
Abstract
Empowerment-themed advertisements (ETAs) often pair ostensibly empowering narratives with objectification imagery. Existing research demonstrates that women do not report feeling empowered after viewing ETAs but cannot confirm why. In this study, 186 female participants were randomly assigned to view captions and/or photos from ETAs while their eye movements were recorded. The empowerment-themed captions increased women’s felt empowerment when presented alone but failed to empower when paired with photos. However, captioning photos with empowerment-themed text did lead to lower self-objectification than captioning them with objectification-themed text. Thus, while the visuals used in ETAs limit their effectiveness, self-objectification may not be responsible.
Keywords
Over a decade ago, body-positive advertisements like the Dove Real Beauty Campaign gained initial notoriety for encouraging women to love their bodies (Dove, 2021). Empowerment-themed advertisements (ETAs) have since emerged as a second generation of these campaigns, moving beyond body-positivity messages to tackle feminist issues like gender stereotypes and workplace inequities. For example, a 2019 Super Bowl ad by Bumble (i.e., a dating company) shares the inspiring story of Serena Williams with the closing tagline, “And most of all, don’t wait to be given power. Because here’s what they won’t tell you—we already have it.” (https://www.youtube.com/watch?v=213c9RK3aw4). While the content varies across advertisements, ETAs share a focus on feminist-themed messages, the use of female talent, and ostensibly empowering content (SheKnows Media, 2016).
ETAs contain explicit messages of empowerment, yet little work has examined whether women feel empowered after viewing them. A notable exception is the study by Couture Bue and Harrison (2019), which found that exposure to ETAs produced by cosmetics and clothing companies failed to increase women’s empowerment while increasing their self-objectification. The authors noted that ETAs often pair empowerment-themed narratives (i.e., text) with visuals that still feature thin-ideal-conforming models, raising concerns about the independent and interactive roles of text and photos in these advertisements. The current study uses experimental design and eye-tracking methods to examine the independent and collective effects of ETA components (i.e., text caption and visual) on women’s body image and felt empowerment—pairing participants’ self-report responses with eye gaze behaviors to examine the visual attention that predicts psychological outcomes.
Empowerment-Themed Advertising
Existing research on ETAs has largely focused on the strategy’s marketing effectiveness rather than its psychological consequences. ETAs primarily appeal to female consumers (Tsai et al., 2021). The phrase “sex sells” is a common refrain in advertising, but recent research indicates that this phrase is a misnomer, particularly among female consumers (Gramazio et al., 2021; Wirtz et al., 2018). Given women’s aversion to objectifying marketing campaigns (Guizzo et al., 2017), ETAs represent a logical departure from traditional, objectifying campaigns.
Compared to other advertisements, advertisements using empowerment-themed appeals increase brand recall and lower consumer reactance (Akestam et al., 2017) while garnering more positive brand associations (Drake, 2017)—particularly in contexts where the message aligns with the company’s existing brand and image (Abitbol & Sternadori, 2016). ETAs are more shared and commented on than their non-empowering counterparts (Wojcicki, 2016), indicating that they lead to greater consumer engagement than other campaign types.
While the narratives in ETAs feature pro-social content encouraging feminist ideals, the visual messages in ETAs often resemble traditionally objectifying campaigns. Specifically, they use idealized models and emphasize the models’ appearance. For example, Pantene’s #ShineStrong series brings awareness to feminist issues such as double standards for women in the workplace while placing visual emphasis on conventionally beautiful models. Similarly, while the Under Armor #IWillWhatIWant commercial featuring Misty Copeland includes a narrative of triumph over setbacks and adversity, visual images in the campaign feature extended close-ups of Copeland’s legs in line with objectification criteria of dismemberment and skin exposure (e.g., Aubrey & Frisby, 2011).
Initial experiments by Couture Bue and Harrison (2019) and Couture Bue et al. (2022) examined the effect that exposure to advertising containing empowerment appeals had on women’s felt empowerment and state self-objectification. In Couture Bue and Harrison (2019), women were randomly assigned to see traditional beauty advertisements, empowerment-themed beauty advertisements (beauty ETAs), or control advertisements without body references. Following this, they participated in a brief speaking task and self-reported felt empowerment. While observers blind to the condition judged women in the ETA condition as slightly (but significantly) more empowered during the speaking task, these women did not report experiencing higher levels of self-efficacy or empowerment than women who saw other genres of advertising. Furthermore, there was evidence that women who saw the ETAs exhibited greater levels of self-objectification post-viewing than participants in the control condition. This initial study raised questions about the effectiveness of the empowering narratives in these advertisements and the interaction between empowering narratives and objectifying visual content more broadly. Couture Bue et al. (2022) expanded on this work to include ETAs from companies outside of beauty products (i.e., general ETAs vs Beauty ETAs) and to measure schema activation following ad exposure. Ultimately, Couture Bue et al. (2022) found that no condition of ETA successfully primed empowerment schemas, although both general and beauty-themed ETAs primed greater body awareness than control ads. Together, these studies call into question whether these ads empower women.
The primary goal of the current study is to examine whether the messages commonly used in ETAs increase women’s felt empowerment, and if not, whether it is the caption, photo, or combination of the two that hinders their effectiveness. The current study also uses eye-tracking methods to extend the findings described earlier. While prior research measured the psychological effects of the different advertising conditions, the current study breaks down ETAs into their respective visual and textual components to test the independent and combined effects of these message parts. Specifically, the current study examines how pairing images with empowerment-themed versus objectifying text affects psychological outcomes (i.e., self-objectification and felt empowerment), and how visual attention when viewing the advertisements predicts these psychological outcomes, to better investigate why these messages may fail to empower.
Scholars have a limited understanding of how objectifying imagery interacts with empowerment message themes; this study provides evidence of the relationship between felt empowerment and objectification when the two co-occur in media. In addition, while prior studies have focused on the effects of exposure to advertising stimuli on outcomes such as self-objectification (e.g., Harper & Tiggemann, 2008), this study provides a novel lens into the visual attention associated with these outcomes.
Media Objectification and Self-Objectification
Our society values women’s appearance over their other attributes and achievements, a framework described in objectification theory (Fredrickson & Roberts, 1997). From an early age, girls’ bodies are observed, commented on, and evaluated by others. In the media, women’s bodies are often objectified and shown as existing for others’ consumption (Fredrickson & Roberts, 1997). Objectification theory posits that repeated exposure to objectified images may lead women to internalize this perspective and value their body’s appearance over health and function—a process referred to as self-objectification (Fredrickson et al., 1998).
Self-objectification has been linked to a number of problematic outcomes, including decreased sexual satisfaction (Calogero & Thompson, 2009), decreased self-esteem (Choma et al., 2010), body image disturbance (Moradi & Huang, 2008; Prichard et al., 2018), and disordered eating (Schaefer & Thompson, 2018). In addition, state self-objectification is associated with decreased performance on cognitive (see Winn & Cornelius, 2020 for a meta-analysis) and physical (Harrison & Fredrickson, 2003) tasks, presumably due to a split in attention between self-monitoring and the task at hand. Thus, self-objectification is linked with harmful outcomes that seem at odds with empowerment.
Reviewing literature on media and objectification can help scholars and advertisers alike better predict what message elements may contribute to self-objectifying behaviors in women. Exposure to various types of media content, including advertising (e.g., Harper & Tiggemann, 2008), popular television programming (e.g., Vangeel et al., 2022), and social media (e.g., Fox et al., 2021) has been linked to increased state self-objectification—either directly or through channels like increased appearance comparisons. Because self-objectification is inherently related to one’s appearance (Fredrickson & Roberts, 1997), scholars tend to primarily discuss visual (i.e., image-based) primes and processes (e.g., Aubrey et al., 2009), and there is ample work showing that exposure to sexually objectifying media content is associated with media effects (e.g., Karsay, Knoll, & Matthes, 2018). Yet surprisingly few scholars make a distinction between the effects of objectifying imagery versus captions when examining the effect of media on self-objectification. Stimuli can be categorized by those that (a) make no distinction between visual and textual message content, (b) contain only imagery, (c) contain only text, and (d) use text to manipulate framing of the image (e.g., Harrison & Hefner, 2014; Veldhuis et al., 2012, 2014). Breaking down the studies in this way allows scholars to consider the independent and collective effects of text and visual messages.
