
Abstract
A new way to study and represent early syntactic development is introduced that offers a promising avenue to improve on standard cumulative approaches to language learning. The analysis is inspired by complex network theory and explores an important issue in psycholinguistics: how children combine words syntactically. To this end, the article exploits the longitudinal data of multiple individual studies stored and publicly available in the CHILDES database. This analysis proves useful in two regards: in coincidence with previous approaches to syntactic development, it reveals a similar linear–nonlinear pattern of syntactic development (a combination of linear periods interrupted by abrupt transitions) in typical children regardless the language they are acquiring. It also provides a straightforward objective measure of syntactic impairment in atypically developing children. A striking difference between typical and atypical children lies in the connectivity of functional words, which suddenly become hubs but only in typical development. Our technique offers a formal measure of impairment with respect to typical syntactic development, which goes beyond the standard notion of retardation in development, for the Down syndrome condition.
1. Introduction
In this study, we explore the possibility of establishing different language development endophenotypes based on a network analysis of spontaneous speech corpora (Barceló-Coblijn, Benítez-Burraco, & Irurtzun, 2015). To do this, we establish a comparison between typically developed and atypically developed children. We compare typical language samples from four Romance languages (Italian, French, Catalan, Spanish), three Germanic languages (English, German, Dutch), and a language isolate (Basque), uncovering a common schema in development despite the typological differences between those languages. Next, we compare the patterns of these typical populations with the patterns issued from the analysis of the speech of atypical populations (Dutch and English-speaking people with Down syndrome (DS)) observing clearly divergent developmental paths.
The structure of the article is the following one: in the remaining of section 1, we frame our study within the field of language development and clinical linguistics. Section 2 very briefly introduces complex networks, and section 3 presents previous applications of complex network analyses to language and speech. Section 4 presents the scope and goals of our study, and section 5 the methods we propose for the analysis of spontaneous speech. Section 6 is devoted to the results and section 7 to their discussion. Finally, in section 8 we discuss the consequences, merits, and limits of our study, and comment on the future research venues that it opens.
1.1. Differing views on language development
The development of new tools and approaches for language analysis has been an important target of many branches in cognitive science. One of the pitfalls that applied linguistics faces concerns the definition of the target of study itself, since it is common to find radically opposed views regarding some aspects of human cognition. Some issues are traditionally discussed dichotomically: does the ability for language develop linearly or non-linearly? How do biological parameters and the environment surrounding the speaker contribute in language development within the individual (cf. the “nature vs. nurture” debate)? Especially, contentious was Chomsky’s claim on syntactic development that domain-general learning is unable to account for language acquisition (cf. i.a.Chomsky, 1975), and that some innate knowledge of grammar has to be hypothesized to account for this process. Authors like Mehler (1974, et seq.) have even hypothesized that learning a language amounts to “unlearning” others (see also Baker, 2005; Lenneberg, 1967; Piattelli-Palmarini, 1989, among many others).
The opposite view to biological-centered approaches (or bio-approaches) concentrates on the use of language: how speakers use language, when, and in which contexts. A common assumption in usage-based approaches to language acquisition has been that syntactic development is a linear, cumulative process (“gradual” and “piecemeal,” in Tomasello’s, 2003, terms). If the biological-centered viewpoint has used the switchboard metaphor, according to which children select a parameter value from a limited set of possibilities (ideally a binary parameter, “on/off,” say, head-first vs head-last), usage-based approaches consider that syntactic categories and structures are mastered “one after another,” so that it should be possible to index the moment a particular category and/or rule is acquired. While bio-approaches consider that children transfer categorial information from one word to another, usage-based approaches are reluctant (if not contrary) to this kind of learning.
1.2. Language development and clinical linguistics
In consonance with the current black-or-white scenario, research in clinical linguistics is often approached dichotomically as well. For example, although there is a research view that considers that linguistic skills in pathologies like DS do progress in a divergent way over the life course, another view held for a long time that DS development was a slowed down process (this view is still held nowadays by some authors). Thus, individuals affected by some pathologies are taken to lag behind their typical peers (often under the term delay, for example, Abbedutto, Warren, & Conners, 2007; Galeote, Soto, Sebastián, Checa, & Sánchez-Palacios, 2014; Mundy, Kasari, Sigman, & Ruskin, 1995; Roberts, Price, & Malikin, 2007).
In many works, individuals affected by a pathological condition are compared to controls not in terms of their biological age, but in terms of their alleged Mental Age (MA). Nevertheless, MA is a measure that can be calculated in several different ways and is not exempt of problems and discussion as Brock (2007) pointed out. That is, atypically developing (AD) individuals are often compared to typically developing (TD) individuals regarding the scores obtained in the particular MA test selected by the scholars. Those problems and different ways to test the MA of an individual have highlighted the necessity for looking for other tools whose measures can complement the information that a researcher is already able to obtain from more traditional systems (such as tests, tasks, recordings, scans, etc.). If one is interested in knowing the syntactic ability of a speaker, one will see that here too the systems used to calculate that ability are indeed many (and sometimes they yield contradictory results).
A basic aspect of the available measures is how they were conceived, that is, whether the creators of that particular measure/device conceived a priori that the language ability is something that develops linearly or not (see Müller and Ball, 2013, for an overview). Research methods can be divided in language production and comprehension methods. Among the former, for example, there are measures such as the Assessment of Intelligibility of Dysarthric Speech (Yorkston & Beukelman, 1981), the Mean Length of Utterance (MLU, Rice et al., 2010), or the Index of Productive Syntax (IPS; Scarborough, 1990), which are used to track syntactic development. These are implicitly committed to a linear view of the ontogeny of syntax. These measures, though, are viewed as imperfect proxies for syntactic development due to the well-known problems of the variability in morphological structure (words may comprise just one or several morphemes), and the critical role of functional, closed-class words for mastering syntax (Leonard & Finneran, 2003; Rollins, Snow, & Willett, 1996). Informative as it is, a crucial weakness of the MLU measure is that sentences of an equal number of words may be very different from a syntactic point of view (they may imply radically different syntactic structures involving hypotaxis vs parataxis, different sorts of dependencies and “displacement” strategies, etc.). As a consequence, these linear measures turn out to be of limited usefulness in characterizing atypical development. Another tool often used nowadays by neurologists (among other researchers) is the Boston Naming Test (Kaplan, Goodglass, & Weintraub, 1983), although the accuracy of this test is still not completely satisfactory since sometimes individuals reach a score that would suggest the patient has no problem at all, even when the individual has been diagnosed on the contrary. Other ways employed to assess the syntactic proficiency of AD individuals have been the Words and Sentences Scale of the MacArthur–Bates Communicative Development Inventory (MCDI), by asking the parents about what the child is able to perform (Fenson et al., 1993), or making the participants to repeat a series of sentences. In general, results of works trying to compare different clinical profiles rely on this type of tools. In the case of asking the parents, the researcher needs to trust what they think the AD child is able to perform, and the results of sentence repetition tasks can vastly vary between pathologies (e.g. people affected by Williams syndrome seem to perform orally better than individuals with DS). Comprehension techniques such as the picture-matching task do not show in and of themselves whether the individual has captured all the intricacies of a specific syntactic construct, from lexical syntax to sentential syntax (cf. Roeper, 2007; Schmitt & Miller, 2010, among others). The above-mentioned IPS seems to address some of the weaknesses in the MLU. The IPS score is obtained from a corpus of 100 utterances, within which 56 specific language structures must be found. IPS has been implemented into a new tool (Sagae, Davis, Lavie, MacWhinney, & Winter, 2010) by combining it with Natural Language Processing techniques. In particular, the new IPS approach introduces dependency structures to identify grammatical relationships (Hudson, 1990). In general, these methodologies have sought to capture in one way or another the level of syntactic complexity reached by the speaker.
In the following section, we present a new approach, focused on an Evo-Devo perspective, which is able to capture aspects of the complexity of the speaker’s linguistic system which were unapproachable with previous techniques. This approach is born from the combination of studies on complexity theory and network science on one hand and linguistic (syntactic) theory on the other hand, and its results are interpreted under the light of an Evo-Devo approach to language development.
1.2.1. An Evo-Devo approach to clinical linguistics
Here, we want to propose a new technique seeking to bypass the dichotomous view of language development. This technique is based on the emerging viewpoint which builds upon Evo-Devo approaches and conceptual work developed in biology (e.g. West-Eberhard, 2003). The Evo-Devo perspective avoids the debate between two apparently opposed viewpoints, the first considering ontogeny focused on genes only and the counter viewpoint considering language acquisition to be something that has nothing to do with biology. Between genes and diseases there exist cognitive, neuroanatomical, neurophysiological, endocrine, or biochemical quantifiable components that can define endophenotypes (Gottesman & Gould, 2003). Accordingly, this new way to observe language development takes into account that the development of an organism tends to follow a particular developmental path. In other words, the psychological ability for language would have been somehow canalized during evolution (Balari & Lorenzo, 2013; Benítez-Burraco & Boeckx, 2014) and clinical linguistics should take into account the many levels at which the development of an organism can be intervened or affected (Benítez-Burraco & Murphy, 2016). This third way recognizes the biological predisposition of humans to develop language in typical conditions and the important role of the environment surrounding the individual. De-canalization (Gibson, 2009) on the other way could explain “the high prevalence of complex diseases (including language disorders) among human populations” (Benítez-Burraco, 2016, p. 264). As we said, between genes and pathologies there exist cognitive, neuroanatomical, neurophysiological, endocrine, or biochemical quantifiable components that can define endophenotypes. Recently, Barceló-Coblijn et al. (2015) have put forward an endophenotype for language disorders which integrates up to four factors: (1) linguistic analysis (syntactic computation), (2) information management (communicative strategies), (3) recent Evo-Devo insights in the nature of phenotypic variation, and (4) network approaches to emergent properties of complex systems. Thus, our reflections and conclusions on the results obtained in the present works have to be envisaged from the Evo-Devo viewpoint, as syntactic networks are considered here proxies of syntactic endophenotypes.
Before starting the linguistic analysis by means of networks, and to better understand a linguistic approach that combines syntactic analyses and complex networks, it is necessary to explain what the concept of complexity is in network science and how it can be integrated in psycholinguistics.
2. Computational approaches to linguistic complexity
The term complexity, as several others in science, is not easy to define. John Locke in his Essay Concerning Human Understanding (ch. XII) says that “Ideas thus made up of several simple ones put together, I call Complex”; and paraphrasing the physicist Neil Fraser Johnson (2007), a neutral, acceptable explanation could be that a complex behavior emerges from the interaction of a collection of objects (but see Mitchell, 2009, ch. 7, for discussion). We consider that complex systems theory offers a promising new approach to language, as it does in many other areas of scientific inquiry (Watts & Strogatz, 1998). The most important tenet of network science (Newman, 2010) is that two networks could contain the same number of nodes (or vertices), but a different number of edges (or connections) and therefore, both networks may show a completely different behavior and radically different scores regarding network complexity measures. In other words, two systems having the same number of elements behave differently due to the different relationships holding between their elements. An interesting aspect of some networks is the presence of hubs. Hubs are highly connected nodes, usually few in number within the network. A network of n nodes can develop the characteristics of a small-world if it has a high cluster coefficient (indicating how many neighbors of a given node are also neighbors of each other) and a low average shortest path length (a small number of links along the shortest paths that must be traversed when navigating the shortest paths in the network). In a nutshell, the number of nodes provides an important descriptor of the size of a network, but even more important is the particular connectivity pattern that the network has. Importantly, the network-based viewpoint is highly versatile, as it can be applied to very different examples, ranging from urban networks (Neal, 2018), to biological networks (Arita, 2005), or to linguistic networks (e.g. among many others, Solé, Corominas-Murtra, Valverde, & Steels, 2010).
