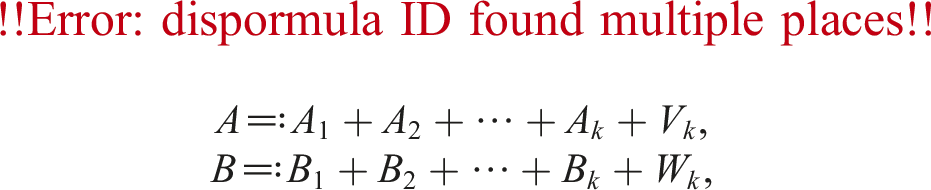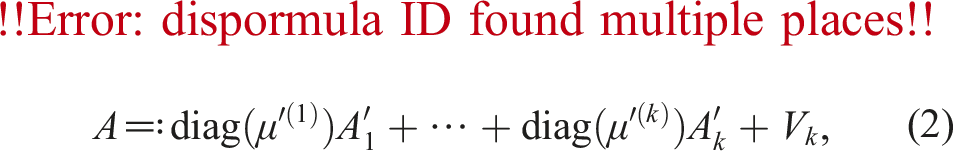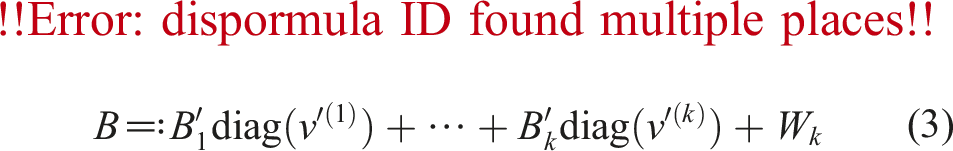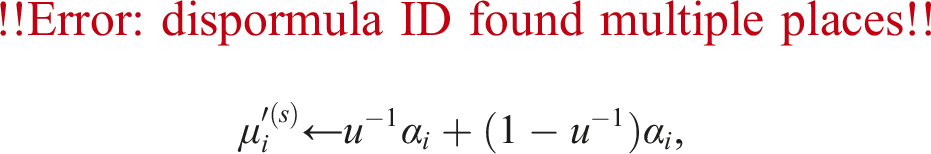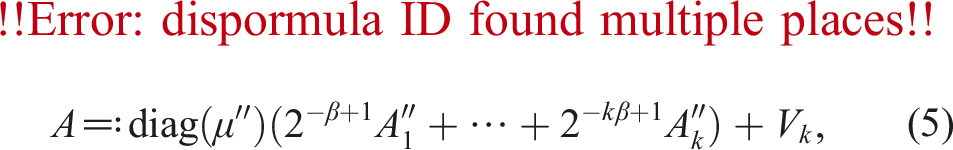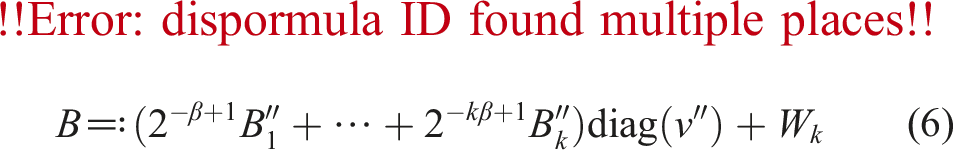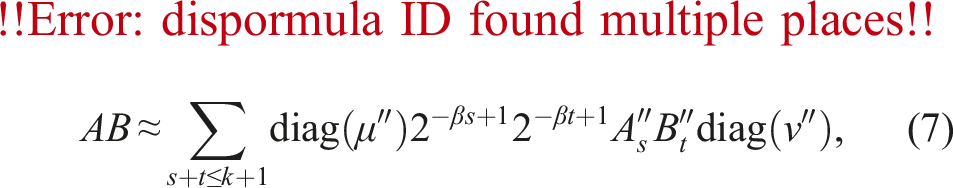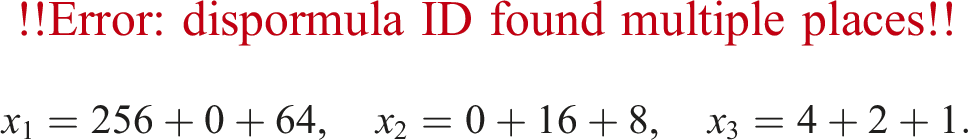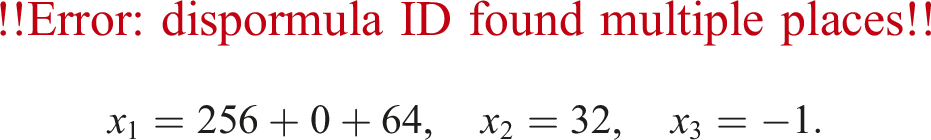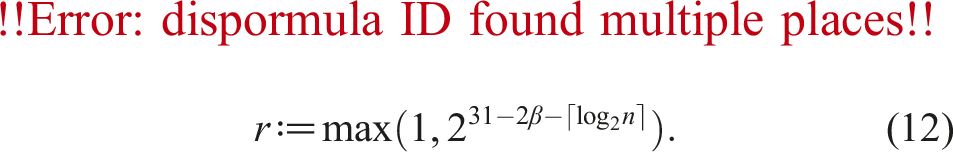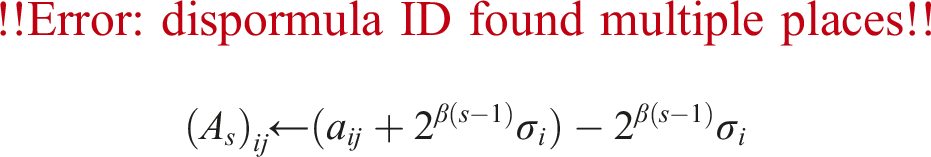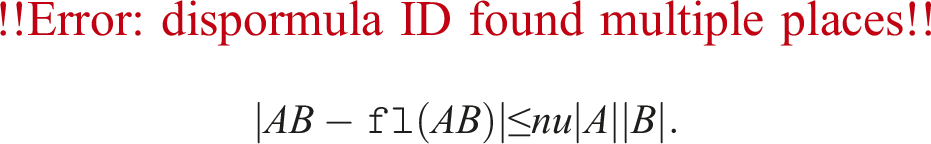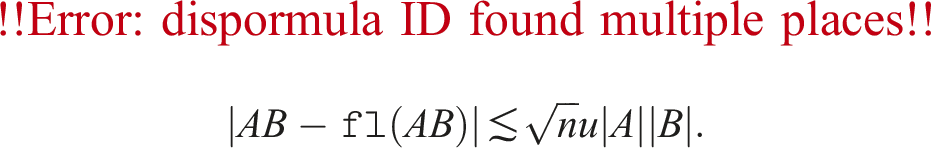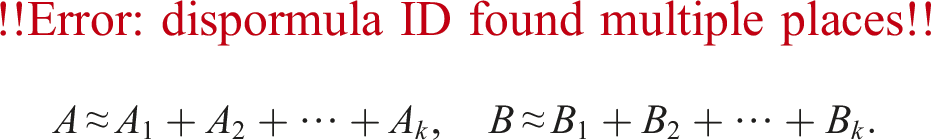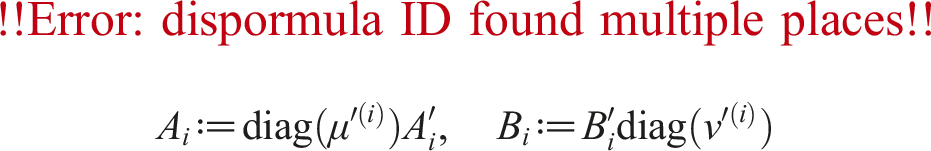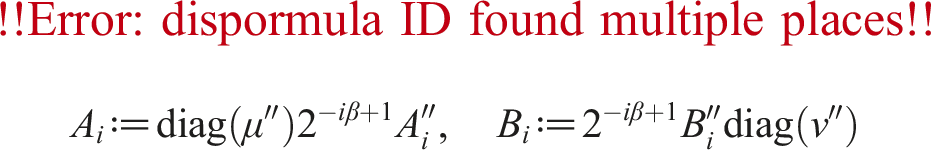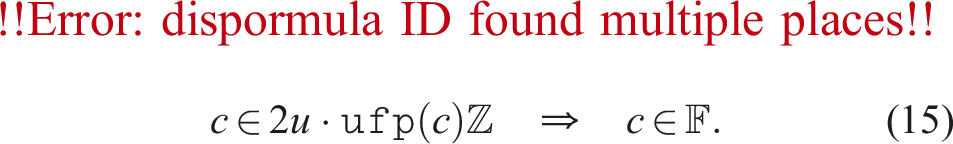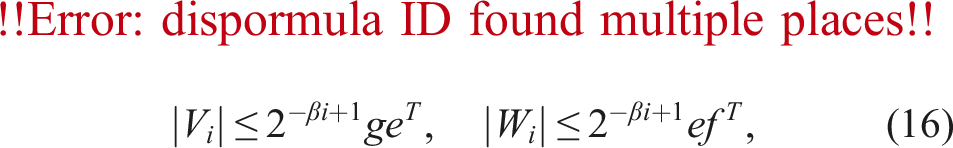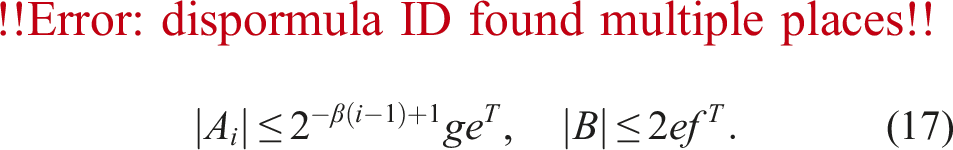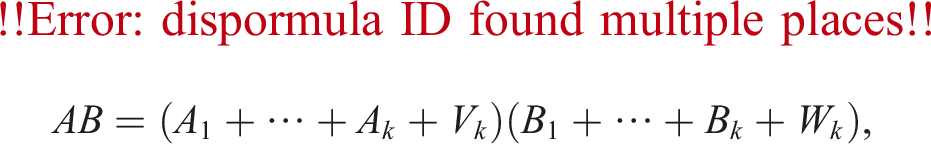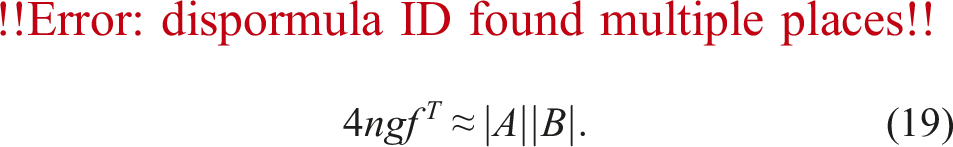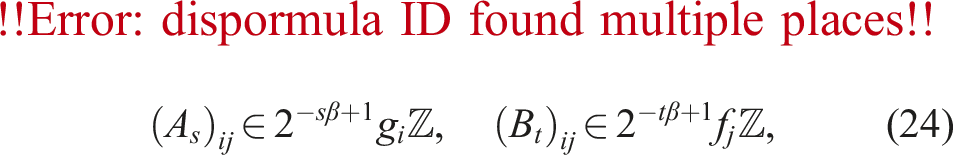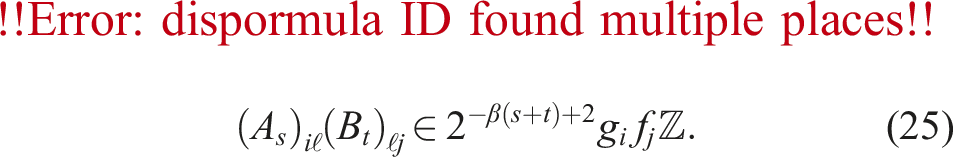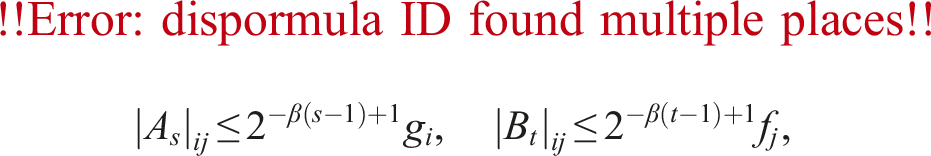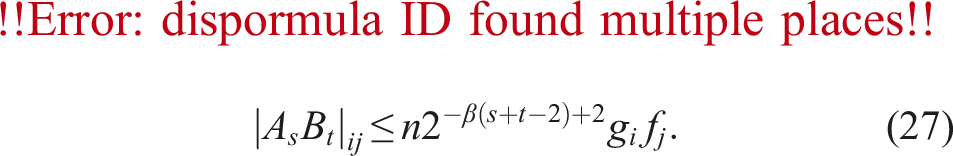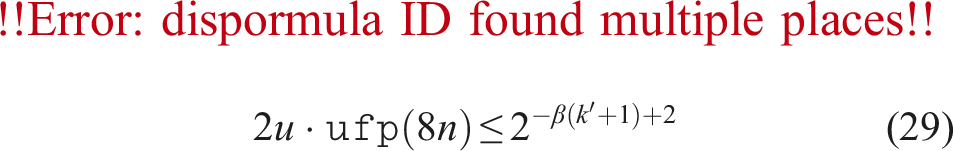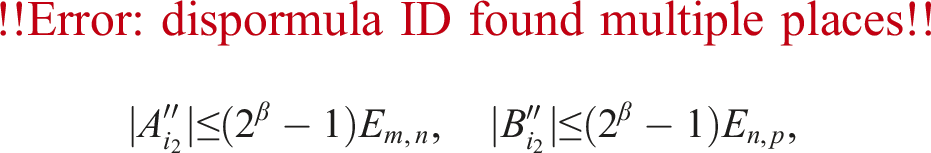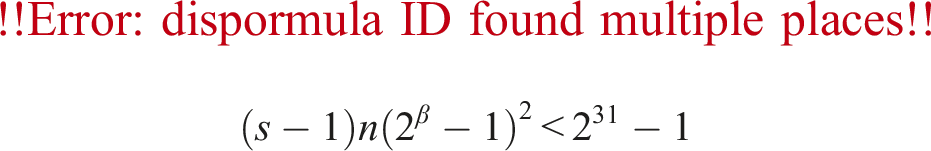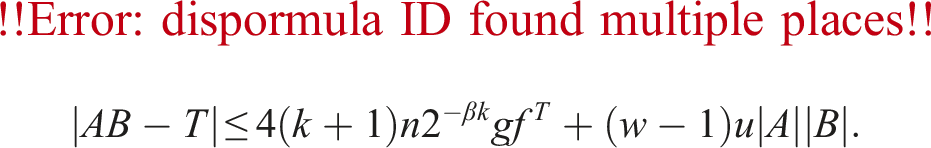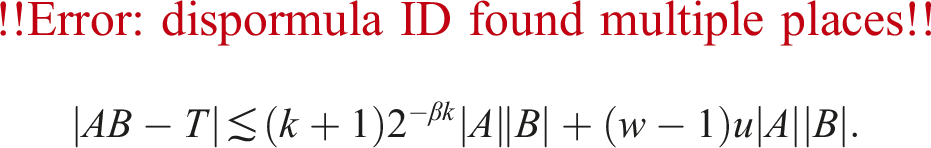This study was aimed at simultaneously achieving sufficient accuracy and high performance for general matrix multiplications. Recent architectures, such as NVIDIA GPUs, feature high-performance units designed for low-precision matrix multiplications in machine learning models, and next-generation architectures are expected to follow the same design principle. The key to achieving superior performance is to fully leverage such architectures. The Ozaki scheme, a highly accurate matrix multiplication algorithm using error-free transformations, enables higher-precision matrix multiplication to be performed through multiple lower-precision matrix multiplications and higher-precision matrix additions. Ootomo et al. implemented the Ozaki scheme on high-performance matrix multiplication units with the aim of achieving both sufficient accuracy and high performance. This paper proposes alternative approaches to improving performance by reducing the numbers of lower-precision matrix multiplications and higher-precision matrix additions. Numerical experiments demonstrate the accuracy of the results and conduct performance benchmarks of the proposed approaches. These approaches are expected to yield more efficient results in next-generation architectures.
