
Abstract
Inter- and intra-rater variability negatively affects the reliability of various histopathology grading scales used as prognostic aids in human and veterinary medicine. The Kenney–Doig categorization (grading) scale, which is used to associate equine endometrial histologic lesions with prognostic estimation of a broodmare’s reproductive potential, has not been evaluated for inter- or intra-rater variability, to our knowledge. To assess whether the Kenney–Doig system produces reliable results among observers, 8 pathologists, all with American College of Veterinary Pathologists certification, were recruited to blindly categorize the same set of 63 digital equine endometrial biopsy slides as well as to re-evaluate anonymously 21 of 63 of these slides at a later time. Cohen kappa values for pairwise comparison of final Kenney–Doig categories were −0.05 to 0.46 (unweighted) and 0.08–0.64 (weighted), with an average Light kappa of 0.19 (unweighted) and 0.36 (weighted) across all 8 pathologists, 0.14 (unweighted) and 0.33 (weighted) for pathologists at different institutions, and 0.22 (unweighted) and 0.46 (weighted) for pathologists at the same institution. Intra-class correlations measuring intra-rater agreement were 0.12–0.77 with an average of 0.55 for all 8 pathologists. We found that only slight-to-moderate inter-rater agreement and poor-to-good intra-rater agreement was produced by 8 pathologists using the Kenney–Doig scale, suggesting that the system is subject to significant observer variability and care should be taken when communicating Kenney–Doig categories to submitting clinicians with emphasis on the quality of endometrial lesions present instead of the category and associated expected foaling rate.
Subfertility in mares is a global phenomenon and with every breeding season comes an influx of equine endometrial biopsies submitted to diagnostic laboratories in an attempt to diagnose any conditions that may be responsible for the mare’s decreased reproductive performance. The international standard for assessing these histologic changes is a categorization (grading) scale proposed by Kenney and Doig. 17
The Kenney–Doig scale is built upon quantifying various histopathologic changes, including fibrosis, inflammation, enlarged lymphatics, cystic endometrial glands, and glandular epithelial atrophy, with descriptive modifiers of absent, mild, moderate, or severe. The combination and relative severity of these markers are summed and used to place the endometrial biopsy in one of 4 categories: I, IIA, IIB, III. Each category is associated with a percent chance that the mare has of maintaining a pregnancy and delivering a live foal.
Despite the prognostic foaling rate associated with each Kenney–Doig category, a truly accurate estimate of a mare’s breeding potential is difficult to make based on histology alone. This is in part because other criteria in the Kenney–Doig scale involve knowing the mare’s reproductive history, including whether she has been barren for ≥2 y, and integrating clinical findings such as transrectal palpation and stage of cycle; this information is not always available to pathologists who are tasked with grading an endometrial biopsy, resulting in assignment of a potentially inaccurate Kenney–Doig category. 17 Theriogenologists are now trained to read their own endometrial biopsies and to integrate histologic findings with the rest of the breeding soundness exam including history, perineal conformation, transrectal palpation, ultrasonography, hysteroscopy, and uterine cytology and culture results. This evolution has resulted in less reliance on the Kenney–Doig categorization in general. 23 Instead, emphasis now revolves around the nature of endometrial histologic lesions present, pathophysiology, the development of novel test methods, and research into new avenues of treatment.43,49 Although this shift in the evaluation of endometrial biopsies is well accepted in the theriogenology community, pathologists at diagnostic laboratories across Canada still receive endometrial biopsies requesting Kenney–Doig categorization.
Since the introduction of the Kenney–Doig scale, concerns regarding the subjectivity of the category guidelines and the potential for observer variation have been raised in the literature.12,38,39,49 Although the evaluation of endometrial fibrosis involves more quantitative criteria, such as the number of layers, or the number of nests per 5.5-mm linear field averaged over 4 or more fields, other histologic lesions such as inflammation are evaluated using more descriptive terms, such as widespread versus scattered, or discrete versus diffuse foci, which may be subject to significant variation in observer interpretation. 17 Therefore, there is concern that there could be significant disagreement regarding the histologic Kenney–Doig category assigned to a biopsy, without accounting for any clinical modifiers such as the history of barrenness.
Our previous work involving retrospective evaluation of the Kenney–Doig grading distribution of biopsies submitted to the Western College of Veterinary Medicine (WCVM; University of Saskatchewan, Saskatoon, Saskatchewan, Canada) and Prairie Diagnostic Services (PDS; Saskatoon, Saskatchewan, Canada) revealed a non-uniform spread of categories with a high incidence of biopsies assigned within the 2 middle categories, IIA and IIB. 54 Although the effect of mare population dynamics on category distribution cannot be excluded, observer variation may also contribute to the significantly higher incidence of middle-ranked categories, as has been seen in other histopathology grading systems in veterinary medicine.19,35 Examination of the individual grading tendencies of 5 of the contributing pathologists at the WCVM and PDS revealed significant differences in category proportions, suggesting that observer bias and possible disagreement regarding use of the scale may be occurring.
Many histopathology scales exist in both human and veterinary medicine, particularly in oncology in which surgical biopsies of tumors are graded and associated with risks of metastasis and other prognostic traits. To be able to trust the results of these scales, validity and reproducibility studies are done to both validate the prognoses associated with each category and to investigate whether significant observer variation exists among pathologists using the scales. 7 Prospective inter- and intra-rater agreement studies have been used to assess the reproducibility of these systems and identify the need for modification of grading guidelines.3,13,16,19,34,35,40,42 Although several studies have focused on proving the validity of the Kenney–Doig scale, to our knowledge, no studies exist that directly measure the inter- and intra-rater agreement that the scale produces among diagnostic pathologists.
The guidelines that Kenney and Doig outlined for their histopathology categorization scale involve describing the severity of multiple endometrial histologic lesions and summing these changes to fall in 1 of 4 categories. Both the quantification of the distribution and severity of these lesions, and the end summation into a final category, may be affected by subjective opinion of the observing pathologist. Several reasons have been postulated by other researchers that could bias an observer and influence how they use any given histopathology system. The creation of a 4-category system may not be sufficiently robust to cover multiple pathologic changes that tend to spread across a continuous scale, making it difficult to accurately quantify them into discrete groups.7,9,32 The criteria used to define these divisions may also be vague and open to interpretation, especially if there is variable severity and distribution of histologic lesions in the tissue, resulting in a heterogeneous rather than a homogeneous spread of changes.8,9,12,35,36,38,39 Additionally, pathologists may disagree on which histologic characteristics may be more important prognostically, thereby affecting how they judge the severity of histologic lesions present and, ultimately, how they combine these features into a final diagnostic category.9,32
To measure the inter-rater agreement produced by the Kenney–Doig scale, we calculated unweighted and weighted kappa values, statistics commonly used to measure observer variability in histopathology.9,14,28,34 Although there is no gold standard associated with a minimum acceptable value for inter-rater reliability in histopathology, suggestions have been made for a minimum unweighted kappa value of 0.60. 32 In a comprehensive summary of inter- and intra-rater variability studies concerning multiple systems for grading cervical dysplasia in human medicine from 1956 to 2001, unweighted kappa values were 0.13–0.63 across 13 different studies. 28 Other studies identified in the literature examining various histopathology systems for oral epitheliomas, breast cancer, and colon cancer biopsy grading have reported 0.24–0.70.3,4,28,42,51 The kappa values obtained in our study were interpreted in the context of other histopathology scale kappa values reported in the literature.
