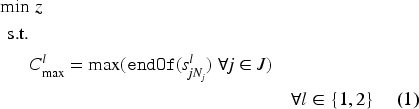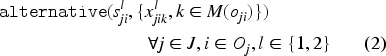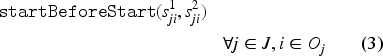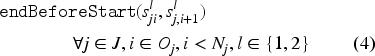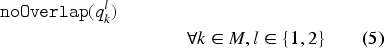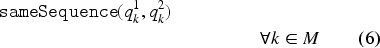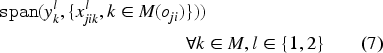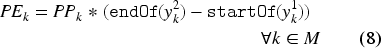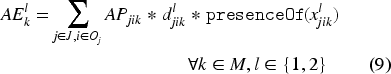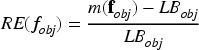This article addresses the flexible job shop problem with interval processing times. Minimising makespan is a well-known scheduling objective that is widely used in many sectors; however, energy efficiency is gaining more importance as climate change intensifies. In this work, we minimise the makespan and the total energy consumption using a lexicographic goal programming approach. A memetic algorithm that is composed of a genetic algorithm and a local search method is developed and tested to solve this problem. The results show that our approach manages to improve the best-known results.
Scheduling problems focus on distributing limited resources across multiple tasks while meeting specific constraints.1 Perhaps the best-known application of scheduling is in manufacturing, for instance, in weapon industry,2 automobile parts industry,3 or steel production.4,5 However, scheduling is also relevant in many other areas, including transportation and logistics,6–8 electric vehicle charging,9 healthcare,10,11 education,12,13 and cloud computing.14 There are many examples of real-life applications of scheduling problems in the literature; for instance, Martins et al.15 propose an algorithm to schedule analytical chemistry tests for a quality control problem of a real-world pharmaceutical company. Another example is an application of scheduling to travel-optimised warehouses in a logistic company where the authors propose a GRASP-based algorithm.16
It is evident that the majority of these problems are intractable due to their inherent complexity. Consequently, precise algorithms cannot be implemented, with the exception of the smallest instances. In light of these challenges, researchers have been developing approximate search strategies that, while no longer guaranteed to achieve optimal results, can provide satisfactory solutions within a reasonable time frame.17
Natural phenomena, such as evolution,18 hydrology and hydrodynamics,19 neurobiological systems,20 or the behaviour of materials,21 have proven to be a fruitful source of inspiration to design such algorithms, often within the field of metaheuristic search. Metaheuristics have also been inspired by mimicry, such as musicians looking for pleasing harmony or animals searching food.22–24 In parallel, the design of metaheuristic methods for hard optimisation problems has advanced considerably with the development of learning methods, sometimes enriching hybrid metaheuristics.25
Within scheduling, the job shop problem (JSP) in its multiple variants constitutes a vibrant field of research simulating practical, technical, and social applications.26 Here, tasks are organised into jobs, so tasks in the same job must be completed in a specific order on specific machines. The flexible job shop scheduling problem (FJSP) is a variant that allows some or all tasks to be executed on multiple machines.27,28 This flexibility results in variability in processing times and energy consumption depending on the machine used.
Even the simplest forms of JSP are NP-hard,29 motivating the use of approximate metaheuristic search algorithms from the field of Artificial Intelligence as solving methods.30,31 These methods work by exploring different possible schedules and evaluating their quality based on criteria such as makespan, energy consumption, due-date satisfaction or machine use.27,32 In particular, memetic algorithms, which combine a metaheuristic with a local search method, are successfully applied to solve these problems.33 To mention but a few, in Mencía et al.34 a JSP with operators is solved using various memetic algorithms, Afşar et al.35 propose an enhanced memetic algorithm to solve a fuzzy variant of JSP, while a different memetic algorithm is used for the fuzzy FJSP.36
Traditionally, scheduling has been concerned with optimising production-related functions, most famously, to reduce the makespan, which is the time required to complete all tasks. However, due to climate change and the need for energy efficiency, there is a growing focus on optimising processes with a consideration for sustainability.37–40 With manufacturing consuming an estimated 37% of global resources,41 it seems essential to incorporate environmental and energy awareness into scheduling processes. In order to ensure the ongoing viability of this fundamental activity and to mitigate the effects of global warming, it is imperative that industry adopts more efficient technologies. These technologies must enable a reduction in energy consumption and emissions without compromising productivity. Consequently, there has been a consistent increase in the volume of research allocated to the domains of energy efficiency and sustainability within the realm of manufacturing engineering.42 Also, according to the 2024 report of the International Energy Agency,43 global data centres are projected to double their electricity consumption by 2026, primarily driven by the growing demand for AI and digital infrastructures. Hence, as cloud computing becomes integral to modern digital infrastructure, energy-efficient scheduling gains more importance.44 Overall, green scheduling seems necessary to achieve the Sustainable Development Goals, in particular to “promote sustainable industrialization” (Goal 9) and “ensure sustainable consumption and production patterns” (Goal 12).45
In most cases, energy-related objectives must be considered in combination with more traditional production-related objectives, such as makespan or tardiness minimisation.46 Perhaps the most common approach in the literature is to assume that all objectives are equally important and use a Pareto approach.35 However, in many production environments objectives of different nature have different priorities and hence a hierarchical approach is more appropriate. For instance, a recent review47 suggests that economic objectives minimising costs and maximising profits are of primary importance to decision makers, with criteria related to minimising the environmental impact of production processes coming in second place.
Traditionally, all parameters in scheduling problems are assumed to be deterministic and well known in advance. However, in reality, many factors such as processing times can vary due to machine or human influences. Uncertainties in increasingly complex environments should be addressed to properly handle the variable nature of various elements of the scheduling process. Uncertainty management will be particularly important in Industry 5.0 solutions that will require close integration of operators and technical systems.48 In the literature, uncertain task durations are typically addressed with stochastic models, where these durations are represented by probability distributions. However, gathering sufficient data to estimate an accurate probability distribution is often not feasible, and, even if such an accurate distribution is available, the associated computational load can be excessive. An alternative is to use fuzzy numbers to model uncertain processing times, particularly in FJSP, which requires less detailed information and offers computational efficiency.36,49,50 Furthermore, in those scenarios, where prior knowledge is very limited, interval-based models can be employed, using only lower and upper bounds to describe task durations. These intervals can be interpreted as uniform probability distributions in the absence of more specific information. Although simple, this modelling allows to obtain more robust solutions, with a performance that is less susceptible to slight variations in task durations.51
Despite the fact that the interval approach is a straightforward uncertainty model, the existing body of literature in interval JSP and FJSP is limited. A genetic algorithm is proposed to reduce tardiness in a JSP with interval due dates and process durations.52 A hybrid methodology integrating particle swarm optimisation and a genetic algorithm tackles a FJSP with interval processing times in a larger framework of integrated planning and scheduling problem.53 Multi-objective interval JSPs are examined in two different papers.54,55 In the first one, an artificial bee colony algorithm is used to minimise both makespan and total tardiness in JSP with flexible maintenance and non-resumable jobs. In the latter, carbon footprint and makespan are minimised lexicographically in a dual-resource restricted JSP with heterogeneous resources using a dynamic neighbourhood search. More recently, Díaz et al.56 consider a JSP with interval task durations and propose a genetic method to minimise makespan. The same problem is addressed employing a variant of artificial bee colony algorithm that incorporates seasonal behaviour of honeybees for further intensification24 and with a memetic algorithm, combining artificial bee colony with local search.57
In this work, we tackle a multi-objective flexible job shop problem with interval processing times. A lexicographic goal programming approach is adopted to minimise makespan and total energy consumption and a memetic algorithm, composed of a genetic algorithm and a local search method, is developed to solve this problem. Hill Climbing (HC) and Tabu Search (TS) algorithms are tested on mono-objective versions of the problem along with tailored neighbourhood structures. Our contributions can be summarised as follows.
Three new neighbourhood structures are defined and tested for each objective
Two local search methods combined with a genetic algorithm have been developed and tested to solve the mono-objective problems
The approaches that give the best results for the mono-objective cases are integrated to solve the multi-objective problem with lexicographic goal programming
The experimental results show that the memetic algorithm manages to improve the best-known solutions of this problem.
We formally define the problem in the Problem Definition Section. Later, we describe our solution approach in detail in Solution Methodology and present the experimental results in the Experimental Results Section. Lastly, the conclusions of our work are given in the Conclusion Section.
Problem definition
In the deterministic job shop problem (JSP), a set of jobs, which can be denoted by , should be completed. Each job is composed of a set of tasks that need to be processed on a specific machine from the set of machines . Moreover, tasks in a job should be processed in a particular order, often referred to as job precedence constraints.
In the flexible variant of JSP, a task can be processed on a machine from a set of alternatives denoted . The processing time of a task depends on the machine on which it is performed and is denoted by . The tasks are non-pre-emptive: they cannot be interrupted until they finish, and a machine cannot work on more than one task at a time.
Processing times are not the only parameters that depend on the task and the machine in the energy-aware version of the FJSP. The amount of active power needed by a machine changes depending on the task it is executing, and therefore it is denoted as . Besides the active power, each machine needs a certain amount of passive power, , while it is on.
A feasible solution of this problem has two components: an assignment of every task to a machine and a feasible schedule , composed of the starting times of all tasks on the selected machines whilst complying with all the other constraints. In our study, two objectives are considered in a lexicographical manner, i.e., the primary objective is to minimise the makespan, whereas the secondary objective is to minimise the total energy consumption.
In real-world settings, the time needed to complete a task is often uncertain and not precisely known beforehand. Usually, only rough estimates of the duration are available. When only the minimum and maximum times are known for each task, this uncertainty can be represented using a closed interval, denoted . In this work, we denote the FJSP with interval uncertainty as Interval Flexible Job Shop (IFJSP).
To calculate our objective functions on a schedule with interval processing times, we require arithmetic operations like addition and maximum between intervals, as well as the addition and multiplication between a scalar value an an interval.58 Assuming that and are two intervals, the addition is defined as and the maximum is calculated as . Given an interval and a value , the addition and product are defined, respectively, as and . When comparing values, closed intervals are not endowed with a natural ordering. Instead, various ranking methods are used in the literature.59. In a recent interval scheduling research work,24 several ranking methods are compared in terms of robustness, supporting the extended use of the midpoint ranking (MP). This has become the most widely used comparison method, where if and only if , with .
The objectives
In this work, we optimise a multi-objective IJSP using lexicographic goal programming. Our primary objective is to minimise makespan, which is the earliest time by which all jobs have been completed. Denoting the starting time of the last task in job by , we can define the makespan as . Since it is an interval, we use the midpoint ranking to choose the best makespan value.
Our second objective is the minimisation of energy consumption. In the literature on manufacturing systems, there are many works that propose sophisticated energy-consumption models.60–62 However, in the energy-aware scheduling literature, simpler methods have been proposed to incorporate energy impact into schedule optimisation. For instance, González, Oddi and Rasconi63 focus solely on the energy consumed when machines are idle, whereas a more recent work assumes that all machines remain on from the beginning until the last task is completed.36 In this study, we assume that each machine starts in the off state and does not consume energy until an operator switches it on. It is reasonable to assume that workers act conservatively, activating the machine only when there is a potential need for it, specifically at the earliest possible starting time of the first task assigned to it, , denoted as , where . The machine remains on until it is no longer needed, shutting down after the completion time of its last assigned task, , represented by , where based on assignment and schedule . During this period, the machine consumes passive power per unit of time. The passive energy consumption of machine is therefore given by . When machine is active and executing a task , it consumes power at a rate of per unit of time. The active energy consumption of is calculated as , with , . Notably, active energy depends on the machine and the task duration, which remains uncertain in this problem, whereas passive energy is deterministic, based on the worker’s decision to turn machines on and off. The total energy consumption is then defined as . Additionally, we can consider the passive energy as being divided in two parts: the energy consumed while potentially executing a task and the idle energy, which is consumed when the machine is idle with certainty.