3. Networks and language
The application of networks to linguistic studies is not brand new and has been applied to semantics, phonology, or to the analysis of texts. At the end of this section, we will show that syntax and the development of the syntactic ability can also be approached with network analyses. Phonology is, probably, the area of linguistics that has gotten most attention in network studies. One such approach is Vitevitch (2008), where the target was to capture relevant aspects of the mental lexicon. A key concept in that work was neighborhood density, which accounts for the number of words that sound as a selected word (thus a word A is a “phonological neighbour” of B, if a single phonological change to A converts A into B). In these regards, the similarities between languages as different as Spanish, Mandarin, Hawaiian, and Basque point into the direction of commonly shared psycholinguistic mechanisms used in the architecture of the mental lexicon (Arbesman, Strogatz, & Vitevitch, 2010). Besides, it has to be noted that the usefulness of this type of approach is also being expanded to clinical studies as well (Kenett et al., 2013; Vitevitch & Castro, 2015).
However, the application of the network science is not limited to phonology. Semantic networks have also been studied in the last years, yielding interesting results and hypotheses. For example, Hills, Mouene, Mouene, Sheya, and Smith (2009) tested three different models of word acquisition, based on preferential attachment (according to which “rich become richer,” that is, new nodes tend to connect to highly connected nodes 1 ), preferential acquisition (early learned words seem to be highly connected because they stand out in the learning environment and are more noticeable), and the lure of associates (“unknown words may be highlighted by known words to which they are related”). In that work semantic networks were built on the basis of 130 nouns. Thus, nodes represented nouns and links represented relationships between nouns (e.g. both ball and apple share the feature round). Interestingly, the authors covered a sensitive period for language development, from 16 to 30 months. Their results called into question that the principle of preferential attachment is the key of language development (and their results also highlighted the relevance of the connectivity of a word in the environment).
Besides, Beckage, Smith, and Hills (2011) investigated the growth of a semantic network by means of word co-occurrence. Their study analyzed both typical and late talkers, and their results support the intuition that small-worldness is related to the child’s lexical development. Until then, most works in semantics were based on English, German, Dutch, and Spanish, but Kenett, Kenett, Ben-Jacob, and Faust (2011) took a step further working on Hebrew—a Semitic language famous for its morphological roots and patterns (e.g. Ravid & Schiff, 2006)—and investigated the networks both at a local and global level and how these two levels interact. Thus, at the local level, these authors observed that the network was organized into sub-cliques, based on semantic categories.
Recent work on semantics and networks has paid attention to the ontogeny of the mental lexicon (Stella, Beckage, Brede, & De Domenico, 2018). These authors have taken into account several properties of lexicon (semantics, taxonomy, and phonology), showing that these properties indeed interact detecting a cluster of highly frequent words. Moreover, Stella and collaborators conclude that emergence of this core of the lexicon occurs abruptly during ontogeny (around age 7).
On another front, it has already been shown that language corpora exhibit a complex system behavior, and that they can be represented in terms of a graph of word interactions (Corominas-Murtra, Valverde & Solé, 2009; Ferrer-i-Cancho & Solé, 2001). 2 In these approaches, however, words are not connected by syntactic or semantic relations between them, but taking into account the “distance” to each other within the sentence. The maximal distance between words—typically between 2 and 3—is assessed by the researcher. These calculations have been used mainly in English. Nevertheless, if applied to other languages such as German or Dutch, which split many verbs into two components, the result could be that these components apparently have no link or relation. Consider, for instance, the following sentences: (1) is an example of split of the verb in present perfect in German and (2) is an example of a phrasal verb in Dutch:
(1) Heute
Today am[AUX] I with my brother at ten hour with the bus to house ridden[PAST PARTICIPE]
Today I
(2) Ik
I stay[VERB] every day at seven hour up[PARTICLE].
I
Notice that, even if “mit dem Bus” is removed in (1), the distance between bin and gefahren still is much longer than 3. This way to consider connectivity is directly based upon the linearity a printed text imposes. By linearity, linguists understand that–in oral languages–one word comes after the other, due to the constraints of the oral channel. In this case, one counts the “positions” and hence the distance between words. This type of approach has two sets of main problems: on one hand, it is built on the idea of counting word positions but as has been argued repeatedly, natural language does not seem to count (see i.a.Chomsky, 1975; Moro, 2008; Newmeyer, 2005), and on the other hand, it is blind to a core property of natural language which is its possibility to establish long-distance syntactic relations (such as the relation between the auxiliary bin and the lexical verb gefahren in (1) or the relation between the particle and the verb of the Dutch particle verb opstaan in (2), or the relation between the interrogative direct object “what” and its corresponding verb “eat” in an English sentence such as “What do you normally like to eat?”). However, although it is true that co-occurrence links are not based on true relations but on distance between words, these networks have anyway captured some aspects that have been also found in syntactic networks, like the central role played by functional items as hubs (Barceló-Coblijn, Corominas-Murtra, & Gomila, 2012; Corominas-Murtra et al., 2009). Network-based approaches have evolved to be able to capture these particularities, as we will see next.
3.1. Longitudinal syntactic networks
We have already mentioned longitudinal network-based approaches to language development which are focused on semantics. But there are also some studies arguing that the same can be done in syntax. An outstanding example is van Geert’s approach to language development based on dynamic theory (Ruhland & van Geert, 1998; van Geert, 1994). Van Geert’s approach to longitudinal corpora shows that the language capacity develops non-linearly. Also in a series of works Ninio (2006) has uncovered non-linear effects in syntactic development. Likewise, Corominas-Murtra et al. (2009) developed a first approximation to combining syntactically hand-annotated sentences with network representations and then tracking the longitudinal stages in linguistic development. In that work, two longitudinal English corpora were syntactically analyzed by hand and then the analyzed sentences of each file were represented by a network program, where syntactic dependency relations constituted the basis of the links or edges in the networks. First, during the syntactic analysis, the linguist syntactically analyzed the sentence deciding which word was connected to which word, using DGA annotator (Popescu, 2003), a program based on Dependency Grammar (Hudson, 1990). Both corpora had 10 chronologically ordered files, containing spontaneous speech of children. This way, their objective was to follow the child’s linguistic development. Corominas-Murtra and collaborators saw that in both cases the ability to combine words represented by the network developed similarly. In that work, two different stages were detected (a phase characterized by tree-like networks and another characterized by scale-free networks with the small-world characteristic), which were separated by an abrupt transition. That transition coincided in time with the emergence of hubs, which interestingly corresponded to functional words, such as “a,” “the,” “that,” and “this” and modal verbs. Such words count with a strong morpho-syntactic load, though they are devoid of a rich denotational semantics. These results are in consonance with results from dynamic approaches, showing the relevance and non-linear emergence of functional words in general (Ruhland & van Geert, 1998), the particular use of prepositions (van Dijk & van Geert, 2007), or determiners (Bassano et al., 2011).
Very similar results were found by Barceló-Coblijn et al. (2012), who analyzed three longitudinal corpora of Spanish, Dutch, and German. In that study, adopting the perspective of dynamic systems, particular attention was paid to the emergence of determiners as hubs in all three languages, showing that morphological diversity needs time to be mastered (see, in particular, Table 5 on the analysis of German determiners). Another relevant difference was that, while Corominas-Murtra et al. (2009) included corpora with 10 files, Barceló-Coblijn et al. (2012) analyzed corpora including up to 17 files. The inclusion of more segments of the child’s first months of life apparently uncovered a third phase. Interestingly, all three children underwent the same three stadia in very similar periods to those found in French by the Labrell et al.’s (2014) study based on dynamic theory.
In a nutshell, complex networks offer us a very useful way for the representation of the ontogeny of this process; words (syntactic items) are represented by nodes, while edges between nodes represent relations of syntactic dependencies. In this sense, the analysis that we will present in the following is similar to that of Sagae et al. (2010), since both use dependency relationships to syntactically analyze a sentence.
The present article also adopts the perspective of considering the cognitive capacity of language as a dynamic, developing system. This study seeks to contribute to this trend of analysis by enlarging the analyzed corpora to include several Romance and isolate languages that were unexplored with any network technique so far (thus allowing typological (crosslinguistic) comparisons), and also by assessing the suitability of the network technique in clinical studies by analyzing the patterns emerging from atypical populations (DS).
4. Comparing different languages and TD and AD populations
Van Geert (2004) made an appealing suggestion of applying the dynamic systems perspective of language development to Specific Language Impairment or SLI. In this article, like in Barceló-Coblijn et al. (2012), we also conceive language ontogeny from the perspective of dynamic systems. Specifically, we propose a new implementation of the network analysis with a comparative analysis of languages from the Romance family (Italian, French, Catalan, and Spanish), the Germanic family (English, Dutch, and German), and a language isolate (Basque). A second analysis will concern two groups of people with DS, 12 English speakers and 20 Dutch speakers. By comparing between different speakers of different languages it should be possible to (1) see whether the type of language has an influence on the ability to combine words (similarly to Bassano et al., 2011). By comparing between different groups of speakers (TD vs AD), it should be possible to (2) reinforce or to discard potential hypotheses about language development like those presented in previous sections. In van Geert’s (2004) words, if typical development follows some general principles (like discontinuity, U-shape, S-shape, particular network structures, etc.), there is no reason that they should not be applied to the development of impairment and disorder, as van Geert (2004) did with SLI.
Such comparison also shows the welcome consequences of the application of the network analysis in the crosslinguistic study of language development in both typical and atypical populations. Typically, network-based approaches tend to compare control networks in size, so that it is possible to compare different systems made of the same number of elements. However, in the case of language ontogeny, such an option loses part of the ecological value of the original source. Analyzing language ontogeny with real data (spontaneous speech) shows an important difference: each period of the child’s lifetime that is analyzed produces a different graph with different nodes (people say different words in different sessions), but also a different number of words (child’s lexicon grows, and her ability to combine words becomes more developed). Here, networks are not always the same in number, and hence the approach is rather different, since what we observe is not one network in comparison to another made of the same elements. The focus of our attention is how much “linguistic signal” the speaker produces in a limited amount of time (a session of spontaneous speech of a limited number of minutes), and what type of complexity can be observed in its underlying linguistic system. If all TD children produce more or less the same linguistic pattern, it will be possible to say that this might be the typical linguistic pattern of development. However, if a speaker greatly differs from the rest of her pairs, this opens the possibility for considering her linguistic ability as atypically developed. Hence, in the present approach we do not put the same quantity of text from the transcriptions (we cannot), since the set of AD children differ from TD children precisely in the quantity and quality of speech. Note that including, say, only 100 lines from a recorded session in both typical and atypical networks would mask the fact that perhaps atypically developed speakers need much more time until they produce the same quantity of words and sentences than TD children. It will be shown that, in general, and coinciding with previous results in the literature, DS speakers produce less words. Moreover, we will show that DS speakers produce less syntactic connections and, hence, produce atypical syntactic networks, in spite of having a similar recording session length (other differences found relate to the nature of lexical hubs).
