
Abstract
Federated Learning is designed to build a global model from a set of local learning tasks carried out by several clients. Each client trains the global model on local data and sends back only the computed model updates. Although this approach preserves data privacy, several issues arise, and model poisoning is one of the most significant issues. According to this attack, a limited number of compromised clients cooperate to cause the corruption of the global model by sending back malicious model updates. A common countermeasure to model poisoning involves discarding model updates that differ from the majority more than a suitable threshold. However, several attacks still occur that elude this countermeasure, such as LIE attack, which aims to introduce an error in the model that is less than the threshold. In this paper, we propose a new approach to detect malicious updates that is based on the use of an LSTM network suitably built and trained. The experimental validation shows that our approach is able to disarm LIE and Fang attacks, which are the most effective in this context.
Introduction
Machine learning techniques are grounded on the availability of large sets of stored data that can be used for training models and performing predictions. Despite the advantage of using a powerful computation infrastructure to carry out machine learning, whenever data are produced by different sources and collected by a server, a privacy issue arises if a data source does not desire to share such data.
Federated Learning was proposed in 2016 to address this problem. 1 In this approach, a centralized server builds a global model; a data source, said client, downloads the model from the server, trains the model on its data, and shares with the server only the parameter variations of the updated model. In this way, several clients retain possession of their data but allow the server to generate a new global model by suitably aggregating the clients’ contributions. Federated Learning solves the privacy issues introduced above but opens new concerns.2–6 The first concern is that each client can see a particular type of data distribution (for example, due to its geographic location) and this may reduce the accuracy of the model. 7 Suitably tuning the model aggregation technique can help reduce this problem. 8 A second concern pertains to communication as Federated Learning introduces overhead due to the necessity of exchanging models between client and server. 9 The typical solution is to use compression to reduce the model size and, consequently, the amount of data exchanged. 10 Another concern regards privacy leakage: even though a client keeps its data private, the transmission of the model parameters may allow an attacker to infer the data used for training. 11 Differential privacy is used to reduce this problem. 12
In this paper, we focus on another relevant security threat in Federated Learning known as poisoning attack. In this attack scenario, the adversary is on the client side and tries to damage the building of the global model. In the data-poisoning version of the attack, the adversary injects wrong data into the client. 13 Model poisoning is more sophisticated than data poisoning: in this case, the adversary controls directly the model parameters sent back from the client to the server. 9 The standard countermeasures are based on measuring the error rate and loss function produced by updating the model to decide whether to reject the received model updates. 14 More specifically, Krum and Trimmed Mean are two aggregation algorithms 15 widely used in the literature to contrast model poisoning attacks. Although these two defense algorithms work quite well against many attacks, they are eluded by the Little is Enough (LIE) attack 16 and the Fang attack. 14 The idea of these attacks is to introduce an error in the model updates that is so little (this motivates the name of the LIE attack) to be undetected.
In this paper, we target the aforementioned Federated Learning scenario, aiming to enhance its security to enable the training of reliable global models, even in the presence of adversaries. To do so, we advance the detection of model poisoning attacks by proposing a new approach, named Control Network, which is driven by artificial intelligence. AI-driven approaches have been extensively investigated in the recent scientific literature to enhance system security. 17 However, to the best of our knowledge, no AI-based approach has been proposed to contrast model poisoning attacks. Our defense approach leverages an AI-driven strategy to build a generalized solution, providing robust defense across diverse attack types. Instead of defining an ad-hoc solution tailored to a specific attack, our AI model learns from threat patterns, allowing it to adaptively contrast new tactics, thus allowing for proactive security against evolving threats. By incorporating an AI-driven mechanism, we strengthen our defense making it comprehensive and dynamic coverage across multiple threat scenarios. Differently from standard solutions for secure aggregation, our Control Network is based on a Long-Short Term Memory (LSTM) network. An LSTM network is a recurrent neural network that learns when to remember or forget information and has been applied to recognition, forecasting, machine translation, sentiment analysis, and healthcare.18–22 In our solution, the LSTM network is trained to classify a gradient update received from a client as benign or malicious. We assume that in an initial phase, called safe period, no attack occurs and this period is used to train the model with data that are benign. Moreover, to generate malicious data, some clients are attacked artificially, and the resulting updates are also used for training.
After the training, the LSTM network can be used to classify a client update as benign or malicious. In case of malicious updates, these contributions are not used to update the global model. Moreover, once a client is detected as malicious, it is possible to apply federated unlearning techniques 23 to reverse the impact of its previous updates on the model.
It is important to remark that our approach does not introduce any communication overhead because the whole processing is done by the central server using only the information exchanged by the federated learning approach. Furthermore, our choice to implement the Control Network using a relatively small LSTM model, rather than a more complex deep model, is driven by the design requirement to keep our defense lightweight and thus deployable in diverse, resource-constrained decentralized settings.
Through an experimental evaluation, we show that the use of our solution is able to contrast both LIE and Fang attacks: indeed we measured that these attacks reduce the mean accuracy of the model from about 0.80 to 0.54, whereas with the use of our technique the mean accuracy is about 0.75 (thus, close to the mean accuracy in the absence of attacks).
The rest of this paper is organized as follows. Section 2 discusses related work. In Section 3, we present our proposal to contrast model poisoning attacks. Section 4 discusses the results of the experiments carried out to validate our proposal. Section 5 provides the conclusions of our study.
Related work
In this section, we focus on model poisoning attacks and possible countermeasures.
The aim of model poisoning attacks is to reduce the performance of a Federated Learning model, which is obtained by sending back model weight updates that are artificially and suitably modified.24,25 In a Byzantine attack, malicious users (named Byzantine workers) modify trained models to corrupt the model 26 : as proved in Blanchard et al., 27 one baleful user can be sufficient to compromise the accuracy of the model. A poisoning attack can rely on a backdoor attack to alter the intermediate data or weights 28 : indeed, in a backdoor attack, the label of attacker-specified classes is changed during training, in such a way that these classes are badly classified. 29
One of the first model poisoning attacks based on a backdoor was proposed in Dumford and Scheirer, 30 where the authors attacked a face recognition system in order to grant access to impostor faces. In the same period, the authors of Rakin et al. 31 showed that it is sufficient to flip a very negligible number of bits (less than 100 of a net with 88 million neurons) to force the model to classify all inputs to a certain target class.
These attacks succeed because the algorithm used to merge the model update information sent from the workers with the global model is commonly a weighted mean computed separately on each dimension of the input, in which the weight depends on the size of the training data used by each worker.
