
Abstract
We apply heterogeneous-agent proximal policy optimization (HAPPO), a multi-agent deep reinforcement learning (MADRL) algorithm, to the decentralized multi-echelon inventory management problems in both a serial supply chain and a supply chain network. We also examine whether the upfront-only information-sharing mechanism used in MADRL helps alleviate the bullwhip effect. Our results show that policies constructed by HAPPO achieve lower overall costs than policies constructed by single-agent deep reinforcement learning and other heuristic policies. Also, the application of HAPPO results in a less significant bullwhip effect than policies constructed by single-agent deep reinforcement learning where information is not shared among actors. Somewhat surprisingly, compared to using the overall costs of the system as a minimization target for each actor, HAPPO achieves lower overall costs when the minimization target for each actor is a combination of its own costs and the overall costs of the system. Our results provide a new perspective on the benefit of information sharing inside the supply chain that helps alleviate the bullwhip effect and improve the overall performance of the system. Upfront information sharing and action coordination in model training among actors is essential, with the former even more essential, for improving a supply chain’s overall performance when applying MADRL. Neither actors being fully self-interested nor actors being fully system-focused leads to the best practical performance of policies learned and constructed by MADRL. Our results also verify MADRL’s potential in solving various multi-echelon inventory management problems with complex supply chain structures and in non-stationary market environments.
Introduction
The unpredictable outbreak of COVID-19 disrupts the global supply chain severely, causing tremendous economic loss. In the post-pandemic era, supply chain management (SCM) has been playing an increasingly critical role in global economics. Inventory management is central in SCM and has a significant impact on the service level and economic efficiency of a supply chain network (SCN) where multiple echelons are involved, and each echelon contains multiple parallel actors. Every actor in the SCN faces complicated inventory decision problems characteristic of lost sales, dual sourcing, and perishable inventory. For the coordination of multiple actors in a supply chain, the demand spikes caused by the pandemic amplify the demand distortion along the supply chain and aggravate the bullwhip effect in many businesses (Stank et al., 2021). The bullwhip effect describes a commonly observed phenomenon that orders faced by different entities from downstream to upstream of a supply chain have increasing variability (Lee et al., 1997), which would lead to significant overstock or backlogs and thereby harm the economic performance of the supply chain.
The literature on inventory management problems is rich, but most theoretical studies require strong assumptions such as independently and identically distributed (i.i.d.) demands and a simple SCN structure, which are typically unrealistic in the practice of SCM. To open up new opportunities for inventory management, artificial intelligence (AI), a disruptive technology for various areas, has attracted increasingly more research interests. As a pivotal technique in AI, reinforcement learning (RL) uses feedback obtained via interactions with the environment to learn the optimal policy for Markov decision processes (MDPs). Deep reinforcement learning (DRL) further improves the learning efficiency for RL by using neural networks (NNs) to parameterize the value function and the policy, which leads to many successful applications in various domains, including gaming, robotic manipulation, and self-driving cars.
The sequential decision problems in inventory management can usually be formulated as MDPs, where DRL naturally applies (Boute et al., 2022). Though current results have clearly demonstrated DRL’s potential in some complex inventory problems where calculating the exact optimal policy is intractable, information sharing and collaboration among multiple actors inside SCN remain unexplored. To apply DRL to inventory management problems with multiple actors, previous studies such as Gijsbrechts et al. (2021), Vanvuchelen et al. (2020), and Harsha et al. (2022) train a centralized agent to make decisions for all actors. The rationale behind this scheme relies heavily on a “central control tower” assumption, that is, there exists a central control tower that has access to all information in the supply chain and can always control every actor. Apparently, such an assumption rarely holds in the practice of SCM. Vosooghidizaji et al. (2020) summarized multiple strategic reasons that cause information asymmetry along the supply chain, such as the fear of losing competitive advantage, getting extra benefits, ensuring compatibility of information systems, and so on. In recent years, the digitization of a supply chain has made data leakage a critical issue that prevents participants of SCM from sharing real-time information. In 2004, Walmart announced not to share data even with some collaborating companies since it takes data as its private resources (Hays, 2004). Furthermore, the increasing number of cyberattacks has made cybersecurity a new concern that obstructs data and information sharing inside the supply chain. To ensure cybersecurity, both companies and governments, such as China, have put out specific rules that regulate the outflow of private data. All the aforementioned factors make it almost impossible to achieve complete information sharing among practical supply chains. How to construct DRL policies for multiple actors in a supply chain with practical information-sharing conditions remains unsolved in both the practical and academic worlds.
To fill such a research gap, we formulate a supply chain as a multi-agent system (MAS) and apply multi-agent DRL (MADRL) to the multi-echelon inventory management problems where multiple actors from different echelons are involved. As a subfield of DRL, MADRL focuses on coordinating a group of autonomous agents to achieve certain goals by interacting with a shared environment. A centralized training and decentralized execution (CTDE) scheme is characteristic of MADRL algorithms. Specifically, each actor learns a policy by resorting to all actors’ observations in the training stage while making decisions only based on their own observations in the execution stage. In the context of decentralized inventory management, CTDE creates a unique coordination mechanism between fully centralized and fully decentralized systems. Specifically, in an upfront training stage, each actor in the supply chain first learns to make coordinated ordering decisions under the knowledge of other actors’ information and then engages in the practice of decentralized inventory management where other actors’ information is not available. CTDE makes MADRL suited for multi-echelon inventory management problems because information sharing is required only in the training stage, so the scheme is implementable in practical supply chain settings. Participants of SCM can use and share historical data to conduct one-time centralized training. The trained models can then be deployed by different participants in a decentralized manner. Such a coordination mechanism may benefit the collaborating partners in a supply chain who have issues with sharing real-time data because of various reasons mentioned before. For example, it may help Amazon work better with its vendors and third-party sellers to improve the efficiency of the whole supply chain, given that each party manages only part of the chain. Meanwhile, it can be beneficial to some large retail or logistics companies that control multiple stages in a supply chain but find it challenging to synchronize data among multiple self-controlled stages in real time.
Our contributions can be summarized as follows:
We provide the formulation of multi-echelon inventory management problems in a serial supply chain system and a supply chain network system as partially observable Markov games (POMGs) and apply MADRL to construct intelligent ordering policies. We investigate a unique form of training objective for each actor from both theoretical and numerical aspects. Compared to setting the target for each actor as minimizing the overall costs, the system achieves lower overall costs when each actor considers minimizing a combination of its own costs and the overall costs of the system. We experimentally verify that MADRL is superior in lowering the overall costs of the system, and the upfront-only information sharing in the training stage of MADRL is effective in alleviating the bullwhip effect.
Related Inventory Management Problems
The most classic inventory management literature considers a single-sourcing backlogged model with stationary customer demand and a deterministic lead time. With linear backlog and holding costs and in the absence of fixed order costs, the base stock policy has proved to be optimal for minimizing expected overall costs. If the fixed costs are also considered in the cost structure, the optimal policy becomes an (
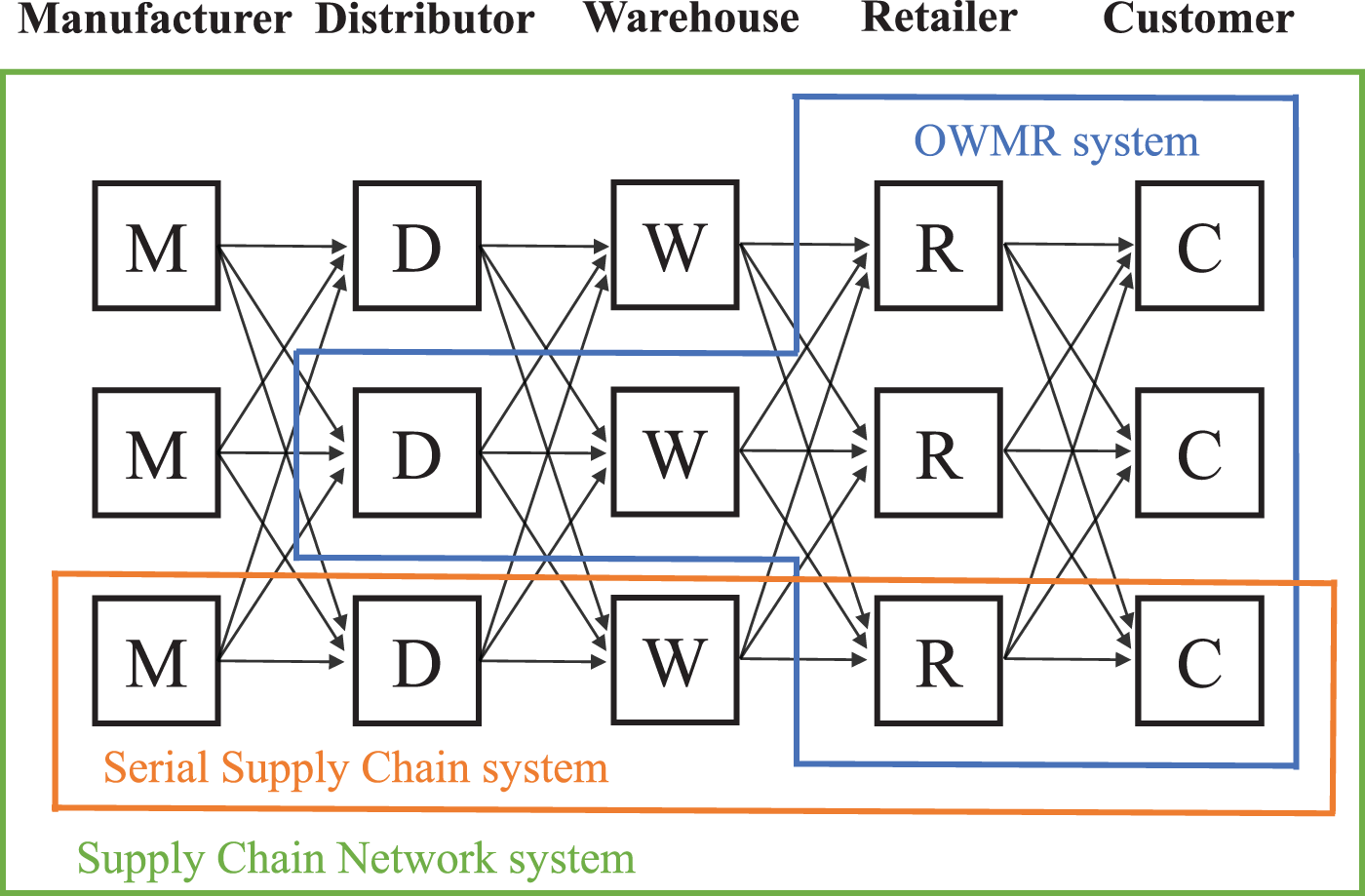
Three extensively studied systems in multi-echelon inventory management problem.
The dual-sourcing model complicates inventory management by assuming that an actor replenishes inventory from two sources: a normal source and an expedited source with a shorter lead time but a higher ordering cost. For the dual-souring inventory management under the assumption of backlog, Veeraraghavan and Scheller-Wolf (2008) proposed a dual index (DI) policy, where two inventory positions are maintained separately for normal and expedited orders. As a variant of DI, the capped dual index (CDI) policy proposed by Sun and Mieghem (2019) adds a cap on normal ordering. It is proven to be optimal with general lead times and stationary or non-stationary demand. Different from DI and CDI, the tailored base surge (TBS) policy proposed by Allon and Mieghem (2010) makes a constant order from the regular source and follows an (
Different from the above-mentioned problems that focus on a single actor in a supply chain, a multi-echelon inventory management problem involves multiple actors from different echelons. As shown in Figure 1, three systems have been studied extensively in the multi-echelon inventory management problem.
