
Abstract
We aimed to develop a software tool that can determine the “tone of a room” in virtual meetings. Our prototype, Kaleidoscope, uses preexisting machine learning and deep learning libraries to analyze the expressed emotions from individuals in an online meeting, and turn that data into an overall analysis of group tone through novel analytic tools. Results from human participants, asked to identify emotions observed from online meeting videos, are used to validate and refine the prototype. The Kaleidoscope prototype currently achieves an overall accuracy greater than 70%, more than double that of human-to-human agreement; and demonstrates the unique capability of identifying the group tone of a meeting. Future extensions could provide facilitators real-time emotion tracking and group tone assessment, paving the way for technology-assisted interventions to combat group polarization and other problematic group dynamics.
Keywords
Introduction
Virtual meetings have become ubiquitous in present day work. We aimed to develop a software tool that can determine the “tone of a room” in virtual meetings. Assessment of the overall tone of a group can eventually lead to better facilitation of meetings and more productive communication through interventions designed to moderate the group tone. Several software tools exist that detect individuals’ emotions from facial expressions or audio. However, these tools have not been utilized together or in group settings to determine the tone of a group from the collective moods of individuals.
Individuals in working groups tend to experience similar levels of affect, which can lead to an overall group affective tone (Bartel & Saavedra, 2000; Collins et al., 2013). When one group member expresses a negative emotion, it may result in other group members also expressing that emotion. A 2016 study on group tone showed how group affective tone can impact a working group’s performance outcome. They found that a more positive group tone was related to higher performance (Paulsen et al., 2016). These findings demonstrate the importance of the prototype: the ability to identify group affective tone will be beneficial to group leaders and facilitators, as well as the group’s performance.
Existing software has shown great promise in terms of being able to comprehend an individual’s emotions based on facial expressions, but little work has been done to address group affect and interactions. To reduce the training and testing time of the neural networks that are required to perform such a computationally intensive task, the current prototype heavily relies on pre-existing libraries from these emotion-detection software tools. In addition to facial expressions and audio, our prototype considers motion and postural cues from the individuals in the meeting, such as the degree of head tilt, eyes open or closed, hand positions and gestures, and more. Through the inclusion of audio, facial expressions, and postural cues, this software will be able to provide an accurate description of each individual’s emotion. We then consolidate these data within individuals through novel analytical processes and, finally, uniquely combine across individuals for group tone output. We validated and refined the prototype output through a series of human-subject research studies.
Our goal through this project is to create a working prototype that can determine the group tone in a virtual meeting by analyzing the emotions of individuals simultaneously and using novel analysis tools to determine group tone. A major benefit of this prototype over human observation is the ability to collect data and analyze all the humans in the meeting all at the same time. Humans have limited attention and a general bias to attend to the speaker or other salient participants. Processing data for all participants at all time points provides a distinct advantage. We view this prototype as the first step to real-time detection and assessment of group tone, with the potential to inform either human facilitators or for autonomous intervention.
Related Work
Previous work has shown great promise in terms of software being able to comprehend an individual’s emotions based on facial expressions, but when it comes to group affect and interactions, little work has been done. Fernández Herrero et al. (2023) created a prototype that analyzes a video taken from a web cam and reports on the emotions seen in participants’ faces. The tool’s accuracy was tested by presenting participants with activities, watching their faces, and then having them self-report their emotions. The tool achieved 70% accuracy, though only 60% of their recorded data was usable—their AI could not detect emotions in the other 40%. Our prototype aims to build on this idea by being robust enough to detect faces of different ages in a variety of settings, even those with poor lighting and video quality.
The current study uses six basic emotions: anger, disgust, fear, happiness, sadness, and surprise (Ekman, 1992) and we also report them collapsed into positive and negative categories (Flynn et al., 2020).
Methodology
We conducted four studies using human participants (N = 323) to validate and refine our Kaleidoscope prototype. We used videos created by professional improv actors based on general scripted elements (Rashmi et al., 2024) we designed with positive, negative, or mixed resolutions. For each study, we report prototype-to-human agreement (looks for agreement from humans for all prototype output), human-to-prototype agreement (starts with human responses and checks prototype output), and human-to-human agreement for group tone and emotional change detection.
Materials
Kaleidoscope Prototype
Our prototype, Kaleidoscope, uses preexisting machine learning and deep learning libraries to analyze the expressed emotions from individuals in an online meeting and turn that data into an overall analysis of group tone through novel analytic tools. The prototype consists of three separate parts: video analysis, audio analysis, and a synthesizer, which pulls the results from the video and audio analyses together to create a comprehensive analysis of group tone and individual emotions throughout the meeting. To build the prototype, we relied heavily on pre-existing tools to reduce the amount of programing, training, and testing time. See Supplemental Materials for details.
