
Abstract
Krylov methods provide a fast and highly parallel numerical tool for the iterative solution of many large-scale sparse linear systems. To a large extent, the performance of practical realizations of these methods is constrained by the communication bandwidth in current computer architectures, motivating the investigation of sophisticated techniques to avoid, reduce, and/or hide the message-passing costs (in distributed platforms) and the memory accesses (in all architectures). This article leverages Ginkgo’s memory accessor in order to integrate a communication-reduction strategy into the (Krylov) GMRES solver that decouples the storage format (i.e., the data representation in memory) of the orthogonal basis from the arithmetic precision that is employed during the operations with that basis. Given that the execution time of the GMRES solver is largely determined by the memory accesses, the cost of the datatype transforms can be mostly hidden, resulting in the acceleration of the iterative step via a decrease in the volume of bits being retrieved from memory. Together with the special properties of the orthonormal basis (whose elements are all bounded by 1), this paves the road toward the aggressive customization of the storage format, which includes some floating-point as well as fixed-point formats with mild impact on the convergence of the iterative process. We develop a high-performance implementation of the “compressed basis GMRES” solver in the Ginkgo sparse linear algebra library using a large set of test problems from the SuiteSparse Matrix Collection. We demonstrate robustness and performance advantages on a modern NVIDIA V100 graphics processing unit (GPU) of up to 50% over the standard GMRES solver that stores all data in IEEE double-precision.
Keywords
Introduction
Krylov solvers enhanced with some type of sophisticated preconditioning technique nowadays compound a sound approach for the iterative solution of large and sparse linear systems (Saad, 2003). In particular, preconditioned Krylov solvers are often preferred over their direct counterparts for the solution of discretized high-dimensional problems (e.g., 3D problems), where a factorization-based direct solver would incur significant fill-in; see, for example, Davies (2006) and Saad (2003). Krylov solvers are also widely appealing for massively parallel architectures (such as graphics processing units or GPUs) due to their superior scalability.
At a high level, Krylov methods construct a basis that spans a Krylov subspace. At each iteration, this basis is expanded by adding another Krylov basis via the multiplication of the sparse coefficient matrix with the Krylov basis vector generated in the previous iteration and a sequence of vector operations and vector scalings to obtain an orthonormal set of Krylov basis vectors (Saad, 2003). Thus, each iteration of a Krylov solver comprises the multiplication of the sparse coefficient matrix with a vector ( • The design of specialized (i.e., application-specific) sparse matrix data layouts that reduce the indexing information (overhead) and/or improve data locality when accessing the contents of the sparse coefficient matrix (Saad, 2003). • The reorganization of the operations inside the body of the Krylov solver trading off reduced communication for an increase of computation per iteration, possibly also at the cost of introducing numerical instabilities that may result in slower convergence of the iteration; see, for example, Hoemmen (2010) and Cools (2019) and the references therein. • The reformulation of the solver as an iterative refinement scheme combined with the use of mixed-precision for the storage of and arithmetic operations with the sparse coefficient matrix (Higham, 2002). • The utilization of adaptive-precision schemes for memory-bound preconditioners (Anzt et al., 2019a).
In this article, we also address the communication costs of Krylov methods, focusing on the generalized minimal residual (GMRES) algorithm, a Krylov solver for general linear systems that explicitly maintains the complete set of Krylov basis vectors instead of relying on short recurrences (as many other Krylov solvers do) (Saad, 2003). Orthogonally to all previous communication optimization efforts, our optimized variant of the GMRES algorithm reduces communication in the access to the Krylov basis during the iteration loop body. In more detail, our GMRES algorithm leverages Ginkgo’s memory accessor, introduced in Anzt et al. (2021) and Grützmacher et al. (2021), to decouple the memory storage format from the arithmetic precision so as to maintain the Krylov basis vectors in a compact “reduced precision” format. This radically diminishes the memory access volume during the orthogonalization, while not affecting the convergence rate of the solver, yielding notable performance improvements. Concretely, we make the following contributions in our article: • We follow the ideas in Anzt et al. (2021) and Grützmacher et al. (2021) and use the therein presented “memory accessor” in order to decouple the memory storage format from the arithmetic precision, specifically applying this strategy to maintain the Krylov basis in reduced precision in memory while performing all arithmetic operations using full, hardware-supported • We analyze the benefits that result from casting the Krylov basis into different compact storage formats, including the natural • We integrate the mixed-precision GMRES algorithm into the Ginkgo sparse linear algebra library (https://ginkgo-project.github.io). • We provide strong practical evidence of the advantage of our approach by developing a high-performance realization of the solver for modern NVIDIA’s V100 GPUs and testing it on a considerable number of large-scale problems from the SuiteSparse Matrix Collection (Davis and Hu, 2011) (https://sparse.tamu.edu/).
The rest of the article is organized as follows. First, we review a list of related works in the direction of mixed-precision Krylov solvers, and then, we briefly recall the GMRES algorithm before motivating the compressed basis GMRES (CB-GMRES) storing the orthonormal basis in reduced precision. Next, we provide details about how we decouple the memory precision from the arithmetic precision and how we realize the implementation of CB-GMRES in Ginkgo. The experimental evaluation of the CB-GMRES implementation follows, assessing the accuracy, convergence, performance, and flexibility of the developed algorithm. We conclude with a summary of the findings and ideas for future research.
Related work
The potential of using lower precision in different components of a Krylov solver has been previously investigated for both Lanczos-based (short-term recurrence) and Arnoldi-based (long-term recurrence) algorithms and the associated methods for linear systems of equations.
From the theoretical point of view, most of those works are based on rounding error analysis for Krylov solvers running in finite precision. In a relevant result, Paige (1980) derived distinct relations between the loss of orthogonality and other important quantities in finite precision Lanczos. Greenbaum (1989) extended these results to analyze backward stability for the CG method in finite precision. She also derived theoretical bounds for the maximum attainable accuracy in finite precision for CG, BiCG, BiCGSTAB, and other Lanczos-based methods (Greenbaum, 1997). Carson (2015) expanded these results to s-step Lanczos/CG variants, deducing that an s-step Lanczos in finite precision behaves like a classical Lanczos run in lower “effective” precision, where this “effective” precision depends on the conditioning of the polynomials used to generate the s-step bases. Additional bounds for Lanczos-based Krylov solvers running in finite precision can be found in Meurant and Strakoš (2006).
Simoncini and Szyld (2003) and van Den Eshof and Sleijpen (2004) established a theory on “inexact Krylov subspace methods” that applies the basis-generating
Concerning long-recurrence strategies, Gratton et al. (2020) combined the previous findings from Björck (1967), Paige (1980), and Paige et al. (2006) to derive theoretical norms for a mixed-precision GMRES algorithm based on modified Gram–Schmidt. In this algorithm, they consider using inexact (e.g., single-precision) inner products in the orthogonalization process, which results in a loss of double-precision (DP) orthogonality of the Krylov basis vectors. This makes the work by Gratton et al. (2020) very similar to our approach. However, our solution is different in several aspects: • In our CB-GMRES solver, we decouple the arithmetic precision from the memory storage format to maintain the basis vectors in lower precision while using high precision in all arithmetic; • we consider not only • we realize a production-ready and sustainable implementation of CB-GMRES for high-performance GPU architectures based on classical Gram–Schmidt with re-orthogonalization; and • we provide comprehensive experimental results analyzing accuracy, convergence, and performance of our CB-GMRES solver.
The GMRES algorithm
Consider the linear system
Algorithmic formulation of the restarted GMRES algorithm for the solution of sparse linear systems.

From the computational point of view, the main kernels appearing in the GMRES algorithm correspond to the application of the preconditioner M and the
The LLS problem in the GMRES algorithm can be solved via the QR factorization (Golub and Loan, 1996), where this decomposition can be cheaply obtained using an updating technique as the Hessenberg matrices for two consecutive iterations that differ only in one column. Therefore, the cost associated with the solution of this problem is minor in comparison with that of the global algorithm. In addition, the operations that are necessary to update the new estimate to the solution x m (Line 17) also contribute a minor cost to the overall procedure, as they are m times less frequent in comparison with the kernel calls in Lines 3, 5, and 8.
CB-GMRES storing the orthonormal basis in reduced precision
For simplicity, consider that the GMRES algorithm integrates a simple preconditioner, such as a Jacobi scheme (or a block-Jacobi variant with a small block size) (Saad, 2003). The performance of the algorithm is then strongly determined by the costs of the
In order to analyze the theoretical memop count of the 1. The right-hand side vectors for both types of matrix–vector products reside in cache. In general, this is not true but, for the following theoretical derivation, the memory layer where the vectors reside is not important. 2. The sparse coefficient matrix is stored using the compressed sparse row (CSR) format. This is a general and flexible data layout that employs one integer per nonzero value to represent its column index, plus n + 1 integers for the row pointers (Saad, 2003). 3. The re-orthogonalization mechanism included in the GMRES algorithm (Lines 7–11 in Figure 1) is not needed.
