg. 4, calculating the required directions from the residual mostly involves updating the sub-tensors of the residual in every step of the sweep. This is not significantly more work than calculating the residual in the first place. Still, the complete algorithm is so cheap that the residual calculation accounts for a significant part of the overall runtime. That is why Dolgov and Savostyanov (2014) discusses several more heuristic ways to determine suitable enrichment directions.
3.3.1. TT-AMEn + ALS
The most promising variant from Dolgov and Savostyanov (2014) is based on an ALS-like approximation of the residual. As the resulting complete algorithm is not explicitly shown there, we illustrate the required steps Alg. 5 and discuss important implementation details.
First, to really decrease the work, one needs a way to check the error without using the global residual norm. In Dolgov and Savostyanov (2014), this is not further discussed but in the code used for the numerical experiments of Dolgov and Savostyanov (2014), the global residual error is estimated using the projected residuals (before solving the local problem), assuming that
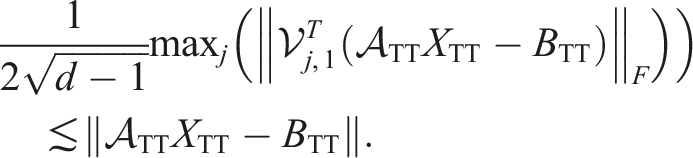
The factor 1/2 is just a heuristic way to ensure that the global residual norm is smaller than the tolerance.
Second, one needs a cheap way to enrich the subspace. For this, a rough approximation of the residual is usually sufficient which can be obtained by a fixed-rank ALS iteration (ALS (l)). This results in the following update of the jth subtensor of the current approximation of the residual 
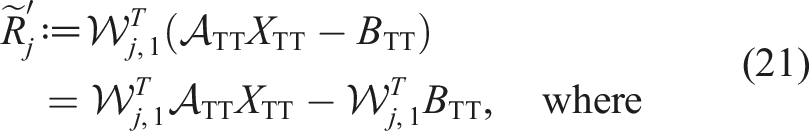
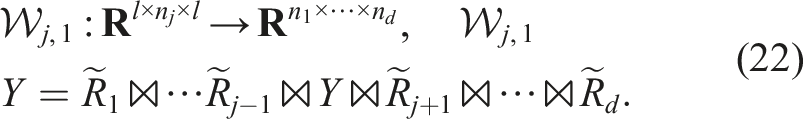
3.4. Preconditioning
For iterative solvers of linear systems, it is a common approach to employ a preconditioner to obtain much faster convergence. Of course, we can precondition all previously discussed algorithms. However, some additional aspects should be considered when preconditioning linear solvers in the TT format. On the one hand, for MALS and AMEn, we can employ local preconditioners for the projected operators • one needs to calculate a different preconditioner in every step of the sweep, • often only a few local iterations are performed, • one may need to contract, for example,
On the other hand, we could employ a global preconditioner which is • either applied to tensor-train “vectors” (TT-GMRES), • or directly to the tensor-train operator • but is not tailored to the local problems for MALS/AMEn.
