
Abstract
Recent works on pose-agnostic anomaly detection (PAD) have addressed the challenge of identifying visual defects when the test object’s pose is unknown, that is, when test images may depict the same object but in arbitrary orientations not seen in the reference anomaly-free dataset. In this unsupervised setting, models rely only on the knowledge of non-defective samples and their task is to detect anomalies appearing anywhere on the object surface. Current state-of-the-art approaches, such as OmniPoseAD, SplatPose, and SplatPose+, have advanced the field by introducing dedicated algorithms and frameworks for pose-agnostic anomaly detection. The present work consists of an engineering-oriented integration effort aimed at adapting existing PAD approaches to realistic industrial scenarios in which background clutter must be addressed for practical deployment. Two main contributions are provided: first, a simulated dataset for pose-agnostic anomaly detection with realistic industrial scenes; second, a complete pipeline that handles the introduced scenarios. Experimental results, carried out in comparison with the state-of-the-art SplatPose+ and measured in terms of pixel-level AUROC, AUPRO, image-level AUROC, and
Introduction
Modern manufacturing processes are progressively incorporating automated inspection techniques as part of the shift toward intelligent and data-driven production, with the goal of reducing human intervention in repetitive quality inspection tasks that require significant time and manpower and are susceptible to human error. In this context, research efforts are increasingly focused on developing innovative approaches for visual anomaly detection, aiming to identify structural defects through deep learning and machine vision techniques. Accordingly, this work positions itself within a broader strand of research1–7 that integrates modern machine learning and advanced computational methods into real-world engineering systems, enabling effective and scalable solutions for practical scenarios. More specifically, the present study focuses on an in-line inspection scenario, where products move along a conveyor during the manufacturing process and are automatically analyzed to detect visual defects, determining whether each item meets quality standards or should be discarded.
When dealing with anomaly detection, defective samples are rare, which makes their collection particularly challenging. Moreover, labeling such data is a time-consuming and costly process, often requiring expert supervision. For this reason, several recent studies, such as work 8 have explored strategies to minimize the labeling effort by adopting semi-supervised or unsupervised learning approaches for visual anomaly detection. Beyond the challenges related to data scarcity and labeling, real industrial environments introduce additional sources of complexity that must be carefully considered. In practice, datasets are often imperfect or contaminated with noise, such as variations in ambient lighting or reflections that affect image quality. Furthermore, despite being constrained on a conveyor system, objects may appear with slight pose mis-alignments or rotations, increasing the difficulty of consistent defect detection. Finally, complex and textured backgrounds can introduce visual artifacts that lead to false positives during object segmentation and anomaly identification, an issue that previous studies such as Stauffer and Grimson, 9 García-González 10 have attempted to address through background estimation methods.
The first contribution of this work is a publicly available dataset that simulates, through a synthetic rendering process, an industrial in-line inspection scenario, with objects moving along a conveyor and presenting varied, unpredictable poses, resulting in images with a realistic background that closely resembles an actual production environment. Regarding illumination, a uniform lighting condition was assumed, as the work does not focus on illumination-agnostic detection; nevertheless, the proposed dataset is more challenging than previous ones because it includes background clutter. Then, the aim is to identify surface anomalies that may occur at arbitrary locations on objects with unknown pose. The training dataset is assumed to contain only non-defective samples, while anomalies are artificially introduced as small and subtle defects, to evaluate the robustness of the proposed methodology under realistic and complex conditions.
The second contribution is an anomaly detection pipeline that leverages existing anomaly detection methods based on Gaussian splatting 11 and is engineered to operate on the proposed dataset.
The remainder of this paper is organized as follows. Section 2 reviews the related work. Section 3 describes the dataset and the proposed methodology. Section 4 presents the experimental results, followed by an ablation study. Finally, Section 5 outlines the conclusions of the paper.
Related works
Recent years have witnessed a growing interest in unsupervised 3D anomaly detection, driving the creation of increasingly challenging benchmarks. Early 3D anomaly detection datasets, such as MVTec 3D-AD, 12 Eyecandies, 13 and PD-Real, 14 primarily relied on single-view RGB-D data, providing only partial object observations. Subsequent datasets moved toward complete object representations: Real3D-AD 15 provides full point cloud geometry without blind spots, while 3D-ADAM 16 and Anomaly-ShapeNet 17 further enrich such representations by incorporating RGB information or synthetic reconstructions, respectively. Other dataset like MAD, 18 Real-IAD, 19 and RAD 20 achieve full object coverage through multi-view RGB images, with the latter two addressing more challenging real-world conditions. Notably, MAD was designed for pose-agnostic anomaly detection (PAD), where the object pose is unknown at test time and must be estimated before anomaly detection. PIAD 21 further extends this setup by introducing illumination changes alongside unknown poses, significantly increasing task difficulty. Furthermore, the PCAD dataset 22 bridges the gap between synthetic and real-world benchmarks by combining real multi-view RGB images with corresponding CAD models, enabling more realistic scenarios. The dataset proposed in this work shares with MAD, Real-IAD, RAD, PIAD, and PCAD the use of a multi-view approach, and furthermore consists of rendered images of synthetic LEGO models combined with synthetic yet visually realistic backgrounds.