Our goal was to investigate the inter- and intra-rater agreement within a group of American College of Veterinary Pathologist (ACVP)-certified pathologists based on their interpretation of the Kenney–Doig scale, and how they use the scale when grading the same anonymized set of endometrial biopsies. This is a preliminary investigation into the reproducibility of the Kenney–Doig system based on the interpretation of practicing pathologists in diagnostic laboratories in Canada and the United States. We hope to encourage inter-disciplinary collaboration when evaluating a mare’s reproductive potential, caution when communicating Kenney–Doig categories and associated expected foaling rates, and critical evaluation of the quality of endometrial histologic lesions present to better direct submitting clinicians toward potential therapies and breeding techniques.
Materials and methods
Slide selection and digitization
Sample size was determined using recommendations for unweighted kappa statistical analysis. 5 A 4×4 table was selected for the 4 possible Kenney–Doig categories available, the power set at 90% with an alpha level of 0.05, and the K1 and K2 values selected at 0 and 0.4, respectively. This resulted in a suggested minimum sample size of n = 25; however, given the unequal frequency distributions observed in our previous retrospective study 54 and the possibility that participating pathologists would categorize in similar distributions, we doubled this number for a minimum sample size of n = 50. 5 Weighted kappa values were not taken into account for sample size given that weighted kappa statistics are more sensitive at measuring agreement than unweighted and therefore require smaller sample sizes in general. Based on the proposed blocking of the surveys described below and the projected timeline for the project, an overall inter-rater agreement sample size of 63 was set, with an additional 21 slides of previously categorized slides to be used for intra-rater agreement.
Endometrial biopsy submissions from the Veterinary Diagnostic Services (1998–2014) and the Prairie Diagnostic Services (2014–2018) databases were selected via random number generator (Excel; Microsoft) to select 16 random biopsies from each of the 4 Kenney–Doig categories as assigned by the original overseeing PDS or WCVM pathologist, for a total of 64 slides. The original glass slide for each biopsy was pulled and examined for preliminary inclusion criteria: adequate amount of physical tissue in the sample and appropriate amount of histologic tissue layers (sufficient intact epithelium, stratum spongiosum, stratum compactum, and glandular density). If the original glass slide could not be located, another slide was prepared from the paraffin block containing the original surgical biopsy by the PDS histology laboratory using routine slide preparation and H&E staining technique. Finally, all slides were screened for adequate staining intensity and recut as previously described if they did not meet appropriate standards.
All 64 slides were digitally scanned (20× objective, VS120 virtual microscope; Olympus) by the WCVM Imaging Suite. The resulting scans were uploaded to a locally maintained database for access via OlyVia software (Olympus, http://wcvmmicroscopy.usask.ca) for viewing.
To control for fatigue bias while grading slides, the slide set was blocked and randomly partitioned into 3 groups of 21 slides, leaving one Kenney–Doig category III slide excluded from use resulting in 16 slides of categories I–IIB and 15 slides of category III randomly mixed throughout the 3 groups. A fourth group of slides was also created by randomly selecting slides within each Kenney–Doig category from the 63 previously selected slides to be used for testing intra-agreement of pathologists at different times, resulting in 5 slides for each of category I, IIB, and III, and 6 slides for category IIA.
Survey design and implementation
To collect Kenney–Doig grading data, surveys were designed for each of the 4 blocks of slides using Survey Monkey software (http://www.surveymonkey.com). Each survey page included the same questions per slide; pathologists were asked to evaluate the amount of inflammation, fibrosis, lymphatic lacunae, and glandular atrophy as absent, mild, moderate, or severe, and to assign a final Kenney–Doig category. Optional comment boxes were included for each slide for additional description if deemed necessary. The first survey also included some basic questions regarding the pathologist’s experience with the Kenney–Doig scale.
Slides were embedded into each survey page with a hyperlink to the corresponding viewing window in the online OlyVIA server. Pathologists were asked to log into the OlyVIA server at the beginning of each session in a separate tab and then access the corresponding slide to each survey page with the embedded hyperlink. In this fashion, pathologists were able to view and categorize the same slides via Survey Monkey and OlyVIA.
Surveys were administered via email invitation over the course of 17 mo, with appropriate breaks to control for fatigue bias and to accommodate scheduling conflicts. The final survey, which consisted of a mixture of previously categorized slides, was administered >2 wk after the last completed survey to control for slide recognition, with some slides having been categorized >12 mo prior.
Pathologist recruitment and participation
Eight ACVP-certified pathologists were recruited for the experiment, 7 of whom routinely assign Kenney–Doig categories to equine endometrial biopsies in practice. All 8 pathologists had completed their residency training at one of 3 academic institutions: 2 in Canada (A, B), and 1 in the United States (C). At the time of this study, 6 of 8 pathologists were practicing at the same academic institution at which they had completed their residency; 2 of 8 pathologists were practicing for a private diagnostic laboratory (D) or a different academic institution (E) than where they had been trained, respectively. Five of 8 pathologists were recruited from institutions A–E. An additional 3 pathologists were then recruited from institution B, resulting in 3 different groupings of observers: all 8 pathologists total, 5 pathologists from A–E (inter-institution group), and 4 pathologists from B (intra-institution group; Fig. 1). Specifics regarding the pathologists, institutions, or diagnostic laboratories involved have been withheld to maintain anonymity of the participants.
