
Abstract
A combination of reaction–diffusion models with moving-boundary problems yields a system in which the diffusion (spreading and penetration) and reaction (transformation) evolve the system’s state and geometry over time. These systems can be used in a wide range of engineering applications. In this study, as an example of such a system, the degradation of metallic materials is investigated. A mathematical model is constructed of the diffusion-reaction processes and the movement of corrosion front of a magnesium block floating in a chemical solution. The corresponding parallelized computational model is implemented using the finite element method, and the weak and strong-scaling behaviors of the model are evaluated to analyze the performance and efficiency of the employed high-performance computing techniques.
Keywords
Introduction
Moving-boundary problems (Crank, 1987) are a subset of the general concept of boundary-value problems which not only require the solution of the underlying partial differential equation (PDE), but also the determination of the boundary of the domain (or sub-domains) as part of the solution. Moving-boundary problems are usually referred to as Stefan problems (Crank, 1987) and can be used to model a plethora of phenomena ranging from phase separation and multiphase flows in materials engineering to bone development and tumor growth in biology. Reaction-diffusion systems are the mathematical models in which the change of state variables occurs via transformation and spreading. These systems are described by a set of parabolic PDEs and can model a large number of different systems in science and engineering, for instance, predator-prey models in biology and chemical components reactions in chemistry (Grindrod, 1996). Combining the reaction–diffusion systems with moving-boundary problems provides a way to study the systems in which the diffusion and reaction lead to the change of domain geometry. Such systems have great importance in various real-world scenarios in chemistry and chemical engineering as well as environmental and life sciences.
In this study, the material degradation phenomenon has been investigated as an example of a reaction–diffusion system with moving boundaries, in which the loss of material due to corrosion leads to movement of the interface of the bulk material and surrounding corrosion environment. More specifically, the degradation of magnesium (Mg) in simulated body fluid has been chosen as a case study. Magnesium has been chosen due to its growing usability as a degradable material in biomedicine, where it is usually used in biodegradable implants for bone tissue engineering and cardiovascular applications (Chen et al., 2014; Zhao et al., 2017). The ultimate application of such a model can be then to study the degradation behavior of resorbable Mg-based biomaterials.
A wide range of different techniques has already been developed to study the moving interfaces in reaction–diffusion problems, which can be grouped into 3 main categories: (1) mesh elimination techniques, in which some elements are eliminated to simulate the interface movement (or loss of material in corrosion problems), (2) explicit surface representation, such as the arbitrary Lagrangian-Eulerian (ALE) method, which tracks the interface by moving a Lagrangian mesh inside an Eulerian grid, and (3) implicit surface tracking, in which an implicit criterion is responsible to define the moving interface during the reaction–diffusion process. Related to the aforementioned case study, studies performed by Gao et al. (2018) and Gastaldi et al. (2011) are examples of the first group. Gao et al. (2018) have constructed a simulation of degradation using the mesh elimination technique. Gastaldi et al. (2011) have developed a continuous damage (CD) model by using an explicit solver to study the degradation. The work of Grogan et al. (2014) is an example of the second group as they have developed one of the first models to correlate the mass flux of the metallic ions in the biodegradation interface to the velocity of said interface. This was used to build an ALE model to explicitly track the boundary of the material during degradation. Studies of the third category are based more on mathematical modeling rather than available models in simulation software packages. This approach results in more flexibility and control over the implementation of the computational model. For instance, Wilder et al. (2014) have derived a system of mathematical equations to study galvanic corrosion of metals, taking advantage of the level set method (LSM) to track the corrosion front. Bajger et al. (2016) have used the definition of velocity of the biodegradation interface as the speed of the moving-boundary in LSM, enabling them to track the geometrical changes of the material during degradation. Similarly, Vagbharathi and Gopalakrishnan (2014) have used a combination of LSM and extended finite element method (XFEM), a method to model regions with spatial discontinuities, to study the moving corrosion front in the pitting corrosion process. A very similar approach and formulation has been taken by Duddu (2014) to model localized pitting corrosion. An alternative method for tracking the moving interface is the phase-field method, which has been used in a wide range of relevant studies. A comparison between the behavior of phase-field and LSM formulations for an evolving solid-liquid interface has been performed by Xu et al. (2012), showing that both methods lead to the same results for diffusion-reaction systems. The approach taken in this study was similar to the one from Bajger et al., where LSM was employed to correlate the diffusion and reaction processes to the movement of the solid-solution interface using continuous variables.
Tracking the moving front at the diffusion interface requires high numerical accuracy of the diffusive state variables, which can be achieved using a refined computational grid. This makes the model computationally intensive, and as a consequence, implementing parallelization is an inevitable aspect of simulating such a model. Such an approach enables the model to simulate large-scale systems with a large number of degrees of freedom (DOF) in 3D with higher performance and efficiency in high-performance computing (HPC) environments. In recent years, parallelization of diffusion-reaction systems simulation has been investigated, but the studies are mainly conducted for stochastic (statistical) models. For instance, Chen and Schutter (2017) have developed a parallel stochastic model for large-scale spatial reaction–diffusion simulation, and similarly, Arjunan et al. (2020) have developed a stochastic high-performance simulator for specific biological applications. Also as an example for massively parallel systems, Hallock et al. (2014) have conducted a simulation of reaction–diffusion processes in biology using graphics processing units (GPUs). Although stochastic models have more parallel-friendly algorithms, explaining the underlying process, especially when it involves reaction–diffusion processes of chemistry and biology, is less complex and more universal using mechanistic (deterministic) models, which are based on well-developed mathematical models of continuous systems (Kendall et al., 1999). To the best of authors’ knowledge, none of the previous contributions to the topic of reaction–diffusion systems with moving interfaces has employed parallelization techniques to increase the performance and speed of execution of the model without compromising the accuracy of the interface tracking.
In the current study, we developed a mechanistic model of a reaction–diffusion system coupled with a moving interface problem. Improving the accuracy of the interface capturing requires a refined computational mesh, leading to a more computation-intensive simulation. To overcome this challenge and yield more interactable simulations, scalable parallelization techniques were implemented making the model capable of being run on massively parallel systems to reduce the simulation time. The investigated case-study is the material degradation process. The developed model captures the release of metallic ions to the medium, formation of a protective film on the surface of the material, the effect of presented ions in the medium on the thickness of this protection layer, and tracking of the movement of the corrosion front (Figure 1). The interface tracking was performed using an implicit distance function that defined the position of the interface during degradation. This implicit function was obtained by constructing and solving a level set model. It is also worth noting that in a real-world application, such systems require a calibration (also called parameter estimation or inverse problem), in which the model should be simulated hundreds of times. This makes the parallelization even more crucial for these models. A schematic representation of different components of the developed model for simulation of the degradation process with a moving front.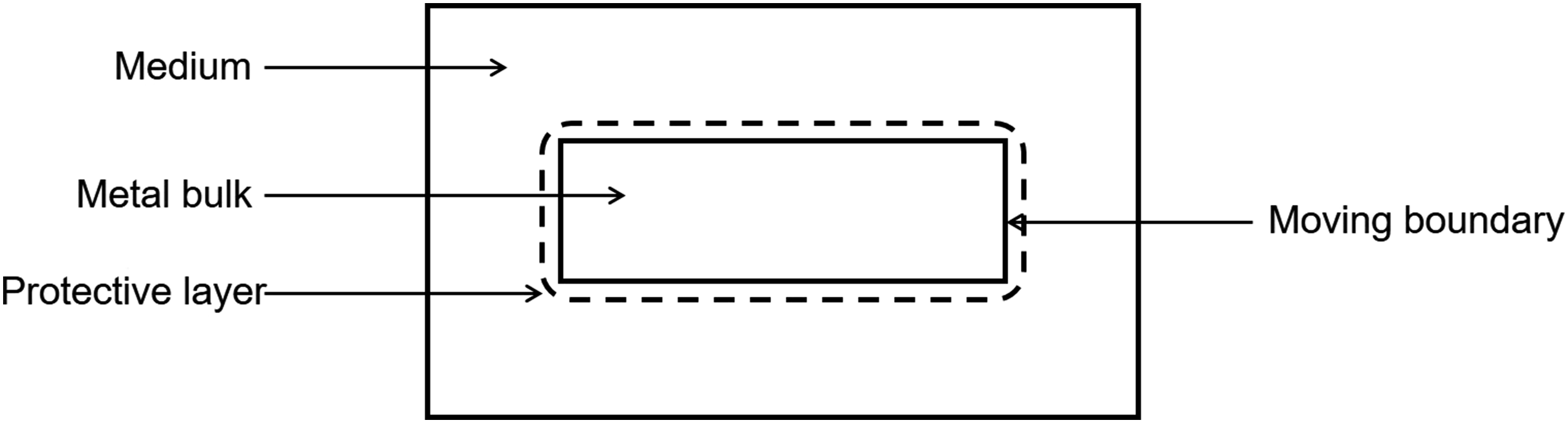
Background theory and model description
Before elaborating the parallel implementation strategy, the mathematical model is briefly described in this section. The model is constructed based on the chemistry of degradation, starting from the previous work by Bajger et al. (2016), in which the ions can diffuse to the medium and react with each other.
