
Abstract
The purpose of this study was to develop and validate the Music Teacher Candidate Assessment (MTCA), a rubric-based tool for evaluating student teachers in music classrooms. Factor analyses of scores issued by university supervisors (USs), cooperating teachers (CTs), and student teachers (STs) supported construct validity, explained 53.5% of the variance, and revealed two subscales: Pedagogy (I) and Professionalism (II). Concurrent validity resulted from a strong correlation (rs = .83) between evaluators’ rubric averages and holistic ratings of performance. Inter-factor correlation (r = .65) confirmed discriminant validity. All groups exceeded the α ≥ .80 threshold for acceptable internal consistency on both subscales with no increase by item deletion. Interrater reliability showed moderate exact agreement (M = 0.54, SD = 0.05) among USs, CTs, and STs. However, exact + adjacent agreement exceeded .90 on all items and averaged .96 (SD = 0.03) overall. The MTCA provides teacher educators with a reliable, discipline-specific assessment and reflection tool for use during the student teaching practicum.
Effective teacher education is essential for high-quality music instruction in PK–12 schools (Concina, 2015). A key component of this process is the student teaching semester, during which candidates practice, develop, and demonstrate their pedagogical and professional competence under the guidance of a cooperating teacher and a university supervisor. In addition to mentoring and support, these individuals complete assessments that provide formative feedback for candidates’ growth and may lead to a summative grade or rating that can affect licensure and employment (Caughlan & Jiang, 2014).
Several measures of teaching performance exist based on expert observation or a portfolio of instructional artifacts (Caughlan & Jiang, 2014; Danielson et al., 2024; Draves, 2009). Authors expect these tools to reflect authentic assessment by calling on teachers to demonstrate knowledge, skills, and dispositions as they are used in practice, and to provide multiple forms of evidence evaluated against criteria relevant for performance in the field (Darling-Hammond, 2000). However, these instruments—intended for teachers of any subject—might not represent authenticity for music educators due to the unique pedagogy and modes of learning in music compared with other subjects (Clements-Cortés, 2011). An evaluation that measures the specific knowledge and skills of music teachers could acknowledge their specialized expertise and guide more meaningful professional growth that enhances PK–12 student learning.
Teacher Performance Assessments
The Educative Teaching Performance Assessment (edTPA) is a portfolio-based measure of student teaching achievement currently utilized by preparation programs in at least 17 states. Based on the Performance Assessment of California Teachers (PACT) developed in 2002, the edTPA aligns with Interstate New Teacher Assessment and Support Consortium (InTASC) standards (Council of Chief State School Officers, 2013) and emphasizes candidates’ ability to apply subject-specific pedagogical knowledge linked through research to effective teaching (Pecheone & Chung, 2006). The EdTPA includes three tasks: Planning, Instruction, and Assessment, each with separate commentaries and reflections. Lesson plans, teaching videos, student work samples, and assessments serve as evidence of candidates’ pedagogical abilities. Trained evaluators outside the college/university and employed by the testing company assess these materials and assign a score based on rubrics in each task (edTPA, 2022).
The Candidate Preservice Assessment of Student Teaching (CPAST), in contrast to the edTPA, is a collaborative measure for use by university supervisors, cooperating teachers, and teacher candidates during the student teaching semester. Developed by faculty in the College of Education and Human Ecology at The Ohio State University (OSU), this instrument contains 21 rubrics related to pedagogy (n = 13) and dispositions (n = 8) with detailed descriptors of observable and measurable behaviors to guide scoring decisions. Rubrics related to pedagogy evaluate planning, instruction, assessment, and analysis of teaching. Rubrics connected to dispositions measure candidates’ professional behaviors, relationships, and ability to reflect on teaching. Preparation programs that adopt CPAST agree to specific guidelines that include self-guided training modules for supervisors and midterm and final meetings between the supervisor, cooperating teacher, and student teacher, each of whom completes the form at both stages. The purpose of these meetings is to discuss ratings and reconcile scores that disagree between the parties, with the final decision left to the university supervisor (Ohio State University [OSU], n.d.).