Constraint programming model
Constraint programming (CP) is a mathematical modelling paradigm that involves defining a problem in terms of constraints that must be satisfied. Problems are typically modelled using variables along with their domains and constraints. CP solvers explore possible variable assignments and use inference techniques, such as constraint propagation, to reduce the search space and efficiently find solutions.64
IBM ILOG CP Optimizer65 (CPO) is a CP solver where a task can be represented by an interval variable that has a starting point and a duration (It should not be confused with the uncertainty of processing times, which is modelled as intervals.). Since the duration of a task on machine is an interval in our problem, i.e., , we need to model the potential starting time of every task as a pair of optional interval variables, namely and with the corresponding durations. In other words, if task is processed on alternative machine , its starting time would be the interval [, ] and its ending time would be [, ]. Moreover, task can be processed on one machine only, and hence only one pair of these optional variables would be present in a feasible solution. The actual starting time of task in the selected machine is modelled by the interval variables , and these will have the same value as the present in the solution. Another type of variable that is introduced in CP Optimizer to facilitate the modelling of a machine is sequence variable which is defined as an unordered set of interval variables. More precisely, since tasks are modelled as interval variables, a machine is modelled as a sequence of tasks () whose order is decided during the resolution phase. Another pair of interval variables, namely , are introduced to compute the passive energy consumption of a machine , . The sets, parameters and variables of the CP model are given in Tables 1 to 3 along with their descriptions, respectively.
The sets of the problem.
Set
Description
set of jobs
set of tasks of job
set of machines
set of machines that can process task
The parameters of the problem.
Parameter
Description
lower and upper bounds of the duration of task on alternative machine
active power use of machine to process task
passive power use of machine
Variables of the CP model.
Variable
Description
interval variables representing the potential starting time of task processed on alternative machine
interval variables representing the starting time of task
interval variables representing machine
sequence variables containing and , respectively
integer variables corresponding to lower and upper bounds of makespan
active energy consumption of machine while processing the task
passive energy consumption of machine while it is on
total energy consumption of machine
Besides interval and sequence variables, CP Optimizer also introduces several expressions that allow the user to easily define scheduling constraints. The expressions and return, respectively, the starting and ending times of an interval variable . The constraint ensures that, if the interval variable is present, then only one of the interval variables of the set is present and it starts and ends at the same time as . The expressions (or ) guarantee that the interval starts (or ends) before the starting time of . The constraint prevents the intervals in a sequence from overlapping. While modelling scheduling problems using CPO, a machine is represented as a sequence of tasks, hence this constraint enforces that a machine is a unary resource. The expression obliges the sequences and to follow the same task order. The constraint states that the interval variable spans over , that is, it starts at the same time as the first present interval in the set and ends with the last one. Finally, is a binary expression with value 1 if the interval variable is present in the solution and 0 otherwise.
The resulting model for our problem is as follows.
The objective function can be equal to or depending on the problem to be solved. Note that in the Experimental Results Section constraints (1)-(10) have been applied to minimise the makespan () and to minimise the total energy () individually. These mono-objective models are referred to as and , respectively.
Equation (1) defines the makespan, which is calculated as the maximum of the completion times of all tasks per component . Constraint (2) makes sure that only one of the alternative intervals among all is selected (or present) and starts and ends with . In other words, it guarantees that a task is processed on one of the alternative machines. Constraint (3) establishes the order between the components of to ensure the order between the lower and upper bound of the starting times. Constraint (4) sets the task precedence order in each job. Constraint (5) ensures that there is no overlap between the tasks that are processed on the same machine. Constraint (6) forces a unique processing order for the sequence variables and . Due to constraint (7), the interval variable starts with the first task that is processed on machine and ends at the same time as the last task finishes on machine . More precisely, the interval variable spans the machine and facilitates the computation of its passive energy consumption. Equation (8) computes the passive energy consumption of a machine . Equation (9) calculates the active energy consumed by machine with the help of expression, which takes the value 1 if machine is selected to process task and zero otherwise. Finally, equation (10) computes the total energy consumed by all machines processing all tasks.
Solution methodology
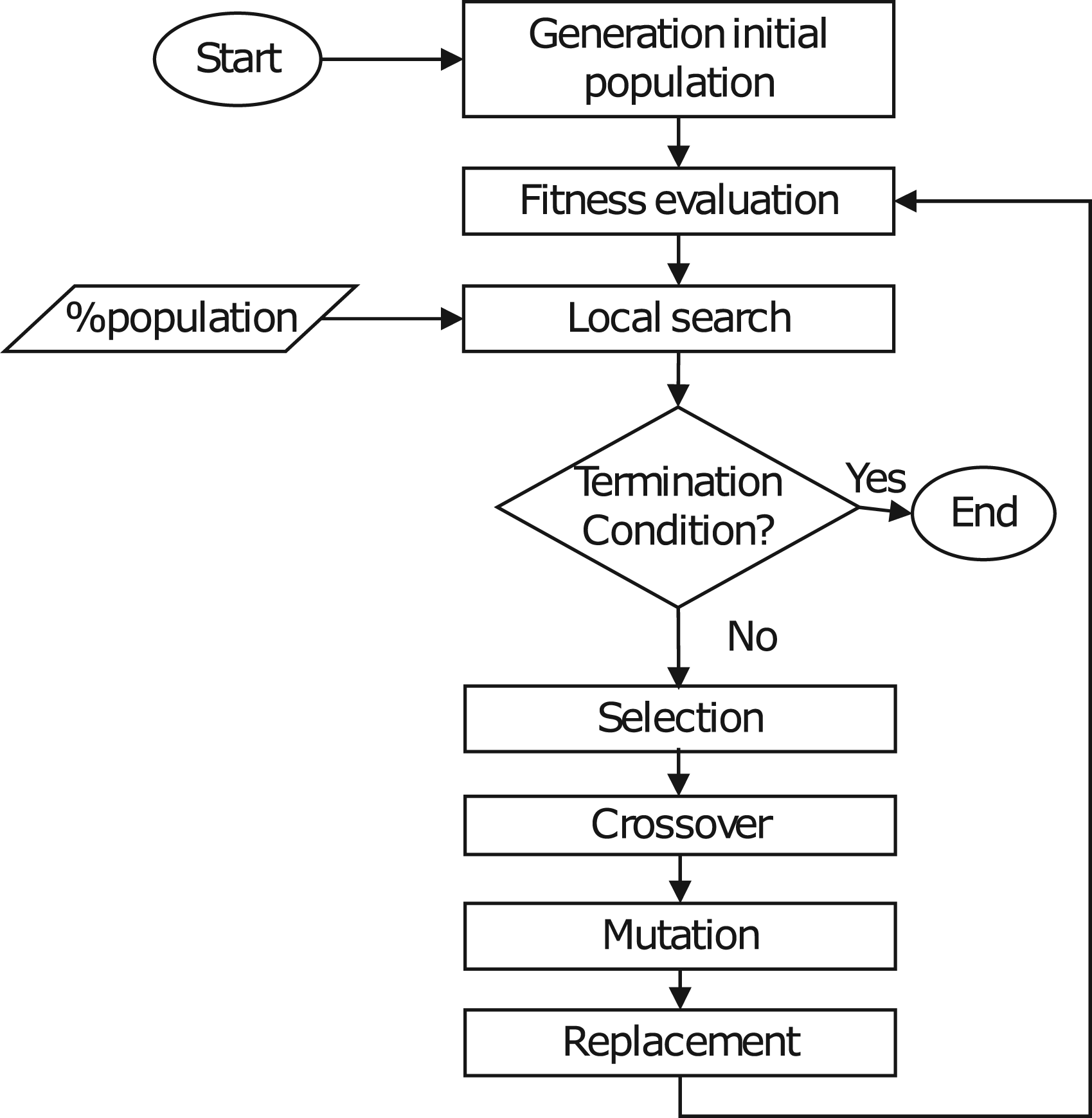
In this study, we adopt the approach proposed by Afşar et al.,66 whereby a genetic algorithm (GA) is applied to both single and multi-objective versions of the problem. In order to improve the results, in this work we incorporate a local search strategy that is dependent on the fitness values of the solutions, resulting in a memetic algorithm (MA), whose general schema is shown in Figure 1.
Diagram of the Memetic Algorithm.
Memetic algorithm
In essence, a typical local search schema begins with a given solution, proceeds to find a neighbourhood by performing some small changes, and then evaluates the neighbours in pursuit of an improved solution. Two well-known search strategies in this regard are hill-climbing and tabu search. In the proposed memetic approach, derived from the GA, we introduce a new local search stage subsequent to the fitness evaluation process. At each iteration, the local search is applied to a percentage of individuals in the current population. Furthermore, Lamarckian evolution is utilised by rebuilding the chromosome from the improved schedule obtained, thereby enabling the transfer of its characteristics to subsequent offspring.
As a novelty, the algorithm may use different local search strategies depending on the fitness of the current solution. Given the nature of our problem, if the solution subject to local search has not reached its makespan goal yet, a local search specific for this objective function is used. Otherwise, a strategy oriented towards energy consumption minimisation is employed. To do that, we introduce different neighbourhood structures depending on the objective to be optimised, or .
Neighbourhood structures
In the context of optimising , three distinct neighbourhood structures are employed. The first one, designated , is based on the neighbourhood structure introduced by González Rodríguez et al.67 There, the authors propose the use of parallel graphs to extend the concepts of critical paths and critical blocks used by Van Laarhoven, Aarts and Lenstra68 to fuzzy job shop scheduling. The same principle can be used in our problem, representing a solution as two parallel graphs and defining a critical task as one that belongs to the critical path of any of the parallel graphs. Specifically, a neighbour is created by reversing a critical arc that is at the beginning or end of a critical block. For the second neighbourhood, designated , each neighbour is generated by taking a critical task and reassigning it to any of its available machines . Following Palacios et al.,49 the task is assigned to its new machine at the earliest possible starting time that maintains the prior relative task order. The final neighbourhood, designated , is formed as a superset resulting from the merging of the two earlier ones, .
To optimise , we also propose three specific neighbourhoods. The initial neighbourhood, denoted , consists in taking a task currently assigned to a machine , and reassigning it to any of its available machines where it consumes less active energy, that is, . As in , the relative order of the tasks is preserved. The computational cost of exploring this solution subspace may be considerable, depending on the amount of flexibility of the instance being solved. For this reason, the following two neighbourhoods are subsets of the former. The second neighbourhood, named , considers only the reassignment of critical tasks. Finally, the third neighbourhood considers all tasks , but reassigns them only to the machine where they have minimum active energy consumption: .
The proposed algorithm employs local search with either makespan-oriented or energy-oriented neighbourhoods, depending on the objective values of the current solution. If the solution has reached the makespan goal, neighbours are created using one of the energy-oriented neighbourhoods: , or . Otherwise, a makespan-oriented neighbourhood is used: , or . With this setting, the algorithm does not use a neighbourhood spanning both neighbours for makespan and neighbours for energy. However, it may happen that during the same local search process, both neighbourhood types are used sequentially. That is, if local search is applied to a solution that has not reached the makespan goal, it will use a makespan-oriented neighbourhood as mentioned before, but if a solution meeting the goal is found during the local search, an energy-oriented neighbourhood will be used from that point on. To avoid losing the makespan goal, energy-oriented neighbourhoods are pruned so they do not contain solutions that can worsen .
Neighbour estimations
When using Hill Climbing, the first-evaluated neighbour that is better than the current solution is accepted as a new solution. But with Tabu Search, all the non-tabu neighbours must be explored, so the best one is accepted. Given the potential size of some of the described neighbourhoods, this can be very time-consuming, since evaluating a new solution tends to have a significant computational cost. In these cases, the use of approximate fitness functions with lower computational cost can make the local search more efficient. Let be the objective value of a solution to a minimisation problem and be its estimation. If the estimation is always a lower bound of the actual objective value, , the number of full evaluations required can be drastically decreased without loss of quality. In the Hill Climbing case, any neighbour of solution such that can be immediately discarded knowing that as well. In Tabu Search, neighbours can be sorted according to their estimated objective value. Then, they are explored sequentially until a neighbour is found with a value greater than the best so far. At that point, there is no need to keep evaluating since the best neighbour has already been found.
For , estimations can be obtained following Palacios et al.. In that work, estimations are calculated both when a critical arc is reversed (i.e. ) and when a task is assigned to a different machine (i.e. ). They are based on the concepts of heads and tails adapted to the case of parallel graph representation. They are also proven to be lower bounds for the actual value. In our case, we adapt the same ideas to the interval case by representing a solution with two parallel graphs instead of three. This also allows us to estimate for neighbours in the energy-oriented neighbourhoods, since they are also based on reassigning tasks to different machines.
For , all the proposed neighbourhoods for this objective function involve reassigning a task to a different machine. Makespan-oriented neighbourhoods are used only when the current solution does not meet the makespan goal and energy consumption is not yet considered, so there is no need for an estimate for in this case. Let be the objective value for the current solution and the estimation after reassigning a task from machine to .