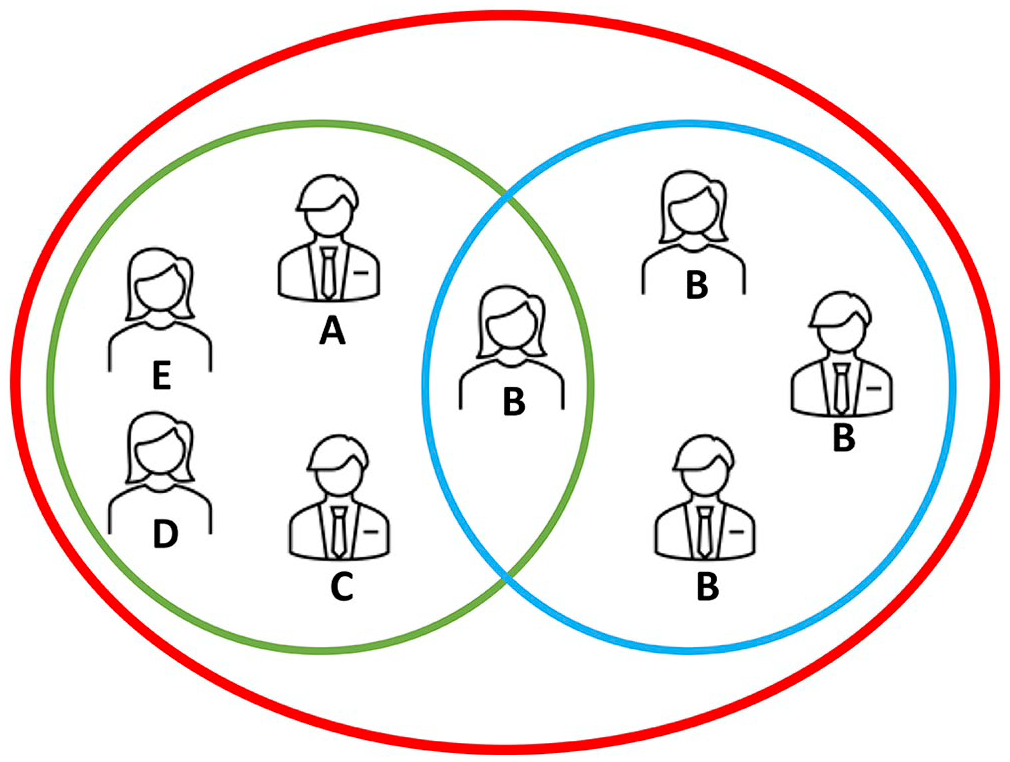
Illustration of different observer groups used to compare the 8 pathologists enrolled in our study labeled with their current practicing institution A–E. Observers were grouped as: all 8 pathologists (red circle), 5 pathologists within an inter-institution group (green circle), and 4 pathologists within an intra-institution group (blue circle).
Each pathologist was provided with a copy of the original Kenney–Doig paper to peruse if desired and a brief introductory statement to the study. 17 Pathologists were instructed to complete the surveys to the best of their abilities, focusing on only the histologic lesions to determine the overall Kenney–Doig category; we did not provide clinical history for any of the slides because reproductive history, stage of sexual cycle, and/or age of the mare had not been given for many of the submissions. Although pathologists were asked to evaluate certain histologic markers as absent, mild, moderate, or severe for inter-agreement and intra-agreement purposes, there was no specific instruction regarding quantification of these features or how to sum into a final Kenney–Doig category given that our goal was to investigate how reproducible the Kenney–Doig scale was in current routine diagnostic pathology practice.
Statistical analysis
Inter-observer agreement was examined using Cohen kappa statistics, a popular choice for observer variation studies in which the observed agreement is compared to the expected agreement as a result of chance, and a number between −1 and 1 is reported, with −1 being perfect disagreement, 0 being no agreement, and 1 being perfect agreement.6,22,28,48
Kenney–Doig grading scores and histologic feature evaluations were recorded for each slide and each observer using Microsoft Excel. These data were uploaded into the statistical software R (v.4.0.2, http://www.R-project.org), and the additional irr package was installed to calculate a variety of statistics for levels on inter-rater and intra-rater agreement. Descriptive statistics for frequency distributions of assigned histologic evaluations and final Kenney–Doig categories were tabulated. Inter-rater agreement was evaluated using unweighted and weighted versions of Cohen kappa. Unweighted kappa values measure the amount of agreement without accounting for the number of categories pathologists may differ by; weighted kappa values were used to examine the magnitude of agreement by placing more emphasis on a disagreement of more than one Kenney–Doig category and awarding partial agreement when differing by only one category. For example, weighted kappa values will measure lower agreement between 2 pathologists who categorize the same biopsy as category I and as category III than an unweighted kappa, given that the unweighted statistic does not differentiate between a disagreement of 1 versus 2 or more categories. Therefore, we used both unweighted and weighted kappa values, with the weighted kappa value using a quadratic formula based on the “squared” option for computing weighted kappa statistics in R.
Unweighted and weighted kappa values were computed for each pathologist observer pair for both final Kenney–Doig categorization of cases and the histologic feature evaluation of inflammation, fibrosis, glandular atrophy, and lymphatic lacunae. The arithmetic means of these kappa values were used to show an average agreement coefficient as described by Light for all 8 pathologists, the inter-institution group, and the intra-institution group. 25 Unweighted Light kappa values were computed using the Light kappa function in R; weighted Light kappa values were computed manually using Microsoft Excel. Kappa statistics were interpreted using the standards in which the kappa coefficient is interpreted as follows: kappa <0.00 = poor agreement, 0.00–0.20 = slight, 0.21–0.40 = fair, 0.41–0.60 = moderate, 0.61–0.80 = substantial, and 0.81–1.00 = almost perfect agreement. 22
Intra-observer agreement was evaluated using intra-class correlation coefficients (ICCs), in which the resulting coefficient is reported between −1 and 1, and is interpreted similarly to Cohen kappa. 21 ICC values and 95% CIs were used to measure intra-rater agreement for each pathologist at 2 times for 21 biopsy slides. ICCs were chosen as the statistic best representing intra-rater agreement given that the 2 measurements made were related instead of independent; they were made by the same individual at 2 different times, which arguably involves less percent agreement as a result of chance than 2 individuals making separate observations at the same time, as is assumed by the kappa statistic.
ICCs and their 95% CIs were calculated using the same R software and irr package previously mentioned, with the “model” set to 2-way, “type” set to absolute agreement, and “unit” set to single comparisons to compare each individual grading attempt versus averaging them for consistency evaluation. ICCs were interpreted using the standards suggested in which an ICC <0.50 = poor agreement, 0.50–0.75 = moderate, 0.75–0.90 = good, and >0.90 = excellent agreement. 21
ICCs were also calculated to measure the intra-rater agreement of the evaluation of the histologic features of inflammation, fibrosis, glandular atrophy, and lymphatic lacunae. The arithmetic mean was calculated for all ICC values using Microsoft Excel, demonstrating the average intra-rater agreement for all 8 pathologists concerning Kenney–Doig categories and histologic features.