In the one-warehouse multi-retailer (OWMR) system, one warehouse is shared by several retailers with separate demands. Compared to the OWMR system, the serial supply chain system has a longer but thinner structure. The general supply chain network system further generalizes the structure of a supply chain by adding parallel actors into an echelon.
Gijsbrechts et al. (2021) applied A3C to an OWMR system. Their result shows that A3C beats a base stock policy by 9%–12%. Harsha et al. (2022) introduced a deep-policy iteration RL method that outperforms several state-of-the-art RL algorithms and the (
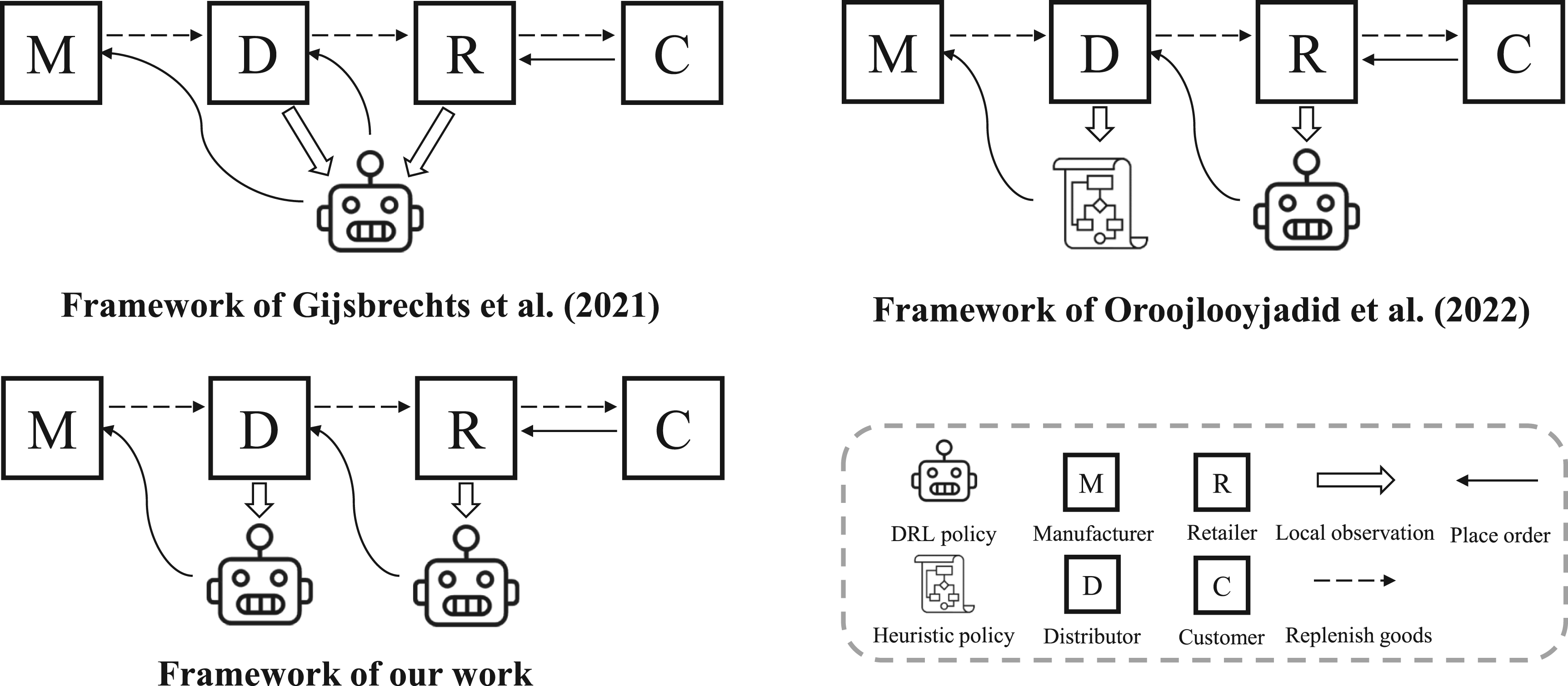
Comparison of our work and previous literature on applying DRL to multi-echelon inventory management problems.
Introduced and studied first by Procter & Gamble (PG) in the 1990s, the bullwhip effect refers to the phenomenon that demand fluctuations increase from downstream to upstream in a supply chain. A further study by Lee et al. (1997) demonstrates how distorted information transmitted along a supply chain leads to the bullwhip effect and thereby causes tremendous inefficiencies such as excessive inventory investment and lost revenue. The authors introduce four potential causes of the bullwhip effect, that is, demand forecast update, order batching, price fluctuations, and shortage gaming. Mason-Jones and Towill (2000) attributed the bullwhip effect to uncertainties in the supply side, manufacturing process, process control, and demand side of the supply chain. Meanwhile, numerous empirical, experimental, and analytical studies aim to find solutions to alleviate the bullwhip effect. There is a consensus in the literature that information sharing through collaboration among actors in the supply chain helps alleviate the bullwhip effect by reducing information distortion. Recently, Liu et al. (2022) observed that panic buying from human buyers during the lockdowns caused by COVID-19 leads to the bullwhip effect and can be mitigated by combining DRL algorithms and fictitious play.
For the measurement of the bullwhip effect, Wang and Disney (2016) provided an extensive review of various methods. We adopt a simple and effective measuring method introduced by Fransoo and Wouters (2000) in which the coefficient of variation is used to measure fluctuations in demand.
Multi-Agent Deep Reinforcement Learning
RL aims to find the optimal policy for MDPs by interacting with the environment and self-learning via collecting rewards. Previously proposed RL algorithms can be divided into three categories: value-based, policy-based, and actor-critic-based (Arulkumaran et al., 2017). In the value-based RL, a state-action value function
Though with rigorous theoretical foundations, the successful applications of the above-mentioned RL algorithms are limited. One of the main reasons is that the function classes used to approximate the state-action function or policy function (i.e., tabular or linear function) are only feasible in low-dimensional problems. To address such a difficulty, DRL takes non-linear NNs as approximators and develops numerous well-performed algorithms by combining deep learning (DL) with RL. As a variant of a value-based RL algorithm called Q-learning, deep Q network (DQN) achieves tremendous success in various Atari games (Mnih et al., 2013). As one of the most classic actor-critic-based DRL algorithms, A3C is characterized by a novel asynchronous training scheme and achieves superior training efficiency and performance (Mnih et al., 2016). Based on the trust region learning proposed by Schulman et al. (2015), proximal policy optimization (PPO) outperforms the previous DRL algorithms by guaranteeing monotonical policy improvement in every training iteration. The superb performance and high scalability of the aforementioned DRL algorithms have inspired numerous applications in various domains, including inventory management. As mentioned, Gijsbrechts et al. (2021) applied A3C to three classic inventory problems and achieve desirable results. Oroojlooyjadid et al. (2022) constructed policies with DQN to play a decentralized beer game. Vanvuchelen et al. (2020) applied PPO to a joint replenishment inventory management problem and achieve much better performance than several heuristic policies.
Although DRL has become a promising method for solving practical problems, there still exists some complex real-world situations where the existing DRL methods may fail, an example of which is the MAS. In a MAS, multiple players cooperate or compete with each other to achieve the same or separate goals in a shared environment. To solve MDPs in MAS, DRL for MAS, that is, MADRL, has been developed. Among various existing MADRL algorithms, a direct extension of DRL to MADRL is to train each agent with a DRL algorithm while taking other agents as part of the environment. Such naive MADRL algorithms typically perform poorly because other agents’ actions would make the environment highly non-stationary, which creates difficulties for models’ convergence. To address such a limitation, a novel CTDE scheme for MADRL has been proposed. In CTDE, all agents are trained with full environment information, while they determine actions only based on their local information. Providing agents with more information makes the training easier, and executing with only local information makes MADRL more practical under situations where only partial observations are available or communication among agents is limited. By applying CTDE to PPO, Yu et al. (2021) introduced multi-agent PPO (MAPPO). They test MAPPO on three commonly used test environments for MADRL and show the superior performance of MAPPO on fully cooperative games. However, the application of MAPPO is limited since agents in MAPPO are required to be homogeneous. To address this issue, Kuba et al. (2021) proposed a sequential policy update scheme and introduce heterogeneous-agent PPO (HAPPO). Agents in HAPPO are heterogeneous, which is also the case in our problem, and the authors prove that the performance of HAPPO will be monotonically improved with policy updates.
MADRL in Serial Supply Chain System
In this section, we demonstrate how to apply MADRL to the multi-echelon inventory management problem in a serial supply chain system.
Model Formulation in Serial Supply Chain System
Dynamics of Serial Supply Chain System
We consider a periodic-review serial supply chain system containing
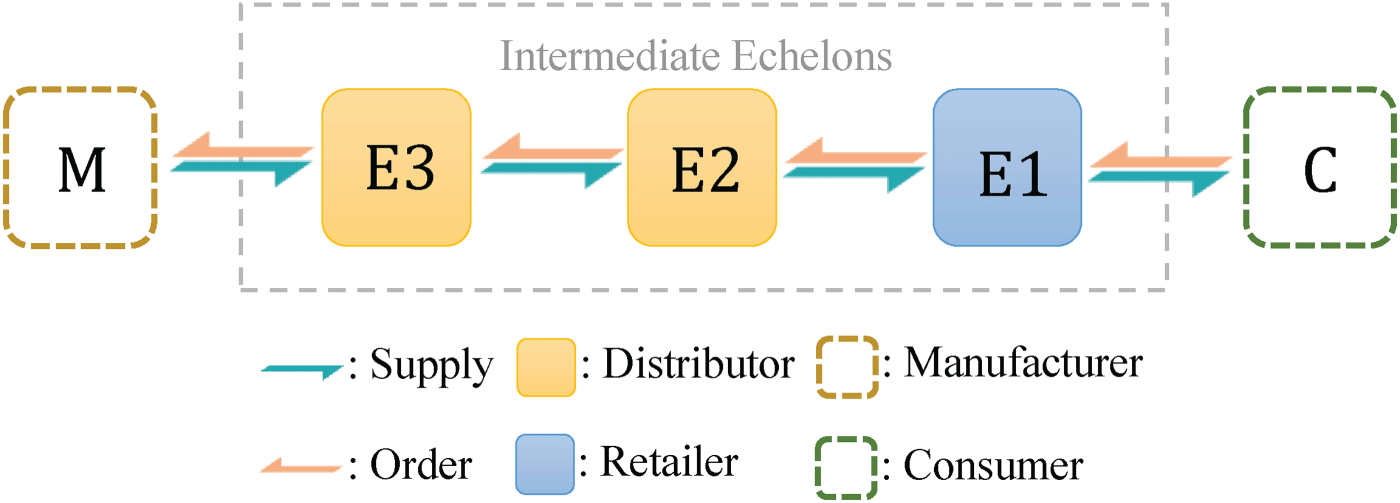
A serial supply chain system with three intermediate echelons.