We compute as the sum of active energy consumed by all tasks scheduled in machine except , , and take for any other machine . In general, . However, if is the first task scheduled in machine (), then , where is the successor of in machine before reallocating. Similarly, if , where is the predecessor of in machine before reallocating. If , . Let and be, respectively, the starting and completion times of in machine after the reallocation. In that case, if , then , and if , then .
Experimental results
The experimental study will be conducted in two phases. The initial series of experiments is designed to identify the most effective local search strategy and neighbourhood structures to optimise the makespan, , and the total energy consumption, . In the second set of experiments, we incorporate the best-found local search strategy and evaluate the efficiency of our lexicographical proposal. Finally, we compare our method with the best one in the literature, which is, to our knowledge, the Genetic Algorithm (GA) by Afşar et al.66
The instance set
As a test bed, we use 12 existing instances for energy-aware IFJSP,66 which are based on the instances for the flexible job shop with fuzzy durations and energy costs.69 The latter are, in turn, adaptations of the well-known instances presented in Dauzère-Pérès and Paulli.70 In the fuzzy instances, the authors employ triangular fuzzy numbers to model uncertainty in task durations. In the work by Afşar et al.,66 the middle component was discarded, and the remaining two were taken as minimum and maximum values of the interval task duration. The instances designated by have 15 jobs and 8 resources, whereas the instances designated by are larger, having 20 jobs and 15 resources. In addition to size, instances are classified according to the average number of machines where each task can be executed, denoted . Instances are divided into three categories: low flexibility instances () represented by 07a, 10a, 13a, 16a (), medium flexibility instances () represented by 08a, 11a, 14a, 17a () and high flexibility instances () represented by 09a, 12a, 15a, 18a (). For the sake of clarity, we include the flexibility category as a suffix of the instance names (e.g. 08a-m).
Parameter selection
For fairer comparisons, the parameters employed in this experimental study are those previously used for the GA66: population size of 100 and 10,000 generations as stopping criterion. The local search is applied to 10% of the population in each generation. Each algorithm is run ten times to obtain representative values. All results have been obtained on a Linux machine equipped with two Intel Xeon Gold 6240 processors and 128GB of RAM. Detailed results are available at http://di002.edv.uniovi.es/iscop.
Lower and upper bounds
In order to facilitate more equitable comparisons, we employ the concept of relative error (RE) between the midpoint of each objective value, designated as and its best-known lower bound, denoted as . Given a solution, for each objective value:
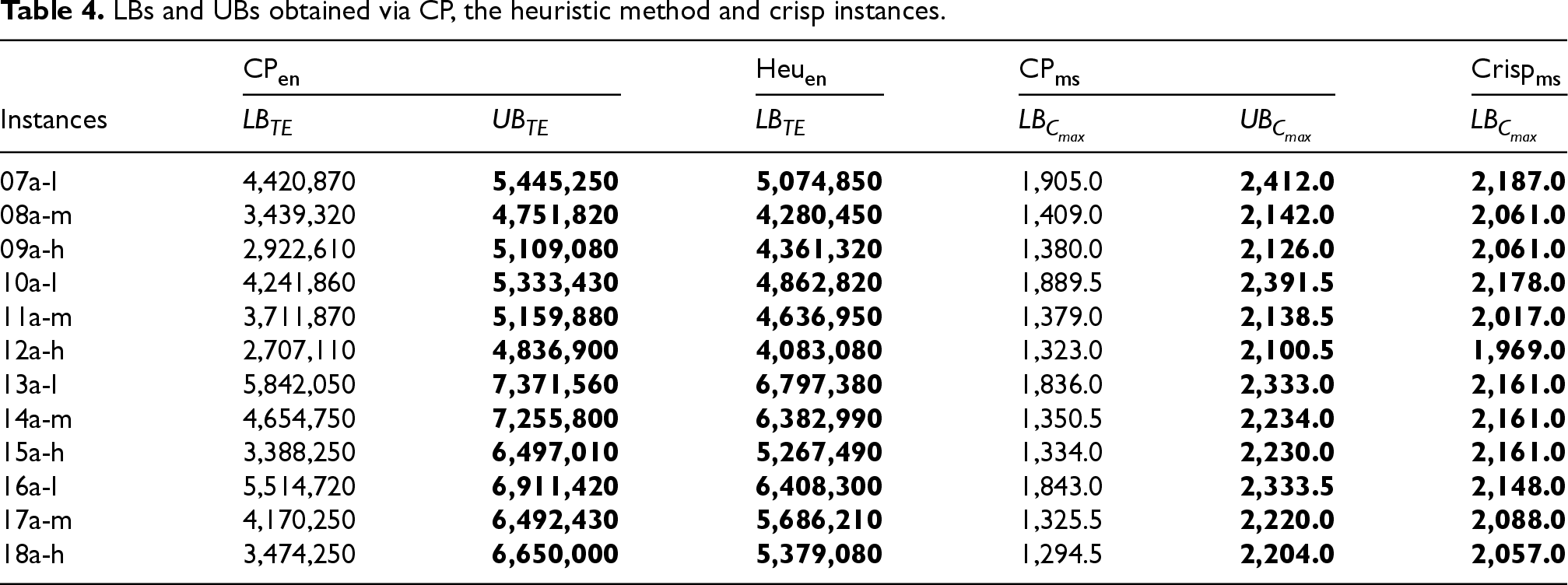
Different methods can be used to find tight lower bounds as reference point.66 First, the CP model described in the Problem Definition Section is solved minimising either or . These are designated and in Table 4 and are solved with the commercial solver IBM ILOG CP Optimizer 12.9 using an implementation in C++ with a time limit of 6 hours and a single thread.65 The time limit was reached in all instances, resulting in the generation of a lower and an upper bound. The mean discrepancy between the lower bound () and the optimal solution () identified by the solver after six hours is approximately 32.5% for both objectives, suggesting that the instances are not easy to solve.
LBs and UBs obtained via CP, the heuristic method and crisp instances.
CP
Heu
CP
Crisp
Instances
07a-l
4,420,870
5,445,250
5,074,850
1,905.0
2,412.0
2,187.0
08a-m
3,439,320
4,751,820
4,280,450
1,409.0
2,142.0
2,061.0
09a-h
2,922,610
5,109,080
4,361,320
1,380.0
2,126.0
2,061.0
10a-l
4,241,860
5,333,430
4,862,820
1,889.5
2,391.5
2,178.0
11a-m
3,711,870
5,159,880
4,636,950
1,379.0
2,138.5
2,017.0
12a-h
2,707,110
4,836,900
4,083,080
1,323.0
2,100.5
1,969.0
13a-l
5,842,050
7,371,560
6,797,380
1,836.0
2,333.0
2,161.0
14a-m
4,654,750
7,255,800
6,382,990
1,350.5
2,234.0
2,161.0
15a-h
3,388,250
6,497,010
5,267,490
1,334.0
2,230.0
2,161.0
16a-l
5,514,720
6,911,420
6,408,300
1,843.0
2,333.5
2,148.0
17a-m
4,170,250
6,492,430
5,686,210
1,325.5
2,220.0
2,088.0
18a-h
3,474,250
6,650,000
5,379,080
1,294.5
2,204.0
2,057.0
Subsequently, a heuristic method is devised which postulates that all tasks are processed on the most energy-efficient machines (i.e., those with the lowest active energy consumption for the task) among the alternatives, without pause between tasks in the same machine. The results are presented in column 4 of Table 4. This heuristic provides lower bounds for total energy consumption () that are, on average, 33% more precise than those obtained by CP, despite the absence of precedence constraints.
Finally, the most widely recognised LBs for the deterministic version of FJSP that minimises makespan are considered and provided in the final column of Table 4.71 This is due to the fact that the LBs for the crisp version of the instances are also valid values. Table 4 presents a summary of all bounds for makespan and total energy. The best lower and upper bounds (LBs and UBs) are highlighted in bold and are the ones used in this work.
In our case, the makespan objective function is of primary importance and, as evidenced in Table 4, the approach yields the best lower bounds for this objective.
Goal values
To test our proposal, we set the makespan target as , where , for each of the instances introduced before. Theoretically, given the lexicographic nature of the problem, the goal for is easier to reach when is large, allowing greater focus on minimising . Conversely, when is small, this focus shifts towards minimising . In this study, five distinct values of are employed: 0.01, 0.05, 0.10, 0.15 and 0.20; larger values of have been shown to be of no special interest.66
Local search parameter selection
The proposed algorithm employs local search with either makespan-oriented or energy-oriented neighbourhoods, depending on the objective values of the current solution as explained in the Memetic algorithm Subsection. In that regard, to find the best neighbourhood and search strategy in each situation, we configure the local search in a single-objective version of the algorithm.
Search strategy
Firstly, we run a set of experiments to find the best local search strategy. We compare a Hill Climbing (HC) approach with a Tabu Search (TS) strategy. For the latter, the stopping criterion is set to 50 consecutive iterations without improvement, and the size of the tabu list is set to 18. We embed both strategies in a single-objective version of the memetic algorithm: or depending on the strategy. For the sake of clarity, the memetic algorithm minimising is denoted as and the version minimising as . For his study, we use the most general neighbourhood structure in each case: in and in . We also test the algorithm without any local search and refer to it as and following the same notation as MA. Finally, we shall include in our study the best upper bounds found by solving the CP model as a reference point (see Table 4).