Logistic regression modeling was used to assess the level of association of each histologic feature with the 4 Kenney–Doig categories. Responses from all 8 pathologists were coded in Microsoft Excel into 3 outcome variables; where a 1 was coded as a) anything categorized as category IIA or higher (KD1), b) anything categorized as category IIB or higher (KD2), and c) anything categorized as category III (KD3). Data were uploaded into R software, and the extra package MASS was installed. The “glm” function was used to build separate logistic regression models for each outcome variable for each histologic feature (inflammation, fibrosis, glandular atrophy, lymphatic lacunae), which were coded as factors with 4 levels (absent, mild, moderate, severe). Using the “predict” function, predicted probabilities were calculated for each logistic regression model. These outcome models were then combined into a single table for each histologic feature describing the predicted probabilities individualized to all 4 Kenney–Doig categories based on the severity assigned to the given histologic feature.
Results
Inter-rater agreement on Kenney–Doig categories
Frequency distributions for Kenney–Doig categories assigned to the same set of 63 endometrial biopsies revealed wide variability in grading tendencies (Fig. 2). None of the 8 participating pathologists’ grading distributions approached the frequency distribution of 25.4% category I, 25.4% category IIA, 25.4% category IIB, and 23.8% category III that was designed based on the original diagnoses of the cases selected from the PDS and WCVM databases. Although 5 of the 8 pathologists utilized category III frequently, category I was the most under-utilized category, and most slides (50.8–88.9%) were assigned to either category IIA or IIB. Only 1 of the 63 biopsy slides was assigned the same Kenney–Doig category by all 8 pathologists; 6 of 63 biopsy slides were assigned all 4 possible Kenney–Doig categories. Three of 63 slides that were also categorized either as category I or III, however, were not given all 4 possible categories among the observers, therefore 9 of 63 biopsy slides involved disagreement between the extreme categories of I and III.
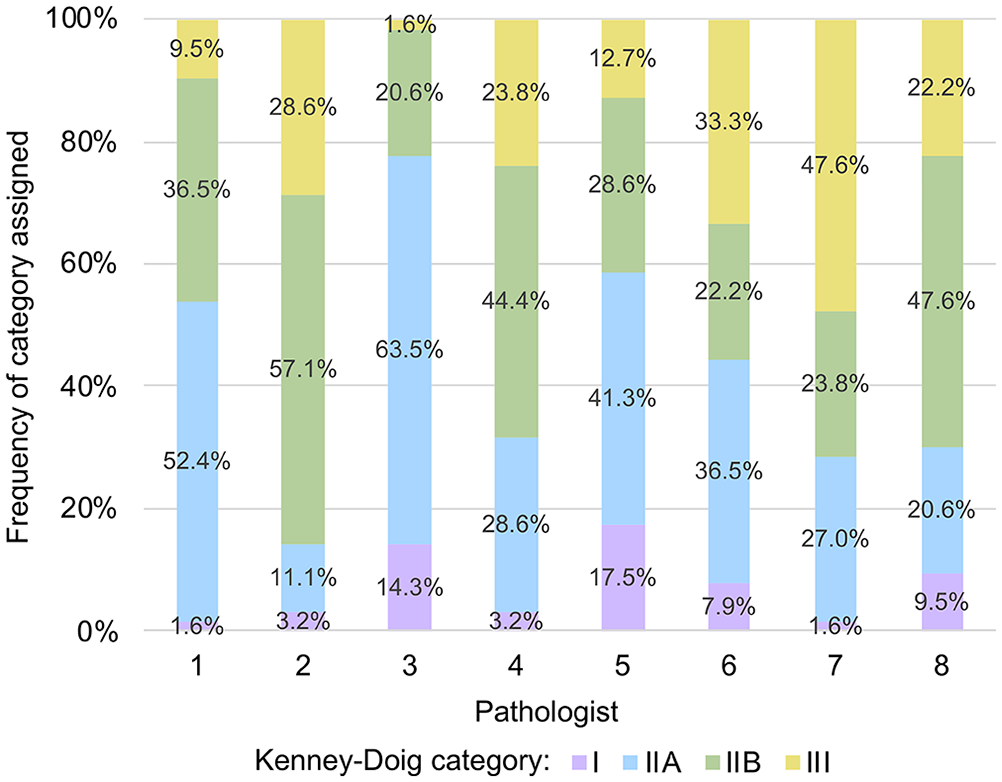
Frequency distributions of Kenney–Doig categories assigned by 8 pathologists to the same set of 63 digitized equine endometrial biopsy slides. The original frequency distribution of the selected slide set was categorized by WCVM and PDS pathologists as 25.4% category I, 25.4% category IIA, 25.4% category IIB, and 23.8% category III.
Unweighted Cohen kappa coefficients for pairwise comparison of all 8 pathologists revealed a range of −0.05 to 0.46 with an average Light kappa coefficient of 0.19 for the entire group, indicating poor-to-moderate agreement among pathologists with an average of only slight agreement (Table 1). Weighted kappa coefficients for pairwise comparison of all 8 pathologists revealed higher levels of agreement, with a range of 0.08–0.64 indicating slight-to-substantial agreement and an average Light weighted kappa coefficient of 0.36, indicating overall fair agreement among raters (Table 1).
Unweighted and weighted Light kappa coefficient measuring the average kappa value of Kenney–Doig categories assigned to the same 63 endometrial biopsies by 8 pathologists.
