
Abstract
An increase in size and complexity prompts research of autonomous control of connected cyber-physical systems (CPS) at the level of intents (high-level goals). Domain-specific solutions such as intent-based networking, and the next generation of supervisory control and data acquisition and manufacturing execution systems, were influenced by the concept of autonomic computing and Monitor-Analyze-Plan-Execute loops over shared knowledge to introduce such control. However, there is a dearth of knowledge concerning the architectural attributes required to enable autonomic computing at a domain-independent level. CPSs are also often contributed by multiple stakeholders, thereby forming systems of systems in which architectures are by necessity federated. Herein, we apply a systematic approach to develop a taxonomy of such attributes, considering the federated nature of architectures, the need to accommodate heterogeneity and the legacy systems commonly encountered in practice. The proposed taxonomy covers nine key dimensions present within different domains of autonomic computing: knowledge representation, learning, distribution, reactivity, environment observability, information acquisition automation, information analysis automation, decision selection automation, and action implementation automation. The utility of the taxonomy is further demonstrated through an application to architectures across domains and scales.
Introduction
With the all-encompassing digitalization of our societies, cyber-physical systems (CPSs) are becoming more complex, growing in numbers, and integrating, forming system of systemss (SoSs) (Boardman & Sauser, 2006), and, in a broader sense, contributing and introducing complexity to the information infrastructure (Hanseth & Lyytinen, 2010). Self-adaptation (Cámara et al., 2016; Horváth & Tavčar, 2022) and, more broadly, autonomic computing (Kephart & Chess, 2003) have been studied and promoted as a means for software components to enable this growth while keeping operator workload manageable. Solutions like Arcaini et al. (2015) offer architecture sketches that shall only be considered abstract and illustrative (see de Lemos, 2023). While reducing system complexity is a well-known best practice (Nilchiani, 2023), doing so could be impractical in large or brownfield SoSs where a systems engineer has limited influence over the final SoS architecture. Further, this poses an additional risk of oversimplification if a system operates in a sufficiently complex domain, potentially leading to violations of the law of requisite variety (Siegenfeld & Bar-Yam, 2019) and, consequently, impacting information-related automation (Parasuraman et al., 2000).
Considering levels of automation in Parasuraman et al. (2000), for example, a human operator needs to interact with the system at some point at levels of automation between 2 and 9 (inclusive). Recent advances in artificial intelligence (AI) (LeCun et al., 2015; Brown et al., 2020; Gleirscher et al., 2018) offer unprecedented opportunities to elevate levels of automation, paving the way to autonomous systems. However, even with these advances, most systems employing AI would be wise to aim for any level of automation short of full automation (level 10), where no operator involvement is necessary. This is because systems where a human operator is a passive observer excluded from system design score lower in scenarios where some fault conditions occur and necessitate operator intervention, chiefly due to a diminished situational awareness (Endsley, 2023). With this in mind, cognitive engineering practices (Hoffman et al., 2009) shall be used to maximize human-machine performance and to avoid situations where routine operator responses are labeled as “human error”. Furthermore, AI techniques shall be seen as the means for attaining the goal of autonomy and the system design shall consider autonomy holistically.
Factoring these aspects at a system scale requires suitable architectures, and more specifically, suitable architectural attributes (Klein et al., 1999). While approaches like architecture-based self-adaptation (de Lemos et al., 2013) have been proposed, they often both take a greenfield approach to architecting and assume that a single stakeholder (architect) can make all key decisions for a system. In real-world applications, systems can often neither avoid incorporating legacy and off-the-shelf components into their architectures, nor are of such a directed type (Maier, 1998). These architectures usually involve multiple stakeholders, where no single entity has full control over the resulting system of systems and its architecture. An example of such a case is one of a smart city, where a municipality could promote a public-private partnership involving energy and construction companies to optimize energy usage at a local level. Such a case will be further discussed in Section “Taxonomy application”. Furthermore, the adoption of self-adaptation and autonomic computing has differed across domains, with intent-based networking being the prime domain influenced by autonomic computing (Leivadeas & Falkner, 2022; Koudouridis et al., 2024). Attributes that make architectures amenable to introducing autonomic computing in a domain-independent manner therefore also need to be studied.
