
Abstract
Homomorphic encryption has seen limited application in real-world settings due to its high computational costs, which often impede practical use in latency-sensitive scenarios. Addressing this challenge, this research work presents an efficient, partially homomorphic encryption framework for privacy-preserving ID creation tailored to biometric applications, such as border control or access to secure restricted facilities. The proposed solution leverages the additive homomorphic properties of Paillier and Elliptic Curve ElGamal encryption schemes to encapsulate biometric data within a secure cryptographic layer, enabling rapid verification while minimizing computation and storage demands. Paillier encryption ensures robust security with maximal accuracy, while Elliptic Curve ElGamal optimizes for minimal ciphertext sizes, both meeting rigorous ISO biometric security standards. Experimental results demonstrate that the framework achieves high accuracy with reduced memory and bandwidth requirements, with encrypted IDs as compact as 4 KiB, making it suitable for scalable deployment. This research work represents a key advancement in homomorphic encryption applications, balancing privacy and efficiency without the usual overhead, and making it feasible for real-time biometric processing. In summary, this framework offers a pioneering solution in secure biometric verification, setting a new standard for privacy-preserving applications, positioning it as a promising model for future secure identification systems.
Introduction
Biometric systems are increasingly being used for authentication, verification, and identification. These systems rely on unique biological characteristics to verify an individual’s identity. The uniqueness, convenience, and permanence of biometric traits have driven this increased adoption in personal verification systems. Among the most widely used biometric attributes are speech,1–3 facial features,4–7 fingerprints,8,9 palm-prints,10–12 iris patterns,13,14 body detection15–17 and other bio-signal sampling. 18 The fusion of multiple biometric traits has proven to be an effective strategy for enhancing the accuracy and robustness of identification systems, significantly surpassing the reliability of token-based methods. Biometric data is utilized in a wide range of scenarios, including single-identity verification, device unlocking, access control systems, and biometric database searches.
However, the storage and transmission of biometric data raise significant privacy and security concerns. Biometric data, if compromised, can be exploited for identity theft or other malicious purposes such as the disclosure of confidential medical information in healthcare settings, and fraudulent access to bank accounts in payment systems. Therefore, biometric information is classified as sensitive personal data under the European Union General Data Protection Regulation (GDPR) 19 and requires robust security measures to prevent unlawful intrusion. In this regard, the encryption of biometric data has become an active field in recent years due to the increasing number of works and applications.20,21
In most biometric applications, it is necessary to perform a comparison between different samples. These samples are typically extracted using Convolutional Neural Networks (CNNs) and represented as embeddings. The comparison between these embeddings relies on measuring the distance between them. However, this representation has an inherent vulnerability: invertibility. That is, an adversary could use deep learning algorithms to reverse the embedding extraction process and obtain an approximation of the original image, thereby compromising data confidentiality.22–24 Moreover, the ISO/IEC IS 24745:2022
25
imposes the following properties for the security and privacy of biometric embeddings:
Renewability: the ability to revoke obsolete templates and generate new ones from the same biometric source. Unlinkability: the prevention of linking two or more encrypted embeddings to the same source. Irreversibility: the use of processes that make the embedding irreversible to its original state. Recognition Performance Preservation: ensuring that the system’s performance is not significantly affected by the encryption.
To address the aforementioned issue, homomorphic encryption (HE) is proposed as a solution. 26 This encryption scheme allows an untrusted party to perform computations on encrypted data without compromising its confidentiality. A significant advantage of this scheme lies in its ability to ensure the continuous protection of a user’s personal data. Even after the contractual or service relationship with the untrusted party has ended, it ensures that shared information cannot be misused. However, HE presents inherent limitations, such as the maximum number of operations that can be performed without data loss and the high computational cost associated with these operations. There are three variants of HE: Partially Homomorphic Encryption (PHE), which allows an unlimited number of a single type of operation (either additions or multiplications); Somewhat Homomorphic Encryption (SHE), which enables a limited number of both additions and multiplications; and Fully Homomorphic Encryption (FHE), which supports an unlimited number of additions and multiplications. 27
The authors’ work aims to leverage HE algorithms to provide a framework for creating an
Related work
There is extensive research on the risks associated with handling private or sensitive information, not only in the field of biometrics28,29 but also in related areas such as biomedical data.30,31 Commonly proposed solutions include strict access control, data anonymization, secure data sharing frameworks, and the application of standard cryptographic techniques. However, a great amount of publications does not sufficiently explore more advanced privacy-preserving methods, such as HE, which can limit effective risk mitigation and data protection. This study seeks to close this gap by exploring how HE can enhance privacy in the field of biometrics.
When exploring cryptographic HE centered solutions, most of the literature focuses on FHE schemes due to their theoretical capability to support an unlimited number of operations. This flexibility has driven extensive research aimed at addressing its primary limitations, such as high computational time and intensive resource consumption. Efforts to enhance FHE are pursued both by optimizing the underlying mathematical functions and by accelerating performance through the use of GPU units. 27 The increasing adoption of cloud services has further fueled interest in this area. One example of an application is the storage of multiple biometric embeddings in the cloud, where one-to-many (1 vs. n) comparisons must be performed with new embeddings submitted by users. To ensure the confidentiality of biometric data throughout the entire process, it is essential to employ HE schemes.20,21
Focusing on PHE schemes, in Shafagh et al., 32 the authors propose Pilatus, a platform designed to facilitate the secure exchange of data in the cloud using a PHE scheme. This proposal aims to ensure that the data remains agnostic to the server. For the scheme’s implementation, the Elliptic Curve ElGamal (ECEG) method is combined with the Chinese Remainder Theorem (CRT), enhancing computational efficiency while maintaining low resource consumption. Mobile applications integrated with Pilatus achieve a decryption overhead of less than one second, ensuring that the encryption process does not negatively impact user experience.
In Liu et al., 33 a distributed learning model is implemented using PHE, where the weights of various neural networks trained in trust zones are shared to create a combined model in the cloud. The decision not to establish a federated server within a secure zone stems from the high resource consumption and prolonged time required to set up such private services. Consequently, for the aggregation of hyperparameters on an untrusted server, the ECEG PHE scheme is employed, as a FHE approach would render the service impractical in real-world applications due to the significant computational overhead. The study also explores a wide range of additional methods to achieve further optimizations, resulting in processes that are far more efficient than simply encrypting the federated database.
