
Abstract
Prior research has shown that automation errors—false alarms and misses—differentially impact operator behavior, yet it is not clear why this difference exists. This study examined how the type of automation error, the automation’s reliability, and the number of experiences a person has with an automated system impacts their perception of the system. Participants responded to the correctness of an automation recommendation about the match between pairs of Mega Block shapes while automation reliability, number of trials, and error type varied. At the end of each block, participants provided their estimates of the automation’s reliability, ratings of their confidence in their reliability estimate, and their trust in the system. Our findings indicated that the type of automation error does not impact operator perceptions of the system. Instead, factors such as working memory limitations and pre-existing biases impact these perceptions.
Keywords
Introduction
Automation has evolved and been introduced into many aspects of our lives. It is essential to understand the relationships between operators and automation; specifically, how operators perceive automated systems. Operator perceptions of automation—such as estimated reliability or trust—may influence their dependence behaviors, but there is a need to understand what influences those perceptions.
Error Types
Decision-support automation errors can occur as false alarms—a suggestion of a target present when it is not—or misses—a suggestion that a target is not present when it is. These errors may then affect two behaviors of an operator—reliance and compliance (Dixon & Wickens, 2006). Reliance is the behavior of the human operator when the alert is silent, signaling that no target is present, or no action needs to be taken. Compliance is when an operator responds to an alert or an indication that action is needed, regardless of the true state of the world. Automation that is prone to misses will degrade reliance and automation that is prone to false alarms will degrade compliance (Dixon & Wickens, 2006; Dixon et al., 2007; Sanchez et al., 2014). Although it has been shown that operator behaviors (objective measure) are subject to change based on the type of error the automation commits, the way that operators perceive the automation (subjective measure) as a result of the type of error warrants further study. The operator’s perceptions of the automation are crucial to understand as they can have additional impacts on the behaviors of the operator and influence other perceptual states of the operator, such as job satisfaction and feelings of autonomy (Rieth et al., 2024).
Trust
A perceptual variable that has garnered a lot of interest is trust, or the extent to which an operator feels that the automation will help them achieve their goals (Lee & See, 2004). An abundance of work has shown that increasing automation errors (decreasing automation reliability) leads to lower trust (e.g., Dzindolet et al., 2003; Parasuraman & Riley, 1997; Pop et al., 2015; Dixon et al., 2007; Dixon & Wickens, 2006; Yang et al., 2017; Azevedo-Sa et al., 2020; Geels-Blair et al., 2013; Hutchinson et al., 2023; Sanchez et al., 2014; Yang et al, 2017; Patton & Wickens, 2024). The impact of the type of automation error on trust, however, is still unclear.
Using dual-task UAV simulations, Dixon and Wickens (2006) suggested that misses may cause operators to trust automation less, but subjective trust was not measured. Azevedo-Sa et al. (2020) found that in a driving simulator, misses from the automated driving system led to lower trust than false alarms. However, this is a risk-specific scenario, where misses (not notifying a driver of a potential collision) are far more dangerous than false alarms. In the phishing domain, Chen et al. (2021) found that false alarms lowered trust behaviors more than misses, but there was no difference in subjective trust measures. Yet, in a different paradigm by Dixon et al. (2007) utilized a system monitoring task which studied system failures among automated aids that were perfectly reliable, false-alarm prone, or miss-prone. The results implied that false alarms reduce operator trust in automated alerting systems as much as misses. In considering these conflicting results, there is still a need to clarify the impact of error type on trust in more general settings.
Additionally, the current experiment was interested in understanding how trust changes with varying levels of experience with the system. Recent work has suggested that trust changes over time, becoming more stable with more experience (operationalized by the number of trials) with an automated system (Yang et al., 2017), regardless of the reliability level of the automation. However, this work did not separate false alarms and misses to understand if the type of error impacts trust differently.
Estimates of Reliability
The level of experience an operator has with a system may also impact their estimates of reliability. Automation perception literature provides two concepts—leaky integrators versus intuitive statisticians—that can be applied to estimating the reliability of autonomous systems. Humans may be considered “leaky integrators” of information due to limitations and constraints of working memory and biases that arise when estimating summary statistics (Patton et al., 2023; Wickens et al., 2020). When humans can estimate the average in a dataset or calculate the average reliability of automation with relative accuracy, they are considered “intuitive statisticians” (Peterson & Beach, 1967; Pollard, 1984).
