
Abstract
Keywords
Implications for Research
Experimental studies, characterized by their ability to manipulate variables and establish cause-and-effect relationships, provide a rigorous way for evaluating the effectiveness of nursing interventions. The proposed decision tree can assist researchers in accurately naming experimental study designs. The decision tree offers standardized terminology about experimental design and can improve clarity and consistency in reporting and interpreting experimental and quasi-experimental studies in nursing.
Conducting experimental studies in nursing research, whether using true or quasi-experimental designs, holds paramount importance, as these studies serve as a methodological cornerstone for advancing evidence-based practice and enhancing patient care outcomes. Experimental studies, characterized by their ability to manipulate variables and establish cause-and-effect relationships, provide a rigorous way for evaluating the effectiveness of nursing interventions (Browner et al., 2022; Grove & Gray, 2018; Rogers & Revesz, 2019; Siedlecki, 2020). For instance, by employing randomized controlled trials (RCTs) and other designs, nurses can systematically investigate the efficacy of specific interventions and their impact on patient health, overall wellbeing, and other patient care and nursing outcomes (Browner et al., 2022; Grove & Gray, 2018). Furthermore, robust experimental designs in nursing research can help generate credible evidence about effectiveness and efficacy of new procedures and processes, offering an evidence base upon which health-care practitioners can confidently base their clinical decisions (Miller et al., 2020; Siedlecki, 2020).
Background
It is important for nurse researchers to have a thorough understanding of the different research designs, including relevant threats to internal validity and strategies to address these threats. The internal validity of a study is to what extent the researchers can make an inference that the exposure is truly causing or influencing the outcomes (Polit & Beck, 2020). Additionally, the threat to internal validity can compromise our confidence in concluding that there is a relationship between exposure and outcome or that the intervention is effective when it is not, and vice versa (Turlik, 2009).
Importance of Correct Names
Incorrectly naming experimental designs can compromise internal validity by leading to misunderstandings about the study's methodology, which can affect how results are interpreted and applied. Mislabeling designs might also obscure the actual design used, resulting in inappropriate conclusions about causality or the effectiveness of interventions. It can also lead to errors in assessing the study's control over confounding variables, thus weakening the credibility of the findings. While some threats are common to different designs (e.g., sources of information bias), others can be more design-specific (e.g., sources of confounding, unit-level analysis for cluster designs). Clinicians and policymakers who critically appraise the research evidence to guide practice also need a good understanding of design-specific threats and strategies to reduce threats to internal validity (Maciejewski, 2020; Polit & Beck, 2020; Rogers & Revesz, 2019).
The Complexities of Naming Designs
Naming experimental designs can pose a surprisingly significant challenge for many novice researchers, who may find it challenging to navigate the distinctions between true experimental designs, characterized by random assignment and concurrent control groups, and quasi-experimental designs, which lack randomization and may have different types of control groups. We have identified three key challenges in nursing literature pertaining to the terminology used for labeling experimental designs.
Incorrect Use of Terms
Some authors use the terms “quasi-experimental” or “an experimental design” as specific names instead of recognizing them as design categories (Al-Mugheed et al., 2022; Chen et al., 2022; El Sebaey et al., 2022; Oikarainen et al., 2022; Öztürk & Dinç, 2014; Tawalbeh et al., 2019).
Mislabeling
Other authors completely misname their designs, for example, labeling a randomized controlled trial (RCT) as a non-RCT (NRCT), which would potentially reduce the valuing of the trial's evidence (Duprez et al., 2022; Ghorbanmovahhed et al., 2022; Mohajer et al., 2023; Rababa & Masha'al, 2020).
Combining Terms
Some nursing researchers use a variety of terms, such as “quasi-experimental pre-posttest study design” (Berga et al., 2021; Bloomfield et al., 2021; Browner et al., 2022; Dukes et al., 2022). Rather than adding precision, this can increase confusion, as quasi-experimental designs inherently involve a baseline and follow-up assessment, most often as a pretest and post-test, and such a term does not identify whether or not there is a control group or the nature of unit under study. This lack of standardized terminology not only hampers effective communication but can also lead to potential misinterpretation of findings within the nursing community and outside the nursing community as well, if transdisciplinary scholars are using the literature.
As researchers delve into the complexities of experimental design, there is a need for accurate and consistent naming of these designs, to foster clarity in communication and to strengthen critical appraisal and drawing conclusions about research evidence. The appropriate identification of experimental designs facilitates a shared understanding among nursing researchers, clinicians, and policymakers, enabling effective collaboration and informed decision-making.