Gómez-Barrero et al. present a novel system for fusing encrypted biometric embeddings using the Paillier homomorphic encryption scheme. 34 The authors investigate various fusion strategies, with a particular focus on feature-level fusion. This approach involves combining the biometric information of individual features into a single template before encryption. A key finding of the study is that computational costs are suitable for real-time applications, with an estimated comparison time per verification as low as 0.5 milliseconds using 4 processor cores.
In Gomez-Barrero et al. 35 a privacy-preserving method for comparing user hand signatures using PHE is presented, specifically utilizing the Paillier cryptosystem. As stated by the authors, PHE is chosen for its reduced computation overhead. This research work achieves very short identification times by mixing a fixed-length comparison approach of pre-extracted general hand signature attributes with a sub-sampling of a variable-length Dynamic Time Warping (DTW) algorithm. Specifically, for a known database of 400 user hand signatures, an identification takes 2.4 seconds, using 4 processor cores, greatly outperforming similar works while almost identical precision and retaining user data security.
Mahesh Kumar et al. describe a novel iris-based biometric verification system, prioritizing user privacy. 36 For this purpose, images of both irises (left and right) were acquired to generate a more robust biometric template. Subsequently, a dimensionality reduction technique based on a modification of the local random projection algorithm was applied. The resulting embeddings were encrypted using the Paillier homomorphic encryption scheme, ensuring the confidentiality of biometric data throughout the entire verification process.
Analyzing some prominent FHE implementations, Bauspieß et al.
37
is of note. The authors propose a novel coefficient packing scheme to compute multiple distances in biometric templates, optimizing the process so that the computational cost is equivalent to that of a single comparison. With this approach, they achieve a 1.6% performance improvement compared to conventional FHE systems. In the first stage, a principal component analysis (PCA) is applied to reduce the dimensionality of the embeddings from 512 to 64 dimensions. This reduction allows for a more compact representation of the data without losing relevant information. Next,
Kolberg et al. propose a system for verification and identification based on iris codes that leverages homomorphisms in the N-th degree truncated polynomial ring units (NTRU) framework. 38 The authors achieve an improvement both in the accuracy rate and in the algorithm performance. Before applying the homomorphism techniques, the bit blocks of the iris code are reordered, placing those that contain more relevant information at the beginning of the sequence. To compare the embeddings, a block-by-block comparison process is carried out. If the distance between two blocks is below a predefined threshold, it is considered that both embeddings come from the same source due to their high similarity, and the comparison terminates. On the other hand, if the distance is greater than a second threshold, it is concluded that the embeddings correspond to different sources. If the distance falls between the two thresholds, the comparison of the remaining blocks continues.
The current research work achieves similar computation times to other PHE implementations, specifically the verifications in Gomez-Barrero et al.34,35 and Morampudi et al. 36 These works make use of additional algorithm optimizations as well as a certain degree of parallelization. The distinguishing factor in this work is the small ciphertext sizes. With the right parameter choice, these require 256 bits per embedding value (before compression), resulting in an 8 times reduction compared to Paillier ciphertexts. Moreover, analyzing FHE algorithms, these are far more suitable for 1-n identification due to batching techniques. However, in the 1-1 case, our PHE implementation achieves promising results compared to FHE alternatives and leaves room for more aggressive optimizations, as discussed in the 6 section.
Taking the previous related work into consideration as well as a general overview of the field, some objectives are established for the encrypted homomorphic ID. These are founded on the Privacy by Design framework39,40 and based on the aforementioned ISO/IEC IS 24745:2022 standard.
25
Firstly, the proposed solution must offer
Last, this paper is organized as follows: 2 describes an overview of the conceptual foundation needed for this solution. 3 summarizes the algorithm architecture and its building blocks as well as the vulnerability assessment under the semi-honest and malicious settings. 5 states key experimental outcomes obtained from profiling the two different implementations. 6 examines said outcomes, presents use cases for the proposed scheme, compares the results with other methods and addresses advantages and limitations. Finally, 7 presents some closing thoughts and future lines of research.
Theoretical framework
Biometric embedding comparison
Biometric information comparison is the process of measuring how similar or different pieces of data (such as images of faces, fingerprints, voice recordings, among others) are based on their content. A common and popular technique for this is to use neural networks, especially CNNs, to capture patterns and features from a piece of data. These networks convert the inputs into vectors of multiple elements called embeddings. Each embedding reflects the distinctive attributes of its corresponding input. By comparing these embeddings in a high-dimensional space, similarities can be accurately calculated.5,41,42
Homomorphic encryption
When describing Homomorphic Encryption (HE), a distinction is made between Fully-Homomorphic Encryption (FHE), Somewhat-Homomorphic Encryption (SHE) and Partially-Homomorphic Encryption (PHE). On the one hand, FHE, conceptualized first in Rivest and Dertouzos,
26
allows arbitrary computation on encrypted data that yields the same encrypted results as if it were performed on plaintexts. Typically, this unlimited computation is reduced to addition and multiplication. For messages
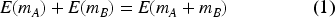
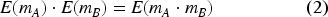
A similar functionality is offered by SHE but with a limited number of operations before data degradation occurs. SHE implementations, although more limiting, remain more efficient in practical scenarios. Most FHE implementations rely on some form of SHE as their base coupled with a bootstrapping technique. Some of the most relevant are explained in: Gentry 43 ; van Dijk et al. 44 ; Fan and Vercauteren 45 ; Brakerski et al. 46 ; Brakerski and Vaikuntanathan.47,48 For a detailed guide to FHE, see 49 and for modern surveys on the field, see Yousuf et al. 50 and Marcolla et al. 51
On the other hand, when using PHE only certain specific operations are possible (usually addition or multiplication). Therefore, this approach is more limiting but can be orders of magnitude faster to compute. Some of the classical partially homomorphic algorithms are outlined here: Rivest et al. 52 ; Elgamal 53 and Paillier. 54 For a modern survey of current implementations, see Ryu et al. 55
Paillier
54
is a well-known probabilistic public-key partially homomorphic cryptosystem. It works as follows:
Key generation. Two large primes Encryption. A message Decryption. The original message
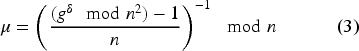
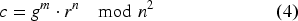
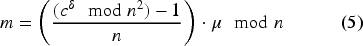
The Paillier encryption system is additively homomorphic modulo
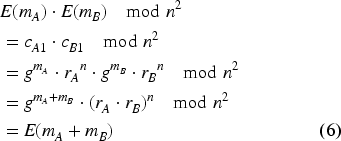
The product of two ciphertexts will correspond to the sum of the original messages once decrypted. It should be noted that, even if
The security of the Paillier encryption scheme is founded on the computational hardness of the Decisional Composite Residuosity (DCR) problem.