Furthermore, a global preconditioner (and also local preconditioners for MALS) should retain the low-rank of the solution and right-hand side. To emphasize this: just the fact that
3.4.1. TT-rank-1 preconditioner
Considering the desired properties, we suggest a simple, global rank-1 preconditioner that usually is cheap to calculate (for operators of sufficiently low rank). The two-sided variant can be constructed as follows: First, approximate the operator with a tensor-train of rank 1 using TT-truncation:
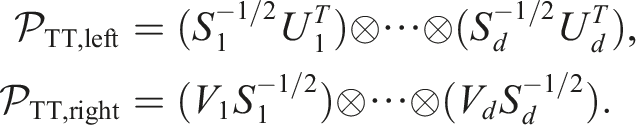
This yields the preconditioned system:
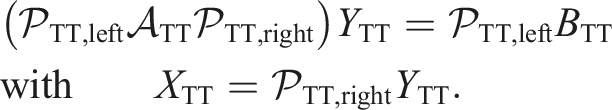
For a symmetric operator
4. Comparison of algorithms
In the following we present numerical experiments for linear systems in TT format. We use the pitts library (Röhrig-Zöllner and Becklas, 2024) which also contains the setup and output for all results shown in this paper. For illustrating the numerical behavior, we consider a simple multidimensional convection-diffusion equation. It is discretized using a finite difference stencil, for example, in 1d the operator is
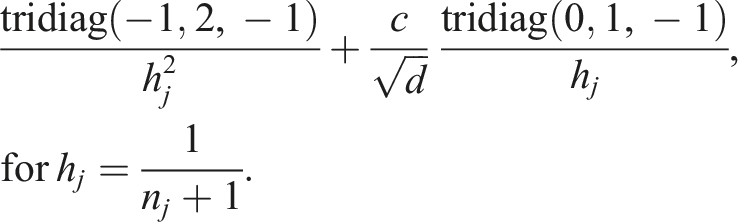
4.1. Behavior of tensor-train ranks in the calculation
First, to understand the computational complexity of the different methods, we show the behavior of the TT ranks during the calculation. As shown in Figure 1(a), the improved orthogonalization in the TT-GMRES algorithms (SIMGS, Alg. 2) results in slightly slower rank growth in the Krylov basis than standard MGS; Both show the expected linear growth (for operators with a displacement structure). A naive MGS implementation (all truncations performed with tolerance δ
i
in Alg. 1) results in exploding ranks after a few iterations. Furthermore, the calculated solutions of the MGS variants are not within the desired residual tolerance (with Tensor-train ranks for the Krylov basis, respectively the approximate solution for a 2010 convection-diffusion problem (c = 10) and RHS BTT of ones. For TT-GMRES (left), both MGS variants lead to inaccurate solutions that are not within the desired residual tolerance in contrast to all cases with SIMGS. Overall, more accurate orthogonalization (SIMGS) without restart and preconditioning features the lowest maximal ranks during the calculation. For MALS (right), the solution ranks only increase slowly with each sweep (as intended), but the Krylov basis vectors of the inner iteration again yield higher ranks. (a) Krylov basis ranks for TT-GMRES. (b) Ranks for precond. MALS with inner TT-GMRES.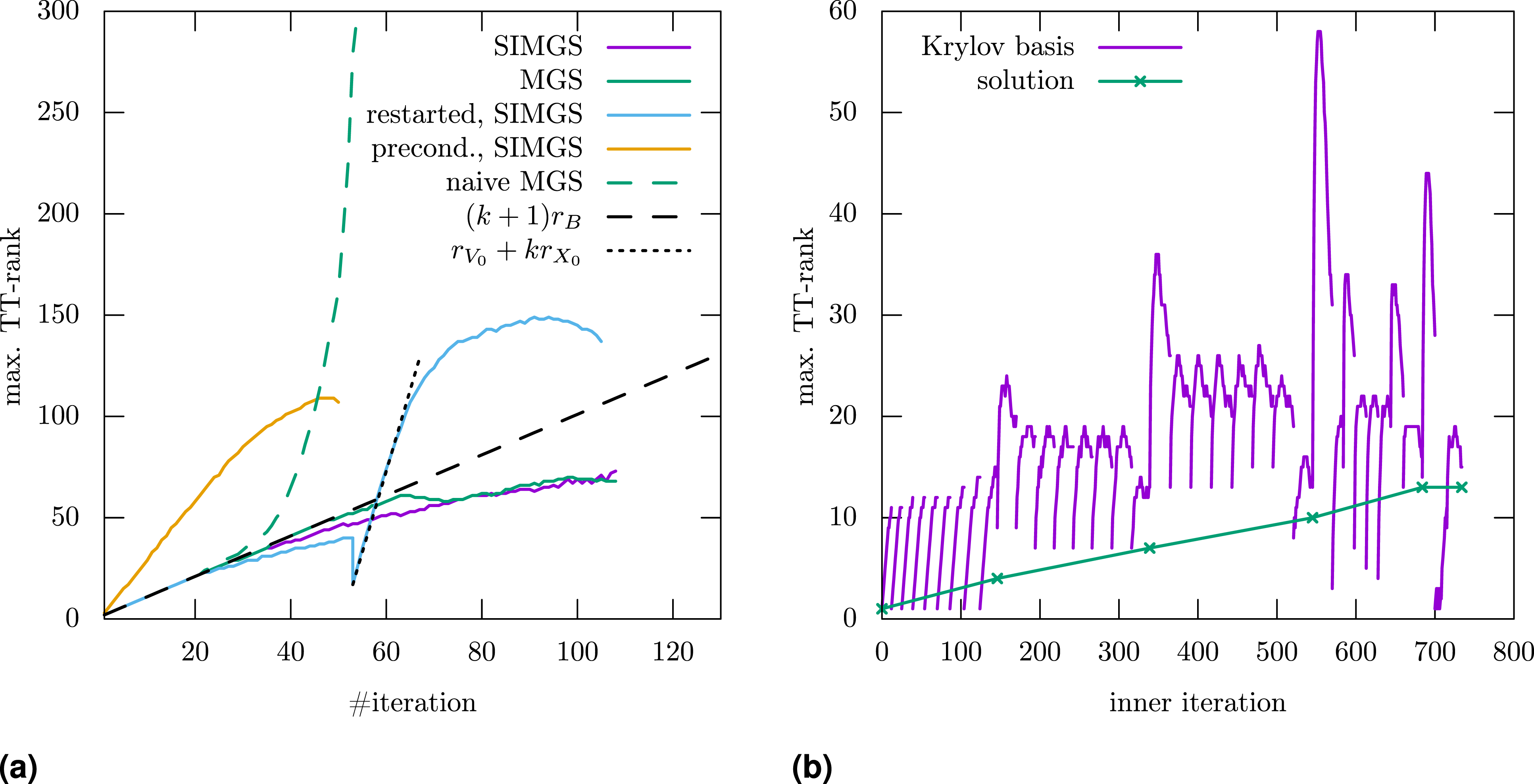