Considering surveys of potentially fitting systems we encounter surveys that are limited to specific domains (Pivoto et al., 2021; Leivadeas & Falkner, 2022), do not contribute a taxonomy (Vargas et al., 2016), present taxonomies (roadmaps) for autonomous systems without considering architectural aspects (Bolles et al., 2022), as well as present taxonomies or individual dimensions where characteristics overlap (Liang et al., 2009; Bǎdicǎ et al., 2011). Taxonomies covering autonomy in specific domains mostly were not built using a well-defined methodology (Bach et al., 2017; Malik et al., 2021; Mariani et al., 2021; Flammini et al., 2024; Gharib et al., 2018; Leivadeas & Falkner, 2023). As a result, the resulting taxonomies contain dimensions where characteristics that are not mutually exclusive (Malik et al., 2021; Mariani et al., 2021; Gharib et al., 2018; Leivadeas & Falkner, 2023) or where dimensions are presented without corresponding characteristics altogether (Gharib et al., 2018; Flammini et al., 2024; Pasandideh et al., 2022). Additionally, domain-specific taxonomic elements cannot be directly generalized, such as a focus on the intent taxonomy (Abassi & Tabbane, 2023) or on airbag and hill assist functionality (Bach et al., 2017). It is clear that existing taxonomies suffer from critical weaknesses regarding their use for generalizing architectural attributes across various domains that involve autonomy by merely conducting a meta-study of existing taxonomies and combining them.
For these reasons, we turn to consider desirable architectural attributes by applying the systematic method by Nickerson et al. (2013) to build a taxonomy of architectures that make use of intelligent algorithms to manage information-intensive systems in distributed data-intensive environments. This resulted in the formulation of three meta-characteristics for building the taxonomy, which was informed by the requirement to handle real-world challenges. These challenges encompass the need to deal with brownfield applications, separating policies from implementation details to handle systems that are not directed, and knowledge-based components that have to interoperate over a common domain. Furthermore, the focus was on architectures that are suitable to be used in a federated context, even if they are not necessarily explicitly federated. A total of four iterations were performed.
The central contribution of this publication is the proposed taxonomy of the aforementioned architectures. The resulting taxonomy consists of nine dimensions: knowledge representation, learning, distribution, reactivity, environment observability, information acquisition automation, information analysis automation, decision selection automation, and action implementation automation. These dimensions were observed among architectures from diverse domains and can be used to consider the suitability of a given architecture for supporting autonomy independent of a domain.
It is worth noting that this paper deals only with the architectural aspects of autonomous systems. While the presented taxonomy was developed with respect for a holistic approach to autonomous systems engineering involving cognitive engineering in a multi-stakeholder environment, the taxonomy does not deal with characteristics specific to particular AI techniques, different kinds of SoS per Maier (1998), or specific cognitive engineering methodologies. The paper is structured as follows: Section “Methods” details development of the taxonomy. Section “System meta-characteristics” synthesizes essential meta-characteristics of the system, while Sections “Methodology summary” to “Subsequent iterations until reaching ending conditions” detail the application of Nickerson et al. for building the taxonomy. In particular, Section “Iteration 1 (qualitative)” considers related work in the first iteration of taxonomy development. The resulting taxonomy is presented in Section “Results”, followed by its application to assess several architectures. Finally, we discuss the results and present the outlook in Section “Discussion”.
Methods
According to Nickerson et al. (2013), there are three major activities in taxonomy development: the definition of a meta-characteristic, a conceptual-to-empirical (qualitative-first) iteration, and an empirical-to-conceptual (quantitative-first) iteration. In Section “System meta-characteristics”, we present the meta-characteristics chosen to inform the taxonomy-building process, followed by the general summary of the methodology and an additional subjective ending condition in Section “Methodology summary”. In Section “Iteration 1 (qualitative)”, we present the first iteration of the taxonomy building, where initial dimensions are chosen based on our experience with the field and presented related work. Section “Subsequent iterations until reaching ending conditions” covers the rest of taxonomy building iterations (four in total) until the ending conditions are reached.