54
The assumption posits that, given a composite number
Paillier provides indistinguishability under chosen plaintext attack (IND-CPA) security. To prove this, an adversary is given two messages,
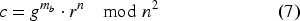
Elliptic Curve Cryptography (ECC)56–58 is a framework for constructing public key cryptosystems that exploits the mathematical properties of elliptic curves over finite fields. An elliptic curve
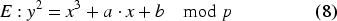
The set of points Point Addition. Given two points Scalar Multiplication. Given point
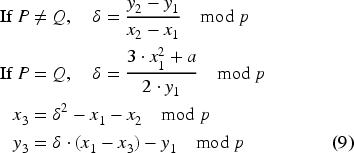
Encryption typically involves the generation of ciphertexts using carefully chosen elliptic curve points. The security of this process fundamentally relies on the Elliptic Curve Discrete Logarithm Problem (ECDLP),56,58 which asserts that given a generator point
ECEG is a probabilistic public-key partially homomorphic cryptosystem based on ECC and the ElGamal scheme.
53
It works as follows:
Key generation. The user selects an appropriate elliptic curve Encryption. The message Decryption. Using the private key

The original ElGamal is multiplicatively homomorphic modulo
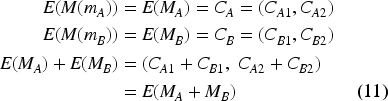
Here,
The security of ECEG encryption relies on the difficulty of solving two problems. For both, an elliptic curve
The ECEG encryption scheme is secure under indistinguishability against chosen plaintext attacks (IND-CPA). To demonstrate this, an adversary is provided two messages Brute force attack. An adversary attempts to directly guess the private key; however, this approach is computationally infeasible for large values of Baby-Step Giant-Step algorithm.63,64 This is a time-space trade-off algorithm that allows an adversary to solve the ECDLP in O( Pollard’s Rho algorithm.65,66 An integer factorization approach that also achieves O( Quantum attacks. If realized, quantum computers could potentially break the ECDLP by employing Shor’s algorithm.67–69
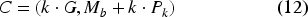
In this section, a general overview of the algorithm is presented. It is visualized in Figure 1 and the pseudo-code is portrayed in Algorithms 1 and 2.
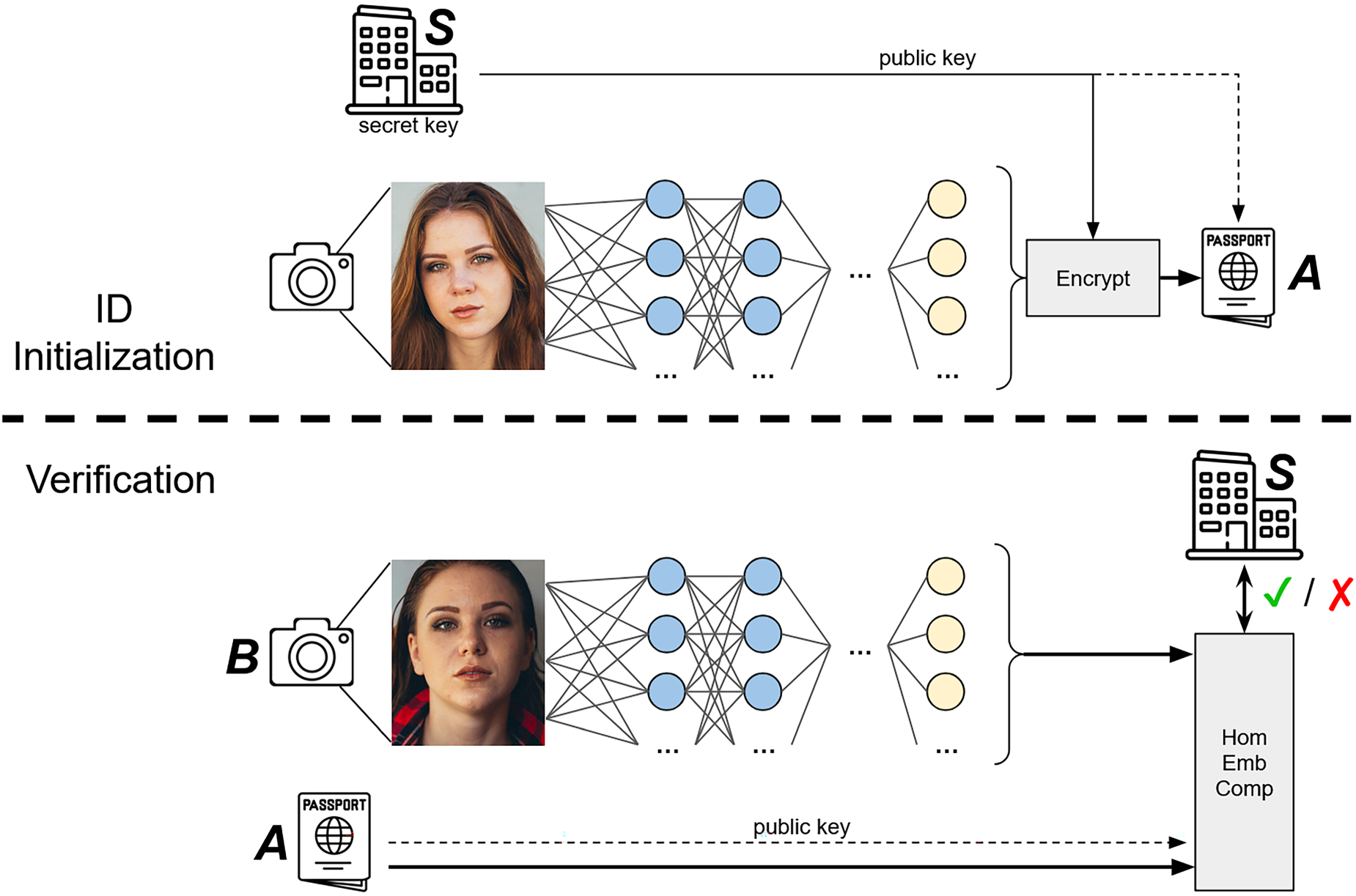
Schematic of ID initialization and verification. Note, both images are obtained from a publicly available digital image repository that provides full permission for academic and commercial use.