4.2. Computational complexity of the different methods
The TT ranks explain the results in Figure 2: TT-GMRES needs 10–100× more operations than MALS. MALS needs 10–100× more operations than AMEn. For larger individual dimensions (n
j
), MALS with inner TT-GMRES needs fewer operations than with inner MALS. In addition, applying the operator becomes more costly, and it is beneficial to use a sparse matrix format for the sub-tensors of the operator (sparse TT-Op variant in Figure 2(a)). We also measured the behavior using the quantics TT format (QTT, Khoromskij, 2011) where we just convert the operator to a Number of floating-point operations measured using likwid (Treibig et al., 2010) for a convection-diffusion problem (c = 10). Dashed lines use the TT-rank-1 preconditioner. Dotted lines first transform the problem to the QTT format (Khoromskij, 2011). In all cases, AMEn requires orders of magnitude fewer operations than MALS and TT-GMRES. (a) Varying dimensions (RHS BTT of ones) (b) Random RHS BTT with varying ranks (dimension 2010).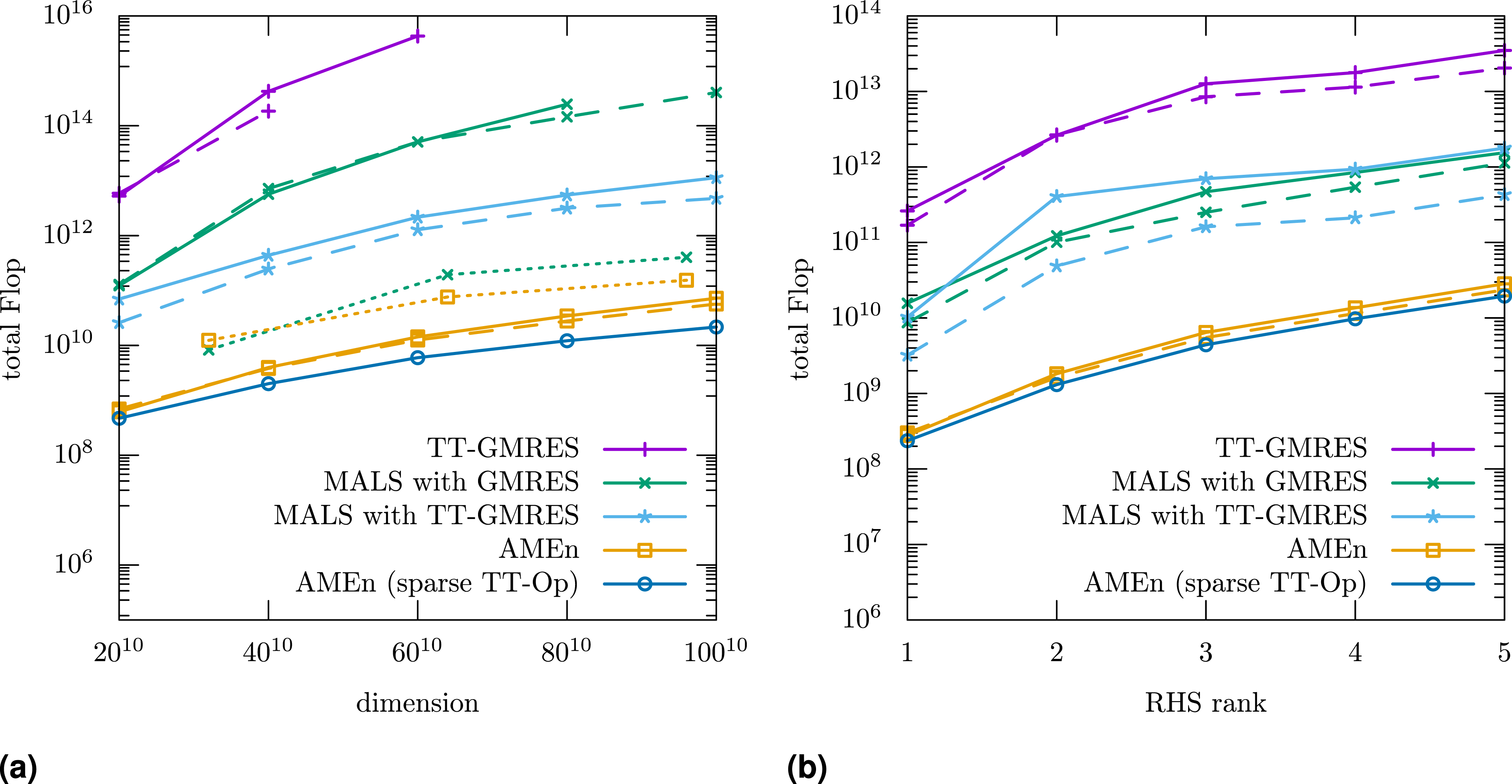
5. Performance of algorithmic building blocks
In the following, we discuss the required basic tensor-train operations (“building blocks”) for the algorithms from Section 3. We focus on the node-level performance on a single multicore CPU with some remarks for a distributed parallel implementation. We only consider those operations where we see a significant improvement over the standard implementation as introduced in Oseledets (2011). These are in particular left-/right-orthogonalization with/without truncation, TT addition with subsequent truncation (TT-axpby + trunc), and faster contractions.
5.1. Replacing costly SVDs and pivoted QR decompositions with faster but less accurate alternatives
In Röhrig-Zöllner et al. (2022), the authors present a significantly faster implementation for decomposing a large dense tensor in the TT format (TT-SVD) using a Q-less tall-skinny QR (TSQR) algorithm. For the TT-SVD, one starts with a decomposition of the form:
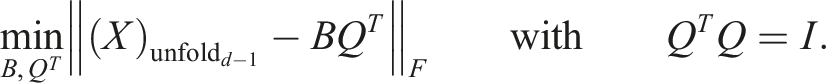
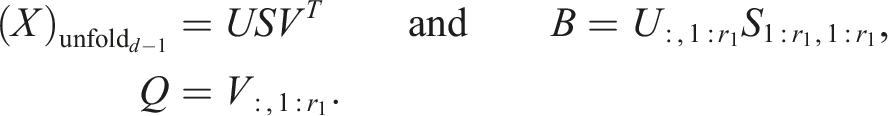
The optimized algorithm uses the following steps instead (grayed-out matrices are not calculated):
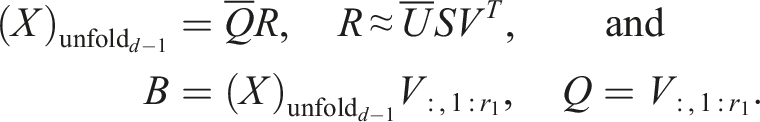
As V has orthonormal columns, the matrix B can be calculated accurately this way.