In the first part of our study, we analyze the syntactic development of three children acquiring a (first) Romance language: Italian, French (Demuth & Tremblay, 2008; Tonelli, Dressler, & Romano, 1995), and Catalan (from the corpus Serra-Solé), and then we compare them to the German, Dutch, and Spanish corpora in Barceló-Coblijn et al. (2012). Moreover, to overcome a possible Indo-European or typological bias we also analyze two corpora of Basque (Soto Valle & Alonso, 2015)—a language isolate. This is the first time that such a language is analyzed with this technique. The inclusion of Basque allows us to overcome two potential issues: first, that the results we obtain could be biased by the phylogenetic relationships between the languages under study (Romance and Germanic languages belong to the same Indo-European family) and second, that this technique is only useful for non-agglutinative languages. In general, although there exist important differences, Romance and Germanic languages share a range of typological properties; Basque, however, is very different broadly speaking (see, for instance, the World Atlas of Language Structures (WALS) database). 3 Basque is unique within the group because it is the only language that has a basic SOV word order and agglutinative properties (see i.a.Laka, 1996; Trask, 1998). It displays a complex morphological system that exploits a lexical process called “agglutination” whereby words are formed by joining affix morphemes to the stem, where to a high degree each morpheme contributes one meaning and vice-versa; that is, each affix is a bound morpheme for one unit of meaning. For example, in Basque “etxe” (house) becomes by affixation “etxea” (the house), “etxeak” (the houses), “etxeko” (from house/homemade), and “etxetik” (from the house/out of house). In Basque it is possible to agglutinatively chain postpositions, obtaining clusters of suffixes and words with a complex morphology and a complex meaning, for example, “etxe-ra-ko-ak” (etxe+ra (allative) +ko (genitive locative) +ak (plural determiner); “those for the house”). Likewise, “gizon” (man) can participate in the generation of complex words like “gizon-a-ren-a-gatik” (gizon+a (determiner.singular) +ren (genitive) +a (determiner.singular) +gatik (because); “because of that of the man.”) 4 Importantly, this typological fact makes word-based MLU-type measurements (MLU-w) non-optimal for crosslinguistic comparison, for example, the number or “words” that are required for the expression of the same sentence varies significantly from language to language. As a consequence, some researchers prefer the use of morphemes as the counting unit for MLU (see Ezeizabarrena & Garcia Fernandez, 2018, for discussion). In our approach, on the contrary, we decompose each sentence in each syntactic unit, separating adpositions from nominals and thus obtaining a much more accurate crosslinguistic comparison.
We will show that the results of our linguistic analyses of TD children acquiring Catalan, French, or Italian are fully convergent with previous works that took into account the perspective of dynamic systems and complexity. Despite procedural differences in the original composition of the corpora and the heterogeneity of the data, a robust common pattern seems to emerge, apparently characterized by three stages of linear development separated by two non-linear phase transitions. In particular, it is intriguing that around 28 months of age a small-world network emerges, with a ratio of word/edges close to 1:2. Such is the case in each corpus, regardless of the language analyzed (this fact could suggest that the child has reached a particular developmental threshold, and that the pattern of word combination here represented by a small-world network was not dependent of the type of language the child acquired). This type of network indicates in all cases the maturity of the cognitive capacity for combining words. It reveals a stage where the child has already discovered the unbounded combinatoriability of the syntactic items in her language via some sort of syntactic “reverse combinatoriality” (in the spirit of the Fodorian “reverse compositionality” (see Fodor, 1998; Fodor & Lepore, 2001)) 5 whereby a learner who has mastered the availability of syntactic combinations such as [α^β], [α^γ], [α^δ], and [ε^β] and [ε^γ] (where α and ε pertain to the same syntactic category (say, determiners), and β, γ, and δ to a different one (say, nouns)) generalizes in terms of their syntactic category and goes on to freely combining elements of the {α, ε} type and elements of the {β, γ, δ} type generating novel combinations such as [ε^δ] and so on. In a nutshell, the network reveals the cohesion level of the child’s linguistic system. In addition, mastering of syntactic combination is related to a proper acquisition of functional words: as we said, the most connected nodes of the network (the “hubs”) are typically functional words and the set appears abruptly at this developmental moment. In sum, our results suggest that the three levels, common in all longitudinal analyses, are a reflection of the developmental path of TD children.
5. Method
5.1. Typical corpora
In the first part of the present work, five sets of corpora of longitudinal studies of typical language acquisition have been analyzed: one for Catalan, one for French, one for Italian, and two for Basque. Corpora were obtained from the international CHILDES database (MacWhinney, 2000). Each corpus contains at least 17 files chronologically ordered. Each file corresponds to a different recording session, which typically lasted between 30 and 60 min of spontaneous linguistic interaction between the child and their parents/caregivers. Children’s age extends from 17 to 32 months of age. Age is typically indicated as follows: “years;months.days,” for example 2;06.25 means 2 years, 6 months and 25 days of life. Age has then been represented in averaged calculation.
The Basque corpora we employed are partially different from the rest, since we could not find corpora extending exactly for the same age periods as the other ones; in fact, there were just these two cases available at the CHILDES database. Both Basque corpora start at 2.6 years of life (30 months). To see the connectivity of Basque postpositions, we syntactically decomposed complex morpho-phonological words and we analyzed how many times a postposition appears, taking into account that repetitions of the same combinations of lexical items are excluded. For example, if the target is the postposition -tik (equivalent to the preposition “from” in English) and it appears in the text 10 times with the noun etxe (“house”), this counts as only one appearance type (10 tokens of the same type), but if it also appears with herri (“town”), then it counts as two appearance types.
5.2. Atypical corpora
The set of clinical corpora are also obtained from CHILDES. The first set contains data of 12 subjects of different age, all of them diagnosed with DS and speaking English (Rondal, 1978a, 1978b). There are two files per individual, with the same age regarding “year” and “month,” and no information regarding the “day.” We decided to average the values of both files to get the final score. The second set contains data of 20 subjects of different ages affected by DS and speaking Dutch (Bol & Kuiken, 1990). However, these files correspond to one session; hence, just one network for each participant could be construed in this case. The group is heterogeneous regarding ages, ranging from 3 to 18 years. Nevertheless, the analysis of a multiplicity of cases (cross-sectional) of each type reveals a common pattern which we would like to argue is characteristic of the impairment in question (see section 6.2).
5.3. Procedure
A team of linguists analyzed each corpus sentence by sentence, following the basic guidelines of Dependency Grammar (Hudson, 1990). This kind of grammatical analysis is known and used in computational approaches to language because it provides essential information about the syntactic structure of the sentence, and the coded sentences are easy to export for further analyses to a network-analysis program. To carry out the syntactic analysis, data were prepared following the same procedure as in previous studies on syntactic networks (Figure 1; Barceló-Coblijn et al. 2012; Corominas-Murtra et al., 2009).
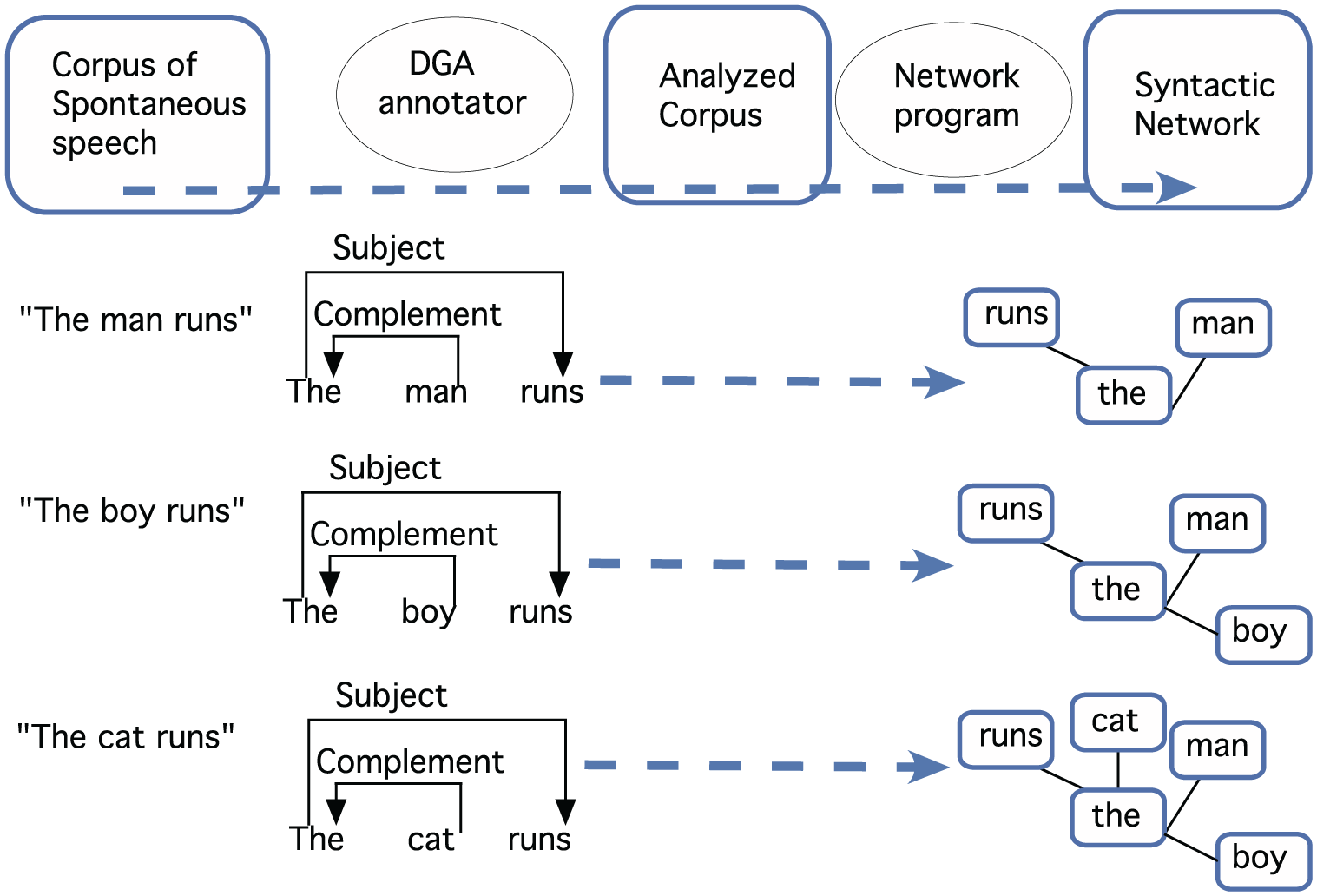
Steps and procedures in order to obtain a syntactic network from a corpus of spontaneous speech.First, the corpus of spontaneous speech is created (on the basis of a spontaneous speech session; in this work, corpora have been dowloaded from CHILDES database). Then each corpus is analyzed (word by word) with the DGA annotator, by establishing the syntactic relations between words. Once the corpus is analyzed, it is adapted by a script in order to be readable by the network program. Finally, the network program reads the annotated corpus and reflects the data as a network, where nodes are words and edges are syntactic relations.
Corpora were downloaded from the CHILDES database, each file was converted into .xml so that it could be read by the syntactic-annotation program, by means of a Perl script. The script also filtered the file, pruning the data that were not produced by the child (e.g. comments of the transcriber, phonetic transcriptions, what the parents say, etc.). The new .xml file was then sent to DGA annotator (Popescu, 2003), a program specifically created for syntactic analysis by means of dependency relationships.
