
Abstract
Coronavirus disease 2019 (COVID-19) outbreak that was declared as a pandemic by the World Health Organization (WHO) on 11 March 2020 has already had severe consequences in all aspects of people’s lives worldwide. The pandemic has affected over 200 countries and has become a major concern. India also faced a stiff challenge in terms of controlling the virus outbreak and through some strict measures such as nationwide lockdown was able to control the further spread of COVID-19 towards the latter part of 2020. Therefore, it is imperative to predict the spread of this virus along with causality analysis of parameters that play a significant role in its spread. The present study employs a series of univariate and multivariate time series forecasting techniques namely MSARIMA, ARMAX and extended VAR models to predict COVID-19 cases in New Delhi, Mumbai and Bengaluru. Besides, providing a robust forecasting performance for COVID-19 cases, the study also deals with finding the causal relationship of the spread of COVID-19 with various mobility and weather parameters. Outcomes of our study establish that the spread of COVID-19 can be associated with mobility and weather parameters apart from the various precautions that are taken by the people to reduce community transmission. However, the type of mobility (residential, retail and workplace) and type of weather conditions (air quality, temperature and humidity) associated with the causality differ with cities. For New Delhi, air quality, residential, retail are the parameters affecting the spread of the COVID-19 cases, whereas masks, temperature, residential and workplace were the significant mobility and weather parameters for Mumbai. In addition, for Bengaluru, the statistically significant causal variables were air quality, masks and residential. Outcomes of this study would help the concerned authorities to predict and contain future COVID-19 spreads in Indian cities efficiently.
Introduction
Today, the world is facing an unprecedented outbreak of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) or commonly referred to as coronavirus disease 2019 (COVID-19). On 11 March 2020, the World Health Organization (WHO) declared the COVID-19 outbreak as a pandemic and encouraged all countries to not only detect and test their people but also treat them by isolating the affected ones. Also, it advised the countries to contact trace the spread of the virus as it will help them prevent a handful of cases from becoming clusters and eventually leading to community transmission.
The virus that migrated from bats to humans first originated in Wuhan, China, rapidly spread to all Chinese provinces and since then has affected majorly all the countries of the world. China tried to contain the spread by undertaking some strict actions like suspension of activities such as public social gatherings or any mass activities, airport and highway closures along with railway interruptions. All these steps were aimed at minimizing the spread of community-level transmission, which is one of the leading factors for the high infection rate of the disease. Many other countries tried to control the initial spread by imposing nationwide lockdown but with time had to relax these rules in order to strike a fine balance between protecting the health of its people, minimizing economic and social disruption, and also respecting human rights. Though numerous efforts were put in place, the virus spread was not contained and till the time the WHO declared the novel coronavirus as a pandemic there were already 118,000 active cases in over 114 countries and 4,291 people had already lost their lives to this deadly virus. As of 2 February 2021, almost 102,942,987 cases have been reported worldwide with a total death count of 2,232,233. According to the WHO COVID-19 Dashboard, the worst affected countries are the USA, India, Brazil, France and Russia in terms of the total number of active cases. The virus that started by infecting a single individual later reached a scale where it is spreading at a cluster level and presently the situation is of community-level transmission making it all the more infectious.
India, with a population of 1.3 billion people, is not only the second-most populous country in the world but also has one of the highest population densities which makes India susceptible to large-scale community transmission, hence India was under the scanner of the whole world when the first confirmed cases of novel coronavirus were detected on 30 January 2020. It has been almost 10 months since the first confirmed case and India is the second worst affected country in the world in terms of the total number of active cases; however, in terms of deaths tally, the USA and Brazil fare much worse than India. In terms of total cases per million population as well as total deaths per million, India is doing better than the USA and other European Union countries which are experiencing second waves of COVID-19 with a potential risk of further new waves owing to ease in government restrictions (Dey, 2020).
In India, as the first few cases of COVID-19 infection surfaced, the government mandatorily started scanning not only the people travelling from China but also the people who had a recent travel history to China. Moreover, India was one of the few countries that imposed a nationwide lockdown when the number of confirmed cases was pretty low and still in a few hundred. The Indian Government announced the first nationwide lockdown on 23 March 2020 and it was for 21 days. Since the first lockdown, the government has kept on further extending the lockdown period to keep a check on the rising number of cases. Other important measures implemented by the government included contact tracing along with providing timely health care facilities to all those affected. Extensive testing was also carried out which was accomplished by setting up new facilities as well as converting some hotels and banquet halls into specialized COVID care units (‘Delhi hotels’, 2020). Although to strike a balance between protecting the health of its citizens and the economic health of the country, the government after three to four months of countrywide lockdown soon started gradually opening its economy basis red, orange and green zones created based on the active cases in that region. Various states have already started to recover from the different challenges that have helped them keep a check on the number of active cases. On the other hand, some states like Maharashtra, Delhi, etc. are still struggling to contain the number of rising cases.
Various research studies have been conducted worldwide to estimate the impact of coronavirus (Fardeen & Shareena, 2020; Sami, 2020 amongst others). Other studies (Abuhasel et al., 2020; Gurumurthy & Mukherjee, 2021; Nosier & Beram, 2020; Singh et al., 2020, among others) focused on forecasting the number of confirmed cases using various time series models to estimate the healthcare infrastructure requirements. Details of these studies have been provided in Table 1. As evident, the majority of these studies were with respect to China, the USA and other Asian and European Union countries and not much work has been done on India. The current study tried to bridge this gap.
