
Abstract

Introduction
Group and organization research involves the study of attributes of groups and the individuals comprising those groups. Often, the most intriguing, but also more complex, contributions emerge when these variables are combined at multiple levels, both theoretically and empirically (Hitt et al., 2007; Klein & Kozlowski, 2000; Peccei & Van De Voorde, 2019; Rapp et al., 2022). As a result, we have witnessed substantial advancements in knowledge over at least two decades regarding how group and individual elements mutually influence each other. This advancement has facilitated better decision-making for managers concerning group dynamics (Kozlowski et al., 2013; Matthews et al., 2022).
Simultaneously, significant progress has been made in research methods enabling such analyses (Henry & Muthén, 2010; Maas & Hox, 2005; Sarstedt et al., 2011; Vermunt, 2008; Zyphur et al., 2016). Therefore, it has become a common practice, often even a necessity, to complement individual data in organizations with information on team, group, and hierarchical structures (Maas & Hox, 2004). While this introduces more methodological complexity compared to single-level models, it has facilitated a better understanding of various management phenomena and allows for more advanced testing and elaboration of relevant theories for, at least, three reasons. First, management research pertains to human behavior primarily occurring through social interactions. Relevant management concepts shape and/or are shaped not only by singled-out individual decisions but also through interactions among people. Therefore, empirical findings often have greater face validity when accounting for the multilevel data structure in organizations, groups, and teams. Second, organizations operate within various hierarchies where management decisions and outcomes are inherently intertwined with (in)formal hierarchies, as well as with the organizational units within these hierarchies. Data and analyses that encompass or focus on more than one hierarchical level allow for operationalizing the complexity of individuals within groups. Also these groups as a whole can be conceptualized and studied. Third, various management concepts are only relevant –or even exist– because of their gradual emergence within multilevel structures (Lang et al., 2018). A multilevel approach has enabled robust measurement and analysis of such concepts (Klein & Kozlowski, 2000; Moritz & Watson, 1998).
In these studies, measures of group-level agreement (or consensus) are often reported, along with related measures on interrater reliability. For the vast majority of these multilevel studies, agreement is operationalized using concrete metrics and argued in terms of technical and methodological criteria. These metrics are used either as conditions for using data or to specify how data is used (e.g., r*WG or Cohen’s Kappa) (Boyer & Verma, 2000; Brown & Hauenstein, 2005; LeBreton & Senter, 2008; Lindell & Brandt, 1999). They are also used to argue for or against applying multilevel model specifications (e.g. intra-class correlation [ICC]) (Bliese, 2000; Bliese et al., 2018; Boyer & Verma, 2000). This illustrates the predominant use of agreement (and interrater reliability) measures for methodological reasons focusing on data and the robustness of methods, rather than on theory development and testing (Loignon et al., 2019).
Here our frustration starts bubbling up as consensus, in itself, may hold significant theoretical value. We advocate for a substantial expansion in the use of agreement measures to facilitate theory development regarding how group or organizational consensus relates to other concepts central to the field of group and organization management research. In essence, we believe that the conventional measures (or adapted versions) used for assessing consensus or agreement should transcend their role in assessing validity and robustness. They could increasingly serve as primary variables in theoretical model testing. Moreover, we start our GOMusing with the observation that there are numerous relevant, robust, and adequate metrics available to operationalize group consensus. However, these metrics could be used to a greater extent in operationalizing consensus as a core theoretical element, rather than solely for methodological validation.
Selection of Key Consensus Studies.

Adhering to the true philosophy of a GOMusing exercise (Cruz, 2021; Cruz et al., 2022), we call for a stronger scientific discussion on the theoretical significance of consensus measures. Such discussion should counterbalance the prevailing methodological application of agreement measures. Indeed, upon examining the majority of multilevel group and organization studies, we believe there have been numerous untapped opportunities thus far to study truly interesting aspects of group consensus. However –constructive and agreeable as we are– we aspire to invigorate the much-needed scientific discussion by posing three guiding questions (GQs): • GQ 1. Does the meaning of agreement about a group-level variable relate to the meaning of the group-level variable itself? • GQ 2. Does the meaning of agreement about a group-level variable relate to the hypothesized antecedents or effects of the group-level variable? • GQ 3. Does the meaning of agreement about a group-level variable relate to the practical implications related to the group-level variable?
