
Abstract
Introduction:
The Chinese generative artificial intelligence (AI) model, DeepSeek-R1, has profoundly taken over the AI market since its launch. Large language models (LLMs) can generate humanoid responses and conduct reasoning tasks by utilising deep neural networks that have been trained on large textual datasets.
Materials and Methods:
Using Deepseek-R1, we conducted a cross-sectional study where 60 higher-order questions and 60 multiple-choice questions (MCQs) from microbiology of the MBBS curriculum were entered as prompts in the online AI chatbot. Three academics from the department evaluated the responses and a statistical analysis was performed.
Results:
The average of the scores of the three evaluators was taken as the final score for analysis. Non-parametric statistical methods were implemented. A one-sample median test was used to evaluate the total results, which was significant at P < .05. A non-significant difference was observed when the scores by the three evaluators were compared by the Kruskal-Wallis H test. One-tailed binomial test showed 98.33% accuracy in the MCQs.
Conclusion:
DeepSeek-R1 is a user-friendly, free-of-cost AI model to improve information retrieval through the application of deep learning methods. DeepSeek has excellent database in microbiology with lucid and elaborative explanations.
Introduction
Artificial intelligence (AI) has gone through a revolution due to the advent of large language models (LLMs), especially in the areas of conversational AI, code generation and natural language processing. These models generate responses that are human-like and carry out intricate reasoning tasks by utilising deep neural networks that have been trained on large textual datasets. AI systems such as ChatGPT and Gemini have become well-known for their capacity to manage a variety of applications across research, industry and various enterprise solutions. From identifying microbial interactions and resistance mechanisms to forecasting drug targets and diagnosing infectious diseases, AI and in particular, machine learning, emerges as a pivotal tool for solving complex microbiological diagnostics.[1]
A new generative AI model called DeepSeek-R1 was released on 27 January 2025 and it quickly became well-liked, turning out to be the most downloaded AI app. While, the initial DeepSeek models were nearly identical to Meta AI Llama, DeepSeek-R1 outperformed OpenAI models on a number of benchmarks and was particularly good at coding and math tasks.[2]
AI is swiftly revolutionising the healthcare sector, necessitating a sophisticated comprehension of its impact on teaching, learning and educational practices in medical education. In present times, AI models are extensively used by students from almost all disciplines to solve multiple-choice questions (MCQs), higher-order questions and even clinical case scenarios. To accomplish an entirely unanticipated reasoning efficiency, DeepSeek-R1 intelligently uses already-existing network tools, including reinforcement learning, data distillation and a combination of experts. DeepSeek is the inaugural LLM platform that displays the user’s ‘chain-of-thought’ in its reasoning process.[3,4]
Our study is the first of its kind to evaluate the new AI chatbot, DeepSeek-R1, in providing correct responses to questions commonly asked in microbiology theory articles for second professional MBBS students in accordance with the Competency-Based Medical Education (CBME) curriculum.[5] The study’s findings will have a mutually beneficial effect as that will also help the developers of DeepSeek to identify areas where they need to expand their database where there is insufficient information.
Methods
The microbiology department at a medical college in Eastern India carried out three-month cross-sectional research by using an online AI chatbot, DeepSeek-R1, to provide responses to higher-order questions and MCQs pertaining to microbiology of the MBBS curriculum. Higher-order questions are designed to assess students’ cognitive ability by pushing students to synthesise their knowledge and construct answers on the basis of concepts and principles.[6]
From the second professional examination question papers of two health universities in West Bengal and Bihar over the preceding five years (2019–2023), higher-order questions were selected at random. All of the questions were selected from the ‘Explain why’ section of the question sheets since answering these questions requires students to concentrate more on the subjects. Three academic members with more than five years of experience in the discipline evaluated the questions for accuracy and content validity.