Summary of Research Studies Focused on Forecasting COVID-19 Cases
Gupta et al. (2020) presented a comprehensive analysis of the COVID-19 outbreak situation by answering different questions pertaining to the effects that various lockdown and social distancing measures had in curbing the number of coronavirus cases. Raju and Patil (2020) analysed the different Indian publications on SARS-CoV-2 and presented a bibliometric study of the WHO COVID-19 database whereas P. Ghosh et al. (2020) presented a state-wise analysis and prediction of the number of coronavirus cases. However, all these studies were conducted when the impact of coronavirus was limited to a few states that led to model performance being impacted by a limited number of data points. Also, no prior studies were conducted on the role played by mobility and weather parameters with respect to the spread of novel coronavirus.
We use a variety of univariate and multivariate models in this study to estimate and forecast the number of COVID-19 cases in three Indian cities: New Delhi, Mumbai and Bengaluru. In addition, the study also explores the connectedness between COVID-19 cases with different mobility and weather parameters.
All the models employed in this study provide forecasts with Mean absolute percentage error (MAPE) of less than 1%, thus providing a variety of accurate and robust methods for forecasting the number of cases in Indian cities. Also, our results point towards the relation that the spread of the novel coronavirus can be associated with mobility and weather parameters along with the precautions and other measures people are taking to reduce community transmission. However, the type of mobility (residential, retail and workplace) and type of weather conditions (air quality, temperature and humidity) associated with the causality differ across cities. The associated connectedness of COVID-19 cases with various mobility and weather-related factors can help in preventing the spread of the new strains that are emerging in different countries.
Materials and Methods
Data Sources and Description
For the duration of 24 July 2020 to 21 October 2020, the data for confirmed COVID-19 cases in Delhi, Mumbai and Bengaluru were gathered from the website Retail and recreation—Visits to restaurants, cafes, shopping malls, amusement parks, museums, libraries, theatres and other similar establishments fall under this category Grocery and pharmacy—Supermarkets, warehouses, farmers markets, specialty food stores and drug stores are included in this category Parks—Beaches, marinas, dog parks, plazas and other public areas are included in this category Transit stations—train stations including subways Workplaces—office complexes Residences—covers residential homes
It shows the change in mobility for every day of the week compared to the baseline (median during 3 January to 6 February 2020). But for this study, we have only considered mobility changes with respect to residential, workplaces and retail and recreation categories.
To take into account the weather parameters namely temperature and humidity, the data were collected from the website
‘Adjusted population density’ is the immunity-adjusted population density. It is the population density multiplied by the square of the proportion of people who are still unprotected. It incorporates the effect of already affected individuals. Furthermore, ‘masks’ is the total amount of Google search interest observed by the different Indian states. It is a proxy indicator for people’s precautions and other efforts to minimize community transmission. People all over the world have begun to use masks, wash their mouths, refrain from touching their faces or shaking other people’s hands, disinfect public surfaces among other steps during this pandemic.
The rationale behind choosing these cities was that the lockdown measures must have had a significant impact on their mobility as they are amongst the biggest metropolitan cities in India along with having distinctive weather conditions.
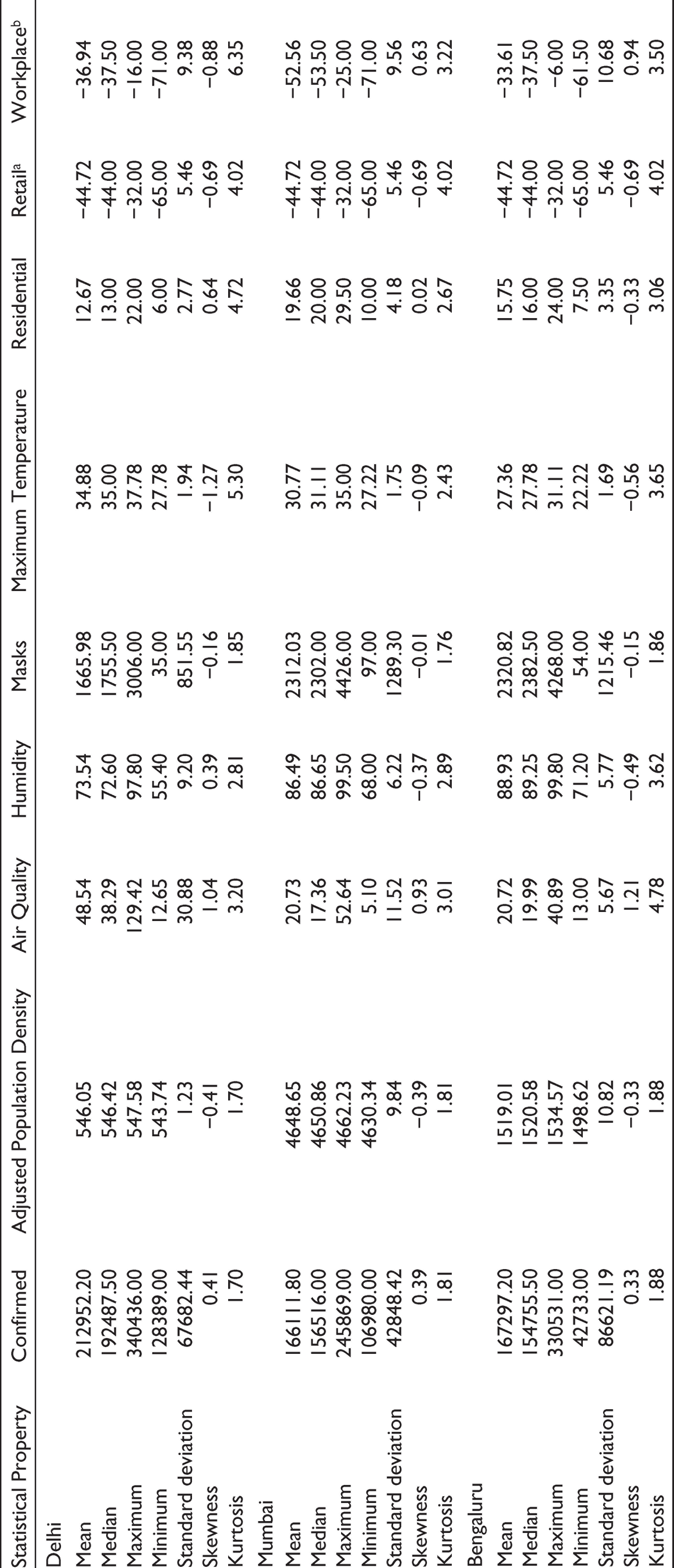
Table 2 gives the summary statistics of the data for all the three cities under consideration.