The scheme is divided in two sections. Firstly, the ID is created (or initialized). During this step, a trusted entity
In the second step, the user’s document is compared to an additional sample of biometric data. An arrival at an airport can be seen as a practical example, where a person must proceed through border control. The user presents their ID, and a frontal face picture is taken; these are then compared to verify a match. This is a standard case of biometric authentication. Within the context of the presented scheme, once the biometric data is obtained, an embedding vector is extracted using the same methodology as the initial step. Utilizing the public key saved on the document, the user’s stored encrypted embeddings are homomorphically compared to the extracted vector using a distance function (typically cosine or Euclidean distance). The result is sent to the entity responsible for the ID issuance
As aforementioned in the 2.2 subsection, fully or somewhat homomorphic systems that support both addition and multiplication of ciphertexts are orders of magnitude slower than partially homomorphic algorithms and restrict the number of operations before data degradation occurs. Therefore, to achieve efficient functionality (as described in the 1.1 section), this work aims to employ PHE.
The chosen distance functions, namely cosine and Euclidean distance, can be computed using only an additive homomorphism. It should be noted that additive PHE also supports multiplication by a known scalar, as this operation can be achieved by adding a ciphertext to itself iteratively. A similar technique was followed in prior work on garbled embedding comparison.
70
As it can be seen, the conventional cosine distance can be broken down into a sum of products. If the values are normalized, the fraction denominator can be removed. For two parties, Only in the case of normalized vectors does the Euclidean distance become almost identical to the cosine distance. No additional cryptographic functionality is required to compute this similarity; instead, the cosine distance is calculated and the desired output is obtained from it. The squared value of the distance is adopted to avoid computationally expensive evaluation of square root operations.
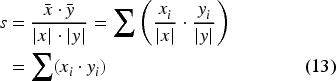

An essential consideration must be addressed. Embedding values are represented as decimal numbers in floating-point notation, rendering them incompatible with most HE schemes without prior transformation. As in Hristov- Kalamov et al.,
70
the scheme utilized here follows a similar approach. To simplify the process, the embedding vectors will be restricted to positive values and, as a first step, will be normalized. Subsequently, all floating-point inputs are converted to a fixed-precision decimal system and treated as scalars; i.e., they are “shifted” left enough times to eliminate the decimal part. For instance, using 8 bits of precision (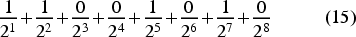
The Paillier cryptosystem is one of the two chosen schemes for this research work. As explained in the 2.3 section, it is an additive PHE algorithm. The implementation for the ID generation is relatively straightforward. First, for a given security parameter
The homomorphic embedding comparison is also straightforward. Once again,
EC ElGamal embedding comparison
The EC ElGamal cryptosystem is the second scheme chosen for this research work. As outlined in the 2.5 subsection, it is an additive PHE algorithm; however, the additive homomorphism works on elliptic curve points rather than on integers. Consequently, a custom mapping function is utilized to adapt this algorithm. In this context, mapping refers to transferring a message from a specific domain to another, specifically from an integer to an elliptic curve point. Most mappings are unsuitable for this scenario, as they do not preserve the linear additive behavior of integers. A somewhat one-way 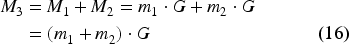
An additional key concept is
During ID generation, given a security parameter
For the homomorphic embedding comparison,
In this section, the presented homomorphic ID scheme is analyzed within both semi-honest and malicious settings, considering the perspectives of all participants. The involved parties are as follows: the user
The only assumption made is that
Security of ID generation
During the generation stage, only two parties are involved:
Security of biometric comparison
In this step, three parties are involved:
For
Party
In the
Since parties
To sum up, the proposed solution is fully secure in the semi-honest setting and partially secure in the malicious setting. This partial security is sufficient for real world applications since the entities responsible for ID generation (e.g. government agencies) and ID verification (e.g. customs agencies) are trustworthy.
Implementation and results
A standard security parameter of
For testing purposes, four different embedding lengths are chosen, based on popular neural network algorithms for face verification. Specifically, the vector sizes are 128, 256, 512, and 4096. In addition, three increasing levels of bit precision are tested: 8, 10, and 12 bits.
All the experimental results are gathered on an AWS EC2 r7iz instance, powered by a 4th Gen Intel Xeon Scalable (Sapphire Rapids) processor operating on a
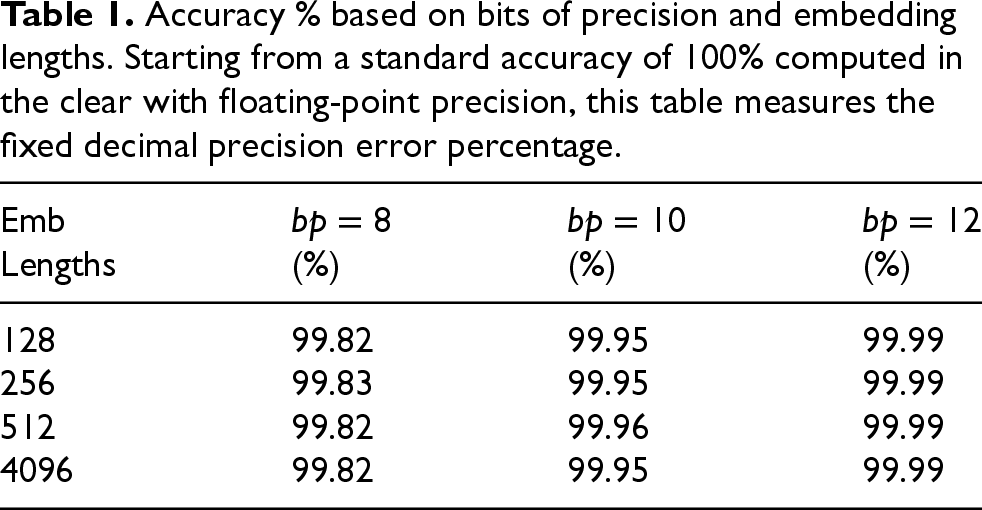
Accuracy % based on bits of precision and embedding lengths. Starting from a standard accuracy of 100% computed in the clear with floating-point precision, this table measures the fixed decimal precision error percentage.
