
Abstract
Timely prediction of corporate financial distress in borrower companies can reduce economic vulnerability, nonperforming assets, and associated costs. This critical issue has consistently attracted scholarly attention from multiple perspectives. This article examines research trends in corporate financial distress prediction using a bibliometric analysis of 984 Scopus-indexed articles published between 2008 and 2023. By analyzing coauthorship networks and keyword co-occurrence using VOSviewer and conducting a thematic analysis of abstracts, it identifies major research themes and their evolution over time. Results show a predominant focus on model development, while relatively few studies seek to identify relevant financial and nonfinancial indicators. The article offers a comprehensive overview of academic contributions in the field and provides insights to guide future research directions globally.
Keywords
Introduction
The global rise in bankruptcy cases (Grosu & Chelba, 2020) has increased the awareness of the importance of early detection, making corporate financial distress prediction an increasingly vital early warning tool for timely intervention and risk mitigation (Grosu et al., 2023).
Corporate financial distress describes a situation where companies struggle to pay their dues to creditors. Prolonged financial distress may eventually lead to bankruptcy (Altman, 1968). A company may be financially distressed if it is unable to pay its financial obligations as they mature (Altman, 1968; Lin, 2009). This state is characterized by cashflow problems, declining profits, and mounting debts. Factors such as poor strategic decisions, market downturns, excessive leverage, and operational inefficiencies can lead to corporate distress (Whitaker, 1999). Corporate distress has significant implications for stakeholders, such as employees, creditors, and investors, resulting in job losses, reduced shareholder value, and broader economic impacts, particularly for lenders (Gilson, 1989). Consequently, predicting corporate bankruptcy and implementing preventive measures is essential. Various models have emerged over time, including the Altman Z-score, which relies on financial ratios (Altman, 1968), and the more recent machine learning (ML) approaches that use big data (Sun & Vasarhelyi, 2017).
The ability to predict corporate bankruptcy is important for effective financial management and business operations. Accurate prediction models enable investors, creditors, and corporate managers to mitigate risks and make informed decisions, thereby supporting financial market stability and safeguarding stakeholder interests. For investors and creditors, assessing bankruptcy risk helps in adjusting investment strategies and managing credit exposure. Internally, management can use these insights to implement timely restructuring and strategic changes, reducing the likelihood of failure (Altman, 1968). The timely prediction of distress serves as a tool in the following cases:
Risk management: Businesses can take timely preventive measures before a situation becomes irrecoverable by adjusting credit terms, redefining investment strategies, or restructuring debts, if necessary (Ohlson, 1980). Investment decision-making: Investors and fund managers benefit from bankruptcy prediction by identifying high-risk stocks, enabling them to avoid significant losses through timely avoidance or exit, whether for personal financial planning or portfolio management (Altman, 1968). Operational adjustments: Internal management uses these predictions to implement operational changes that prevent irreversible decline, such as cost cutting, diversifying revenue streams, or altering business models to improve financial health (Ohlson, 1980). Regulatory compliance: For regulators, timely insights into distress signs ensure that the integrity of the financial market is maintained, preventing the cascading effects of unexpected corporate collapses on the economy (Altman, 1968).
Research Progress
Research has centered on the importance of bankruptcy prediction and the development of models to forecast a company’s likelihood of failing to meet financial obligations. These models traditionally rely on financial statements, accounting data, and market information. Recently, there has been a growing emphasis on applying ML techniques to test, refine, and develop new predictive models.
The foundation was established by Altman (1968), who introduced the Z-score model, a weighted combination of five financial ratios estimated using multiple discriminant analysis. This model has been widely validated and remains a key tool in bankruptcy prediction. Building on this, Ohlson (1980) developed a logistic regression model that introduced a probabilistic approach to forecasting financial distress, thus improving upon earlier linear methods. Together, their foundational work continues to underpin modern bankruptcy risk assessment in finance.
Research has progressed by integrating advances in statistical and computational methods. Beaver (1966) pioneered corporate failure prediction using a univariate analysis approach, laying the groundwork for more complex multivariate models. Current trends emphasize ML techniques, such as neural networks and support vector machines, to capture nonlinear relationships and interactions among multiple financial indicators (Kumar & Ravi, 2007). Further studies have addressed changes in regulatory environments and economic conditions. Following the IT bubble burst, models began incorporating macroeconomic variables and market-based indicators to better capture the broader economic impacts on corporate health (Shumway, 2001). The literature shows that corporate bankruptcy prediction is a dynamic field, which is continually adapting to new technologies and evolving market conditions to enhance accuracy and timeliness. This area has attracted significant interest from academics, policymakers, and researchers, with extensive studies conducted over the past five decades (Shi & Li, 2019).
Researchers have reviewed progress and trends in bankruptcy and financial distress prediction through several review papers. For example, Suffian et al. (2023), in their study “Corporate Financial Distress and Performance in Emerging Countries via Bibliometric Analysis,” analyzed key research themes, influential authors, and leading journals in the field, focusing specifically on emerging markets. Grosu et al. (2023) reviewed evaluation models for bankruptcy risk, while Shi and Li (2019) focused on intelligent techniques for bankruptcy prediction. Prado et al. (2016) conducted a bibliometric study on the use of multivariate data analysis methods. Klopotan et al. (2018) provided insights into bibliometric trends in early warning systems across management, economics, public administration, and finance. Sun et al. (2014) examined state-of-the-art definitions, modeling, sampling, and feature selection approaches through bibliometric analysis.
Corporate bankruptcy prediction largely depends on the selection of financial and nonfinancial variables and the modeling methods used. Existing reviews have not thoroughly examined whether current research emphasizes variable selection or advances in statistical and ML models. This study aims to assess the focus of recent research, particularly post-subprime and COVID crises, and identify gaps using bibliometric analysis. It addresses key research questions to provide a comprehensive understanding of trends in corporate distress prediction:
Identify the prominent contributors in bankruptcy prediction research over the last 15 years (post-subprime crisis). Identify the progress in publications over time, including contributing authors and major journal sources. Identify bibliometric trends, such as coauthorship, geographical distribution, co-citation metrics, keyword co-occurrence, and term extraction, in bankruptcy prediction. Extract common themes from abstracts to determine whether the focus is primarily on variable selection or model development, and highlight underexplored areas that suggest opportunities for future research.