Statistical Summary of the Data
Models Description
In this study, three statistical models (ARMAX, SARIMA and VAR models) are used to predict the spread of COVID-19 in New Delhi, Mumbai and Bengaluru. Extended VAR model is used to understand the causal dynamics between the number of COVID-19 cases with weather and mobility parameters.
MSARIMA Model
A time series data set is essentially a data series that over time is collected consecutively. In any time series, an inherent feature of the data set is that the adjacent observations are naturally dependent. The study of this dependency is essentially considered as a sophisticated and commonly used model for forecasting and is referred to as time series analysis. Time series data usually include four components: secular trends, seasonal fluctuations, cyclical movements and random components. The movement of the business cycles that are captured by the cyclical aspect induces substantial changes over a long period. Therefore, for a short time period, it becomes extremely difficult to distinguish between secular trends and cyclical movements of the time series data set.
Msarima (x,y,z) (X,Y,Z)s
MSARIMA belongs to the group of models known as univariate time series, which refers to a data set consisting of sequentially reported single observations over equal time intervals. Univariate analysis of a time series data set involves the usage of historical data from the variable in question to build a model that explains the behaviour of the variable. As a result, we can forecast using this constructed model. MSARIMA is an excellent technique to forecast a time series data set of high frequency where the effect of secular trends and seasonal fluctuations of a non-stationary time series Yt is taken into account and expressed as:
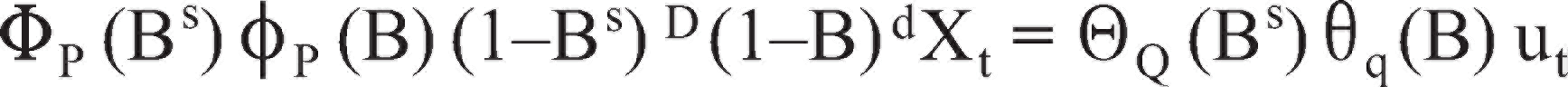
where B is the backward shift operator, f and Φ are non-seasonal and seasonal autoregressive (AR) parameters while q and Θ are non-seasonal and seasonal moving average (MA) parameters, respectively. D is the order of seasonal differencing whereas d is the order of non-seasonal differencing.
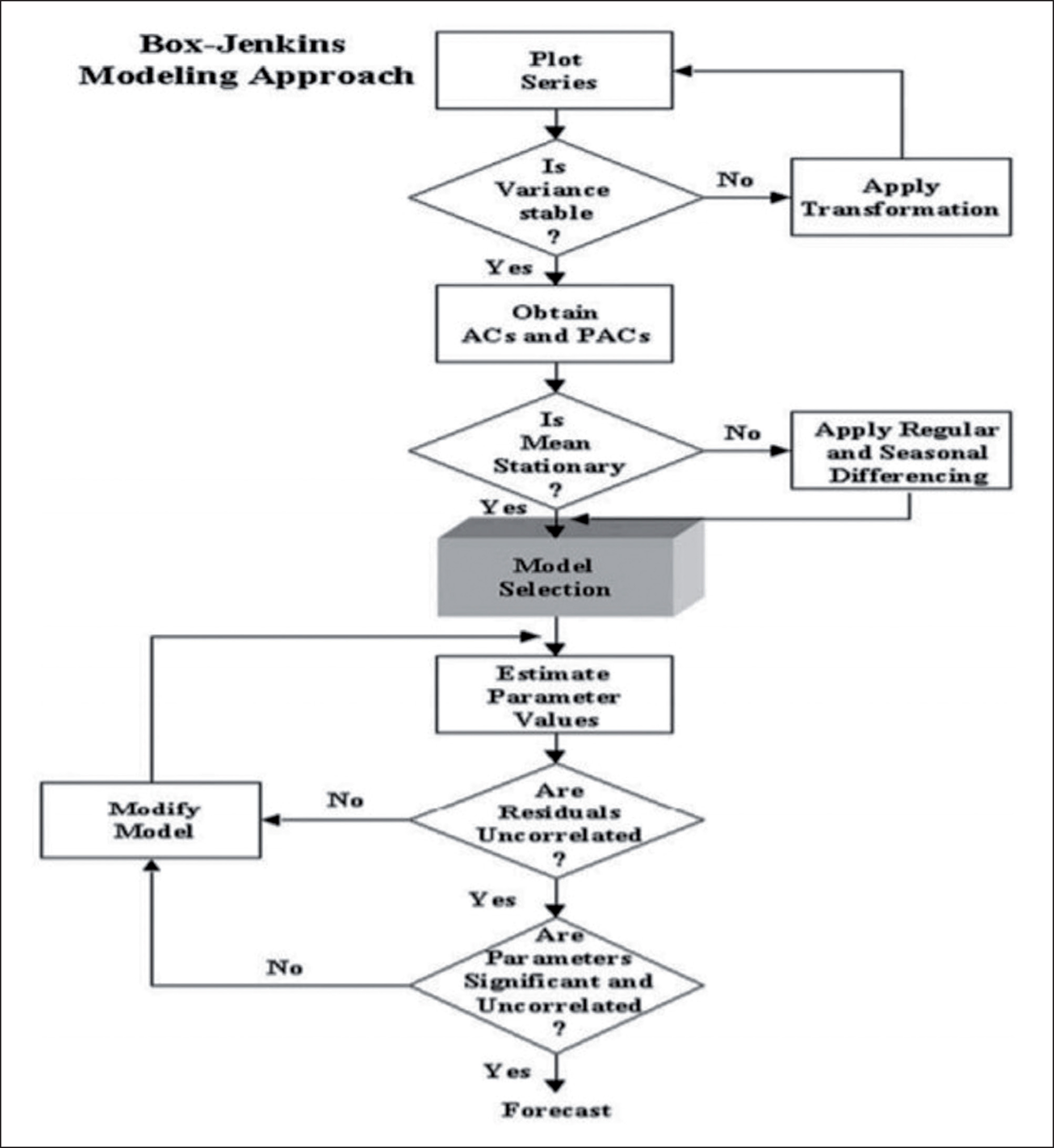
