
Abstract
This study assesses the effects of adding low- or high-frequency information to the band-limited telephone-processed speech on bimodal listeners’ telephone speech perception in quiet environments. In the proposed experiments, bimodal users were presented under quiet listening conditions with wideband speech (WB), bandpass-filtered telephone speech (300–3,400 Hz, BP), high-pass filtered speech (f > 300 Hz, HP, i.e., distorted frequency components above 3,400 Hz in telephone speech were restored), and low-pass filtered speech (f < 3,400 Hz, LP, i.e., distorted frequency components below 300 Hz in telephone speech were restored). Results indicated that in quiet environments, for all four types of stimuli, listening with both hearing aid (HA) and cochlear implant (CI) was significantly better than listening with CI alone. For both bimodal and CI-alone modes, there were no statistically significant differences between the LP and BP scores and between the WB and HP scores. However, the HP scores were significantly better than the BP scores. In quiet conditions, both CI alone and bimodal listening achieved the largest benefits when telephone speech was augmented with high rather than low-frequency information. These findings provide support for the design of algorithms that would extend higher frequency information, at least in quiet environments.
For technological and economic reasons (e.g., to save the bandwidth of communication channels), the public telephone network only passes spectral information between 300 Hz and 3400 Hz. Thus, in telephone speech, low-frequency information below 300 Hz and high-frequency information above 3400 Hz is mostly severely distorted. This bandwidth was selected according to the study on speech intelligibility by French and Steinberg (1947) for normal-hearing listeners. The band limiting poses only negligible challenges for listeners with normal hearing; however, the reduced spectral information can have negative impact on speech intelligibility for listeners with cochlear implants (CIs). Several previous studies (see, e.g., Cohen, Waltzman, & Shapiro, 1989; Cray et al., 2004; Fu & Galvin, 2006; Horng, Chen, Hsu, & Fu, 2007; Ito, Nakatake, & Fujita, 1999; Milchard & Cullington, 2004) evaluating conventional CI listeners’ telephone usage have demonstrated that their recognition of telephone speech is significantly worse than their recognition of wideband speech, and it has been generally established that the reduced bandwidth of the telephone speech accounts for a significant amount of performance deterioration. These studies support the hypothesis that techniques to extend the bandwidth for telephone speech can potentially improve CI listeners’ telephone speech perception. So far, only a few studies have examined bandwidth extension techniques for improving CI users’ perception of telephone speech. For listeners who wear conventional CI devices, a recent study by Liu, Fu, and Narayanan (2009) used bandwidth extension techniques based on Gaussian mixture models to partly restore higher frequency information, and their results showed improvement of telephone speech recognition by seven listeners wearing conventional CI devices.
Most existing studies that examined the bandwidth effect of telephone speech focused on the performance comparison of recognizing broadband and band-limited speech among CI listeners (see, e.g., Fu & Galvin, 2006; Horng et al., 2007). The band-limiting effect derived from low frequency (i.e., f < 300 Hz) and high frequency (i.e., f > 3400 Hz) usually was not differentiated in their investigations. (For listeners who wear conventional CI devices, this practice is reasonable as the fundamental frequency [F0] cues in the low-frequency [<300 Hz] acoustic portion are beyond the access of the CI coding strategies based on envelope-vocoding processing, which can only make use of the weakly conveyed F0 cues in the temporal envelopes. However, severely distorted low-frequency content in telephone speech might degrade the vocoding representation of first formant [F1] for some vowels.) For instance, Horng et al. (2007) found that CI users showed significant intersubject variability in terms of the effect of band-limited speech. They directly attributed this variability to the lack of effective use of higher frequency speech cues in some CI listeners, and the low-frequency speech cues were not considered in their study.
A growing number of CI listeners with low-frequency residual hearing now use combined electric and acoustic stimulation and are fitted with both hearing aids (HAs) and CIs in either the same ear or contralateral ears (the so-called bimodal conditions). Many studies (see, e.g., Dorman, Gifford, Spahr, & McKarns, 2008; Gantz, Turner, & Gfeller, 2006; Hu & Loizou, 2010; Kiefer et al., 2005; Kong, Stickney, & Zeng, 2005; Turner, Gantz, Vidal, Behrens, & Henry, 2004; von Ilberg et al., 1999) have documented the improved speech intelligibility, especially in noise, when low-frequency acoustic sound is added to the electrical information presented by the CI. These benefits were at least partly attributed to a better representation of F0 cues from the low-frequency acoustic energy (see, e.g., Chang, Bai, & Zeng, 2006; Hu, 2010; Qin & Oxenham, 2006; Zhang, Dorman, & Spahr, 2010b). The presence of variation in the F0 has been shown to be a useful cue for bimodal listeners for identifying word boundaries, thereby facilitating lexical segmentation (Spitzer, Liss, Spahr, Dorman, & Lansford, 2009). Our rationale for the present study is threefold: (a) by differentiating the contribution of low- and high-frequency information, the present study complements prior ones that focused on high-frequency information; (b) with improved representation of the F0 information, bimodal listeners may benefit from adding low-frequency information (i.e., f < 300 Hz) to band-limited telephone speech, and therefore, this study will provide guidance for the development of bandwidth extension techniques; and (c) it is worthwhile to examine whether HAs benefit recognition of band-limited telephone speech by CI listeners, as HAs could well convey some low-frequency information overlapping with the telephone speech bandwidth.