The analysis was carried out by a linguist manually line by line, sentence by sentence, determining the syntactic dependency relationships between words by means of a dependency arrow. Other criteria followed by the linguists’ team are gathered in a public protocol (Corominas-Murtra, 2007) applied in previous studies.
After analyzing all files, another Python script specifically created for this kind of studies turned them into .txt files, which is a format accepted by the network-analysis program Cytoscape (Shannon et al., 2003).
Once Cytoscape reads the data, it produces a graph. In this study at least 17 graphs were obtained for each typical child acquiring an Indo-European language. The first of these graphs corresponds to a date of the child’s life of around 18 months, and the last graph corresponds to about the 30th month. This way, the evolution through time of the network—that represents how words are combined—can be readily visualized. In the case of Basque, two small corpora (representing two children) of five files each have been analyzed.
One graph was obtained for each session (i.e. 17 graphs per child, 5 in the Basque cases). Each word in a graph corresponds to a node in the network, while edges reproduce the syntactic dependencies between words. It is important to keep in mind that the dependency arrow reproduced by Cytoscape respects the direction of the arrow created by the DGA annotator. Cytoscape also allowed to visualize the arrow point. However, in spite of the careful linguistic analysis, information about the kind of syntactic relationships could not be integrated. Therefore, since it was not possible to see the kind of link between nodes, it was decided to be cautious and conservative and the analysis of edges was made as undirected edges.
We would like to stress that our approach is not frequentist, but a different, complementary way of observing linguistic data. In a graph, one can see how many different words and how many different dependency relationships have been employed by the child. This fact implies that repetitions—of either lexical items or dependency relationships—are not taken into account in this approach. If the child repeats “Pluto barks” 10 times, it counts as only one type of dependency relation: one node for “Pluto,” one node for “barks,” and a dependency relationship from “Pluto” to “barks.” It is the breath of vocabulary and the word combinations effectively produced which are used as a measure of linguistic development (i.e. we measure the knowledge that a speaker has obtained of the combinatorial properties of the items in her lexicon, as represented in her speech). Hence, it is the number of different linguistic expressions—and not the number of productions—the focus of this study. However, it is true that the high number of connections of the most connected words—the hubs—also reflects their condition as the most used words.
In a graph one can see several disconnected networks, depending on how well connected the words were. Each piece is called a “connected component.” The typical graph of a network analysis of a corpus contains one large network (sometimes two), several small networks with two or three nodes, and a number of isolated nodes (words that were uttered in isolation and hence were not connected with other words, such as, for example, “no” in a plain denial answer, or “cat” when pointing to a cat).
Cytoscape (or any other network program) also makes it possible to calculate multiple mathematical measures for each network; the most relevant for our purposes are
the relative size of the largest connected component (or LCC), which indicates the size of the largest component regarding the whole graph;
the average clustering coefficient (C), which indicates the extent to which two connected nodes are also connected to a third one, creating a triangle (this is a real number between 0 and 1 (when there is no clustering the value is 0, while 1 indicates maximal clustering));
the average shortest path length (L), which indicates the mean number of intermediate nodes that connect any two of them; and finally
the average degree of the LCC (<k>), which refers to the average number of connections per node; in our study, it indicates the average number of dependency relations for each particular word.
6. Results
6.1. Typical development
The study of TD corpora by analyzing longitudinal corpora of different languages aims to answer the following questions: (1) are there differences between German and Romance languages? and (2) what would happen in the case of typologically different languages?
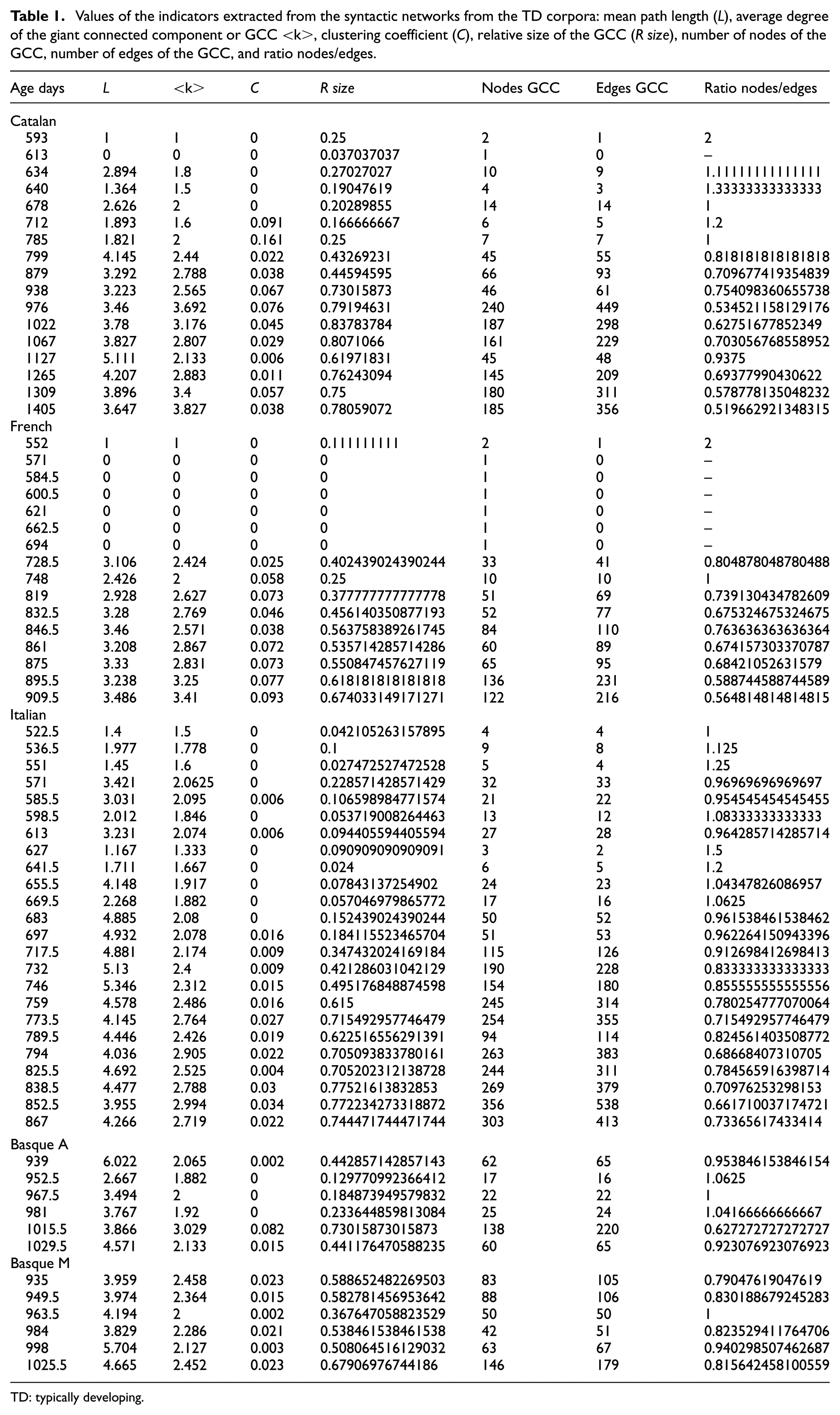
Once analyzed and compared, the three new corpora (Catalan, Italian, and French) show a similar developmental pattern (Table 1 and Figure 2) to the one observed in German, Dutch, and Spanish (Barceló-Coblijn et al. 2012). Thus, so far, all TD children exhibit the same pattern of syntactic development, regardless of the particular language they are learning. This pattern is apparently characterized by three different phases:
In the first phase, the networks emerging from their speech have a tree-like structure, characterized by a higher number of nodes (words) than edges (word combinations), and which appears with a relatively small LCC;
In the second phase, the child’s pattern is characterized by networks in which edges overcome the number of words and, as expected, some hubs appear (these are “promiscuous” words that combine with several others, thus providing cohesion to the network, and increasing the relative size of the LCC);
In the third phase, a final phase, the LCC almost equals the whole graph. The characteristic path length decreases and a high clustering appears, showing a strong cohesion in the network. An interesting aspect is that at this phase the tendency is evolving to a ratio of nodes (words)/edges (syntactic links) of 1:2, that is, two connections for each word.
Values of the indicators extracted from the syntactic networks from the TD corpora: mean path length (L), average degree of the giant connected component or GCC <k>, clustering coefficient (C), relative size of the GCC (R size), number of nodes of the GCC, number of edges of the GCC, and ratio nodes/edges.
TD: typically developing.
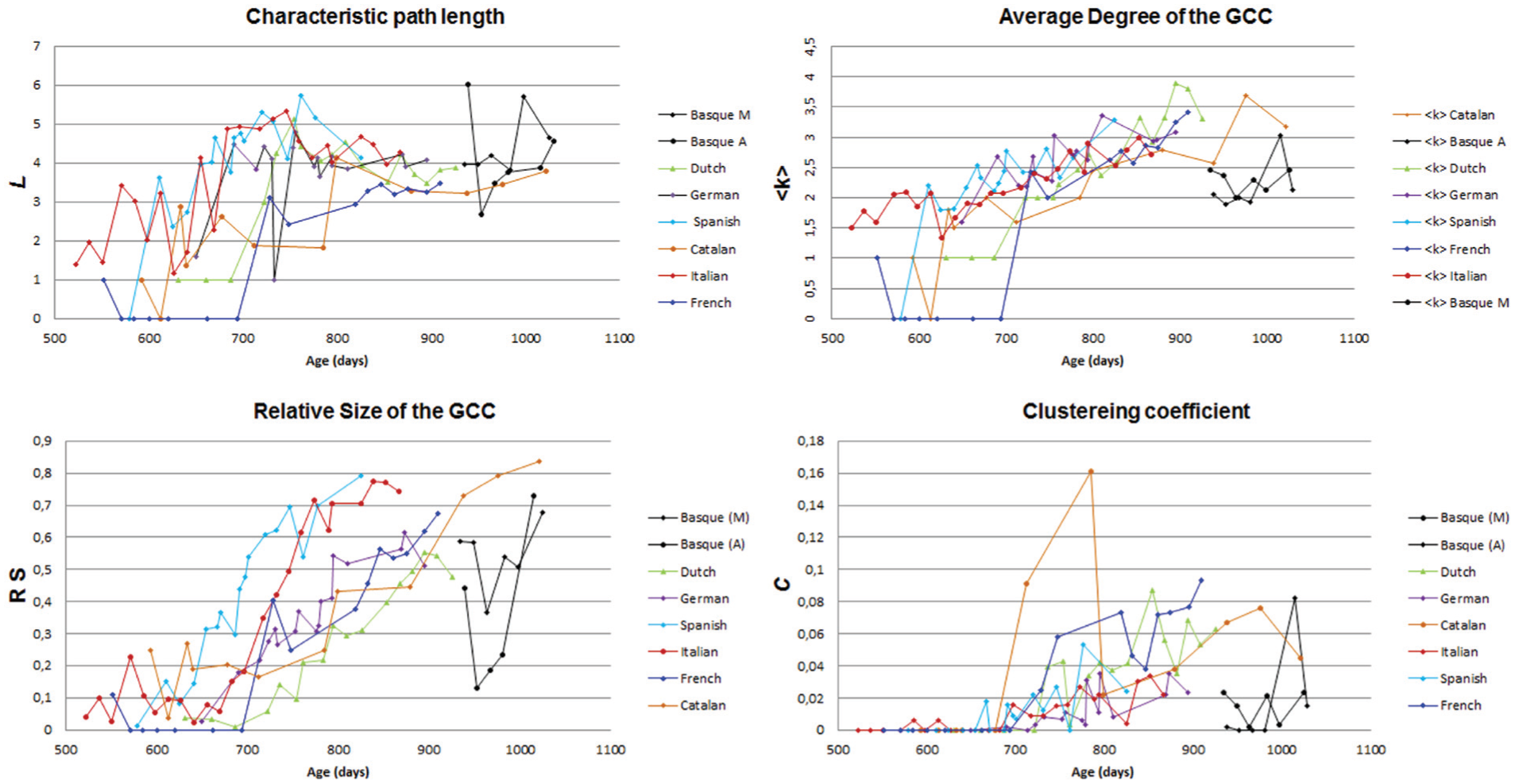
Summary of results for the relevant measures of the resulting networks for eight typically developing individuals.Each point displayed represents a single moment and not a mean score. We have integrated the five new corpora of this study with our previous results, in German, Dutch, and Spanish (Barceló-Coblijn, Corominas-Murtra, & Gomila, 2012). The same developmental pattern was found by Corominas-Murtra, Valverde, and Solé (2009), with two English learners.