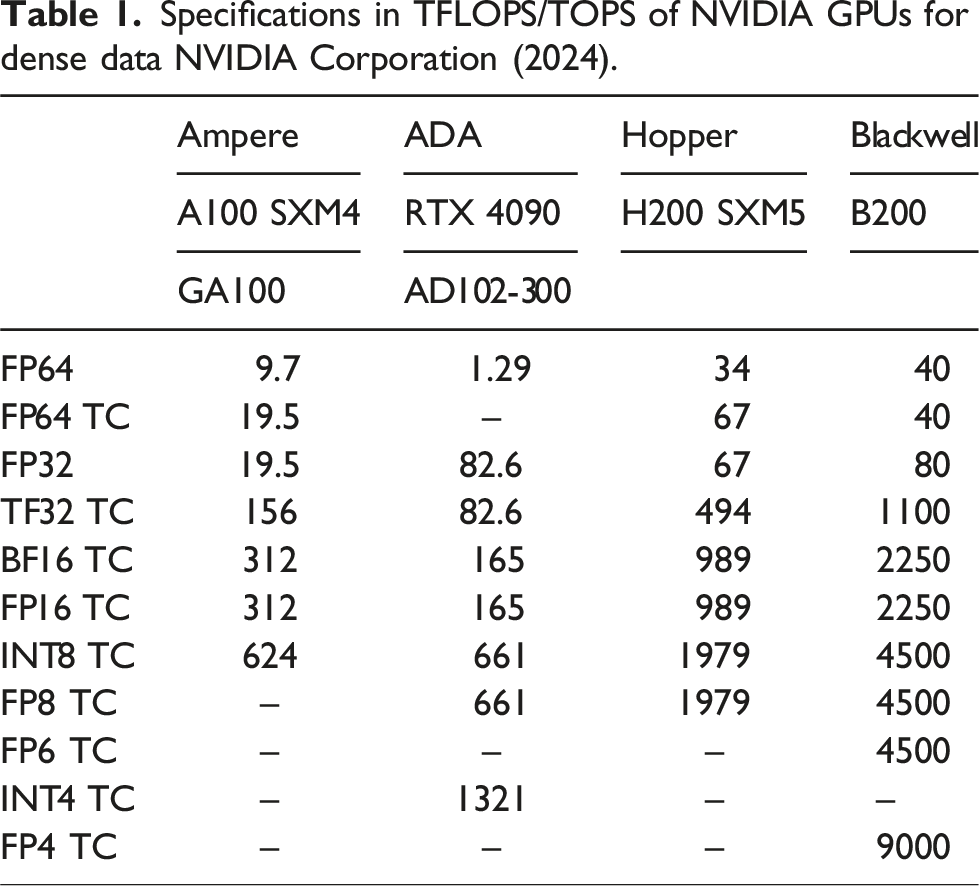
The field of machine learning, including AI, is evolving daily, and the scale and complexity of machine learning models are continually increasing. Recent architectures are designed to process these models rapidly and with high energy efficiency. For machine learning models, matrix multiplications using low-precision floating-point systems and integers are essential. Therefore, recent architectures are equipped with high-performance low-precision floating-point and integer matrix multiplication units, and high-performance mixed-precision matrix multiplication units that leverage these capabilities. A prime example of this is the NVIDIA Tensor Cores (see NVIDIA Corporation (2024)). Table 1 shows the specifications of the NVIDIA GPUs equipped with Tensor Core technology. Note that the specification of FP16 TC on RTX 4090 (165 TFLOPS) is for FP16 input and FP32 output, the specifications for the H100 and GH200 are the same as those for the H200, and the specifications for the B200 in the table is based on NVIDIA’s Technical Brief. In the future, numerical computation algorithms that leverage the performance of cutting-edge architectures will be essential. This study focused on researching high-performance matrix multiplication algorithms that maximize the potential of the latest architectures.
A highly accurate matrix multiplication scheme via the error-free transformation of matrix products was proposed by Ozaki et al. (2012). The scheme is called the Ozaki scheme and it converts a matrix product into a sum of multiple matrix products. It is also possible to convert a matrix product into a sum of lower-precision matrix products to take full advantage of the immense computational power of recent architectures. In order to compute D ← AB for higher-precision matrices and , the Ozaki scheme using lower/mixed-precision, provided by Mukunoki et al. (2020), is constructed as the following four steps:
(i) Extract the lower-precision matrices A1, A2, …, Ak from the higher-precision matrix A, where k is specified by the user, shifting Ai to prevent overflow and underflow at lower-precision arithmetic.
(ii) Extract k lower-precision matrices Bi from B in the similar way as Ai.
(iii) Compute AiBj for i + j ≤ k + 1 using lower/mixed-precision arithmetic.
(iv) Reverse (shift) AiBj and accumulate the results into D using higher-precision arithmetic.
When emulating the GEMM routine, the following fifth step is also performed:
(v) Compute C ← αD + βC for scalars α, β and a matrix C.
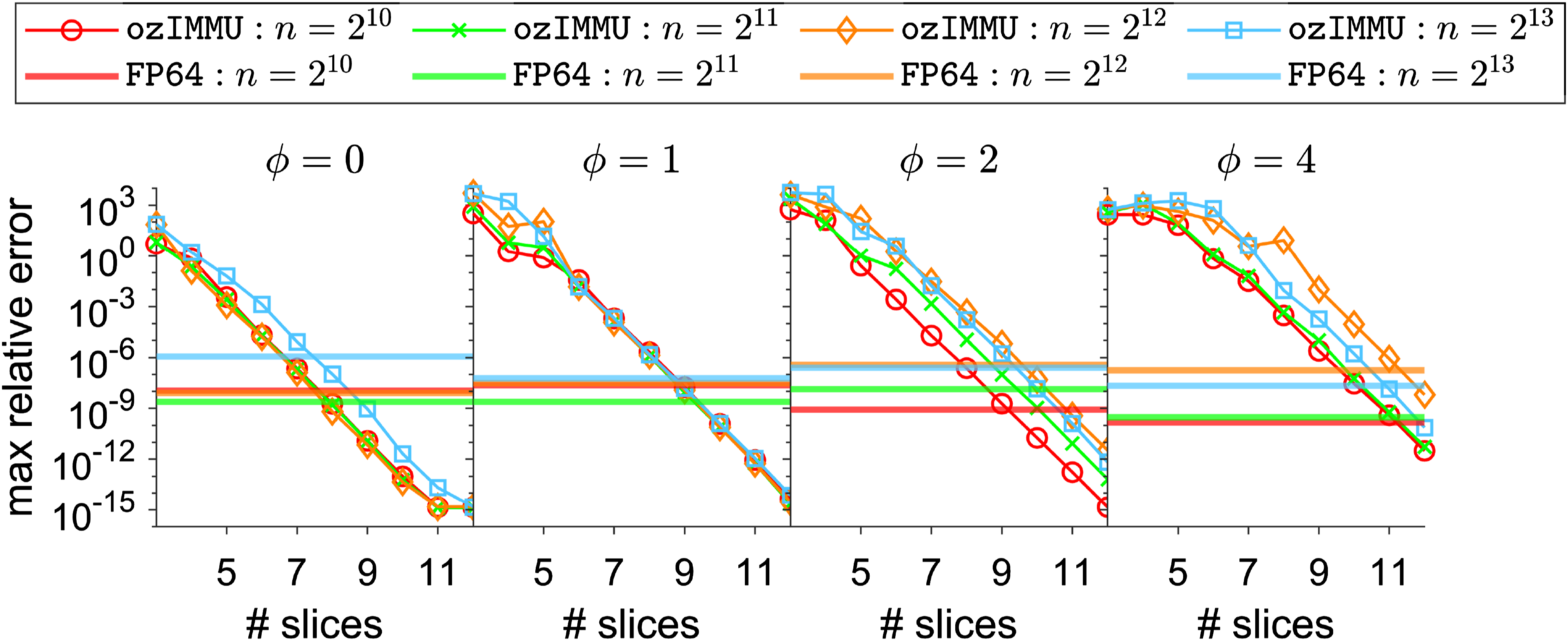
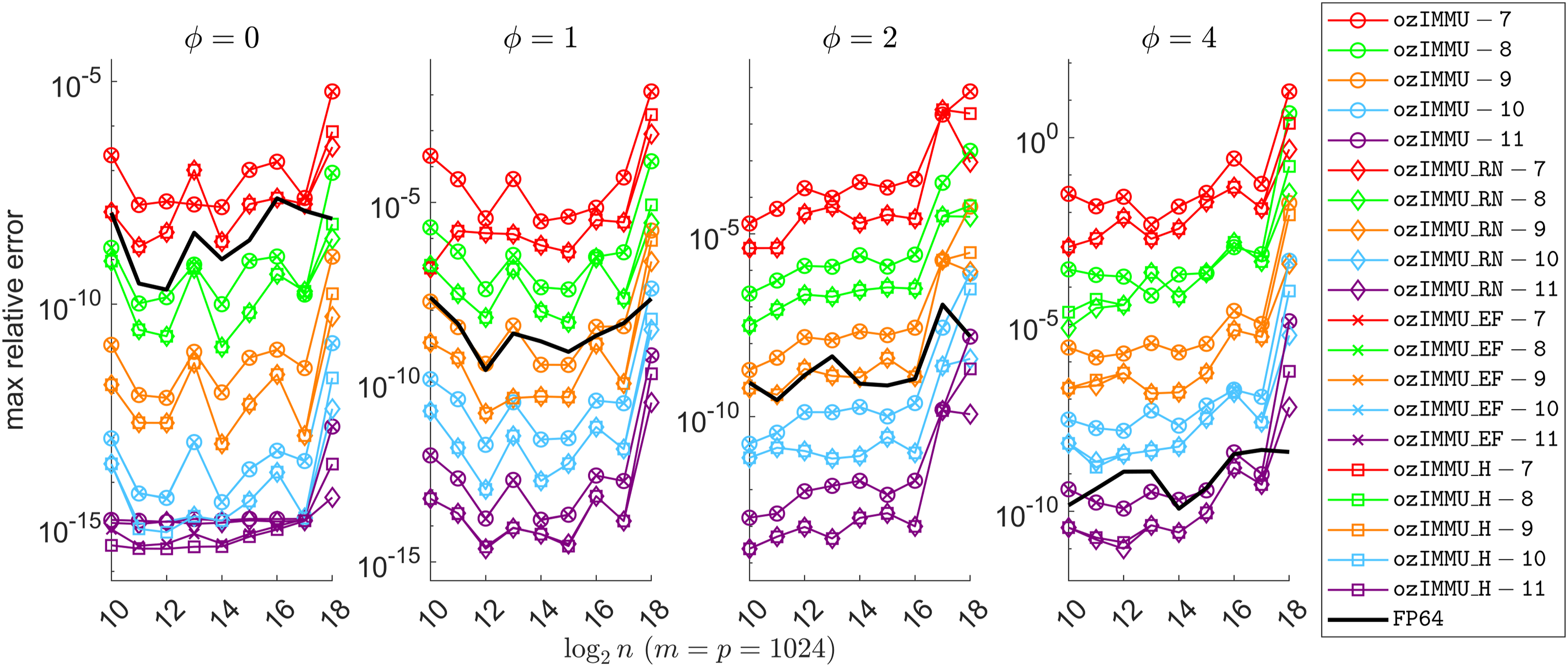
Ootomo et al. (2024) implemented the Ozaki scheme using the INT8 Tensor Cores and evaluated the performance for emulating DGEMM, an FP64 matrix multiplication routine. The Ozaki scheme implemented by Ootomo is named the “Ozaki Scheme on Integer Matrix Multiplication Unit” (ozIMMU), and the code is available from the GitHub repository by Ootomo (2024). Figure 1 shows the accuracy of ozIMMU. Herein, ϕ specifies the tendency of the difficulty in terms of the accuracy of matrix multiplications. At least 7 or 8 slices are required to obtain sufficiently accurate results, even for well-conditioned matrix multiplications. As ϕ increases, more slices are required to obtain sufficient accuracy. Ootomo’s implementation for splitting matrices offers bit masking. Thus, the extracted matrices Ai, Bi may not be optimal and the splitting method can be improved (see Section 3.1 for details). Improvement of the splitting method should contribute to improving the accuracy of results.
