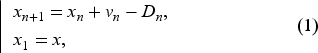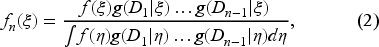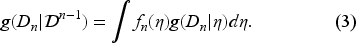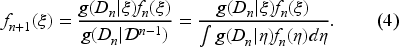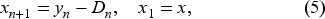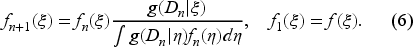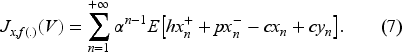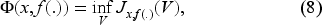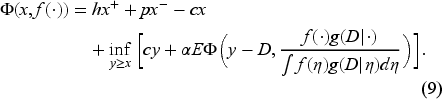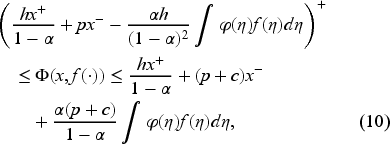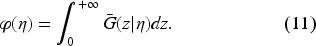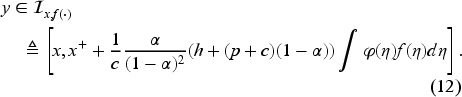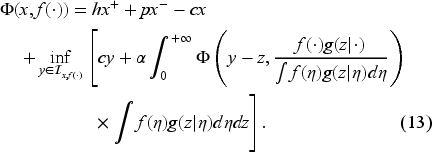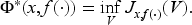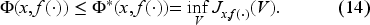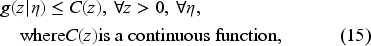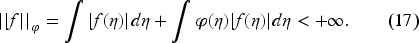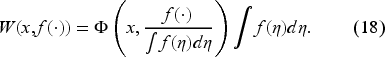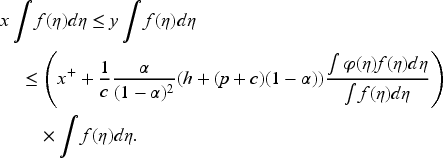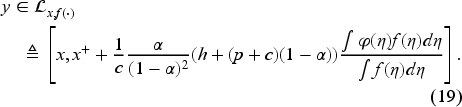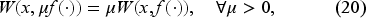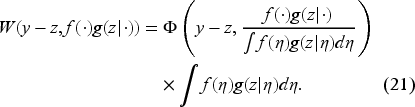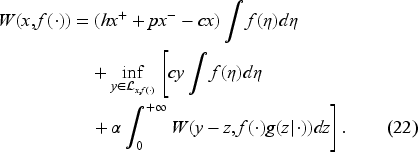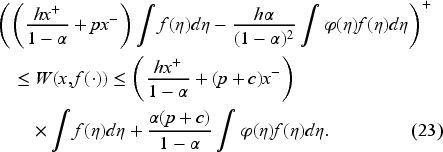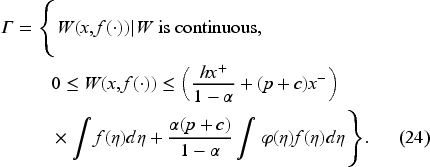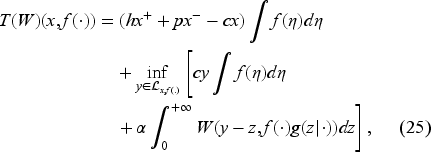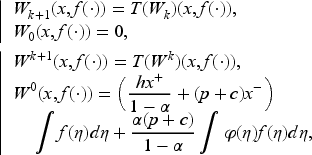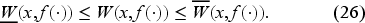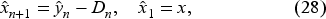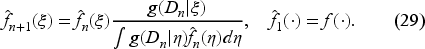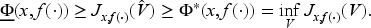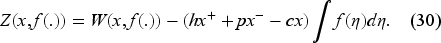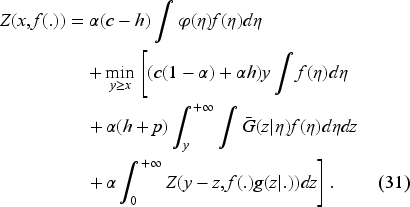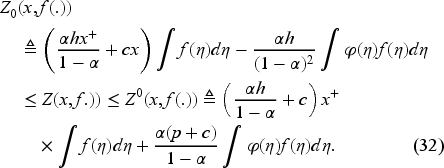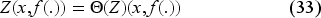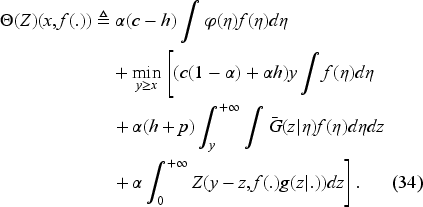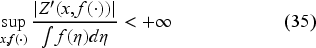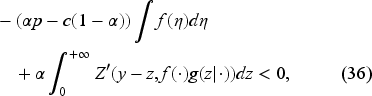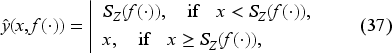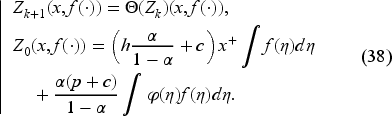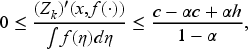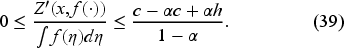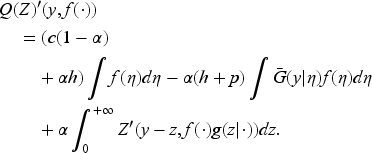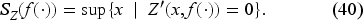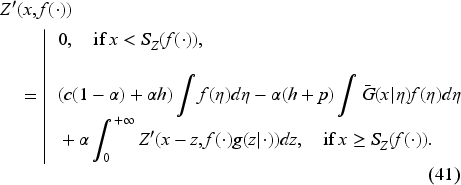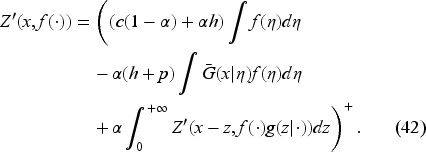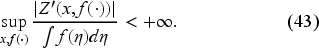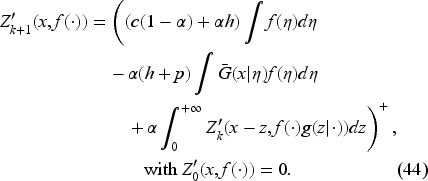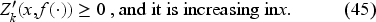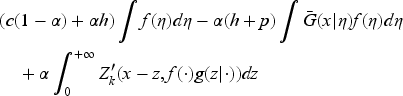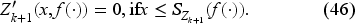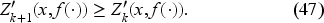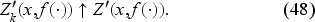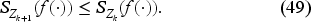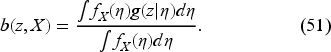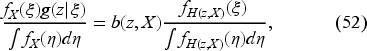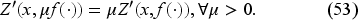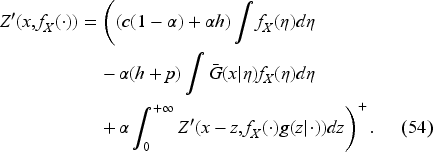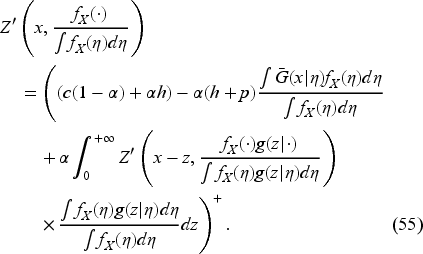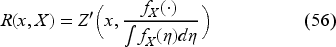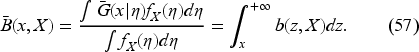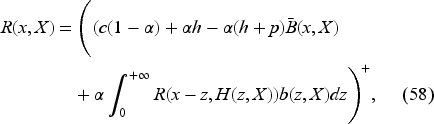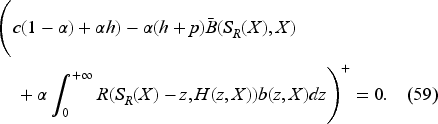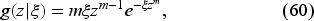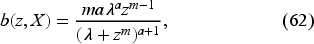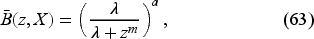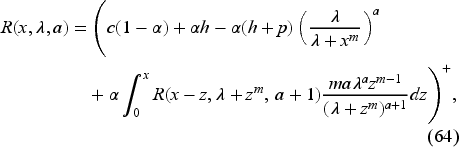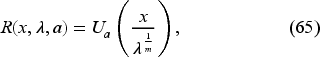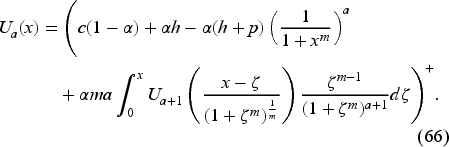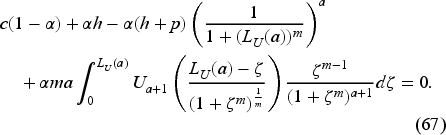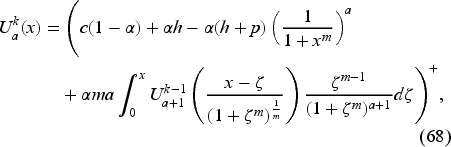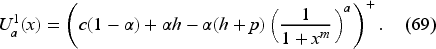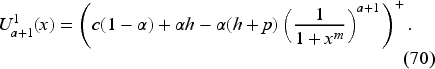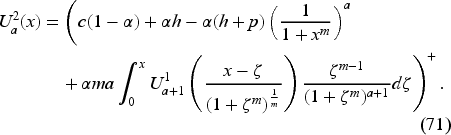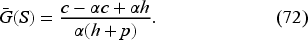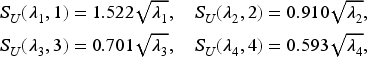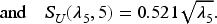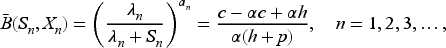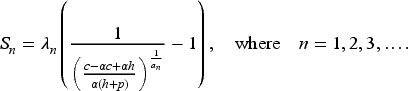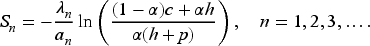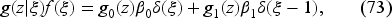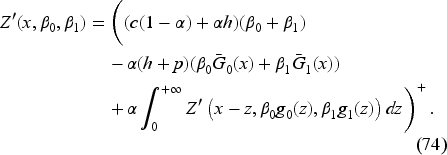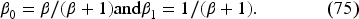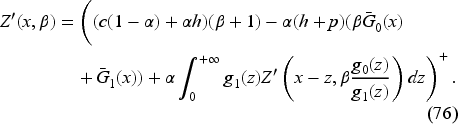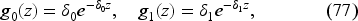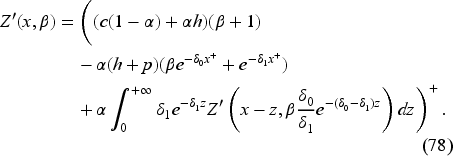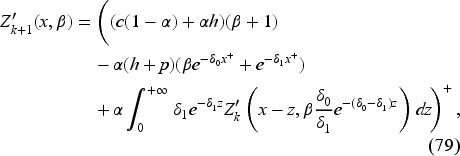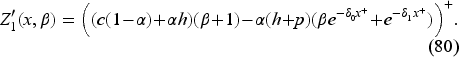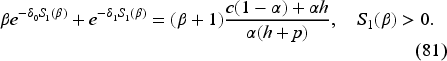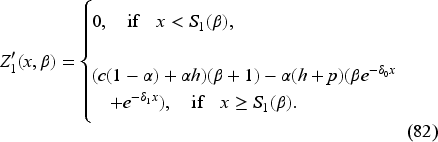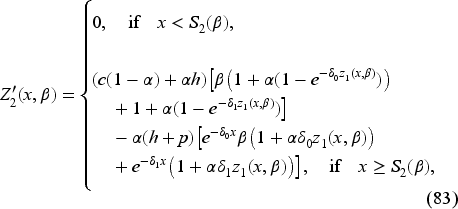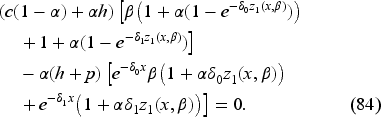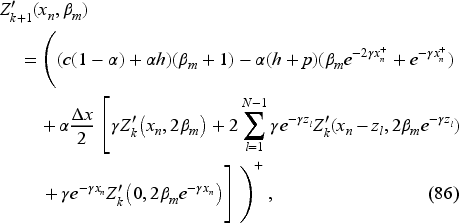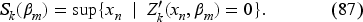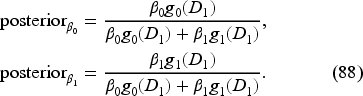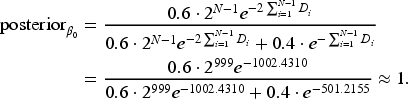This article advances the literature on the optimality of the base-stock policy for a general demand distribution and a general prior belief, which we update as we observe realized demands, assumed to be continuous, independent and identically distributed, random variables. The value function depends on the belief, so the functional Bellman equation is infinite-dimensional. Significantly, in contrast with traditional approaches, we derive a functional equation for the derivative of the value function with respect to the inventory level, which provides a direct approach to computing the optimal base-stock policy. In two well-known cases, we characterize how the base-stock level depends on the belief, and we implement the approach to compute the optimal base-stock level. In the first case of conjugate probabilities, the infinite-dimensional state reduces to a finite-dimensional sufficient statistic. That allows us to solve two numerical examples of exponential and Weibull demands. Moreover, for the exponential demand example, we compare the optimal cost with the costs achieved by two myopic policies with three guesses of the initial belief. We find that the optimal policy improves upon the first myopic policy by 12.6%, 13.0%, and 9.2%, and upon the second myopic policy by 28.7%, 26.9%, and 27.7%. The second case considers the demand to come from one of two possible distributions, but we do not know which. Here, we derive a functional equation in one hyperparameter expressing the ratio of the weights assigned to the two distributions. We then develop an approximation scheme to solve it, show that it converges, and implement it numerically to obtain the optimal base-stock levels over time.
