
Abstract
Psychopathy, narcissism, and Machiavellianism, the “Dark Triad” (DT), share a common core of personality facets from the (dis)agreeableness domain (e.g., callousness, deceitfulness). Most DT scales neglect facet-level measurement, instead, adopting broad multidimensional scales that undermine precision and clarity. In contrast, the Elemental Psychopathy Assessment, Five-Factor Machiavellianism Inventory, and Five-Factor Narcissism Inventory used the basic trait approach (i.e., combining relevant Five-Factor Model [FFM] facets) to avoid these issues and provide numerous innovations. However, because they were developed separately, simultaneous use is problematic due to length and three forms of redundancy: (1) identical facets are used in multiple scales, (2) near-identical facets with different labels are used in multiple scales, and (3) numerous ostensibly different facets, derived from the same FFM facet, were developed. The unintended consequence being construct proliferation and jingle-jangle fallacies. This article describes a multi-study integration of these measures to develop a single set of unique facets to assess the DT at facet (e.g., Straightforwardness), domain (e.g., Antagonism), and construct (e.g., Psychopathy) level: the Faceted Dark Triad (FDT) Scale. The FDT, in long, short, and super-short form, provides efficient and theoretically coherent assessment of the DT, with superior psychometric properties and criterion prediction, compared with the original measures and Short Dark Tetrad (SD4).
Public Significance Statement
Individuals with high levels of antagonistic personality traits play disproportionate roles in a range of socially deleterious outcomes, including bullying, employment difficulties, and criminal convictions. This article introduces the Faceted Dark Triad (FDT) scale which resolves long-standing conceptual and measurement issues. The FDT provides accurate, efficient, and predictively powerful assessment of psychopathy, narcissism, and Machiavellianism.
Development of the Faceted Dark Triad Scale
The Dark Triad (DT; Paulhus & Williams, 2002) refers to three broad malevolent, sub-clinical, personality constructs: psychopathy, narcissism, and Machiavellianism. Each is theoretically distinct but shares a common core of personality traits from within the broad domains of antagonism or (dis)agreeableness (Vize & Lynam 2020, 2021). Amongst other characteristics, psychopathy is characterized by callousness and recklessness, narcissism by callousness and grandiosity, and Machiavellianism by callousness and strategy (Paulhus & Williams, 2002).
Simultaneous study of the DT has demonstrated that all three traits are related to socially deleterious outcomes; sometimes in consistent ways (see Muris et al., 2017; Vize et al., 2018, for meta-analytic reviews), sometimes not (Hughes et al., 2023), and sometimes in an additive manner (O’Boyle et al., 2012). Thus, simultaneously studying the DT provides a powerful tool for theory testing and furthering understanding of many of the most prominent social problems that we face as a species: crime (Mathieu et al., 2014), sexual misconduct (Muris et al., 2017), toxic and abusive leadership (Harms et al., 2011), workplace deviance (Ellen et al., 2021; O’Boyle et al., 2012), bullying (Tokarev et al., 2017), and even terrorism (Perri & Brody, 2011). It is difficult to overstate just how harmful elevated levels of the DT are, with psychopathy alone estimated to cost the U.S. economy $460 billion per year (De Brito et al., 2021; Gatner et al., 2023). Future efforts to address many of our most pressing societal issues would be incomplete without adequately accounting for the DT.
Understanding the nature and effects of the DT has developed despite notable limitations with available assessment tools. Individual (e.g., Levenson Self-report Psychopathy Scales, Levenson et al., 1995; MACH-IV, Christie & Geis, 1970) and combined measures (e.g., Dirty Dozen, Jonason & Webster, 2010; Short Dark Triad, Jones & Paulhus, 2014) have been frequently and justifiably criticized with respect to construct validity, discriminant validity, and weak psychometric properties (Rose et al., 2022). Of particular interest to the current study, the two major combined measures, the Dirty Dozen and Short Dark Triad, lack construct validity due to the omission of important personality traits (Vize et al., 2018) and fail to properly distinguish their sub-factors (i.e., lack discriminant validity, Maples et al., 2014; Miller et al., 2012; Schreiber & Marcus, 2020; Vize et al., 2018). In particular, the psychopathy and Machiavellianism sub-scales are indistinguishable in item content, factor analyses, and external correlations (Vize et al., 2018), making it difficult to assess their relative effects (Miller et al., 2017; Tokarev et al., 2017). The Short Dark Tetrad (Paulhus et al., 2020), a development of the Short Dark Triad plus sadism, was a notable improvement and addressed some of these concerns (e.g., its psychopathy and Machiavellianism scales correlate ≈.3; Paulhus et al., 2020). However, there is debate regarding the conceptualization and distinctiveness of the psychopathy and sadism scales (c.f., Blötner & Mokros, 2023; Kay et al., 2025), and the psychopathy and Machiavellianism scales (e.g., Kay et al., 2025), and some items assess characteristic adaptations (e.g., hobbies, interpretations/attitudes; DeYoung, 2015) or outcomes of personality (e.g., been in trouble with the law; seen as a natural leader) that can contaminate personality-outcome relations, producing causal illusions via endogeneity biases (Antonakis et al., 2010; Fischer et al., 2021; Hughes et al., 2018).
Seeking to address such limitations, three self-report measures derived from the facets of the Five-Factor Model (Costa & McCrae, 1990) were developed: the Elemental Psychopathy Assessment (EPA; Lynam et al., 2011), Five-Factor Narcissism Inventory (FFNI; Glover et al., 2012), and Five-Factor Machiavellianism Inventory (FFMI; Collison et al., 2018). The general premise of this “basic trait” approach to assessing the DT, and personality disorders more generally, stems from suggestions by Wiggins and Pincus (1989) that all personality disorders (i.e., DSM-5 Section III) could be understood as combinations of facet-level traits found within general personality models (i.e., the FFM; Lynam & Widiger, 2001; Widiger et al., 1994). There is now a substantial body of evidence supporting the utility of the basic trait approach (e.g., Widiger & Costa, 2013; Widiger & McCabe, 2020).
When developing the EPA, FFNI, and FFMI, Lynam, Miller and colleagues used numerous methods to identify relevant facets, including expert ratings (e.g., Miller et al., 2001), translating items from DT measures into their respective FFM facets (e.g., Widiger & Lynam, 1998), and correlating DT measures with the FFM domains and facets (e.g., Derefinko & Lynam, 2006). There is generally strong consensus across these methods regarding the relevant facets (e.g., see Lynam & Widiger, 2007, for psychopathy). However, “normal range” personality scales, such as the NEO-PI-R, may lack sensitivity and provide insufficient information at the extreme ranges (cf. Walton et al., 2008), so the EPA, FFNI, and FFMI authors wrote new items that were more sensitive to variations at the extreme ends of the traits.
The resulting measures do not address all extant concerns. For example, some of the scale total scores are relatively highly correlated, perhaps suggesting some redundancy. In addition, some facets within each trait are moderately or even negatively correlated (e.g., r = −.32 between FFNI-Shame and FFNI-Authoritativeness; Glover et al., 2012), which could create interpretational difficulties when using total scores (McNeish & Wolf, 2020).
Nevertheless, the facet-level modeling approach provides a uniquely useful framework to test and refine conceptualizations of antagonistic traits (Irwing et al., 2024). For example, researchers can add or omit facets according to theoretical proposition and/or weight them differentially, before testing which conceptualization is most accurate and appropriate across differing circumstances (Hughes, 2018). The EPA, FFNI, and FFMI also have numerous other strengths, including links to the wider personality trait literature, theoretically coherent factor structures and nomological nets (i.e., correlation profiles), as well as the flexibility to assess psychopathy, narcissism, and Machiavellianism at the facet, domain, and construct level. However, three considerations limit the current utility of the FFM-based DT measures: scale length, construct proliferation, and redundancy.
Regarding length, the EPA-Short Form (EPA-SF; Lynam et al., 2013), FFNI-Short Form (FFNI-SF; Sherman et al., 2015), and FFMI have four items per facet, summing to a total 184 items, which is unwieldy for many research endeavors. In response, Rose et al. (2022) developed a 46-item integrated measure, the FFM Antagonistic Triad Measure (FFM-ATM), which overcomes some concerns. However, the FFM-ATM has just one item per facet and so does not provide facet-level scoring, unlike its parent measures. And because the FFM-ATM combined super short-forms of the EPA, FFNI, and FFMI, it did not overcome the two remaining concerns regarding potential redundancy.
The EPA, FFNI, and FFMI were developed separately, meaning numerous variants of FFM facets were developed. In total, 46 scales were developed to measure 24 FFM facets (see Table 1), which creates some redundancy and confusion, when used simultaneously. There are three likely forms of proliferation and redundancy across the EPA, FFNI, and FFMI, which risk future difficulties in synthesizing the literature, especially in meta-analyses.
Overlap in Facets Across the Three FFM Measures of the Dark Triad.
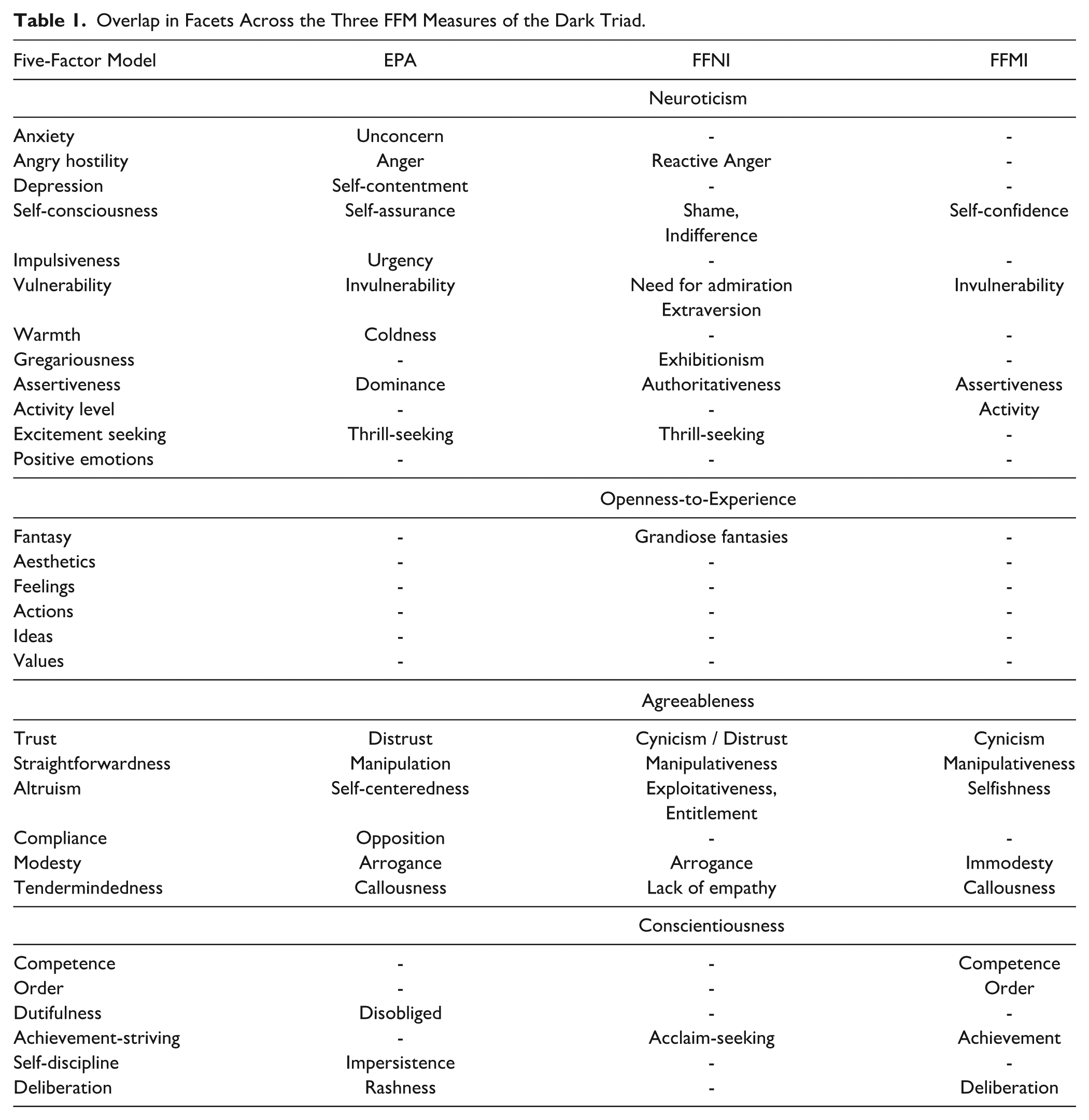
First, the FFM-Excitement-seeking facet is replicated in its entirety in the EPA and FFNI, via scales entitled: Thrill-seeking. Any consolidated tool does not need two identical scales. Second, the FFM-Deliberation facet is represented as Rashness in the EPA and Deliberation in the FFMI. Despite differing labels, three of the four items are identical (i.e., both contain the items: “Act first, think later” describes me well; I tend to jump right into things without thinking very far ahead; I like to carefully consider the consequences before I make a decision). Given the degree of similarity, it is unlikely that both scales are required. Third, during the construction of the EPA, FFNI, and FFMI one key assumption was that FFM facets are multidimensional (Irwing et al., 2024) and would be expressed differently for those high in psychopathy, narcissism, or Machiavellianism. Thus, sometimes FFM facets were split into multiple scales in different ways in different measures. For example, the FFM-Self-consciousness facet is represented by a total of four scales: Self-assurance in the EPA, both Shame and Indifference in the FFNI, and Self-confidence in the FFMI. In total, 12 FFM facets are represented by multiple scales across the EPA, FFNI, and FFMI. They are: Achievement-striving; Angry Hostility; Altruism; Assertiveness; Excitement-seeking; Modesty; Self-consciousness; Straightforwardness; Tendermindedness; Trust; and Vulnerability. One outstanding question is whether these different manifestations of the same FFM facets are indeed unique. If so, they must be retained. However, if not, their unique labels will create unnecessary complexity and confusion.