Many poisoning attacks expect that the attackers own some knowledge of the local models of the other clients or can obtain real training samples for several classes. When this assumption is unreasonable, generative adversarial networks (GANs) have been proposed to overcome this need.32–34 GANs are trained to mimic samples of other clients and then produce new samples with the aim of generating poisoned updates of the global model. A schema depicting this type of attack is reported in Figure 1, where the first client works following a correct federated learning task, whereas the second client trains the local model on fake data suitable generated by a GAN network composed of a generator and a discriminator.
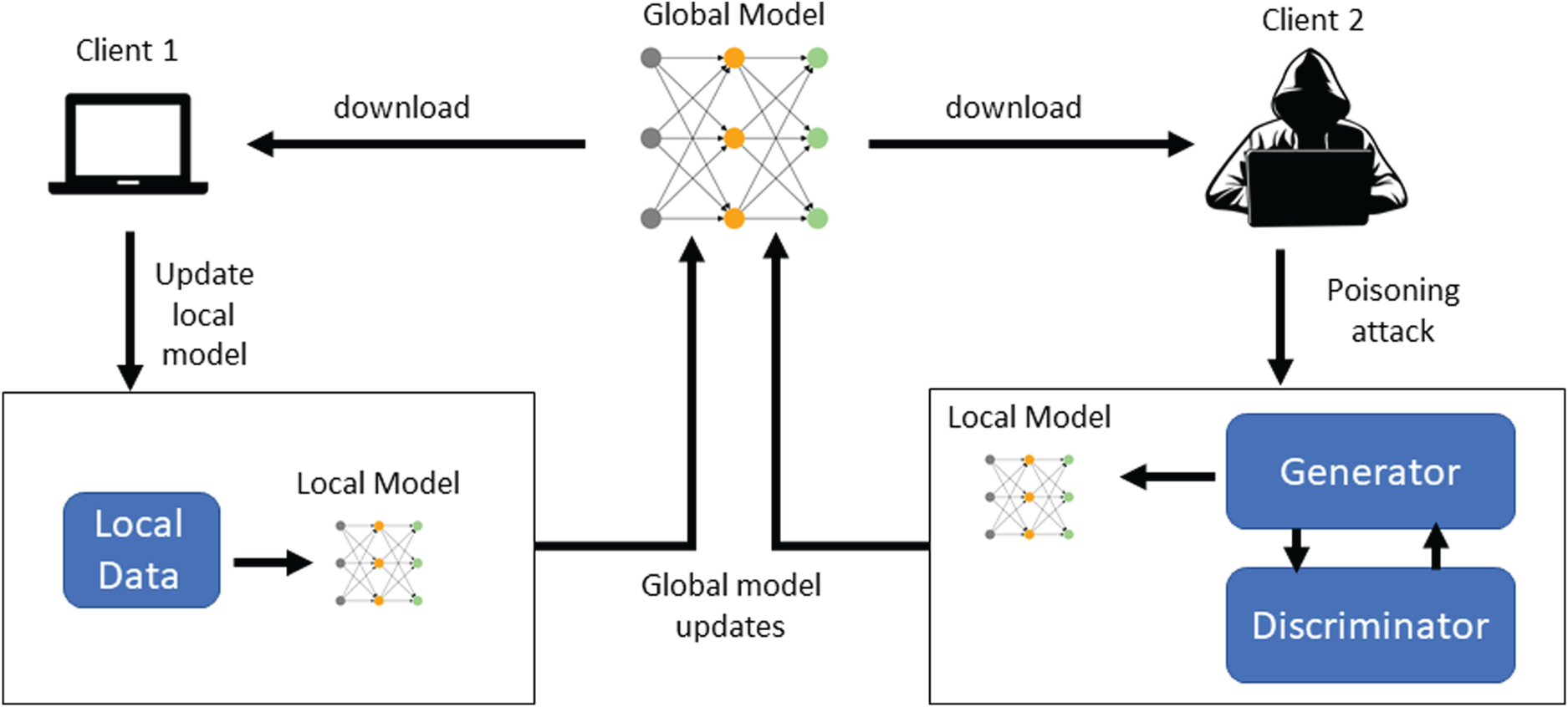
Example of a GAN-based poisoning attack.
To make the model robust against these attacks, robust aggregation protocols (AGRs) have been proposed.
15
The state-of-the-art AGRs are based on Krum and Trimmed Mean. Given
In contrast, Trimmed Mean works on each dimension separately and is a defense in which the weighted mean used to aggregate the workers’ contributions is computed on a subset of the contributions. Specifically, given
Bulyan is a combination of Krum and Trimmed Mean 37 : first, Krum is used to find a set of candidate contributions and, then, the Trimmed Mean approach is applied to compute aggregation. However, Bulyan is not effective against an attack able to trick both Krum and Trimmed Mean (as in our case).
However, the use of AGRs does not protect against model poisoning because numerous attacks are proposed in the literature. 38 Among them, one of the most significant and effective is the LIE attack. 16 The Little is Enough (LIE) attack exploits the assumption done by most AGRs that the attacker chooses updates that are far away from the correct value of the update to corrupt the model (e.g., by returning a gradient that is opposite to the computed gradient, thus attacking the global model convergence). The basic idea of the attack is thus to find a suitable neighborhood of the correct gradient such that a gradient belonging to this neighborhood is not detected as malicious. The expected result is that, since some honest workers are farther away from the mean, they are detected as corrupted workers and skipped from the gradient computation.
Another relevant model poisoning attack is the Fang one. 14 The underlying idea is to corrupt the global model by suitably crafting the local models sent from malicious workers at each iteration with the target of deviating the most towards the opposite of the direction that the global model would take in the absence of an attack. The attack is performed by solving an optimization problem aiming at finding the maximum local model crafts that are not detected by the standard countermeasures. By both a theoretical analysis and an experimental evaluation, the authors show that the Fang attack is able to elude both Krum and Trimmed Mean aggregation algorithms.
In this paper, we go a step ahead in improving model poisoning defense by proposing a new methodology that is very effective in contrasting both the LIE and the Fang attacks.
It is worth noting that there exist two techniques, namely Flame
39
and FoolsGold,
40
proposed to prevent these attacks. These strategies need, at each epoch, to calculate the pairwise cosine similarity between the updates, and for Flame, an additional step of clustering is required. Compared to this approach that achieves similar results our strategy has an advantage in terms of time complexity. Since both make use of cosine similarities, they have at least a time complexity of
This section is devoted to the definition of the proposed approach. We start by presenting a federated learning scenario, where a poisoning attack occurs.