The rest of the article is structured as follows. The second section outlines the methodology, detailing the phase-wise bibliometric data analysis. The third section presents the results under the heading “Performance Analysis.” The fourth section discusses themes and subthemes extracted from paper abstracts, highlighting research gaps and formulating related research questions. The fifth section offers an overall discussion, while the sixth section concludes with the study’s limitations and research implications.
Methodology: Bibliometric Data Analysis
Bibliometric analysis employs quantitative techniques to examine publication year, subject, source, country, authorship, institutional affiliations, and more. This study used data from the Scopus database, known for its extensive coverage of high-quality journals, especially in social sciences. Scopus is frequently used in bibliometric research (Donthu et al., 2021). The analysis followed a three-phase protocol—scanning, curating, and reporting—based on Khanra et al. (2021). VOSviewer software was used for visualization, and themes were identified through primary screening of abstracts.
Scanning Phase
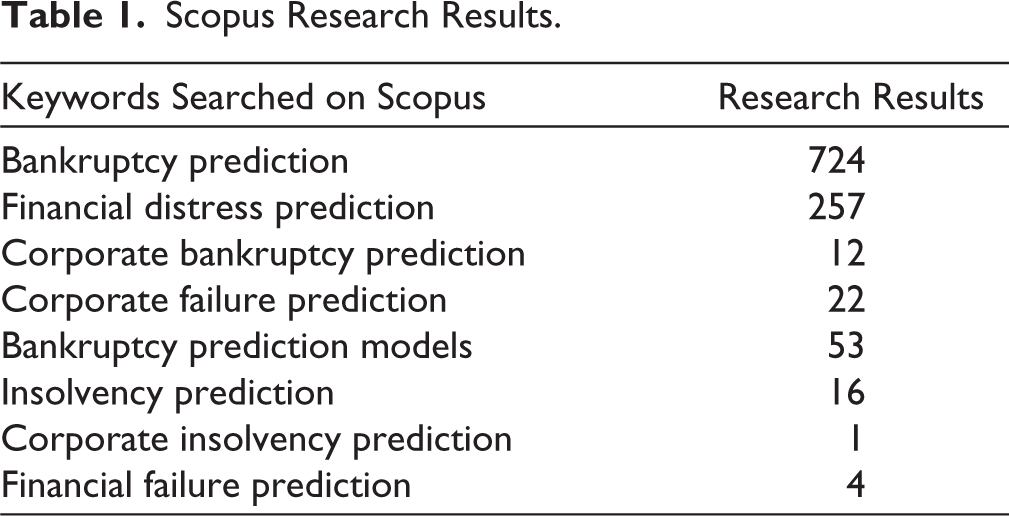
The study employed the Scopus database for data collection. Accurate keyword selection is critical for successful retrieval (Batra & Singh, 2023; Suffian et al., 2023). Related terms identified include “Bankruptcy Prediction,” “Financial Distress Prediction,” and “Corporate Bankruptcy Prediction,” which are the related terms to “Corporate Distress Prediction.” Thus, the query adopted for the search was: TITLE-ABS-KEY (*Corporate and distress) AND (Prediction) and (LIMIT-TO) (EXACTKEYWORD, “Bankruptcy Prediction”) or LIMIT-TO (EXACTKEYWORD, “Financial Distress Prediction”) or LIMIT-TO (EXACTKEYWORD, “Corporate Bankruptcy Prediction”) or LIMIT-TO (EXACTKEYWORD, “Corporate Failure Prediction”) or LIMIT-TO (EXACTKEYWORD, “Bankruptcy Prediction Models”) or LIMIT-TO (EXACTKEYWORD, “Insolvency Prediction”) or LIMIT-TO (EXACTKEYWORD, “Corporate Insolvency Prediction”), or LIMIT-TO (EXACTKEYWORD, “Financial Failure Prediction”).
Curating Phase
The initial search results were refined, with a focus on publications from 2008 to 2023 due to a notable increase in studies following the subprime crisis. Among the curated papers, only those ranked A*, A, B, and C in the ABDC-listed category journals (Australian Business Deans Council, n.d.) were considered to ensure high quality, along with non-indexed papers receiving over 50 citations (Joshipura et al., 2023).
Performance Analysis
The initial search yielded 1,089 papers (details provided in Table 1). After careful screening of titles and abstracts to exclude unrelated studies, duplicates, and non-English papers, 984 articles remained for analysis (Suffian et al., 2023). No time restrictions were applied. The document types included articles, books, and conference proceedings across subject areas, such as business management and accounting, economics, econometrics and finance, computer science, and related fields.
Scopus Research Results.
