
Abstract
Stock price estimation and prediction have been the popular topics for ages for various market participants, including investors, traders, financial analysts and researchers. Understanding the expected direction of stock prices can provide insights into broader market trends and sentiments. Different methods have been tried to find out future predictions with the least degree of error. Autoregressive integrated moving average (ARIMA) and artificial neural networks (ANN) are two popular methods for time series forecasting, including stock price prediction. This paper attempts to forecast stock prices with more accuracy by using ARIMA and ANN tool modelling with secondary data NIFTY 50 of the National Stock Exchange from December 2005 to July 2019. Stock price prediction through ARIMA and ANN was calculated and compared. Results obtained revealed that the ANN method of forecasting stock prices has more accuracy as compared to ARIMA modelling. Future studies can be based on different sector-based data across different sectors and stock markets.
Introduction
With the growth of the Indian economy and various reforms regarding the securities markets, stocks have become an intrinsic part of India’s economic development, and speculation of these has become an area of concern for the people. Stock price prediction for future behaviour of the stocks has become a matter of concern not only for the investors but also for the company, market experts and researchers. Stock prices have a dynamic nature so they change quickly and in such a scenario prediction of stock price becomes difficult. Increasing advancements in technology are making it easy for stock traders to predict the price of stocks so that they can sell those stocks before the prices fall, to book profits. The availability of enormous amounts of data has made it possible to use advanced systems for stock price prediction rather than to depend only upon the experience of the stock traders.
Several techniques for the prediction of stock prices have been studied in research which can be basically divided into two categories: namely, soft computing and statistical techniques. Some statistical techniques used are regression, moving average, autoregressive integrated moving average (ARIMA), exponential smoothening and generalized autoregressive conditional heteroskedasticity (GARCH) (Wang et al., 2012). These are linear models which assume that there is a linear correlation structure among the data values of time series. Since non-linear impact cannot be captured from the above models, artificial neural network models (ANN) are used to overcome the limitations of the linear models (Banerjee, 2014; Flury & Riedwyl, 1988). ANN has a set of functions which are trained on the basis of historical data to make future predictions. Results of many papers show that while comparing the different methods, ARIMA models are found to be more robust and effective than other structural models as far as forecasting for the short term is concerned (Flury & Riedwyl, 1988; Ho et al., 2002).
There are several fields such as engineering, finance, economics and business where soft computing-based ANNs are used for forecasting and are also found superior to ARIMA predictions in many research papers (Alon et al., 2001; Bagherifard et al., Khashei & Bijari, 2010; 2012; Pieleanu, 2016). Some studies have also reported that for short-run prediction ARIMA results are better and for long-run prediction, ANN results are much better (Valipour et al., 2013).
There are several features of ANN which make them more captivating for the people working in industries and research. First, the popularity of ANN is increasing because of their ability to make composite non-linear systems for the forecasting of the time-series data. Applications of ANN have been widespread these days because of their ability to learn and predict as well as of the large storage capacity in these systems to hold (Yaseen & Okasha, 2016). These are self-adaptive systems using few assumptions and universal approximators because they can approximate a function which is continuous to a chosen level of accuracy (Adebiyi et al., 2014). These systems are also found efficient in solving non-linear problems (Khashei & Bijari, 2010). This creates a contrast between the ARIMA models and ANN as the former which are known as traditional models, assume that the series used for prediction are linear in nature but in most economic data the series used for the prediction are non-linear in nature (Pieleanu, 2016). This creates a need to study the robustness of the prediction models on the data relating to the Indian economic scenario (Banerjee, 2014). This paper applies the ARIMA model and ANN for the same time-series data set to develop a contrast between the two methodologies regarding the prediction accuracy and to confirm the contradictory results reported in prior research papers, thus finding out the dominance of one model over another.
The paper in the later part is organized in the following manner. The next section discusses the work related to the search for effective prediction techniques comprising of ARIMA and ANN and related models. Section 3 discusses the research methodology used in the study. Experimental results are discussed in Section 4 followed by the conclusion in Section 5.