System Meta-Characteristics
The first step to developing a methodology according to Nickerson et al. is to define a meta-characteristic of a system, which is used to shape the taxonomy development focus. In this sub-section, we will consider key requirements posed on the system and synthesis of the meta-characteristics.
Assuming that a resulting architecture would have to be applied in a commercial brown-field environment, legacy, as well as commercially available off-the-shelf components, would have to be integrated. It can be expected in a modern environment that such components expose service-based application programming interfaces (APIs). Thus, the architecture would have to integrate over those heterogeneous APIs for information acquisition, information analysis, decision selection, and action implementation (as per Parasuraman et al., 2000). Modern information processing needs further include dealing with event-based, transactional, and analytical workloads (Kleppmann et al., 2019), often at scale.
Acknowledging the hierarchy of data, information, knowledge, and understanding (Ackoff, 1989), the architecture shall be equipped not only to operate on information and data but to cover knowledge as well as to elevate the level of automation in the system. Knowledge needs to be extracted and kept updated based on the information flows in the system. For that, means of explicitly recording knowledge are needed, both ontological (such as vocabularies, taxonomies, schemata, ontologies, and reference data) and procedural (such as rules encoded explicitly and codified implicitly). Homoiconicity in the representation of ground facts, ontological, and procedural knowledge—for example, using Resource Description Framework (RDF) graphs (Hogan et al., 2021)—is desirable, as it allows uniform manipulation of these entities. Furthermore, brownfield deployment would require integration (alignment) of domains on all levels, including models (ontologies), data, and protocols in order for the knowledge-based components to interoperate over a common domain.
In order to improve explainability and to allow for reconfigurability, it is valuable to separate policy definitions (such as rules, goals, and intents) from system implementation details. This way, system behavior can be explained by considering policies separately, provided the implementation running the policies has well-defined semantics. The modification of system behavior also becomes more straightforward, which is relevant for evolving systems. The declarative (multilevel) policy-based control of cyber-physical system of systems (CPSoS) is preferred, reducing the need to develop detailed low-level policies, and lowering duplication.
Finally, not all knowledge can be formalized conclusively. In order to achieve autonomous decision-making, the system should consider support for symbolic methods to make use of the encoded knowledge through reasoning as well as for probabilistic methods to handle uncertainty, partial observability, and other areas where symbolic methods have limited applicability. Additionally, backward chaining and forward chaining both have advantages in the symbolic subsystem to enable solving problems of different kinds efficiently (Feigenbaum et al., 1988: p. 35).
We therefore propose a combination of 3 meta-characteristics for a system of interest:
being able to rely on a wide body of information across the enterprise to power its decision-making, and being able to operate in a distributed data-intensive environment of modern information systems. being able to use intelligent algorithms appropriately to manage large information-intensive systems,
Methodology Summary
Nickerson et al. propose a methodology that combines conceptualization and empiricism in an iterative approach, being rooted in design science and treating “design as a search process”. It is further aimed specifically at information systems, which matches the focus of this publication. Nickerson et al. suggest to alternate between qualitative and quantitative steps in each iteration until ending conditions are reached. Nickerson et al. emphasize both subjective and objective conditions to be considered, encouraging sets of conditions to be extended if necessary. We adopt the objective ending conditions without changes:
All objects or a representative sample of objects have been considered. No object was merged with a similar object or split into multiple objects in the last iteration. At least one object is classified under every characteristic of every dimension. No dimensions or characteristics were added in the last iteration. No dimensions or characteristics were split or merged in the last iteration. Every dimension is unique and not repeated. Every characteristic is unique within its dimension. Each cell is unique and not repeated.
When it becomes difficult to classify most of the papers covered in the previous iterations according to all newly proposed dimensions.
