
Abstract
This research explores the overtime learning trends of multimodal gaze-based interactions in tasks involving the movement of augmented objects within extended reality (XR) environments. This study employs three interactions, including two multimodal gaze-based approaches, and compares them with an unimodal hand-based interaction. The underlying hypothesis posits that gaze-based interactions outperform other modalities, promising improved performance, lower learnability rates, and enhanced efficiency. These assertions serve as the foundation for investigating the dynamics of self-learning and exploration within XR-based environments. To this end, the study addresses questions related to the temporal evolution of learnability, post-learning efficiency, and users’ subjective preferences regarding these interaction modalities. This research shows that gaze-based interactions enhance performance, exhibit a lower learnability rate, and demonstrate higher efficiency compared to an unimodal hand-based interaction. Our results contribute to the design and refinement of more effective, user-friendly, and adaptive XR user interfaces.
Keywords
Introduction
The landscape of human-computer interaction has witnessed transformative advancements, notably with the integration of gaze interaction as a cornerstone feature within XR technology. Unveiling crucial insights into human states and emotions, gaze interaction stands out for its precision. As the field evolves, the need to explore and understand the nuances of multimodal gaze-based interactions becomes increasingly apparent, especially in scenarios requiring dynamic object movement. In the context of XR interactions, self-exploration and learning refer to the user’s adaptive process of becoming proficient in utilizing novel interaction modalities. XR, encompassing virtual reality (VR), augmented reality (AR), and mixed reality (MR), offers unique challenges and opportunities for users as they engage with digital content and virtual elements in real-world settings.
Self-exploration in XR interactions involves users actively discovering and familiarizing themselves with the functionalities and affordances of the XR interface. This process often includes understanding the spatial relationships between virtual and real-world elements, exploring the available interaction modalities (such as gaze, gesture, or hand controllers), and experimenting with how these modalities can be employed to manipulate and interact with virtual objects. Self-exploration is crucial in XR environments, where the integration of digital content into the physical world requires users to develop a spatial and perceptual understanding beyond traditional two-dimensional interfaces. Learning object manipulation XR interactions extends beyond the initial exploration phase and involves the user acquiring and refining skills over time.
In response to this imperative, our research investigates of multimodal gaze-based interactions, unveiling their potential within XR environments. In contrast to the prevalent focus on pointing and selection tasks, our study introduces three interaction methods, including two multimodal gaze-based interactions, and a traditional unimodal hand-based interaction and focuses on the learnability and efficiency of these interactions.
According to the literature, gaze interaction offers enhanced performance, learnability, and efficiency especially when it is combined with other modalities. Therefore, we formulate the following hypotheses for this study:
Performance (H1): Multimodal gaze-based interactions are hypothesized to improve overall performance by:
(H1a): Lowering task completion times (TCT).
(H1b): Reducing fine-tuning requirements.
Learnability (H2): Multimodal gaze-based interactions are expected to show a lower learnability rate compared to unimodal hand-based interactions, reflecting the intuitive nature of gaze as an input modality as shown in the literature.
Efficiency (H3): Multimodal gaze-based interactions are hypothesized to demonstrate higher efficiency in completing tasks within XR environments compared to unimodal hand-based interactions
To understand the dynamics of self-learning and exploration in XR-based interactions, our study aims to address the following questions:
Learnability (Q1): How does learnability change over time, and what strategies do users employ for error recovery during the learning phase?
Post Learning Efficiency (Q2): After users have become acquainted with the interactions, which modality allows for more efficient task execution?
Subjective Preferences (Q3): What are the subjective preferences of users regarding the different interaction modalities, and what factors contribute to these preferences?
By delving into these questions and hypotheses, our research seeks to provide a comprehensive understanding of the impact of self-learning and exploration in XR-based interactions. The study aims to investigate how users autonomously navigate the learning curve, understanding the efficiency, preferences, and strategies employed in error recovery over time. It recognizes that users engage in a dynamic process of exploration, experimentation, and adaptation as they integrate these interaction modalities into their cognitive and motor skill repertoire within the XR environment. The research seeks to shed light on the temporal evolution of this learning process, providing insights that can inform the design of more adaptive XR interfaces.