We consider a discrete-time infinite-horizon inventory problem with demand depending on an unknown parameter and allowing for backlogging of unmet demands, which makes the realized demands fully observed (Section 3). A Bayesian framework is often used to study such problems when intuition and previous experience supply a prior parameter distribution. Bayes’ rule provides a way to incorporate new information (observed demands in our case) into the decision model as it becomes available. As far back as 1959, Herbert E. Scarf studied this problem in the case of exponential demand and showed that a base-stock policy is optimal with the base-stock level depending on a single sufficient statistic—the mean of past demand observations. Scarf (1959) first uses dynamic programming to study the finite-horizon version of the problem and then treats the infinite-horizon version using an asymptotic analysis. He mentions that the base-stock functions are difficult to obtain analytically, so he focuses on their properties and asymptotic expansion under some regularity conditions.
Since inventory managers do not fully know the demand distribution in many practical situations and the problem is exciting and theoretically challenging, many well-known authors have built upon the work of Scarf (1959, 1960) in several notable demand cases. Early ones include Azoury (1985), Iglehart (1964), Karlin (1960), and Lovejoy (1990). However, they studied only finite-horizon problems, not the stationary infinite-horizon problems we study. We review the more recent relevant literature in Section 2 and tangentially related literature in EC.1 (Section EC.1 in the E-Companion). We make several contributions to the literature.
1.1. We advance the extant literature by assuming a general demand distribution depending on an unknown parameter and a general initial belief about the unknown parameter. Then, the state equation evolves in the infinite-dimensional state space of the current inventory and belief density, which gets updated as the demand history unfolds. We show rigorously that the optimal ordering policy is a base-stock policy with the base-stock level dependent on the current infinite-dimensional belief density of the unknown parameter. In contrast, this result has been rigorously established only for finite-horizon problems in particular demand cases in the literature.
1.2. We consider an infinite-horizon setting, which is quite helpful in practice as it dispenses the time argument when accounting for future periods and thus brings the advantage of a single period setting. But then, we must solve a functional Bellman equation instead of considering a sequence of functions indexed by time. The study of the functional equation is direct, without first solving a finite horizon problem and then going to the limit.
Consequently, our subsequent analysis represents significant methodological contributions that are more generally applicable. The Bellman equation for our problem is a functional equation in an infinite-dimensional space. To facilitate its study, we enlarge the domain of belief functions to positive integrable functions, called unnormalized probabilities, which are not necessarily probability densities. This procedure results in an equivalent unnormalized Bellman equation, and its state is a finite-dimensional inventory and an unnormalized infinitely dimensional belief regarding the parameter. As a result, the unnormalized Bellman equation becomes more straightforward to analyze.
Zakai (1969) introduced the concept of unnormalized probability in the nonlinear filtering theory. It was first applied to partially observed inventory problems by Bensoussan et al. (2007) to establish the existence and uniqueness of the solution of the Bellman equation. While this methodology is efficient for the value function in terms of establishing the existence and uniqueness of the solution of the Bellman equation and was later used by Bensoussan et al. (2008a, 2008b, 2009) and Bensoussan and Guo (2015) for that purpose, it does not easily give the optimal feedback policies one looks for in stochastic control problems.
1.3. Even though our analysis of the Bellman equation has similarities with the above works in which the state is the infinite-dimensional belief, there is an essential difference in the sense that our state is mixed, consisting of the finite-dimensional inventory and the exogenous infinite-dimensional belief. Because we allow backlogging, we can observe realized demands, so the belief evolution does not depend on inventory observations. However, these enable us to obtain the optimal feedback policy, which is a base-stock policy with the base-stock level depending on the current belief.
1.4. Since the Bellman equation involves an inf operation to obtain the optimal policy, we must differentiate the unnormalized value function with respect to inventory. Then, why not derive a functional equation for the requisite derivative rather than obtain the value function and take its derivative? If we can, the advantage would be that we can work on a space of bounded functionals on a functional space and rely on a contraction mapping theorem to obtain the derivative directly as the fixed point of an equation (namely, (42) in Subsection 6.3) by an iterative procedure. Once we have this derivative, we can obtain the base-stock level as a function of the belief specified in (40) in Subsection 6.3. Also, while solving for the value function is no longer necessary to obtain the optimal policy, we can compute it if needed. This innovative and constructive approach to obtaining the base-stock level has beneficial monotonicity properties specified in (47) and (49) in Subsection 6.3. These properties facilitate the development of an iterative procedure, which we write for the general case in EC.6.4 (Subsection EC.6.4 in the E-Companion). The procedure yields a monotonic decreasing sequence of nonnegative threshold values converging to the belief-dependent base-stock level. As we get a new demand observation each period, we update the belief and use the procedure offline to obtain the base-stock level for the next period.
Scarf (1959) mentioned the difficulty of obtaining base-stock functions analytically for the problems we consider. Lovejoy (1990) stated that these problems are more complicated to solve than the ones with known demand distributions and will not yield simple operational policies. By simple operational policies, he meant policies based on the critical fractile. Since the optimal policies for the problems are base-stock policies, we interpret that to mean that the optimal base-stock levels are challenging to obtain. No wonder the literature provides no computational procedures for computing optimal base-stock levels, even if we limit ourselves to parameterized distributions! The main difficulty is that we cannot solve the Bellman equations to obtain the value functions analytically, making it extremely difficult to take their derivatives as the next step for obtaining the optimal base-stock levels.
Thus, coming up with a contraction mapping for the derivative of the value function, which enables us to obtain the base-stock level for the current belief directly, is very significant. Moreover, the fact that we can obtain a self-contained equation for the derivative of the value function by differentiating the Bellman equation is peculiar to Bellman equations and not well known. We take advantage of it since, in general, there is no reason why differentiating a functional equation would yield a self-contained equation for its derivative. Our approach finesses that for the first time, by computing the derivative of the value function directly as a fixed point of a contraction mapping. We apply our approach to a few particular cases as described below.
1.5. We treat two particular cases when the belief function depends on some hyperparameters. Then, the underlying infinite-dimensional problems become finite-dimensional ones, the dimension being the number of hyperparameters. A popular choice of the belief density is to choose the conjugate-prior for the demand density. We can then express the belief in terms of its hyperparameters that can be updated based on the observed demands, and thus, the base-stock level becomes a function of this sufficient statistic. So, our first particular case is that of well-known Weibull demand whose scale parameter is unknown and whose conjugate-prior is the family of Gamma densities characterized by two hyperparameters. We represent the base-stock level in terms of these two hyperparameters and obtain them numerically. We apply our approach to two particular examples of Weibull demand. For each example, we create demands for 1,000 periods according to an assumed true distribution, start with an initial belief about the hyperparameters, update them using simulated demands following the true demand distribution, obtain the sequence of the optimal base-stock levels over the periods in terms of the updated hyperparameters, and see its march toward the base-stock level, which turns out, as it should, to be the optimal level in the corresponding infinite-horizon problem with the true demand distribution known with certainty. In the remainder of the article, we shall refer to this level for brevity as the asymptotic base-stock level. To save space, we tabulate the optimal base-stock levels in the examples only for the first five periods.
Our second particular case is new to the related literature, and we can treat it since our model allows for general demands and general beliefs. This case considers the demand to come from one of two possible distributions, but we do not know which. Here, we can work with a single hyperparameter expressing the ratio of the weights assigned to the two distributions. We use our theory to write the functional equation satisfied by the derivative of the value function, develop an approximation scheme to solve for the derivative, and obtain the optimal base-stock level in each period. We also illustrate this scheme by numerically solving an example involving high or low exponential demand distributions and tabulating the results.
1.6. Lastly, we compare our method to two critical fractile approaches in the exponential demand case. Lovejoy (1990), recognizing the difficulty of solving the problems under consideration, analytically explores the critical fractile policies. He referred to them as myopic policies according to Sobel (1981), who defined a policy as myopic if it can be deduced from an optimum of a static problem. We implement the critical fractile policies on a rolling horizon basis, as by Avci et al. (2020) and Treharne and Sox (2002). We obtain the current updated demand distribution in each period and use the critical fractile formula to determine the base-stock level. In our first myopic policy, the updated distribution in our exponential demand case is the gamma distribution, given the hyperparameter values. For our second myopic policy, we can ask why not use a procedure that seeks updated distributions within the exponential class. We can accomplish this by beginning with an initial belief about the mean demand and updating it each time we observe a new demand. Fortunately, we already have the updated mean demand given by a ratio of the two hyperparameter values. Since the mean demand is a sufficient statistic for the exponential distribution, we can use it to obtain the critical fractile base-stock level. As expected, our comparison finds that the optimal policy achieves the best cost, albeit using slightly more computational time than the two myopic policies (see Subsection 7.3).