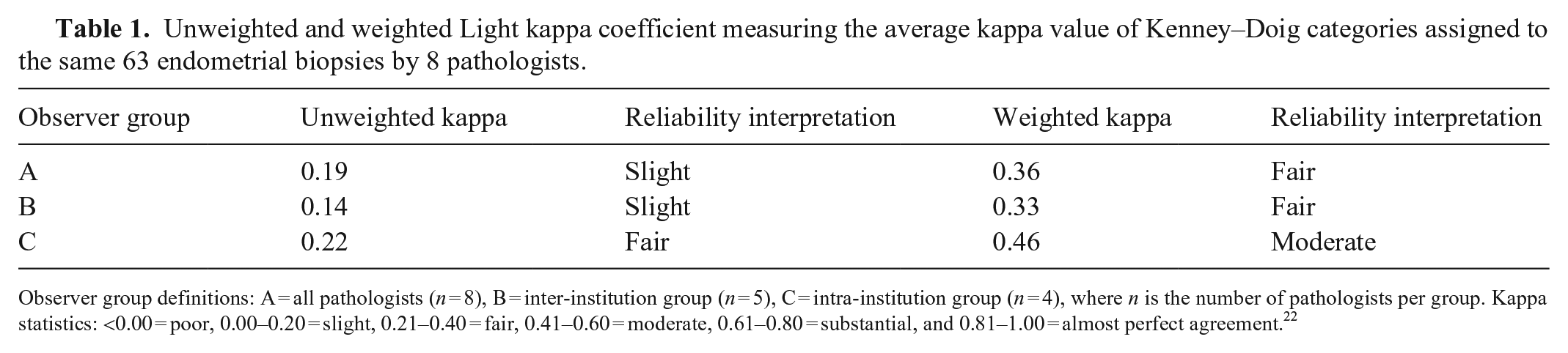
Observer group definitions: A = all pathologists (n = 8), B = inter-institution group (n = 5), C = intra-institution group (n = 4), where n is the number of pathologists per group. Kappa statistics: <0.00 = poor, 0.00–0.20 = slight, 0.21–0.40 = fair, 0.41–0.60 = moderate, 0.61–0.80 = substantial, and 0.81–1.00 = almost perfect agreement. 22
The inter-institution group of pathologists had unweighted kappa values of −0.05 to 0.46, with an average unweighted Light kappa of 0.14 (Table 1). In comparison, the intra-institution group had unweighted kappa values of 0.12–0.33 with an average unweighted Light kappa of 0.22 (Table 1). Weighted kappa values for the inter-institution group were 0.08–0.64, with an average of 0.33; the intra-institution group was 0.38–0.54, with an average of 0.46 (Table 1). Overall, the intra-institution group had higher average levels of agreement than those at different institutions, with fair agreement seen in unweighted calculations and moderate agreement in weighted calculations.
Inter-rater agreement on histologic features
Unweighted and weighted pairwise kappa values were calculated for the evaluation of inflammation, fibrosis, glandular atrophy, and lymphatic lacunae. The average agreements for both unweighted and weighted kappa values were calculated and summarized across all 8 pathologists, the inter-institution group, and the intra-institution group (Table 2).
Summary of the unweighted (U) and weighted (W) Light kappa values for the histologic descriptors assigned to the same 63 endometrial biopsies by 8 pathologists.
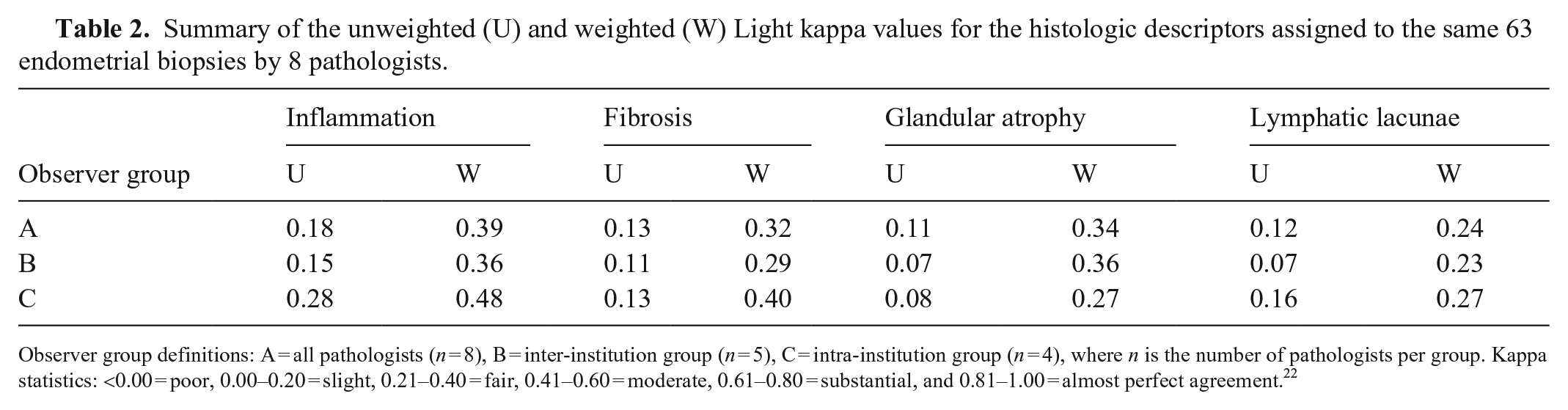
Observer group definitions: A = all pathologists (n = 8), B = inter-institution group (n = 5), C = intra-institution group (n = 4), where n is the number of pathologists per group. Kappa statistics: <0.00 = poor, 0.00–0.20 = slight, 0.21–0.40 = fair, 0.41–0.60 = moderate, 0.61–0.80 = substantial, and 0.81–1.00 = almost perfect agreement. 22
Across all 8 pathologists, evaluation of inflammation had the highest average unweighted and weighted kappa values at 0.18 and 0.389 respectively, indicating slight-to-fair agreement. Evaluation of glandular atrophy had the lowest average unweighted kappa value of 0.11, indicating slight agreement. However, the lowest average weighted kappa value of 0.24 was for the evaluation of lymphatic lacunae, indicating fair agreement. Findings were similar in the inter-institution group in which inflammation had the highest levels of agreement at 0.15 and 0.36 for average unweighted and weighted kappa values, and lymphatic lacunae had the lowest levels of agreement at 0.07 and 0.23 for average unweighted and weighted kappa values. Consistent with the other groups, inflammation produced the highest average kappa values indicating fair-to-moderate agreement in the intra-institution group (0.28 unweighted kappa, 0.48 weighted kappa); glandular atrophy and lymphatic lacunae had the lowest average unweighted and weighted kappa values respectively, resulting in only slight-to-fair agreement among pathologists.
Intra-rater agreement on Kenney–Doig categories
Intra-rater agreement concerning Kenney–Doig categories assigned to the same set of 21 slides at 2 different times was measured by calculating ICC values for each pathologist with accompanying 95% CIs. ICC values were 0.12–0.77, with an average ICC of 0.55 for the entire group (Table 3). Interpretation based on the single ICC values indicated a range of poor-to-good agreement concerning intra-rater reliability for the studied slide set. CIs for ICC values had larger variation, widening the interpretation from as little as poor agreement to as much as excellent intra-rater agreement within the group.
Average intra-class correlation coefficients (ICCs) measuring intra-agreement across 8 pathologists using Kenney–Doig categories and the descriptive modifiers of absent, mild, moderate, or severe for grading the same set of 21 endometrial biopsies at 2 separate times. Glandular atrophy was only measured using 7 pathologists because one pathologist did not assess this marker.