Several evaluations for preservice teachers measure dispositions specifically (Neu, 2022). The Professional Competencies, Attitudes, and Dispositions (ProCAD) assessment developed at the University of Tennessee-Knoxville, for example, evaluates teacher candidates based on dispositions articulated by the Council for the Accreditation of Educator Preparation (CAEP) and the InTASC framework. Like CPAST, developers intended the ProCAD for use by supervisors, mentors, and candidates themselves. Each stakeholder rates the preservice teacher in eight categories using a 4-point scale ranging from unsatisfactory to exemplary. An unsatisfactory rating in any category triggers an Area of Refinement Plan to aid in professional growth (Laughter et al., 2022).
Many preparation institutions have developed local assessments of teacher candidates (e.g., Bastian et al., 2016; Oluwatayo & Adebule, 2012) while others have adopted measures intended for inservice educators, especially the Danielson Framework for Teachers (Danielson et al., 2024). Additional standardized observation instruments include the Marzano Focused Teacher Evaluation Model (Marzano Evaluation Center, 2023), the McREL Teacher Evaluation System (McREL, n.d.), and the Marshall Teacher Evaluation Rubric (Marshall, 2024).
All these tools separate teaching into various categories and assess each with multiple rubrics. The Danielson Framework (Danielson et al., 2024), for example, consists of four domains (Planning and Preparation, Learning Environments, Learning Experiences, Principled Teaching) divided into five or six components. The 22 total components are further distilled into 76 elements, each with a rubric that describes levels of achievement related to teacher performance. Although originally intended to define good teaching, the Framework evolved into an evaluation tool following its inclusion in the Measures of Effective Teaching research study funded by the Bill and Melinda Gates Foundation in 2009 (Kane & Staiger, 2012).
Proponents of standardized preservice teacher assessments claim that these instruments authentically measure effectiveness in real classroom settings. In addition, these tools can facilitate a consistent assessment process across disciplines, provide PK–12 cooperating teachers with guidance for mentoring candidates, and inform preparation institutions on strengths and weaknesses of their programs (Pecheone & Whittaker, 2016). All the standardized assessments mentioned above are based on research related to teacher effectiveness and have been evaluated for various forms of validity and reliability. Consequently, educator preparation programs can use the resulting data as evidence to support accreditation by CAEP or other agencies (Caughlan & Jiang, 2014; OSU, n.d.).
Music Teacher Assessment
The application of standardized assessments of teachers across all disciplines presents distinct challenges for music education (Powell & Parkes, 2020; Prichard, 2018). Widely used evaluation systems such as those by Danielson et al. (2024) and Marzano Evaluation Center (2023) were not designed with arts instruction in mind. As a result, these instruments might overlook the specialized content knowledge and pedagogical approaches integral to music educators’ practice (Nierman et al., 2016).
Regarding the edTPA, critics in music education have questioned the assessment’s reliability and validity (Austin & Berg, 2020; Hash, 2021; Musselwhite & Wesolowski, 2019) and have noted that candidates may prioritize earning high scores over meeting students’ needs. Stakeholders have further expressed concern that the required video component can distort teaching, raise privacy issues, and diminish the authenticity of classroom interactions. Additional critiques highlight the considerable time, stress, and financial burden placed on candidates, the reliance on external evaluators, and reduced program autonomy (Bernard & McBride, 2020; Parkes & Powell, 2015; Powell & Parkes, 2020). Scholars have also pointed to ambiguous instructions, demanding project timelines, misalignment between program expectations and assessment requirements (Heil & Berg, 2017), and the influence of candidates’ writing proficiency and vocabulary use on final scores (Wagoner & Juchniewicz, 2021).
Content-specific observation tools might be more effective in measuring teacher performance compared with instruments intended for instructors in any subject (Johnson & Semmelroth, 2014). Researchers have developed observation tools for several disciplines including science (Forbes et al., 2013), literacy (Smith et al., 2002), mathematics (Hill et al., 2008), social studies (Jay et al., 2025), history (Gestsdóttir et al., 2018), physical education (Society of Health and Physical Educators [SHAPE], 2017), and visual art (Arts Impact, 2003). Each of these measures demonstrate validity and reliability through statistical analysis and two align with other commonly used observation forms including the Danielson Framework and the Marzano Model (Arts Impact, 2003; SHAPE, 2017).