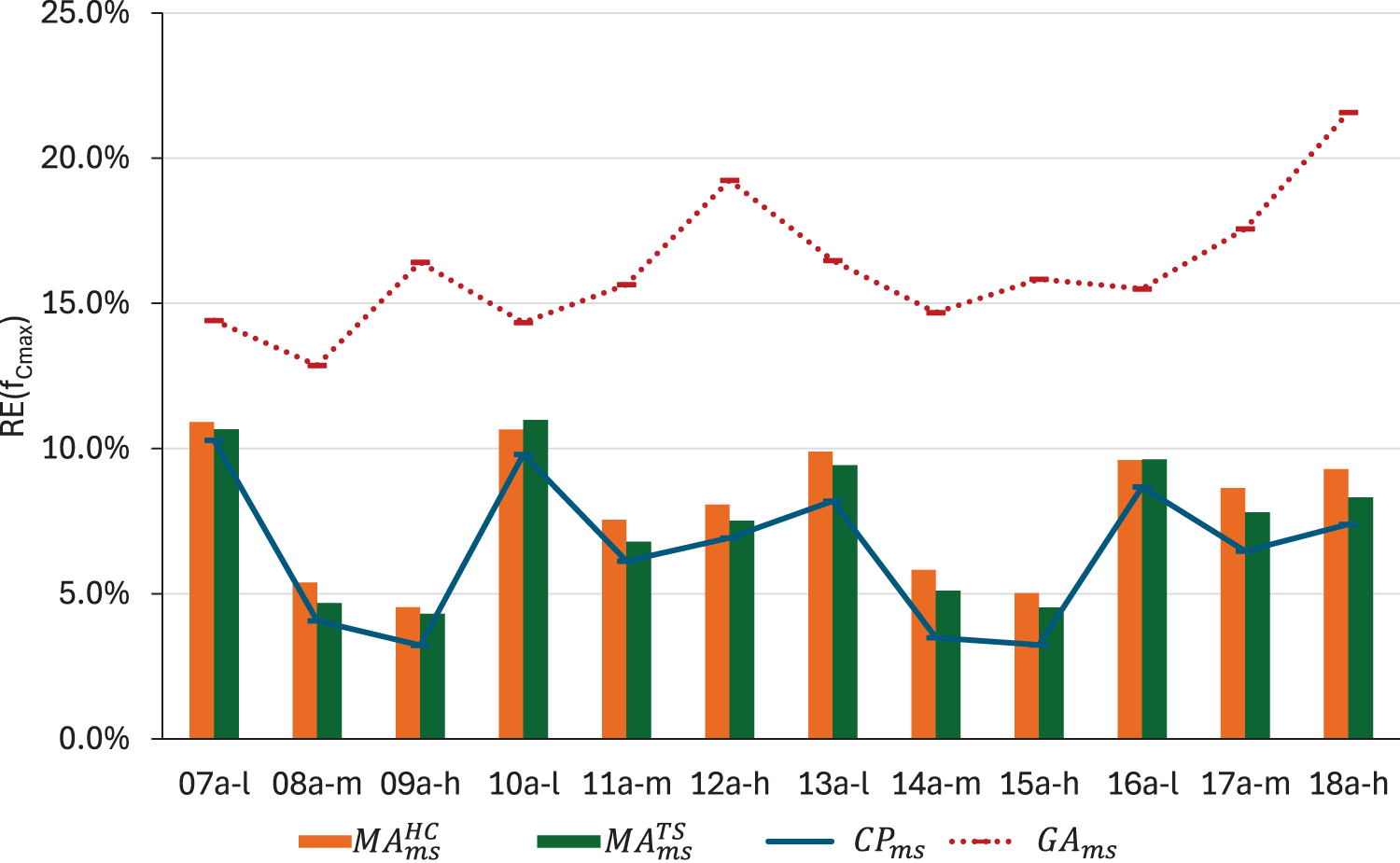
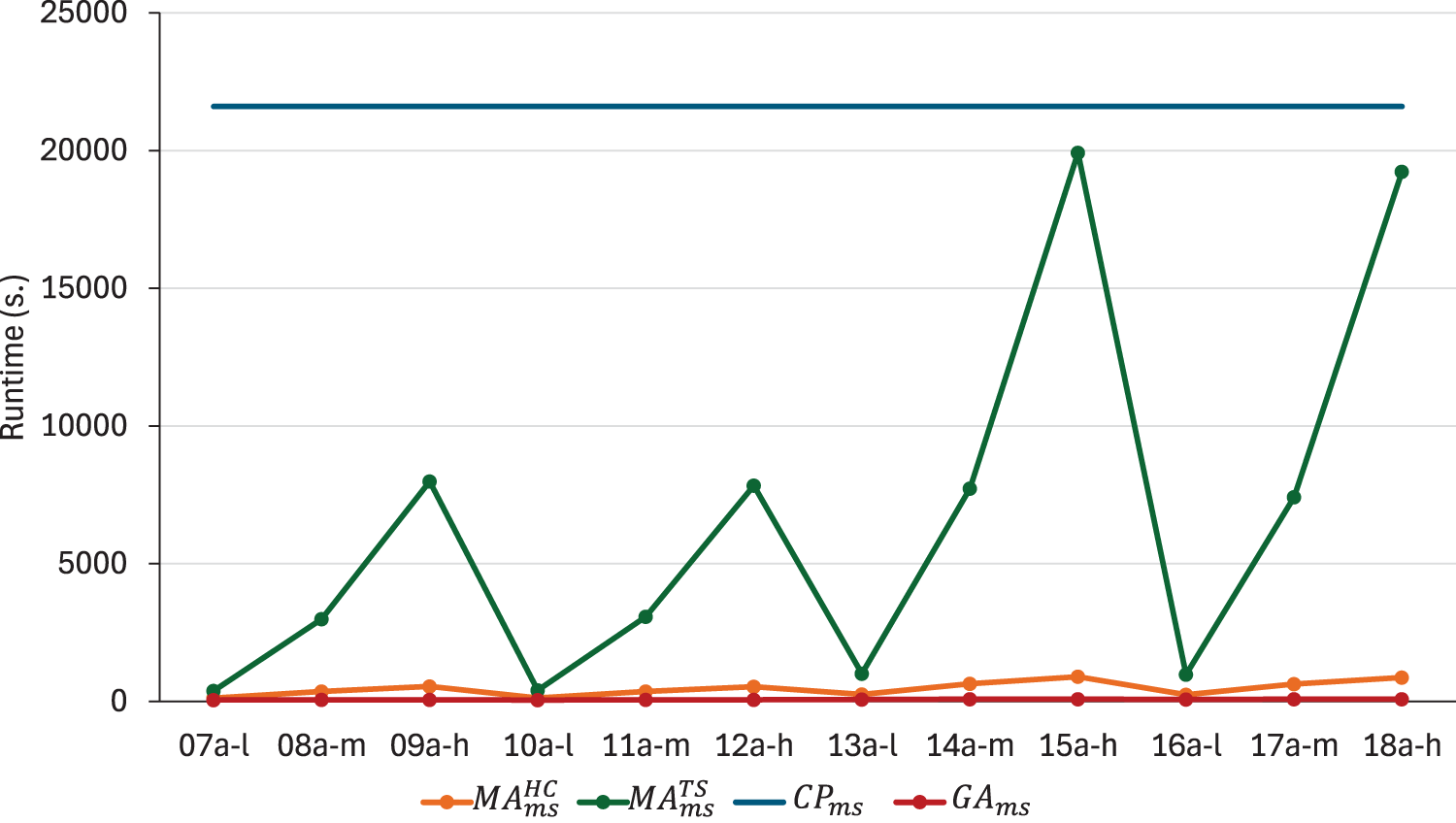
Figure 2 depicts the comparative analysis between the values obtained by and . The values obtained by and by solving are illustrated with lines. It is evident that both versions of the memetic algorithm significantly reduce the values yielded by . In medium and high flexibility instances, this reduction is always above 50%, reaching up to 72,4% in instance 09a-h. Furthermore, the relative errors of the memetic solutions are comparable to the upper bounds obtained by solving the model during 6 hours. Comparing both local search strategies, there is no clear winner. seems to be better in most instances, but not all of them, and the differences are not sufficient to justify a preference for one over the other. In this scenario, CPU times can be an indicator for decision-making. The average runtimes for all methods are shown in Figure 3. does not seem to be a viable option in terms of computational resource consumption. The CPU time increases with both size and flexibility, with instances 15a-h and 18a-h requiring approximately 5 hours, compared to approximately 14 minutes for . Taking into account the small differences in terms of relative errors, we consider that represents the most reasonable choice.
values obtained by , , and .
CPU time in seconds used by , , and .
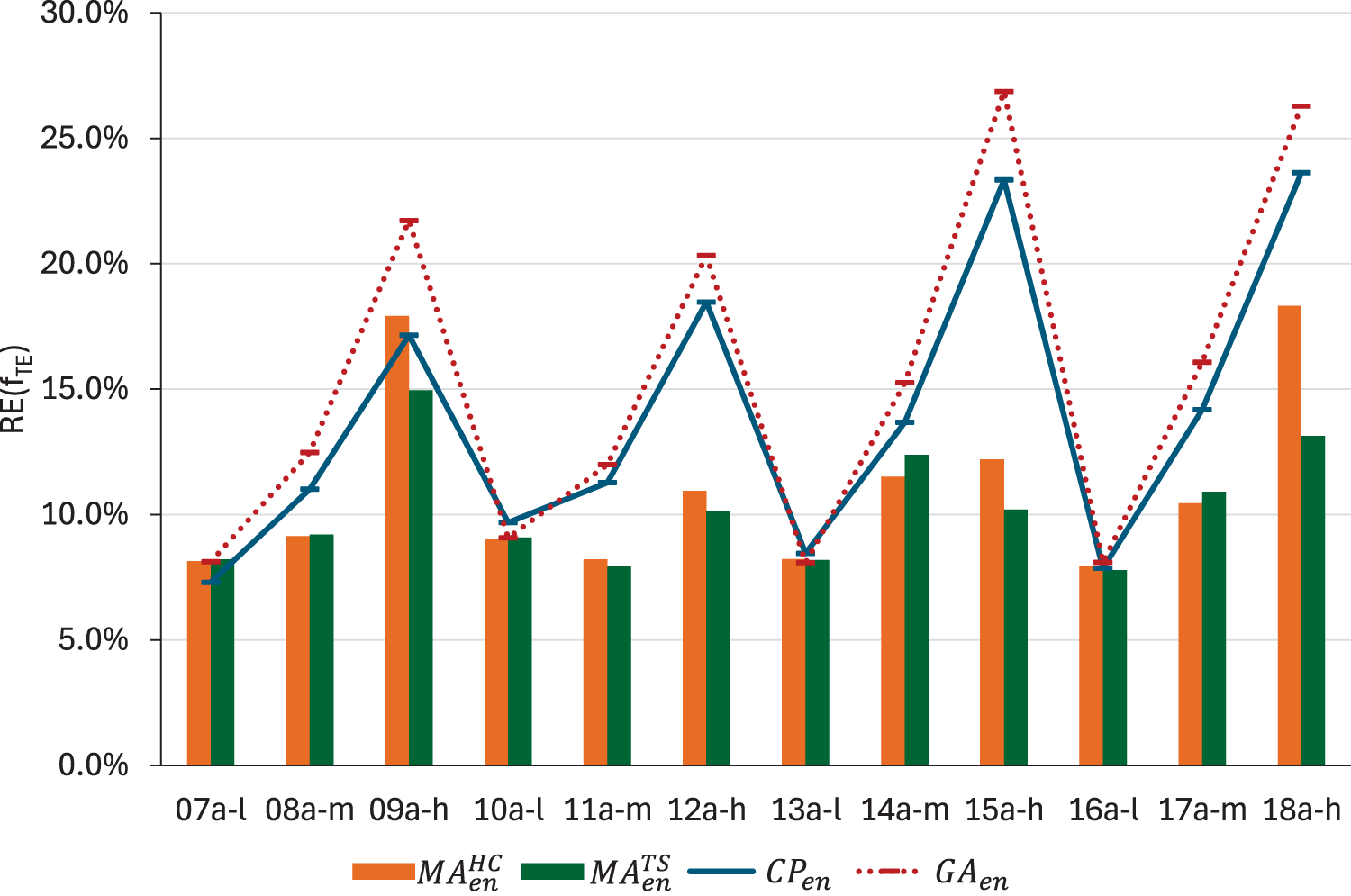
values obtained by , , and .
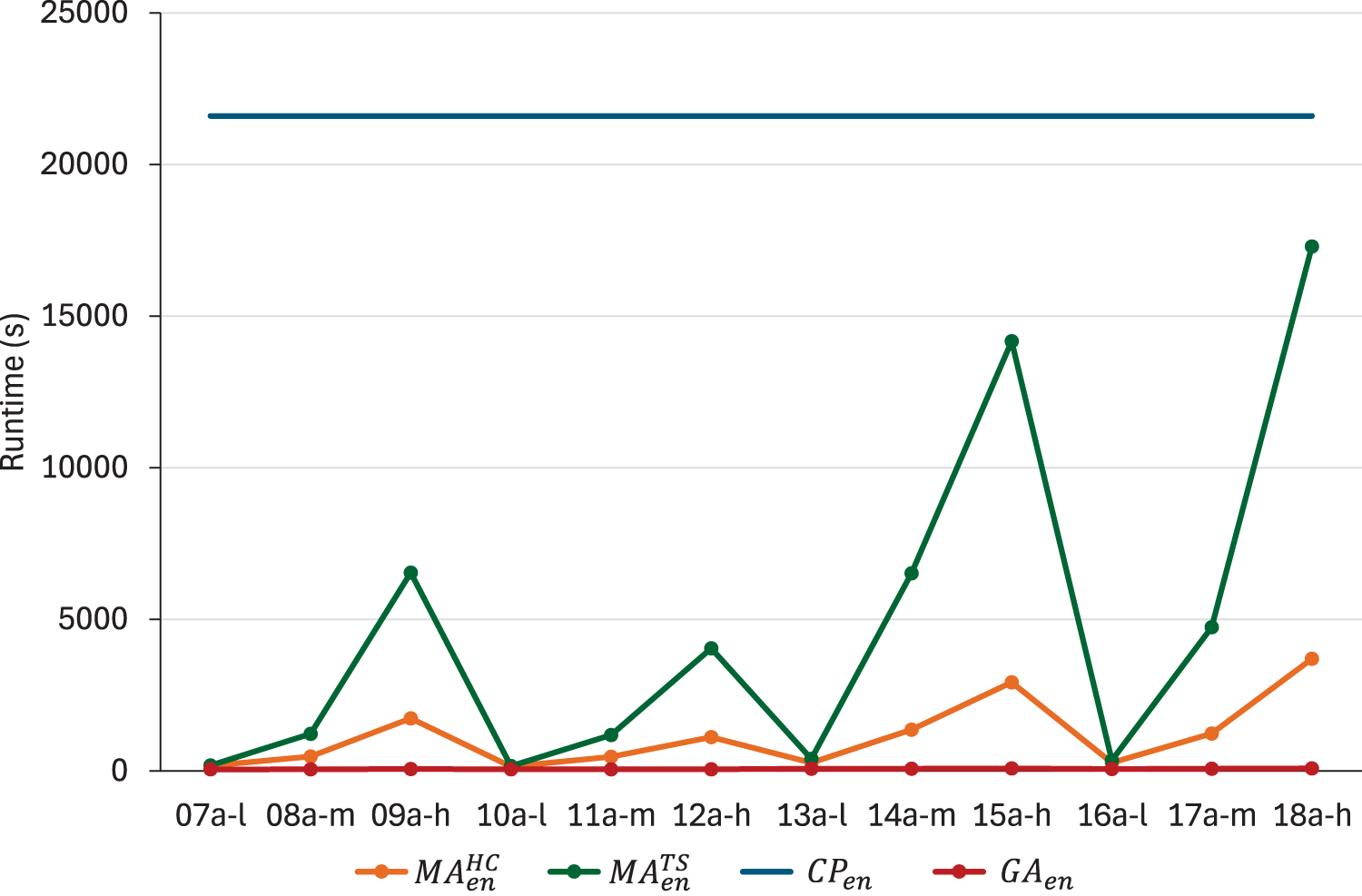
CPU time in seconds used by , , and .