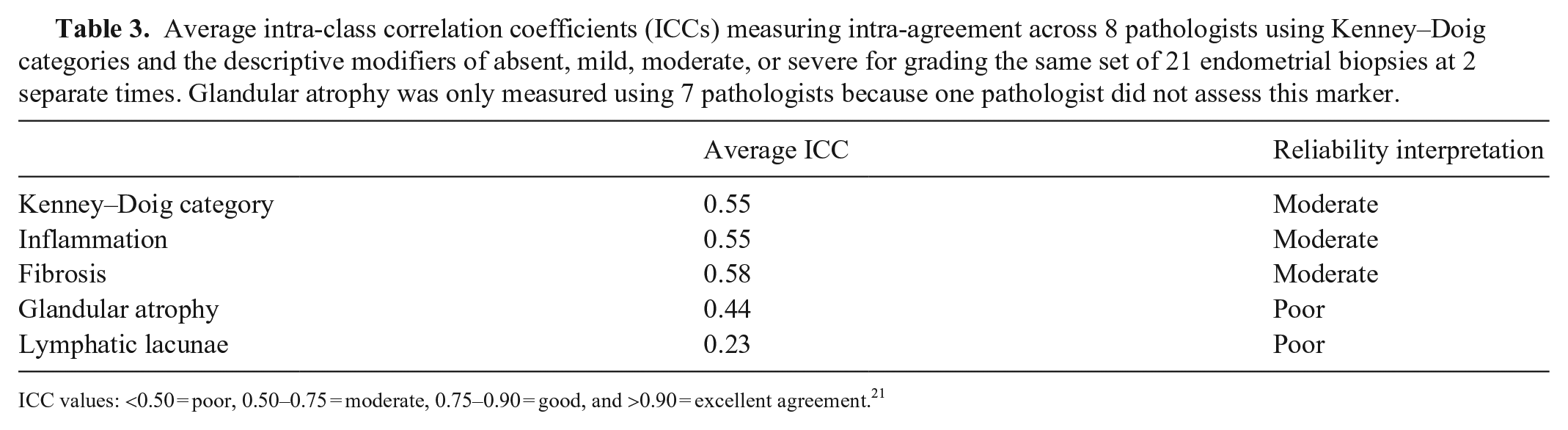
ICC values: <0.50 = poor, 0.50–0.75 = moderate, 0.75–0.90 = good, and >0.90 = excellent agreement. 21
Intra-rater agreement on histologic features
The intra-rater agreement for each pathologist concerning the evaluation of histologic features of inflammation, fibrosis, glandular atrophy, and lymphatic lacunae using descriptive modifiers of absent, mild, moderate, or severe was analyzed using ICC statistics. The average ICC was calculated for each histologic feature and summarized (Table 3).
The evaluation of fibrosis had the highest ICCs among the pathologists (range: 0.29–0.76), suggesting the best consistency for intra-rater agreement, with an average ICC of 0.58 and moderate overall agreement. Intra-rater agreement concerning the severity of lymphatic lacunae in biopsies was the lowest of all histologic features measured, with ICC values of −0.16 to 0.64 and an average ICC of 0.23, indicating only poor intra-rater reliability.
Logistic regression modeling and predictive probabilities
Based on the logistic regression models for inflammation and fibrosis, the associated predicted probabilities for histologic severity on Kenney–Doig category both had a positive relationship between increasing severity of histologic feature and increasing probability of a more severe Kenney–Doig category assignment (Table 4). Notably, biopsies in which either severe inflammation or fibrosis were present had >90% probability of being assigned to category III.
Predicted probabilities of a biopsy being assigned to a certain Kenney–Doig category based on logistic regression modeling of the influence of evaluating either histologic inflammation or fibrosis as absent, mild, moderate, or severe.
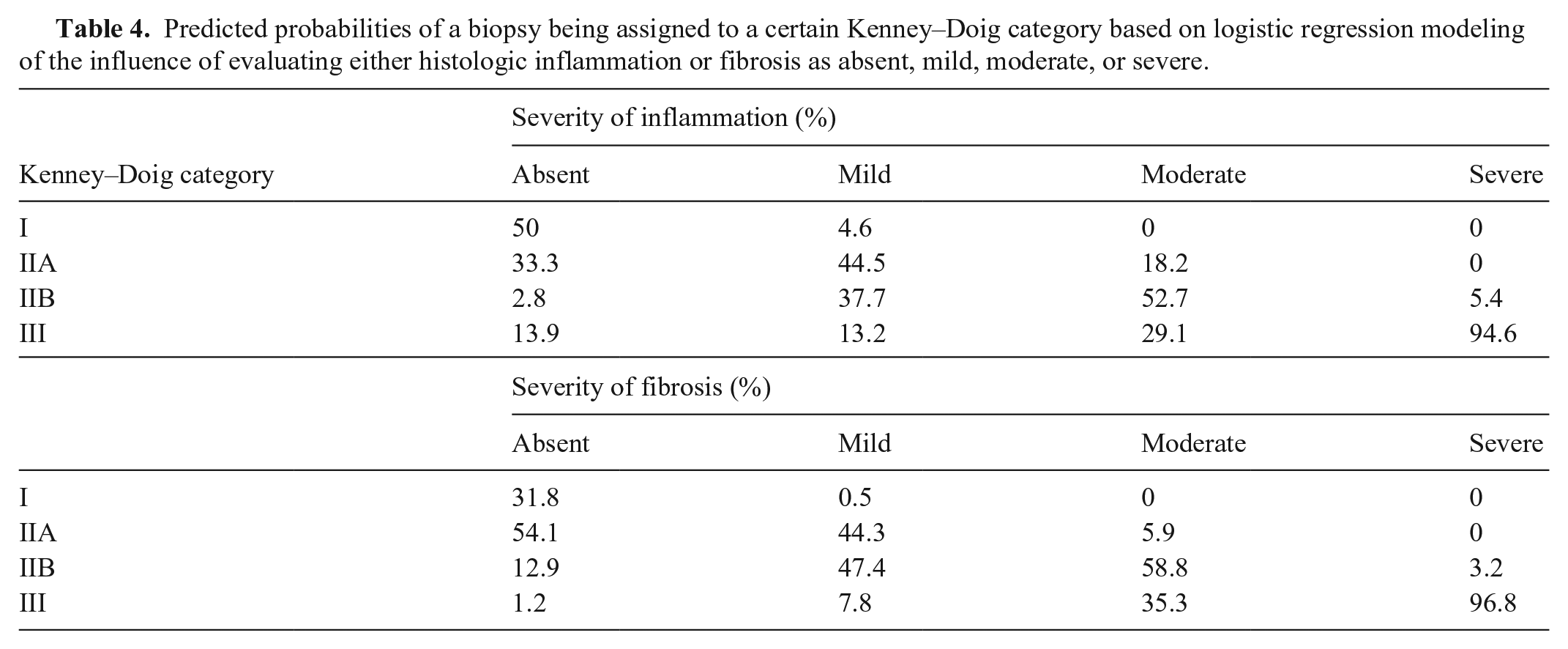
Results for glandular atrophy and lymphatic lacunae did not follow this trend. For glandular atrophy evaluated as absent, mild, or moderate, most biopsies were predicted to be classified as either category IIA or category IIB (absent: 51.2% for category IIA and 24.6% for category IIB; mild: 33.5% for category IIA and 41.5% for category IIB; moderate: 14.8% for category IIA and 43.7% for category IIB). Severe glandular atrophy was only associated with a 57.1% likelihood of classifying a biopsy as category III.
