
Abstract
The current study examined vocalizations that occurred during training of the Picture Exchange Communication System for three U.S. preschool-age participants with autism spectrum disorder. In Phase IV, the protocol incorporates a delay to reinforcement in an effort to encourage vocalizations; however, the manual does not suggest additional strategies to try when vocalizations do not occur during the delay to reinforcement. Researchers evaluated a vocal model prompt following the delay to reinforcement and continued to measure vocalizations when the delay to reinforcement alone did not increase vocalizations. Two of the three participants increased independent vocalizations after the addition of the vocal model. Implications for practitioners and future research are discussed.
Keywords
Diagnostically, individuals with autism spectrum disorder (ASD) exhibit delayed communication across multiple environments and contexts. Delays in communication can include a lack of social reciprocity and joint attention and can impede development of relationships (American Psychiatric Association, 2013). People with ASD may also experience complex communications needs (CCNs) requiring intensive services (Mirenda, 2003) due to “little or no speech or spoken word capacity and other significant communication impairments” (Simpson, 2019, p. 5). According to the Centers for Disease Control and Prevention (2018), 40% of individuals with ASD do not develop functional speech. Deficits in functional communication are associated with challenging behaviors (Sigafoos, 2000), limited access to general education settings and inclusive opportunities (Ganz et al., 2012), and caregiver stress (Bebko et al., 1987). Due to negative impacts associated with deficits in communication, children with ASD and CCN should have access to early intensive services that incorporate augmentative and alternative communication (AAC; Light & Drager, 2002). Augmentative and alternative communication provides individuals with CCN a functional form of communication that may also positively impact language, literacy, and potentially speech development (Beukelman & Mirenda, 2013).
Beginning communication with low-tech AAC may benefit children by teaching the basic functions of communication (Schwartz et al., 2019). Picture Exchange Communication System (PECS) is a common form of low-tech AAC consisting of six phases designed to teach individuals with CCN to exchange pictures to request, label, and answer questions (Bondy & Frost, 1994). Sulzer-Azaroff et al. (2009) reviewed 34 peer-reviewed published reports of PECS and found evidence to support the use of PECS globally for individuals with CCN. Flippin et al. (2010) replicated and extended those findings by assessing quality and providing quantitative analyses. Furthermore, Bondy and Frost reported in their initial findings of PECS evaluations that increases in speech often occurred during Phase IV, and these claims were substantiated by other research groups (Charlop-Christy et al., 2002; Ganz & Simpson, 2004; Tincani, 2004).
Although access to AAC strategies such as PECS may lead to greater vocalization development than no access (White et al., 2021), families may be hesitant to implement AAC systems in fear that AAC may hinder the eventual development of speech (Blischak et al., 2003). Therefore, practitioners often continue targeting vocalization development alongside AAC training with young children because this form of communication may be more efficient (Cress & Marvin, 2003) or better understood by a wider audience. Given the necessity for AAC with individuals with CCN and the continued focus on natural speech, researchers have evaluated the potential for vocal development in the context of AAC (Millar et al., 2006). For example, Cagliani et al. (2017, 2019), Tincani (2004), and Tincani et al. (2006) incorporated various delays to reinforcement in the context of PECS and found increases in vocal approximations during the delay for some participants. In addition, Ganz et al. (2010) evaluated the effects of a vocal model prompt and found small increases in vocalizations for participants. Frost and Bondy (2002) recommended incorporating a delay to reinforcement in Phase IV, but do not provide guidance if vocalizations do not occur beyond this step. Several researchers have combined these two strategies, delay to reinforcement and vocal model prompts, in the context of PECS and a speech-generating device (SGD), demonstrating notable increases in nonword vocalizations, vocal approximations, and target-word vocalizations (Bishop et al., 2019; Gevarter et al., 2016; Greenberg et al., 2014).
Greenberg et al. (2014) evaluated the effects of PECS training, delay to reinforcement, and vocal model prompts on speech production through a series of studies. PECS Phases I through IV led to minimal changes in vocalizations. Following initial PECS training, researchers incorporated a delay to reinforcement and vocal model prompt in a subsequent study, which led to increases in vocalizations for two of the three participants. These findings were promising but preliminary as vocalizations were not necessarily phonetically related to the item the participant requested with picture exchange.