Then, the ratio between the contributions of the two
For a non-restarted version of GMRES, the size of the Krylov subspace m′ steadily grows with the iteration count (m′ = j − 1 at iteration j), which hints that the memory operations related to the orthogonalization can quickly dominate the cost. In practical implementations though, the GMRES solver is usually enhanced with a restart mechanism, as in the formulation of the algorithm in the previous section, to keep both the memory requirements and the orthogonalization cost at reasonable levels. Depending on the problem size and the available resources, the typical values for the restart parameter vary between m = 30 and 200. At the same time, the nonzero-per-row ratio s is in general relatively small and often significantly smaller than the restart parameter m. Therefore, considering the memory operations in that restart cycle, equation (2) then becomes
The decoupling strategy provides full flexibility in terms of choosing a memory representation format, enabling the usage of the natural
For convenience, we refer to the resulting algorithm as compressed basis GMRES (CB-GMRES) in the remainder of the article. We again emphasize that we still use DP in all arithmetic operations and only use lower precision formats for the memory operations.
To close this section, we emphasize that:
• Our approach is complementary to other techniques which aim to reduce the memory access overhead, in the sense that it can be combined with these other optimizations. For example, CB-GMRES can be complemented by customizing the sparse matrix data layout to the application, operating with an iterative refinement scheme, or exploiting customized precision in the preconditioner, among others.
• The arithmetic precision is decoupled from the representation format so that we can actually store the data for the Krylov basis in any format while relying on the data types with hardware support for the arithmetic operations.
Implementation of CB-GMRES
The Ginkgo sparse linear algebra library
For convenience and ease of use, we have realized the CB-GMRES algorithm in the Ginkgo ecosystem (Anzt et al., 2020a,b): Ginkgo is a sparse linear algebra library implemented in modern C++ that embraces two principal design concepts: The first principle, aiming at future technology readiness, is to consequently separate the numerical algorithms from the hardware-specific kernel implementation to ensure correctness (via comparison with sequential reference kernels), performance portability (by applying hardware-specific kernel optimizations), and extensibility (via kernel backends for other hardware architectures). The second design principle—pursuing user-friendliness—is the convention to express functionality in terms of linear operators: every solver, preconditioner, factorization, matrix–vector product, and matrix reordering are expressed as linear operators (or composition thereof). This allows to easily combine the CB-GMRES with any preconditioner available in Ginkgo and to select the realization of the
Ginkgo relies on an “executor” concept to favor platform portability. The executor encapsulates all information about memory location and execution domain of linear algebra objects and automatically orchestrates memory allocation, memory transfers, and kernel selection. For the CB-GMRES implementation with the orthonormal Krylov basis stored in reduced precision, the executor concept is extended with a “memory accessor,” described next, that handles the data conversion transparently to the user.
Memory accessor
At a high level, the idea of the CB-GMRES solver is to compress the orthogonal matrix/vector before and after the memory operations using one of the reduced/customized storage formats but still use the working precision (i.e.,
To decouple the memory access and conversion from the code development effort, we use a memory accessor that converts the data between DP and the memory storage/communication format on-the-fly (see Figure 2). The efficient implementation of the accessor aims to hide the cost of these data conversions by overlapping them with the memory accesses, in principle introducing a minor or even negligible overhead. In addition, the introduction of this technique can accelerate the execution as accessing the data in lower precision significantly reduces the volume of memory accesses per iteration. Accessor separating the memory format from the arithmetic format and realizing on-the-fly data conversion in each memory access.
Considering the realization of the CB-GMRES algorithm, after the new basis vector v j = v is formed at iteration j, the memory accessor is activated in order to compress the DP contents of this vector before storing them into memory; see Lines 13 and 14 in the algorithm in Figure 1. The memory accessor is also active when retrieving the full orthogonal basis V j from memory; see Lines 5 and 8 of the algorithm.
On the technical side, the accessor leverages static polymorphism (via C++ templates) for both the arithmetic precision (in our work, fixed to
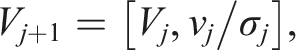
Experimental evaluation of the compressed basis GMRES
In this section, we analyze several properties of the CB-GMRES algorithm in order to assess the benefits of this solver as part of a production code. Concretely, we investigate the following questions: 1. Can we achieve high accuracy in the solution approximations? 2. How significant is the convergence delay introduced by moving away from the “full” precision Krylov basis vectors and utilizing instead basis vectors that are low precision approximations of these orthonormal vectors? 3. What are the performance advantages of the CB-GMRES over the standard (DP) GMRES? 4. Which specific storage format should we use for the memory operations?
Setup
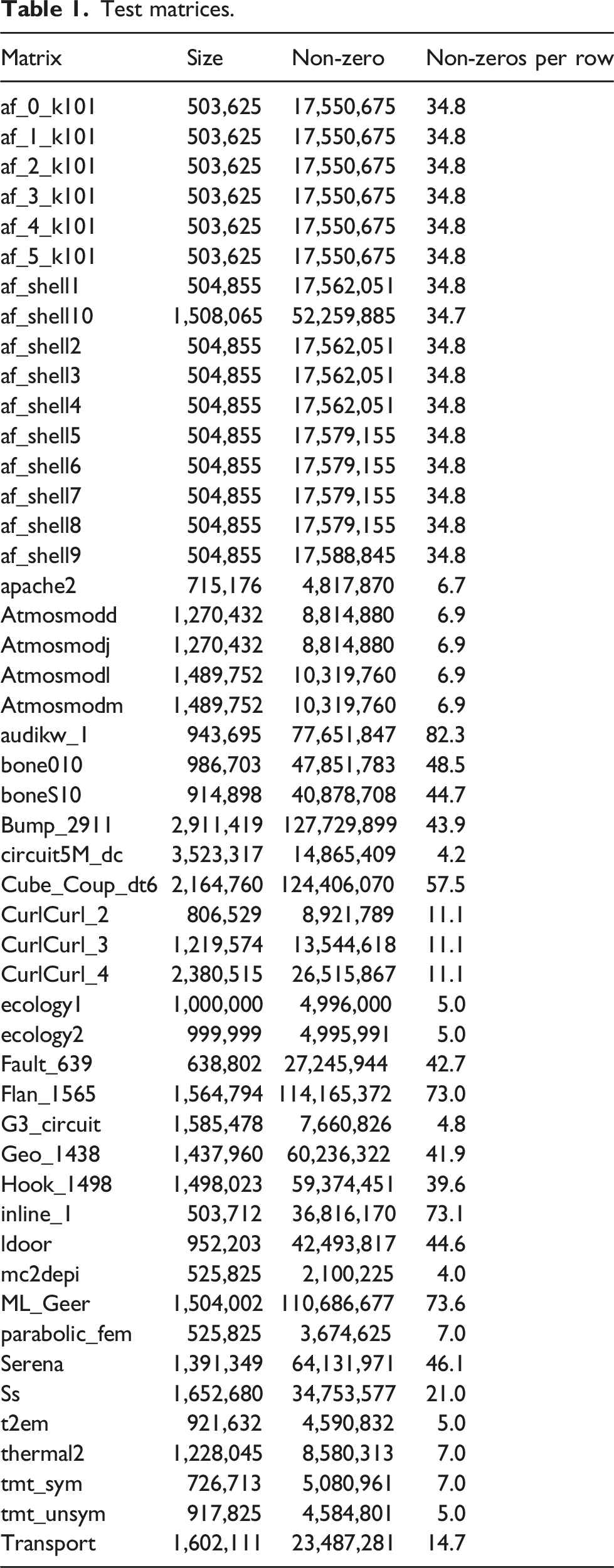
Test matrices.
List of solvers we consider along with the markers we use in the remainder of the article.

In the performance tests, we utilize Ginkgo’s CUDA executor, which is heavily optimized for NVIDIA GPUs. We run all experiments on an NVIDIA V100 GPU with support for compute capability 7.0 NVIDIA Corp (2017). The V100 accelerator board is equipped with 16 GB of main memory, 128 KB L1 cache, and 6 MB of L2 cache. A bandwidth test reported 897 GB/s for main memory access in this particular device (Tsai et al., 2020). The theoretical peak performance for the V100 GPU is 7.83 DP TFLOPS (i.e., 7.83 ⋅ 1012 floating-point operations per second). Ginkgo’s CUDA backend was compiled using CUDA version 9.2.