Similarly, lymphatic lacunae evaluated as absent, mild, or moderate were also predicted to be categorized as either category IIA or IIB (absent: 43.3% category IIA and 31.7% category IIB; mild: 33.2% category IIA and 38.8% category IIB; moderate: 8.6% category IIA and 42% category IIB). Assessing the lymphatic lacunae in a biopsy as moderate or severe gave similar predicted probabilities for both category IIB and category III (moderate: 42% category IIB and 46.9% category III; severe: 50% category IIB and 50% category III).
Discussion
Overall, the inter-rater agreement that we observed showed an average well below 0.60, a suggested minimum acceptable unweighted kappa value for histopathology scales. 32 Our study only achieved slight-to-fair agreement among all 8 pathologists when using both unweighted and weighted Light kappa means. These results were consistently in the lower ranges of observed inter-rater agreement found throughout the literature, suggesting less reliability compared to other histopathology systems used in clinical practice.3,4,28,42,51 When examining the pairwise observations for weighted kappa values, only 2 observer pairs demonstrated substantial agreement; most exhibited only slight-to-fair agreement. Notably, in the entirety of this slide set, only a single biopsy was consistently given the same category (IIB) grading by all 8 pathologists. In contrast, 6 of 63 slides were assigned all 4 possible Kenney–Doig categories, meaning that ~1 in every 10 slides spanned the breadth of all possible categories on the scale. Additionally, 9 of 63 slides were categorized as a category I or III by at least 2 of the observing pathologists. Combined with the relatively low weighted kappa statistic, which accounts for partial agreement based on the number of categories by which observations differ, this suggests that disagreement occurs not only by a single category, but also by multiple categories spanning the most extreme Kenney–Doig categories.
Interestingly, the average kappa values for pathologists practicing at the same institution were higher than those practicing at different institutions and all 8 pathologists as a whole, reaching moderate agreement with the weighted statistic. This finding may not be surprising given the fact that colleagues at the same institution often collaborate during rounds sessions, seek one another’s opinions on cases, and frequently train pathology residents under similar curricula. The 4 intra-institution pathologists in our study also completed their residency training at the same institution (B). In contrast, 3 of the 5 pathologists included in the inter-institution group were trained at the same center (A), whereas the remaining 2 pathologists each trained at different institutions (B and C). Similarities in residency training, including shared mentorship, coursework, and similar caseload and variety, may also have contributed to the higher levels of agreement observed in the intra-institution group.
Intra-rater variability presents another problem for reliability concerning histopathology grading systems. Although some differences in opinion are expected between individuals, there is also the issue regarding an individual’s own variability on a day-to-day basis. Some comparable studies in the literature found a range of ICCs from 0.53 to as high as 0.92, with some group averages reported of 0.68–0.76 for different scoring systems.3,20,53 In our study, pathologists’ intra-rater agreement ICCs were 0.12–0.77 with a group average of 0.55, a spread of poor-to-good agreement with the mean indicating moderate agreement. Although this wide spread of intra-rater agreement may be related to the vagueness of the scale, other confounding variables, such as individual pathologists’ experience, training, and caseload of equine endometrial biopsies, must be considered. However, when combined with the relatively low inter-agreement, there is strong evidence of inconsistencies inherent in the use of the Kenney–Doig scale as it is being used in diagnostic laboratories today.
Although the evaluation of inflammation produced slight-to-moderate inter-rater agreement, intra-rater agreement was highest when evaluating fibrosis, but still only moderate. Evaluation of both lymphatic lacunae and glandular atrophy produced very low levels of both inter- and intra-agreement. There appears not only to be disagreement in the final summation of a Kenney–Doig category, but also in the very building blocks of subjective quantification used to reach each conclusion. Pathologists do not appear to agree on exactly what descriptive modifiers of which histologic feature constitute a given Kenney–Doig category, and even more concerning, they do not always agree with their own evaluations of the same slide at different times.
To try and establish whether some observers may consider certain histologic lesions more prognostically significant than others regarding endometrial biopsy categorization, logistic regression modeling was done to assess the influence of each individual histologic feature measured against the different Kenney–Doig categories given by the 8 pathologists. Both inflammation and fibrosis showed a clear trend in which increasing severity of descriptive modifiers assigned to either histologic feature resulted in a higher predicted probability for these biopsies to be assigned to increasingly severe Kenney–Doig categories. Notably, the presence of severe inflammation or severe fibrosis alone predicted that biopsies would be assigned to category III 94.6% and 96.8% of the time, respectively. Glandular atrophy and lymphatic lacunae, however, revealed more ambiguous predicted probabilities, with most biopsies likely to be classified within category IIA or IIB regardless of being evaluated as absent, mild, or moderate. Both histologic features showed a ≥50% probability of assigning a category III to the biopsy if evaluated as severe; however, neither feature’s predicted probability approached the clear majority predicted based on the evaluation of inflammation or fibrosis.
The wide range of predicted probabilities across all 4 Kenney–Doig categories that we found for both glandular atrophy and lymphatic lacunae suggest that pathologists are not giving these histologic features the same consideration when assigning a final diagnosis as inflammation or fibrosis. This finding was expected given that both inflammation and fibrosis are more likely to be attributed to primary disease processes such as endometritis or endometrial fibrosis. Glandular atrophy and lymphatic lacunae, on the other hand, are commonly considered secondary changes caused by more significant endometrial disease, and often appear with concomitant evidence of endometrial fibrosis in particular.1,15,18,24,26,31,43,50 Therefore, using inflammation and fibrosis as more significant drivers in assessing Kenney–Doig categorization, with glandular atrophy and lymphatic lacunae as additional summating modifiers, seems appropriate. There should be consideration, however, given to the relative weighting of inflammation versus fibrosis.
Within the paper outlining the categorization guidelines of the Kenney–Doig system, the authors state that, although inflammation is reversible and treatment may result in an improved Kenney–Doig category, fibrosis is a progressive and irreversible change. 17 A study that compared endometrial biopsies to subsequent foaling rates also found that when evaluating histologic inflammation and fibrosis, only fibrosis was correlated significantly with foaling outcome; this study supported the idea of transient endometritis as a physiologic response to breeding and hence that inflammation and fibrosis be weighted differentially when assigning a final Kenney–Doig category. 30 Based on our predicted probabilities, there do not appear to be significant differences in how pathologists are assigning Kenney–Doig categories based on inflammation and fibrosis.