However, these two concepts provide conflicting indications of how operators estimate automation reliability by suggesting that operators can have accurate or inaccurate estimates of automation accuracy, warranting further investigation. By exposing operators to varying numbers of trials (10, 50, or 100), Patton et al. (2023) seemingly disconfirmed the intuitive statistician approach as participants were not increasingly confident in their reliability estimate with more exposure to an automated system. If then, operators tend to be leaky integrators, this suggests that working memory plays a role in estimates of reliability. Should this be the case, then as the number of trials increases, we would expect to see less accurate estimates. Additionally, false alarms tend to be more salient than misses (Foroughi et al., 2023), which may be more memorable and thus cause estimates of the automation reliability to be lower than when the automation is miss-prone (Dixon et al., 2007; Geels-Blair et al., 2013). Experience and error type together could create a multiplicative effect, but research has not yet investigated this issue.
Current Study
The current study builds upon the methodology of Patton et al. (2023) as we sought to further explore the impact of automation error type on perceived reliability, operator confidence ratings, and trust in the system. Three hypotheses were put forth:
H1a: False alarm-prone automation will reduce both reliability estimates and trust more than miss-prone automation because false alarms are more salient than misses.
H1b: This effect will be more pronounced as the number of trials increases, due to an overall increase in saliency from a higher number of errors.
H2: Operators’ confidence in their ratings of automation reliability will remain consistent for misses as trials are presented, as seen in Patton et al. (2023), but will increase for false alarms due to their saliency making them more memorable.
Methods
Participants
Forty-one participants completed this study for partial course credit at a large university. Screening for outliers was done by participant accuracy in identifying the correctness of the automation’s recommendation. Seven participants whose accuracy scores fell below three standard deviations from the mean were excluded from the dataset.
Task
Participants were presented with two images either on the left or right side of the screen. The images featured sets of Mega Blocks arranged in varying shapes and colors against a black background (Figure 1).
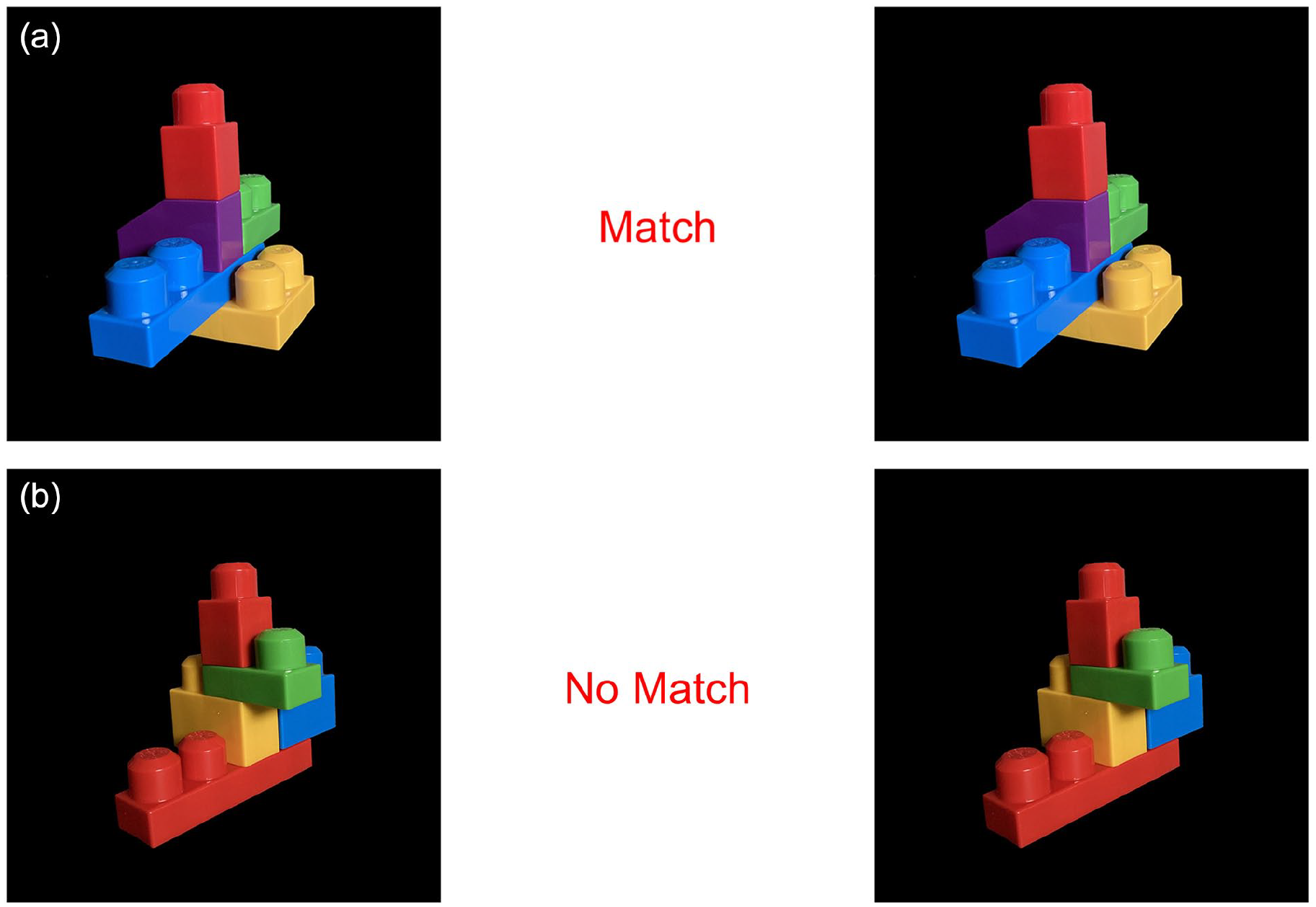
(a) Example of matching trials with a correct recommendation from the automation shown in the middle and (b) Example of a matching trial with an incorrect automation recommendation (false alarm) shown in the middle.