Interestingly, that final topology is reached more or less around the same age, 800 days of life, in spite of the heterogeneity of the original data in terms of sampling time, procedures, periodicity, and so on. The Basque cases (shorter in number of recordings) show a slight delay, in part, due to the lack of data from previous ages, but it could also be related to its more agglutinative character. Nevertheless, networks with a high clustering and a low path length are also obtained in this language.
Furthermore, the hubs that abruptly give rise to the small-world networks tend to belong to the same lexical class: these are the so-called functional words (mostly determiners; see Supplementary Material for a sample of the evolution of hubs in Dutch and for a sample of the evolution of connectivity of determiners in Catalan), a result that coincides with the previous results. This pattern is found in all cases late and abruptly, coinciding with an important change in the network topology (see Table 1 in comparison to Table 5). Determiners (e.g. “the,” “a”) emerge as hubs in all languages so far analyzed following this late, abrupt transition pattern. In the previous work on networks in English (Corominas-Murtra et al., 2009), the hubs were “the,” “a,” “that,” and “it.” These nodes have at 30 months of life between 30 and 40 links, almost 80 in the case of “a.” Articles in Dutch, German, and Spanish also obtained similar numbers, producing around 30 and 40 syntactic dependency links. Some language-specific differences are always expected: the use of “it” in English does not correspond with the use of the equivalents in Dutch (het) or in German (es). Spanish and Catalan have three and two demonstratives respectively (some Catalan dialects show three demonstratives, but they are not represented in the sample), while Dutch and English have two and German has only one. However, German has a declension system, complicating a little bit the proper use of each form. The Romance languages here analyzed, Italian, French, and Catalan, follow the very same pattern, which is the pattern previously observed in Spanish.
One of the benefits of making a longitudinal analysis is that one can observe the evolution of the graph over a long period of time. As said, each graph contains several “components” (or networks of one or more nodes). Interestingly, in all languages analyzed until now (Catalan, Italian, French, Spanish, Basque, German, English, and Dutch) the number and size of components behaved in a very similar way: when the child began to speak (tree-like network stage), there were many small components of two and three nodes, and sometimes a couple of larger networks of four or five nodes (plus a large number of isolated nodes, representing unconnected words which were uttered in isolation). As the child grew and developed her linguistic ability to combine words, we observed the emergence of a LCC of a dozen or more nodes, sometimes followed by one or two small networks of five to seven nodes (plus the mini networks of one, two, or three nodes). When the child got to the second phase, small networks larger than four nodes seldom appeared. Instead, there was a clear and dominant LCC, and a number of networks of one and two nodes, followed by a smaller number of components with three nodes. Finally, when children got to the last stage, we observed an enormous LCC. In this stage, there was no independent network larger than three nodes, and even the presence of three-node networks is not guaranteed.
The second main question that concerned typical development and network analysis is related to the agglutinative features of languages like Basque, and whether this represents an obstacle for its application. From the two corpora of Basque that we analyzed, we obtained networks very similar to those of the non-agglutinative languages. We also performed a separate analysis of postpositions to see their connectivity pattern (Table 2).
Affixes in Basque from the Maider corpus (each one is treated as an independent node).

Under each suffix form, a number within parenthesis refers to the class of suffix: (0) bare form with no morphological suffix; (1) singular article, absolutive; (2) plural article, absolutive; (3) ergative; (4) possessive; (5) comitative; (6) inessive; (7) allative; (8) ablative; (9) auxiliary verb; (10) suffix for the generation of manner adverbs, akin to English “-ly”; (11) result-denoting suffix (akin to English “-ed”); (12) participial; (13) imperfect; (14) future. The bottom row indicates the number of other nodes each of the suffixes combines with.
Even in Basque, where determiners can be both free lexical units (e.g. bat “one/a,” as in etxe bat “a house”) or suffixes attached to the nominal stem (e.g. -a like in etxe
6.2. Atypical development
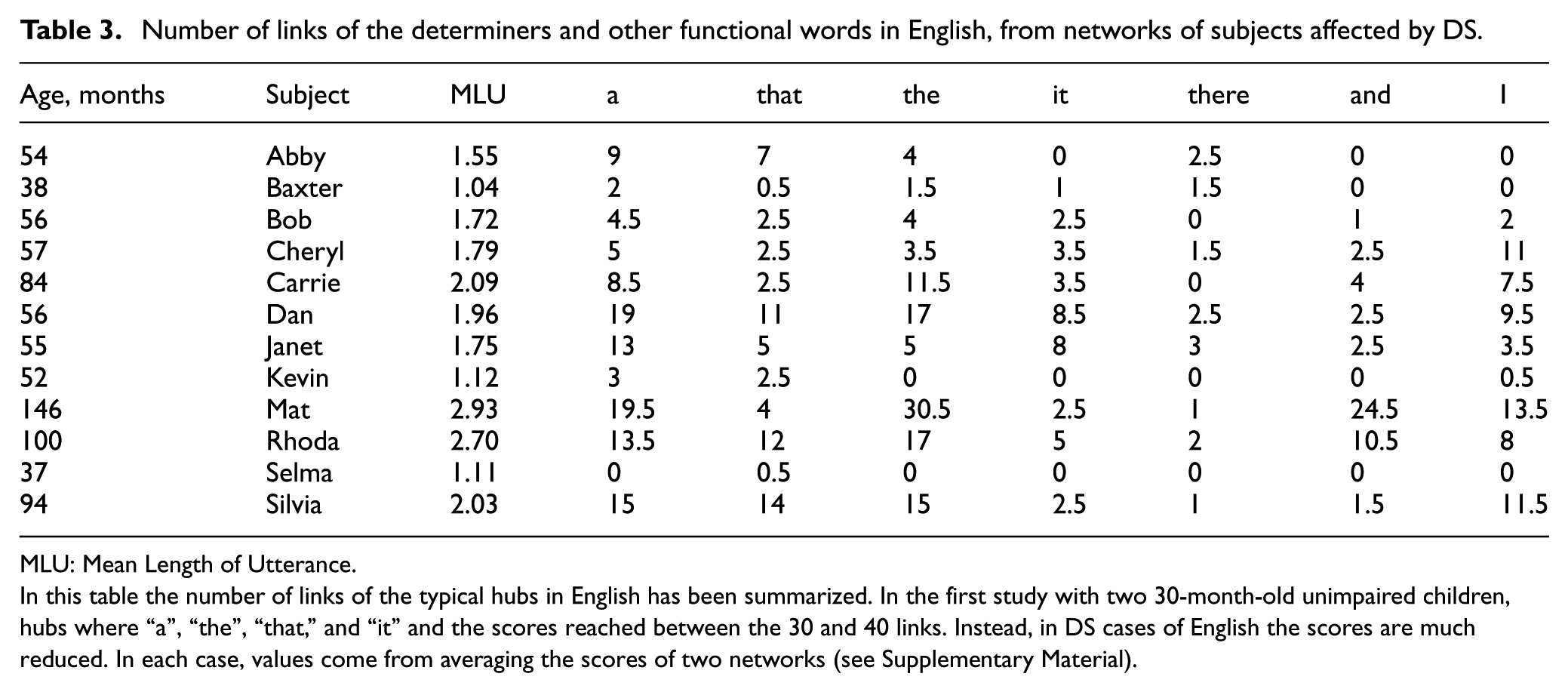
The third main question was whether there are differences between typically and atypically developed children. As expected, the answer is positive. One large group of 32 speakers with DS was analyzed. The group is divided into two subgroups, depending on the language they spoke, Dutch or English. The networks that characterize the syntactic performance reached by DS children of older ages are notably dissimilar. Results are shown in Tables 3–5. English DS children became able to produce a very low number of words and to barely combine them (the speaker “Mat” stands out in comparison to the group, though he is still far from TD younger speakers; see Figure 3).
Number of links of the determiners and other functional words in English, from networks of subjects affected by DS.
MLU: Mean Length of Utterance.
In this table the number of links of the typical hubs in English has been summarized. In the first study with two 30-month-old unimpaired children, hubs where “a”, “the”, “that,” and “it” and the scores reached between the 30 and 40 links. Instead, in DS cases of English the scores are much reduced. In each case, values come from averaging the scores of two networks (see Supplementary Material).
Number of links of the determiners and other functional words in Dutch, from networks of subjects affected by DS.
