
Abstract
General matrix-matrix multiplications with double-precision real and complex entries (DGEMM and ZGEMM) in vendor-supplied BLAS libraries are best optimized for square matrices but often show bad performance for tall & skinny matrices, which are much taller than wide. NVIDIA’s current CUBLAS implementation delivers only a fraction of the potential performance as indicated by the roofline model in this case. We describe the challenges and key characteristics of an implementation that can achieve close to optimal performance. We further evaluate different strategies of parallelization and thread distribution and devise a flexible, configurable mapping scheme. To ensure flexibility and allow for highly tailored implementations we use code generation combined with autotuning. For a large range of matrix sizes in the domain of interest we achieve at least 2/3 of the roofline performance and often substantially outperform state-of-the art CUBLAS results on an NVIDIA Volta GPGPU.
1. Introduction
1.1. Tall & skinny matrix multiplications
The general matrix-matrix multiplication (GEMM) is an essential linear algebra operation used in many numerical algorithms and hardware vendors usually supply an implementation that is well optimized for their hardware. In case of NVIDIA, this is part of CUBLAS (NVIDIA, 2019a). However, since these implementations are focused on mostly square matrices, they often perform poorly for matrices with unusual shapes.
This paper covers two types of matrix multiplications with tall & skinny matrices, i.e. matrices that are much taller than they are wide. We define skinny as having in the range of
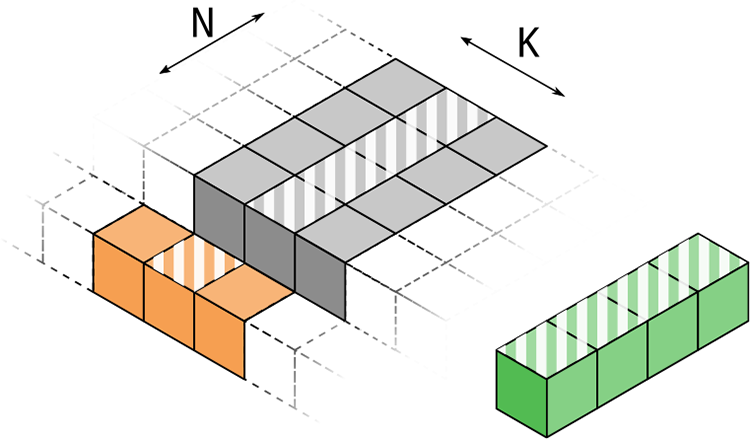
The two variants are shown in Figures 1 and 2: The Tall & Skinny Matrix Transposed times Tall & Skinny Matrix (TSMTTSM) multiplication
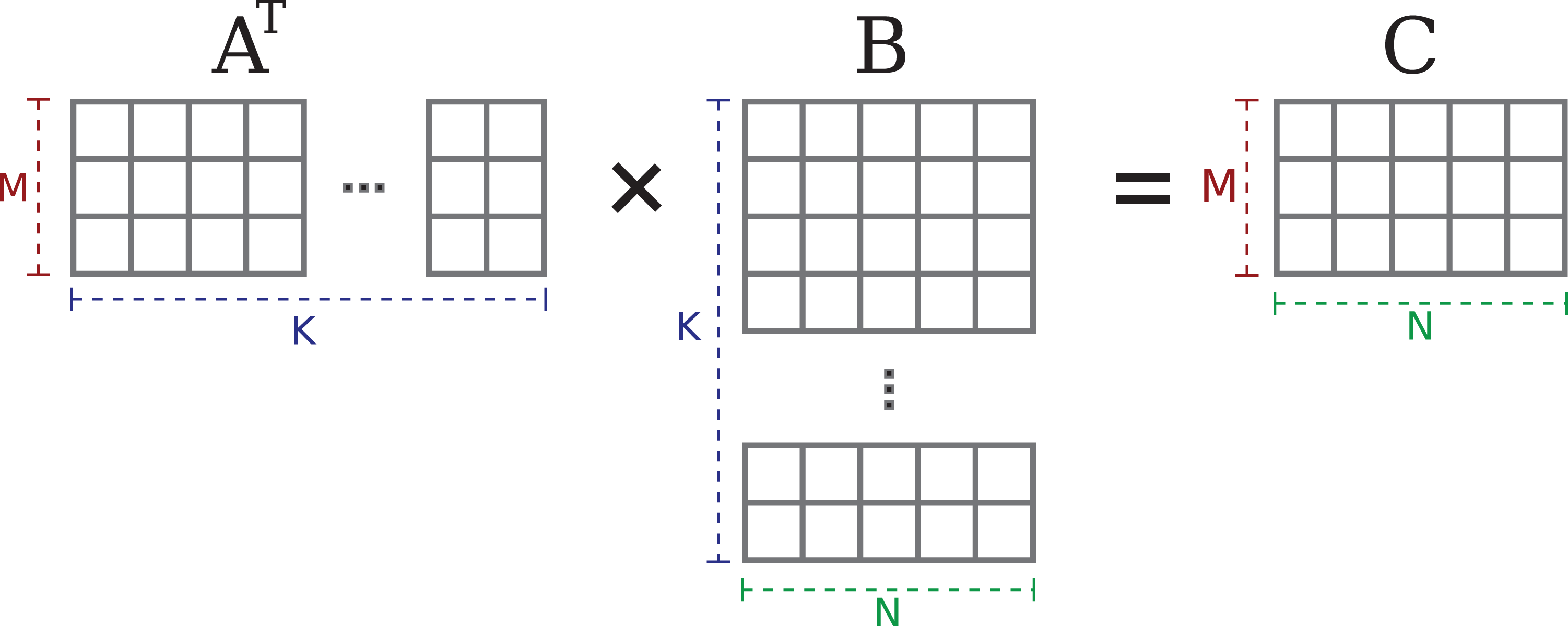
The TSMTTSM operation
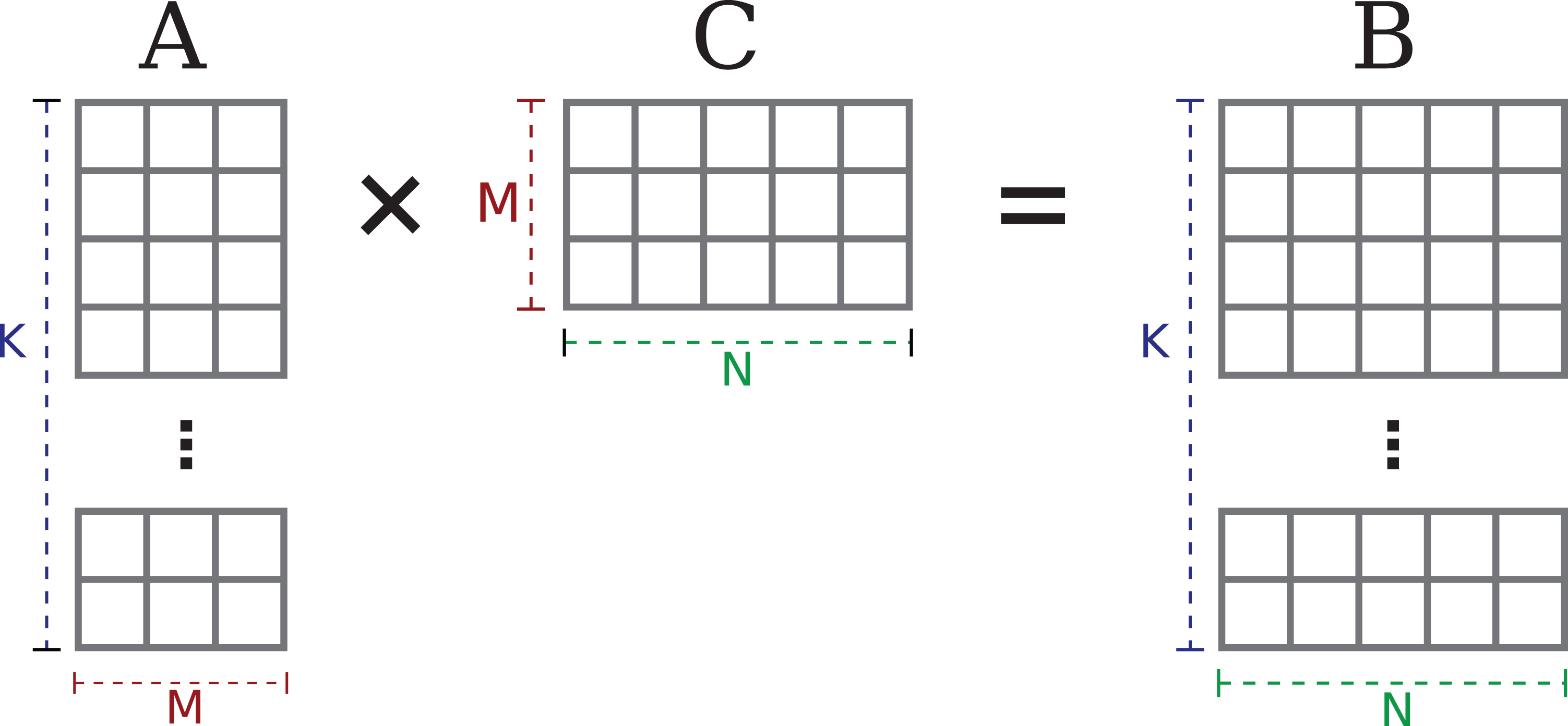
The TSMM operation
1.2. Application
Row-major tall & skinny matrices are the result of combining several vectors to block vectors. Block Vector Algorithms are linear algebra algorithms that compute on multiple vectors simultaneously for improved performance. For instance, by combining multiple, consecutive sparse matrix-vector (SpMV) multiplications to a sparse matrix-multiple-vector (SpMMV) multiplication, the matrix entries are loaded only once and used for the multiple vectors, which reduces the overall memory traffic and consequently increases performance of this memory-bound operation. This has first been analytically shown by Gropp et al. (1999) and is used in many applications; see, e.g. Röhrig-Zöllner et al. (2015); Kreutzer et al. (2018).
The simultaneous computation on multiple vectors can also be used to gain numerical advantages. This has been shown for block vector versions of the Lanzcos algorithm (see Cullum and Donath, 1974), of the biconjugate gradient algorithm (see O’Leary, 1980), and of the Jacobi-Davidson Method (see Röhrig-Zöllner et al., 2015), each of which use block vectors to compute multiple eigenvectors simultaneously. Many such algorithms require multiplications of block vectors. For example, both the TSMTTSM (
1.3. Roofline model
We use the roofline model by Williams et al. (2009) to obtain an upper limit for the performance of these kernels. In all cases, each of the three matrices has to be transferred between the memory and the chip at least once. Even though the directions of data transfers differ between the kernels, the total data volume does not, as GPUs generally do not need a write-allocate transfer. Therefore the arithmetic intensity ID
is the same for both kernels if M and N are the same.
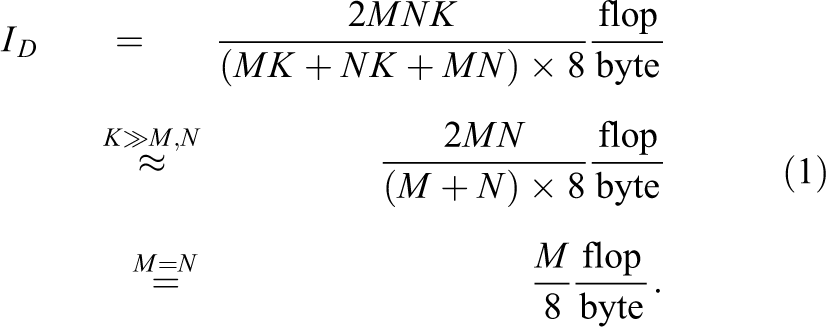
In this symmetric case, the arithmetic intensity grows linearly with M. We will show measurements only for this symmetric case, although the nonsymmetric case is not fundamentally different, with the intensity being proportional to the harmonic mean of both dimensions and consequently dominated by the smaller number. If the achievable memory bandwidth is bs
(see below in Section 1.6), the model predicts
With proper loop optimizations in place, the GEMM is usually considered a classic example for a compute-bound problem with high arithmetic intensity. However, at
It is possible to judge the quality of an implementation’s performance as the percentage of the roofline limit. This metric is shown for CUBLAS in Figures 3 and 4, where the ratio of measured and roofline performance is plotted as a function of the matrix width. There is very little performance improvement headroom for CUBLAS’ TSMM implementation for real-valued matrices, but there is some opportunity for complex matrices. For the TSMTTSM kernel, there is a
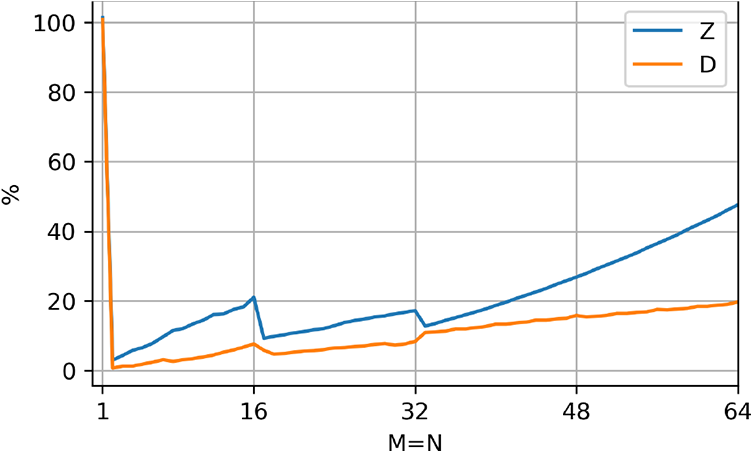
Percentage of roofline-predicted performance achieved by CUBLAS for the TSMTTSM kernel in the range
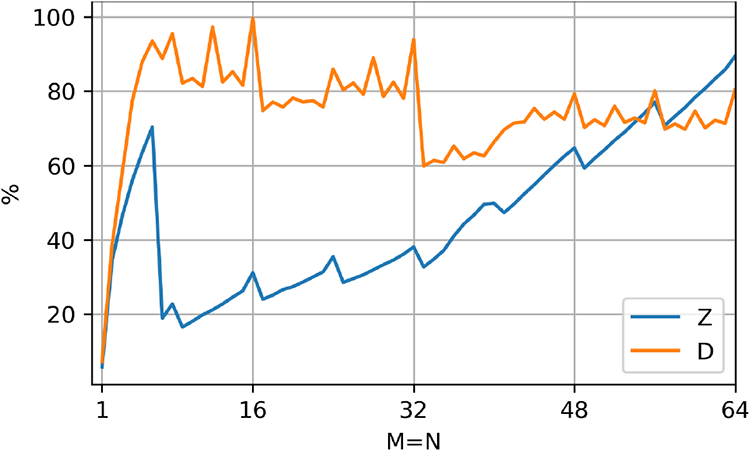
Percentage of roofline-predicted performance achieved by CUBLAS for the TSMM kernel in the range
1.4. Contribution
This paper presents the necessary implementation techniques to achieve near-perfect (i.e., close to roofline) performance for two tall & skinny matrix-matrix multiplication variants on an NVIDIA V100 GPGPU with real- and complex-valued matrices.