Accuracy of ozIMMU. Matrix A has entries aij≔(Uij − 0.5) ⋅ exp(ϕ ⋅ Nij), where Uij ∈ (0, 1) are uniformly distributed and Nij are drawn from standard normal distribution for 1 ≤ i, j ≤ m and m = n = p. Matrix B is composed similarly.
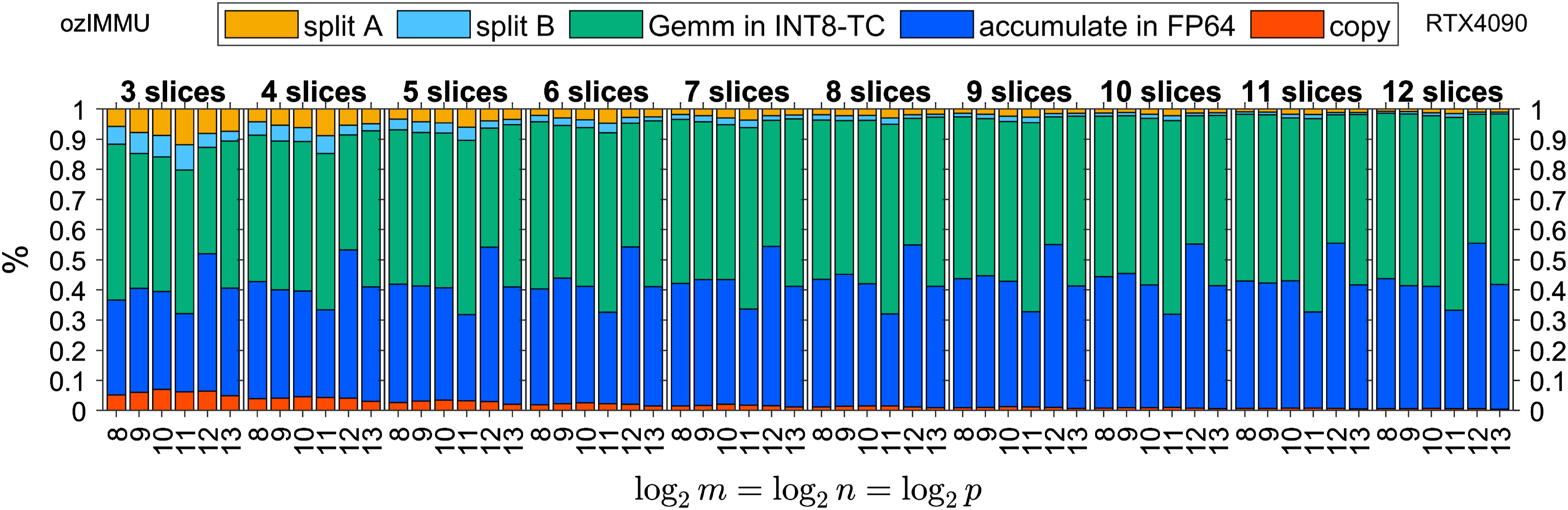
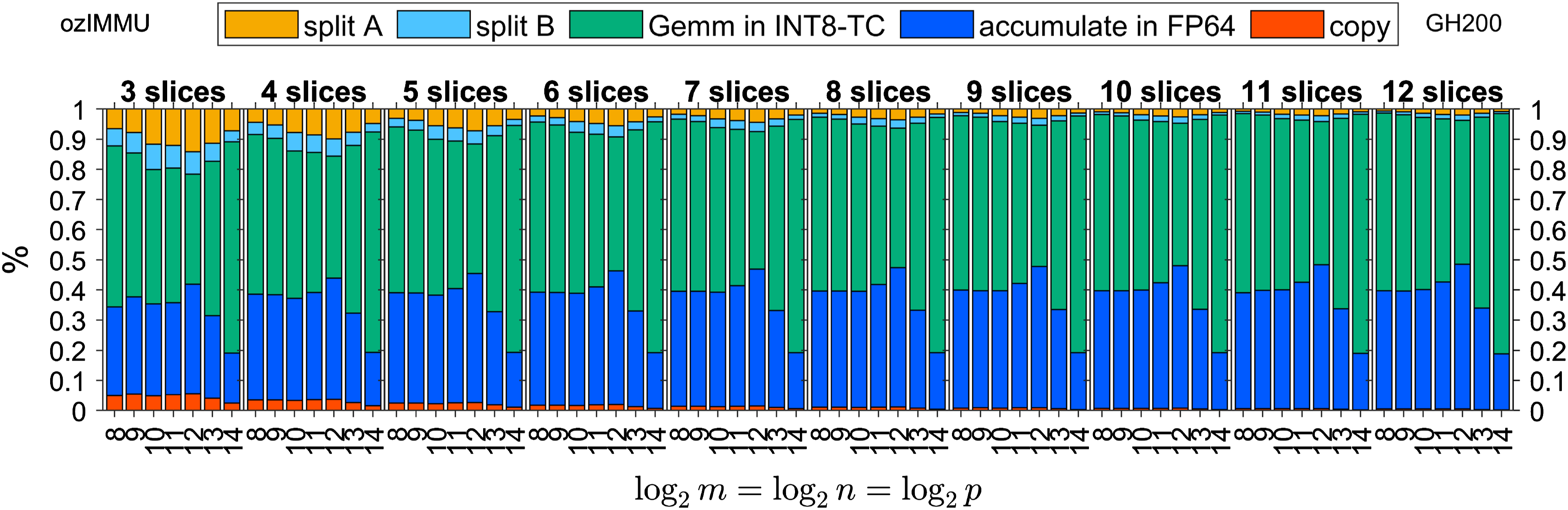
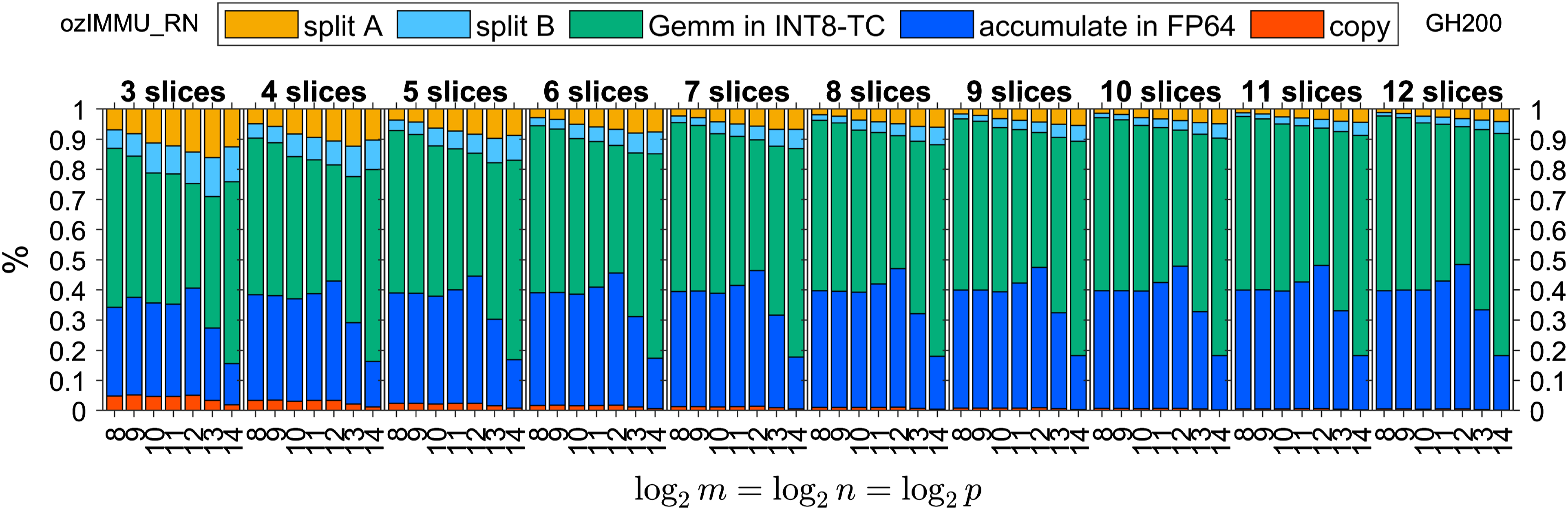
Figures 2 and 3 show the time breakdown of ozIMMU for double-precision matrices and , defined by IEEE Computer Society (2019), on GeForce RTX 4090 and GH200 Grace Hopper Superchip, respectively. Note that “split A”, “split B”, “Gemm in INT8-TC”, “accumulation in FP64”, and “copy” correspond to the steps (i), (ii), (iii), (iv), and (v) in the Ozaki scheme for emulating the GEMM routine, respectively. It can be seen that the computing time for the accumulation of matrix products in FP64 is not negligible even though the computation cost is operations. This is because the performance of the INT8 Tensor Core is nearly 512 times and 60 times higher than that of FP64 on the RTX 4090 and GH200, respectively. Because this ratio increases significantly on the B200 and future architectures, accelerating the accumulation process is critical for the Ozaki scheme.
Time breakdown of ozIMMU on NVIDIA GeForce RTX 4090.
Time breakdown of ozIMMU on NVIDIA GH200 Grace Hopper Superchip.