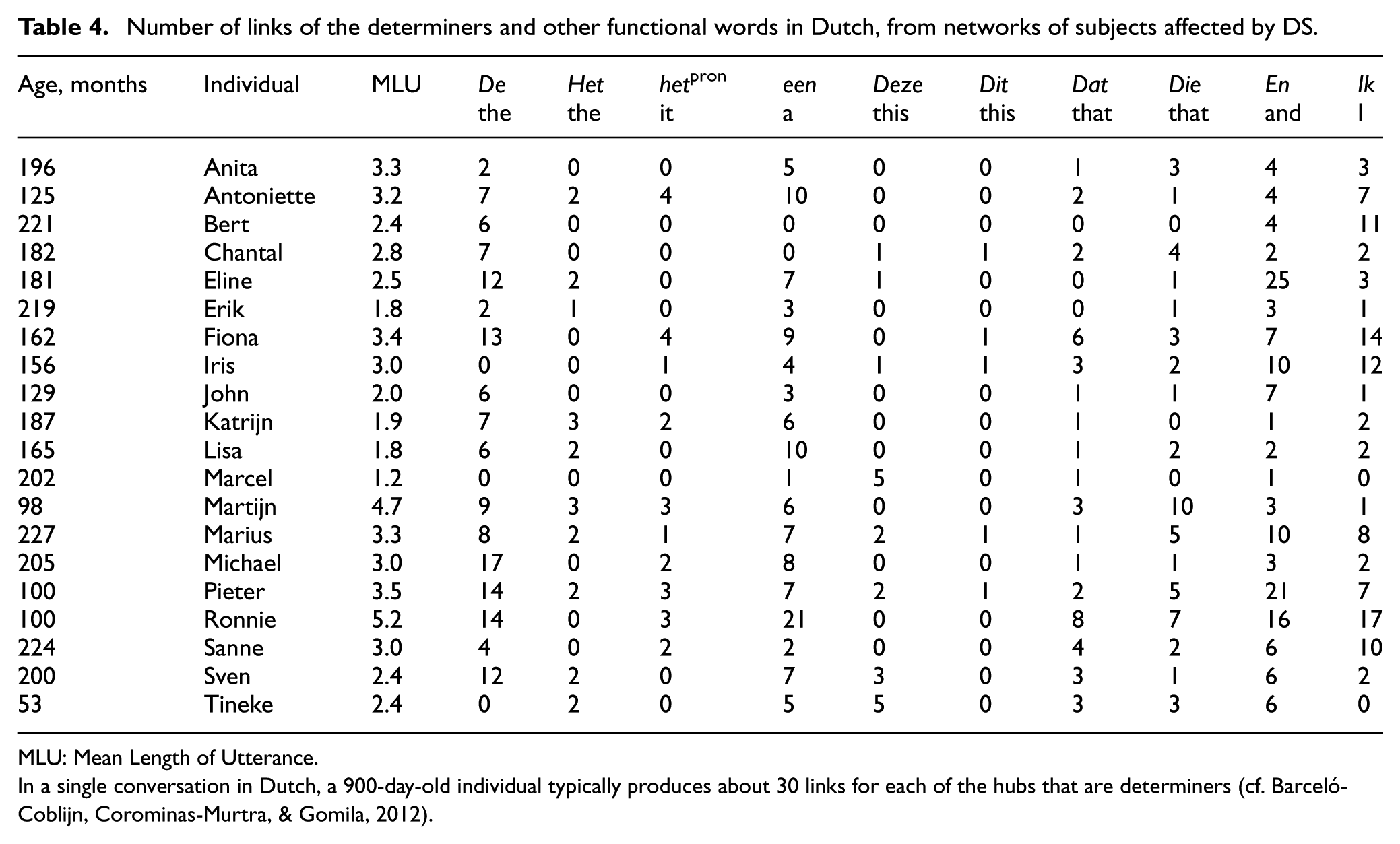
MLU: Mean Length of Utterance.
In a single conversation in Dutch, a 900-day-old individual typically produces about 30 links for each of the hubs that are determiners (cf. Barceló-Coblijn, Corominas-Murtra, & Gomila, 2012).
Information about the Dutch and English DS speaker’s networks.
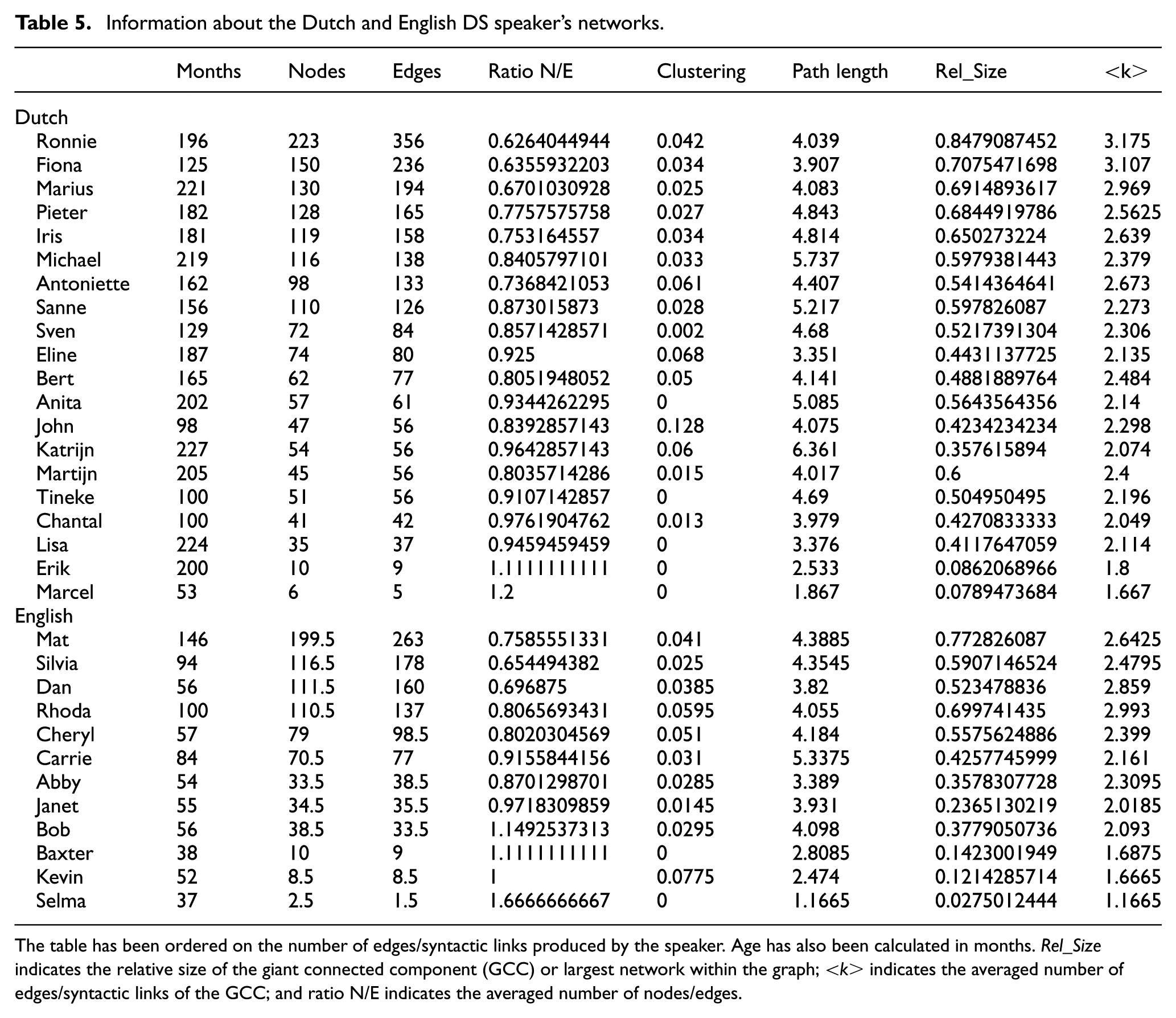
The table has been ordered on the number of edges/syntactic links produced by the speaker. Age has also been calculated in months. Rel_Size indicates the relative size of the giant connected component (GCC) or largest network within the graph; <k> indicates the averaged number of edges/syntactic links of the GCC; and ratio N/E indicates the averaged number of nodes/edges.
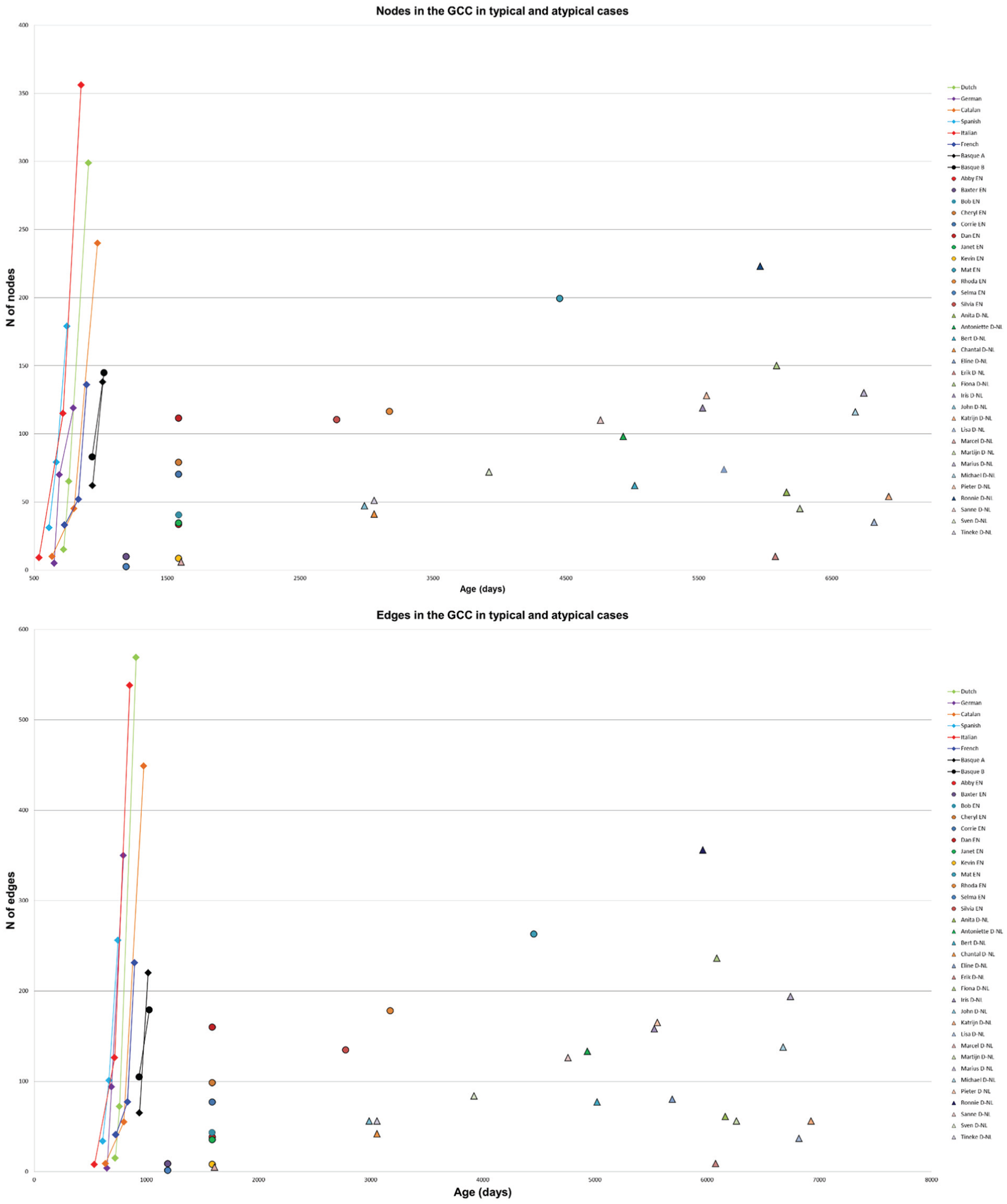
Number nodes (top) and edges (bottom) produced by typical and atypical individuals.
Then, the number of words increased over time, but very slowly, given the ages of the speakers. In the case of Dutch DS children, their vocabulary is still small but there seems not to be an analogous difficulty for combining words syntactically (even though only one case reached a small-world topology), and in spite of possible morpho-syntactic deficits (Bol & Kuiken, 1990). Interestingly, network measures clearly showed that their respective developmental paths differ substantially from the one followed by neurotypicals.
Crucially, our data showed that up to eight DS speakers produced a larger number of different words than the neurotypical children (it has to be noted that our DS speakers are significantly older than our TD speakers) but the number of syntactic connections was noticeably smaller for DS speakers, and only three DS speakers produced as many edges as TD younger children did. That is, vocabulary size does not directly map onto higher network complexity: in our case TD children with smaller vocabularies showed a richer command of their combinatorial properties than AD children with larger vocabularies. This is a clear outcome of our study, which may go unnoticed to the naked eye, but was uncovered by the network analysis.