Accuracy % based on bits of precision and embedding lengths. Starting from a standard accuracy of 100% computed in the clear with floating-point precision, this table measures the fixed decimal precision error percentage.
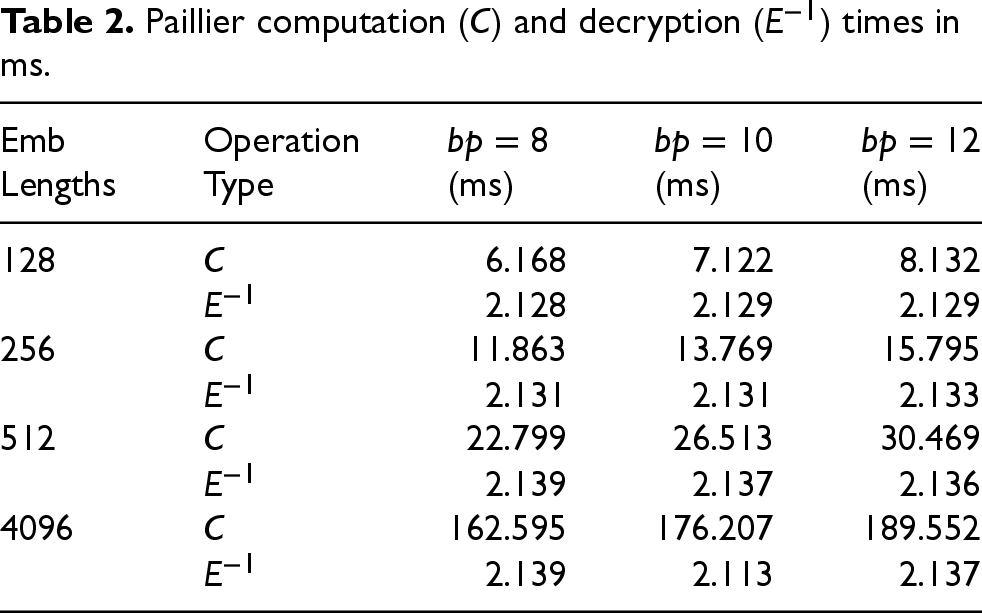
Paillier computation (
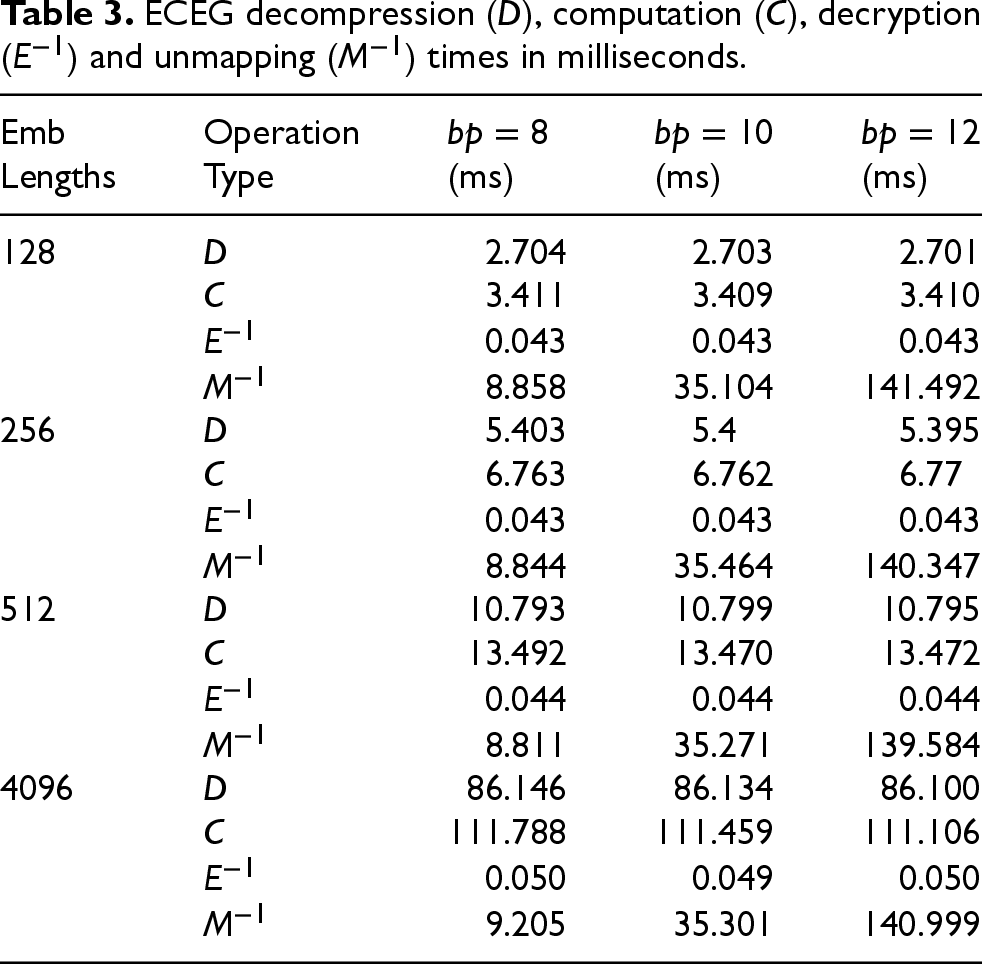
ECEG decompression (
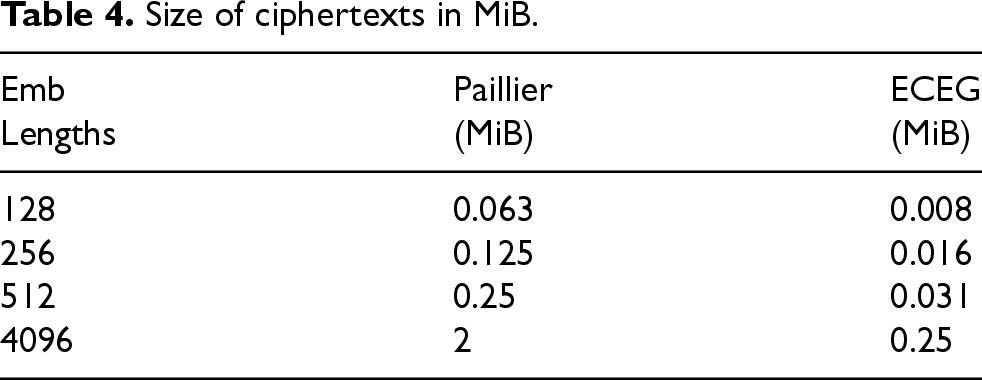
Size of ciphertexts in MiB.