Furthermore, Gevarter et al. (2016) examined the effects of delay to reinforcement and vocal model prompts with SGD instruction on target-word vocalizations. Following SGD output, Gevarter et al. incorporated a 5-s delay to reinforcement to provide an opportunity for participants to vocalize. Two of the four participants did not vocalize during the delay to reinforcement. For the two other participants, researchers incorporated a vocal model prompt and differential reinforcement, which was effective for increasing vocalizations with one participant. For these participants, researchers provided a model prompt and differentially reinforced the various responses based on preference. Gevarter et al. (2016) extended the findings of Greenberg et al. (2014) demonstrating an increase in full-target words or vocal approximations following AAC training, delay to reinforcement, and vocal model prompts.
Bishop et al. (2019) replicated and extended the findings by Gevarter et al. (2016) by evaluating the effects of differential reinforcement and vocal model prompts on novel vocalizations. Novel vocalizations were defined as sounds, full words, and vocal approximations that had not been previously observed during sessions. Novel vocalizations increased for all three participants, and vocal requests increased for two of the three participants during the differential reinforcement and model prompt condition. These findings are consistent with the aforementioned research but extended findings by Gevarter et al., (2016) and Greenberg et al., (2014) by demonstrating increases in vocalizations beyond the initial target responses.
Researchers have found that a delay to reinforcement is effective in evoking vocalizations for some individuals with CCN who primarily communicate with AAC, but some individuals may need additional methods (Cagliani et al., 2017, 2019). Response prompts, such as vocal model prompts, increase the likelihood of correct responding and, therefore, provide more opportunities for the learner to access reinforcement (Wolery & Gast, 1984). For children who do not respond to the delay to reinforcement and differential reinforcement during PECS Phase IV, vocal model prompts may be a sufficient method for establishing stimulus control for vocalizations during PECS. Gevarter et al. (2016) and Bishop et al. (2019) found vocal model prompts in combination with delay to reinforcement evoked target and novel word vocalizations in the context of SGD instruction. Greenberg et al. (2014) also evaluated these variables in the context of PECS but did not differentiate between phonetically related and unrelated vocalizations. Therefore, the purpose of this study was to evaluate the effects of adding a vocal model prompt when vocalizations did not increase with standard PECS Phase IV procedures. Researchers sought to answer the following research question: Is there a functional relation between delay to reinforcement, differential reinforcement, and vocal model prompts and an increase in vocalizations and PECS exchanges in three preschool children with ASD?
Method
Participants
Researchers recruited participants from a U.S. university-affiliated classroom. Participants were considered for inclusion if they (a) did not have prior experience with PECS or other modes of AAC; (b) did not use speech to communicate; (c) were eligible for special education services under the IDEA category of ASD or significant developmental delay; (d) received special education services for 40 hours per week; (e) received speech and language services; (f) primarily communicated with gestures, facial expressions, or nonword vocalizations; and (g) engaged in some (score > 1) vocal imitation ability as indicated by the Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP; Sundberg, 2014) Early Echoic Skills Assessment (EESA; Esch, 2008). The classroom teacher communicated with participants’ parents that fit the eligibility for recruitment, reviewed the institutional review board–approved consent documents, and began the project after receiving the signed documentation of their permission. Researchers gathered information about the participants from their guardians and educational records. Each participants’ educational records included scores from the Developmental Profile 3 (DP-3; Alpern, 2007). Administered by the school psychologist, the DP-3 required caregivers to provide feedback on cognitive functioning. DP-3 scores are included below for each participant. An average score across all domains is between 85 and 115.
Neville, a 4-year-old African American male, scored a 23 (Group 1: 15.5/25; Group 2: 7/30; Group 3: 0.5/30) on the EESA, demonstrating he engaged in some vocal imitation of single- and two-syllable sounds including vowels, diphthongs, and early consonants. Neville scored <50 in the cognitive, physical, and social/emotional/behavioral domains. He scored 53 in communication and 52 in daily living. At the beginning of the study, Neville mainly used a mix of intelligible and unintelligible words during free play. Researchers observed that his vocalizations occurred in the form of vocal stereotypy. His primary means of communication included pointing and other gestures to request items, crying to express disapproval, and occasional use of the manual sign for “my turn” to request for his toys back. Neville engaged in challenging behaviors (e.g., dropping to the floor, self-injurious behavior in the form of head-banging, aggression, and disruptions) throughout the day but most notably when transitioning from a highly preferred activity to a less preferred activity.
