
Abstract
The neuropsychological construct of executive functions (EFs), and the psychometric Cattell–Horn–Carroll (CHC) theory of cognitive abilities are both approaches that attempt to describe cognitive functioning. The coherence between EF and CHC abilities has been mainly studied using factor-analytical techniques. Through multivariate regression analysis, the current study now assesses the integration of these latent constructs in clinical assessment. The predictive power of six widely used executive tasks on five CHC measures (crystallized and fluid intelligence, visual processing, short-term memory, and processing speed) is examined. Results indicate that executive tasks—except for the Stroop and the Tower of London—predict overall performance on the intelligence tests. Differentiation in predicting performance between the CHC abilities is limited, due to a high shared variance between these abilities. It is concluded that executive processes such as planning and inhibition have a unique variance that is not well-represented in intelligence tests. Implications for the use of EF tests and operationalization of CHC measures in clinical practice are discussed.
Keywords
In neuropsychology, executive function (EF) refers to multiple higher order cognitive control processes (Miyake, Friedman, Emerson, Witzki, & Howerter, 2000). It is defined as a phenomenon describing the efficiency with which cognitive tasks or demands are handled and problems are solved. There is no consensus on the amount of subfunctions EF exists of, with a previous review reporting up to 18 different EFs (Packwood, Hodgetts, & Tremblay, 2011). In general, processes like attention, emotion regulation, flexibility, inhibitory control, initiation, organization, planning, self-monitoring, and working memory can be identified as executive processes (Goldstein, Naglieri, Princiotta, & Utero, 2014; Naglieri & Goldstein, 2013; Miyake et al., 2000; Packwood et al., 2011). Impairments in these processes may lead to severe dysfunction in a wide range of behaviors (Lezak, Howieson, Bigler, & Tranel, 2012). The concept of EF is primarily concerned with information processing and originates from neuropsychological theory such as the central executive hypothesis (Baddeley, 1996; describing a control system with multiple functions) and Luria’s (1980) planning, attention, simultaneous, and successive (PASS) information processing model (Das, Naglieri, & Kirby, 1994; see also Goldstein et al., 2014). Although EF has typically been related to prefrontal lobe function, neuroimaging studies increasingly indicate that (multiple) neural networks are involved in these higher-order complex cognitive processes, which demonstrates the shift to a more holistic and integrative approach on EF (Duncan, 2013, Packwood et al., 2011).
In the past decades, few theories of cognitive abilities have been studied more extensively than the Cattell–Horn–Carroll (CHC) theory of cognitive abilities (McGrew, 2009; Schneider & McGrew, 2012). In CHC theory, the general intelligence factor, or g (Spearman, 1927), stands on top of a hierarchy of cognitive abilities. CHC theory currently identifies 16 broad abilities each consisting of multiple narrowly defined capacities (Schneider & McGrew, 2012). Of these abilities, six domain-independent general capacities have been described: fluid reasoning (Gf), short-term memory (Gsm), long-term storage and retrieval (Glr), processing speed (Gs), reaction and decision speed (Gt), and psychomotor speed (Gps). In addition, four abilities address acquired knowledge: comprehension-knowledge (Gc), domain-specific knowledge (Gkn), reading and writing (Grw), and quantitative knowledge (Gq). Six further abilities concern domain-specific sensory and motor functions: visual processing (Gv), auditory processing (Ga) and olfactory (Go), tactile (Gh), kinesthetic (Gk), and psychomotor (Gp) abilities.
Both EF and CHC theory are useful in describing cognitive functioning, and both strive for process-pure measurement of cognitive abilities in individuals. In clinical practice, both EF measures and intelligence tests are used in neuropsychological assessments. Both traditions, however, face important issues with respect to operationalization. Especially EF tasks have always been afflicted with task impurity (Miyake et al., 2000). That is, process-pure measurement of EF is hardly possible, as tasks often also rely on other, nonexecutive cognitive functions, such as memory, alertness, or language. Consequently, test scores provide no insight into the underlying EF processes. In turn, assessment of intellectual function deals with similar problems. For example, mapping CHC abilities on intelligence (sub)tests is complex (Benson, Hulac, & Kranzler, 2010, Van Aken et al., 2017; Weiss, Keith, Zhu, & Chen, 2013). Furthermore, it is unclear to what extent subtests are a good representation of these broad abilities. For instance, whereas the working memory index of the WAIS-IV (Wechsler Adult Intelligence Scale–Fourth Edition) is a valid measure of working memory, it has a too low manipulation load and does not incorporate nonverbal working memory demands, thereby not comprising the full scope of the Gsm factor (Egeland, 2015). Furthermore, factor analysis has shown that most subtests of intelligence batteries are impure measures of CHC abilities, showing cross-loadings with other subtests and latent factors (Grégoire, 2013).
Neuropsychological EF theory aims to understand cognitive processes that predict and explain (pathological) behavior, relevant for clinical practice. Therefore, EF has been studied mostly in clinical settings. CHC abilities are mainly derived through factor analysis of large datasets and have predominantly been studied in nonpathological samples. Whereas the neuropsychological approach focuses on predictive and external validity of tests, for instance aiming to predict daily functioning of patients after brain injury, the psychometric approach aims to develop “pure” measurements of empirically identified latent constructs (internal and structural validity; McGrew, 2010).
The role of neuropsychological constructs, particularly EF, in CHC theory is currently under debate (Jewsbury, Bowden, & Duff, 2016). From their respective definitions only, it may be argued that EF and intelligence are partly overlapping constructs. Executive functions operate as “control mechanisms” for several cognitive processes and have been found to share great variance with general intelligence, facilitating complex behavior, and (creative) thought (Benedek, Jauk, Sommer, Arendasy, & Neubauer, 2014; Floyd, Bergeron, Hamilton, & Parra, 2010; Salthouse, 2005). The relationship between EF and Gf has been studied extensively and is considered strong (Diamond, 2013; Godoy, Dias, & Seabra, 2014; Salthouse, Atkinson, & Berish, 2003; Van Aken, Kessels, Wingbermühle, Van der Veld, & Egger, 2016; Duggan & Garcia-Barrera, 2015). Particularly working memory and Gf are strongly related (Chuderski, 2013; Duncan, Schramm, Thompson, & Dumontheil, 2012; Redick, Unsworth, Kelly, & Engle, 2012; Salthouse & Pink, 2008; Schneider & McGrew, 2012).