For any time series data set, it is essential to determine the MSARIMA model capable of generating the series. In other words, to make accurate predictions for the given time series which model should be considered that adequately captures its behaviour. This study employs the methodology developed by Box–Jenkins to identify the most appropriate model. It considers the model building as a reiterative process that can be divided into four stages: identification, estimation, diagnostic checking and forecasting which are explained below:
Identification: In this stage, appropriate AR and MA components are identified along with their seasonal counterparts based on the correlogram of the stationary form of the data series. Estimation: Here, point estimates of the coefficients identified in earlier stage can be obtained by the method of maximum likelihood. Also, the provided associated standard errors along with t-statistics suggest the coefficients that can be dropped. Diagnostic checking: This stage examines the residues of the estimated model to establish whether they have reached the white noise process. Forecasting: Here, one tries to forecast the future values of the time series variable under-study after completion of the diagnostic checking process.
Flow chart of Box–Jenkins model building strategy is shown in Figure 1.
ARMAX Model
The ARMAX model is generally specified as:
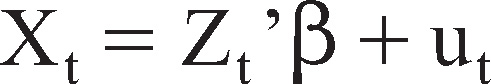
where Zt’ is a (1 × h) vector containing h exogenous variables at time t, β is a (h × 1) vector of parameters and ut follows an ARMA(p, q)(P.Q) process.
The various exogenous variables used in this study are as follows:
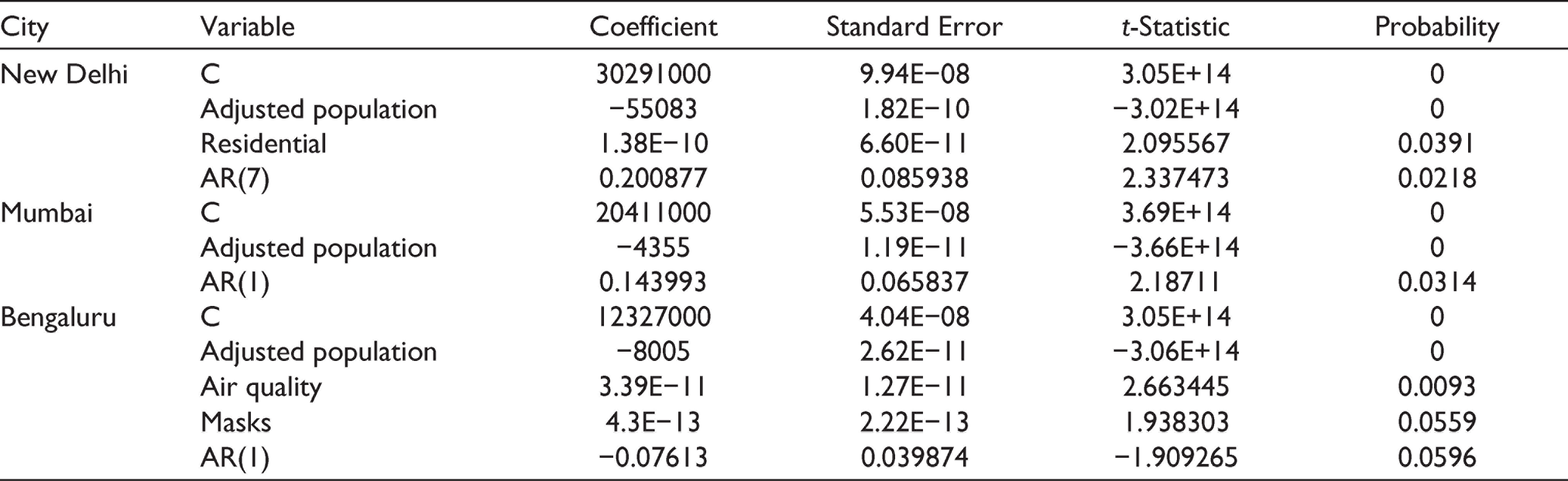
Residential, Workplace, Retail that is the percentage changes in mobility with respect to the residential, workplace and retail and recreation categories from Google Mobility reports Adjusted Population Density is the original population density times the square of the proportion of still vulnerable people. It incorporates the effect of already affected individuals. Masks represent a proxy variable that measures the extent to which individual precautions are being taken by the people living in various states. For our study, ‘Masks’ is the cumulative Google search interest observed at state level. It serves as a proxy variable for precautionary measures people are taking to reduce community transmission. Temperature represents the maximum temperatures in degree Celsius at state level. Humidity represents state-level daily time series data on humidity. Air quality represents state-level daily time series data on air quality measured using PM 2.5 levels.