Testing Videos
Ten videos were created for the human-subjects research experiments. Three videos are scripted to have positive resolutions, three to have negative resolutions, and three to not resolve (mixed resolution). These videos were created by a group of professional improv actors based on general scripted elements we designed. Overall, 14 different actors appeared in these videos, typically between four and five at a time. Actors had various backgrounds, distances from the screen, methods of recording, and demographics.
Kaleidoscope Analysis Toolkit (KAT): Leveraging Emotions to Investigate Dynamics Overall (LEIDO)
We needed a consistent method for analyzing the prototype against the participant data we had gathered. We therefore developed an analysis tool that outputs the degree of agreement between the prototype’s output and participants’ responses. First, we needed to match the format of participants’ responses using the prototype’s data. Participant responses are organized as a list of objects, where each object contains a timestamp, an emotion, the strength of the emotion, and the individual or group the participant believes is experiencing that emotion. Therefore, we looked through each of the detailed synthesis outputs—the emotion of each individual and the group at every analyzed timestamp—and searched for each time an emotion appeared at least three times in a row with an average strength above some threshold.
Once we have generated the participant-formatted prototype responses, we compare the prototype responses against each participant’s responses to see with how many participant responses the prototype agrees. A participant response consists of one emotion and one actor. If the participant responded that several actors experienced the same emotion at the same time, we break this response up into one per actor for easier comparison.
This tool also determines how many of the participant-formatted prototype responses are agreed to by at least one participant. Using only the formatted responses and participant responses, LEIDO looks through each formatted response, consisting of a timestamp, an emotion, a strength, and a single actor, and looks in each participant’s response to check for a matching response of emotion and actor within 20 s before or after the prototype’s response.
Finally, this tool compares participant responses to what the overall group tone was at the end of the meeting to the last 30 s of group data from the prototype outputs and compares if the strongest emotion matches participant responses.
KAT: Comparing Human Responses for Internal Substantiation (CHRIS)
CHRIS works similarly to LEIDO in that it takes one participant’s response at a time and looks for a match between all other participant’s responses within 20 s before and after. A match is found if the same actor with the same emotion is reported by two different participants within that time threshold. Every combination of participants is compared, including comparing participant A with participant B and participant B with participant A, which will likely give different accuracies because A and B may have different sizes and the size of the set is used in the formula. For example, if participant A gave 5 responses and participant B gave 10 responses, responses A1, A3, and A4 might match with B4, B6, and B8, giving an accuracy of A to B of 3/5, and it’s possible that B2 and B4 both match to A1, and then B6 matches A3 and B8 matches A4, giving us 4/10 for B to A. CHRIS also calculates the accuracy each participant achieved on the attention check questions. Overall accuracy on the attention check questions was 88% and is not discussed further.
Participants
This online study was conducted through the Prolific platform and participants were compensated for their time. Participants were included if they were adults 18 years or older, residing in the United States, fluent in English, completed the whole study and passed an attention test. Participants (N = 323) were aged 18 to 74 years (M = 38, SD = 13). This study was approved as exempt by the WCB Institutional Review Board and all participants gave informed consent.
Procedure
Participants completed the experiment in an environment and on a device of their choosing. Once a participant chose to complete a study, they would be taken to a website that we created. Typically, a study consisted of a participant watching a video all the way through once, then answering a set of review questions. After they completed the review questions, they would watch the video again, this time using a panel on the right of the page to indicate emotional shifts they detected in the video. Finally, they would be shown a short clip from the video they just watched and asked one final set of questions concerning the emotions in the clip (see Figure 1). Each time an emotion-based question was asked, participants were given six options: Anger, Disgust, Fear, Happy, Sad, and Surprise.