Each shape was composed of five unique blocks that were combined to create shapes that varied in color and size. Image sets either matched or did not match and matches always appeared in the same plane (i.e., not rotated). A blank space between the two photos provided the participants with an automation recommendation which indicated if the shapes in each image were a “Match” or “No Match.” Based on the average response time (2.5 s) during the pilot phase, each participant was provided 5 s per trial to respond with a keypress to indicate whether the automation recommendation was correct or incorrect. Participants were explicitly instructed to respond to the correctness of the automation’s recommendation, not the true state of the photos.
Design
This study utilized a mixed design: 3 (automation reliability; within) × 3 (number of trials; within) × 2 (automation error type; between). Dixon and Wickens (2006) established 70% reliability as the minimum threshold where a human-automation team tends to outperform the human alone. For this experiment, the automation was either 50%, 80%, or 90% reliable in each block. The automation failures occurred pseudo-randomly throughout each block such that trials were presented in identical order to participants to allow for the systemic distribution of automation failures within the blocks, preventing them from appearing first, last, or all together and reducing potential recency, primacy, and peak-end effects.
Automation reliability was distributed through sets of 10, 50, or 100 trials. Nine total blocks were presented randomly, each a combination of automation reliability and the number of trials. After each block, participants provided ratings from 0 to 100 on perceived reliability and confidence in their reliability estimate. Participants were instructed that they were evaluating the accuracy of different uniquely named systems (i.e., System “Alpha” or System “Delta”) at the start of each block as a preventative measure of residual effects from the previous system’s accuracy. Information about system reliability or the number of trials on any block was not provided but the initial instructions stated, “Sometimes the aid will be correct and sometimes it will be incorrect.”
Participants were assigned to either the “miss” condition or the “false alarm” condition. In the “miss” condition, every automation failure was a miss, or recommending not a match when the images were really a match. In the “false alarm” condition, every automation failure was a false alarm, or stating the images were a match when they were not really a match.