Literature Review
An empirical work regarding the comparison of ANN and ARIMA results in Malaysian stock markets showed the supremacy of ANN back propagation on ARIMA results. Better prediction can be made without using extensive data from the Kuala Lumpur Stock Exchange. The paper also reported some technical problems while using ANN with the making the choice of time frames and results were good towards the end of the training period in ANN which indicates ‘recency problem’ (Yao et al., 1999).
A case of Chinese stock markets where the random walk model pattern of the stock market is tested strongly supports ANN as a potentially useful device for prediction in stock markets. The paper utilizes ARIMA, GARCH and ANN models to test whether the prices in the Shanghai Stock Exchange follow a random walk. Back-propagation algorithm is used in ANN, and all three models were compared on the basis of RMSE, MAE and Theil’s U. Results of ANN were best but not risk and transaction cost adjusted so it does not necessarily mean profitable trading always with prediction with ANN only (Darrat & Zhong, 2000).
A study concerning the U.S. stock market’s aggregate retail sales value which contains a pattern of trend and seasonality (Priyadarshini, 2015) compares traditional models such as the Box–Jenkins ARIMA model, Winter exponential smoothening and multivariate regression with ANN models. The author found ANN results closest in changing economic conditions, but the application of these models requires an expert hand on the software, and the ANN results were parsimonious as reported in the paper (Alon et al., 2001). An analysis concerning the prediction of the compressor failure for a repairable system in Singapore used ARIMA and neural network models. The results revealed that both the models were good enough for forecasting in the short run, but simulation results of feed-forward neural network were inferior to ARIMA (Ho et al., 2002).
Altay (2005) compared ANN and ARIMA forecasting in the Istanbul Stock Exchange and found that ANN outperforms ARIMA in generating good trading strategies. The paper also reports that RMSE, MAE and Theil’s U, which are the accuracy statistics to forecast are the same in value as in ARIMA models, but still, the forecasted value of ANN was better. An Iranian study forecasted Spring inflow in ‘Amir Kabir’ reservoir with the help of ANN and ARIMA models. Hydro climatological data forecast gave better results with the ANN models (Mohammadi et al., 2005). Bagherifard et al. (2012) conducted research on the prediction accuracy between ANN and ARIMA models on the Tehran Stock Exchange. The outcome of the research showed that the prediction error of the neural network was less than ARIMA results. The predictions done by both the models were quite close to the real results, but ANN model results were more accurate than ARIMA approving their supremacy on the linear model. Priyadarshini (2015) while working on the Indian stock market using Sahara mutual fund’s six years of data found the ANN results of forecasting are better than the ARIMA model. Sánchez Lasheras et al. (2015) proved the predominance of ANN on ARIMA in prediction results of COMEX (new your commodity exchange). While researching Volkswagen’s future prices in Romanian markets, the primacy of ANN over ARIMA is also proved but it was reported in the paper that during the period of study, there was a dispute involved in the company which may affect the model’s prediction (Pieleanu, 2016).
Merh et al. (2010) used ARIMA, ANN and hybrid models for forecasting in Indian stock market indices. The results showed that in many instances ARIMA predictions are better than ANN results. A study conducted on Hong Kong’s Shenzhen index used ARIMA, back propagation of ANN and a hybrid model to see the prediction accuracy of the models. The authors found that the hybrid model proposed by them was giving the best prediction results (Wang et al., 2012). The Colombo Stock Exchange has high volatility as a common phenomenon. The time-series forecasting in the Sri Lankan market done by a hybrid model of the ARIMA–ANN approach gave the best results of prediction as MAPE was the least for this model (Ratnayaka et al., 2015).
Wijesinghe and Rathnayaka (2020) used traditional techniques such as simple exponential smoothing and ARIMA have been effective in forecasting the next lag of time series. However, few studies have focused on the Colombo Stock Exchange to find new predictive approaches for high-volatility stock price indexes. This article explores whether and how newly developed deep learning algorithms for the projection of time series data, such as the Back Propagation Neural Network (BPNN), are greater than traditional algorithms. The results show that deep learning algorithms like BPNN outperform traditionally based algorithms like the ARIMA model. The MAE and MSE values relative to ARIMA and BPNN suggest BPNN’s superiority to ARIMA.