Petunia, a 4-year-old African American female, scored a 39.5 (Group 1: 20.5/25; Group 2: 16/30; Group 3: 1/30; Group 4: 0/15; Group 5: 2/15) on the EESA (Esch, 2008), demonstrating vocal imitation skills of single- and multi-syllable sounds including vowels, diphthongs, and early consonants and minimal ability to imitate other features including pitch, loudness, and vowel duration. Petunia scored <50 on the cognitive and social/emotional/behavioral domain and 52 on the daily living domain. No score was reported for the physical domain. Her primary means of communication included gestures, grunting, and pulling on adults. Petunia engaged in high rates of echolalia throughout the day; however, the pronunciation of most words was inconsistent with the actual word. Petunia engaged in challenging behaviors such as dropping to the floor, disruptions (e.g., swiping or throwing work materials), and eloping from less preferred activities to highly preferred activities.
Albus, a 4-year-old African American male, scored a 3 (Group 1: 3/25) on the EESA, demonstrating limited ability to imitate single-syllable sounds including vowels, diphthongs, and early consonants. He scored <50 on the cognitive, communication, and social/emotional/behavioral domains, 52 on daily living, and 51 on physical. Albus babbled throughout the day, and his primary means of communication included the manual sign for “more” and pulling on adults’ hands or pushing them toward food items on the table. Albus also engaged in several challenging behaviors (e.g., dropping to the floor, eloping, aggression toward adults and peers, and disruptions) throughout the day. The researcher and classrooms teachers hypothesized these behaviors were maintained by access to positive reinforcement in the form of access to tangible items and attention and negative reinforcement in the form of escape.
Setting, Researchers, and Materials
The study took place in a self-contained classroom serving 3- and 4-year-old children with ASD and significant developmental delay in a Title-1 funded early intervention school in the Southeastern United States. The curriculum included goals pertaining to self-help skills (e.g., toilet training, using utensils appropriately), receptive and expressive communication, motor skills, and state-mandated prekindergarten standards. The classroom was operated by university special education, behavior analysis faculty, and graduate students. The first author completed the Pyramid Educational Consultants Level 1 PECS training before the onset of the study and trained all classroom staff with behavior skills training. The first author provided an explanation of the research procedures, modeled the procedures, and provided an opportunity for rehearsal and feedback (Miltenberger, 2011). Sessions were conducted during mealtimes (breakfast, snack, and lunch) that occurred in 20-min increments in the typical schedule at the classroom table. Sessions occurred 80 min apart and lasted between 5 and 10 trials to account for shifting preferences.
Each participant used an individualized 19- × 22-cm three-ring binder containing laminated photographs of their preferred items, including edibles and toys, relative to the classroom. Pictures resembled actual photos of the items used within the classroom. Their binder contained a sentence strip, constructed out of a jumbo popsicle stick and Velcro, and included a strap for carrying. Data collected by the communication partner occurred in vivo with pen and paper.
Dependent Variables and Recording Method
Effects of the independent variables on PECS exchanges and vocalizations were evaluated. PECS exchanges were defined as the participant independently picking up, reaching, and releasing the picture into the hand of a communication partner (Frost & Bondy, 2002). Vocalizations were categorized as occurring before the delay, during the delay, or after the delay (represented on the graph as an imitated vocal). All vocalizations were full word or vocal approximations that included recognizable sounds corresponding with the item requested. Researchers collected data using discrete categorization by recording prompted and independent responses on trial-by-trial data sheets. From these data, researchers calculated the percentage of independent responses in comparison to the number of trials that occurred during that session. Each session consisted of no fewer than five trials and up to 10 trials.
Research Design
Researchers evaluated differential reinforcement, delay to reinforcement, and vocal model prompts on vocalizations with a design comprising multiple baselines across participants (Gast et al., 2018) in the context of PECS Phase IV. Researchers included PECS Phases I through III data for each participant to demonstrate that vocal emergence did not take place during these phases as expected (Frost & Bondy, 2002). Introduction to Phase I was not staggered. Once each participant mastered Phase III, researchers began implementing Phase IV without delay to reinforcement during mealtimes, which served as baseline. All three participants acquired the steps necessary to complete a Phase IV exchange. Researchers staggered the introduction of delay to reinforcement across participants, and the order of participants was randomized. If participants did not engage in a vocalization or vocal approximation in at least 80% of trials after six sessions of delay to reinforcement, the researcher incorporated the vocal model prompt. Data were analyzed through visual inspection of the level, trend, and variability of the data until the final participant begins intervention (Gast et al., 2018).