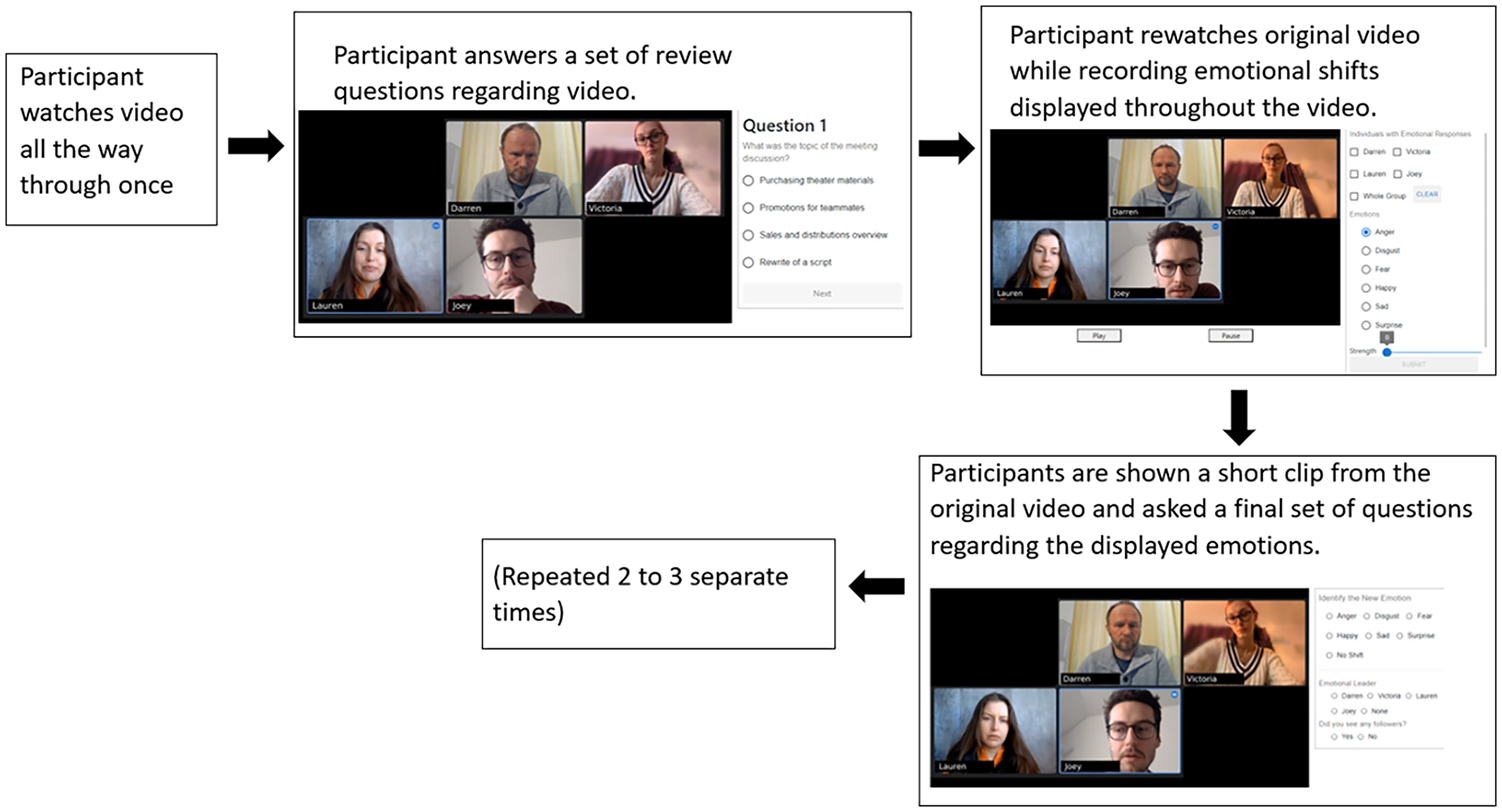
General procedure.
Analysis
Group Tone Detection
In the review portion of the UI, participants are asked “What was the overall group tone at the end of the meeting?” This analysis compares their answers to Kaleidoscope’s data using LEIDO. Kaleidoscope values are taken from the last 20 s of each video. Negative tone is calculated by adding up the values for anger, disgust, fear, and sad; Positive is based on the value for happy. Surprise is ignored in these calculations. Some of the videos were deliberately created not to have a unified group tone at the end, labeled mixed emotions. We expected Kaleidoscope to perform better (have more human agreement) and indicate higher strength when the humans were more aligned at the end of the meeting.
We report the percentage of humans who agreed with the Kaleidoscope output and also report Cohen’s Kappa score, a standard method of calculating interrater reliability where values can be interpreted as follows: values ≤0 as indicating no agreement and .01 to .20 as none to slight, .21 to .40 as fair, .41 to .60 as moderate, .61 to .80 as substantial, and .81 to 1.00 as almost perfect agreement (McHugh, 2012).
Emotional Change Detection
LEIDO takes the output of Kaleidoscope and turns it into a format that matches human responses. It then looks for major emotional changes defined by the strength of that emotion and how long that emotion is the strongest emotion (see Figure 2 for details). We analyzed emotional changes in three ways: (1) By checking human participant responses against LEIDO output, (2) by starting with LEIDO output and looking for human agreement, and (3) by checking agreement between human participants.

Leveraging Emotions to Investigate Dynamics Overall (LEIDO) output explanation.
For each video, CHRIS takes every possible pair of humans and determines how much agreement there is between the two. The human subjects are watching the video and only entering a response when they detect an emotion change so the comparison really contains two levels: did the other human detect anything within that 20 s? and if so, did the emotion detected match with the other human? It is unlikely for agreement to occur by chance.
We report the percentage of humans who agreed with the Kaleidoscope output and Cohen’s Kappa score. See Figure 3 for the list of steps followed to calculate the Kappa scores for each study.