Scenario
Consider a group of clients needing to solve a specific problem (typically, a classification or regression problem). Each client owns a dataset that can be used to train a machine learning model. Having the possibility to use the datasets of other clients to train the model would enhance the model performance but, in many situations, clients cannot share their datasets due to the need to keep confidential the dataset content (privacy).
For this reason, the clients decide to adopt federated learning to take advantage of their combined expertise while adhering to data privacy needs. The federated learning task is schematized in Figure 2, where, for the sake of simplicity, only two clients are considered.
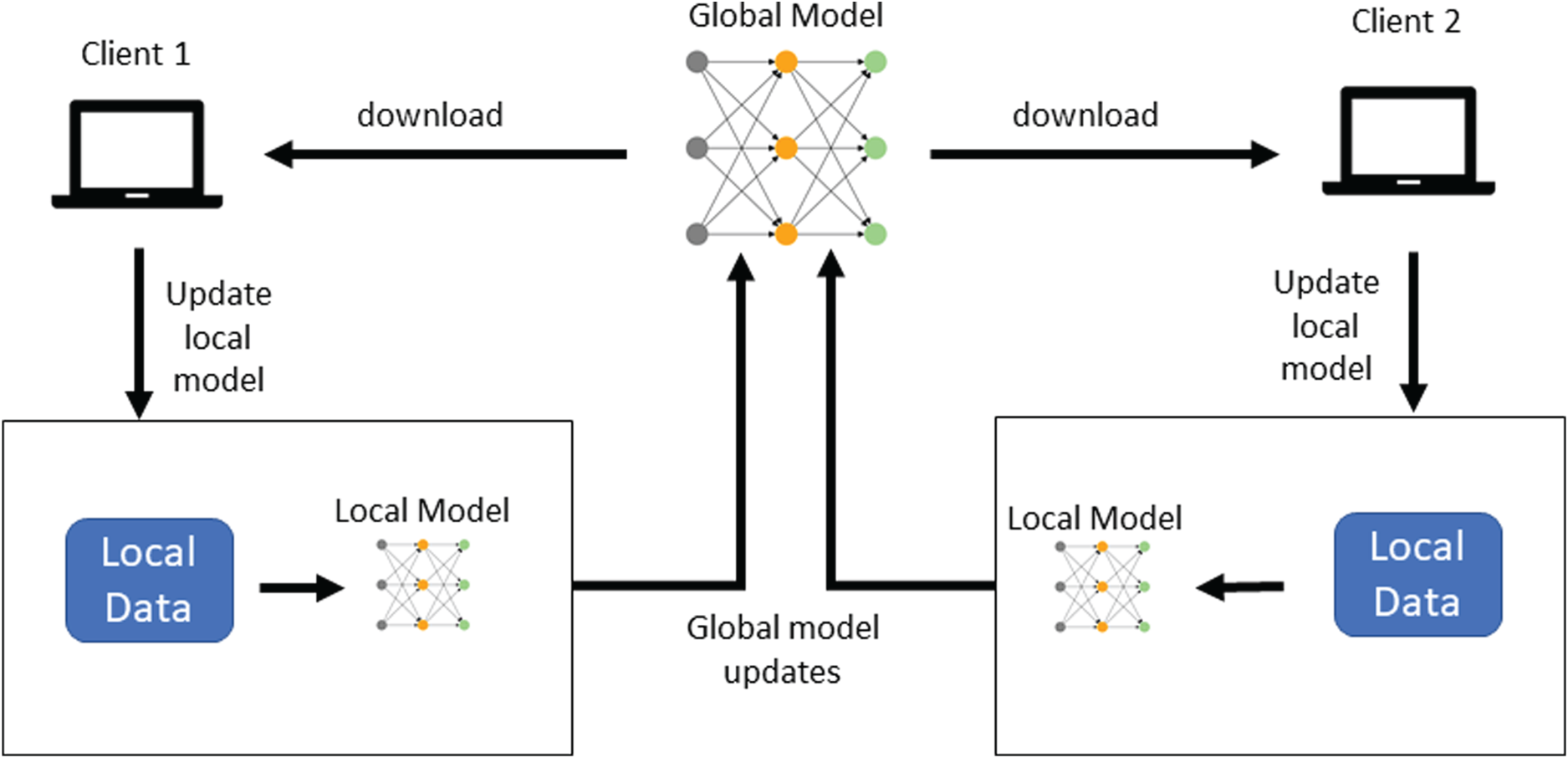
Federated learning scheme.
The process begins with the generation of an initial model, called the global model, which is handled by a server. Each client downloads the global model and trains it on its dataset. The obtained model is called the local model. Then, each client sends the updates of the local model (e.g., model parameters or gradients) to the server, which aggregates them to update the global model. At the next iteration, this new global model is distributed back to the clients for further refinement.
In this scenario, a poisoning attack is performed by a malicious client participating in the training of the model, which sends back to the server malicious updates to influence the model, ultimately aiming to disrupt the entire federated learning process.
In the scenario described in the previous section, our strategy aims to detect malicious updates of the global model sent by adversaries, leveraging a deep learning model trained with both malicious and benign updates.
In the literature, many approaches have been devoted to the definition of solutions, typically referred to as AGRs, to inhibit attackers from obtaining advantages by altering the updates of targeted clients, during the training phase of a federated model. AGRs strategies typically adopt statistical information and suitable derived heuristics to filter or smooth out any anomalous update from involved clients. Although such approaches work reasonably well for untargeted attacks, researchers have demonstrated that the menaces can be refined to deceive such heuristics.16,14,26
In general, this is due to the fact that existing protection strategies are grounded on the assumption that the attacker does not have background knowledge of the other clients’ behavior (non-omniscience assumption) and, therefore, the (blind) variation introduced by the attack on the statistics of the gradients updates, received by the clients during a training epoch, is not negligible. However, as discussed in Baruch et al., 16 in the case in which the experimented variance between clients’ gradients is high, a blind attack can be performed within the variance of the admissible gradient’s updates. This makes existing AGRs vulnerable, thus requiring more advanced defense approaches, possibly using knowledge from the history of gradient updates to detect the presence of attacks.
The use of historical data poses several issues that must be faced to build suitable data-driven protection strategies. Indeed, the gradient variances of the different clients during a training task strongly depend on several parameters, such as (i) the number of involved clients, (ii) the training task, and (iii) the distribution of the data batches across each client. Therefore, the information exploitable to build a protection mechanism should be related to the task specificity and, intuitively, cannot be derived from different ones.