These GQs should be integral to every multilevel group study, simultaneously serving as sources of inspiration for future research. Even though we use the concept of Work Social Capital (WSC) as an illustrative example to underscore our argument, our GQs-approach is pertinent to a much broader range of management phenomena, concepts, and theories, some of which include: organizational citizenship behavior and extra-role behavior (Becker et al., 2018; Kidwell et al., 1997), organizational culture (Bosak et al., 2017; González-Romá et al., 2009; Pandey & Pandey, 2019), strategic plan quality (Meyfroodt et al., 2019), strategic decisions (Rapert et al., 1996), team member exchange quality (Willems, 2016a), and supplier selection objectives (Meschnig & Kaufmann, 2015).
Consensus Measures: From Methodological Conditions to Theoretical Logic
Agreement within a group about a concept is often seen solely as a methodological condition for aggregating individual opinions into a group-level variable for subsequent analysis. This assumption rests on the premise that common variance in opinions within a group is influenced by a latent, group-level variable that similarly influences individual opinions (LeBreton & Senter, 2008; Moritz & Watson, 1998). Hence, high common variance indicates that the latent variable is perceived similarly by group members, supporting the claim that it is a group-level variable (Burke & Dunlap, 2002; Lebreton et al., 2003). Conversely, low agreement implies that the individuals may not perceive the concept correctly and/or it may not genuinely be a group-level variable. Thus, data from teams with insufficient agreement on a concept may be considered less reliable for constructing a robust group-level variable (LeBreton & Senter, 2008). Therefore, we first provide an intuitive example of some pitfalls that arise from adopting a too strict and heuristic-based approach to applying consensus measures solely for methodological purposes. Next, we pinpoint some advantages of using consensus metrics for theoretical purposes, which brings us at our three GQs.
An Intuitive Example
Consider a scenario in which scholars measure WSC in a team context to assess whether it positively impacts team performance or decision-making quality, or reduces absenteeism among group members (Cole et al., 2002; Hu & Randel, 2014; Pihl-Thingvad et al., 2020; Stevenson & Radin, 2009). As WSC is a group-level attribute, the conventional approach is first gauging the opinions of different team members using validated survey constructs. Next, it is determined whether responses from the various team members can be aggregated by assessing the ‘sufficiency’ of the interrater agreement (LeBreton & Senter, 2008). Finally, an aggregate group-level measure is used to quantify the group-level concept for further analysis.