Chemistry of degradation
In metals, degradation occurs through the corrosion process, which usually consists of electrochemical reactions, including anodic and cathodic reactions as well as the formation of side products (Zheng et al., 2014).
For Mg, the corrosion reactions comprise the following steps (Zheng et al., 2014): first, the material is released as metallic ions and free electrons, which causes the volume of the bulk material to be reduced
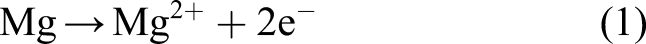
The free electron reduces water to hydrogen gas and hydroxide ions
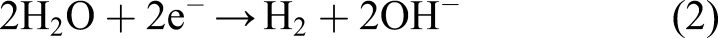
Then, with the combination of the metallic and hydroxide ions, a porous film is formed on the surface, slowing down the degradation rate by protecting the material underneath
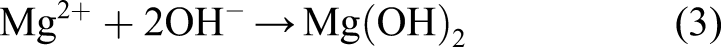
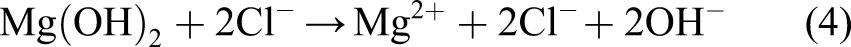
The degradation process of metals is a continuous repetition of the above reactions.
Reaction–diffusion equation
A reaction–diffusion partial differential equation can describe the state of a reaction–diffusion system by tracking the change of the concentration of the different components of the system over time (Grindrod, 1996). The equation is a parabolic PDE and can be expressed as
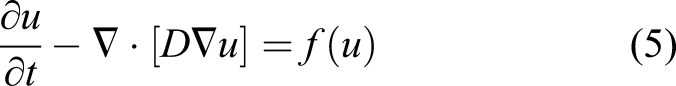
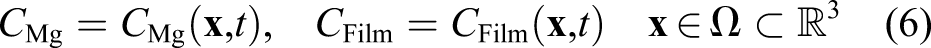
Ω is the whole domain of interest, including the bulk material and its surrounding medium. So, by assuming that the reaction rates of equations (3) and (4) are k1 and k2, respectively, one can write the change of those state variables according to equations (3) and (4) as
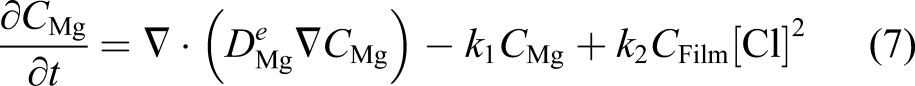
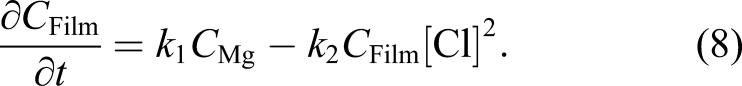
We assumed that the concentration of the chloride ions is constant (denoted by [Cl] in the equation) and does not diffuse into the protective film. The missing part of the model described by equations (7) and (8) is the effect of the protective film on the reduction of the degradation rate. To this end, we defined a saturation term,
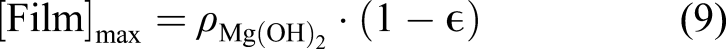
The defined saturation term acts as a function of space that varies between 0 and 1 in each point. By adding this term to the concentration of Mg ions, we can write
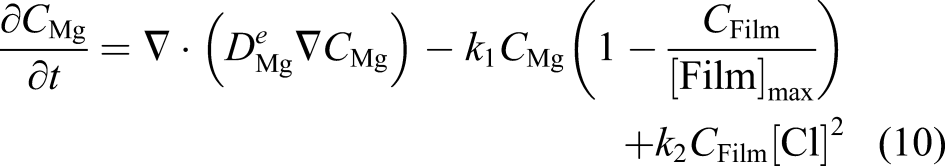
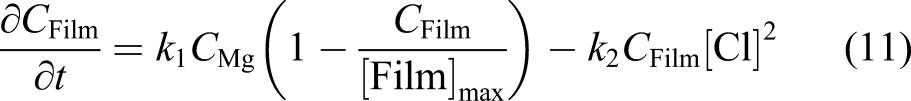
Since the film is a porous layer and allows the ions to diffuse through it, the diffusion coefficient in equation (10) is a function of space and not a constant value (which is the reason for being denoted as
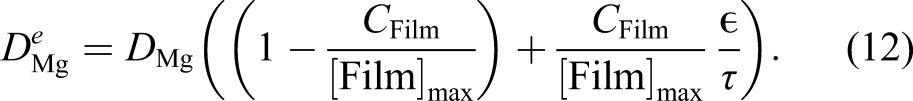
Level set method
The level set method is a methodology that allows moving interfaces to be described by an implicit function. In other words, the boundaries of domains can be tracked as a function instead of being explicitly defined. In the level set method, a signed distance function, ϕ = ϕ(x, y, z, t), describes the distance of each point in space to the interface, and the zero iso-contour of this function implies the interface (Ronald Fedkiw, 2002). In the current study, this function was defined in a way that divides the domain into two sub-domains: (1) the bulk material, in which the implicit function is positive (ϕ > 0), and (2) the medium, in which the function is negative (ϕ < 0). The interface is defined as the points in space where ϕ = 0. Figure 2 shows a schematic representation of the solid-medium interface in the current study, in which the interface moves as the material degrades over time. A schematic representation of the implicit function definition in the current study. V denotes the shrinkage speed of the interface due to degradation.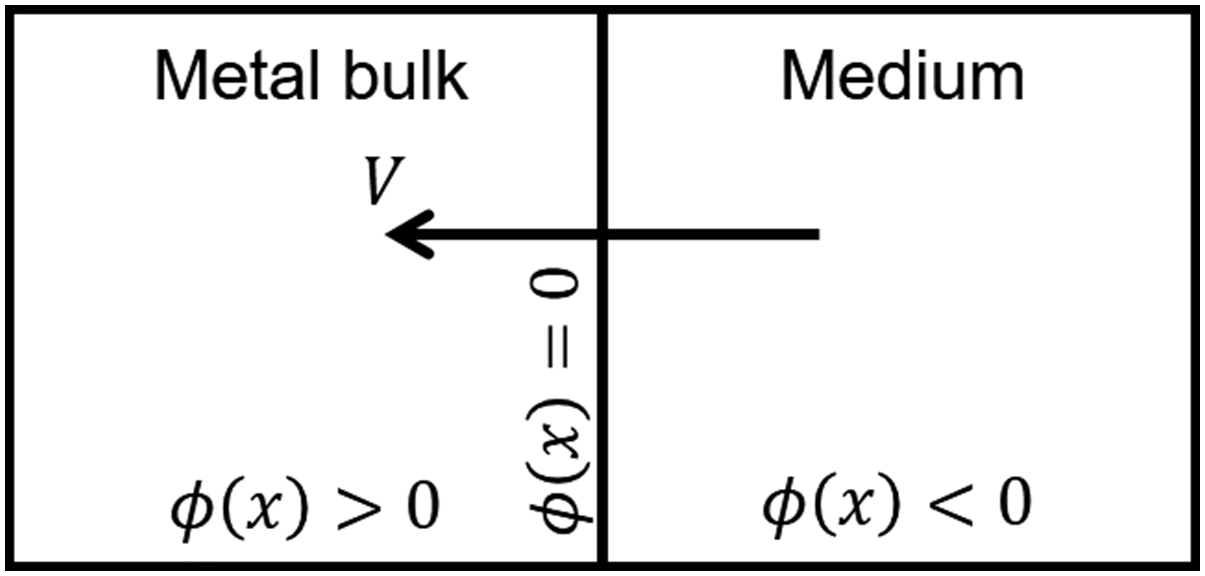
The level set equation defines this implicit function. The full level set equation can be written as (Ronald Fedkiw, 2002)
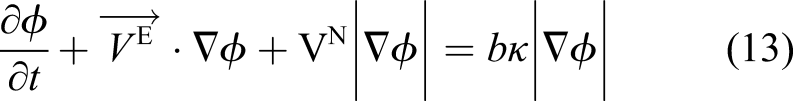
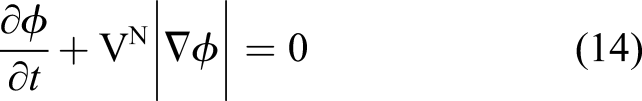
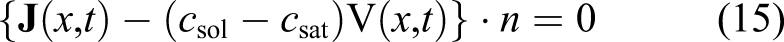
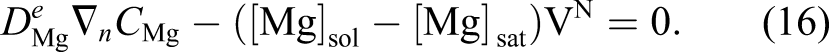
Inserting the obtained velocity of equation (16) into equation (14) and considering the direction of the shrinkage velocity, which is in the opposite direction of the surface normal vector, yields
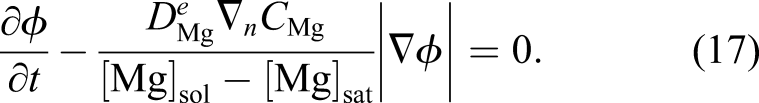
Equation (17) is the final formulation of the level set equation in the current study, which alongside equations (10) and (11), forms the mathematical model of degradation of Mg with a moving interface. Equation (17) contributes indirectly to the evolution of equations (10) and (11) as it defines the boundary, the zero iso-contour of the ϕ function, on which the boundary conditions of the equations are applied.
