
Abstract
Despite enormous efforts to develop defenses against phishing attacks, humans still struggle to detect phishing emails given the constantly evolving attacker strategies. This paper aims to test the predictive capabilities of a cognitive model that represents the individual susceptibility to phishing emails. We developed an instance-based learning model (IBL) that captures the frequency, recency, and familiarity aspects of decision-making and explores its potential for personalized anti-phishing training. We investigate the same cognitive model using three different methods. At the same time, we compare the performance of these three models to human classification of phishing and ham emails and determine the synchronization rates with human participants in a Phishing Training Task. Our results reveal that using prior human experience and optimizing parameters improves model accuracy. These findings suggest significant advances in modeling human decision-making patterns and cognitive processes, demonstrating strong alignment with human decisions during training.
Keywords
Introduction
Phishing is a malicious activity performed to spread emails masquerading as being generated from a trustworthy source. These emails aim to persuade the targeted users to expose their sensitive data so that such confidential information could help the attackers indulge in fraudulent activities on behalf of innocent users (Khonji et al., 2013). Phishing emails have been the most common method of launching cyberattacks (Gupta et al., 2018), and people are exposed to such phishing emails regularly but fail to detect them accurately, which leads them to become victims of cyberattacks. There has been a massive advancement in cybersecurity in recent years. However, phishing emails still pose a challenge for users around the world due to the new and constantly evolving techniques used by attackers to create and launch phishing attacks.
In the fight against phishing attacks, user education and the use of tools to differentiate legitimate emails from phishing attempts are crucial (Alsharnouby et al., 2015). However, phishing detection tools need to be improved to adapt to evolving tactics and understand the complexity of phishing emails. Non-technical challenges, such as the lack of motivation of users to learn and the inconvenience of modifying behavior, contribute to improper use of phishing detection tools (Khonji et al., 2013). Traditional methods such as in-person training were deemed less effective, and embedding training began to take over (Berryman, 2016; Nguyen, 2018). In this newer technique, a set of simulated phishing attacks is tested on humans, and their responses are collected to analyze human intuition when exposed to cyberattacks to develop training methodology. Designing and executing reliable training programs for human phishing classification tasks can be demanding due to the complexities (e.g., number of manipulation factors, tracking the learning ability of participants etc.) involved. A cognitive model that mimics human cognitive processes can be a strong alternative for evaluating training programs.
Research on human factors and cognitive behaviors has been used for several years to understand the under- lying factors influencing susceptibility to phishing attacks. Shonman et al. (2022, 2024) used computational cognitive modeling to investigate the impact of previous email experiences of users on their processing of new emails in a simulated environment. Although these cognitive models excel at simulating complex phishing attack scenarios and rigorously testing cognitive processes, they have certain limitations that must be considered. Their reliance on algorithms and predefined parameters can restrict their ability to understand individual variability and contextual influences, which are important in decision-making. In another line of research, (Cranford et al., 2019) developed an Instance Based Learning model (Gonzalez et al., 2003) in the ACT-R (Anderson et al., 2004) architecture to predict human decision in phishing classification task. In general terms, IBL is an approach that simulates human-like decision-making using past experiences (instances) while relying on similarity-based reasoning (Gonzalez et al., 2003). Furthermore, (Xu et al., 2022; Xu & Rajivan, 2024) used prediction-based models and advanced NLP techniques to improve email classification accuracy. Although cognitive modeling approaches such as IBL have shown efficiency in emulating human decision-making, there is a need to understand certain aspects of IBL models. The primary objective of this research is to develop and explore phishing models’ behavior that will allow us to understand the following aspects of IBL models: (a) Can a cognitive model without any aware ness of the end-user predict their actions? (b) How does the model’s performance improve when prior experiences are provided? and (c) Does calibrating the memory decay for each end-user help in better prediction? The ultimate goal is to create a model that can adapt and personalize antiphishing training to an individual level for better training efficacy.