Babu and Reddy (2015) while studying the best forecasting model in the Indian stock market compared the results of ARIMA, wavelet ARIMA, GARCH and hybrid model ARIMA–GARCH. It was found that the best results were derived from the hybrid model proposed by them. Khashei and Hajirahimi (2017) used the hybrid model of ARIMA-MLP and MLP–ARIMA in series and parallel combination for stock market prediction in the Hong Kong Stock Exchange found that the series combination of the above models gave better prediction results.
Ma (2020) suggested that the ARIMA model, commonly used in stock price prediction, is a linear regression model that can be used for analysis and prediction. However, it may have some deviations when facing complex non-linear practical problems. ANN, a data-driven adaptive model, is widely used in finance, commerce and engineering. It is effective in solving non-linear problems and can provide better results in terms of stock price prediction compared with traditional models. LSTM, a variant of the recurrent neural network, has a feedback connection that makes it easier to find development trends through the back propagation of current historical prices and prices. The hybrid models are only tested in the papers they are proposed, but ARIMA and ANN are standard models and are tested on various types of data in various countries. This paper aims to find out the predictive ability of standard ANN and ARIMA regarding the stock prices of the Indian stock market index. The results of the study are based on the empirical analysis of time series data of the National Stock Exchange (NSE) of India.
Methodology
The data used in this study are from the website of the NSE of India. In the analysis part MATLAB neural network software is used for the ANN model, and EViews 9 software is used for the ARIMA model.
The data used in this empirical paper are the closing price of the NIFTY 50 index from NSE of India. NIFTY 50 is the flagship index of the NSE. It keeps track of the behaviour of the largest blue-chip companies in India and covers many major sectors of the Indian economy. NIFTY 50 stocks cover almost 65% of the total of float-adjusted market capitalization of NSE. The index data consist of high price (maximum of the day), low price (minimum of the day), volume traded, open (opening price of the index) and close price (price at time of the closure of the market). The research paper utilizes the closing price of the index for the purpose of model and prediction because it is the closing price which represents the whole day-long activity of the index. The time period of the data is from December 2005 to July 2019 which makes a total of 3,379 observations. The data of the NSE index are not stationary at the level and contain the random walk pattern. Smoothening of close values of the NSE index is done by using the 90-day moving average method to eliminate noise in data. Figure 1 shows the graph of the NSE index which helps us to know that the series is not stationary and to confirm this we use the correlogram method. The moving average of the series is taken for the study.