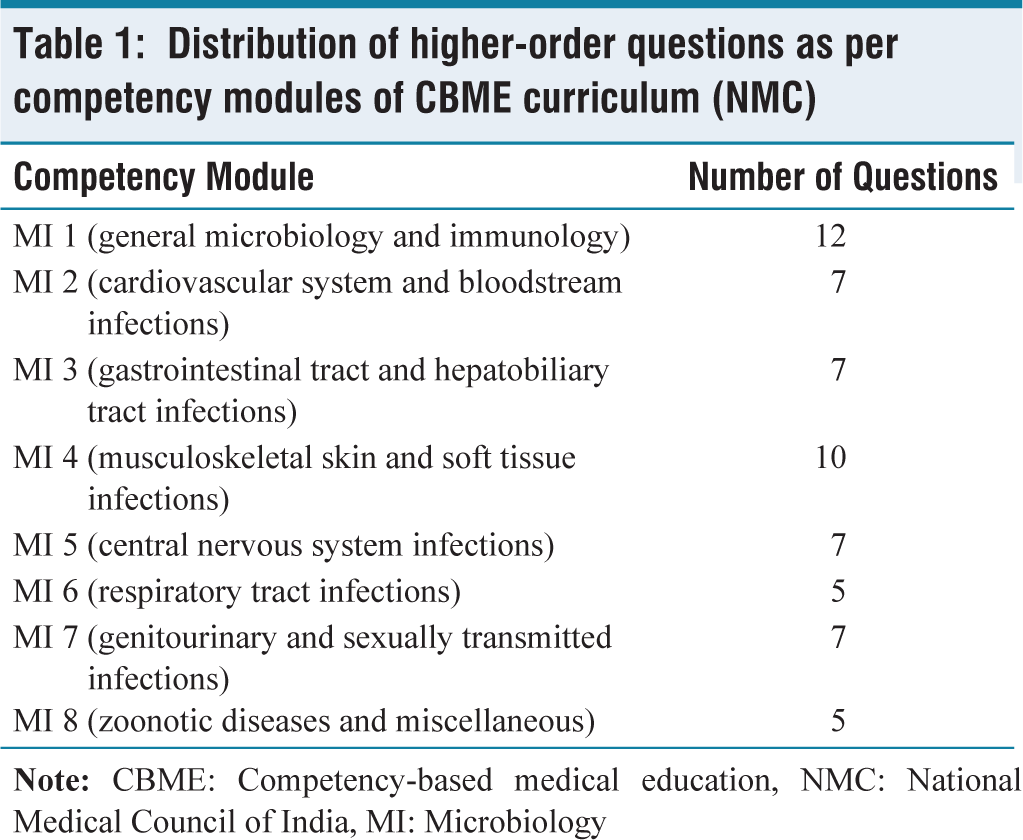
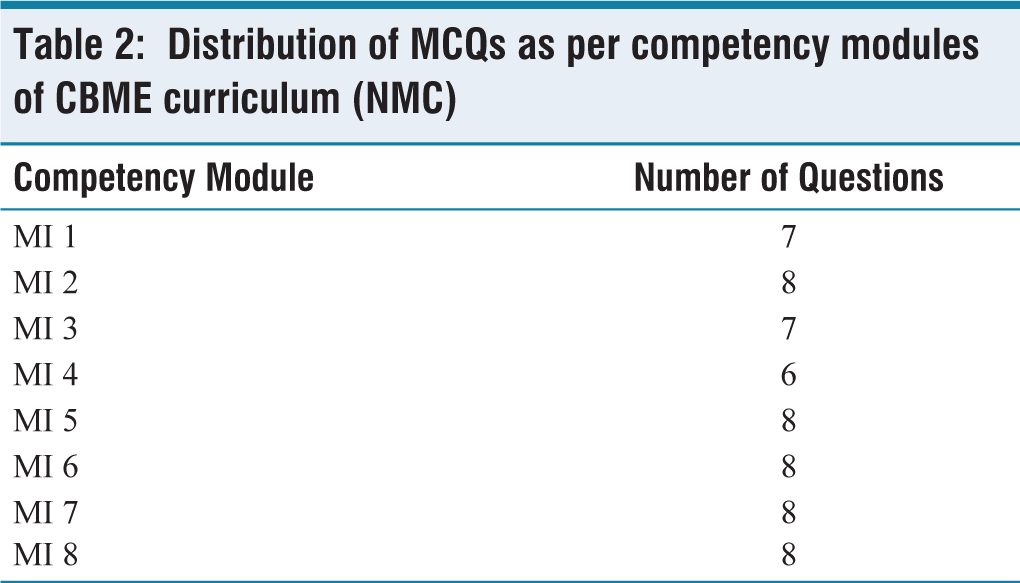
CBME has rearranged microbiology into eight competencies for the second professional undergraduate students. For the higher-order questions, a total of 60 questions were collected from all eight competencies of microbiology combined; their distribution is shown in Table 1. We also selected a total of 60 MCQs selected from the eight competencies [Table 2 shows the distribution of competencies for MCQs] and the questions were entered as prompts via a chat session accompanied by the sentence, ‘Please choose the best correct answer’. Two assistant professors selected the MCQs and created the answer key, which was reviewed by a senior professor in the department. All MCQs were ‘single-select best answer’ type.