Related Work
As XR technologies continue to evolve, understanding the effects of self-directed learning and the role of exploration within these immersive environments becomes paramount. The literature on this topic dives into diverse dimensions, encompassing cognitive processes, user engagement, and the overall impact on skill acquisition. This review aims to synthesize current research findings and better understand self-learning behaviors and the exploration of XR environments, offering insights into the potential of these interactions on user proficiency and satisfaction.
One of the early works on the topic of interface exploration measured people’s capacity for exploring computer systems (de Mul & van Oostendorp, 1996). The study monitors the evolving nature of user knowledge and looks at how different learning methods affect their exploratory behavior. The findings of their first experiment indicate that users experience a major shift in their knowledge while trying new paths. However, the user experience was not appreciably enhanced by eliminating facilities that supported the investigation. The other experiment improved procedural knowledge and system functionality by utilizing the think-aloud method. In both tests, learning style had no discernible effects.
Exploratory learning is a behavior where users investigate new interface capabilities without clearly defined short-term goals. However, this behavior has been little investigated outside laboratory and training situations. Sutcliffe and Kaur (2000) examined the task of exploration in abstract terms, guiding a field study into user behavior and attitudes. Cognitive models and laboratory studies reveal that task-oriented exploration is preferred by most users, followed by different strategies related to task completion.
Gaze interaction in XR refers to using eye tracking to enable users to interact with virtual objects and environments. Piotrowski and Nowosielski (2020) and Pfeuffer et al. (2017) both addressed this topic while the former explored the potential of this technology, proposing a steering mechanism for VR headsets, and the latter focused on introducing the Gaze and Pinch interaction technique, which combines eye gaze for target selection and freehand gestures for manipulation. Hirzle et al. (2019) provided a comprehensive overview of the design space for gaze interaction on head-mounted displays, considering human depth perception and technical requirements. Many studies have explored the potential of self-learning and exploration in AR and VR. Alizadeh and Cowie (2022) found that VR can enhance engagement, focus, and collaboration but also identified challenges such as cybersickness while Essmiller et al. (2020) highlighted the potential of MR to facilitate learning. These studies collectively highlight the potential of gaze interaction in XR, and the need for further research and development in this area.
Methods
Three XR interactions, including two multimodal gaze-based interactions named Eye-Gaze & Pinch and Eye-Gaze & Voice, and one unimodal hand-based interaction named Drag & Drop were developed using Unity 3D and Mixed Reality Toolkit. The applications were implemented on HoloLens 2.
A usability testing with log data collection and post-experiment semi-structured interviews was conducted. Usability testing happened without the think-out-loud technique since learnability and efficiency are being studied. Participants were observed, and notes were taken from their actions. They were asked to perform box stacking in a simple pick-and-place task. The three interaction modes require different hand and eye movement levels to perform a pick-and-place task in the XR environment.
Experiment Design
The experiment has a within-subject format where all participants experience all conditions of the tasks in a counterbalanced order. Each participant did 10 trials of each interaction to give them enough exposure. In Eye-Gaze & Pinch mode, the user can interact with objects from a distance without physically touching them. The user points to the object with their eye and pinch them while gazing at it. This is similar to mid-air gestures, but in this mode, their eyes and hand hands are synchronized for a more accurate and easier selection and placement. Integration of eye-gaze with voice command also follows a similar mechanism, except instead of employing hand gestures, the user must utilize predetermined voice commands to complete the task. To pick the objects, the user should say “Put that” and position the object by saying “There.” However, with Drag & Drop, their eye is not interactive; therefore, they should solely rely on their hands for interaction. The main difference between Drag & Drop and Eye-Gaze & Pinch is that in the former, they can grab the object with their hand in any position, while in the latter, they should perform the pinching gesture without touching the objects.