Since each echelon contains only one actor, we use integers from
In each period
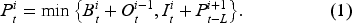

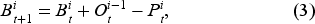
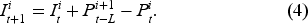

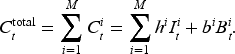
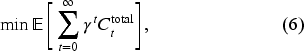
To apply MADRL, we formulate the serial supply chain system as a POMG (Littman, 1994), which can be defined by a tuple
Following the above scheme, we treat actor
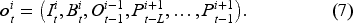
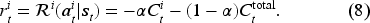
When applying a joint policy
When applying MADRL algorithms, we need to evaluate the current joint policy
When applying a joint policy
Proposition 2 shows that as
Propositions 1 and 2 thereby form a bias-variance trade-off controlled by the parameter
In addition, the introduced bias-variance trade-off has three distinctive features. First, it is unique to MADRL since the variance aspect is essentially caused by the fact that MADRL, as a numerical method, uses finite simulations to estimate the expected reward. Second, it is unique to the cooperative multi-echelon inventory setting where each actor has a positive linear contribution, for example, individual costs, to the ultimate common objective, for example, overall costs of all actors. Third, it is unique to the reward definition (8), which is a convex combination of the individual contribution of each actor and the ultimate common objective of the system. Therefore, when applying MADRL on cooperative multi-echelon inventory systems with an additively contributed objective, for example, the overall costs across echelons, the aforementioned trade-off implies that setting the individual objective for each actor as the common objective may not give the best performance because of the practical training mechanism of MADRL. One can consider applying the reward shaping (8) and conduct additional experiments to find the optimal
To simulate a volatile environment where the bullwhip effect is more likely to happen, we generate non-stationary customer demand by a Merton jump diffusion model (MJD) (Merton, 1976). Originally used to simulate stock price data with high peaks and heavy tails, MJD adds jumps to a diffusion process to model sudden changes. Such features can well capture customer demands in the real world where bursts or stagnant sales randomly appear due to external shocks such as the COVID-19 outbreaks. We simulate MJD by a method by Glasserman (2004). Specifically, we compute the demand
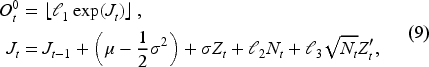
Other than the Merton demands, we also conduct some experiments with Poisson distributed demands and real-life demands. Provided in the M5 forecasting competition (Howard et al., 2020), the real-life demand data comes from the retailing goods of Walmart. The statistical information of the real-life data we use is summarized in Appendix B. Examples of Merton, Poisson, and real-life demands are provided in Figure 4.
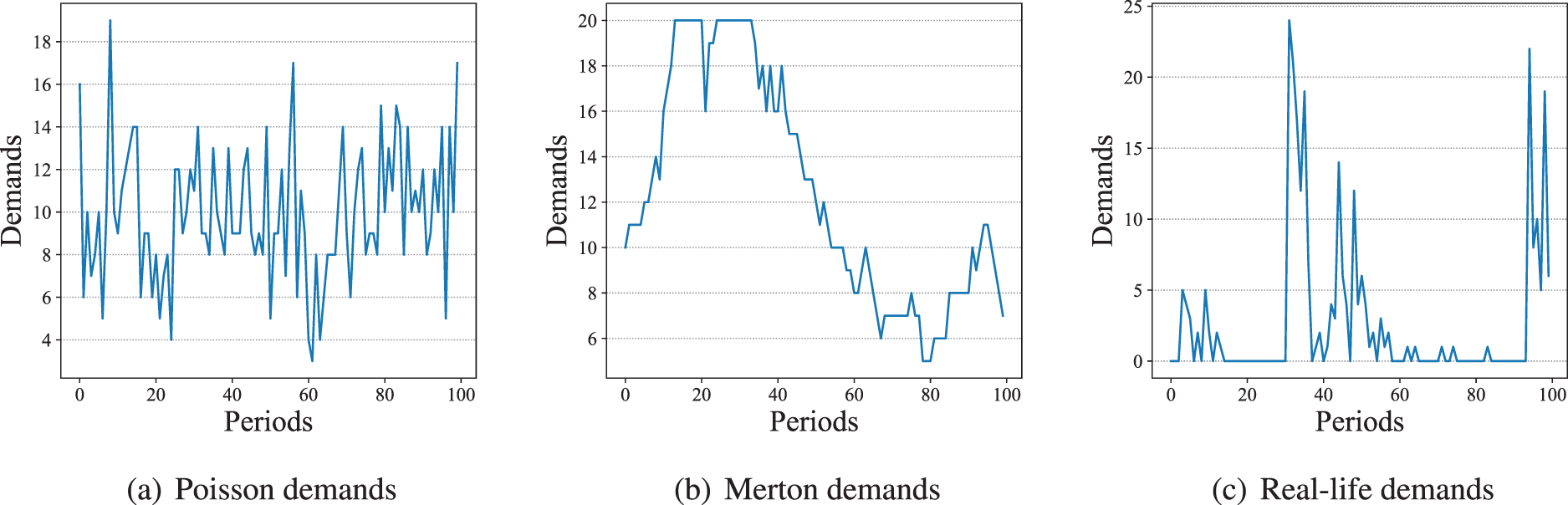
Examples of Poisson, Merton, and real-life demands.
We apply HAPPO to construct ordering policies for the POMG defined in Section 3.1. HAPPO applies an on-policy PPO for each actor and follows a CTDE structure. For every actor
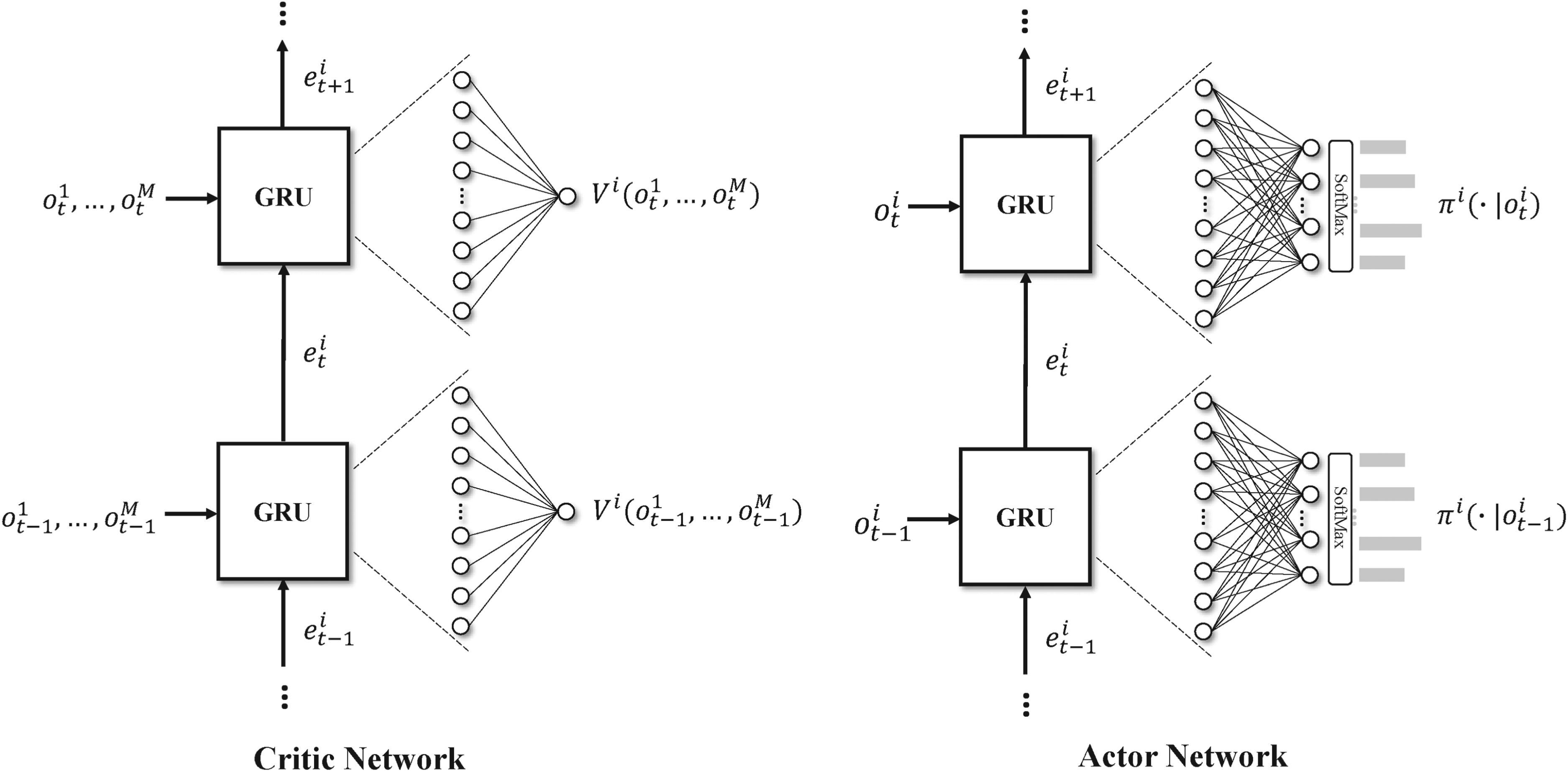
Diagram of actor and critic networks based on RNN with GRU. RNN: recurrent neural network; GRU: gate recurrent unit.
For the actor network, in each period
For the actual training process of each actor
By applying HAPPO to the POMG constructed from the serial supply chain with
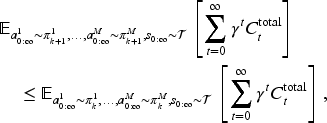
The proof of Proposition 3 can be found in Appendix A.
We implement both heuristic and DRL policies as baselines to evaluate HAPPO’s performance. Since most of our experiments are conducted using non-stationary Merton and real-life demands, we implement non-stationary base-stock and (
We design the following six sets of experiments to evaluate the performance of HAPPO.
Optimality Test in Serial Supply Chain System
To validate HAPPO’s convergence, we consider two simplified problems in the serial supply chain system where the optimal policy is tractable.
First, we consider the deterministic setting of zero lead time, no startup inventory, no startup backlog, and deterministic demand, which means the external demand
For the serial supply chain system with
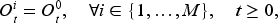
Then, we consider the stochastic setting of non-zero lead time, no startup inventory, no startup backlog, and stochastic demands. The demand
As mentioned, parameter
Policy Comparison in a Typical Serial Supply Chain System
We evaluate the performance of HAPPO and other baseline policies in a typical serial supply chain system with three, four, and five echelons by using Merton and real-life demands, respectively. We use the overall costs as our metrics for the numerical comparison of different policies. To evaluate the bullwhip effect, as introduced in Section 2.2, we use the coefficient of variation as our metric. Specifically, for actor
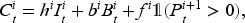
Sensitivity Analysis With Different Lead Times and Cost Coefficients
To verify the robustness of policies constructed by HAPPO, we evaluate HAPPO and baseline policies’ sensitivity with respect to different lead times and different cost coefficients when using Merton demands without fixed costs. Since lead time determines the size of the observation space (see Section 3.1), we train different HAPPO and PPO models for different lead times. For the sensitivity to cost coefficients, we train those models under one set of cost coefficients and evaluate their performances under other settings of cost coefficients.