Regarding energy optimisation, Figures 4 and 5 illustrate that both versions of the algorithm outperform , as above. While this improvement is not as pronounced as that observed in makespan, it still ranges from 17% to 55% in medium and high flexibility instances. What is more important, reaches better results than the upper bound obtained by solving the model in most instances, especially in higher flexibility ones. When comparing both strategies, appears to obtain smaller relative errors than in the majority of instances. As in the case of makespan minimisation, we consider that the reduction in quality is not sufficient to offset the high computational resource consumption, which can reach up to 5 hours. Therefore, in terms of energy consumption, is also a preferable option.
To enhance readability, we shall remove the superscripts from the method’s name in the following sections.
Neighbourhood structure
Once the local search strategy has been set to Hill Climbing, the neighbourhood structure that is most appropriate for each objective will be identified through this analysis.
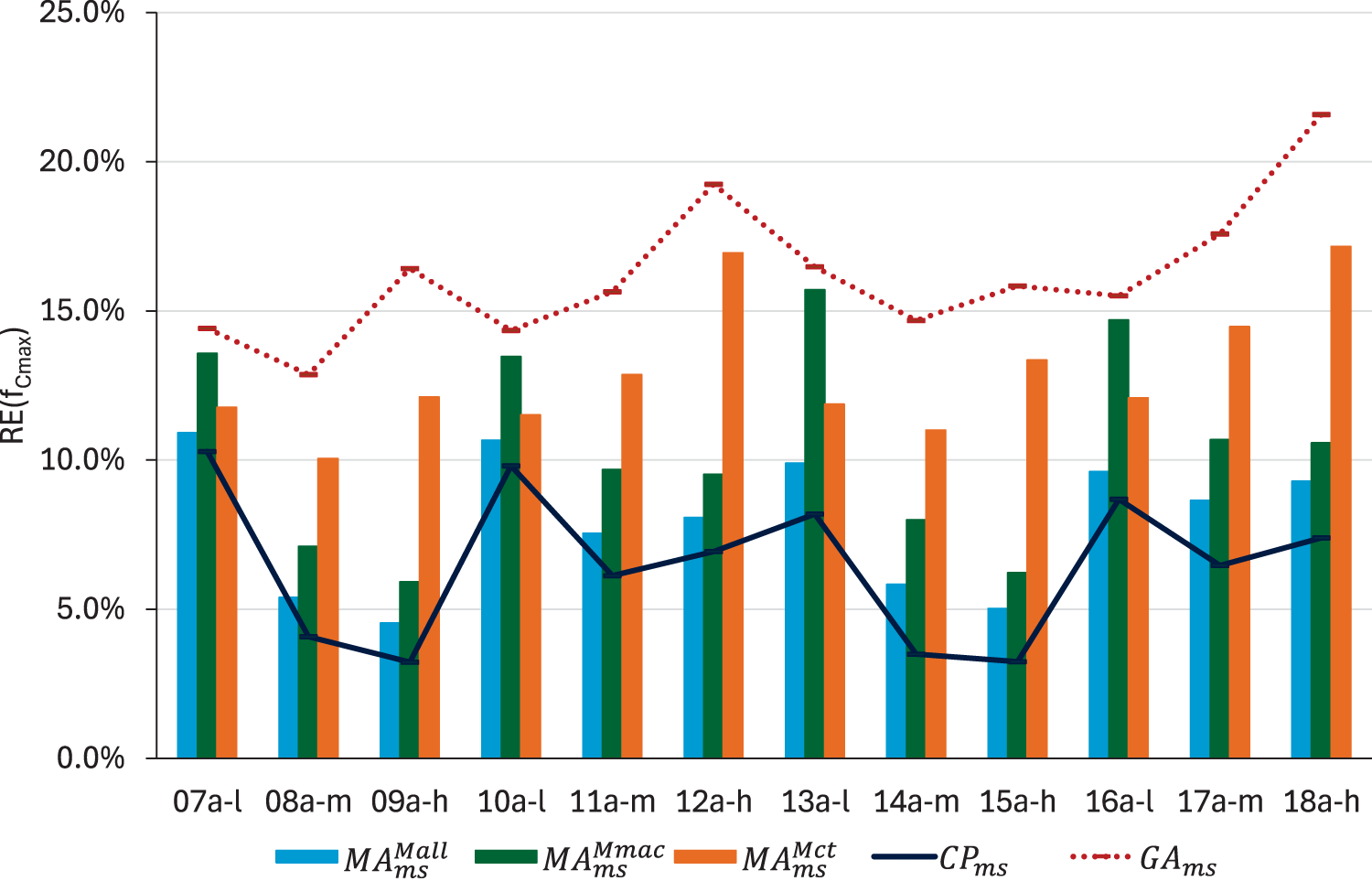
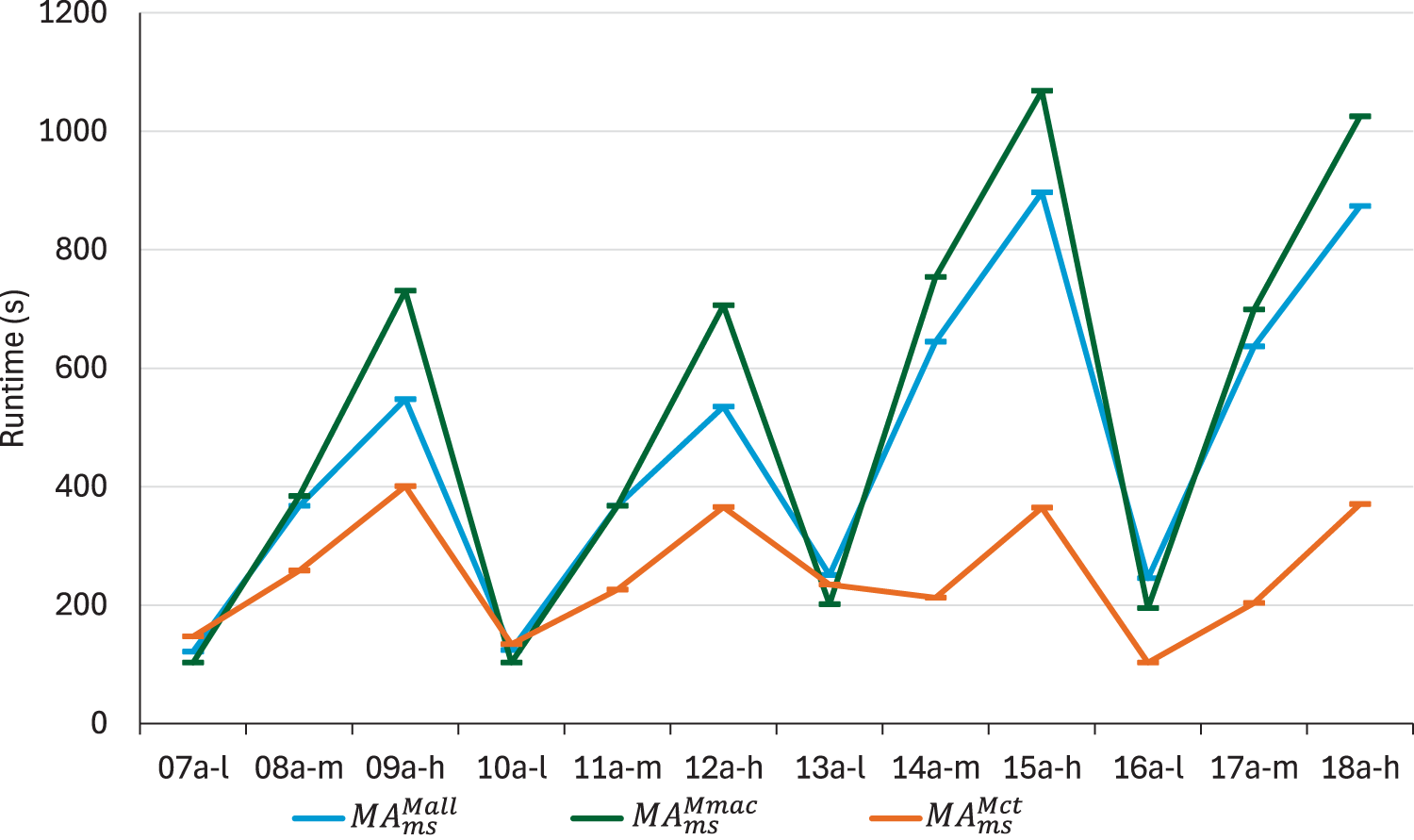
First, we focus on makespan optimisation. Figure 6 depicts the values reached by using the three proposed neighbourhoods for : reassigning critical tasks to other machines (), swapping critical arcs at the extremes of critical blocks () and the union of both neighbourhoods (). The three memetic algorithms that result from using these neighbourhoods are denoted , , and , respectively, in this study. The results obtained by and solving are also included for reference. The average runtime in seconds is shown in Figure 7. In terms of quality, is clearly better than the others. Moreover, it is not the most time consuming algorithm, which is . This can be explained by the use of the estimation filter. The estimation is more realistic in the neighbours from , which allows us to prune the neighbourhood better. In turn, even though is larger than , it requires less evaluations to find the best neighbour. On the other hand, appears as the fastest, reducing the runtime of by 3 minutes and a half on average. However, the relative errors obtained are significantly worse than those obtained by , even doubling them in some instances with high flexibility. Therefore, given the differences in terms of relative errors, we consider that using is, overall, the best option to minimise makespan.
values obtained by , and .
CPU times obtained by , and .
Compared to the version of the algorithm without local search, , we see a clear improvement when intensification is applied using . The improvement increases with flexibility, going from an average reduction of 4.9% in type instances to 8.3% in type instances and 11.5% in type instances. Regarding solving , the memetic algorithm reaches solutions that are slightly worse in quality, as expected, but it takes less than 8 minutes on average compared to the 6 hours required by the CP method.