Task Procedure
Upon arrival at the laboratory, participants received basic verbal instructions about the task and overall procedure. After signing the consent form, they were asked to complete the tasks as quickly and accurately as possible. They were not given in-depth formal instructions or practice trials as the task focused on learnability and interface exploration. Since there were 3 interaction modes, each participant finished a total of 30 trials, and their qualitative and quantitative feedback was collected. After each trial, they were also encouraged to rest between sessions for a few minutes before starting the next trial to prevent fatigue. Also, after finishing the experiment, they were interviewed for about 10 min, and their overall experience and subjective preferences were recorded. The experiment took about 90 min in total.
Data Collection
In this study, number of trials with 10 repetitions and interaction technique with 3 levels of Eye-Gaze & Pinch, Eye-Gaze & Voice, and Drag & Drop are considered as independent variables. Since learnability and efficiency are two important aspects of the study, there was a trade-off between time and accuracy. During the experiment, the task completion time and the number of fine-tunings which we define as the number of times the users attempted to adjust the accuracy of the placement after the initial placement were recorded. These variables are indicators of user performance (task time and accuracy/error); more broadly, they show learnability and efficiency. The learnability patterns were recorded in each trial when the user was still exploring the interface. At the end of the last trial, the learnability is measured. It shows how efficiently they were able to perform each interaction after they learned them over multiple trials. Also, the number of fine-tunings shows the number of times the users tried to adjust the placement accuracy to obtain a perfectly aligned stack of boxes. The users’ actions were recorded using the built-in camera of the HoloLens, and notes were taken while they were being observed during the task. At the end of the experiment, they were asked for a semi-structured interview to better understand their experiences, expectations, and, most importantly, preferences regarding the three interactions. This interview also helps to understand the “why” behind each number.
Participants
A total of 10 adults, 6 females and 4 males with ages ranging from 26 to 35 (M = 29, SD = 4.12) participated in this study. Participants were not highly experienced with AR/VR interfaces and associated interactions, but some had previously used them for gaming purposes. On average, they reported a 60% experience in XR, and none of them reported prior experience with gaze interactions.
Results
The preliminary results from 10 participants were analyzed both quantitatively and qualitatively.
Quantitative Analysis
For the quantitative analysis, after pre-processing and applying D’Agostino Pearson normality test, a Linear Mixed Model (LMM) was applied to identify the influence of fixed and random effects. We specified participants as random effects, and the mode of interaction and trials were considered as fixed effects.
Performance Learnability
Learnability was measured separately across 10 trials for each interaction. It was measured on two dimensions of task completion time and the number of fine-tunings.
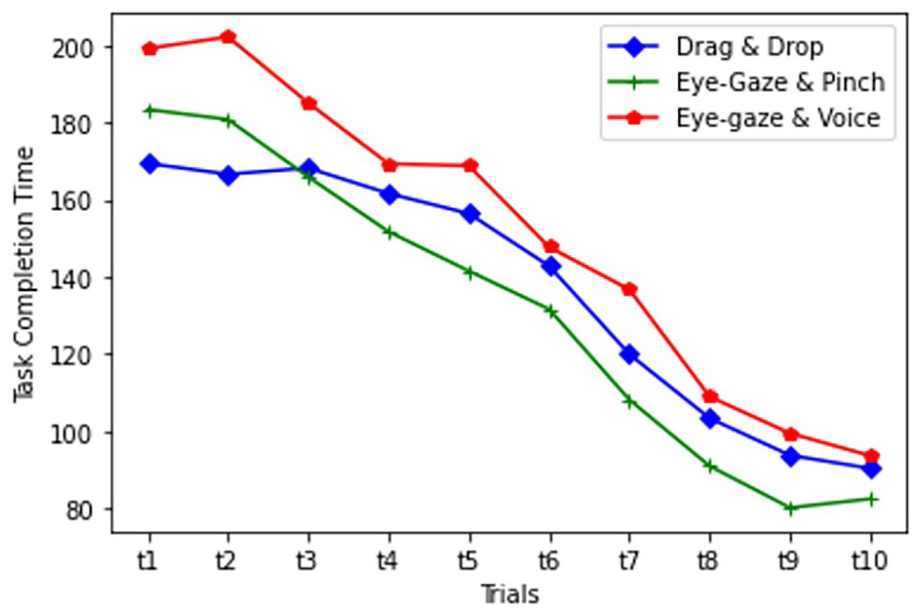
TCT pattern of learnability for each interaction.