Purpose
The aim of this article is to propose a decision tree to guide novice researchers in accurately and consistently naming experimental and quasi-experimental designs. By providing an approach that is both structured and systematic, the decision tree seeks to reduce ambiguity and enhance the accuracy of design categorization, thereby contributing to the overall quality and reliability of critical appraisal of nursing research.
Data Sources
Research texts by Browner et al. (2022), Grove and Gray (2018), Polit and Beck (2020), and Rogers and Revesz (2019), along with the Public Health Agency of Canada Critical Appraisal Tool Kit (Moralejo et al., 2017), and articles from journals such as PLoS ONE, Journal of Clinical Nursing, Nurse Education in Practice, and Nurse Education Today, were selected to illustrate the challenges and characteristics of various experimental and quasi-experimental study designs. These journals were researched using Cumulative Index to Nursing and Allied Health Literature (CINAHL) and PubMed with keywords “Quasi-experimental study,” “Experimental study,” “Pre-test and post-test design,” and “Before-and-after study.”
Discussion
Overview of Experimental and Quasi-Experimental Design Characteristics
True experimental and quasi-experimental are the two main categories of experimental designs, each with distinct key characteristics. Understanding and clarifying these key characteristics is crucial in accurately naming, conducting, and critically appraising nursing research. To illustrate these key characteristics, Table 1 provides examples for most of the commonly used experimental study designs, which are RCTs and cluster RCTs, and quasi-experimental designs, which are NRCTs, controlled before–after (CBA) studies, uncontrolled before–after (UCBA) studies, and interrupted time series (ITS) (Effective Practice and Organization of Care [EPOC], 2016).
True and Quasi-Experimental Designs With Examples.
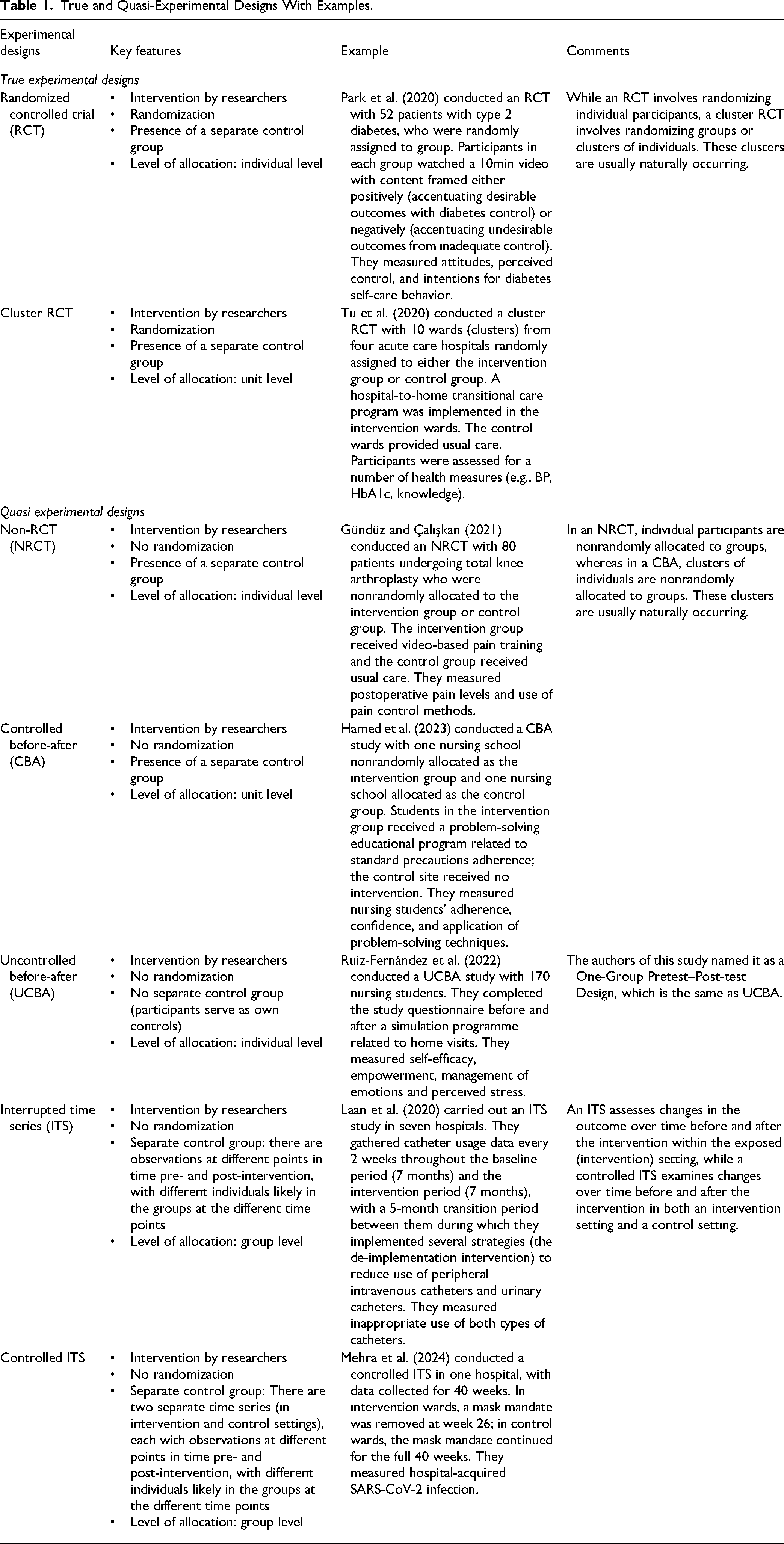
Before discussing the decision tree, we will review key characteristics of experimental and quasi-experimental designs.