Furthermore, it has been mentioned that an indicator of the cohesion of networks is the clustering coefficient (C). It is interesting to see whether networks that are similar in the number of nodes and edges differ regarding C, because this would be the clearest indicator that there is a substantial difference in the cohesion of the network (see Table 5). For example, only one of the DS Dutch speakers, “Ronnie,” reached the threshold of the small-world characterized by a ratio of word/syntactic relations of 1:2. Does this mean that there is no difference between this DS speaker’s linguistic combinatorial ability and that of TD speakers? Let’s compare data: the networks of the TD Dutch speaker “Daan” at 926 days have the following values: N = 223, E = 368, C = 0.063, while the DS Dutch Ronnie at the much older 5963 days reaches N = 223, E = 356, C = 0.036; thus, two networks quite similar regarding the n of nodes and edges show a notable difference regarding the C. By contrast, the TD German speaker “Simone” (in purple in Figure 3) reaches the DS Dutch Ronnie’s C with barely half of the elements: at 873 days (N = 139, E = 206, C = 0.035). In other words, the 3-year-old TD German speaker, with much less lexical elements, shows a pattern of linguistic cohesion which is similar to the pattern attested in the big DS linguistic network. These empirical data confirm again what Watts and Strogatz (1998) theoretically proposed: in networks, nodes are important, of course, but connectivity is a crucial factor that can sharply distinguish between two apparently similar networks. Again, a network smaller in the number of nodes can be more cohesive (i.e. have a higher C and a lower L) than a network with a larger number of nodes; the size matters, but is not the only important indicator. In our study, we interpret this as suggesting that a more connected network shows a richer command of the combinatorial properties of lexical items; a more disconnected one, on the other hand, seems to treat combinations more as extensional exceptions than as a general intensional rule that can be recursively applied.
Summarizing, our network analysis proves to be a useful clinical tool and clearly shows the difference between population groups, providing objective and formal indicators of complexity in performance reached by different individuals/groups.
On a different note, the comparison of the hubs found provides also an important source of clinical information (Tables 3 and 4). While hubs in the atypicals largely belong to the same functional class of hubs in TD networks, the number of combinations in AD is much smaller. Although it can be said that these are still hubs, the number of links is considerably smaller in comparison to that of healthy individuals. English speakers affected by DS produced a few more than a dozen syntactic links with the word “the.” Only the oldest individual (“Mat”) produced 30 combinations. In the case of “it,” this item is seldom produced (almost disappeared) and it does not constitute any hub. In the study of DS in Dutch, results also show striking differences in the scores of hubs. The number of links is in the best case (“Ronnie”) half of that of TD children. However, there appears a different hub, represented by the word en (“and”), suggesting that these speakers exploit coordination (parataxis) as a linguistic strategy maybe to avoid the complexities of structural embedding (hypotaxis). Interestingly, the number of links of the set of demonstratives is severely reduced in both DS groups, which in several cases amounts to zero links. See Table 3 for the DS performance in English, Table 4 for the Dutch cases, and Table 5 for the network values of DS syntactic networks.
Finally, an additional, interesting question is whether or not this network-based technique has convergent validity. Given that the MLU measure was available for both groups of DS individuals in the CHILDES database and in the original works (Bol & Kuiken, 1990; Rondal, 1978a, 1978b), we further investigated the relationship between this measure and our basic ones: the number of nodes (words) and edges (dependency relationships) of the LCC, the largest network in each graph (Figure 3). First of all, we checked for normality and homoscedasticity of the data. Both normality and homoscedasticity were met. Then we wanted to know whether both MLU and linguistic networks measured the same linguistic aspect. Hence, a Pearson correlation was performed and it revealed a similar level of correlation between MLU and both network measures (r = .704 for nodes and r = .709 for edges, in both cases with p < .001), suggesting that both measures keep track of the same growth process.
An important question was whether the type of language could affect the network analysis. For this reason, three ANOVAs (analyses of variance) were performed setting language as independent variable, and MLU, nodes, and edges as dependent variables. Analyses showed that for MLU, the language variable accounts for 27% of the differences between groups (F(1, 30) = 11.03; p = .002; η = .27; CI (η)95%: .025–.971). On the contrary, the type of language only accounts for 1.4% in the case of nodes (F(1, 30) = 0.44; p = .512; η = .014; CI 95%: .025–.487) and 1.3% in the case of edges (F(1, 30) = 0.38; p = .542; η = .013; CI 95%: .025–.458)—even if the latter are non-significant. This outcome suggests that complex networks can help overcoming the language-specific problems of morphology and closed-class words that the word-based MLU measurement faces, becoming a useful complementary methodology to assess the linguistic competence of DS speakers.
7. Discussion
The present work has explored incipiently the dynamicity of language ontogeny in both typical and atypical conditions. This has been possible thanks to the combination of linguistic theory and network science. The sentences produced by the speakers have first been analyzed syntactically following syntactic theory: syntactic items were detected and their dependency relationships, if any, labeled with a dependency link. In contrast to other network approaches based on word co-occurrence, here networks have been created on the basis of large collections of sentences, each of them syntactically analyzed by a linguist, word by word, item by item. These analyses have been transmitted to a network program, which interpreted words as nodes and syntactic links as edges, creating a network from each file (Figure 1). This procedure takes a considerable amount of time, though we think it is worth it, given the results we obtained, which uncovered a pattern of crosslinguistic unity and cross-population variation (we observed similar developmental paths traversing the same phases at similar ages across genetically and typologically different languages, and radically diverging developmental paths in DS populations). Admittedly, the procedure followed during the analyses of corpora could have affected or influenced in the resultant structure (see Gruenenfelder & Pisoni, 2009). Barceló-Coblijn, Duguine, and Irurtzun (2019) analyzed twice the same language corpora of three languages (Basque, French, and Dutch), adopting different linguistic theoretical hypotheses each time (related to the role of determiners as governors or as dependent elements of nouns). Results clearly show that the same corpus produces two different networks and that the degree of edges of determiners is severely altered depending on the adopted hypothesis. However, clustering (C) was also affected in an important way. In the present work, we have adopted and applied always the same theoretical decisions to both typical and DS corpora. Differences between these two groups of children are clear, separating typical children from DS children. The absence of mixed scores between typical and atypical reinforces our intuition that these first, explorative results could be on the right track.
A preliminary conclusion is that the apparent existence of several developmental phases crosslinguistically could imply that linguistic development is not a process that follows either a simple linear or a non-linear progress, but a “saltational” process that combines both kinds of progresses (and thus overcoming the black-or-white scenario mentioned above): when the system reaches a particular level, it takes some time until the next phase transition; during this period a pattern of linear progress is also observed in the network growth. These results are in agreement with Labrell et al. (2014) who found a developmental path characterized by several spurts and plateaus and also with recent findings in the ontogeny of English syntactic networks (Corominas-Murtra, Sànchez Fibla, Valverde, & Ricard Solé, 2018). However non-linearity is evident when the network radically changes its topology, from one type of network into another of a completely different type. Until now, in the present work this kind of dual progression has been confirmed in seven longitudinal corpora of seven different languages. Although the group size is still too small for a statistic generalization, and therefore the nature of the present work remains explorative, we think that our results suggest that this is not happenstance. Interestingly, our results and the results found in Barceló-Coblijn et al. (2012) have both found non-linearity of developmental patterns, coinciding with other works based on dynamic systems theory (Corominas-Murtra et al., 2018; Labrell et al. 2014; Ruhland & van Geert, 1998).
Changes in topology coincide with the increase of the degree of functional words, as if they were they core of the syntactic capability. This is not something new, as it has been pointed out in empirical works in linguistics (Bassano et al., 2011; Ruhland & van Geert, 1998; van Dijk & van Geert, 2007), though the present work, in spite of its exploratory aim, provides a global perspective of how these words emerge and occupy their place within the system. The perspective that the linguistic system evolves so that several stages must be traversed during ontogeny, and that the system changes when important, structural elements are incorporated, filling structural gaps, has already been put forth in recent works on semantics and lexicon ontogeny (Stella, Beckage, & Brede, 2017). More recently, Stella et al. (2018) have shown how the lexicon could evolve during ontogeny through an abrupt transition at age 7, and that the key of that developmental abruptness is the acquisition of the core set of vocabulary. Interestingly, the results of network-based approaches on both syntax and semantics suggest that the language capacity develops following quite similar patterns regarding syntax and semantics, something that nicely fits Elisabeth Bates’ classic hypothesis about the “inseparability of grammar and the lexicon” and that “the emergence of grammar is highly dependent upon vocabulary size” (Bates & Goodman, 1997).
With respect to atypical development, our study might have uncovered a pattern that is unobservable by other means even if the paucity of linguistic structures in AD children is considered symptomatic and related to their atypical condition. The present approach provides a framework to change our conception of AD: in agreement with previous findings, atypical cases are not just delayed stages in the course of typical development. And in coincidence with previous works (e.g. Chapman, Hesketh & Kistler, 2002; Chapman, Sindberg, Bridge, Gigstead, & Hesketh, 2006), a large degree of variability has been found within the DS group. We would like to stress that several DS children could reach a high score in their lexical production and that notwithstanding their syntactic performance—their capability to syntactically combine lexical items—clearly differed from their typically developed peers. This suggests that focusing on word counting only could mask important information related to the individual’s language capacity. In our study, most of the times the DS speakers did not reach the TD speakers’ topology (only 1 speaker out of 32 did, and at a significantly older age), nor their use and connectivity of functional words was the same, which could be interpreted as being due to a specific difficulty in grasping the syntactic rules and mastering the combinatoriability of functional, closed-class words in combination to the general difficulty to learn new vocabulary (Assen & Bol, 2012). This strongly suggests that the connectivity in atypical cases like DS is essentially different. Note that, for example, up to eight DS speakers have a number of nodes (words) larger than several neurotypicals. The clearest example is the German TD speaker (“Simone,” in purple, in Figure 3)—a child qualified as “exceptionally gifted” according to IQ tests (see CHILDES online manuals). If it were all about the number of words, the TD German child should have a less developed linguistic skill than the group of DS speakers that have produced more words than her (or their production should be more complex than hers). But, as repeatedly said in this work, the difference is not the number of words only, because two structurally different networks could have a similar number of words/nodes. To us, the crucial difference is in the way nodes are interconnected, the number of edges (syntactic connections), and in the connectivity of hubs, most of the times represented by functional words. Here, the performance of Simone, reflected in the network, undergoes an explosion of syntactic edges and they are connected in such a way that the network develops the structure and topology of a network with a high clustering coefficient and a low average path length (thus suggesting small-worldness). Like the rest of TD children, Simone’s hubs were functional words and the relation between words and syntactic links is near to 1:2 (for each word, two syntactic relationships). Differences in the network topology are the reflection of their different linguistic performance (see Figure 4 for comparison). In DS networks, there are less connections in number, but also the type of long-distance connections—allegedly the promoter of small-worldness—is considerably reduced, if not completely absent. Moreover, the hubs of the network also show an atypical behavior, with very low scores or with lexical differences. These results coincide again with Bates & Goodman (1997), who pointed out that some structures like function words are especially vulnerable to brain damage in neurological intact speakers under perceptual degradation (see Barceló-Coblijn et al. 2017 for a first syntactic network analysis of linguistic development of a couple of twins, one of them affected by a focal brain injury).