However, when drawing from the literature on (diversity) faultlines, dominant coalitions, and workplace bullying or exclusion (Henle et al., 2023; Kaczmarek et al., 2012; Li & Hambrick, 2005; Van Knippenberg et al., 2011; Wu et al., 2021), a situation may arise in a group where a substantial subgroup highly agrees on the high WSC. In contrast, others may feel excluded, resulting in lower ratings of group dynamics and reduced overall agreement, as visualized in Figure 1. When the agreement metric still meets the data reliability threshold, such a situation would be treated similarly to a group where high agreement exists about the fact that the group dynamics are more or less good, but that there is still room for improvement. However, from a theoretical perspective, these are quite different situations with distinct causes, effects, and managerial implications (Kessler, 2019). If, on the other hand, agreement in this case falls below the arbitrary data reliability threshold, intriguing situations that deserve scientific attention consistently go unanalyzed, limiting theoretical conclusions to a narrow selection of team dynamics. In sum, Figure 1 can guide scholars in understanding the conceptual implications of low or high aggregated scores in conjunction with high or low agreement on group-level constructs. Clarification of (1) inherently distinct cases and (2) interesting but excluded research cases.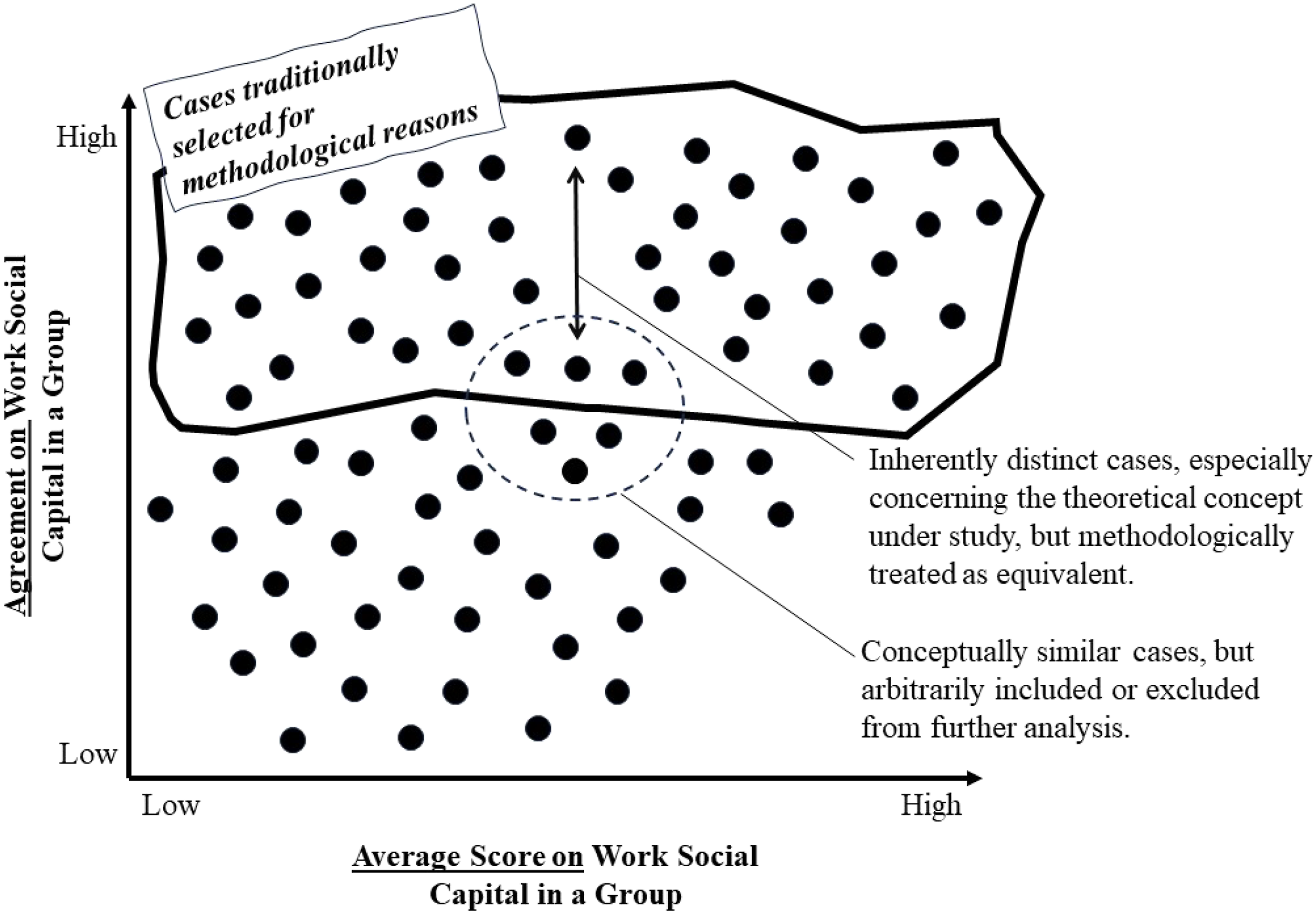
Therefore, Consensus should also and relatively more be considered a “meaningful, higher level construct rather than a statistical prerequisite for aggregation” even if the operationalization of both constructs are based on the same survey items (Holt et al., 2017, p. 64). Consensus, as a theoretical concept, refers to the variability within or between groups regarding perceptions on a specific facet (Luria, 2008; Schneider et al., 2002) and originates from two streams of literature in organizational sciences: (1) the literature on the compositional models in psychology, based on Chan (1998); and (2) the literature on organizational culture/climate or consensus, stemming from Martin (1992), and Trice and Beyer (1993).