In this paper, we propose new implementation methods for accelerating the accumulation of the Ozaki scheme using the INT8 Tensor Core. In addition, an alternative splitting method is also applied to improve the accuracy of results. For the number of slices, the splitting method contributes to obtaining more accurate results than those of Ootomo’s ozIMMU. The remainder of this paper is organized as follows: Section 2 overviews previous studies about the Ozaki scheme using an integer matrix multiplication unit; Section 3 presents the proposed method for accelerating the accumulation and optimizing the splitting method; Section 4 shows numerical results to illustrate the efficiency of the proposed methods; Section 5 provides a rounding error analysis of the Ozaki scheme with the proposed methods; and Section 6 presents final remarks.
2. Previous study
In this section, we briefly summarize previous studies. Let u be the relative error unit, e.g., u = 2−53 for double-precision floating-point numbers defined in IEEE 754. Define as a set of binary floating-point numbers with u. Let Om,n be an m × n zero matrix. Suppose that and . Ozaki et al. (2012) proposed an error-free transformation of a matrix product AB. For a user-specified constant , the Ozaki scheme transforms each of A and B into k + 1 matrices
where , ,
such that and for i ≤ k, and holds if for s = 1, …, k − 2, and Bs satisfies the corresponding relation. If the technique provided by Minamihata et al. (2016) is used, then holds when . Note that and are obtained depending on and , respectively.
Let be a set of N-bit binary floating-point numbers. For the Ozaki scheme using the FP16 Tensor Core with accumulation in FP32 and outputs in FP32, the mixed-precision splitting method with shifting to prevent overflow and underflow was utilized by Mukunoki et al. (2020). For and , the splitting method produces
with double-precision shift values , and half-precision matrices , for i = 1, …, k. Algorithm 1 represents the splitting method for obtaining (2) using Minamihata’s technique. Equation (3) can be obtained by transposing the results of Algorithm 1 executed for BT. Algorithm 1 can be described as a loop that is executed until s = k for simplicity; however, the loop terminates when A = Om,n in practice. Note that the binary logarithm is used at the 3rd line in Algorithm 1; however, the calculation using the binary logarithm occasionally returns erroneous results. Therefore, it is better to use a calculation method without the binary logarithm, such as a bitwise operation or a technique leveraging rounding error in floating-point arithmetic as follows:
where αi≔maxj|aij|. This technique was developed by Rump and provided by Ozaki et al. (2013).
Algorithm 1 Mixed-precision splitting method from Mukunoki et al. (2020) for Ozaki scheme between FP64 and FP16 using floating-point arithmetic in roundto-nearest-even mode with Minamihata’s technique from Minamihata et al. (2016)
Input:, Output:, , s = 1, …, k 1: β ←⌈(29 − log2n)/2⌉
holds and there is no rounding error in for 1 ≤ s, t ≤ k on the FP16 Tensor Core. In the method implemented by Mukunoki et al. (2020), the approximation of AB was computed only using matrix multiplications with the FP16 Tensor Core, as
shown in Algorithm 2. This method was referred to as the “Fast Mode” defined by Mukunoki et al. (2020). For larger k, and are smaller and the approximation is more accurate.
Algorithm 2 Mixed-precision matrix multiplication method for Ozaki scheme using FP16 Tensor Core in fast mode from Mukunoki et al. (2020)
Input:, , , , s = 1, …, k Output:
1: C ← Om,p {}
2: forg = 2, …, k + 1 do
3: fors = 1, …, g − 1 do
4: {Compute using GEMM on FP16 Tensor Core}
5: C ← C + diag(μ′(s))FP64(C′)diag(ν′(t)) {Compute in FP64}
6: endfor
7: endfor
Let be a set of N-bit signed integers. It holds that −2N−1 ≤ i ≤ 2N−1 − 1 for all . Remember that no error occurs in integer arithmetic, barring overflow. For the Ozaki scheme using the INT8 Tensor Core with accumulation in INT32, the mixed-precision splitting method via bit masking with shifting is offered in Ootomo et al. (2024) and provided by Ootomo (2024). Algorithm 3 shows the splitting method. Let
Assume that β ≥ 1, i.e., n ≤ 229. That splitting method produces
with double-precision shift values , and 8-bit integer matrices , for i = 1, …, k.
Algorithm 3 Mixed-precision splitting method for Ozaki scheme via bit masking from Ootomo et al. (2024). This algorithm is specialized for the Ozaki scheme using the INT8 Tensor Core.
Input:, Output:, , s = 1, …, k
1: β ← min(7, ⌊(31 − log2n)/2⌋)
2: for i = 1, …, m
3: fors = 1, …, kdo
4: Extract sth β bits of mantissa of aij∀i, j via bit masking and hold those as INT8 variable
holds and there is no error in for 1 ≤ s, t ≤ k on the INT8 Tensor Core barring overflow. In the method implemented by Ootomo et al. (2024), the approximation of AB is computed using only matrix multiplications with the INT8 Tensor Core, as
shown in Algorithm 4. For larger k, and are smaller and the approximation is more accurate.
Algorithm 4 Mixed-precision matrix multiplication method for Ozaki scheme using INT8 Tensor Core from Ootomo et al. (2024)
Input:, , , , s = 1, …, k Output:
1: β ← min(7, ⌊(31 − log2n)/2⌋)
2: C ← Om,p {}
3: forg = 2, …, k + 1 do
4: fors = 1, …, g − 1 do
5: {Compute using GEMM on INT8 Tensor Core}
6: C ← C + diag(μ″)2−βs+12−β(g−s)+1FP64(C″)diag(ν″) {Compute in FP64}
7: endfor
8: endfor
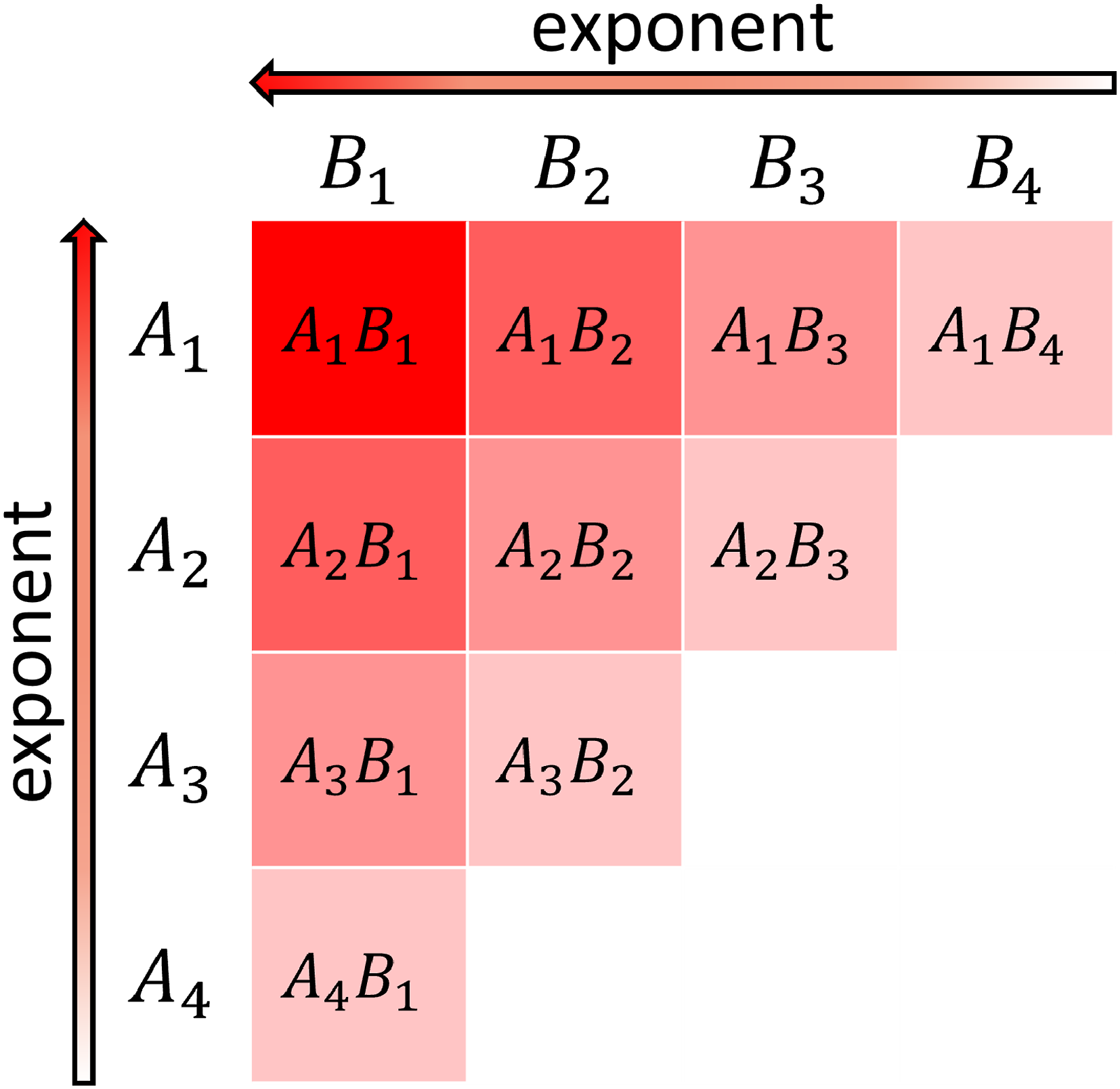
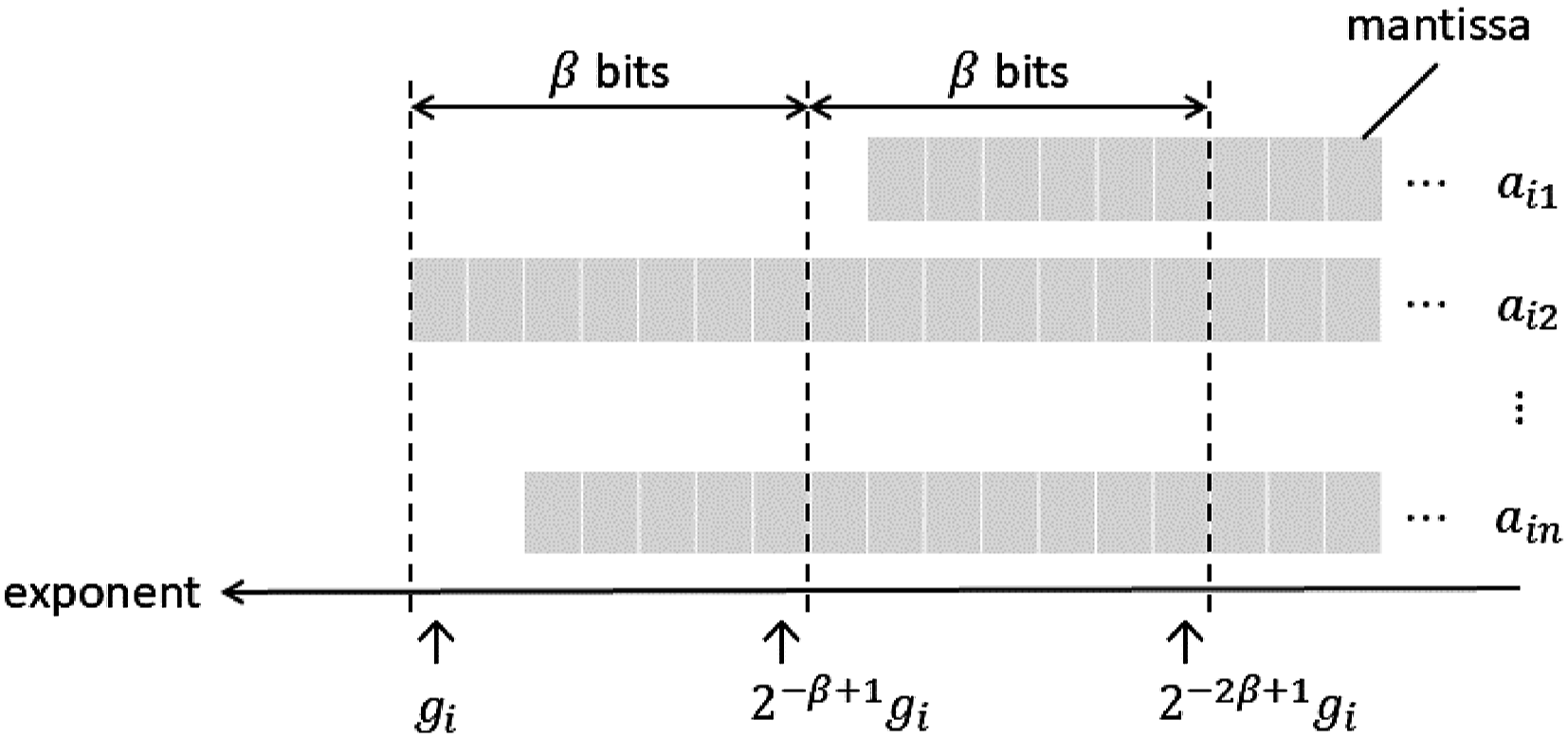
Figure 4 represents images of Algorithms 2 and 4. In Figure 4, and for Algorithms 1 and 2, and and for Algorithms 3 and 4. The exponent of AiBj is larger for smaller indices of i, j, so those terms have stronger effects on the accuracy of the final result.