Scholarship investigating the effects of exposure to images alone provides an important understanding of which images prompt self-objectifying behaviors in women. In studies that manipulate state self-objectification by exposing women to objectifying images, exposure to stand-alone images has been shown to lead to greater state self-objectification in participants (Aubrey et al., 2009). In addition, Harper and Tiggemann (2008) found that participant state self-objectification was higher following exposure to media containing thin-ideal images than after viewing control images, regardless of whether men appeared in the advertisement. In contrast, exposure to body competence images, such as those depicting athletic performance, may reduce state self-objectification (Grey et al., 2016). Thus, perhaps intuitively, the image content (independent of text) impacts women’s self-objectification levels, with sexualized or appearance-focused images leading to greater self-objectification.
Fewer studies have examined the independent effect of textual information on participants’ state self-objectification, presenting mixed evidence on whether exposure to objectifying text alone primes state self-objectification in women. Roberts and Gettman (2004) asked women to unscramble sentences that contained suggestions of objectification or body functionality, finding that women who saw suggestions of objectification reported higher state self-objectification than women in the body competency condition. Lending further support to the argument that textual captions in advertisements may be enough to trigger self-objectification independent of photos, commentary surrounding women’s bodies, whether complementary (Calogero et al., 2009) or critical (Gapinski et al., 2003), has been shown to lead to greater state self-objectification in female participants under some circumstances. However, within more recent social media research, studies examining appearance-based comments have found that positive appearance comments had no impact on state self-objectification (Guizzo et al., 2021; Tiggemann & Barbato, 2018) but were associated with greater body dissatisfaction (Tiggemann & Barbato, 2018). Finally, even indirect textual references may lead to greater state self-objectification, as evidenced in an experiment by Calogero and Jost (2011) comparing the effects of reading passages endorsing benevolent or complementary sexism to control texts. Thus, the textual content of advertisements may lead to greater self-objectification, even in the absence of imagery, although this effect may not be as consistent or as impactful as photo stimuli.
The finding that exposure to sexualizing media is linked to increased self-objectification is robust (see Karsay, Knoll, & Matthes, 2018), as are the adverse outcomes associated with self-objectification, but objectification theory offers little explanation regarding the visual patterns that occur prior to increased self-objectification. Recent work using eye-tracking to examine objectification of others by Hollett et al. (2022) demonstrated that both male and female participants who viewed an adults-only video game exhibited sexually objectifying gaze behaviors when viewing an attractive model (i.e., a preference for body over face). In addition to this work, Karsay, Matthes, et al. (2018) used eye-tracking to show that participants who were primed with objectifying music videos exhibited a body-biased gaze behavior, whereas those in the control condition did not, and Gervais et al. (2013) found that appearance primes led both male and female participants to adopt a body-focused gaze when looking at photos of models. Thus, objectifying cues in media can prime body-focused eye gaze behaviors, at least as they relate to objectifying others. To our knowledge, there is no work that shows how visual attention of others relates to self-objectification.
One unique benefit of eye-tracking is that it allows researchers to examine how visual attention to specific regions of a body, either on oneself or a model, predicts psychological outcomes. When asked to look at bodies, visual attention biases have been demonstrated for individuals with high thin-ideal internalization (Hewig et al., 2008), body dysmorphia (Grocholewski et al., 2012), body dissatisfaction (Gao et al., 2014; Roefs et al., 2008), and disordered eating symptomatology (Bauer et al., 2017; Horndasch et al., 2012; Tuschen-Caffier et al., 2015). Certain body regions, such as the thigh gap, waist, and breasts, are given elevated cultural significance in determining overall attractiveness (e.g., Leboeuf, 2019), while biases in visual attention toward thin-orienting (Hewig et al., 2008) and high-anxiety body regions (Couture Bue, 2020; Smeets et al., 2011) are associated with body dissatisfaction in both clinical and non-clinical samples. Greenberg et al. (2014) also examined visual attention to self-reported attractive versus unattractive facial regions in a clinical sample—finding that participants who exhibited eating disorder symptomatology showed a visual bias for unattractive regions on their own face and the corresponding regions on others’ faces (i.e., a negativity bias). Accordingly, it is important to make additional distinctions beyond a model’s face and body when examining visual processing of the body, and visual attention to self-reported high-anxiety regions may serve as important predictors of downstream outcomes.
Given the visceral, visual nature of photos and the existing literature confirming the ability of photos to consistently prime self-objectification in viewers, the images shown in ETAs may be as, or even more, important than the text. Photos that accompany ETAs place an emphasis on appearance; thus, it is plausible that the objectification-themed messages present in ETAs will overshadow the empowerment narrative. Using eye-tracking methods to measure visual attention is an important step to understanding how textual and visual messages contribute to self-objectification, and ultimately, why these durable outcomes keep occurring. Based on this, we expect that visual attention to the empowerment-themed captions will be beneficial, whereas visual attention to the photos (which contain attractive models) will be harmful. We also expect that attention to objectifying captions (OCs) may prime viewers to adopt a body-biased gaze.
Felt Empowerment
Empowerment refers to the process of gaining mastery over life outcomes (Zimmerman & Rappaport, 1988). It is an interdisciplinary term used to describe both individual characteristics and group-level behaviors (Narayan, 2005). Rather than thinking of empowerment as a unified theory, it is useful to consider empowerment as an umbrella term that encompasses multiple levels and constructs. The current study uses felt empowerment to describe the transitive experience of feeling control and mastery over life outcomes—the level of empowerment most relevant to the purported purpose of ETAs. Feelings of empowerment can be difficult to quantify via self-report (Dolničar & Fortunati, 2014; Thomas & Velthouse, 1990; Zimmerman, 1995), as the manifestations of feeling empowered change over time and behaviors are both context- and person-specific. As with prior research on ETAs (e.g., Couture Bue & Harrison, 2019), the current study uses the Affective Empowerment Checklist (AECL-24), an adaption of the Multiple Affective Adjective Checklist (Zuckerman & Lubin, 1965), to measure how strongly participants endorse 24 adjectives related to empowerment. Thus, the AECL measures the individual’s perceived emotional state at the time of measurement.
There is limited quantitative scholarship examining felt empowerment as an outcome of media effects, and much of what we know about empowerment comes from fields like social work and organizational communication. In studies examining context-specific felt empowerment outside of a media environment, feeling empowered is typically associated with beneficial outcomes, including increased managerial effectiveness (Spreitzer, 1995), reduced employee burnout (Livne & Rashkovits, 2018), improved employee health and well-being (Laschinger et al., 2016), and greater community involvement (N. A. Peterson et al., 2006). Accordingly, feeling empowered is a desirable outcome that may be at odds with the objectification themes present in the ETA visuals.
Little research outside of Couture Bue and Harrison (2019) and Couture Bue et al. (2022) has examined the ability of media campaigns to increase women’s empowerment, with the notable exception of Thøgersen-Ntoumani et al. (2022). This study examined campaigns encouraging women to exercise, finding that exposure to ads improved outcomes like body compassion (Thøgersen-Ntoumani et al., 2022). While, to our knowledge, there is little work that has measured felt empowerment and self-objectification directly, prior work has studied the relationship between felt empowerment and body image more broadly—showing that empowerment may have a protective effect on body satisfaction. In a correlational study, Kinsaul et al. (2014) found that female college students who reported greater feelings of empowerment also tended to report more positive body image. Both Kinsaul et al. (2014) and R. D. Peterson et al. (2008) found that reported empowerment was a better predictor of body image than feminist beliefs. Given that objectification has been a source of oppression for decades (Fredrickson & Roberts, 1997), objectification and empowerment may be interrelated, such that self-objectification makes it difficult to feel empowered (or vice versa). Alternatively, the two may be theoretically orthogonal. Based on this, and the appearance-oriented focus of the photos used in ETAs, we present the following hypothesis and research question:
The Current Study
The current experiment used eye-tracking methods to investigate the effect of message components (visual and textual) on women’s empowerment and self-objectification after viewing ETAs. Data collection for this study was part of a larger, three-study project using eye-tracking methods to examine media effects. Eye-tracking is time- and resource-intensive. Due to the brevity of the individual studies, participants completed two additional, unrelated studies within the lab visit; the current study was presented second in the sequence. More information on the two additional studies can be found in the Supplemental Online Appendix.