In parallel, numerous unsupervised approaches have been proposed. Since anomalies are absent from the training set, these methods learn a model of normality solely from normal samples, classifying any deviation at inference time as anomalous. A prevalent strategy is reconstruction-based detection, where models are trained to reconstruct normal inputs but fail to accurately reproduce anomalies, as in works.17,23–27 In addition, several works24,28–31 attempt to leverage RGB information by fuzing it with depth data. In other approaches,32–37 the architecture generates simulated anomalies on normal images for training purposes; it then learns to reconstruct the normal appearance from the anomalous image, and at inference time employs the extracted features to drive the anomaly detection process using the reconstructed normal object as a guide. Other studies38–43 adopt a different approach based on the paradigm introduced by PatchCore, 44 in which features from normal images are extracted during training and stored in a feature dictionary, referred to as a memory bank. At test time, features extracted from the query item are compared against the memory bank, and an anomaly score is assigned based on their distance from the stored features.
Gaussian splatting 11 was introduced as a method for 3D scene modeling using RGB images with known camera poses, which enables rendering images from arbitrary viewpoints. Since its introduction, it has been applied to the PAD problem. The first approaches, SplatPose 45 and IGSPAD, 46 leverage the differentiability of Gaussian splatting to design a pose estimation module that solves an optimization problem with respect to the pose, a strategy that is also adopted in PIAD. 21 In contrast, SplatPose+ 47 departs from this idea and estimates object poses at test time via PnP 48 -based optimization. The latter is then adapted in the proposed pipeline to handle background content, which is not considered in previous related approaches.
The proposed system
The proposed approach builds upon the SplatPose+ framework, which is briefly reviewed in the next subsection. The subsequent subsections detail the proposed dataset and the original pipeline.
Pose estimation and anomaly detection
In SplatPose+, the 3D representation of non-anomalous models is learned through Gaussian splatting, where the scene is modeled as a collection of splats, characterized by parameters such as 3D position, color, opacity and 3D shape.
The training process consists of optimizing the parameters of these splats so that the rendered views of the reconstructed model closely match the input RGB images.
To initialize the Gaussian splatting model, a preliminary 3D reconstruction is obtained using Structure-from-Motion (SfM).49,50 The resulting SfM point cloud is scale-consistent and therefore provides an approximate yet reliable representation of the object geometry; each 3D point, containing only positional information, is used as the initial location of a Gaussian splat. Subsequent optimization refines these splats, enriching them with additional attributes such as color, opacity, and spatial extent.
In addition, SplatPose+ leverages the optimized SfM reconstruction to estimate test-time camera poses via PnP optimization and anomaly detection is then performed directly in the image domain. Specifically, a synthetic view of the object is rendered from the same viewpoint using the learned Gaussian splatting model, which represents the normal, defect-free appearance. This rendered image serves as a reference and is compared with the corresponding real test image. Both images are processed through a feature extraction backbone, and the resulting feature maps are analyzed to measure their discrepancy. Regions showing significant differences between the two sets of features indicate deviations from normality, allowing the detection and localization of surface anomalies.

Methodology
The proposed pipeline is shown in Figure 1 and described in Algorithm 1. In this work, particular attention is devoted to addressing the pose-agnostic anomaly detection problem under conditions that more closely resemble real industrial environments. The main challenge arises from background elements in the test images. Because objects have no fixed pose, neither their pose is known a-priori nor is their arrangement with respect to the background consistent across different objects. As a result, training a Gaussian splatting normal model that includes background content and comparing it to a test image with background is unreliable: even when the object view matches, the background pose does not, and vice versa. To mitigate this, the processing pipeline aims to remove the influence of the background. Accordingly, the Gaussian splatting model is trained on images with a null background, represented by a uniform white surface, as in previous published works. To ensure a consistent comparison between rendered and test images, the test background must be suppressed. This requires an accurate object segmentation and restricting the comparison to the object mask, thereby eliminating background influence.
As will be explained in the dataset section, anomalies can involve missing, modified, or added parts. In the case of missing parts, detection must focus on the region where the part should be. The object mask from the test image is therefore insufficient, because it can exclude the removed part, as would happen in the example shown in Figure 2(a) where the removed part is above the background. Then, it is necessary to also use the object mask from the synthesized normal image, which delineates the expected extent of the part, so that the corresponding area can be analyzed.