Toda Yamamoto Extended VAR Model
Traditional Granger causality tests are conditional on the presumption that the underlying variables are integrated of order zero in nature or stationary in an unrestricted VAR environment. The basic stability condition of the VAR is violated if the time series is non-stationary. This means that the tests used to determine the joint importance of the other lagged endogenous variables in VAR equations, such as the χ2 (Wald) test statistics for Granger causality, are no longer accurate. Co-integration must be investigated in the case of non-stationary data, and if it occurs, the vector error correction model should be used in place of unrestricted VAR. No long-term relationship test is used if the time series is not of order I(1) or is integrated with different orders. If tests like unit root and co-integration are used; however, they can have low power compared to the alternative. As a result, they could be misplaced and subject to pre-testing bias (Pesaran et al., 2001; Toda & Yamamoto, 1995).
To mitigate most of these problems, Toda and Yamamoto (1995) and Dolado and Lutkepohl (1996) limit the number of VAR(k) parameters using a modified Wald test, where k is the lag length of the VAR method. Using this method, the right order of the model (k) is increased by maximum integration order (dmax), then the VAR(k+dmax) is computed using the coefficients of the last lagged dmax vector. Toda and Yamamoto (1995) confirm that the Wald statistics converge with degrees of freedom equal to the number of the omitted lagged variables in distribution to a chi-square random variable, irrespective of whether the method is stationary, possibly around a linear pattern or co-integrated.
The Toda Yamamoto (TY) method is unique, firstly, since it does not necessitate pre-testing of the system’s co-integrating properties, which eliminates the potential for bias associated with unit roots and co-integration tests (Clarke & Mirza, 2006; Zapata & Rambaldi, 1997). Secondly, it suggests a causality test in a possibly arbitrary ordered system be it integrated or co-integrated using a higher VAR modelling standard, which allows for long-run details that are often ignored in systems that requires pre-whitening and first-differencing (Clarke & Mirza, 2006; Rambaldi & Doran, 2006) and finally the MWALD test statistics hold till the time the true lag length of the method is not exceeded by the process’s order of integration (Toda & Yamamoto, 1995).
However, there are some disadvantages to the TY method. Since the VAR model is purposefully over-fitted, the solution is ineffective and has some loss of power (Toda & Yamamoto, 1995, p. 247). For small sample sizes, Kuzozumi and Yamamoto (2000: 212) caution that the asymptotic distribution might be a poor approximation of the distribution of test statistics.
A VAR of order p can be represented by:

where xt is a (m × 1) vector of endogenous variables, t is the linear time trend, a0 and a1 are (p × 1) vectors, wt is a (q × 1) vector of exogenous variables and ut is a (m × 1) vector of unobserved disturbances where ut ~ N (0, Ω), t = 1, 2, …, T.
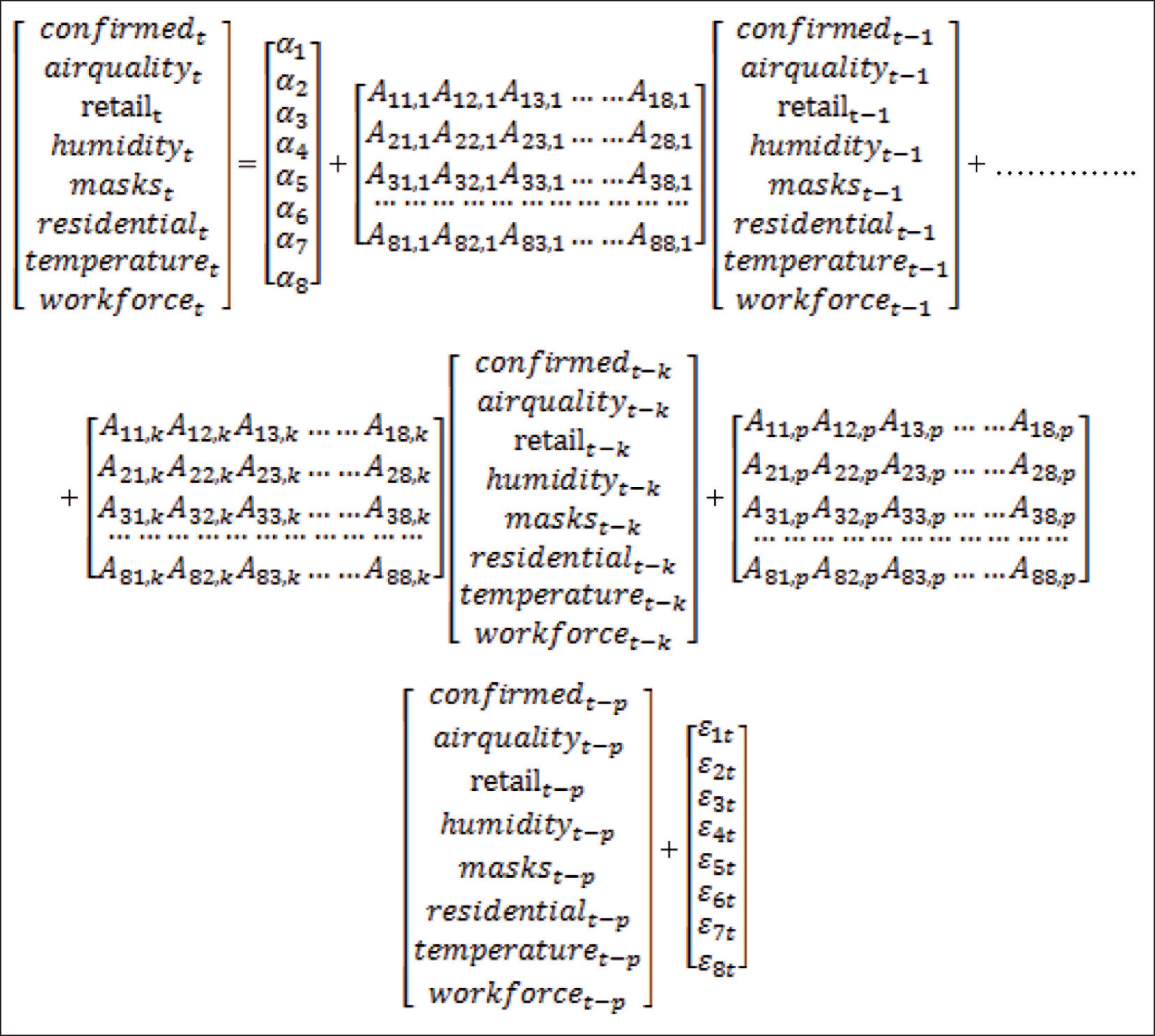
In our case, the TY version of the VAR(k+dmax) can be written as:
where d is the first-difference operator and (k + dmax) represents the order of p. By applying standard Wald tests to the first ‘k’ VAR coefficient matrix, we can detect the directions of Granger causality.