Method
Phishing Training Task Description
This paper attempts to model phishing classification decisions by humans using a phishing training task (PTT) (Singh et al., 2019, 2023). The PTT comprised 60 trials divided into the pre-training, training, and post- training phases. There were 40 trials in the training phase and 10 trials in each of the pre- and post-training phases. The training phase included three levels of phishing email frequency manipulation: low (10/40), medium (20/40), and high (30/40). Phishing emails appeared in two of the ten trials conducted before and after training. All individuals completed the same pre- and post-training activities. The pre-training phase assessed participants’ capacity to recognize phishing emails before any training exposure, while the post-training phase evaluated the effectiveness of the training provided. In each trial, an email was chosen randomly from a corpus of 239 emails (phishing and ham combined). Participants received instant outcome-based feedback during training but no feedback during pre and post-training stages. Plus, they only saw their final score after the pre and post-training phases.
We used the human data set collected in the (Singh et al., 2019) experiment, which includes a total of 296 individuals recruited through Amazon Mechanical Turk. The 296 participants were divided into low, medium, and high conditions, with 98, 99, and 99 participants in each condition, respectively.
Instance Based Learning (IBL) Models
For the Phishing classification task, we developed a cognitive model of the end user using Instance-Based Learning Theory (IBLT) (Gonzalez et al., 2003). According to IBLT, a human makes decisions by generalizing past decision experiences that are analogous to the present decision situation. Each experience (i.e., an instance) is represented as a triplet, encompassing the situation, the decision, and the outcome. IBL models accumulate the decision experiences encountered by the end-user and stores them as individual instances. During the recognition process, the model computes the similarity between the current situation and the existing instances in memory. Using the blending mechanism, the model calculates the expected utility for each possible decision. This is done by adding past results and weighting them by the probability of memory retrieval, which is based on contextual similarity to previous instances, as well as the frequency and recency of past experiences (i.e., Activation memory mechanism). The decision with the highest expected utility is executed. Finally, the expected utility is updated and aligned with an experienced utility once the outcome of a decision is known. IBL models continuously refine their knowledge and reuse these updated decisions for future decision-making.