The compatibility of neuropsychology and CHC theory has largely been studied using factor-analytic modeling. Hoelzle (2008) re-analyzed existing data of seven cognitive domains, including EF, grouping neuropsychological domains into empirically supported CHC domains. In general, the examined attention tests were associated with Gs, executive tests mostly represented Gf and Gv, and most perceptual measures reflected Gv. Memory tests were identified as Glr, and language tests all included Gc. Floyd et al. (2010) examined the compatibility of EF and CHC theory using the Delis–Kaplan Executive Function System (D-KEFS; Delis, Kaplan, & Kramer, 2001) and concluded that subtests of the D-KEFS were just as much a measure of EF as of g and the broad CHC abilities. Outcomes of a large study on tests of EF and cognitive abilities and their unique contributions to aging (using both structural modeling and regression techniques) suggested similar conclusions (Salthouse, 2005). The hypothesized EF tasks were found to explain unique variance over the variance explained by the other cognitive abilities. Most EF tasks were closely related to reasoning and perceptual speed tasks, the latter having better psychometric properties than the EF tasks.
Recently, Jewsbury et al. (2016) concluded that the concept of EF is redundant in the CHC model. A separate EF factor in the model did not add to the explained variance by the CHC model. Instead, EF variables could be explained mainly by the Gs, Gv, Gsm, and Gf abilities. In contrast, Roberds (2015) emphasized the distinctiveness between executive processes and the CHC model. Using canonical correlation and multiple regressions, she not only demonstrated a large shared amount of variance but also showed measures of both CHC abilities and EF to have unique variance. Again, Gsm, Gv, Gs, and Gf were identified as the most important CHC abilities in describing the relationship with tests of executive function. Recently, Miyake’s widely used classification of executive functions that highlights three major processes, that is, switching, inhibition, and updating (Miyake et al., 2000), has been studied in terms of CHC theory. Using confirmatory factor analysis, Jewsbury, Bowden, and Strauss (2015) found that switching could be classified as a narrow factor under Gs, inhibition was entirely explained by Gs, and updating best fitted on the Gsm factor.
Factor analysis in itself is helpful to unravel the coherence between EF processes and CHC constructs, both by exploring their relation at a latent level, and by studying which observed variables are good indicators of the latent construct. Previously, we also studied latent constructs of EF and intelligence test through factor analysis, finding overlap mainly between EF and Gf/Gv (Van Aken et al., 2014; Van Aken et al., 2016; Van Aken et al., 2017). As Schneider and McGrew (2012) state, other (multivariate) statistical techniques should be used next to factor-analytic investigations of latent constructs, “to allow for the simultaneous examination of content (facets), processes, and processing complexity of CHC measures” (p. 109). At present, we aim to gain more insight into the translation and applicability of these latent constructs to the daily use of tests in clinical practice, extending previous results obtained with factor-analytical studies on this topic. To do so, the current study adopts a directive approach to examine the possible cohesion and overlap between the operationalizations of EF and CHC theory. It will examine the predictive value of widely used EF tests for the performance on intelligence tests in a clinical population. Since EF and CHC share similar latent constructs, it can be hypothesized that EF assessment is capable of predicting the overall level of functioning (as a reflection of g) as well as the outcome on different IQ/index scales as the operationalization of separate CHC abilities. Although one could argue that the direction of this hypothesis can also be reversed (i.e., intelligence as a predictor of EF), the hypothesized direction is chosen since executive processes are more directly related to neurocognitive models, brain function, and neural efficiency than the psychometric construct of intelligence. Furthermore, using CHC abilities as starting point in explaining variance addresses the critique of “overfactoring” (Canivez & Kush, 2013; Frazier & Youngstrom, 2007). This critique states that adding complexity to a latent model will lead to a better model fit, just because there is more to account for in a complex model, and not because of content arguments.
A set of six traditional and frequently used EF tests will be studied, tapping a wide range of EF abilities that are measured by both singular and more complex executive tasks (Goldstein et al., 2014; Lezak et al., 2012). Hypothesized effects (see Table 1) are based on previous studies on EF tests and CHC (Hoelzle, 2008; Floyd et al., 2010; Roberds, 2015; Salthouse, 2005). Some studies reported conflicting relations, but given the exploratory nature of the current study, we used all positive correlations described by earlier studies to substantiate our hypotheses. The hypotheses are based on described associations between constructs using the same or similar versions of the tasks.
Hypothesized Effects of Executive Tasks on Cognitive Abilities.