For example,
H01: A12,1 = A12,2 = ……. = A12,k = 0, suggests air quality does not Granger cause confirmed H02: A21,1 = A21,2 = ……. = A21,k = 0, suggests confirmed does not Granger cause air quality H03: A13,1 = A13,2 = ……. = A13,k = 0, suggests retail does not Granger cause confirmed H04: A31,1 = A31,2 = ……. = A31,k = 0, suggests confirmed does not Granger cause retail and so on.
Model Performance Measures
Time series forecasting models can be assessed using the following commonly used accuracy measurement functions:
Root mean square error (RMSE) = Root mean square relative error (RMSRE) = Mean absolute error (MAE) = MAPE =
where zI and
In this study, three statistical models (ARMAX, SARIMA and extended VAR models) are used for predicting the spread of the virus in three metropolitan cities in India, namely, New Delhi, Mumbai and Bengaluru along with causality analysis of weather and mobility parameters on the number of COVID-19 confirmed cases. The rationale behind choosing these cities was that the lockdown measures must have had a significant impact on their mobility as they are amongst the biggest metropolitan cities in India along with having distinctive weather conditions. To provide information regarding good model fit, each model’s performance was evaluated by using the above set of performance metrics.
Results and Discussion
For MSARIMA analysis, for each of the cities, either the de-trended series or de-seasonalized series or in some cases both were analysed as suggested by the correlogram of the original series. To make an MSARIMA(p,d,q)(P,D,Q)s model, the AR order p and MA order q in a univariate ARMA model along with its seasonal components were identified using the autocorrelation function (ACF) and partial autocorrelation function (PACF) of the de-trended or de-seasonalized series or both. If then also, any autocorrelation remained, it was inspected in the residual series.
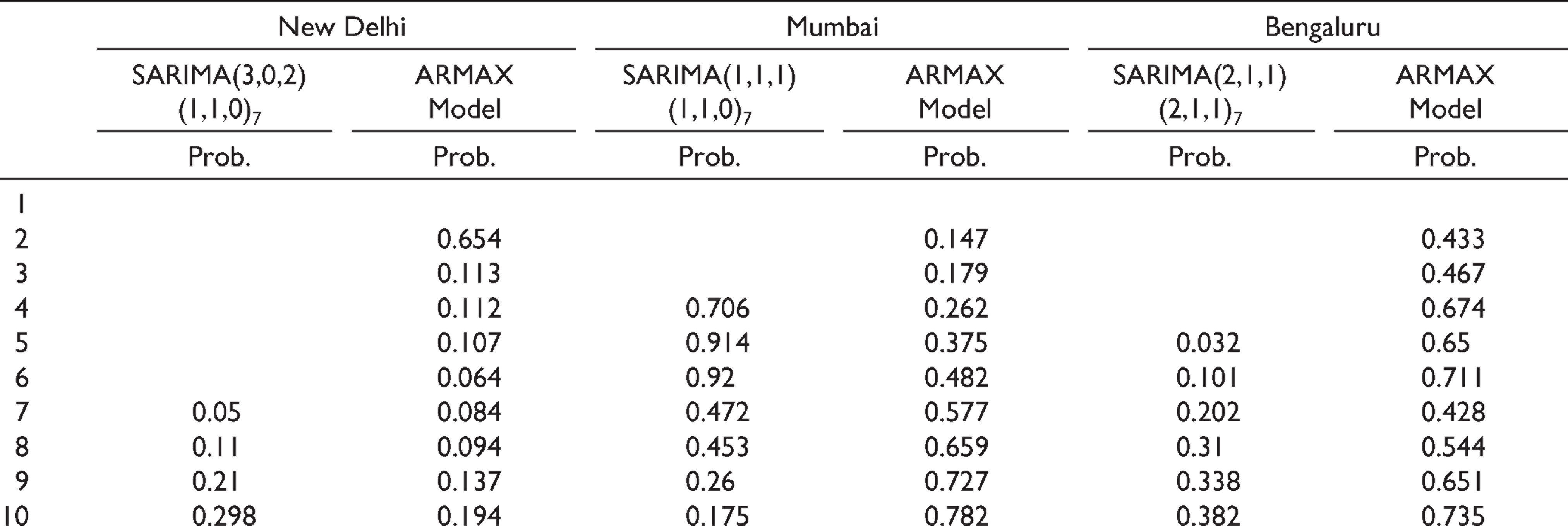
For New Delhi, we have found that SARIMA(3,0,2)(1,1,0)7 model along with SARIMA(1,1,1)(1,1,0)7 models for Mumbai and SARIMA(2,1,1)(2,1,1)7 model for Bengaluru gives the best forecasting performance amongst various MSARIMA models. The estimated AR and MA parameters along with their seasonal components are found to be statistically significant at a 5% level. The stationarity as well as the invertibility conditions for respective seasonal and non-seasonal components, that is, AR and MA terms were also satisfied. Also, in all the cases, the residual series appears to be purely white noise as are shown in Table 4.