The subjective ending conditions are reached when the taxonomy is (sufficiently) concise, robust, comprehensive, extensible, and explanatory. We consider
The main purpose of the added criterion is to stop when previously surveyed papers do not contain enough specific information to re-classify them under a prospective dimension. For example, if a new dimension is Version Control System and most of the papers surveyed previously contain little information about the version control system used, we consider that the ability to add the dimension while keeping the taxonomy robust and comprehensive is limited if the taxonomy is expanded further.
Iteration 1 (Qualitative)
In the first iteration of taxonomy development, we chose to apply the conceptual-to-empirical approach. We considered a number of taxonomies known to us from related work as a starting step. Liang et al. (2009) focuses on types of rule engines:
Prolog-based, deductive databases, triple-based, production and reactive rules, knowledge-based.
As it is, this taxonomy violates objective ending condition no. 7 (OEC 7) “every characteristic is unique within its dimension” according to Nickerson et al. because a system may be developed in Prolog, use triples to represent information, use this information in backward-chaining mode for deduction and forward-chaining mode to infer knowledge and evaluate production rules all at the same time.
Bǎdicǎ et al. (2011) considers approaches to scaling rule-based systems:
parallelization, partitioning, distribution.
It equally violates OEC 7, because a system may be distributed, choose to partition its data and workloads, and have multiple nodes in a distributed system execute in parallel.
In Endris et al. (2020) (building on Özsu et al., 1999), a three-dimensional classification scheme for data integration systems was presented: heterogeneity, distribution, and autonomy. The distribution dimension overlaps with Bǎdicǎ et al. (2011).
Russell & Norvig (2016) define two components for considering intelligence: the problem and the solution. The problem is tightly connected to the environment and the solution is modeled on a concept of an intelligent agent interacting with the environment. Task environments are defined as a combination of:
performance measure, environment, actuators, sensors. fully or partially observable, single-agent or multi-agent, competitive or cooperative, deterministic or non-deterministic (stochastic is not considered non-det.), episodic or sequential, static or dynamic (also semi-dynamic, cf. p. 64), discrete or continuous, known or unknown (by the designers/engineers). simple reflex, model-based, planning-based, utility function based, learning.
Task environments are further classified as:
Norvig et al. offer a classification of the agents:
Finally, expressiveness of environment and task representation is considered and three characteristics are proposed: atomic, factored, and structured (Russell & Norvig, 2016: p. 77).
In Hogan et al. (2021), a comprehensive overview of the knowledge graphs is provided. The following dimensions could be considered for extraction:
data model: tabular, relational, graph; knowledge: expressed in simple statements, expressed in quantified statements, deductive, inductive; querying approaches: based on homomorphism-based semantics, and on isomorphism-based semantics;
At the same time, Hogan et al. (2021) was focused on a narrow set of systems, only considering ones based on Description Logics. One of the aspects that is of high relevance is a discussion of the truthiness of facts within a context (Hogan et al., 2021: p. 20). While the importance of context awareness is well-known (Guha et al., 2004; Augusto, 2022), we skipped it from consideration for initial dimensions given how challenging it is to evaluate how context-aware the system truly is.
At the end of the iteration, a set of initial dimensions was derived and it was applied on a set of architectures known to us from prior experience and the survey by Lucentini & Gudwin (2015): ACT-R (Ritter et al., 2019), SOAR (Laird, 2019), MECA (Gudwin et al., 2017), KMARF (Feljan et al., 2017), LIDA (Franklin et al., 2013), CLARION (Sun, 2006), and FRE (Berezovskyi et al., 2024). The results of this application are shown in Table 1.
An Initial Taxonomy Derived at the End of the First Iteration Performed Using the Conceptual-to-Empirical Approach.

As it can be seen, most dimensions violate objective ending criterion (OEC) no. 3 as they contain characteristics that no object was classified with. It was decided to eliminate the Information heterogeneity dimension immediately and consider the rest after completing the next iteration that would involve classifying new objects.