The major unintended consequence of each potential form of redundancy (whether the scales are used together or independently) is construct proliferation, which will likely exacerbate general concerns related to jingle (i.e., scales with the same/similar labels have different definitions and item content) and jangle (i.e., scales with different labels sometimes share definitions and item content) fallacies (Irwing et al., 2024; Ziegler et al., 2013). Both problems appear when we examine the facets within the EPA, FFNI, and FFMI.
Current Study
Thus, the goal of the current study is to develop a single set of facets, free from redundancy and issues of jingle-jangle, that can assess psychopathy, narcissism, and Machiavellianism at facet, domain, and overall construct level. We do this through three studies designed to facilitate empirical integration of the EPA-SF (Lynam et al., 2013), FFNI-SF (Sherman et al., 2015), and FFMI (Collison et al., 2018).
When developing psychometric scales, it is widely accepted that researchers should demonstrate the reliability and “validity” of the tool (Cronbach & Meehl, 1955). Reliability is well understood and commonly evidenced via internal consistency, test–retest stability, and parallel forms reliability. Validity is more contentious and inconsistently assessed (Cizek, 2012, 2016; Cizek et al., 2010; Flake et al., 2017; Hughes, 2018), often resulting in suboptimal measure development. According to the American Psychological Association’s Standards for Educational and Psychological testing (American Educational Research Association, American Psychological Association, & National Council on Measurement in Education [AERA, APA, NCME, 2014]), there are five sources of validity evidence: test content, response processes, internal structure, relationships with other variables, and consequences of test use (see also, Cronbach & Meehl, 1955; Messick, 1989). Building on this framework, Hughes (2018) suggested that the five types of validity evidence are best considered in response to two separate questions: (1) Does the test measure what it purports to (accuracy) and (2) is the test useful for some specified purpose (appropriateness). Two distinct questions that require distinct evidence and operate in a sequential fashion, with psychometricians first assessing the accuracy of their measure and subsequently assessing its appropriateness for use in relevant domains. We adopt the Accuracy and Appropriateness framework in the current study.
Study 1 and Study 2 focused on accuracy by examining the content, response processes, and psychometric properties of the scales. Study 3 focused on the appropriateness of the scales (i.e., suitability for research use and theory testing) by examining the relation of scale scores to other variables and considering the feasibility of test use (i.e., length-prediction trade-offs). Collectively, the three studies present evidence supporting the accuracy and appropriateness of three scales: a long form (comprising four items per facet), a short form (two items per facet), and a super-short form (one item per facet).
Study 1
The overarching goal of this research program is to combine the EPA-SF, FFNI-SF, and FFMI by developing a single set of facets, free from redundancy and issues of jingle-jangle, that collectively assess psychopathy, narcissism, and Machiavellianism at facet, domain, and overall construct levels. Thus, the first step is to examine whether redundancy exists and if so, decide on the best resolution.
To recap, the EPA, FFNI, and FFMI consist of 46 facets designed to assess 24 base Five-Factor Model facets (see Table 1). Twelve FFM facets are represented by a single instantiation and thus are not redundant across measures. The remaining 12 FFM facets are represented by two or more instantiations (34 facets in total), and thus could have a degree of redundancy across measures. As described earlier, there are three forms of potential redundancy.
First, the FFM facet of Excitement-seeking is replicated in its entirety (labeled Thrill-seeking, within the EPA and FFNI). Second, the FFM-Deliberation facet is represented as Rashness in the EPA and Deliberation in the FFMI; both share three items. Third, 10 other FFM facets are represented by multiple ostensibly different scales within and across the EPA, FFNI, and FFMI.
Study 1 entailed five major steps. First, we assessed whether the multiple scales derived from a single FFM facet were empirically distinct by assessing discriminant validity evidence in the form of their inter-correlations and the fit of combined single-factor confirmatory factor analysis (CFA) models. Second, where facets were not discriminant, we consolidated the set of scales into a single-factor four-item scale, selecting the best items, based on item wording, factor loadings, and IRT parameters, that also retained construct breadth. We chose four-item scales because the 12 FFM facets represented with a single scale had four items, thus ensuring that the final scales were balanced. Third, we developed two-item and one-item versions of each retained facet to assess the feasibility of short- and super-short forms. Fourth, we assessed the degree of convergence between the original EPA, FFNI, and FFMI and the four items per facet (long), two items per facet (short), and one item per facet (super-short) versions developed here. Fifth, we assessed the response processes of the one-item scale using a think-aloud-protocol interview.
Method
Participants
Study 1 used 870 participants from two international samples. Sample A (N = 570) was collected via convenience sampling on Prolific.co (Palan & Schitter, 2018). Participants were paid £1.88, meeting the minimum payment requirement for a survey this size. Sample A comprised 59.1% males and 39.8% females, with 0.7% reporting being of another gender and 0.4% of individuals providing no response. Their ages ranged from 18 to 69 years old (M = 33.1, SD = 9.8). Respondents came from 50 different countries, worked in a variety of occupations, with 40.7% holding an undergraduate degree. Supplementary Table S1.1 contains a full breakdown of all demographic data for Sample A.
Sample B (N = 300) was also collected via convenience sampling on Prolific.co. Participants were paid £4.00 as part of a larger data collection process. Sample B was comprised of 55.3% males and 43.0% females, with 1.0% reporting other and 0.7% providing no response. Ages ranged from 18 to 72 (M = 30.7, SD = 9.42), with 83.7% younger than 40. There were 40 nationalities and 36 different occupations represented in Sample B. Supplementary Table S1.2 contains full details.
Measures
Participants first read an introduction explaining the purpose of the study and completed a consent form. Participants completed a demographic questionnaire, followed by the personality questionnaire. Participants in Sample A completed the Elemental Psychopathy Assessment Short-form (EPA-SF; Lynam et al., 2013), the Five-Factor Narcissism Inventory Short-form (FFNI-SF; Sherman et al., 2015) and the Five-Factor Machiavellianism Inventory (FFMI; Collison et al., 2018). Participants in Sample B completed a subset of EPA-SF, FFNI-SF, and FFMI items, retained after initial analysis. Table S1.3 contains reliabilities for all scales.
The Elemental Psychopathy Assessment Short-form (EPA-SF; Lynam et al., 2013) uses 72 items to measure 18 facets across four domains. The domain of Antagonism (Ω = .87) comprises Callousness, Coldness, Distrust, Manipulation and Self-Centeredness. The domain of Emotional Stability (Ω = .78) comprises Invulnerability, Self-contentment, and Unconcern. The domain of Disinhibition (Ω = .86) comprises Urgency, Thrill-Seeking, Opposition, Disobliged, Impersistence, and Rashness. The domain of Narcissism (Ω = .60) comprises Anger, Self-Assurance, Dominance, Arrogance. In the present study, reliabilities averaged Ω = .79 at the facet-level (range of Ω = .53 to .94) and the reliability of the total score was Ω = .89.
The Five-Factor Narcissism Inventory Short-form (FFNI-SF; Sherman et al., 2015) uses 60 items to measure 15 facets. These facets can be combined to produce scores for three domains (Antagonism, Agentic Extraversion, and Narcissistic Neuroticism) or two domains (Grandiose Narcissism and Vulnerable Narcissism). At the three-domain level, the domain of Antagonism (Ω = .89) comprises Arrogance, Manipulativeness, Exploitativeness, Entitlement, Lack of Empathy, Reactive Anger, Distrust, and Thrill-seeking. Agentic Extraversion (Ω = .83) comprises Acclaim-seeking, Dominance, Grandiose Fantasies, and Exhibitionism. Narcissistic Neuroticism (Ω = .74) comprises Shame, Indifference, and Invulnerability. At the two-domain level, Vulnerable Narcissism (Ω = .78) comprises Reactive Anger, Shame, Need for Admiration, and Distrust. Grandiose Narcissism (Ω = .89) comprises Indifference, Exhibitionism, Authoritativeness, Grandiose Fantasies, Manipulativeness, Exploitativeness, Entitlement, Lack of Empathy, Arrogance, Acclaim-seeking, and Thrill-seeking. In the present study, reliabilities averaged Ω = .86 at the facet level (range of Ω = .75–.96) and the reliability of the total score was Ω = .88.
The Five-Factor Machiavellianism Inventory (FFMI; Collison et al., 2018) uses 52 items to measure 13 facets, which are distributed across three domains: Antagonism, Agency, and Planfulness. Antagonism (Ω = .82) comprises Selfishness, Immodesty, Manipulative, Callousness, and Cynical. Agency (Ω = .88) comprises Achievement, Activity, Assertiveness, Competence, Self-confidence, and Invulnerable. Planfulness (α = .73) comprises Deliberation and Order. In the present study, reliabilities averaged Ω = .86 at the facet level (range of Ω = .72–.90) and the reliability of the total score was Ω = .86.
Items were presented in blocks of 30. Within each block, items were randomized to minimize order effects (Couper, 2008). Consistent with the original scales (Collison et al., 2018; Lynam et al., 2013; Sherman et al., 2015), we employed a five-point Likert-type response scale ranging from “Strongly Disagree” (1) to “Strongly Agree” (5). Two attention checks (e.g., “To check your attention, please select strongly agree”) from the Elemental Psychopathy Assessment (EPA; Lynam et al., 2011) were also included to ensure data quality by identifying inattentive participants. No participants failed both attention checks.
Ethics
All three current studies received ethical approval from the Alliance Manchester Business School Ethical Review Board (References: 2021-10133-17770 and 2022-13672-22487). They were designed and conducted in accordance with the ethical guidelines of the British Psychological Society (Oates et al., 2021).
Transparency and Openness
We report all measures in the study, and we follow JARS (American Psychological Association, 2020). All data, analysis code, and research materials are available at https://osf.io/g9h2u/. Analyses were conducted in Mplus (Muthén & Muthén, 2017) and R (R Core Team, 2021). This study’s design and its analysis were not pre-registered.
Results
Tests of Discriminant Validity Evidence
First, we assessed whether the 34 EPA, FFNI, and FFMI scales developed to assess different elements of 12 FFM facets (see Table 1) were empirically distinct. To do so, we estimated inter-facet correlations for each “set” of facets derived from the same FFM facet (e.g., FFNI-Acclaim-seeking and FFMI-Achievement derived from FFM-Achievement-striving). Informed by simulation studies and best-practice guidelines (Irwing et al., 2024), we interpreted correlations greater than .80 as indicative of a potential lack of discriminant validity (Kline, 2011; Rönkkö & Cho, 2022). In addition, we estimated a single-factor CFA model for all items within a given “set.” If this single-factor model fit the data, we interpreted this as a second piece of evidence indicative of a potential lack of discriminant validity (Rönkkö & Cho, 2022). Table 2 contains summaries of these analyses and the related decisions.