Impact on basis orthogonality
As a first step in the experimental analysis, we investigate how rounding the values in the Krylov basis vectors to a lower precision format affects the quality of the Krylov basis. In particular, we are interested in the orthogonality loss. For that, we choose the GMRES<fp64,fp32> configuration where all arithmetic operations use Orthogonality of the Krylov basis vectors before and after re-orthogonalization for the standard DP GMRES and SP GMRES and the CB-GMRES GMRES<fp64,fp32>. The test matrices are parabolic_fem (top), ss (center), and circuit5M_dc (bottom).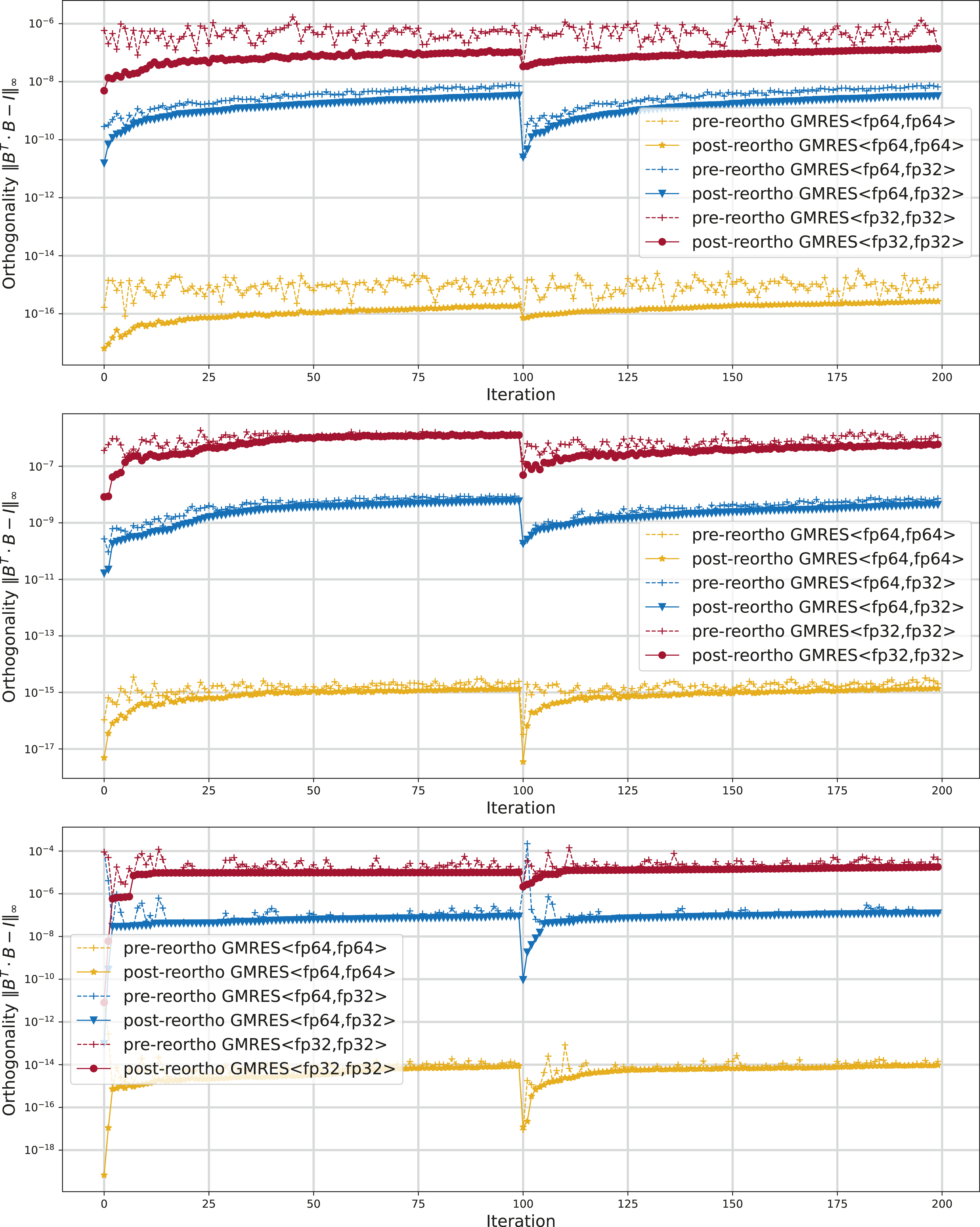
Accuracy of CB-GMRES
To investigate whether the CB-GMRES can match the accuracy levels attained by DP GMRES, we consider 49 linear systems of the form Ax = b, with the coefficient matrix defined from the test matrices in Table 1. For each problem, we set the i-th entry of the exact solution x to x [i] = sin(i), i = 1, 2, …, n; then scale x to a unit norm (x≔x/‖x‖2); and finally generate b as b≔A ⋅ x. The GMRES algorithm is started with an initial guess x0 = 0, uses a restart parameter m = 100, and is stopped when the solution approximation x* yields a residual ‖Ax* − b‖2 ≤ 10−12‖b‖2. In this experiment, we consider both the non-preconditioned solvers and a setting where all methods (both GMRES and CB-GMRES) are left-preconditioned with a scalar Jacobi preconditioner—which is equivalent to scaling the linear problems to a unit diagonal prior to the iterative solution process. The motivation is that a Jacobi-preconditioned GMRES is more realistic for production use while the non-preconditioned GMRES may enhance numerical instabilities. The Jacobi preconditioner is always stored in the arithmetic precision of the solver in order to isolate the convergence difference to the change in the storage format.
To avoid expensive explicit residual computations, the GMRES algorithm internally updates a recurrence residual that is used to check convergence. However, when using finite precision and due to the accumulation of rounding error, this iteratively computed residual can diverge from the real residual, and the GMRES algorithm may stop “too early” even though the real residual did not fall below the selected threshold. Using the compressed basis formats to store the orthonormal basis may enlarge this effect. To tackle this problem, we modify all the implementations to compute the explicit residual once convergence is indicated by the recurrence residual but continue iterating with the updated residual in case the actual accuracy threshold is not fulfilled.