Procedure
Consent was obtained from participants and a brief set of instructions about the task were given, followed by two sets of practice trials that mimicked the real trials. The initial set of 10 practice trials informed the participant if the automation recommendation was correct or incorrect and how the participant should respond. They were not timed. The second set of 10 practice trials replicated the real trials and implemented the 5-s time limit while removing the explanation for the automation recommendation. Following the practice trials, all nine blocks of the experiment were presented in random order. Participant estimates of the automation’s reliability, ratings of their confidence in their reliability estimate, and trust in the system were collected after each block. The experiment concluded with a debrief form and participants were awarded partial course credit.
Results
Estimates of Reliability
Two participants did not respond to every estimated reliability question in one of the nine blocks and were excluded from the analysis. An ANOVA revealed that error type did not have a significant impact on estimates of reliability (F [1, 30] = 1.93, p = .18, η2 = 0.02). A main effect of true automation reliability (50%, 80%, 90%) was significant; (F [2, 60] = 98.82, p < .001, η2 = 0.42). Follow-up t-tests indicated that participants estimated the 50% reliable automation (M = 48%) lower than the 80% reliable automation (M = 71%; t [33] = −8.87, p < .001, d = 1.74) and lower than the 90% reliable automation (M = 81%; t [33] = −13.406, p < .001, d = 2.59). Additionally, participants estimated the 80% reliable automation lower than the 90% reliable automation (t [33] = −7.14, p < .001, d = 1.03).