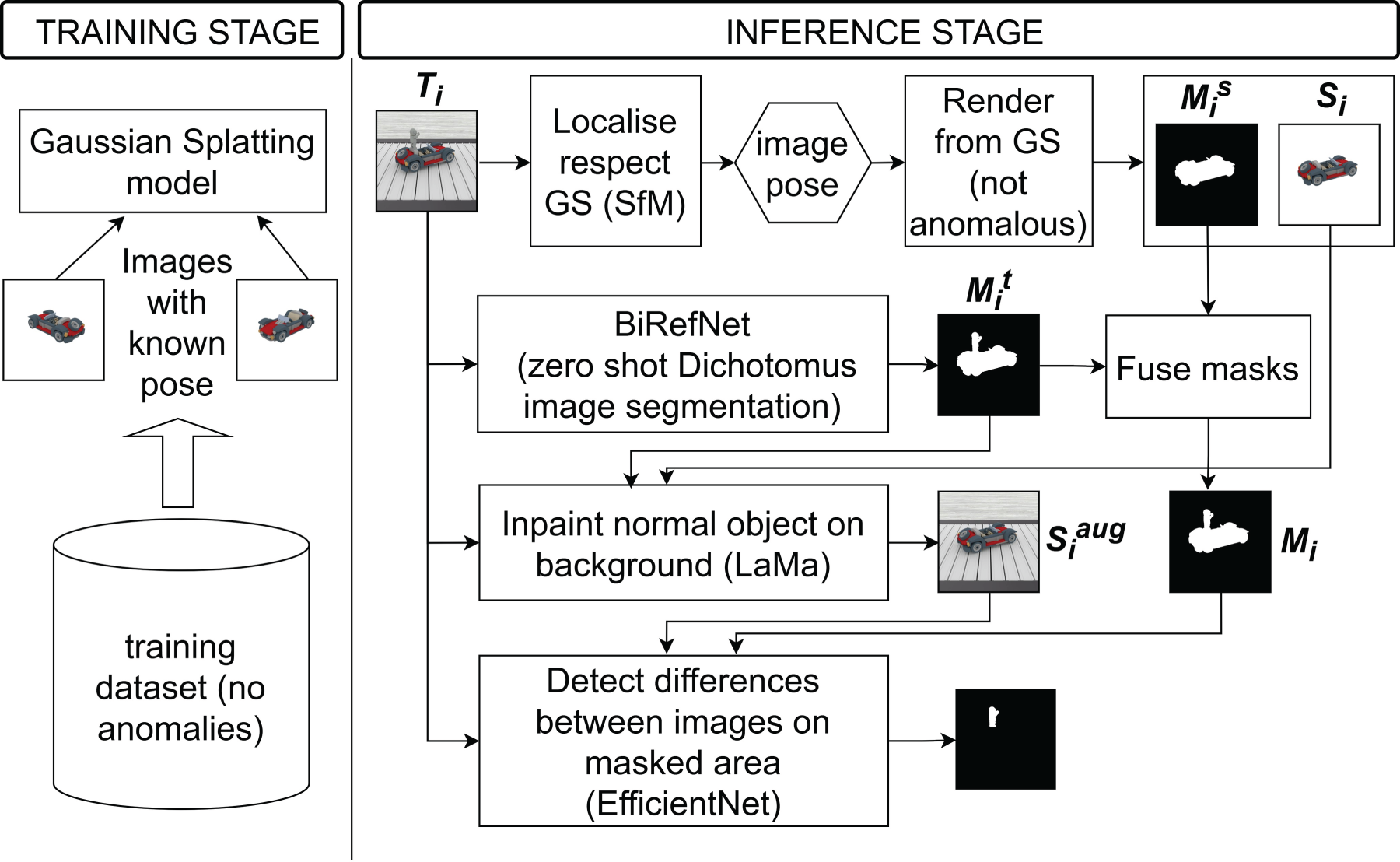
Proposed architecture.
On the contrary, for added parts, relying only on the synthesized normal mask would miss the anomalous region, since anomalies can lie outside the expected support, like in the example shown in Figure 2(b); the test-image object mask must therefore be used to include those extra areas. In practice, the union of the two masks is analyzed: regions present only in the normal mask indicate missing parts, regions present only in the test mask indicate added parts, and discrepancies within the overlap correspond to modified parts.
Formally, let 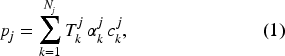
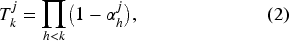

Left: (a) Removed part (mirror) visible against the background (red box). Right: (b) Added defect visible against the background (red box).
Intuitively,
To obtain
This is still not sufficient, as residual errors depend on mask accuracy. In particular, if the mask spills beyond the foreground object, the comparison will include background regions, which may be detected as false anomalies. To mitigate this issue, an inpainting strategy is applied to suppress background content within the comparison region. Specifically, the test image
Finally, the anomaly detection is performed between

From left to right: (a) test image with the anomaly highlighted (box); (b) synthetic normal image; (c) foreground mask; (d) inpainted normal object on the reconstructed background; (e) anomaly detection image.