Policy Comparison With Different Information Sharing Conditions
As mentioned in Section 3.2, a typical MADRL method using CTDE assumes that each actor has access to all other actors’ information during training and only has access to its local information during execution. This set of experiments aims to study whether decentralization in execution harms the performance of HAPPO when applied to inventory management. We construct a baseline called “centralized HAPPO,” where each actor has access to all other actors’ information not only during training but also during execution. More precisely, the input to the actor network
Besides, under certain scenarios of supply chain management, one actor may only have access to information about its neighbors. Practical evidence also shows that the limited observations can be an important reason for the sudden collapse of modern “just in time” supply chains (Dvorak, 2009). Hence, to test HAPPO’s performance with the limited observations during training, we change the input of value network
Policy Comparison With Price Discounts and Random Shipping Loss
As introduced by Lee et al. (1997), price discounts provided by upstream actors can aggravate the bullwhip effect because it leads to bulk purchases from downstream actors and thereby causes the distortion of real demand information. To examine the bullwhip effect when the ordering decision is made by actors trained by HAPPO in the presence of price discounts, we change the cost structure in equation (5) by introducing ordering costs. We use
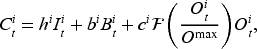
Other than price discounts, uncertainties in multiple stages of the supply chain also contribute to the bullwhip effect (Mason-Jones and Towill, 2000). Hence, we create additional uncertainties in the system by introducing a random shipping loss. Suppose a random portion of goods is spoiled during the shipment. The quantity of shipment in equation (1) and inventory update in equation (4) under this scenario can be modified as follows:
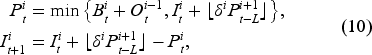
Exogenous parameters used in the aforementioned experiments, including cost coefficients and lead times, are summarized in Table 1. For all policies, we conduct the evaluation on 20 different demand traces and record the average value of the considered metrics on 20 demand traces. For each experiment conducted on HAPPO and the PPO baseline, we repeat the training processes for 10 times to reduce the randomness caused by the model’s training. The mean and the confidence interval of considered metrics that come from 10 repeated training processes are presented in related figures. For heuristic policies, the evaluation only needs to be conducted for one time, and the average value of metrics on 20 demand traces is presented in related figures.
Coefficients in experiments conducted on the serial supply chain system.
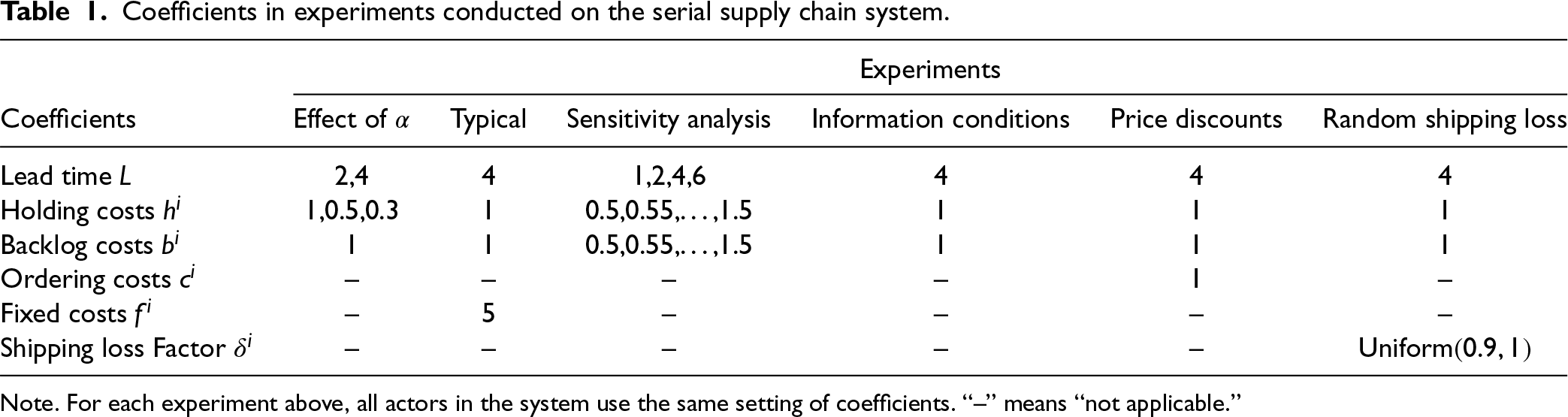
Note. For each experiment above, all actors in the system use the same setting of coefficients. “–” means “not applicable.”
In this section, we provide numerical results and related discussions for experiments in Section 3.3.
Results of Optimality Test in a Simplified Serial Supply Chain System
For the deterministic setting, we consider a two-echelon system and record each echelon’s average ordering, average inventory, and average costs for every training episode. We consider three different settings of coefficients for holding and backlog costs, that is,
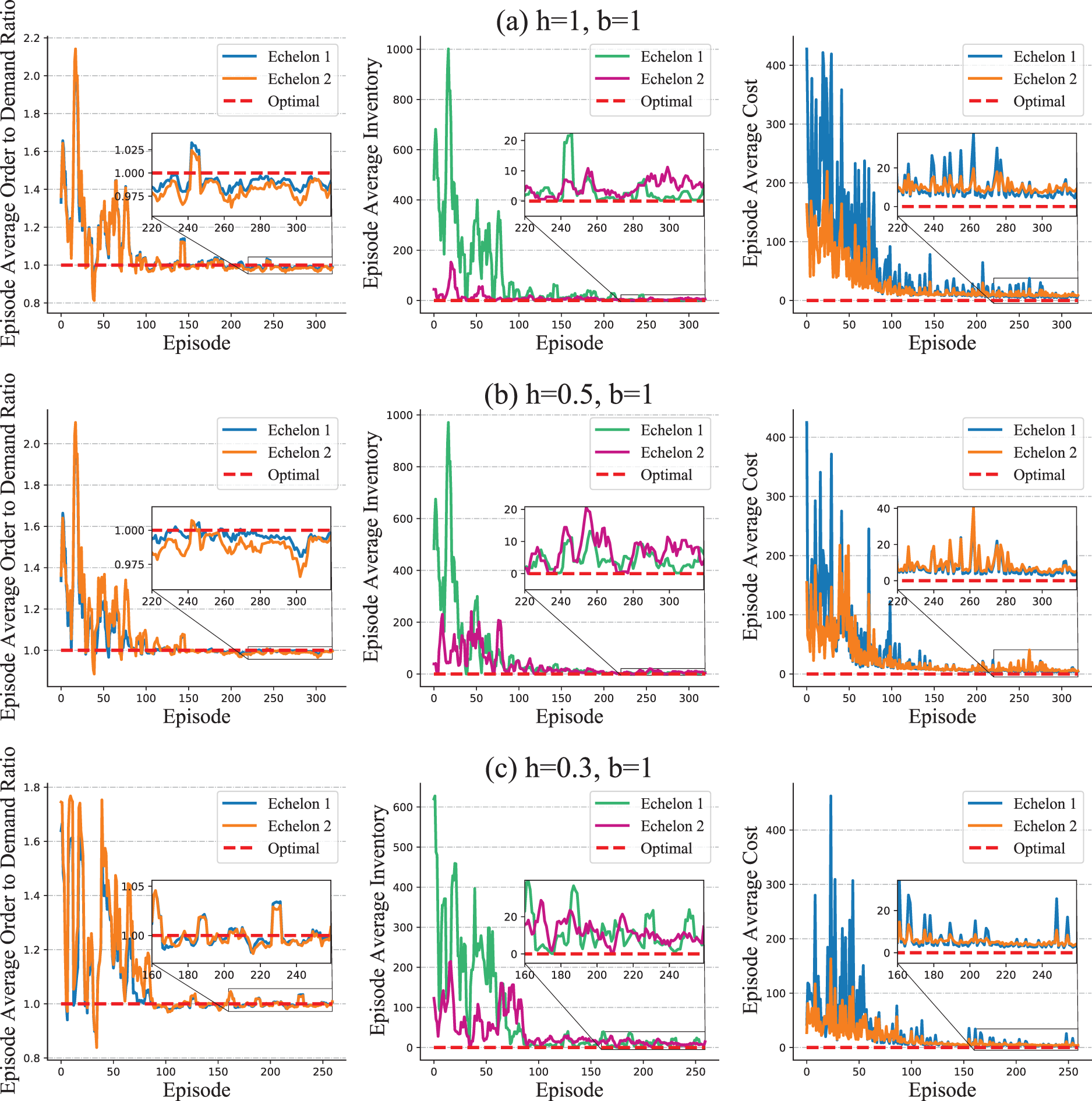
Optimality test in simplified serial supply chain system with deterministic demands.
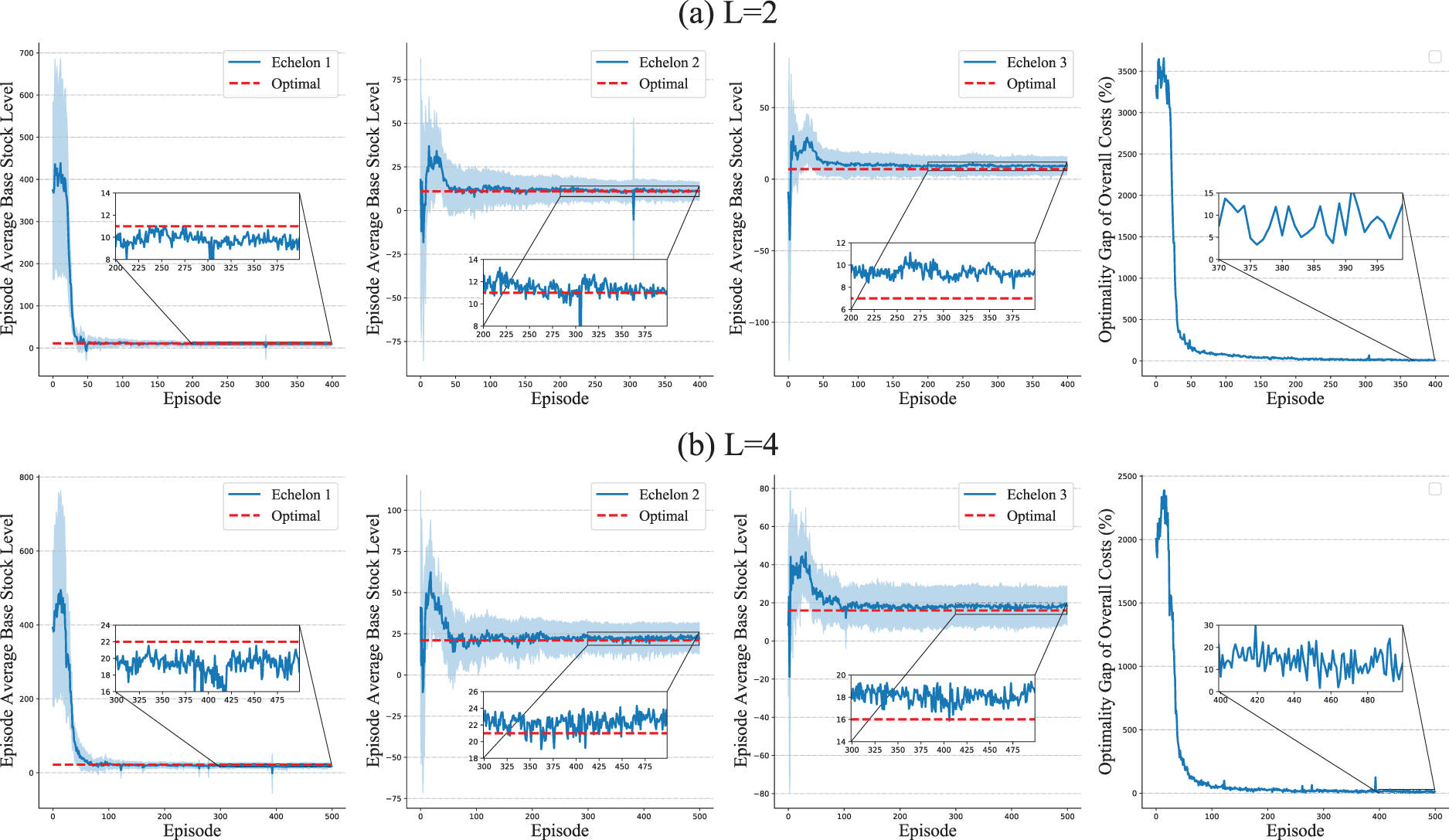
Optimality test in simplified serial supply chain system with stochastic demands.