Starting from this observation, in our approach we designed an AI-driven solution that exploits data from a Federated Learning task to feed the training of a control network to identify normal vs. altered gradient variations. Such a control network should learn the characteristics of benign updates from the clients, as well as the anomalies, even if slight, introduced in the case of an attack carried out by one or more clients. With this capability, the obtained defense mechanism could be deployed as a firewall on the central server orchestrating the construction of the global federated model. Once built, such a control network is used to protect the Federated Learning task. However, since the control network was trained on a specific scenario (number of clients, data distribution, etc.), its performance and reliability are contingent upon that scenario remaining consistent. If the scenario changes, the control network may no longer be effective because it was not trained to handle the new data patterns. This scenario is typical in industrial environments in which the model must be updated (and, hence, re-trained) periodically to include newly generated data from the sources. However, although the scenario above remains interesting and important, our solution faces a more general and ambitious task, i.e., building and deploying a control network to protect an on-going Federated Learning task.
One of the major problems in the design of such a solution is related to the construction of a training set containing balanced data of benign and malicious updates, strictly related to the specific (running) Federated Learning task. This requirement imposes that the training set cannot be obtained offline but must be built during the execution of the federated solution.
The control network solution is built in two steps, which are discussed in the next sections. The proposed solution is intended to build an ensemble model capable of detecting multiple attacks keeping the single models binary and lightweight.
Dataset derivation
The first objective of our solution is to build a training set, say
The assumption of a “safe period” is realistic and can be obtained by applying standard practices during training, as briefly discussed in the following. In an industrial setting, devices are often deployed in controlled environments where physical security can be achieved by limiting to authorized and trusted personnel the access to the physical clients. Network security can be achieved by using IDPS (intrusion detection and prevention systems) and isolating the internal network from the external network to allow communication only between clients and servers. Each client device can be checked to ensure that it functions correctly and has not been compromised by validating firmware and software versions. Since the training phase goes over short time intervals, it is realistic to apply the combination of these protection strategies during the training, in such a way that the likelihood of a significant attack during such a limited period can be considered negligible.
In the safe period, only controlled attacks can be carried out. In the absence of attacks, the obtained data are used for training the model with benign samples. While the benign portion of the training data is derived directly from the monitored running federated task, the portion of the training set containing information about the possible attacks must be generated by introducing controlled attacks. To do so, our solution defines an “Attack Simulation” module that, starting from a set of benign clients’ updates, alters a portion of this set by simulating specific attacks on target clients of the federated system. This module can be configured to carry out attacks of the considered type and to simulate a variable number of attacked clients.
Figure 3 sketches the strategy described above for both the “safe period” and the “unsafe one”.
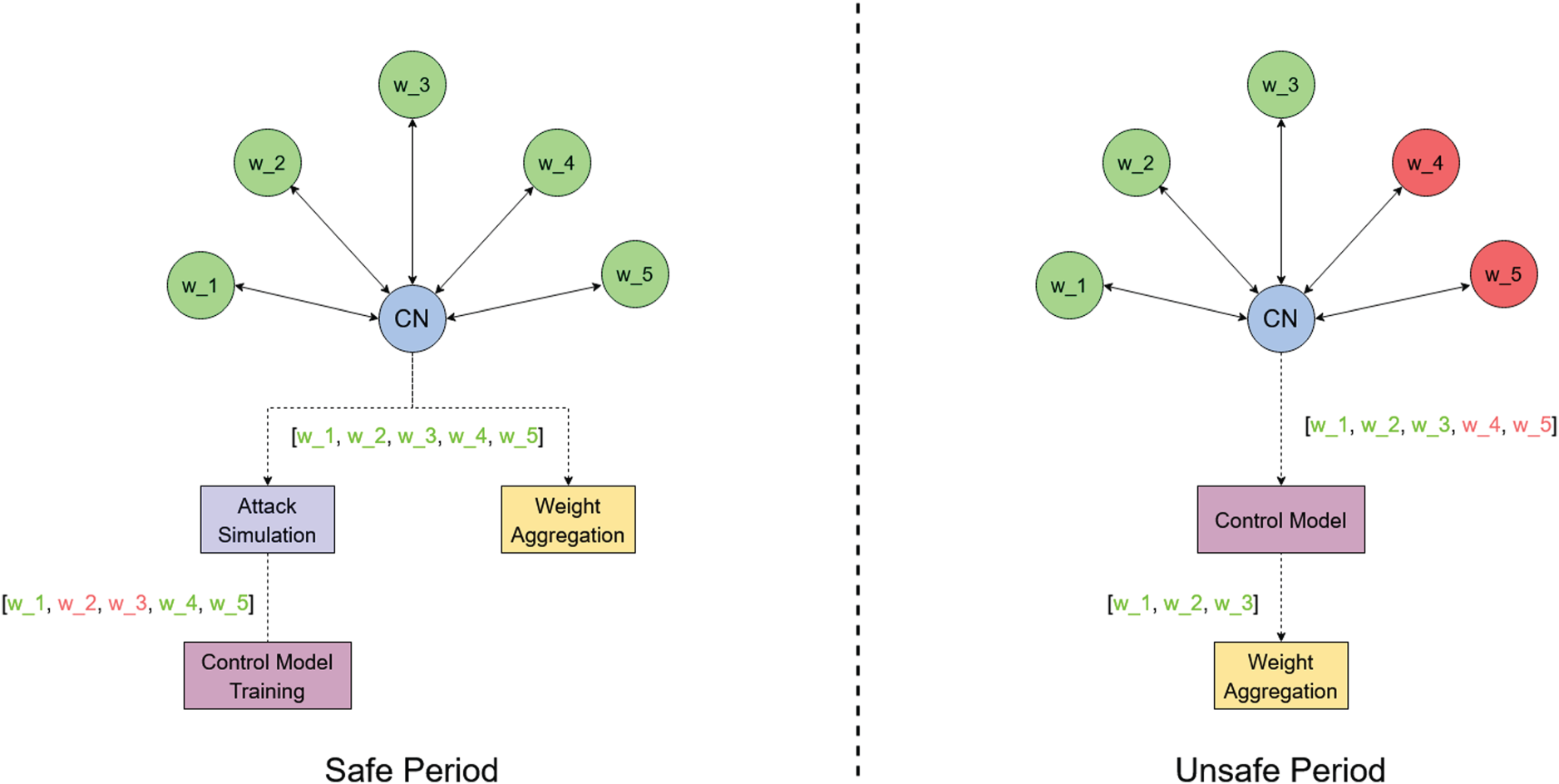
A general representation of the strategy adopted in our solution.