The current study’s primary goal was to test the overall effectiveness of ETAs at increasing women’s empowerment—providing an indication of whether text and/or photos limited the effectiveness of these campaigns. Thus, conditions were designed to include empowerment or OCs presented alone (i.e., empowerment captions [EC] and OC conditions, respectively), photos alone (i.e., Photo Only condition), and each caption type paired with the photos used in the photo-only condition (i.e., EC + Photo and OC + Photo conditions) for a total of five conditions (Table 1). The dependent variables included attention to text versus image, attention to the model’s face versus body (i.e., visual objectification of the model), and how visual attention relates to feelings of self-objectification and empowerment.
Stimulus Description.
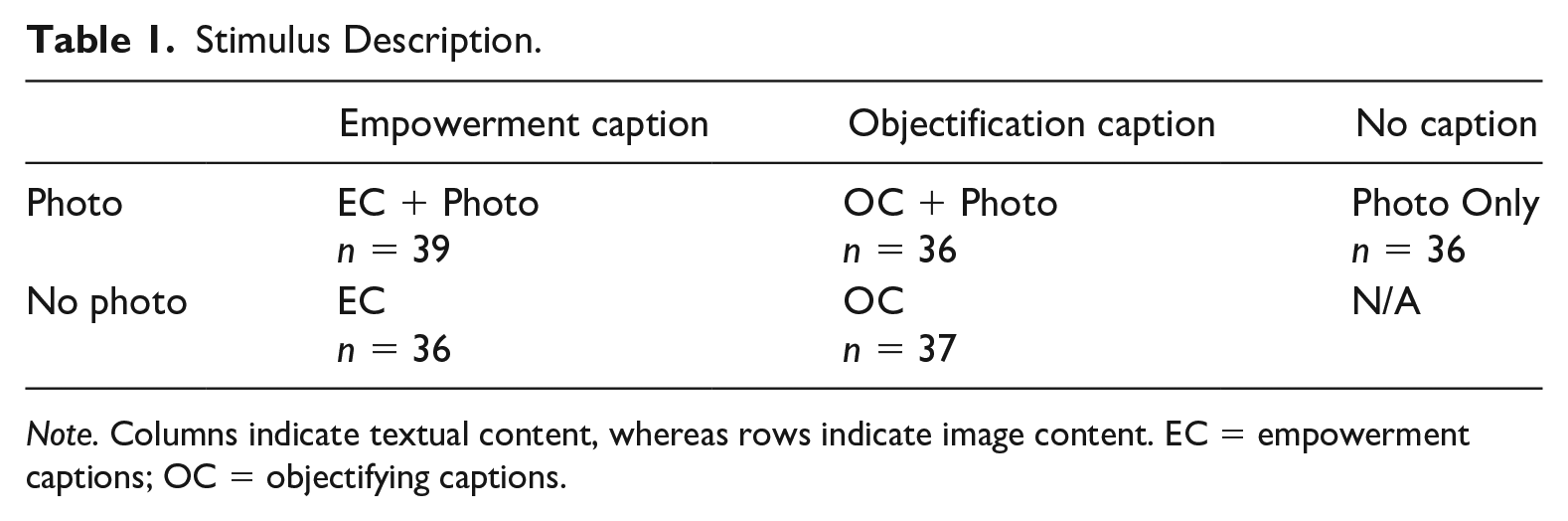
Note. Columns indicate textual content, whereas rows indicate image content. EC = empowerment captions; OC = objectifying captions.
Method
Stimulus Development
Photos and captions from each condition were selected from print advertisements and pretested for use in the study by 50 female-identifying participants recruited on Amazon’s Mechanical Turk. Additional information about the pretest study and stimulus characteristics can be found in the online appendix. The photos and captions selected from the pretest were combined to create the five experimental conditions described in Table 1, with 10 stimuli per condition. Typefaces for each caption were matched across conditions, and texts in the caption + photo conditions were edited to be roughly the same length and the same shape on the screen.
Procedure
This study was approved by the University of Michigan Health Sciences and Behavioral Sciences Institutional Review Board. Participants completed an online survey at least 1 week prior to the lab session that included baseline measures of felt empowerment, self-objectification, and body anxiety, among filler items.
Lab sessions took place individually in a neutral office space. Participants were randomly assigned to one of the five conditions described earlier. Because visual attention to the photos was of primary interest, eye-tracking was only conducted in the three conditions containing a photo (i.e., Photo Only, EC + Photo, OC + Photo Conditions). Participants in the caption-only conditions (i.e., EC condition and OC condition) followed a similar procedure to the eye-tracking conditions but did not complete the eye-tracking calibration or the additional studies described in the Supplemental Materials. Following random assignment to a condition, stimuli from the respective conditions were displayed for 20 seconds before automatically advancing for a collective total of 200 seconds of exposure. After viewing the stimuli, participants were immediately directed to a survey that measured felt empowerment and state self-objectification and then debriefed about the purpose of the study upon completion.
Participants
Women of ages 18–35 years were recruited from an introductory Communication Studies Participant Pool and a health research pool website associated with a large, public Midwestern university. The study was described as a “fashion study” examining the visual processing of advertisements and social media posts. A total of 335 participants completed the pretest measure, 214 of whom completed the in-person session (73 without eye-tracking). Of the 141 data recordings in the eye-tracking session, 14 (10%) were flagged for a data quality issue due to sampling percentages less than 70%, 6 (4%) were flagged due to visible offset in the eye-tracking, and 10 (7%) participants were eliminated due to having less than 33% of the recorded time resulting in fixation durations. This left 111 recordings that passed the quality metrics, with roughly 36 participants per condition (see Table 1). An additional three participants did not follow instructions for the Twenty Statements Test (i.e., omitting more than 10 responses); these three participants were excluded from analyses using state self-objectification.
Of the participants who completed both waves of the study with data that met the quality metrics, 126 (69%) participants were Caucasian/White (non-Hispanic), 10 (5%) were Biracial/Multiracial, 6 (3%) were African American/Black, 15 (8%) were Hispanic/Latino/a, 22 (12%) were Asian/Asian-American, 1 (1%) participant reported that she was Pacific Islander/Native Hawaiian, and 4 (2%) selected the “other” category. The average age in the sample was 23 years (SD = 4.93). The median reported total household income in the sample was between $70,000 and $100,000, indicating that the participants were generally from a high socioeconomic status, with 76 (41%) participants reporting income greater than $100,000, and only 34 (19%) participants reporting incomes less than $30,000. Most of the sample (n = 83) reported having completed “some college.” Fourteen participants (8%) reported that their highest level of education was high school, 31 (17%) were college graduates, 20 (11%) had completed some graduate school, and 36 (20%) participants had completed a graduate degree.
Measures
Baseline Measures
Baseline levels of felt empowerment and trait self-objectification were measured in the pretest survey taken at least 1 week before the in-person lab session. The AECL-24 (Couture Bue & Harrison, 2019) was used to measure participants’ reports of typical felt empowerment. Participants indicated the extent they felt a series of 24 adjectives related to empowerment typically described them. Twelve of the adjectives represented empowerment words (e.g., empowered, mighty, capable), and 12 adjectives represented disempowerment words (e.g., timid, ineffective, exploited). Final scores were calculated by subtracting the total score of disempowerment words from the total score on empowerment words. Possible scores ranged from −72 to 72; the mean score in this sample was 24.10 (SD = 19.61), indicating that most participants reported greater feelings of empowerment than disempowerment at baseline. Reliability using Cronbach’s alpha was excellent for empowerment words (α = .91) and good for disempowerment words (α = .89).