Distribution of higher-order questions as per competency modules of CBME curriculum (NMC)
Distribution of MCQs as per competency modules of CBME curriculum (NMC)
The study generated responses using DeepSeek-R1, a free, open-source AI technology. The questions (both higher-order and multiple-choice) were handed to a department faculty member who was not involved in the analysis of the answers. He submitted the prompts in the platform unaltered. Each question was examined in a new chat session and the first response was considered for further study. The ‘regenerate response’ option was not executed. Three academics from the microbiology department copied and pasted answers to higher-order questions into a Microsoft Word document (Microsoft Corporation, Redmond, Washington, USA) for analysis. Each answer was given a score ranging from 0 to 5 and the results were entered in a Microsoft Excel spreadsheet. This study also includes some inaccurate responses generated by the language model.
For MCQs, one evaluator entered the responses in a Microsoft Excel sheet (Microsoft Corporation), followed by the second evaluator, who cross-checked the whole set of data, which was final checked by the third evaluator (professor), who looked for any discrepancies in the results. MCQs were scored either 0 or 1 based on the accuracy of responses. After compilation of all the responses, statistical analysis was performed. Figure 1 demonstrates our study protocol.
Study protocol
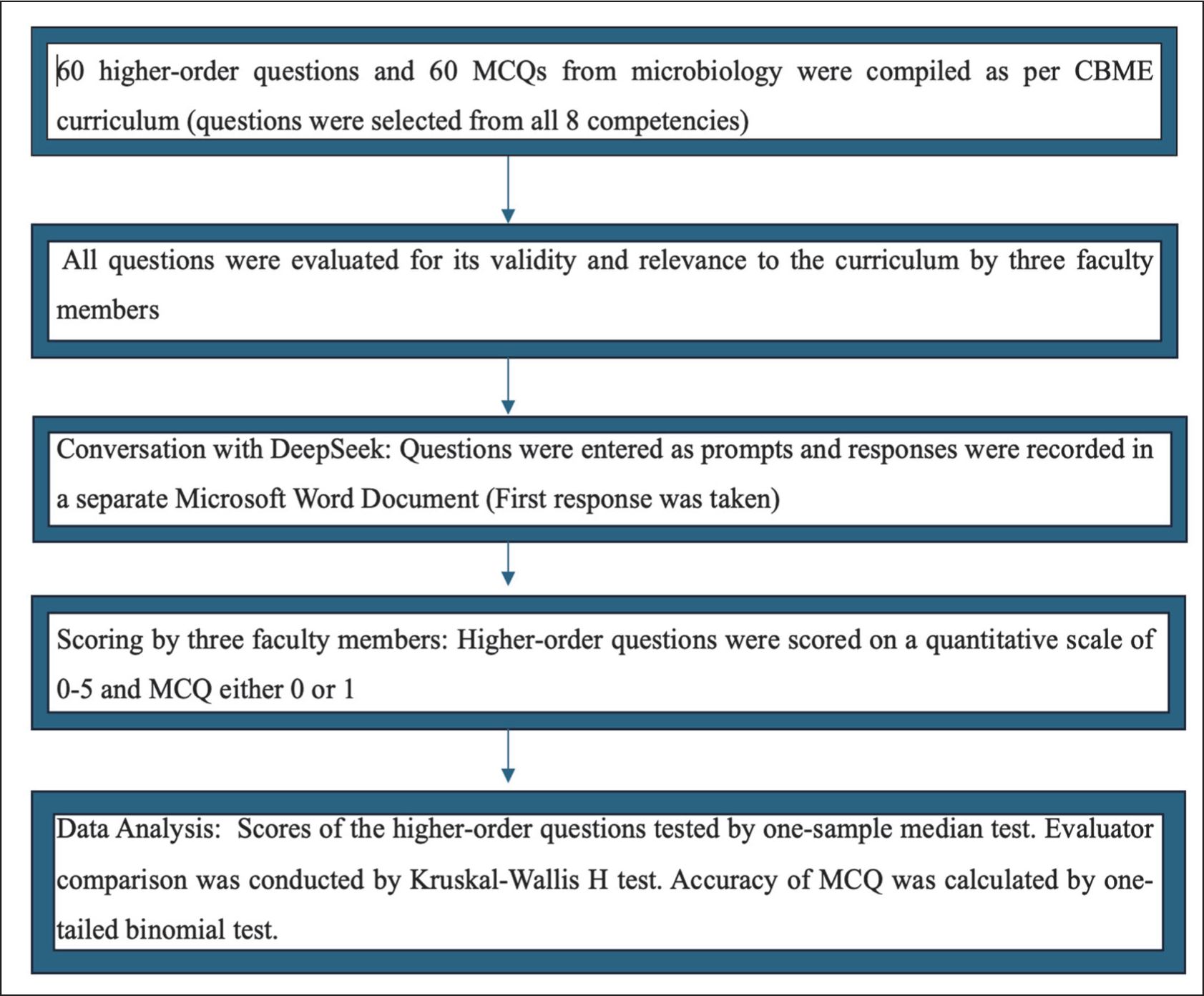