For the left-/right-orthogonalization (see first loop in TT-rounding in Oseledets, 2011), we unfortunately need slightly different operations, for example, in the left-to-right QR sweep:
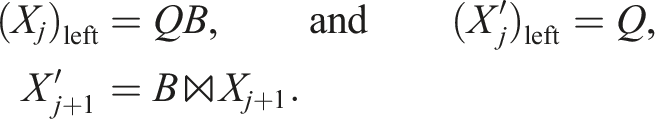
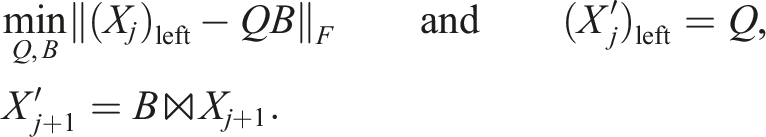
The only difference is that the pure orthogonalization is exact up to the numerical rank whereas the truncation intentionally cuts off with a given tolerance. We can use the same trick as for the TT-SVD in a slightly different way here. For the orthogonalization, one obtains with pivoting matrix P:
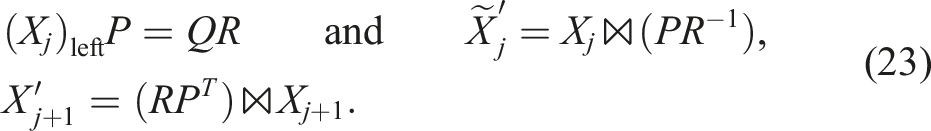
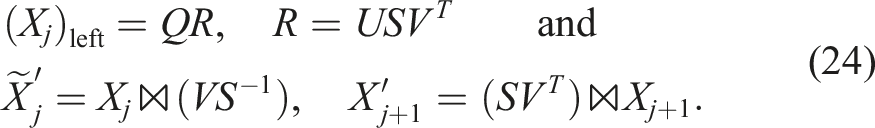
There is a difference to the TT-SVD here: in both cases, the faster formulation might introduce a significant numerical error
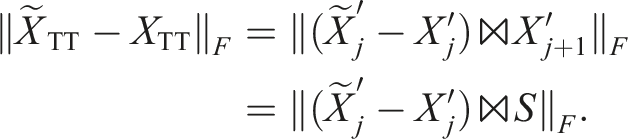
This is not ensured for the orthogonalization step. However, this shows that the error should be weighted by the singular values of the corresponding unfolding of the approximated tensor. So for the truncation, the left-to-right QR sweep is followed by a right-to-left SVD sweep with:
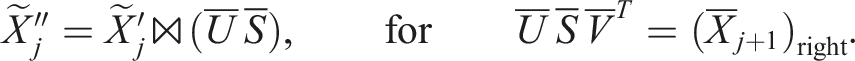
We suggest checking the error a posteriori using the orthogonalization error weighted by the singular values of the jth unfolding:
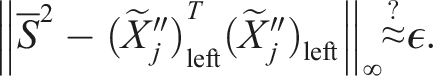
In our numerical tests this was always the case even if
5.2. Exploiting orthogonalities in TT-axpby + trunc
To add tensors in TT format (ZTT = αXTT + βYTT = Z1 ⋈ ⋯ ⋈ Z
d
), one combines their sub-tensors:
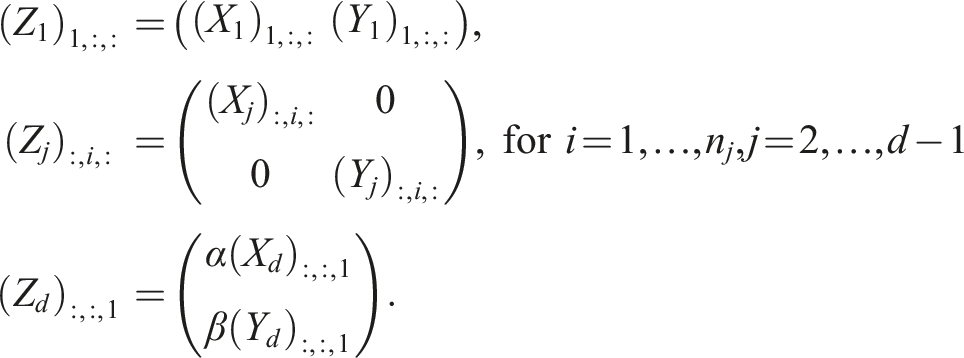
This operation is needed in the TT-GMRES algorithm as well as in MALS and the standard AMEn. For AMEn, the operation is performed step-by-step in each step of a sweep. In all cases, the sub-tensors of XTT and YTT are already left- or right-orthogonal. And after the addition, one performs a left- or right-orthogonalization of the ZTT for a subsequent truncation step. We can exploit the block non-zero structure and pre-existing orthogonalities. In the following, we assume rankTT (XTT) ≥ rankTT (YTT) and that X1, …, Xd−1 are left-orthogonal. Then, we can compute left-orthogonal sub-tensors for