The IBL agent uses three textual features of an email as attributes: Body of the email, Subject of the email, and Sender of that email (see Figure 1). To compare different instances in memory and calculate their activation, we used advanced NLP techniques like pre-trained language models of Bidirectional Encoder Representation of Transformer (BERT) and Sentence Transformer: bert-base-nli-mean-tokens. These techniques generate high-dimensional vector embedding based on the semantic and contextual aspects of emails. The similarity matrices used by IBL models while classifying are thus obtained from the cosine similarity function applied to the model features. Therefore, these obtained matrices allowed the IBL model to compare features of emails while mimicking human-like decision-making. The IBL agents emulate the training experimentation done in previous human experiment scenarios (Singh et al., 2019, 2023). In practice, IBL agents received the same experimental design as the PTT described earlier. To accommodate the no-feedback in the pre and post-training phases, we employed a delay feedback mechanism. We utilized the default parameters of ACT-R for the decay and noise (0.5 and 0.25, respectively). Furthermore, a mismatch penalty of 10 was applied to all features in the IBL model.
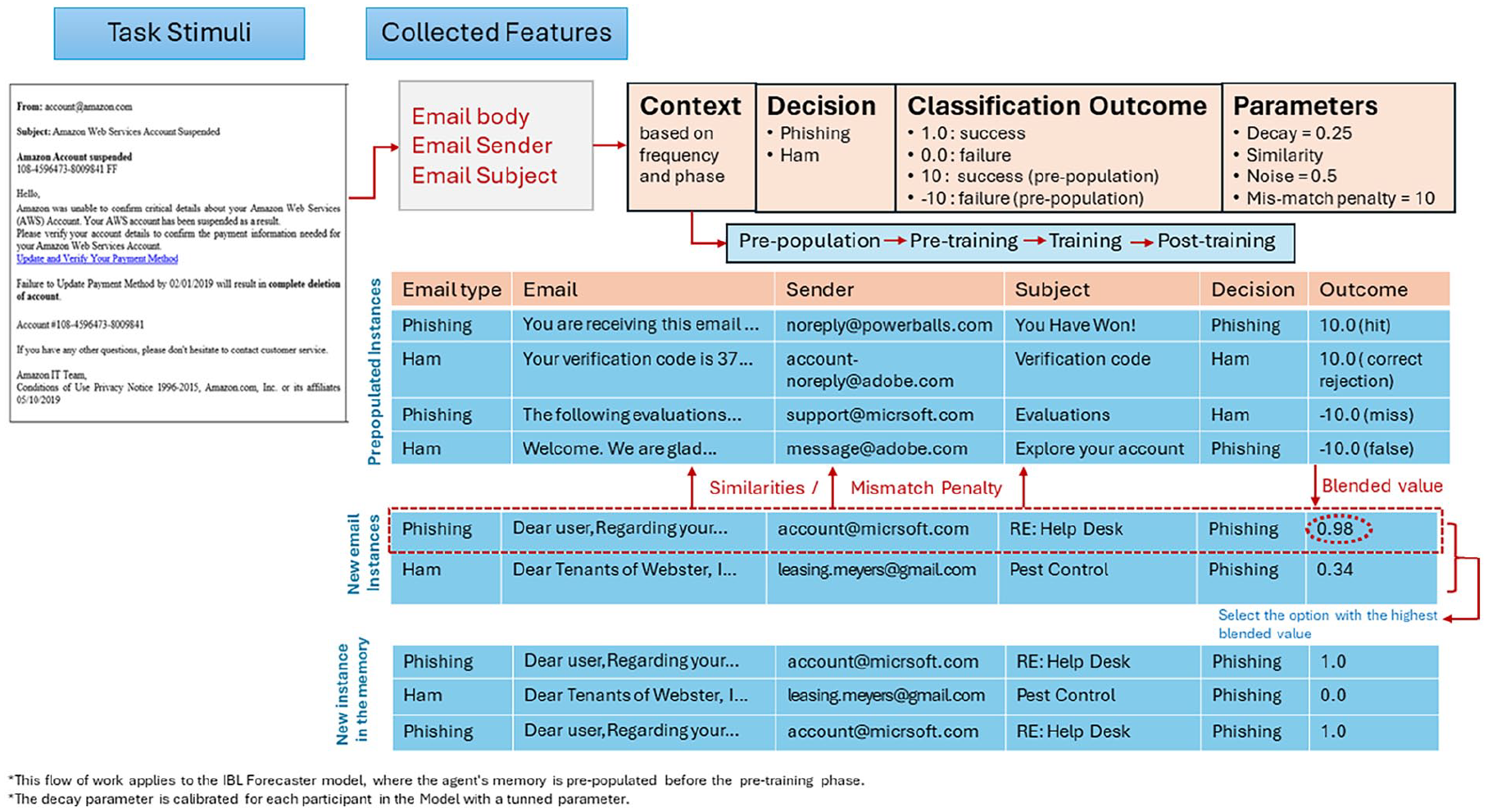
Workflow of IBL model in email classification.
Using the above procedure, three types of IBL agents were implemented in Python based IBL model (Morrison & Gonzalez, 2015): the Forecaster, the Human-Assisted, and the Parameter-Calibrated.
Model 1: Forecaster
We developed a pure prediction model to perform the phishing training task. The agent’s memory was prepopulated with some labeled Ham and Phishing emails to simulate the agent for the classification sophistically. The idea behind the simulation takes account of both the randomness of human error and the probabilistic nature of decision-making in the IBL system. Each agent received ten random emails, four phishing, and six ham. The accuracy of these email classifications was defined as a normally distributed function with a mean of 0.5 and a standard deviation of 0.005. The agent was rewarded with an outcome of 10 for making a correct prediction but a negative score of −10 for an incorrect prediction.
Model 2: Human-Assisted
The Human-Assisted IBL agent operates similarly to the IBL Forecaster, using the same parameters such as default noise, mismatch-penalty, decay values, and employing an identical process to extract similarities for igniting memory activation. However, the main difference between these two agent types is the pre-population strategies applied during the pre-training phase. We modified the IBL Forecaster model to prepopulate the agent’s memory with Phase 1 responses of human participants during PPT. Phase 2 and Phase 3 are now influenced by the exact decisions of the participants in Phase 1. This ensures that there is an exact replication of human experience before making the predictions in Phase 2 and Phase 3. The primary reason for prepopulating the agent’s memory is to understand several bias factors that can affect human decision-making during email classification tasks. The simulation aims to improve agent performance by considering human past experiences and minimizing cognitive biases encountered during similar classification tasks in the future.