Therefore, during the “safe period”, given an epoch
As will be explained later in this section, an important point in this configuration is that, because the gradient variations computed by the clients are related to the particular training epoch of the federated model, the control network must be aware of the evolution of the federated task to make decisions on the trustworthiness of received updates. Therefore, the updates alone are not sufficient to identify the correct evolution of the Federated Learning training. For this reason, at each epoch
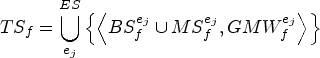
An important point to underline is related to the choice of including information about the status of the global model in the training data for our control network. As said above, the reason behind this choice resides in the fact that, due to the oscillations in the loss optimization (during the initial phases, especially), gradients’ updates alone are not sufficient to understand whether their values may correspond to an attack attempt or not. Our control network needs baseline information allowing for the estimation of the deviance of the gradients from the expected values. Therefore, we include the weights of the global model at the current step as input to our control network, so that, measuring the variation in the global model weights between the previous status and the current one (recall that we are using an RNN to preserve, to some extent, a memory of the input sequence) can help our model distinguishing an expected variation in the gradients from an anomalous one.
We report in Algorithm 1 the pseudo-code implementing the procedure described above. In the setup, the model is randomly initialized and model weights are sent to all clients (Line 2). In the safe period (guaranteed by the assertion in Line 4), the updates from clients are collected and the model weights are updated and stored in
We conclude this section by observing that the time complexity of Algorithm 1 is linear in the number of samples (thus, if we double the number of samples for the training, the training time will take twice as long).

In our proposal, the control network is built as a binary classifier capable of distinguishing between benign and malicious gradient updates from clients. The design of our control network is guided by three key requirements (which will be explored further in the following):
model poisoning attacks typically unfold over multiple training epochs through gradient alterations, necessitating a defense mechanism that can backtrace (through some memory capability) these sequences for effective detection; during our initial architecture tests, we observed that using an ensemble of simple binary predictors outperformed more complex multi-label classifiers, providing better accuracy and robustness; the need for a general lightweight solution that could be deployed in desperate, and even resource constrained environments such as the Internet of Things, led us to prioritize simpler, smaller models over deep, complex architectures to ensure efficiency without compromising performance.
A crucial point in the design of such a classifier is related to the condition in which the final control network will be deployed as a defense mechanism for the Federated Learning scenario. As stated before, the most general application context would require the availability of the control network as soon as possible during just the first federated training task.
More formally, we denote by
Of course, once built, it might be applied also to any subsequent re-training activity of the same Federated Learning scenario. Such a design choice requires the development of an incremental learning strategy due to the online nature of the considered scenario. Roughly speaking, because the training of the control network must consider the gradient updates reported by the clients at each epoch, it can be seen as a sequence of learning tasks each focused on an epoch of the Federated Learning approach. Incremental learning has been thoroughly studied in the recent scientific literature and is still an open issue, especially in contexts in which new classes can be added during the different sequential increments. In fact, learning new classes might cause a detriment to the old class knowledge, thus resulting in the well-known “catastrophic forgetting” problem.42–44 In our context, at each epoch, the number of involved classes is constant (binary classification) and, therefore, the “catastrophic forgetting” is not likely to happen. In addition, from a preliminary experimentation having an ensemble of multiple binary classifiers dedicated to each attack achieves better results than having a single multi-class classifier. However, a memory of the previous tasks can still be crucial to assess the admissibility of specific ranges of gradient fluctuations during a stage of the Federated Learning process. Finally, an important requirement for our approach design is related to the need for a lightweight defense solution that can be deployed also in low-resource environments, such as the Internet of Things, often leveraging Federated Learning.45,46
Following this reasoning, we implement the control network as a Long-Short Term Memory (LSTM, for short) network.
47
As for the model architecture, our final configuration consists of an LSTM layer with
Experiments
This section is devoted to the experiments we carried out to validate our proposal. For our experiments, we used a machine with an AMD Ryzen 5800X CPU paired with 32GB of RAM and an RTX 3070ti with 8GB of VRAM. The techniques have been developed using Python and Tensorflow library. All the experiments have been run more than 10 times for each setting and the average results have been reported.
We start by describing the datasets and the scenarios used in the experiments. Then, in Section 4.2, we describe how the model used to detect malicious updates is built and trained. Finally, in Section 4.3, we analyze the results obtained by applying our proposal to various attack scenarios. Figure 4 presents the diagram block of the general workflow used to run the experiments. On the left side, the training of the control network is done by providing both benign samples and malicious samples (the latter obtained by simulated attacks). After the control network model is built, it is used to predict whether a real attack is carried out (on the right side of the figure).
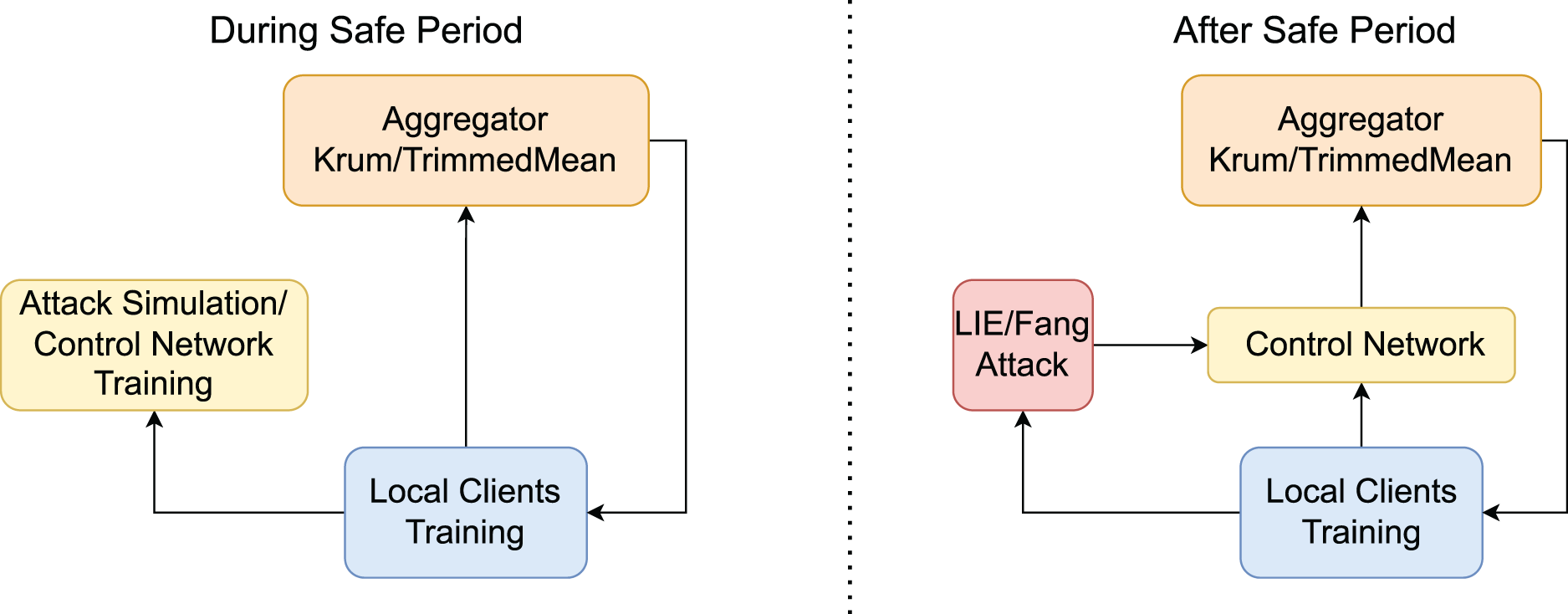
Diagram block of the experiment workflow.