To assess the solution accuracy, in Figure 4, we report the normalized explicitly computed residual ‖Ax* − b‖2/‖b‖2 for the solution approximations generated with the distinct CB-GMRES versions either executed as a plain algorithm (top) or enhanced with a scalar Jacobi preconditioner (bottom). For comprehensiveness, we report the final residual norm also for those cases where the accuracy target cannot be reached. In these initial results, we observe that the standard DP GMRES based on CGS with re-orthogonalization (GMRES<fp64,fp64>), the standard DP GMRES based on modified Gram–Schmidt (MGS-GMRES<fp64,fp64>), and the CB-GMRES variants storing the basis vectors in 32-bit floating-point precision (GMRES<fp64,fp32>) or 32-bit fixed-point precision (GMRES<fp64,int32>) generally achieve the same residual accuracy for both the non-preconditioned application and the Jacobi-preconditioned case. We furthermore observe that an SP GMRES (MGS-GMRES<fp32,fp32>) fails to provide solution approximations of the same accuracy level and may therefore be disregarded as a valid option when aiming for high accuracy. By storing the Krylov basis in fp16 or int16, the CB-GMRES algorithm converges to a solution of lower accuracy, however, often still achieving a residual accuracy better than an SP GMRES (MGS-GMRES<fp32,fp32>). Normalized residual of plain GMRES (top) and Jacobi-preconditioned GMRES (bottom) using different precision for arithmetic and memory operations. Detailed results are listed in the supplementary material.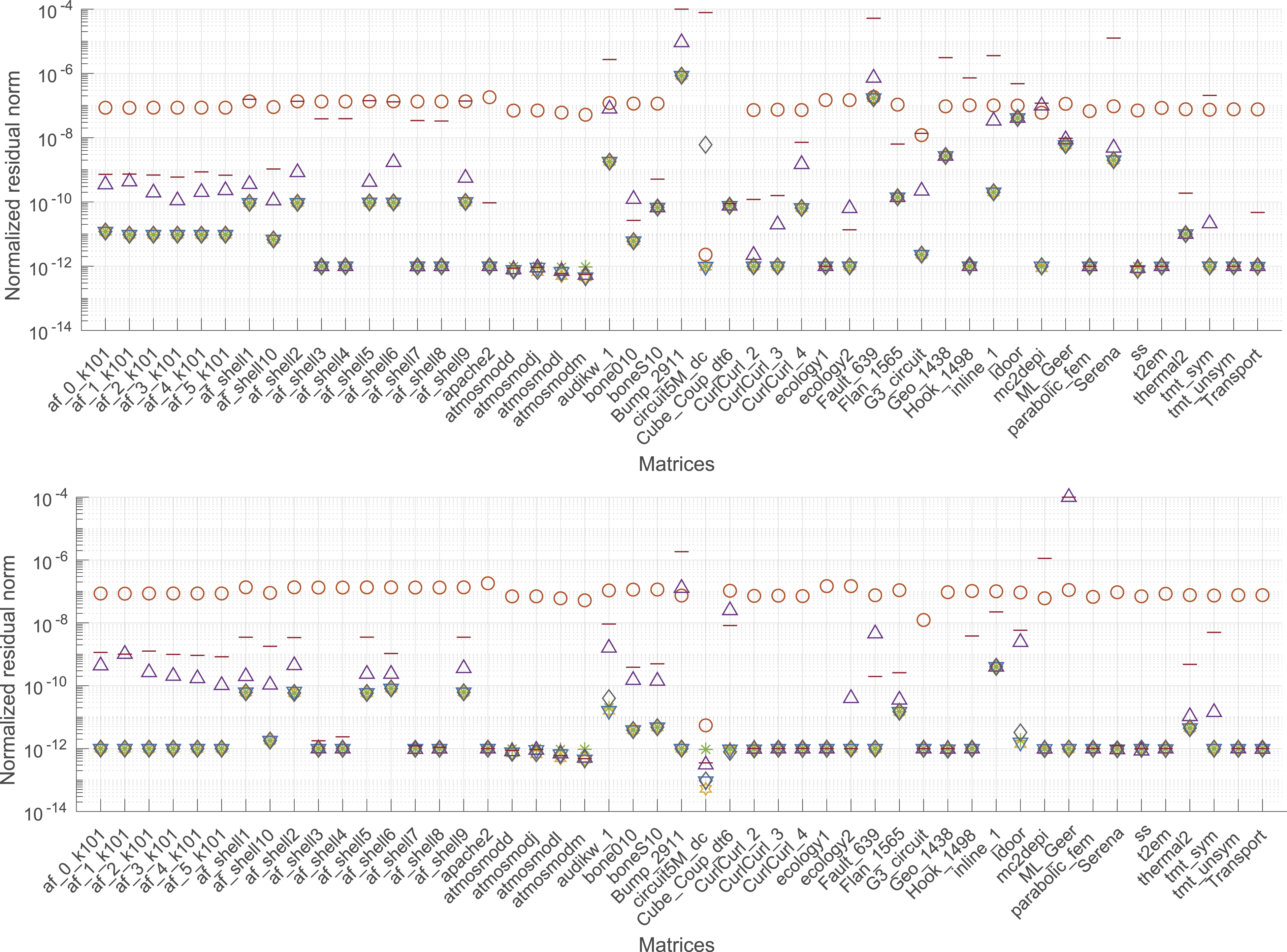
Convergence of CB-GMRES
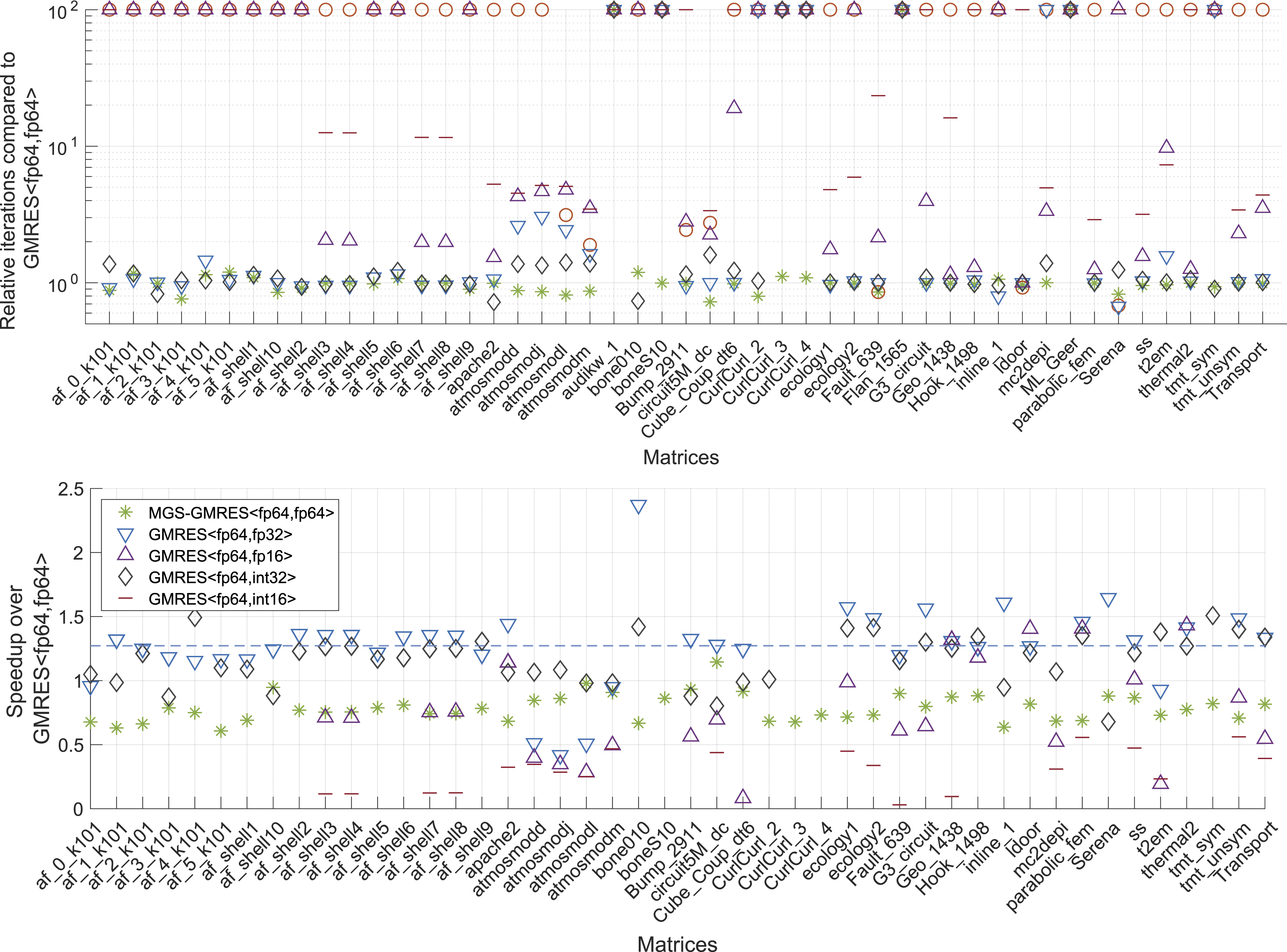
Next, we investigate the impact of storing the basis vectors in a compressed format on the convergence of GMRES. To expose the effects, in Figure 5, we visualize the convergence behavior of the Jacobi-preconditioned CB-GMRES variants for the circuit5M_dc and Serena problems. While all CB-GMRES variants ultimately reach the relative residual stopping criterion, the storage format selected for the Krylov basis impacts the convergence rate and, in consequence, the iteration count. The spikes in the residual curves occur in the iterations where the recurrently computed residual is updated by an explicit residual. This occurs when the Krylov basis size reaches the restart parameter or the recurrence