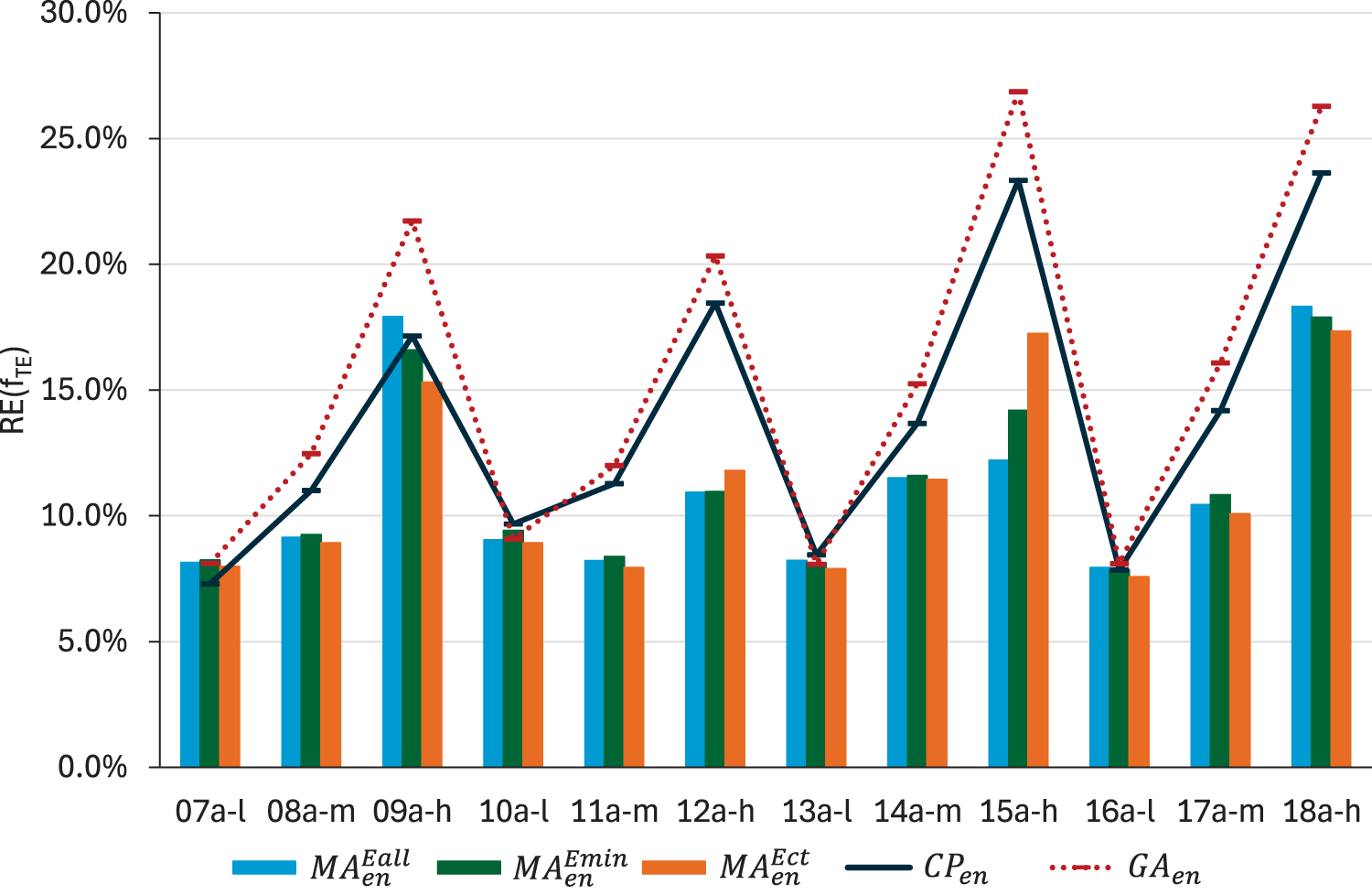
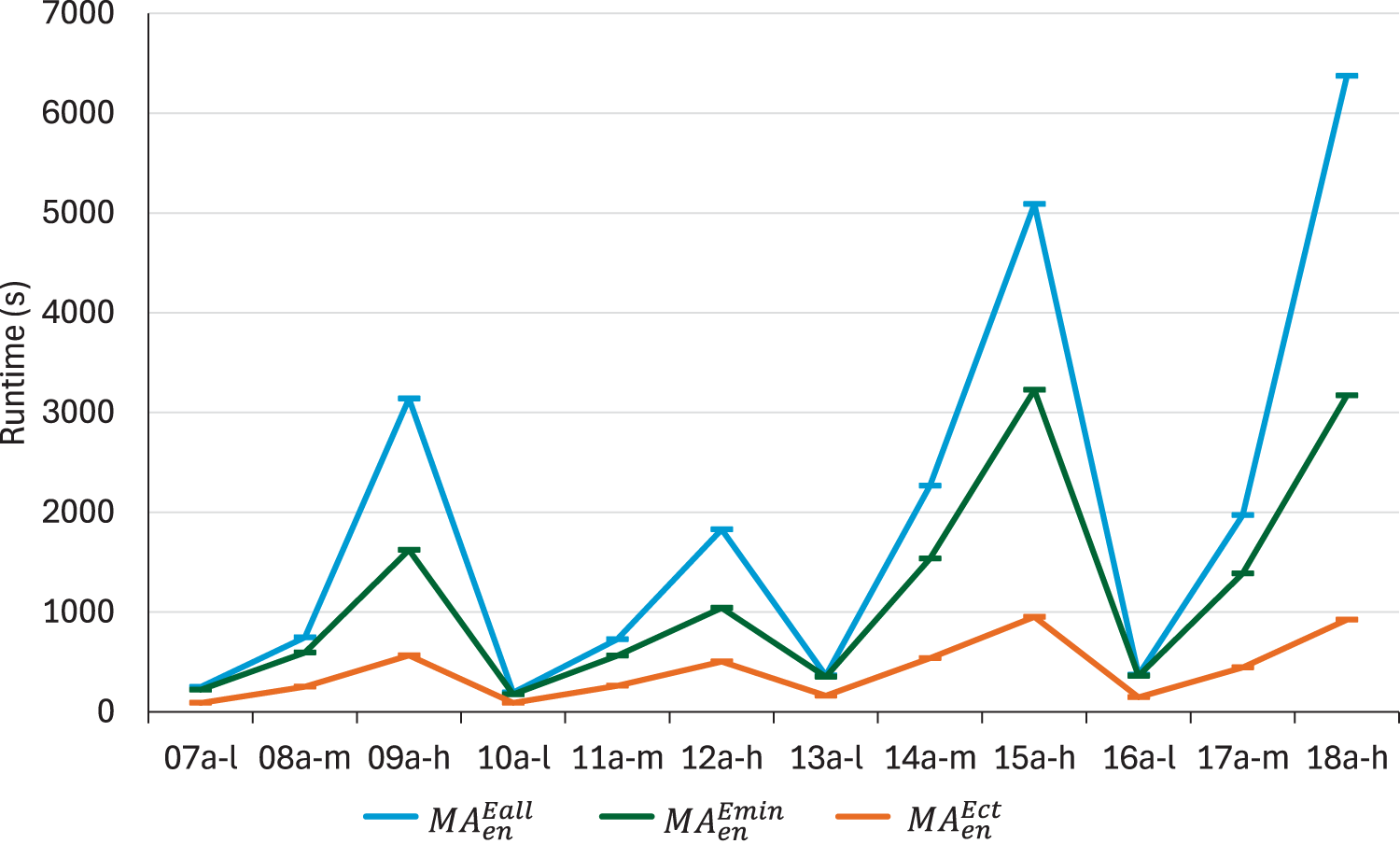
In terms of energy optimisation, we also compare the three proposed neighbourhood structures to minimise : reassigning any task to a machine where it consumes less energy (), reassigning a critical task to a machine where it consumes less energy () and reassigning any task to the machine where it consumes the least amount of energy (). Following the previous notation, we shall denote the three resulting memetic algorithms as , and respectively. In Figure 8 we can see that no algorithm outperforms the others for every instance in terms of . reaches the best relative error in all but two instances: 12a-h and 15a-h, where it is actually the worst. But in most of the instances, there are not significant differences between the three algorithms. However, this is not the case when comparing runtimes. In instances with high flexibility, the CPU times used by as can be seen in Figure 9 are one order of magnitude smaller than those used by , and significantly better than those obtained with . This makes sense: higher flexibility means that there are more candidate machines to reassign a task to and, consequently, more neighbours to explore. However, since the neighbourhood is restricted to critical tasks only, its size is much less affected by flexibility.
values obtained by , and .
The change in neighbourhood may affect the choice of the search strategy made in the previous subsection. To verify if this is the case, an additional experiment has been conducted comparing again and using the new neighbourhood, . The results are in line with those obtained previously, so we have maintained the choice of using Hill Climbing Figure 9. The results also show the benefits of using local search versus not using it (). When choosing the neighbourhood, we cannot appreciate a significant improvement in low-flexibility instances (). But for the type- ones, there is an average reduction of of 4.4%, which increases to 8.4% in type- instances. What is more remarkable is that the memetic algorithm gets similar results to solving in type- instances, but it is significantly better in instances with higher flexibility.
CPU times obtained by , and .
In summary, we setup our lexicographic method by using Hill Climbing with when the solution does not meet the makespan goal and Hill Climbing with when it does. Notice that the energy-oriented neighbourhood is only used on solutions with a good makespan value. This may affect the number of neighbours considered and, therefore, the number of good candidate solutions to evaluate. If this decreases enough, one may think that Tabu Search could become viable in this setting, and even the use of the larger neighbourhood . We have tested this and the results obtained show that using Hill Climbing with is 86.1% faster than using Tabu Search with , while sacrificing only 0.5% of . Therefore, we consider that Hill Climbing with is also the best option for energy-oriented local search in the lexicographic setting.
Lexicographic analysis
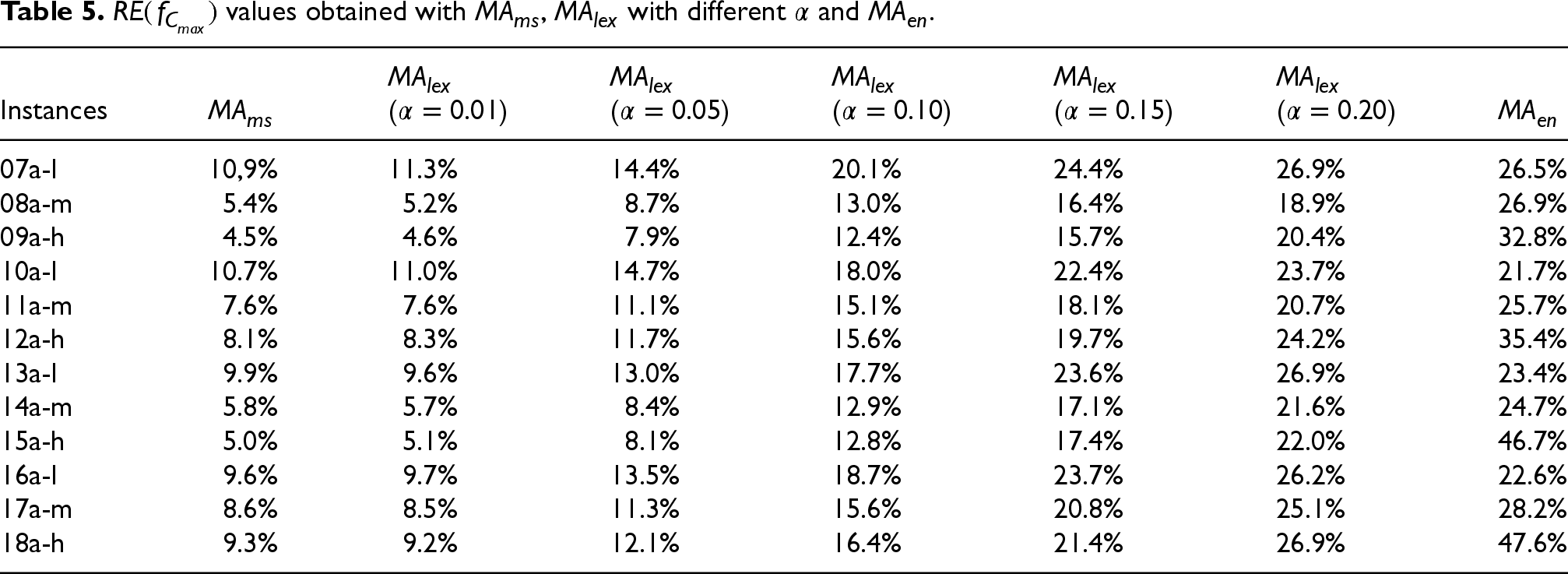
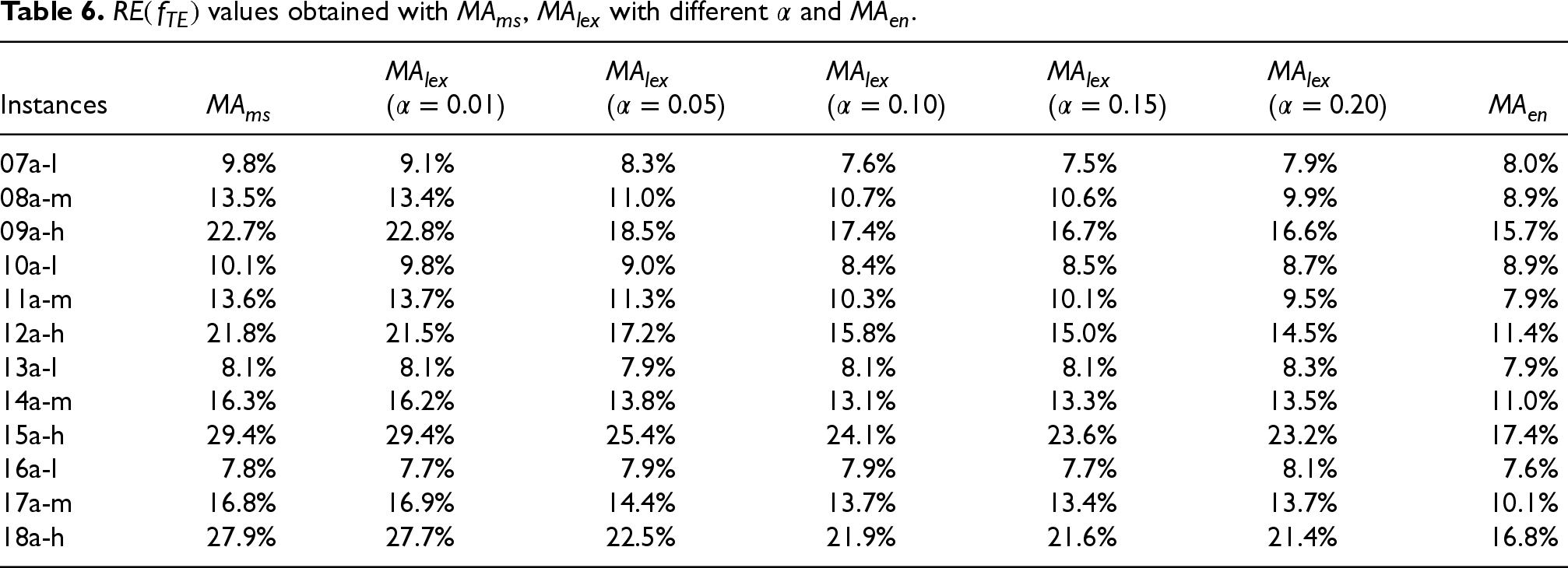
Once the best setup for the algorithm has been chosen, we test its performance in this section. Tables 5 and 6 report, respectively, the relative errors for and obtained with . We include results obtained with different values for the makespan goal. For comparison, we also report the obtained by the single-objective versions, and , after their tuning in the previous subsection. For these versions, we drop the superscript previously used for simplicity.