Discriminant Validity of Facets that Exhibited Potential Redundancy.
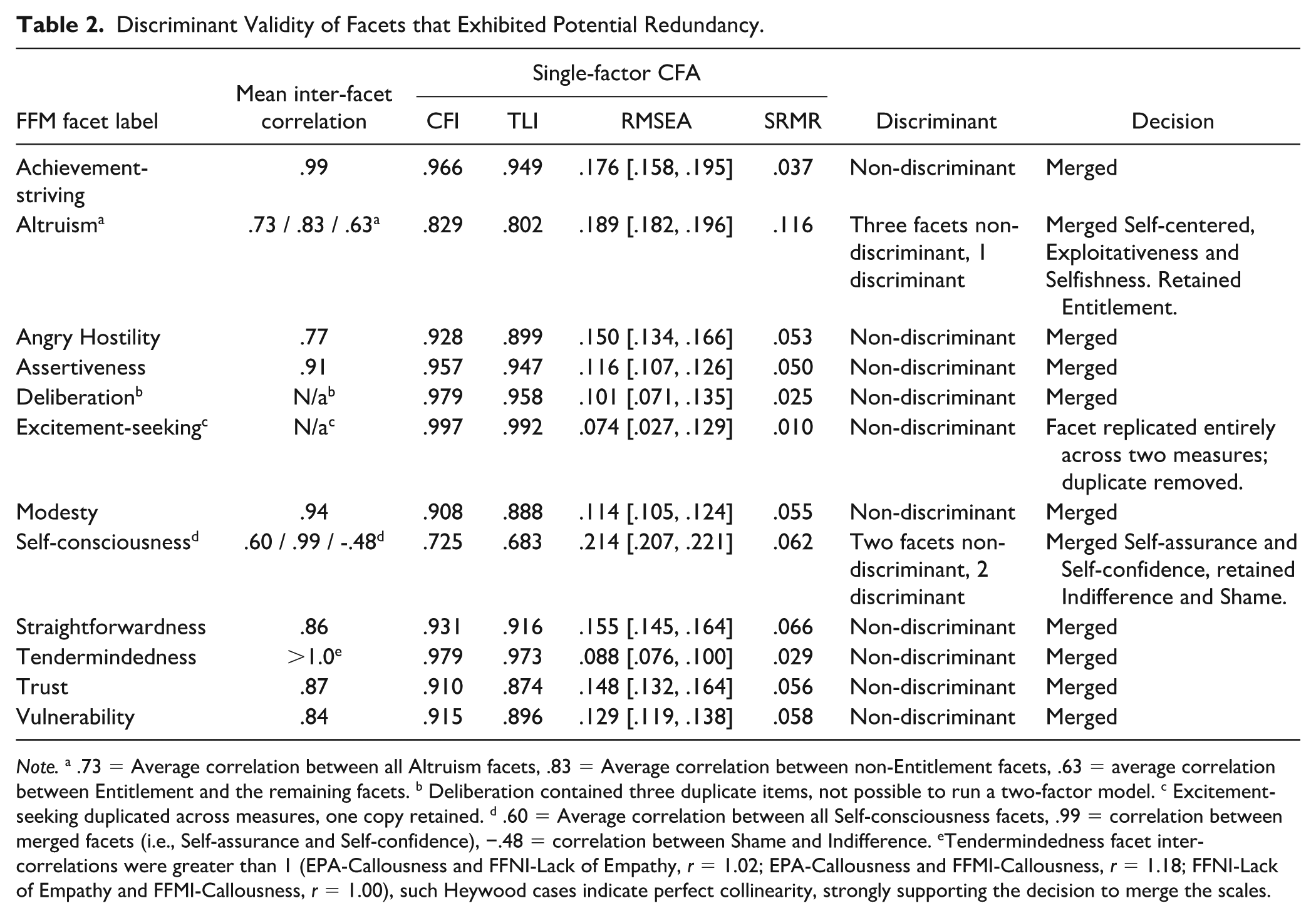
Note. a .73 = Average correlation between all Altruism facets, .83 = Average correlation between non-Entitlement facets, .63 = average correlation between Entitlement and the remaining facets. b Deliberation contained three duplicate items, not possible to run a two-factor model. c Excitement-seeking duplicated across measures, one copy retained. d .60 = Average correlation between all Self-consciousness facets, .99 = correlation between merged facets (i.e., Self-assurance and Self-confidence), −.48 = correlation between Shame and Indifference. eTendermindedness facet inter-correlations were greater than 1 (EPA-Callousness and FFNI-Lack of Empathy, r = 1.02; EPA-Callousness and FFMI-Callousness, r = 1.18; FFNI-Lack of Empathy and FFMI-Callousness, r = 1.00), such Heywood cases indicate perfect collinearity, strongly supporting the decision to merge the scales.
We considered good model fit to be indicated by CFI ≥ .90 (Hu & Bentler, 1999; Schermelleh-Engel et al., 2003). Typically, SRMR and RMSEA values of ≤ .06 are indicative of good model fit. However, simulation studies show that the RMSEA .06 criterion is inappropriate for scales with few items and large loadings (Kenny, 2020; McNeish et al., 2018). In cases with approximately five or fewer indicators that load above .7, RMSEA values in the range of .20 are considered acceptable (McNeish et al., 2018).
In summary, 12 sets of facets failed to demonstrate discriminant validity due to possessing duplicate items or according to the correlation and CFA results. In these cases, we merged or consolidated the various facets into single, four-item scales, retaining the FFM facet label to reduce construct proliferation and concerns of jingle-jangle. In all cases, we retained items that provided comprehensive coverage of the facet, had high factor loadings, and strong item response theory (IRT) properties from graded response models (GRM; Samejima, 1969); the appropriate IRT model for Likert-type scale data. We examined discrimination (α) and difficulty(β) parameters for each item, and overall test information curves (±3 SDs). The majority of these parameters were in acceptable ranges (see Table 3, supplemental materials B and Figure S1.4). Collectively, we ensured that the four items maximized model fit and reliability, while also retaining construct breadth (see Irwing & Hughes, 2018). Supplemental materials B contains a detailed description of item selection procedures.
Summary of the Psychometric Properties of the 27 Retained Facets in Sample A and Sample B.
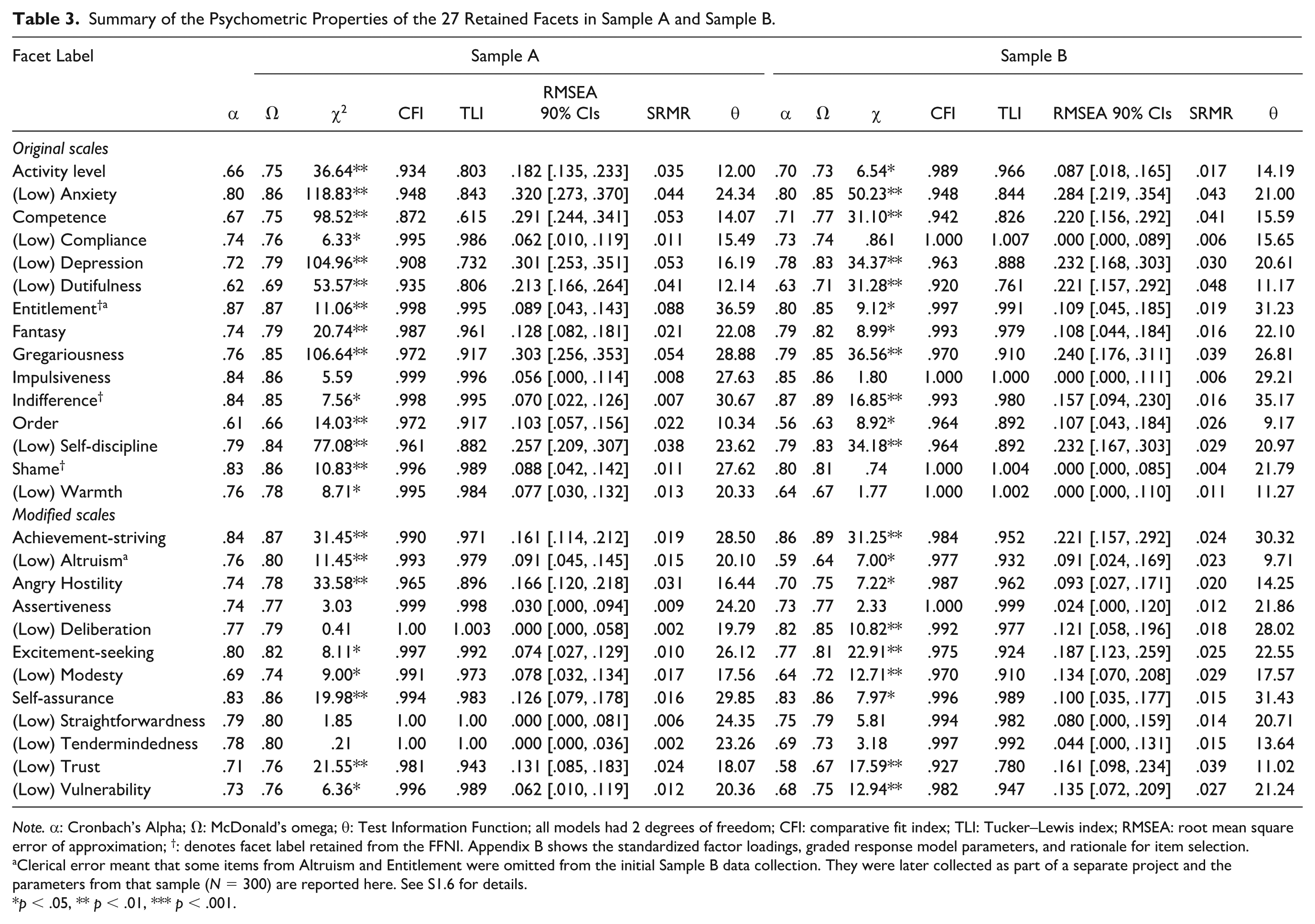
Note. α: Cronbach’s Alpha; Ω: McDonald’s omega; θ: Test Information Function; all models had 2 degrees of freedom; CFI: comparative fit index; TLI: Tucker–Lewis index; RMSEA: root mean square error of approximation; †: denotes facet label retained from the FFNI. Appendix B shows the standardized factor loadings, graded response model parameters, and rationale for item selection.
Clerical error meant that some items from Altruism and Entitlement were omitted from the initial Sample B data collection. They were later collected as part of a separate project and the parameters from that sample (N = 300) are reported here. See S1.6 for details.
p < .05, ** p < .01, *** p < .001.
The two remaining sets of facets were more complicated. The FFM facet of Altruism is represented by four facets across the EPA-SF, FFNI-SF, and FFMI: Self-centeredness, Exploitativeness, Selfishness, Entitlement. The average correlation between these four facets was .73 and the single-factor model did not fit the data (CFI = .83, TLI = .80). Further investigation suggested that Self-centeredness, Exploitativeness, and Selfishness were highly related (average r = .83), and their items loaded strongly within the single-factor CFA. In contrast, Entitlement shared moderate correlations (average r = .63) with the other facets and its items had the lowest loadings within the single-factor CFA model. We then estimated two separate models, one combining Self-centeredness, Exploitativeness, and Selfishness, and a separate model for Entitlement. Both models fit the data, and thus we consolidated Self-centeredness, Exploitativeness, and Selfishness into a single scale and retained Entitlement in its original form. An identical process was followed for FFM-Self-consciousness, which is represented by four facets: Self-assurance, Self-confidence, Indifference, and Shame. In this instance, we consolidated Self-assurance and Self-confidence and retained Indifference and Shame in their original forms.
Overall, of the 34 facets assessed, three were empirically distinct and therefore retained in their original form. The remaining 31 facets were consolidated as described above. Table 2 and supplemental materials B contain summaries of all decisions.