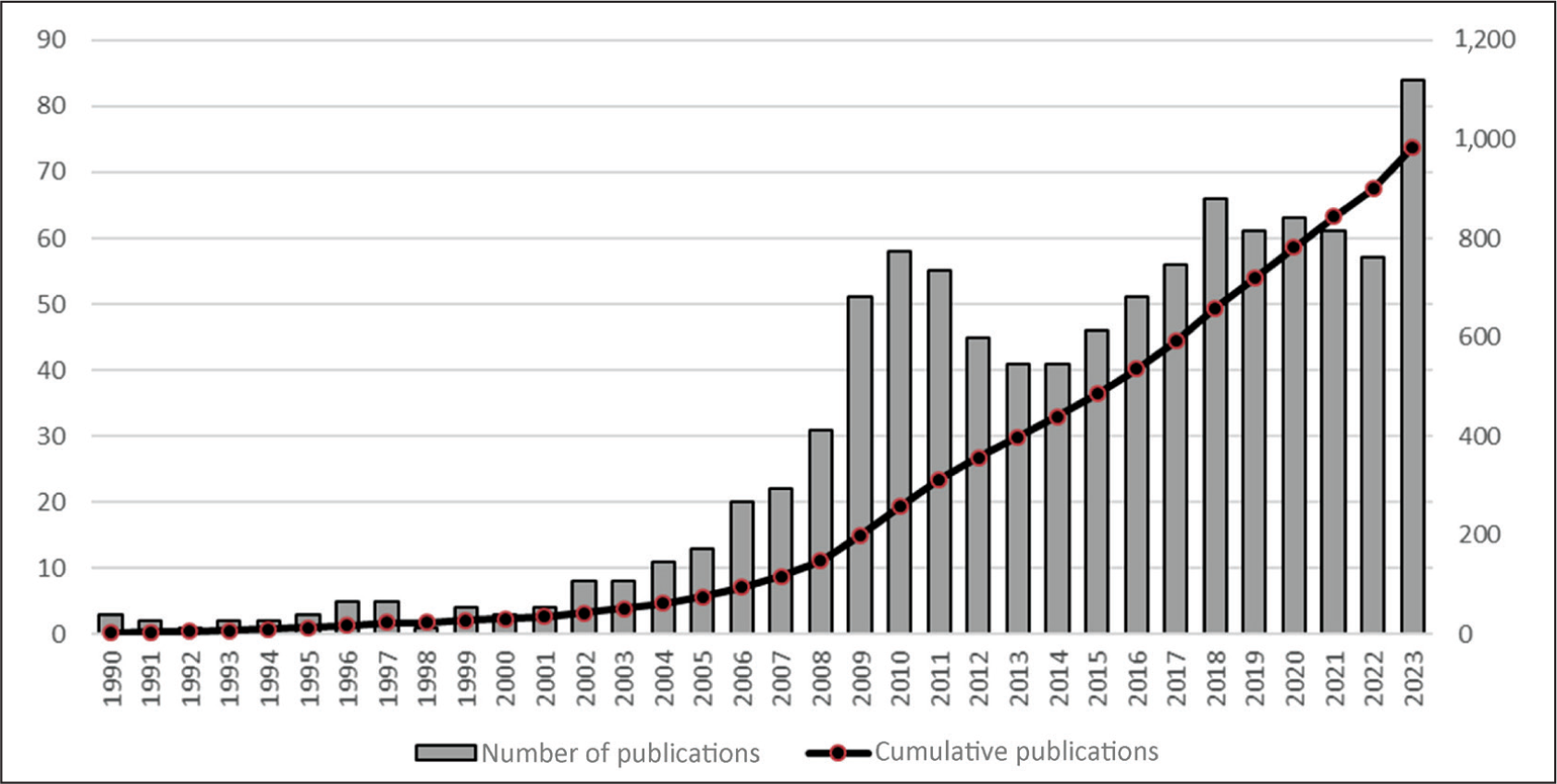
Trends in Publication
The 984 publications from the scanning phase were further refined. Figure 1 illustrates a marked increase in publications following the 2009 subprime crisis (Arslan & Karan, 2010; Yu et al., 2010). Thus, the time period from 2008 to 2023 was considered for further analysis. After curating the papers based on the methodology discussed, 307 papers were considered for bibliometric and thematic analyses.
Number of Publications.
Analysis Results
The analysis revealed 687 authors from 60 countries contributing to the literature through 117 journals. Expert Systems with Applications led with 62 articles on predicting distress, followed by Knowledge-based Systems (14 articles) and Decision Support Systems (12 articles).
Most-influential Authors
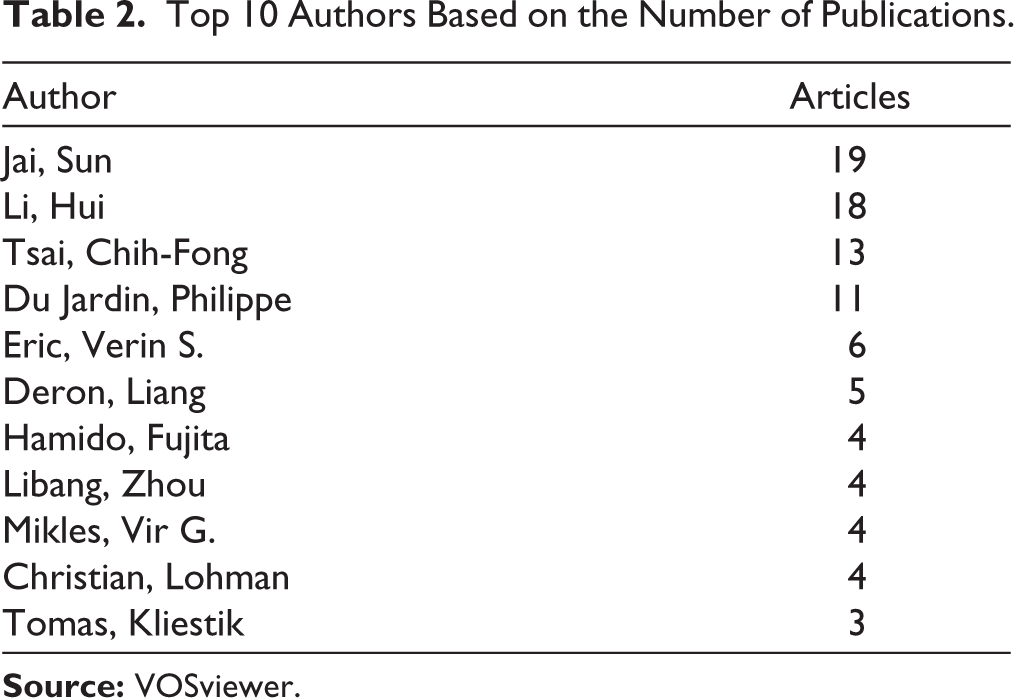
Table 2 lists the top 10 most influential authors, based on the number of publications. Sun Jai and Li Hui are the most influential authors based on the number of documents published.
Top 10 Authors Based on the Number of Publications.