residual indicates convergence. For GMRES<fp64,int16> in particular, we notice significant corrections of the recurrence residual. Overall, we observe that using a compressed format to store the Krylov basis can delay convergence and require additional basis vectors. In order to quantify this effect for a broad range of problems, in Figure 6, we display the iteration count of the CB-GMRES variants relative to the DP GMRES iteration count if they reach the same residual accuracy (even if that accuracy does not fulfill the residual norm stopping criteria). Again, we include results for the non-preconditioned solvers (top) and the Jacobi-preconditioned solvers (bottom). If a solver does not succeed in reaching the same residual accuracy, we set the iteration overhead marker to “100” to clearly indicate that this solver is not a valid option. Detailed convergence analysis of the Jacobi-preconditioned CB-GMRES variants for the circuit5M_dc and Serena problems. Iteration overhead of the CB-GMRES variants relative to the DP GMRES iteration count. The upper graph represents the results for the plain solver runs and the lower graph for the Jacobi-preconditioned solver runs.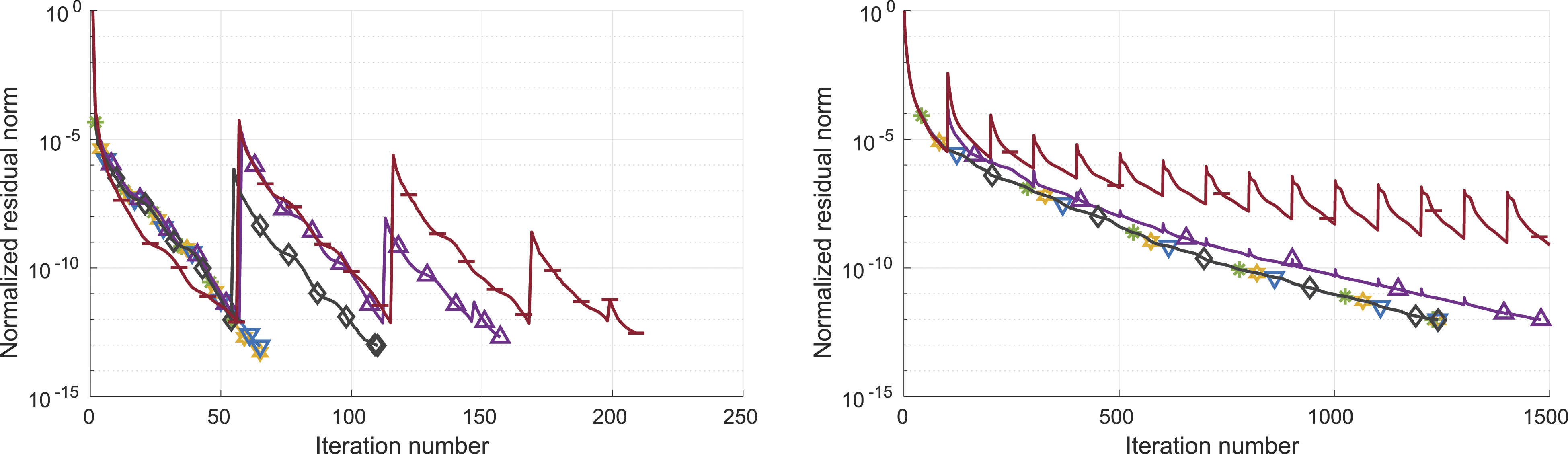
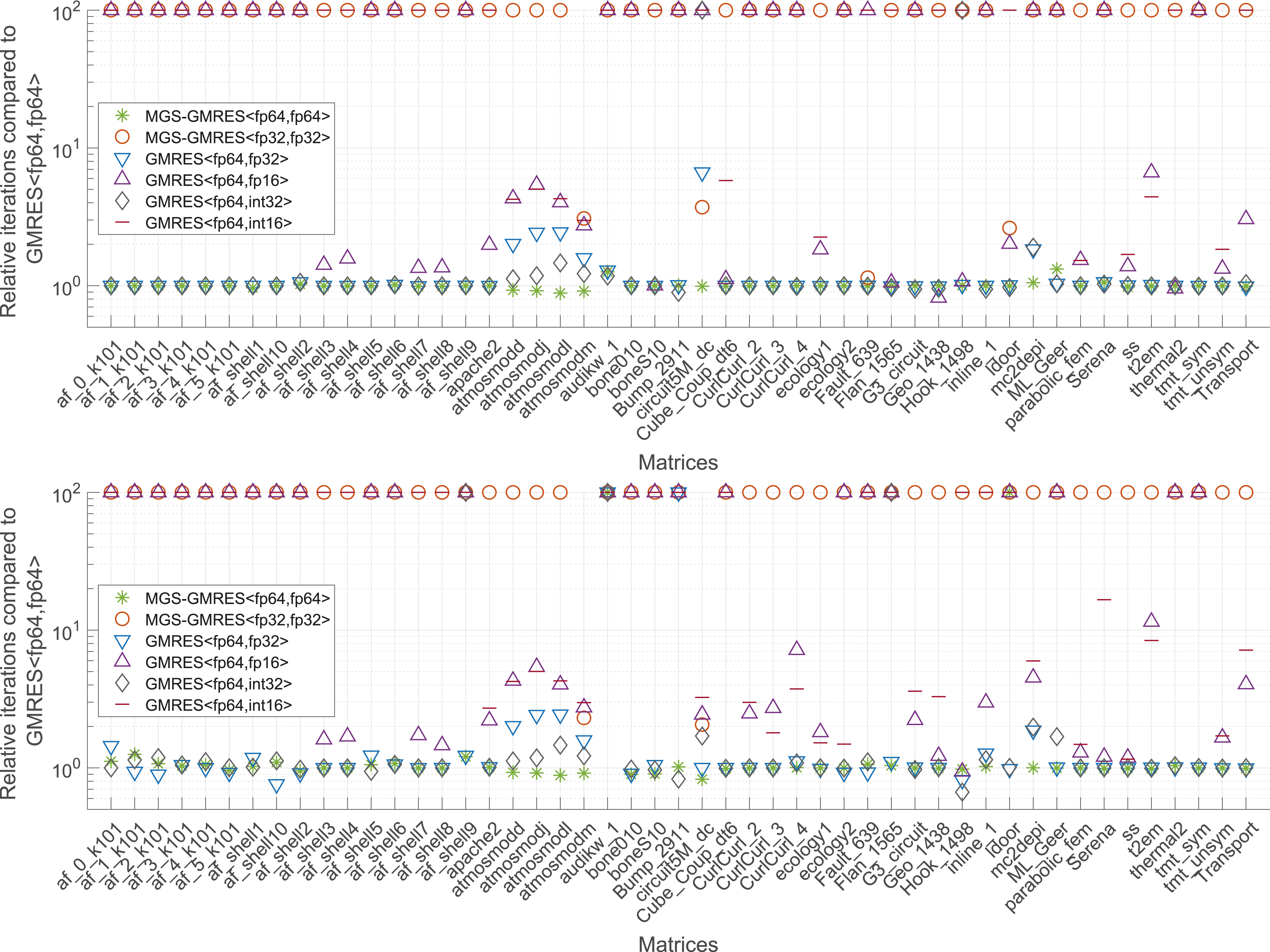
This experiment shows that the CB-GMRES realizations GMRES<fp64,fp32> and GMRES<fp64,int32> generally match the iteration count of DP GMRES. Exceptions are the
In the left-hand side plot in Figure 7, we report a few key statistics obtained from the experimental evaluation with the 49 test problems using either the non-preconditioned GMRES or the Jacobi-preconditioned GMRES. While storing the Krylov basis in fp32 or int32 generally incurs no iteration overhead, when using fp16 storage, we obtain a median iteration overhead of 1.5× with the 50%-quantiles reaching up to 2.5× and the 90%-quantiles reaching up to 5×. For int16, we obtain a median iteration overhead of 2.5× with the 50%-quantiles reaching up to 4× and the 90%-quantiles reaching up to 8×. Statistics obtained from running the CB-GMRES algorithms on the 49 test problems. Left: iteration overhead (relative to DP GMRES) and right: speed-up relative to DP GMRES. The data reflects both the non-preconditioned runs and the Jacobi-preconditioned settings.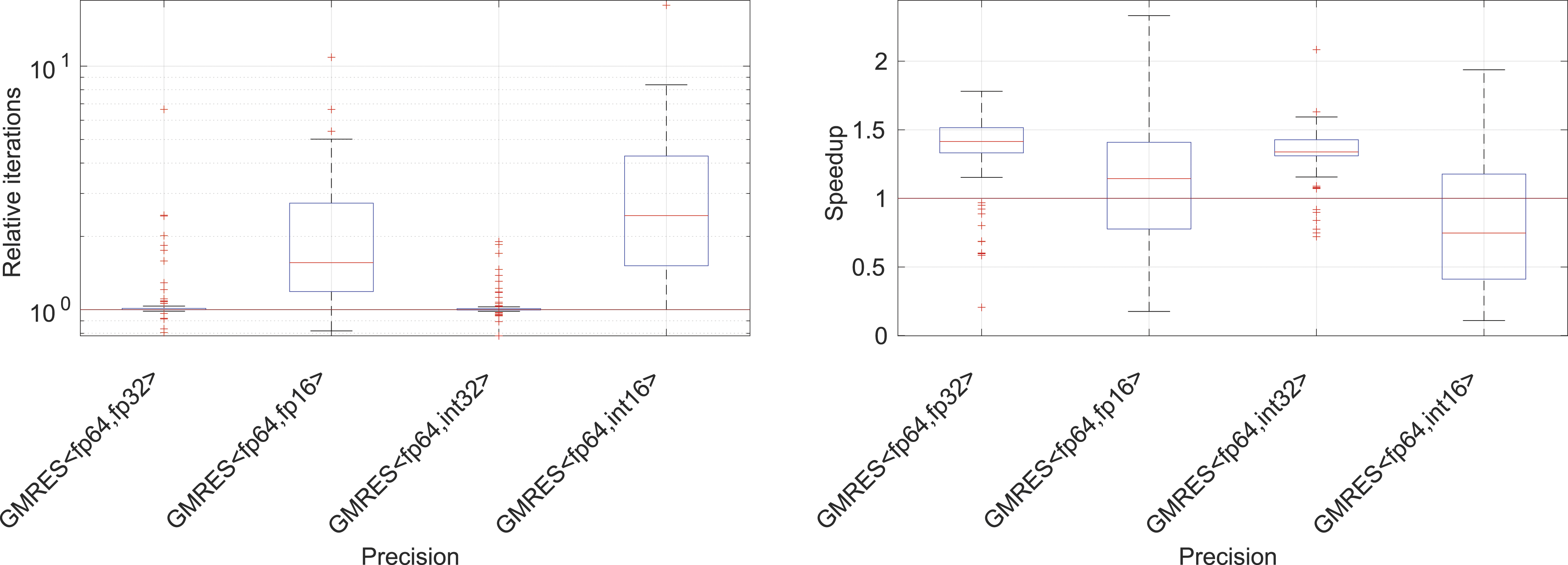
Performance of CB-GMRES
Statistics for the CB-GMRES speed-up relative to the GMRES<fp64,fp64> baseline implementation on the test matrices listed in Table 1.