values obtained with , with different and .
Instances
()
()
()
()
()
07a-l
10,9%
11.3%
14.4%
20.1%
24.4%
26.9%
26.5%
08a-m
5.4%
5.2%
8.7%
13.0%
16.4%
18.9%
26.9%
09a-h
4.5%
4.6%
7.9%
12.4%
15.7%
20.4%
32.8%
10a-l
10.7%
11.0%
14.7%
18.0%
22.4%
23.7%
21.7%
11a-m
7.6%
7.6%
11.1%
15.1%
18.1%
20.7%
25.7%
12a-h
8.1%
8.3%
11.7%
15.6%
19.7%
24.2%
35.4%
13a-l
9.9%
9.6%
13.0%
17.7%
23.6%
26.9%
23.4%
14a-m
5.8%
5.7%
8.4%
12.9%
17.1%
21.6%
24.7%
15a-h
5.0%
5.1%
8.1%
12.8%
17.4%
22.0%
46.7%
16a-l
9.6%
9.7%
13.5%
18.7%
23.7%
26.2%
22.6%
17a-m
8.6%
8.5%
11.3%
15.6%
20.8%
25.1%
28.2%
18a-h
9.3%
9.2%
12.1%
16.4%
21.4%
26.9%
47.6%
values obtained with , with different and .
Instances
()
()
()
()
()
07a-l
9.8%
9.1%
8.3%
7.6%
7.5%
7.9%
8.0%
08a-m
13.5%
13.4%
11.0%
10.7%
10.6%
9.9%
8.9%
09a-h
22.7%
22.8%
18.5%
17.4%
16.7%
16.6%
15.7%
10a-l
10.1%
9.8%
9.0%
8.4%
8.5%
8.7%
8.9%
11a-m
13.6%
13.7%
11.3%
10.3%
10.1%
9.5%
7.9%
12a-h
21.8%
21.5%
17.2%
15.8%
15.0%
14.5%
11.4%
13a-l
8.1%
8.1%
7.9%
8.1%
8.1%
8.3%
7.9%
14a-m
16.3%
16.2%
13.8%
13.1%
13.3%
13.5%
11.0%
15a-h
29.4%
29.4%
25.4%
24.1%
23.6%
23.2%
17.4%
16a-l
7.8%
7.7%
7.9%
7.9%
7.7%
8.1%
7.6%
17a-m
16.8%
16.9%
14.4%
13.7%
13.4%
13.7%
10.1%
18a-h
27.9%
27.7%
22.5%
21.9%
21.6%
21.4%
16.8%
As expected, Table 5 shows that obtains the best solutions in terms of makespan and obtains the worst. Conversely, Table 6 shows that gets the best results for energy optimisation and , the worst. However, we can see that the room for improvement is much larger in makespan and it highly depends on the flexibility of the instances. When minimising , the difference in low flexibility instances goes from an average 23.6% RE obtained by to 10.3% when using : 13.6% difference. This value increases to 19.5% in medium flexibility instances (26.4% vs. 6.9%) and 33.9% in high flexibility instances (40.6% vs. 6.7%). Similarly, when minimising the differences are 0.8% for -type instances, 5.6% for -type ones and 10.1% for -type ones. In this case, in favour of . The reason for this behaviour is that, when more machines are available to execute each task, the energy consumption can be reduced by waiting for the machine with the lowest energy consumption for each task. Obviously, this has a big impact on the makespan. This happens is especially relevant in our model, where machines are turned on when starting executing the first assigned task, so delaying their execution to wait for the most energy-efficient machine does not increase the consumed passive energy too much.
The lexicographic memetic algorithm, due to its nature, is focused first on reaching the makespan goal. But what is more important in our algorithm is that, when the goal is relatively easy to reach, it is capable of finding solutions with energy consumptions close to those obtained when minimising only this objective function. We can appreciate this behaviour by looking at the different columns for , where the goal is easier to achieve the larger the value of . It can be appreciated that with , the improvement in energy consumption is small compared to not considering it (). However, with , the solutions are very close to those obtained by in terms of energy consumption.
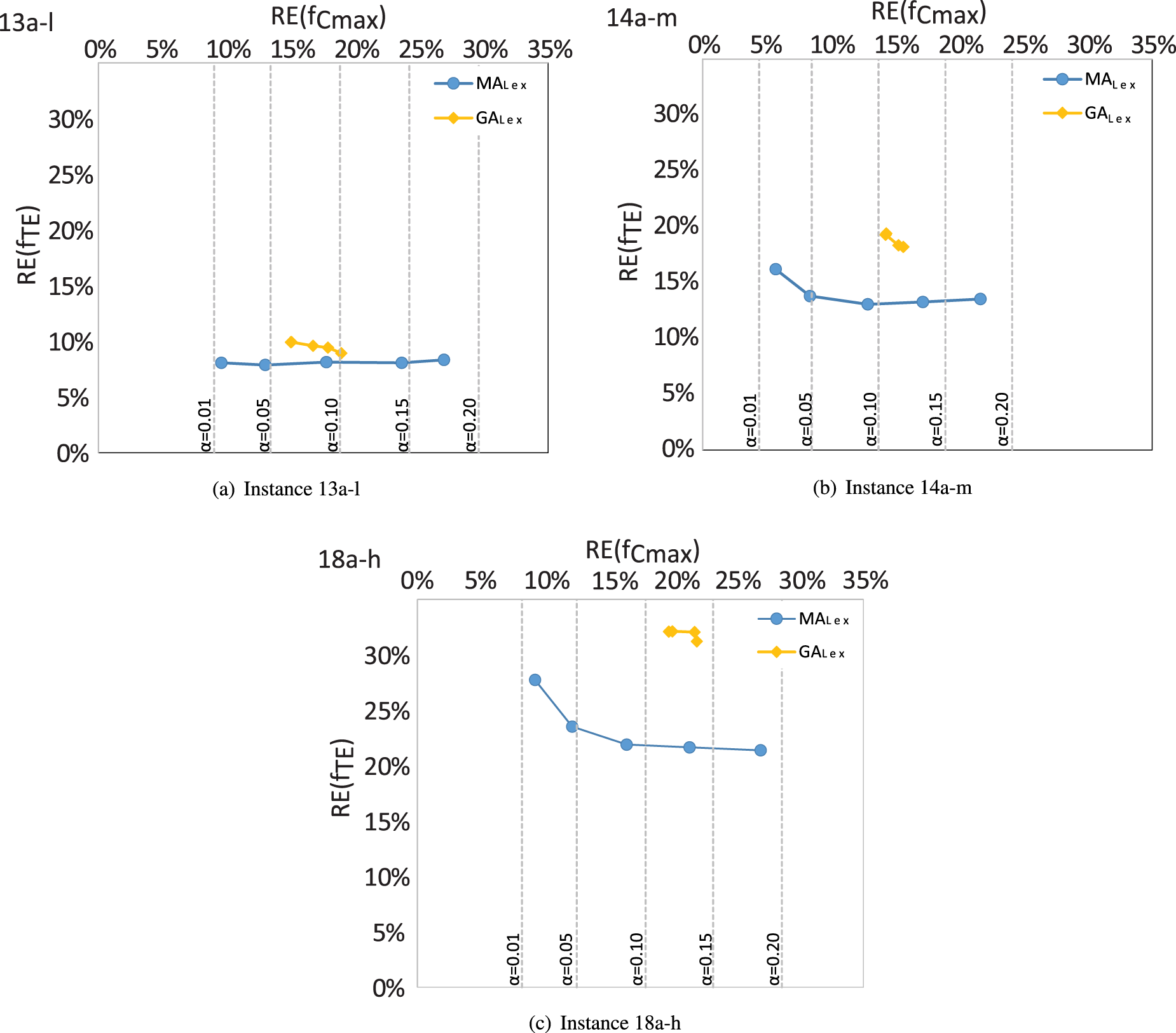
To better illustrate this, we plot the results of for different values of in Figure 10. An instance of each flexibility level is depicted. The leftmost point of each line represents and increases to at the rightmost point. We also include the state-of-the-art results for our problem obtained by a .66 We can see that the proposed is capable of reaching the makespan goal for all values of except 0.01, while can barely reach it when and the flexibility is medium or high. Most importantly, leads to a reduction in total energy consumption in all instances and values of . It seems that, when the goal is relaxed, reaches it easily and, from that point, focusses its effort on optimising , as expected. Meanwhile, struggles to optimise the energy without losing the makespan goal even when it can reach it. As a consequence, it loses the ability to keep the makespan close to its goal while decreasing . This behaviour can be observed across all instances.
and obtained in different flexibility type instances using , with varying values. Corresponding goals are shown as vertical dashed lines.
Conclusion
In this study, we address flexible job shop problem with interval processing times considering two objectives: minimising makespan and total energy consumption. Despite having two objective functions, there is a clear hierarchy between them. It is desirable to consume less energy; however, a certain quality of service should be guaranteed in the first place. Therefore, minimising makespan is the primary objective, but after it reaches a certain level, we can focus on minimising the total energy consumption. To address this problem, a lexicographic goal programming approach is adopted.
A memetic algorithm, which is composed of a genetic algorithm combined with a local search, is developed to solve our problem. Local search algorithms entail defining neighbourhood structures. In this work, three different neighbourhoods are established and tested for each objective along with two local search methods: hill climbing and tabu search. After testing the neighbourhoods and the local search methods in the mono-objective cases, the most adequate options are selected.
In this memetic algorithm, a dynamic strategy is implemented that allows to choose the neighbourhood depending on the objective that is being optimised at each step. Firstly, it focusses on reaching the makespan goal by using the makespan-oriented neighbourhoods. Once this goal is achieved, the method switches to energy-oriented neighbourhoods to minimise the second objective. Moreover, to speed up the local search, we provide easy-to-compute estimates for each objective value that enable faster evaluation of neighbours and pruning the neighbourhood without compromising quality.
Our experimental results indicate that the proposed algorithm reaches the makespan goal in many more cases compared to previous methods. Moreover, the new method behaves more accordingly to expectations: once the makespan goal is reached, it stops putting effort into that objective function and instead it greatly minimises the total energy consumption. This impact is even more obvious for instances with higher flexibility, which are significantly harder due to their larger solution spaces.