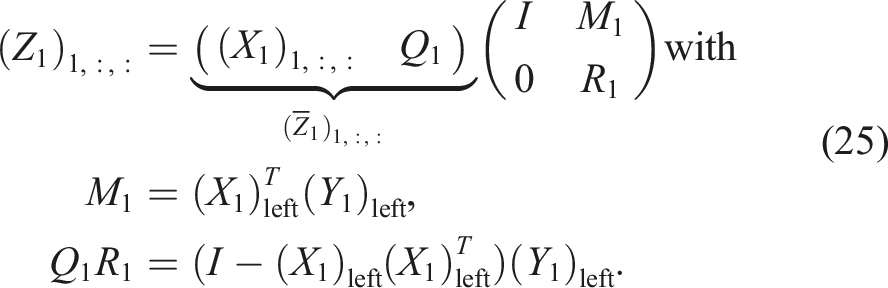
For the next sub-tensors j = 2, …, d − 1, we obtain:
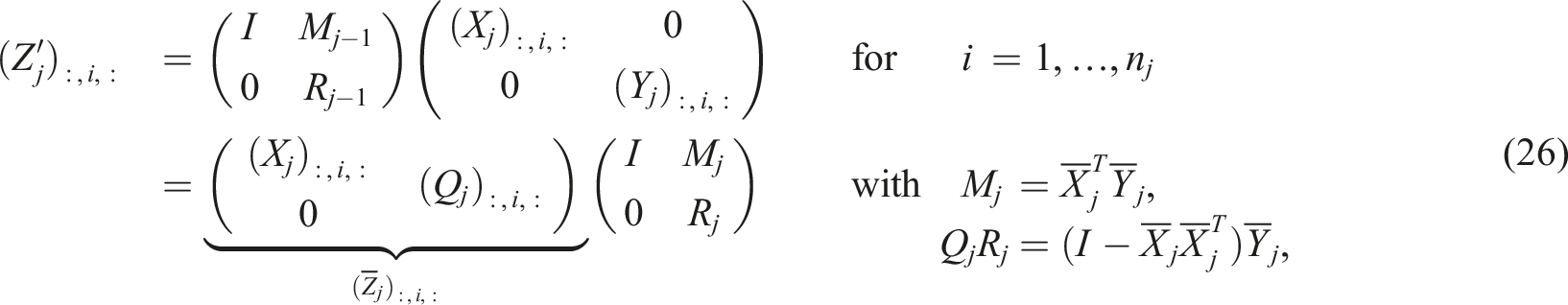
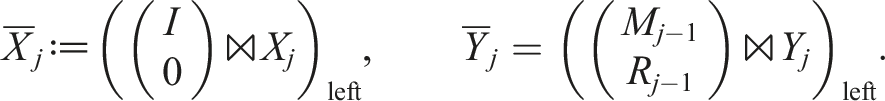
The last sub-tensor simply results in:
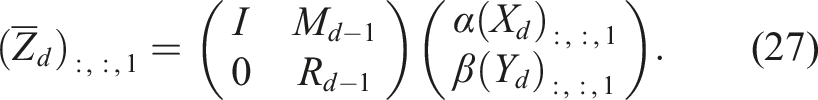
5.2.1. Stable residual calculation with inaccurate orthogonalization
For (standard) AMEn and MALS, we update a left- respectively right-orthogonal representation of
In general, when combining inaccurate orthogonalization with the optimized TT-axpby + trunc algorithm, we need to adjust the formulas in (25) and (26) to compensate for the loss of orthogonality. Assuming
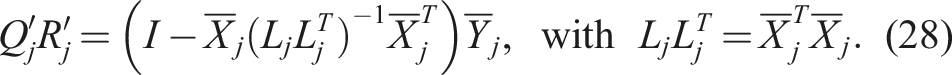
This emulates re-orthogonalization but is faster if
5.3. Faster contractions: inner iteration of AMEn
In AMEn, one needs to apply the projected TT operator from (19) to a dense tensor:
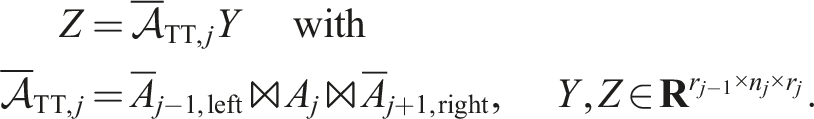
We can calculate this with the following contractions assuming that the ordering of dimensions denoted by : is equal on the left- and right-hand sides of the equations:
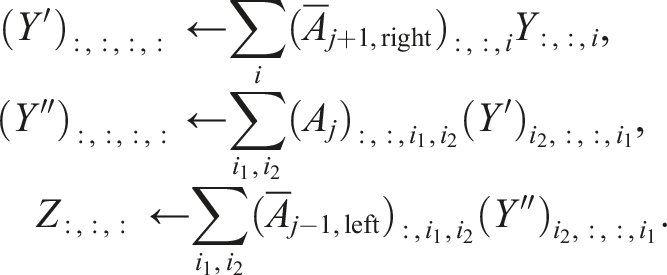
If we reorder the array dimensions of the sub-tensors of
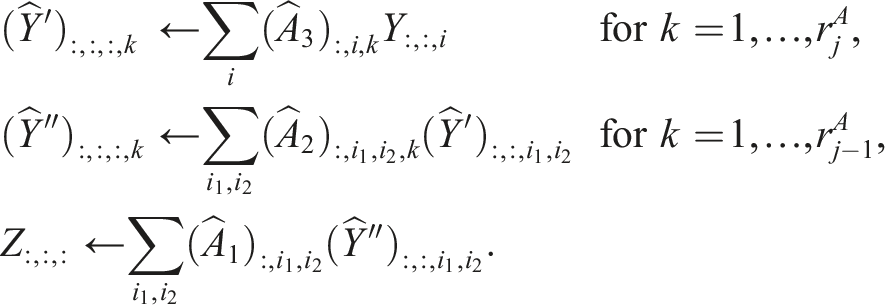
The benefit of this reordering is that we can combine the contracted and “free” dimensions ((i1, i2) and (:, :)) to obtain fewer large dimensions which reduces overhead in the implementation. In addition, we employ a column-major storage with a padding to obtain array strides that are multiples of the cache line length but not high powers of 2 to avoid cache thrashing. Another approach consists in using optimized tensor contractions as discussed in detail in Springer and Bientinesi (2018) which may reduce the overhead due to several small dimensions.