In summary, there is both empirical experimental and theoretical support that extension manipulation (i.e., low- or high-frequency extension) should yield performance benefits. The natural experimental control afforded by bimodal listeners allows the present investigation to address this question: If efforts are to be devoted to increasing the bandwidth for improved telephone recognition, should those efforts be focused on extending the low frequencies (<300 Hz) or the high frequencies (>3400 Hz)? This study aims to assess the relative importance of the addition of low- or high-frequency information to telephone speech perception by bimodal listeners. The goal was to shed light on future efforts to develop bandwidth extension techniques for improving telephone speech perception by both CI and bimodal listeners, at least in quiet environments. These results for telephone speech perception might be representative for other listening conditions characterized by band-limited information.
Methods
Subjects and Stimuli
A total of 11 postlingually deafened individuals fitted with both an HA and a CI in contralateral ears participated in this study. Figure 1 shows the aided thresholds from each subject’s nonimplanted ear (the unaided thresholds were not able to be measured due to time constraint), and Table 1 shows the demographical data for all subjects. At the time of testing, all subjects had at least 1.5 years of experience with their CI and 6 years of experience with their HA. The target speech materials consisted of sentences from the IEEE database (IEEE, 1969) and were obtained from Loizou (2007). The IEEE corpus contains 72 lists of 10phonetically balanced sentences produced by a male speaker (the mean of the F0 values is about 128 Hz, and the standard deviation is around 21 Hz) and recorded in a double-walled sound-attenuation booth at a sampling rate of 25 kHz.
Individual aided thresholds for the subjects’ nonimplanted ears. Note: Missing markers indicate no response. Subjects’ Demographical Data Including Age, Gender, Etiology of Hearing Loss, Implanted Ear, Duration of Hearing Loss in the Nonimplanted and Implanted Ear, CI Device, Duration of Experience with CI and HA. Note. CI = cochlear implant; HA = hearing aid; NIE = nonimplanted ear; IE = implanted ear.

Signal processing
Four filtering configurations were created that were designed to simulate the receiving frequency characteristics of telephone handsets. The original wideband speech signals were filtered by the modified Intermediate Reference System (IRS) filter used in ITU-T (P.862, 2000; this IRS filter was also used to evaluate noise reduction algorithms in telecommunication applications by Hu and Loizou, 2007), and the frequency response of the IRS filter is shown in the top panel of Figure 2. More specifically, the magnitude gain values (in dB) were designed such that between 588 Hz and 3238 Hz, the gain is 0 dB; at 3488, and 3988 Hz (and above), the gain is −8, and −212 dB, respectively; and at 488, 388, 338, 288, 238, 188, 148, 113, 88, 38, and 0 Hz, the gain is −1, −2, −4, −6, −8, −12, −18, −24, −32, −52, and −173.6 dB, respectively. It can be seen that for most of the F0 frequency values from the IEEE sentences used in this study, the gain values ranged mostly from −20 dB to −30 dB. To evaluate the potential contributions of low-frequency information (below 300 Hz) and high-frequency information (above 3400 Hz) to extending the bandwidth of telephone speech, a low-pass filtering network and a high-pass filtering network were used. The middle panel in Figure 2 shows the frequency response of the low-pass filtering network, which has the same response as the IRS filter at the frequency of 300 Hz and above but does not introduce any distortion in the lower frequency (i.e., f < 300 Hz); the bottom panel in Figure 2 shows the frequency response of the high-pass filtering network, which has the same response as the IRS filter at the frequency of 3400 Hz and below but does not introduce any distortion in the higher frequency (i.e., f > 3400 Hz). For the fourth filtering configuration, the wideband speech was passed without any modifications (i.e., all-pass filtering network).