Additional memory needed for computation in KiB.

Before analyzing specific results, it is important to discuss the chosen embedding lengths. The values correspond to widely recognized face comparison models and libraries such as FaceNet (128 vector dimensions), DeepFace (4096 vector dimensions), VGGFace (4096 vector dimensions), VGGFace2 (512 vector dimensions), ArcFace (512 vector dimensions), CosFace (512 vector dimensions), SphereFace (512 vector dimensions), Dlib (128 vector dimensions), OpenFace (128 vector dimensions) and the 256-dimensional variant of ArcFace (256 vector dimensions).
It should be noted that most modern face comparison schemes are trained using angular loss, triplet loss, or contrastive loss functions, which typically work with L2 normalized inputs and outputs. Therefore, the authors’ choice to compute distances between normalized vectors is completely valid and additionally offers greater computational efficiency.
In Table 1, the cosine distance was first computed in the clear, using standard floating-point operations and subsequently calculated using our fixed-precision approach with 8, 10 and 12 bits of precision. The latter results were then compared to the former. Two aspects can be observed. On the one hand, accuracy is independent of embedding length. On the other hand, accuracy increases slightly with a higher fixed-bit count. While this is intuitively expected, the observed improvement remains minimal.
In Table 2, homomorphic arithmetic and decryption times were recorded as a function of embedding size and bit precision. Upon examining the computation metrics, a slight linear increase in time is observed with higher bit precision, while a significantly larger linear increase is seen with longer embedding lengths. Last, decryption time remains constant across all cases, as only a single final value requires decryption in each scenario. This behavior is consistent with expectations.
In Table 3, the times for EC point decompression, homomorphic computation, decryption and unmapping were measured as a function of embedding size and bit precision. Point decompression and PHE computation remain constant in regard to bit precision but increase linearly as embedding length grows. Decryption is both fully constant and incredibly fast, owing to the fact that, irrespective of setup, deciphering the result requires only a single point multiplication and addition. Finally, the time to unmap a point to a valid message is exponentially dependent on bit precision, which can be attributed to the
Table 4 provides a straightforward measurement of the ciphertext sizes for both schemes. It is crucial to note that these values affect the storage requirements for the protected ID as well as the networking considerations when sending a single encrypted result to the trusted entity
Table 5 indicates the additional auxiliary memory required for each approach. Only ECEG uses an increase in RAM usage as bit precision increases, due to the
After analyzing the data presented in the results tables, several considerations emerge. For the Paillier solution, bit precision proves practically irrelevant, allowing accuracy to be prioritized. A precision higher than those tested, such as Identifying a point mapping function that preserves scalar homomorphism without exhibiting exponential complexity behavior. Retraining the face comparison model used, incorporating custom fixed-precision arithmetic in the loss function. However, this approach would render the proposed solution no longer agnostic to the underlying neural network.
As a final remark, it is worth noting that embedding length can be further reduced to 64 values, effectively halving the required PHE arithmetic. This technique is successfully leveraged in Bauspieß et al.
37
Additionally, further optimizations can be applied to the presented algorithms. Distance calculation, whether performed in the clear or homomorphically, is inherently parallelizable and can be accelerated by utilizing multiple CPU cores or GPU processing. This means that parallelization linearly improves computation speed; for instance, using eight cores would decrease execution times approximately by a factor of eight. Since this linear behavior is very common in cryptographic research, establishing a
Disadvantages and limitations
In the 3 section, it is stated that the presented solution requires a constant internet connection to execute biometric verification effectively. This dependency poses a disadvantage compared to existing systems that do not have such a requirement. The ECEG variant with point compression reduces the data exchange to a 512-bit request and 1-bit response; however, the necessity of an internet connection remains a potential limitation.
Furthermore, the stringent protection of biometric data may present practical challenges. For instance, in a customs checking scenario, this level of protection may complicate the tasks of border control agents, as a face image is not immediately available on the document. This limitation is inherent to the design of this approach and is explicitly defined as an objective in alignment with privacy by design principles. If a biometric comparison can be performed without accessing the underlying sensitive data, it must be conducted accordingly. Nevertheless, the authors acknowledge that such rigorous standards may present difficulties in practical implementation. Moreover, the proposed approach requires synchronization among multiple entities, such as various governments, border control agencies, and other organizations involved in the process. Thus, the complexity of this system may introduce additional challenges in terms of deployment.
Finally, and perhaps most importantly, the data comparison process is entirely reliant on a neural network. In fact, it is impossible for a human to access the underlying information. Consequently, the effectiveness of the solution is highly dependent on the accuracy and reliability of the verification model.
