
Abstract
Studies benchmarking automation-assisted decision making against models of optimal use have shown that assisted performance is highly inefficient. However, these exercises have used novice populations performing simplified decision tasks, limiting their generalizability. Cao et al. (2023) described a machine learning algorithm capable of screening CT scans for early signs of pancreatic cancer with an extremely high sensitivity (area under the curve ≥ 98.5%) and demonstrated that the algorithm improved human clinicians’ diagnoses. We reanalyzed the data of Cao et al. (2023) to assess the efficiency of the clinicians’ aid use. Assisted performance was highly inefficient, roughly matching the predictions of a model that assumes participants randomly defer to the aid’s advice with a probability of 50%. Moreover, aid use was equally poor across varying levels of clinician expertise. The results replicate previous findings of poor decision aid use and confirm that they generalize to real-world tasks using expert decision makers.
Introduction
Machine learning and artificial intelligence (AI) are providing human decision makers increasingly powerful diagnostic aids in various safety-critical contexts. For instance, diagnostic aids can help physicians interpret electrocardiograms (Bond et al., 2018; Novotny et al., 2017), aviation security officers screen x-rays of passenger baggage (Huegli et al., 2020), and educators recognize plagiarized text (Foltýnek et al., 2020).
Many tasks of the sort performed with a diagnostic aid require the operator to discriminate between binary states of the world, a form of signal detection task (Green & Swets, 1966; Hautus et al., 2022). Ideally, the human operator assisted by a decision aid will achieve a higher sensitivity—the ability to accurately distinguish states of the world—than either the human operator or the aid could by itself (Robinson & Sorkin, 1985; Sorkin & Dai, 1994). In fact, though, operators assisted by an aid fail to even match the performance of the aid by itself (e.g., Meyer, 2001; Munoz Gomez Andrade et al., 2022). This pattern implies disuse (Parasuraman & Riley, 1997), a tendency to underweight the aid’s advice.
To better characterize operators’ diagnostic aid use, Bartlett and McCarley (2017) compared observed performance levels in an aided signal detection task to the levels predicted by various models of aid use, ranging from perfectly efficient to highly inefficient. The most efficient models assumed that operators integrated their own judgment with the aid’s every trial. Under these models, noise in the two agents’ judgments would tend to cancel out, improving decision quality.
In contrast, the least efficient models considered assumed that operators made no effort to integrate their judgments with the aid’s on a trial-by-trial basis, but simply chose one response or the other to act on each trial. The Probability Matching (PM) model (cf., Bliss et al., 1995) assumed that if the aid and operator disagreed on a given trial, the operator acted on the aid’s judgment with a probability equal to the aid’s average reliability and otherwise acted on their own judgment. The Coin Flip (CF) model (cf., Bahrami et al., 2010) assumed that in the event of a disagreement between the operator and aid, the operator chose a response randomly and with 50/50 odds. In effect, the CF and PM models assume that an operator discards one judgment—either their own or the aid’s—each trial. Assuming the aid is more sensitive than the human operator, the aided operator will tend to perform worse than the aid by itself.
Remarkably, the performance of operators assisted by aids 90%-reliable or better has been found to roughly match the predictions of the highly inefficient CF and PM models—generally closer to CF-level performance. This result has held across a variety of tasks, from simple color discrimination (Bartlett & McCarley, 2017, 2019) to more complex and naturalistic visual search (Boskemper et al., 2022) and forensic face matching (Bartlett et al., 2024). This pattern provides a qualitative benchmark of aid-use efficiency and suggests that the PM and CF models might be useful as heuristic models for predicting aided performance levels, for example, for cost-benefit planning.
As yet, however, demonstrations of PM- or CF-level performance have come from abstract decision tasks or simplified simulations of real-world tasks, and have used non-expert samples recruited through student subject pools or online recruitment services. A demonstration of similar results in a more expert sample, performing a more naturalistic task, would provide more convincing evidence for the generalizability of the PM/CF pattern. Data from a recent study of AI-aided cancer detection offer the opportunity for this.
Cao et al. (2023) investigated the efficacy of AI to screen for pancreatic ductal adenocarcinoma (PDAC), the most common form of pancreatic cancer. PDAC results in nearly half a million deaths annually (Bray et al., 2024) and is the third most common cause of cancer death in the United States (Lucas & Kastrinos, 2019; Siegel et al., 2024). Unfortunately, PDAC is not generally diagnosed until a late stage, and 5-year survival rates are low (Lucas & Kastrinos, 2019). The low prevalence of the disease, however, makes widespread screening of asymptomatic individuals impractical using current methods (Grossberg et al., 2020; Lucas & Kastrinos, 2019).