We present the overall costs of the system associated with different values of
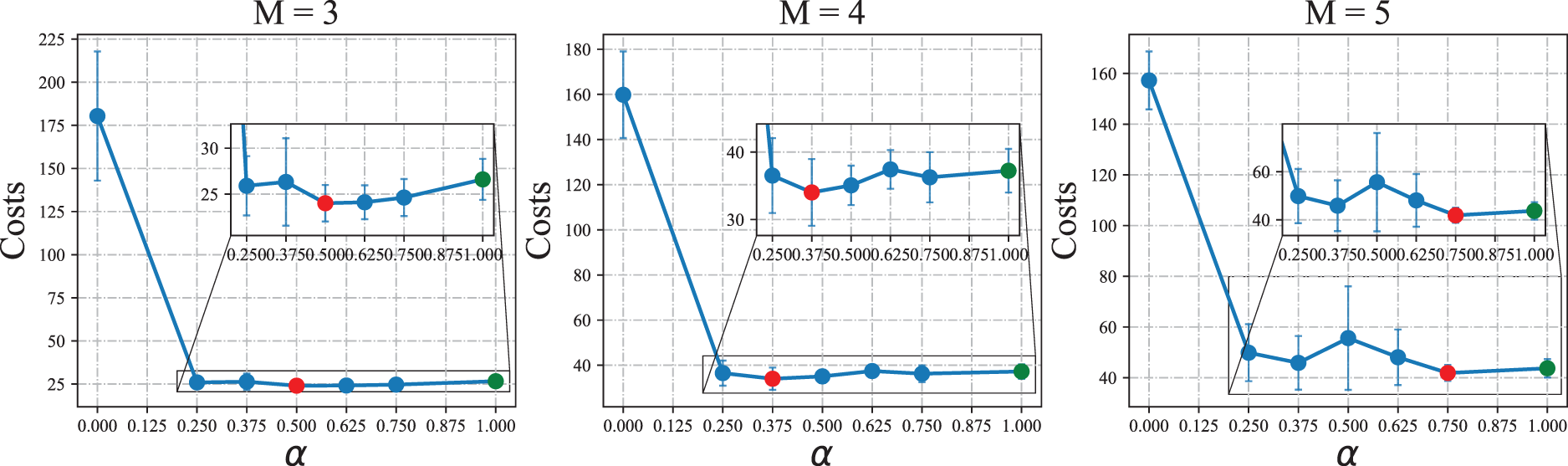
Effect of parameter
When applying HAPPO on a serial supply chain, the best performing
Observation 1 shows that HAPPO achieves the best practical performance when each actor considers both its own costs and other actors’ costs. This phenomenon is consistent with our analysis in Section 3.1. The parameter
With non-stationary external demands, results in Figure 9 show that HAPPO achieves the lowest overall costs, and both HAPPO and the PPO baseline outperform the non-stationary base stock and (
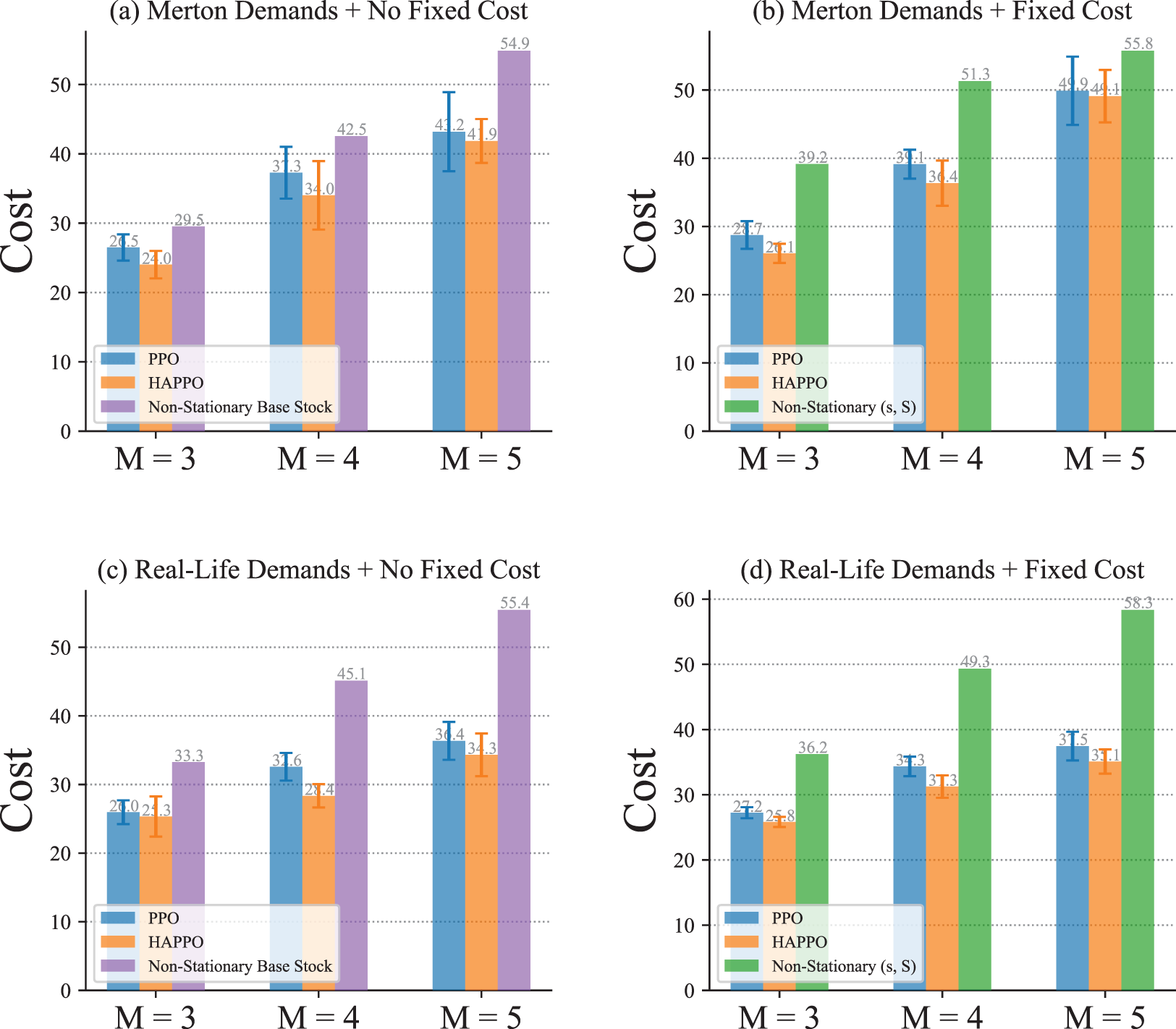
Comparison of system’s overall costs in a typical serial supply chain.
The comparison of the bullwhip effect in the serial supply chain system is shown in Figure 10. The bullwhip effect that demand fluctuation amplifies from downstream to upstream is more significant in the PPO baseline compared to HAPPO. Specifically, as shown in Table 2, both the average and the amplification of demand fluctuation are smaller in HAPPO compared to the PPO baseline, which implies that the bullwhip effect is effectively alleviated by HAPPO. These results indicate the effectiveness of the upfront-only information-sharing mechanism in HAPPO and also provide an explanation for HAPPO’s superiority in reducing the overall costs of the system. We provide a policy visualization in the serial supply chain system in Appendix I.
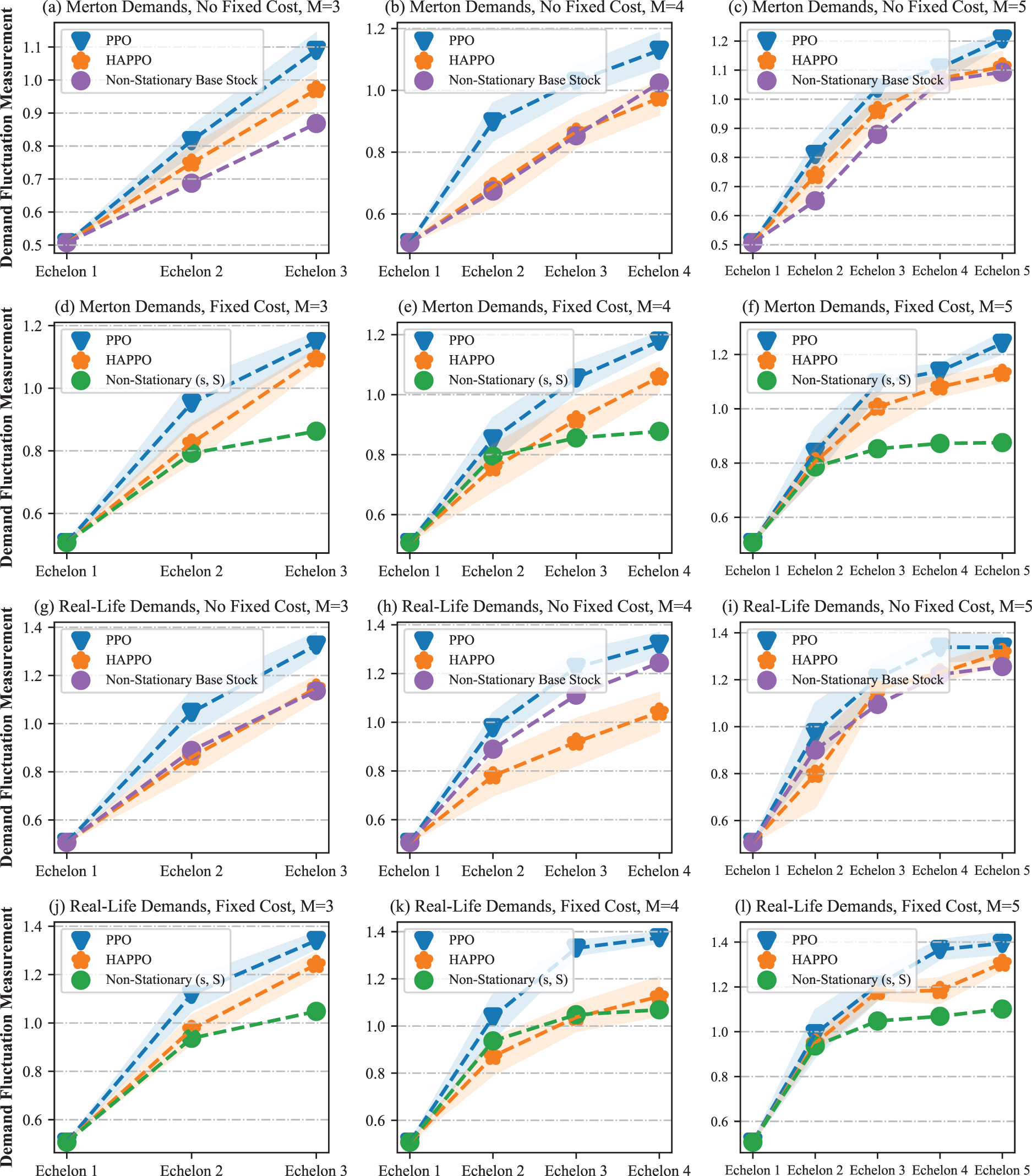
Comparison of the bullwhip effect in a typical serial supply chain.
We conduct sensitivity analysis on a typical serial supply chain system with three echelons. As shown in Figure 11, HAPPO constantly achieves the lowest overall costs with different lead times, which demonstrates HAPPO’s robustness to changes in lead time. The demand fluctuation amplification for both the PPO baseline and HAPPO is generally larger when lead time increases, which is consistent with the argument by Lee et al. (1997) that a longer lead time aggravates the bullwhip effect. Nevertheless, the demand fluctuation amplification for HAPPO is smaller than that for the PPO baseline in all settings, which demonstrates HAPPO’s robustness to changes in lead time in terms of alleviating the bullwhip effect.