Despite the number of evaluation tools available, I found no assessment designed specifically for inservice or preservice music educators. Using a general teacher evaluation with music specialists might lead to inaccurate or unfair assessments due to the performance-based, collaborative, and creative nature of music instruction compared with some other subjects (Nierman et al., 2016). The general criteria in these assessments could force teachers to conform to non-musical models of instruction (Powell & Parkes, 2020), resulting in less meaningful feedback and limited professional growth (Johnson & Semmelroth, 2014).
Purpose
The purpose of this study was to develop and validate a rubric-based assessment tool for preservice music educators during the student teaching semester. The resulting instrument, the Music Teacher Candidate Assessment (MTCA), offers a music-specific alternative to existing standardized and locally developed assessments intended for educators across all subject areas (e.g., Danielson et al., 2024; Marzano Evaluation Center, 2023; OSU, n.d.). The primary goal was to create a valid and reliable measure of the specific and observable pedagogical and professional behaviors expected by music teacher candidates in daily practice. To enhance usability, the MTCA was intentionally designed with accessible language to support university supervisors, cooperating teachers, and student teachers in the processes of mentoring, reflection, and evaluation. This instrument requires no formal training—unlike tools such as the CPAST, Danielson Framework, and Marzano Model—and is freely available to those involved in music teacher education. The following questions guided this research:
Are there significant differences between MTCA scores issued by university supervisors (USs), cooperating teachers (CTs), and student teachers (STs)?
To what extent does the factor structure of the MTCA reflect a model of pedagogy and professionalism?
What level of interrater agreement is demonstrated on the MTCA among USs, CTs, and STs?
To what extent do high school and college grade point averages (GPAs) and state content examination scores predict performance on the MTCA?
Method
Instrument Design
I designed the MTCA (see Figure 1 in the Online Supplemental File) after reviewing other teacher performance assessments such as the edTPA (Sanford Center for Assessment, Learning, & Equity [SCALE], 2025), the CPAST (OSU, n.d.), and the Danielson Framework (Danielson et al., 2024). These and other evaluations informed the development of the MTCA in terms of structure and general content. However, the MTCA is a unique instrument intended specifically for preservice music educators rather than a modification of an existing measure.
Like the CPAST (OSU, n.d.), the MTCA separates teaching into two broad categories: Pedagogy and Professionalism. Pedagogy is divided into three domains including Planning and Preparation, Instruction, and Classroom Management. Professional Behaviors define the fourth domain. Each domain contains three to six components, all measured with separate rubrics that define four achievement levels: Unacceptable (well below expectations), Emerging (developing), Proficient (expected of a novice teacher), and Advanced (comparable to an experienced teacher).
A Proficient rating in each component is the target for student teachers at the conclusion of their clinical experience. I included the Advanced rating to acknowledge and document exemplary performance and support continued growth for candidates who have reached the target before the end of the semester. Including an Advanced level also provides clearer differentiation among candidates, supports more precise feedback, and creates better statistical sensitivity in analyses (Brookhart, 2013; Jonsson & Svingby, 2007).
As indicated on the form, each component includes a key question to enhance clarity and aligns with standards and competencies from InTASC (Council of Chief State School Officers, 2013) and/or the National Association of Schools of Music (NASM, 2025). (See Figure 1 in the Online Supplement.) These alignments support the use of MTCA data in accreditation processes for NASM or other agencies such as CAEP. Evaluators provide feedback in text boxes for each domain and a summative statement at the end of the assessment. However, I did not analyze these data for this study or include text boxes on the form provided in the Online Supplement.
Scoring the MTCA
Users of the MTCA can determine summative ratings for Pedagogy and Professionalism through the following procedure: (a) convert each component rating to a numerical value (Advanced = 4; Proficient = 3; Emerging = 2; Unacceptable = 1); (b) calculate the average score of all components within the category; and (c) use the average to assign a summative rating for that category. A candidate with an average between 3.60 and 4.00 and no components marked as Emerging or Unacceptable will be classified as Advanced. A mean score of 3.00 to 3.59 with no Unacceptable components will result in a Proficient rating. An average between 2.00 and 2.99 with no Unacceptable marks will be rated as Emerging. Scores below 2.00 or the presence of any Unacceptable components will lead to an Unacceptable rating.
An Unacceptable mark in any component should prompt the development of a remediation plan (e.g., Laughter et al., 2022). Multiple Unacceptable ratings from university supervisors or cooperating teachers may warrant removal of the student teacher from their placement and/or a reevaluation of the candidate’s eligibility for licensure.