Most-cited Documents
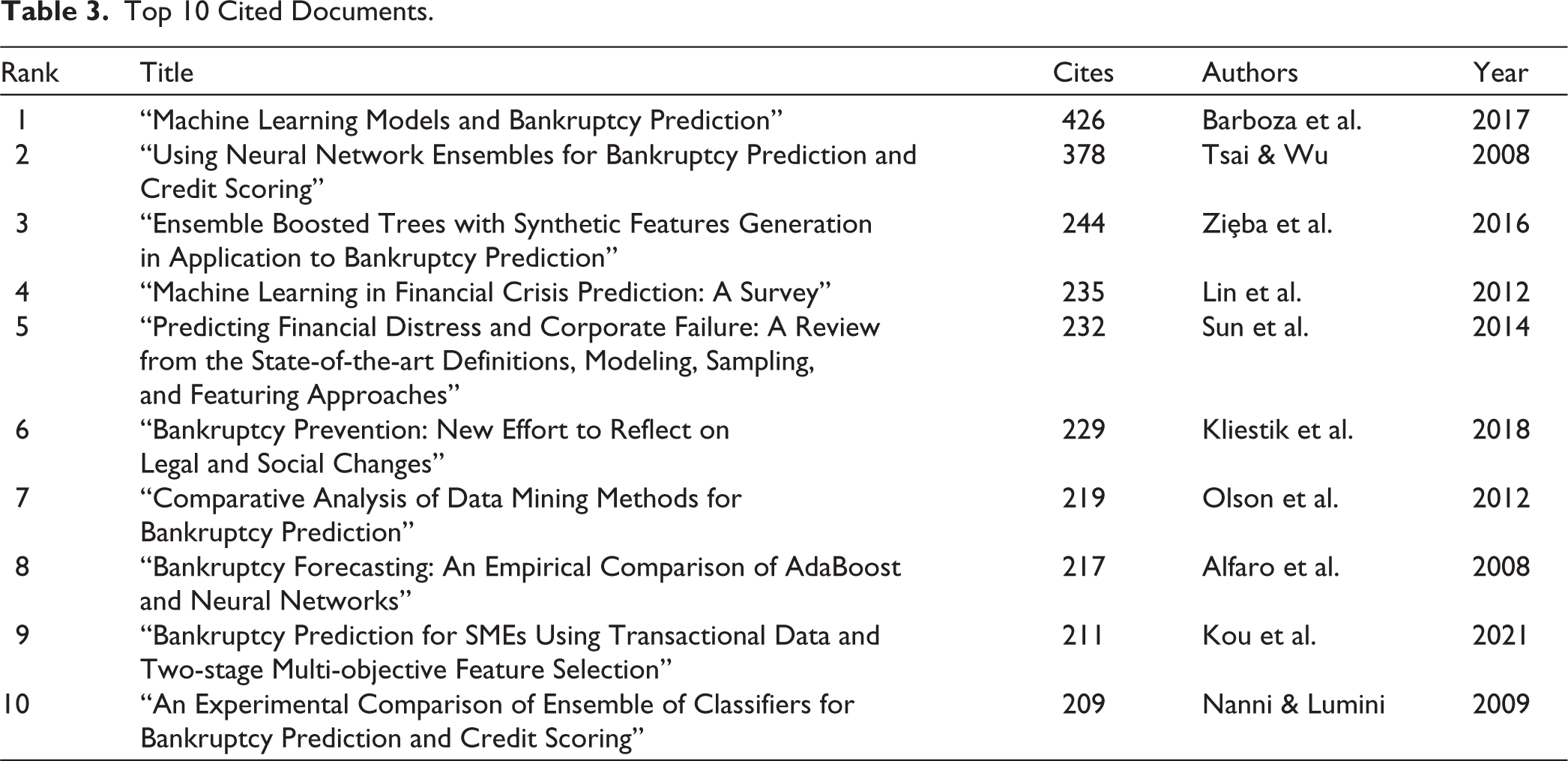
Table 3 lists the 10 most-cited documents based on keyword search. Barboza et al. (2017), Tsai and Wu (2008), Ziȩba et al. (2016), Lin et al. (2012), and Sun et al. (2014) top the list of the most-cited papers, with all focusing on ML and algorithms, except for Sun et al. (2014).
Top 10 Cited Documents.
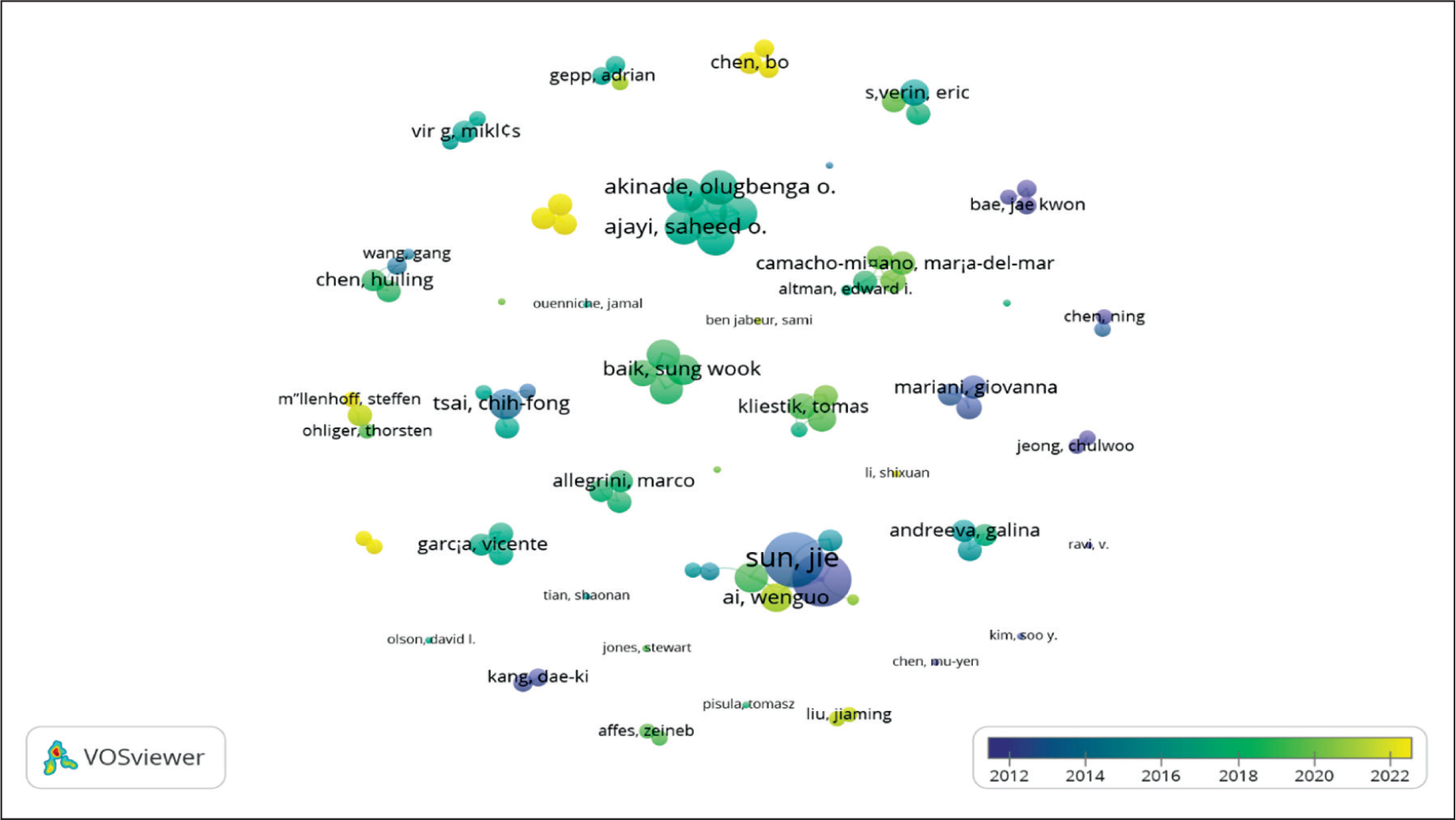
Coauthorship Based on Author
Coauthorship based on authors suggests there are 687 authors contributing to the literature under study. Among them, 94 authors have published two or more coauthored papers in Scopus-listed