For policies’ sensitivity to cost coefficients, Figure 12 shows that HAPPO achieves the lowest overall costs in all settings we consider. The results also show that HAPPO still maintains its superiority under the parameter settings that are not used during training. This indicates the desirable generalization ability of policies constructed by HAPPO.
Results of Policy Comparison With Different Information Sharing Conditions
We conduct the comparison of overall costs and bullwhip effect with different information-sharing conditions. From the results shown in Figure 13, we summarize the following Observation 2.
When applying HAPPO and PPO on a serial supply chain, the overall costs of the supply chain system decrease, and the bullwhip effect alleviates as the information sharing increases in the order of PPO
Observation 2 firstly indicates that more information sharing leads to better performance of actors constructed with DRL algorithms. Also, Observation 2 is consistent with the intuition that more information sharing leads to a less significant bullwhip effect in a serial supply chain. What’s more, HAPPO is still effective in alleviating the bullwhip effect even when each actor only has access to information about its two neighbors in the supply chain during the training. What should be motioned is that although the centralized HAPPO shows superiority over the other considered methods, it needs the “central control tower” assumption introduced before and thereby may be unimplementable in the practice of multi-echelon supply chain management.
We also conduct a comparison of the convergence speeds for HAPPO with different information-sharing conditions. The results of training episodes needed to achieve the best performance for different methods are presented in Table 3. In general, centralized HAPPO converges faster than HAPPO with full observation during training, which converges faster than HAPPO with limited observation during training. These results indicate that more information sharing leads to a faster convergence speed. An intuitive explanation for such a phenomenon is that with more information provided, it is easier for each actor to capture the dynamics of the whole inventory system and thereby faster to converge to a desirable policy.
Statistics of demand fluctuation under different experiment settings.
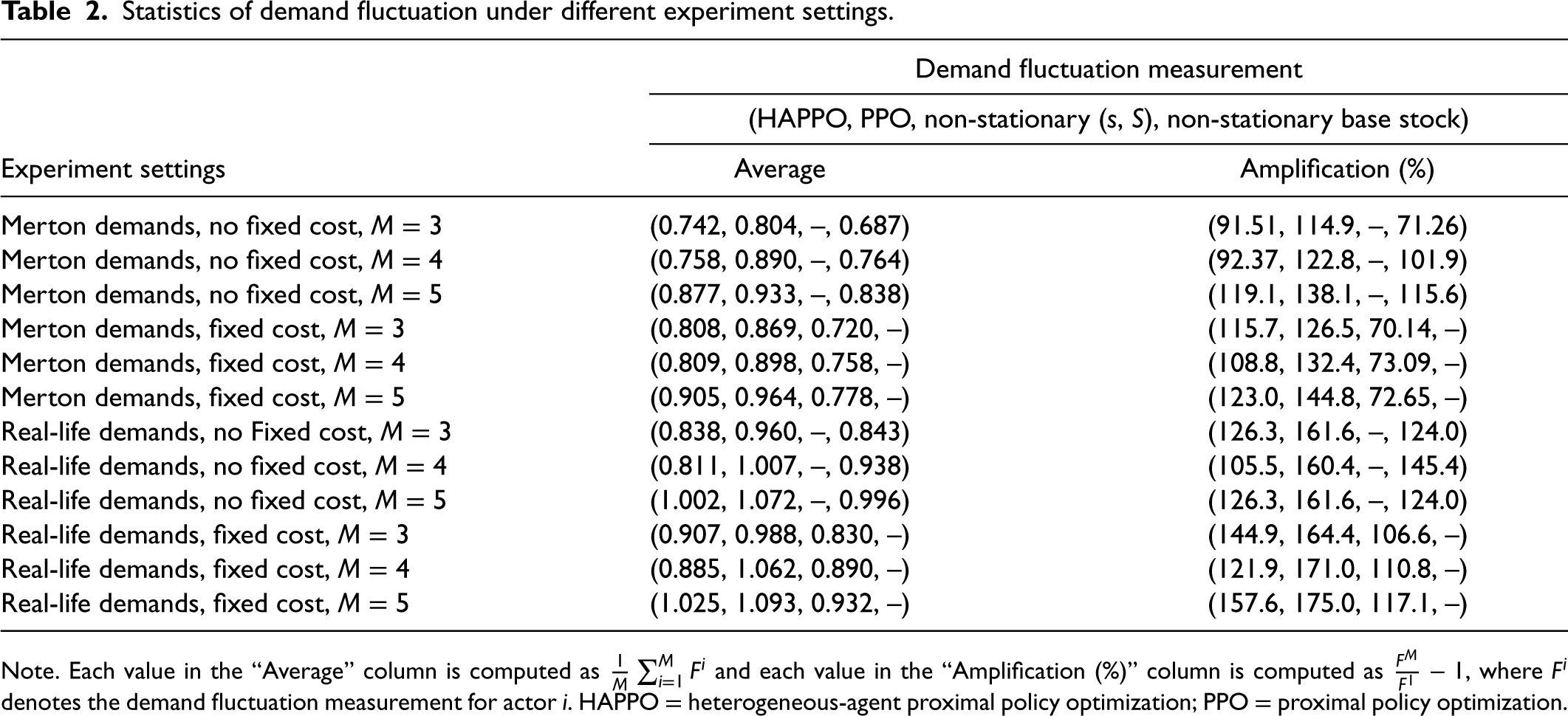
Note. Each value in the “Average” column is computed as
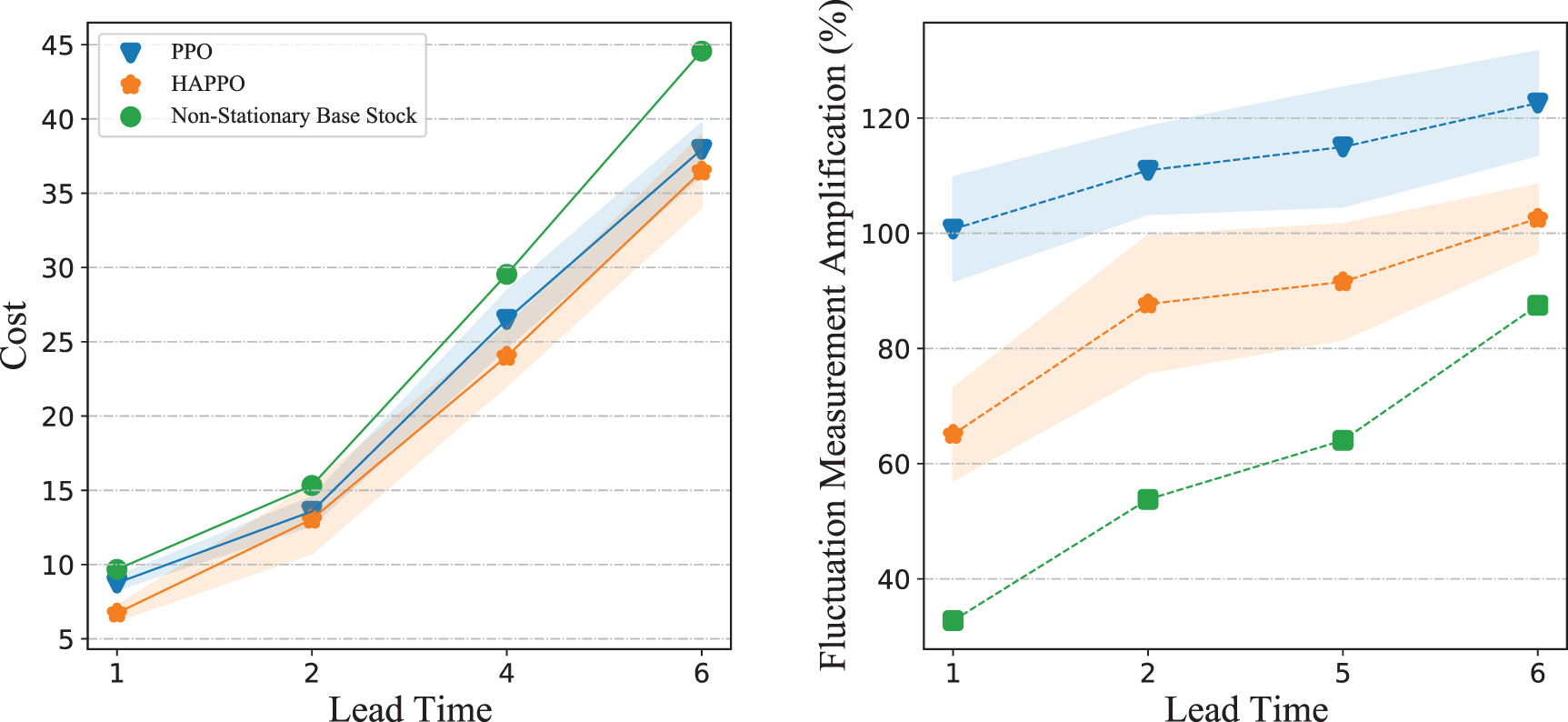
Sensitivity of different policies with respect to different lead times.
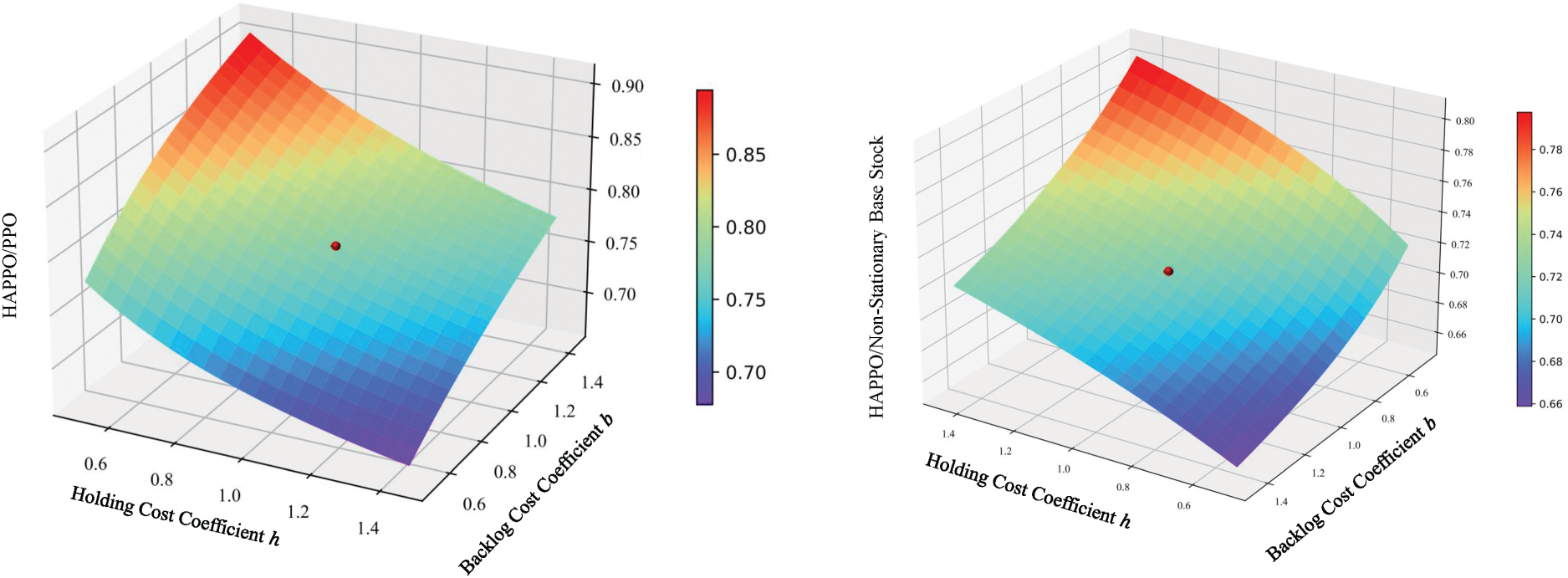
Sensitivity of different policies with respect to different cost coefficients. Note. The Z-axis is the cost ratio of heterogeneous-agent proximal policy optimization (HAPPO) to different baseline policies. The red point in each figure represents the settings of cost coefficients used in training.