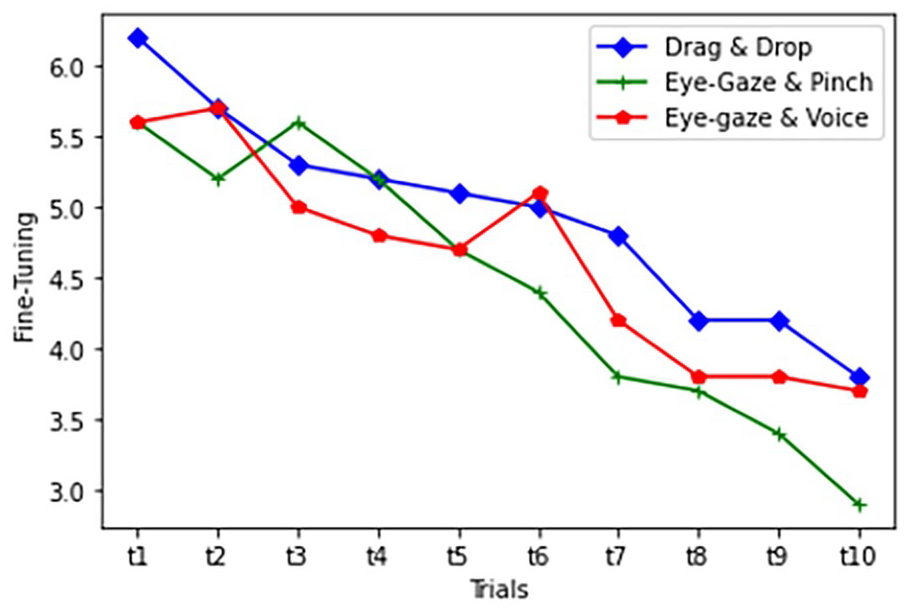
The fine-tuning pattern of learnability for each interaction.
Performance Efficiency
Efficiency is measured on the final trial when they learned the interactions. It is measured on two dimensions of task completion time and the number of fine-tunings.
Qualitative Analysis
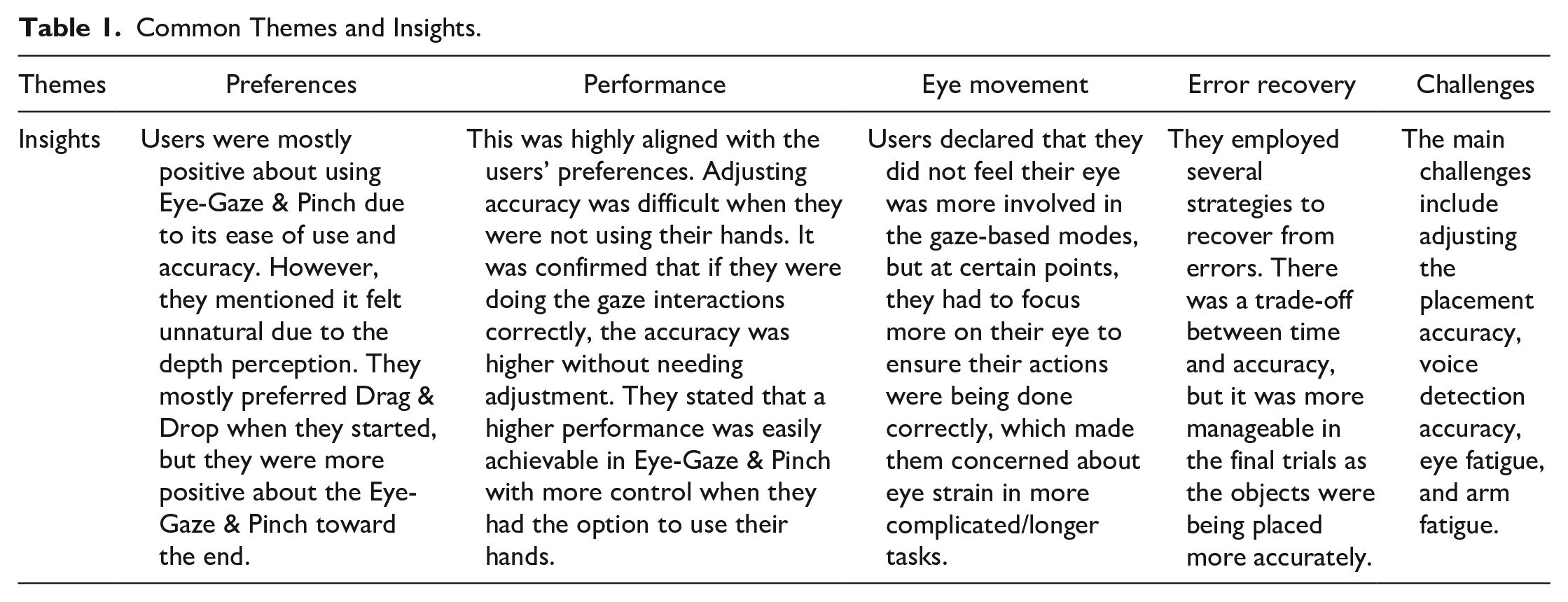
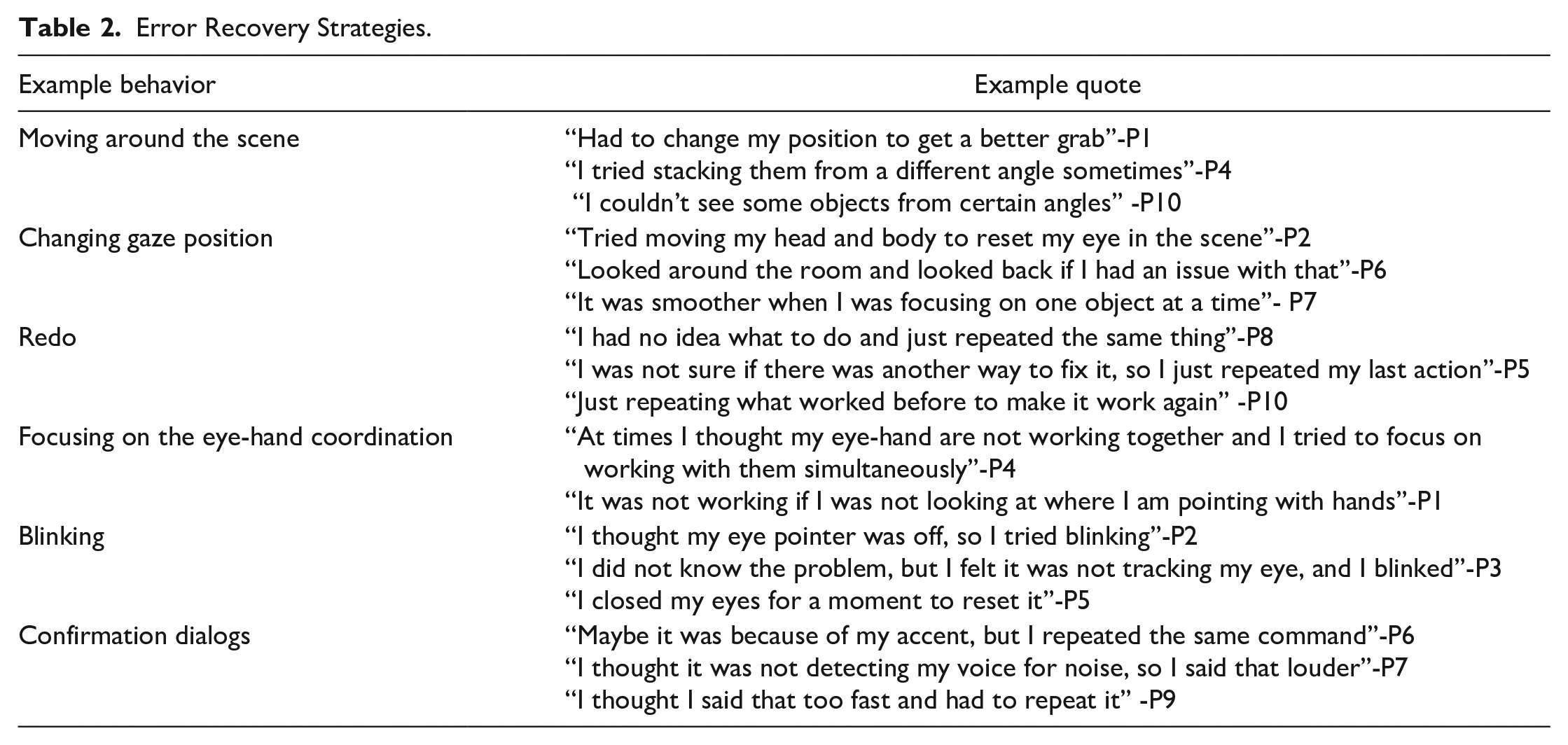
For the qualitative analysis, we started by Identifying common themes and how these themes connect with each other based on the questions asked during the interview. We did an inductive reflexive analysis with open coding and no coding framework. The most common themes and insights are presented in Table 1. Moreover, since one of the main research questions involves error recovery strategies, a deeper analysis is provided in Table 2.
Common Themes and Insights.
Error Recovery Strategies.
Discussion
In this study, the learnability regarding task completion time showed a significant difference across the trials. As expected, Drag & Drop had a shorter task completion time during the first few trials. However, as the participants explored the interface and learned how to interact with them in the next trials, the gaze-based modes also performed as fast and accurate. Although the