Frequency response of the simulated telephone filtering networks. Note: The top panel shows the IRS filtering network, the middle panel shows the low-pass filtering network, and the bottom panel shows the high-pass filtering network.
Procedure
The subjects were tested in quiet conditions, as most (if not all) prior studies used quiet conditions (in their study, Horng et al., 2007) used 35-dB Gaussian noise to simulate transmission noise, and it was not for the purpose of testing noisy listening conditions). The subjects were tested in three listening modes. In the first configuration, the subjects only used their HA (A); in the second, the subjects only used their CI (E); and in the third listening mode, the subjects used both their HA and CI (A + E).
Speech recognition was assessed in A condition, E condition, and A + E condition. In the E condition, to reduce the impact of the residual acoustic hearing of the unimplanted ear, the HA was removed by each subject and an EAR foam plug plus (DAP World, Inc., Sherman Oaks, CA, USA) a circumaural headphone were used to occlude the unimplanted ear. The stimuli were presented in sound field at 65 dB sound pressure level via a loudspeaker placed at a distance of 1 m in front of the listener. Prior to testing each listening configuration, there was a 30-min practice session to familiarize the subjects with the listening conditions and procedures, and sentences from the AzBio (Arizona State University, Tempe, AZ, USA) database (Spahr & Dorman, 2005) were used in practice. The HA and CI settings were kept the same as their daily settings during the testing.
The subjects and an experimenter were seated in a double-walled sound-treated booth, and the experimenter played the stimuli to the subjects and recorded the responses from the subjects. The subjects were asked to repeat verbally to the experimenter what they heard, and they were allowed to ask the experimenter to replay the stimuli. No feedback was provided during the testing. In total, there were 12 (= 4 filtering configurations × 3 listening configurations) conditions, each of which used two IEEE sentence lists. The presentation order of the conditions was randomized for each subject, and no list was presented more than once.
Analyses and Results
Performance was measured in terms of percent of words identified correctly (all words were scored except articles such as a/an/the). Figure 3 shows the percent correct scores for the 11 subjects using HA (A), CI (E), or combined HA and CI (A + E). WB indicates the unprocessed (wideband) stimuli, BP indicates the bandpass-filtered stimuli (i.e., 300 Hz < f < 3400 Hz), LP indicates the low-pass filtered stimuli (i.e., f < 3400 Hz), and HP indicates the high-pass filtered stimuli (i.e., f > 300 Hz). In the HA configuration, the mean percent correct values for WB, BP, LP, and HP are 29.20%, 23.44%, 21.20%, and 28.63%, respectively. In the CI-alone configuration, the mean percent correct values for WB, BP, LP, and HP are 69.96%, 53.75%, 58.99%, and 67.37%, respectively. In the bimodal configuration, the mean percent correct values for WB, BP, LP, and HP are 79.58%, 67.51%, 73.05%, and 76.77%, respectively. As can be seen, there was substantial performance variability across subjects, particularly in the HA-only and CI-only conditions. For comparison across conditions, the scores shown in Figure 3 were first converted to rational arcsine units using the rationalized arcsine transform proposed by Studebaker (1985).