Graphical Representation of NSE Index Close Price at Level and after Differencing.
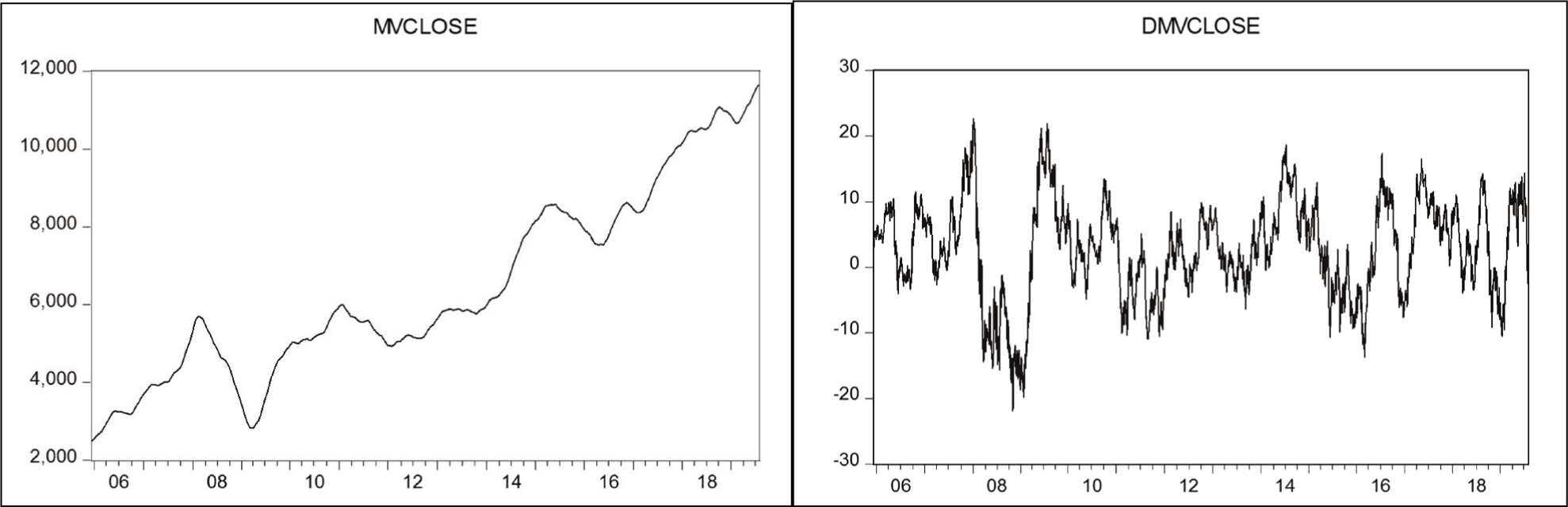
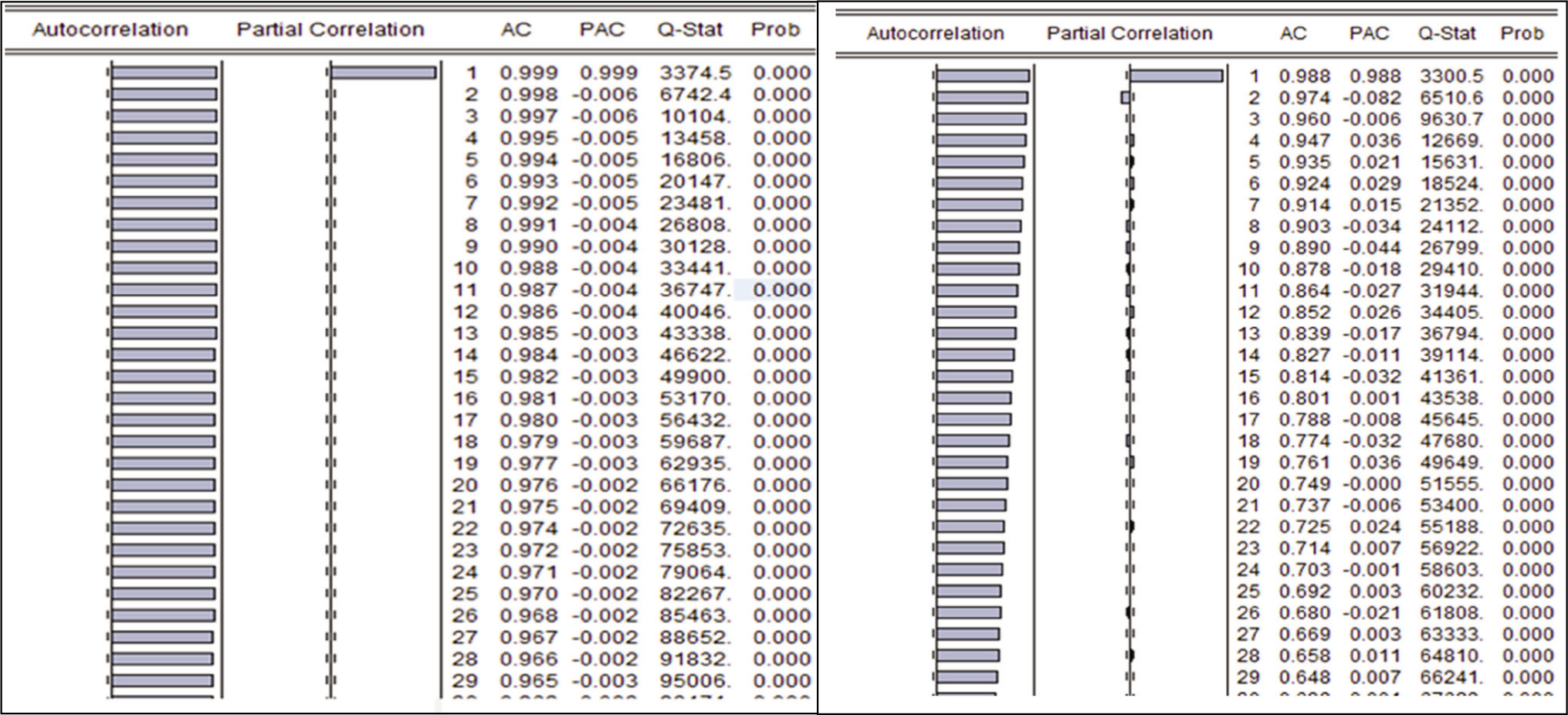
A correlogram is used to determine whether the series selected for the study is stationary or not. The autocorrelation function (ACF) of a correlogram decays rapidly from its starting point at lag 0 which that means that the series is stationary but if the ACF gradually dies down, then that means the series is non-stationary. In the case of the NSE index, the correlogram of the series dies down very slowly which proves the series to be non-stationary as can be seen in Figure 2. The series is differenced once to make it stationary and the value of the difference (d) is found by finding the number of times it is differenced.
Correlogram of NSE Index Close Price at Level (Left) and after Differencing (Right).
ARIMA Model
The full form of ARIMA is the autoregressive integrated moving average. The forecasting equation contains the lag of the differenced series which are known as autoregressive terms, whereas the forecast error lags are known as moving average terms. When the time series is differenced to make it stationary it is called the integration order of the series. An ARIMA model is represented as ARIMA (p, d, q) where the number p is given to the autoregressive terms, d represents the integration order and q is given for lagged