journals between 2008 and 2023. Figure 2 illustrates the coauthorship network, with countries represented as nodes and collaborative ties shown as edges.
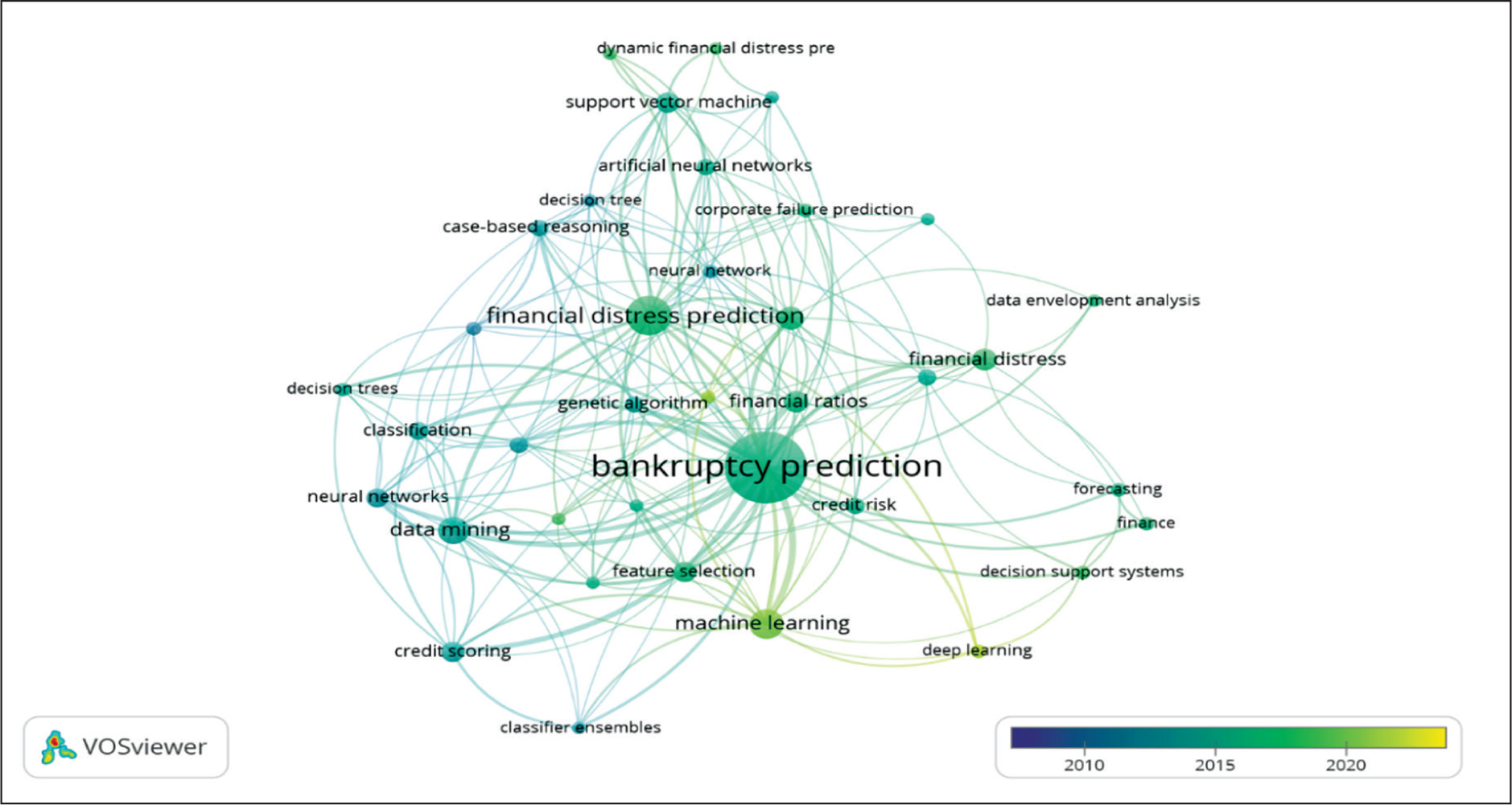
Co-occurrence of Author Keywords
Among the 807 author keywords, 38 met the threshold for co-occurrence based on a minimum of five appearances. Figure 3 shows that most keywords cluster around prediction methods, primarily ML- and algorithm-based approaches, followed by those related to financial statements and their analysis. From 2008 to 2023, research evolved from decision tree models to more advanced ML techniques.