Estimated Parameters of ARMAX Model
Probability Values for Residual Series Depicting White Noise for Different Models
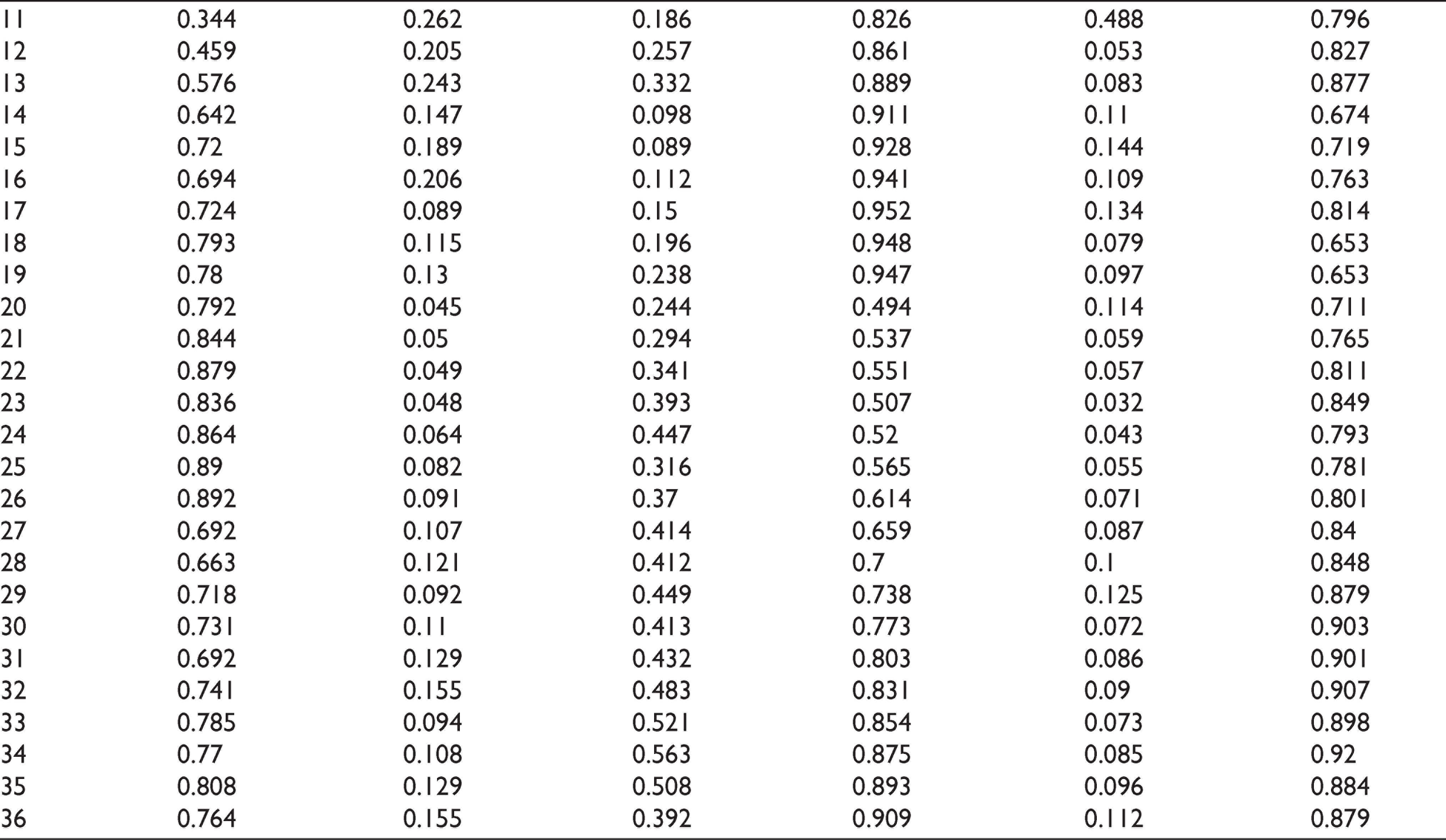
Results of the estimated ARMAX models are shown in Table 3. Adjusted population density appears to be the only statistically significant exogenous variable for all the cities which influence the number of COVID-19 confirmed cases. Apart from adjusted population density, the percentage change in residential mobility for New Delhi along with masks and air quality parameters for Bengaluru were other statistically significant exogenous variables. In addition, for New Delhi there are statistically significant seasonal ARMA(1,0) components, for Mumbai and Bengaluru there are statistically significant non-seasonal ARMA(1,0) components. The residual series, as shown in Table 4, appears to be white noise.
In the next stage, we estimate the VAR model. For New Delhi, the order of the VAR based on the AIC (Akaike information criterion) and HQ (Hannan-Quinn information criterion) is found to be 7. Similarly, for Mumbai and Bengaluru the order of the VAR was found out to be 2 and 7, respectively.