difference between the three modes on the final trial is marginal, it shows the potential for an enhanced learning experience in gaze-based modes. Numerical data may not completely show why this happened and what led people to behave differently as they get more familiar with the tasks. However, the observations and interview data helped to understand the reason behind this. When users start working with the interface, their prior experience in the real world provides a background to affect their perception of the tasks. Since the users use their hands to move objects in the real world, they felt that using their eyes was unnatural and strange for moving the objects. Therefore, the task completion time for Drag & Drop was lower in the first few sessions. However, as they explored the interface, they learned how to interact with gaze-based modes. It is also confirmed based on the descriptive data and participants’ feedback. They performed better in Eye-Gaze & Pinch after 10 trials. The reason behind this is that they felt more control over the task when they could use their hand while using their eyes to precisely point to a correct target location. In contrast, they needed to manually move objects and move around the environment to obtain high accuracy in Drag & Drop. They also mentioned that Eye-gaze & Voice was not as convenient as Eye-Gaze & Pinch due to voice detection issues and less control over the task. They also mentioned feeling frustrated when they had to manipulate objects in Eye-gaze & Voice after an inaccurate placement.
There are also some limitations in this study. First, the research may not be generalizable to the whole population since we are not testing the interface for a specific application or user population. Participants who took part in this study may never use these interactions or have the intention to use them. Since the experiment is a highly controlled in-lab experiment, it imposes some limitations regarding ecological validity. The results could have differed if it had been a more contextual type of methodology. Finally, since the HoloLens 2 was the only device used in this study, it cannot be claimed that the same results will be obtained using a different device.
For future research, objective and subjective ways such as gaze data collection and questionnaires will be used to better understand how eye gaze will affect the workload or whether this workload is related to eye movement for interaction or eye strain due to the use of an AR headset.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.