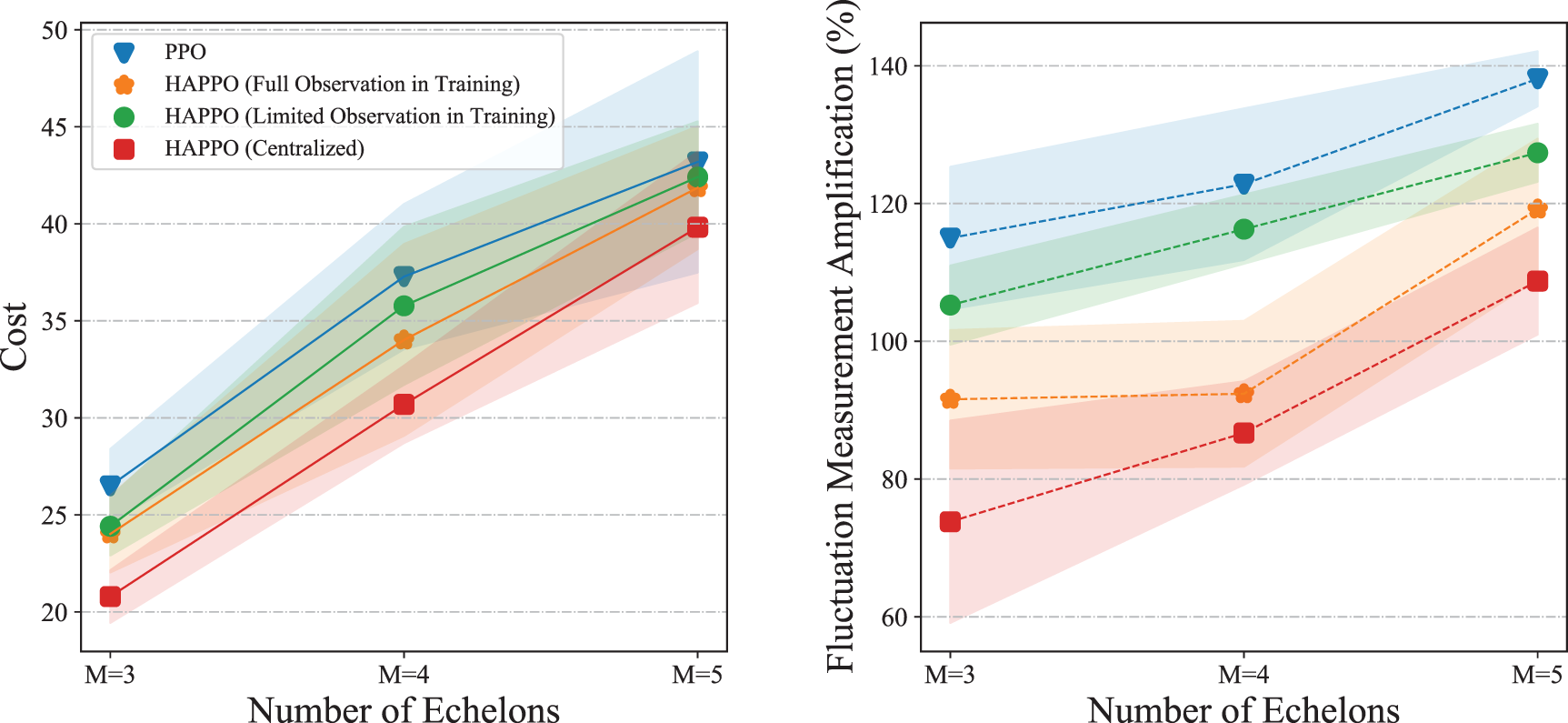
Comparison of system’s overall costs and bullwhip effect under different information-sharing conditions.
The experiments are conducted on the serial system with three echelons. The comparison of overall costs in Figure 14 shows that HAPPO still achieves the lowest overall costs with both the price discounts and the random shipping loss. Also, Figure 14 shows that the bullwhip effect is less significant by using HAPPO than the PPO baseline in both two settings. Table 4 shows that the demand fluctuation amplifies by 121% in the PPO baseline with the price discounts (114% without price discounts shown in Table 2) and 100% in HAPPO with the price discounts (91% without price discounts shown in Table 2) along the supply chain. These results substantiate that adding price discounts to the system aggravates the bullwhip effect for both the PPO baseline and HAPPO, which is consistent with the empirical finding by Lee et al. (1997) that suppliers providing price discounts is an important cause for the bullwhip effect. In contrast, the random shipping loss contributes to a surprising decrease in demand fluctuation amplification for both HAPPO and the PPO baseline, that is, a decrease from 91% (Table 2) to 50% for HAPPO and a decrease from 114% (Table 2) to 75% in the PPO baseline. An explanation is that the random shipping loss brings uncertainties into the actual quantities of goods actors receive in each period. Hence, instead of making orders by closely following the fluctuations of customer demand, actors learn to order a bit more and steadily to deal with such uncertainties in goods replenishment.
Comparison of training episodes for heterogeneous-agent proximal policy optimization (HAPPO) under different information-sharing conditions.
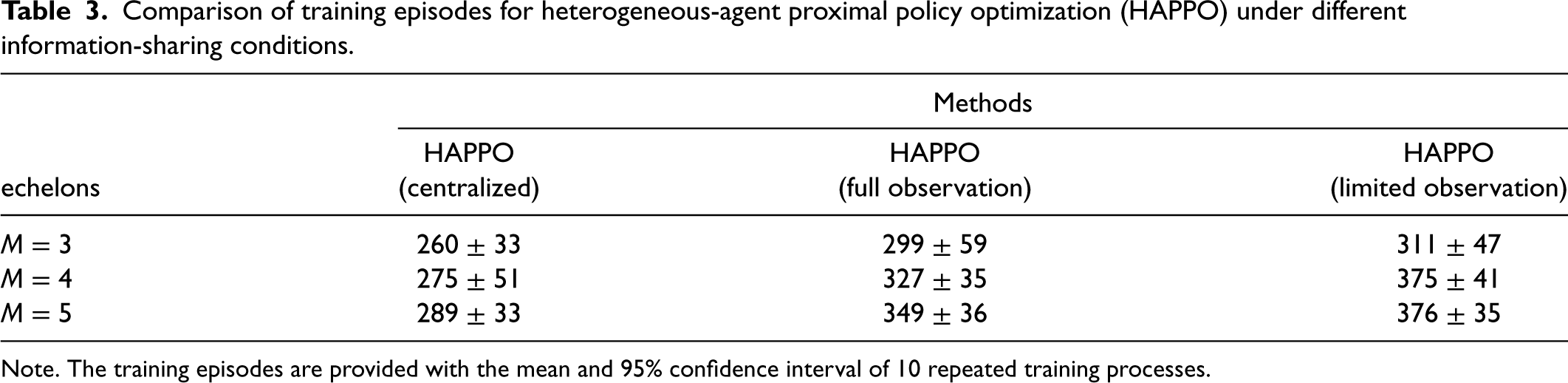
Comparison of training episodes for heterogeneous-agent proximal policy optimization (HAPPO) under different information-sharing conditions.
Note. The training episodes are provided with the mean and 95% confidence interval of 10 repeated training processes.
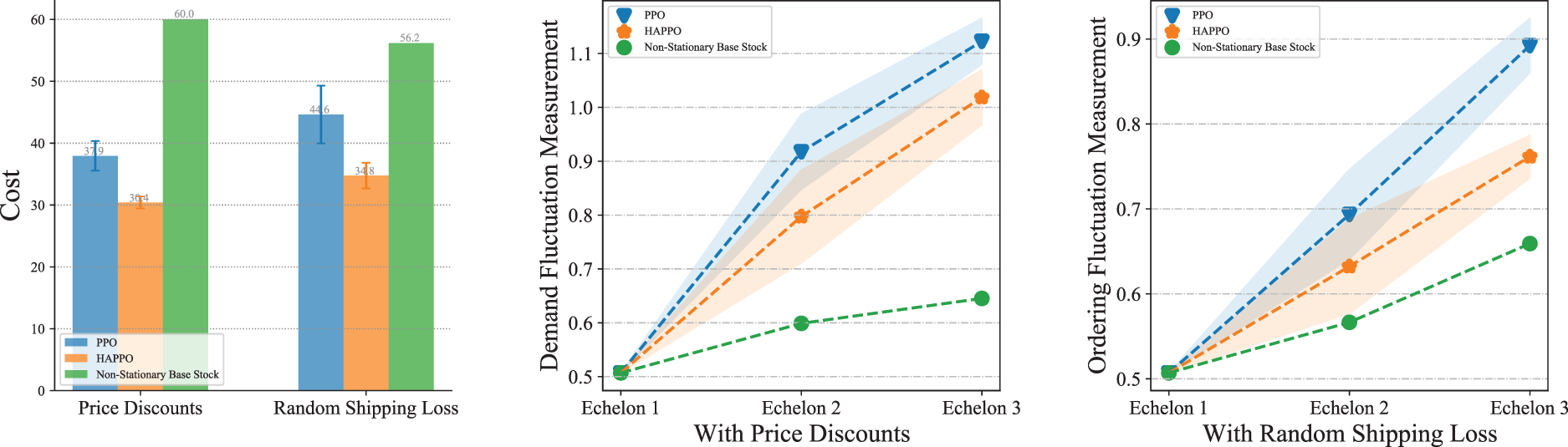
Comparison of system’s overall costs and bullwhip effect with price discounts and random shipping loss.
Statistics of demand fluctuation with price discounts and random shipping loss.
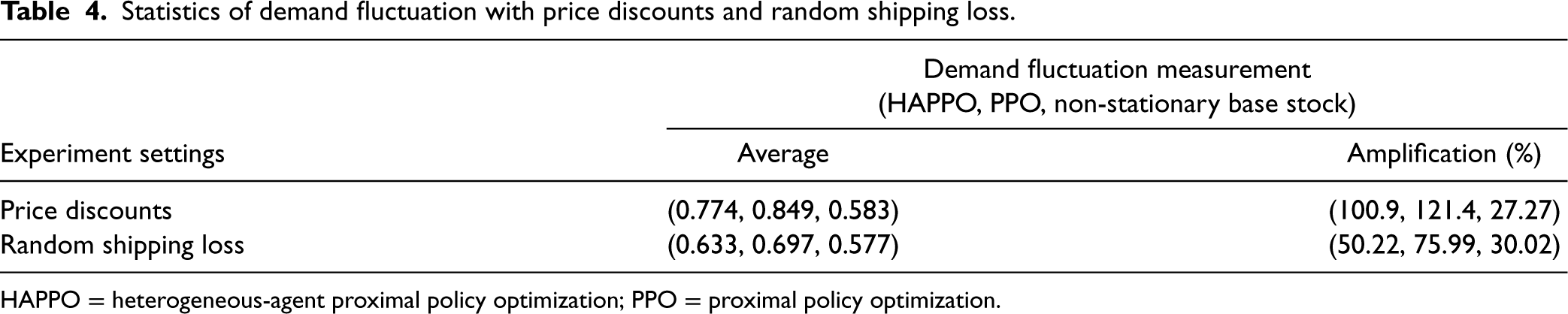
HAPPO = heterogeneous-agent proximal policy optimization; PPO = proximal policy optimization.