The testbed used in our experimental campaign has been chosen to reproduce exactly the original configurations and datasets used by the official attack implementations to compare our defense in the best-case scenario for the attacks. The setting of our experiments is presented in the next sections.
MNIST, a dataset of 60,000 28–28 pixel grayscale images of handwritten single digits between 0 and 9
48
; FMNIST, a dataset of 60,000 28–28 pixel grayscale images of clothing articles labeled from 10 classes
49
; CIFAR10, a dataset of 60000 32x32 color images of means of transport and animals labeled from 10 classes.
50
As usual for these datasets, no pre-processing, augmentation, or noise reduction have been performed on the data. Moreover, the considered error metric is accuracy, which measures the fraction of predictions that the model got right.
Krum, which selects the gradient from the input gradients that is closest to the TrimmedMean, which aggregates each dimension of input gradients separately and removes the
It is important to note that other AGR mechanisms exist that are built upon Krum and Trimmed Mean, mainly targeting specific contexts. Krum and Trimmed Mean are foundational, general-purpose AGR strategies that are widely regarded as baseline approaches for achieving robustness in federated learning.
52
Little Is Enough (LIE), where malicious clients send gradient vectors in which elements are modified by adding noise depending on the estimated coordinate-wise mean and standard deviation of the benign updates.
16
We set the number of workers to Fang,
14
where clients send malicious gradient vectors in such a way that the aggregated global model moves to the opposite of the direction along which the global model would go in the absence of attacks. We set the number of workers to
In the next section, we identify the configuration of the proposed control network that gives the best performance.
Control network tuning
In our proposal, we need to build a machine learning model able to classify whether a received gradient vector is malicious or not. As explained in Section 3, the control network leverages an LSTM network equipped with
Experiment description
We performed the following two experiments:
In the first experiment, we aim to identify the right balance between data from normal clients and data from malicious ones during the training. We injected a variable percentage of attackers introducing random noise (“random” attackers, hereafter) in the Federated Learning solution. We used the data generated in such a scenario to build a training set for our control model. Hence, we studied the percentage of malicious traffic needed to train our model with the best possible performance. To do so, both the traffic generated by the attackers and the normal clients have been suitably labeled. The second experiment aims to identify the best number of epochs that must be used to build the training set for our control model. In our scenario, the training set is derived from the data exploited by the Federated Learning model during the training task. This task is composed of several training epochs, each characterized by a set of batches obtained from the global training set and, according to the Federated Learning strategy, distributed across the different clients. During each epoch, the result of the processing of the batches is returned from the workers to the central aggregating node. Therefore, during an epoch, the workers compute the corresponding parameter variations for the neural network model on the basis of the processed batches. In our approach, we use the variations produced during a sub-set of the epochs of the overall training as a training set of our control model (also injecting a percentage of malicious data).
Experiment results
In the following, we discuss the results obtained from each experiment.
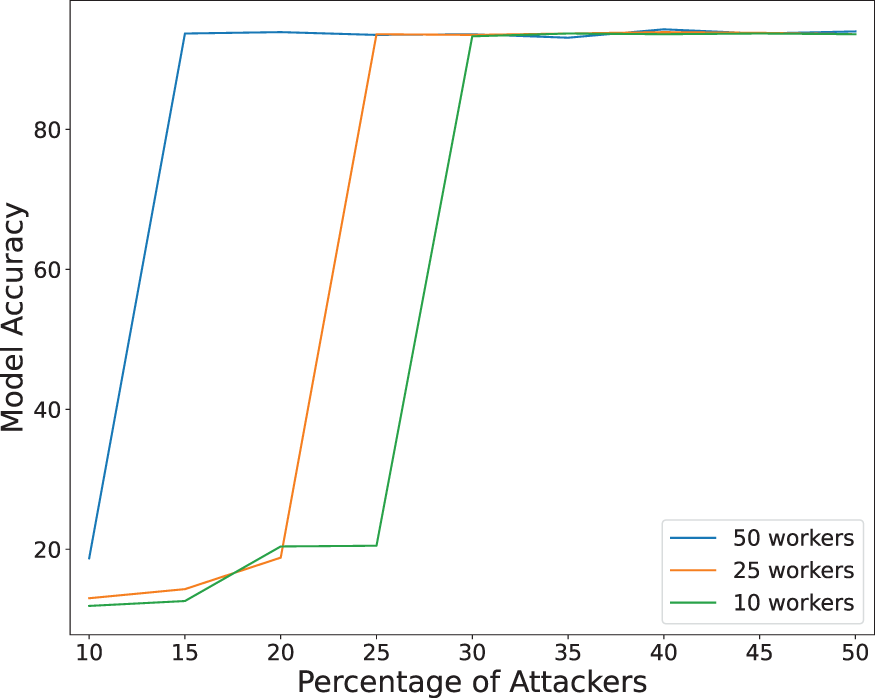
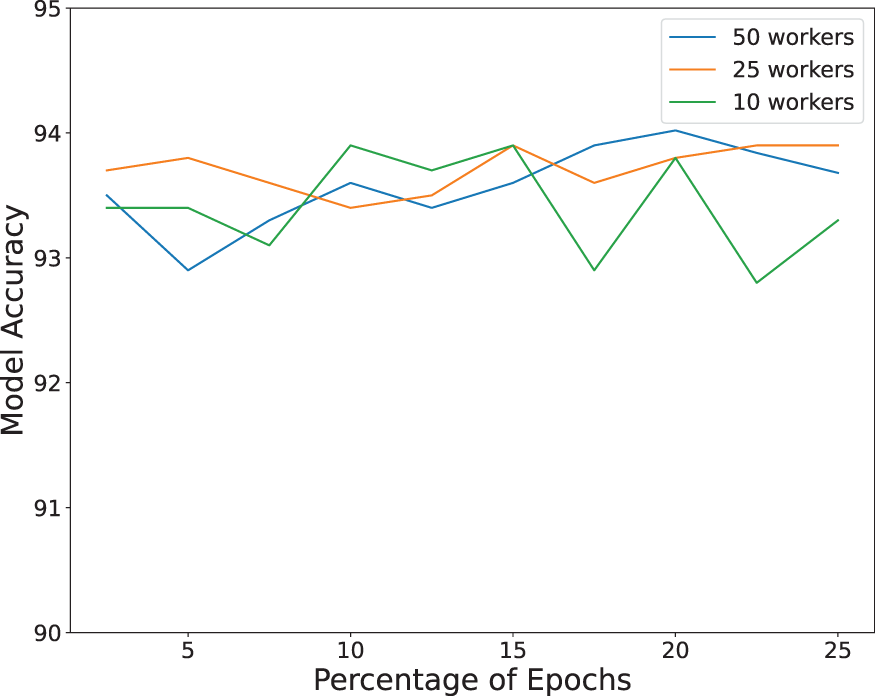
The results of the first experiment are shown in Figure 5, where we report the accuracy of the Federated Learning approach (including our control model) against the percentage of “random” attackers. The curves are associated with configurations characterized by different numbers of workers (i.e., Accuracy of our solution versus attacker percentage. By analyzing this figure, we can see that the higher the percentage of attackers the more balanced the corresponding training set for our control model and, hence, the better the performance of the Federated Learning solution. Indeed, better performance of our control model implies a higher capability to discard malicious training data in Federated Learning. In particular, we found that the minimum percentage to obtain the higher accuracy spans from about In the second experiment, we measured the accuracy obtained by the Federated Learning solution including our control model versus the variation of the percentage of epochs of the Federated Learning used to build the training set for our control model. The obtained results are reported in Figure 6.