Methodology of model implementation
The developed mathematical model comprises equations (10), (11), and (17), and cannot be solved using analytical techniques. The alternative approach in these scenarios is solving the derived PDEs numerically. In this study, we used a combination of finite element and finite difference methods to solve the aforementioned equations. In the developed numerical model, the PDEs are solved one by one, each of which is a linear equation, so the model implementation follows the principles of solving linear systems. In the following section, only the process to obtain the solution of equation (10) is described in detail, but the other PDEs were solved using the same principle. Although the adopted finite element method is standard, we elaborate on its derivation to clarify the bottlenecks of the later-discussed implementation.
Finite element discretization (bottleneck of the algorithm)
In order to solve equation (10) numerically, we used a finite difference scheme for the temporal term and a finite element formulation for the spatial terms. For simplicity of writing, notations of variables are changed, so CMg is represented as u (the main unknown state variable to find), CFilm is denoted by p, [Cl] is denoted by q, and the saturation term
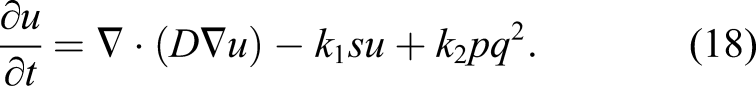
To obtain the finite element formulation, the weak form of derived PDE is required. In order to get this, we define a space of test functions and then, multiply each term of the PDE by any arbitrary function as a member of this space. The test function space is
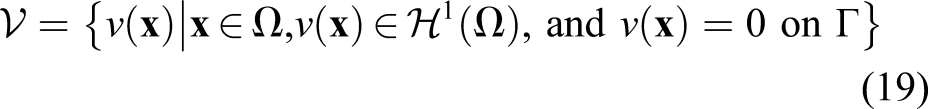
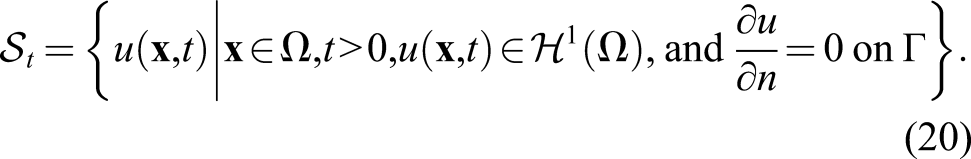
Then, we multiply equation (18) to an arbitrary function
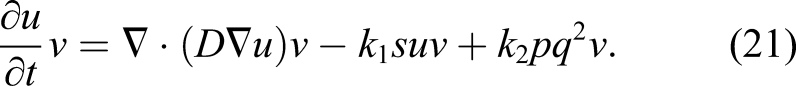
Integrating over the whole domain yields
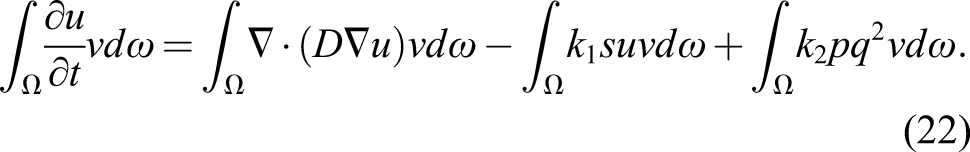
The diffusion term can be split using the integration by parts technique
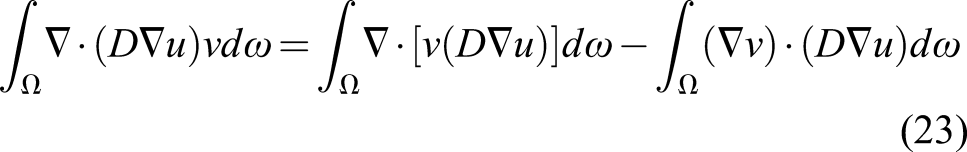
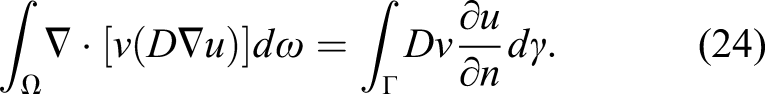
For the temporal term, we use the finite difference method and apply a first-order backward Euler scheme for discretization, which makes it possible to solve the PDE implicitly

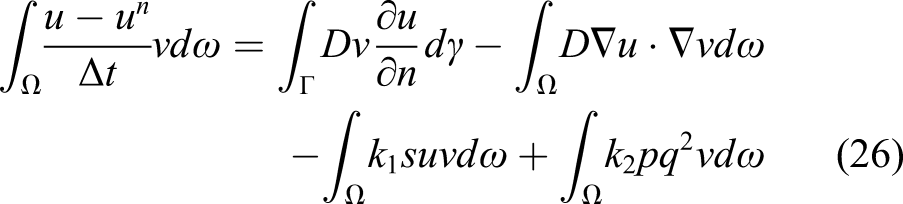
The surface integral is zero because there is a no-flux boundary condition on the boundary of the computational domain (defined in the trial function space according to equation (20)). By reordering the equation, we get the weak form of equation (18)
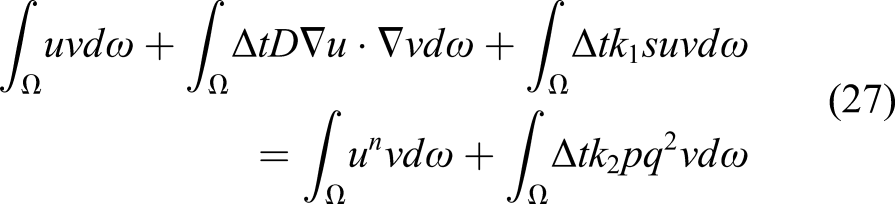
So, the problem is finding a function
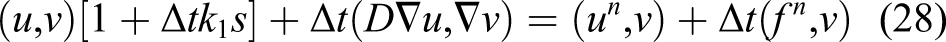
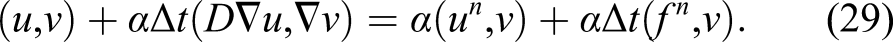
One can approximate the unknown function u in equation (29) by
In order to derive a linear system of equations for obtaining the unknown coefficients c
j
, we define
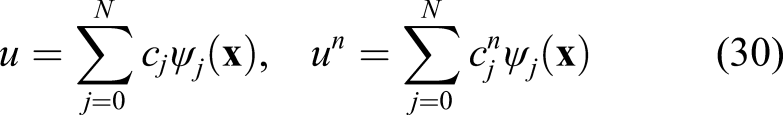
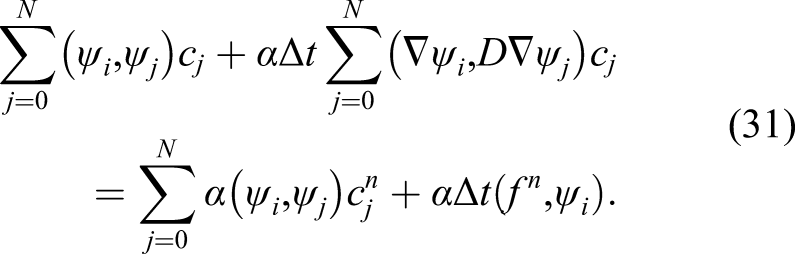
Equation (31) is a linear system

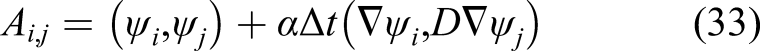
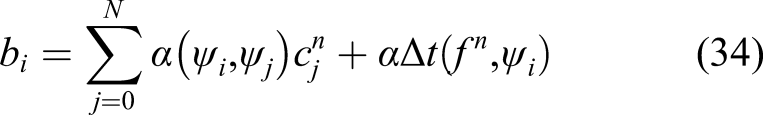
By solving equation (32) and substituting the obtained c in equation (30), u (CMg in the example in this study) can be calculated in the current time step. As stated before, the same approach can be applied to equations (11) and (17) to get CFilm and ϕ. This procedure is repeated in each time step to compute the values of CMg, CFilm, and ϕ over time.