The plan of this article is as follows. Section 2 reviews the related literature. In Section 3, we formulate an inventory problem with the demand depending on a parameter, introduce a general belief density, and use Bayesian learning to update it based on the demands observed over time. In Section 4, we use dynamic programming to obtain the functional Bellman equation and bounds on its solution to ensure a unique solution. In Section 5, we unnormalize the Bellman equation, prove that the value function is the only solution to the Bellman equation, and show that an optimal state-dependent (feedback) policy exists. Section 6 derives the functional equation for the derivative of the value function, shows that the optimal policy is a base-stock policy where the base-stock level depends only on the current belief function, and develops an iterative procedure to obtain the base-stock level. In Section 7, we treat the particular case of conjugate probabilities with the belief modeled by the conjugate-prior of the demand distribution and characterize the base-stock-level’s dependence on the belief distribution’s hyperparameters. We apply the theory to two particular cases of the Weibull-gamma conjugates. For the exponential demand case, we also compute and compare the costs achieved by myopic and certainty-equivalent control policies against the optimal cost our method obtains. Section 8 considers the case when demand comes from two possible distributions without knowing which. We develop an approximation scheme to obtain the optimal base-stock level and show its convergence numerically. Section 9 concludes the article. An E-Companion contains the proofs of results, derivation of some of the equations, and a review of the additional literature related but only tangentially to the specific topic of the base-stock policy.
Literature Review
The earliest papers on stochastic dynamic inventory management with known demand distributions establish the structure of the optimal inventory policies, such as the base-stock and policies. We refer the reader to Porteus (2002) and Zipkin (2000) for an overview of this classical literature.
In practice, however, we do not fully know the demand distribution. Thus, how one should make inventory decisions forms a significant line of inquiry in this case. Two main approaches exist in the literature: the Bayesian approach, whereby, given a prior demand distribution, unknown parameters of the demand distribution are dynamically learned from observed demands, and the nonparametric approach, in which the demand distribution does not belong to a specific parametric family and the decision maker has access to samples of demand data from an unknown distribution. Our setting falls under the Bayesian category, and we will mainly review this literature here, briefly mentioning other tangentially related literature.
Inventory problems with Bayesian learning of an unknown demand trace their roots back to seminal works such as those by Dvoretzky et al. (1952), Scarf (1959), and Scarf (1960). Scarf’s contributions, particularly his pioneering Bayesian approach demonstrated by Scarf (1959), remain foundational and highly relevant to our study. Scarf (1959) establishes the optimality of the base-stock policy within demand learning scenarios, assuming a prior distribution conjugate to the unknown demand distribution. He treats an infinite-horizon inventory problem. He assumes an exponential demand and derives the base-stock policy based on a single sufficient statistic: the mean of the past demand observations.
Building upon Scarf’s framework, subsequent studies extend the analysis to broader families of demand densities. Iglehart (1964) and Karlin (1960) expand Scarf’s results to encompass a range of densities with monotone likelihood ratio properties, ensuring the nondecreasing nature of the base-stock level in terms of their respective sufficient statistics. Scarf (1960) addresses computational challenges by introducing tractable assumptions, such as letting demand follow a gamma distribution. This simplification facilitates determining optimal base-stock levels without recursive computations over multiple variables. Subsequent extensions by Azoury (1985) and Lovejoy (1990) further streamline the dynamic programming approach, culminating in myopic optimal policies in specific cases. Unlike ours, none of these papers provide a computational procedure to obtain the optimal policy.
Treharne and Sox (2002) consider a discrete-time finite-horizon inventory system with bounded discrete demands, full backlogging, deterministic replenishment lead time, and the total cost criterion. The demand distribution is conditional on the state of the world modeled by a finite-state Markov chain, as by Sethi and Cheng (1997) and Song and Zipkin (1996). These world states are not observed and estimated based on past demand data. They model the problem as a partially observed Markov decision process (POMDP), whose states are the inventory position and the belief about the state of the world. They show the optimal policy to be a belief-dependent base-stock policy. They compare the performance of some suboptimal policies against the optimal policy in a five-period problem as longer horizon problems take excessively long computational times. In particular, for the myopic policy, the average optimality gap was 5.19%, and the largest optimality gap was 44.84% on a test bed of 252 instances. Even so, the myopic policy dominates certainty equivalent control.
Avci et al. (2020) study the infinite-horizon version of the problem of Treharne and Sox (2002) with the average cost criterion. They allow unbounded demand, assume ergodicity, and use the standard vanishing discount method (see Beyer et al., 2010) to show the existence of an optimal average cost independent of the system’s initial state as well as the optimality of a belief-dependent base-stock policy. Their computations on a test bed of 108 instances revealed that the average cost of the myopic policy deviates by a few percent from the best lower bound on the optimal average cost obtained from their discretization see also (Lovejoy, 1991). The poor performance of the myopic policy reported by Treharne and Sox (2002) on a test bed of 252 instances prompted them to use the same test bed to find that the average optimality gap is only 0.41% and the largest optimality gap is 3.61%. They conclude that the myopic policy performs significantly better in the average cost problem than in the finite-horizon total cost problem.
Our problem setup differs from Avci et al. (2020) and Treharne and Sox (2002) since we consider an unknown, continuous demand distribution, no lead time, and the discounted cost criterion over an infinite horizon. More importantly, we can compute the optimal cost, against which we compare the costs achieved by the two myopic policies. In the exponential demand case, the percentage improvements by the optimal policy over the first myopic policy are 12.6%, 13.0%, and 9.2%, respectively, for three different initial belief guesses. The corresponding improvements of the optimal policy over the second myopic policy are 28.7%, 26.9%, and 27.7%.
Our problem can also be viewed as a POMDP on a general state space with non-compact decision sets considered by Feinberg et al. (2012, 2013), Feinberg and Kasyanov (2021) and Luque-Vasques and Hernández-Lerma (1995). However, in our case, although the state space is infinite-dimensional, we can take advantage of a particular structure that allows us to use the state space as the space of unnormalized probabilities and the topology of . Specifically, our state space is , allowing us to use standard techniques for finite-dimensional state spaces when working with the gradient of the value function. While our approach can cover POMDPs in general, it avoids using an abstract setting and allows a formulation with easily verifiable assumptions instead. We can then prove the existence and uniqueness of the solution of the resulting Bellman equation using an innovative method. Our objective in this article is not to contribute to the general POMDP theory but to enhance the literature on the optimality of the base-stock policy in situations where the demand distribution is not fully known, and Bayesian learning is used to update the beliefs, starting with a general prior belief.
Larson et al. (2001) adopt a non-parametric Bayesian approach to treat finite and infinite horizon problems in which a Dirichlet process on the space of distributions represents a firm’s prior information about the demand distribution. We note that this setting also makes the hyperparameter a probability measure. As the authors allow for a fixed ordering cost, they focus on showing the optimality of a history-dependent policy. Furthermore, they show that if these policies take a limit as demand information accumulates, they converge to the optimal policy for the underlying demand distribution. They point out the limitation of their approach in that it does not smooth beliefs, unlike in conjugate family settings, where typically observing a high outcome implies that other high outcomes are more likely.
Thus far, we have reviewed the relevant inventory papers that assume backlogging, making the demand observable. If there is no setup cost, the optimal policy is a base-stock policy. Next, we briefly review the literature on the Bayesian and nonparametric models with demand censoring, as it is not a setup that we are concerned with in this article. For a broader view of this literature, see (Chen and Mersereau, 2015). The case of censored demand is challenging to analyze because sales histories directly depend on past order quantity decisions. Simple policies like the base-stock and policies are no longer optimal. So, the focus is on studying the structural properties of optimal decisions. A significant result is “stock-more” (e.g., Bensoussan et al. 2009, Ding et al. 2002, Jain et al. 2015, Lu et al. 2008), implicitly explaining the exploration-exploitation trade-off. In a recent paper, (Chuang and Kim, 2023) explicitly characterize the “exploration boost” in terms of some basic statistical measures of uncertainty.
We conclude this review by noting that none of the mentioned papers on inventory models with partially observed demand provide a computational procedure for obtaining the optimal policy. The exception is Treharne and Sox (2002), who compute the optimal policy in a five-period problem with discrete Markov-modulated demands while stressing that longer horizon problems take excessively long computational times. In comparison, our computational procedure obtains optimal policies in many infinite-horizon problems with partially observed demands in reasonable amounts of time. Moreover, we find that the performance of the optimal policies is much better than the state-of-the-art suboptimal policies.
Inventory Model With Demand Learning
We study an infinite horizon inventory problem in which the inventory manager (IM) does not fully know the demand’s probability density function (PDF). We write this density as with , a parameter unknown to the IM. We allow backlogging so the IM can learn about by observing realized demands over time. We let denote the cumulative distribution function (CDF), and complementary CDF (CCDF), Since the information comes from observing demands, we introduce the filtration The order quantity in period is adapted to . At the beginning of period 1, the given inventory , the IM has no information except an initial belief about expressed by the PDF on From the inventory evolution equation,
we see that the inventory process is also adapted to .
The updated belief after observing the demands can be written as follows:
because the numerator gives the joint probability density of since the demands are independent given the parameter and the denominator is the joint probability density of the demands as they are no longer independent in the presence of the parameter. We use to obtain the conditional density of , given , as
The state of our dynamic system is a stochastic process adapted to with the state space where is the set of probability densities on We can now define our inventory control problem. We set the decision with where denotes the order quantity in period Let and represent the inventory and the backlog in period respectively. Let and denote the backlog cost per unit per period, inventory holding cost per unit per period, and unit ordering cost, respectively. Let be the discount factor. Then, the expected total cost is
We define the value function as follows:
where is the initial system state.
Dynamic Programming and Required Bounds
We use dynamic programming to write the functional Bellman equation for the value function
As the Bellman equation may have many solutions, we develop the conditions under which the value function becomes its unique solution. In Subsection 4.1, we obtain lower and upper bounds on the value function, allowing us, as in Section 5, to show that the solution of the Bellman equation is unique when restricted to these bounds and is, indeed, the value function. Furthermore, we can use these bounds also to obtain an upper bound on the order-up-to-level decision . Note that the initial inventory level is naturally a lower bound on . These decision bounds allow us to obtain a modified Bellman equation, which, together with an intermediate comparison result obtained in Subsection 4.2, help us prove the uniqueness of the Bellman equation solution and the existence of an optimal state-dependent policy in Section 5.
Bounds on Value Function and Decision
Lemma 1 below gives the bounds on the value function (derived in EC.3.1 in the E-Companion) sufficient to ensure it is the unique solution to the Bellman equation (9).