As described in SplatPose+, an SfM model is built from the training images to initialize Gaussian splatting and to localize test images, using NetVLAD 53 for retrieval, SuperPoint 54 and LightGlue 55 for matching, and hloc 50 for triangulation. The Gaussian splatting model is subsequently trained under the same settings, with 15000 iterations, a densification interval of 1000 iterations, and a spherical harmonics degree of 3.
Anomaly detection is performed as in OmniposeAD,
18
where features are extracted using a pre-trained backbone (EfficientNet
56
) on both the synthesized reference and the test image. In this work, however, the comparison is carried out using the normalized
For background reconstruction with LaMa, the inpainting region is obtained by dilating the mask
Dataset
The dataset used in this work was developed in Blender, 57 which enables the creation of consistent industrial scenarios.
Following the approach introduced in the MAD dataset, the proposed dataset was built using LEGO-based models specifically designed by expert modelers, who provided the original, defect-free base structures. Nine distinct vehicle models were employed which are police car, coupe car, amphibious car, off-road car, tank, desert car, truck, loader and racing car; these models were chosen to represent objects with increasing structural complexity. While simpler models such as the coupe exhibits compact and mostly closed shapes, the amphibious car, the tank, the truck, the loader, the off-road car, the racing car, the desert car introduce more intricate geometries, and the police car model features a high number of detailed parts and open regions. This progression from simple to complex shapes not only increases the number of components but also introduces concave and perforated structures, where background visibility through small openings may occur, potentially leading to false positives in anomaly detection.
For each class, corresponding to one vehicle model, 100 defect-free training images were rendered with known intrinsic and extrinsic camera parameters defining the pose
Additionally, 13 further objects per class were generated for testing and each of them was placed in a random pose distinct from the pose of the training object. Seven of them were modified by adding small, subtle surface defects to simulate realistic flaws. The considered defects fall into the categories of additions, removals, and color alterations, which are implemented by respectively adding, deleting, or replacing LEGO components. Specifically, for each class, two of the modified objects exhibit color changes, two present removed components, and three include added components. The remaining six objects were left intact, representing non-defective items with unseen orientations; this setup was intended to simulate a realistic production scenario in which normal items are also inspected and should not be classified as anomalous. For each test object, 9 RGB images at 800
Percentage of anomalous test images per class.

Percentage of anomalous test images per class.
The modifications were intentionally kept minimal with respect to the overall object volume, so that the proposed method can be evaluated under challenging conditions. An example is shown in Figure 4(a). Moreover, some anomalies were made larger, especially in the case of added parts. This choice was made to account for perspective effects: depending on the viewpoint, anomalies may appear either over the object or over the background as in Figure 4(b). By introducing sufficiently large anomalies, it becomes more likely to include cases where the added parts appear on the background rather than always overlapping the object itself. Indeed, if anomalies overlap just the object and not the background, their detection is simplified, as background clutter is eliminated.

Left: (a) Small added defect (box). Right: (b) Added defect visible against the background (box).
During rendering, the test images included a realistic background, whereas the training images were rendered on a white background. This choice allowed the construction of reference normal models representing only the object of interest, without the background, which would be unnecessary and possibly misleading for the anomaly detection stage. However, to maintain consistent illumination between the training and test data, all renders were produced within the same scene and lighting setup; the training objects were subsequently cropped and placed on a white background, which is a reasonable assumption since training data can be pre-processed offline. The background scene consisted of a conveyor model and a textured floor, designed to avoid monochromatic regions while keeping the setup minimal. The conveyor was modeled as a series of metallic plates, providing a moderately complex yet regular texture. Moreover, for each test object, the conveyor position was kept fixed across its rendered views but slightly shifted between different objects, ensuring that the background pattern remained consistent within the same object while varying across samples. This promotes generalization and reduces background bias.
The following sections present quantitative and qualitative evaluations comparing the proposed method with the state-of-the-art SplatPose+.
Metrics
In accordance with prior works,18,45,47 the evaluation metrics includes pixel-level AUROC, AUPRO, 12 and image-level AUROC, where image-level anomaly score is defined as the maximum of the pixel-wise anomaly map. Higher values of pixel-level AUROC and AUPRO indicate better localization of true anomalies, as explicitly assess the spatial accuracy of the pixel-wise map.
While the previous metrics are threshold-free, qualitative visualization and practical anomaly detection require setting a decision threshold, which in turn enables the computation of the
Quantitative evaluation
Table 2 reports the performance of the proposed pipeline and the per-image inference time for all nine classes, based on experiments run on an NVIDIA RTX-A4500 GPU. The results are reported up to the third decimal digit and this level of precision is required especially for pixel-level AUROC and AUPRO because the anomalous pixel class is unbalanced relative to the non-anomalous class. High numerical precision is therefore required to capture small variations in the detection of fine anomalies.
Proposed method evaluation results and inference times.