A significant main effect was found for the number of trials presented (F [2, 60] = 2.51, p = .08, η2 = 0.02). T-tests indicated that estimates of automation reliability were higher at 10 trials (M = 70%) than at 100 trials (M = 64%; t [33] = 2.25, p = .03, d = 2.59). The interaction for error type and number of trials presented was not significant (F [2, 60] = 2.291, p = .11, η2 = .01). The interaction for error type, automation reliability, and the number of trials was significant (F [4, 120] = 5.71, p < .001, η2 = 0.05; Figure 2).
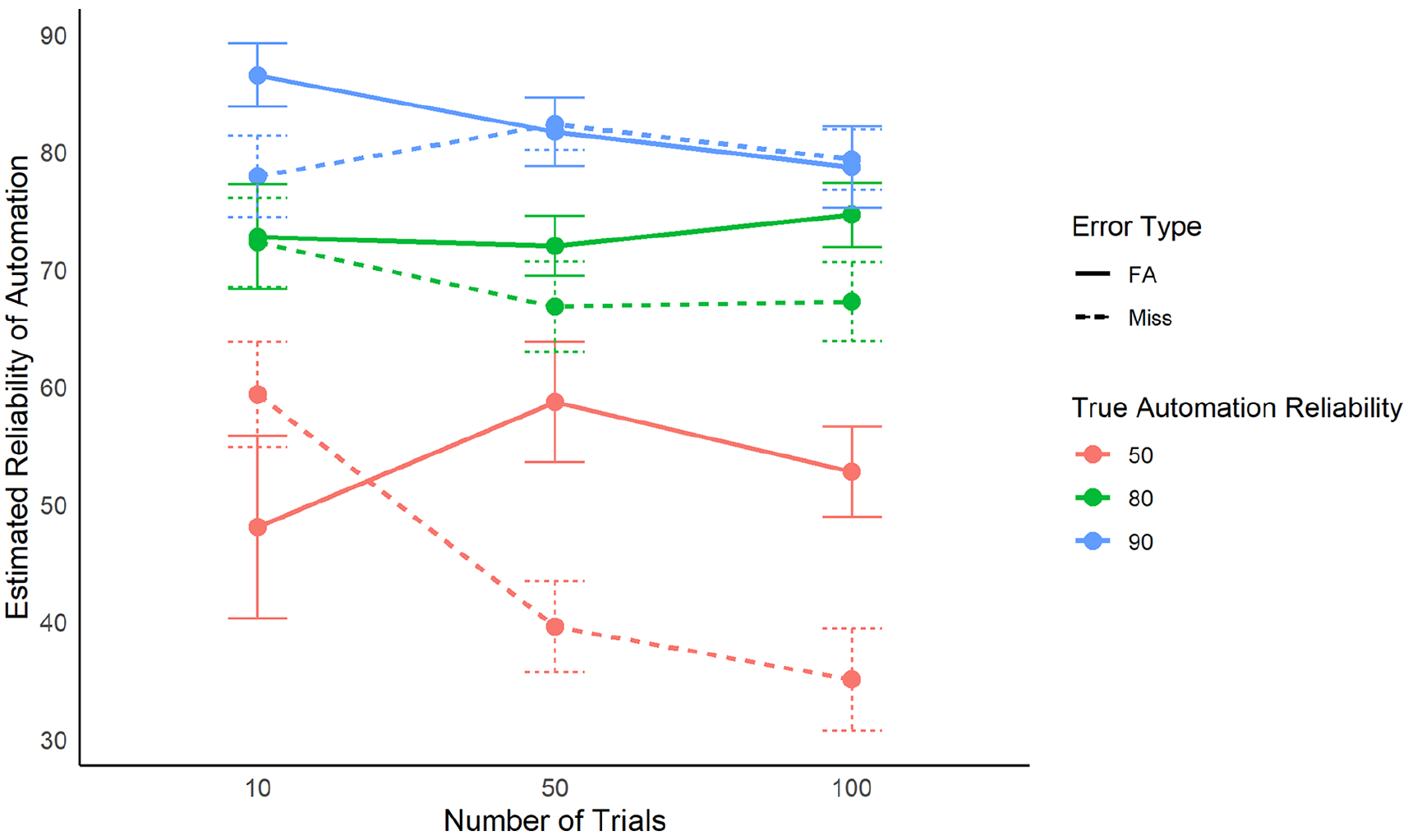
Interaction of number of trials, true automation reliability, and error type on the average estimates of reliability. Error bars represent one standard deviation.
Trust
An ANOVA revealed that error type did not have a significant impact on operator trust in automation (F [1, 32] < 1, p = .97, η2 < 0.01). A significant main effect for the actual automation reliability was found (F [2, 64] = 72.15, p < .001, η2 = 0.03; Figure 3). Follow-up t-tests indicated that participant ratings of trust in the 50% reliable automation (M = 4.06) were lower than the 80% reliable automation (M = 5.72; t [33] = −8.81, p < .001, d = 1.18) and the 90% reliable automation (M = 6.70; t [33] = −10.35, p < .001, d = 1.88). Trust ratings in the 80% reliable automation were lower than the 90% reliable automation (t [33] = −4.77, p < .001, d = 0.67).
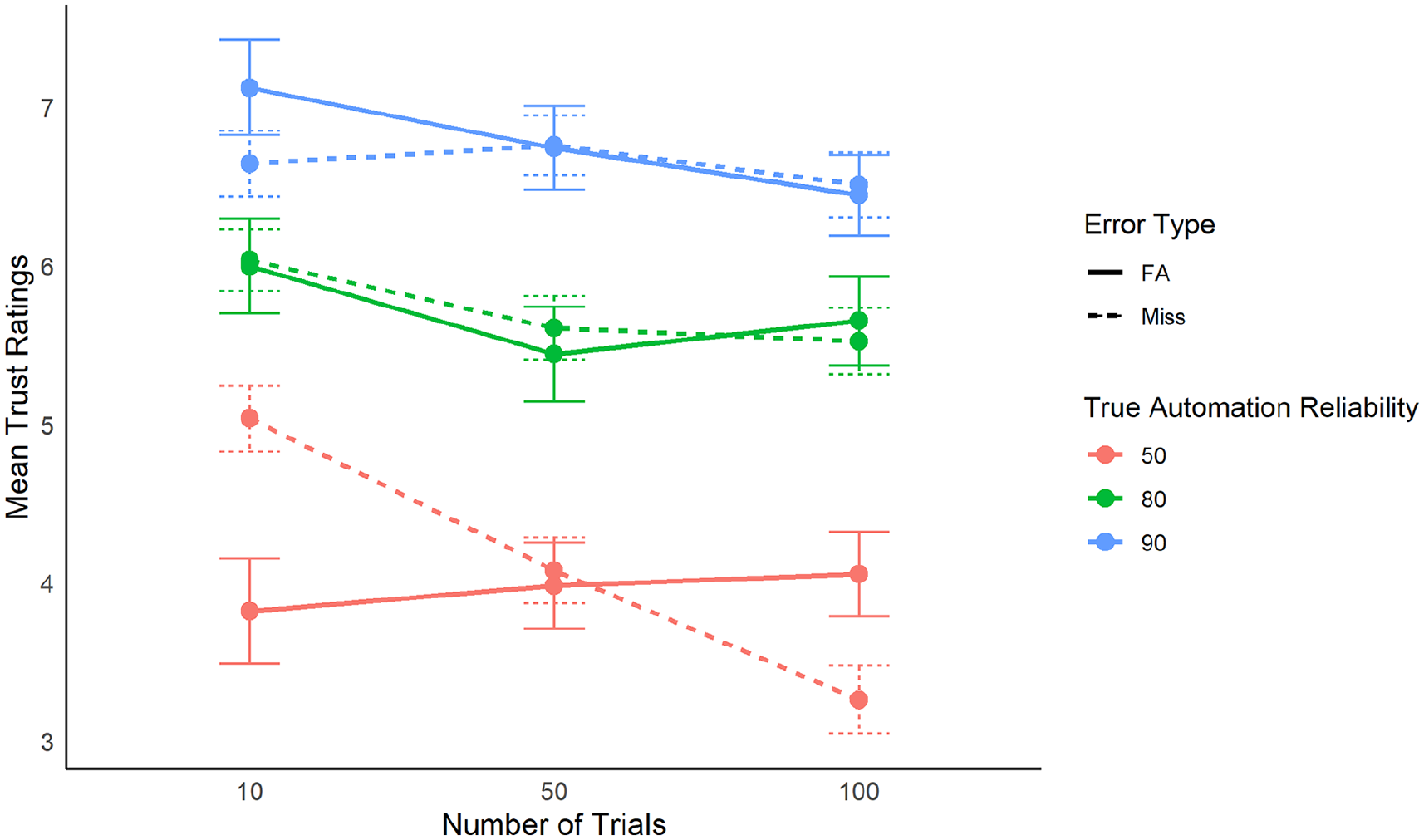
Interaction of number of trials, true automation reliability, and error type on the average ratings of trust. Error bars represent one standard deviation.
A main effect was also found for the number of trials presented (F [2, 64] = 4.73, p = .01, η2 = 0.02). T-tests indicated that participant ratings of trust at 10 trials (M = 5.81) were higher than at 100 trials (M = 5.23; t [33] = 2.84, p = .007, d = 0.42). T-tests were conducted for 10 and 50 trials (M = 5.44; p = .056, d = 0.26) and 50 and 100 trials (p = .084, d = 0.17), but while they neared significance, the effect sizes were small.
Confidence in Estimates