In Figure 8, we provide a detailed performance evaluation by visualizing the speed-up for the distinct test problems, distinguishing between the non-preconditioned GMRES (top graph) and the Jacobi-preconditioned GMRES (bottom graph). Here, we notice a rather uniform picture concerning the speed-ups for GMRES<fp64,fp32> and GMRES<fp64,int32>, with the exception of the atmosmod problems where the iteration overhead cannot be compensated with faster memory access. Overall, GMRES<fp64,fp32> is slightly superior over GMRES<fp64,int32>, which is likely due to the overhead of the scaling process and the additional scaling factors needed when storing the basis vectors in int32. From this experiment, we conclude that the GMRES<fp64,fp32> is an appropriate choice for a wide range of problems. We also note that GMRES based on modified Gram–Schmidt orthogonalization (MGS-GMRES<fp64,fp64>) is consequently slower than GMRES based on classical Gram–Schmidt orthogonalization (GMRES<fp64,fp64>). This may be expected as MGS requires the use of less efficient BLAS-1 operations. Speed-up of the non-preconditioned CB-GMRES (top) and Jacobi-preconditioned CB-GMRES (bottom) over the respective DP GMRES variants.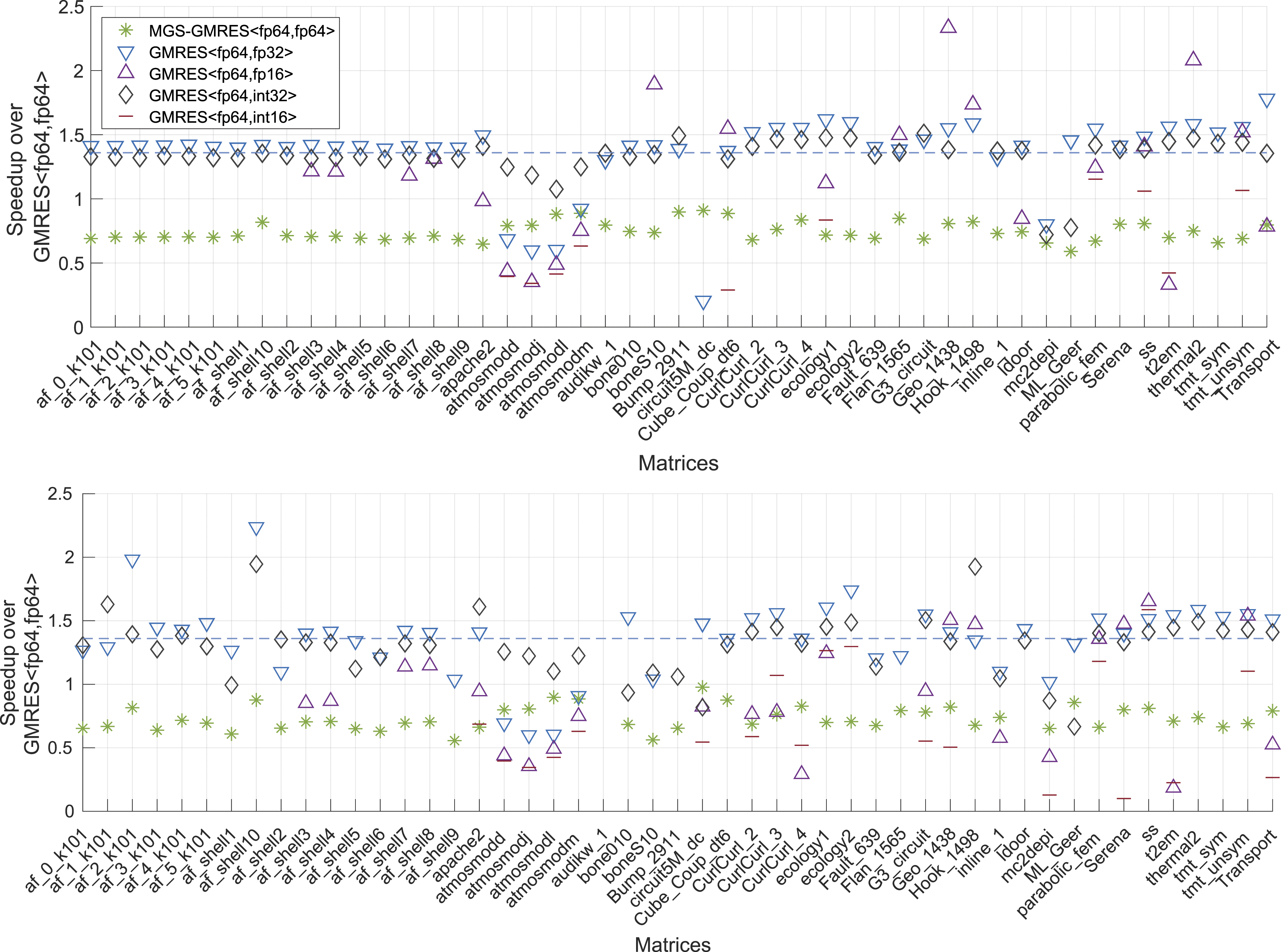
Varying the Krylov subspace dimension
When motivating the use of a more compact storage format to maintain the orthonormal vectors in an earlier section, we argued that the memory savings against DP GMRES grow with the dimension of the Krylov subspace m. In more detail, when ignoring numerical effects, we can expect that the speed-up asymptotically reaches the ratio between the storage format complexities: 4× when using GMRES<fp64,fp16> or GMRES<fp64,int16> and 2× when using GMRES<fp64,fp32> or GMRES<fp64,int32>. In Figure 9, we quantify those speed-ups experimentally, considering restart parameters in the range 10–300. We note that larger restart values are rarely employed as they come with high computational complexity and memory requirements typically exceeding the hardware capabilities. We emphasize that in this experiment, we ignore any numerical effects but only focus on the runtime needed to execute 10 restart cycles with different restart sizes. Also, even though we already identified the GMRES<fp64,fp32> as being superior in terms of convergence and performance, we include all CB variants in this analysis. In Figure 9, we employ gray lines to indicate the speed-up behavior for the distinct matrices and use boxplots to illustrate the statistics for the CB-GMRES variants. The results indicate that the average speed-ups for GMRES<fp64,fp32> or GMRES<fp64,int32> asymptotically approach a value below 2×, with the speed-ups being constantly higher for the former (which requires no scaling). The speed-up is smaller than 2× because the cost savings are limited to those obtained from the compressed storage of the orthogonal basis but not in other parts of the algorithm , for example, the Speed-up for different CB-GMRES variants (GMRES<arith,mem>) over DP GMRES (GMRES<fp64,fp64>) for increasing restart values.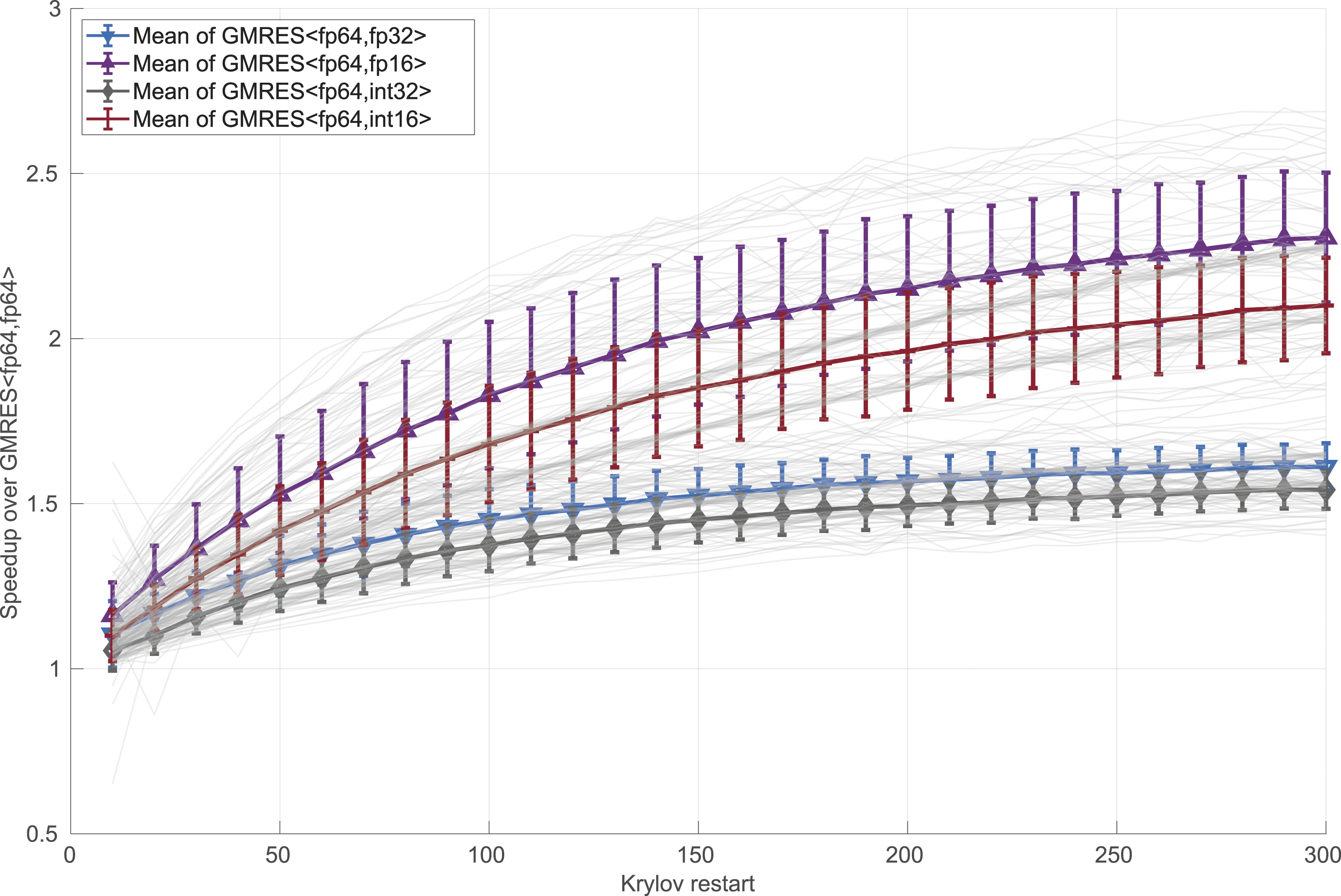
Acknowledging that Figure 9 does not reflect the numerical effects that occur when using larger restart parameters, in Figure 10, we quantify the actual iteration overheads (left) and speed-ups (right) for the non-preconditioned and Jacobi-preconditioned CB-GMRES over the DP GMRES variants when increasing the restart value to m = 300. Compared to Figure 7, we notice a moderate growth in the iteration overhead and a more substantial increase of speed-up. The median speed-ups increase to 1.6× for GMRES<fp64,fp32> and 1.5× for GMRES<fp64,int32> over the DP GMRES baseline, respectively. The fact that these speed-ups match those expected from Figure 9 indicates that using 32-bit formats for storing the Krylov basis in CB-GMRES has only a negligible impact on the convergence behavior. Conversely, the speed-ups for GMRES<fp64,fp16> and GMRES<fp64,int16> do not fulfill the expectations, confirming that 16-bit formats are insufficient for storing the Krylov basis in CB-GMRES. Statistics obtained from running the CB-GMRES algorithms on the 49 test problems. Left: iteration overhead (relative to DP GMRES) and right: speed-up relative to DP GMRES. The data reflects both the non-preconditioned runs and the Jacobi-preconditioned settings, all using the restart parameter m = 300.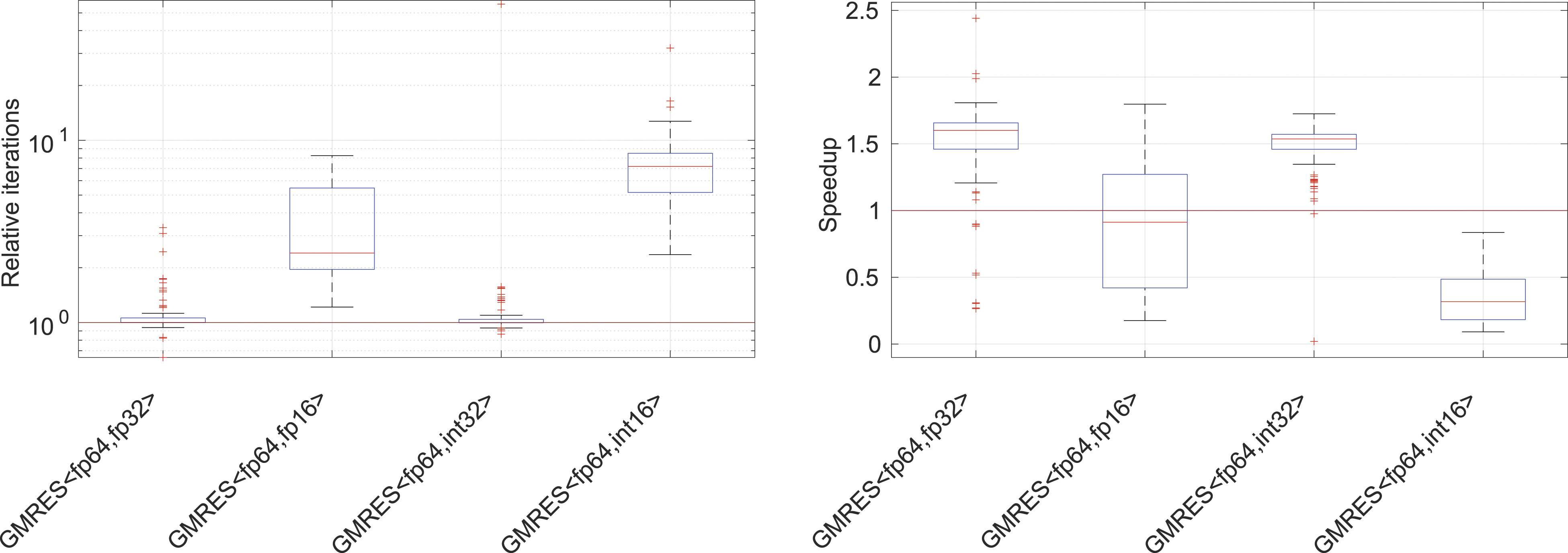
Combining CB-GMRES with incomplete factorization preconditioning