CFA and IRT Models for the 27 Retained Facets
Next, we estimated CFA and IRT models for all facets, 15 retained in their original form, and 12 that represented consolidated facets. Table 3 contains the CFA fit, and Alpha and omega estimates of reliability for the final 27 facets. With respect to the CFI and SRMR, all but one scale (the unmodified Competence scale) achieved adequate CFA fit in Sample A and all scales achieved adequate fit in Sample B. For six scales (Anxiety, Competence, Depression, Dutifulness, Gregariousness, and Self-discipline) the RMSEA was somewhat elevated in both samples, but as previously noted the RMSEA is prone to inflation when models have few indicators (i.e., five or fewer) and high factor loadings (i.e., >.70; McNeish et al., 2018). Thus, the CFA models evidence satisfactory fit.
Next, we conducted IRT analyses, using the Graded Response Model, for the items within the 27 retained facets. According to Baker’s (2001) classification for discrimination parameters (a), 67 of the retained items were very high functioning (a ≥1.70), 22 were high functioning (a of 1.35–1.70), and 19 were moderately informative (a < 1.35). Test information curves plot the Test Information Function across difficulty/extremity levels (θ: ± 4 SDs, see Figure S1.4) and can be used to calculate marginal reliability (Green et al., 1984). As indicated by the lines in Figure S1.4, 12 facet scales showed good to excellent reliability (.82–.92), 12 showed adequate reliability (.74–.79), and three scales showed weaker reliability of >.50 over a range of levels of θ.
In totality, the discriminant validity procedures reduced the 46 facets of EPA, FFNI, and FFMI measures into a single set of 27 facets, free from redundancy and issues of jingle-jangle. Henceforth, we refer to these 27 facets as the Faceted Dark Triad Scale or FDT for short. We use the common parlance of “Dark Triad” to ensure researchers can find the scale and relate it to existing work. However, we encourage researchers to describe the FDT as a measure of “antagonistic” personality traits, rather than “dark” traits (see Miller et al., 2022; Paulhus, 2023), which is arguably more scientifically precise (Chester et al., 2025). 1
Short and Super-Short Forms of the FDT
Next, because one of the major goals was to develop scales that are feasible for different research purposes, we created short (i.e., two items per facet) and super-short forms (i.e., one item per facet). To do so, we selected the two strongest items from each facet and the strongest item from this pair, respectively. All decisions were based on the same criteria that we applied when consolidating facets that failed the test of discriminant validity. Specifically, we retained items that optimized construct representation, that had high factor loadings, and strong IRT parameters (see Irwing & Hughes, 2018). See supplemental materials B for detailed description of the item retention process. Henceforth, the long-form (108 items; four items for each of the 27 facets) will be referred to as the FDT-L, the short-form (54 items; two items for each of the 27 facets) as the FDT-S and the super-short form (27 items; one item for each of the 27 facets) as FDT-SS. The Appendix lists all items along with administration and scoring instructions for the FDT-L, FDT-S, FDT-SS. A correlation matrix of the 27 FDT facets can be seen in Table S1.5.
We then conducted an IRT analysis comparing the measurement properties of the FDT-L, FDT-S, and FDT-SS measures of psychopathy, narcissism, and Machiavellianism. The resulting Test Information Curves are shown in Figure 1. For psychopathy, the long (reliability >.90), short (reliability ~ .80), and super-short (reliability >.70) forms evidence good to excellent measurement properties over a substantial range of θ. The same pattern is observed for narcissism and Machiavellianism, except that the reliabilities are uniformly higher for narcissism and slightly lower for Machiavellianism.
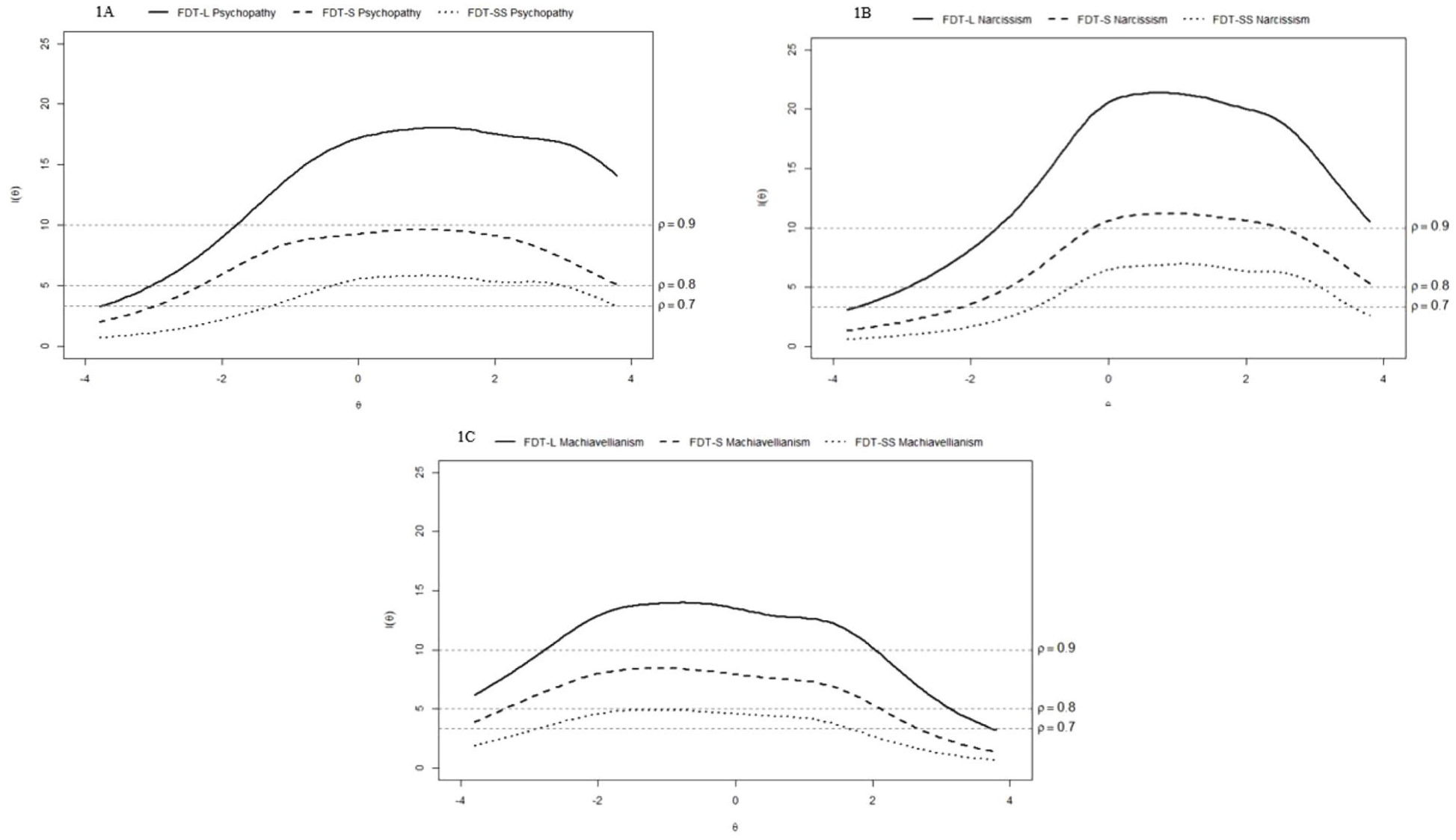
Test Information Curves for Psychopathy, Narcissism and Machiavellianism in the FDT-L, FDT-S, and FDT-SS
Assessing Convergent Validity Evidence for the FDT
Having developed the FDT, it was imperative to ensure that the construct scores derived from the scale remain consistent with the construct scores derived from the original scales (i.e., “convergent validity evidence”). We examined convergent validity evidence through the estimation of bivariate correlations between the FDT scores for psychopathy, narcissism, and Machiavellianism and the equivalent scores from the EPA, FFNI, and FFMI (see Table 4).
Correlation Matrix of Total Scores From Facet-Level Dark Triad Scale, EPA, FFNI, and FFMI.
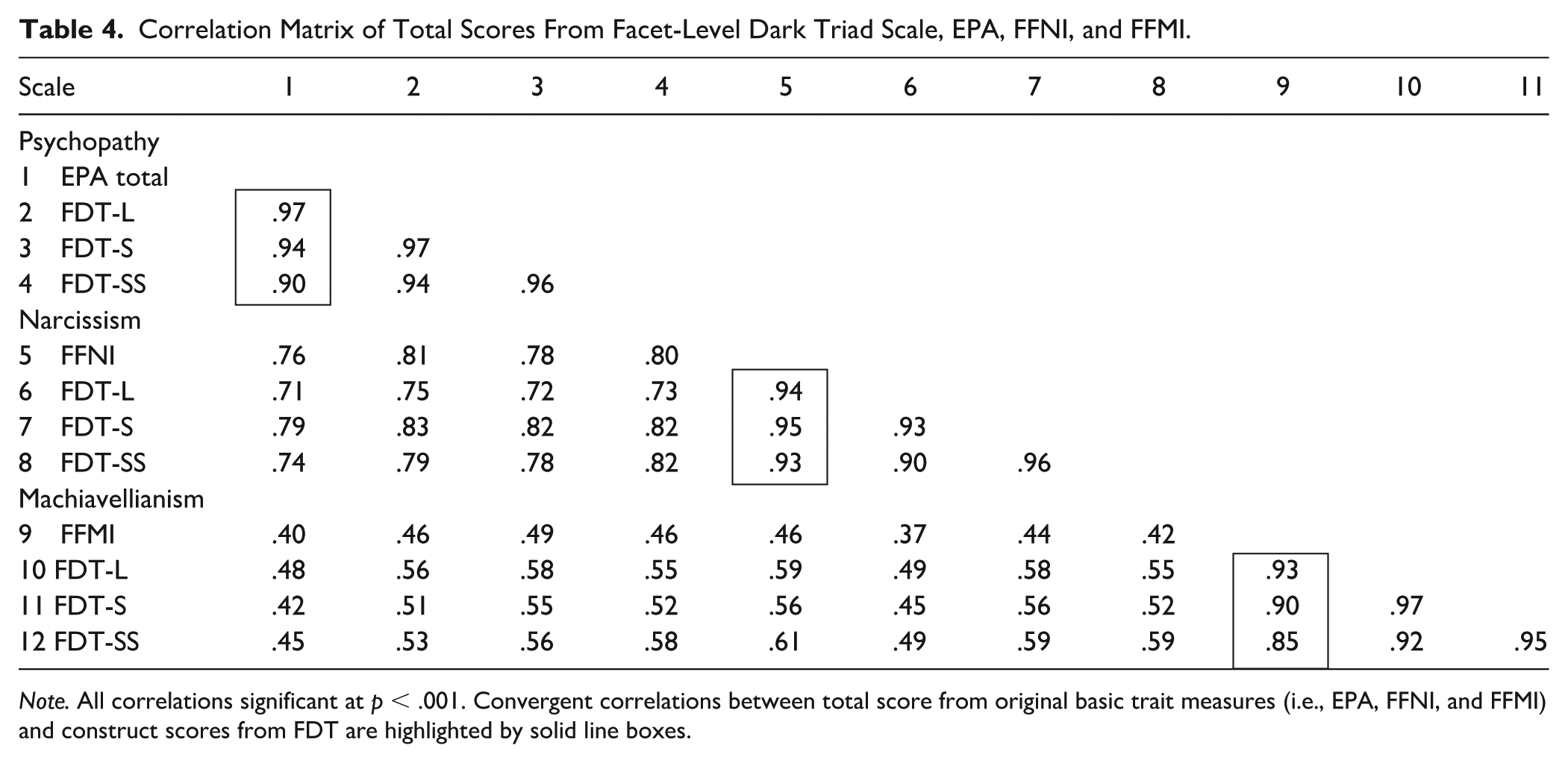
Note. All correlations significant at p < .001. Convergent correlations between total score from original basic trait measures (i.e., EPA, FFNI, and FFMI) and construct scores from FDT are highlighted by solid line boxes.