Trait self-objectification was measured using the Self-Objectification Questionnaire (Fredrickson et al., 1998), which asks participants to rank-order 10 statements about their physical self-concept in order of personal importance. It includes statements representing functional values (e.g., “When considering your physical self-concept, what rank do you assign to physical coordination?”) and esthetic values (e.g., “When considering your physical self-concept, what rank do you assign to physical attractiveness?”). The final score was calculated by subtracting the sum of competency items from the appearance items. Scores ranged from −25 to +25, with positive scores indicating higher importance placed on appearance (i.e., higher trait self-objectification). For this sample, the mean score was −2.92 (SD = 13.64), suggesting relatively higher importance placed on body competency.
Participants responded to the Physical Appearance Trait Anxiety Scale (PASTA) (Reed et al., 1991) to indicate the extent to which they generally felt nervous about the appearance of 16 body parts. Response options ranged from 1 (Not at all) to 5 (Exceptionally), α = .88, with average scores across items ranging from 1 to 3.7 (M = 1.99, SD = .62).
Posttest Measures
Directly following the experimental manipulation, state self-objectification was measured with the Twenty Statements Test (Fredrickson et al., 1998), with participants providing open-ended answers to complete the statement “I am . . .” 20 times. Following the procedure of Fredrickson et al. (1998), the statements were coded into five categories: 0 for references to body shape and size (e.g., “small,” “overweight,”), 1 for other appearance descriptions (e.g., “blonde,” “unattractive,”), 2 for physical competence words (e.g., “strong,” “athletic”), 3 for traits and abilities (e.g., “sister,” “mother,”), 4 for states or emotions (e.g., “happy,” “bored,”), and 5 for items that were ambiguous or otherwise not codable. The state self-objectification score represents the sum of words coded as either 0 (body shape or size) or 1 (physical appearance). Statements that pertained to physical competency (e.g., “strong”; “athletic”) were not counted as state self-objectification. Scores in this sample ranged from 0 to 8 (M = 1.26, SD = 1.29), with most participants (68%, n = 123) using either zero or one body word. Momentary felt empowerment after stimulus exposure was again assessed using the AECL-24 (Couture Bue & Harrison, 2019), with participants responding to the extent to which they currently felt the 24 empowerment-themed adjectives applied to them. Posttest AECL scores ranged from −41 to 70 (M = 28.67, SD = 21.77, empowerment words α = .94, disempowerment words α = .91).
Participant Gaze Metrics
Participants’ eye movements were recorded in Tobii Studio (Version 3.3.1.757; Tobii Technology AB, 2015) at a sampling rate of 60 Hz using a remote eye tracker (Tobii X2-60 Compact Edition; Tobii Technology, Inc.) affixed to a 21.5-inch computer monitor set to 1920 × 1080 resolution. The Tobii X2-60 eye tracker uses a dual-camera system to automatically select dark or bright pupil tracking based on superior performance during calibration. All participants completed a nine-point calibration procedure. This eye tracker does not require the use of chin rests; it is non-invasive and allows for a natural viewing position.
In the three conditions featuring photos, polygonal areas of interest (AOIs) were specified for each photo. Specifically, research assistants tagged the models in each photo for the following regions: text, person, face, hair, chest, arms, waist, hips, upper legs, and lower legs. AOIs that refer to “person” included the entire model, whereas “body” refers to the model excluding the face. Dimensions and placement of body AOIs were identical across the three conditions; a sample AOI-tagged photo is included in the online appendix. As described in greater detail in the following section, baseline PASTA scores (Reed et al., 1991) were used to designate body regions as high vs low anxiety for each participant.
Data Analysis Strategy
Participants’ baseline responses on the PASTA scale (Reed et al., 1991) were used to classify the body regions on the model (face, stomach, hips, thighs, and legs) as low-anxiety vs high-anxiety regions; these designations were then used to create AOIs for each participant. Specifically, two composite attention measures were created for each participant: one variable calculating visual attention to all body regions self-reported as high-anxiety (3+ on the PASTA scale) and a second variable calculating visual attention to all body regions self-reported as low anxiety (1 or 2 on the PASTA scale). Analysis of co-variance (ANCOVA) models were used to test differences in (a) self-objectification, (b) felt empowerment, and (c) differences in attention to AOIs across conditions. Regression analysis was used to test visual attention as a predictor of post-exposure outcomes.
Results
Preliminary Analyses
Analyses were conducted to confirm that random assignment was effective. Participants assigned to each condition did not significantly differ in age, F(4, 178) = .86, p = .49; BMI, F(4, 176) = 1.14, p = .34; ethnic background, χ2(24) = 35.14, p = .07; or income, F(4, 176) = .65, p = .63. Accordingly, these variables were not included in further analyses. There were also no differences in baseline felt empowerment, F(4, 179) = .378, p = .82, or trait self-objectification, F(4, 179) = 1.83, p = .13, by condition.
Hypothesis Testing
State Self-Objectification
Average state self-objectification scores for each condition are shown in Table 2. The effect of condition on state self-objectification was tested with an ANCOVA model. Trait self-objectification was included as a covariate in this analysis.
State Self-Objectification and Posttest Felt Empowerment by Condition.
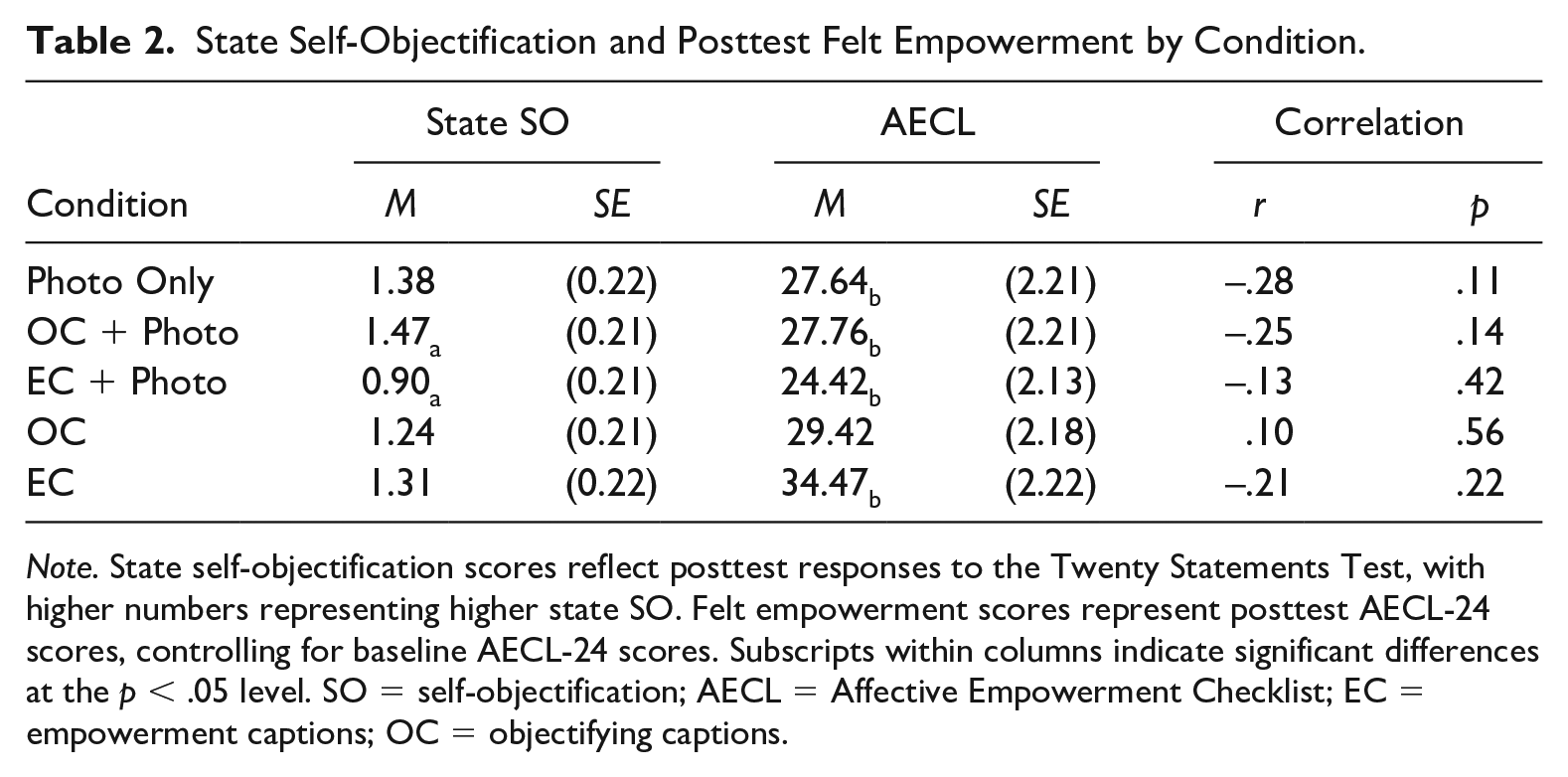
Note. State self-objectification scores reflect posttest responses to the Twenty Statements Test, with higher numbers representing higher state SO. Felt empowerment scores represent posttest AECL-24 scores, controlling for baseline AECL-24 scores. Subscripts within columns indicate significant differences at the p < .05 level. SO = self-objectification; AECL = Affective Empowerment Checklist; EC = empowerment captions; OC = objectifying captions.