Subsequent Iterations Until Reaching Ending Conditions
Three more iterations were performed, with the second iteration using a conceptual-to-empirical approach, followed by an empirical-to-conceptual approach in the third iteration, while the fourth and last iteration applied a conceptual-to-empirical approach.
In the second iteration, the information heterogeneity dimension was removed because no system was classified along any of its characteristics. The ‘hardware’ and ‘software’ characteristics were removed from the fault tolerance dimension (no classifications) and the dimension was renamed into environment robustness. The knowledge representation dimension was extended with a ‘structured’ characteristic to account for systems storing data using relational databases and spreadsheets. The learning dimension was changed to consist of ‘none’, ‘non-continual’, and ‘continual’ characteristics because previous characteristics were not mutually exclusive. Finally, no architecture was classified as ‘hierarchical’ and this characteristic was removed from the distribution dimension.
In the third iteration, a Web-of-Science search was carried out with the following query:
The query was intended to find relevant architecture-related surveys covering intelligent systems, CPS, (systems) integration, and intent-based networking yielded 142 results at the time. A total of 54 papers were rejected (chemistry, cognitive science, architectures of built environments instead of software). A total of 48 papers contained the mention of “intelligent systems”, and 14 results mentioned CPS. The empirical-to-conceptual steps did not exhaustively classify every architecture mentioned in every survey. Instead, architectures were classified within the iteration until it became apparent that the taxonomy needed to be revised. Additionally, the iterative process was terminated when the ending criteria were reached.
In the last iteration, the autonomy dimension was replaced with four dimensions: information acquisition automation, information analysis automation, decision selection automation, and action implementation automation. These dimensions were reused from Parasuraman et al. (2000), with the simplification of the scale ranging from 1 (low) to 10 (high) down to three values: low, medium, and high. The main reason behind the scale reduction was to simplify classification. Also, the software implementation dimension was removed, as it did not directly relate to the meta-characteristics as required by the method.
While replacing a dimension in the last iteration violates the OEC 4 (“no dimensions or characteristics were added in the last iteration”), we decided to conclude the iterative process. According to the method, the rationale behind OEC 4 is that new characteristics within the introduced dimensions or new dimensions altogether may be introduced. There is no risk of more characteristics being identified within the dimensions other than low, medium, and high. Further, we consider the dimensions from Parasuraman et al. (2000) to be well-known and unlikely to cause further dimensional change. Finally, all other conditions were considered to have been met.
Results
Applying Nickerson et al., a total of four iterations of taxonomy development were carried out guided by the meta-characteristics. Iterations alternated between conceptual-to-empirical and empirical-to-conceptual approaches until we determined that both objective and subjective ending conditions were sufficiently reached. The final proposed taxonomy contains nine dimensions:
Herein, “n/a” denotes a classification that could be used when either there is insufficient information to classify the architecture along a certain dimension, or when the architecture explicitly provides users the freedom to attain the desirable architectural attribute, e.g., by introducing certain components.
Taxonomy Application
In order to assess the utility of the proposed taxonomy, we employ it to analyze a few architectures, representative of how it could be used by practitioners in the field. To demonstrate the versatility of the taxonomy, the architectures chosen should represent multiple domains and architectural scales. Furthermore, while the choice of particular architectures is subjective to a large degree, the architectures should not overlap with the architectures considered in any iteration of taxonomy development. We chose to consider the architectures of the systems discussed in the Society 5.0 book (Hitachi-UTokyo Laboratory, 2020). Every architecture presented in the book and described in sufficient detail to apply the taxonomy was covered:
Kashiwa-no-ha smart city Area Energy Management System (AEMS), City Data Exchange Copenhagen, Symbiotic autonomous decentralization system.