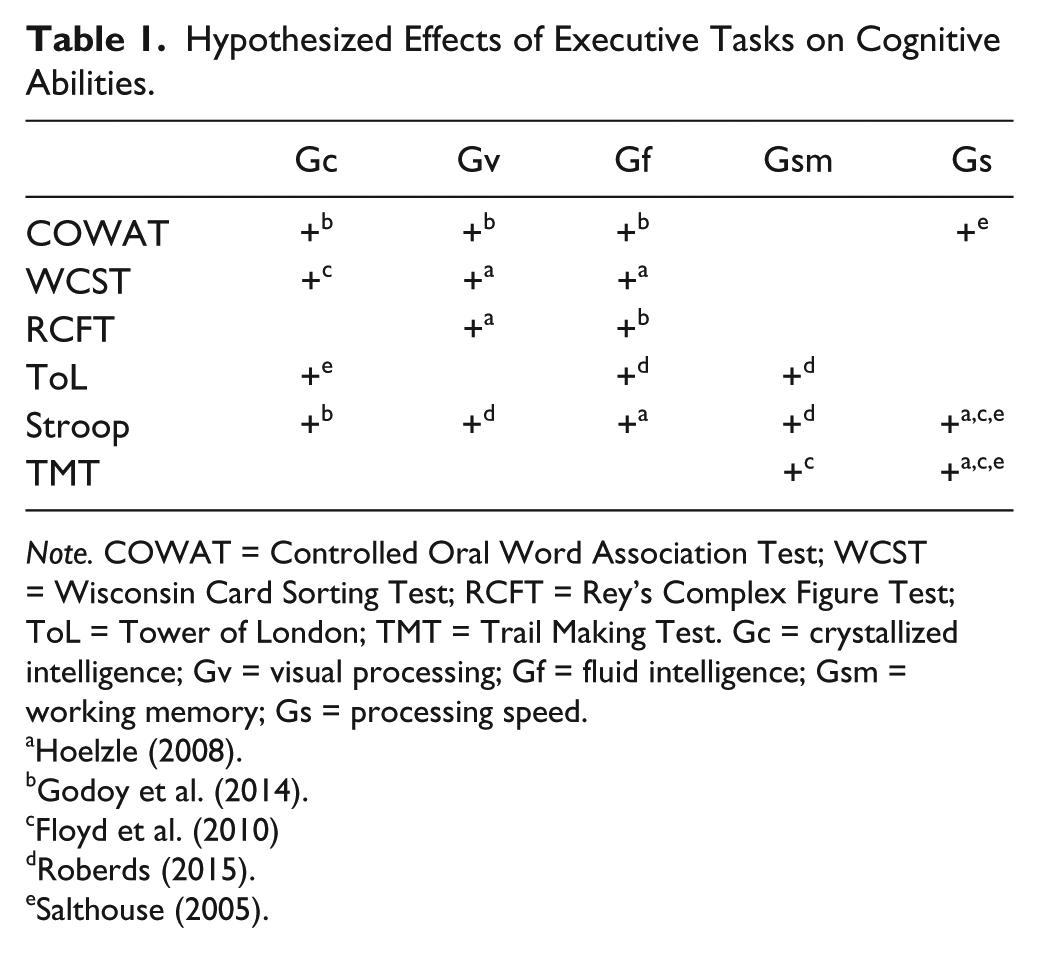
Note. COWAT = Controlled Oral Word Association Test; WCST = Wisconsin Card Sorting Test; RCFT = Rey’s Complex Figure Test; ToL = Tower of London; TMT = Trail Making Test. Gc = crystallized intelligence; Gv = visual processing; Gf = fluid intelligence; Gsm = working memory; Gs = processing speed.
According to Schneider and McGrew (2012)
CHC based neuropsychological assessment holds great potential. Much clinical lore within the field of neuropsychological assessment is tied to specific tests from specific batteries. CHC theory has the potential to help neuropsychologists generalize their interpretations beyond specific test batteries and give them greater theoretical unity. (p. 109)
The authors argue that the integration of CHC theory and executive function using predictive techniques is relevant for both theorization as well as clinical practice, by bridging the gap between both fields and understanding cognitive processes underlying the CHC abilities.
Method
Participants
Participants were 1,185 in- and outpatients (Mage = 35.8 ± 15.0, 57.2% men, MIQ = 88.1 ± 16.9) of the Vincent van Gogh Institute for Psychiatry in Venray, the Netherlands. In accordance with the guidelines of the institutional review board, concealed patient records were drawn from a large electronic database, containing test results of patients registered in the period from January 2004 to November 2015. Data collection was part of a more extensive (neuro)psychological assessment, which generally took place in two sessions of approximately 3 hours testing time. The majority of patients received psychopharmacological treatment to relieve symptoms of mental illness. Psychological assessment is not a standard procedure during admission to the institute, so only complex comorbid cases with multiple DSM-IV-TR diagnoses (including affective and anxiety disorders, psychotic disorders, impulsivity related disorders, developmental disorders, and comorbidity with personality disorders) were referred for assessment, mostly being patients with cognitive complaints and/or impaired cognitive abilities.
Materials
Executive Function
Included were the Dutch-language versions of the Controlled Oral Word Association Test (COWAT; included for analysis: animal and profession naming [Van der Elst, Van Boxtel, Van Breukelen, & Jolles, 2006a], N = 620), the Stroop Color Word Test (Stroop; included for analyses: time on card 1 divided by time on card 3 [Stroop, 1935; Van der Elst, Van Boxtel, Van Breukelen, & Jolles, 2006b], N = 915), the Trail Making Test (TMT; included for analyses: time used for letter-number version -TMT-B- divided by time used for number version -TMT-A- [Bowie & Harvey, 2006], N = 712), the Wisconsin Card Sorting Test (WCST; included for analyses: total number of cards used [Heaton, Chelune, Talley, Kay, & Curtiss, 1993], N = 789), the Tower of London (ToL; included for analyses: total score [Shallice, 1982], N = 747), and Rey’s Complex Figure Test (RCFT: included for analyses: total copy score [Rey, 1941] N = 833).
Intelligence
All participants completed one out of three intelligence tests; either the Kaufman Adolescent and Adult Intelligence Test (KAIT: Kaufman & Kaufman, 1993; Mulder, Dekker, & Dekker, 2005), or the Dutch-language versions of the third or fourth edition of the Wechsler Adult Intelligence Scale (WAIS-III: Wechsler, 1997, 2000; WAIS-IV: Wechsler, 2008, 2012a, 2012b). The index scores of these intelligence tests are used as operationalizations of CHC constructs. For the KAIT and the WAIS-III, the used IQ/index scores are not a direct translation of the referring CHC construct(s). From now on, therefore, when mentioning the IQ/index score, the corresponding CHC ability will always be pointed out.
KAIT (n = 212)
The KAIT is an intelligence test based on, among others, the Gf-Gc theory of Horn and Cattell (1966). A total of six subtests make up two scales—a Crystallized IQ scale (CIQ) and Fluid IQ scale (FIQ), which are included in the current study as measures of respectively Gc and Gf. Subtest reliability of the Dutch language version of the KAIT (Cronbach’s alpha) varies between .78 and .91 (Mulder et al., 2005).
WAIS-III (n = 779)
Scores of the four indices representing different CHC constructs (Alfonso, Flanagan, & Radwan, 2005) were included for analyses: The Verbal Comprehension Index (VCI) representing Gc; the Perceptual Organization Index (POI) as a combined measure of Gv and Gf; the Working Memory Index (WMI) representing Gsm; and the Processing Speed Index (PSI) as a measure of Gs. Split-half reliabilities of the Dutch-language versions of the WAIS-III subtests are similar to the U.S. version and vary between .72 and .93.