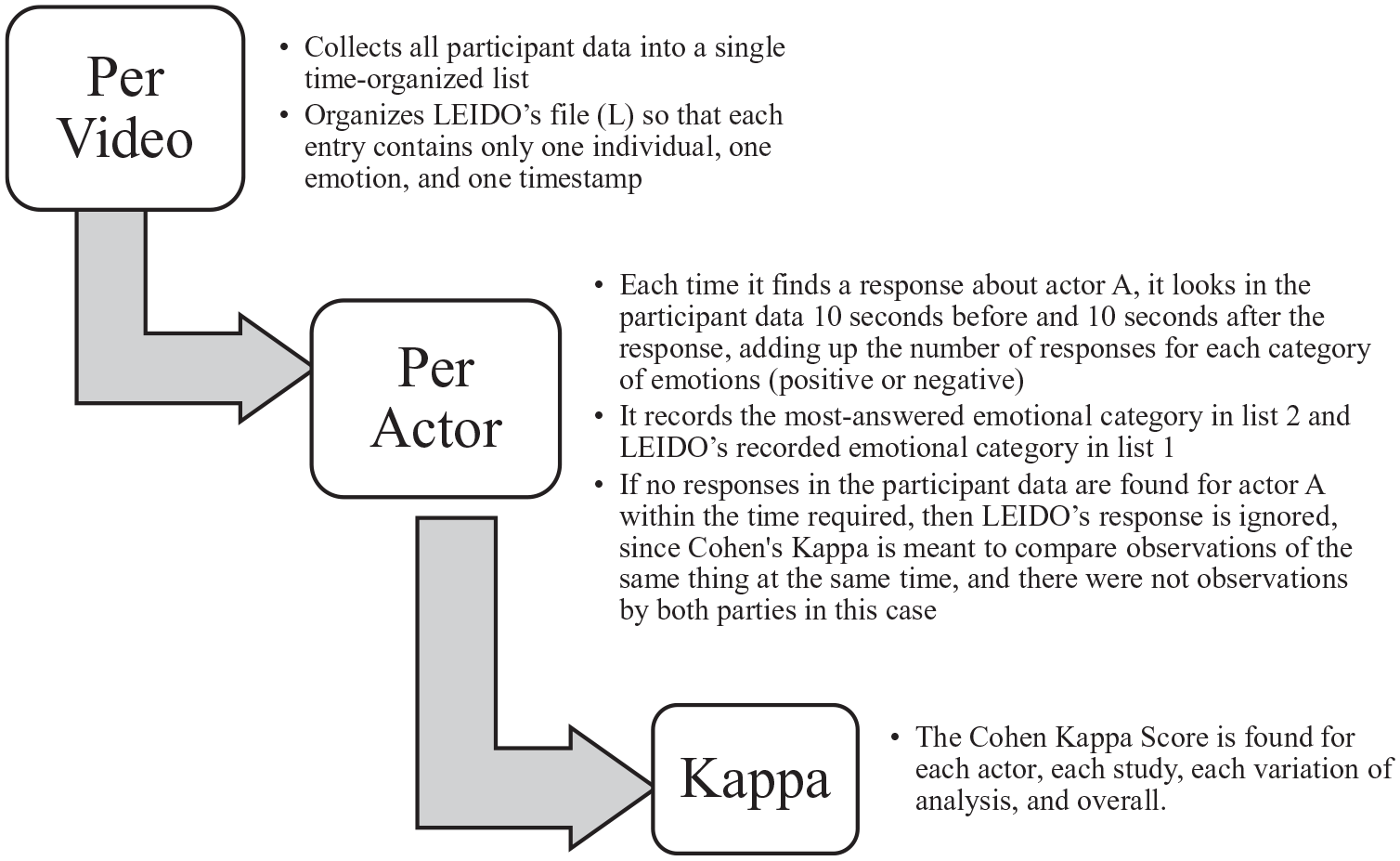
Cohen’s Kappa calculation procedure.
Results
Study 1
In the first study, participants watched three randomly selected videos such that the three videos met certain conditions: there must be one video from each category (positive, negative, and mixed), and exactly one video should be short. All videos were presented to the participants with sound.
Group Tone Detection
Kaleidoscope accurately detected the scripted group tone intention (positive vs. negative) on all six videos with an average 92.35% agreement with the human raters on the positive tone and 83.56% agreement on negative tone.
On the deliberately mixed emotion videos, the agreement rate between Kaleidoscope and human raters was only 44.86%, demonstrating the intended manipulation check when a group’s emotional consensus did not emerge. Likely in these cases, Kaleidoscope is taking an average of all participants while humans are focusing on one or two participants at a time. The overall Kappa coefficient for group tone in Study 1 is .58.