Three participants did not respond to every estimate of confidence question in one of the nine blocks and were excluded from the analysis. An ANOVA revealed that error type did not have a significant impact on the operators’ confidence in their rating of the automation reliability (F [1, 29] = 2.09, p = .16, η2 = 0.04). A significant main effect for the actual automation reliability was found (F [2, 58] = 5.3, p = .008, η2 = 0.01). Follow-up t-tests indicated that participants’ ratings of confidence in their estimate of 50% reliable automation (M = 75.63) were lower than the 80% reliable automation (M = 79.04; t [33] = −2.29, p = .03, d = 0.22) and lower than the 90% reliable automation (M = 80.96; t [33] = −3.6, p = .001, d = 0.37). There was no significant main effect for the number of trials presented on the operators’ confidence in their rating of automation reliability (F [2, 58] = 2.92, p = .06, η2 = 0.01). However, to mirror the prior analyses, we conducted follow-up t-tests. Participants’ ratings of confidence in their estimate at 10 trials (M = 81.19) were higher than at 100 trials (M = 76.44; t [33] = 2.07, p = .04, d = 0.30), but no other differences were significant (all p’s > .05).
Discussion
Error Type
Our findings suggest that error type does not impact operator estimates of automation reliability, confidence in their reliability estimates, nor trust in automation. We hypothesized (H1a) that false alarms would reduce reliability estimates and trust, but this was not supported. This suggests that, on a general level, the type of automation error does not impact operator perceptions of the system. This goes against prior work that suggests the error type does impact trust (Dixon & Wickens, 2006; Dixon et al., 2007) and instead suggests that the way error type influences behavior is not a result of the error’s impact on perceptions of reliability.