The theoretical relevance of consensus within a group regarding a group-level variable depends on three elements: (1) the concept’s meaning at the group level, (2) hypothesized antecedents and effects of the group-level concept, and (3) the theoretical and practical implications derived from the findings related to the group-level concept. Our guiding questions relate to these three elements.
GQ 1. Does the Meaning of Agreement About a Group-Level Variable Relate to the Meaning of the Group-Level Variable Itself?
Consider our example of WSC. WSC is a group variable, and its aggregated measure can be tested for its predictive power regarding team performance (a group level variable), or job satisfaction of the members in the team (a nested individual measure). However, within-group agreement on the level of WSC can also shed light on aspects related to WSC itself. Said differently, not only does an aggregated measure provide insight, but also a measure on the within-group consensus reveals information about WSC in a group. For instance, a sub-group or dominant coalition (Janssens & Brett, 2006) in the team might perceive WSC favorably and rate it highly, and thus with strong internal agreement. They might even enjoy exchanging memes and gossip about one or two socially excluded team members, who understandably rate WSC substantially lower. Depending on the specific agreement measure used and the arbitrary cut-off for robust observations (LeBreton & Senter, 2008), such cases can be on the edge of inclusion for further analysis from a traditional methodological perspective (see Figure 1).
When employing a standard methodological approach that excludes teams like these from further analysis due to limited inter-rater reliability, specific yet realistic manifestations of WSC remain unnoticed. Namely, researchers confine themselves to studying teams where there is high agreement regarding WSC, whether it is low or high. This not only oversimplifies the concepts under study but also narrows down their findings and recommendations to a specific category of teams. However, considering the abundance of literature on within-group dominant coalitions and the exclusion of team members (Henle et al., 2023; Lee & Brotheridge, 2013), scenarios like the one described deserve considerably more scientific attention.
In contrast, when cases like these merely meet an arbitrary inclusion threshold for further analysis (e.g., contingent on the relative size of a specific subgroup/dominant coalition), they are conceptually equated with teams where there is high agreement on WSC being moderately good, but not excellent. These scenarios are fundamentally distinct, and scholars would likely oversimplify any differences in types of WSC. Moreover, levels of consensus can also change over time and/or as a result of other factors (e.g. managers doing a good job in improving WSC in their team). New theoretical and methodological developments (Lang et al., 2018, 2021) provide a promising avenue to operationalize the level of consensus as a core theoretical variable while studying it in relation to time (emergence). Such approach allows to determine the turning point at which we observe dominant coalitions or faultlines within groups.
GQ 2. Does the Meaning of Agreement About a Group-Level Variable Relate to (a) the Hypothesized Antecedents or (b) Effects of the Group-Level Variable?
This GQ focuses on whether hypothesized antecedents of a group-level variable can explain both the group level variable and the agreement on it. In Figure 1, this implies identifying variables that can explain not only variation along the horizontal axis, but also along the vertical axis (Loignon et al., 2019). Scholars can thus examine for a wide range of concepts whether different situations in Figure 1 have different causes (Colquitt et al., 2002; Lindell & Brandt, 2000; Willems, 2016b).
Various methods for testing this in a multilevel, multivariate analysis are available, allowing researchers to predict the mean values of a dependent variable and its within-group variance. Referring back to our example, this would entail antecedents like team leadership styles, expected organizational change, perceived workload or job security (Hu & Randel, 2014; Parzefall & Kuppelwieser, 2012). In the context of strategic priorities (Kellermanns et al., 2011), for instance, antecedents like demographic and ideologic diversity (Meyfroodt et al., 2019), middle-level managers involvement (Wooldridge & Floyd, 1990), different types of conflict (Amason, 1996) have proven to explain shared knowledge in a (top management) team, as well as the extent to which individual opinions deviate from that.
GQ 3: Does the Meaning of Agreement About a Group-Level Variable Relate to the Practical Implications Related to the Group-Level Variable?