Emotional Change Detection
Across the full set of videos, 59.17% of the human participant responses agreed with Kaleidoscope output. In addition, 60.93% of Kaleidoscope responses were agreed with by at least one participant and 29.48% of Kaleidoscope responses agreed with three or more human participants. Human to human agreement occurred only 30.37% of the time.
Study 2
Study 2 was created to test if Kaleidoscope and humans detect more similar emotions if neither had audio context. In this study, participants watched only two videos that we hand-selected based on them having the most consistent emotional mix-ups between Kaleidoscope and participants in Study 1. This modified study presented participants with a silent video and the side panel used to indicate emotions.
Group Tone Detection
Kaleidoscope accurately detected the scripted group tone intention (positive) with the full set of indicators with an average 92.30% agreement with the human raters who viewed the video without audio content. Kaleidoscope accurately detected the scripted group tone intention (negative) with a face-only analysis with an average 58.18% agreement with the human raters who viewed the video without audio content, but not with the full set of indicators. Overall Kappa coefficient for group tone in Study 2 is <.01.
The difference between Kaleidoscope analysis in Study 1 and in Study 2 is the elimination of vocal intonation. This resulted in only one of two videos being accurately designated positive or negative based on their scripted group tone at the end. The positive video was accurately classified but without including vocal intonation in the analysis, Kaleidoscope classified the negative video as positive.
Emotional Change Detection
Across the full set of videos, 67.14% of the human participant responses agreed with Kaleidoscope output using face and motion analysis. In addition, 72.77% of Kaleidoscope responses were agreed with by at least one participant and 44.06% of Kaleidoscope responses agreed with three or more human participants. Human to human agreement occurred 24.84 % of the time.
Study 3
After the second study, we made the final modifications to the prototype. We added sentiment analysis to help break ties between emotions with similar strengths and we updated the synthesizer’s analysis of motion data to more closely rely on research. All of these updates were fine-tuned using the data from Study 1 and tested during this study. Study 3 followed the same format as the first study except participants were presented with the two videos that had the highest level of human-to-human agreement from Study 1.
Group Tone Detection
Kaleidoscope accurately detected the scripted group tone intention (positive vs. negative) on all four videos with an average 97.37% agreement with the human raters on the positive tone and 78.25% agreement on negative tone. On the deliberately mixed emotion videos, the agreement rate between Kaleidoscope and human raters was higher than Study 1, at 70.62%. The overall Kappa coefficient for group tone in Study 3 is .98 (almost perfect agreement).
Emotional Change Detection
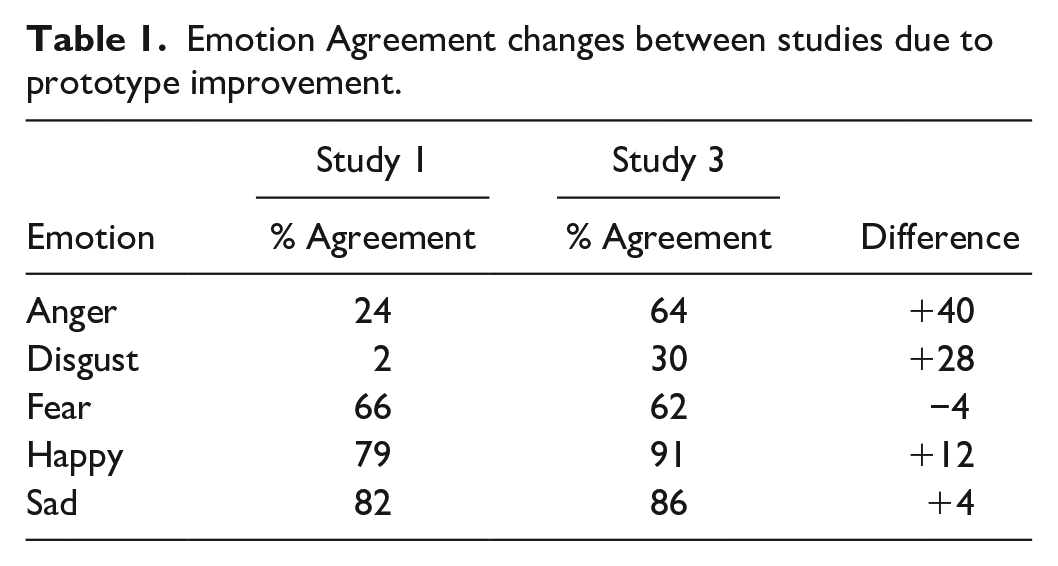
Across four videos, Kaleidoscope agreed with 70.10% of participant responses. Table 1 depicts the changes in individual emotion agreement from Study 1 to Study 3 due to prototype improvements. Approximately, 75.63% of Kaleidoscope responses were agreed to by at least one human, and 49.46% of Kaleidoscope responses were agreed to by at least three humans. Human to human agreement occurred 29.95% of the time. With sentiment analysis added to the prototype, 73.10% of participant responses were agreed to by Kaleidoscope, 77.19% of Kaleidoscope responses were agreed to by at least one human, and 52.63% of Kaleidoscope responses were agreed to by at least three humans (see Table 2).