These bounds also provide an upper limit for the order-up-to-level decision . Furthermore, given that by definition, we establish the following admissibility interval for in EC.3.2 in the E-Companion:
We replace the domain in (9) with the interval (12) to obtain the modified Bellman equation
In Subsection 5.1, we transform (13) into its unnormalized counterpart (22) and the interval (12) into (19). This compact admissibility interval aids in determining the state-dependent policy. Specifically, the right-hand side in equation (22) is continuous in and thus achieves its minimum at in the compact admissibility interval. In Subsection 5.2, we show that the unique solution of (13) and (12) is the value function.
Comparison of Value Function With Solutions of Bellman Equation
We present a significant comparison result between any solution of (13), satisfying the bounds in (10), and the value function defined in (8). For clarity, we temporarily denote the value function as follows:
Any solution of the functional equation (13) honoring (10) holding satisfies
This result (proved in EC.4.1 in the E-Companion) will be required to establish a central result in the next section.
Uniqueness of Solution of Bellman Equation and Existence of Optimal Policy
We prove that the value function is the unique solution of the Bellman equation and that an optimal state-dependent policy exists. We make the following assumptions:
We provide their rationale at the end of Subsection 5.1. These assumptions will remain in force in this section and Section 6, and they are satisfied in the particular cases treated in Sections 7 and 8.
For any probability density on such that the value function is the unique functional such that (10) and (13) hold. Moreover, there exists a that attains the inf in (13).
For its proof, it is convenient to work with unnormalized probability, now a standard trick making the belief updating (13) linear and facilitating our study of the Bellman equation in Subsections 5.1 and 5.2.
Unnormalized Bellman Equation
Consider the space of functions on such that
This space is denoted as , a Banach space for the norm , as shown in EC.4.2 in the E-Companion. The subset of positive functions denoted by is closed.
We introduce the unnormalized Bellman equation by extending the domain of to unnormalized probabilities, which include positive integrable functions encompassing probability densities. Thus, a functional on and probability densities extends to a functional on via the formula
Note that and coincide when is a probability density.
From (12) and (18), it is evident that the decision satisfies
Thus, combining (13), (18), and (21), we obtain the unnormalized Bellman equation
Furthermore, utilizing Lemma 1, we can readily derive the following bounds on
Before proceeding to prove Theorem 1, it is worth noting that a solution of (22) and (23) satisfies (20). Also, (22) and (23) are equivalent to (13) and (10), respectively, and the optimal state-dependent policy, if it exists, remains identical for both Bellman equations. However, due to the simpler nature of (22) and the linearity in updating , we choose to work with (22) and (23). Finally, we provide the rationale for assumptions (15)-(16): the former ensures the well-definedness of , and the latter guarantees the integrability of in , allowing us to employ Lebesgue’s dominated convergence theorem.
Steps in Proof of Theorem 1
We base our proof on a monotonicity argument, a classical tool for variational inequalities, quasi-variational inequalities, and Bellman equations. Here, we list the five main steps in the proof and give the complete proof in EC.5 in the E-Companion.
Since must be positive, instead of requiring the sharper constraint on the left of (23), we only need to consider the set of functionals on such that
We define a monotone nonlinear operator on as
and show that the operator maps into itself.
For the existence of a solution to (22), note that it is a fixed-point equation. Then, the functional must satisfy . We define two monotone sequences:
and show that is lower semi-continuous, converging to a lower semi-continuous function , and is upper semi-continuous, converging to an upper semi-continuous function . Indeed, is the smallest solution, is the largest solution, and if is any solution of (22), then we necessarily have
For the uniqueness of the solution, we revert to functions , which are probability densities. We can transfer the results in to results in and thus obtain the minimum and the maximum solutions and of (13). Thanks to the feedback given by the selection theorem, we construct the processes , and by the iterations
We show that the minimum solution coincides with the value function by first setting and showing that
Since is the smallest solution, all solutions are larger than the value function. On the other hand, by Lemma 2, all solutions are smaller than the value function. Necessarily, the solution is unique and coincides with the value function.
Finally, the feedback allows us to construct an optimal control by using (27) to (29). The following section proves that this feedback is a base-stock policy.
Our proof diverges significantly from previous works on partially observable inventory control problems, such as Bensoussan et al. (2007, 2008a, 2008b, 2009) and Bensoussan and Guo (2015), despite some shared aspects, such as the utilization of unnormalized Bellman equations. Moreover, our value function has the inventory state and not just the probability density state, as in the value functions in the papers mentioned above. According to Bensoussan et al. (2007) and Bensoussan et al. (2009), the uniqueness of the solution is established through contraction mapping, although there are similarities in establishing the solution’s continuity. Meanwhile, Bensoussan et al. (2008a) employ induction arguments but omit monotonicity arguments. According to Bensoussan et al. (2008b), the uniqueness and continuity of the solution to dynamic programming equations are proved under certain conditions, allowing the use of Banach’s fixed-point theorem to establish the existence and uniqueness of the solution to the optimality equation directly, along with the value iteration algorithm. In contrast, Bensoussan and Guo (2015) also use the unnormalized Bellman equation and find that the optimal order-up-to level when stockout times are observable exceeds those when lost sales are observable.
Before proceeding to the next section, let us mention that obtained in Theorem 1 is continuous from the facts that is l.s.c., is u.s.c., and .
Optimality of Base-Stock Policy
When there is no unknown parameter, there is no learning, and the optimal feedback is a base-stock policy. When there is learning, the optimal policy is also a base-stock policy, with the base-stock level now depending on the current belief updated based on the realized past demands. Here, we obtain this result in a more general setting than in the literature.
Instead of Bellman equation (22), it is convenient to consider an equivalent problem by setting
Let us note that we do not need to impose the upper bound on to minimize the right-hand side of (30), as it will be automatically satisfied at a minimum point. We can write the Bellman equation for as follows:
The details of the transformation from (22) to (31) are in EC.6.1 in the E-Companion. The advantage of this formulation is that appears only in the constraint on . We know from Theorem 1 that this equation has a unique continuous solution in the following interval:
The solution of (31) is a fixed point of the operator
with
It is a nonlinear operator on functionals defined on and satisfying the bounds in (32).
Preserving Convexity
The following property (proved in EC.6.2 in the E-Companion) aids us in establishing the convexity required to demonstrate the optimality of a base-stock policy.
Suppose the function is continuously differentiable, increasing, and convex in . Assume that
and
where is the derivative of with respect to . Then, and have the same properties.
Assumption (35) ensures that the norm of the specified derivative of the operator is well-defined. Equation (36) is required to demonstrate that the function, dependent on the order-up-to-level decision , has a root.
Base-Stock Policy
We now show the optimal policy as a base-stock policy.
is continuously differentiable, increasing, and convex in . The optimal policy is
where is the base-stock level depending only on the current belief .
We consider the increasing sequence
Note that the function is continuously differentiable in except at and it satisfies (35) and (36). Note also that appears inside an integral in (34), and is constant for Thus, by way of (38), the operator transforms into a continuously differentiable function. Then, by the stability properties of Proposition 1, we get sequentially the same properties for and consequently for the limit . Also, we can check sequentially that
which carries to the limit
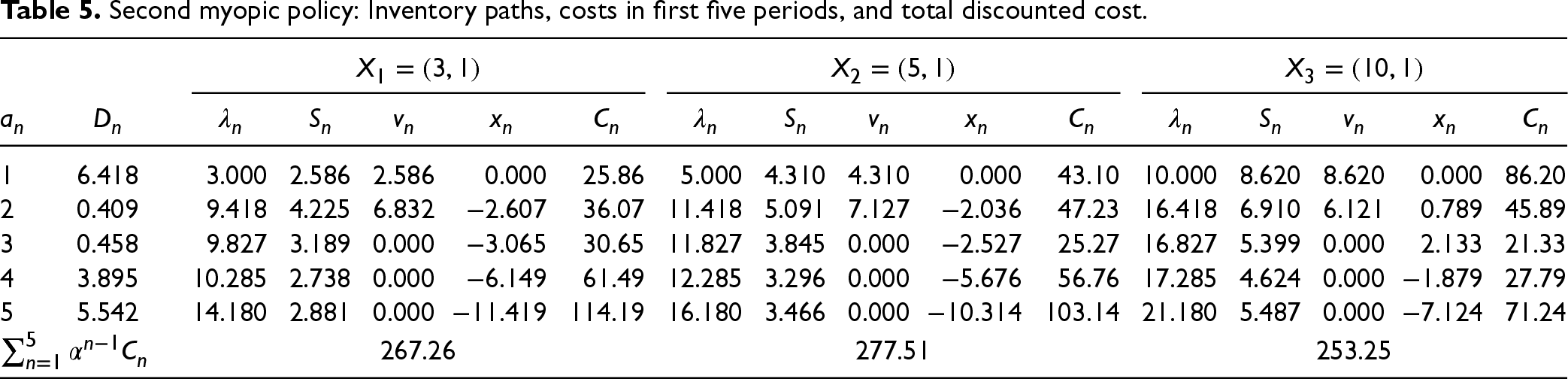
The optimal feedback is then the base-stock policy (37) with the base-stock level as the unique solution of where is the derivative of expression inside the min operation on the right-hand side in (34) with respect to . In EC.6.2 in the E-Companion, we show it to be given by the following equation:
Obtaining the Base-Stock Level
We define
Thus, to obtain the base-stock level, we do not need to obtain if we could find directly. Indeed, we have
Since the second expression is positive, satisfies
The following property (proved in EC.6.3 in the E-Companion) demonstrates that (42) has a unique solution . Furthermore, we can recover the value function if needed.
Equation (42) has one and only one solution in the functional space of continuous functions on with the norm
We introduce an algorithm for computing the base-stock level and obtain interesting properties of non-negativity, monotonicity, and convergence of the iterative sequence.
Monotonicity Properties
We consider the iterative sequence
By recurrence, we see that
Consequently,
is increasing in Since it reduces to at and is larger than at , there exists a unique such that
Also, By recurrence again, we have
Since (42) is a fixed point of a contraction, we can assert that
From the definition of we immediately get a valuable monotonicity property regarding the base-stock level for any given belief, that is,
Thus,
These monotonicity properties allow us to develop an iterative procedure to compute the optimal belief-dependent base-stock level for any given belief as the limit of a decreasing sequence of nonnegative numbers. We provide this procedure in EC.6.4 in the E-Companion. This procedure yields the stationary function , which we can use offline to obtain the optimal base-stock level in period once we have the updated belief in that period. Knowing the inventory and the base-stock level in that period, we can make the optimal ordering decision based on the order-up-to level according to (37). Then, we observe the demand in that period, allowing us to update the belief to and move to the next period , obtain the optimal base-stock level , and so on.
For computations in the case of a general infinite-dimensional belief, there will be a need to discretize the belief density to obtain this function for offline use. In Sections 7 and 8, we limit ourselves to parametric demand and belief densities so that the belief density is finite-dimensional, and we can obtain the function without discretization.
Learning With Conjugate Probabilities
Here, we focus on the case of conjugate probabilities discussed in much of the related literature, including Azoury (1985), Iglehart (1964), Scarf (1959), and Scarf (1960). They study only finite-horizon problems and analyze them via a sequence of functions. By contrast, we study stationary infinite-horizon problems and do not need their setup as we treat them as particular cases of our general theory.