Recommendations for practice can differ significantly depending on the level of agreement on the focal concepts in a study. Furthermore, incorrect assumptions about agreement levels can lead to recommendations having unintended or even counterproductive effects. Referring again to the WSC example, a manager observing moderate WSC in the team, might contemplate improvement strategies. However, if there is a false assumption of high agreement on moderate WSC, actions might not be perceived as appropriate by anyone in the team: High-scorers might see them as redundant or not ambitious enough, while low-scorers might deem them far-fetched and unrealistic. This situation could escalate to exclusion or next-level bullying during team-building events organized by a dominant coalition. In contrast, management actions related to inclusive leadership or conflict resolution may be more appropriate (Henle et al., 2023; Maltarich et al., 2018).
Therefore, the quality and relevance of scholars’ recommendations from their research may depend on the level of actual group agreement on the focal concepts of their studies. Hence, when formulating practical recommendations related to group-level concepts, managers and researchers should consider whether agreement is a condition, a catalyst, or even a moderator influencing the likelihood of management recommendations being effective (Willems et al., 2012). Consequently, ascribing substantive significance to (the meaning of) agreement can enhance both theoretical understanding of group and organizational dynamics, as well as the practical relevance of group and organizational research.
Implications for Multilevel Group and Organization Studies
Figure 2 summarizes our considerations of the three GQs in a decision tree. While we are aware that many more relevant questions can be asked, and more options to choose from are likely possible, we hope it provides additional guidance and inspiration for developing and conducting concrete studies. For specific research projects, scholars should verify whether excluding data due to low group-level agreement on particular group-level concepts reduces the relevance of findings and/or excludes cases requiring special attention in their study’s context. Alternatively, researchers can include metrics on agreement in their analysis, interpreting them within a two-dimensional logic according to the axes in Figure 1. For example, antecedents can explain variation between cases along both the horizontal and vertical axes. Alternatively, agreement, when combined with aggregate mean values per group, can be incorporated into polynomial regression analyses aimed at explaining other variables’ variance (e.g., team efficiency, performance, and team member job satisfaction). The main considerations from our three guiding questions (GQs).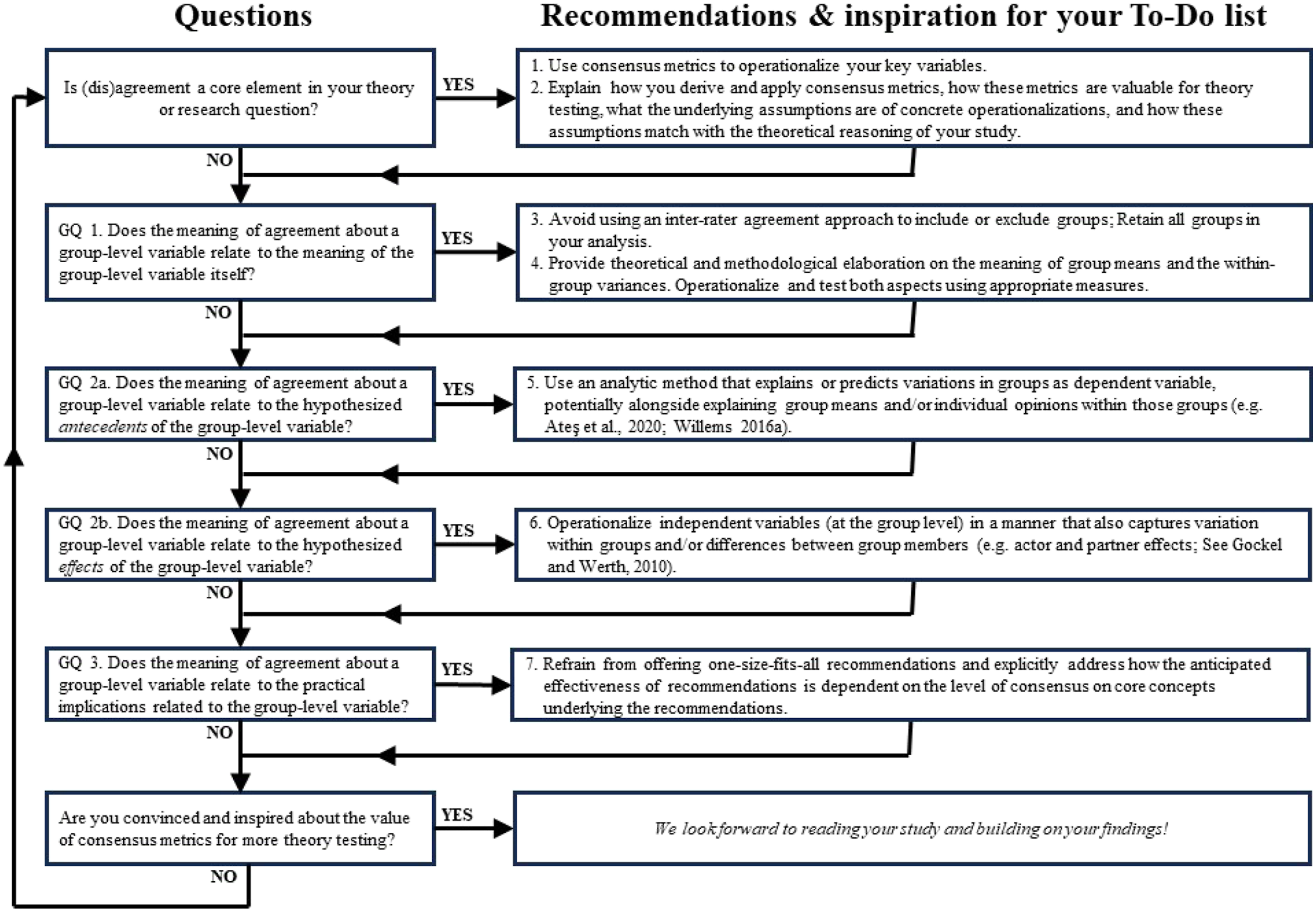
Identifying and Overcoming Barriers for the Research Community