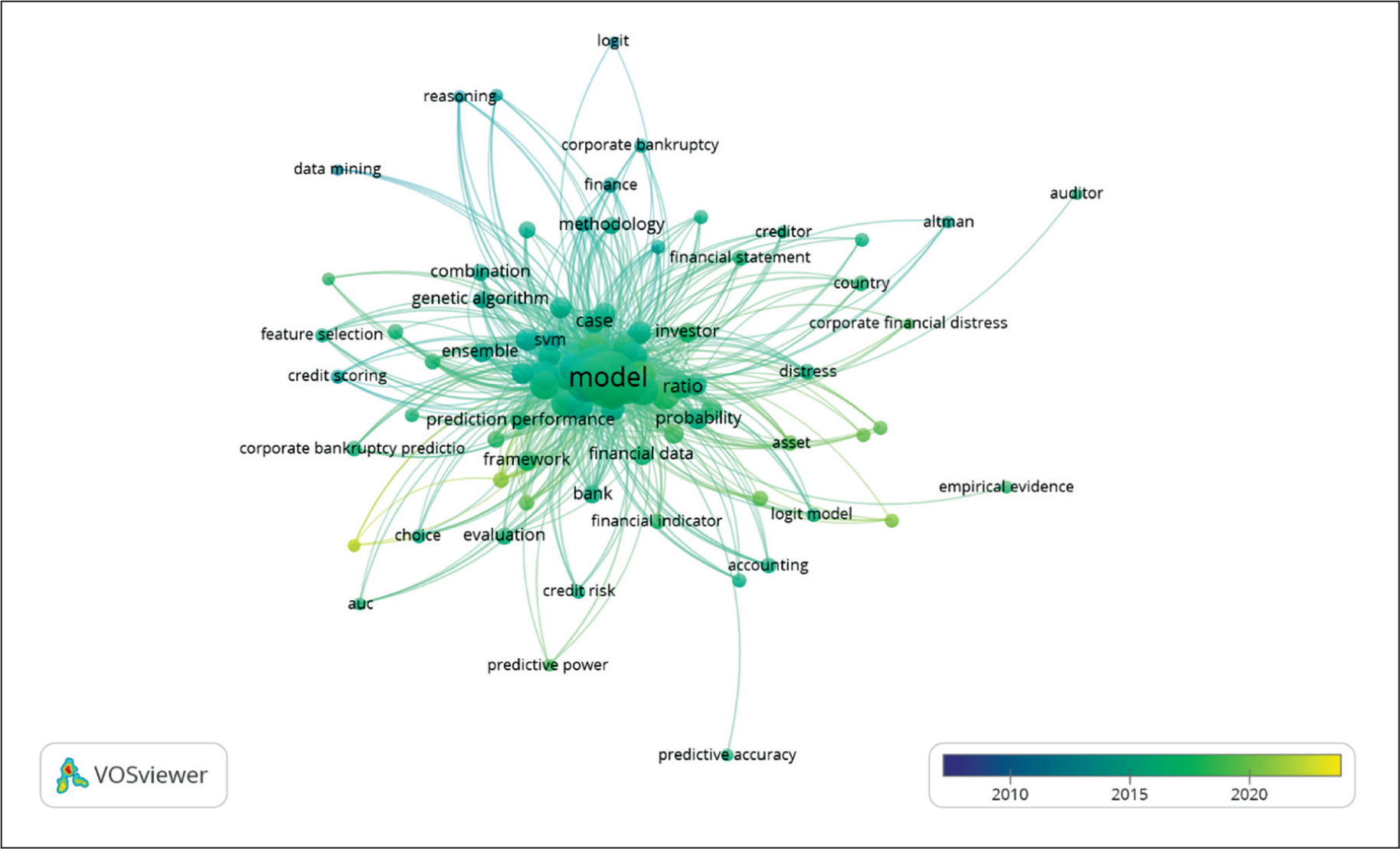
Term Extraction from Abstract and Title
Text data from titles and abstracts were analyzed to extract the most frequently used and relevant terms. Using full counting with a minimum threshold of 10 occurrences, 162 terms met the criteria. Earlier studies commonly referenced traditional models, such as Altman’s Z-score, decision trees, and credit scoring. Over time, the focus has shifted and stabilized toward ML and deep learning approaches for bankruptcy prediction.
Term extraction from titles, using full counting with a minimum of 10 occurrences, revealed frequent terms, such as bankruptcy prediction, models, and bank. This indicates that much of the research has centered on evaluating and testing prediction models, particularly within the domain of ML.
Thematic Analysis
A thematic approach was adopted to explore prior research focus and identify gaps in the literature. Qualitative content analysis using ‘Term Extraction from Title and Abstract’ (Figure 4) using VOS viewer software was taken as a base level theme identification, combined with manual thematic clustering, was conducted based on keywords, objectives, and methodologies described in each abstract. Abstracts were coded using row numbers in an Excel file. The initial classification distinguished between studies focused on identifying predictive variables and those centered on model development. Using an inductive approach (Elo & Kyngäs, 2008), additional themes and subthemes were identified. Each abstract was thoroughly reviewed to detect recurring patterns in keywords, methods, and findings, which were then coded and grouped into major themes and subthemes.
This study conducts a detailed review of document abstracts to identify key themes and corresponding subthemes, offering a comprehensive understanding of the research landscape in corporate financial distress prediction. By identifying research gaps within each theme, the study highlights areas for future investigation. Addressing these gaps can enhance the accuracy, efficiency, and practical relevance of distress prediction models, thereby supporting more effective financial management and decision-making.
A more comprehensive description of the themes with key aspect explanations and areas not covered in the data set is provided in the next section.