A common practice to save time for solving equation (32) for a constant time step size is to compute the left-hand side matrix [A in equation (33)] once and compute only the right-hand side vector of the equation at each time iteration. But in this case, although the time step size is fixed, due to the presence of the α coefficient, the matrix changes along the time. The α coefficient is not constant and should be updated in each time step because it depends on the penalization term s [which is a function of the concentration of the film as can be seen by comparing equations (10) and (18)]. In addition to this, the diffusion coefficient is not constant [Equation (12)], making the second term in equation (33) non-constant even in the absence of α coefficient. Consequently, the left-hand side matrix of the equation (32) cannot be computed before the start of the main time loop, and computing it in each time step is an extra but inevitable computational task in comparison to similar efficient and high-performance finite element implementations. This contributes to a slower algorithm for solving the aforementioned PDEs.
Implementation and parallelization
The model was implemented in FreeFEM (Hecht, 2012), which is an open-source PDE solver to facilitate converting the weak formulation [Equation (27)] to a linear system Ax = b [with A from equation (33) and b from equation (34)]. The computational mesh was generated using Netgen (Schöberl, 1997) in the SALOME platform (Ribes and Caremoli, 2007) by a set of linear tetrahedral elements, and all the other preprocessing steps were performed in FreeFEM. The mesh was adaptively refined on the material-medium interface in order to increase the accuracy of the level set model. Postprocessing of the results was carried out using Paraview (Ahrens et al., 2005).
Computing the diffusion solely in the medium domain causes oscillations close to the interface, and to prevent this, the mass lumping feature of FreeFEM was employed. In this technique, the desired mass matrix is handled node-wise and not element-wise. Technically speaking, this means that the state variable is stored in the mesh nodes, and although this is the natural formulation in the finite difference method, it requires artificial modification in the standard finite element formulation (Wendland and Schulz, 2005). The mass lumping feature of FreeFEM applies a quadratic formula at the vertices of elements to make the mass matrix diagonal, which contributes positively to the convergence of the solution.
The main parallelization approach for the current study was domain decomposition, in which the mesh is split into smaller domains (can be overlapping or non-overlapping), and the global solution of the linear system is achieved by solving the problem on each smaller local mesh. What really matters in this approach is providing virtual boundary conditions to the smaller sub-domains by ghost elements, transferring neighboring sub-domain solutions (Badri et al., 2018). As a result, a high-performance parallelism is feasible by assigning each sub-domain to one processing unit.
In computational science, preconditioning is widely used to enhance the convergence, which means instead of directly working with a linear system Ax = b, one can consider the preconditioned system (Daas et al., 2019)

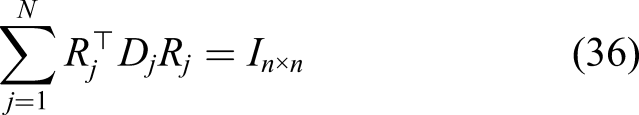
In this study, we decomposed the mesh by using the one-level preconditioner Restricted Additive Schwarz (RAS) Overlapping domain decomposition in the current study. Each color shows a separate sub-domain, and the narrow lighter bands are the overlapped regions. Comparison of the sparsity patterns (highlighting non-zero elements) of the global matrix A for a different number of decomposed domains: (a) 1 domain, (b) 2 sub-domains, (c) 4 sub-domains, and (d) 8 sub-domains.

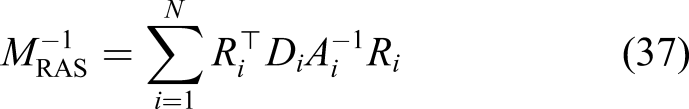
Generally, two categories of methods have been used to solve a large linear system of equations on parallel machines: direct solvers [e.g., Multifrontal Massively Parallel Sparse, MUMPS (Amestoy et al., 2001)] and iterative solvers [e.g., Generalized Minimal Residual Method, GMRES (Saad and Schultz, 1986)]. While direct solvers are quite robust, they suffer from the memory requirement problem on large systems. Inversely, iterative solvers are quite efficient on memory consumption, but similar to other iterative approaches, they are not very reliable in some cases (Saad, 2003). Direct solvers modify the matrix by factorization (e.g., Cholesky decomposition), but an iterative solver does not manipulate the matrix and works solely using basic algebraic operations. However, for an efficient usage of iterative solvers, a proper preconditioner is crucial (Saad, 2003). By evaluating and comparing the performance of the aforementioned methods for the current model, we decided to use an iterative approach using the Krylov subspaces (KSP) method, in which we preconditioned the equation using a proper preconditioner [Equation (35)] and then solved it with an iterative solver.
Krylov methods have been frequently used by researchers as robust iterative approaches to parallelism (Ipsen and Meyer, 1998). What matters in this regard is ensuring proper scaling of the parallelized algorithm for both the assembling of the matrices and the solution of the linear system of equations. One good solution to this challenge is taking advantage of HPC-ready mathematical libraries to achieve efficient distributed-memory parallelism through the Message Passing Interface (MPI). In the current study, we used the PETSc (Portable, Extensible Toolkit for Scientific Computation) library (Balay et al., 2019), which provides a collection of high-performance preconditioners and solvers for this purpose.
In order to yield the highest performance, a variety of different combinations of KSP types and preconditioners were evaluated, such as Conjugate Gradients (CG) (Hestenes and Stiefel, 1952), Successive Over-Relaxation (SOR) (Habetler and Wachspress, 1961), block Jacobi, and Algebraic Multigrid (AMG) (McCormick, 1987), to name a few. The performance tests results are presented in the supplementary materials of this paper. The best performance for the reaction–diffusion system model was achieved using the HYPRE BoomerAMG preconditioner (Falgout and Yang, 2002) and the GMRES solver (Saad and Schultz, 1986). This was the combination used for all the performance analysis tests.
Level set issues
As mentioned before, in order to track the interface of the bulk material and the surrounding fluid, an implicit signed distance function is defined as the solution of equation (17). This equation can be solved using the aforementioned finite element discretization, but in a practical implementation, there are usually a couple of problems associated with this PDE.