Images of matrix multiplications in Ozaki scheme for k = four.
3. Proposed methods
3.1. Splitting with rounding to nearest
We begin by explaining our motivation with a simple example. Algorithm 3 described in Section 2 used bitmask for the splitting. We assume that each number keeps three bits. Let a floating-point number be x≔377, represented by (101011111)2 in binary format. The bitmask strategy divides x into three numbers x = x1 + x2 + x3:
In decimal format,
Here x1 is not the nearest number to x.
On the other hand, let x1 and x2 be the nearest number to x and x − x1, respectively. Then,
In decimal format,
There are two drawbacks in the bitmask strategy. One drawback is that even if the leading bit is zero, we keep it, so that the number of significant figures decreases as in x2 in (8). The other drawback is that the truncation error can be reduced. For example, if we set two slices, there is a difference in the truncation error |x3| in (8) and (9). It is expected that the nearest strategy makes the truncation error small. Summarizing, even if we obtain a computed result with k slices using the rounding to nearest strategy, the accuracy may be comparable to that with k + 1 slices using the bitmask strategy described in Section 2 as the previous study. In this case, we must carefully monitor the following via numerical examples:
• the increase in the splitting cost because the cost for the bitmask is low;
• the reduction in the number of matrix multiplications; and
• the reduction in the term for the accumulation.
Note that in the worst case, the results of the splitting with bitmask and the nearest strategy are the same. It can be explained using the following example:
For the bit mask strategy, we have
For the rounding to the nearest strategy, we obtain
The following is an algorithm for the splitting with the round to nearest strategy.
Algorithm 5 Proposed method for mixed-precision splitting for Ozaki scheme between FP64 and INT8 using floatingpoint arithmetic in round-to-nearest-even mode with Minamihata’s technique from Minamihata et al. (2016)
Input:, Output:, , s = 1, …, k
1: β ← min(7, ⌊(31 − log2n)/2⌋)
2: fors = 1, …, kdo
3: for i = 1, …, m
4: for i = 1, …, m
5: for i = 1, …, m {Extract in round-to-nearest-even mode}
6: {Convert to INT8}
7:
8: endfor
3.2. Group-wise error-free accumulation
Next, we propose a method for accelerating the accumulation in FP64 for ozIMMU. Algorithm 4 requires the computation of a sum of k(k + 1)/2 FP64 matrices at the 6th line. The accumulation accounts for a large ratio of the total computation time of ozIMMU as shown in Figures 2 and 3. For this challenge, we propose a method for accelerating ozIMMU by reducing the number of additions in FP64.
Recall that Algorithm 4 performs
The inner sum of (10) can be expressed as follows:
If no overflow occurs in (1 ≤ s ≤ g − 2) in INT32, the summation can be performed on the accumulator of GEMM on the INT8 Tensor Core. Therefore, applying the above transformation reduces the numbers of slow conversions from INT32 to FP64, scalings, and slow summations in FP64. Let be
Then, the summation
can be computed without error using GEMM on the INT8 Tensor Core. The summation of r instances of for s = 1, 2, …, r can be computed without error; however, the summation of all instances of for s = 1, 2, …, g − 1 cannot always be computed without error. The proof validating error-free summation is provided in Section 5. Finally, we present Algorithm 6, which has a reduced number of summands in FP64 accumulation.
Algorithm 6 Proposed method for groupwise error-free accumulation for Ozaki scheme using INT8 Tensor Core
Input:, , , , s = 1, …, k Output:
1: β ← min(7, ⌊(31 − log2n)/2⌋)
2: {#addends for error-free accum.}
3: C ← Om,p
4: forg = 2, …, k + 1 do
5: q ← 0
6: C″ ← Om,p {}
7: fors = 1, …, g − 1 do
8: q ← q + 1
9: {Compute using GEMM on INT8 Tensor Core}
10: ifq = r or s = g − 1 then
11: C ← C + 2−βg+2diag(μ″)FP64(C″)diag(ν″) {Compute in FP64}
12: q ← 0
13: C″ ← O
14: endif
15: endfor
16: endfor
Assuming r ≥ k for simplification, all for s = 1, 2, …, g − 1 can be accumulated without overflow for g = 3, …, k + 1. Algorithm 7 shows the Ozaki scheme with groupwise error-free accumulation for r ≥ k.
Algorithm 7 Simple version of proposed method for groupwise error-free accumulation for Ozaki scheme using INT8 Tensor Core for r ≥ k
Input:, , , , s = 1, …, k Output:
1: β ← min(7, ⌊(31 − log2n)/2⌋) = 7
2: C ← Om,p
3: forg = 2, …, k + 1 do
4: C″ ← Om,p {}
5: fors = 1, …, g − 1 do
6: {Compute using GEMM on INT8 Tensor Core}
7: endfor
8: C ← C + diag(μ″)2−βg+2FP64(C″)diag(ν″) {Compute in FP64}
9: endfor
3.3. Combination of proposals
Next, we accelerate ozIMMU by reducing the number of summands in FP64 accumulation and improving the splitting method. For this purpose, we combine the methods proposed in Sections 3.1 and 3.2. In order to use group-wise error-free accumulation as in Algorithm 6, A and B need to be expressed as in (5) and (6). Thus, we determine
as the 3rd and 4th lines in Algorithm 5. Then, As are extracted using rounding to nearest floating-point arithmetic as
for the constant 2β(s−1)σi with a common ratio of 2β. Finally, we obtain Algorithm 8. The shift values for As are ; thus, are determined before the “for” statement and the shift values for As for s ≥ 1 are calculated by shifting by a constant ratio 2β. Hence, the algorithm finds the maximum absolute values maxj|aij| for i = 1, …, m only once before the “for” statement. On the other hand, the shift values are determined inside the “for” statement in Algorithm 5. Therefore, the algorithm finds the maximum absolute values maxj|aij| for i = 1, …, m at most k times.
Algorithm 8 Another proposed method for mixed-precision splitting for Ozaki scheme between FP64 and INT8 using floating-point arithmetic in round-to-nearest-even mode with Minamihata’s technique from Minamihata et al. (2016). The results can be expressed as in (5) for error-free group-wise accumulation.
Input:, Output:, , s = 1, …, k
1: β ← min(7, ⌊(31 − log2n)/2⌋)
2: for i = 1, …, m
3: fors = 1, …, kdo
4: for j = 1, …, m
5: {Extract in round-to-nearest-even mode}
6: {Convert to INT8}
7:
8: endfor
4. Numerical examples
We have implemented the proposed methods in the GitHub repository by Uchino (2024), replacing specific code in Ootomo’s ozIMMU library with our code. All numerical experiments were conducted on NVIDIA GH200 Grace Hopper Superchip and NVIDIA GeForce RTX 4090 with the GNU C++ Compiler 11.4.1 and NVIDIA CUDA Toolkit 12.5.82. The tested methods will be denoted as follows:
• ozIMMU-k: Ootomo’s implementation with k slices
• ozIMMU_RN-k: Proposed method in Section 3.1 with k slices
• ozIMMU_EF-k: Proposed method in Section 3.2 with k slices
• ozIMMU_H-k: Proposed method in Section 3.3 with k slices.
4.1. Accuracy
Figure 5 shows the accuracies of ozIMMU-k, ozIMMU_RN-k, ozIMMU_EF-k, and ozIMMU_H-k for k = 7, …, 11. We set as aij≔(Uij − 0.5) ⋅ exp(ϕ ⋅ Nij), where Uij ∈ (0, 1) are uniformly distributed random numbers and Nij are drawn from the standard normal distribution, for 1 ≤ i, j ≤ n. The constant ϕ specifies the tendency of the difficulty in terms of matrix multiplication accuracy. A matrix is set similarly to A.
Comparison of accuracy between ozIMMU and proposed methods. Matrix A has entries aij≔(Uij − 0.5) ⋅ exp(ϕ ⋅ Nij), where Uij ∈ (0, 1) are uniformly distributed random numbers and Nij are drawn from the standard normal distribution, for 1 ≤ i, j ≤ m and m = n = p. Matrix B has a similar composition.
The accuracy deteriorated for n > 217 because the maximum number of significant bits β = min(7, ⌊(31 − log2n)/2⌋) of the elements of the split matrices is less than 7. The accuracies of ozIMMU and ozIMMU_EF are comparable, as are those of, ozIMMU_RN and ozIMMU_H. ozIMMU_RN and ozIMMU_H, which use a splitting method via rounding to nearest floating-point arithmetic, are more accurate than ozIMMU and ozIMMU_EF, which use a splitting method via bit masking. Occasionally, to obtain results comparable with that of FP64, ozIMMU_RN-k, ozIMMU_H-k, ozIMMU-(k + 1), and ozIMMU_EF-(k + 1) are required; i.e., ozIMMU_RN and ozIMMU_H require fewer splits than ozIMMU and ozIMMU_EF. In particular, for ϕ = 2, ozIMMU_RN-9 and ozIMMU_H-9 produce comparable results to FP64; however, the accuracies of the results of ozIMMU-9 and ozIMMU_EF-9 are worse than that of FP64. In such cases, k = 10 is required for ozIMMU and ozIMMU_EF to attain more accurate results than FP64.