In the previous sections, we have analyzed the convergence and performance of CB-GMRES when being used as a stand-alone solver or a preconditioned method equipped with a lightweight scalar Jacobi scheme. Some situations, however, require the use of a more sophisticated preconditioner to aggressively reduce the iteration count. One of the most popular and general preconditioners is the ILU(0) preconditioner, belonging to the class of incomplete LU factorization (ILU) preconditioners (Saad, 2003). The ILU preconditioners approximate the factorization of the system matrix, ignoring some of the fill-in that would arise in an exact factorization, and applying the preconditioner by solving the triangular systems coming from the incomplete factors (Saad, 2003). The most popular ILU preconditioner is ILU(0), which actually ignores all fill-in, therewith preserving the sparsity pattern of the system matrix in the incomplete factors. As both the ILU generation via a modified Gaussian elimination and the ILU application in terms of sparse triangular solves are inherently sequential, significant efforts are being spent on developing algorithms that are capable of leveraging the parallelism of GPU architectures (Chow et al., 2015 and Anzt et al., 2015). To acknowledge the goal of evaluating a high-performance realization of an ILU-preconditioned GMRES solver, we next consider the application of the (left) ILU preconditioner in terms of matrix–vector multiplications with inverse approximations of the incomplete factors. Specifically, in this experiment, the ILU preconditioner generation is handled via NVIDIA’s cuSPARSE ILU, followed by the approximate inversion and subsequent application by the Incomplete Sparse Approximate Inverse (ISAI) algorithm (Anzt et al., 2018), both available in the Ginkgo library. Similar to Jacobi, all sections of the ILU preconditioner compute and store the values in the arithmetic precision of the corresponding solver in order to isolate the Krylov basis storage precision as the only difference. We ignore test matrices where the generation of an ILU preconditioner or the ISAI triangular solver fails. Using this setup, in Figure 11, we report the attainable relative residual accuracy of the ILU-preconditioned CB-GMRES variants using a restart parameter m = 100 and a relative residual stopping criterion of 10−12. As in the previous experiments, the ILU-preconditioned SP GMRES (MGS-GMRES<fp32,fp32>) is unable to provide the same accuracy as the DP GMRES (ILU-GMRES<fp64,fp64>). Conversely, the CB-GMRES using low precision only for storing the Krylov basis generally succeeds in providing the same accuracy if 32-bit storage is used (ILU-GMRES<fp64,fp32> and ILU-GMRES<fp64,int32>). Using 16-bit storage usually decreases the approximation accuracy, while often still providing higher accuracy than the SP GMRES. In Figure 12, we quantify the iteration overhead (top) and speed-up (bottom) that the ILU-preconditioned CB-GMRES achieves over the DP counterpart. Again, markers indicating a 100× iteration overhead represent solvers that were unable to achieve the same approximation accuracy. We highlight that the ILU-preconditioned ILU-GMRES<fp64,fp32> mostly exhibits a negligible iteration overhead over the ILU-preconditioned DP GMRES (top graph in Figure 12), resulting again in attractive speed-ups over the DP GMRES (bottom graph in Figure 12). Compared with the un-preconditioned and Jacobi-preconditioned solver configurations reported in Figure 8, the advantages of the ILU-GMRES<fp64,fp32> over the standard DP GMRES decrease when using an ILU preconditioner. This is expected as the ILU preconditioner accounts for a significant portion of the solver execution time, giving the CB-GMRES less room for improving the overall runtime. Normalized residual of ILU-preconditioned GMRES and ILU-preconditioned CB-GMRES using different precision for arithmetic and memory operations. Iteration overhead (top) and speed-up (bottom) of the ILU-preconditioned CB-GMRES over the ILU-preconditioned DP GMRES.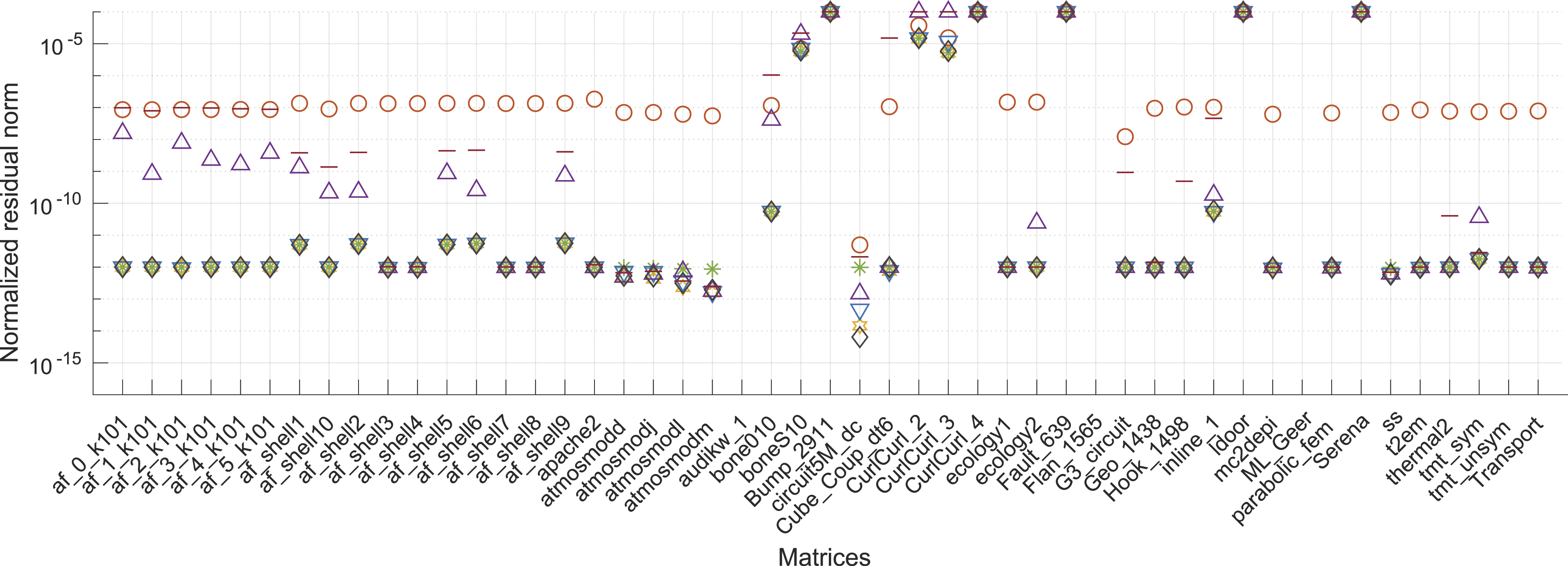
Summary and outlook
We have introduced and evaluated a GMRES algorithm that maintains the Krylov basis in a compressed (compact) form, in order to reduce the traffic between memory and the processor arithmetic units, while performing all arithmetic in double-precision, to preserve the hardware-supported high precision arithmetic in all computations. The key to this approach lies in decoupling the memory storage format of the orthogonal basis from the arithmetic precision when operating with that basis. This general strategy was proposed and integrated into Ginkgo’s library, in the form of a memory accessor, which is leveraged and applied in our work to the specific case of the GMRES algorithm.
We have integrated a high-performance realization of the CB-GMRES operating with 16-bit and 32-bit Krylov basis storage into the Ginkgo open source library. The performance evaluation of this solver on an NVIDIA V100 GPU demonstrates the practical advantages of the communication-reduction technique, which are aligned with the acceleration that could be expected from Amdahl’s law. Using 32-bit storage for the Krylov basis, the algorithm achieves an average 1.6× speed-up over a standard double-precision GMRES. On the other hand, the 16-bit formats further reduce the communication volume, but they regularly fail to preserve the convergence characteristics of the GMRES solver. Overall, we believe that the proposed technique is useful as it tackles the memory wall problem that dominates the performance of many current processors-applications. Furthermore, its benefits are orthogonal and, therefore accumulative, to those that can be attained with other communication-reduction techniques applied, for example, to the preconditioner, the realization of