Percent correct scores for the 11 subjects using hearing aid alone, cochlear implant alone, or hearing aid and cochlear implant. Note: Error bar indicates one standard error of mean.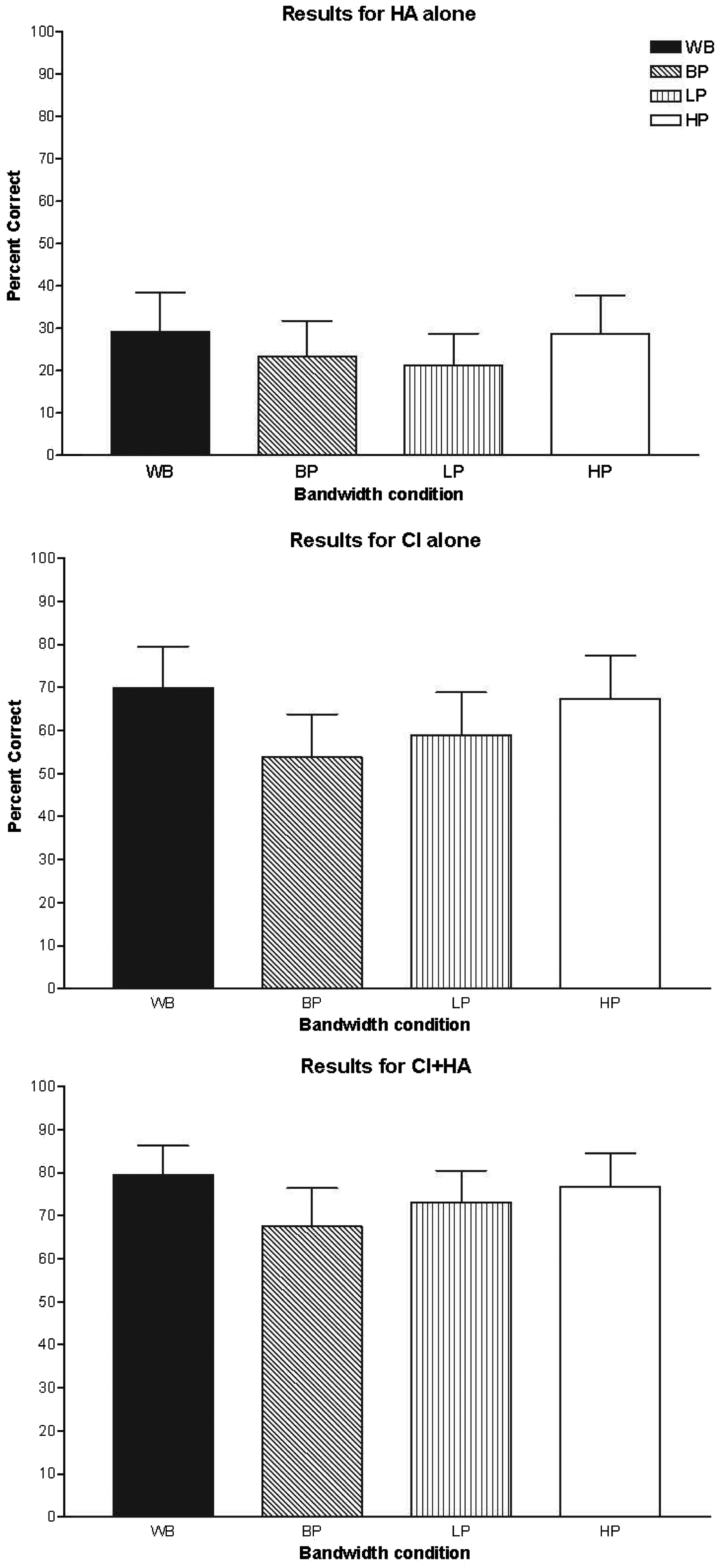
To examine the benefits of acoustic stimulation (from HA) when combined with electric stimulation (from CI), for the wideband and band-limited stimuli, paired-sample ttests were conducted between the converted scores obtained with CI (E) and the converted scores obtained with combined HA and CI (A + E; α = .05). The comparisons indicated that for all four types of stimuli (WB, BP, LP, and HP), listening with both HA and CI is significantly better than listening with CI alone (p < .05), and the mean benefit across the four types of stimuli is about 12 percentage points.
To examine the effect of bandwidth on speech perception by electric stimulation alone (E), multiple paired comparisons with Bonferroni correction were run between the converted scores obtained in the various E conditions. The Bonferroni corrected statistical significance level was set as p < .0125 (α = .05). The comparisons indicated no statistically significant differences between the LP and BP scores (p > .1) and between the WB and HP scores (p > .2). The WB scores were not significantly (weakly) better than the LP scores (p = .035). However, the HP scores were significantly better than the BP scores (p < .01). To examine the effect of bandwidth on speech perception by HA alone (A), multiple paired comparisons with Bonferroni correction were run between the converted scores obtained in various A conditions. The comparisons indicated no statistically significant differences between the LP and BP scores (p > .2), between the WB and HP scores (p > .7), and between the HP scores and BP scores (p > .1). The WB scores were not significantly (weakly) better than the LP scores (p = .023). Similarly, to examine the effect of bandwidth on speech perception by electric and acoustic stimulation (A + E), multiple paired comparisons with Bonferroni correction were run between the converted scores obtained in the various A + E conditions. The comparisons indicated no statistically significant differences between the LP and BP scores (p > .1) and between the WB and HP scores (p > .1). The WB scores were significantly better than the LP scores (p = .001). As in the electric only condition, the HP scores were significantly better than the BP scores (p < .01). Note that the differences between LP and HP (in terms of the mean percent correct values) were smaller for the bimodal condition than the CI-alone condition.