forecast error. To identify the best ARIMA model, three steps are involved as per the Box–Jenkins approach. First based on initial information a tentative model is identified. Then based on that tentative model the corresponding parameters of the model are estimated. In the last, the goodness-of-fit model is calculated. There can be several combinations for the parameters p, d, q, which are tested to find the best model on the following criterion.
Comparatively small Akaike information criterion (AIC)
Relatively small standard error of regression
Fairly high adjusted R2
There should be no significant pattern left in ACF and PACF (partial ACF) of the residuals which mean that the left residuals are white noise.
Table 1 shows the results of different ARIMA models on the NSE index.
Results of Different ARIMA Models on the NSE Index.
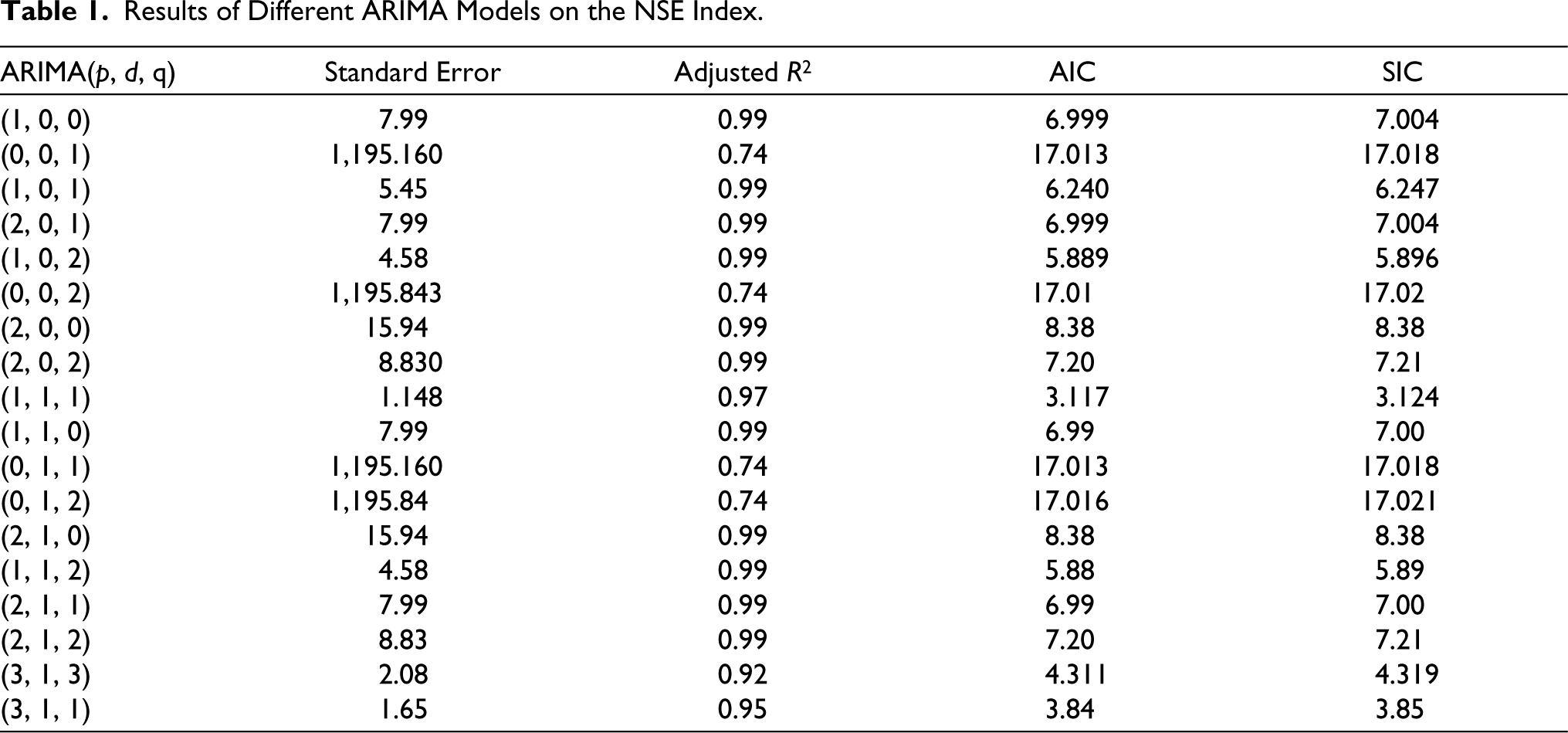
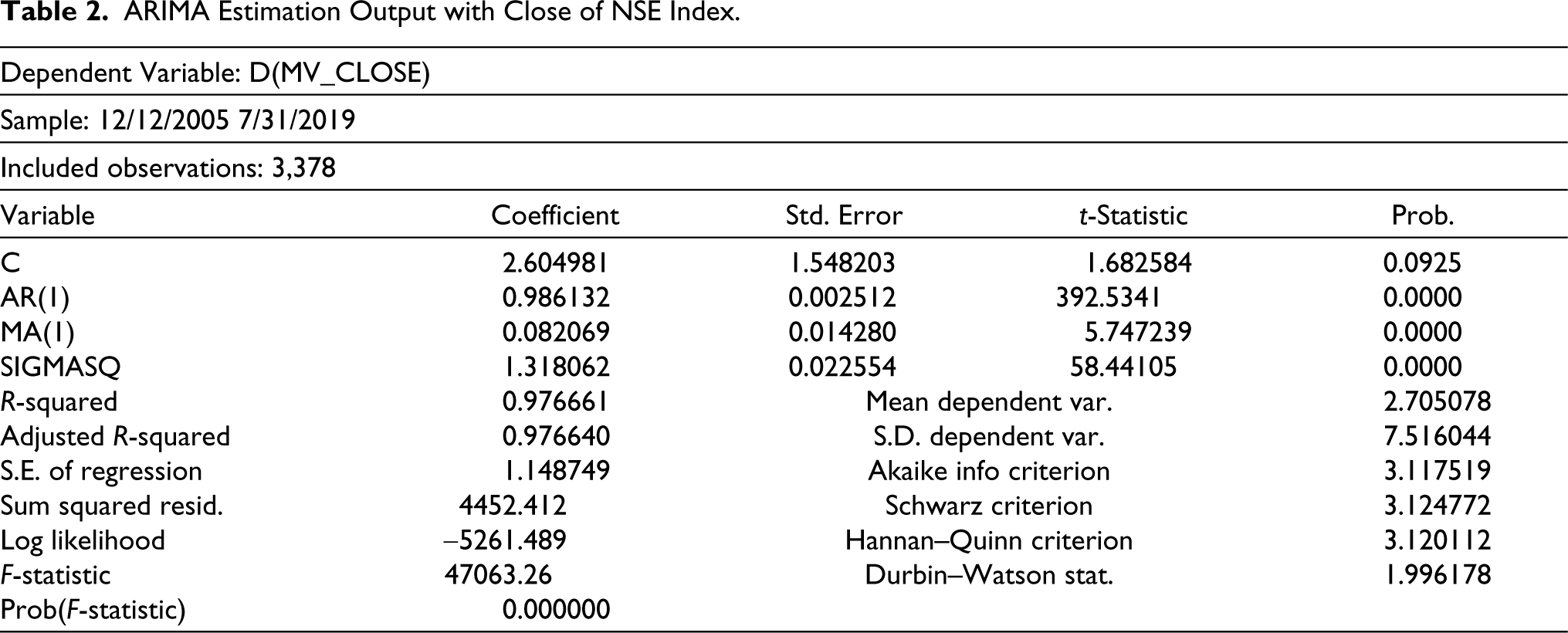
Out of the above models, ARIMA (1, 1, 1) is considered the best model as it gives the least value of standard error, AIC and BIC with the corresponding high R2 as shown in Table 2. The Q statistics of the above model showed that there is no significant pattern remaining in the autocorrelation and partial ACFs of the residuals. This means that the residual of the selected model is white noise.
The ARIMA model can be expressed as:
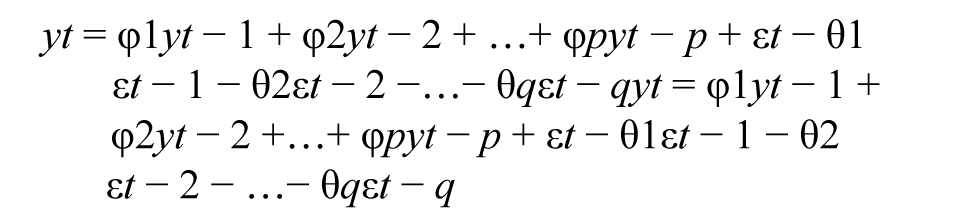
where yt is the model actual variable, εt is the random error, and p and q are the model parameters. The value φi (i = 1, 2…..p) and θj(j = 1, 2….q) are the order of this autoregressive model.
Table 2 shows the results of the ARIMA (1, 1, 1) model on the close price of the NSE index.
ARIMA Estimation Output with Close of NSE Index.
The ANN Model
The term ANN, which has derived its origin from the human brain/nervous system, is developed to store various information, data and figures in a systematic form. Here in computing systems, algorithms are prepared to predict and analyse the output in advance. In the technical era, modes and methods are looked at to bring more accuracy to predictions. ANN is one such innovative method. ANN is involved in various neurons which are designed to consolidate the results depending upon the specific network design. From speech recognition to face recognition, to health care and marketing, and forecasting of future stock prices of stock, neural networks have been used in a varied set of domains. The first step towards ANNs came in 1943, when Warren McCulloch, a neurophysiologist, and a young mathematician, Walter Pitts, wrote a paper on how neurons might work (Keijsers, 2010). A neural network (Figure 3) functions when a set of data inputs are fed into the system with a special characteristic of adapting to the changing surrounding environment. This adaptability feature has been inspired from the human brain only whereby the human brain easily catches things and accordingly may relate them to the future according to the changing surroundings.
A Typical Neural Network.