In Subsection 7.1, we specialize the belief function introduced in our general approach to depend on a vector of hyperparameters, writing it as . We then show that the general problem gives the hyperparameter vector as a sufficient statistic and provides an equation to be satisfied by the base-stock level expressed as a function of . Since we settle the existence and uniqueness issues in a general setting, our results transfer the settlement of these issues to the cases treated in this section.
In Subsection 7.2, we consider particular cases of Weibull demand whose scale parameter is unknown. So, we choose our belief function from its conjugate-prior family of gamma densities, characterized by two hyperparameters. We obtain the optimal base-stock level as a function of the two gamma hyperparameters; see EC.7.1 in the E-Companion for details. We also present two numerical examples by generating demands for five periods according to supposedly true exponential and Weibull densities in Subsections 7.2.1 and 7.2.2, respectively. We obtain the sequence of optimal base-stock levels learned from these demands, order accordingly, and evolve the inventory dynamics. We also generate demands for one thousand periods and see the sequence of base-stock levels tending to converge to the asymptotic base-stock level in each example.
In Subsection 7.3, we compute base-stock levels using two myopic policies for the exponential example treated in Subsection 7.2.1. We then highlight the extent of their suboptimality by comparing their costs to the optimal cost. Due to space limitations, we omit this comparison for the examples in Subsection 7.2.2 and Section 8.
We define the demand’s probability density given as follows:
We assume
which defines a coupling between the family and the probability density . Here, is a vector of the same size as . These are the conjugate probabilities.
Sufficient Statistic
We want to study equation (42) for conjugate probabilities and see that the infinite-dimensional problem reduces to a problem of the dimension equaling the size of the vector of hyperparameters. We first note that has the same property as in (20), namely,
Using the property (53), we can write the following equation:
Then we let
and the CCDF
Importantly, because of (51) and (52), (55) becomes
a finite-dimensional functional equation. It has one, and only one, solution on the set of bounded functions of and . We have for , and there exists a single such that for . Moreover, can be obtained as the unique solution of
Weibull Demand and Computation of Optimal Base-Stock Level
As a specific example, we consider the demand distributed according to the Weibull probability density
as by Azoury (1985) and Bensoussan (2011), where is the shape parameter, is the scale parameter, and . As typical in the related literature, we assume that is known while is unknown. The mean demand is , where is the gamma function. When , (60) reduces to the exponential density with the mean demand .
For our belief on , we consider the unnormalized gamma family
with the hyperparameter , where and are known as the rate and shape hyperparameters, respectively, in this shape-rate parametrization of the unnormalized gamma density. Moreover, , where stands for the gamma function defined as The standard version of the gamma density is . In our context, denotes the current period, denotes the cumulative th power of the observed demands, so is the observed mean of the th power of the observed demands.
Substituting (60) and the conditional demand density
as calculated in EC.7.1 in the E-Companion into (52), we see that (52) is satisfied with , that is, .
We have for . We have thus reduced the dimensionality of the problem from to just and have obtained a simpler recursion (66), as is common in related literature. From (59), we see that the base-stock level , where is the solution of
The inventory manager can use equations (66) and (67) to compute in advance a surrogate base-stock level for each period that depends only on the shape hyperparameter in that period and not on the scale (size) of the demand. Then, he can determine the optimal base-stock level to use in each period by scaling the surrogate by the current best estimate of the demand, given by the scale hyperparameter consisting of the sum of the initial belief of the demand and the observed past demands. Each demand observation is raised to the power of to appropriately account for the characteristics of the Weibull distribution, which can exhibit skewness or heavy-tailed behavior, as governed by its shape parameter .
We approximate the solution of equation (66) by the recursive scheme
for with the initial guess for all .
Here, we illustrate the iterative procedure to compute for and only and provide a detailed description of the procedure in EC.7.2 in the E-Companion. Then, the solution is given by .
Set Then,
For , the computation of requires knowing appearing inside the integral in (68). We obtain by replacing with in (69). That gives
We can then obtain
We use the iterative procedure to solve two numerical examples given by the parameter values , , , and and .
Case ,
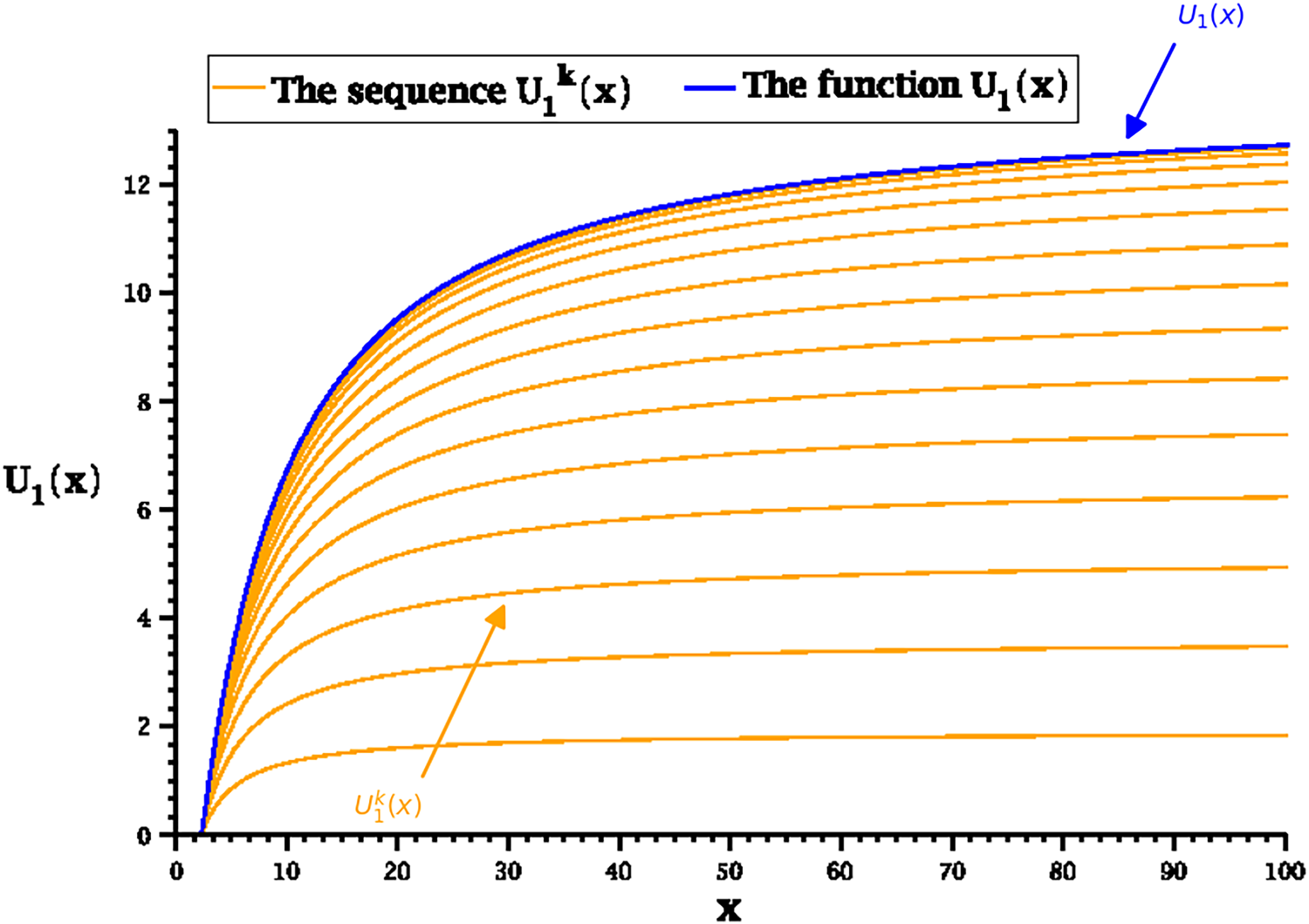
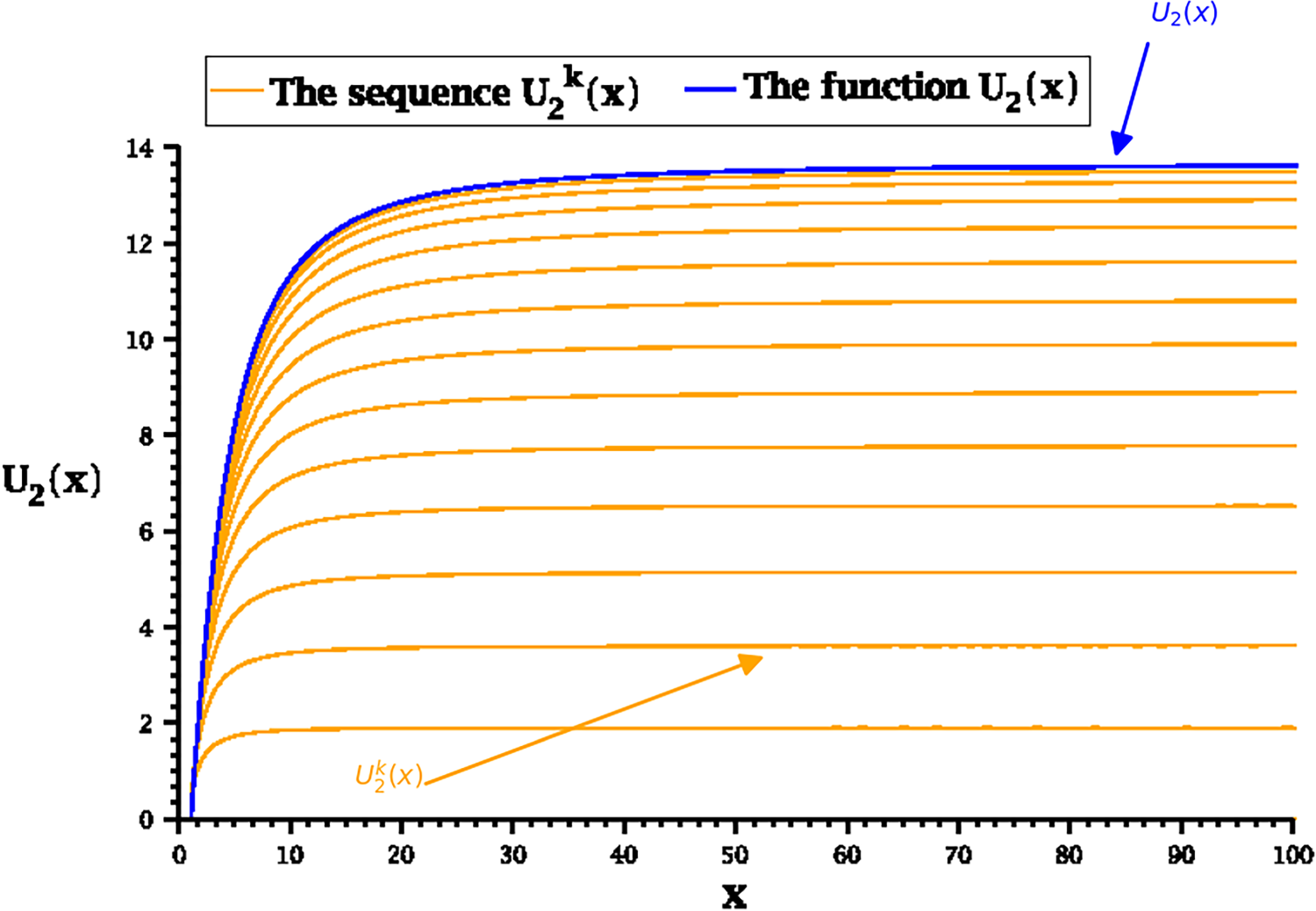
We compute and but display the results for only and in Figures 1 and 2, respectively.