4.2. Time breakdown
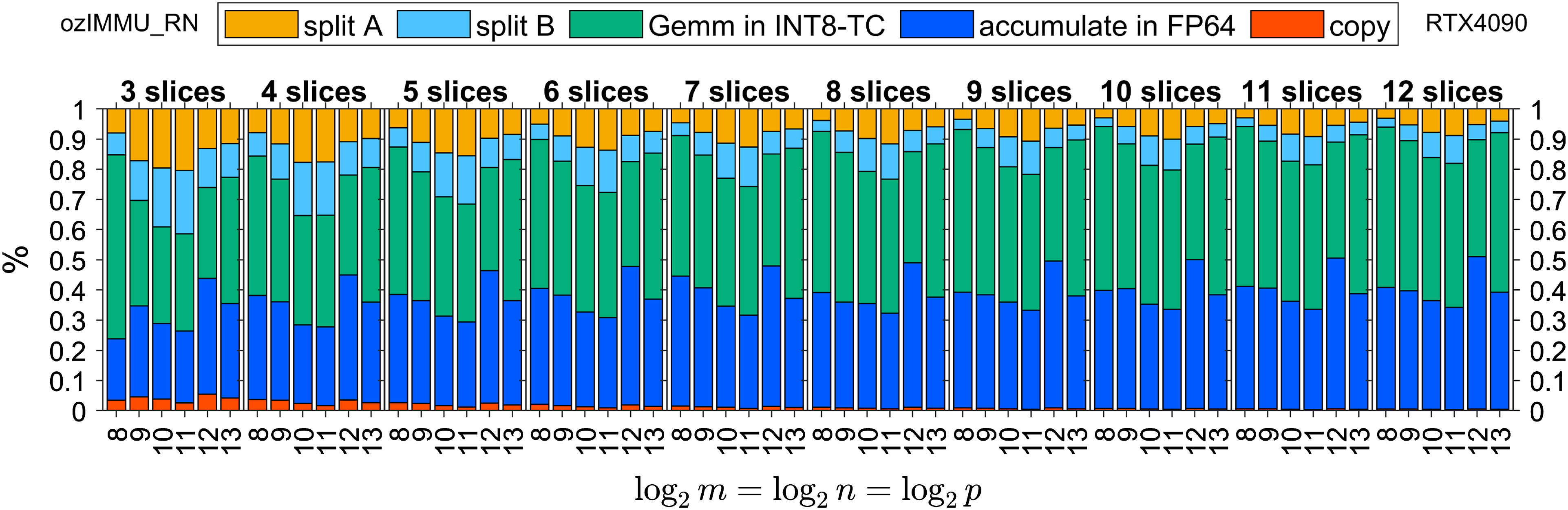
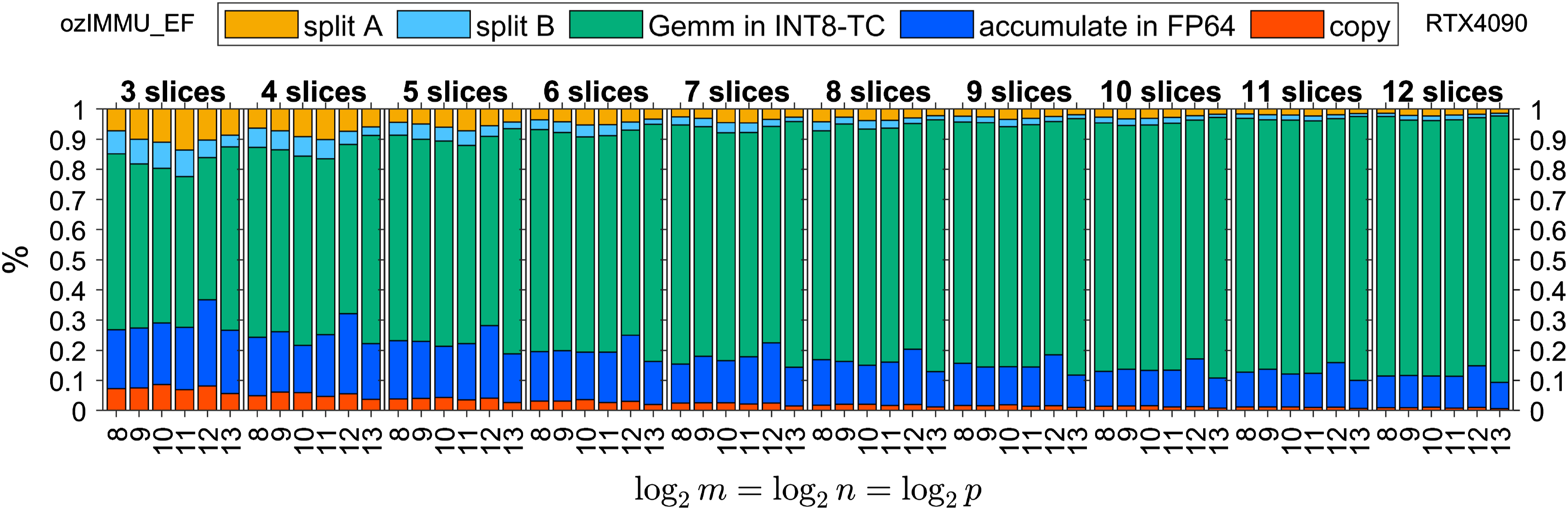
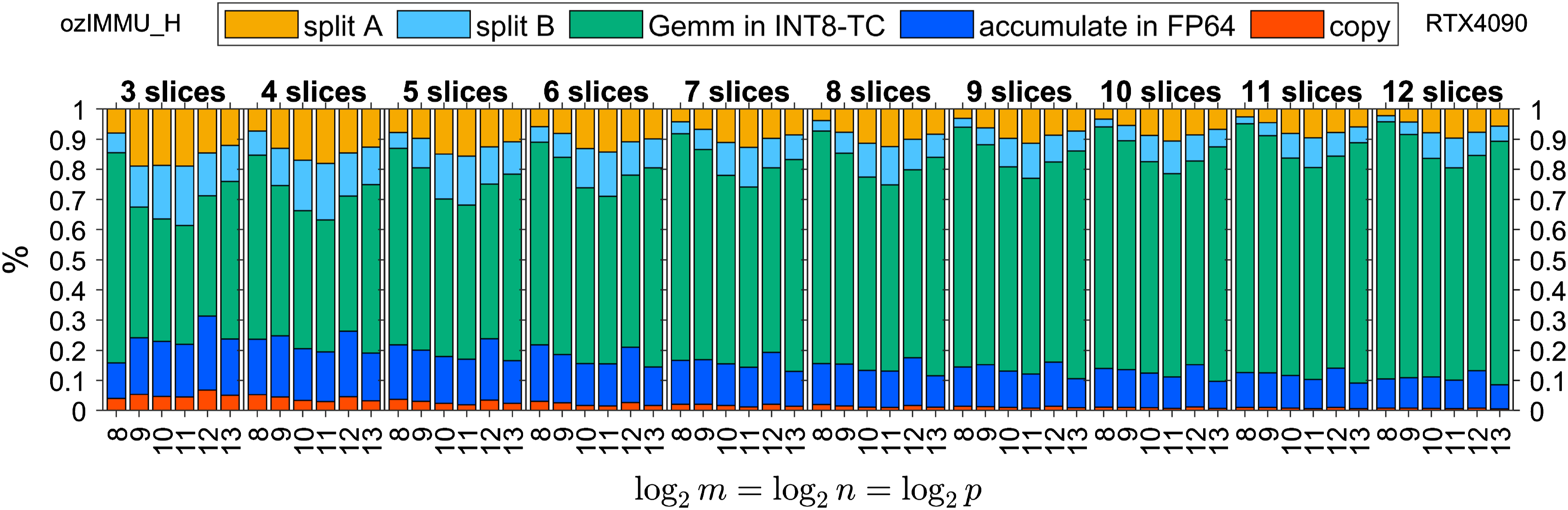
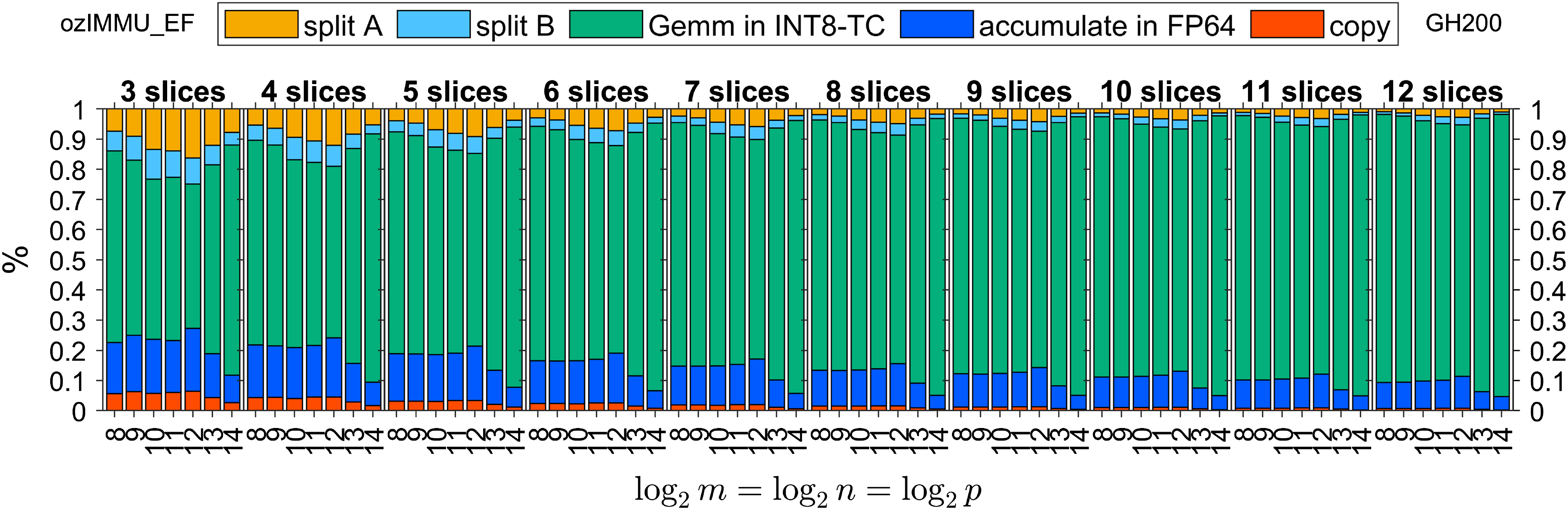
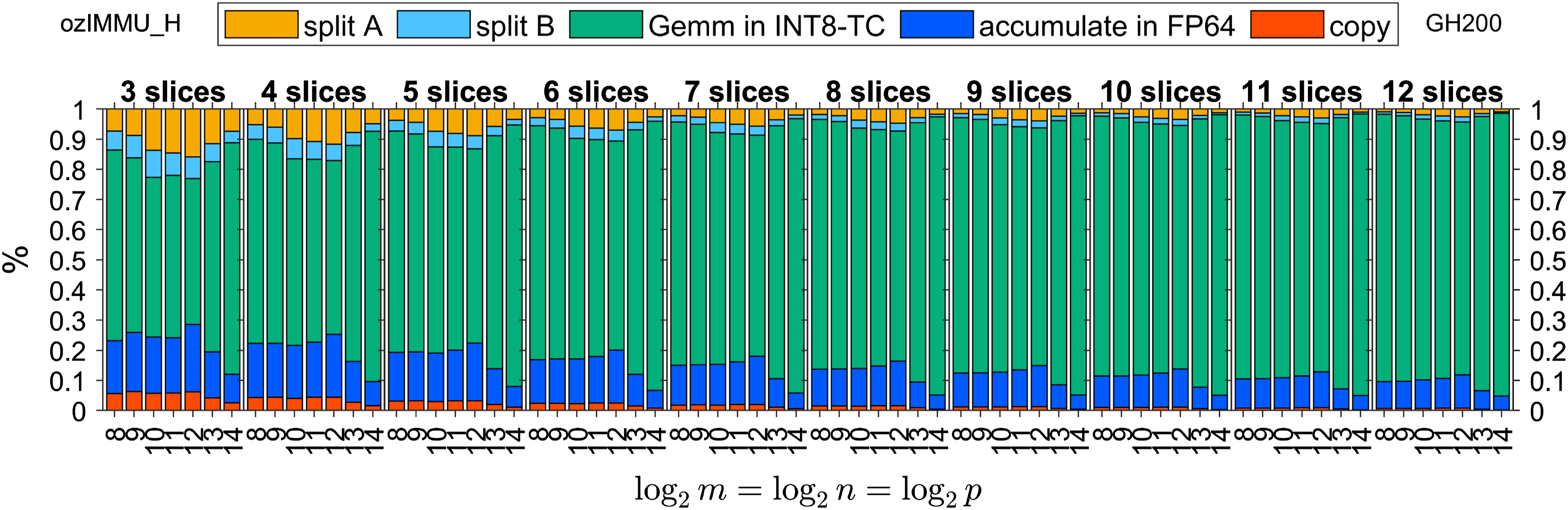
Figures 6–8 and Figures 9–11 show time breakdowns of the proposed methods on RTX 4090 and GH200, respectively. Note that “split A”, “split B”, “Gemm in INT8-TC”, “accumulation in FP64”, and “copy” correspond to the steps (i), (ii), (iii), (iv), and (v) in the Ozaki scheme for emulating the GEMM routine as shown in Section 1.
Time breakdown of ozIMMU_RN on NVIDIA GeForce RTX 4090.
Time breakdown of ozIMMU_EF on NVIDIA GeForce RTX 4090.
Time breakdown of ozIMMU_H on NVIDIA GeForce RTX 4090.
Time breakdown of ozIMMU_RN on NVIDIA GH200 Grace Hopper Superchip.
Time breakdown of ozIMMU_EF on NVIDIA GH200 Grace Hopper Superchip.
Time breakdown of ozIMMU_H on NVIDIA GH200 Grace Hopper Superchip.
The execution time of FP64 accumulation in ozIMMU_RN is not negligible, because the number of additions in FP64 is not reduced. The execution times of FP64 accumulation in ozIMMU_EF and ozIMMU_H are less than those in ozIMMU and ozIMMU_RN. From Figures 6–8, the computation time of splitting via rounding to nearest floating-point arithmetic is not so fast because FP64 is much slower than the lower-precision arithmetic on RTX 4090. From Figures 10 and 11, the ratios of the computation time of splitting in ozIMMU_EF and ozIMMU_H are comparable on GH200.