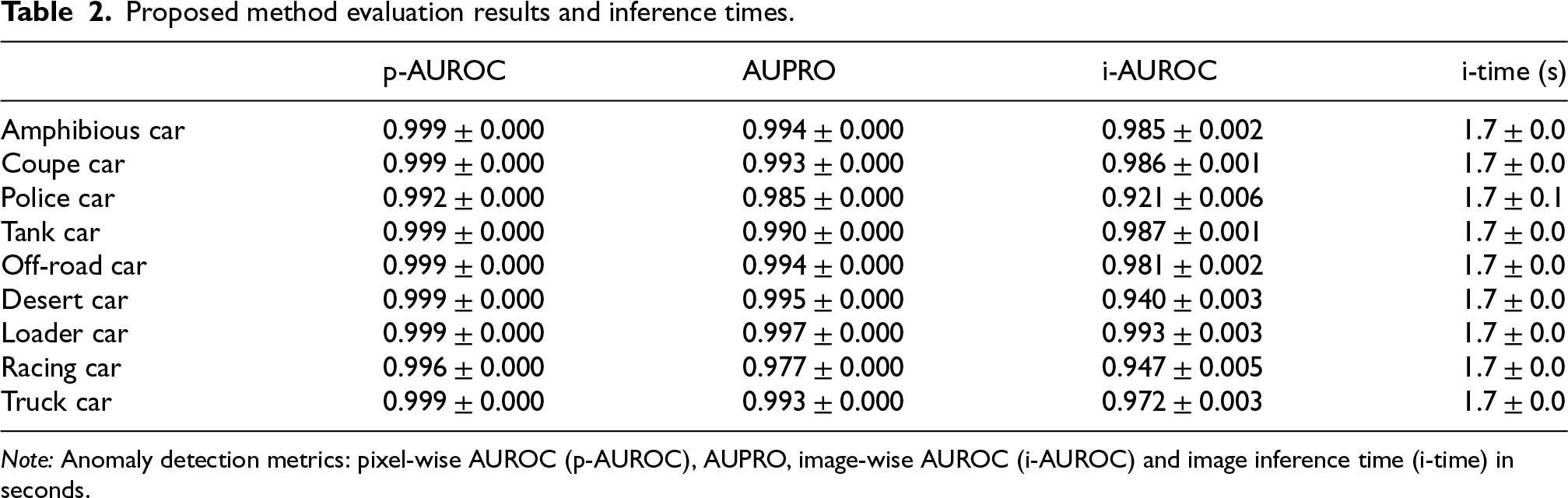
Proposed method evaluation results and inference times.
Note: Anomaly detection metrics: pixel-wise AUROC (p-AUROC), AUPRO, image-wise AUROC (i-AUROC) and image inference time (i-time) in seconds.
To the best of the authors’ knowledge, all existing methods addressing the PAD problem assume that backgrounds are removed from test images. A direct comparison with such approaches would therefore be misleading, as their performance is expected to degrade substantially under the proposed setting, which includes background clutter. Then, to obtain a meaningful point of reference to the state-of-the-art SplatPose+, the comparison is conducted by evaluating SplatPose+ on a simplified dataset with same objects and poses, but with backgrounds removed, whereas the proposed pipeline is evaluated on the original dataset that retains background clutter. The results show that the proposed pipeline attains comparable performance to SplatPose+ in this setting, indicating that any remaining gap is not due to the background-handling challenge addressed by the pipeline, but reflects difficulty intrinsic to the task even under simplified conditions. The resulting scores, are written in Table 3. Table 4 shows, instead, the per-class
SplatPose+
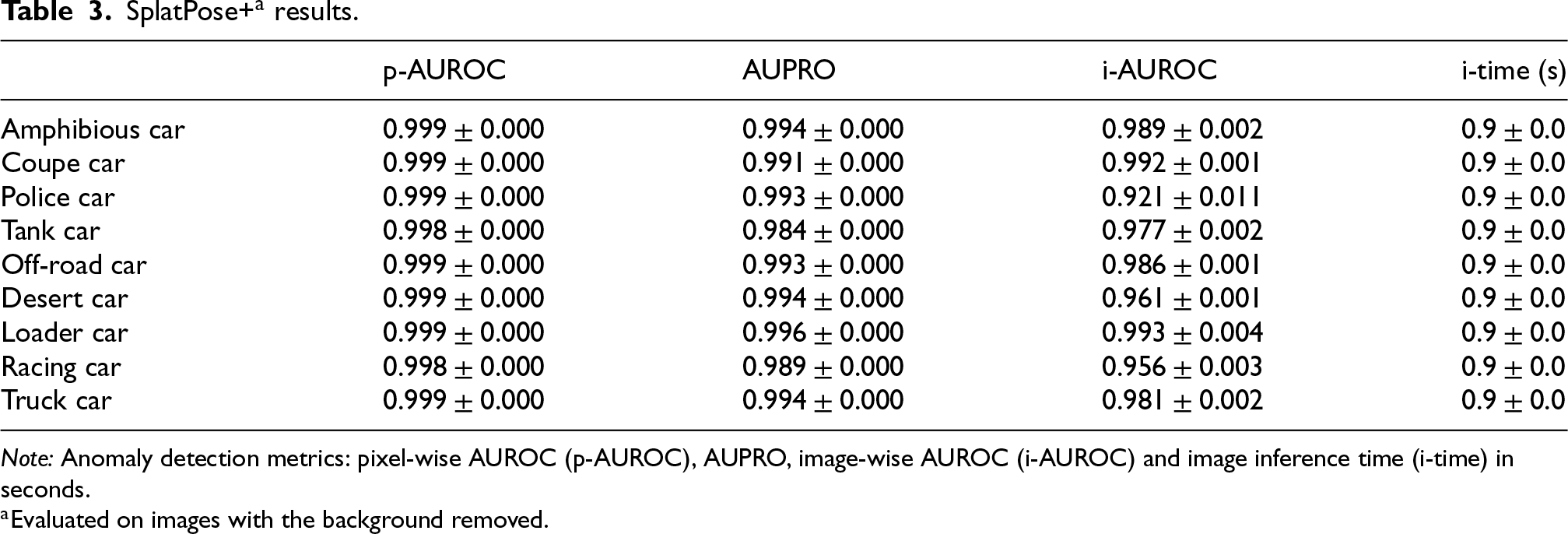
Note: Anomaly detection metrics: pixel-wise AUROC (p-AUROC), AUPRO, image-wise AUROC (i-AUROC) and image inference time (i-time) in seconds.