WAIS-IV (n = 194)
As for the WAIS-IV, the original index scores (VCI, PRI [Perceptual Reasoning Index], WMI, and PSI) were translated to CHC scores (Gc, Gv, Gf, Gsm, and Gs), according to the CHC factors found in previous research (Benson et al., 2010; Van Aken et al., 2017, Weiss et al., 2013). The CHC scores are a summation of the scaled subtest scores; Gc consists of the four VCI subtests Similarities, Vocabulary, Information, and Comprehension. Gv is made up of the three PRI subtests Block Design, Visual Puzzles, and Picture Completion. Gf consists of the PRI and WMI subtests Matrix Reasoning, Figure Weights, and Arithmetic. Gsm consists of the WMI subtests Digit Span and Letter-Number Sequencing, and Gs is made up of PSI subtests Symbol Search, Coding, and Cancellation. In the case of cross-loadings, the subtest was attributed to the factor of its highest loading (for instance, Arithmetic is part of the WMI and does measure Gsm, but is mainly a test of Gf).
To correctly transform the five CHC (summed scaled subtests) scores into comparable IQ scores, ratio scores were calculated. To do so, the summed CHC scores were corrected for the number of subtests. For instance, the four Gc subtests all contributed 75% to the total factor score, to get a ratio score comparable to the VCI, which was based on three subtests. Next, the ratio scores of Gc, Gsm, and Gs were compared with respectively the VCI, WMI, and PSI converting tables of the WAIS-IV manual. Gf and Gv were compared with the PRI table. Reliability statistics of the Dutch language versions of the WAIS-IV subtests vary between .75 and .93.
Procedures and Analysis
Multiple datasets (KAIT, WAIS-III, and WAIS-IV) were used to prevent one-sided interpretation of the CHC constructs. WAIS-III data were included because this data set included a planning test (i.e., the ToL) that was not available in the WAIS-IV data set. Finally, the WAIS-III dataset makes it possible to draw highly reliable conclusions, given the power of the large dataset available.
All tests were administered and scored according to the published test manuals. Each participant completed the executive tasks and one of the three intelligence tests. Since each intelligence tests represents similar CHC constructs (each intelligence test has an index representing Gc, for instance), all analyses were performed on each separate dataset. Data were analyzed using LISREL 8.80 (Jöreskog & Sörbom, 2008). First, three multiple regression analyses were performed to examine whether EF assessment was able to predict overall level of intellectual functioning, including the full-scale IQ scores (FSIQ) of all three IQ tests as dependent variables. Second, multivariate regression analyses were conducted to examine the predictive value of the six executive tests on CHC abilities. This was done using the full information maximum likelihood (FIML) estimator. Standardized estimates (beta-weights) were used to examine the effects of independent variables (executive tests) on the IQ/index scales, including respectively two (CIQ, FIQ; KAIT), four (VBI, POI, WMI, PSI; WAIS-III), and five (Gc, Gv, Gf, Gsm, and Gs; WAIS-IV) criteria per analysis. Because of the small number of participants that completed the ToL in the WAIS-IV sample, this predictor was eliminated for analysis with the WAIS-IV. Other missing values were dealt with according to standard procedures in LISREL 8.8.
Results
Table 2 and 3 show the intercorrelations of all measures. Negative correlations with the WCST are the result of the used measure of this test (total number of cards used; higher scores indicate a worse performance). First, three multiple regression analyses were conducted to predict the FSIQ of the three intelligence tests based on the selection of executive instruments. Second, three multivariate regression analyses were conducted on each intelligence test to examine the predictive value of the EF tests on the IQ/index scales. See Table 4 for the standardized solutions of all analyses.
Correlations Between Executive Tests and Intelligence Batteries.
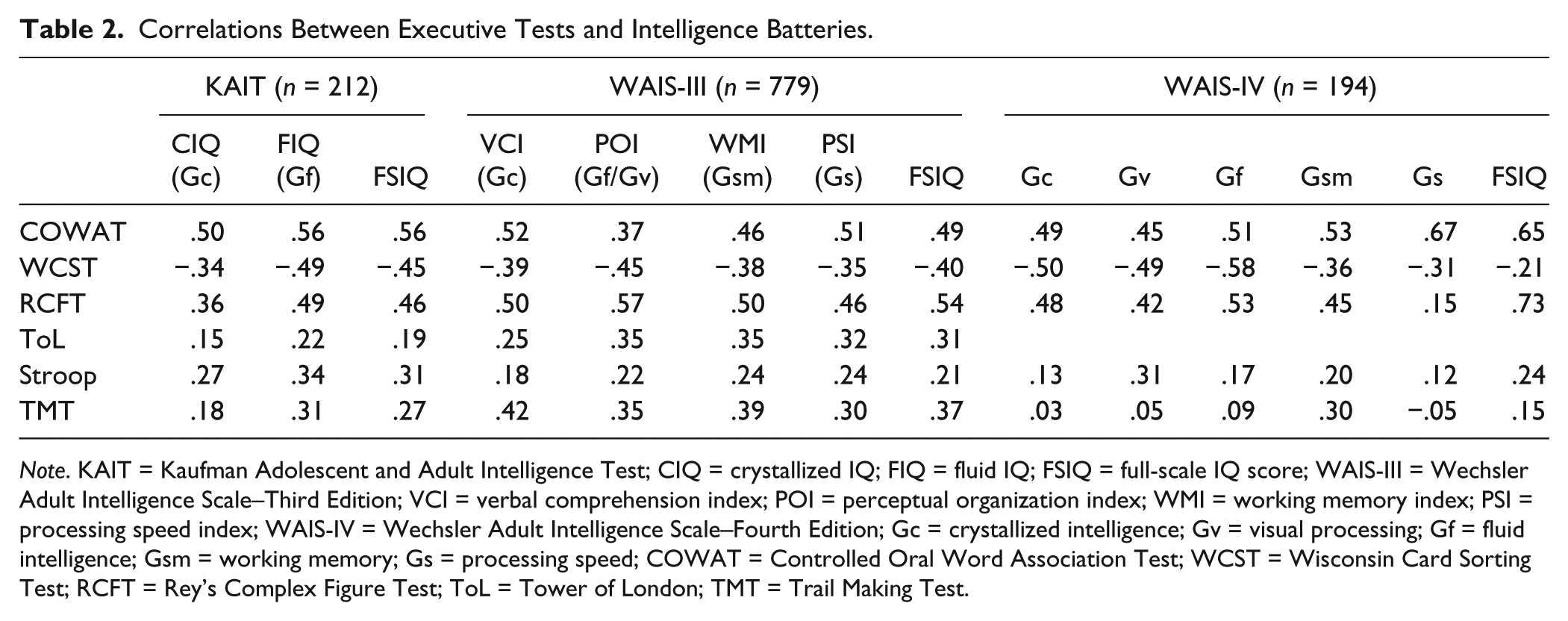
Note. KAIT = Kaufman Adolescent and Adult Intelligence Test; CIQ = crystallized IQ; FIQ = fluid IQ; FSIQ = full-scale IQ score; WAIS-III = Wechsler Adult Intelligence Scale–Third Edition; VCI = verbal comprehension index; POI = perceptual organization index; WMI = working memory index; PSI = processing speed index; WAIS-IV = Wechsler Adult Intelligence Scale–Fourth Edition; Gc = crystallized intelligence; Gv = visual processing; Gf = fluid intelligence; Gsm = working memory; Gs = processing speed; COWAT = Controlled Oral Word Association Test; WCST = Wisconsin Card Sorting Test; RCFT = Rey’s Complex Figure Test; ToL = Tower of London; TMT = Trail Making Test.