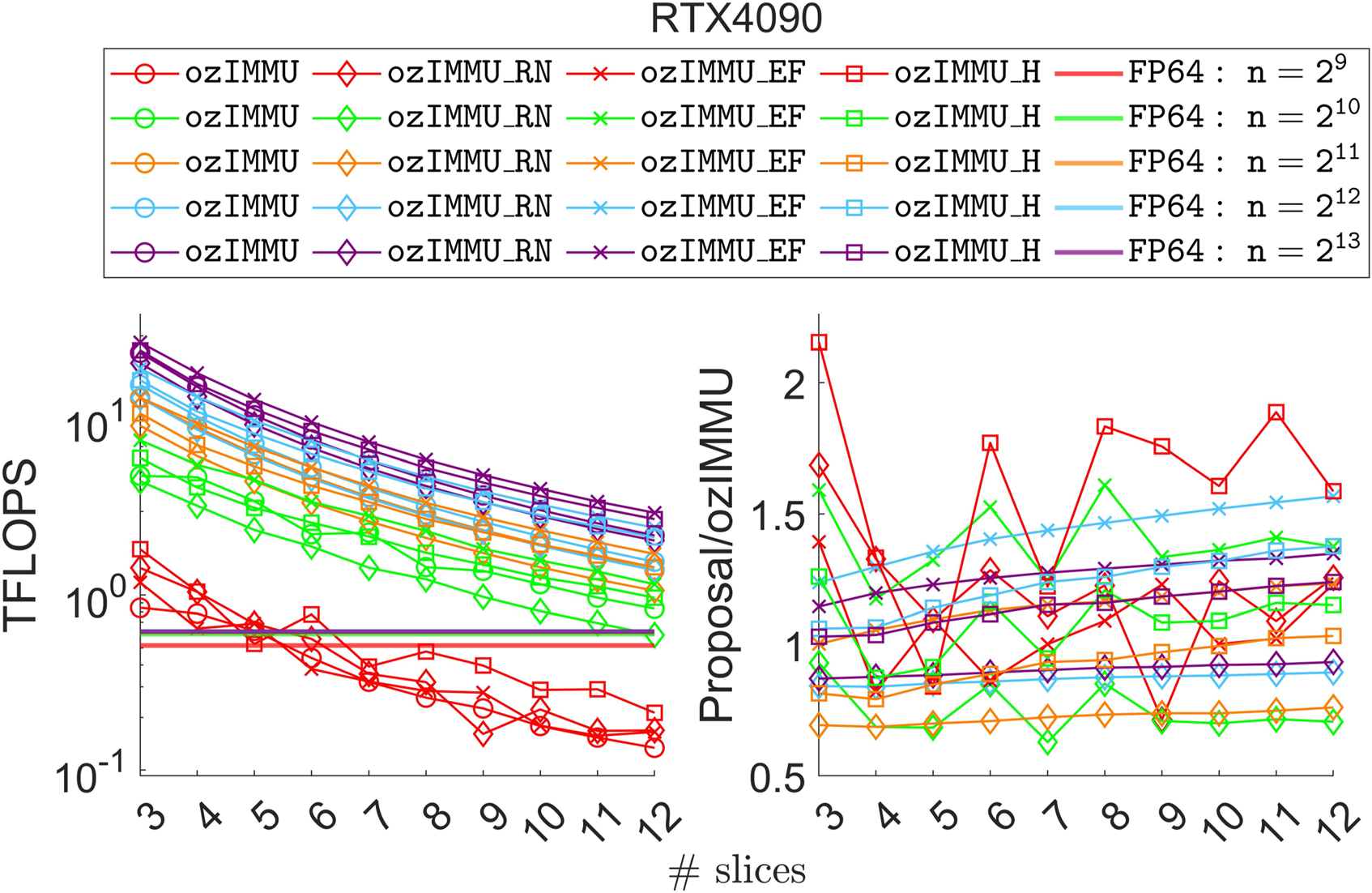
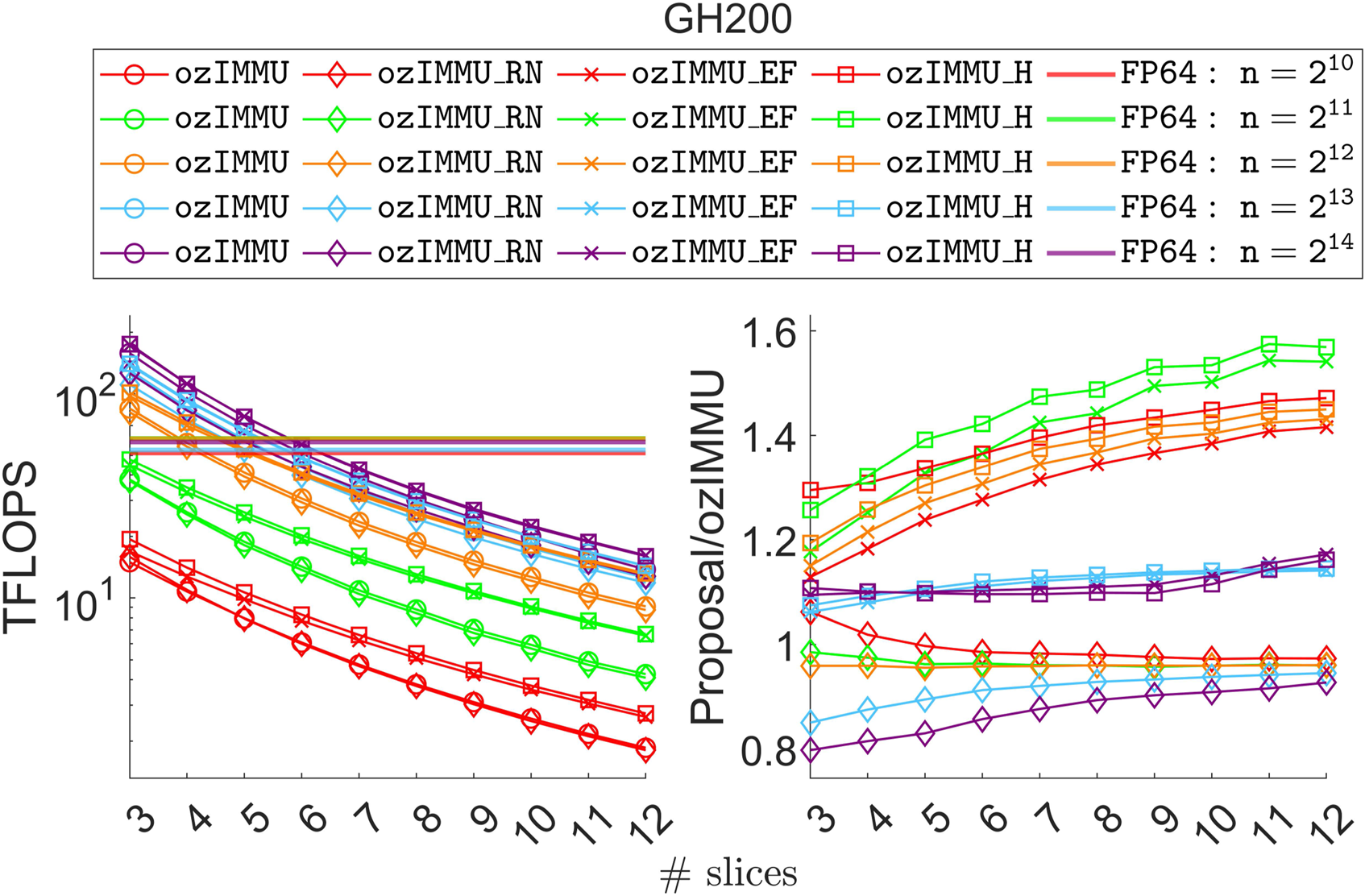
4.3. Performance
Figures 12 and 13 show throughput in TFLOPS and ratio to ozIMMU. A smaller number of slices corresponds to better performance because the total computation cost is less.
Throughput comparison (left) and speedups to ozIMMU (right) on NVIDIA GeForce RTX 4090.
Throughput comparison (left) and speedups to ozIMMU (right) on NVIDIA GH200 Grace Hopper Superchip.
On RTX 4090, all methods are faster than or comparable to matrix multiplication in FP64 for n ≥ 1024 because FP64 is much slower than the lower-precision arithmetic. ozIMMU_EF and ozIMMU_H are faster than ozIMMU almost everywhere. In particular, ozIMMU_EF-12 and ozIMMU_H-12 are respectively 1.6 and 1.4 times faster than ozIMMU for n = 4096. ozIMMU_RN is slower than ozIMMU. For k = 3, ozIMMU, ozIMMU_RN, ozIMMU_EF, and ozIMMU_H are 38.8, 33.8, 44.4, and 40.0 times faster than matrix multiplication in FP64 for n = 16384, respectively. For k = 12, ozIMMU, ozIMMU_RN, ozIMMU_EF, and ozIMMU_H are 1.4, 1.0, 1.9, and 1.6 times faster than matrix multiplication in FP64 for n = 1024, respectively. In addition, ozIMMU, ozIMMU_RN, ozIMMU_EF, and ozIMMU_H are 9.4, 8.5, 12.0, and 10.9 times faster than FP64 for k = 7 and n = 16384, and 7.4, 6.8, 9.5, and 8.6 times faster than FP64 for k = 8 and n = 16384.
On GH200, the methods with small k are faster than matrix multiplication in FP64 for n ≥ 4096; however, the methods are much slower than FP64 otherwise. ozIMMU_EF and ozIMMU_H are faster than ozIMMU. In particular, ozIMMU_EF-11 and ozIMMU_H-11 are respectively 1.5 and 1.6 times faster than ozIMMU for n = 2048. ozIMMU_RN is not as slow on GH200 as it is on RTX 4090. For k = 3, ozIMMU, ozIMMU_RN, ozIMMU_EF, and ozIMMU_H are 2.7, 2.2, 3.0, and 3.0 times faster than matrix multiplication in FP64 for n = 16384, respectively. ozIMMU-5, ozIMMU_RN-5, ozIMMU_EF-6, and ozIMMU_H-6 have comparable computation times to matrix multiplication in FP64 for n = 16384; however, ozIMMU-k, ozIMMU_RN-k, ozIMMU_EF-(k + 1), and ozIMMU_H-(k + 1) are slower than FP64 for n < 16384 or k > 5.