The omnibus model testing the effect of condition on state self-objectification was not significant, F(4, 175) = 1.15, p = .33; η2 = .026, which was unsurprising given the overlapping stimulus elements between conditions. Trait self-objectification was the only significant predictor in this model, F(1, 175) = 9.08, p < .01; η2 = .049. Planned pairwise comparisons indicated significant differences between the EC + Photo and OC + Photo conditions at the p < .05 level (p = .043, dCohen = .46). Women in the EC + Photo condition used an average of 0.59 fewer appearance-related words than women in the OC + Photo condition. No other pairwise comparisons approached significance, providing partial support for H1.
A follow-up analysis compared self-objectification scores between conditions with a photo (EC + Photo, OC + Photo, and Photo Only Condition) and the conditions without a photo (EC and OC conditions). There was no significant difference in state self-objectification when grouping the stimuli in this way and controlling for trait self-objectification, F(1, 178) = .247, p = .62, ηp2 = .001, indicating that the photo conditions did not lead to greater self-objectification than the text conditions. Trait self-objectification was a significant predictor in this model, F(1, 178) = 11.22, p < .001, ηp2 = .059.
Felt Empowerment
Differences in posttest felt empowerment were tested using an ANCOVA model with condition as the independent variable and posttest AECL-24 scores as the dependent variable, controlling for baseline AECL-24 scores. This model was significant, F(4, 178) = 2.829, p = .03, ηp2 = .06, indicating differences in felt empowerment by condition (Figure 1). In support of H4, felt empowerment was highest in the absence of a photo. Planned pairwise comparisons revealed that participants in the EC condition reported greater felt empowerment than those in the Photo Only condition (p = .030, dCohen = .15), the EC + Photo condition (p < .001, dCohen = .22), and the OC + Photo condition (p = .03, dCohen = .20). Felt empowerment in the OC condition did not significantly differ from felt empowerment in the EC + Photo condition (p = .11, dCohen = .14). No other pairwise comparisons were significant (Table 2).
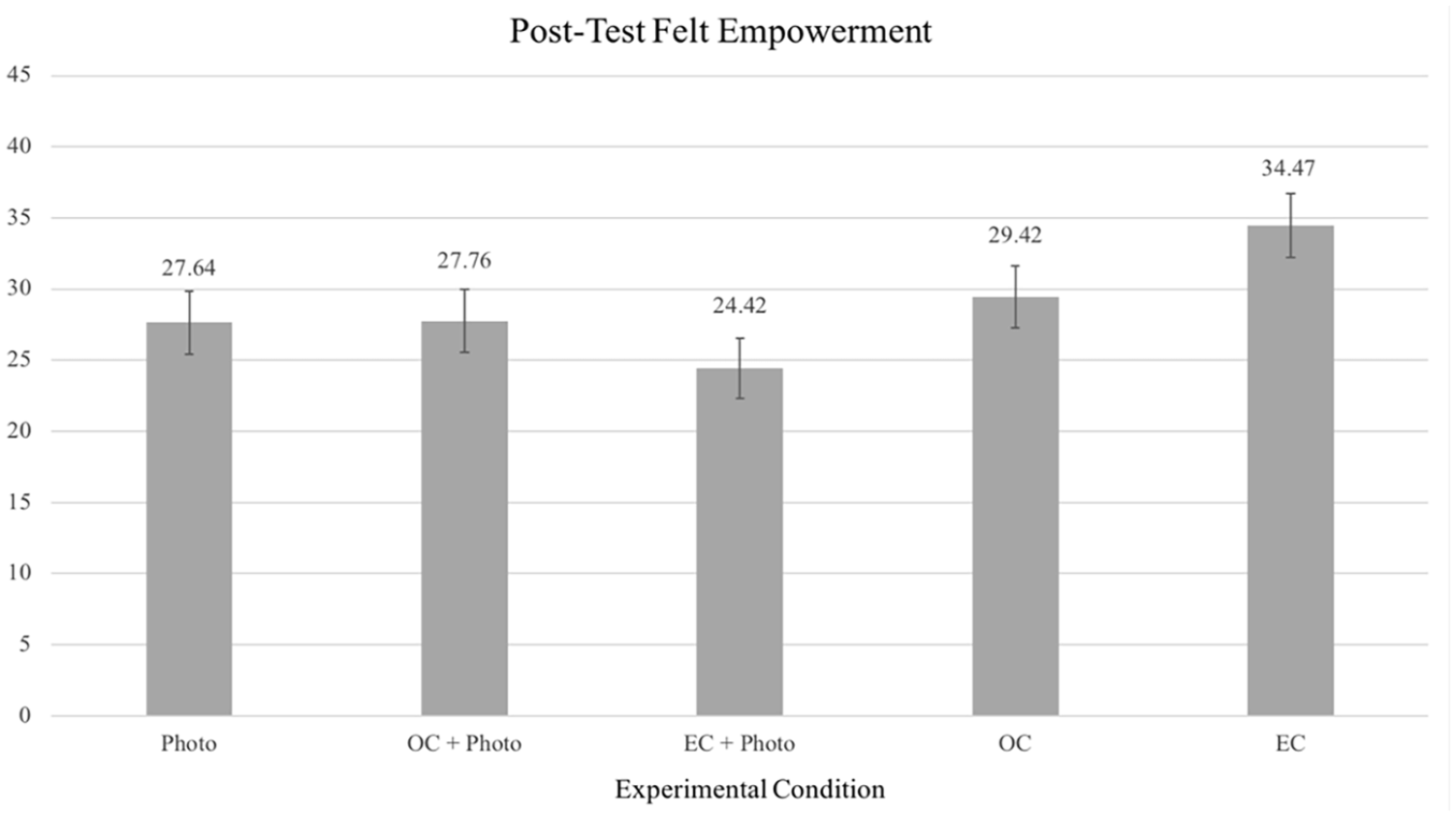
Posttest Felt Empowerment Comparisons Between Conditions
Relationship Between Felt Empowerment and State Self-Objectification
When looking at the sample as a whole, posttest measures of felt empowerment and state self-objectification were negatively correlated, r(181) = −.158, p = .03. This finding suggests that individuals who reported greater self-objectification reported lower felt empowerment, answering RQ1. There was no significant relationship between posttest felt empowerment and self-objectification within any condition, potentially due to the small sample size (Table 2).