The final analysis score was calculated by taking the average of the three scores. For statistical analysis, at first, the Lilliefors test was done. A one-sample median test with hypothetical values of 4 and 5 was used to test the overall results. Evaluators’ scores were compared using the Kruskal-Wallis H test, where H = [ 12/N (N+1)] [Σ((ΣR) 2/n)]– 3 (N+1). A P value < .05 was considered statistically significant. A descriptive statistical analysis of scores from the competency modules was also conducted. All tests were performed using GraphPad Prism 7 (Dotmatics, Boston, MA). As no human or animal subjects were involved in our study, ethical clearance was not necessary under current guidelines.
Results
In this study, we examined how the Chinese chatbot interface DeepSeek-R1 responded to a series of higher-order and multiple-choice type microbiology questions.
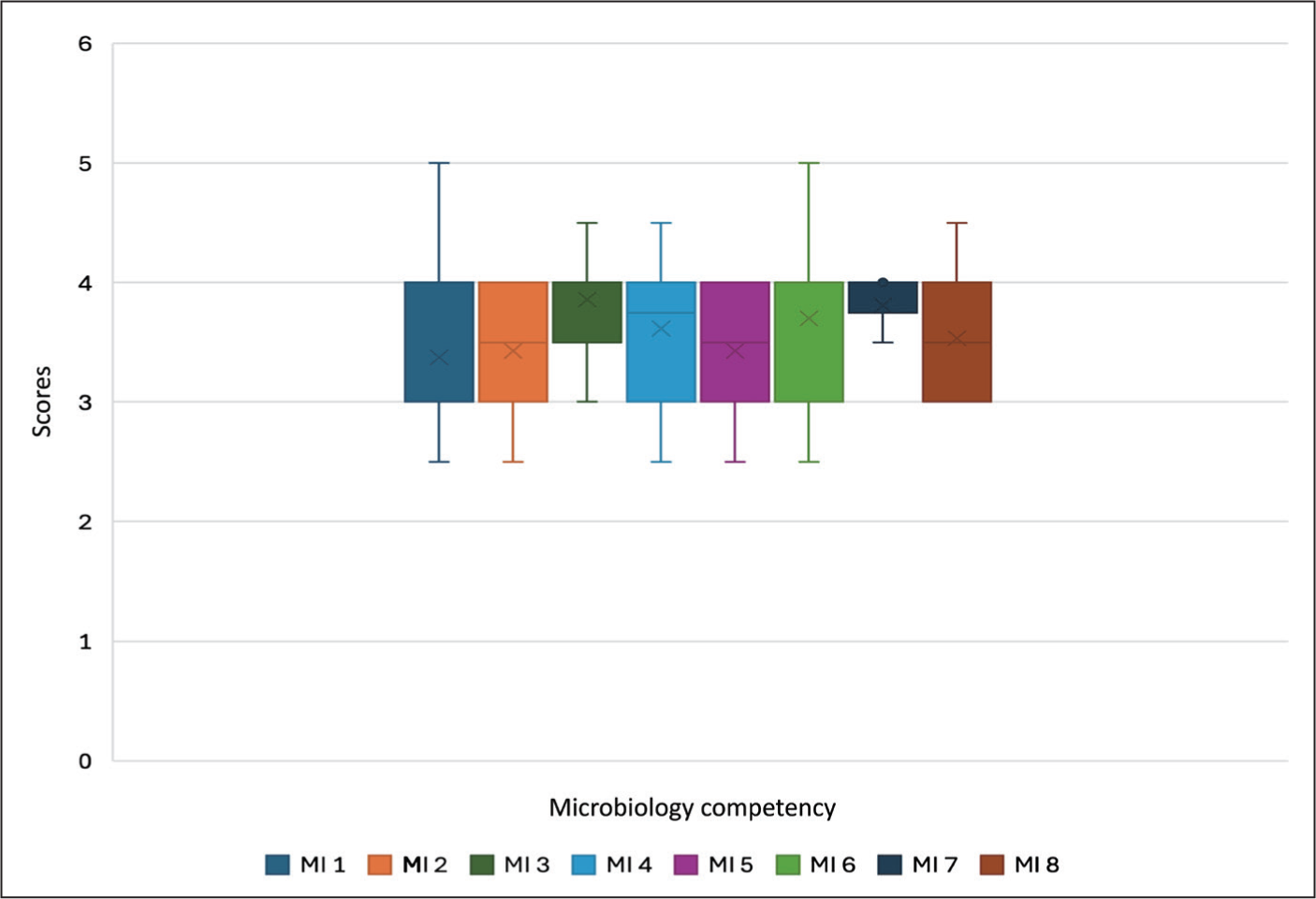
The AI software answered a total of 60 questions requiring higher-order thinking with a mean score of 3.5 and a median score of 3.5. (Q1–3, Q3–4). The average of the scores of the three evaluators was taken as the final score for analysis. The Lilliefors test was performed with the dataset, which showed the distribution was not normal, thus making the difference statistically significant. Non-parametric statistical tests were employed for analysis because the data were not normally distributed. The competency-wise scoring of the responses expressed as mean, median, standard deviation and first, second and third quartiles, standard error of mean and coefficient of variation using descriptive statistical tests has been shown in Table 3 and illustrated in Figure 2.