Intercorrelations Between All Independent and Dependent Variables.
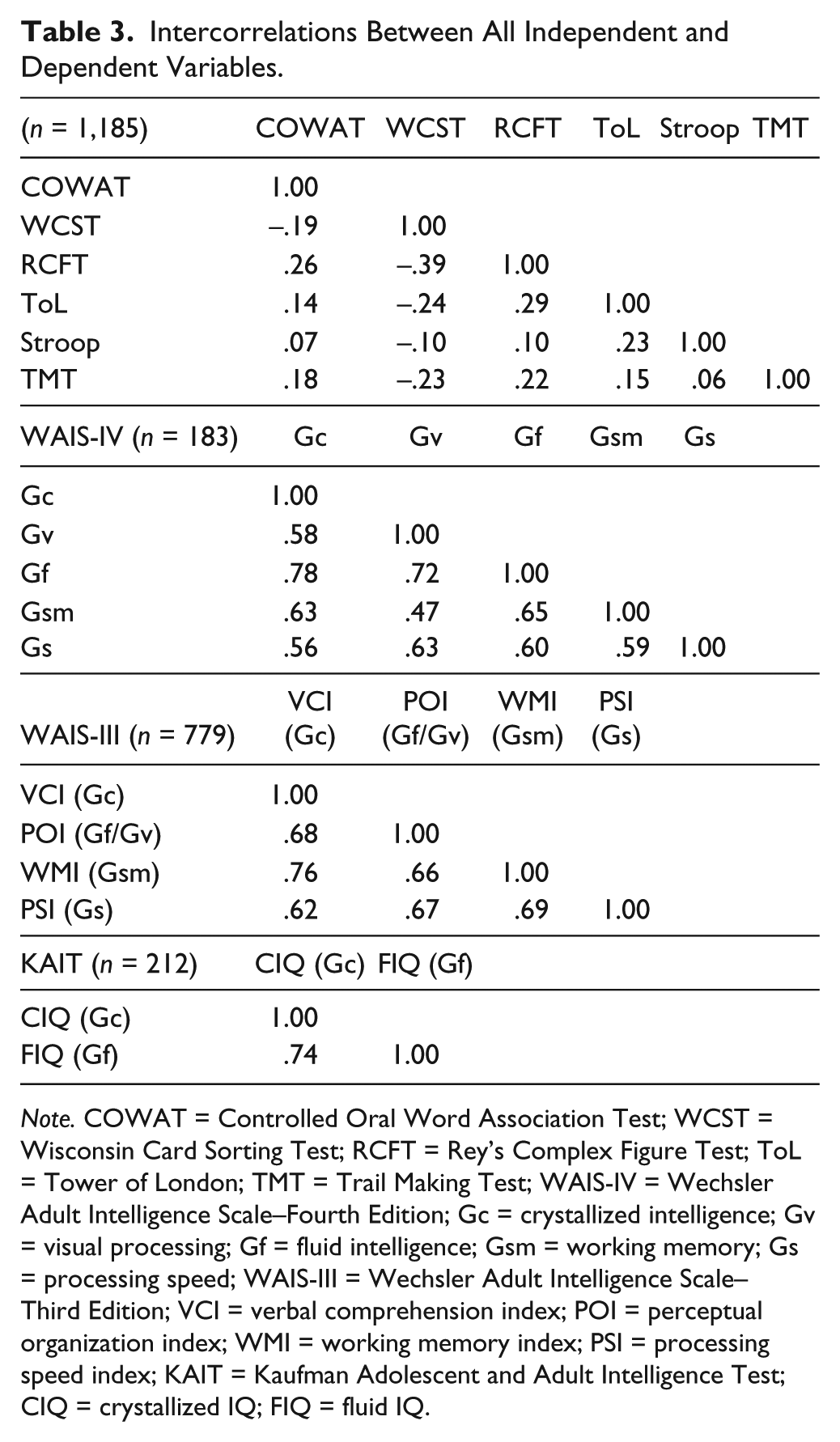
Note. COWAT = Controlled Oral Word Association Test; WCST = Wisconsin Card Sorting Test; RCFT = Rey’s Complex Figure Test; ToL = Tower of London; TMT = Trail Making Test; WAIS-IV = Wechsler Adult Intelligence Scale–Fourth Edition; Gc = crystallized intelligence; Gv = visual processing; Gf = fluid intelligence; Gsm = working memory; Gs = processing speed; WAIS-III = Wechsler Adult Intelligence Scale–Third Edition; VCI = verbal comprehension index; POI = perceptual organization index; WMI = working memory index; PSI = processing speed index; KAIT = Kaufman Adolescent and Adult Intelligence Test; CIQ = crystallized IQ; FIQ = fluid IQ.
Standardized Total Effects of Six Predictors on Performance on the KAIT, WAIS-III, and WAIS-IV IQ/Index Scales.