The first issue is defining
The next issue is a well-known problem of the level set method: If the velocity of the interface is not constant [as in Equation (13)], the level set function ϕ may become distorted by having too flat or too steep gradients close to the moving front. This could cause unwanted movements of the interface. The problem becomes even worse when the distance function is advected. A solution to this issue is re-initializing the distance function in each time step (re-distancing), but this operation requires solving a new PDE. From numerical investigations, it has been observed that this operation inserts new errors in the numerical computation of the level set equation (Russo and Smereka, 2000). This can be resolved by improving the method of reconstruction of the distance function (Russo and Smereka, 2000).
However, re-initialization results in another issue on a massively parallel implementation: as the mesh is partitioned into smaller sub-meshes, it is not feasible anymore to evaluate the distance to the interface globally on each sub-domain. As a result, the inverse process of domain decomposition should be taken to assemble the mesh again. This can be done by the restriction matrix and the partition of unity [defined in Equations (36) and (37)], but it is rather a very inefficient procedure regarding the parallelization of the simulation and results in a long execution time in each time step.
In the current study, the distance function ϕ was initialized only once at the beginning of the simulation. The re-initialization process was unnecessary in this case because according to equation (17), the distance function is advected only in the regions where there is a gradient of the concentration of Mg ions, which means that advection is applied only on the regions close to the interface in the medium. This prevented the whole distance function of being distorted, and as a result, it was not required to re-initialize it in each time step. This also removed the need for inverting the decomposition process.
Simulation setup
In order to verify the performance of the developed model, a degradation experiment was reconstructed in-silico, in which the degradation of a block of Mg (with the size of 13 mm × 13 mm × 4 mm) was investigated in a simulated body fluid solution. All the experimental parameter data (used to setup the simulation), as well as the degradation rates (used to calibrate and validate the numerical model) were extracted from Mei et al. (2019).
As can be seen in equations (1) and (2), each mole removed from the Mg block corresponds to one mole of the produced hydrogen. As a result, instead of a direct measurement of mass loss, one can collect and measure the amount of produced hydrogen to monitor the degradation rate. This is a common way of reporting degradation in this type of studies (Abidin et al., 2013). In order to get this quantity out of the developed model, we used the level set model output. The total mass loss of Mg at each desired time can be calculated based on the movement of the corrosion front
The geometry of the simulation experiment is depicted in Figure 5. Based on this geometry, an Eulerian computational mesh was constructed by generating tetrahedral elements on the whole domain, including the Mg block and the medium. This resulted in 830,808 elements with a total of 143,719 DOFs for each PDE [equations (10), (11), and (17)], which indicates the size of matrix A in equation (33). Model parameters and material properties were obtained from Bajger et al. (2016). The diffusion coefficient of Mg was calculated using an inverse problem setup in which a Bayesian optimization process (Mockus, 1989) was used to run the simulation code multiple times and minimize the difference of the model output and the experimental data reported by Mei et al. (2019). A time step convergence study was performed to measure the sensitivity of the model to the time stepping parameter, and based on the results, the time step value was set to 0.025 h. Representation of the experimental setup simulated to perform numerical validation of the developed model and evaluate parallel performance. (a) A cuboid of Mg (with the size of 13 mm × 13 mm × 4 mm) is floating inside a simulated body fluid solution to investigate the degradation process, and (b) a cross-section of the computational mesh, refined on the metal-medium interface to increase the interface capturing accuracy.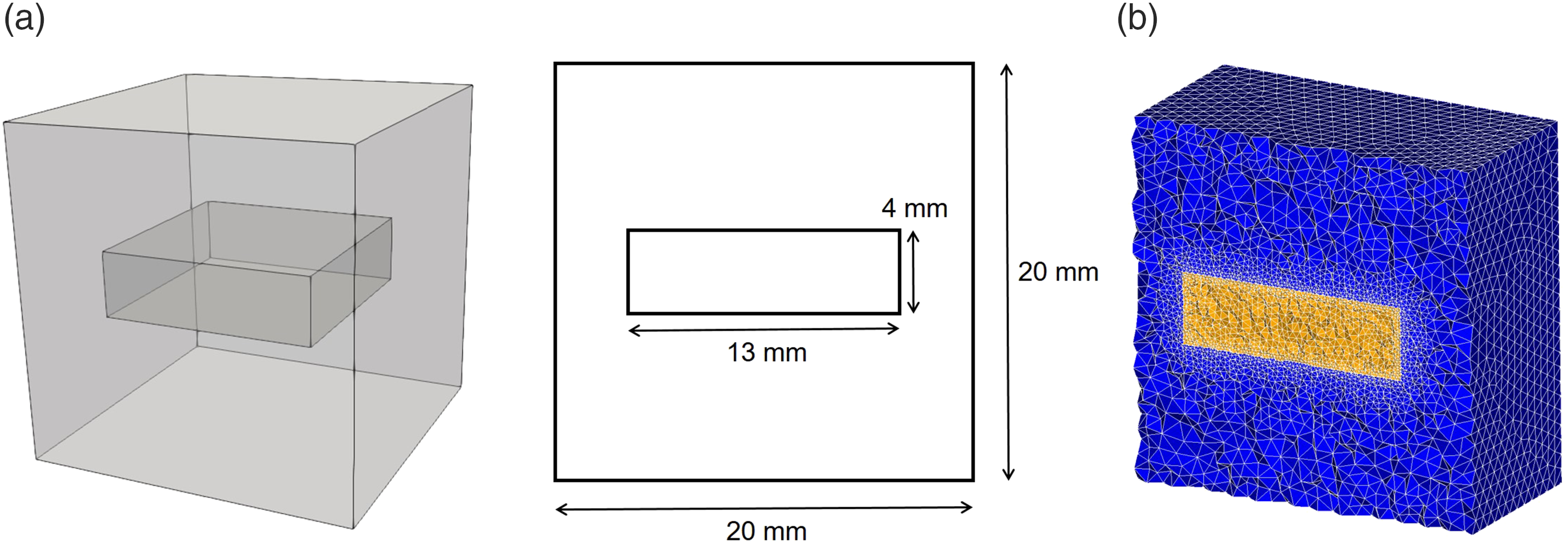
Performance analysis
To investigate the performance and scaling behavior of the implemented parallel code, we conducted a set of weak-scaling and strong-scaling tests on the computational model. To do this, the time required to solve each PDE in each time step was measured in a simulation. This acted as a rough estimation of the time required in each time step because it ignores all the other factors contributing to speedup results such as communication costs, load imbalance, limited memory bandwidth, and parallelization-caused overhead.
Weak-scaling was evaluated by dividing the computational domain into smaller sub-domains (each of which was Models used for weak-scaling, in which the number of elements was doubled each time while doubling the number of computational cores. Upper row: actual computational domain in which colors show the medium (blue) and the material block (red). Lower row: domain decomposition for parallelization, colors show different decomposed mesh parts (distributed to different MPI processing units). Each column corresponds to a different simulation with (a) 1 MPI unit, (b) 2 MPI units, (c) 4 MPI units, and (d) 8 MPI units.
After calculating the speedup of each test (by comparing the differences in execution time), we can use Gustafson’s law (Gustafson, 1988) to calculate the sequential and parallelizable portion of computation in the current implementation in weak-scaling evaluation
The strong-scaling evaluation was performed using the entire domain. The evaluation was done using 1, 8, 16, 40, 60, 90, 200, and 300 MPI cores. In strong-scaling, Amdahl’s law (Amdahl, 1967) is used to calculate the portion of the algorithm that runs in parallel
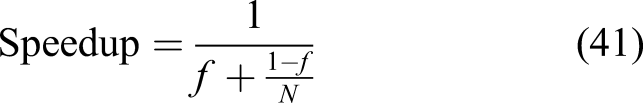
Compute environment
Simulations were conducted on the VSC (Flemish Supercomputer Center) supercomputer with the availability of Intel CPUs in three different micro-architectures: Ivy Bridge, Haswell, and Skylake. Due to a better performance, the strong and weak-scaling measurements were solely performed on the Skylake nodes. On this supercomputer, we made use of 9 nodes, 36 cores each, with 1.7 TB of the total memory, each node holding 2 Intel Xeon Gold 6132 CPUs with a base clock speed of 2.6 GHz. The supercomputer uses CentOS 7.6.1810 with kernel version 3.10.0. For interprocess communication, Intel’s MPI implementation 2018 was used.