To this end, two parallel reduction schemes are implemented and analyzed as to their suitability for small matrices.
A code generator is implemented that produces code for specific matrix sizes and tunes many configuration options specifically to that size. This allows to precompute many indexing and control flow expressions at compile time. As a result, our implementation outperforms state-of-the-art vendor implementations for most of the parameter range.
1.5. Related work
This work is an extended version of Ernst et al. (2020). In comparison to that paper we have added a different variant of matrix-matrix multiplication (TSMM), added a more in-depth performance analysis, extended the analysis to double precision complex data types, and examined a new TSMTTSM thread mapping scheme.
CUBLAS is NVIDIA’s BLAS implementation. The GEMM function interface in BLAS only accepts column-major matrices, but our inputs are row-major. The memory contents of a row-major tall & skinny matrix (TSM)
CUTLASS (NVIDIA, 2019b) is a collection of primitives for multiplications especially of small matrices, which can be composed in different ways to form products of larger matrices. One of these is the
TSM2 (Chen et al., 2019) is another implementation that meets the challenges of tall & skinny matrix multiplication, albeit for a different application case (in our nomenclature it would be MTSM, the multiplication of a large, square matrix with a TSM). Some of the challenges like low arithmetic intensity, data reuse, and the need for a flexible thread mapping scheme are the same.
The Strassen algorithm (Strassen, 1969) for matrix-matrix multiplications was profitably employed by Huang et al. (2016, 2020) on CPUs and GPUs even for comparatively small matrices. However, we decided against employing the Strassen algorithm, because, as the authors of the latter paper point out, “it still trades memory operations (mops) for floating point operations (flops).” The extremely non-square nature of the matrices examined in our work makes the kernels memory bound; hence, the trade-off offered by the Strassen algorithm, i.e. fewer floating point operations in exchange for higher memory data volume, is unfavorable.
1.6. Hardware
In this work we use NVIDIA’s V100-PCIe-16GB GPGPU (Volta architecture) with CUDA 10.1. The hardware data was collected with our own CUDA micro benchmarks, which are available at Ernst (2019) together with more detailed data.
1.6.1. Occupancy
The V100-PCIe-16GB GPU consists of 80 Streaming Multiprocessors (SM), each of which has four quadrants with a scheduler and execution units. Similarly to CPUs with simultaneous multi-threading (SMT), each scheduler does not run just a single warp at a time but selects from up to 16 warps to schedule the next instruction. The large number of warps to pick from decreases the chance that there is no warp that can currently execute because of dependencies. The ratio of active warps on an SM to the maximum number of active warps supported by the SM is called occupancy. It is limited by the resources required by the warps, first and foremost the number of registers. The compiler can allocate a different number of registers for each program individually. While the compiler tries to minimize the number of allocated registers in order to maximize occupancy, this is often impossible beyond some point without spilling of registers to memory or generating non-optimal machine code.
For the maximum occupancy of 100% (64 warps per SM or 16 per quadrant), each thread must not allocate more than 32 registers. At the maximum amount of 256 registers per thread, only eight warps per SM or two warps per quadrant can be run simultaneously.
1.6.2. Memory bandwidth
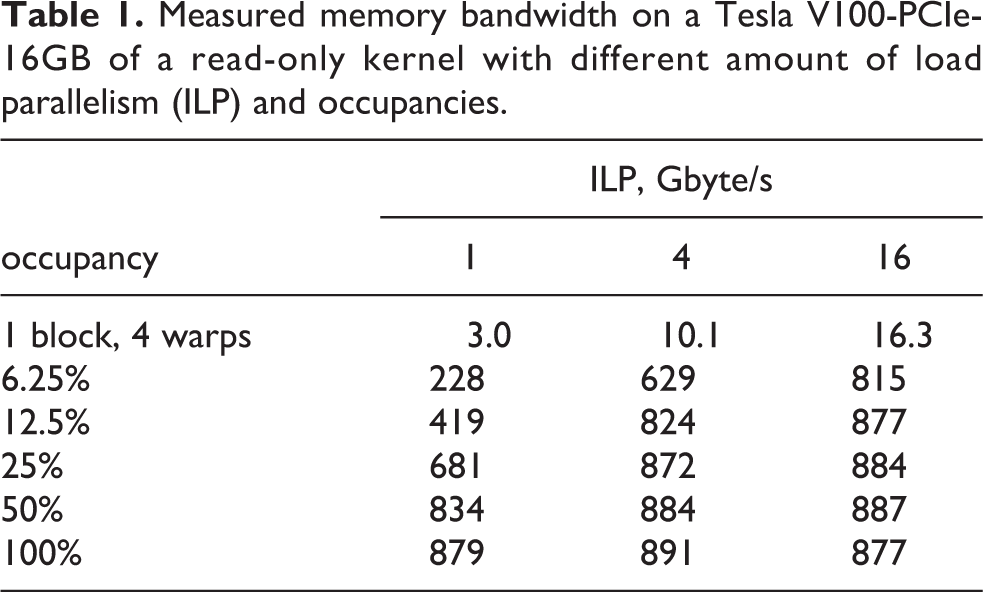
Whereas the TSMM operation has a read and a write stream and fits well to the “scale” kernel from the STREAM benchmarks (McCalpin, 1995), the TSMTTSM is read-only. We thus use a thread-local sum reduction to estimate the achievable memory bandwidth bs (see Table 1). Read-only has a much higher maximum ceiling of about 880 Gbyte/s, compared to 820 Gbyte/s for a “scale” kernel. Maximum bandwidth is only attainable with sufficient parallelism, either through high occupancy or instruction level parallelism (ILP) in the form of multiple read streams, achieved here through unrolling.
Measured memory bandwidth on a Tesla V100-PCIe-16GB of a read-only kernel with different amount of load parallelism (ILP) and occupancies.
1.6.3. Floating-point throughput
The V100 can execute one 32-wide double precision (DP) floating point multiply add (FMA) per cycle on each of its 80 streaming multiprocessors (SMs) and runs at a clock speed of 1.38 GHz for a DP peak of
1.6.4. L1 cache
The L1 cache is instrumental in achieving the theoretically possible arithmetic intensity. Though load and DP FMA instructions have the same throughput of
1.6.5. Shared memory
The Shared Memory uses the same physical structure on the chip as the L1 cache. It has the same bandwidth, but lower access latency than the L1 cache.
2. General implementation strategies
2.1. Code generation
A single implementation cannot be suitable for all matrix sizes. In order to engineer the best code for each size, some form of meta programming is required. C++ templates allow some degree of meta programming but are limited in their expressiveness or require convoluted constructs. Usually the compiler unrolls and eliminates short loops with known iteration count in order to reduce loop overhead, to combine address calculations, to avoid indexed loads from arrays for the thread-local results, to deduplicate and batch loads, and much more. Direct generation of the intended code offers more control, however. For example, when using a thread count per row that is not a divisor of the matrix width, some threads would need to compute fewer results than others. This is achieved via guarding if statements around computations that would access out-of-bounds elements. These can be omitted wherever it is safe, i.e. all threads compute a valid value, in order to not compromise performance for even, dividing thread mappings. We therefore use a code generating script in Python, which allows to prototype new techniques much quicker and with more control. Many different parameters can be configured easily and benchmarked automatically, for example whether leap frogging and unrolling (see below in Section 3) are used, how the reduction is performed, and what thread mapping to set. The same reasoning for code generation is made by Herrero and Navarro (2006), Huang et al. (2017), and Benson and Ballard (2015).
2.2. Thread mapping options
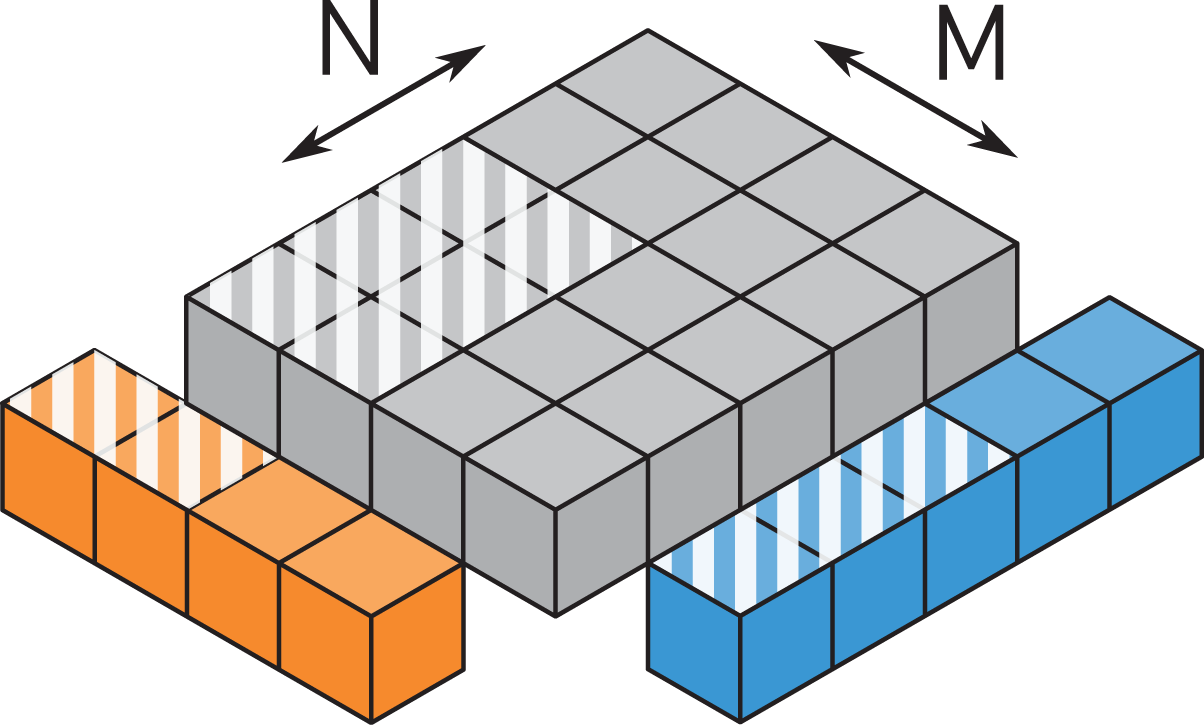
The parallelization scheme, i.e. the way in which work is mapped to GPU threads, plays an important role for data flow in the memory hierarchy. The canonical formulation of an MMM is the three-level loop nest shown in Listing 1.