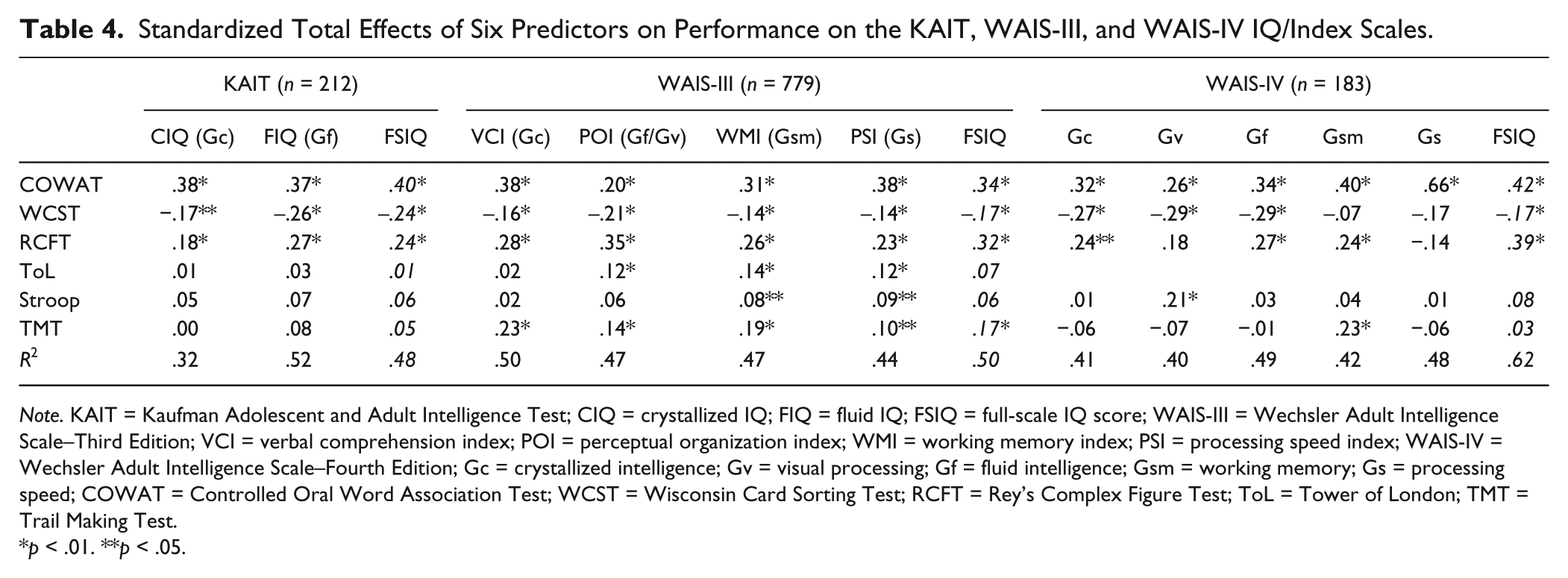
Note. KAIT = Kaufman Adolescent and Adult Intelligence Test; CIQ = crystallized IQ; FIQ = fluid IQ; FSIQ = full-scale IQ score; WAIS-III = Wechsler Adult Intelligence Scale–Third Edition; VCI = verbal comprehension index; POI = perceptual organization index; WMI = working memory index; PSI = processing speed index; WAIS-IV = Wechsler Adult Intelligence Scale–Fourth Edition; Gc = crystallized intelligence; Gv = visual processing; Gf = fluid intelligence; Gsm = working memory; Gs = processing speed; COWAT = Controlled Oral Word Association Test; WCST = Wisconsin Card Sorting Test; RCFT = Rey’s Complex Figure Test; ToL = Tower of London; TMT = Trail Making Test.
p < .01. **p < .05.
Overall, the EF tests accounted for 48%, 50%, and 62% of the variance of the FSIQ of the KAIT, WAIS-III, and WAIS-IV, respectively. As can be seen in the FSIQ columns in Table 4 (in italics), the COWAT, RCFT, and WCST significantly contributed to the prediction of the FSIQ scores of all three IQ tests. The TMT only predicted the FSIQ of the WAIS-III, and the ToL and Stroop did not contribute to FSIQ performance at all. To enhance clarity, effects of EF tests on the separate IQ/index scores are discussed per intelligence test.
KAIT
Hypotheses of the predictive value of the COWAT, RCFT, and WCST were confirmed. The Stroop and ToL did not predict performance on CIQ (Gc) and FIQ (Gf), which was contrary to our expectations. Furthermore, the RCFT predicted CIQ performance (Gc), and the TMT did predict FIQ performance (Gf).
WAIS-III
All hypothesized effects were confirmed, except for the Stroop, which did not predict performance on the POI (Gf/Gv), and the ToL, which did not predict VCI (Gc) performance. Moreover, other effects than those hypothesized were found as well: COWAT predicted outcome on the WMI (Gsm), and the WCST on the WMI (Gsm) and PSI (Gs). The RCFT demonstrated an effect on all indices, while only the POI (Gf/Gv) was hypothesized. A small significant effect of the ToL on PSI (Gs) next to POI (Gf/Gv) and WMI (Gsm) was found (as was hypothesized), and the TMT also predicted VCI (Gc) and POI (Gf/Gv) performance besides the predicted effects on WMI (Gsm) and PSI (Gs). Predictors with the largest effects were COWAT and RCFT, but they did not differentiate between criteria as hypothesized.
WAIS-IV
Contrary to our expectations, the Stroop only predicted the outcome on the Gv factor. Not all hypothesized effects were confirmed. Comparable to the WAIS-III, the COWAT was found to be the most important indicator for all CHC factors, although hypothesized to not have an effect on Gsm. All WCST hypotheses were confirmed (i.e., effects on Gf, Gc, and Gv were found). The TMT predicted performance on the Gsm scale, but did not influence Gs outcome, in contrast to our hypothesis. Lastly, the hypothesized influence on Gv and Gf of the RCFT was not confirmed. The RCFT was related to Gc and Gsm performance, which was unexpected.