Green flexible job shop scheduling with interval processing times is a new and fast-growing research field, and there remain many questions to be answered. One of the potential future research directions could involve evaluating the robustness of the solutions found under uncertainty. Furthermore, it would be interesting to develop new solution methods that combine different algorithms to increase solution quality without compromising efficiency. Finally, incorporating more sophisticated power use models that take more realistic properties into account (such as power spikes at machine activation or time-varying power use) would increase the applicability of these models in real-life scenarios.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been supported by the Spanish Government under research Grants TED2021-131938B-I00 and PID2022-141746OB-I00, and by the Principality of Asturias under research Grant GRU-GIC-24-018.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
ChenJCWuCCChenCW, et al.Flexible job shop scheduling with parallel machines using genetic algorithm and grouping genetic algorithm. Expert Syst Appl2012; 39: 10016–10021.
3.
Alvarez-ValdesRFuertesATamaritJ, et al.A heuristic to schedule flexible job-shop in a glass factory. Eur J Oper Res2005; 165: 525–534.
4.
IanninoVCollaVMaddaloniA, et al.A hybrid approach for improving the flexibility of production scheduling in flat steel industry. Integr Comput Aided Eng2022; 29: 367–387.
5.
TorresNGreivelGBetzJ, et al.Optimizing steel coil production schedules under continuous casting and hot rolling. Eur J Oper Res2024; 314: 496–508.
6.
AhnSLeeSBahnH. A smart elevator scheduler that considers dynamic changes of energy cost and user traffic. Integr Comput Aided Eng2017; 24: 187–202.
7.
GuoWXuPZhaoZ, et al.Scheduling for airport baggage transport vehicles based on diversity enhancement genetic algorithm. Nat Comput2020; 19: 663–672. DOI: https://doi.org/10.1007/s11047-018-9703-0
8.
JinX. Application of metaheuristic algorithm in intelligent logistics scheduling and environmental sustainability. Intell Decis Technol2024; 18: 1727–1740.
9.
MencíaCSierraMRMencíaR, et al.Evolutionary one-machine scheduling in the context of electric vehicles charging. Integr Comput Aided Eng2019; 26: 49–63.
10.
HuangCCLiuHMHuangCL. Intelligent scheduling of execution for customized physical fitness and healthcare system. Technol Health Care2016; 24: S385–S392.
11.
RazaliMAbd RahmanAAyobM, et al.Research trends in the optimization of the master surgery scheduling problem. IEEE Access2022; 10: 91466–91480.
12.
TeohCKWibowoANgadimanMS. Review of state of the art for metaheuristic techniques in academic scheduling problems. Artif Intell Rev2015; 44: 1–21. DOI: https://doi.org/10.1007/s10462-013-9399-6
13.
Imaran HossainSAkhandMBhuvoM, et al.Optimization of university course scheduling problem using particle swarm optimization with selective search. Expert Syst Appl2019; 127: 9–24.
14.
MalekimajdMSafarpoor-DehkordiA. A survey on cloud computing scheduling algorithms. Multiag Grid Syst2022; 18: 119–148.
15.
MartinsMSViegasJLCoitoT, et al.Minimizing total completion time in large-sized pharmaceutical quality control scheduling. J Heurist2023; 29: 177–206.
16.
PerezCSalidoMA. A grasp-based search technique for scheduling travel-optimized warehouses in a logistics company. In: Scheduling and planning applications workshop (SPARK). Workshop of ICAPS’20, 2020. Association for the Advancement of Artificial Intelligence.
17.
GendreauMPotvinJY. Handbook of Metaheuristics, International series in operations research & management science, Vol. 272. 3rd ed., 2019, Springer. ISBN 978-3-319-91085-7,978-3-319-91086-4. DOI: https://doi.org/10.1007/978-3-319-91086-4.
SiddiqueNHAdeliH. Water drop algorithms. Int J Artif Intell Tools2014; 23: 1430002.
20.
ParkHSAdeliH. Distributed neural dynamics algorithms for optimization of large steel structures. J Struct Eng1997; 123: 880–888.
21.
SiddiqueNHAdeliH. Simulated annealing, its variants and engineering applications. Int J Artif Intell Tools2016; 25: 1630001.
22.
SiddiqueNHAdeliH. Harmony search algorithm and its variants. Int J Patt Recognit Artif Intell2015; 29: 1539001.
23.
AkhandMAyonSShahriyarS, et al.Discrete spider monkey optimization for traveling salesman problem. Appl Soft Comput2020; 86: 105887.
24.
DíazHPalaciosJJGonzález-RodríguezI, et al.An elitist seasonal artificial bee colony algorithm for the interval job shop. Integr Comput Aided Eng2023; 30: 223–242.
25.
WangJZhongDWangD, et al.Smart bacteria foraging algorithm-based customized kernel support vector regression and epnn for compaction quality assessment and control of earth-rock dam. Exp Syst2018; 35: e12357.
26.
XiongHShiSRenD, et al.A survey of job shop scheduling problem: The types and models. Comput Oper Res2022; 142: 105731.
27.
XieJGaoLPengK, et al.Review on flexible job shop scheduling. IET Collab Intell Manufact2019; 1: 67–77.
28.
Dauzère-PérèsSDingJShenL, et al.The flexible job shop scheduling problem: A review. Eur J Oper Res2024; 314: 409–432.
29.
LenstraJRinnooy KanABruckerP. Complexity of machine scheduling problems. Ann Disc Mathem1977; 1: 343–362.
30.
ChaudhryIAKhanAA. A research survey: review of flexible job shop scheduling techniques. Int Trans Oper Res2016; 23: 551–591.
31.
Fazel ZarandiMHSadat AslAASotudianS, et al.A state of the art review of intelligent scheduling. Artif Intell Rev2020; 53: 501–593.
32.
CoelhoPPintoAMonizS, et al.Thirty years of flexible job-shop scheduling: A bibliometric study. Procedia Comput Sci2021; 180: 787–796.
33.
GaoKCaoZZhangL, et al.A review on swarm intelligence and evolutionary algorithms for solving flexible job shop scheduling problems. IEEE/CAA J Automat Sin2019; 6: 904–916.
34.
MencíaRSierraMRMencíaC, et al.Memetic algorithms for the job shop scheduling problem with operators. Appl Soft Comput2015; 34: 94–105.
35.
AfşarSPalaciosJJPuenteJ, et al.Multi-objective enhanced memetic algorithm for green job shop scheduling with uncertain times. Swarm Evol Comput2022; 68: 101016.
36.
Garcıa GómezPGonzález-RodrıguezIVelaCR. Enhanced memetic search for reducing energy consumption in fuzzy flexible job shops. Integr Comput Aided Eng2023; 30: 151–167.
37.
LiXLiWCaiX, et al.A hybrid optimization approach for sustainable process planning and scheduling. Integr Comput Aided Eng2015; 22: 311–326.
38.
GahmCDenzFDirrM, et al.Energy-efficient scheduling in manufacturing companies: A review and research framework. Eur J Oper Res2016; 248: 744–757.
39.
Alvarez-MeazaIZarrabeitia-BilbaoERio-BelverRM, et al.Green scheduling to achieve green manufacturing: Pursuing a research agenda by mapping science. Technol Soc2021; 67: 101758.
40.
Garrido-HidalgoCRoda-SanchezLFernandez-CaballeroA, et al.Internet-of-things framework for scalable end-of-life condition monitoring in remanufacturing. Integr Comput Aided Eng2024; 31: 1–17.
41.
LiMWangGG. A review of green shop scheduling problem. Inf Sci (Ny)2022; 589: 478–496.
42.
WangQLiuHLYuanJ, et al.Optimizing the energy-spectrum efficiency of cellular systems by evolutionary multi-objective algorithm. Integr Comput Aided Eng2019; 26: 207–220. DOI: https://doi.org/10.3233/ICA-180575
GhafariRKabutarkhaniFHMansouriN. Task scheduling algorithms for energy optimization in cloud environment: a comprehensive review. Cluster Comput2022; 25: 1035–1093.
ParaJDel SerJNebroAJ. Energy-aware multi-objective job shop scheduling optimization with metaheuristics in manufacturing industries: a critical survey, results, and perspectives. Appl Sci2022; 12. DOI: https://doi.org/10.3390/app12031491
47.
GuggeriEMHamCSilveyraP, et al.Goal programming and multi-criteria methods in remanufacturing and reverse logistics: systematic literature review and survey. Comput Indust Eng2023; 185: 109587.
48.
BakonKHolczingerTSuleZ, et al.Scheduling under uncertainty for industry 4.0 and 5.0. IEEE Access2022; 10: 74977–75017.
49.
PalaciosJJGonzálezMAVelaCR, et al.Genetic tabu search for the fuzzy flexible job shop problem. Comput Oper Res2015; 54: 74–89.
50.
Garcıa GómezPVelaCRGonzález-RodrıguezI. Neighbourhood search for energy minimisation in flexible job shops under fuzziness. Nat Comput2023; 22: 685–704.
51.
DíazHPalaciosJJDíazI, et al.Robust schedules for tardiness optimization in job shop with interval uncertainty. Logic J IGPL2022; 31(2): 240–254. DOI: https://doi.org/10.1093/jigpal/jzac016
LiKChenJFuH, et al.Uniform parallel machine scheduling with fuzzy processing times under resource consumption constraint. Appl Soft Comput2019; 82: 105585.
54.
LeiD. Multi-objective artificial bee colony for interval job shop scheduling with flexible maintenance. Int J Adv Manuf Technol2013; 66: 1835–1843.
55.
LeiDGuoX. An effective neighborhood search for scheduling in dual-resource constrained interval job shop with environmental objective. Int J Produc Econ2015; 159: 296–303.
56.
DíazHPalaciosJJDíazI, et al.Tardiness minimisation for job shop scheduling with interval uncertainty. In: International Conference on Hybrid Artificial Intelligence Systems, 2020, pp.209–220. Springer.
57.
DíazHPalaciosJJGonzález-RodríguezI, et al.Fast elitist abc for makespan optimisation in interval jsp. Nat Comput2023; 22: 645–657.
58.
MooreREKearfottRBCloudMJ. Introduction to Interval Analysis. Philadelphia: Society for Industrial and Applied Mathematics, 2009. ISBN 0898716691.
59.
KarmakarSBhuniaAK. A comparative study of different order relations of intervals. Reliable Computing2012; 16: 38–72.
60.
DuflouJRSutherlandJWDornfeldD, et al.Towards energy and resource efficient manufacturing: a processes and systems approach. CIRP Annals2012; 61: 587–609.
61.
SeowYRahimifardS. A framework for modelling energy consumption within manufacturing systems. CIRP J Manufact Sci Technol2011; 4: 258–264.
62.
SchmidtCLiWThiedeS, et al.A methodology for customized prediction of energy consumption in manufacturing industries. Int J Precis Eng Manufact-Green Technol2015; 2: 163–172.
63.
GonzálezMAOddiARasconiR. Multi-objective optimization in a job shop with energy costs through hybrid evolutionary techniques. In: Proceedings of the 27th international conference on automated planning and scheduling (ICAPS-2017), 2017, pp.140–148.
64.
RossiFVan BeekPWalshT. Constraint programming. Found Artif Intell2008; 3: 181–211.
65.
LaboriePRogerieJShawP, et al.IBM ILOG CP optimizer for scheduling. Constraints2018; 23: 210–250.
66.
AfşarSPuenteJPalaciosJJ, et al.A genetic approach to green flexible job shop problem under uncertainty. In: International work-conference on the interplay between natural and artificial computation, 2024, pp.183–192. Springer.
67.
González RodríguezIVelaCRHernández-ArauzoA, et al.Improved local search for job shop scheduling with uncertain durations. In: Proceedings of the nineteenth international conference on automated planning and scheduling (ICAPS-2009), 2009, pp.154–161. Thesaloniki: AAAI Press. ISBN 9781577354062.
68.
Van LaarhovenPAartsELenstraK. Job shop scheduling by simulated annealing. Oper Res1992; 40: 113–125.
69.
Garcıa GómezPGonzález-RodrıguezIVelaCR. Reducing energy consumption in fuzzy flexible job shops using memetic search. In: Proceedings of the 9th international work-conference on the interplay between natural and artificial computation, IWINAC 2022, Puerto de la Cruz, Spain, Lecture Notes in Computer Science, Vol. 13259, 2022, pp.140–150. DOI: https://doi.org/10.1007/978-3-031-06527-9_14.
70.
Dauzère-PérèsSPaulliJ. An integrated approach for modeling and solving the general multiprocessor job-shop scheduling problem using tabu search. Ann Oper Res1997; 70: 281–306.
71.
MastrolilliMGambardellaLM. Effective neighborhood functions for the flexible job shop problem. J Sched2000; 3: 3–20.