Per-class
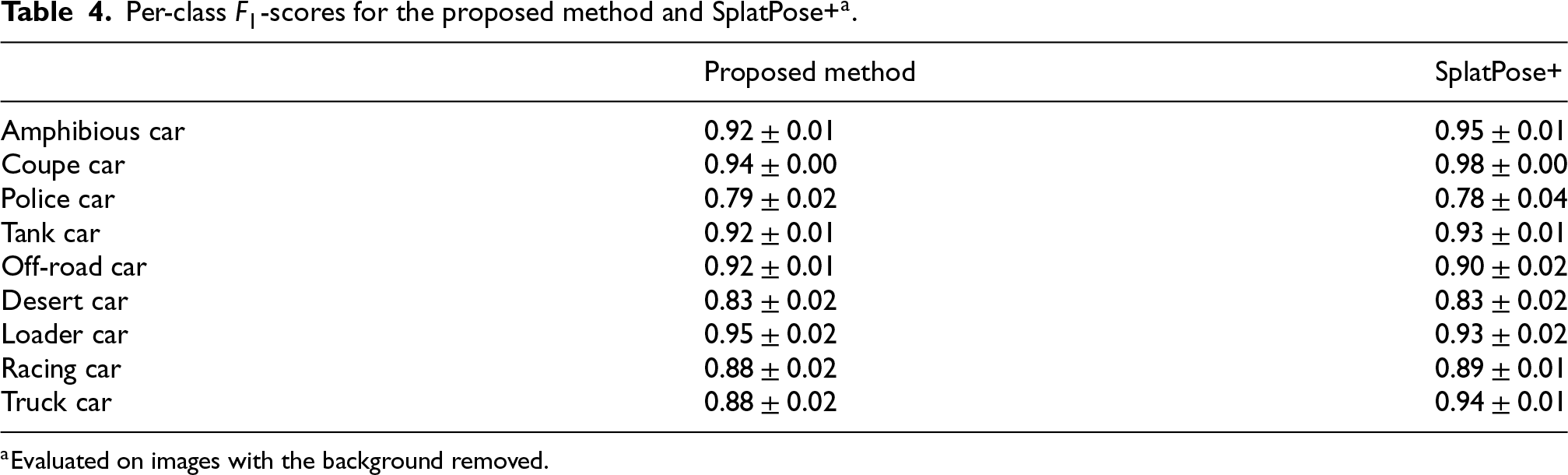
All evaluations are averaged over multiple runs of the same pipeline and results are reported as mean and standard deviation. The variability is intrinsic to the Gaussian splatting technique. During model optimization, new splats may be introduced with a small degree of randomness, which can lead to slight differences across runs even when training on the same data.
Overall, the performances between methods are comparable even though the proposed method is evaluated on original images with background clutter, unlike SplatPose+, which is tested on background-removed images.
The easiest class, coupe car, achieves the best results, as expected, since it is relatively compact and lacks small holes or irregularities in its shape that could degrade the anomaly detection performance.
Conversely, complex objects, such as the police car present fine structural details like small open regions that make accurate detection more challenging, lowering the scores. More specifically, concave regions and small holes may be incorrectly detected by BiRefNet as part of the object rather than as background. In such cases, LaMa is employed to mitigate this issue; however, when holes are located within the object and are very small, the inpainting technique may still be insufficient to accurately reconstruct the background in these regions, as shown in Figure 6. These aspects represent the main limitations of the proposed pipeline. However, SplatPose+ also exhibits limitations when dealing with small holes or concavities, as illustrated in Figure 6. In particular, the Gaussian splatting technique may fail to accurately reconstruct small holes and cavities during training; as a consequence, during anomaly detection, these regions can be incorrectly identified as anomalous, leading to false positives.