Naive matrix-matrix multiplication (MMM) pseudo code for
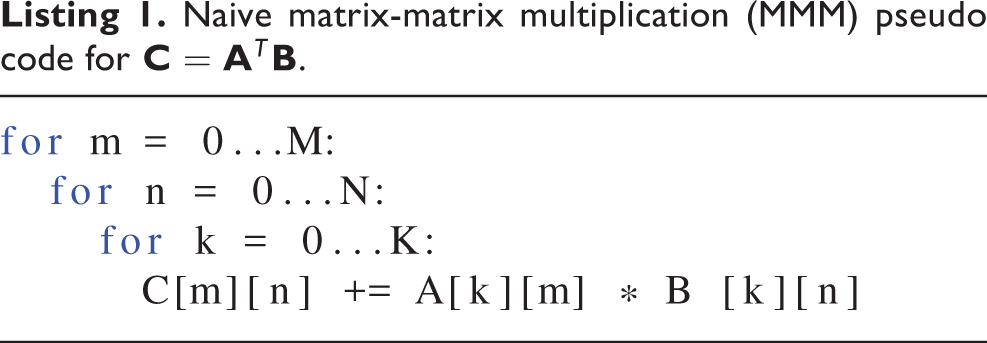
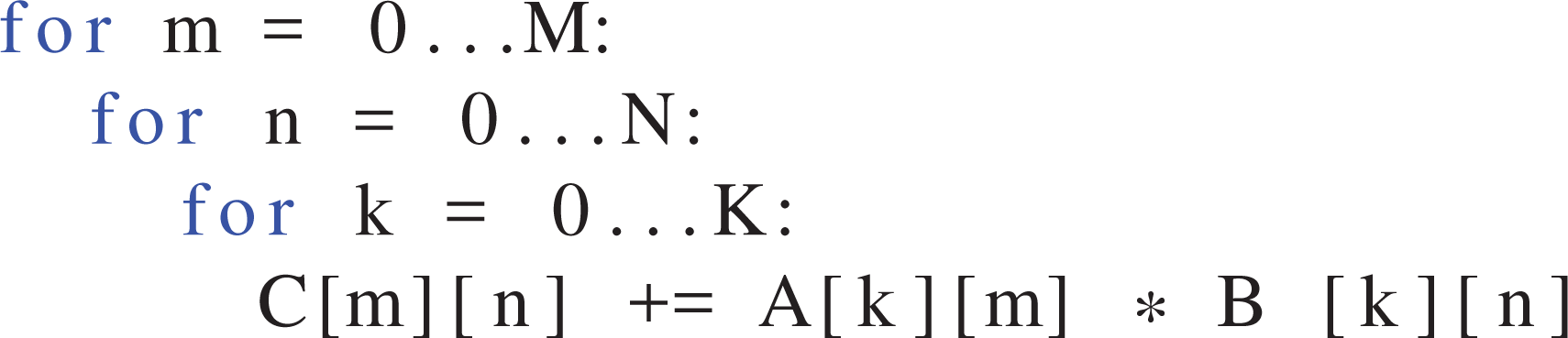
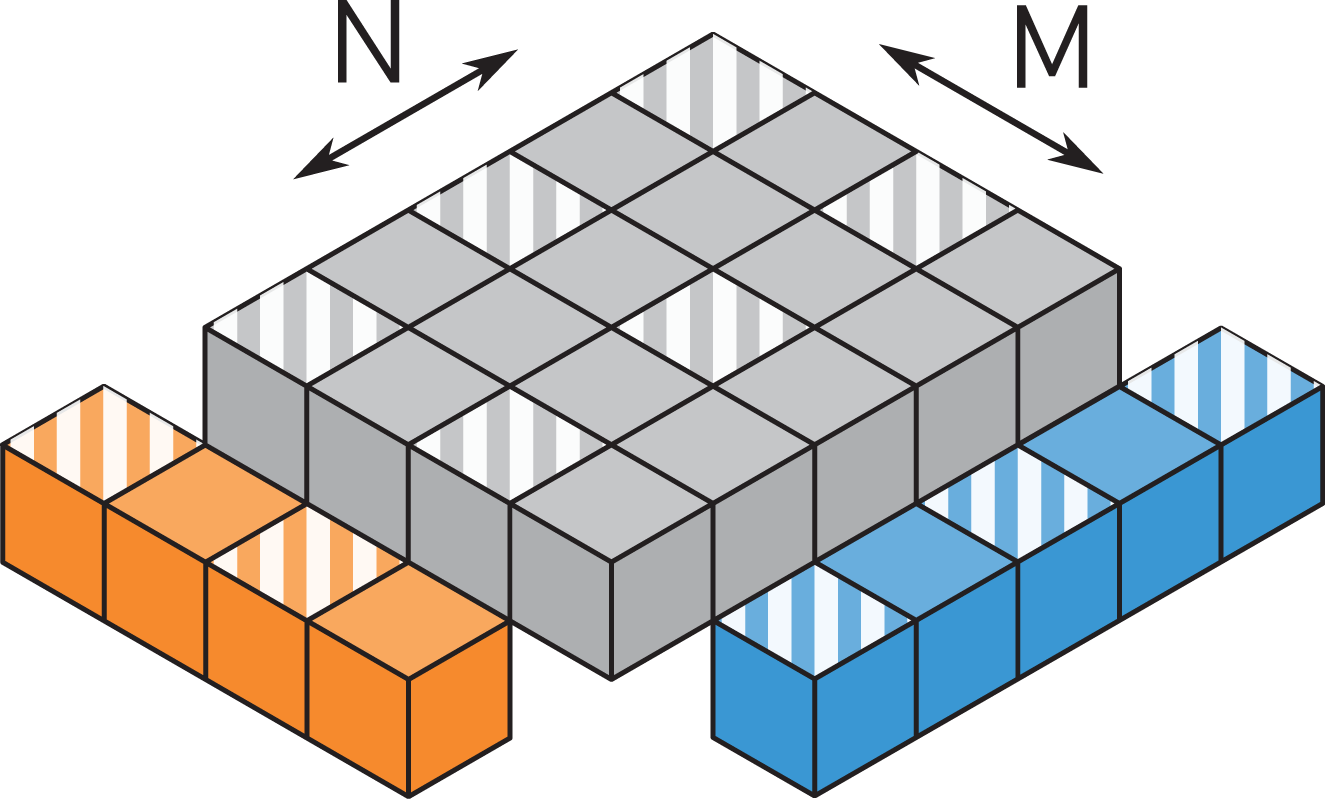
The iteration space of an MMM can be visualized as a cuboid spanned by the outer product of the two matrices being multiplied. For the TSMTTSM (Figure 5), the matrices
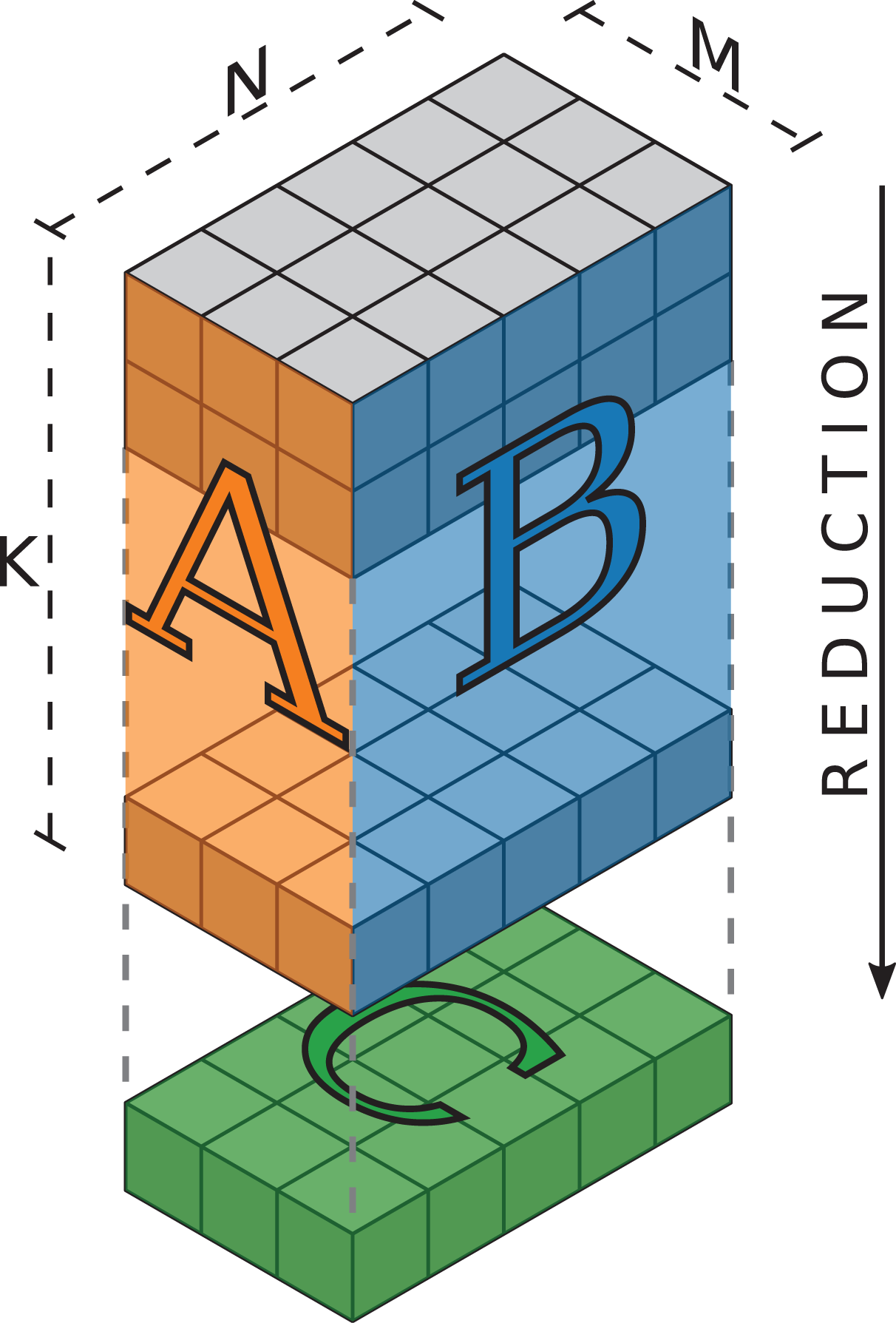
Illustration of the iteration space of the TSMTTSM operation
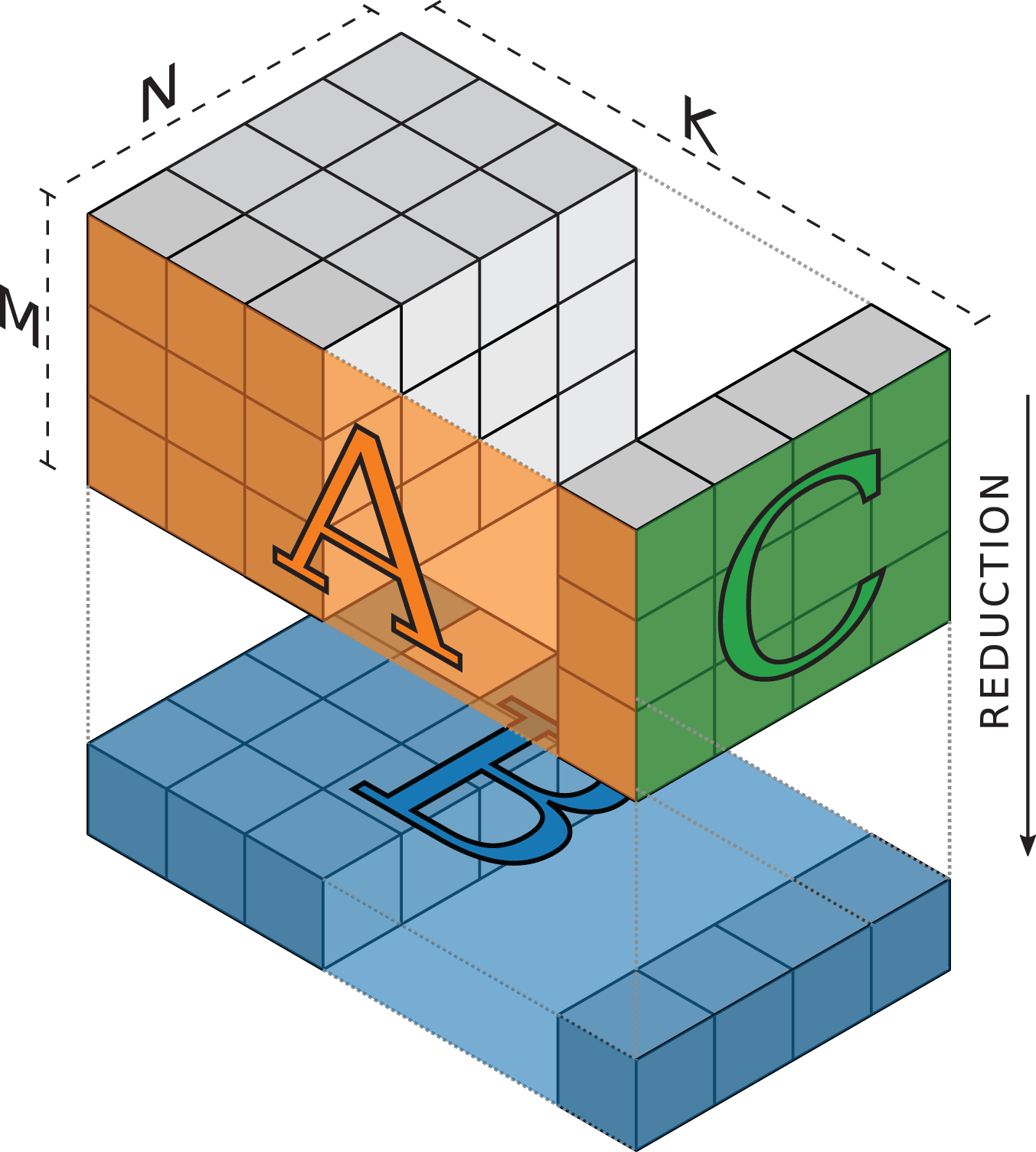
Illustration of the iteration space of the TSMM operation
This representation allows to visualize the locality of data transfers. Looking at a slice of the cube perpendicular to the long K axis spanned by one row of
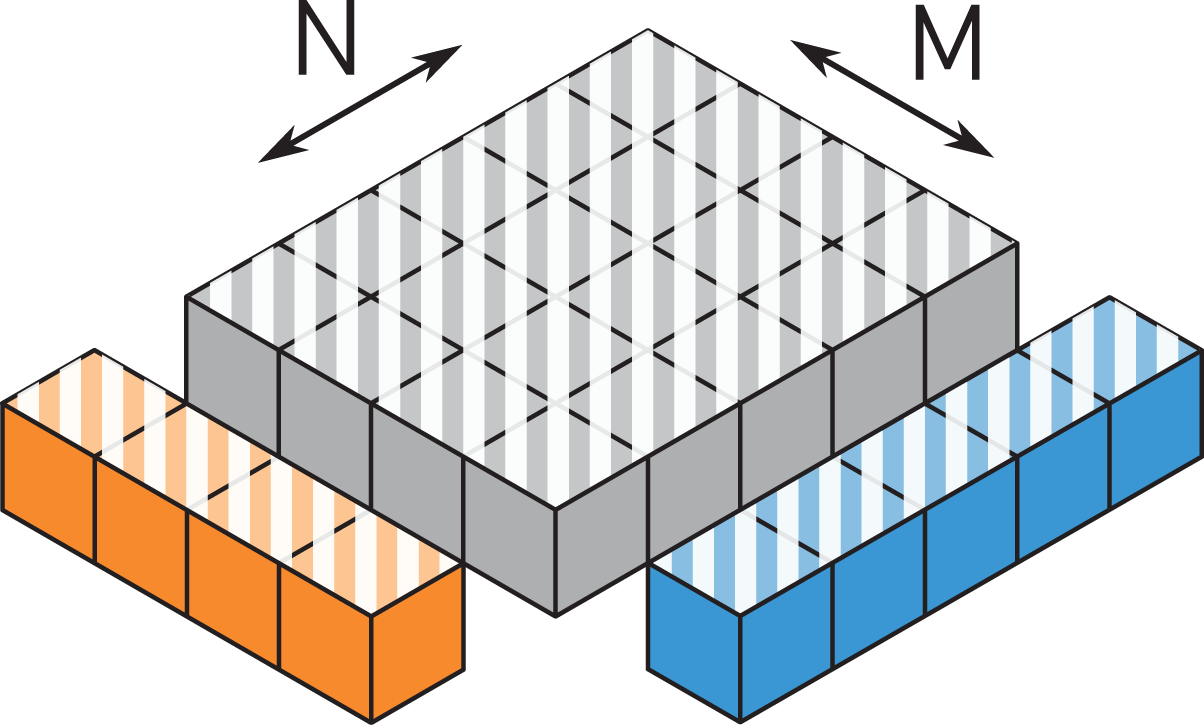
TSMTTSM: Parallelization over K only.
