
Abstract
It is challenging to design complex interfaces that support efficient visual searches. It requires understanding how numerous sources of information contribute to attentional selection, along with an understanding of the tools and tasks used to study visual search. This work is intended to examine visual salience, a pre-attentive process often overlooked in traditional design approaches. Although the importance of visual salience in task-driven searches has been debated, recent evidence suggests this stimulus-driven property contributes to the guidance of attention. Computational modeling has proven effective in predicting the influence of salience (e.g., N-SEEV and Attentional Priority models). With advances in this area of research, continuing examination of the applications and limitations of computational salience models is warranted. Therefore, the present work also examines the predictive power of computational models in displays like web pages and mobile interfaces. Emphasis is placed on the role salience should play in optimizing interface search efficiency.
Statement of Purpose
Designers typically want their system displays to be usable. In other words, users ought to be able to interact with systems safely, efficiently, and intuitively. A well-designed interface capitalizes on users’ natural perceptual capabilities. This is only achievable by understanding the cognitive processes that underly visual search. Visual search is supported by an array of complex cognitive mechanisms, but it is also characterized by notable resource capacity limitations. Naturally, capacity restrictions result in selection of a subset of available visual information for further processing (see classic review: Johnston & Dark, 1986). Therefore, understanding what factors influence attentional selection becomes critical for predicting search efficiency.
The present work is meant to provide an overview of stimulus-driven influences from a Cognitive perspective, recognize the tradition of salience modeling in Human Factors, and explore how salience can be revealed in displays. An exhaustive review of computational salience models is beyond the scope of this proceeding as that would cover a broad multidisciplinary literature. Instead, we will highlight models developed to support designers. More specifically, those models that can be used to improve search efficiency in interfaces like webpages and mobile interfaces. A discussion of the strengths and weaknesses of these models provides direction for future research.
Guidance of Visual Attention
Role of Stimulus-Driven Influences
Designers strive to create products that guide users effectively through an interface, but many are unaware of influences arising from pre-attentive stages of processing (Treisman & Gelade, 1980). With the ability to predict these influences, designers could leverage this fast and low-resource stage of processing to improve designs. For instance, research has shown that co-locating task-relevant information with salient visual features reduces search times and often facilitates successful task completion (Wolfe, 2007; Wolfe & Horowitz, 2017). Salient features are those that are visually unique relative to their surroundings (Duncan & Humphreys, 1989; Parkhurst et al., 2002). Some examples of high salience are apparent, like bolded text amongst non-bolded text. Text is typically uniform making bolding a simple way to attract the reader’s attention. However, many interfaces are rich with visual media. This obscures points of high salience as multiple feature dimensions are in play. Given this complexity, designers are often forced to make their best guesses about which regions are salient or depend on a computational model to reveal the salience distribution. Among the features that contribute to salience, transient signals that exogenously attract attention (Yantis & Jonides, 1984) like flashes or sudden onsets are typically ranked the highest in attentional priority. Because these signals are apparent to designers and they do not add insightful value to the usage of salience models, they are not discussed further in this work.
The world we operate in is overwhelming, but attention regulates what enters awareness. Attention is guided by two low-level, early influences to cope with our conscious capacity limitations. One influence, visual saliency (Itti et al., 1998), impacts humans uniformly (an exception being those with vision-related abnormalities like colorblindness). A second influence comes from culturally based schemas learned during previous interaction experiences (c.f., Chun, 2000; Malcolm & Henderson, 2010). These schemas can reflect design conventions (J. D. Still & Dark, 2010, 2013); they act to prioritize certain interface regions over others. Salience models have been developed to accommodate both types of influence; they can be used to identify the highest salient regions likely to be viewed first (J. D. Still, 2018) and to provide a ranking of attentional deployment. The latter of which is much more difficult to achieve.