Our results support the hypothesis that pathologists may not agree on the identification and evaluation of histologic lesion and their severity in a given equine endometrial biopsy, or the combination of these lesions into a discreet Kenney–Doig category, and that the grading of biopsies may not be consistently repeatable among all individuals. Although none of the participating pathologists’ frequency of categories assigned reflected accurately those assigned by the original WCVM or PDS pathologist for the selected slide set, we emphasize that there is no gold standard for assigning Kenney–Doig categories. The differences in frequency distribution do not reflect whether one observer may be considered more “correct” than another, they only serve to further illustrate the variability in inter-rater agreement that we observed.
Although the level of inter-rater agreement that we found may be low, weighted kappa values were considerably higher than unweighted kappa values for all measures, indicating that agreement improved when accounting for the magnitude of deviation among Kenney–Doig categories. More often than not, pathologists seem to be deviating by only one category in their diagnoses as opposed to multiple. However, 9 of 63 cases were still assigned a category I or III by at least 2 pathologists among the group, indicating that disagreement across the breadth of the scale occurs relatively frequently. This results in an ~70% difference in foaling rate prognosis that may be communicated to the client. Even with a single category disagreement, if that disagreement is between category IIA and IIB, that is a difference between a 50–80% expected foaling rate and a 10–50% foaling rate, respectively. Ultimately, disagreements in Kenney–Doig category, whether by a single category or all 3 possible categories, can result in significantly different clinical consequences for the broodmare in question.
Given the low inter- and intra-rater reliability and the significant influence a misplaced Kenney–Doig category may have on equine clinicians, their clients, and their patients, where does that leave the Kenney–Doig scale? Although attempts have been made to improve the system with the addition of more objectively quantifiable variables including various staining and immunohistochemistry techniques, no routinely used methods are being implemented in North America to augment the scale.2,12,15,27,29,33,37,52 Researchers in Germany have implemented a modified Kenney–Doig scale to try to clarify the distinction between different categories, but this is not commonly used by North American pathologists. 45 The same group have described new histologic lesions that should arguably be included when evaluating an equine endometrial biopsy, such as endometrial maldifferentiation and angiopathies.15,24,44–47 These studies support the idea that certain histologic features should be differentially weighted and considered when predicting a final prognosis based on an equine endometrial biopsy.
Other histopathology systems that have produced less than desirable inter- and intra-rater agreement have been either abandoned or altered, sometimes by splitting the more ambiguous middle categories into either extreme, thereby reducing a multi-category system into only 2 possible categories.19,35 Authors have also suggested that histologic grading and staging may be best used in a research environment with fewer observers, and that those in clinical practice should focus more on the description of the histologic lesions present, integrating those changes, communicating possible etiologies, and directing the submitting clinician to the best course of therapy.7,16 Three informative review papers on equine endometrial biopsies have summarized this concept well in regard to the Kenney–Doig scale, endometrial histologic lesions, and current understanding regarding pathophysiology, effects on fertility, and treatment of various endometrial diseases.41,43,49
The concept of integrating clinical information with histologic changes seen echoes Kenney’s final advice concerning the use of his scale, where he described developing an “epicrisis”, an overarching diagnosis that takes into account not only the Kenney–Doig category, but also the mare as a whole including her age, general and reproductive history, such as maiden status or years barren, her overall physical exam parameters, her reproductive exam parameters, such as anatomical appearance, vulvar seal integrity, rectal palpation, ultrasonic and possibly endoscopic visualization of the uterus, as well as cytology and culture results.17,18 The integration of this information by the attending clinician is crucial to accurately evaluate the reproductive efficiency of a mare, as is practiced by the theriogenology community in which the assignment of a Kenney–Doig category has become less significant and endometrial biopsies are done after a robust breeding soundness examination to investigate the presence and nature of any endometrial disease and direct therapy accordingly. Diagnostic pathologists do not have access to the patient, full history, or often the results of other aspects of the breeding soundness exam that may be crucial in accurately interpreting an endometrial biopsy. These disadvantages, combined with the low levels of inter- and intra-rater agreement that we found, suggest that the evaluation of equine endometrial biopsies may be best done in specialized laboratories with equine reproductive pathologists or theriogenologists with access to the patient’s full history and breeding soundness exam results. Although this shift may improve inter- and intra-rater agreement using the Kenney–Doig scale, more work is needed to evaluate the reproducibility of the system within these specialties as well, given that no observer variability studies for the scale have been reported using theriogenologists or equine reproductive pathologists, to our knowledge.
Although the levels of inter- and intra-rater agreement that we found seem low, some limitations may have affected our results and influenced the inter- and intra-observer agreement. Digitized slides have been found to produce almost perfect agreement with their glass slide counterparts; however, differences in computer screen brightness and resolution may have contributed to lower agreement between pathologists.11,53 Digital viewing also prohibits the ability to focus through different planes of the slide, which may hamper evaluation. 11 The sample size used to calculate the ICCs for intra-rater agreement was relatively small, reflected in the wide CIs obtained. The stage of cycle and reproductive history was not included for any slide in our study, given that this information is not always available to the diagnostic pathologist receiving the case. However, the omission of this information and differences in interpreting what histologic features may be physiologic given the mare’s stage of cycle at the time of biopsy versus pathologic change may act as another source of observer variability. Finally, we set out to investigate how the Kenney–Doig system is currently being used and interpreted by practicing pathologists, therefore no formal training was done pre-grading to ensure relatively uniform interpretation of the published scale guidelines. A joint training session with specific instruction based on the published criteria regarding histologic feature evaluation and the additive nature of the scale may improve the inter- and intra-rater agreement values reported here and shed light on where disagreements or misinterpretations using the scale may be occurring, as has been done with other histopathologic systems. 10
Despite these limitations, our study enabled 8 pathologists to evaluate the same slide set in a convenient and affordable manner. Our study was blocked appropriately to control for grading and screen-time fatigue. Pathologists were anonymized to the original case diagnosis and were given adequate rest between inter- and intra-rater slide sets to control for slide recognition.
Footnotes
Acknowledgements
We are grateful to the participating pathologists, without whom we would not have been able to complete our study. We deeply appreciate all the time and effort they dedicated to grading these biopsies and making this work possible. We thank our other committee members Drs. Claire Card, Elemir Simko, and Andy Allen for continuing support throughout the project. Finally, a special thanks to Jen Lindquist for her statistical assistance.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Our project was supported by Townsend Equine Health Research Fund and Interprovincial Graduate Student Fund.