Convergence to the function .
Convergence to the function .
We use (67) to find and , and formula yields the base-stock levels and
To illustrate how to implement our model, let us suppose the exponential demand (i.e., ) with . Thus, the mean demand is 4. We recall the base-stock level provided in EC.2 in the E-Companion as the unique solution of
Then, the base-stock level using (72) is . However, the IM does not know this value and makes an initial guess of the hyperparameter . We will illustrate with three different guesses , , and , where represents the initial mean of as 3, 5, and 10, respectively.
We use the predefined Matlab function to generate a sample path of demands from the exponential distribution with . These are and
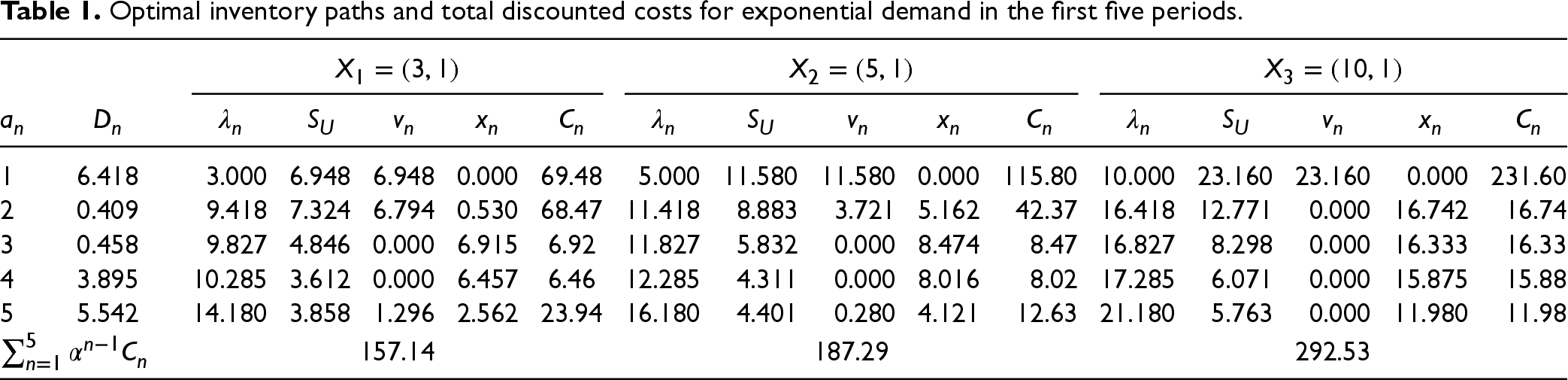
With our first guess of , we evolve the inventory using (1), starting with an initial . The base-stock level , so we order the quantity . This results in . The cost for period 1 is calculated as In period 2, the updated parameters are . The base-stock level is . We then order , leading to and Following this process, we compute the inventory levels and costs for the first five periods. Similarly, we complete the dynamics corresponding to the initial guesses and . We summarize the results, including the total discounted costs, in Table 1.
Optimal inventory paths and total discounted costs for exponential demand in the first five periods.
1
6.418
3.000
6.948
6.948
0.000
69.48
5.000
11.580
11.580
0.000
115.80
10.000
23.160
23.160
0.000
231.60
2
0.409
9.418
7.324
6.794
0.530
68.47
11.418
8.883
3.721
5.162
42.37
16.418
12.771
0.000
16.742
16.74
3
0.458
9.827
4.846
0.000
6.915
6.92
11.827
5.832
0.000
8.474
8.47
16.827
8.298
0.000
16.333
16.33
4
3.895
10.285
3.612
0.000
6.457
6.46
12.285
4.311
0.000
8.016
8.02
17.285
6.071
0.000
15.875
15.88
5
5.542
14.180
3.858
1.296
2.562
23.94
16.180
4.401
0.280
4.121
12.63
21.180
5.763
0.000
11.980
11.98
157.14
187.29
292.53
The -column shows the base-stock levels over time. To see its march toward its asymptotic value of 3.448, we repeat the procedure for N 1,000 periods and compute
For our three initial guesses , 5, and 10, we obtain , 2880.7, and 2918.3, respectively. The corresponding base-stock levels are , 3.457, and 3.502, respectively. Note that these base-stock levels are close to the asymptotic base-stock level of 3.448. The corresponding computation times (in seconds) for the three initial guesses are 5.12, 5.67, and 5.81, respectively.
Case
We now assume the true demand follows a Weibull distribution with shape parameter and scale parameter . Then the mean demand is , and the asymptotic base-stock level, using (72), is With the same initial guess and initial inventory , the base-stock levels for the first five periods are as follows:
Using the standard inverse transform sampling method, we generate a sample path of random demands from the Weibull distribution with . Like Table 1, we tabulate the results for this in Table 2 for the three initial guesses: , , and .
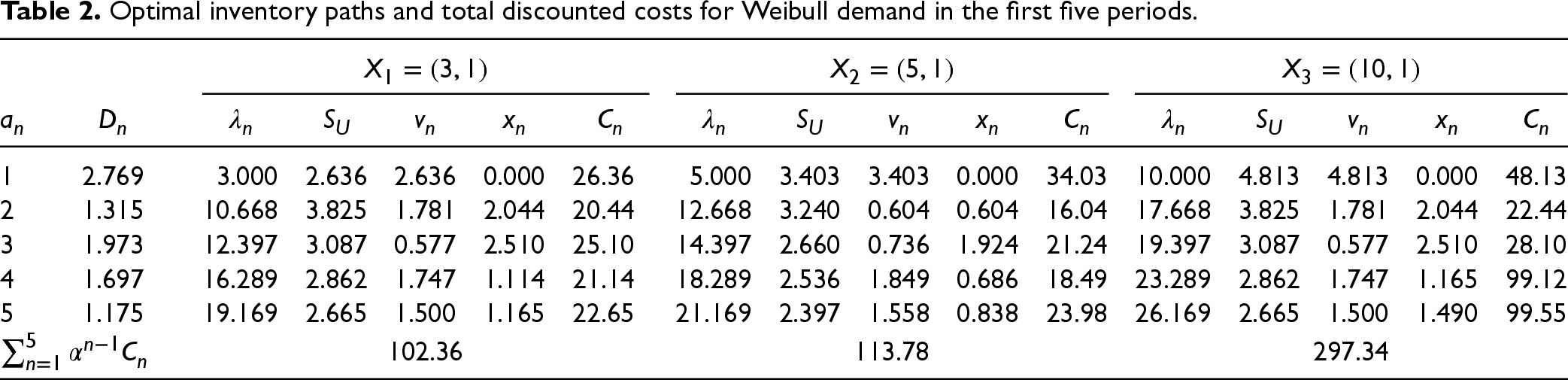
Optimal inventory paths and total discounted costs for Weibull demand in the first five periods.
1
2.769
3.000
2.636
2.636
0.000
26.36
5.000
3.403
3.403
0.000
34.03
10.000
4.813
4.813
0.000
48.13
2
1.315
10.668
3.825
1.781
2.044
20.44
12.668
3.240
0.604
0.604
16.04
17.668
3.825
1.781
2.044
22.44
3
1.973
12.397
3.087
0.577
2.510
25.10
14.397
2.660
0.736
1.924
21.24
19.397
3.087
0.577
2.510
28.10
4
1.697
16.289
2.862
1.747
1.114
21.14
18.289
2.536
1.849
0.686
18.49
23.289
2.862
1.747
1.165
99.12
5
1.175
19.169
2.665
1.500
1.165
22.65
21.169
2.397
1.558
0.838
23.98
26.169
2.665
1.500
1.490
99.55
102.36
113.78
297.34
As before, we repeat the procedure for periods and compute . For the three initial guesses , 5, and 10, we obtain , 4166.6, and 4180.2, respectively. The corresponding base-stock levels are , 2.195, and 2.207, which are close to the asymptotic base-stock level of 2.190. The corresponding computation times (in seconds) for the three initial guesses are 5.73, 6.09, and 6.32, respectively.
Comparison With Myopic Policies in the Case of Exponential Demand
This subsection proposes two myopic policies in the exponential demand example of Subsection 7.2.1. Each uses the critical fractile formula for its updated demand distributions to obtain base-stock levels over time. We can then compute the cost achieved by each policy and compare it to the optimal cost.
First Myopic Policy: In period , we have the belief dependent upon the hyperparameters . For the exponential demand, the updated CCDF on is (63), a gamma distribution with . Equating this to the critical fractile on the right-hand side of (72) gives us the base-stock level for that period. That is, we use
to obtain the base-stock levels
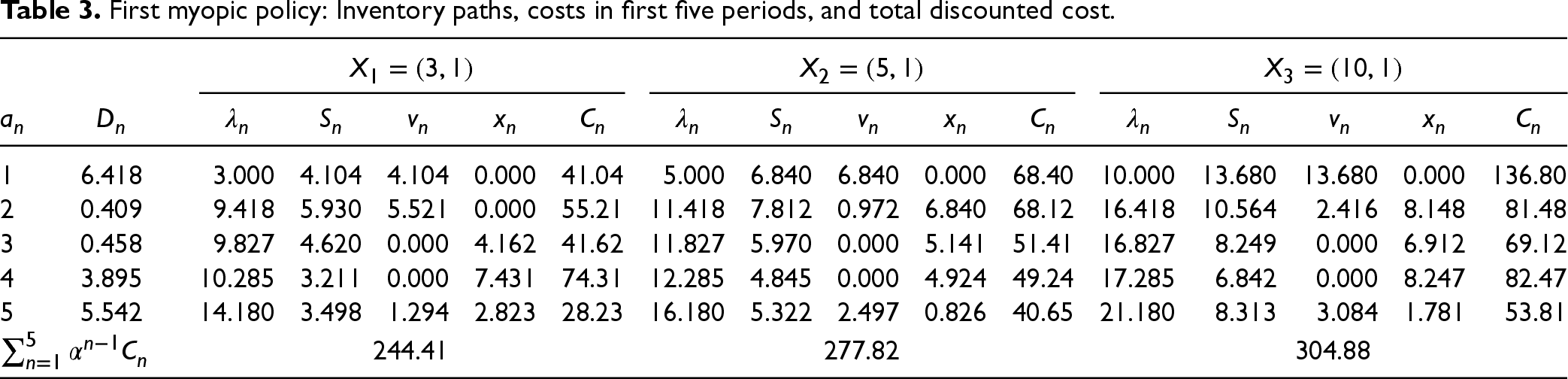
With these base-stock levels, we can summarize the first myopic policy results in Table 3, similar to Table 1 for the optimal base-stock levels.