According to Wickens and McCarley (2008), a “computational model guided solely by bottom-up salience calculation can do a reasonable job of simulating human search behavior (Itti & Koch, 2000), but models incorporating a top-down component perform better (Navalpakkam & Itti, 2005)” (p. 71). We agree that top-down influences have large effects on visual search performance. But, accounting for enough top-down information to make accurate predictions is often not practical, particularly for items associated with a large number of tasks - consider the possible tasks for something as simple as a website homepage. Regardless, salience still guides attention. Even so, the amount of control salience exerts over attention compared to an individual’s task and goals has been the subject of much debate in the Cognitive literature (for seminal discussion, see Luck et al., 2021).
Brief Overview of Attentional Capture Theory
Beyond transient signals (e.g., blinking lights), certain visual features can automatically capture attention and serve as a singleton. Wolfe and Horowitz (2004) identified a variety of these guiding attributes. They suggested that some features were undoubted (e.g., color, motion, orientation) while others were probable (e.g., shape, break in a line, direction of curvature) in their ability to automatically capture attention. A group of researchers provided evidence that attentional capture can occur regardless of the task, suggesting that salience can exert influence independently of other top-down influences (c.f., Jonides & Yantis, 1988; Theeuwes, 1993). However, other researchers examined the claims of independence and discovered boundary conditions (c.f., Folk et al., 1992). For instance, they demonstrated that capture was contingent on the task attentional set. After decades of debate, we are starting to see some resolution. At least, we see enough resolution for practical application to move forward.
According to Luck et al. (2021), “the debate has undergone [a] significant transformation, partly as the result of growing evidence that an inhibitory process can sometimes prevent attentional capture even if a stimulus produces a priority signal (Cosman et al., 2018; Gaspelin & Luck, 2018, 2019; Vatterott et al., 2018; Weaver et al., 2017)” (p. 2). Although individual explanations for these effects may vary, all research camps agree that singletons are suppressible when there is a small set size and none of the elements are highly salient. Taking Theeuwes’ viewpoint, singleton suppression can occur in small display searches as a result of learning. Both reactive and proactive suppression result from regular experiences with distractor features and/or spatial locations (Theeuwes, 2010). Observers can learn that a location or feature is irrelevant, which produces rapid disengagement during searches. Wang and Theeuwes (2020) explored the top-down feature suppression theory further. They replicated Gaspelin et al.’s (2015) four item display showing the suppression effect. However, in larger displays with 6 and 10 items, the traditional stimulus-driven effect returned; there was no singleton suppression. From a practical perspective, this means that designers creating typical displays with more than four items, they do not need to worry about inhibitory processes and can follow a traditional understanding of stimulus-driven influences. Simply put, recent findings in this area suggest that in typical displays (those with more than four items) all salient elements, transient or feature-based, influence attention regardless of task demands.
Computational Models of Salience
Historical Implementations in Human Factors
The Human Factors literature often highlights the importance of considering visual salience, especially, in alert design. For instance, Steelmann and colleagues, integrated a computational salience model into Wickens et al.’s (2003) SEEV model (Steelman-Allen et al., 2009). The SEEV model attempts to account for four dimensions influencing attention: Salience, Effort needed, operator’s Expectancy, and task-releVance (SEEV). The updated N-SEEV includes the processing of static visual saliency by adopting Itti et al. (1998). This goes beyond the traditional SEEV dimension of color to include the feature dimensions of intensity and edge orientation. They showed a good fit between model predictions and pilot’s overt attention.
Still and colleagues have also shown that a saliency model can predict fixations within web pages (Masciocchi & Still, 2013; J. D. Still & Masciocchi, 2010) and mobile interfaces (Stills et al., 2020). Further, salience continues to guide attentional deployment even during a naturalistic task like e-commerce product searches (J. Still & Still, 2019). Web developers can employ a salience model instead of depending on their understanding of visual hierarchy. Traditionally, designers have relied on heuristics like those provided by Faraday (2000), to gain insight into element visual dominance across an interface. Unfortunately, there is limited empirical evidence supporting the effectiveness of these heuristics within displays (Grier et al., 2007). For example, J. D. Still (2018) showed Faraday’s heuristics do a poor job of predicting initial fixations. However, he did reveal that spatial positioning and visual distinctiveness were the best predictors. These considerations can be computationally implemented in a salience model that includes a convention map instead of relying on an individual to interpret and apply the heuristic.