Content Validity
An expert panel consisting of three university faculty members and two veteran PK–12 music educators—each with over 30 years of experience in teaching and mentoring—assessed the content validity of the MTCA. Following the guidelines of Yusoff (2019), the panel rated the relevance of each component to student teaching in the music classroom using a 4-point scale (1 = not relevant, 2 = somewhat relevant, 3 = relevant, 4 = highly relevant). A component achieved validity if all panelists rated it as a 3 or 4. All components met this criterion, confirming content validity of the instrument.
Another music teacher educator and I aligned the MTCA with the standards/competencies from InTASC (Council of Chief State School Officers, 2013) and NASM (2025). We discussed each component in relation to the standards/competencies until we reached consensus. I piloted the MTCA at a large university in the Midwest over three semesters from fall 2023 to fall 2024 to test efficacy, check initial reliability, and orient supervisors to the instrument prior to the main study.
Participants
Data for this study consisted of MTCA scores (N = 472 completed forms) collected over three semesters between spring 2024 and spring 2025 for student teachers at a large university in the Midwest United States. Student teachers taught two or three levels (elementary, middle school, high school) of ensembles or a combination of ensembles and general music in either one 16-week or two 8-week internships. Placements involved schools in urban, suburban, town, and rural communities throughout the state. Supervisors (N = 19) completed the MTCA for each student teacher four times—during weeks 4, 8 (midterm), 12, and 16 (final). Cooperating teachers (N = 115) and student teachers (N = 63) completed the assessment in weeks 8 (midterm) and 16 (final).
Data Analysis
Findings for this study resulted from analyses of MTCA scores issued by university supervisors (USs) and cooperating teachers (CTs), and self-evaluations from the student teachers’ (STs) themselves. I compared rater’s scores using descriptive statistics (M, SD) and a univariate ANOVA. Post hoc analyses included Levene’s test for homogeneity of variances, followed by either a Tukey HSD test when variances were equal or a Games–Howell test when they were unequal. Cronbach’s alpha provided a measure of internal reliability. I also measured exact and exact + adjacent interrater agreement on each rubric between USs, CTs, and STs on the second and fourth assessments for candidates with completed forms from all stakeholders (n = 53).
I established construct validity through factor analyses for data generated by USs, CTs, and STs. This process involved principal axis factoring with Kaiser normalization, Promax rotation, and kappa set at the default value of 4. The goal was to determine the best model fit using criteria for simple structure (Klien, 1994). According to these criteria, each row of the rotated matrix should include at least one near-zero loading (–.10 to +.10), and each factor should have at least as many zero loadings as there are factors. In addition, each pair of factors should contain variables with significant loadings (≥ .30) on one factor and near-zero loadings on the other, while only a few variables should have significant loadings on both factors or loadings ≥ .30 on multiple factors. In addition to their contribution to simple structure, I also considered the effectiveness of individual items based on the extent to which they achieved a high loading (≥ .40) (Miksza & Elpus, 2019) on their intended factor.
Data from the pattern matrix (unique contribution of each factor to a variable’s variance) determined which items clustered into factors. However, the structure matrix (correlation of each variable and factor) and communalities (proportion of each variable’s total variance accounted for by all factors) also contributed to the interpretation. Bartlett’s test of sphericity indicated if there were adequate correlations for data reduction, and the Kaiser–Meyer–Olkin (KMO) measure determined sampling adequacy (Miksza & Elpus, 2019). I also examined inter-factor correlations to determine if the factor structure met the criteria (r ≤ .85) for discriminant validity (Brown, 2015).
Establishing concurrent validity involved examining the correlation between the average rubric score on the MTCA for each student teacher with a wholistic rating of their performance by the same rater. After providing scores for each rubric, evaluators responded to the following prompt: “Without considering the rubric ratings above, please provide a holistic rating of the teacher candidate's current level of performance.” The scale for the 7-point wholistic rating progressed in .5 increments from 1.0 (Unacceptable—Performance well below expectations at this stage of development) to 4.0 (Advanced—Performance at the level of an experienced teacher). Although rubric averages and wholistic ratings by the same evaluator based on a single observation are not independent, comparison of these data lends some support to the assertion that the teaching skills and professional behaviors measured in the rubrics are considered by raters as components of competency in the profession (Pecheone & Chung, 2006).