Procedures
Early Echoic Skills Assessment
Before the start of baseline, researchers conducted the EESA, a component of the VB-MAPP for each participant (Esch, 2008; Sundberg, 2014) to assess echoic repertoires. During the assessment, researchers vocalized 100 single-syllable or syllable-combination sounds for the participant to imitate (e.g., ah, hop, foo-ey). Participants had three opportunities to respond, and according to the EESA scoring protocol, they received a score of zero (no response or response with incorrect vowels or missing syllables), one-half (response was recognizable but included extra syllables or incorrect consonants), or one point (correct responses) based on their response. The EESA comprises five groups of sounds. Group 1 contains sounds typically acquired when a child is 18 months old and includes single consonants, vowels, and diphthongs (25 points; wow). Groups 2 and 3 presents two- and three-syllable early consonant sounds (30 points each; baby, tubby toy). Groups 4 and 5 assess the child’s ability to imitate the pitch, loudness, and vowel durations (15 points each; no WAY, echo, whispering).
Preference Assessment
To identify highly preferred edibles for each individual, researchers conducted a multiple stimulus without replacement (MSWO; DeLeon & Iwata, 1996) preference assessment. The first author placed an array of five edible items in front of the participant and instructed the child to pick one. Once the participant chose an item, the researcher recorded the choice and provided the participant an opportunity to consume the edible. The researcher placed the remaining items in front of the participant and continued the MSWO until achieving a ranking order of the five items for each participant. The items used were specific to each participant and identified by parents and classroom staff as being highly preferred. The complete MSWO occurred before the pretraining conditions. Across all conditions and sessions, the researcher presented two to three of the preferred items identified in the MSWO preference assessment and offered the opportunity for the participant to choose which one they wanted to account for motivating operations.
Pretraining
Pretraining served as a baseline for PECS Phases I–III training. During this condition, the communication partner restricted access to the preferred item during mealtimes and held one hand open, palm facing up. A picture of the highly preferred edible was placed in front of the child on the table, but the communication partner did not provide any prompts during this condition. The participant received one bite of the edible when they reached for it, vocalized the name of the item, or exchanged the picture for the item. Planned contingencies for challenging behavior included ignoring disruption and safely blocking aggression. Sessions lasted for 20 min or after five opportunities for the participant to initiate for the item, whichever came first.
PECS I–III Training
Before baseline, participants received PECS Phases I–III training in the context of their scheduled mealtimes. Training was consistent with the PECS manual except during Phase II when the participant did not travel away from the table during sessions. During Phase II, the communication partner focused on teaching persistence to exchange a picture to a communication partner that became less available as sessions progressed (e.g., not facing the participant directly, turning away slightly after each trial). Phase III taught both discrimination between highly preferred and nonpreferred items (determined to be disliked by classroom staff) and also correspondence between multiple preferred items. Correspondence training continued until the participant could scan between five pictures on the cover of their communication book. After this step, all pictures remained in their communication book, and participants received training on opening and scanning to find pictures located inside their book. Consistent with the PECS manual, the communication partner did not expect, encourage, or require speech within Phases I–III.
Once the participants met criteria for mastery across PECS Phases I–III for 80% of independent requests per session across three sessions, the research study began. The research question was addressed through the following three conditions: Phase IV (baseline), differential reinforcement and delay to reinforcement, and the vocal model prompt.
Phase IV Baseline
During Phase IV, participants learned to move two pictures—one that said, “I want,” and the other, a picture of the reinforcer—onto a sentence strip and then to exchange the strip with a communication partner. Upon the exchange, participants pointed to each picture on the strip as the communication partner read the strip aloud. Once participants demonstrated mastery in moving both pictures onto the strip and pointing to the pictures, the researcher incorporated the delay to reinforcement.