Interface-Oriented Models: Web Page and Mobile
The employment of a salience model can be intimidating. A screenshot of an interface is used to render a corresponding saliency map that provides predictions about where users will fixate. To complicate matters, not all saliency models are created equal and most models do require the employment of MATLAB to render the computation. A seemingly useful web-based implementation has become popular in the last decade; unfortunately, according to J. D. Still et al. (2016), the saliencytoolbox implementation does not perform above chance level performance. In our experience, it is best to employ the traditional Itti et al. (1998) implementation; we recommend the simple version provided by Harel et al. (2006). This Itti et al. model produces a saliency map that predicts the relative salience of different regions within an image. It first extracts feature channels -intensity, color, and orientation. Then, the difference of center-surround is calculated for each feature channel and is normalized. These feature maps are combined to form a single saliency map with each pixel value ranging from 0 (unlikely to be salient) to 100 (very likely to be salient). These maps were designed to predict fixations in images of nature scenes, home interiors, urban scenes, and computer-generated fractal images (Parkhurst et al., 2002). The present research focuses on two models that build on the traditional salience model. Other recent examples found in the computer science literature do not fit into this discussion of saliency – they focus on explainability and crowdsourcing data (Cheng et al., 2023; Samuel et al., 2021).
The Attentional Priority model adapts a saliency model (Itti et al., 1998) to web pages by accounting for unique spatial biases. These spatial biases can manifest as conventions, learned from common design patterns, that implicitly guide users’ expectations. Conventions are best elicited by observing users’ interactions with an interface (Still et al., 2015) as opposed to asking individuals to introspect about them. The convention map for the Attentional Priority model was generated using Masciocchi and Still’s (2013) fixation database. The map reflects a viewing pattern that roughly resembles a combination of top left bias with an overlayed F viewing pattern. Their work suggests that in the final attentional priority map salience should contribute 60% of the weighting while the remaining weighting is assigned to the convention map.
The Mobile Interface Attentional Priority model also adopts the saliency model (J. D. Still & Hicks, 2020) and, like the Attentional Priority model, it includes a convention map. The unique mobile interface convention map resembles a railroad-like pattern. Although mobile displays mostly fall within the fovea and do not require many fixations, surprisingly, saliency still drives attentional selection. According to Still et al. (2017) the saliency model was able to predict the deployment of attention across the first six fixations within a mobile screen. Stills et al. (2020) also demonstrated that target saliency impacts tablet search efficiency. Participants found higher salience targets faster than lower saliency targets on a tablet.
Current Models: Strengths, Weaknesses, Future
In the rare case that a display is uniform, salient elements do appear to pop-out (e.g., a single yellow button among red buttons). In design, it is seldom the case that an interface element is on a uniform background and pops out visually. Instead, we view displays like those in Figure 1 where it would be difficult-to-predict distribution of salience across the display. The highest points of salience are not available through introspection and we cannot simply assume certain characteristics will be salient in all contexts (e.g., red or bold text). Salience is emergent; it is not an independent property associated with an element. The major strength of employing a computational saliency model is to reveal the underlying distribution of salience across a display.