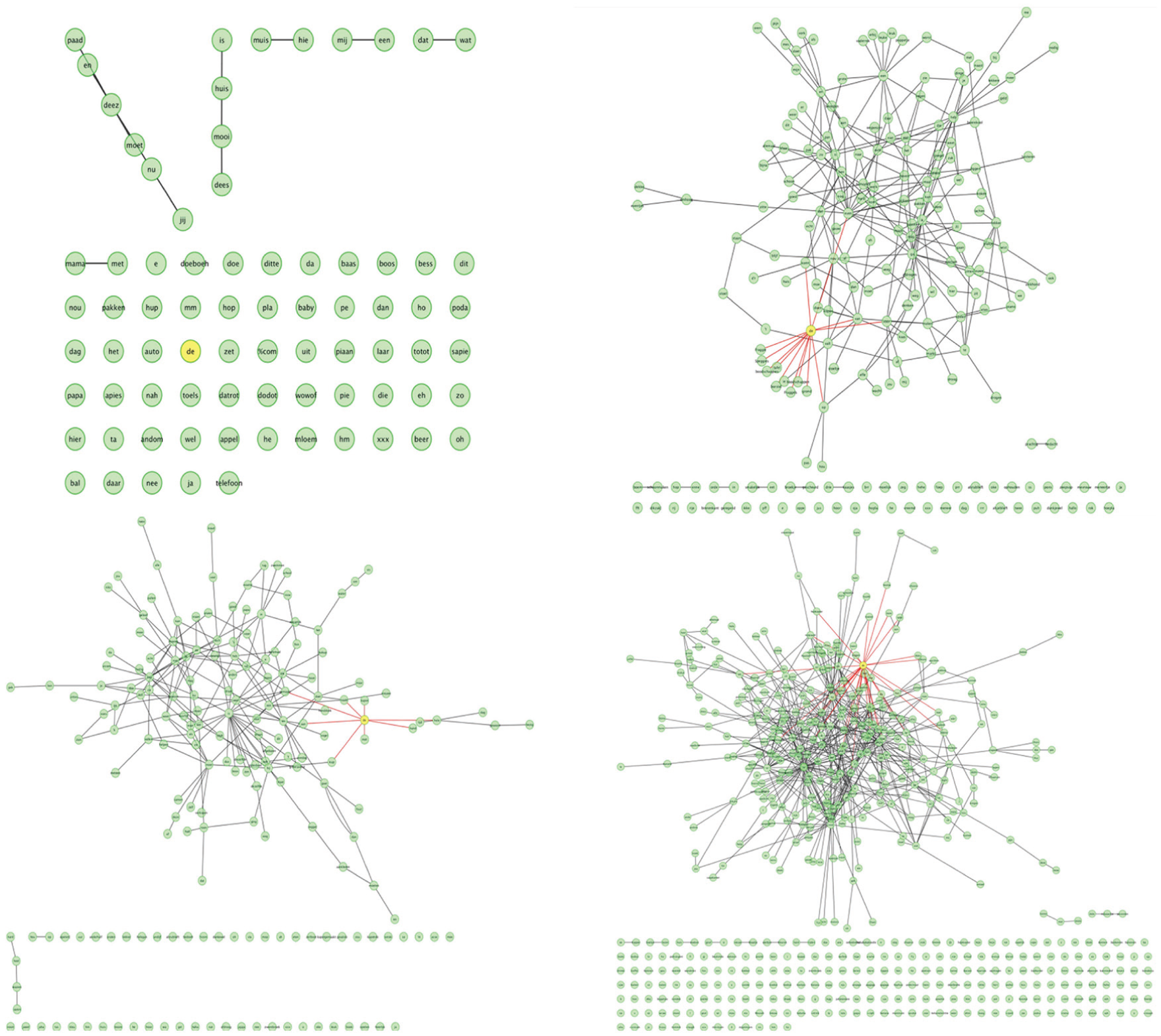
Four graphs from Dutch corpora—three samples of linguistic performance affected by Down syndrome: top left (age 04;04.21), top right (age 10;05.03), and bottom left (age 18;05.02). Bottom right, typical child’s performance (age 02;06.25).The Dutch determiner “de” has been highlighted.
Regarding the use and applicability of networks in psycholinguistics, statistics also indicate that this technique has convergent validity and hence that it can complement other measures such as the MLU. As a complement to MLU or other techniques, a network analysis is not their substitute. A network analysis extracts formal indicators from a corpus that otherwise cannot be obtained. Other techniques are more focused on the analysis of sentences as independent entities. From a tree-like network, one could track the path of one of the sentences, but it is certainly a challenge for humans to track a sentence in a small-world network with hundreds of nodes and edges. Although the creation of specific software could perhaps track a sentence within a small-world network, this would be of little use for the macroscopic view we took in this work. Tracking the original sentences is not the function of networks. In our view, what they are really useful for is for providing formal indicators of the pattern of connectivity extracted from a linguistic corpus. An outstanding example of this central idea, applied to semantic association, is Kenett, Gold, and Faust’s (2015) approach to semantic organization of people with Asperger syndrome (AS). Their networks suggest that AS speakers have a particular (hyper-modularized), more compartmentalized, mental lexicon.
With respect to syntactic theory, we think that the present work contributes to solving at least part of the issues raised by Ninio (2014). We think that some parameters are more useful than others, depending on the nature behind the network that is being analyzed. The small-world topology is a first indicator of efficiency (Martin, 2012), but in our case, the linguistic context is really important (Čech, Mačutek, & Liu, 2016). It is a cognitive context, and it is a (developing) organism what is under study and hence a dynamical process (van Geert 1994; Barceló-Coblijn, Corominas-Murtra, & Gomila 2012). Nonetheless, this is not enough. Importantly, a crucial characteristic of AD speech is the atypical, low connectivity of the typical hubs, or even the emergence of other words as hubs, something that has already been pointed out in other network-based approaches to clinical studies (Crossley et al., 2014). Moreover, in our approach, syntactic connections/edges are not random but established following syntactic theory. The linearity imposed by speech is not a problem for our approach, since the analysis is based on syntactic dependency relations and syntactic theory, which are not limited by linear distance between words within a sentence. The absence of any linearity constraints is more important than it may seem at first glance, because, among other reasons (e.g. remind Zweig’s (2016) observations regarding the true nature of co-occurrence networks), our syntactic analysis goes beyond the transcription and takes benefit of advances in contemporary syntactic theory. In this aspect, we agree with Čech, Mačutek, and Liu’s (2016) observation that answers about the role of syntax in networks should take into account linguistic theory, and we think that the speaker’s syntactic ability affects several relevant aspects, like the nature and connectivity of hubs. However, theoretical syntax itself can also affect hubs’ connectivity, depending on the theoretical choice one applies—for example, the degree <k> (n of edges) of determiners (see Barceló-Coblijn et al., 2019, and Supplementary Material in the present work). Importantly, notice that acknowledging syntactic relations as something real—that is, not as mere theoretical labels—would open the door to analyses of directed networks.
Finally, we would like to also frame our approach within contemporary debates in cognitive science. Here the psychological ability for language is considered a complex dynamic system. Complexity emerges when different elements within a system interact with each other. In the case of language, indicators of complexity had already been detected in phonology (e.g. Vitevitch, 2008) or semantics (Bilson, Yoshida, Tran, Woods, & Hills, 2015; Hills, Maouene, Riordan, & Smith, 2010; Hills et al., 2009), and the present work shows that the ability to combine words also shows clear indicators of a complex behavior. By comparing TD and AD speakers, we have seen that the latter do develop, although following a different developmental path. Our studies fit that third Evo-Devo approach to human ontogeny mentioned in the introduction, according to which the individual development follows both linear and non-linear progressions (e.g. see the classic Evo-Devo biology, for example, Alberch & Alberch, 1981; Alberch, Gould, Oster, & Wake, 1979). An Evo-Devo approach also provides a conceptual framework to make sense of our results on atypical development: they are to be viewed not as delays, but as different phenotypical paths (hence meeting Karmiloff-Smith’s, 2007, and van Geert’s, 2004, viewpoint). Therefore, we think that syntactic networks can be used as psychiatric endophenotypes (Barceló-Coblijn et al., 2015) since the network and its formal, objective indicators meet the criteria of a biomarker bridging genotype and phenotype. When a biologically driven disturbance constraints development, like in DS, the linguistic phenotype stabilizes differently. Such divergent development due to the effect of the trisomy in DS populations is also supported by studies of the connectome that show that the connectivity pattern of DS brains resembles a random network, while the connectivity pattern of neurotypicals is small-word (Ahmadlou, Gharib, Hemmati, Vameghi, & Sajedi, 2013). Future research will deal with linguistic samples of other syndromes that also affect language, to see whether or not it is possible to visualize a phenotypic morpho-space, as hypothesized by Barceló-Coblijn and Gomila (2014). On another front, more control is necessary during corpus creation. If session time is selected as a crucial feature, then it should be controlled both during recording sessions (all sessions with the same duration) and between sessions (the same intervals in days between recordings). Other aspects, like the intervention of other actors (relatives, friends, etc.) should also be strongly controlled. This could be solved with the development of a specific protocol. The same can be said regarding the hypothesis the linguist follows during the syntactic analysis. As in any other discipline, syntactic theory contains several hypotheses. Syntactic network approaches would greatly benefit from a detailed syntactic protocol created and shared to the community.
8. Limitations and future directions
The present work contributes to the issue of the suitability of network analyses vis-à-vis language variation. It argues for such a suitability, provided that the network modeling is combined with a proper linguistic analysis. However, there still are some aspects that could be improved in the future. One of them is the integration of syntactic information from the syntactic links inside edges. Until now, the available software does not allow such integration. Ideally, information from the syntactic link such as “subject,”“complement,” and so on (Figure 1) should be encapsulated inside the edge so that it can be analyzed further. As mentioned before, this would make possible an analysis of directed networks, since the information “inside” the edge could be checked anytime. Information about lexical categories (i.e. noun, verb, adjective, determiner, etc.) is also lost during file transformation in current work. Ideally, in future developments such information should also be saved to see automatically which lexical categories vertebrate the network, for example, using a specific program for these matters (e.g. Barceló-Coblijn et al., 2017). Another important aspect to reinforce is the statistical information that can be obtained from this kind of approaches. The present work is exploratory due to the size of corpora. Future work including a larger number of participants and languages could draw a stronger conclusion on the developmental trajectories between TD and AD children. In relation to this, and as observed in the previous section, gathering new data from spontaneous speech controlling time session, intervals, and the number of intervening actors will discard potential biases affecting the analysis.
Supplemental Material
Supplementary_material – Supplemental material for How children develop their ability to combine words: a network-based approach
Supplemental material, Supplementary_material for How children develop their ability to combine words: a network-based approach by Lluís Barceló-Coblijn, Aritz Irurtzun, Cristina Real Puigdollers, Emilio López-Navarro and Antoni Gomila in Adaptive Behavior
Footnotes
Acknowledgements
We thank Paco Calvo and Manuel G Bedia for their support in the development of this work.
Handling Editor: Alberto Antonioni, University College London, UK
Authors’ Note
Cristina Real Puigdollers is now affiliated with Universitat Pompeu Fabra, Barcelona, Spain.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the following projects and grants: IT769-13 (Basque Government), FFI2017-87140-C4-1-P (MINECO), BIM (ANR), UV2 (ANR-DFG), PSI2014-62092-EXP, TIN2016-80347-R and PGC2018-096870-B-100 (MiCIU, AEI & FEDER, EU).
Supplemental material
Supplemental material for this article is available online.
Notes
About the Authors
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.