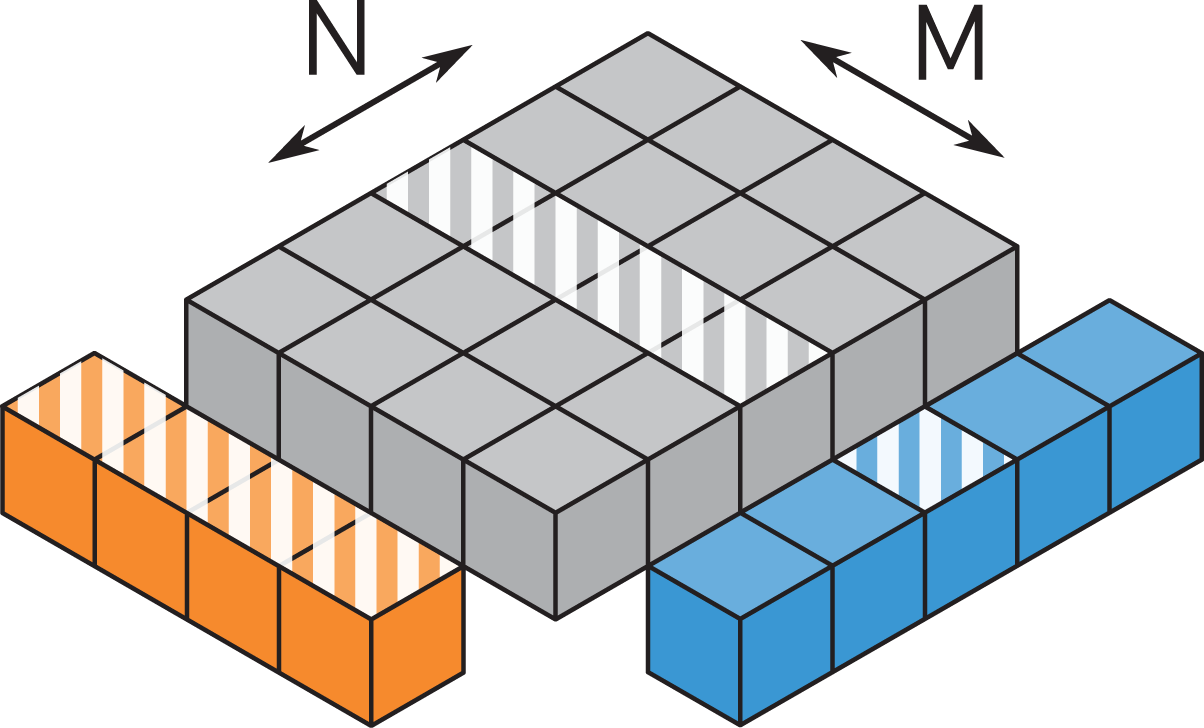
TSMTTSM: Parallelization over the K and N loop.
TSMTTSM: Parallelization over K and tiling of the two inner loops, here with tile size.
The fastest way to reuse values is to use a register and have the thread the register belongs to perform all required operations on this data. Data used by multiple threads can (preferably) be shared in the L1 cache for threads in the same thread block or in the L2 cache otherwise. This works only if some spatial and temporal access locality is in place. Therefore, the mapping of cells, i.e. work, to threads determines which thread requires what data for its computations and the locality of data access.
3. TSMTTSM
For the TSMTTSM, the two outer loops, which are completely independent and therefore well parallelizable, are usually the target of an implementation focused on square matrices. For skinny matrices, these loops are much too short to yield enough parallelism for a GPU. In consequence, the loop over the long K dimension has to be parallelized as well, which also involves parallelizing the sum inside the loop. There are many more terms in the parallel reduction than threads, so that each thread can first serially compute a thread local partial sum, which is afterwards reduced to a total sum (see Listing 2). Here, a so-called grid stride loop, described by Harris (2013), is used to map rows to threads.
TSMTTSM pseudo code, with the K loop parallelized as a grid stripe loop.

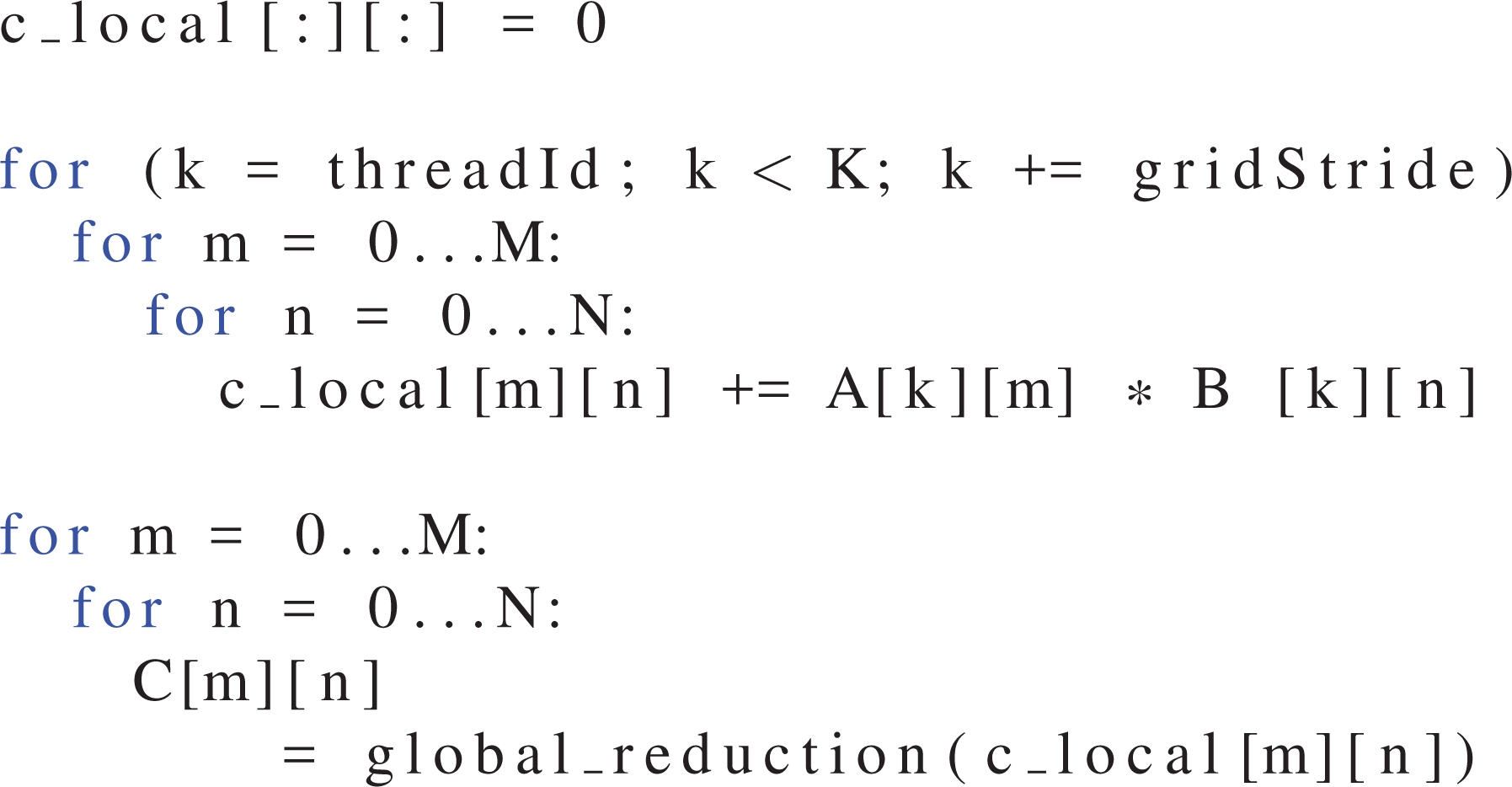
For data locality, the two small loops have to be moved into the K loop. Since they are short loops with constant loop trip count, they can be unrolled completely, which also allows to map the intermediates to local variables instead of indexing into a local array (see Listing 3). Depending on whether and how the two small loops are parallelized, each thread computes only some of these
TSMTTSM pseudo code with parallelized K loop, after unrolling the two inner loops (here shown exemplarily for

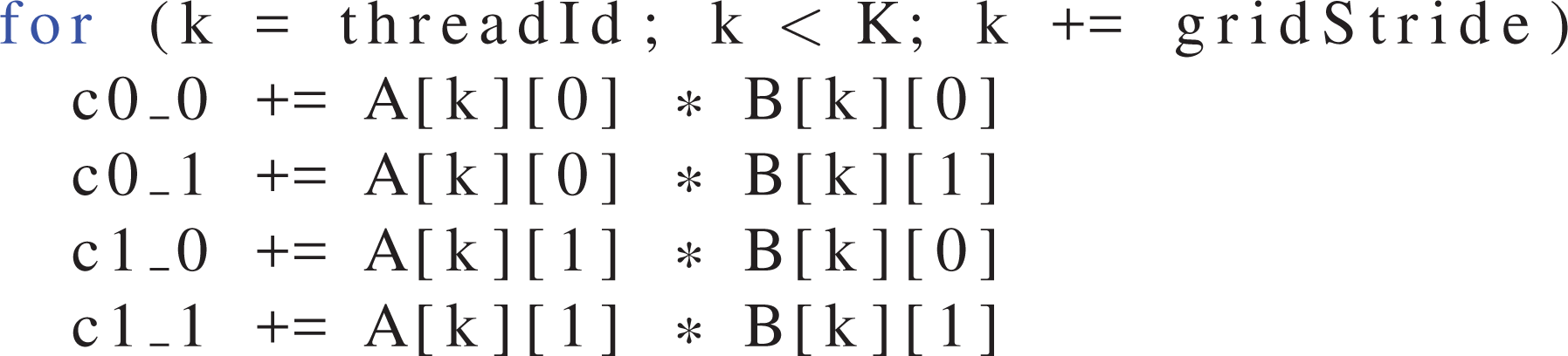
Since the L1 cache is not able to deliver one operand per FMA instruction, a high FMA-to-load ratio is desirable. This can be achieved by maximizing the area and the “squareness” of the area that is computed by a single thread. At the same time, more intermediate results per thread increase the register count, which can limit the occupancy and eventually lead to spilling.
The approach of only parallelizing the K loop (shown in Listing 2 and Figure 7) easily achieves this goal. While it maximizes the arithmetic intensity already in the L1 cache, the
Parallelizing one of the inner loops as well (Listing 4) leads to the pattern shown in Figure 8. The amount of registers required is only M here, so there is no spilling even at
TSMTTSM pseudo code, with the K and N loop parallelized. The global reduction is omitted.