The application domain of the architectures is sufficiently distinct from the domains of architectures used in taxonomy development, which is beneficial to demonstrate broad domain applicability of the proposed taxonomy. Additionally, in order to contrast the two architectures, City Data Exchange Copenhagen is considered side by side with the International data spaces (IDS) reference architecture model (RAM) version 4 (Steinbuss, 2022). This represents a plausible scenario involving consideration of whether the existing architecture of the concluded City Data Exchange project is sufficient for building autonomy on top of it, for example, by introducing novel artificial intelligence (AI) techniques or whether a fundamental change of architecture is warranted. The results of applying the taxonomy to chosen architectures are summarized in Table 2.
Application Results of the Proposed Taxonomy to Select Architectures.
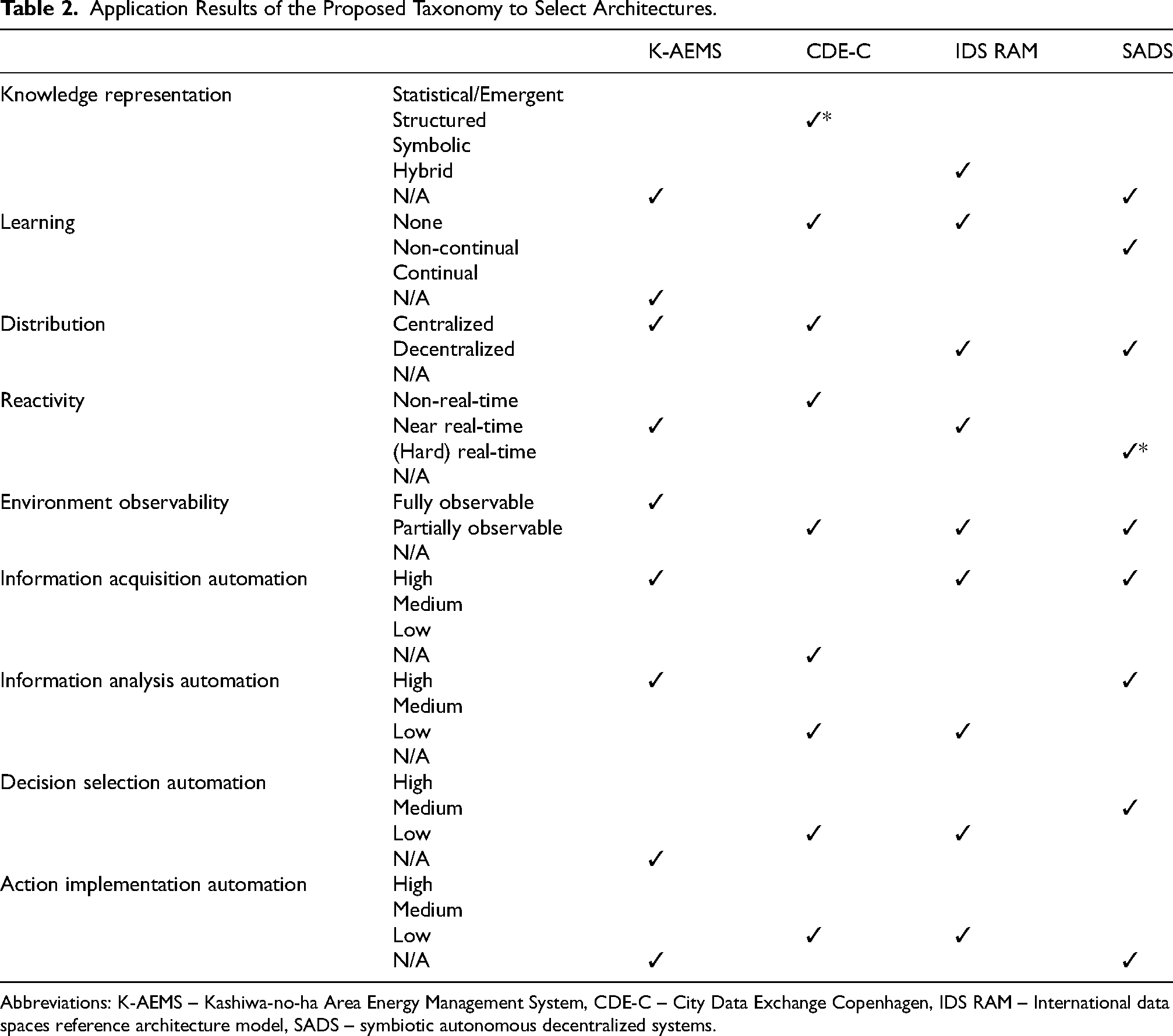
Abbreviations: K-AEMS – Kashiwa-no-ha Area Energy Management System, CDE-C – City Data Exchange Copenhagen, IDS RAM – International data spaces reference architecture model, SADS – symbiotic autonomous decentralized systems.