Results
Numerical simulation results
The performed numerical simulation produces the output of three main quantities: the concentration of the Mg ions in the medium [as the solution of equation (10)], the concentration of the protective film [as the solution of equation (11)], and the level set function values at each element [as the solution of equation (17)]. In addition to this, a quantitative prediction of the mass loss is also generated according to equations (38) and (39).
In order to have quantitative predictions, the coefficients of equations (10) and (11) (diffusion rates and reaction rates) should be calibrated using an inverse problem. Figure 7 shows the results produced by the computational model after this parameter estimation stage. A narrow layer of the protective film is formed on the surface of the Mg block, and the volume of produced hydrogen gas is compared with values obtained from experiments. Additionally, by plotting the zero iso-contour of the level set function, we can obtain the shape of the material block as it degrades during the degradation process (i.e., tracking the moving corrosion front). This is depicted by the gray surface in Figure 7. Numerical simulation result. Left: formation of a protective layer on the surface of the Mg block (red region). Right: comparison of the produced hydrogen (a surrogate for the material loss) in the computational model and the experimental data, which is a validation of the full model as both the reaction–diffusion equations and the level set equation are involved in the computation of this quantity.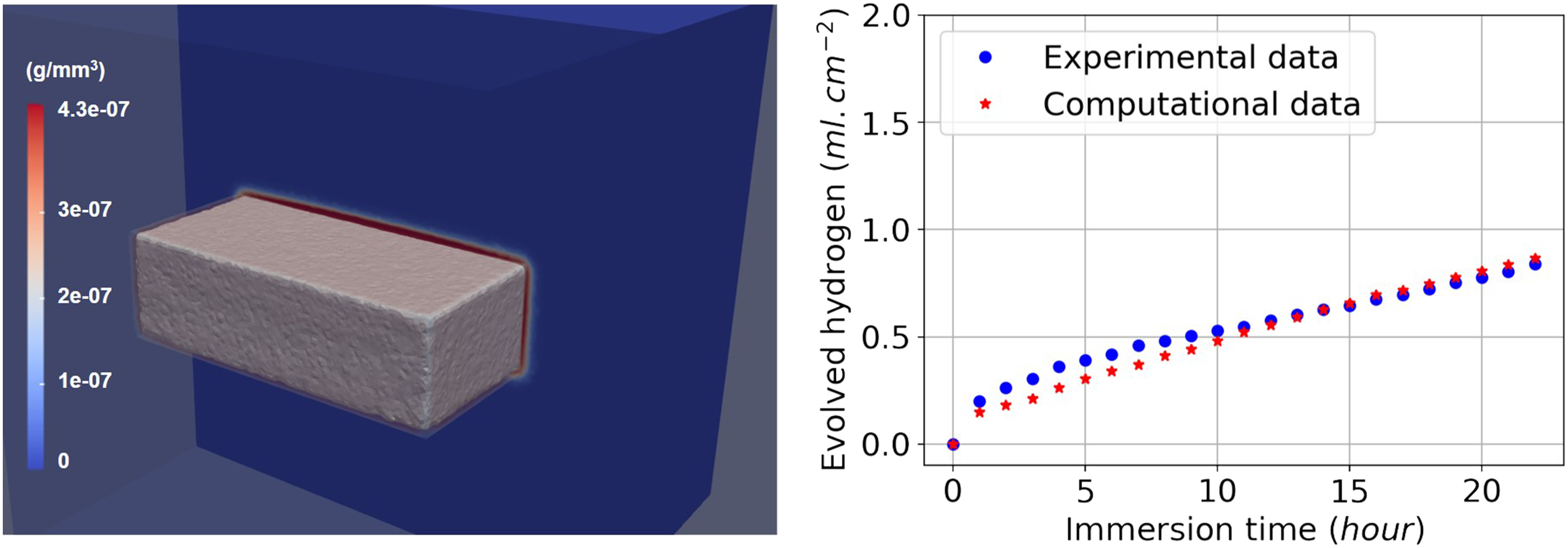
Weak and strong-scaling results
Weak-scaling results are plotted in Figure 8, in which the execution time of each time step is broken down into the time spent on each PDE. The results show good scalability of the parallel implementation. Weak-scaling test result. Results are broken down into contributions for each PDE, which are plotted cumulatively and separately in the left and right plot, respectively.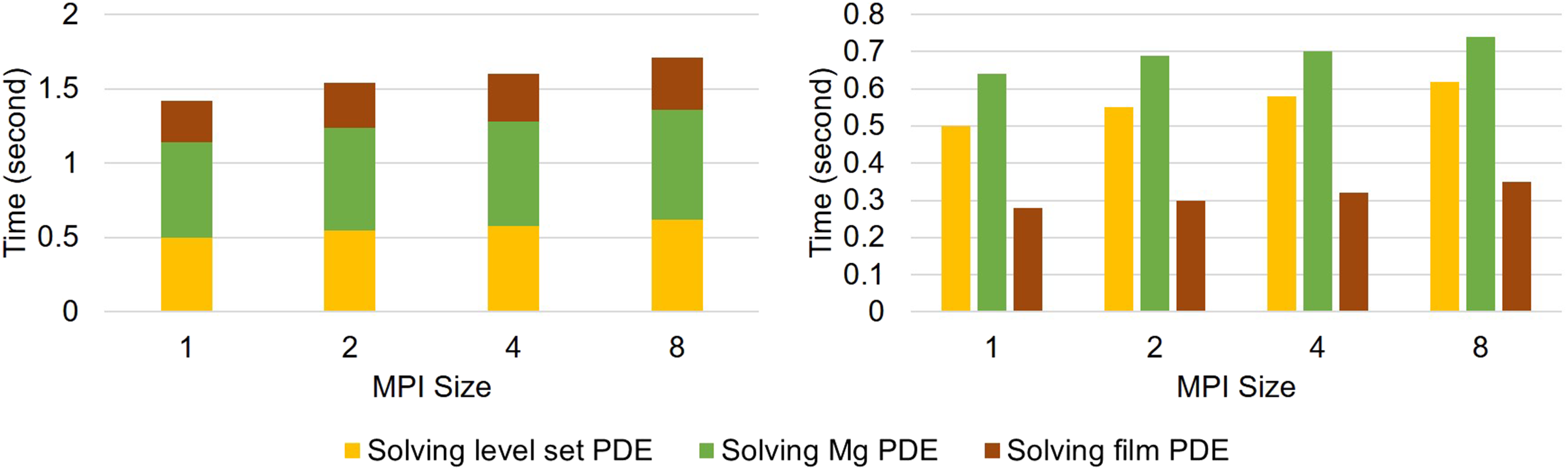
Speedup and parallel efficiency of the weak-scaling experiment is plotted in Figure 9. By fitting a curve based on the Gustafson equation [equation (40)] on the obtained results (Figure 9), the sequential proportion of the current implementation was calculated to be 18%, which means that 82% of the code can be parallelized, which is a proper but not an ideal scalability. Speedup and parallel efficiency of the weak-scaling experiment. The orange line in the left plot shows the fitted curve based on the Gustafson equation.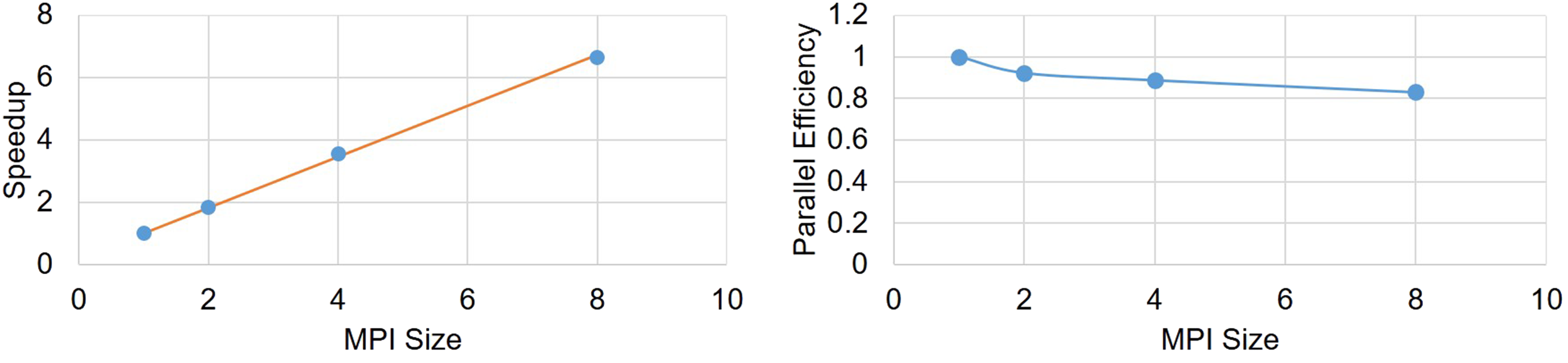
The strong-scaling results are plotted in Figure 10, which shows a better scalability in comparison to the weak-scaling test. For a better representation, exact measured values are presented in Table 1. Strong-scaling test result. Results are broken down into contributions for each PDE, which are plotted cumulatively and separately in the left and right plot, respectively. Strong-scaling test result, presented by the execution time of each PDE in simulations with a different number of employed MPI cores.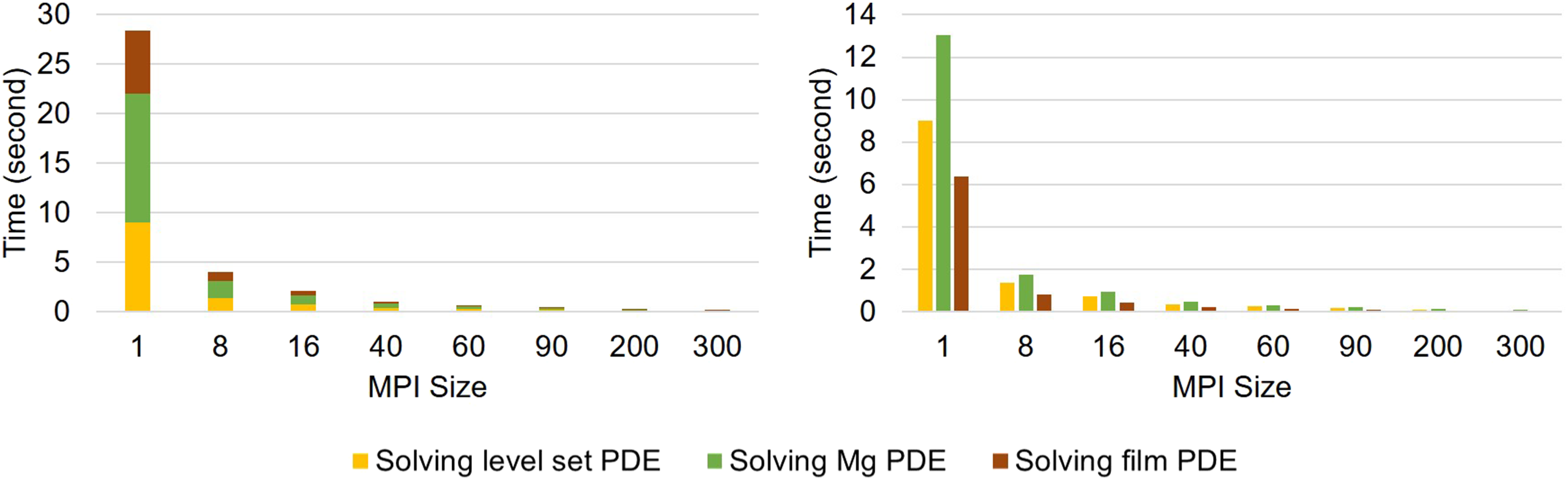

Similar to weak-scaling results, Figure 11 demonstrates the speedup and parallel efficiency of the developed code for strong-scaling evaluation. From the results, it is obvious that increasing the number of cores leads to a better performance but a lower efficiency. By fitting Amdahl’s equation [equation (41)] on the obtained speedup results (Figure 11), f was obtained as 0.01, which means in strong-scaling terms that 99% of the code can run in parallel. Speedup and parallel efficiency of the strong-scaling experiment. The orange line in the left plot is the fitted equation based on the Amdahl rule.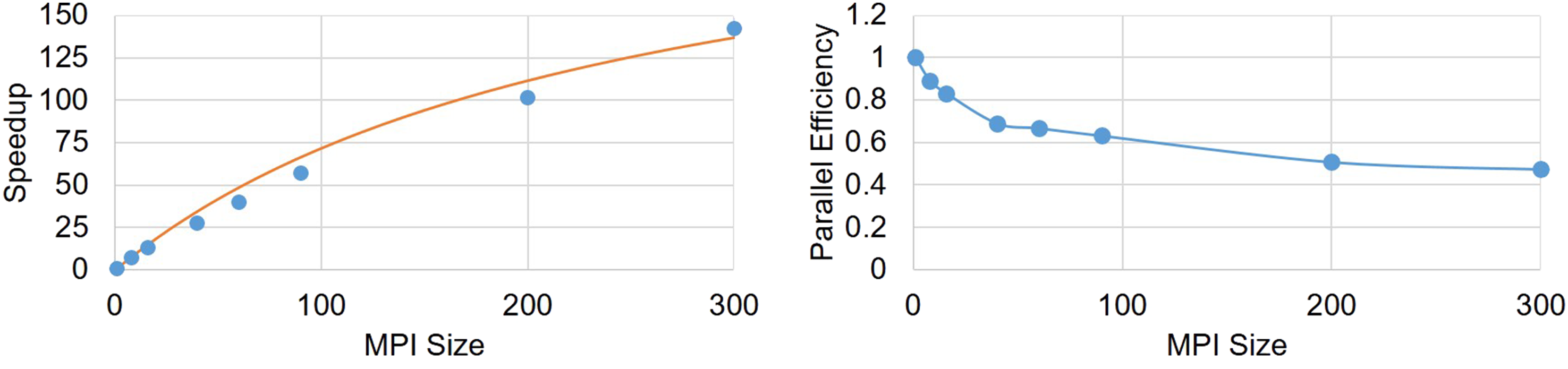