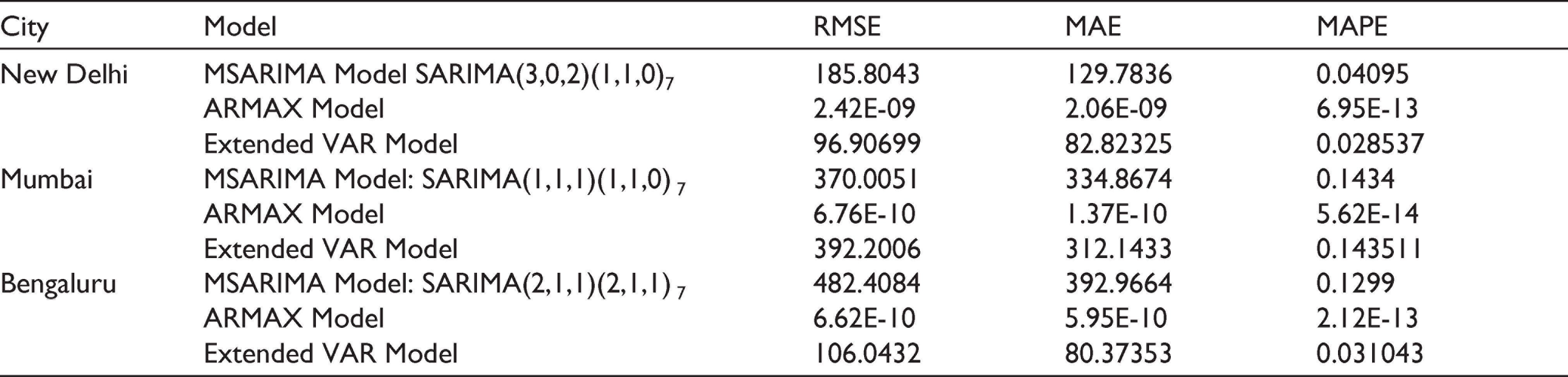
Estimated ARMAX, MSARIMA and VAR models are finally used to forecast COVID-19 confirmed cases for the period 21 September 2020 to 21 October 2020, and the forecasts are then evaluated based on MAE, RMSE and MAPE, which are standard performance criterion used in time series forecasting. Two performance criteria, that is, RMSE and MAE usually depend on the scale of the variable. On the other hand, MAPE is generally not sensitive to the variable’s scale. The forecasting performance of the series is better if the errors are smaller.
As shown in Table 5, MAPE values between actual and predicted values by the three models, that is, MSARIMA, ARMAX and extended VAR models for the last one month (21 September to 21 October) of the data span is less than 1. Also, it is evident that the ARMAX model slightly outperforms the other two models.
Forecasting Performance
Results of Granger causality after running the extended VAR model are shown in Table 6.
Granger Causality Tests (Linear)


For New Delhi, air quality, residential and retail variables were statistically significant at a 10% confidence interval. Hence, the Granger causality runs from all these statistically significant variables to the number of COVID-19 confirmed cases. Similarly, for Mumbai, masks, temperature, residential and workplace were the statistically significant variables, suggesting that the Granger causality runs from all these statistically significant variables to COVID-19 confirmed cases.
For Bengaluru, the statistically significant variables were air quality, masks and residential, suggesting that the Granger causality runs from all these variables to COVID-19 confirmed cases.
Conclusion
In this study, univariate and multivariate time series techniques are used for forecasting COVID-19 cases in three Indian cities namely New Delhi, Mumbai and Bengaluru. All the models explored have lower forecasting errors; however, it was found that ARMAX slightly outperforms other models. One of the contributions of this study is that it develops robust forecasting models to predict COVID-19 cases. The models explored in this study provide very low forecasting errors (MAPE of less than 1%), thus providing a variety of accurate and robust methods for forecasting the number of cases. It also helps in finding the causal relationship of the spread of COVID-19 with various mobility and weather parameters. In addition, the study also establishes the connectedness between COVID-19 cases with various mobility and weather-related factors.
It was found that ARMAX models outperform both MSARIMA and extended VAR in terms of forecasting daily confirmed cases in the three studied cities. For New Delhi, ARMAX models suggest that the increase in COVID-19 confirmed cases is only influenced by adjusted population density and percentage change in residential mobility. Similarly, the ARMAX model suggests that masks and air quality parameters for Bengaluru were the other statistically significant exogenous variables. The statistical significance of residential, masks and air quality exogenous variables in some cities points towards the relation that the spread of the novel coronavirus can be associated with mobility and weather parameters along with the precautions and other measures people are taking to reduce community transmission. This argument is further strengthened by the results of the Granger causality tests, which states that certain mobility parameters along with weather conditions influence the spread of COVID-19. However, the type of mobility (residential, retail and workplace) and type of weather conditions (air quality, temperature and humidity) associated with the causality differ with cities.
For New Delhi and Bengaluru, as air quality is one of the causal variables, it points to the fact that exposure to air pollution may increase the risk of contracting the COVID-19 infection. Hence, the concerned authorities should especially pay attention to the poor communities, who are at greater risk of contracting the COVID-19 infection, as they are more susceptible to be exposed to indoor air pollution. For preventing the further spread of the COVID-19 virus, monitoring air quality should also be counted as an important aspect of public health protection. For Mumbai, as masks represent one of the causal variables, it points to the fact that the concerned authorities should further strive towards raising awareness about the precautions and other measures they should be taking to reduce community transmission. Wearing masks, disinfecting public surfaces, not touching their faces or shaking other people’s hands, washing hands, etc. are some of the steps that should be constantly advertised.
The availability of a novel coronavirus vaccine is a positive step towards the eradication of this pandemic; however, the emergence of new COVID-19 strains has raised serious concerns about the efficacy of the newly developed vaccine. The associated connectedness of COVID-19 cases with various mobility and weather-related factors can help in preventing the spread of the new strains.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.