First myopic policy: Inventory paths, costs in first five periods, and total discounted cost.
1
6.418
3.000
4.104
4.104
0.000
41.04
5.000
6.840
6.840
0.000
68.40
10.000
13.680
13.680
0.000
136.80
2
0.409
9.418
5.930
5.521
0.000
55.21
11.418
7.812
0.972
6.840
68.12
16.418
10.564
2.416
8.148
81.48
3
0.458
9.827
4.620
0.000
4.162
41.62
11.827
5.970
0.000
5.141
51.41
16.827
8.249
0.000
6.912
69.12
4
3.895
10.285
3.211
0.000
7.431
74.31
12.285
4.845
0.000
4.924
49.24
17.285
6.842
0.000
8.247
82.47
5
5.542
14.180
3.498
1.294
2.823
28.23
16.180
5.322
2.497
0.826
40.65
21.180
8.313
3.084
1.781
53.81
244.41
277.82
304.88
To obtain its total cost, we generate 1,000 sample paths of demands of = 200 periods based on the assumed true demand distribution. Since a cost of $1 in the 200th period is , a negligible number, we can ignore the total cost for the periods beyond 200. Thus, the total cost of the first 200 periods approximates the infinite horizon cost. Then, we average these costs associated with the 1,000 sample paths to obtain the expected total cost. Additionally, we calculate the average computational time (in seconds) and find values of 1.25, 1.30, and 1.28 for the three initial guesses of , , and , respectively. We report these results in Table 4.
Comparison of average total costs, computation times, and base-stock levels.
Optimal policy
First myopic policy
Second myopic policy
Initial guess
Cost
Time
Base stock
Cost
Time
Base stock
Cost
Time
Base stock
412.39
5.12
3.279
464.32
1.25
3.752
530.86
1.23
3.744
428.05
5.67
3.507
483.84
1.30
3.761
543.10
1.20
3.753
467.05
5.81
3.533
509.91
1.28
3.783
596.20
1.23
3.774
The updated demand distribution used in this policy is a gamma distribution, although the true demand distribution is exponential with the mean demand 4. As the introduction mentions, we can use a procedure that seeks updated distributions within the exponential class, and we can accomplish this by beginning with an initial belief about the mean demand and updating it each time we observe a new demand. Moreover, we already have the updated mean demand in period as , a sufficient statistic for an exponential distribution. These observations justify the second suboptimal policy described below.
Second Myopic Policy: In period , the CCDF of the exponential distribution with the mean is Then, the critical fractile formula gives optimal base-stock levels
Treharne and Sox (2002) refer to such a policy as certainty equivalent control. Using these base-stock levels from the same 1,000 demand sample paths gives us the results in Table 5.
Second myopic policy: Inventory paths, costs in first five periods, and total discounted cost.
1
6.418
3.000
2.586
2.586
0.000
25.86
5.000
4.310
4.310
0.000
43.10
10.000
8.620
8.620
0.000
86.20
2
0.409
9.418
4.225
6.832
36.07
11.418
5.091
7.127
47.23
16.418
6.910
6.121
0.789
45.89
3
0.458
9.827
3.189
0.000
30.65
11.827
3.845
0.000
25.27
16.827
5.399
0.000
2.133
21.33
4
3.895
10.285
2.738
0.000
61.49
12.285
3.296
0.000
56.76
17.285
4.624
0.000
27.79
5
5.542
14.180
2.881
0.000
114.19
16.180
3.466
0.000
103.14
21.180
5.487
0.000
71.24
267.26
277.51
253.25
For the three initial guesses , , and , the total average discounted expected costs are 530.86, 543.10, and 596.20, and the average computational times (in seconds) are 1.23, 1.20, and 1.23. We report them in Table 4.
Using the same 1,000 demand sample paths, we can find the optimal base-stock levels utilizing the procedure in Subsection 7.2 for each sample path. We also report these results in Table 4.
Table 4 presents the average total costs, average computation times (in seconds) over 1,000 sample paths for a horizon of 200 periods, and base-stock levels in the 200th period for the three approaches: optimal, first myopic, and second myopic. The results show that the optimal policy achieves the lowest expected cost. Specifically, the percentage improvements by the optimal policy over the first myopic policy are 12.6%, 13.0%, and 9.2%, respectively, for the three initial guesses , , and . The corresponding improvements of the optimal policy over the second myopic policy are 28.7%%, 26.9%, and 27.7%. We also see that the first myopic policy dominates the second, consistent with the observation of Treharne and Sox (2002). These represent substantial losses of using myopic policies. On the other hand, as expected, the optimal policy requires more computational time, but not prohibitively more.
Finally, we want to point out that the base-stock levels in all three policies should converge to the true base-stock level of 3.448 in the limit. That is because, for the first myopic policy, we show in EC.7.3 in the E-Companion that the CCDF of the gamma distribution, reflecting the distribution of the updated demand given the hyperparameters, converges to the CCDF of the true Weibull distribution (which is the exponential distribution in our example). The result is evident in the second myopic policy case. As for the optimal policy, our computations indicate the march of the optimal base-stock levels over time. Moreover, in the march toward the true base-stock level of 3.448, the optimal policy does the best, and the first and second myopic policies follow it in that order.
When Demand Follows One of Two Distributions
We consider the case when the demand is known to come from one of two possible distributions, but we do not know which. For example, this could represent high-demand and low-demand environments. Thus, we model this in Subsection 8.1 by a belief function with a two-dimensional hyperparameter, which can be reduced to their ratio. We rewrite the functional equation for the particular case involving two exponential demands. This model of demand learning is new to the inventory literature with Bayesian updating, and it illustrates the generality of our approach. In Subsection 8.1.1, we develop a convenient approximation procedure involving iterations of the unique solution of the functional equation. In Subsection 8.1.2, we apply the method to an example of high and low exponential demands.
Let us consider the belief function where and represent the Dirac masses at 0 and 1, respectively, and and are hyperparameters. Since it is not a probability density, this writing is formal. We set the demands and which can be very general. We have
which gives us a formal representation of the demand measure given the values and of the hyperparameters. It preserves, relating to the fact that it is also the sum of two Dirac measures at 0 and 1.
The functional in (42) can be written as depending on the hyperparameters and instead of , and it satisfies the equation
We can assume and to be strictly positive and set Otherwise, if one is zero, we know the actual demand, and there is no need to learn. Since we have
Noting (53), we have By setting , we obtain immediately from (74) the following equation:
Thus, we are left only with one hyperparameter to learn from the demand observations. We solve (76) using an approximation method in the remainder of Section 8. We only consider the exponential demand case and develop an approximation in Subsection 8.1.1. In Subsection 8.1.2, we illustrate the method by a numerical example.
Exponential Demand Case
Let the demand densities be
where . These densities represent low and high-demand environments, respectively, as their mean demands satisfy . The functional equation we need to solve is
Iterative Approximation Procedure
To compute the integral in equation (78), we iteratively refine our approximation of . We accomplish this by rewriting (78), in the iterative form, as follows:
starting with the initial guess
We first define by solving
The function is decreasing, and is given by the following equation:
Note that a straightforward but lengthy calculation shows (see EC.8.1 for details in the E-Companion) that can be obtained as follows:
where is given in EC.8.1 in the E-Companion and is the solution of
For , we can only consider an approximate solution to (79). First, note that the upper limit for the integral in (79) can be replaced by because for all when . Let
be a rectangle in the -plane, and define a grid on with grid spacings and such that and . We compute at the grid points by approximating the integral in (79) using the composite trapezoidal formula
where . This method extends the basic trapezoidal rule to handle integration over multiple subintervals, providing enhanced accuracy and efficiency. We use the trapezoidal rule within each subinterval to approximate the integral and sum the results to obtain the overall approximation. The method balances simplicity and accuracy, making it a popular choice for numerical integration. Our iterative approximation method uses the composite trapezoidal formula to efficiently approximate the integral defined in (78) over a predefined grid.
Since is given explicitly by (80) during the computation of the right-hand side of (86) is known precisely. For , the second component of is not a grid value, and, therefore, we obtain by interpolation using the neighboring grid point values.
For illustrative purposes, we set the parameter values as follows: , , , and (as defined in Section 7), and let , , with and . In EC.8.2, we show the structure of the curves , , and in .
Knowing the data points we can extract the values
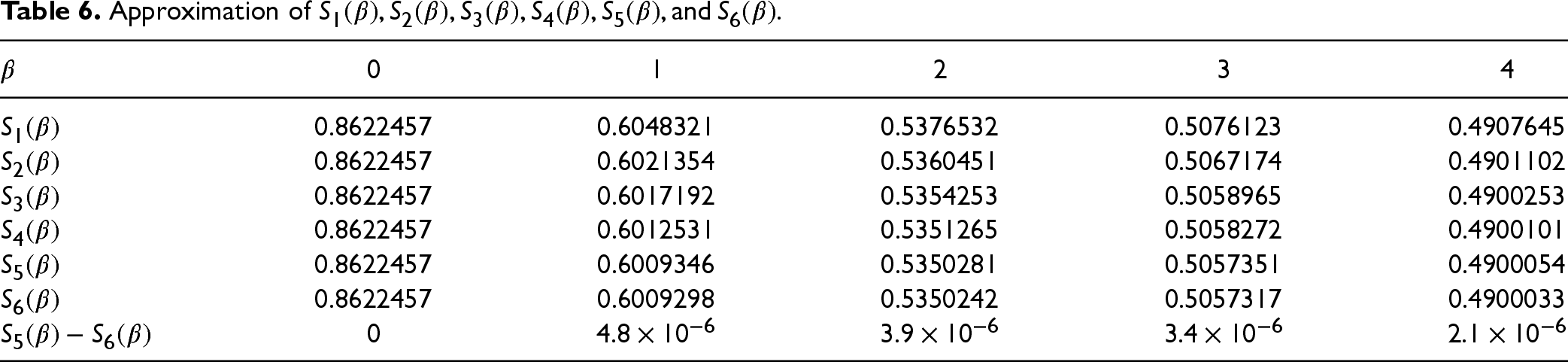
We use the convergence criterion of to terminate the iterative process. Specifically, we terminate the process once the change in successive iterations reaches the tolerance level . Table 6 displays for and . Based on these results, we use the approximation .
Approximation of .
0
1
2
3
4
0.8622457
0.6048321
0.5376532
0.5076123
0.4907645
0.8622457
0.6021354
0.5360451
0.5067174
0.4901102
0.8622457
0.6017192
0.5354253
0.5058965
0.4900253
0.8622457
0.6012531
0.5351265
0.5058272
0.4900101
0.8622457
0.6009346
0.5350281
0.5057351
0.4900054
0.8622457
0.6009298
0.5350242
0.5057317
0.4900033
0
Computation of Base-Stock Level for Exponential Demands
We consider the demand densities (77) with and , and the parameter values , , , and as in Section 7. To demonstrate the implementation of our model, we assume that the true demand density is . Then, the true mean is , and the asymptotic base-stock level computed using (72) is . Since the IM does not know the true demand, he makes an initial guess of the hyperparameters and such that .