Model 3: Parameter-Calibrated
To build this model, we rely on model fitting techniques and use the same IBL implementation as Model 2. The model was fine-tuned by integrating a grid search method to find the optimal decay parameter for each participant. This systematic calibration process allowed the IBL model to explore various decay values and select the best fit at an individual level. We rely on the same method as (Konstantinidis et al., 2022) and run a grid search of decay values in the range of [0.1; 3] with increments of 0.01 and noise kept as default value that is, 0.25. We used the Root Mean Square Error (RMSE) to estimate the best performance of each model-decay. The model-decay with the lowest RMSE value was then used to decide the best fit for the participant’s data, In the case of multiple RMSE with the lowest value, the decay with the highest value was chosen.
Results
The model performance is measured through Synchronization Score (Sync Score). Sync Score refers to the alignment between human choices and model predictions. It measures the overall correctness of the model’s performance in relation to human decisions.
Model Performance at Aggregate Level
The learning curves in Figure 2 present a detailed comparison of the three IBL phishing detection models: Forecaster, Human-Assisted, and Parameter-Calibrated. The performance of these models (Sync Score) was evaluated and compared across Base Rate: Low, Medium, and High and two Phases: Phase 2 and Phase 3. We also present learning curves at the aggregate level per trial (combined Synchronization plot) with average Sync Score results highlighting how well the models align with human decisions in classifying emails as either phishing or ham.
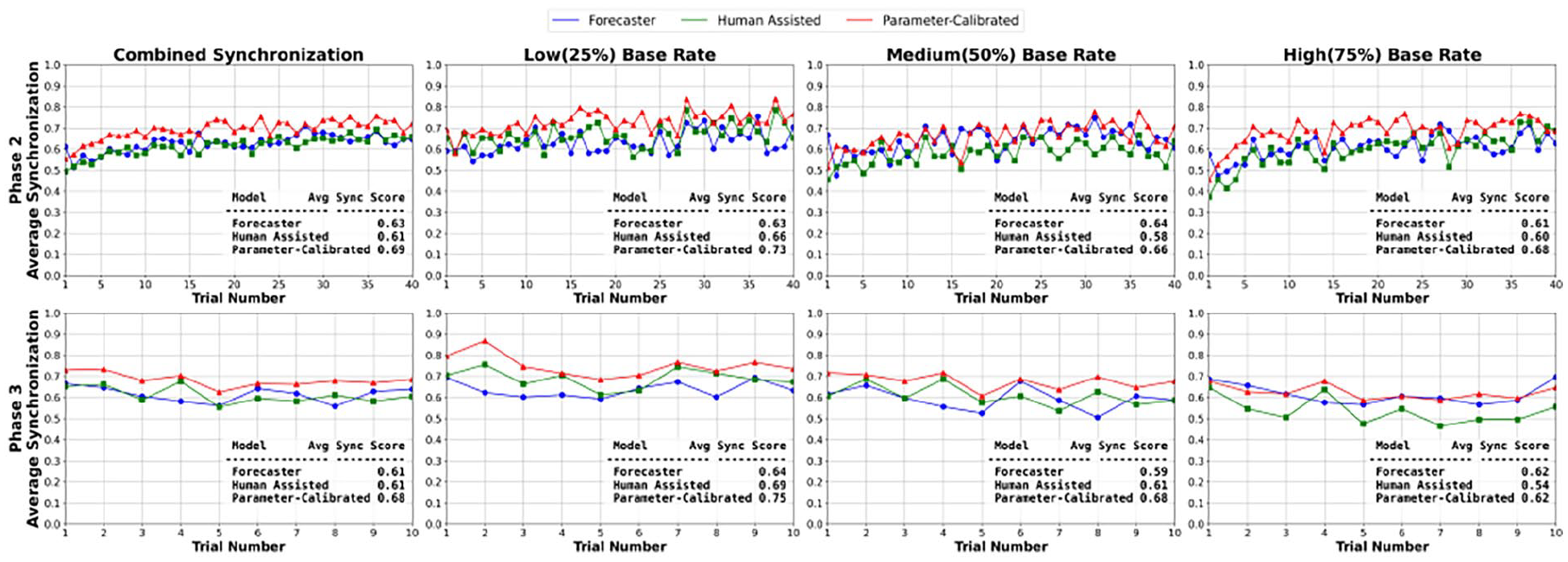
Learning curves over the course of trials by phase and frequency rate.