Emotion Agreement changes between studies due to prototype improvement.
Summary of emotion change results.
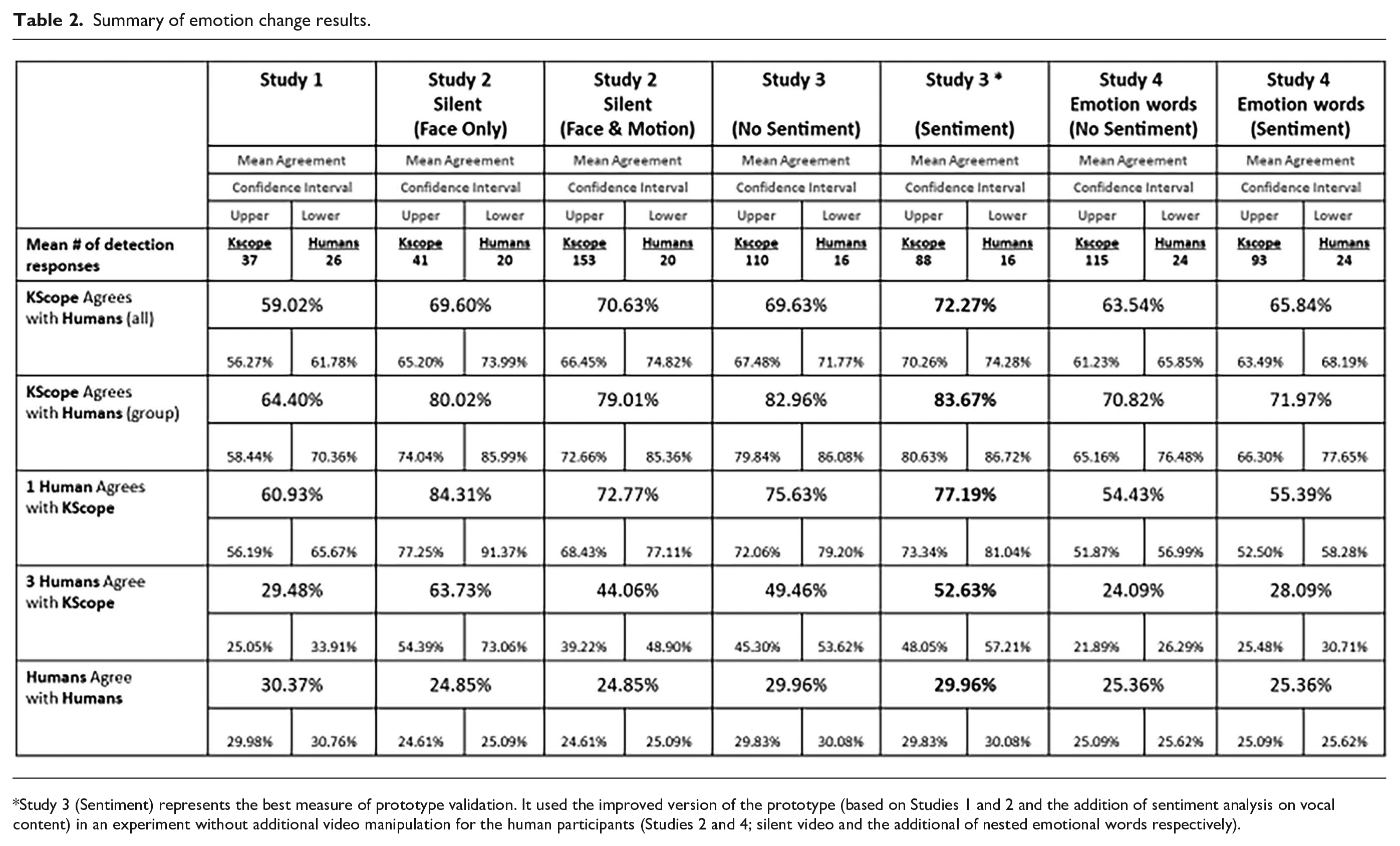
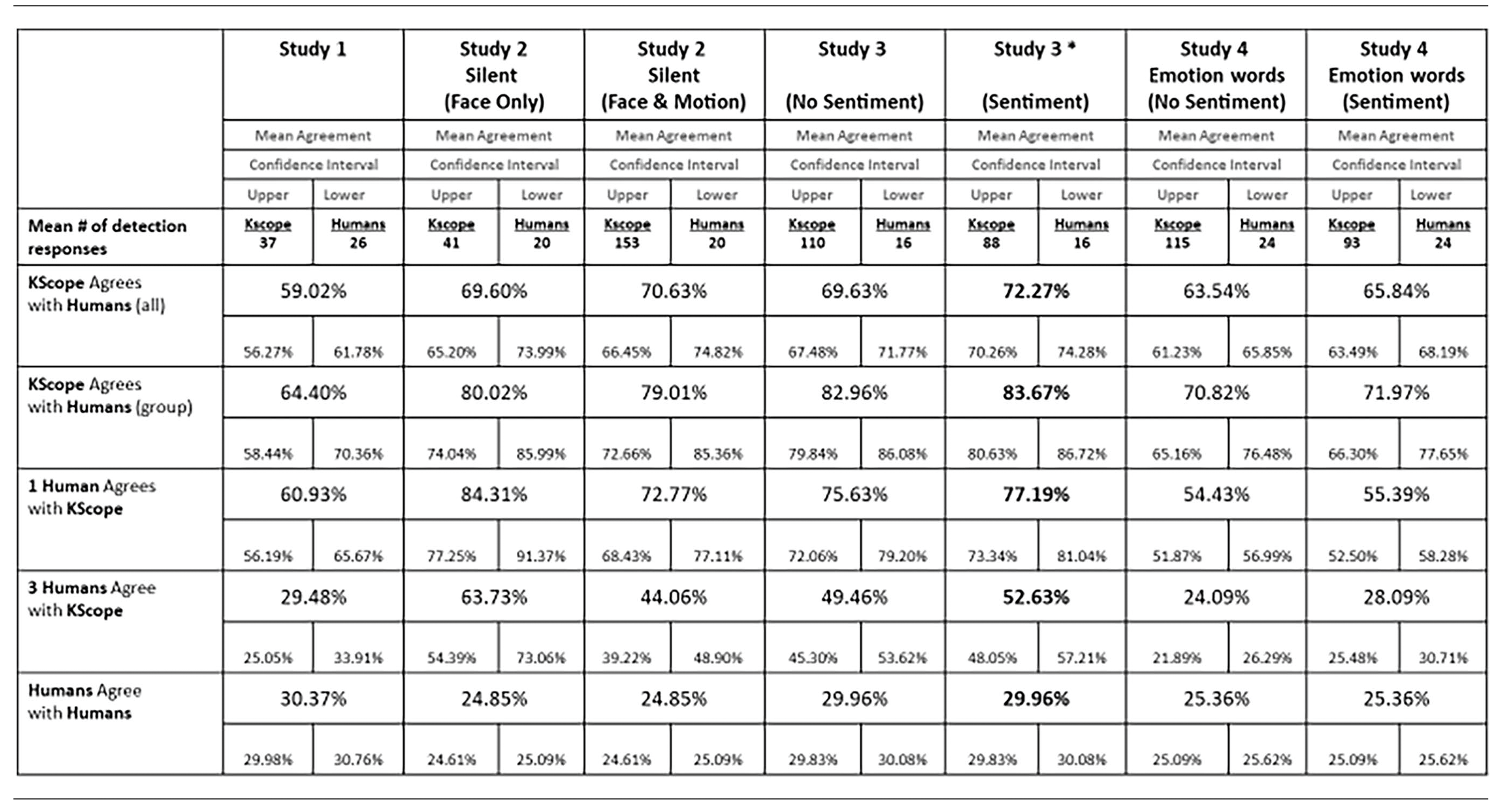
Study 3 (Sentiment) represents the best measure of prototype validation. It used the improved version of the prototype (based on Studies 1 and 2 and the addition of sentiment analysis on vocal content) in an experiment without additional video manipulation for the human participants (Studies 2 and 4; silent video and the additional of nested emotional words respectively).
Study 4
In the first three studies, the human-to-human agreement was very low. Some participant responses to long-form questions mentioned the lack of options and how they didn’t know how to categorize some emotions they observed. We hypothesized that humans may not agree on the broad categories and may show higher agreement with each other (and the prototype) if given more options. For Study 4, we provided participants with 25 emotions, nested into the original 6 provided in the other studies (see Figure 4).

Study 4 nested emotions.
To choose the more fine-grained emotions for this experiment, we looked through all the human free responses from the previous studies including the question that prompts participants to describe any emotional shifts they saw during their first viewing of the video, the question asking participants about group tone at the end of the video, as well as answers to the “Other” text field. We listed all of the responses that varied from the original six emotions. We then researched sources that categorized more fine-grained emotions into Ekman’s six emotional categories (Demszky et al, 2020; Plutchik, 2001; TenHouten, 2023; Wang & Zong, 2021). After we came up with this list, we chose three to four emotions from each major category (see Figure 4) based on their frequency of appearance from previous participants and coverage of the variations within each main emotion. The analysis of Study 4 data is still based on the six categories of emotion but we hypothesized that participants would respond more often and use “other” (incomparable to Kscope output) less frequently, increasing both human to human agreement and prototype agreement.