Table 4 contains all correlations. Convergent correlations between the original scales and the FDT-L scales were all ≥.93, providing strong evidence that the construct scores are consistent across measures. The FDT-S and FDT-SS also performed well, with convergent correlations ranging from .85 to .95. The pattern of discriminant correlations, those between different Dark Triad construct scores (e.g., psychopathy and Machiavellianism), was more complex. In some cases (e.g., psychopathy and Machiavellianism, narcissism and Machiavellianism) correlations were typically in the .4 to .6 range (i.e., approximately 16%–35% shared variance), suggesting clear discrimination. In the case of psychopathy and narcissism, however, the correlations were larger ranging from .71 to .83 (i.e., approximately 50% to 69% shared variance), suggesting more substantial overlap.
Think-Aloud-Protocol Analysis of Response Processes
The final stage of analysis in Study 1 was to conduct a think-aloud protocol with 26 participants (see Table S1.7 for demographic information) to examine whether item responses accurately reflected their target facets (Borsboom et al., 2004; Hughes, 2018). Think-aloud protocols give insight into the cognitive mechanisms that generate item responses by asking participants to complete the questionnaire in an interview session with a researcher, while concurrently verbalizing their interpretations of items, thought processes while deliberating, and justifications for their response choice (Ericsson & Simon, 1998; Zumbo & Hubley, 2017). Think-aloud protocols thus provide direct evidence regarding the nature of participants’ response processes and ensure that items provide accurate assessments of the target construct.
The full summary of results is shown in Table S1.8. They demonstrate that the items selected were easily read and interpreted, are discriminant, and item responses accurately reflect self-perceptions of the focal trait at appropriately increased levels for each response category. For example, the responses to the item “I remain cool, calm, and collected when things get stressful” (which assesses Vulnerability) move from impaired emotion regulation to effective emotion regulation in a positive linear direction as the response categories move from strongly disagree to strongly agree. Similar patterns are observed for all items in the super-short FDT, meaning we can be confident that “strongly agree” responses represent greater levels of the trait than “agree” responses, which reflect greater levels than “neutral” or “disagree” responses. Thus, the items are fit for purpose and accurately capture variation in the target construct (Hughes, 2018).
Discussion
The goal of Study 1 was to develop a single set of facets, free from redundancy and issues of jingle-jangle to assess psychopathy, narcissism, and Machiavellianism at facet (e.g., Straightforwardness), domain (e.g., Antagonism), and overall construct (e.g., psychopathy) level. In pursuit of this goal, we reduced the 46 facets from the EPA-SF, FFNI-SF, and FFMI to a single set of 27 non-redundant facets, labeled the FDT. All consolidated scales had adequate levels of internal consistency, strong factor loadings, and fit a single-factor CFA model. In addition, the FDT demonstrated strong convergent validity (i.e., correlations between the same construct) and discriminant validity (i.e., correlations between different constructs) evidence. Of particular note, the consolidation of redundant facets did not harm the differentiation between psychopathy and Machiavellianism (see Table 4), which had plagued past measures and was a key motivation for developing the FFMI (Miller et al., 2017; Vize et al., 2018) and FDT.
Collectively, the results of Study 1 suggest that the FDT has equivalent or superior psychometric properties to the original scales and provides equivalent assessment of the Dark Triad. This is particularly notable given the reduction from 184 items assessing 46 facets to 108 items assessing 27 facets within the FDT-L. The FDT-S and FDT-SS scales provide even more efficient assessments that based on this initial evidence appear viable and contain just 54 and 27 items, respectively.
Study 2
In accordance with the Standards for Educational and Psychological Testing (AERA, APA, NCME, 2014) we assessed internal consistency with Cronbach’s Alpha and McDonald’s omega estimates derived from Study 1 (Raykov & Marcoulides, 2011; Revelle & Condon, 2018), parallel forms using split-half reliability and the test–retest reliability (rtt) of the Faceted Dark Triad (FDT) Scale. Provided the trait measured is relatively consistent over time, test–retest measures of reliability provide a useful supplement to internal consistency estimates (e.g., Revelle & Condon, 2018). Specifically, they assess the effects of random response (e.g., attention) and transient response (e.g., mood) errors on reliability (Irwing & Hughes, 2018; Schmidt & Hunter, 1996).
Methodology
Participants from Study 1, Sample A, were invited, at random, to complete the full FDT, on a second occasion, each paid £2.00, until our maximum sample of 201 (the largest possible given research budget constraints; Lakens, 2022) was obtained. The time-lag for all participants was either 390 or 391 days. Supplementary Table S2.1 presents complete details of the sample. Briefly, the sample comprised 60.7% males and 37.3% females and ranged in age from 19 to 70 years (M = 35.4, SD = 10.4). There was no missing data.
The 369 Study 1 Sample A participants who did not participate in Study 2 were older (35 vs. 32), not significantly different in gender proportions, χ2(2) = 1.56, p = .67, Machiavellianism, or narcissism, but significantly lower, albeit to a very small degree, in psychopathy, M = 2.47 vs. 2.54; t(465) = −2.16, p = .03, d = .19. See Tables S2.2, S2.3, and S2.4 for more detail.
Results and Discussion
Internal Consistency and Split-Half Reliability
Table 5 displays Cronbach’s Alpha, McDonald’s omega, split-half reliability, and test–retest estimates of reliability for the FDT-L, FDT-S and FDT-SS. For comparison, internal consistency coefficients for the EPA, FFNI, and FFMI are shown. There are no absolute cut-off values for reliability. What is adequate depends on the purpose for which scores are to be used and the analytic techniques to be employed (Lance et al., 2006; Nunnally & Bernstein, 1994). That said, for most research purposes internal consistencies > .70 or .80 are adequate (Lance et al., 2006; Raykov & Marcoulides, 2011). Considering the internal consistency coefficients in Table 5, the McDonald’s omega estimates are higher than Alpha as expected, due to the multidimensional nature of psychopathy, narcissism, and Machiavellianism. Based on the omega estimates, all the FDT scales whether composed of four-, two-, or one-item facets are of acceptable reliability, with similar levels to the EPA, FFNI, and FFMI. Only the FDT-SS Machiavellianism scale, composed of one-item facets, is an exception. The average split-half reliability was over .7 for all FDT scores except for the FDT-SS Machiavellianism at time-point one and time-point two. Thus, the one item per facet version should only be used when very brief assessment is essential.
Internal Consistency and Test-Retest Estimates of Reliabilities of the Facet-Level Dark Triad Scales From Studies 1 and 2.
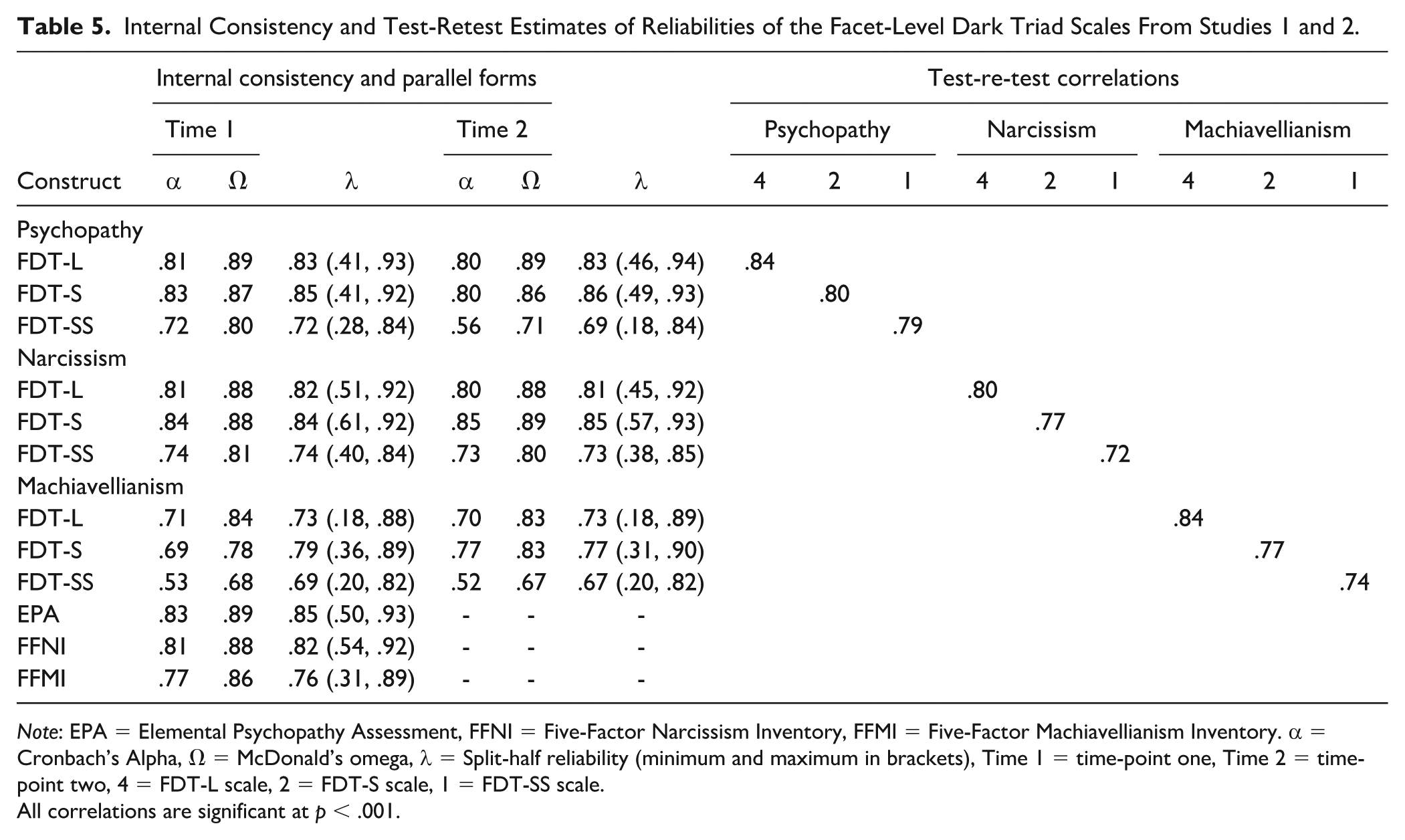
Note: EPA = Elemental Psychopathy Assessment, FFNI = Five-Factor Narcissism Inventory, FFMI = Five-Factor Machiavellianism Inventory. α = Cronbach’s Alpha, Ω = McDonald’s omega, λ = Split-half reliability (minimum and maximum in brackets), Time 1 = time-point one, Time 2 = time-point two, 4 = FDT-L scale, 2 = FDT-S scale, 1 = FDT-SS scale.
All correlations are significant at p < .001.
Test–Retest Reliability
Test–retest estimates of the reliability of the FDT scales largely reinforce conclusions based on the internal consistency estimates. They are a little lower, which is to be expected given the retest interval of over a year. However, all are above .8, which suggests considerable stability over a 390-day period.
Overall, the FDT scale shows adequate levels of test–retest reliability and internal consistency that are equivalent to the longer EPA, FFNI, and FFMI scales. For most research purposes, the FDT-L or FDT-S are to be preferred; however, the FDT-SS is suitable when very brief assessment is required.
Study 3
We next examined relationships between the Faceted Dark Triad (FDT) and other relevant variables. Such examinations are often labeled as tests of the nomological network (although the nomological network actually refers to a much broader set of validity evidence; Cronbach & Meehl, 1955; Hughes, 2018). Specifically, we examined correlations with related variables, likely outcomes of the Dark Triad, and assessed the relative predictive validity of the FDT in comparison with the EPA, FFNI, and FFMI. Such examinations are crucial to establish the appropriateness of the scale for future research (Hughes, 2018).
Previous validation work with the EPA, FFNI, and FFMI is extensive and includes estimates of convergent and divergent validity with most of the recognized measures of the DT (e.g., SRP-III, NPI, MACH-IV, SD3, DD) as well as estimates of correlations with measures of the NEO-PI-R facets, impulsivity, and externalizing behaviors (e.g., Collison et al., 2018; Glover et al., 2012; Lynam et al., 2011; Rose et al., 2022). Given that Study 1 showed that FDT psychopathy, narcissism, and Machiavellianism scores are almost isomorphic with the EPA, FFNI, and FFMI total scores (correlating at .97, .93, and .92, respectively), it is highly likely that past validation work extends to the FDT.