Rather than relegating consensus and agreement metrics to methodological conditions, they could and should move towards testing ‘centerpiece’ research questions. We started this GOMusing from the observation that some studies have successfully attempted this, and numerous relevant metrics exist or could be readily adapted to operationalize consensus for theory testing. For example, seminal work by Gockel and Werth (2010), Lindell and Brandt (2000), Kellermanns et al. (2005), and Lang et al. (2018, 2021) can be further elaborated to provide recommendations on combining aggregate mean measures with agreement measures and test relationships between aggregate and agreement measures of group-level concepts. Moreover, the work of Tarakci et al. (2014) is relevant for further theorizing through case-by-case evaluations and accessible visualizations of consensus.
However, although we believe there are still substantial opportunities for the use of consensus metrics for theory, several barriers may impede researchers from progressing in this direction. There are the usual suspects like the necessity of having large and longitudinal data sets, while ensuring that residuals follow a normal distribution when opting for a consensus emergence model approach (Lang et al., 2018), or the fact that small-group data (i.e., fewer than five individuals per group) is often deemed problematic for hierarchical linear modelling approaches (Maas & Hox, 2005; Moritz & Watson, 1998). However, through this GOMusing, we aim to mitigate any lack of interest, should it be a substantial barrier. We hope to inspire other scholars to explore novel approaches and operationalize consensus in different ways. Also editors and reviewers could exhibit greater openness and willingness to engage with manuscripts using metrics in non-traditional ways, diverging from the standard and traditional heuristics for specific metrics, as discussed in “Goal 2: Cause Readers to Re-think Their Old (and Often Outdated) Assumptions or Opinions” in Cruz et al. (2022, p. 893).
Evidently, this would also necessitate authors to dedicate substantial efforts to clearly elucidate in their contributions: (1) the precise application or derivation of consensus metrics, (2) the value of these metrics for theory testing, and (3) the underlying assumptions of concrete operationalizations and their alignment with the theoretical framework of their study. Additionally, this process would likely benefit from more methodological contributions, coupled with user-friendly software and methodological protocols, to facilitate the straightforward derivation of consensus metrics that can be integrated into other analyses for theory testing.
In Sum
This is a GOMusing after all. Therefore, we hope that some readers disagree to agree, while others agree to disagree. Probably, some might even agree to agree. All this (lack of) consensus can only benefit a good scientific discussion. That is our aim at this point, and … would in itself proof our point: Consensus deserves more theoretical attention (insert a mic drop here).
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Author Biographies