Eye-Tracking Analyses
Attention to Person
A one-way ANOVA model examining the effect of condition on visual attention indicated significant differences in attention to both person AOIs (i.e., full model, including the models’ faces), F(2, 107) = 41.74, p < .001, ηp2 = .438, and body AOIs (i.e., body regions excluding the models’ faces), F(2, 107) = 27.56, p < .001, ηp2 = .34. However, planned pairwise comparisons indicated that this result was driven by differences between the photo-only condition and the conditions that included text, likely because women in the photo-only condition had no text to read. Specifically, individuals in the photo-only condition spent significantly more time focused on the person AOI than individuals in the EC + Photo condition (p < .001, dCohen = 1.91) or the OC + Photo condition (p < .001, dCohen = 1.70). In a similar pattern, individuals in the photo-only condition spent significantly more time looking at the models’ bodies than individuals in EC + Photo condition (p < .001, dCohen = 1.48) or OC + Photo condition (p < .001, dCohen = 1.43). Contrary to H2, there was no significant difference in attention to the models’ bodies between the EC + Photo and OC + Photo conditions (p = .96).
A one-way ANOVA model indicated significant differences in attention to faces across conditions, F(2, 107) = 23.30, p < .001, η2 = .303, with significant differences again emerging between the photo-only condition and the two conditions containing both photos and captions. Participants in the photo-only condition fixated on faces for an average of 18.92 seconds longer than those in the EC + Photo condition (p < .001, dCohen = 1.53) and 13.58 seconds longer than individuals in the OC + Photo condition (p < .001, dCohen = 1.02). The difference in attention to faces in the EC + Photo and OC + Photo conditions was nonsignificant (p = .065, dCohen = .48).
Visual Attention and Outcome Variables
Regression models were created to test the relationship between attention to AOIs and state self-objectification and felt empowerment (Table 3). Contrary to the prediction in H5, time spent looking at the empowering caption in the EC + Photo condition did not predict participants’ posttest felt empowerment scores when controlling for baseline AECL-24 scores, β = .14, t(36) = 1.40, p = .17, r2 = .06.
Descriptive Data for Eye-Tracking and Correlations With Self-Objectification and Felt Empowerment.
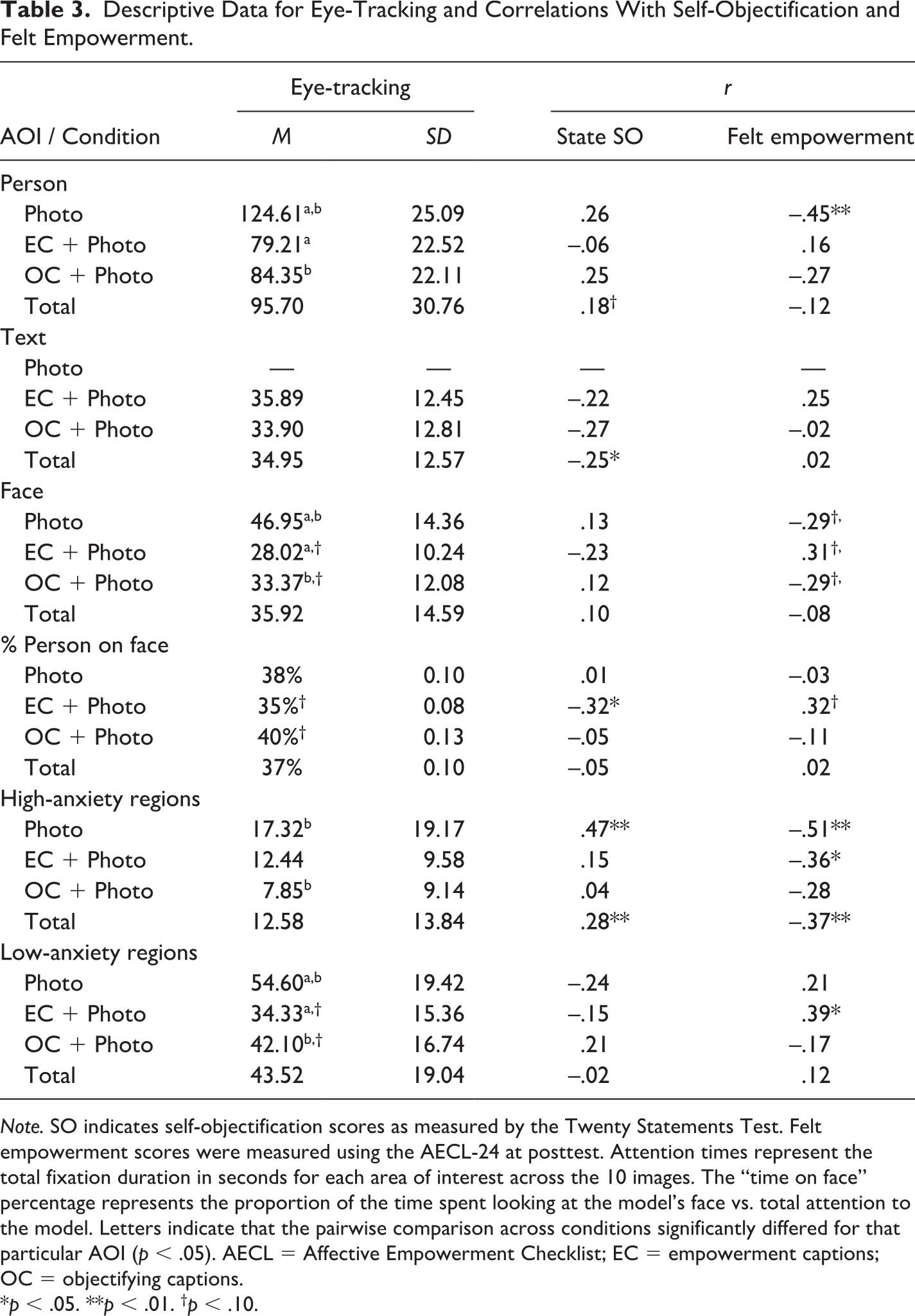
Note. SO indicates self-objectification scores as measured by the Twenty Statements Test. Felt empowerment scores were measured using the AECL-24 at posttest. Attention times represent the total fixation duration in seconds for each area of interest across the 10 images. The “time on face” percentage represents the proportion of the time spent looking at the model’s face vs. total attention to the model. Letters indicate that the pairwise comparison across conditions significantly differed for that particular AOI (p < .05). AECL = Affective Empowerment Checklist; EC = empowerment captions; OC = objectifying captions.
p < .05. **p < .01. †p < .10.
Controlling for trait self-objectification, visual attention to self-reported high-anxiety body regions across all conditions with photos predicted state self-objectification levels, β = .26, t(104) = 2.48, p = .02, whereas attention to low-anxiety body regions did not, β = .08, t(104) = .795, p = .43, (Table 4). Upon further examination of the results, the photo-only condition drove the pattern of the results, with fixation to high-anxiety body regions predicting state self-objectification in the photo-only condition but no other condition. This provides limited support for H3b in the photo-only condition.
Hierarchical Regression Results for State Objectification.