To enable more effective detection of early-stage pancreatic cancer, Cao et al. (2023) developed and tested a deep learning model as a screening tool. The model, which they called pancreatic cancer detection with artificial intelligence (PANDA), was trained to detect and diagnose pancreatic lesions, including PDAC and seven different types of non-PDAC lesion in non-contrast computed tomography (CT) imagery of the abdomen and chest. As output, it produced a probability estimate for each potential form of lesion, along with a segmentation mask indicating the location of possible pancreatic lesions.
A preliminary evaluation tested the PANDA model’s ability to distinguish between patients with and without pancreatic lesions in a sample of 291 radiographic images. The model achieved an area under the curve of .996, a hit rate of .949, and a false alarm rate of 0.00 (Cao et al., 2023). A follow-up study asked whether assistance from PANDA would improve human readers’ ability to detect lesions. Readers were three groups of physicians differing in pancreatic expertise: radiology residents, general radiologists, and pancreatic imaging specialists. Each reader performed the diagnostic task once unaided, then later with assistance from PANDA. Assistance from the model improved the human readers’ performance, raising their hit rates and reducing their false alarm rates. Nonetheless, human readers assisted by PANDA performed more poorly than PANDA did by itself, indicating highly inefficient use of the model’s guidance. To better characterize the human readers’ aid use, the current study reanalyzed the human reader data to compare performance to heuristic benchmark models that have been found to characterize aid use in other studies.
The Present Research
Earlier research has found that participants assisted by a highly reliable (90% or better) diagnostic aid achieve performance levels roughly consistent with the CF and PM models of aid use (Bartlett et al., 2024; Bartlett & McCarley, 2017, 2019; Boskemper et al., 2022). In all these studies, however, participants have been non-experts, recruited through student subject pools or online participant recruitment services.
To test whether earlier findings generalize to a sample of more expert decision makers, the current study reanalyzed data from the reader study of Cao et al. (2023). We reanalyzed hit and correct rejection rates taken from the supplementary data reported by Cao et al. (2023) using a hierarchical signal detection model (Rouder & Lu, 2005) to provide estimates of sensitivity and accuracy rates for individual and AI-assisted performance, and compared performance to the predictions of the CF and PM models of collaborative decision making used by Bartlett and McCarley (2017).
Method
We performed a secondary analysis of data from the first reader study reported by Cao et al. (2023), which was designed to assess whether PANDA could effectively assist image readers in detecting PDAC- and non-PDAC lesions within non-contrast CT imagery. We provide a general summary of the relevant methodology below. For a detailed description please see Cao et al. (2023).
Participants were 33 image readers recruited from 12 medical institutions. Eleven readers were radiology residents, 11 were general radiologists, and 11 were pancreatic imaging specialists. Stimuli were a set of 291 non-contrast CT images collected from the Shanghai Institution of Pancreatic Diseases between December 2015 and June 2018. One hundred and eight of the images were taken from PDAC patients, 67 from non-PDAC patients, and 116 from normal controls. Readers were also provided the age and sex of the patient in each image.
Each reader performed two experimental sessions, separated by at least 1 month. In the first session, the readers were asked to view the stimulus images and classify each of the patients as PDAC, non-PDAC, or normal, working without assistance from PANDA. In the second session, the readers performed the same classification task using the same images, but were provided with the lesion segmentation map and primary diagnostic probabilities generated for each image by PANDA. Readers were informed that the stimulus set would include a higher proportion of cases with pancreatic lesions than is typically observed in clinical practice, but were not told the exact proportion of PDAC, non-PDAC, and normal cases within the set. They performed the task without time limits.
Analysis
Cao et al. (2023) analyzed their data in two different ways. The first analysis considered discrimination of PDAC and non-PDAC versus control. The second analysis considered discrimination of PDAC versus non-PDAC + control. The current modeling will focus on the first of their analyses.
Data were true positive and true negative detection rates reported in supplementary tables 6 (control) and 7 (assisted) of Cao et al. (2023). Data were analyzed using a hierarchical signal detection model (Rouder & Lu, 2005) implemented as a generalized linear mixed model with a binomial probability distribution and probit link function (DeCarlo, 1998; Zloteanu & Vuorre, 2024). The model provided posterior distributions of group-and individual-level d’ and c.