Discussion
The goal of the present study was to examine whether EF tasks were able to predict level of intelligence in terms of CHC abilities in a clinical population. This approach was used next to a multitude of latent variable analyses on the topic, in order to investigate the applicability and operationalization of CHC abilities in clinical neuropsychological assessment. Results showed that EF tasks accounted for 48%, 50%, and 62% of the variance of the overall performance on the KAIT, WAIS-III, and WAIS-IV, respectively. Table 5 gives an overview of the confirmed and rejected hypotheses concerning the IQ/index scales as well as nonhypothesized effects we found. Except for the Stroop, which did not predict performance on Gf and Gc, all hypothesized effects were confirmed as described in Table 1, indicating that EF indeed predicts the general level of functioning, but that these effects differentiate insufficiently between the separate CHC abilities. In general, COWAT, RCFT, WCST, and TMT show a similar pattern of effects on all CHC abilities, albeit with different magnitudes.
Confirmed, Rejected, and Nonhypothesized Effects.
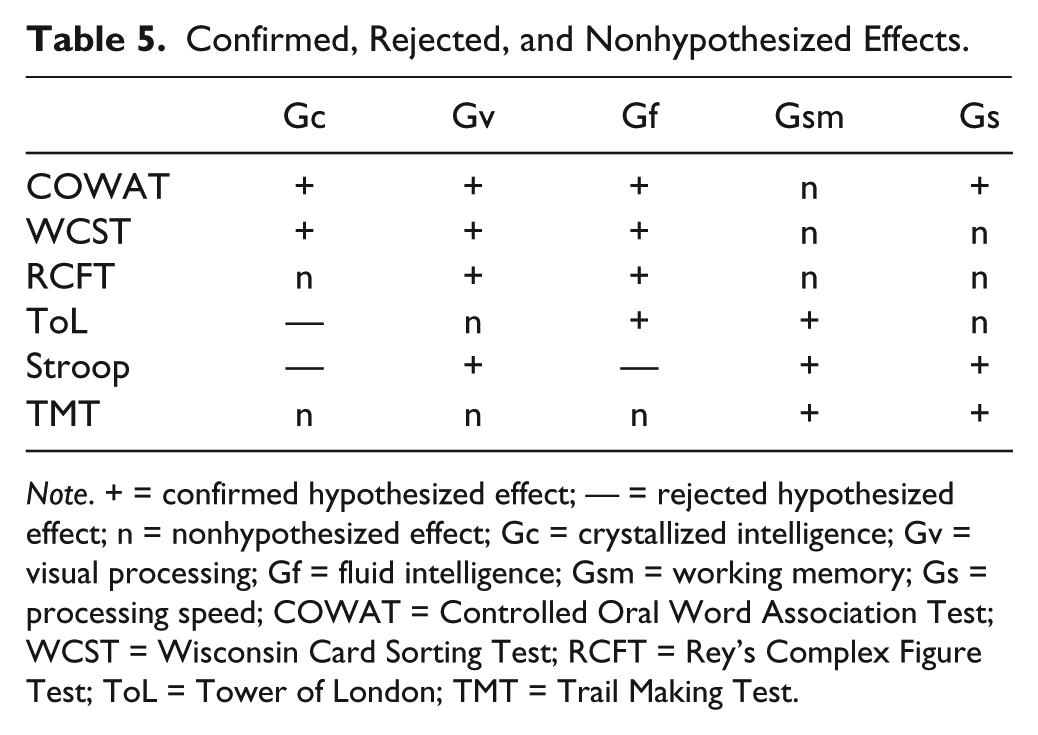
Note. + = confirmed hypothesized effect; — = rejected hypothesized effect; n = nonhypothesized effect; Gc = crystallized intelligence; Gv = visual processing; Gf = fluid intelligence; Gsm = working memory; Gs = processing speed; COWAT = Controlled Oral Word Association Test; WCST = Wisconsin Card Sorting Test; RCFT = Rey’s Complex Figure Test; ToL = Tower of London; TMT = Trail Making Test.
Both the COWAT and RCFT had significant predictive values for all CHC abilities, explaining on average 36% and 24% of the variance, respectively. Verbal fluency is known to involve multiple EF processes (Godoy et al., 2014), but it is also suggested to rely on non-EF cognitive processes as well (Packwood et al., 2011). The same holds for the the RCFT (Van der Meer & Eling, 2008). It can be argued that “g saturation” of both the COWAT and RCFT is probably high, explaining effects on nearly all CHC constructs. However, the opposite may also be true, looking at the small intercorrelations (except for the correlations of the RCFT with both the Stroop and WCST) between EF tasks and high correlations between IQ scales: The latter share more variance (up to 60%), and mostly appear to be measures of g, explaining why broad EF tasks like the COWAT and RCFT do not differentiate between CHC constructs.
Both measures of cognitive flexibility—that is, the WCST and the TMT—also predicted performance on all CHC abilities, with 19% and 11% shared variance on average, respectively. However, both tasks are known to measure a broader range of cognitive functions (Nyhus & Barceló, 2009; Oosterman et al., 2010; Sánchez-Cubillo et al., 2009), which may explain the predictive effects of these tests on all CHC constructs in the current analyses. For instance, the TMT is sensitive for brain impairment, but is unable to differentiate between specific frontal dysfunctions, since multiple (nonfrontal) functions are involved in test performance (Chan et al., 2015; Oosterman et al., 2010). The ToL had small effects on all CHC constructs, except on Gc. The share of planning or problem solving skills (as measured with the ToL) in current intelligence tests therefore seems small. Furthermore, current results indicate that the Stroop test is capable of specifically predicting performance on some Gs, Gsm, and Gv tasks, although it did not contribute to the prediction of overall intellectual functioning. The correlation matrix in Table 2 suggest coherence between the Stroop and the KAIT-Gf, in the absence of an effect of the Stroop on Gf in the regression analysis. In addition to all other neuropsychological tasks, the effect of the Stroop on intellectual performance seems to be negligible. These results are somewhat contradictory, but can be considered to reflect the mixed results on the relation between inhibition and intelligence, particularly Gf (Benedek et al., 2014; Chuderski, Taraday, Necka, & Smoleń, 2012; Hoelzle, 2008)
CHC constructs, and their relation to other (cognitive) theories, are mainly assessed in non-patient populations (Jewsbury et al., 2016). Intelligence tests are used on a daily basis in clinical practice, and studies like the current one are essential to examine the functionality and robustness of the CHC constructs (and their relation to the clinically based construct of EF) in clinical populations and in diagnostic assessments of our patients. However, clinical data have somewhat different properties than those obtained in healthy samples. As can be seen, the FSIQ score of our sample as a whole is below average, and this clinical sample shows higher correlations between the intelligence scales (Table 3) than those reported in the (Dutch) normative samples of the intelligence tests (Mulder et al., 2005; Wechsler, 2000; Wechsler, 2012b, see also Van Aken et al., 2017). Interpretation is further complicated by (unknown) noncognitive influences such as psychopathology, motivation, or the use of medication. Generalizing results must be done with great caution. Fortunately, studies on measurement invariance across clinical and healthy samples are promising (Jewsbury et al., 2016; Van der Heijden & Donders, 2003; Weiss et al., 2013), demonstrating the robustness of the CHC model in clinical populations. In that respect, future research could further examine current results by investigating different diagnostic groups.