Intervention
All experimental and quasi-experimental designs involve researchers administering interventions to assess their impact on outcomes (Bloomfield & Fisher, 2019; Rogers & Revesz, 2019). Interventions could include educational programs, new procedures, or drugs. Researcher-led interventions distinguish true and quasi-experimental designs from observational studies (cohort and case-control), where the intervention occurs naturally, that is, was not manipulated by the researchers. An ITS design can be used for both researcher-led and naturally occurring interventions and exposures; in this paper we will focus on the former.
Randomization
Novice researchers often confuse randomization, which is random allocation to group, with random sampling, which is selecting participants at random. Randomization means that every participant, once entered into the study, has an equal chance to be allocated to one of the groups, whereas random sampling means that everyone in the sampling frame has an equal chance of being selected into the study (Polit & Beck, 2020; Zabor et al., 2020). Random allocation ensures that participants are assigned impartially to intervention or control groups; this aids in controlling confounders and biases, crucial for internal validity (Lim & In, 2019; Zabor et al., 2020; Suresh, 2011). In contrast, random sampling can help strengthen generalizability (external validity). True experimental designs employ randomization, while quasi-experimental designs do not include random allocation (Polit & Beck, 2020; Zabor et al., 2020)
Presence of A Separate Control Group
The control group is the group that is similar to the intervention group in baseline data except it receives no or a different intervention (Polit & Beck, 2020). The control group can also be a waitlist of individuals who are awaiting a certain intervention. For example, when using a waitlist as a control group, participants can be informed that they will eventually receive the treatment but must await completion of the treatment by participants in the treatment group (Cunningham et al., 2013). The intervention group can receive any type of an intervention designed by the researcher, whereas the control group may receive one of the following: (1) a placebo treatment, (2) a different intervention, (3) usual care, or (4) no intervention (Polit & Beck, 2020; Maciejewski, 2020). The same outcomes are compared in both the intervention and control groups; the aim of the control group is to enable the researchers to evaluate whether the observed effects of an intervention are just random events. For example, if outcomes are similar in both groups, they are likely due to random error and not due to the intervention.
Quasi-experimental designs vary in their use of control groups; NRCTs and CBAs include separate control groups, which are similar to their use in RCTs. In contrast, participants in a UCBA serve as their own controls. In ITS studies, the main goal is to assess whether the data pattern after an intervention differs from the pattern observed before the intervention (Hudson et al., 2019). For example, a series of observations (measurements), such as hand hygiene adherence or patient falls, are taken at different time periods and a line graph can be drawn to show trends over time; the series is “interrupted” by an intervention and the researchers can compare the trends before and after the intervention using specific types of regression modeling (Hudson et al., 2019; Penfold & Zhang, 2013). Having a minimum of three baseline measurements distinguishes an ITS from a repeated measures design (applicable to an RCT, NRCT, CBA, or UCBA), where there are several follow-up measurements. In an ITS, individuals being assessed in the different pre-intervention time periods may or may not be the same individuals and may differ from those assessed in the post-intervention time periods, but individuals in the pre-intervention time periods are considered as nonconcurrent controls (Hudson et al., 2019). It is possible, though not common, to have a true control group; in a controlled ITS, observations are also taken in a separate setting where the intervention was not implemented.