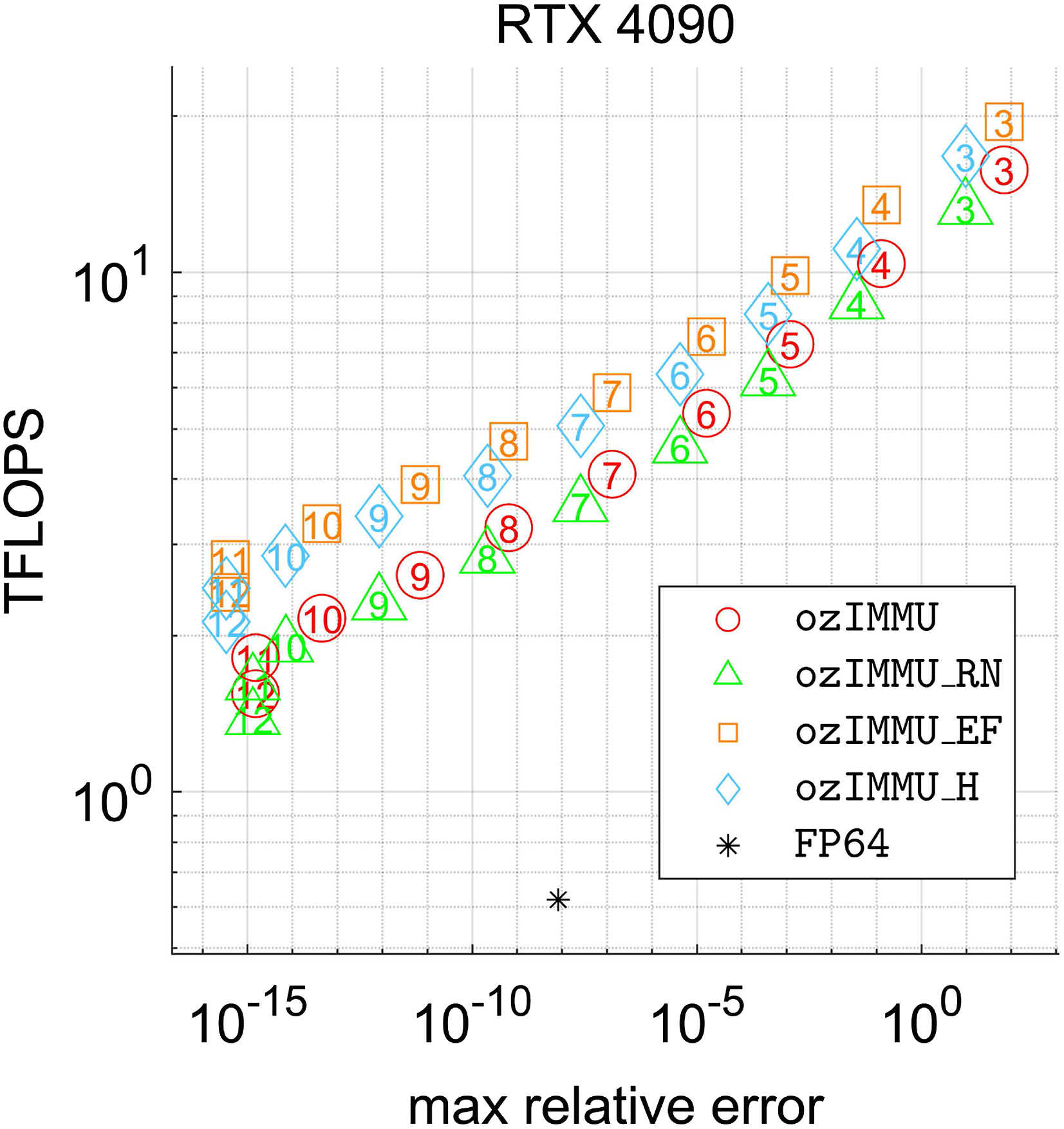
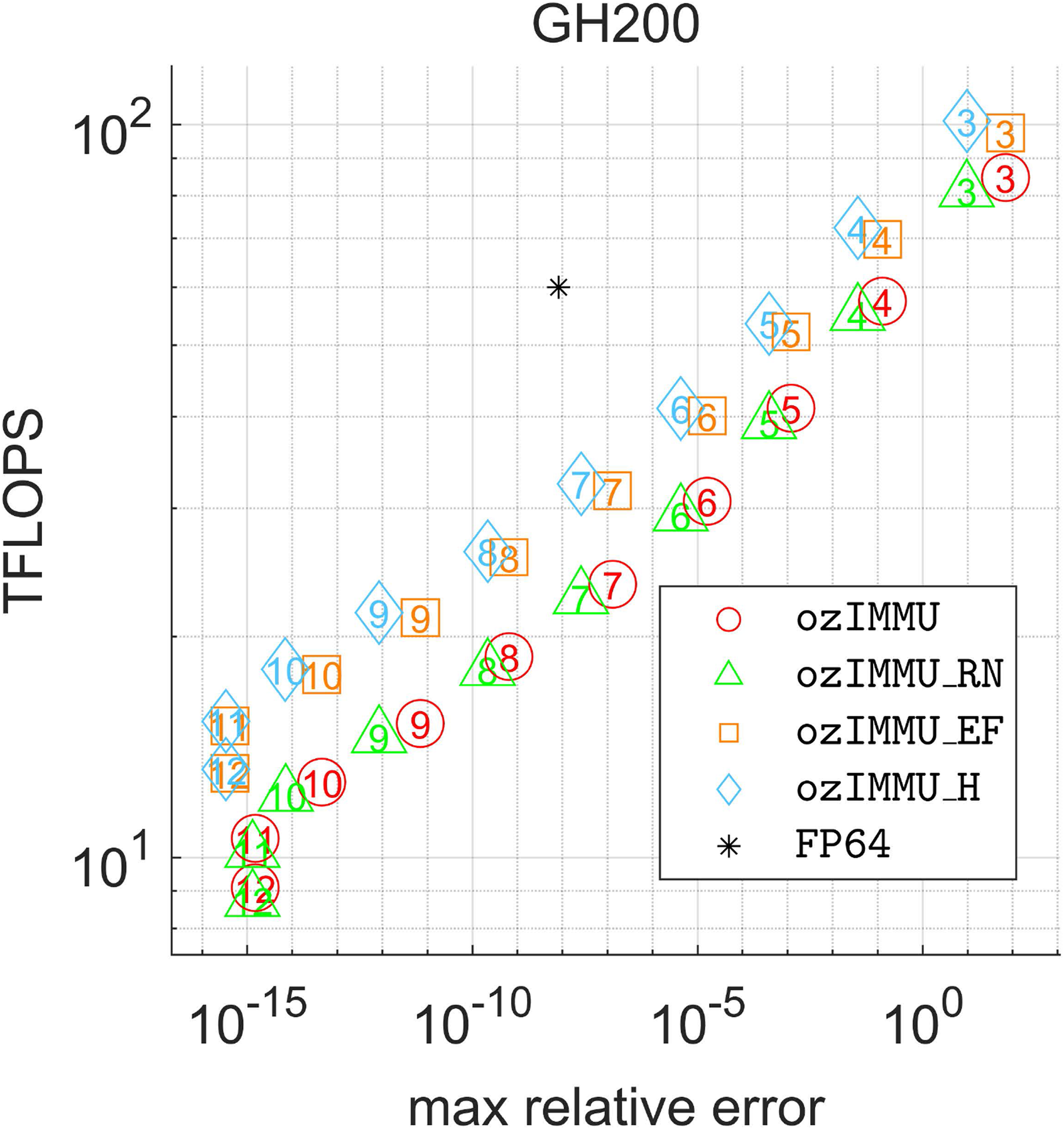
4.4. Performance vs. Accuracy
Figures 14 and 15 show throughput in a TFLOPS vs. Accuracy plot, illustrating relationships between performance and accuracy for the Ozaki scheme and for matrix multiplication in FP64 for n = 4096 and ϕ = 0. The numbers inside the symbols are the numbers of splices for the Ozaki scheme.
Relationship between performance and accuracy for n = 4096 and ϕ = 0 on NVIDIA GeForce RTX 4090.
Relationship between performance and accuracy for n = 4096 and ϕ = 0 on NVIDIA GH200 Grace Hopper Superchip.
On RTX 4090, all methods are better than matrix multiplication in FP64 with respect to both performance and accuracy for k ≥ 8. ozIMMU_H and ozIMMU_EF produce results with comparable performances that are more accurate than those of ozIMMU. In particular, ozIMMU_H-8 and ozIMMU_EF-9 produce results with comparable performances that are more accurate than those of ozIMMU-7. On GH200 as well, ozIMMU_H and ozIMMU_EF produce results with comparable performances that are more accurate than those of ozIMMU. In particular, ozIMMU_H-7 and ozIMMU_EF-7 produce results with comparable performances that are more accurate than those of ozIMMU-6. These results also indicate that ozIMMU_H and ozIMMU_EF can be computed with less memory consumption than ozIMMU.
5. Rounding error analysis
In this section, we give a rounding analysis for a fixed number of slices. We have described Algorithms 3 and 4 (ozIMMU), and proposed Algorithms 5 and 6, Algorithms 3 and 6, and Algorithms 8 and 6. Even if we used the rounding to nearest strategy as in Algorithms 5 and 8, their error bounds would be the same as that of the bitmask strategy used in Algorithm 5. Therefore, we focus on Algorithms 3 and 4 (ozIMMU) and Algorithms 3 and 6. Below, absolute value notation applied to a matrix means the matrix from applying absolute value element-wise. We assume that neither overflow nor underflow occurs. For and , the following deterministic error bound is given by Jeannerod and Rump (2013):
The following alternative probabilistic error bound comes from Higham and Mary (2019) (which has the details on the assumptions and probabilities):
In this section, our aim is to derive an error bound on the computed result. Let be a computed result using k slices, such as
Note that for i = 1, 2, …, k,
for Algorithms 1, 2, and 5, and
for Algorithms 3, 4, 6, 7, and 8. Let Tk be an approximation of AB with k slices. Our aim is to obtain the upper bound on |AB − T| as follows:
Note that we can obtain the exact product AiBj in the above by using GEMM in the INT8 Tensor Core and scaling by powers of two. The first term of the bound in (13) indicates the truncation error, and the second term shows an error arising in the accumulation process. As matrix scaling does not affect rounding errors, a discussion on it is omitted.
In the following subsections, we use an upper bound provided by Jeannerod and Rump (2013) for a sum:
Let for be defined as
The following condition is used to check whether a real number is a floating-point number. For , if |c| is smaller than the maximum floating-point number and c is an integral multiple of the minimum positive floating-point number, then it holds that
5.1. Error bound for Algorithms 3 and 4 (ozIMMU)
Let matrices and be defined as in (1) where these show the truncation errors of A and B for the case of k slices, respectively. Notation e indicates the vector . Define two vectors and related to row-wise maximums in A and column-wise maximums in B in the sense of the unit in the first place as
for β ≥ 1. This is why constant r was set as in (12).
If we define the number of the terms, w, for the accumulation as
we have
If (19) is satisfied, then we have
6. Conclusion
We proposed three implementation methods for accelerating the Ozaki scheme using the INT8 Tensor Core. In the original implementation, ozIMMU, provided by Ootomo et al., the ratio of the accumulation in FP64 is not negligible, as it accounts for approximately 40–50 % of the total computation time. The proposed methods ozIMMU_EF and ozIMMU_H reduce the computation time ratio of the accumulation to approximately 10–20 % and achieve a 1.2- to 1.6-fold speedup. With future architectures expected to achieve high speed in lower-precision matrix multiplication, the computation time ratio of the accumulation in FP64 is expected to increase. Thus, these proposed methods contribute to leveraging the performance of future architectures more effectively than ozIMMU. The proposed methods ozIMMU_RN and ozIMMU_H offer alternative splitting methods using floating-point arithmetic in round-to-nearest-even mode and produce more accurate results than ozIMMU for the same number of slices.
Footnotes
Acknowledgements
We appreciate the reviewers and Dr Massimiliano Fasi from the University of Leeds for the kind comments on our paper. We thank Dr Hiroyuki Ootomo from NVIDIA for his helpful comments on the implementation of ozIMMU.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was partially supported by JSPS Grant-in-Aid for JSPS Fellows No. 22KJ2741, JSPS Grant-in-Aid for Research Activity Start-up No. 24K23874, and JSPS KAKENHI Grant No. 23K28100.
ORCID iD
Yuki Uchino
Author biographies
Yuki Uchino is a postdoctoral researcher at RIKEN R-CCS. He received his PhD in engineering from Shibaura Institute of Technology in 2024. His research interests include reliable computing, numerical linear algebra, and highly accurate algorithms. He won the student poster presentation award at the 38th JSST Annual International Conference on Simulation Technology (JSST 2019) and the student presentation awards at JSST 2021 and International Workshop on Reliable Computing and Computer-Assisted Proofs (ReCAP 2022).
Katsuhisa Ozaki is a full professor in the Department of Mathematical Sciences at Shibaura Institute of Technology. He received his PhD in engineering from Waseda University in 2007. He was an Assistant Professor (2007-2008) and a Visiting Lecturer (2008-2009) at Waseda University. At Shibaura Institute of Technology, he has served as an Assistant Professor (2010-2013) and an Associate Professor (2013-2019), and has currently been a Professor since 2019. His research interests include reliable computing, particularly addressing rounding error problems in finite-precision arithmetic. He mainly focuses on numerical linear algebra and develops fast and accurate algorithms.
Toshiyuki Imamura is a team leader of Large-scale Parallel Numerical Computing Technology Team at RIKEN R-CCS, and is responsible for developing numerical libraries on Fugaku. He received his Diploma and Doctorate in Applied Systems and Sciences from Kyoto University in 1993 and 2000. He was a Researcher at CCSE, JAERI (1996-2003), a visiting scientist at HLRS (2002), and an associate professor at the University of Electro-Communications (2003-2012). His research interests include HPC, auto-tuning technology, and parallel eigenvalue computation. His research group won the HPL-MpX ranking (2020-2021) and was nominated as the Gordon Bell Prize finalist in SC05, SC06, and SC20.
References
1.
HighamNJMaryT (2019) A new approach to probabilistic rounding error analysis. SIAM Journal on Scientific Computing41(5): A2815–A2835.
2.
IEEE Computer Society (2019) IEEE standard for floating-point arithmetic. IEEE Std 754-2019 (Revision of IEEE 754-2008). NJ, USA: IEEE.
3.
JeannerodCPRumpSM (2013) Improved error bounds for inner products in floating-point arithmetic. SIAM Journal on Matrix Analysis and Applications34(2): 338–344.
4.
MinamihataAOzakiKOgitaT, et al. (2016) Improved extraction scheme for accurate floating-point summation. In: The 35th JSST Annual Conference International Conference on Simulation Technology,Kyoto, Japan.
5.
MukunokiDOzakiKOgitaT, et al. (2020) Dgemm using tensor cores, and its accurate and reproducible versions. In: SadayappanPChamberlainBLJuckelandG, et al. (eds) High Performance Computing. Cham: Springer International Publishing, 230–248.
OotomoHOzakiKYokotaR (2024) Dgemm on integer matrix multiplication unit. The International Journal of High Performance Computing Applications, in Press. DOI: 10.1177/10943420241239588.
9.
OzakiKOgitaTOishiS, et al. (2012) Error-free transformations of matrix multiplication by using fast routines of matrix multiplication and its applications. Numerical Algorithms59(1): 95–118.
10.
OzakiKOgitaTOishiS, et al. (2013) Generalization of error-free transformation for matrix multiplication and its application. Nonlinear Theory and Its Applications, IEICE4(1): 2–11.