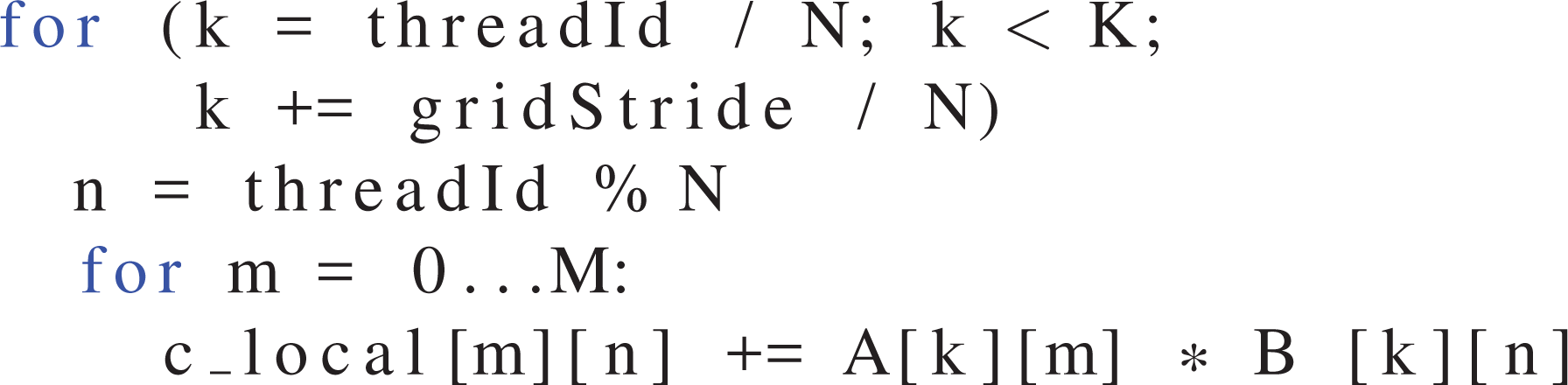
A better approach, which combines manageable register requirements with a more square form of the tile is to subdivide the two smaller loops into tiles (see Listing 5 and Figure 9). This mapping also allows for much more flexibility, as the tile sizes can be chosen small enough to avoid spilling or reach a certain occupancy goal but also large enough to create a high FMA/load ratio. Tile sizes that are not divisors of the small loop dimensions can be covered by generating guarding statements for tile entries that could possibly overlap to only be executed by threads with a tile index that does not extend beyond the border of the slice. This is helpful for matrix dimensions that have few divisors, e.g. prime numbers.
TSMTTSM pseudo code, with tiled M and N loop using tile sizes TM and TN . The global reduction and row calculation in the K loop is omitted.

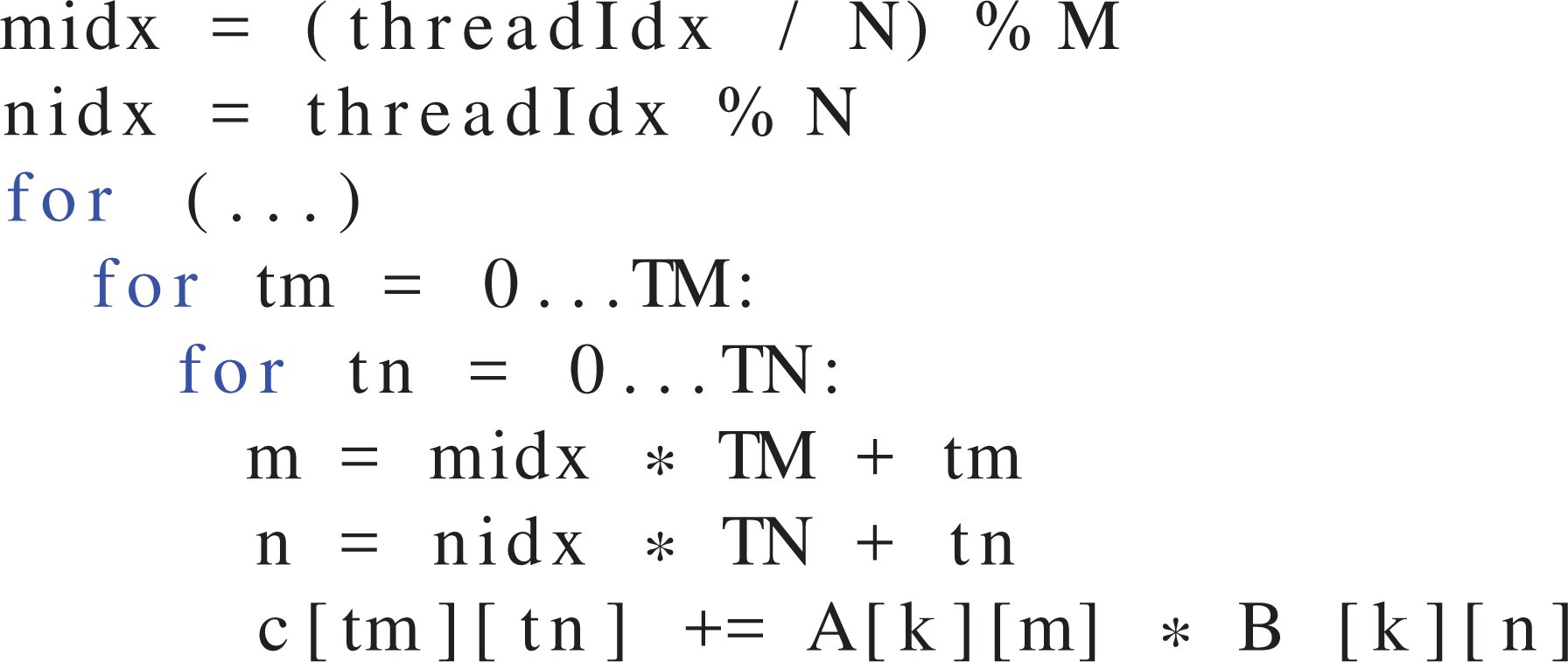
Mapping a continuous range of values to a thread leads to strided loads, which can be detrimental to performance. The same entry in two consecutive threads’ partitions is always as far apart as the tile side length. A more advantageous, continuous load pattern can be achieved by transposing the threads’ tiles, as shown in Figure 10. The elements belonging to a thread do not form a contiguous range anymore but are interleaved. Therefore, when all participating threads load their n-th element, the addresses referenced by that load have a uniform stride. With a transposed mapping, the 2D TSMTTSM mapping from Figure 9 becomes Figure 11.
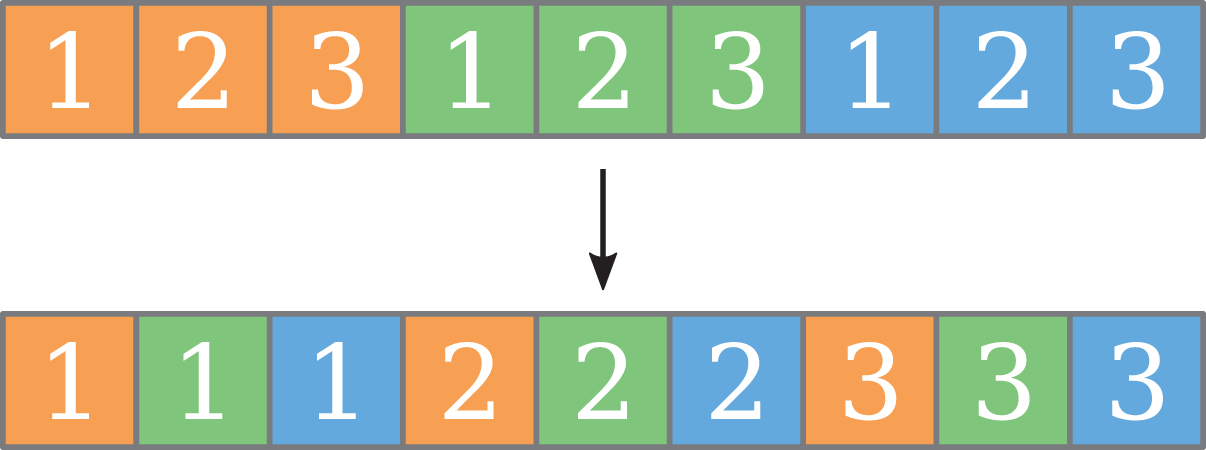
Example for transposing a 1D continuous thread mapping. The colors denote which thread the element belongs to, the numbers are their positions in the thread.
TSMTTSM: Parallelization over K and transposed tiling of the two inner loops, here with tile size
3.1. Leap frogging
On NVIDIA’s GPU architectures, load operations can overlap with each other. The execution will only stall at an instruction that requires an operand from an outstanding load. The compiler maximizes this overlap by moving all loads to the beginning of the loop body, followed by the floating-point (FP) instructions that consume the loaded values. Usually at least one or two of the loads come from memory and thus take longer to complete than other queued loads, so that execution stalls at the first FP instruction. A way to circumvent this stall is to load the inputs one loop iteration ahead into a separate set of next registers, while the computations still happen on the current values. At the end of the loop, the next values become the current values of the next loop iteration by assignment. These assignments are the first instructions that depend on the loads and thus the computations can happen while the loads are still in flight. This is a common technique for loops that iterate over data items, and a similar strategy is also used by Chen et al. (2019) for TSM2.
3.2. Global reduction
After each thread has serially computed its partial, thread-local result, a global reduction is required, which is considered overhead. Its runtime depends only on the thread count, though, whereas the time spent in the serial summation grows linearly with the row count. The time spent for the global reduction therefore becomes marginal for large row counts compared to the time for the serial summation. However, as shown by Thies et al. (2019), the performance at small row counts can still be relevant, as the available GPU memory may be shared by more data structures than just the two tall & skinny matrices, limiting the data set size.
Starting with the Pascal architecture, atomic add operations for double precision values are available for global memory, making global reductions more efficient than on older systems. Each thread can just use an
4 TSMM
4.1. Thread mapping
In contrast to the TSMTTSM kernel, the summation is done along the short M axis, with no need for a global reduction. Though the short sum could be parallelized, this is not necessary in this case, as the other two loop dimensions supply sufficient parallelism. The visualizations in Figures 12 –14 show slices perpendicular to the M axis, since this dimension will not be parallelized.
TSMM: Parallelization over K, a single thread computes a full result row of
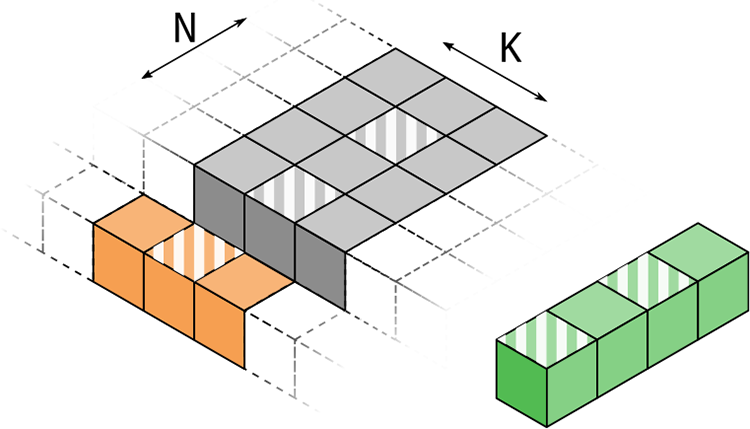
TSMM: Parallelization over K and N, two threads compute two results each. Slice horizontal to the M axis, the (long) K axis extends “indefinitely” on both sides.
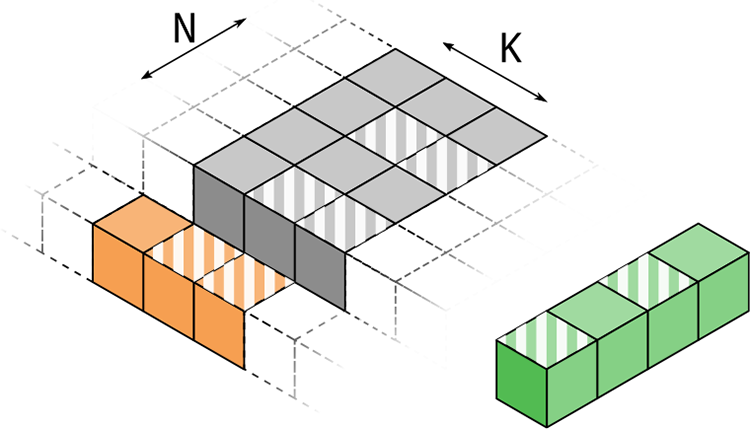
TSMM: Parallelization over K and N and
The first option is to only parallelize over the long K dimension as shown in Figure 12. Each entry in
This can be avoided by parallelizing the N loop. Each thread computes a single result of the output row of
A more balanced approach is to have a smaller group of threads compute on each result row, with a few results computed by each thread. Each value loaded from
4.2. Data from
Our discussion of thread mappings and data transfers so far has ignored the entries of the matrix
The loads from
On the V100, the shared memory has the same bandwidth as the L1 cache, given that they occupy the same hardware structure. However, shared memory accesses guarantee cache hits, as they avoid conflict misses with other data. They also have a lower latency, since no tags have to be checked.