Additional use cases
While the primary aim of this research work is the development of a protected ID for customs and border control, homomorphic biometric comparison has potential applications across various other domains. Any secure access point could utilize this scheme. For instance, a private facility might require a biometric sample, such as an iris scan, for entry. To avoid central storage of this information, an encrypted ID could be issued and employed alongside the biometric scan.
An emerging use case lies in payment systems that leverage biometric authentication for enhanced security. For instance, fingerprint-based payment methods are becoming increasingly prevalent, wherein a user’s fingerprint is compared to an encrypted version of their fingerprint ID, stored either on their mobile device or in the cloud. In these scenarios, the encryption ensures that sensitive biometric data remains secure while enabling user-friendly operation. Such scenarios would follow an identical process, whereby a PHE-encrypted ID is pre-generated by a trusted entity and homomorphically compared to an extracted fingerprint during a payment transaction. These systems are typically automated, requiring no human supervision, and are often managed by private companies, which further underscores the need for robust privacy protections.
Last, the proposed ID system can be adopted in law enforcement agencies to guarantee the protection of citizens’ civil rights. For example, if a police agency possesses a picture of a crime suspect and aims to match it against a broad population, homomorphic identification can be employed to conduct the comparison without accessing individuals’ underlying biometric data. This approach preserves both privacy and security throughout the identification process.
Other methods comparison
A comparison with alternative approaches is performed in this subsection as well as a discussion on whether these other frameworks meet the laid-out requirements in the 1.1 subsection. First, FHE is analyzed as it is the primary candidate for an alternative. As described in the 1.1 section, many implementations utilize FHE to achieve a similar purpose. Additionally, since FHE supports all the operations and privacy features of SHE, it also meets most of the outlined requirements. Utilizing the latest literature that profiles the different state-of-the-art FHE libraries,73–75 a direct comparison is made emulating the necessary operations for a cosine distance performed exactly as detailed in the Homomorphic Distance Function formula. To conduct this comparison, the four principal libraries most commonly referenced in the literature have been employed, namely, https://github.com/microsoft/SEALSEAL, https://gitlab.com/palisadePALISADE, https://github.com/homenc/HElibHElib and https://www.ckks.org/HEAAN. Specifically, the CKKS scheme is examined as it is the main one used in privacy-preserving deep learning, especially in the biometric or biomedical fields.
To compute the cosine distance as efficiently as possible, batching is utilized allowing for all embedding elements to be encrypted into the same ciphertext. A singular ciphertext representing
The required computation is dependent on circuit depth. FHE implementations have a so-called “noise budget” that measures the number of operations that can be performed, i.e. the depth of the circuit. If this budget is spent, a valid output can no longer be decrypted. To reset the “noise budget”, a special calculation called bootstrapping is carried out. This action is very performance-intensive. When setting up the FHE library, a shorter circuit depth can be chosen where each operation is faster, but bootstrapping might be required, or a longer depth can be implemented with slower operations. This aspect is showcased in Table 6 where the cost of each operation is visualized for the smallest and largest depths specific to the cosine distance. Moreover, Table 7 displays the total estimated timings for the shortest and longest depths compared to the timings obtained in this research work. The following parameters are chosen for the FHE calculations: security level
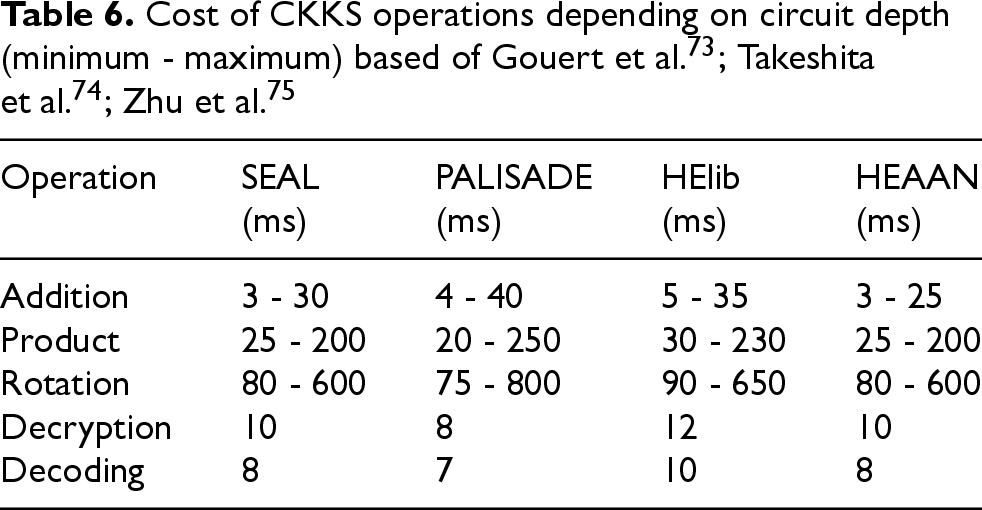

Analyzing the estimated timings in Table 7, some aspects are of note. On the one hand, a maximum depth circuit presents results orders of magnitude slower than the SHE findings obtained in this research work. On the other hand, while minimum depth values showcase somewhat shorter durations, it is important to mention that bootstrapping can take
Additionally, the sizes of FHE elements, as profiled in Takeshita et al., 74 are also of note. A compressed ciphertext can take approximately 30 KB of data, making it strictly better than our Paillier scheme but worse than our ECEG scheme for most practical embedding lengths. However, when uncompressed the ciphertext balloons to 4 - 8 MB of size, thus leading to much greater memory demands. Similarly, an uncompressed public key necessitates an additional 4 - 8 MB. Last, for the rotation operation to be possible, another element is required, the Galois keys. These can take up to 30 MB of space, imposing some limitations on storage (especially if the digital ID is placed in a small embedded device or digital card). All of this leads to the conclusion that, without some custom implementation or strategy, FHE is less adequate for the specific scenario outlined in this publication than the presented Paillier and ECEG schemes.