The results may appear sometimes slightly inconsistent, since for some classes a higher image-level AUROC does not necessarily correspond to a higher
Regarding computational time, the background subtraction stage implemented using the LaMa and BiRefNet modules introduces an average inference time of approximately 0.8 seconds per class. This is consistent with the results reported in Tables 2 and 3, where the last column shows a difference of 0.8 seconds between the proposed pipeline and SplatPose+.
The masked regions in the bottom row of Figure 5 indicate anomalous pixels obtained by applying the previously defined decision threshold, while the first and second rows show the test images and the synthesized normal images, respectively. Figure 6 highlights, within boxes, examples of false positives and false negatives for the proposed method in the first row and for SplatPose+ in the second row; the third row displays the ground-truth masks. The images show that both approaches can produce spurious or missing detections.

Examples for each class. Top row: testing images. Middle row: synthetic normal images. Bottom row: image with detected anomaly.

Qualitative comparison of detection errors. Examples of false positives and false negatives are highlighted with boxes. Top row: proposed method; middle row: SplatPose+; bottom row: ground-truth masks.
Finally, two ablation studies are conducted. The first analyzes the impact of the LaMa inpainting and BiRefNet segmentation modules. The second reports the results obtained by running the proposed pipeline on background-free images, following the SplatPose+ setting.
Table 6 reports results obtained when comparing test and reference images only within the object mask of the synthesized normal image, which is the mask derived from residual transmittance. Performance remains strong because, in many views, anomalies are small and lie well inside the object rather than near its boundaries, making this mask sufficient in numerous cases. However, this cannot always be assumed: in worst-case scenarios where anomalies occur on the border, restricting the comparison to the synthesized mask misses relevant regions. In such cases, the full proposed pipeline is required to recover the complete comparison area. Consistently, Table 2 shows improved results, as it also addresses the border cases discussed above. Table 5 reports the
Per-class
-scores obtained without employing BiRefNet and LaMa modules.

Per-class
Results and inference times obtained without employing BiRefNet and LaMa modules.
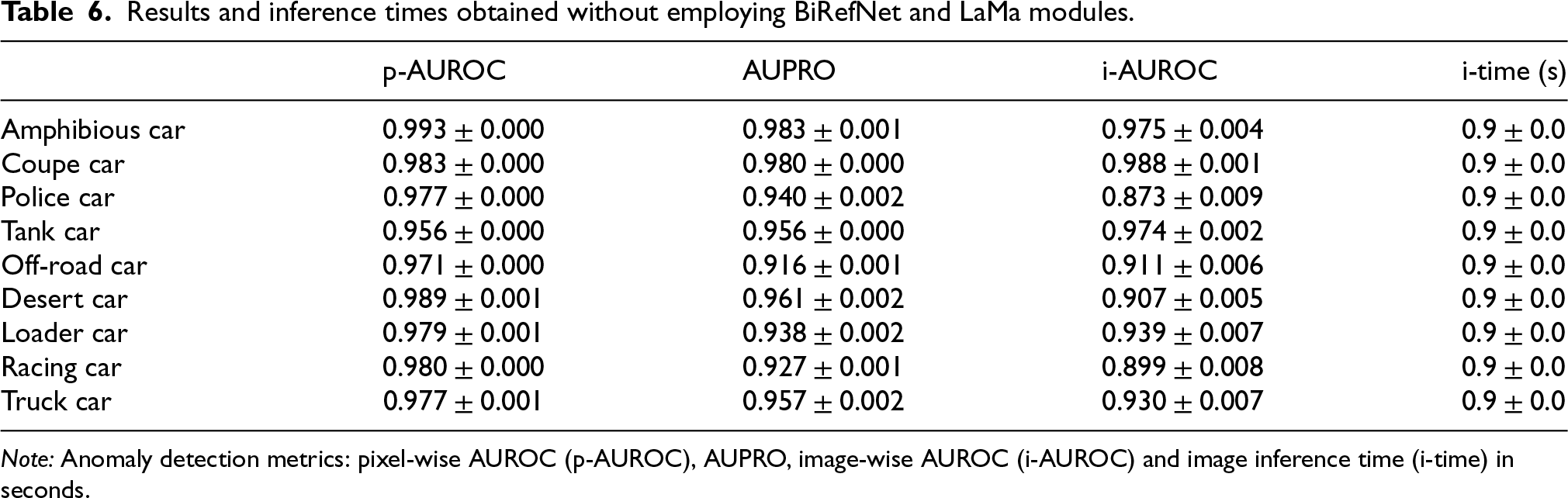
Note: Anomaly detection metrics: pixel-wise AUROC (p-AUROC), AUPRO, image-wise AUROC (i-AUROC) and image inference time (i-time) in seconds.