I examined predictive validity by correlating average MTCA Pedagogy and Professionalism scores assigned by university supervisors (USs) during the fourth observation with student teachers’ high school and college GPAs, and their cumulative and subtest scores on the state content exam. High school GPAs are reported on a 4-point scale. However, weighted classes (e.g., Advanced Placement courses) can result in GPAs above 4.0. Composite and subtest scores on the state content exam can range from 0 (min.) to 300 (max.). The composite score is the average of the subtests (music listening, theory, creation and performance, history and culture, and pedagogy) and a minimum of 240 is required to pass. Individual MTCA scores for Pedagogy and Professionalism reflect the average of the component ratings within each category.
Results
Data from 370 MTCAs completed for evaluations 2 and 4 by USs (n = 121), CTs (n = 124), and STs (n = 125) showed that STs rated themselves lower than USs or CTs on 12 of the 13 Pedagogy components, whereas Professionalism ratings were more aligned across groups (see Table 1). A univariate ANOVA showed a significant difference in average Pedagogy ratings, F(2, 367) = 7.18, p < .001, η²p = .038. Levene’s test indicated unequal variances, F(2, 367) = 4.95, p = .008. A Games–Howell test showed that STs (M = 3.0, SD = 0.4) rated themselves significantly lower than both USs (M = 3.2, SD = 0.5, p = .003) and CTs (M = 3.2, SD = 0.5, p = .002). There was no significant difference between the average Pedagogy ratings issued by USs and CTs. Likewise, analysis of average Professionalism scores indicated no significant difference among USs (M = 3.5, SD = 0.4), CTs (M = 3.6, SD = 0.5), and STs (M = 3.5, SD = 0.4), F(2, 467) = .75, p = .473, η²p = .00.
Component Means and Standard Deviations for Observations 2 and 4.
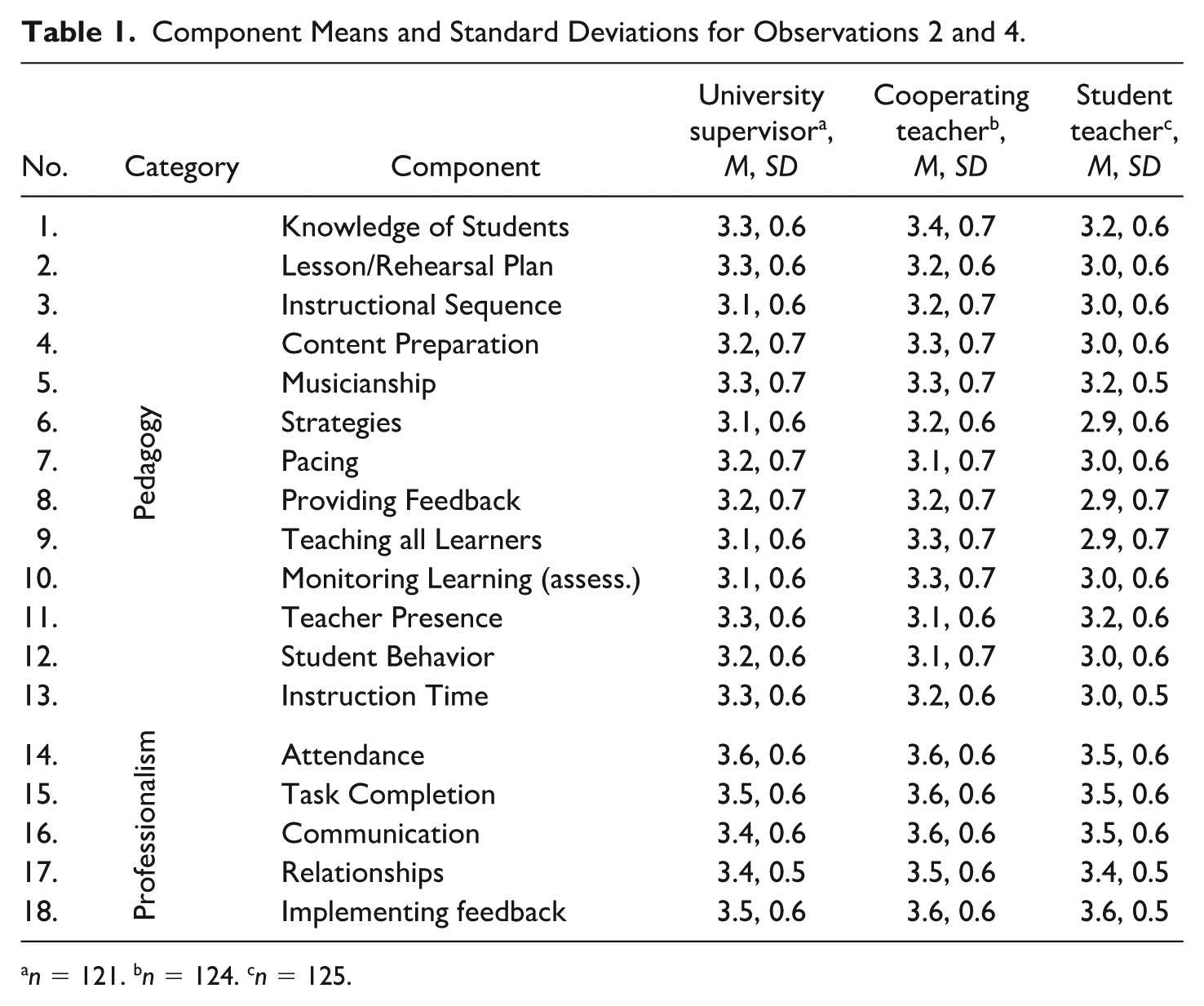
n = 121. bn = 124. cn = 125.
Construct Validity
Separate factor analyses on MTCAs (N = 468) completed by USs (n = 219), CTs (n = 124), and STs (n = 125) indicated similar factor structures among these groups around Pedagogy and Professionalism (see Online Supplement, Tables 1–3). Therefore, I combined these data to determine overall construct validity but used data from only observations 2 and 4 (N = 370) to create equal representation of USs, CTs, and STs.