In particular, the combined Synchronization results revealed that in Phase 2, all three models are adapting over time, with the Parameter-Calibrated model outperforming all others, with an average Sync score of 0.69. Similarly, in all frequency conditions, we can observe that the models are learning and agreeing with human decisions. Overall the sync score in low-frequency condition among all three frequency conditions, with score of Forecaster: 0.63, Human-Assisted: 0.66, and Parameter-Calibrated: 0.73 and Forecaster: 0.64, Human-Assisted: 0.69, and Parameter-Calibrated: 0.75 in Phase 2 and Phase 3 respectively. The slow start of the models in medium and high-frequency condition may be attributed to the base rate fallacy, possibly due to the frequency of ham emails that agents received in the pre-training phase.
Furthermore, the learning curves in Phase 3 exhibit more stable patterns across all frequency conditions with Forecaster and Human-Assisted: 0.61 and Parameter-Calibrated: 0.68 average Sync score in the combined Synchronization plot. However, the Human-Assisted model results also revealed no advantage over the Forecaster model and fall shorts to match the Parameter-Calibrated model.
Model Performance on Ham and Phishing Emails
Figure 3 illustrates the Sync score of the three models based on the ground truth of the email (email type) across different base rates and phases. Overall, the sync score for all the models on ham emails is better than phishing emails (exceptions discussed below). The performance of models on Ham emails with low frequency is high in both phases. The Sync scores on Ham Emails in Phase 2 with the low-frequency condition are Forecaster: 0.70.
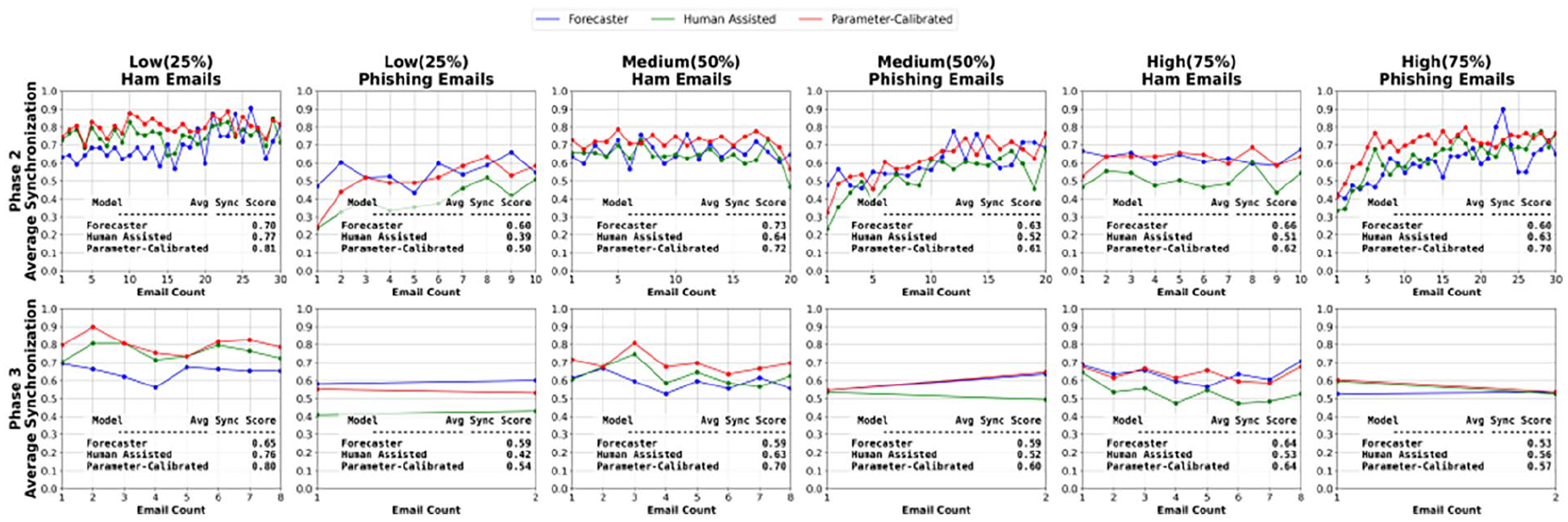
Learning curves per ground truth (Email Type) over the course of email count by phase and frequency rate.