In this section, we consider the multi-echelon inventory management problem in a supply chain network system. With little modification, MADRL can be easily adapted to the supply chain network system.
Model Formulation in Supply Chain Network System
We study the supply chain network system with
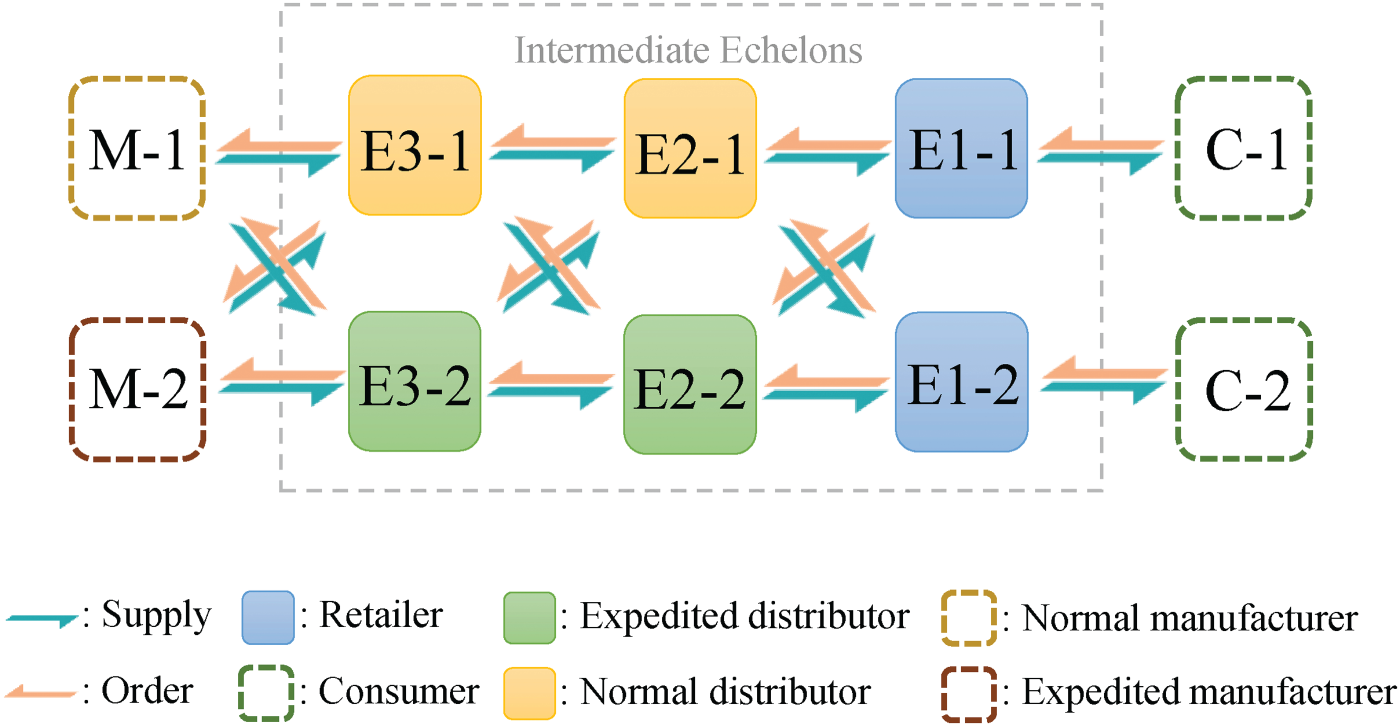
A supply chain network system with three echelons.
We use a 2-tuple
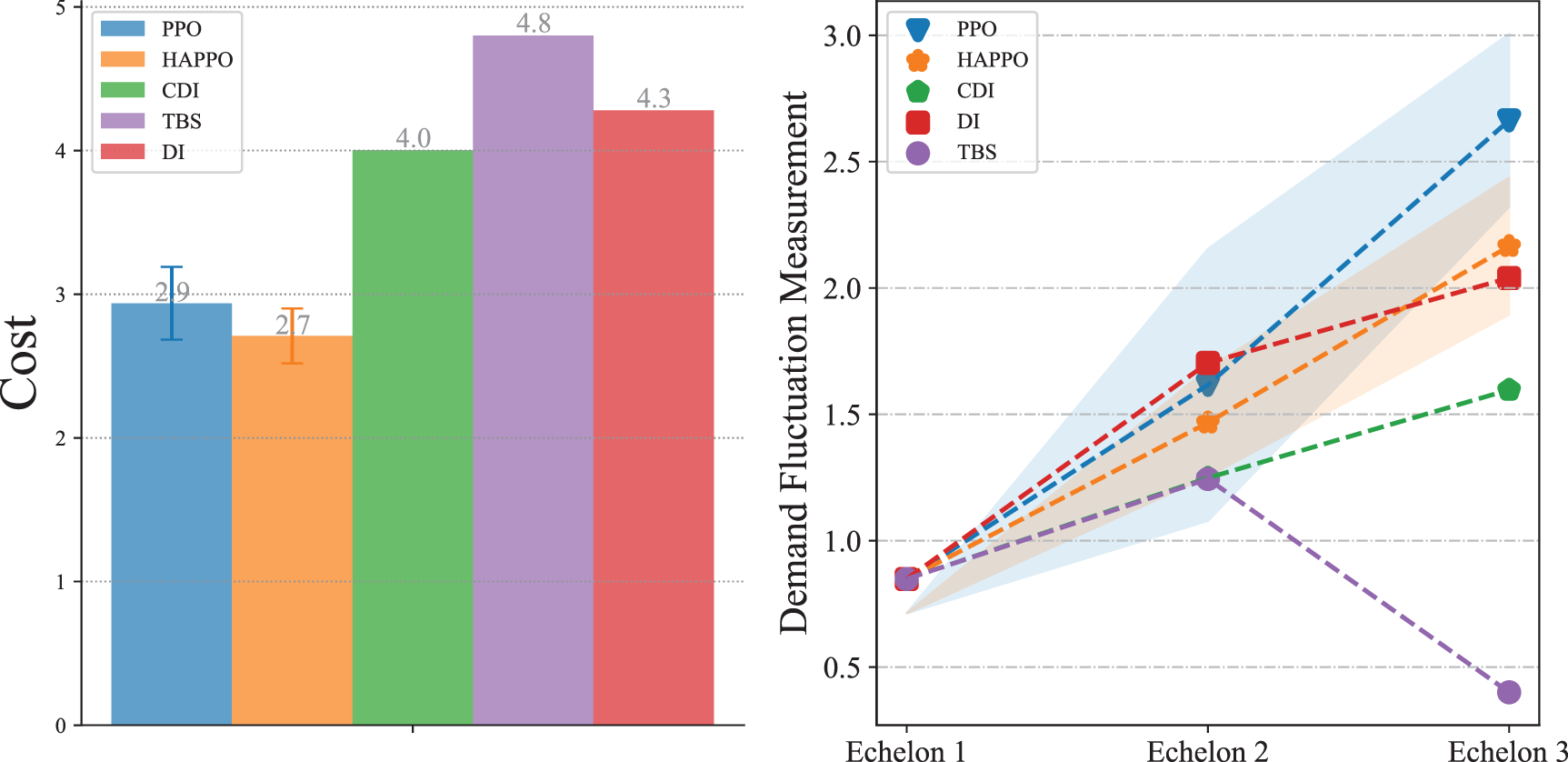
Comparison of system’s overall costs and the bullwhip effect in the supply chain network system.
Similar to the serial supply chain system, the actor’s ordering is constrained by the inventory state of its upstream suppliers. In each period 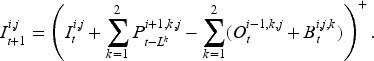
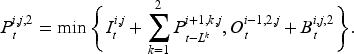
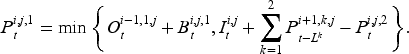
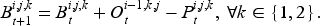
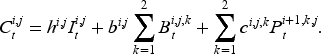
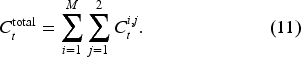
To include the information on inventory, backlogs, historical demand, and in-transit orders, actor 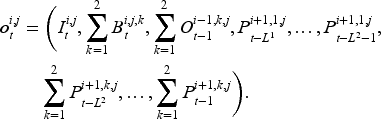
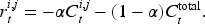
Similar to Section 3.3, we construct both the PPO baseline and several heuristic policies to evaluate HAPPO’s performance in the supply chain network system. Specifically, we choose three heuristic policies for the dual-sourcing inventory management problem, that is, DI, CDI, and TBS, whose implementation is provided in Appendix F.
For the experiment settings, we compare the overall costs of the system and the bullwhip effect for different policies in a typical supply chain network system with
Numerical Results
As shown in Figure 16, HAPPO achieves the lowest overall costs among all the policies we consider. Also, HAPPO leads to a less significant bullwhip effect compared to the PPO baseline. The results indicate that with a more complex supply chain structure, HAPPO is still superior in reducing the costs of the system and effective in alleviating the bullwhip effect. We provide the detailed policy visualization in the supply chain network system in Appendix I.
Conclusions
In this article, we demonstrate the superiority of MADRL in multi-echelon inventory management problems with limited information sharing, a complex supply chain structure, and non-stationary market environments. In both a serial supply chain system and a supply chain network system, policies constructed by HAPPO achieve the lowest overall costs among policies constructed by PPO, a single-agent DRL method, and other heuristic policies. Also, policies constructed by HAPPO yield a smaller bullwhip effect than policies constructed by PPO, which indicates the advantage of the upfront-only information-sharing mechanism used in MADRL. As the main takeaway of applying HAPPO in multi-echelon inventory management, compared to setting the minimization target of each actor as the overall costs of the system, HAPPO achieves lower overall costs when each actor learns to minimize a combination of its own costs and overall costs of the system.
In principle, MADRL can be applied to any multi-echelon inventory management problem as long as it can be formulated as a POMG. Other than HAPPO, there also exist some other effective MADRL algorithms following the CTDE scheme, such as Lowe et al. (2017), which can be used to tackle various multi-echelon inventory management problems where information sharing among actors is somehow restricted.
We provide extensible codes for applying HAPPO to any customized multi-echelon inventory management problem at https://github.com/xiaotianliu01/Multi-Agent-Deep-Reinforcement-Learning-on-Multi-Echelon-Inventory-Management which can serve as a base for quick implementation and future research.
Supplemental Material
sj-pdf-1-pao-10.1177_10591478241305863 - Supplemental material for Multi-Agent Deep Reinforcement Learning for Multi-Echelon Inventory Management
Supplemental material, sj-pdf-1-pao-10.1177_10591478241305863 for Multi-Agent Deep Reinforcement Learning for Multi-Echelon Inventory Management by Xiaotian Liu, Ming Hu, Yijie Peng and Yaodong Yang in Production and Operations Management
Footnotes
Acknowledgments
The authors thank the Departmental Editor, Professor Maxime Cohen, the Senior Editor, and two anonymous reviewers for valuable comments and suggestions throughout the whole review process.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by the National Science Foundation of China [Grants 2325007 and 72250065] and the Natural Sciences and Engineering Research Council of Canada [Grant RGPIN-2021-04295].
Notes
How to cite this article
Liu X, Hu M, Peng Y and Yang Y (2024) Multi-Agent Deep Reinforcement Learning for Multi-Echelon Inventory Management. Production and Operations Management 34(7): 1836–1856.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.