Accuracy of our solution versus training set size. We can see that the accuracy negligibly varies when passing from Since our control network uses a limited number of epochs (we do not make any assumption on the global model targeted by the Federated Learning task), the scalability of our solution is only bounded by the scalability of Federated Learning task and does not add any additional scalability concerns. The execution times of our solution.

In this table, each row reports the mean execution times of the overall Federated Learning task for each training epoch, in three different cases: (i) without the adoption of our solution (FL Only), (ii) during the training of our solution (FL + CN Training), and (iii) with our solution deployed as a protection (FL + CN Inference).
The obtained results show that the time overhead introduced by our approach is negligible with respect to the baseline Federated Learning execution time. Indeed, such overhead does not exceed
In this section, we study the effectiveness of our strategy as a countermeasure against state-of-the-art attacks on Federated Learning. We describe the experiments carried out and the obtained results.
Experiment description
We performed the following three experiments for each dataset using the model architectures defined in Section 4.2:
In the first experiment, we tested the Convergence Prevention variant of the LIE attack presented in Baruch et al.
16
The attack aims at impacting the overall performance of the global model built through Federated Learning. The main objective is to inhibit the model convergence by altering its capability to properly classify the input items. Although this attack works also in the absence of any secure aggregation algorithm (AGR), it has been specifically designed by targeting Krum and TrimmedMean secure AGRs.
26
For this reason, to avoid penalizing the attack performance, in our experiment, we do not consider the case in which our defense is the only available in the server. Therefore, for the target Federated Learning system, we considered three cases in our experiments: (i) no defense, in which no AGR is used, (ii) KR, when the Krum AGR is used, and (iii) KR+CN, when both Krum AGR and our control network are enabled. In the second experiment, we considered a variant of the LIE attack, named Backdoor.
16
The idea behind this attack is not to prevent the convergence of the model training but, instead, to train the model with a set of crafted samples obtained by adding a noise that follows a specific pattern on some of the involved input features. The goal of the attacker is to identify the correct features and corresponding “forged” noise so that, any input for which the target features have been jeopardized according to the established noise pattern, will be classified by the trained model as belonging to a specific target class. In summary, backdoor attacks are more stealthy strategies aiming to preserve the general behavior of the model and its performance and to create a backdoor that can be activated by the attacker through specific hidden patterns in the input data. Once the backdoor is activated the model alters its behavior by producing an unattended, controlled by the attacker, classification result. In the third experiment, we considered the Fang attack.
14
This attack can work in different configurations strictly related to the role of the workers in the network: we focus on the configuration in which the workers have a partial knowledge of the network.
Experiment results
In the following, we discuss in detail the results obtained from each scenario, in terms of accuracy. Note that we measured sensitivity equal to
The results of the first experiment are reported in Table 2, where best performances is shown in bold (this occurs also in the next tables). First, we observe that the results obtained for KR (second row) are in line with those reported in Baruch et al.
16
Accuracy against the convergence prevention attack using Krum AGR.
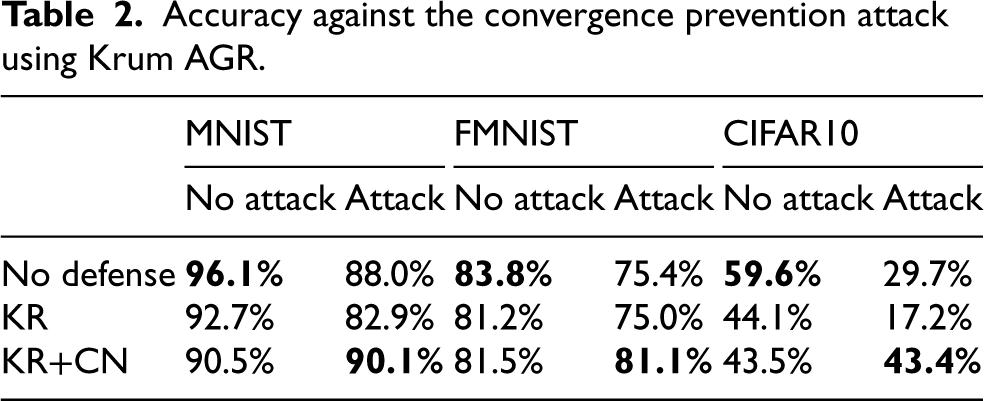
We can see that, without the use of our control network, the convergence prevention attack is able to reduce the accuracy with a detriment of almost
The relevant result is that when our control network is enabled, the accuracy in presence of attacks is about the same as for the scenarios without attacks. These results show how our model has successfully detected anomalous variations in the updates of the malicious workers.