Statistical analysis of scores of various competency modules as per the CBME curriculum in microbiology
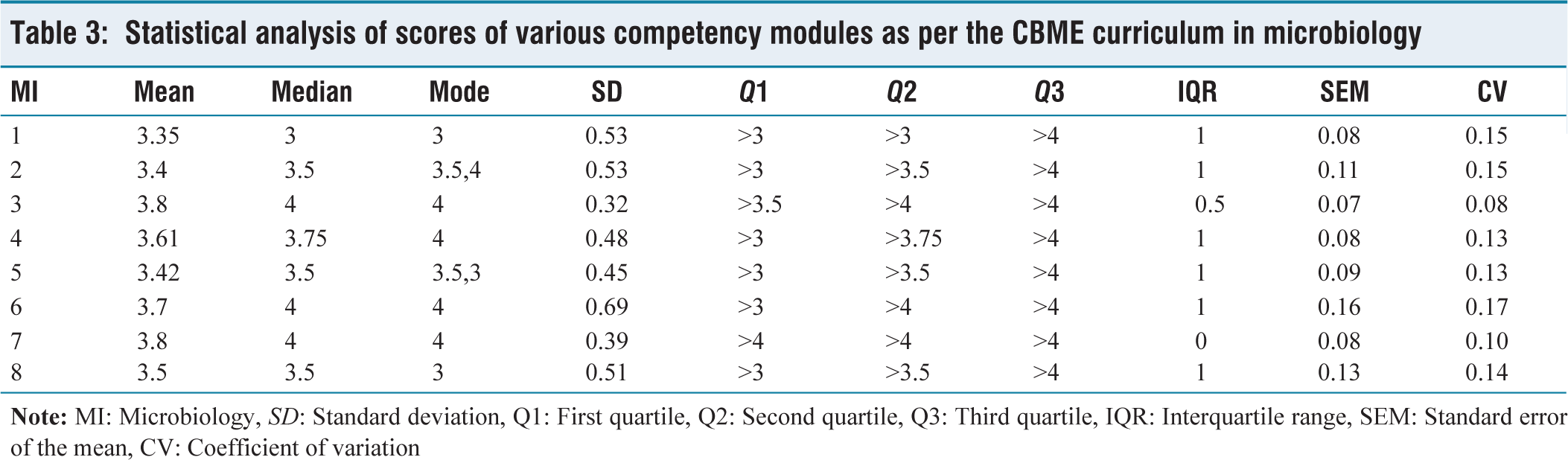
The competency-wise scoring of the responses using descriptive statistical tests
A one-sample median test with hypothetical values of 4 and 5 was used to test the overall results. With a hypothetical value of four, the z-value was 5.74456 and the P value was < .00001. Whereas a z-value of 7.74597 and a P value of < .00001 was obtained with a hypothetical value of five. In both cases, the test result was significant at P < .05.
Additionally, the three evaluators’ scores on the AI platforms were compared. We performed the Kruskal-Wallis H test for the analysis and it indicated that there is a non-significant difference between the evaluators, P value = .126, the test statistic H equals 4.1464, which is in 95% region of acceptance. The mean rank scores of evaluators 1, 2 and 3 were 99.87, 90.04 and 81.59, respectively. In this instance, the difference in mean ranks amongst three evaluators is not statistically significant.
Sixty MCQs were used to assess DeepSeek. It answered 59 of them correctly and one erroneously, for an accuracy of 98.33%. Assuming a 25% chance-level accuracy, a one-tailed binomial test was performed (i.e., random selection among four alternatives per item). A significant result (P < .0001) was obtained from the test, confirming DeepSeek’s accuracy in answering the MCQs and strongly implying that its performance was not the result of chance.
Discussion
Our study objective was to ascertain the capability of DeepSeek-R1 to answer higher-order microbiology questions and MCQs. There are several studies that check the ability of other AI platforms (such as ChatGPT or Gemini) for medical educational applications. Our study is the first of its kind in assessing this new Chinese chatbot, DeepSeek, in microbiology (second professional MBBS curriculum), which is gaining immense popularity worldwide, including India. In contrast to proprietary models such as ChatGPT, DeepSeek-R1 is completely open-source and requires a fraction of the development resources. It can be dowNloaded, installed and used locally by users, removing the need for cloud-based services and increasing accessibility for a larger audience.
In a study by Sallam et al. the effectiveness of generative AI models varied as per Bloom’s taxonomy levels (in the Remember category, DeepSeek-V3 scored 0.92 in terms of accuracy).[7] Although not all of Bloom’s taxonomy levels were assessed in our study, DeepSeek showed high accuracy in answering both higher-order questions as well as MCQs.
According to Roy et al. Gemini scored higher for competencies 1 and 4, while ChatGPT got the highest overall mean score for questions from competencies 2, 3, 5, 6, 7 and 8.[8] In this study, DeepSeek showed a high mean score in competencies 3,7 and 6.