Level of Allocation To Groups
In experimental designs, the differentiation between allocating at the unit level and allocating at the individual level plays a crucial role in selecting the appropriate study design. Allocating at the unit level may be deemed necessary when randomization at the individual level is impractical, as it helps prevent contamination between treatment groups (Rutterford et al., 2015; Taljaard et al., 2020). Allocation to the unit level involves assigning interventions or treatments to entire nursing units or wards instead of individual patients. For example, in a study evaluating the efficacy of a multifactorial intervention strategy for safe patient handling, 12 health-care units were randomly allocated to either arm A or arm B (Wåhlin et al., 2023).
In contrast, allocation to the individual level involves assigning interventions or treatments to individual patients rather than entire nursing units or wards. For instance, in a clinical trial investigating the impact of a nurse-led mobile health intervention to prevent excessive gestational weight gain in women diagnosed as overweight or obese, 92 pregnant women were randomly assigned to receive the MyHealthyWeight app and a wearable activity tracker and the controls received standard antenatal treatments with no mHealth-based elements (Chen et al., 2023).
Allocation to either individual or unit level is applicable in both true and quasi-experimental designs. For instance, in RCTs, individuals are allocated, while cluster RCTs allocate entire units (e.g., hospital wards or long-term care facilities). Similarly, NRCTs allocate individuals, whereas CBAs allocate entire units. In a UCBA, there is no allocation, due to the absence of a separate control group. Data in ITS and controlled ITS are regarded as being at the group level. The level of allocation is critical for conducting appropriate statistical analysis and accurately naming the designs.
A Decision Tree For Naming Experimental and Quasi-Experimental Designs
A shown in Figure 1, a decision tree has been designed with multiple steps to provide guidance for researchers and reviewers in accurately naming a study design. Use of this decision tree would address the previously identified challenges, promoting accuracy, precision, and consistency. The Public Health Agency of Canada Critical Appraisal Tool Kit has an algorithm for naming study designs that incorporates observational studies, and considers first how participants were chosen, how many groups and when they were assessed, and then if allocation was random (Moralejo et al., 2017). The decision tree in Figure 1 includes only experimental and quasi-experimental designs and focuses on the key characteristics described above: intervention controlled by the researcher, randomization, presence of a separate control group, and level of allocation.
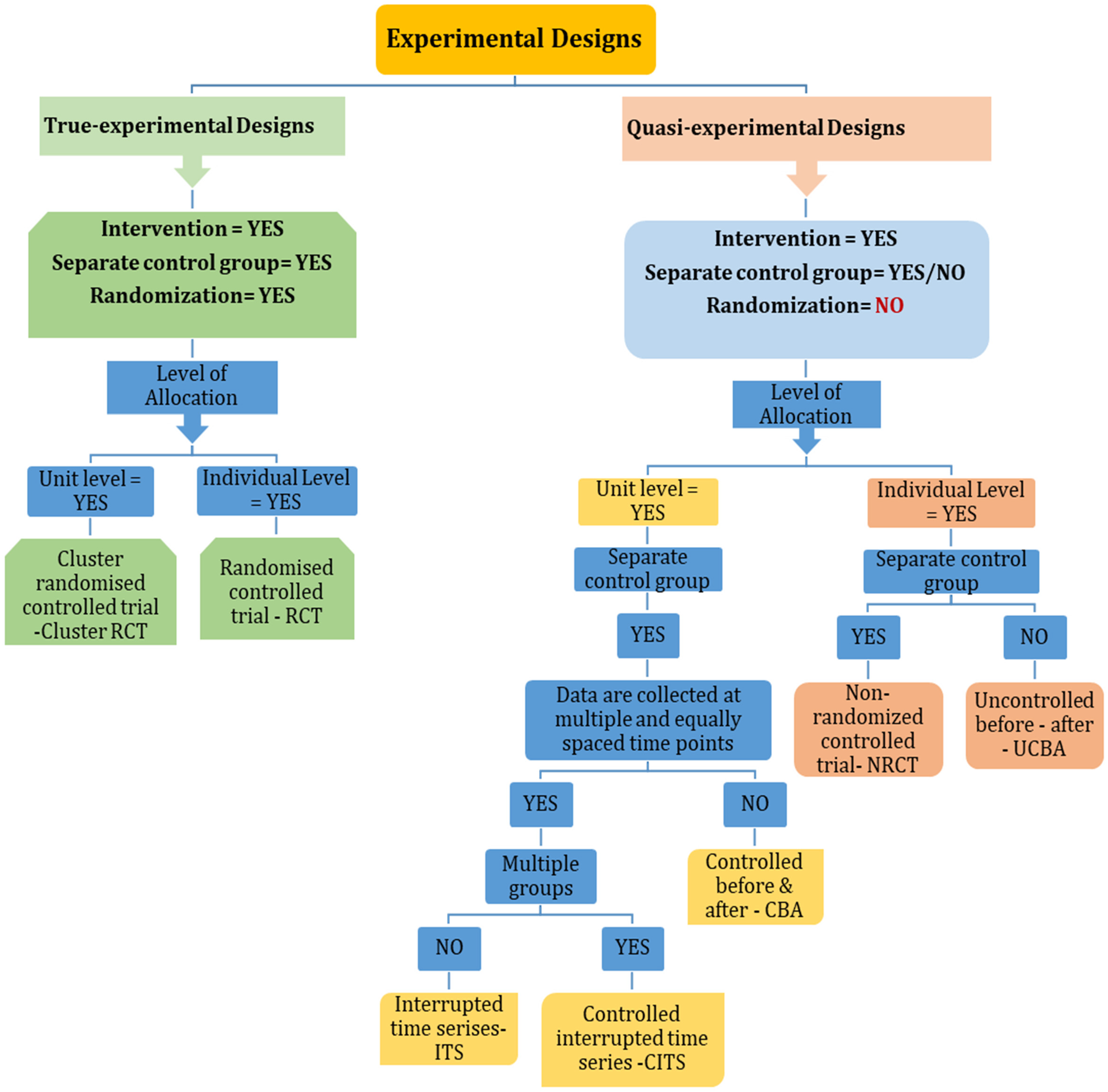
Decision tree: naming true experimental and quasi-experimental designs.