A factor analysis using the eigenvalue-of-one criterion yielded a two-factor solution that explained 53.5% of the total variance and converged after three iterations. Bartlett’s test (χ2 = 3099.17, p < .001) determined that there were correlations in the data appropriate for factor analysis and the KMO measure (.95) indicated adequate sample size. Subject-to-variable ratio exceeded the 5:1 ratio recommended by Miksza and Elpus (2019) and equaled 20.56:1. Communalities ranged from .29 to .56 after extraction (M = 0.48, SD = 0.07) and all factor loadings exceeded .50 with no significant cross loadings between factors. This model met all criteria for a simple structure except that four variables slightly exceeded +/− 1.0 and failed to produce a 0 loading on its opposite factor.
The factor solution (see Table 2) for ratings on the MTCA supported the model around Pedagogy (Factor I, initial eigenvalue = 8.01) and Professionalism (Factor II, initial eigenvalue = 1.61) and accounted for 44.5% and 8.9% of the variance respectively. Inter-factor correlation (r = .65) met the cutoff for discriminant validity (Brown, 2015). Data also indicated concurrent validity through a strong relationship (rs = .83) between average rubric scores and wholistic ratings of student teacher performance.
Combined USs, CTs, STs Factor Analysis: Observations 2 and 4.

Note. N = 370. Factor loadings in bold type.
P&P = Planning & Preparation, I = Instruction, CM = Classroom Management, PB = Professional Behaviors. Factor loadings above .30 are in bold.
Predictive Validity
Individual MTCA scores (N = 61) for Pedagogy (M = 3.4, SD = 0.4) and Professionalism (M = 3.5, SD = 0.4) were moderately related (r = .60) on USs’ fourth evaluations. However, the relationship (r = −.07 to .20) between these scores and candidates’ high school (N = 53, M = 3.92, SD = 0.53) and college (N = 61, M = 3.62, SD = 0.32) GPAs indicated that prior academic performance did not significantly predict achievement during the student teaching semester. Similarly, weak and non-significant relationships between supervisors’ MTCA ratings and STs’ (N = 61) subscale (listening: M = 252.9, SD = 24.5; theory: M = 259.4, SD = 31.7; performance and creation, M = 264.0, SD = 24.0; history and culture, M = 258.6, SD = 21.6; pedagogy: M = 255.1, SD = 21.8) and composite (M = 258.3, SD = 17.2) scores on the state content test showed minimal association (r = −.09 to .20) between these variables (see Table 4 in the Online Supplement).