Bankruptcy Prediction Models
The majority of studies focus on developing, evaluating, and refining bankruptcy prediction models. These works primarily focus on enhancing predictive frameworks using a variety of statistical and ML techniques to detect early signs of financial distress. These models consider various financial indicators and operational metrics to form comprehensive risk assessment tools. Given the dominance of this theme, it is essential to further classify it into the following subthemes for a more in-depth analysis.
Risk assessment: This subtheme encompasses studies centered on predictive models used to assess corporate financial health. These works emphasize methods for quantifying risk and enabling early identification of firms at risk of bankruptcy. A total of 37 papers fall under this subtheme.
Model complexity: This subtheme includes 18 papers that explore the sophistication of predictive models. These studies focus on integrating multiple variables and advanced algorithms to enhance forecasting accuracy by capturing more nuanced indicators of financial distress.
Research Gaps Identified
Nontraditional data sources: Most bankruptcy prediction studies rely on financial indicators for model development, while research incorporating nontraditional data sources, such as published reports, real-time market conditions, or social media sentiment, is notably absent. This gap presents an opportunity for future research, either as standalone studies or integrated with traditional data.
Cross-industry validation: Most models focus on specific industries, leaving significant scope for cross-industry validation studies to enhance the robustness and generalizability of bankruptcy prediction models.
We propose the following research questions based on the identified gaps in literature:
Can textual disclosures by the firm be integrated into modern forecasting models to create or improve the bankruptcy prediction models?
Can news sentiment related to the firm be integrated into modern forecasting models to create or improve the bankruptcy prediction models?
Are the models created equally efficient across industries?
Machine Learning Tools for Bankruptcy Prediction
Post-2009, there has been a substantial increase in scholarly attention toward the use of ML techniques for predicting corporate bankruptcy. The proliferation of digital financial records, the advancements in computational power, and the limitations of traditional statistical models have all contributed to this paradigm shift. From 2013 to 2017, research shifted from decision trees and support vector machines to ensemble methods, such as AdaBoost and Random Forest, followed by a growing adoption of deep learning techniques such as Convolutional Neural Network and Long Short-term Memory Networks. The recent era, post-2021, has seen the integration of textual sentiment, temporal features, and external macroeconomic data into ML models, alongside increasing calls for model interpretability and real-time application.
A set of 52 studies explore cutting-edge ML algorithms, emphasizing their predictive capabilities and optimal application contexts. The other subarea of focus, advanced neural networks (52 papers), explores comparative studies on ML techniques, assessing their efficacy and suitability for different predictive scenarios in the financial domain. The papers focus on the implementation of ML tools in predicting financial distress.
Research Gaps Identified
However, a gap remains in developing interpretable ML models that enable stakeholder understanding of predictions and in integrating real-time data for timely forecasting.
We propose the following research questions based on the identified gaps:
How can ML models be made more interpretable without compromising accuracy?
What role do hybrid models play in integrating structured financial data with textual or behavioral inputs?
How can real-time financial data streams be effectively used for continuous bankruptcy risk monitoring?
“Ensemble Methods” in Prediction
Papers in operations and finance often highlight ensemble methods, which combine multiple models to improve the accuracy and robustness of financial distress predictions. The development can be observed from basic ensemble frameworks, such as bagging and boosting in bankruptcy studies in the period immediately post-subprime crisis to proliferation of ensemble models using Support Vector Machines (SVM), AdaBoost, and Random Forests during 2015–2018. The emphasis shifted to hybrid feature engineering and model stability. Post-2019, studies have explored temporal ensembles and real-time ensemble scoring mechanisms, incorporating deep learning modules, macro-financial indicators, and high-dimensional feature selection. Seventeen papers primarily focus on enhancing prediction robustness through ensemble methods, while five compare the performance of ensemble models against single-model approaches. Though limited, these studies provide valuable insights into the advantages of ensemble techniques.
Research Gaps Identified
Ensemble methods reflect their superiority in delivering robust bankruptcy predictions. However, questions remain regarding their scalability and efficiency for deployment in large-scale financial systems, particularly in maintaining performance consistency across dynamic and evolving time periods. We propose the following research questions based on the identified gaps:
Do ensemble models perform with the same efficiency across different firm sizes, leverage levels, or capital structures over time?
Can ensemble techniques be optimized to balance computational load and predictive reliability in volatile market conditions?
Distress Indicators
The use of financial indicators is the predominant approach in model development across 41 reviewed papers. These studies mainly examine financial ratios and accounting-based indicators as early warning signals of corporate distress. In the early time period, post-subprime crisis, studies such as Altman’s Z-score dominated the research with the use of univariate and multivariate financial ratios. This was followed by studies exploring financial statement trend analysis, logistic regression, and early applications of ML post-2012. The last decade of studies has seen the emergence of integrated models with widespread adoption of natural language processing, real-time data integration, and behavioral signal extraction to supplement core financial indicators.
Subthemes
Financial statement analysis: Papers in this theme discuss methodologies for extracting predictive indicators from financial data, using both traditional ratio analysis and modern data-driven techniques to improve the accuracy of financial health forecasts. Over the years, there has been a shift from static ratio-based models to more complex statistical and ML-driven frameworks that use historical financial data in dynamic ways.
Qualitative methodology: A few papers focus on qualitative data analysis, such as textual analysis of published reports, management discussions, auditor reports, board quality assessments, and even media sentiment analysis. Financial metrics are integrated and analyzed to enhance the predictive accuracy of distress models. Functional integration through textual analysis is a key development. However, only a limited number of studies demonstrate that simpler financial indicator-based models can achieve efficiency comparable to or exceeding that of more complex, algorithmically intensive models.
Research Gaps Identified
Qualitative and behavioral indicators: The majority of papers focus primarily on quantitative financial ratios. However, recent literature shows a decline in interest in identifying new financial indicators, with emphasis shifting to methodological advancements and model development. Textual analysis has advanced the identification of nonfinancial indicators of corporate distress, yet studies integrating these with financial metrics remain limited. Key signals such as management entry–exit timing and strategic decisions are underexplored. Behavioral finance perspectives are notably absent, and integrating financial data with HR and marketing insights offers untapped potential for improving prediction models.