5. Results: TSMTTSM
5.1. Transposition and leap frogging
An exhaustive search was used to find the best tile size and configuration for each matrix size. The simpler mapping schemes are subsets of the tiled mapping. E.g. the mapping in Figure 8 corresponds to a tilesize of
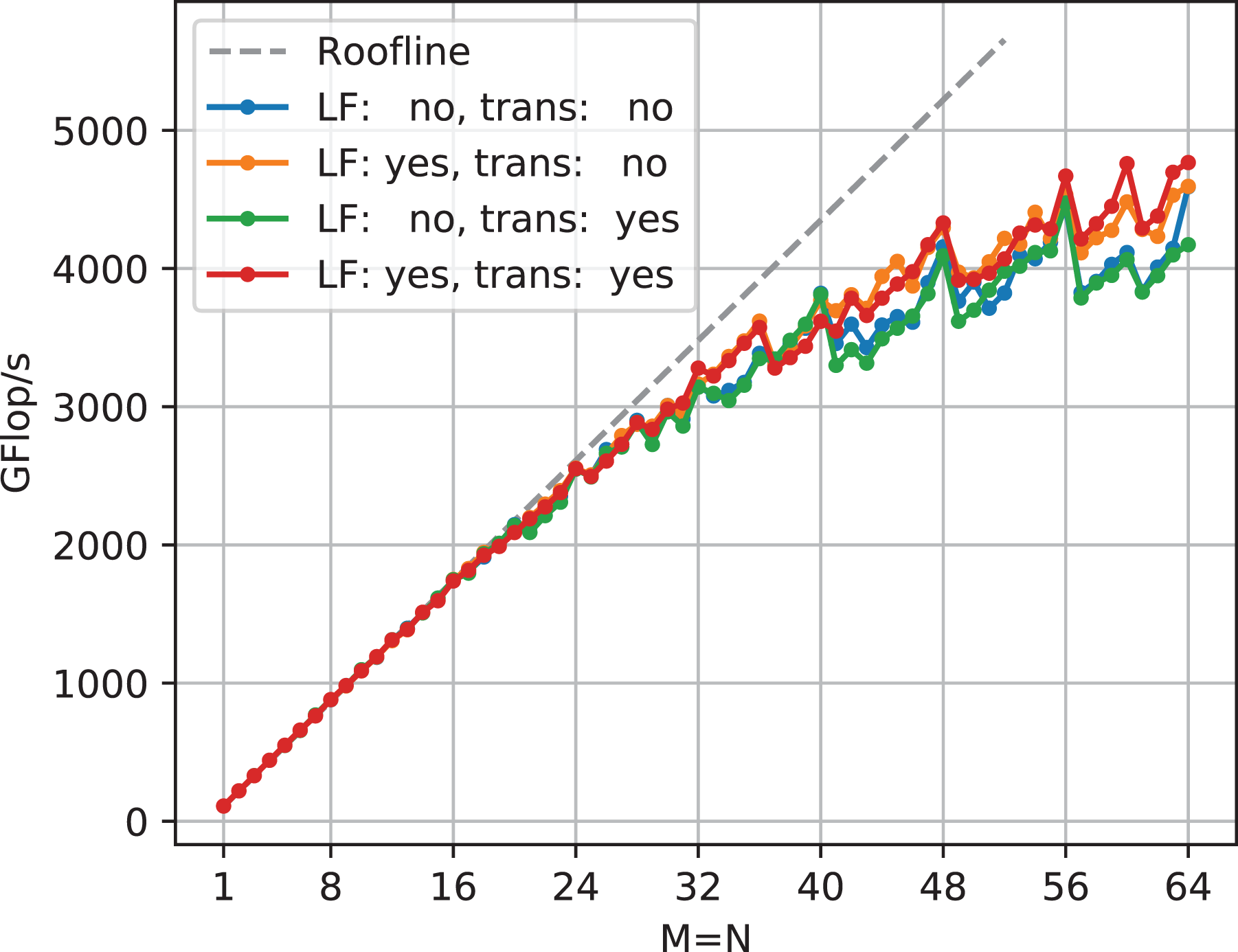
Performance comparison of real-valued double-precision TSMTTSM vs. quadratic tile size with
5.2. Tile sizes
Figure 16 shows the dependence of performance on the tile sizes TM
and TN
for the case
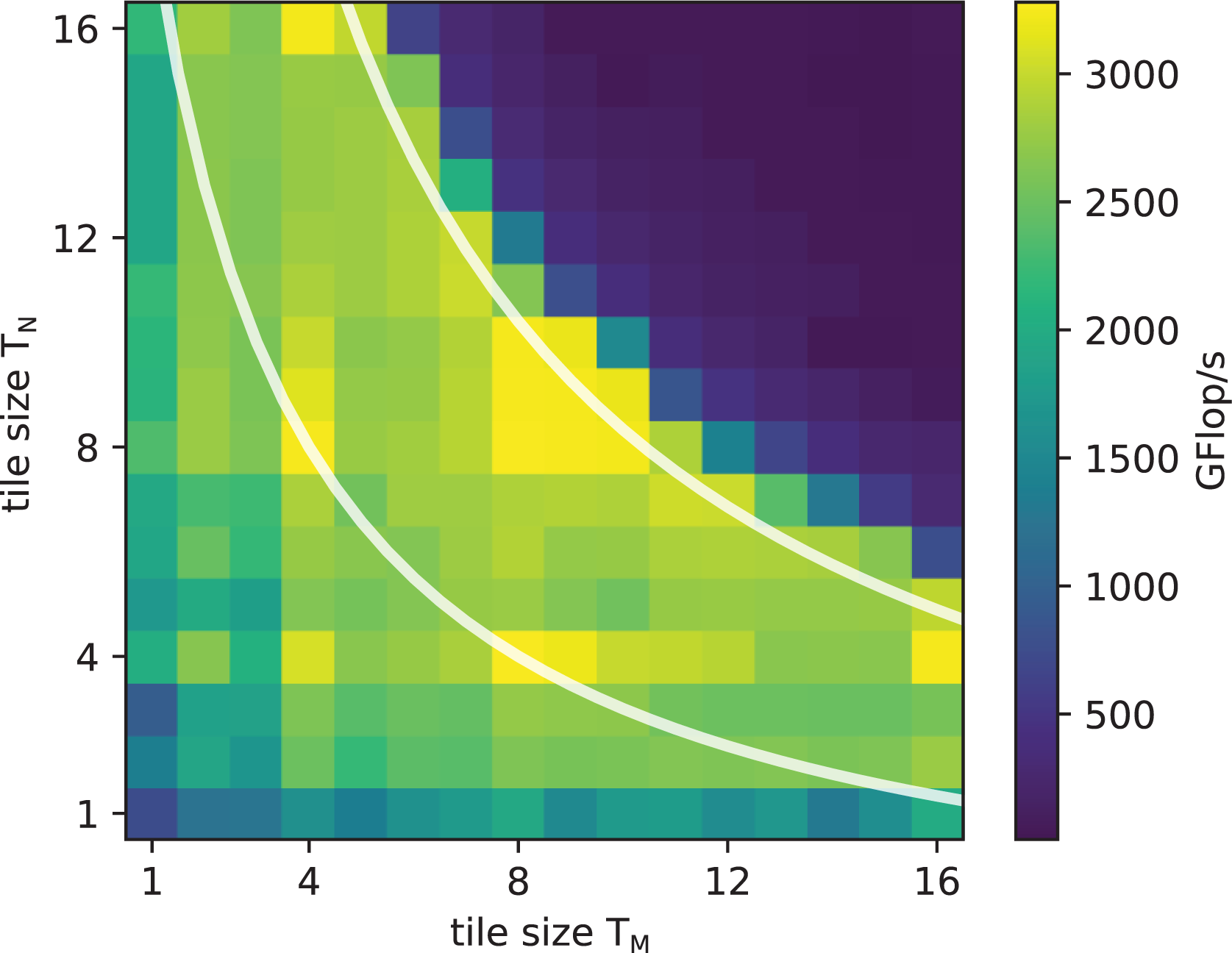
Performance of TSMTTSM for
The best-performing tile sizes generally sit on or just below these lines, maximizing the area of the tile for a given occupancy. The dimensions are largely symmetric but not perfectly so, as threads are mapped to tiles in M direction first. There are clear patterns favoring powers of two as those are divisors of the matrix size 32 and avoid both the overhead of guarding statements and idle threads.
5.3. Analysis
According to the roofline model, at
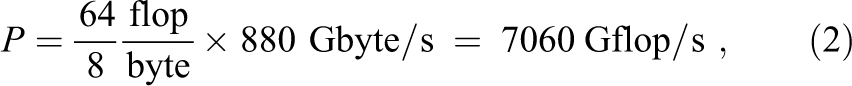
which is almost exactly the
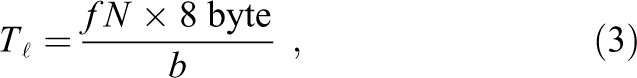
with f being the clock frequency, N the thread count, and b the memory bandwidth. For the unloaded case in the first row of Table 1 (ILP = 1), the latency according to (3) is
The best tile size without leap frogging is
Leap frogging does improve the situation, as even with a single warp the memory latency and compute times can overlap. However, additional registers are required to hold the data for the next iteration, which either necessitates smaller tile sizes or reduces occupancy, both of which are bad for overlapping. Overall, leap frogging is still beneficial, though.
Figure 17 shows an experiment that gives insight into the relationship of latency and occupancy. A modification of the generated kernels allows testing the impact of higher occupancies even for kernels with larger tile sizes, where the high register requirements usually limit the occupancy to the minimum of eight warps per SM. Instead of computing
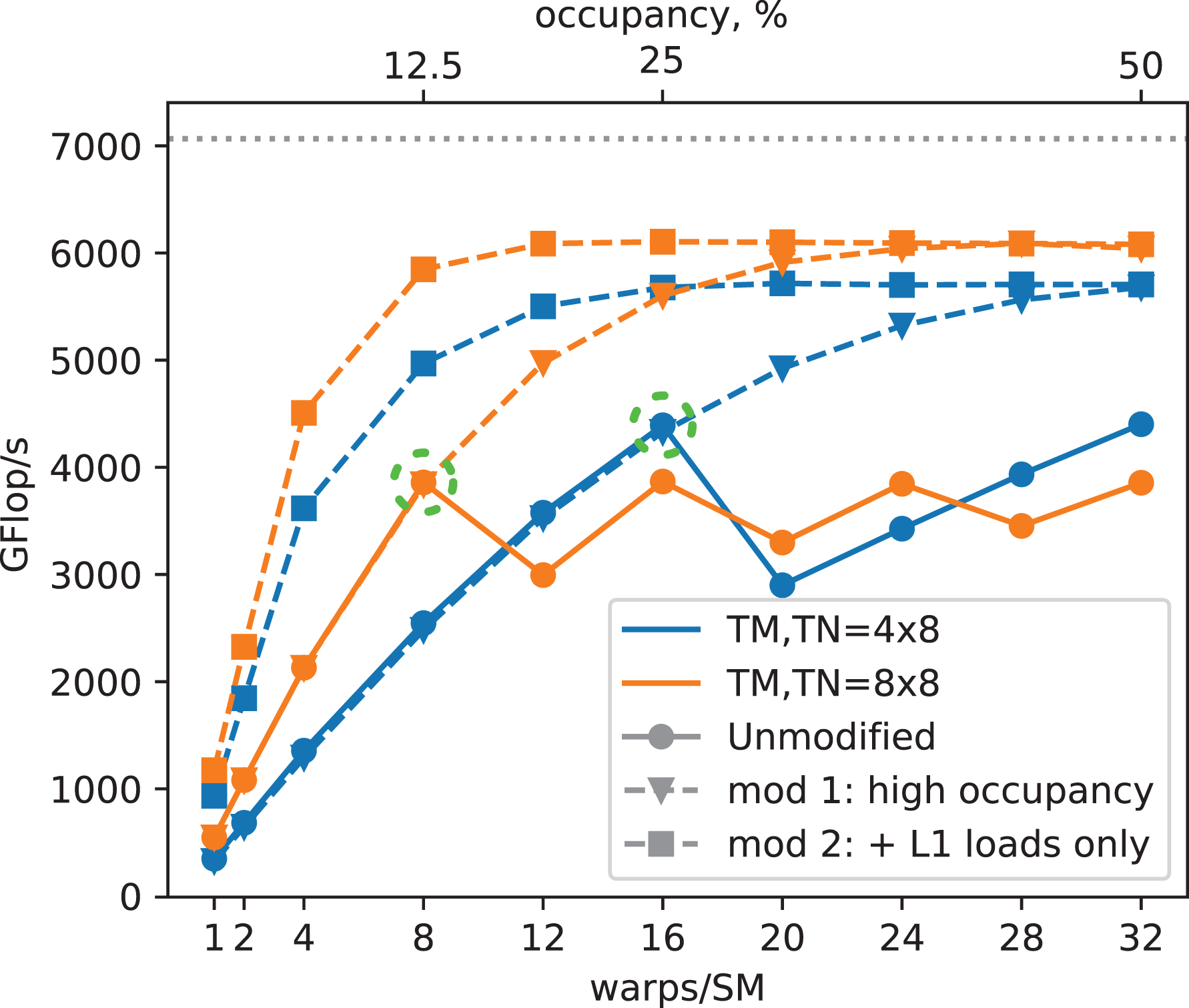
TSMTTSM performance vs. occupancy of real, correct kernels and two modified (incorrect) kernels at tile sizes of
With tile sizes of
The kernels modified for higher occupancy (triangle symbols) have the same performance as the unmodified kernels up to these points, but allow to see the hypothetical speedup if more thread blocks could run concurrently, which would be possible on a hypothetical V100 with four times as many registers.
The performance increase is linear in all cases up to four warps per SM, as this is the minimum to fill all four quadrants of an SM. For both tile sizes, the L1 load kernels (square symbols) profit somewhat from a second warp on each quadrant to overlap the remaining latency and overhead but quickly saturate at ceilings of
The two experiments with the normal, higher latency from memory (triangular symbols) need many more warps to overlap their longer latency to eventually saturate at the same level as the L1 load kernels. At least two to three times larger register files would be required to get there. At the same time, it also shows how devastating it would be if the register files were half as large, a situation that is not dissimilar to the older Kepler GPU architecture, where double the number of execution units were backed by a similar sized register file. The larger tile size saturates more quickly, because it amortizes the same latency over twice the number of floating-point operations. Note that in the end, both tile sizes have a similar real-world performance, as the higher possible occupancy of 16 warps per SM compared to 8 warps per SM balances the smaller amount of work per iteration.
This simple model also helps to explain the rather small benefits from using the transposed mapping. The transposed mapping changes the load pattern to contiguous blocks instead of long strides. This in turn reduces the number of touched cache lines, and increases the rate at which the L1 cache can serve the outstanding loads after the data has arrived from memory. However, this rate is only really a limiter at low FMA/load ratios, or at the beginning of the floating-point operation phase, where the FP units still wait for enough registers being filled for uninterrupted operation. The transposed mapping therefore only gives a small speedup in the phase that is mostly not the limiter, but at the same time also makes smaller tile sizes more feasible.