A model comparison approach was used to test for effects of reader Expertise (Resident, Radiologist, Specialist) and Aid Condition (Unaided vs. Aided). Five models were fit. The first was a Full Model that included main effects of Expertise and Aid Condition, along with the interaction of the two factors. The second was a Main Effects model that included only effects of Expertise and Aid Condition but excluded the interaction. The third model included only the main effect of Expertise, and the fourth included only the main effect of Aid Condition. The last was a Null model that included no effects of Expertise or Aid Condition. Model performance was assessed by comparing Bayes factors estimated though a bridge sampling procedure (Gronau et al., 2017).
Finally, group-level estimates of Unaided d’ and c extracted from the best-performing model were used to generate benchmark predictions of Aided d’ using two of the heuristic models of collaborative decision making described in our earlier work (Bartlett & McCarley, 2017, 2019; Boskemper et al., 2022), the PM and CF models. Analysis focused on these models because preliminary data inspection confirmed that aided performance was far below the levels predicted by more efficient aid-use strategies considered in our earlier papers.
To calculate predictions, both models first used estimated d’ and c for unaided trials to determine the marginal unaided hit rate, HRUnaided, and false alarm rate, FARUnaided, for the human reader. Marginal hit rate HRAI for the aid was 0.949 and marginal false alarm rate FARAI was 0.00, as taken from the data reported by Cao et al. (2023). The models assumed that for a given true-positive image on an AI-aided trial, the probability of a correct classification by the reader was HRUnaided and the probability of a correct classification by the aid was HRAI. Similarly, they assumed that for a given true-negative image on an AI-aided trial, the probability of a false-positive classification by the reader was FARUnaided and the probability of a false-positive classification by the aid was FARAI.
The PM and CF models differed only in how they resolved disagreements between the reader and the AI. The PM model assumed that on trials in which the reader and AI disagreed about the classification of an image, the reader randomly accepted the AI’s recommendation with a probability equal to the AI’s marginal accuracy rate. The CF model assumed that on trials in which the reader and AI disagreed, the reader randomly accepted the AI’s recommendation with a probability of 0.5. Finally, hit and false alarm rates predicted by the PM and CF models were transformed to estimates of d’ and mean accuracy. Note that because the models both violate the parametric assumptions that underlie calculation of d’, estimates should be considered equivalent d’ scores, that is, the d' values corresponding to an equal-variance normal signal detector that produced the estimated hit and false alarm rates (Murrell, 1977).
Analysis was performed in R (Version 4.4.1; R Core Team, 2023). Bayesian regression was conducted using brms (Version 2.21.0; Bürkner, 2018). Additional packages used for analysis and visualization included bridgesampling (Version 1.1–2; Gronau & Singmann, 2021), tidybayes (Version 3.0.6; Kay, 2023), emmeans (Version 1.10.3; Lenth, 2024), and ggplot2 (Version 3.5.1; Wickham, 2016).
The Bayesian estimation procedure used Monte Carlo Markov chains of 2,500 warm-up steps and 5,000 post warm-up steps each, giving 10,000 total post warm-up steps for analysis. Estimation used the brms default priors. As a check on absolute model performance, posterior parameter estimates from the best-fitting model were used to generate posterior predictive hit and false alarm rates for comparison to empirical values (Lee & Wagenmakers, 2013).
Data and analytic scripts are openly available at the project’s Open Science Framework page (https://osf.io/kcnuf/?view_only=516e9b1d5cdd4e0fa5b67c4198ff503b).
Results
Bayes factors were indifferent between the Full model and Main Effects model, B10 = 1.07, but strongly favored the Full model over the model including only an effect of Expertise, B10 = 11.68, and the model including only the effect of Aid Condition, B10 = 11.09, and decisively favored the Full model over the Null model, B10 = 4.85 × 1081.
Results indicate that performance varied across levels of Expertise and between Unaided and Aided blocks, but provide no meaningful evidence for or against an interaction of Expertise and Aid Condition. Inspection of Figure 1 reveals a close match between subject-mean posterior predictive hit and false alarm rates and the corresponding empirical scores, indicating an acceptable model fit.