Reliability
Internal consistency of MTCA ratings from each group exceeded the α ≥ .80 threshold for acceptable reliability (Krippendorff, 2018) on both Factor I (Pedagogy: USs, α = .94; CTs, α = .93; STs, α = .87) and Factor II (Professionalism: USs, α = .84; CTs, α = .85; STs, α = .82) with no increase by any item deletion. Exact interrater agreement (IRA) on each component ranged from .48 to .71 (M = 0.59, SD = 0.06) for USs and STs, .41 to .61 for USs and CTs (M = 0.53, SD = 0.06), and .39 to .61 (M = 0.51, SD = 0.06) for CTs and STs. Exact IRA for USs, STs, and CTs averaged .54 (SD = 0.05) overall. However, reliability coefficients for exact + adjacent agreements exceeded .90 for all items and averaged .96 (SD = 0.03) among participants. (See Table 5 in the Online Supplement.)
Discussion and Recommendations
The purpose of this study was to develop and validate the MTCA, a rubric-based assessment tool for preservice music educators during the student teaching semester. Data indicated that this measure demonstrated acceptable to strong validity and reliability when completed by USs, CTs, and STs. Music teacher educators might consider this instrument for evaluations by USs and/or CTs, and as a reflection tool for STs. College faculty could also align methods course curricula around the domains and components of the MTCA, thereby strengthening the connection between preservice coursework and the student teaching semester.
The MTCA provides a framework for defining effective instruction and professionalism for music student teachers similar to other established models for general education (e.g., Danielson et al., 2024; Marzano Evaluation Center, 2023). In this capacity, the assessment could contribute to the preparation of USs and CTs by clearly outlining candidate expectations and stages of development. The MTCA might also facilitate mutually beneficial experiences in school-university partnerships by promoting best practices, aligning expectations, involving CTs in the evaluation of STs, and improving the learning experiences of PK–12 students (Mercado et al., 2024).
Several factors might have contributed to lower ratings issued by STs for Pedagogy compared with their USs and CTs. STs in this study may have experienced imposter syndrome (Nápoles et al., 2024) or lacked a clear understanding of the rubric criteria for each performance level. They were also encouraged to provide honest, reflective evaluations and assured that their ratings would not influence their final student teaching grade. Consequently, some candidates may have been hesitant to assign themselves higher scores when uncertain about which descriptor best reflected their performance.
The factor solution for the MTCA derived from STs self-evaluations as well as the correlation between their average rubric scores and wholistic rating were acceptable but less robust than findings from analyses of US and CT data. (Compare Tables 1–3 in the Online Supplement.) In addition, exact IRA indicated that STs self-reported scores matched those of their USs and CTs only 50% to 60% of the time. These findings suggest that USs and CTs might have a different perspective on the competencies measured by the MTCA compared with STs. Perhaps integrating the MTCA as a tool for reflection and formative assessment in preservice coursework could help align candidates’ expectations with those held by USs and CTs.
USs and CTs also agreed on MTCA ratings only about half of the time. One possible explanation is that USs based their scores on single observations and limited contact with their STs, while CTs rated candidates based on daily interactions and ongoing experiences in the classroom. Additional communication between USs and CTs might increase agreement and provide scores that more accurately represent ST performance overall.
STs and USs demonstrated higher levels of agreement on the second and fourth assessments than STs and CTs did. This finding might reflect the influence of USs scores and feedback from observations in weeks 4 and 12 on candidates’ self-evaluations in weeks 8 and 16. Encouraging CTs to reference the MTCA in feedback to their STs might help establish a shared understanding of expectations and lead to more consistent levels of IRA between all stakeholders.
Readers should interpret exact + adjacent IRA with caution. Creators of the edTPA (Pearson, 2025) and CPAST (OSU, n.d.) reported exact + adjacent IRA coefficients to support the reliability of these instruments. For comparison, I also analyzed exact + adjacent interrater agreements for the MTCA and found indices similar to those provided for the edTPA (M = 0.97) and CPAST (M = 0.98). Nonetheless, the use of exact + adjacent agreements is problematic on a 4- or 5-point scale, especially when scorers rarely use the highest and/or lowest categories. With the MTCA, evaluators seldom marked the lowest rating (i.e., Unacceptable). Adjacent agreement is less problematic when estimating reliability for longer scales because of the underlying possible score range and the precision required to attain perfect agreement (Stemler & Tsai, 2008).