5.4. Resulting building block performance
Here, we show experiments on a single CPU socket of an AMD EPYC 7773X (“Zen 3 V-Cache”) with 64 cores and the Intel oneMKL (Intel, 2023) as underlying BLAS/LAPACK library. 1 We use the Q-less TSQR implementation discussed in Röhrig-Zöllner et al. (2022).
Figure 3(a) shows timings for different variants of the TT-axpby + trunc operation. We observe significant speedup through replacing SVDs and pivoted QR decompositions by a fast Q-less TSQR implementation: For the QR orthogonalization sweep alone, the runtime improves by a factor of ∼4.5 for the largest case (difference between colored an black lines). For the subsequent SVD sweep, the runtime improves by a factor of ∼2.5. Overall speedup is about ∼3.5. We only see a small effect through reusing the orthogonality in the example here. It uses random tensor-trains as inputs, so the rank of the result is the sum of the individual ranks. In practice, for example, for the Arnoldi iteration or for calculating the residual in AMEn, the rank of the resulting tensor-train is often smaller which leads to less work in the SVD sweep and thus a bigger effect through reusing orthogonalities in the preceding QR sweep. Effect of building block optimizations: For adding two tensors in the tensor-train format (left), we obtain a speedup of ∼3.5 by mapping the calculation onto faster linear algebra operations as explained in Section 5.1 and Section 5.2. For applying the linear operator of the inner problem in AMEn (right), we obtain a speedup of ∼3 through directly calling optimized BLAS routines and through reordering array dimensions. (a) Timings for the truncated addition of two tensor-trains (dim. 5010, ranks r
X
= 50 and r
Y
= 1, …, 700). (b) Performance of the contractions for multiplying a 3d TT-operator with a dense tensor (dim.: r × 50 × r).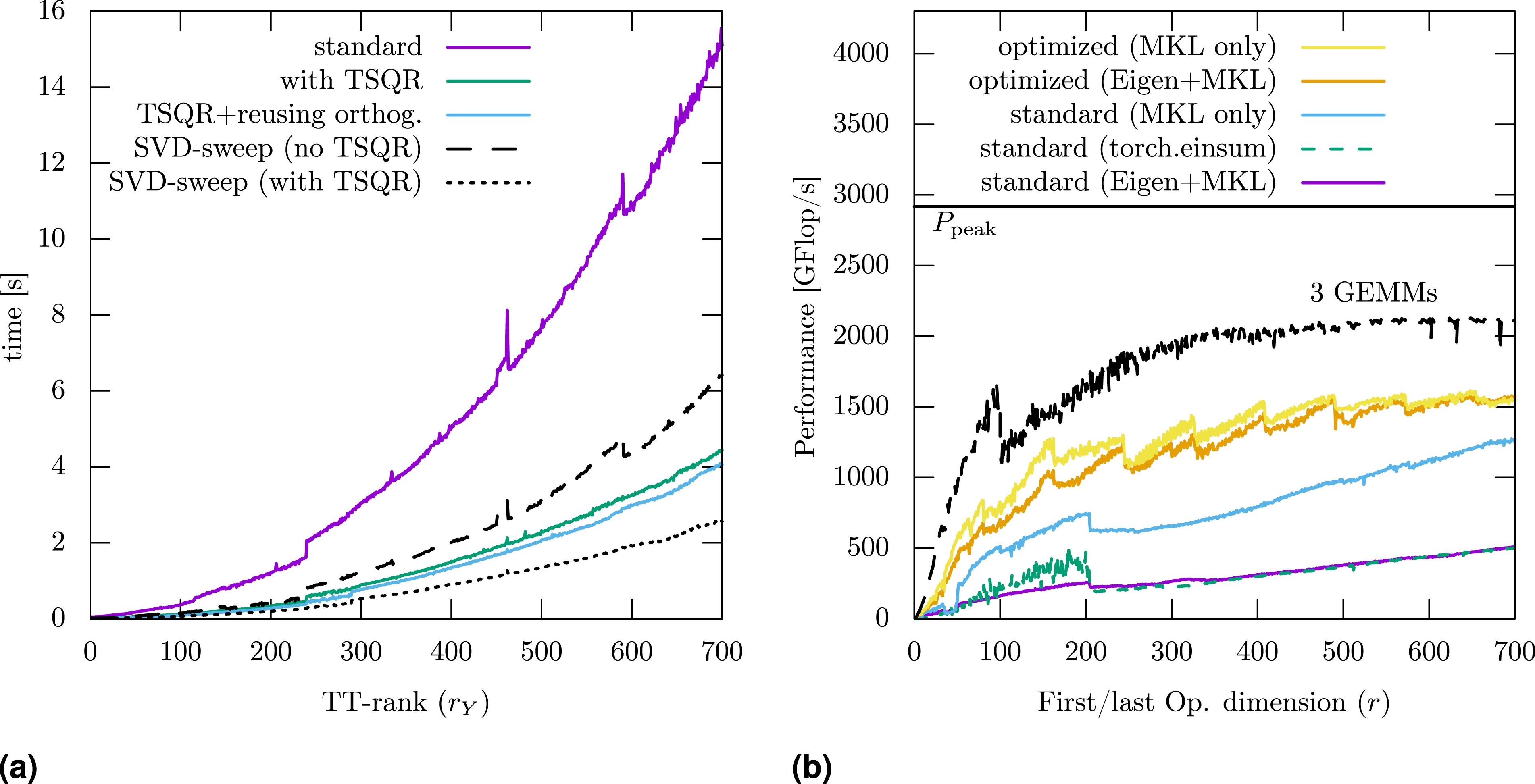
For the contraction in the inner iteration of AMEn, we illustrate the performance of different variants in Figure 3(b). The operation consists of 3 tensor contractions, one of them is memory-bound and the other two are compute-bound for the chosen dimensions (for r ≳ 100). The dotted line shows the performance of 3 equivalent matrix-matrix multiplications (GEMM). In particular for small dimension r, there is a significant improvement through reordering and combining the dimensions as discussed in Section 5.3. Without appropriate padding, there are performance drops whenever the r is close to a number dividable by, for example, 128 (not shown here). Overall, there is also a significant difference between using Eigen (Guennebaud and Jacob, 2010) with MKL as backend and directly calling MKL through the cblas interface, possibly because Eigen explicitly initializes the result to zero. The standard implementation used here loops over a lot of possibly small GEMM operations. We also show results using the function