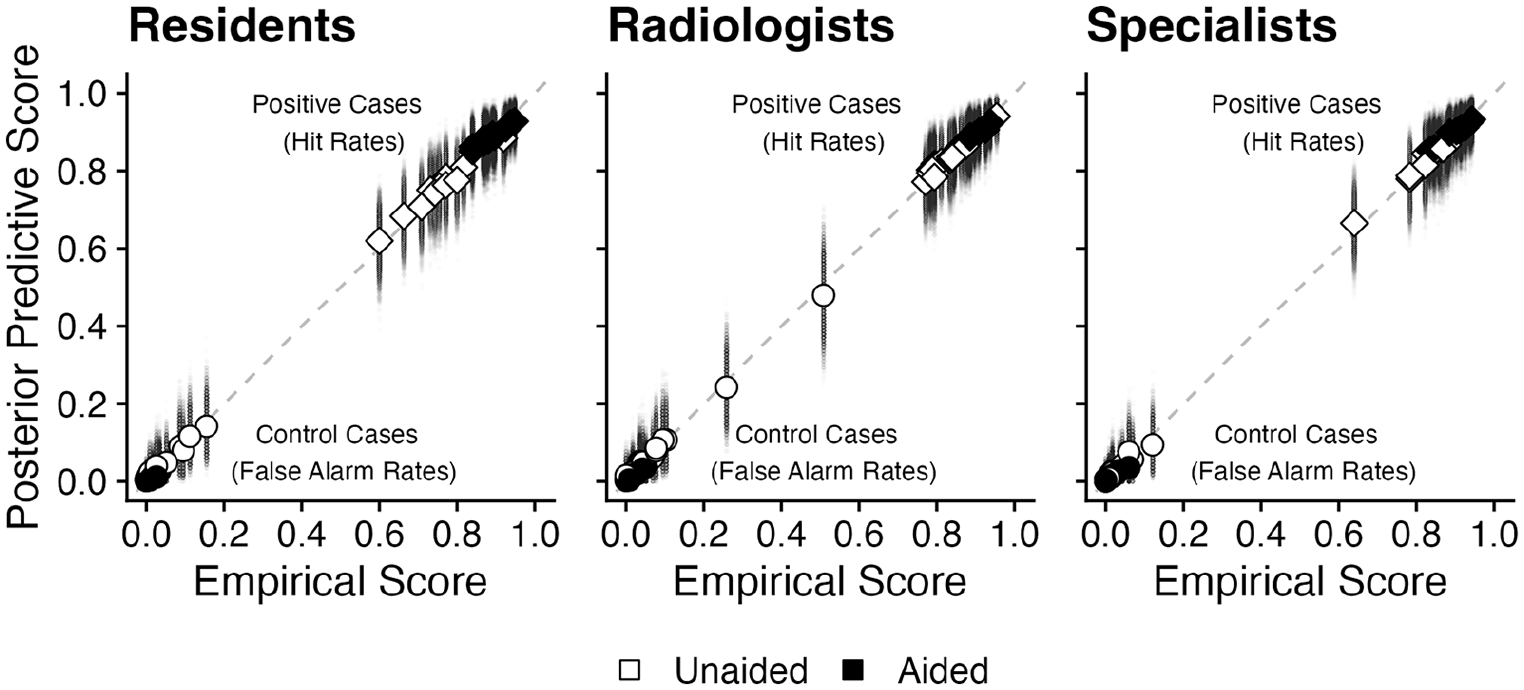
Posterior predictive hit rates (diamonds) and false alarm rates (circles) for individual readers, plotted as a function of the corresponding empirical values. Large symbols represent posterior predictive means, small symbols represent values corresponding to individual steps of the MCMC procedure.
Inspection of Figure 2 confirms that equivalent d’ was higher in the Aided than in the Unaided condition, as expected, and suggests that Specialists had higher equivalent sensitivity than either of the other two groups. Consistent with earlier benchmarking efforts, however, performance in the Aided condition was highly inefficient, falling between the predictions of the CF and PM models.