Discussion
In this investigation, the derivation and implementation of a reaction–diffusion model with moving boundaries were presented. Such an approach finds application in many scientific and engineering problems. The target application in the current work was the degradation of a bulk metal cuboid in a liquid environment, specifically Mg in an aqueous ion solution as a representative for temporary medical devices. The simulations were based on the corrosion of Mg metal to Mg ions to form a film of Mg hydroxide that partially protects the metal block from further degradation except where this film is impacted by reaction with other ions in the environment (such as chloride ion). The reactive moving-boundary problem was cast in the form of equations in which the change of the concentrations of the different chemical components is represented by parabolic PDEs. The coupled equations depend on several kinetic constants that have been calibrated from experiments. The moving interface between the metal bulk and the liquid phase was described by an implicit function using the level set method. The derivation led to equations that require the use of numerical techniques for which a combination of finite difference and finite element methods was implemented. As the required high accuracy on the moving interface results in an increase in computation time, parallelization was crucial for the computational model to decrease the execution time of the simulations. The results of the total execution time in each time step (Table 1) clearly indicate that without the parallelization, the simulation of the model is slow and as a result, less interactable for real-world simulation analyses. Considering the properly employed parallelization, the computational time has been decreased noticeably for the investigated case-study.
The output of the conducted numerical simulation demonstrates that the developed mathematical model is capable of capturing the degradation interface movement and of modeling of the underlying chemical phenomena. The predicted mass loss is in line with the experimental results, and the simulated corrosion behavior is as expected for such a system. It is worth noting that the chosen system is highly idealized as a model for medical devices. A more realistic chemical environment would contain many more species that play a role in the formation of either soluble ions or the protective film. Moreover, in real-world scenarios, corrosion occurs in a more complex way than the simplified one described in this paper, which will have a significant influence on the local concentration of ions in the regions close to the solid surface. Nevertheless, the developed framework is capable of capturing these physical and chemical phenomena in the future by simply adding the appropriate terms to the base PDEs without any major changes in the computational model. Furthermore, although it requires some changes to the parallelization approach, the addition of the fluid flow around the block is feasible by adding convective terms to form a reaction–diffusion-convection system. Such a system can be used to model relevant systems such as experimental bioreactor setups in biology and medical sciences.