Correlations of MTCA ratings with high school and college GPAs and state content exam scores indicated that these data were negligible to weak predictors of achievement during student teaching. These findings were similar to Austin and Berg (2020), who found weak correlations between the edTPA—another measure of student teaching performance—and HS (r = .22) and cumulative college (r = .26) GPAs, and a state licensing assessment (r = .20).
Several factors might have contributed to weak correlations between the MTCA and the predictor variables examined here. First, GPA and/or the state content exam may relate to variance not explained by MTCA scores, as academic performance does not always translate to effective teaching practice (Darling-Hammond, 2000). In addition, low variability in both the MTCA scale and student teacher GPAs could have limited the strength of observed relationships. Standard deviations for HS and college GPAs and MTCA scores for the preservice teachers involved in this study indicated relatively low variability on these measures. Nonetheless, these findings suggest that HS and college GPAs might not be reliable indicators of teaching potential. Faculty should, therefore, critically consider such data when making decisions about admission or continued enrollment in teacher preparation programs. Likewise, policymakers should reassess the effectiveness of standardized content exams in the teacher licensure process.
Limitations
Preparation programs adopting the MTCA should be aware of potential limitations. For example, this form did not account for approximately 47% of the variance in student teacher performance. Furthermore, the use of percent agreement did not consider agreements that might have happened by chance. I did not apply statistics such as Cohen’s kappa or interclass correlation because the data violated assumptions for those procedures (Gisev et al., 2013). In addition to these limitations, data suggested that USs, CTs, and STs might have differing perceptions of candidates’ performance. Therefore, faculty should consider multiple methods of evaluation, which could include supplementing the MTCA with reflection journals or rubrics related to specific aspects of instruction such as technology use (e.g., Harris et al., 2010) or culturally responsive teaching (e.g., Consortium for Policy Research in Education, 2023).
Future Research
In this study, the MTCA demonstrated validity and reliability comparable to other measures of student teacher performance (e.g., Pearson, 2025; OSU, n.d.). Future research might continue to refine this instrument to increase the amount of variance explained and improve the validity and reliability demonstrated for candidates’ self-evaluations. Accomplishing these goals might include adding components, revising descriptors, implementing training for USs and CTs, and/or using the MTCA in methods classes prior to the student teaching semester.
Researchers could use the MTCA as a basis for examining student teachers’ reflections on their emerging practice and progress throughout the semester. Other studies might compare MTCA scores to potential predictor variables such as ACT and SAT scores, grades in various methods classes, or evaluations during field experiences prior to student teaching (Austin & Berg, 2020). Further development of the MTCA might involve creating a companion measure similar to the pre-CPAST (OSU, n.d.) for use in field experiences prior to student teaching.
In addition to studies related to the MTCA, future researchers might also examine the efficacy of using teacher evaluations designed for all content areas (e.g., Danielson et al., 2024) with preservice and inservice music educators. Several authors have examined the edTPA in relation to music teacher preparation (e.g., Parkes & Powell, 2015). However, fewer studies exist involving the use of general evaluation frameworks in music classrooms.
The MTCA offers teacher educators a subject-specific, reliable assessment and reflection tool for use during student teaching, and as a source of data for program accreditation. Anyone involved with music teacher preparation is welcome to use this instrument. The Online Supplement to this article (p. 1) provides a link to a Google Drive folder containing the MTCA in Microsoft Word (.docx) and Portable Document Format (.pdf), as well as versions available as a Google Form and a Microsoft Form.
Supplemental Material
sj-docx-1-jmt-10.1177_10570837261430922 – Supplemental material for Development and Validation of a Music Teacher Candidate Assessment
Supplemental material, sj-docx-1-jmt-10.1177_10570837261430922 for Development and Validation of a Music Teacher Candidate Assessment by Phillip M. Hash in Journal of Music Teacher Education
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Ethical Considerations
The IRB at Illinois State University determined that this study did not meet the Federal Regulation’s definition of human subject research under the Revised Common Rule. Therefore, further IRB review was not necessary (IRB-2025-298).
Consent to Participate
Not applicable.
Data Availability
Not available. Note that the submission includes an online supplemental file with figures and tables to support the narrative.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.