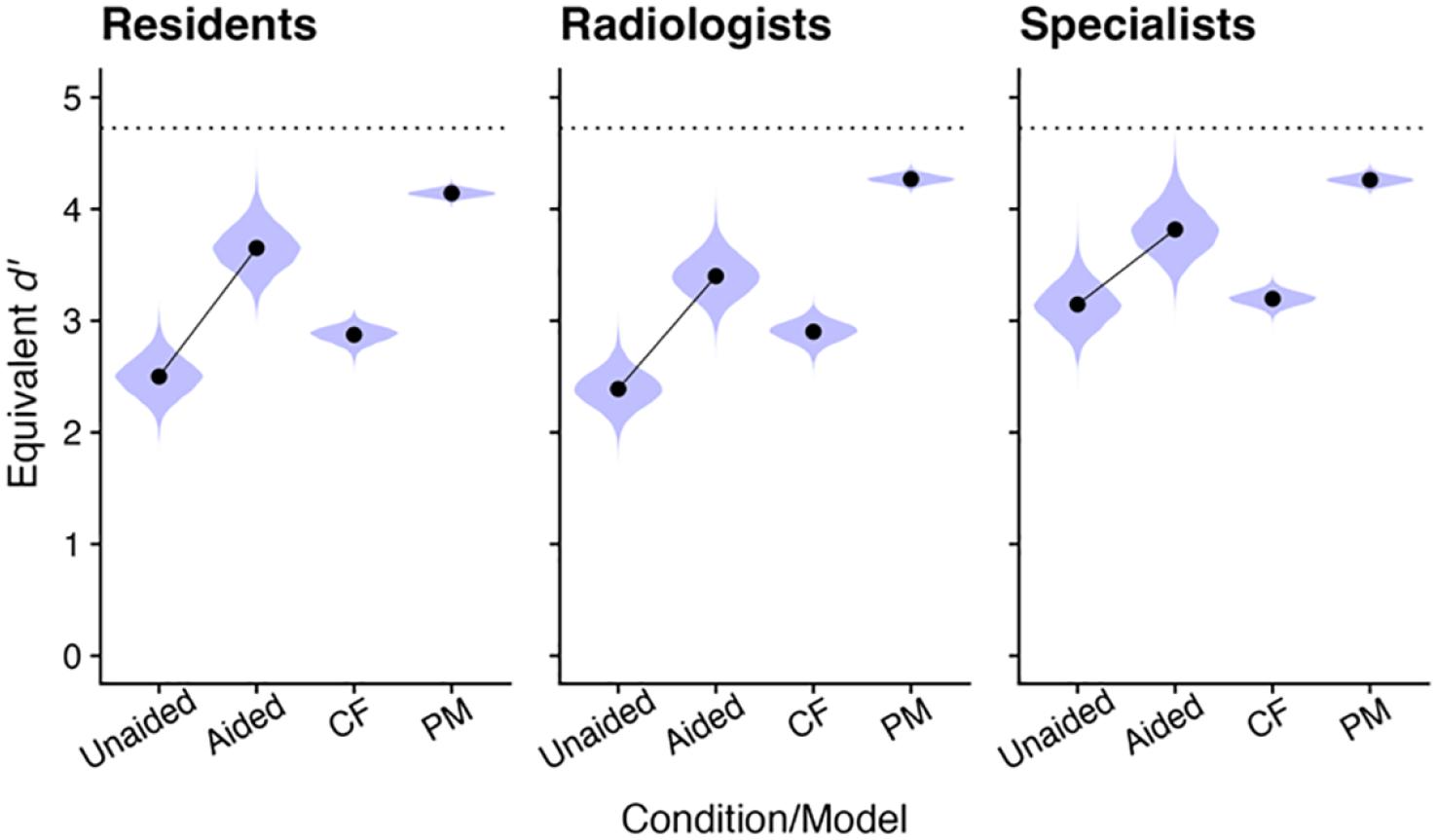
Estimates of empirical and model-predicted d’. Symbols represent posterior means. Violin plots represent posterior distributions of MCMC values. The two leftmost points in each panel, connected by lines, represent empirical data. The two rightmost points in each panel represent predictions from heuristic benchmark models. The horizontal dotted line corresponds to performance of the AI by itself.
Discussion
We performed a secondary analysis of data by Cao et al. (2023) to test the generality of past reports of PM/CF-level performance in aided signal detection tasks. While aided d’ was higher than unaided d’ for all levels of reader expertise, this benefit was well below achievable levels. Consistent with prior accounts (Bartlett et al., 2024; Bartlett & McCarley, 2017, 2019; Boskemper et al., 2022; Munoz Gomez Andrade et al., 2022; Tikhomirov et al., 2023), observed sensitivity in the aided condition fell in the range of the PM and CF models, collaborative strategies that effectively discard one agent’s decision, either the aid’s or operator’s, each trial. Although this level of inefficiency is similar to that observed in earlier studies, it is perhaps more surprising in the current context. Here, participants were not novices making inconsequential decisions, but experts performing a familiar and meaningful task. Moreover, the decision aid in this case, PANDA, provided the image readers rich supporting information, including diagnostic probabilities and segmentation maps highlighting potential lesions. In many previous studies, contrastingly, the AI provided only binary yes-or-no cues. Given the detailed output of the PANDA model, much higher levels of aided performance should have been achievable.
It is important to note that, although performance fell in the range of the PM and CF models here, the data do not confirm that operators were in fact using these strategies. It is possible that readers employed alternative and potentially more sophisticated strategies that simply happened to mimic PM/CF-level performance (Tikhomirov et al., 2023). Future modeling efforts are necessary to identify operators’ actual aid use strategies.
The tendency toward disuse presents a challenge to the adoption of powerful diagnostic aids in medicine (Topol, 2019) and other critical domains (Steyvers & Kumar, 2023). Future research should aim to understand the conditions under which AI-powered aids are likely to be valuable, and to develop decision making protocols to protect against disuse.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.