5.5. Complete TT-AMEn algorithm
For the complete algorithm for solving a linear system, we focus on the AMEn method as it needs at least an order of magnitude fewer operations than the other methods. As shown in Figure 4, the full AMEn variant needs approximately twice the time of the ALS variant. This is due to calculating the global residual Timings for TT-AMEn for solving a linear system from a 5010 convection-diffusion problem (c = 10) and random RHS BTT with varying ranks. Dashed lines use the TT-rank-1 preconditioner. Dotted black lines illustrate the asymptotic complexity using the formula c (0.35 (r/700)3 + 0.65 (r/700)2). The heuristic ALS variant (right) is about twice as fast as the full variant (left). For both variants, the time-to-solution is reduced by a factor of ∼5 by combining all suggested optimizations. (a) Full variant (AMEn + SVD) (b) ALS variant (AMEn + ALS).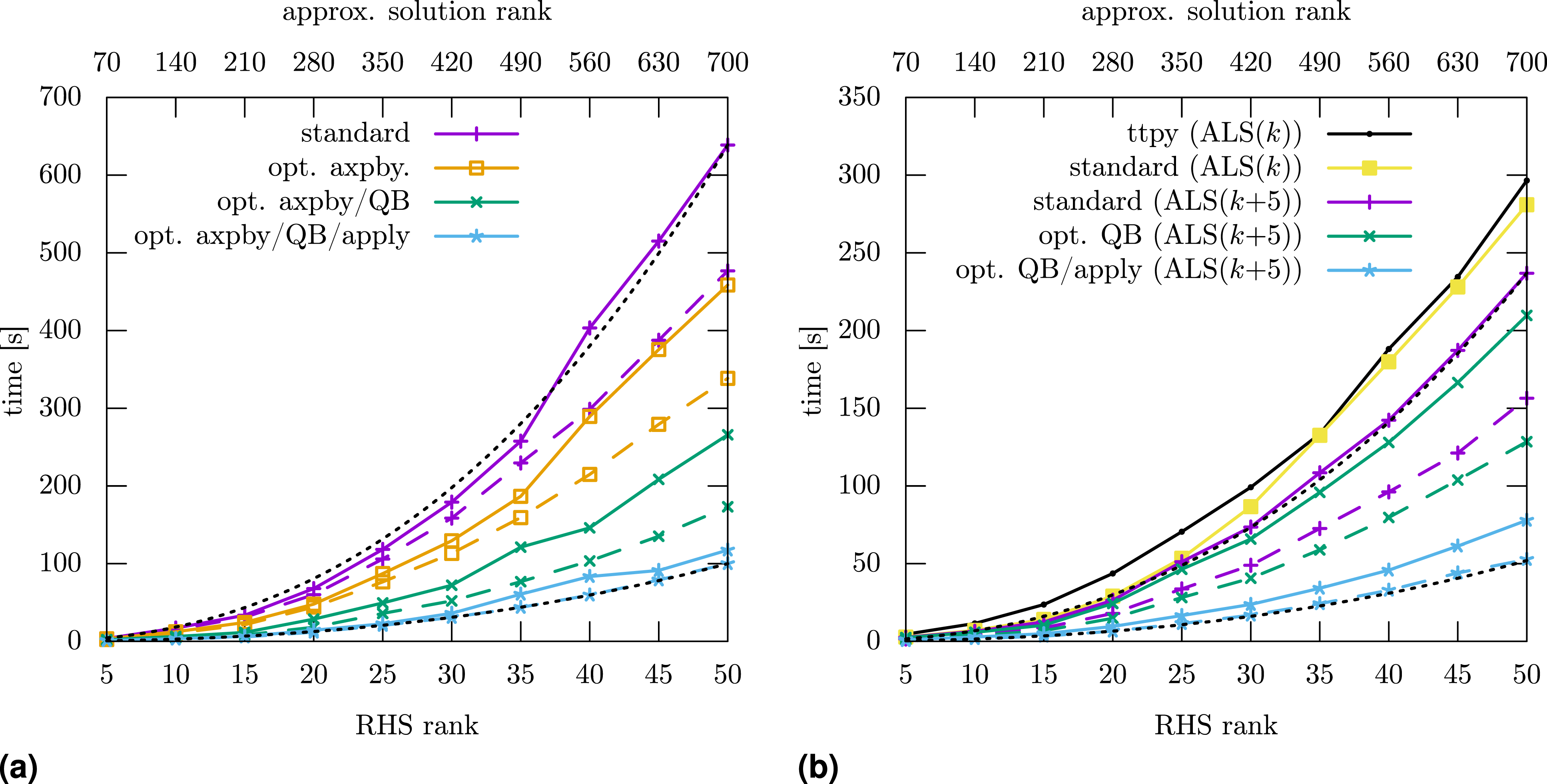
6. Conclusion and future work
In this paper, we discussed the complexity and the performance of linear solvers in tensor-train format. In particular, we considered three different common methods, namely TT-GMRES, MALS (DMRG approach for linear systems) and AMEn, and tested their behavior for a simple, non-symmetric discretization of a convection-diffusion equation. Concerning the complexity in terms of floating-point operations, we illustrated that AMEn can be about 100× faster than MALS, which in turn can be about 100× faster than TT-GMRES. These results already include an optimized orthogonalization scheme for the Arnoldi iteration in the TT-GMRES method which is also used as inner iteration of the MALS method.
Concerning the performance, we focussed on the required building blocks on a many-core CPU. We suggested three improvements over the standard implementation: (a) exploiting orthogonalities in the TT-addition with subsequent truncation, (b) using a Q-less tall-skinny QR (TSQR) implementation to speed up costly singular value and QR decompositions, and (c) optimizing the memory layout/ordering of required tensor-contraction sequences for applying the tensor-train operator in the inner iteration. As improvements (a) and (b) lead to less robust underlying linear algebra operations, we discussed their accuracy in the context of the required tensor-train operations. In addition, we presented a simple generic preconditioner based on a tensor-train rank-1 approximation of the operator. Overall, we obtained a speedup of about 5× over the reference implementation on a 64-core CPU.
For future work, we want to investigate building block improvements for other tensor-network algorithms which are often based on very similar underlying operations.