To continue this validation, we chose to assess relationships with other variables that are commonly explored with respect to the Dark Triad, but which are mostly unique from previous validations of the EPA, FFNI and FFMI. Specifically, we assessed the Big Five and impulsivity to maintain some continuity and added novel investigations of social dysfunction (Lawton, 2014), and workplace behavior (O’Boyle et al., 2012), which were chosen because the Dark Triad should evidence differential patterns of correlations.
Table 6 contains the hypothesized correlations between the FDT scales and the outcome variables, according to Gignac and Szodorai’s (2016) classification of effect sizes (r ≤│.10│ = small, r ≤│.30│= moderate, r > .30 = large). Hypotheses were generated through three processes. First, the Big Five and impulsivity hypotheses were directly estimated from the EPA, FFNI, and FFMI validation studies (e.g., Collison et al., 2018; Glover et al., 2012; Lynam et al., 2011). Second, where possible, hypotheses were based on previous meta-analytic (e.g., job performance, O’Boyle et al., 2012) or review findings (e.g., social dysfunction, Niven et al., 2024). One caveat here is that developing predictions for Machiavellianism was more complex given that the FDT Machiavellianism scale is substantively different from most previous measures and represents a much closer approximation to the theoretical notion of the construct. Thus, in some cases we deviated from meta-analytic findings, instead hypothesizing based on theory. Third, where no previous evidence was available, we hypothesized using the relationships between the Big Five profiles and outcomes. The general principles and sources used to derive hypotheses are more fully explained in S3.1.
Hypothesized Relations Between Dark Triad Scales and Outcomes.
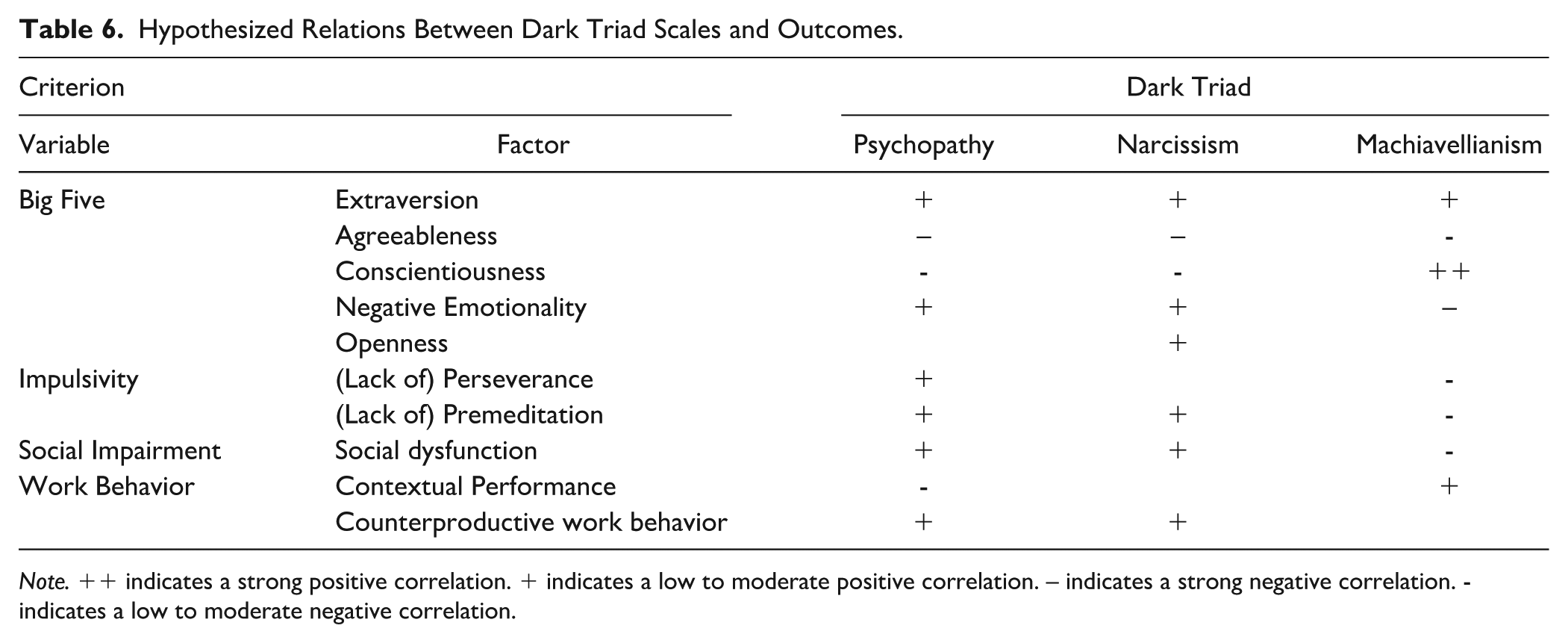
Note. ++ indicates a strong positive correlation. + indicates a low to moderate positive correlation. – indicates a strong negative correlation. - indicates a low to moderate negative correlation.
Methodology
Participants and Procedure
Seventeen days after data collection from Study 1 was completed a sub-sample was selected to complete the survey for Study 3. We opted for a time-separated design to reduce common method biases due to consistency, availability, and transient measurement errors (e.g., mood). In total, 534 of the 570 participants in Study 1 Sample A participated here. They ranged in age from 18 to 69 years (M = 338, SD = 9.8). The sample was comprised of 59% males and 40.3% females. Table S3.2 contains complete details of sample demographics. There were no meaningful differences between the primary sample and the sub-sample in age, t(1,058) = .02, p = .84, d = .01, or gender, χ2(2) = .29, p = .86; see Tables S3.3 and S3.4.
In response to a thoughtful reviewer comment, we also collected additional data from a novel sample to facilitate a post hoc, exploratory, test of the relative predictive properties of the FDT and Short Dark Tetrad (SD4) in relation to markers of anti-social behavior. This novel sample numbered 202, with 101 males, 101 females, aged from 22 to 68 (M = 35.9). See supplement S3.7 for further details.
Measures
All items, except those from the Short UPPS-P Impulsivity Scale, and anti-social behavior items, used a 5-point Likert-type response scale ranging from “Strongly Disagree” (1) to “Strongly Agree” (5). Table S3.5 provides full details for the outcome measures in Study 3 and Table S3.6 contains all descriptive statistics.
Big Five Inventory 2 Extra Short Form (BFI-2-XS; Soto & John, 2017) is a 15-item self-report measure of the Big Five. Reliabilities for the BFI-2-XS ranged from Ω = .55 for Openness-to-experience to Ω = .78 for Neuroticism.
Short UPPS-P Impulsivity Scale (SUPPS-P). To assess impulsivity, we used the Premeditation (Ω = .77) and Perseverance (Ω = .78) scales from the SUPPS-P (Cyders et al., 2014), rated using a 4-point Likert-type scale ranging from “Strongly Disagree” (1) to “Strongly Agree” (4).
The Scale of Unpleasant Relational Conduct Effects (SOURCE; Lawton, 2014; Oltmanns & Widiger, 2018) is a four-item scale that assesses social impairment (Ω = .86), via interpersonal difficulties, including being hard to like and difficult to get along with, and difficulty co-operating and makes others feel uncomfortable.
Individual Work Performance Questionnaire (IWPQ; Koopmans et al., 2014a) has 23 items that assess four dimensions of work performance: task, contextual (i.e., organizational citizenship behavior), adaptive, and counterproductive (Koopmans et al., 2014b). Contextual performance (Ω = .87) and counterproductive work behavior (Ω = .79) were included in this study.
Exploratory Post Hoc Measures
Short Dark Tetrad (SD4; Paulhus et al., 2020) is a 28-item scale that assesses psychopathy (Ω = .81), narcissism (Ω = .88), Machiavellianism (Ω = .82), and sadism (Ω = .88).
Interpersonal Adjustment (Neumann et al., 2022). Interpersonal Adjustment, the ability to relate to others, was measured using the item: “Many people dislike me.”
Misinformation sharing (Littrell et al., 2023). Misinformation sharing, the deliberate communication of information known to be false, was measured using the item: “I share information on social media about politics even though I believe it may be false.”
Interpersonal Circumplex (IPIP-IPC; Markey & Markey, 2009). The Unassuming-Submissive (Ω = .49) and Unassuming-Ingenuous sub-scales (Ω = .73) of the IPIP-IPC were used to assess levels of dominance and warmth (Markey & Markey, 2009).
Anti-social behavior. Participants completed a series of items assessing the frequency of key anti-social behaviors, presented in a form similar to the Behavior Report Form (Paunonen & Ashton, 2001). The items (e.g., How many times have you . . . been fired?) were rated using a 5-point Likert-type response scale ranging from “Never” (1) to either “Daily” (5) or “Four or more times (4+)” (5), depending on whether the question asked about frequency or lifetime occurrence. A full list of the items is displayed in Table 9.
Results and Discussion
First, we calculated correlations between the EPA, FFNI, FFMI, and FDT scales and the other variables to examine the similarity or disparity in correlation profiles between the original and FDT scales. Table 7 displays profile similarities calculated using double entry intra-class correlation coefficients (McCrae, 2008).
Correlation Profiles of Dark Triad Scales and Outcomes in Study 3.
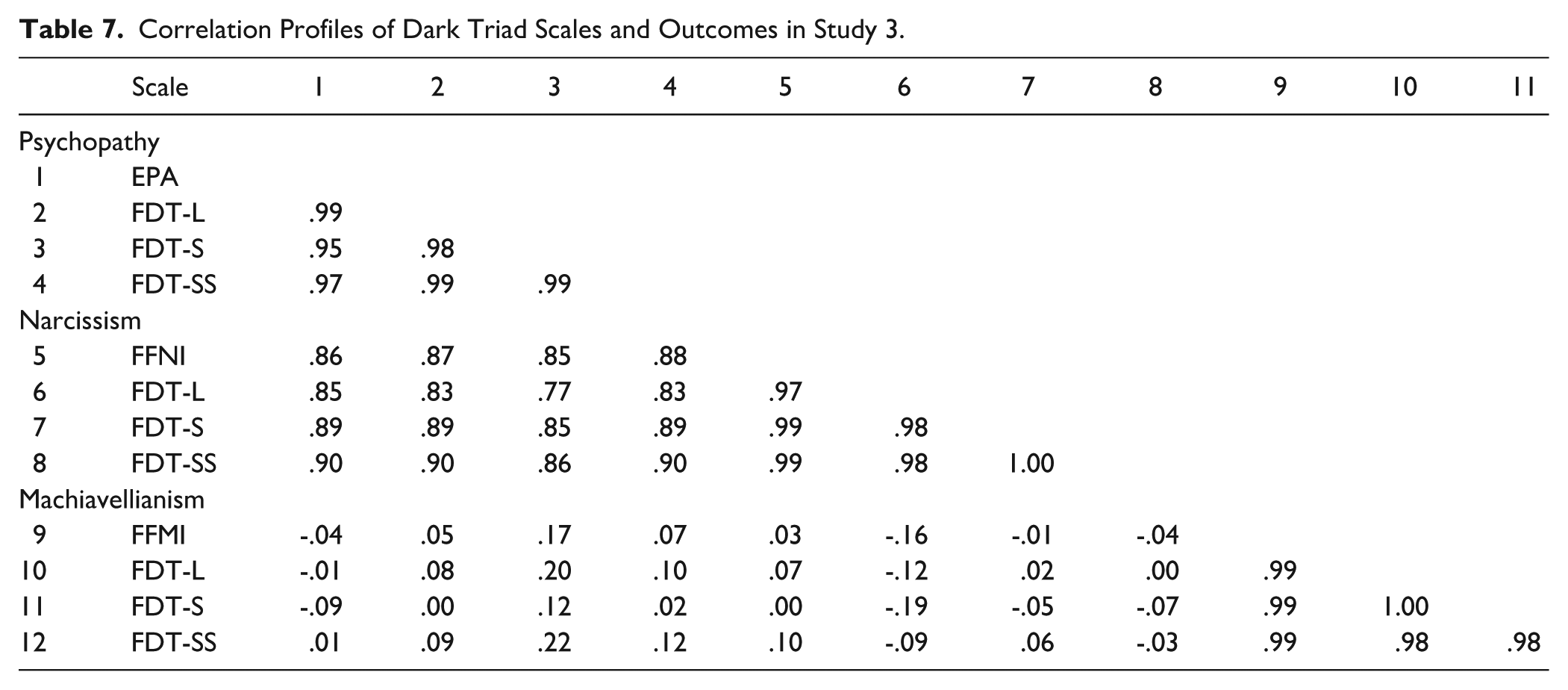
Focusing on convergent correlation profiles (e.g., psychopathy with psychopathy), the EPA, FFNI, and FFMI and the FDT are highly similar in terms of their relationships with the other variables assessed here. The mean intra-class correlation is .98 across all versions of the FDT, suggesting considerable convergence, even when the FDT assesses facets with just one item.