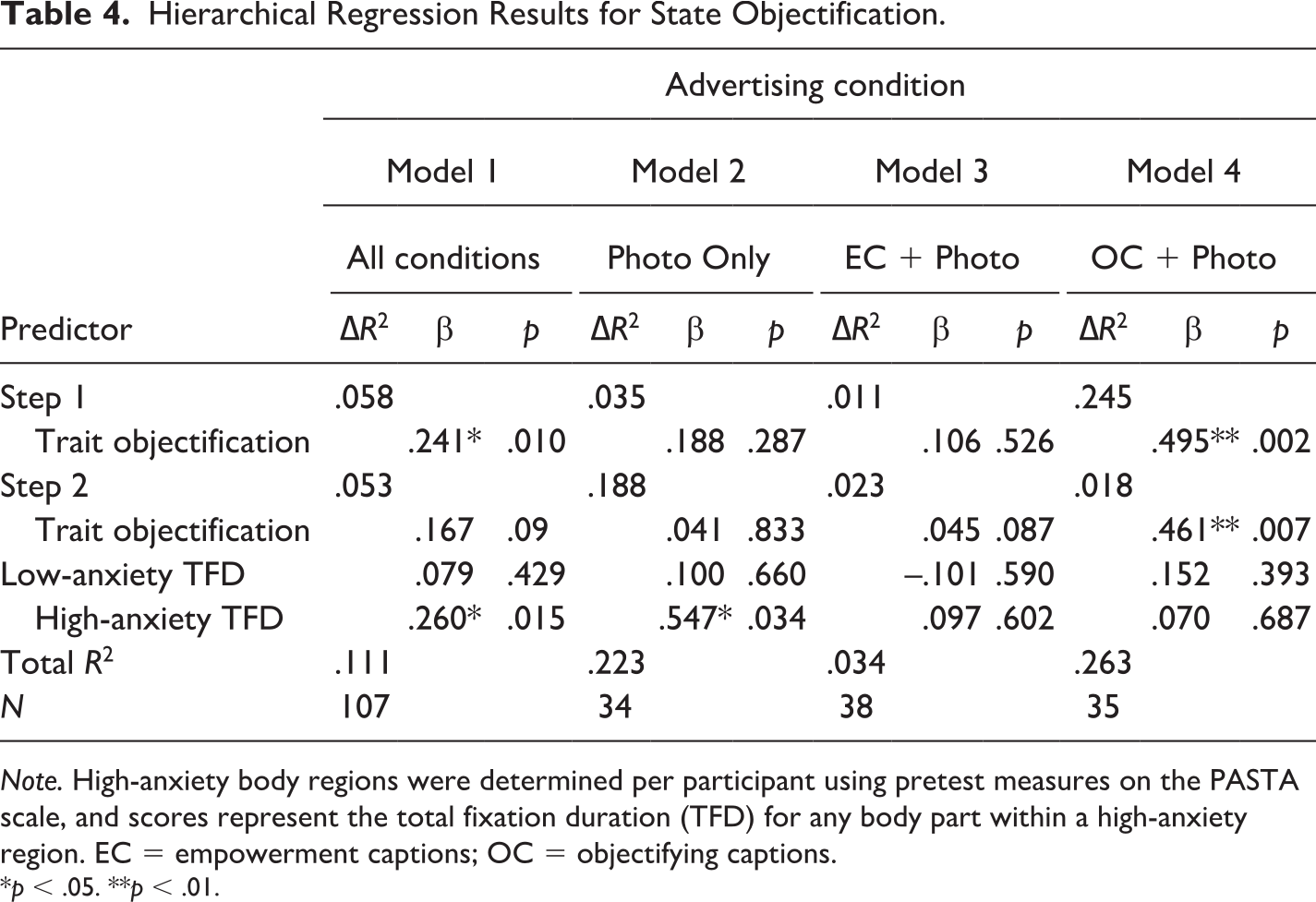
Note. High-anxiety body regions were determined per participant using pretest measures on the PASTA scale, and scores represent the total fixation duration (TFD) for any body part within a high-anxiety region. EC = empowerment captions; OC = objectifying captions.
*p < .05. **p < .01.
Discussion
ETAs, which pair textual themes of empowerment with objectifying imagery, are popular advertising appeals among companies targeting female consumers. These advertisements provide a valuable opportunity to examine the relationship between empowerment and self-objectification in media messages. Preliminary research on the psychological effects of ETAs found that exposure to ETAs from beauty companies may increase women’s self-objectification without increasing feelings of empowerment—suggesting that photo-induced self-objectification may limit the benefits of these advertisements for women (Couture Bue & Harrison, 2019). The current study tests this suggestion by (a) differentiating between the effects of visual and textual stimuli in ETAs, (b) examining the relationship between felt empowerment and self-objectification, and (c) using eye-tracking methods to explore how visual attention relates to psychological outcomes such as self-objectification.
Summary of Key Findings in the Current Study
Exposure to text-only empowerment messages led to significantly greater empowerment, but the empowering quality of the caption dissipated once the ECs were paired with photos (i.e., the typical format of ETAs).
Pairing the photo with objectifying text led to the greatest levels of self-objectification of any condition, while pairing the photo with empowerment-themed captions led to the lowest levels of self-objectification—suggesting a potential benefit of the ECs.
Pairing the photos with text that was objectifying (vs. empowering) did not lead to body-biased gaze behaviors.
Focusing on high-anxiety body regions was associated with greater levels of self-objectification, particularly in the photo-only condition.
Psychological Effects of ETAs
The present study asked whether exposure to ETAs increased women’s feelings of empowerment, finding that exposure to ETAs did not lead to greater feelings of empowerment once captions were paired with photos. This finding offers further evidence that exposing female participants to idealized (but non-sexualized) photos of models paired with empowerment-themed captions does not increase women’s feelings of empowerment. Among the five conditions, the conditions that presented text without an image were the only conditions that led to greater momentary feelings of empowerment. These findings are in line with the initial study by Couture Bue and Harrison (2019), confirming that visual content used in ETAs limited their effectiveness—if effectiveness is to be defined as a feeling of empowerment among their audiences. The photos in this study reflect industry norms and were rated in a pretest study as relatively empowering; thus, while they appear to be empowering, there was no evidence in this study that they produced feelings of empowerment in viewers.
The study by Couture Bue and Harrison (2019) raised concerns about increased self-objectification when presented with ETAs. The current study suggests that ETAs are an improvement over traditional ads in this area, as they led to significantly less self-objectification than photos paired with OCs. This finding suggests that while exposure to the EC + Photo condition did not increase felt empowerment, the empowering caption may have prevented self-objectification. This finding is also contrary to the initially proposed hypotheses, which suggested that the visual image would override textual message effects. Studies examining the relative importance of text and visuals in other contexts, such as exemplification theory, have also predicted greater impact of photos only to ultimately find that vivid text and photos led to equivalent effects (e.g., Tukachinsky et al., 2011). The inability of the photos to empower seems to be related to another relationship, with a possible explanation explored in the next subsection.
The literature review presented an inherent tension between empowerment and objectification. This anticipated relationship was somewhat supported in the current study, although self-objectification does not seem to explain why the ads were ineffective at empowering. There was a significant and negative relationship between felt empowerment and self-objectification when looking across conditions, with participants who reported higher self-objectification typically reporting lower felt empowerment. Although it is appealing from a theoretical perspective to interpret this as self-objectification inhibiting felt empowerment, this suggestion was not supported by planned pairwise comparisons. If self-objectification was the primary hindrance to increasing felt empowerment, we would expect to see significant differences in self-objectification scores at posttest between the EC + Photo condition and the condition that only included the EC (i.e., EC condition). This was not found in the current study. Rather, women who saw ECs alone reported comparable self-objectification to women in the EC + Photo conditions. Furthermore, state self-objectification and felt empowerment were uncorrelated at posttest in the condition where photos were paired with empowerment-themed text, suggesting that self-objectification and empowerment (while negatively correlated in the entire sample) are not strongly inversely related as one might expect. Future work should continue to explore this complex relationship.
Interestingly, and contrary to initial expectations, participants who saw objectification-themed captions reported statistically comparable levels of felt empowerment to participants who saw empowerment-themed captions. Greater felt empowerment in response to the empowerment text-only condition is in line with the predictions made at the start of the study, but the finding that objectifying text led to the second highest feelings of empowerment was unexpected. One possible explanation for this finding may be that beauty is highly valued in our society, especially for women (Fredrickson & Roberts, 1997), and thus the objectification-themed captions that provided women with suggestions about appearance improvement (e.g., “Making myself HOT”) were perceived as empowering so long as they were not paired with threatening imagery. While this study presents an initial exploration of the relationship between felt empowerment and self-objectification, future work should more closely examine the relationship between feeling attractive and feeling empowered.