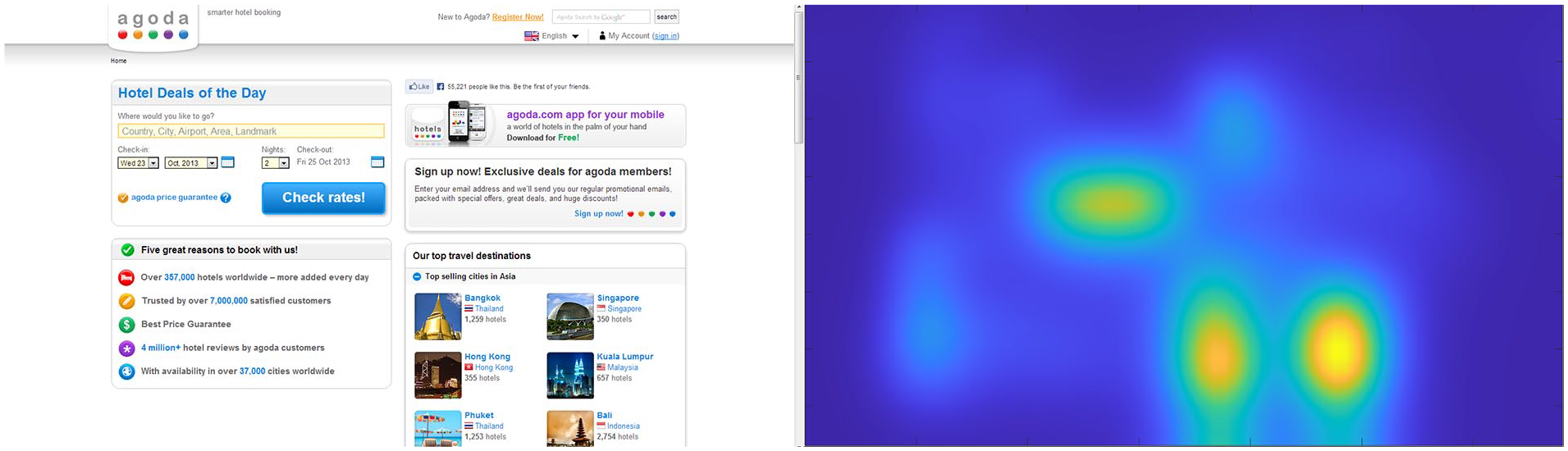
Example of a webpage interface and its associated salience map.
Current salience models are proficient at detecting the most salient regions in a display; thus, predicting early fixations is what the models do best. With this information, designers can at least verify critical elements are, in fact salient. This information can also help designers determine entry points (i.e., where a user will begin their search). However, the ability to predict scan paths—the order in which an individual will search these areas of high salience—within interfaces is still underdeveloped. It is possible that further examination of relative salience could be used to improve these predictions. The models can rank how salient an element is relative to others, perhaps this information can be leveraged.
While salience maps identify specific areas of high salience, they also happen to reveal other areas likely to benefit from attentional resources. For example, J. Still and Still (2019) found that items near an area of high salience benefit from higher search efficiency even though those items are not high salience themselves. With this knowledge designers have a solution in cases where attributes of critical features cannot be changed; they can manipulate the salience of a neighboring item to “drive traffic” to the critical element.
Even with these benefits, a critical limitation of current salience models is that they are context-bound. There is no absolute scale of salience. We lack norming data to understand just what those relative differences mean in terms of search efficiency and noticeability. The more designers employ salience as a measurement, the greater our understanding will grow. Along similar lines, there is the question of when to use a salience model in the design process. It cannot be employed during low-fidelity prototype deployment because there simply is not enough visual data to make accurate computations. Future research is needed to reveal the best practices for employment during the design process. While it is possible that it could be used during mid-fidelity, it has only been assessed for high-fidelity products.
Once salience data have been obtained, it can be difficult to know what to do next. The model is only descriptive, it is not prescriptive. That is, the model output will not help the designer know what specific change would increase the relative salience of an interface element. Therefore, even with the use of a salience model, iteration will be needed to reach design goals. Because of this, future models should provide greater transparency. Designers need to know what feature dimensions to manipulate to change the existing salience distribution. Providing insight into the usage of feature dimensions, such as color, is heavily used, but orientation is also available. These technical insights can empower designer decision-making.
Finally, it is imperative to recognize the significant, practical impact, task information has on search efficiency. Across two experiments, J. Still and Still (2019) asked observers to find a product after only hearing the name or after previewing the exact image. Task information (name or picture) and stimulus-driven salience both contributed to search efficiency. However, providing a picture of the target instead of the name improved search times by 714 msec, which is a much greater benefit than the 188 msec saved by being near an area of higher visual salience. While additional research is needed to further quantify the relative contributions of task information and salience, this clearly demonstrates the strong contribution of task. From a practical perspective, though, it is worth remembering that to effectively design for task-relevant information you have to know what an individual is looking for. This is not always possible. Salience, by contrast, is a constant influence therefore, designers ought to appreciate the influence of salience and use it to their benefit.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.