Regarding discriminant correlation profiles (e.g., psychopathy with Machiavellianism), Machiavellianism is markedly distinct from both psychopathy and narcissism, further supporting measurements of Machiavellianism that arise from the basic trait approach, given that most extant Machiavellianism scales are indistinguishable from psychopathy scales (Vize et al., 2018). Discriminant correlation profiles for narcissism and psychopathy show a much higher degree of similarity (r = .80–.88) but are significantly different from 1.
Next, we examined the bivariate correlations between the EPA, FFNI, FFMI, and FDT scales and the other variables (displayed in Table 8, left-half). Eighty-eight per cent (22/25) of correlations conform to the hypotheses in Table 6. An exact one-tailed binomial sign test showed that our prediction rate was much greater than chance (50%) levels (p < .001, 95% CI = [.72, .100]). Even where hypotheses were not strictly supported, the discrepancies were small in magnitude (Gignac & Szodorai, 2016). That the FDT correlations broadly conform to hypotheses based on past research and theoretical prediction provides good validation evidence for the appropriateness of the FDT scales.
Correlations Between the Original Measures and FDT Variants, and Personality Traits and Behavioral Outcomes.
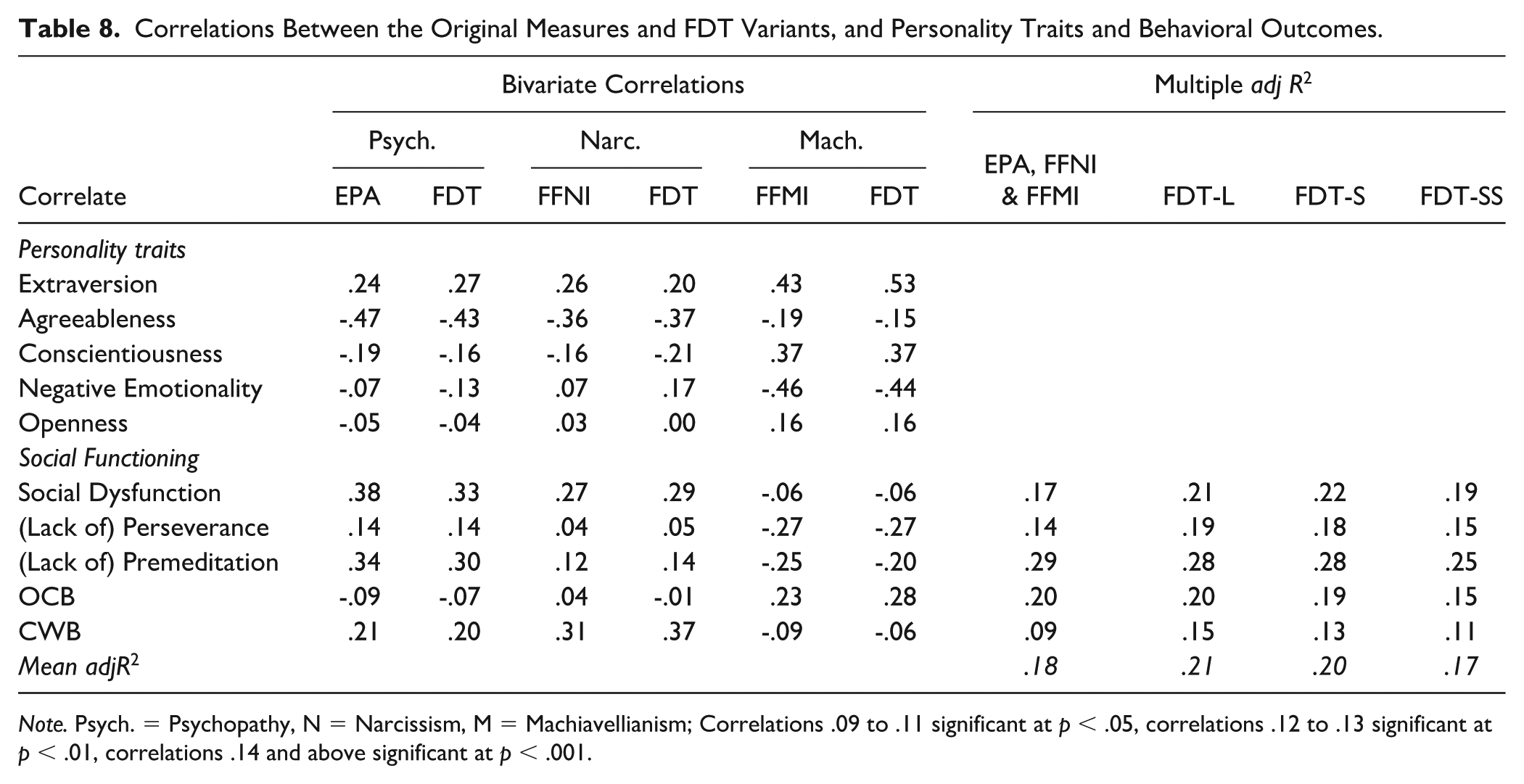
Note. Psych. = Psychopathy, N = Narcissism, M = Machiavellianism; Correlations .09 to .11 significant at p < .05, correlations .12 to .13 significant at p < .01, correlations .14 and above significant at p < .001.
Much as the profile similarity data shows, psychopathy and narcissism are similar but not identical in terms of their external relations. As a concise summary, both are strongly antagonistic (BFI-Agreeableness) and averagely emotionally stable (BFI-Negative emotionality) and show moderate (psychopaths) or low (narcissists) levels of impulsivity (UPPS-P, Lack of premeditation). Both are moderately correlated to social dysfunction (SOURCE) and CWB.
In contrast, Machiavellianism is moderately correlated with antagonism (BFI-Agreeableness) and emotional stability (BFI-Negative emotionality), weakly correlated with impulsivity and shows no evidence of a correlation with social dysfunction (SOURCE). In terms of work behavior, Machiavellianism is moderately correlated with OCB, and shows no evidence of a correlation with CWB.
Next, we compared predictive properties, in the form of variance explained. We regressed the social functioning variables, but not the Big Five due to content overlap, onto psychopathy, narcissism, and Machiavellianism calculated via the original scales and the FDT. Table 8 (right-half) displays the total variance explained for each model. Both the FDT-L (21%) and FDT-S (20%) explain more variance in the outcomes, on average than the EPA, FFNI, and FFMI (18%). The FDT-SS, with just one item per facet, shows marginally weaker prediction (17%) but given it has just 27 items compared with the 184 contained with the EPA, FFNI, and FFMI, it is surprisingly close. This predictive validity evidence suggests that the removal of redundancy and issues of jingle-jangle when merging the EPA, FFNI, and FFMI has not undermined predictive validity, rather it has improved it.
Exploratory Analysis
Finally, responding to a reviewer request, we collected additional data to compare the predictive properties of the FDT and SD4 in relation to markers of pro- and anti-social behavior (see Table 9). Supplement S3.7 contains a full write-up of this additional study, including bivariate correlations between the FDT, SD4, and the pro- and anti-social behavior variables.
Standardized Beta Coefficients and Adjusted Multiple R2 for Each of the Pro- and Anti-Social Outcomes Regressed onto the FDT-L and SD4.
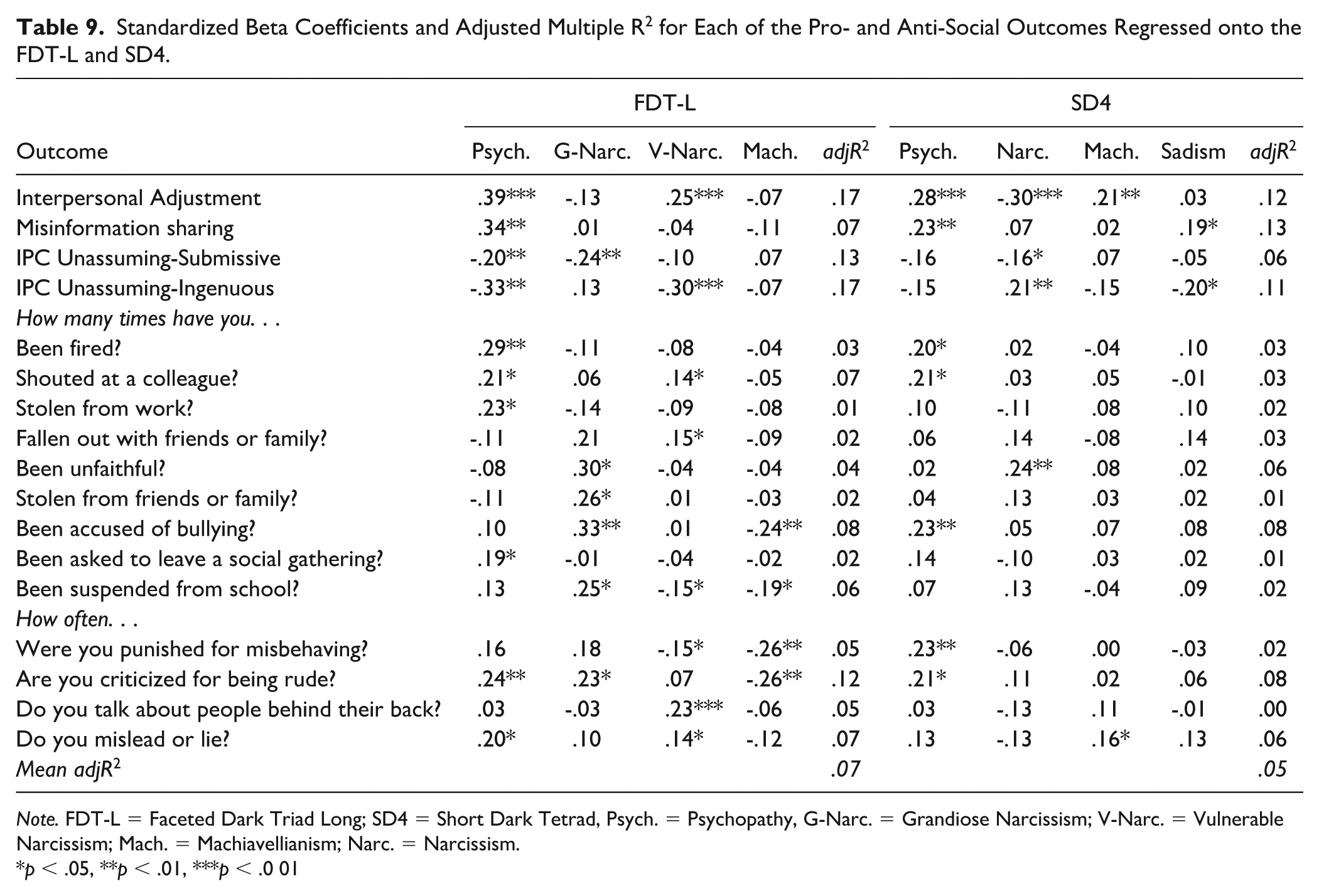
Note. FDT-L = Faceted Dark Triad Long; SD4 = Short Dark Tetrad, Psych. = Psychopathy, G-Narc. = Grandiose Narcissism; V-Narc. = Vulnerable Narcissism; Mach. = Machiavellianism; Narc. = Narcissism.
p < .05, **p < .01, ***p < .0 01
To test the relative predictive properties of the FDT and SD4, we first regressed each of the 17 pro- and anti-social behavior variables onto four traits from the FDT-L (psychopathy, grandiose narcissism, vulnerable narcissism, and Machiavellianism), before regressing them onto the SD4 (psychopathy, narcissism, Machiavellianism, and sadism). We chose this level of FDT scoring to keep the comparisons as similar (e.g., SD4 narcissism most closely aligns with FDT grandiose narcissism) and fair (e.g., both scales have four predictors) as possible. Table 9 contains the parameter estimates for each regression model.