We repeated the experiment by replacing the Krum AGR with the TrimmedMean AGR (TM in the table), and the obtained results are reported in Table 3. We observe that the use of TrimmedMean is more effective in contrasting the convergence prevention attack because the measured accuracy is always higher than that measured with Krum AGR. Also in this case, the use of our control network returns the best accuracy in all the compared scenarios. We measured that the attack reduced the mean accuracy of the model from about 0.80 to 0.59. The use of the Control Network limits the accuracy loss to 0.76.
Accuracy against the convergence prevention attack using TrimmedMean AGR.

Accuracy against the backdoor attack using Krum AGR.

Accuracy against the backdoor attack using TrimmedMean AGR.

By looking at the results of these experiments, we see that the model accuracy in all the cases in which the attack is performed is only slightly decreased. In contrast, the attack success rate is very high (from 78 % to 100%) when our control network is not used, whereas it has a limited impact (less than about 11%) when our control network is enabled. These results show that our proposal has been effective against all the considered LIE attack variants.
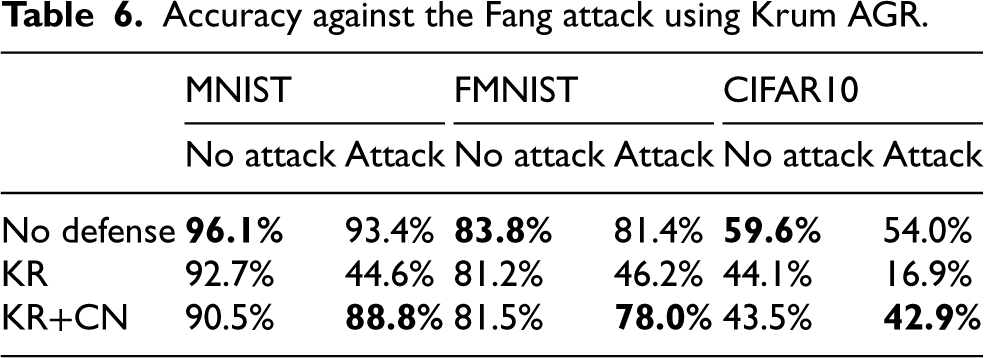
Accuracy against the Fang attack using Krum AGR.
Accuracy against the Fang attack using TrimmedMean AGR.
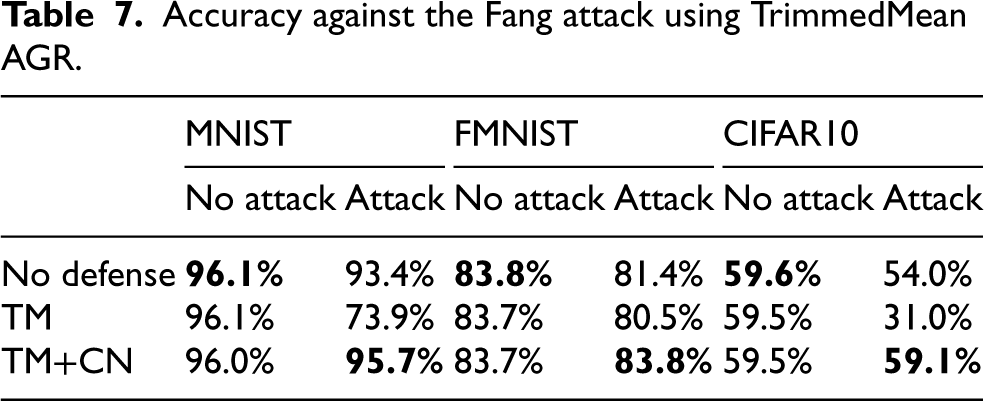
Observe that the Fang attack has been designed to work against the Krum AGR strategy and, therefore, the best attack performance is obtained in scenarios in which such an AGR is enabled. Although with a smaller reduction in accuracy, also the TrimmedMean AGR suffers from this attack. At the same time, the introduction of our Control Network is able to filter malicious updates out and restore the performance very close to the original performance without attacks. Indeed, we measured that the attack reduces the mean accuracy of the model from about 0.80 to 0.49, whereas with the use of the Control Network, the mean accuracy is about 0.75. These results show that our solution has able to evade also the Fang attack.
In this paper, we proposed an Artificial-Intelligence-driven approach to contrast model poisoning attacks on a Federated Learning system. Researchers have designed several countermeasures to model poisoning attacks, such as Krum and Trimmed Mean, mostly based on heuristics targeting the aggregation phase on the server to suitably identify and remove anomalous gradient updates from clients. However, recent studies have proposed refined attacks capable of bypassing such protection strategies and inferring important damages to a Federated Learning task.
The main contribution of this paper is to contrast two attacks, namely the Little is Enough (LIE) and Fang attacks, by designing a deep-learning-based approach to build a Control Network. This Control Network is used as a firewall to filter out malicious gradient updates as generated by such attacks, and the proposal has been validated experimentally.
A second contribution of the paper is that the proposed solution is general and, therefore, could be extended to contrast other attacks with the same characteristics of these studied in this paper. Moreover, it is designed to be trained online, during a controlled initial set of training epochs of an on-going Federated Learning task, and deployed to protect the completion of the current task and any other subsequent re-training activity, typical of industrial contexts.
The research described in this paper must not be intended at its final stage because several other interesting development directions can be identified. First off, Federated Learning has been recently adopted in fully distributed scenarios, such as the Internet of Things, in which no central server can be exploited to execute our Control Network. In such a setting, the design of a distributed approach to build and include our solution is, for sure, an interesting objective that we are planning to pursue. Moreover, our future work includes the application of newer and sophisticated machine learning algorithms such as Neural Dynamic Classification, 53 Finite Element Machine for fast learning, 54 and self-supervised learning, 55 which have been successfully used in other application contexts.
Footnotes
Funding
This paper has been partially supported by the POS RADIOAMICA project funded by the Italian Minister of Health (CUP: H53C22000650006) and by the PRIN 2022 Project “HOMEY: a Human-centric IoE-based Framework for Supporting the Transition Towards Industry 5.0” (code: 2022NX7WKE, CUP: F53D23004340006) funded by the European Union - Next Generation EU.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.