We also hypothesized (H1b) that the increasing number of trials would exacerbate this effect, but there was no interaction between error type and number of trials for estimates of reliability nor trust in the automation. However, the interaction between error type, automation reliability, and number of trials was significant. Post-hoc, it appeared that for the lowest automation reliability, miss-prone automation was estimated increasingly less accurate as the number of trials increased (Figure 2). While this goes against our original hypothesis, it suggests that in certain conditions, error type and experience with a system may have an impact on estimates of reliability. This could provide additional evidence toward understanding why there are mixed results in the prior literature (Geels-Blair et al., 2013; Dixon et al., 2007; Hutchinson et al., 2023; Pop et al., 2015)—the reliability of the system and the context appear influential on perceptions.
In light of these findings, it is important to note that in the current paradigm, participants were asked to respond based on the automation’s correctness, rather than on the true state of the stimuli. As a result, their attention was overtly focused on the automation’s recommendations, rather than working to combine the automation’s recommendations and their own beliefs, as is typical in other experiments and real-world settings. This may have reduced the saliency of the false alarms compared to the misses, thus reducing the effects seen in prior work. However, the combination of the lack of influence from the number of trials and the error type on perceptions may suggest that using overt attention to the automation’s recommendation allows operators to quickly make judgments about a system. This could be used in training procedures to cut down on the time it takes to become familiar with a system—our work suggests only 10 trials are needed for an operator to make a judgment with relative accuracy. It also suggests that the initial judgment may not change much over time; an important consideration for training protocols.
Perfect Automation Schema
There was partial support in favor of our second hypothesis (H2). We hypothesized that confidence ratings would not change across the number of trials, which was true, and mimicked the results of Patton et al., (2023). However, we also hypothesized that the increased saliency of false alarms would increase confidence in ratings, as the errors would be more memorable and provide a false sense of confidence, similar to the mere exposure effect (Zajonc, 1968). This was not supported, as there was no effect of error type on confidence. This suggests that it is not the saliency of the errors that impacts an operator’s confidence in their perceptions of the automation.
Instead of the number of trials influencing confidence, it was related to the system’s reliability, such that when the automation was more accurate, participants were more confident in their reliability estimates—even though the estimates were consistently about 10% lower than the actual reliability. Together these findings indicate the presence of the perfect automation schema (PAS)—a belief that error rates of automated aids are extremely low, leading to decreases in trust when an error is experienced (Dzindolet et al, 2002; Meritt et al., 2015; Lyons & Guznov, 2019). Here, the higher level of trust and estimated higher automation reliability with fewer trials suggests the presence of a PAS with high expectations that were lowered as participants experienced more trials. Likewise, when presented with trials with lower automation reliability, the operators reported lower confidence in their estimates of automation reliability, as if the lower reliability went against expectations.
Limitations
The current study does not mimic how automation aids are used in the real world, as it required direct attention to whether the automation suggestion was an error or not, which may explain why our results diverge from similar literature (Dixon & Wickens, 2006; Dixon et al., 2007). Moreover, the current paradigm was low-risk and thus did not provide an inherent bias for or against one type of error, which could impact results in a real-world risky scenario. Future research should explore the impact of the operator’s working memory and the extent of their perfect automation schema.
Conclusions
Error type—false alarms versus misses—did not impact operator perceptions of reliability, trust, or confidence in their estimates in a task where responses were focused on the automation’s suggestion. While this contrasts prior work, the focus on the automation’s recommendation may provide insights into one way to improve operator perceptions regardless of the error type.
Additionally, when operators had less experience with a system, they estimated higher reliability in the system, reported higher trust, and believed their estimates to be more accurate, regardless of error type. This provides support for the presence of the perfect automation schema, indicating that operators often have high levels of dispositional trust and feel confident in their perceptions when the automation aligns with those initial expectations. These initial judgements are made quickly, and additional experience with the system does not inherently improve them. These findings have implications for real-world scenarios where operators are working with automation over long periods of time. For example, TSA agents who look for contraband at security checkpoints during long shifts may rely on the automation more often when it has been correct recently, even if their perceptions of its accuracy are not correct.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.