Discussion and Conclusion
The present study examined the effect of bandwidth on speech perception with electric and acoustic stimulation. By manipulating the stimuli bandwidth in quiet environments, the experiment targeted two questions: (a) Does an HA facilitate perception of band-limited speech when combined with a CI? and (b) Do low-frequency information and high-frequency information play different roles for CI and bimodal listeners in terms of bandwidth extension to improve their perception of telephone speech? It should be noted that a few other studies assessed the effect of limiting the information accessible to bimodal users by either low passing the acoustic stimuli (Zhang et al., 2010b), or high passing the electric stimuli and low passing the acoustic stimuli (Zhang, Dorman, & Spahr, 2010a). They showed that the F0 was the beneficial cue for the bimodal benefits in speech recognition in noise by electroacoustic stimulation. In those studies, however, the bimodal users still had access to high-frequency information, which was absent in the present study in telephone speech.
Experimental results showed that under quiet conditions, the HA benefited speech perception in various band-limited conditions for bimodal users. For telephone speech with a passband between 300 Hz and 3400 Hz, bimodal was significantly better than implant alone by 13.76 percentage points; For low-pass filtered speech with a passband below 3400 Hz, bimodal was significantly better than implant alone by 14.06 percentage points; for high-pass filtered speech with a passband above 300 Hz, bimodal was significantly better than implant alone by 9.4 percentage points; and for wideband speech, bimodal was significantly better than implant alone by 9.62 percentage points.
It appears that the addition of a contralateral HA benefited CI hearing the most (14.06 percentage points) when low-frequency information was present and high-frequency information was absent. In contrast, when low-frequency information was absent and high-frequency information was present, the HA benefited CI users the least (9.4 percentage points), although the amount of the difference is not so large. This is consistent with the observation that HAs mainly facilitate access to lower frequency information; however, on their own, these low-frequency cues are not adequate for speech intelligibility. Figure 1 shows that many subjects had poorer aided thresholds in high frequencies relative to low frequencies, yet for the HA-alone conditions, speech-recognition performance of several subjects appeared still better with high-frequency information than with low-frequency information. Note that these differences were not statistically significant. For telephone speech characterized with a passband between 300 Hz and 3400 Hz, the addition of a contralateral HA showed significant benefit (13.76 percentage points) for CI listening. Although this is probably due to increased spectral resolution (as would be the case if there was overlap between A and E [apical] information, this is true for many subjects in our study; see Figure 1), this finding warrants further investigation into two questions using noisy listening conditions: (a) In noisy conditions, the redundancy of this band-limited information will only result in benefits provided that the CI and the HA transmit different signal-plus-noise samples. Is it possible that bimodal listeners may take advantage of the redundant band-limited information (provided by the use of an HA) with mostly distorted F0 information? (b) Will the results stay similar for noisy band-limited speech materials? If so, it appears that other mechanisms may exist underlying the bimodal benefits in addition to F0 cues.
Another observation is that under quiet listening conditions, for both conventional CI hearing and bimodal hearing, low- and high-frequency information played different roles in speech perception. Consistent with earlier findings (Horng et al., 2007), missing high-frequency information reduces CI listeners’ speech recognition, although the decrease is slightly smaller for bimodal listeners. Our results also showed that in quiet environments, for both CI and bimodal listening, adding low-frequency information to telephone speech makes no difference in terms of speech recognition, in contrast, extending high-frequency information to telephone speech significantly improved speech recognition. In noisy conditions, it is expected that bandwidth extension toward lower frequencies will benefit bimodal users due to the improved glimpsing and F0 representation facilitated by the use of an HA (Li & Loizou, 2008; Zhang et al., 2010a). The results of this study provide support for the design of algorithms that would extend higher frequency information, at least in quiet environments. However, caution needs to be exercised to draw this conclusion, in particular for those listening conditions in noisy environments.
Previous results and the present study clearly show that the low-frequency cues do not appear useful on their own but they are beneficial when provided to bimodal listeners via HA, and this suggests that although simply extending the bandwidth of speech below 300 Hz does not improve speech recognition for both CI and bimodal listening, transmitting this low-frequency information via a different mode will do. The eventual improvements of the coding strategies are expected to extend the bandwidth of telephone speech toward both low and high frequencies.
Authors’ Note
Part of this work was presented at the Association for Research in Otolaryngology 34th Annual MidWinter Meeting, Baltimore, MD, USA, February 19–23, 2011.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by NIH/NIDCD Grants R03-DC008887 (Y. H.) and K23-DC008837 (C. R.) and in part by Research Growth Initiative from University of Wisconsin-Milwaukee.
Acknowledgments
The authors thank Dr. Julie Liss for insightful discussions and editorial assistance during this project and Sarah Mleziva for her assistance with data collection. The authors also thank Dr. Charles Limb and the anonymous reviewer for their constructive and helpful comments of the earlier version of the manuscript.