Delay to Reinforcement and Differential Reinforcement
A 5-s delay to reinforcement was inserted after the communication partner read, I want. If vocalizations did not occur during the delay, the communication partner named the item requested and delivered the item to the participant. Consistent with the PECS manual, the communication partner did not insist on speech at this step and provided a larger quantity of the item along with a statement of verbal praise for vocalizations. Once the delay to reinforcement was inserted in Phase IV, the communication partner began encouraging speech by delay to reinforcement and differential reinforcement but always honored the exchange of the sentence strip and delivered the item regardless of whether the participant vocalized. To address the primary research question around the effects of incorporating a vocal model, Phase IV with delay to reinforcement and differential reinforcement functioned as the baseline condition. With the addition of the vocal model condition, researchers diverged from the PECS manual.
Vocal Model Prompt
For participants who did not independently vocalize at 80% or above during sessions with the 5-s delay to reinforcement, a vocal model prompt was introduced during the sequence. After the exchange of the sentence strip, the communication partner stated, “I want,” and inserted a 5-s delay to reinforcement to give the participant the opportunity to name the edible being requested. If the participant did not vocalize after 5 s, the communication partner introduced a vocal model prompt, Say “I want” (insert corresponding item name), and waited another 5 s. If the participant imitated the model during the 5 s, the communication partner delivered the item. If the participant did not imitate the model after 5 s, the communication partner stated the name of the item again and delivered a smaller portion of the edible. If the participant independently vocalized, the communication partner reinforced the behavior by immediately providing a larger quantity of the item and a statement of verbal praise.
Reliability and Procedural Fidelity
A secondary observer collected data simultaneously for at least 33% of all sessions across conditions and for all participants. Data collectors were graduate students with experience in implementing PECS with young children in a classroom context, were familiar with the students, and all received training on data collection before baseline. Researchers calculated interobserver agreement (IOA) with point-by-point agreement (total number of agreements divided by agreements plus disagreements multiplied by 100; Ledford et al., 2018). For Phases I–III, the mean IOA for Neville was 100%; for Petunia, it was 100%; and for Albus, it was 98% (range: 80%–100%). In Phase IV, the mean IOA for Neville was 95% (range: 90%–100%); for Petunia, 98% (range: 80%–100%); and for Albus, 97% (range: 90%–100%). During the delay to reinforcement condition, the mean agreement was 95% for Neville (range: 90%–100%), 90% for Petunia (range: 80%–100%), and 100% for Albus. The vocal model prompt condition resulted in a mean agreement of 100% for Neville, 98% for Petunia (range: 90%–100%), and 90% for Albus (range: 80%–100%).
Procedural fidelity reflected the procedures outlined by the PECS manual along with the specific procedures surrounding the research questions. An additional component was added to each checklist to ensure the communication partner did not name the item before the participant exchanged the picture. For the vocal model prompt condition, the procedural fidelity checklist incorporated checks to ensure the communication partner provided a vocal model prompt following the 5-s delay, waited 5 s before delivering the item, and provided the item regardless of a vocalization. Procedural fidelity data sheets are available upon request by contacting the first author. Fidelity checks, collected by an independent observer, took place at each phase of PECS and for 30% of all sessions across conditions and for each participant. Calculations of fidelity for each participant resulted in a mean score of 97% and a range of 90%–100% for each participant in each condition.
Results
PECS exchanges increased for all three participants, and they all mastered PECS Phases I–IV. Independent and imitated vocalizations remained at zero levels across Phases I–III for all participants. An immediate change in level for independent vocalizations during the delay occurred for two of three participants after the introduction of the delay to reinforcement and differential reinforcement. An accelerating trend for independent vocalizations before the delay occurred for two of three participants after the introduction of the vocal model prompt. The description of results for each condition is further described below.
Prestudy Conditions
During pretraining sessions, Neville engaged in one independent picture exchange. Neville mastered PECS Phase I in 15 sessions, Phase II in three sessions, and Phase III in 13 sessions. Similar to Neville, Petunia engaged in one independent exchange during the pretraining condition. Petunia mastered Phase I in four trials, Phase II in 13 sessions, and Phase III in 13 sessions. Albus did not engage in picture exchange during pretraining. Albus mastered Phase I in 16 trials, Phase II in 5 sessions, and Phase III in 27 sessions.
During the pretraining condition, none of the participants vocalized. Neville vocalized following the exchange and vocal label for 3 of 10 trials in one session during PECS Phase IIIB. Petunia vocalized following a label for 4 of 10 trials during one session of Phase IIIA and once during two Phase IIIB sessions. Albus did not imitate the vocal label during any prestudy conditions. None of the participants vocalized independently during the prestudy conditions. The data and graphs for the prestudy phases are available upon request from the first author.