Kashiwa-no-ha smart city AEMS (Hitachi-UTokyo Laboratory, 2020: p. 49) aims to optimize energy usage and reduce emissions by peak shifting and electrical interchange between blocks (such as residential apartment blocks), among other goals such as disaster preparedness. While the electrical infrastructure is by nature distributed, AEMS centralizes information processing in the “AEMS smart center”. This is reflected in the centralized characteristic for the
City Data Exchange Copenhagen (Hitachi-UTokyo Laboratory, 2020: p. 58), Hitachi (2018) was a pilot project to facilitate public-private information sharing in a smart city via a marketplace. When considering system autonomy, we assume the smart city to be the system boundary. Because an information marketplace architecture is not suited to autonomous control, the
In contrast, the main difference IDS RAM architecture is that it is decentralized. Being an architecture focused on secure data sharing between multiple stakeholders, its
Symbiotic autonomous decentralization system (Hitachi-UTokyo Laboratory, 2020: p. 75), Irie et al. (2016) is a more generic architecture and has a broader scale. While not limited to a particular application domain, the architecture has roots in control systems and the manufacturing domain. Due to its more generic nature, it is natural that some dimensions cannot be classified without having the architecture instantiated within a particular system of interest. For example,
Looking at the classifications of the architectures, certain obstacles to autonomy clearly stand out, such as low
Discussion
Correspondence Between the Taxonomy Dimensions and the Meta-Characteristics
The main reason behind defining meta-characteristics as part of the methodology application is to ensure the dimensions of the resulting taxonomy are a consequence of the meta-characteristics. Looking at the final set of proposed dimensions, it is, therefore, worthwhile to reflect on how they contribute to characterizing the system with respect to its meta-characteristics. The first meta-characteristic (being able to rely on a wide body of information across the enterprise to power its decision-making) is covered by dimensions
The second meta-characteristic (being able to operate in a distributed data-intensive environment of modern information systems) is covered by dimensions
The third meta-characteristic (being able to use intelligent algorithms appropriately to manage large information-intensive systems) is covered by dimensions
Influence of the Taxonomy on the Architectural Suitability for Autonomous Computing through the Lens of Cognitive Systems Engineering
It shall be noted that the most suitable architecture for a given use case does not necessarily need to be classified with the most “sophisticated” characteristics along every dimension. Most architectural decisions involve trade-offs that shall be carefully evaluated (cf. Kazman et al., 1998). For example, some systems with fixed yet complex domains can benefit from not having to deal with learning and using standards-based knowledge representation. Furthermore, as argued successfully in Parasuraman et al. (2000), higher levels of automation are not unequivocally superior for systems with a human operator. The potential downsides include elevated mental workload, diminished situation awareness, complacency, and skill degradation. High levels of
Limitations and outlook
One of the central challenges while building the taxonomy has been the difficulty in extracting the information needed to classify the architectures. When required information was missing in surveys, we referred to the original, which was not sufficient at times. The second cause was making some architectural aspects vague or explicitly leaving certain aspects to be “filled in” by implementers in order to make architectures “open”. This challenge is the main reason behind the taxonomy not being overly specific. For example, the dimensions of fault tolerance and information heterogeneity were removed partly due to this challenge. It is also the reason behind adding the “n/a” characteristic to the dimensions. The software implementation dimension had to be removed because the implementation aspects are not directly related to the meta-characteristics, as required by the method.