We use the predefined Matlab function exprnd(1/2, 1, 5) to generate simulated demands according to the true probability density . These are , , , , and . Given (73), we obtain the posteriors of and as follows:
It is straightforward to see from (88) that in each period. We illustrate our model with two different guesses: and . These give us the initial and , respectively.
With , the base-stock level . Assuming the initial inventory , the order quantity , giving . In period 2, , , , and the base-stock level . Thus, the order quantity and . This way, we can complete Table 7. Similarly, we complete Table 8 for the second initial guess
Optimal path starting with
1
2
3
4
5
0.1522
0.9613
0.1323
0.0338
0.2135
1.5
2.5776
1.9704
3.4522
6.6752
0.5512
0.5072
0.5271
0.4882
0.4588
0.5512
0.1082
0.9812
0.0934
0.0044
0
0.3990
0.3948
0.4544
Optimal path starting with
1
2
3
4
5
0.1522
0.9613
0.1323
0.0338
0.2135
0.6667
1.1451
0.8757
1.5344
2.9668
0.5512
0.5779
0.6065
0.5491
0.5074
0.5512
0.1788
0.9899
0.0749
0
0
0.3990
‒ 0.3835
0.4741
0.5152
The fourth row in Tables 7 and 8 shows the base-stock level updates. As before, we generate demands according to the exponential density and simulate for periods. We compute and . Both values are the same and close to the asymptotic base-stock level of 0.4311, with computation times (in seconds) of 4.41 and 4.13, respectively. We also observe that in period , our method has led to the value of the hyperparameter , which is very close to its true value of 1.
Concluding Remarks
We have considered a standard discrete-time infinite-horizon inventory problem with unknown general demand and backlog allowed. We begin with a general belief density prior and update it as the demand history unfolds. We prove the optimality of a belief-dependent base-sock policy by analyzing the resulting functional Bellman equation for the value function, which depends on the current inventory level and the current (updated) infinite-dimensional belief. We provide an iterative procedure to compute the optimal belief-dependent base-stock level for any given belief as the limit of a decreasing sequence of nonnegative numbers. We use the resulting stationary function offline to obtain the optimal base-stock levels over time as we update beliefs based on observed demands. We apply our methodology to the cases when the initial belief is a conjugate prior and when the true demand density belongs to one of two possible densities. Our method can be extended to handle the case of multiple possible densities, but we leave that for future research.
We illustrate our theory and the algorithm by solving a few numerical examples. In each example, the optimal base-stock levels march toward the asymptotic optimal value over time. Also, in the case of the example assuming exponential demand, we compare the performance of two critical-fractile-based myopic policies against the optimal policy and show that our policy results in significant cost reduction. For this example, we also prove that the optimal base-stock levels converge to a base-stock level, which is the optimal level in the corresponding infinite-horizon problem when the true demand distribution is known.
While the case of lost sales has been studied in the literature (reviewed in Section 2 and EC.1 1 in the E-Companion), our approach extends to this case, provided we can somehow infer the demands. Then, we can update the belief as in this article, and a base-stock policy would remain optimal. Finally, given that our method is quite general, exploring its applications to inventory problems with non-zero lead times and fixed ordering costs would be exciting topics for future research. In the lead-time case, we expect an optimal belief-dependent base-stock policy for the so-called inventory position. In the fixed-cost case, we expect a belief-dependent policy to be optimal.
Footnotes
Acknowledgments
Alain Bensoussan gratefully acknowledges the support of the National Science Foundation under Grant NSF-DMS 2204795.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Suresh P Sethi
Abdoulaye Thiam
Supplemental Material
Supplemental material for this article is available online (doi: ).
How to cite this article
Bensoussan A, Sethi SP, Thiam A and Turi J (2025) Optimality of Base-Stock Policy Under Unknown General Demand Distributions: New Methods, New Results, and Computations. Production and Operations Management 34(11): 3701–3722.
References
1.
AvciHGökbayrakKNadarE (2020) Structural results for average-cost inventory models with Markov-modulated demand and partial information. Production and Operations Management29(1): 156–173.
2.
AzouryKS (1985) Bayes solution to dynamic inventory models under unknown demand distribution. Management Science31: 1150–1160.
3.
BanGY (2020) Confidence intervals for data-driven inventory policies with demand censoring. Operations Research68(2): 309–326.
4.
BanGYRudinC (2019) The big data newsvendor: Practical insights from machine learning. Operations Research67(1): 90–108.
5.
BensoussanA (2011) Dynamic Programming and Inventory Control. Optimization and Statistics, Vol. 3. IOS Press, Amsterdam: Studies in Probability.
6.
BensoussanAÇakanyildirimMMinjarez-SosaJARoyalASethiSP (2008) Inventory problems with partially observed demands and lost sales. Journal of Optimization Theory and Applications136(3): 321–340.
7.
BensoussanAÇakanyildirimMMinjarez-SosaJASethiSPShiR (2008) Partially observed inventory systems: The case of rain checks. SIAM Journal on Control and Optimization47(5): 2490–2519.
8.
BensoussanAÇakanyildirimMSethiSP (2007) A multiperiod newsvendor problem with partially observed demand. Mathematics of Operations Research32(2): 322–344.
9.
BensoussanAÇakanyildirimMSethiSP (2009) A note on “The censored newsvendor and the optimal acquisition of information”. Operations Research57(3): 791–794.
10.
BensoussanAGuoP (2015) Managing nonperishable inventories with learning about demand arrival rate through stockout times. Operations Research63(3): 602–609.
11.
BesbesOMouchtakiO (2023) How big should your data really be? Data-driven newsvendor: Learning one sample at a time. Management Science69(10): 5848–5865.
12.
BesbesOMuharremogluA (2013) On implications of demand censoring in the newsvendor problem. Management Science59(6): 1407–1424.
13.
BeyerDChengFSethiSTaksarMI (2010) Markovian Demand Inventory Models. New York: Springer.
14.
BurnetasANSmithCE (2000) Adaptive ordering and pricing for perishable products. Operations Research Letters48(3): 436–443.
15.
ChenLMersereauAJ (2015) Analytics for operational visibility in the retail store: The cases of censored demand and inventory record inaccuracy. In: AgrawalNSmithSA (eds) Retail Supply Chain Management. 2nd ed. New York: Springer, 79–112.
DaiTJerathK (2013) Salesforce compensation with inventory considerations. Management Science59(11): 2490–2501.
19.
DingXPutermanMLBisiA (2002) The censored newsvendor and the optimal acquisition of information. Operations Research50(3): 517–527.
20.
DvoretzkyAKieferJWolfowitzJ (1952) The inventory problem: II. Case of unknown distributions of demand. Econometrica20: 450–466.
21.
FeinbergEAKasyanovPO (2021) MDPs with setwise continuous transition probabilities. Operations Research Letters49(5): 734–740.
22.
FeinbergEAKasyanovPOZadoianchukNV (2012) Average-cost Markov decision processes with weakly continuous transition probabilities. Mathematics of Operations Research37: 591–607.
23.
FeinbergEAKasyanovPOZadoianchukNV (2013) Berge’s theorem for noncompact image sets. Journal of Mathematical Analysis and Applications397: 255–259.
24.
GallegoGMoonI (1993) The distribution-free newsboy problem: Review and extensions. Journal of Operational Research Society44(8): 825–834.
25.
GodfreyGAPowellWB (2001) An adaptive, distribution-free algorithm for the newsvendor problem with censored demands, with applications to inventory and distribution. Management Science47(8): 1101–1112.
26.
HeeseHSSwaminathanJM (2010) Inventory and sales effort management under unobservable lost sales. European Journal of Operations Research207(3): 1263–1268.
27.
HuhWTLeviRRusmevichientongPOrlinJB (2011) Adaptive data-driven inventory control with censored demand based on Kaplan-Meier estimator. Operations Research59(4): 929–941.
28.
HuhWTRusmevichientongP (2009) A nonparametric asymptotic analysis of inventory planning with censored demand. Mathematics of Operations Research34(1): 103–123.
29.
IglehartDL (1964) The dynamic inventory problem with unknown demand distribution. Management Science10: 429–440.
30.
JainARudiNWangT (2015) Demand estimation and ordering under censoring: Stock-out timing is (almost) all you need. Operations Research63(1): 134–150.
KunnumkalSTopalogluH (2008) Using stochastic approximation methods to compute optimal base-stock levels in inventory control problems. Operations Research56(3): 646–664.
33.
LarsonCEOlsonLJSharmaS (2001) Optimal inventory policies when the demand distribution is not known. Journal of Economic Theory101: 281–300.
34.
LeviRRoundyROShmoysDB (2007) Provably near-optimal sampling-based policies for stochastic inventory control models. Mathematics of Operations Research32(4): 821–839.
35.
LeviRShiC (2013) Approximation algorithms for the stochastic lot-sizing problem with order lead times. Operations Research61(3): 593–602.
36.
LiyanageLHShanthikumarJF (2005) A practical inventory policy using operational statistics. Operations Research Letters33: 341–348.
37.
LovejoyWS (1990) Myopic policies for some inventory models with uncertain demand distributions. Management Science36: 724–738.
LuXSongJSZhuK (2008) Analysis of perishable-inventory systems with censored demand data. Operations Research56(4): 1034–1038.
40.
Luque-VasquesFHernández-LermaO (1995) A counterexample on the semicontinuity of minima. Proceedings of the American Mathematical Society123(10): 3175–3176.
41.
PerakisGRoelsG (2008) Regret in the newsvendor model with partial information. Operations Research56(1): 188–203.
42.
PorteusEL (2002) Foundations of Stochastic Inventory Theory. Stanford CA: Stanford University Press.
43.
PowellWRuszczyńskiATopalogluH (2004) Learning algorithms for separable approximations of discrete stochastic optimization problems. Mathematics of Operations Research29(4): 814–836.
44.
RamamurthyVGeorge ShanthikumarJShenZJM (2012) Inventory policy with parametric demand: Operational statistics, linear correction, and regression. Production and Operations Management21(2): 291–308.
45.
ScarfH (1959) Bayes solutions to the statistical inventory problem. Annals of Mathematical Statistics30: 490–508.
46.
ScarfH (1960) Some remarks on Bayes solutions to the inventory problem. Naval Research Logistics Quarterly7: 591–596.
47.
SethiSPChengF (1997) Optimality of policies in inventory models with Markovian demand. Operations Research45(6): 931–939.
48.
ShiCChenWDuenyasI (2016) Nonparametric data-driven algorithms for multiproduct inventory systems with censored demand. Operations Research64(2): 362–370.
49.
SobelMJ (1981) Myopic solutions of Markov decision processes and stochastic games. Operations Research29(5): 995–1009.
50.
SongJSZipkinPH (1996) Inventory control with information about supply conditions. Management Science42(10): 1409–1419.
51.
TreharneJTSoxCR (2002) Adaptive inventory control for nonstationary demand and partial information. Management Science48(5): 607–624.
52.
ZakaiM (1969) On the optimal filtering of diffusion processes. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete11(3): 230–243.
53.
ZhangHChaoXShiC (2018) Perishable inventory systems: Convexity results for base-stock policies and learning algorithms under censored demand. Operations Research66(5): 1276–1286.
54.
ZipkinPH (2000) Foundations of Inventory Management. New York: McGraw-Hill.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.