In future work, we will investigate whether compression techniques that are traditionally used to compress large datasets can pose an alternative to the use of 32-bit and 16-bit fixed- and floating-point formats for storing the compressed basis vectors.
Supplemental Material
Supplemental Material - Compressed basis GMRES on high-performance graphics processing units
Supplemental Material for Compressed basis GMRES on high-performance graphics processing units by José I Aliaga, Hartwig Anzt, Thomas Grützmacher, Enrique S Quintana-Ortí, and Andrés E Tomás in The International Journal of High Performance Computing Applications.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: José I. Aliaga and Andrés E. Tomás were supported by Project PID2020-113656RB-C21 funded by MCIN/AEI/ 10.13039/501100011033, whereas Enrique S. Quintana-Ortí was supported by Project PID2020-113656RB-C22 funded by MCIN/AEI/10.13039/501100011033. Hartwig Anzt and Thomas Grützmacher were supported by the “Impuls und Vernetzungsfond” of the Helmholtz Association under grant VH-NG-1241 and the US Exascale Computing Project (17-SC-20-SC), a collaborative effort of the U.S. Department of Energy Office of Science and the National Nuclear Security Administration.
Supplemental Material
Supplemental Material for this article is available online.
Author biographies
José I. Aliaga is a Professor in the Department of Computer Science and Engineering at the University Jaume I, CastellÃn. His main research interests include the application of high-performance computing on sparse numerical linear algebra and Krylov subspace methods, improving both the performance and the energy efficiency of parallel implementations in hardware accelerators, shared-memory multiprocessors, and clusters. José has published more than 70 papers in journals and conferences and has also participated in over 40 research projects funded by both national and private organizations (in Spain or within the EU), leading 10 of these projects. He was also involved in four technology transfer contracts (two in Spain and two within the EU), leading three of them.
Hartwig Anzt is a Junior Professor and Research Group Leader at the Steinbuch Centre for Computing at the Karlsruhe Institute of Technology (KIT). Hartwig Anzt has a strong background in numerical mathematics, specializes in iterative methods and preconditioning techniques for the next generation hardware architectures. He holds a Ph.D. in Mathematics from the Karlsruhe Institute of Technology. Hartwig Anzt has a long track record of high-quality software development. He is the author of the MAGMA-sparse open-source software package and managing lead of the Ginkgo numerical linear algebra library.
Thomas Grützmacher is a Ph.D. researcher at the Karlsruhe Institute of Technology. He received a bachelors degree from the KIT in 2015 with an emphasis on software development for mobile computing and IoT. In 2018 he completed his Masters studies with an emphasis on High-Performance Computing and unconventional precision formats. Thomas Grützmacher’s research focus is on designing a modular precision ecosystem. He also is among the core developer team of the Ginkgo open-source library.
Enrique S. Quintana-Ortí is a Professor of Computer Architecture at Technical University of Valencia. Enrique’s research pursues the optimization of numerical algorithms and deep learning frameworks for general-purpose processors as well as hardware accelerators. He has co-authored 300+ papers in peer-reviewed scientific journals and international conferences. He has also participated in international projects funded by European organizations as well as in USA projects from DoE and NSF. Enrique’s research on fault-tolerance has been recognized in by USA NASA with two awards, and his contributions to the acceleration of linear algebra algorithms received the 2008 NVIDIA Professor Partnership Award.
Andrés E. Tomás gives lectures about parallel programming at the Universitat de ValÃncia and is a research associate at the Univesidad PolitÃcnica de ValÃncia. His main research interests are iterative Krylov methods, orthogonal decompositions, and GPUs. His Ph.D. work on parallel eigensolvers is available at the SLEPc library. He has co-authored more than fifty publications and participated in a number of research projects, including three financed by the European Commission.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.