Table 7 reports the usual performance metrics of the proposed pipeline when applied to background-free images. The results are comparable to those obtained on images with background and to the performance achieved by SplatPose+ on background-free images.
Evaluation results of the proposed method on background-free images.
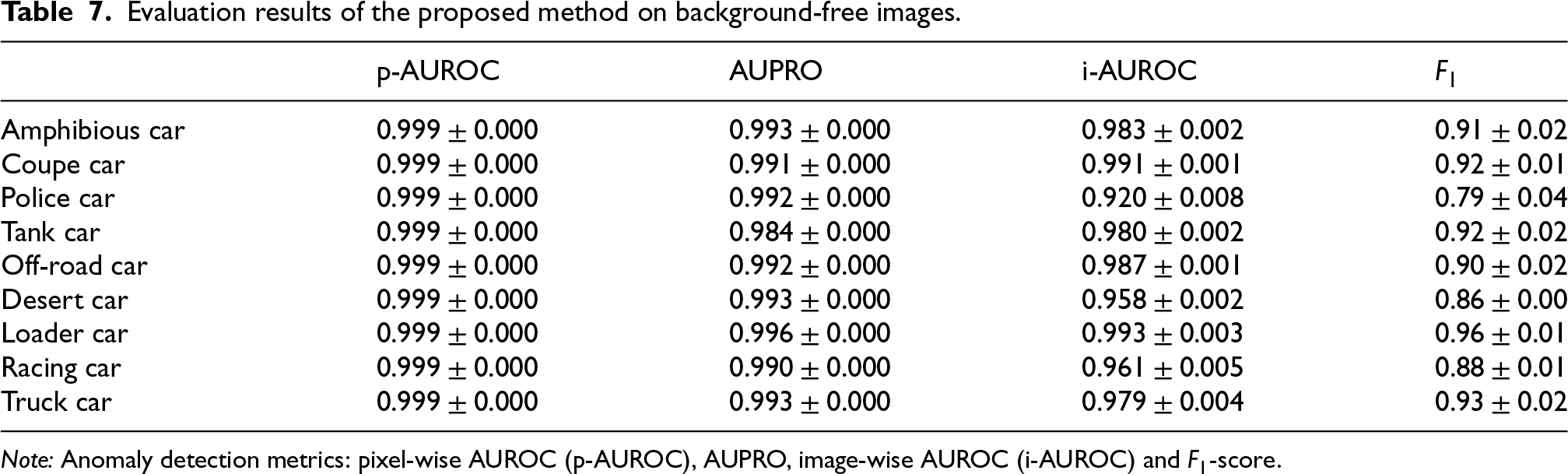
Note: Anomaly detection metrics: pixel-wise AUROC (p-AUROC), AUPRO, image-wise AUROC (i-AUROC) and
A dataset for pose-agnostic anomaly detection was introduced to reflect realistic industrial inspection conditions by incorporating a realistic, yet synthetic, cluttered background, along with a pipeline engineered by integrating existing modules such as SplatPose+, LaMa, and BiRefNet to address the practical constraints inherent in the data The proposed method is able to detect anomalies, although some aspects remain unresolved.
A primary issue concerns the image-level decision rule. Small amounts of random noise can produce false positives, because nothing prevents the noise features from exhibiting large magnitude differences relative to normality. Since the aggregation uses the maximum across pixel scores, a single spurious peak can cause a normal image to be classified as anomalous. Similar failures arise in small surface holes. These regions are difficult to separate from the object, often lie within the object silhouette, and are compared against non-anomalous exemplars that exhibit blank white backgrounds in those holes. This mismatch can introduce false positives. The proposed pipeline limits many of these cases, but performance is not yet perfect. Further investigation is required to refine these borderline scenarios and to improve robustness. Moreover, the computational time could be improved, and further research is needed to reduce it.
This work has some limitations, most notably the fact that the proposed approach is evaluated in a controlled synthetic environment. As a result, there is room for future work aimed at developing a pipeline that is closer to real industrial scenarios, where noise is more pronounced. Furthermore, illumination conditions, which were assumed to be uniform in this study, should be addressed in future work to reduce sensitivity to lighting changes and to variability arising from the temporal degradation of equipment and environmental conditions.
Footnotes
Acknowledgements
The authors gratefully acknowledge the support of Łukasz Leon Grzywacz (https://www.seymouria.pl/) for providing the 3D LEGO-based models used in the dataset. ChatGPT was used exclusively throughout the text for grammatical review (e.g., punctuation, singular/plural agreement, and verb tenses consistency) and to assess sentence clarity; it was not used to generate any original content. This paper was partially supported by University of Udine project on “Piano Stretegico Dipartimentale on Artificial Intelligence” (PSD-AI) (2022-25) project at the University of Udine.
Ethical approval and informed consent
Not applicable. This study did not involve human participants, human data, or animal experiments.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.