The lack of information also led us to be conservative when adding new dimensions. It could be argued that a different approach may be needed to build a more comprehensive taxonomy, one that does not solely rely on architectural descriptions alone. This is especially relevant for the taxonomic dimensions to cover algorithms for managing information-intensive systems. We purposefully did not venture into that for two reasons. First, considering algorithms sans architectures which they are designed to manage would not necessarily contribute to the taxonomy of architectures per se. Second, considering algorithmic and architectural research independently would have required a major change to the protocol. In particular, it would be uncertain if ending conditions could be met satisfactorily. At the same time, we believe that the proposed taxonomy allows to evaluate the suitability of applying certain algorithms within a certain architecture without prior changes to the latter. For example, a system that largely deals with emergent knowledge and uses statistical representations of it could be a poor fit for applying methods that rely on symbolic representation. Additionally, the taxonomy can be expanded to consider architectural suitability for various methods for increasing levels of automation, taking into account architectural requirements posed by specific AI techniques.
We believe these limitations do not diminish the applicability of the proposed taxonomy dimensions and the satisfaction of the meta-characteristics overall. At the same time, we think that if future research publications would contain more details on implementation, fault tolerance, and information heterogeneity, this would allow better evaluation of architectures overall. In particular, it could be relevant to consider an exclusion criterion for future studies to only cover architectures that have well-evaluated implementations. In the same line, the consideration of context awareness (Augusto, 2022) is both important and related to the meta-characteristics. Thus, it would be valuable to consider it in future research, possibly when context awareness becomes better evaluated as intelligent systems are deployed in more environments (for example, given the recent interest spurred by large language models, e.g. Brown et al. (2020)). More broadly, future work may involve adding dimensions to the taxonomy to account for architectural requirements within different application domains while retaining a common base for autonomy assessment.
Conclusions
In this publication, we considered the common characteristics shared by architectures of systems that involve autonomy in some form across a number of domains, such as CPS, autonomous driving, and intent-based networking. This consideration was inspired by the idea of autonomic computing and, to a certain extent, self-adaptation. The work was structured as a systematic taxonomy development and the main contribution is a proposed taxonomy with nine dimensions: knowledge representation, learning, distribution, reactivity, environment observability, information acquisition automation, information analysis automation, decision selection automation, and action implementation automation.
The resulting taxonomy supports the hypothesis that architectures of systems in different domains that consider autonomy indeed share common characteristics. The support for this was established in two ways. First, the taxonomy was developed following a systematic method by Nickerson et al. (2013) and the development reached both objective and subjective ending conditions. Second, the utility of the proposed taxonomy was demonstrated by application to a number of architectures of different scales across multiple domains.
We envision a number of ways the taxonomy could benefit the community. First, existing architectures without support for autonomy could be classified according to the taxonomy as part of the analysis of whether it is feasible to introduce autonomy within the context of the existing architecture or whether a complete change is warranted. The meta-characteristics behind the taxonomy should increase the relevance of the taxonomy for real-world industrial applications, in particular, the focus on distributed data-intensive environments (meta-characteristics are further discussed in Section “Correspondence between the taxonomy dimensions and the meta-characteristics”). At the same time, the architecture that has more sophisticated characteristics on various dimensions of the taxonomy is not necessarily most suitable for autonomy, as discussed in Section “Influence of the taxonomy on the architectural suitability for autonomous computing through the lens of cognitive systems engineering” with cognitive systems engineering principles in mind.
Second, by considering architectural attributes of autonomous systems’ architectures across different domains, greater research synergies could be possible. From a cognitive engineering perspective, the taxonomy could aid contextual inquiry by providing a domain-independent set of dimensions to characterize the system context. On the constructive side, the taxonomy and its domain independence may be useful when implementing and evaluating cognitive aids, such as decision support systems. Finally, the taxonomy could serve as a basis for future improvement, as new domains are covered and more academic architecture-focused research focuses on system autonomy.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.