Footnotes
Acknowledgements
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially performed as part of the Helmholtz School for Data Science in Life, Earth and Energy (HDS-LEE) and received funding from the Helmholtz Association of German Research Centres. This work was also partially funded by the Quantum Computing Initiative of the German Aerospace Center (DLR) and the German Federal Ministry for Economic Affairs and Climate Action (Bundesministerium für Wirtschaft und Klimaschutz); see ![]() .
.
Note
Author biographies
Melven Röhrig-Zöllner studied Computational Engineering Science at the RWTH Aachen University. Since 2014, he works as a researcher in the High-Performance Computing department of the Institute of Software Technology of the German Aerospace Center (DLR). His research focuses on the performance of numerical methods, in particular in the field of numerical linear algebra. He also supports scientific software development for HPC systems in the DLR, for example, concerning software engineering practices and testing parallel codes.
Manuel Becklas received his Bachelor's degree in mathematics at the University of Cologne in 2023. He currently pursues his Master in Innovation and Research in Informatics at the Polytechnic University of Catalonia. He worked as a student at the German Aerospace Center in Cologne in the Institute of Software Technology from 2022 to 2023. His scientific interests include high-performance computing, modern C++, linear algebra and machine learning theory.
Jonas Thies is an assistant professor and HPC advisor at the Delft University of Technology. He received his PhD in Mathematics from the University of Groningen in 2011, a Masters degree in Scientific Computing from KTH in 2006, and a Bachelors degree in Computational Engineering from the University of Erlangen Nuremberg in 2003. His research and teaching activities focus on parallel numerical algorithms, high-performance computing, and applications like CFD, oceanography and quantum physics.
Dr.-Ing. Achim Basermann is head of the High-Performance Computing Department at German Aerospace Center’s (DLR) Institute of Software Technology. In 1995, he obtained his Ph.D. in Electrical Engineering from RWTH Aachen University followed by a postdoctoral position in computer science at Jülich Research Centre, Central Institute for Applied Mathematics. From 1997 to 2009 he led a team of HPC application experts at the C&C Research Laboratories, NEC Laboratories Europe, before joining DLR. Dr. Basermann’s current research is focused on extremely parallel linear algebra algorithms, performance engineering for many-core and GPU clusters, data partitioning methods, optimization tools for CFD simulation, high-performance data analytics, scientific machine learning and quantum computing.