Of the 17 outcomes, 11 were best explained by the FDT, four by the SD4, and two to an equal extent. On average, the FDT provided a 37% increase in variance explained relative to the SD4. In addition, each of the FDT scales were unique predictors more often than their SD4 counterparts. For example, FDT psychopathy was a significant predictor in 10 regressions, whereas SD4 psychopathy was a predictor in 7. The same pattern is evident for all four scales. The overall pattern of results is consistent for the FDT-S and FDT-SS; however, the SD4 and FDT-SS are similarly predictive. Thus, compared with the SD4, the FDT is more predictive (average 37% increase in R2), of more outcomes (11 vs. 4), and each sub-scale adds more unique variance. In addition, the FDT can also be scored more flexibly than the SD4 and explored at the facet level, which would increase variance explained further and help to identify which elements of the Dark Triad drive any observed effects (Irwing et al., 2024).
General Discussion
Following the holistic accuracy and appropriateness validation framework (Hughes, 2018), the goal of the current study was to develop a single set of facets, free from redundancy and issues of jingle-jangle that can assess all three of the Dark Triad traits at facet, domain, and overall construct level. We achieved this by consolidating the facets from three separate measures, the EPA-SF (Lynam et al., 2013), FFNI-SF (Sherman et al., 2015), and FFMI (Collison et al., 2018) into a single measure entitled the Faceted Dark Triad (FDT) scale. A key strength of the EPA, FFNI, FFMI and thus the FDT is their use of the basic trait approach, which represents a significant advance in theoretical clarity and measurement precision (e.g., Widiger & Costa, 2013; Widiger & McCabe, 2020). Building on this work, we developed the 27-facet FDT, which provides robust, powerful, and parsimonious assessment of the Dark Triad in a single measure. The FDT can be scored to assess psychopathy, Machiavellianism, narcissism, grandiose narcissism and vulnerable narcissism, as well as their constituent domains and facets, as currently conceptualized (e.g., Miller et al., 2017; Paulhus & Williams, 2002; Vize et al., 2018).
Psychometric and Predictive Properties
The FDT removes numerous instances of redundancy and jingle-jangle present in the EPA, FFNI, FFMI, and the redundancy within the one extant combined measure, the FFM Antagonistic Triad. The reduction of jingle-jangle and consolidation of facets did not significantly alter the interpretation of the scale scores. Indeed, FDT scores of psychopathy, narcissism, and Machiavellianism correlated with their counterparts from the EPA-SF, FFNI-SF, and FFMI in the range of .92 to .97 (Study 1). The FDT facet scales demonstrated strong psychometric properties in terms of CFA fit, internal consistency, high factor loadings, IRT parameters (Study 1) and test–retest reliability (Study 2). In addition, when compared with the EPA-SF, FFNI-SF, and FFMI (with 46 facets and 184 items), the FDT-L (with 27 facets and 108 items) demonstrated equivalent or superior prediction of four of the five outcomes assessed in Study 3 (i.e., Social Dysfunction, (Lack of) Perseverance, OCB, and CWB). With respect to the remaining outcome (i.e., (Lack of) Premeditation), the FDT-L explained almost equivalent proportions of variance, with the difference not being greater than .01. A similar pattern is evident with the FDT-S (two items per facet, 54 items in total) which provides equivalent or superior prediction for three of five outcomes (i.e., Social Dysfunction, (Lack of) Perseverance, and CWB). Even the FDT-SS, with just one item per facet, provides equivalent or superior prediction in three of five cases (i.e., Social Dysfunction, (Lack of) Perseverance, and CWB) and in the other cases explains similar proportions of variance.
In addition, the FDT, whether scored in long, short, or super-short form, compares favorably with the SD4. Both the FDT and SD4 predicted a range of anti-social criteria, but relative to the SD4, the FDT explained an average of 37% more variance and its scales were unique predictors more often than their SD4 counterparts. Thus, the predictive equivalence, or superiority, of the FDT over the SD4, in addition to the fact that the FDT can be scored more flexibly and explored at the facet-level, suggests the FDT is a valuable tool for future research. One note of caution pertains to the high inter-correlations between the FDT psychopathy and FDT narcissism (r = .71–.83) total scores. Given the magnitude of this association, researchers are best advised to use the grandiose and vulnerable narcissism scores separately, unless there is a strong rationale not to do so.
Theoretical Utility
The FDT provides a theoretically informed tool, derived from the basic trait approach to understanding personality disorders, that is primed to enhance our understanding of the nature, causes and consequences of dark traits. For example, many existing psychometric tools fail to distinguish psychopathy and Machiavellianism, largely because they fail to assess, or appropriately model, the strategic, self-controlled elements of Machiavellianism (e.g., Miller et al., 2017; Vize et al., 2018). As a result, studies often provide misleading empirical conclusions regarding the similarities and differences between psychopathy and Machiavellianism that are little more than random sampling error. In contrast, studies using the FDT will be better able to estimate accurate effects that will enhance and clarify understanding of these two important socially aversive traits. For example, results in Study 3 demonstrate that FDT Machiavellianism correlates positively with some adaptive outcomes as theorized (e.g., organizational citizenship behavior), while also having highly dissimilar correlation profiles from psychopathy and narcissism.
In addition, facet-based models almost always provide more powerful prediction, and useful explanation, than do broad trait models (Irwing et al., 2024). Thus, being able to decompose the DT into their constituent components allows researchers to identify which facets are driving which associations, enabling fuller understanding of the DT. Furthermore, because every facet in the FDT is derived from the FFM, one advantage of the FDT compared with more commonly used scales (e.g., SD3/4, DD), is the ability to relate the findings to the broader personality literature. Being able to translate DT assessments into the common parlance of broader personality research will help synthesize work, improve hypothesizing (e.g., we were able to make accurate predictions of correlations based on FFM work) and allow for more accurate cross-fertilization between the traditions. The FFM-ATM scale has the same advantage. However, as discussed in the introduction, the FFM-ATM has one item for each of the original 46 facets contained within the EPA, FFNI, and FFMI and thus has some conceptual redundancy. In contrast, all FDT scales are free from redundancy, and the equivalent one-item version, the FDT-SS, has just 27 items, making it preferable when short scales are required. Furthermore, the FDT-S has similar psychometric properties to the FDT-L and a similar number of items to the FFM-ATM. Thus, the FDT-S is likely to be suitable in all cases in which the FFM-ATM could be used.
Two other major theoretical debates that the FDT is well-placed to advance are: (1) which specific conceptualizations of psychopathy, narcissism, and Machiavellianism are “best,” and (2) which facets are central or “core” to antagonistic traits. Each DT trait can be described through competing conceptualizations, all of which propose the traits to be multidimensional, either explicitly or implicitly, but few of which agree on the nature, number, and weighting of dimensions. Each DT scale developed contains some common personality content and some unique to the specific conceptualization, making cross-study comparison and/or aggregation difficult. Ultimately, producing a field fragmented due to scale idiosyncrasies. Because the FDT contains all facets argued to be of relevance to the DT traits, it can be a useful tool to test and adjudicate between competing conceptualizations. Researchers can model facets (i.e., select and weight in a scale score, or CFA model) according to two or more competing conceptual models and empirically examine which is most accurate or appropriate (Hughes, 2018) for a range of purposes. Such work can drive conceptual clarity and refinement, and regardless of which conceptualizations are preferred, if they are assessed via FDT facets, aggregation and comparison will be straightforward.
Researchers are also actively working to identify which facets can be considered common to all dark traits and which are unique (e.g., Bader et al., 2022; Dinić et al., 2021; Hilbig et al., 2021; Moshagen et al., 2020; Rose et al., 2022; Vize et al., 2020). Many of these studies use factor analytic, network, or similar models, all of which are undermined due to scale limitations (e.g., Booth & Murray, 2018), including poor reliability, idiosyncratic content, repeated and redundant content, and items that often stray away from personality content into characteristic adaptations (e.g., hobbies, attitudes, outcomes of personality; DeYoung, 2015). The FDT is an improvement in each of these regards.
Limitations, Constraints on Generality, and Future Directions
There are two major limitations to consider when interpreting the current findings. First, the use of self-report data, which can result in social desirability issues in DT research (Bonfá-Araujo et al., 2021). Self-report data is the bedrock of personality assessment and arguably provides the most accurate account of a person’s internal patterns of thought, feelings, and behavior, and several studies now demonstrate that anonymous individuals, such as those sampled here, readily report heightened levels of Antagonism and other socially undesirable traits (Kowalski et al., 2018; Sleep et al., 2017, 2018). Furthermore, in Study 3, we assessed the FDT and outcomes in a time-separated manner to reduce common method biases due to consistency, availability, and transient measurement errors (e.g., mood). Nevertheless, future research would benefit from the use of other-report personality data and objective outcome criteria where sensible. The original EPA also contains social desirability items (e.g., “I have never been envious of anyone else”), which were omitted here, but could be useful for evaluating response biases in some circumstances.
Second, all samples were recruited via Prolific.ac (Palan & Schitter, 2018) and used English speakers, which may constrain generalizability. However, as observed in our data, participants in panel samples tend to be more diverse in age, family composition, religiosity, and political beliefs than the samples commonly found in psychological research (Chandler et al., 2019). Nevertheless, future research would benefit from examining the FDT within more diverse samples recruited from more diverse environments (e.g., the workplace, clinical and forensic populations).
Conclusion
The three studies documented within this article describe the development of the Faceted Dark Triad scale which contains a single set of facets, free from redundancy and issues of jingle-jangle that can assess all three of the DT traits at facet (e.g., Straightforwardness), domain (e.g., Antagonism), and overall construct (e.g., Psychopathy) levels. Whether using the four- (FDT-L), two- (FDT-S), and one-item (FDT-SS) per facet versions, the FDT compares favorably to and often outperforms existing scales. Given the importance of examining the DT when studying many of our most pressing societal issues, the FDT, which builds upon and consolidates decades of rigorous research (e.g., Lynam & Widiger, 2007; Miller et al., 2001; Widiger & Costa, 2013), represents a valuable tool. In short, all versions of the FDT provide accurate, efficient, and robust measurement that will produce theoretically coherent and empirically robust estimates that will help improve our understanding of the nature, antecedents, and consequences of the DT.
Supplemental Material
sj-docx-1-asm-10.1177_10731911251388351 – Supplemental material for Development and Validation of the Faceted Dark Triad (FDT) Scale
Supplemental material, sj-docx-1-asm-10.1177_10731911251388351 for Development and Validation of the Faceted Dark Triad (FDT) Scale by John-Paul Martindale, David J. Hughes, Paul Irwing and Leigha Rose in Assessment
Supplemental Material
sj-docx-2-asm-10.1177_10731911251388351 – Supplemental material for Development and Validation of the Faceted Dark Triad (FDT) Scale
Supplemental material, sj-docx-2-asm-10.1177_10731911251388351 for Development and Validation of the Faceted Dark Triad (FDT) Scale by John-Paul Martindale, David J. Hughes, Paul Irwing and Leigha Rose in Assessment
Supplemental Material
sj-pptx-3-asm-10.1177_10731911251388351 – Supplemental material for Development and Validation of the Faceted Dark Triad (FDT) Scale
Supplemental material, sj-pptx-3-asm-10.1177_10731911251388351 for Development and Validation of the Faceted Dark Triad (FDT) Scale by John-Paul Martindale, David J. Hughes, Paul Irwing and Leigha Rose in Assessment
Footnotes
Authors’ Note
We are very indebted to Professor Josh Miller and Professor Donald Lynam for their extensive comments on earlier drafts.
CReDIT Statement
J-PM, DJH, and PI contributed to conceptualization, methodology, funding acquisition, formal analysis, investigation, and writing of the original and edited drafts. J-PM provided data curation and project administration. DJH and PI provided supervision to J-PM. LR contributed to conceptualization and writing of edited drafts.
Data Availability Statement
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: An Alliance Manchester Business School Research Support Fund grant of £4,996 facilitated some of the data collection. No other funding from agencies in the public, commercial, or not-for-profit sectors was received.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.