The format of the study was the same as Study 1: each participant went through the basic study format three times, with randomly chosen videos meeting the two conditions stated above. In this study, when participants watched the video while reporting emotions, as soon as they began to report an emotion, the video paused to give them a chance to answer without missing another emotional shift.
Group Tone Detection
Kaleidoscope accurately detected the scripted group tone intention (positive vs. negative) on 5/6 videos (one positive video was misclassified), with an average 93.33% agreement with the human raters on the positive tone and 81.95% agreement on negative tone. The overall Kappa coefficient for group tone in Study 4 is .65 (substantial agreement).
Kaleidoscope accurately detected the scripted group tone intention (positive vs. negative) with an average 63.81% agreement with the human raters on the positive tone and 81.95% agreement on negative tone. On the deliberately mixed emotion videos, the agreement rate between Kaleidoscope and human raters was 70.62%, demonstrating the intended manipulation check when a group emotional consensus did not emerge.
The addition of new emotion words nested within the original six emotion words (see Figure 4) produced the desired reduction in “other” responses from humans to 1.52% (CI [0.04%, 3.00%]) compared to Study 3 (4.11%; CI [1.89%, 6.34%]). However, the increase in human choices did not improve the human-to-human agreement or the human to prototype agreement from Study 3 to Study 4 (see Table 2) as hypothesized.
Emotional Change Detection
Across the full set of videos, 66.49% of the human participant responses agreed with Kaleidoscope output. In addition, 55.39% of Kaleidoscope responses were agreed with by at least one participant and 28.09% of Kaleidoscope responses agreed with three or more human participants. Human to human agreement occurred only 25.35% of the time.
Discussion
The Kaleidoscope prototype currently achieves an overall accuracy greater than 70%—more than double that of human-to-human agreement—and demonstrates the unique capability of identifying the group tone of a meeting. A primary advantage of the prototype is reliance on simultaneous monitoring of all individuals within the meetings. The prototype produces, on average, 25 more emotional change detections per meeting than a human observer.
We used two studies to refine the prototype and observed a 20% improvement in agreement. Study 3 best represents the current prototype. Kaleidoscope accurately detected the scripted group tone intention (positive vs. negative) on all four videos with an average 97.37% agreement with the human raters on the positive tone and 78.25% agreement on negative tone. The overall Kappa coefficient for group tone in Study 3 is .98 (almost perfect agreement).
We also validated emotional change detection through agreement with human participants. With sentiment analysis added to the prototype, Kaleidoscope agreed with 73.10% of participant responses. Around 77.19% of Kaleidoscope responses were agreed to by at least one human, and 52.63% of Kaleidoscope responses were agreed to by at least three humans. Human-to-human agreement occurred only 29.95% of the time.
To our knowledge, Kaleidoscope is the first prototype to accurately identify group tone in a virtual meeting. The current work also introduces a novel approach to validating deterministic prototype output with human responses. The detection advantage of the prototype over human observers highlights the importance of reliance on software to capture the whole picture (every frame) of emotion changes.
Future Work
Future extensions could provide facilitators with real-time emotion tracking and group tone assessment, paving the way for technology-assisted interventions to combat group polarization and other problematic group dynamics. Effectively assessing group tone using a combination of facial expression, posture, gesture, vocal intonation, and sentiment analysis from a group of individuals represents a novel contribution to the field and opens the possibility for performance enhancement in group work through real-time assessment and intervention. Accurate detection of emotional changes opens up a plethora of opportunities for passive data collection using video monitoring. The output provided by Kaleidoscope could be used to identify features of software that produce negative affect without having to ask the user for explicit feedback. These pain points in software design could be addressed early in the design process.
Human-machine teaming is becoming a ubiquitous part of work and life. This prototype represents an early step toward real-time assessment and adjustment of machine teammates to their human counterparts in ways that are uniquely human-to-human right now. A human teammate may choose to provide more or less information, provide a little extra guidance or help, or task teammates differently based on intuitive human perception of emotional state. This adjustment may, in fact, change overall outcomes for the team. We suggest that providing machine teammates with these same (or better) capabilities to adjust features (e.g., information presentation, load, or transparency) based on human affective state will lead to higher trust, more fluid teaming, and ultimately superior performance.
Supplemental Material
sj-docx-1-pro-10.1177_10711813241260746 – Supplemental material for Kaleidoscope: Detecting the Tone of the Room
Supplemental material, sj-docx-1-pro-10.1177_10711813241260746 for Kaleidoscope: Detecting the Tone of the Room by Kaitlyn Choy, Jennifer McVay, Victoria Romero, Gillian Baseri, Nate Deml and Scott Warner in Proceedings of the Human Factors and Ergonomics Society Annual Meeting
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no external financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.