We propose the following research questions based on the identified gaps:
Does the management quality influence the firm’s likelihood of financial distress?
Do the management decision-making and entry–exit timing of management personnel signal bankruptcy?
Does a shift in customer retention rates predict cash flow deterioration or bankruptcy risk?
Does a high employee turnover rate alongside financial ratios signal early warning for bankruptcy?
Data Identification Process
In bankruptcy prediction research, some papers focus on identifying and leveraging key data features through data mining techniques to reveal patterns that improve model accuracy and predictive power. These methods improve model interpretability, reduce overfitting, and enhance responsiveness to economic shifts. From initial use of simple filtering and correlation-based feature selection, the studies have shifted attention to the adoption of embedded feature selection using optimization algorithms for dimensionality reduction. The last few years have seen the emergence of advanced pattern discovery through deep learning and unsupervised clustering.
Approximately 18 papers focus on feature optimization, selecting relevant feature subsets to enhance model performance through targeted evaluation methods. Two papers, on the other hand, explore pattern discovery using advanced data mining techniques to identify critical patterns in complex financial data sets.
Research Gaps Identified
The studies in this area majorly focus on static financial ratios though recently some qualitative textual data studies have been initiated. But the variables central to concept of sustainability, i.e. Environmental, Social, and Governance (ESG) attributes, have largely been overlooked as variables in bankruptcy prediction models. The existing literature is predominantly centered on shareholder-oriented indicators such as profitability, liquidity, and other financial metrics. In contrast, stakeholder-oriented variables-reflecting broader dimensions of corporate responsibility and sustainability have been incorporated in only a limited number of studies. Further, automated feature selection for news and dynamic data remains largely unexplored. Applying data mining to unstructured qualitative sources like reports or news articles is a significant gap, and current studies underutilize streaming and real-time financial indicators that capture evolving business risks.
We propose the following research questions based on research gaps:
How can real-time feature selection be automated for streaming financial and news data?
How can hybrid models better integrate structured financial features with insights from qualitative and behavioral data?
Do ESG risk factors predict corporate bankruptcy?
Corporate Governance, Risk, and Financial Stability
A few studies investigate how corporate governance affects company performance and financial stability, focusing on the relationship between governance practices, mechanisms, and financial distress. The trend is shifting from examining individual governance factors, such as ownership and board structure, to multifactor governance models. Recently, there has been growing emphasis on integrating governance data into ML models to underscore the role of effective corporate governance. Nine papers focus on this area, including one study that uses governance quality indices to assess their impact on a firm’s financial health.
Research Gaps Identified
The intersection of corporate governance and bankruptcy prediction highlights the importance of nonfinancial variables in assessing firm risk. Governance practices not only affect strategic choices but also signal internal stability to external investors and regulators. However, detailed analysis of governance characteristics, both demographic and non-demographic, and their impact on financial health remain underexplored. Additionally, research establishing links between ownership structures and financial stability represents a significant gap. Further, a meaningful incorporation of marketing indicators, employee satisfaction metrics, or consumer loyalty data and its effect on bankruptcy prediction remains a research gap.
We propose the following research questions based on the research gaps:
Do cultural variations in governance structure impact financial health of a firm?
Do board diversity and leadership structure influence the timing and trajectory of financial distress?
Do promoters matter? Do they rise or sink the financial health of the firm?
Discussion
This thematic content analysis not only broadens the description of each theme but also highlights potential research areas that have not been covered in the data set. This can guide future investigations and help in understanding the evolving landscape of financial research.
The thematic analysis clearly indicates that the majority of studies during the selected period have focused on model creation using statistical methods, ML techniques, or ensemble approaches, with 181 papers dedicated to this area. In addition, 20 papers on data identification can also be considered part of model creation, as they primarily focus on model optimization. These studies typically use variables derived from existing models or available data, incorporating all possible financial ratios as inputs for model development.
The thematic analysis reveals a clear lack of focus on variable selection amid changing economic contexts. There is a gap in identifying the most impactful financial variables and assessing their applicability across broader economic settings, such as emerging versus high-income economies, or manufacturing versus service sectors. Most studies tend to concentrate on country- or industry-specific analyses, limiting generalizability.
Studies incorporating nonfinancial variables remain very limited. Given the growing importance of sustainability, analyzing ESG factors and their impact on financial distress prediction represents a crucial, underexplored area.
Conclusion
In conclusion, the study identified collaboration patterns among authors, highlighting that a few key researchers have played a significant role in encouraging research partnerships. Their major contribution lies in advancing the literature and actively promoting collaboration within the field.
The terms extracted from abstracts and titles reflect the evolving focus in bankruptcy prediction research. Initially, traditional and diverse models, such as decision trees, case-based studies, Altman’s Z-score, and regression dominated. In recent years, the emphasis has shifted toward ML and data mining techniques. This trend highlights the current and future direction of research, providing valuable insights for scholars in the field. Given the varied accuracy results across studies, conducting a meta-analysis could help identify the most effective predictive models.
The major focus of the studies has been on model creation, often with limited attention to practical applicability. The selection of appropriate financial variables lacks sufficient justification, while research on nonfinancial factors as predictors remains scarce. This gap offers researchers an opportunity to explore the role and impact of such variables. Enhancing the relevance of these studies can benefit end users, such as lenders, banks, and regulators by providing more robust tools for assessing bankruptcy risk.
The themes identified from screening the abstracts of the selected sample provide valuable guidance for researchers to align with current trends and identify gaps in the literature. The coauthorship network also highlights collaboration opportunities. However, since the study focuses only on the period post-subprime crisis, expanding the time frame could reveal different themes and additional research gaps.
Footnotes
Authors’ Contribution
Conceptualization—M. G. and H. G.; Methodology—M. G. and H. G.; Investigation—M. G. and H. G.; Resources—H. G.; Writing—M. G., G. T., and H. G.; Supervision—G. T. and H. G.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: the authors received funding support from TRTI for this study.