Baseline (PECS Phase IV)
Figure 1 displays the percentage of trials with PECS exchanges, independent vocalizations before the delay (“I want” and the item name), independent vocalizations during the delay (item name only), and imitated vocalizations (“I want” and the item name or the item name only). Neville and Petunia independently engaged in all the steps for PECS Phase IV by the fourth and second sessions, respectively. Neville and Petunia independently engaged in PECS across all conditions. Albus took longer than Neville and Petunia to master Phase IV. His PECS responding reached 100% independence at Session 17 but remained variable throughout the remainder of the study.
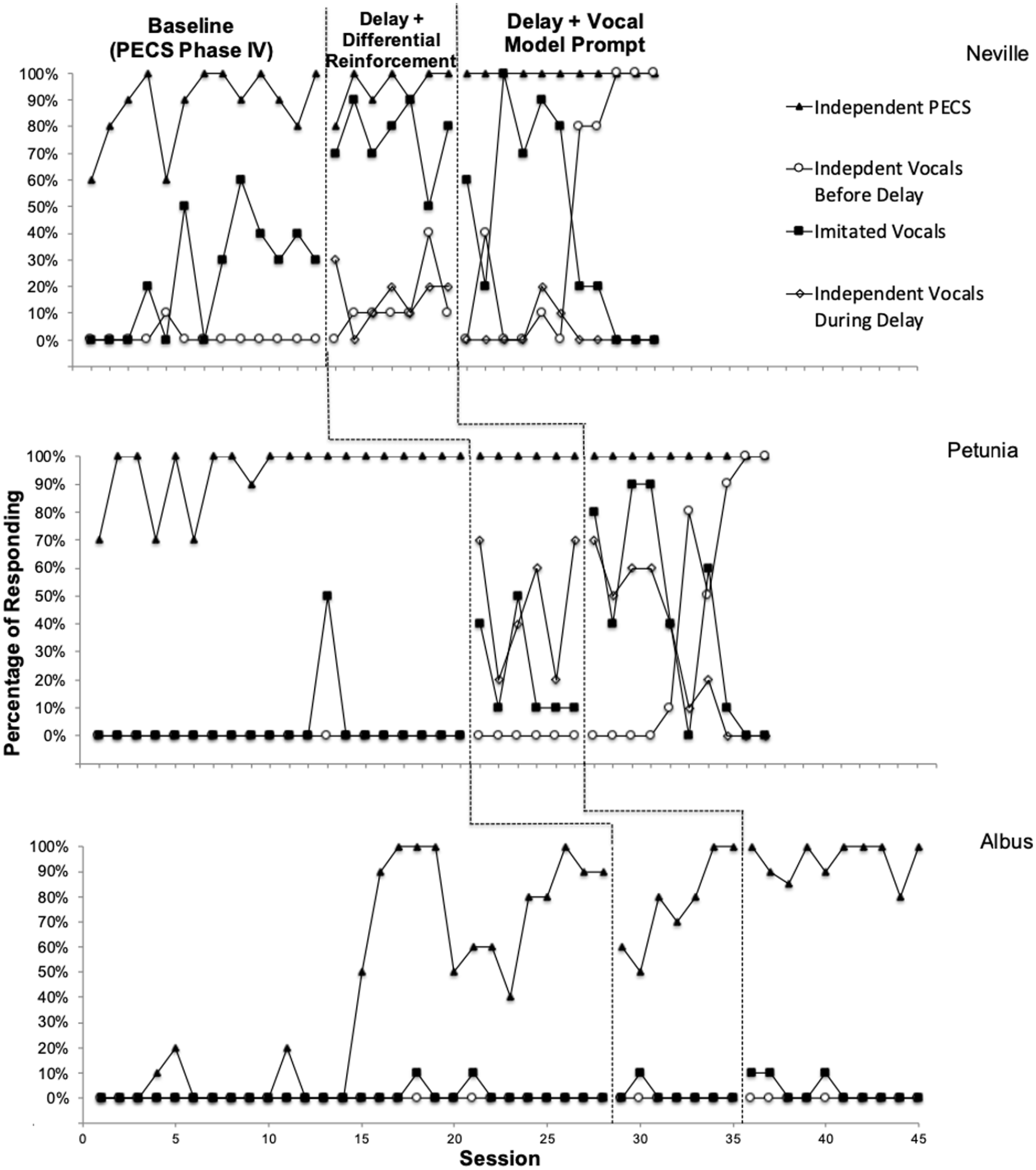
Percentage of Responding of PECS Phase IV and Vocalizations.