Human-Assisted: 0.77, and Parameter-Calibrated: 0.81 and in Phase 3 Forecaster: 0.65, Human-Assisted: 0.76, and Parameter-Calibrated: 0.80. However, the Sync scores of all three models on Phishing Emails in the low-frequency condition in both phases are low especially when models (human-assisted and parameter-calibrated) is exposed to human decisions in Phase 1. The limited exposure of phishing emails: two in pre-training and only ten in the training phase, is likely to be the cause of model’s poor performance, pointing to inadequate opportunities to learn and correctly classify phishing emails. Even though the performance of Parameter-Calibrated is bad in low base rate with Phishing emails, it improves gradually as we move to medium and high frequency in Phase 2 such Low: 0.50, Medium: 0.61, and High: 0.70. Thus, our analysis suggests that the Human-Assisted model doesn’t show any differences in the phishing classification task compared to our baseline model Forecaster. The better performance of Forecaster over Human-Assisted can be linked to the pre- population with more phishing emails in its initial learning, aiding to broader foundation for classification across various scenarios. In contrast, Human-Assisted, although pre-populated with part of human-experienced data, with fewer phishing emails, reflects the model’s inability to generalize effectively to varied phishing emails resulting in poorer results. However, the Parameter-Calibrated model demonstrates reliable performance with increasing frequency conditions in both email types.
Discussion
Our research presents three models that closely emulate the cognitive processes of human decision-making using Instance Based Learning (IBL) Theory. These models: the Forecaster, the Human-Assisted, and the Parameter-Calibrated showed a gradual improvement with increasing synchronization with human-decisions over the number of trials and email counts. First, this paper attempted to investigate the ability of IBL-based cognitive model to predict human actions without any awareness of human actions (Forecaster Model). The Forecaster model can fairly predict the end user’s actions achieving slightly more than 60% synchronization score. The result suggests that randomly populating the agent’s memory and allowing the model to predict in their actual training does work progressively as the model bases their foundation for phishing classification. To further improve the performance of the model, this paper created a Human-Assisted model where the IBL agents are provided with human decisions in the pre-training phase. Incorporating part of human-experienced data into the agent’s memory demonstrated no significant improvement over the Forecaster. The results indicate that only relying on human’s past experiences may not help in the current experimental setting. The pre-training phase had only 20% phishing emails which create an imbalance in experiences on phishing and ham emails. The model is also impacted by the accuracy of human decisions that is, if the participants classified both the phishing emails as ham, the model will lack ever those two decisions in pre-population. Similar to humans, the IBL model was impacted by frequency of phishing emails indicative of base rate fallacy observed in human actions.
To further improve the model performance and ad-dress above mentioned limitations, this paper presented a Parameter-Calibrated model, to find of out best memory decay values for each model participants. The Parameter-Calibrated model significantly outperformed both. As per the results, we can conclude that human experiences to an agent’s memory along is not sufficient, but calibrating the parameters of the IBL model can lead us to better performance. The Parameter-Calibrated model with decay calibrated to find the optimal decay value for each participant, improved the model’s synchronization with human decisions. This personalized parameter calibration in cognitive IBL models opens up intriguing aspects as part of future research.
Nevertheless, our models have several limitations that need to be addressed. Our results show that the number of phishing emails exposed to the agents during the initial learning phase plays a crucial role in model adaptation. Therefore, this aspect must be taken into consideration so that the model could better generalized to varied frequency of phishing emails while classifying. Additionally, the similarity is currently being calculated using an NLP-BERT method, which may not represent the best methodology for how humans compare and recall textual content from memory. We used only three features of emails, which might not be enough for an IBL agent to make a decision in phishing classification. Therefore, including more comprehensive email features like attached links (URLs), urgency, and offering cues may result in better IBL phishing detection models. In addition, the calibration of multiple parameters, such as decay and noise simultaneously to find the optimal values at the individual level, rather than using one calibrated parameter, could be the next possible area of research. Lastly, realizing the complexities and underlying factors of human decision-making processes we encounter during this research, different techniques known as model tracing could be a viable option to explore in the phishing classification tasks.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is partially sponsored by University of Texas at El Paso, the Army Research Office and accomplished under Australia-US MURI Grant Number W911NF-20-S-000.