The parallel algorithm was implemented using a domain decomposition method. Standard domain decomposition preconditioners, such as restricted additive Schwarz, are widely used for parallel implementation of computational models. In a parallel implementation, such preconditioners bring the benefit of relatively low communication costs (Daas et al., 2019). Beside this, the formed linear system of equations in each partition of the mesh was solved using Krylov methods by taking advantage of the highly-efficient preconditioners and iterative solvers of the PETSc library. According to the obtained results, the employed parallelization approach of the current study yields reasonable scaling with respect to the available computational resources (or the number of sub-domains). Out of multiple evaluations, the best performance was achieved using the preconditioner/solver combination of HYPRE/GMRES, which is in agreement with findings in more specific studies in this regard (Ghai et al., 2018).
To evaluate the scaling performance of the implemented parallelism, a set of weak and strong-scaling tests was conducted. In weak-scaling, the main approach is changing the problem size proportional to the change in the available computing resources. In an ideal parallelization, we expect that the speedup remains the same for all the setups because we provide double resources as we double the size of the problem. In strong-scaling, the size of the problem remains constant, but the number of computing units increases. So, in an ideal case, we should observe a double speedup as the number of computing units doubles. By fitting Gustafson’s and Amdahl’s laws on the scaling test results (Figures 9 and 11), the maximum parallelizable portion of the code was calculated to be 82% and 99% for the weak-scaling and strong-scaling tests, respectively. This is a reasonable theoretical scaling for both cases.
The obtained scaling behavior is similar to other conducted studies for diffusion or diffusion-convection systems (Hassan and El-Shenawee, 2011; Rettinger et al., 2017), in which the efficiency of the parallelization decreases with increasing the number of available computational resources. The reason behind this behavior in the current model lies in the mesh partitioning process. Indeed, the mesh is partitioned into semi-equal partitions, each of which has the same number of elements, but the main computation is only carried out on the nodes located outside the degrading material block (i.e., in the medium). In other words, the computational resources assigned to the nodes inside the material bulk do not contribute significantly to the simulation. This limitation can be prevented by modifying the mesh generation process in a way that a lower number of elements be generated inside the material block, but doing this requires remeshing of the interior region as the moving interface approaches it, which imposes even more complexity to the algorithm due to the partitioned mesh. Another bottleneck of the current model, as discussed before, routed in the non-constant right-hand matrix of the linear system [equation (32)], which requires computing the A matrix [equation (33)] in each time step and leads to a slower execution time.
One important point in this regard is that the way that the results are interpreted does not necessarily imply the true scaling behavior of the system. Indeed, it is more like a surrogate model of the system performance. The correct methodology for obtaining true scaling factors is rather starting from an analysis of the code and time used in each routine for a non-parallel run. Then, based on the fraction of routines that are possible to execute in parallel, one can get a theoretical limit for the speedup. This will be reduced by practical limitations such as load balancing and communication costs of the network. Since it is a theoretical limit, it is not fully correct to ignore those extra parts and use the execution time to invert the relation to predict the fraction of the code that is parallel. However, for a complex computational model like the one that was developed in the current study, doing such a measurement of each routine is very difficult due to the complexity of the orchestrated libraries and tools. As a result, we were limited to use the roughly approximated speedup limit to evaluate the scaling of the constructed model. Regarding the scalability results, it is worth mentioning that although having studies with thousands of MPI ranks is more common in this field, due to the limitation we faced in accessing computational resources, the maximum number of employed cores were limited to 300. The goal of the current study was to demonstrate the scalability of the developed model on massively parallel systems, and the behavior of the model in moving from 90 cores to 300 shows the consistency in the performed performance analysis. As a result, we expect to see the same scalability behavior for problems in a larger scale with a higher number of employed computing nodes.
Conclusion
In this work, a mathematical model of a reaction–diffusion system with a moving front was constructed, and the corresponding computational model was implemented using the finite element method. In order to correlate the diffusion phenomenon to the moving-boundary position, high numerical accuracy is necessary at the diffusion interface, which requires a finer discretization of space near the moving front. This leads to an expensive computational model, which makes employing HPC techniques crucial in order to improve the simulation execution time. To this end, a high-performance domain decomposition approach was employed to partition the mesh and distribute the workload to available computing resources. Additionally, an efficient preconditioner/solver combination for reaction–diffusion PDEs was used to optimize the model to be used for the high-performance simulation of large-scale systems in which the movement of system boundaries is controlled by reaction–diffusion phenomena.
The investigated problem was the degradation of a magnesium block inside a solution, in which the surface of the block moves due to the reaction–diffusion phenomena in the metal-medium interface. The implemented model showed a good agreement with the experimental data in terms of the degradation rate and chemical reactions, and the parallel efficiency and linear scalability were appropriate in performance evaluation tests. For the next stage of the study, it could be interesting to evaluate the model and its performance on a much larger system and tune the resources and memory usage by testing different preconditioners and solvers.
Supplemental Material
sj-pdf-1-hpc-10.1177_10943420211045939 – Supplemental Material for Highly scalable numerical simulation of coupled reaction–Diffusion systems with moving interfaces
Supplemental Material, sj-pdf-1-hpc-10.1177_10943420211045939 for Highly scalable numerical simulation of coupled reaction–Diffusion systems with moving interfaces by Mojtaba Barzegari and Liesbet Geris in The International Journal of High Performance Computing Applications
Supplemental Material
sj-pdf-2-hpc-10.1177_10943420211045939 – Supplemental Material for Highly scalable numerical simulation of coupled reaction–Diffusion systems with moving interfaces
Supplemental Material, sj-pdf-1-hpc-10.1177_10943420211045939 for Highly scalable numerical simulation of coupled reaction–Diffusion systems with moving interfaces by Mojtaba Barzegari and Liesbet Geris in The International Journal of High Performance Computing Applications
Supplemental Material
sj-tex-3-hpc-10.1177_10943420211045939 – Supplemental Material for Highly scalable numerical simulation of coupled reaction–Diffusion systems with moving interfaces
Supplemental Material, sj-tex-1-hpc-10.1177_10943420211045939 for Highly scalable numerical simulation of coupled reaction–Diffusion systems with moving interfaces by Mojtaba Barzegari and Liesbet Geris in The International Journal of High Performance Computing Applications
Footnotes
Data accessibility statement
Acknowledgments
The computational resources and services used in this work were provided by the VSC (Flemish Supercomputer Center), funded by the Research Foundation – Flanders (FWO) and the Flemish Government – department EWI.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is financially supported by the Prosperos project, funded by the Interreg VA Flanders – The Netherlands program, CCI grant no. 2014TC16RFCB046 and by the Fund for Scientific Research Flanders (FWO), grant G085018N. LG acknowledges support from the European Research Council under the European Union’s Horizon 2020 research and innovation program, ERC CoG 772418.
Supplementary Material
Supplementary material for this article is available online.
Author biographies
Mojtaba Barzegari is a Ph.D. researcher at KU Leuven in Belgium, in the field of computational biomedical engineering. His work is mainly focused on developing mathematical models and high-performance numerical simulations of tissue engineering systems. His research interests include scientific computing, computational tissue engineering, machine learning, and high-performance computing. He has published several peer-reviewed journal papers, conference papers, and book chapters.
Liesbet Geris is Collen-Francqui Research Professor in biomechanics and computational tissue engineering at the University of Liège and KU Leuven in Belgium. Her research focuses on the multi-scale and multi-physics modeling of biological processes. Together with her team and their clinical and industrial collaborators, she uses these models to investigate the etiology of non-healing fractures, to design in silico potential cell-based treatment strategies, and to optimize manufacturing processes of these tissue engineering constructs She has received 2 prestigious ERC grants to finance her research and has received a number of young investigator and research awards.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.