Alternative Explanations
While untested in the current study, the failure of the photos paired with empowerment text to increase felt empowerment may be due to social comparison processes—a suggestion that should be explored in future work. Many of the images used in ETAs show conventionally attractive women performing impressive athletic feats. While these images may inspire and create awe, they may also provide a target for upward social comparison, which could contribute to feelings of inadequacy in the viewer—both in terms of physical competency and attractiveness. In the context of science, technology, engineering, and mathematics (STEM) role models for girls, Betz and Sekaquaptewa (2012) found that presenting girls with counter-stereotypic images of women who were both feminine and successful in STEM led to lower expectations of STEM success than neutral models, in part due to the perception that success in both areas was unattainable. There may be a similar relationship emerging here with physical attractiveness and competency, a possibility that should be examined in future research.
Eye Gaze Patterns and Psychological Outcomes
Participants’ eye movements were recorded while they viewed stimuli in the three conditions that contained a photo as part of the stimulus. Because participants saw each image for a fixed amount of time (i.e., 20 seconds), the captions in the EC + Photo and OC + Photo conditions competed with the photo for visual attention. Since participants in the photo-only condition did not have text to read, they naturally spent an average of 4.3 additional seconds per stimulus photo looking at the model. A more informative test is provided by comparing the conditions with both text and a photo. Contrary to the initial hypothesis, which suggested that photos with objectifying text would prompt greater attention to the models than photos with empowering text, participants in both caption + photo conditions visually processed the models similarly. This was true for the total fixation time on the models (including faces) and the percentage of time spent looking at the models’ bodies. In other words, objectifying text did not prompt greater scrutiny of the model or more body-focused gaze behaviors.
While visual processing of the photos was largely similar across conditions, a few other significant differences are worth highlighting. As noted earlier, participants in the photo-only condition spent more time looking at every part of the model, as they did not have text to look at. In this condition alone, visual attention to the model was negatively correlated with feelings of empowerment. This is further evidence that exposure to the photo did not help women feel more empowered. Recent research indicates that visible muscle tone has replaced thinness as the current body ideal (e.g., Boepple et al., 2016; Bozsik et al., 2018). Many of the models in the photos were performing impressive athletic feats, demonstrating their physical competency while still meeting conventional beauty standards. Thus, although the photos highlighted body function over appearance, the photos were still idealized.
The current study also provided information on how attention to participants’ self-reported high- versus low-anxiety body regions impacted their state self-objectification. While significant differences based on attention to high-anxiety body regions did not emerge in conditions where photos and captions were presented together, visual attention to high-anxiety body regions in the photo-only condition predicted greater state self-objectification. This finding is in line with other research linking visual attention to high-anxiety body regions with body image-related outcomes (e.g., Couture Bue, 2020).
Limitations and Future Directions
As with all research, the present study has limitations. The study was conducted among a convenience sample of female-identifying participants. As eye-tracking research had to be done in the lab, participants in near geographic proximity to the university were most likely to be included in the sample. The use of a participant pool helped to expand recruitment beyond a student sample, but the participants in this study were largely White, educated, and from upper-class families. Thus, the results of the current study cannot test the effect of ETAs on male participants, older women, or minoritized individuals.
Visual attention and cognitive attention are linked (Just & Carpenter, 1980), and eye-tracking methods allow researchers to capture visual attention as viewers process messages. Still, eye-tracking alone cannot illuminate what viewers are thinking as they view the advertisements. Future work should continue pairing eye-tracking methods with survey measures or interviews to capture thought processes associated with alternative psychological processes (e.g., social comparison) and to probe deeper into the mechanisms associated with the current study’s findings. Recruiting a larger sample would also provide sufficient statistical power to test mediation and moderation analyses related to social comparison.
This study did not include conditions with objectifying or neutral images, and as such, it is not a fully factorial design. This strategic decision was made for two reasons: It was challenging to locate media images that did not objectify the model in some way, particularly within advertising. Second, while it is intuitive to pair an OC with an ambiguously empowering photo, pairing an empowerment-themed caption with a traditionally passive, sexually objectifying photo created an entirely different effect. Such pairings appeared sarcastic and even comical. In short, it was easier to use text to objectify an “empowered” woman than to present an objectified woman as empowered. This led to the decision to use ambiguously empowering photos that were not overtly objectifying. Photos used in this study were taken from existing ETAs and reflected industry norms. As such, they contained visual elements of both empowerment and objectification. This emphasis on ecological validity also meant that the OCs contained explicit sales pitches, whereas the ETAs did not. Future work should consider also including control photos and captions, like the travel photos used in other recent studies on social media (e.g., Brown & Tiggemann, 2016).
The present study also diverged from my ETAs by using still images rather than video clips. Print images were chosen for this study due to photo-tagging limitations associated with eye-tracking studies. These images are representative of print-based ETAs. Still, they diverge from video ETAs in a few notable ways, including the ability to evoke emotion through music in video advertisements and the inability to show active, moving bodies in print campaigns. While not tested in the current study, music may serve to enhance the emotions associated with empowerment-themed campaigns. Future work should explore these directions.
Finally, it is worth noting that the results speak to media images that did not empower women and cannot suggest alternative images that would better support empowerment-themed text. The fact that self-objectification and empowerment were uncorrelated in other individual conditions also makes it challenging to identify the mechanism that limited the empowering potential of the visuals. While identifying visuals that could effectively increase women’s felt empowerment was beyond the scope of the current study, future work should aim to determine the types of photos of women that are best paired with empowering text to increase women’s felt empowerment.
Conclusion
Ultimately, while empowering messages were effective at increasing women’s felt empowerment when presented alone, neither the advertising photos alone nor the combination of photos and empowering text were effective at increasing women’s feelings of empowerment. The empowerment-captioned version of the images led to less self-objectification than the objectification-captioned version, so in that regard, ETAs are an improvement from traditional advertising. At the same time, however, the presence of photos hindered feelings of empowerment compared to reading the messages alone. The empowerment-captioned version of the images also did not substantially change visual attention to the model as compared to the objectification-captioned version, with participants in both the empowerment-captioned photo and objectification-captioned photo conditions spending a similar amount of time looking at the models’ bodies. Future campaigns with the primary goal of empowering women should consider alternative visual themes that would more effectively increase felt empowerment among women while remaining diligent to avoid both visual and textual objectification in their advertising.
Supplemental Material
sj-docx-1-jmq-10.1177_10776990231217739 – Supplemental material for Measuring Gaze: Women’s Visual Processing of Empowerment and Objectification Messages in Empowerment-Themed Advertisements
Supplemental material, sj-docx-1-jmq-10.1177_10776990231217739 for Measuring Gaze: Women’s Visual Processing of Empowerment and Objectification Messages in Empowerment-Themed Advertisements by Amelia C. Couture Bue and Kristen Harrison in Journalism & Mass Communication Quarterly
Footnotes
Acknowledgements
The authors thank Sonya Dal Cin, Jan van den Bulck, and Allison Earl for their invaluable feedback on this project. The authors would like to also thank Alicia Carmichael and the team at the Biosocial Methods Collaborative at the University of Michigan for their assistance in project planning and data collection. The members of the MadLab and MaPiEL labs at the University of Michigan both provided instrumental feedback for this project, for which the authors are very grateful. Finally, this project would not have been possible without the following team of undergraduate research assistants who helped with data collection and AOI tagging: Ellery Benson, Lindsey Burnside, Emily Coplan, Nick Dolloff, Nicklas Helton, Pravalika Jarugula, Alexandra Lobingier, Cyrus Najarian, Celeste Pan, Mingyu (Mimo) Shen, Shuta Suzuki, Xinge (Lily) Tian, Megan Tobin, JJ Wright, and Leigh Yeh.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.