For Neville, a change in level for imitated vocalizations (following the initial exchange and label) occurred in Session 4 PECS Phase IV training. During Session 13, Petunia engaged in imitated vocalizations during five trials. Albus also imitated vocalizations once during Sessions 18 and 21. Responding remained stable with no change in level, trend, or variability for independent vocalizations before for all three participants (PECS Phase IV).
Delay to Reinforcement and Differential Reinforcement
An immediate change in level occurred for Neville’s imitated vocalizations during the delay to reinforcement condition, ranging from 50% to 90% of trials per session. Independent vocalizations and vocalizations during the delay also increased slightly above baseline for Neville, ranging from 0% to 30% independent vocalizations during the delay and 0% to 40% before the delay and model/during the exchange. For Petunia, a change in level above baseline responding also occurred for independent vocalizations during the delay (10%–50%) and imitated vocalizations following the initial exchange and label (20%–70%). Albus vocalized following the exchange and label once during this condition.
Vocal Model Prompt Plus Delay to Reinforcement
For Neville, a decelerating trend for imitated vocalizations and an accelerating trend for independent vocalizations occurred following the sixth session of this condition. Neville engaged in independent vocalizations 100% of trials for the last three sessions during this condition. For Petunia, imitated vocalizations increased above the previous conditions, and there was a decreasing trend for imitated vocalizations following the fourth session of this condition. During the last two sessions, Petunia independently vocalized in 100% of trials. Albus’s prompted and independent vocalizations did not rise above baseline levels during either condition. The average number of sessions conducted per day was 1.72 (1–4) for Neville, 1.89 (1–4) for Petunia, and 1.95 (1–5) for Albus. Sessions were conducted across 30 school days for Neville and Petunia and 44 school days for Albus.
Discussion
This study evaluated the effects of delay to reinforcement combined with differential reinforcement in the context of PECS Phase IV and a troubleshooting strategy, vocal model prompts, when independent vocalizations did not occur with standard Phase IV procedures. Following independent picture exchange during PECS Phase IV, researchers delayed delivery of reinforcement for 5 s following the “I want” label in an attempt to evoke vocalizations. When independent vocalizations did not occur before or during the delay consistently, the researcher provided a vocal model prompt and an additional 5-s delay. All participants became proficient in PECS through Phase IV. For two of three participants, the delay to reinforcement and differential reinforcement condition led to a change in responding for imitated and independent vocalizations above baseline. However, the independent vocalizations were inconsistent and happened often during the delay to reinforcement. Following the addition of the vocal model prompt, participants gradually began engaging in independent vocalizations during the PECS exchange.
Overall findings from this study provide preliminary support and extend earlier research on incorporating delay to reinforcement and vocal prompts to evoke target-word vocalizations and vocal approximations in the context of AAC use (Bishop et al., 2019; Cagliani et al., 2017, 2019; Gevarter et al., 2016; Greenberg et al., 2014). Specifically, Greenberg et al. (2014) found that the vocal model prompt led to an increase in vocalizations but did not specify whether the vocalization were phonetically related to the requested item and were described as “unrelated consonant-vowel combinations.” This study extends those findings to only target vocalizations that included the correct sounds and number of syllables or a similar sound and number of syllables. However, because the findings were not replicated across all three participants, a functional relation was not demonstrated. The discussion around the third participant that did not demonstrate an increase in vocalizations is described in the “Limitations” section.
Directions for Clinical Practice and Future Research
The PECS manual suggests adding a delay to reinforcement after the exchange of the sentence strip and differential reinforcement of vocalizations to encourage vocalizations. A vocal model prompt, a type of response prompt, is an additional strategy to encourage vocalizations if the delay alone is not sufficient as a vocal model prompt. Notably, several studies, including this one, did find at least some increase in speech production (vocal approximations) in the context of AAC with individuals who had previously been identified as nonvocal (Carr & Felce, 2007; Charlop-Christy et al., 2002; Greenberg et al., 2014; Yoder & Stone, 2006). Additional research is necessary to determine what components of AAC facilitate this change. Specifically, in the context of PECS Phase IV, additional research is necessary to determine which component of this phase results in increased vocalizations before delay to reinforcement and differential reinforcement and why this change of responding does not occur in previous phases.