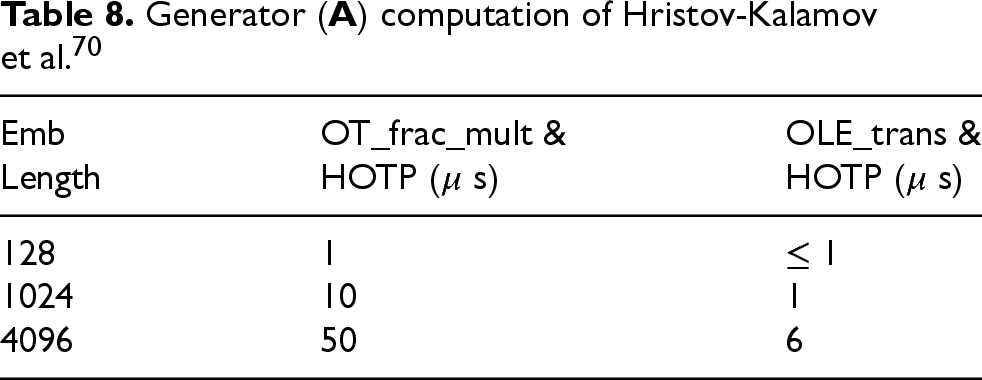
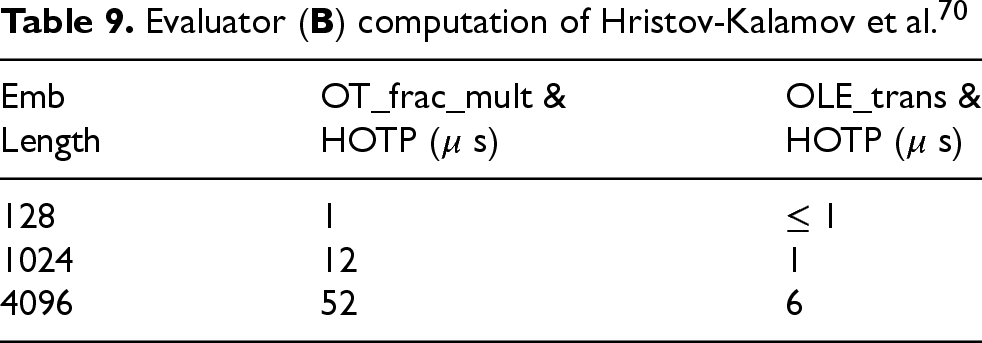
Aside from HE, a comparison can be made with other privacy-preserving protocols. These can include Garbled Circuits (GC), Function Secret Sharing (FSS), Homomorphic Secret Sharing (HSS) or direct computing with Oblivious Transfer (OT) or Oblivious Linear Evaluation (OLE). In the previous work of Hristov-Kalamov et al.,
70
a similar setup of embedding comparison was implemented and profiled. This approach was based on exploiting a simple homomorphism of a One-Time Pad coupled with the OT and OLE protocol. The proposed solution emphasized speed above all else. The measured computation times were significantly faster, requiring microseconds to complete, as shown in Tables 8 and 9. The memory and networking requisites were closer in size but also lesser, as portrayed in Table 10. However, this scheme relies on both parties performing some computation each time embeddings are compared. Therefore, as outlined in the 1.1 subsection, it breaks the
Generator (
Evaluator (
Data exchange requirements of Hristov-Kalamov et al. 70

This juxtaposition highlights how privacy-preserving algorithms can require drastically different amounts of resources, where the same operation (in this case, a cosine distance) can take up several seconds, milliseconds, or even microseconds and how seemingly small requirements can completely change the possible solutions.
As a final comparison, since this research work merges neural networks and cryptography, CryptoNets become a natural candidate. Recent advances in privacy-preserving machine learning have introduced architectures which are designed to perform inference over encrypted data by adapting neural networks to operate within cryptographic constraints. CryptoNets demonstrate the feasibility of learning directly on encrypted inputs through polynomial approximations of activation functions, offering an appealing direction for privacy-focused applications.76,77
Currently, CryptoNet-style approaches remain relatively early in their development and lack extensive empirical validation. These algorithms cannot, for now, substitute conventional cryptography and are thus excluded as potential substitutes. However, as part of the future work, the viability of CryptoNet-style architectures will be investigated in privacy-sensitive settings. Furthermore, we will consider adversarial scenarios in which malicious CryptoNet-like models may attempt to infer information from encrypted embeddings, and we will aim to design safeguards to mitigate such risks.
In this research work, a secure, privacy-preserving ID creation framework is presented. By leveraging HE, particularly PHE, the entire biometric comparison process remains encapsulated in a cryptographic layer, mitigating data theft and preventing information leakage. Two schemes are detailed, Paillier and ECEG, each offering distinct advantages in computational efficiency, memory usage, storage requirements, and network bandwidth.
Upon analyzing the objectives outlined in the 1.1 subsection, it can be shown that most of them are accomplished with only minor compromises. The algorithm is fully functional and optimized for efficiency, though it introduces some overhead for computation, memory, storage, and communication. The created document solely stores data, rendering it static. Biometric information is entirely irrecoverable without authorization from the party or entity that generated the ID. This one-way property is enforced by the IND-CPA security guarantees provided by the Paillier and ECEG cryptosystems. The biometric verification process is completely oblivious, ensuring that the party responsible for the verification process has no access to the underlying biometric data contained in the ID. Last, all encrypted information is stored locally with the user, requiring only a central database for the encryption private keys. The proposed solution is also fully compliant with the security and privacy properties outlined in the ISO standard for biometric embeddings, 25 as defined in the 1 section. Any issued ID can be renewed by decrypting the old document and generating a new one with a different private key. The original private key is discarded, ensuring that the obsolete ID cannot be reused. The data remains unlinkable and irreversible, supported by the IND-CPA security guarantees of the PHE schemes.
In conclusion, this framework highlights the potential for HE to transform sensitive applications like biometric verification. While there are performance trade-offs and deployment limitations, these are offset by robust privacy guarantees that safeguard biometric data throughout its lifecycle. The future work will focus on optimizing computational performance and exploring advanced methods, such as ciphertext packing, to further enhance efficiency while maintaining strong security.
Footnotes
Funding
This work was partially supported by the State Research Agency of Spain (Agencia Estatal de Investigación – AEI) under Grants PID2021-124176OB-I00 and PID2023-152984OB-I00.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.