Based on research by Das et al. ChatGPT answered higher-order microbiology questions with 80% accuracy.[9] In another investigation conducted by Ranjan et al. ChatGPT 3.5 and Gemini provided 71% and 70.5% of correct answers, respectively.[10] A study done by Wang et al. reported an overall similar accuracy of DeepSeek and ChatGPT in a Taiwan national pharmacist licensing examination, with a score of 80.9% and 81.7% for DeepSeek and ChatGPT, respectively.[11] Xu et al. in their study showed that DeepSeek outperformed Gemini 2.0 Pro, OpenAI o1 and OpenAI o3-mini in bilingual complex ophthalmic reasoning MCQs.[12] Agarwal et al. evaluated the accuracy of ChatGPT, Claude, DeepSeek, Gemini, Grok and Le Chat in solving MCQs on blood physiology and found that Claude 3.7 (95%), followed by DeepSeek (93%), demonstrated the highest reliable accuracy among all the LLMs.[13] An accuracy of 98.33% was seen in our study in the case of MCQs answered by DeepSeek. Certain responses to higher-order questions also lacked complete and relevant information. According to the National Tuberculosis Elimination Programme guidelines in India, the definition of extensively drug-resistant tuberculosis, in answer to the prompt ‘combination antimicrobial drugs are given for treatment of tuberculosis’, was inaccurate. The three primary species of Clostridium that cause gas gangrene were listed by DeepSeek in response to another query titled ‘Gas gangrene is polymicrobial in origin’. However, the other likely species were not included.
In the context of the National Medical Commission (NMC) curriculum and clinical microbiology, LLMs such as ChatGPT and DeepSeek have emerged as powerful tools for tackling higher-order questions and MCQs. The initial version of ChatGPT-3 was launched on 30 November 2022 and was found to be inaccurate and unreliable with regard to scientific publications. Since then, OpenAI has released a newer version, ChatGPT-4, which is thought to be more trustworthy and accurate, with many more capabilities. Furthermore, ChatGPT is an emerging technology and the data provided must be accurate to be used in healthcare. The faults and mistakes can be given back into the AI tool to create newer, more updated and safer algorithms for better patient care applications.[14]
Vaishya et al. deduced from literature searches and ChatGPT interactions with medical enquiries that ChatGPT produces answers quickly but recounts information from existing online literature, making the current version of ChatGPT helpful for medical professionals, in certain situations, but researchers should also verify the claims made while bearing in mind its limits.[15] ChatGPT can complement human scientific peer review, enhancing efficiency and promptness in the editorial process. However, a fully automated AI review process is currently not advisable and ChatGPT’s role should be regarded as highly constrained for the present and near future.[16]
AI chatbots are ubiquitous in clinical practice as well as in diagnostics, offering solutions in a matter of seconds and are available for free to use on their smartphones and other devices, leading to a greater desirability by students to utilise them to find answers. Undergraduate students usually use these AI platforms more commonly for MCQs and ‘explain why’ or ‘comment on’ questions because the answers to these questions either require reading the complete text or may not be included in some textbooks. Nevertheless, our research does not advise students to depend on these internet resources to learn topics or find answers to queries. Notwithstanding their benefits, these platforms have a number of drawbacks. Using ambiguous or imprecise instructions is a significant barrier to fully utilising the potential of generative AI. To get the right response, all prompts must be entered accurately. Along with these restrictions, a significant drawback of students utilising AI platforms is their incapacity to have a conceptual understanding of intricate clinical situations. Faculty members should also adjust to these changes in medical education in light of this rapidly shifting trend.
Conclusion
Medical undergraduates can leverage DeepSeek as a highly effective personalised tutor to accelerate their medical training, as it can quickly summarise lengthy research articles, extract key guidelines and help structure intensive study schedules. Students must, however, always cross-reference AI-generated insights with peer-reviewed medical textbooks and verify clinical protocols, as language models can occasionally hallucinate or provide outdated medical data during study sessions. Currently, indigenous AI models (BharatGen, Sarvam AI, Intellihealth and Fractal Analytics) are rapidly becoming the preferred choice over the Chinese AI models.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Institutional ethical committee approval number
Not required as the study did not involve any research participants.
Informed consent
Not applicable as there are no study participants.
Credit author statement
All authors have reviewed the final version to be published and agreed to be accountable for all aspects of the work.
Concept and design: Das D, Roy RD
Acquisition, analysis, or interpretation of data: Gupta SD
Drafting of the manuscript: Roy RD, Gupta SD
Critical review and editing of the manuscript: Das D, Gupta SD, Roy RD
Supervision: Das D
Data availability
Data supporting the findings of this study can be provided by the corresponding author.
Use of artificial intelligence
The authors hereby declare that Artificial Intelligence was not used in the above article.