Overall, future research should continue to evaluate vocalization development in the context of PECS training and the effects of delays and vocal model prompts. Given the initial demonstrations of the effect for Neville and Petunia following delay to reinforcement and previous research that incorporated longer delays (Cagliani et al., 2017, 2019), additional research may be necessary to determine the necessary length of the delay and exposure to delays to reinforcement. Perhaps longer delays may have led to greater response variability for Petunia and Neville.
Given the diverse responses, researchers evaluating vocalization development in the context of AAC training should provide detailed participant descriptions as this information could be helpful when choosing an intervention package for an individual or when attempting to transition from AAC to vocalizations. Research shows imitation ability is correlated with communication development in young children with ASD (Dawson & Adams, 1984; Toth et al., 2006), and success with PECS can be attributed to young age and no additional diagnosis of intellectual disability (Ganz et al., 2012). Albus did not vocalize during the delay to reinforcement or following the vocal model prompt. This may be due to Albus’s limited experience with responding to these types of prompts, filling in the blanks and vocal (intraverbal) model prompts (echoic). Perhaps incorporating interventions specifically targeting vocal imitation in the context of AAC may be necessary for similar participants. Furthermore, the participants’ experience with attending to and imitating model prompts (vocal and gross motor) should be considered.
Additional research is necessary to evaluate how to transfer stimulus control for vocalizations from the vocal model prompt to the presence of the item. Neville and Petunia vocalized consistently following a model. Although combining vocalizations and AAC is an effective form of communication, researchers and practitioners may be interested in helping individuals with ASD and CCN communicate solely with vocalizations at the appropriate time. Finally, while participants continued engaging in picture exchange in addition to vocalizations, researchers and practitioners should note the benefits of training multiple modalities of communication. Training multiple modalities (e.g., PECS and vocalizations) may lead to greater persistence of functional communication in environments where AAC is not an effective form of communication or when the AAC tool is unavailable (e.g., lost, broken).
Limitations
Despite the increases in independent vocalizations for two of the three participants, limitations exist. Research has suggested participant characteristics before the intervention impact the effectiveness of interventions (Ganz et al., 2014), and as discussed in the participant descriptions, the third participant, Albus, had an EESA score of three compared with the two participants who did increase their vocalizations after the introduction of the vocal model; Neville’s EESA score was 23 and Petunia’s EESA score was 39.5, both notably greater than Albus. While a functional relation did not occur in this study, future evaluation of AAC interventions when focusing on speech production should assess and consider idiosyncratic participant descriptions. These findings are consistent with a systematic literature review (White et al., 2021) that evaluated the effects AAC interventions have on speech production. White et al. (2021) revealed not all participants introduced to AAC increased speech above baseline levels, and for those who did increase speech, levels did not surpass AAC usage. The separation of independent target-word vocalizations and target-word approximations may have provided more transparency of the data.
In addition, consistent low independent vocal responding mitigates potential threats to internal validity, but these threats are worth mentioning. Given the emphasis on communication in the classroom, teachers and SLPs modeled speech production across the day and implemented systematic instruction targeting expressive and receptive communication. Classroom staff were asked not to provide prompting for targets associated with mealtimes. Furthermore, the word “say” was included in the vocal model prompt condition. Overall, participants did not echo the word “say,” but this is a limitation in that a true echoic would have included the entire vocal model (e.g., Say “I want chip”.)
Frost and Bondy (2002) recommend teaching PECS users to communicate across settings and for multiple types of items. For the purpose of this study, PECS training was limited to the context of mealtimes. Researchers promoted generalization by rotating familiar adults and requested food items. Data were not variable across different communication partners and items, but researchers were unable to evaluate whether generalization occurred to new untrained items and people. In addition, the study could have been improved by measuring social validity and maintenance.
Conclusion
Despite the limitations, this study demonstrated incorporating delays to reinforcement and vocal model prompts in the context of PECS-produced changes in independent vocalizations for some individuals with ASD and CCN. This study extends previous research on vocalization development in the context of AAC. This study indicates future research is warranted to evaluate strategies such as delay to reinforcement and vocal model prompts for transitions from AAC to vocalizations.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.