On the other hand, the strided access patterns of the nontransposed mapping touch most cache lines already on the first load, and therefore already cause most cache misses with the first load. Subsequent loads are cache hits. With the transposed mapping, with its contiguous blocks of addresses per load, cache misses are postponed until later loads, which starts the memory latency penalty later. That is why the configuration using the transposed mapping without leap frogging performs worst (see Figure 15). However, in combination with leap frogging it is faster than the two variants with the nontransposed mapping.
5.4. Comparison with libraries
Both CUBLAS’ and CUTLASS’ performance (see Figure 18) is far below the potential performance, except for
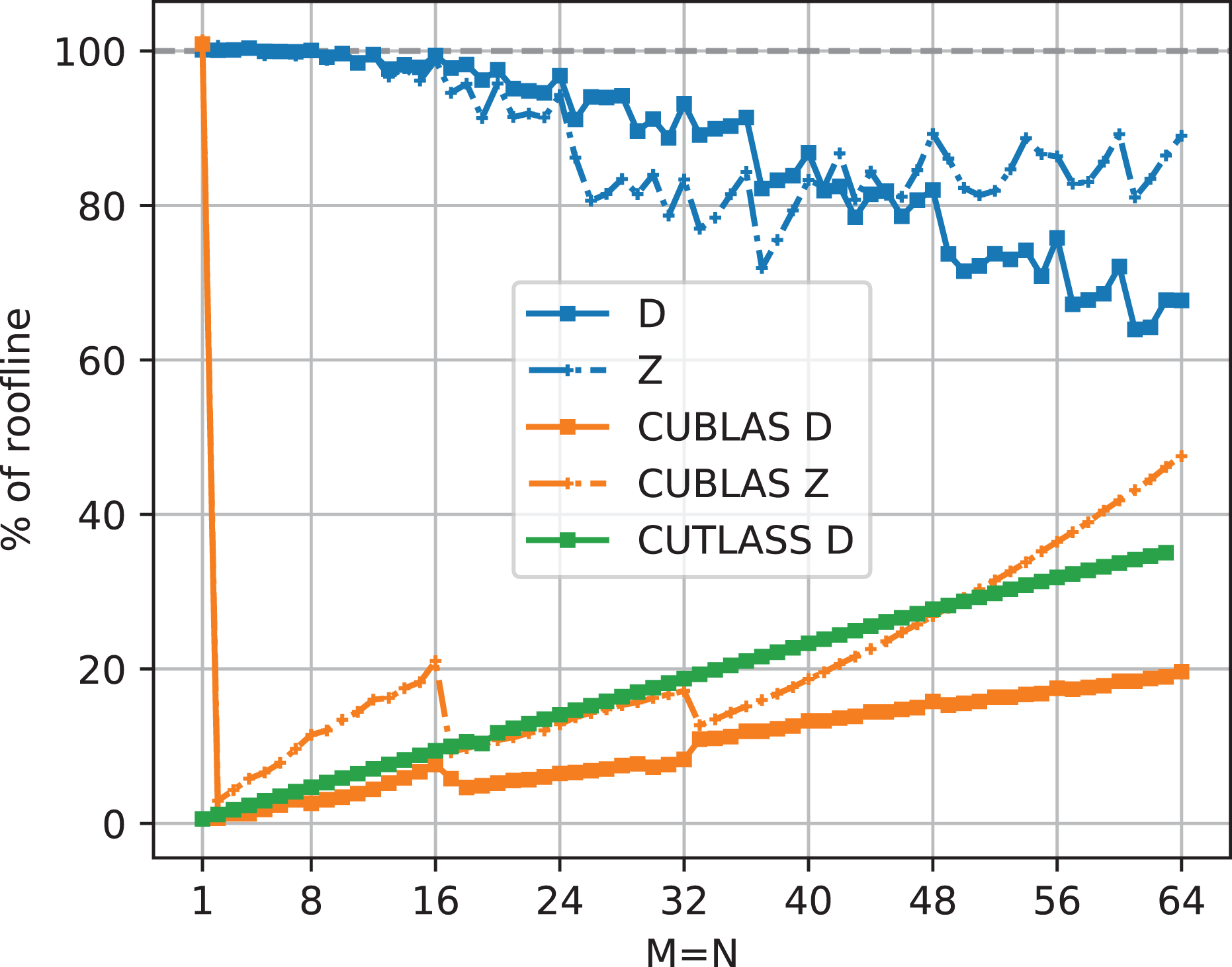
TSMTTSM percentage of roofline-predicted performance for real (D) and complex (Z) double-precision data in comparison with CUBLAS and CUTLASS.
In contrast, the presented implementation shows full efficiency for narrow, clearly memory bandwidth limited matrices, and utilization slightly drops off as matrices become more compute bound. For complex-valued matrices, the TSMTTSM becomes compute bound already at
5.5. Impact of reductions
Figure 19 shows the relative performance of our TSMTTSM implementation versus row count with respect to a baseline without any reduction for a selection of inner matrix sizes and tile sizes, choosing either of the two reduction methods described in Section 3.2. As expected, the impact of the reduction generally decreases with increasing row count. The method with only global atomics is especially slow for the narrower matrices (
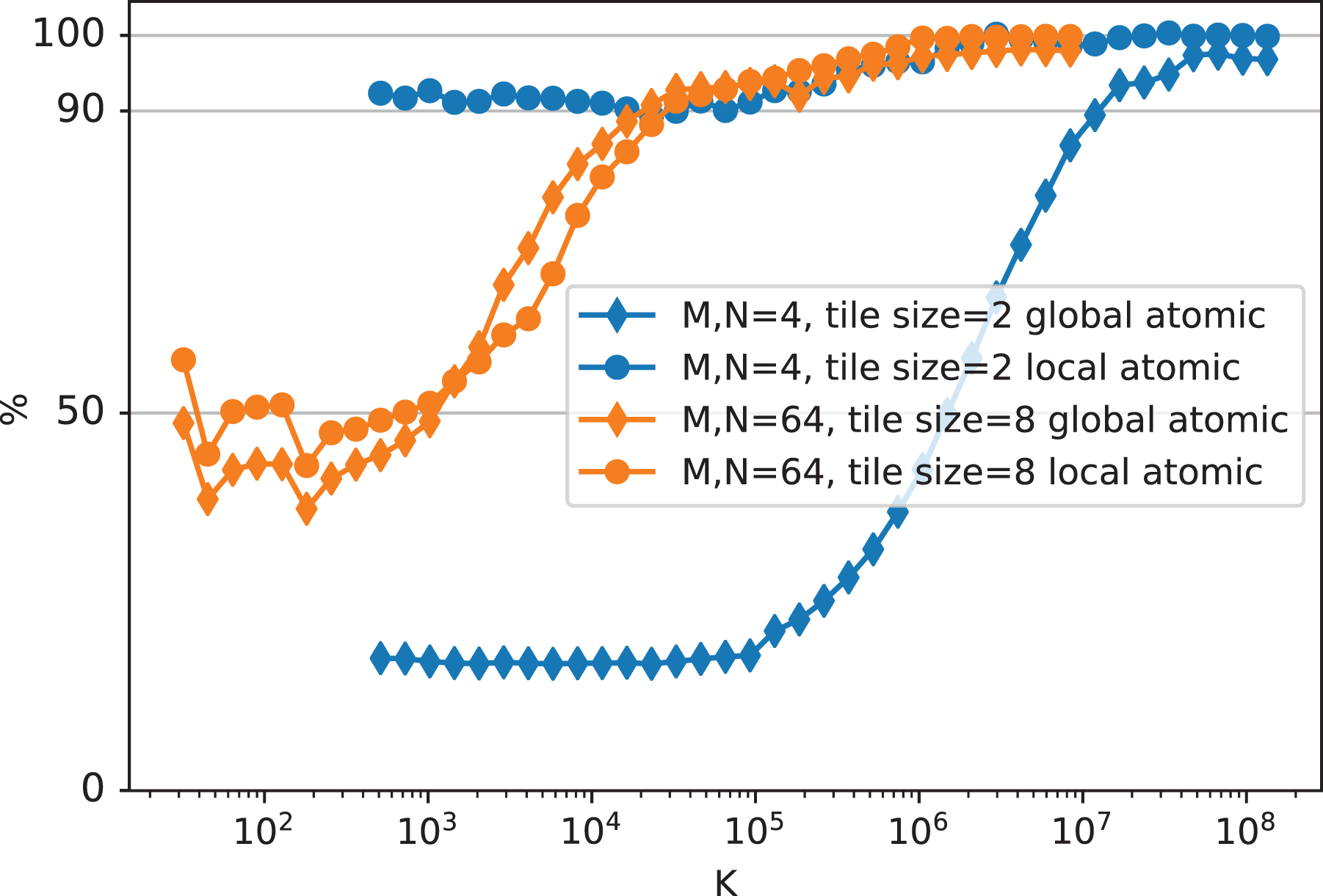
Global reduction impact for TSMTTSM: Performance when using each of the two global reduction variants as the percentage of the performance of a kernel without a global reduction, using two different matrix widths and tile sizes. (Real-valued double-precision matrices).
6. Results: TSMM
The described methods and parameters open up a large space of configurations. Each of the Figures 20, 21, and 22 shows a cross section of each configuration option by displaying the best-performing value for each choice for that configuration option.
6.1. Source of
The data in Figure 20 demonstrates that trying to keep the values of matrix
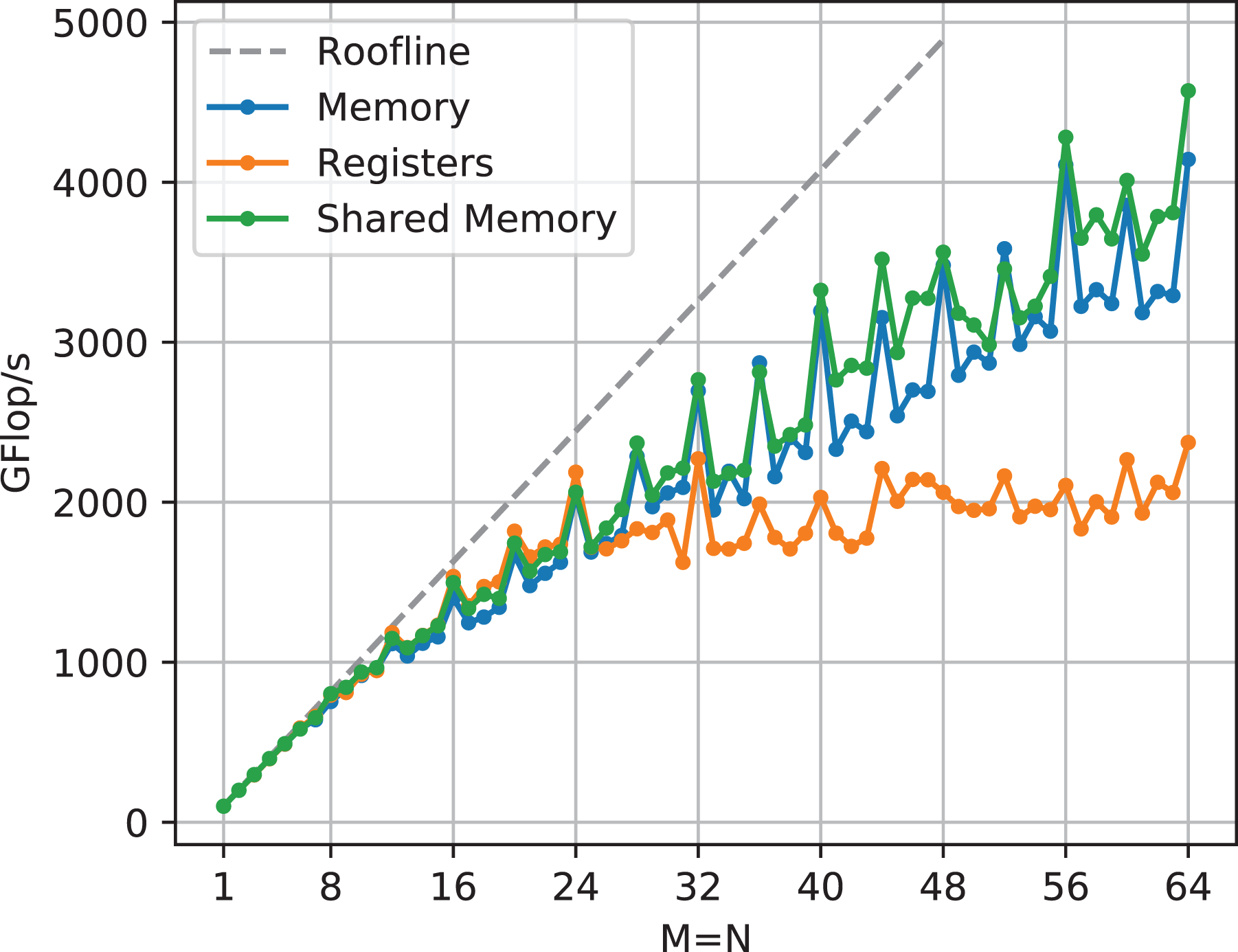
TSMM performance comparison at
Reloading values from shared memory has a consistently small performance advantage especially for sizes that are not multiples of four, due to a smaller penalty because of misaligned loads. Each additional cache line that gets touched because of misalignment costs an additional cycle.