The current study has some limitations. Considerable differences in correlations and effects (see Tables 2 and 5) between EF tests and the CHC abilities per intelligence test were found, especially between the two Wechsler scales which share similar structures. These discrepancies may be due to variations across subtests and measurement error between intelligence tests, resulting in different estimations of the same higher order factors. In other words, even though similar theoretical constructs are measured, there are considerable differences in their operationalizations, which questions the justification to align these indices as measurements of the same latent trait. This exposes operationalization difficulties of CHC theory, and emphasizes the need to better capture these abilities. This should be done by using CHC as a framework for test development, instead of attempting to match CHC abilities onto already existing subtest structures. In doing so, clinicians still should be aware that intelligence tests only tap a small selection of CHC abilities. Attempts are being made to further operationalize and purify CHC factors in intelligence tests. For instance, the WISC-V already includes a total of six CHC factors, and Gf and Gv are now separate indices (Wechsler, 2014).
The somewhat arbitrary built-up of test indices influences both intercorrelations and extratest correlations of the intelligence tests. The same task-impurity problem holds for the EF tasks, resulting in high measurement error and vague conceptualizations (Miyake et al., 2000; Packwood et al., 2011; Salthouse, 2005). In other words, the concept of EF offers a valid framework in explaining behavior, but EF test outcomes do not. For instance, a ToL total performance score does not give any information on how the participant planned and organized his behavior, or if he used adequate strategies to execute the task. Such static outcome measures complicate the operationalization of EF, which pleads for more process-oriented assessment techniques.
Another point of discussion is the direction of the analysis. Coming from a neuropsychological perspective, we aimed to predict or identify well-defined (and much researched) CHC constructs using tests known to assess executive behavior. One could also argue that this should be studied the other way around given the task impurity of EF tests, for instance. Nevertheless, looking at the high correlations between the CHC measures (IQ/index scales) compared with intercorrelations between EF tasks, the current direction seems preferable. Furthermore, EF is more closely related to cognitive models on brain functioning than the empiricially derived CHC abilities; and the selected tests are, despite possible task impurity or lack of specificity, indeed measures of executive behavior (Packwood et al., 2011).
Current results relate to previous factor-analytic research. Clearly, EF tests are most certainly associated with all included cognitive abilities defined by CHC. Floyd et al. (2010) found similar results and concluded that EF tasks are “too contaminated” by g. However, visual inspection of the correlation matrix shows that EF tasks overlap less with each other than the IQ scales, which favors the reverse direction of argumentation. The CHC measures include too much g, complicating the differentiation between them, while low correlations between EF tasks reinforce their distinctiveness.
Some studies state that interpretation of intelligence tests should be limited to the level of g, or the FSIQ, and should not include the level of the first-order CHC factors (Canivez & Kush, 2013; Canivez & Watkins, 2010). This seems valid looking at our current results. Understanding cognitive functioning in patients, however, requires a more fine-grained interpretation. This pleads for supplementary neuropsychological assessment during intelligence testing.
According to Hoelzle (2008), it would be preferrable to use CHC theory as a blueprint for test development rather than as a framework for comprehensively classifying existing measures. We strongly support his view, since our present results confirm that both CHC factors in current intelligence tests and EF tasks are limited in their specificity and are drained by common variance explained by g. Depending on the diagnostic questions, clinicians must be aware of the “g saturation” of a test and focus on the unique contributions of that test, for instance by correcting for overall intellectual functioning in the normative data, as is already done in most EF tasks.
To summarize, the current study adopted a directive and hypothesis-driven approach to clarify the relation between EF and CHC theory and found (a) that EF assessment is able to predict overall level of intellectual functioning and (b) a high shared variance between CHC measures making it hard for EF tasks to distinguish between separate cognitive abilities. The Stroop and the ToL had only small contributions to the other EF tests in predicting overall IQ performance, indicating the existence of unique variance that is not represented in the current intelligence tests. These outcomes contribute to a great amount of latent variable analyses on the relation between EF and CHC. Current results potentially seem to support the fact that identified relations between CHC and EF at a latent level cannot be directly translated to a behavioral level using manifest variables, due to operationalization difficulties in current intellectual and executive assessment.
Results plead for further clarification of both theory and operationalization. Instead of merely being an empirical approach of classifying and describing cognitive abilities on a psychometric level, the CHC model could contribute to the understanding of cognitive processing by expansion into an information processing theory with underpinnings in cognitive neuroscience research. A step in the right direction has been suggested by Schneider and McGrew (2012), who introduced a model on “how CHC broad abilities might function as parameters of information processing” (p. 135). Although CHC can and may serve as a theoretical framework of cognitive processing, researchers should be aware of the possible consequences of creating models merely based on broad abilities as a starting point, risking to lose sight of the validation of new tests and/or (statistical) techniques in terms of identifying sources of unique variance. In turn, neuropsychological theory of EF is superior in describing cognitive processes, but operationalization of concepts has turned out to be quite difficult (see also Packwood et al., 2011), which could question the applicability of the theory. Neuropsychologists should invest in developing new and better tests to better capture EF processes like planning and problem solving. For instance, dynamic testing tools are preferrable, since they may contribute to capturing underlying processes (Resing, 2016). Finally, researchers should not only rely on factor analysis to increase insight into the examined constructs (Schneider & McGrew, 2012), but also use other techniques such as nonlinear dynamic statistics or network analysis (Borsboom & Cramer, 2013) to examine complex behavior.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.