The first decision to be made, as shown in Figure 1, is whether there was an intervention that was controlled by the researcher. If the answer is no, then one would not proceed further in naming the design as either experimental or quasi-experimental. Instead, one would consider whether the study was observational (e.g., cohort or case-control) or cross-sectional. The next decisions to be made relate to whether there was a separate control group and whether allocation to group was random. Random allocation is a method that assigns individuals to treatment and control groups purely by chance, without considering researchers’ preferences or patients’ condition. If the answer to both questions is yes, then one is looking at a true experimental design, and the final decision before naming the true experimental design is to look at whether individuals or units, for example, clusters, were randomly allocated to group. If allocation was conducted at the individual level, the study design is classified as an RCT. Alternatively, if allocation was at the unit level, it is categorized as a cluster RCT.
If there was no random allocation to group, then one needs to look at both the number and nature of the control groups and level of allocation (individuals or units) in order to name the quasi-experimental design. The subsequent stage of the decision tree initially evaluates the allocation level into groups, followed by assessing the presence and characteristics of the control group. If allocation occurred at the individual level and a distinct control group was present, the study is classified as an NRCT. Conversely, if there was no separate control group and individuals acted as their own controls, it is identified as a UCBA. On the other hand, if allocation took place at the unit level, and there was a separate concurrent control group, the study is categorized as a CBA. However, if there were several pre-intervention measurements conducted over time with a nonconcurrent control group at each time point, the design is classified as a single group ITS. In cases where there was a separate control group with comparable measurements over time, the design is named a controlled ITS. Practice going through the algorithm with different studies should be helpful in strengthening skills in naming experimental research study designs. This decision tree was developed to help novice researchers accurately name commonly used true and quasi-experimental designs. Therefore, we did not cover other types of RCTs such as explanatory or pragmatic trials, parallel RCTs, or crossover RCTs designs.
Conclusion
Naming the study design is a critical step in designing research methodology and in critical appraisal of research. Using the decision tree will help researchers and those critically appraising evidence to name a study design accurately and precisely. They can then identify potential limitations associated with the specific design, and whether appropriate strategies were used to address those threats. In doing so, researchers can strengthen their intervention studies, and critical appraisers can appropriately assess strengths and limitations of a study and the certainty of the evidence. Using a common language for identification of experimental designs can facilitate a shared understanding among nursing researchers, clinicians, and policymakers, enabling effective collaboration and informed decision-making.
Footnotes
Author Contributions
AH and DM made substantial contributions to conception and design, or acquisition of data, or analysis and interpretation of data. AH, DM, and AD were involved in drafting the manuscript or revising it critically for important intellectual content. All authors gave final approval of the version to be published. Each author has participated sufficiently in the work to take public responsibility for appropriate portions of the content; and agreed to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.