6.2. Unrolling
Although there is little improvement with further unrolling beyond
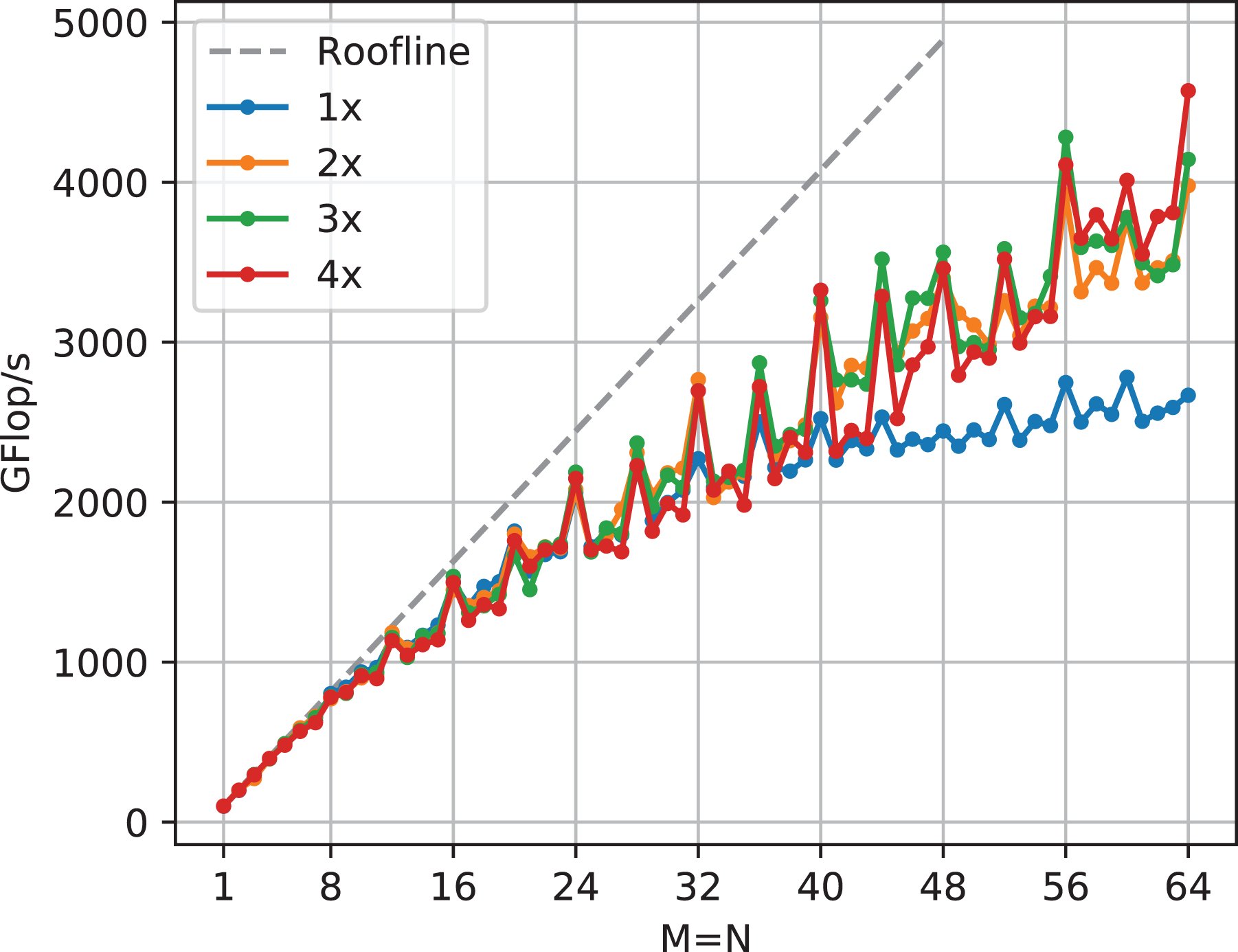
TSMM performance comparison of different degrees of unrolling at
6.3. Thread count
Fewer threads per row mean more work per thread. For large matrix sizes, this can result in huge kernels with high register requirements, which is why Figure 22 does not show measurements for the whole matrix size range for one and two threads per row. These two thread counts are the slowest variants, as they show the effects of strided writes the most. With four threads writing consecutive values, there is at least a chance of writing a complete 32-byte cache line sector. The difference between 4, 8 or 16 threads is not large, although the larger thread counts perform slightly more consistently (i.e., with less fluctuation across M).
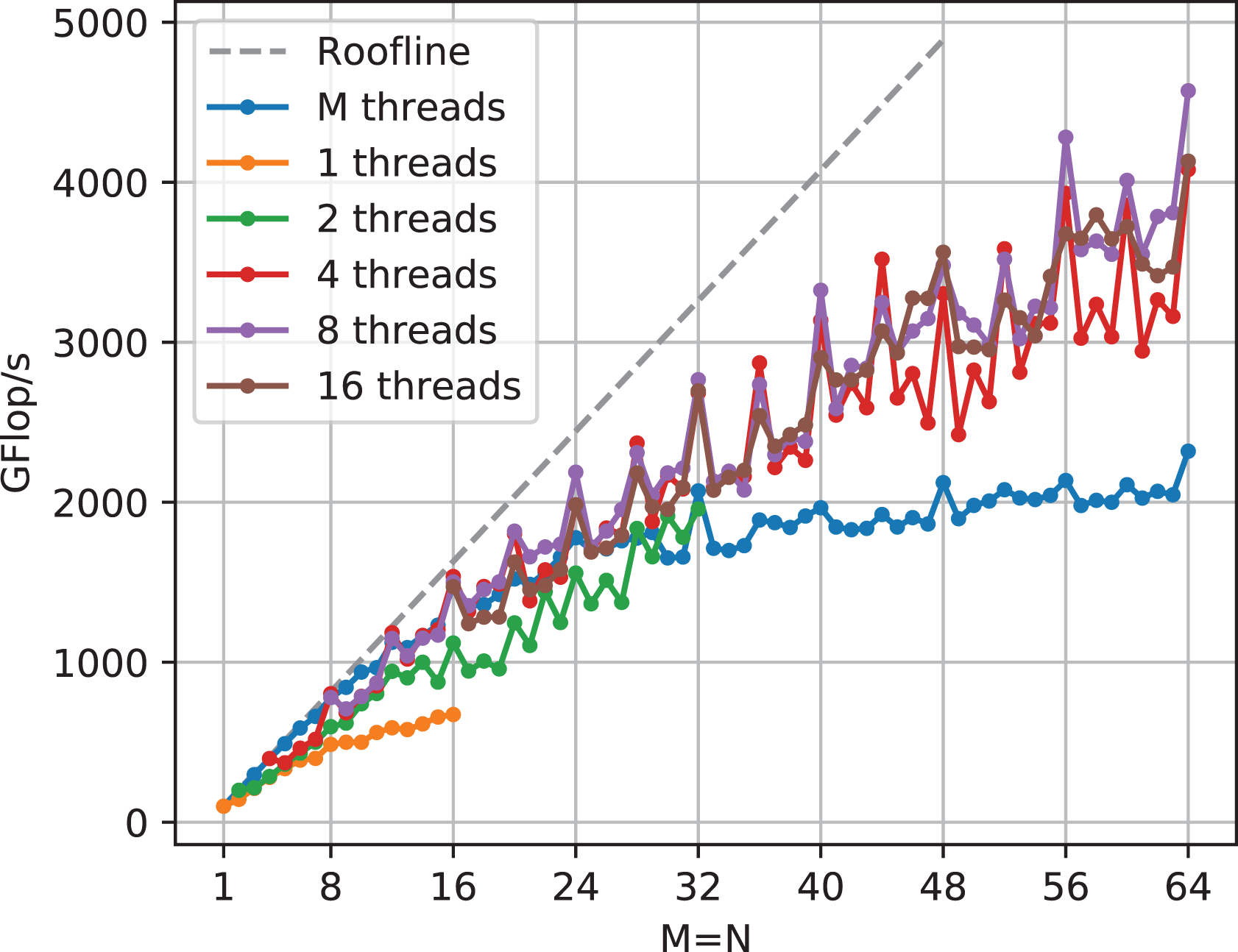
TSMM performance comparison of different thread counts per row at
The performance analysis for TSMM shows a clear preference for the small matrix dimension
6.4. Comparison with libraries
Figure 23 shows that, except for very small
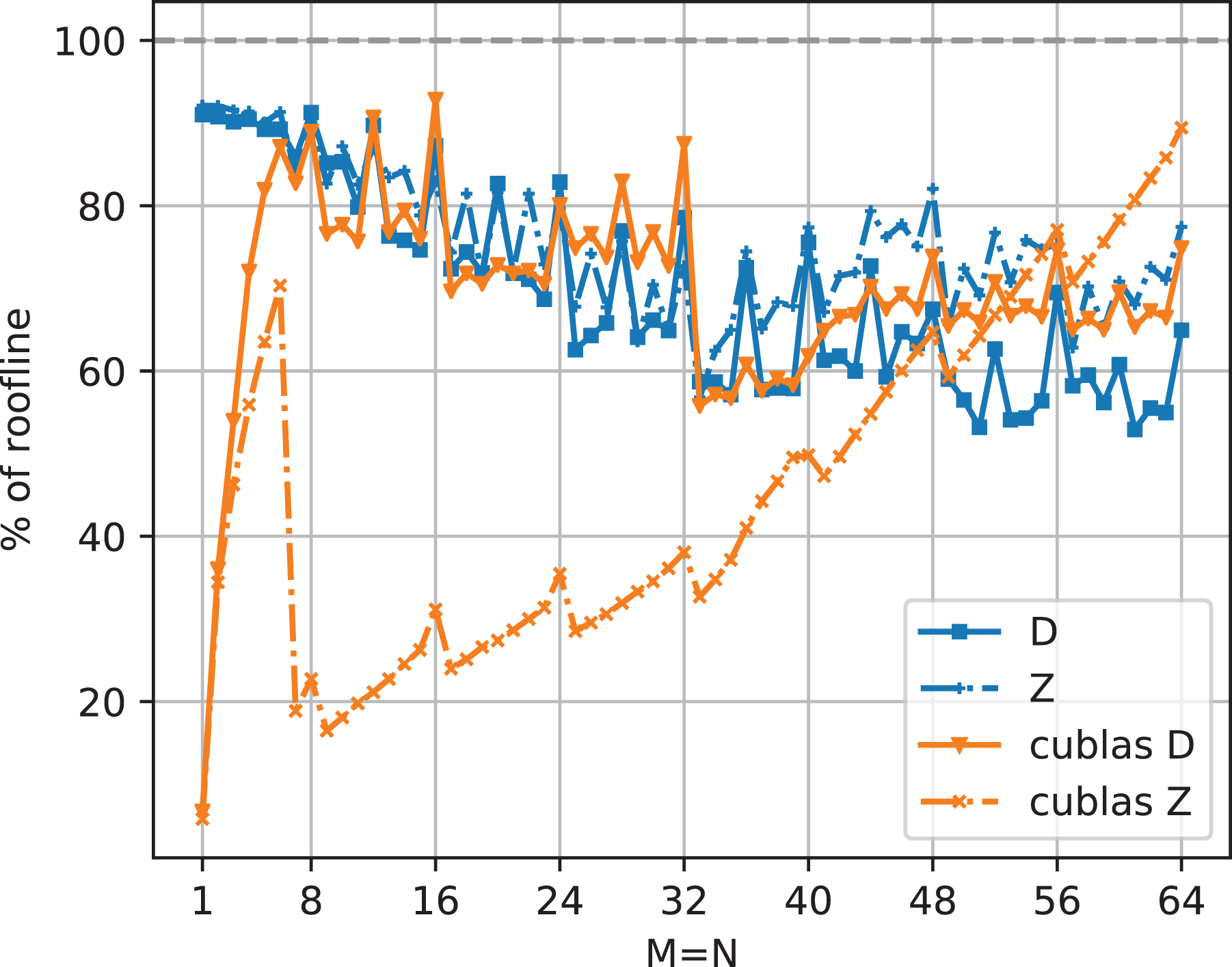
TSMM percentage of roofline-predicted performance for real (D) and complex (Z) double-precision data in comparison with CUBLAS.
7. Conclusion and outlook
We have shown how to optimize the performance for two types of multiplication of double-precision, real and complex tall & skinny matrices on a V100 GPU. With matrices narrower than 32 columns, near-perfect performance in accordance with a roofline performance model could be achieved. Over the rest of the skinny range up to a width of 64, between 60% and 67% of the potential performance was attained. We used a code generator on top of a range of suitable thread mapping and tiling patterns, which enabled an exhaustive parameter space search. Two different ways to achieve fast, parallel device-wide reductions for long vectors have been devised in order to ensure a fast ramp-up of performance already for shorter matrices. An in-depth performance analysis was provided to explain observed deviations from the roofline limit. Our implementation outperforms the vendor-supplied CUBLAS and CUTLASS libraries by far or is on par with them for most of the observed parameter range.
In future work, in order to push the limits of the current implementation, shared memory could be integrated into the mapping scheme to speed up the many loads, especially scattered ones, that are served by the L1 cache.
The presented performance figures were obtained by parameter search. An advanced performance model, currently under development, could be fed with code characteristics such as load addresses and instruction counts generated with the actual code and then used to eliminate bad candidates much faster. It will also support a better understanding of performance limiters.
Prior work by us in this area is already part of the sparse matrix toolkit GHOST (Kreutzer et al., 2016) and we plan to integrate the presented work there as well.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the ESSEX-II project in the DFG Priority Programme SPPEXA.