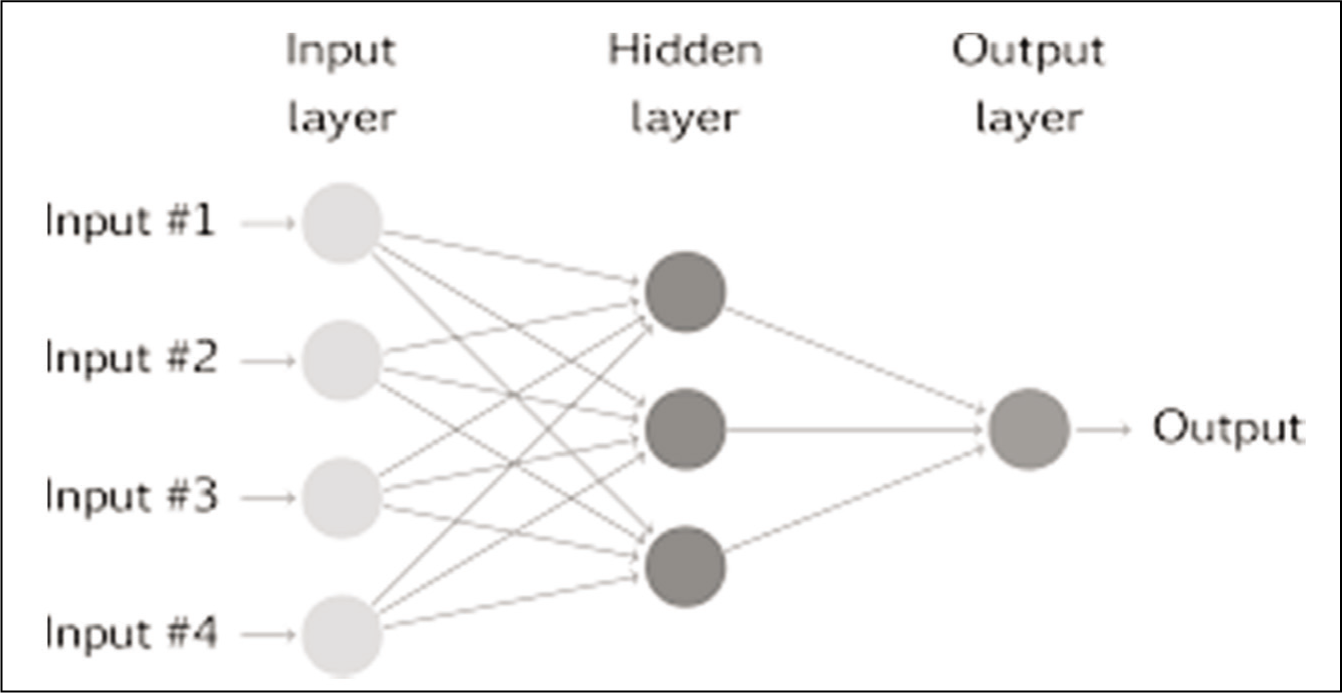
ANNs have been used widely to solve many problems due to their versatile nature (Samek & Varachha, 2013). This input layer is the main layer, and the last layer is the output layer. These data are processed through the perceptrons in order to get the desired output. Between the input and output layers, there may be additional layer(s) of units, called hidden layer(s). The connecting layers are often termed neurons.
The Neural Network Toolbox for MATLAB, developed by MathWorks, is a simulator for building ANNs. The toolbox runs under MATLAB, a linear algebra-based mathematical simulation package.
Methodology
Data Selection and Normalization
NN toolbox in MATLAB is used to predict the input data or the predicted values, as shown in the Figure 4. A time-series app is used with the closing price of the NSE to predict the future values with the help of the time-series app of NN Toolbox in MATLAB. The time-series app is useful in forecasting or prediction and hence has been taken for future prediction of stock prices. A nonlinear auto-regressive neural network (NARNN) is a recurrent neural network. It forms a discrete, non-linear and autoregressive system with endogenous inputs and can be written in the following form Ibrahim et al., 2016):
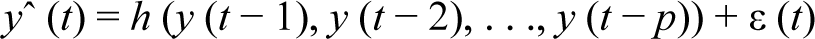
Neural Network Structure.
Results and Performance Evaluation
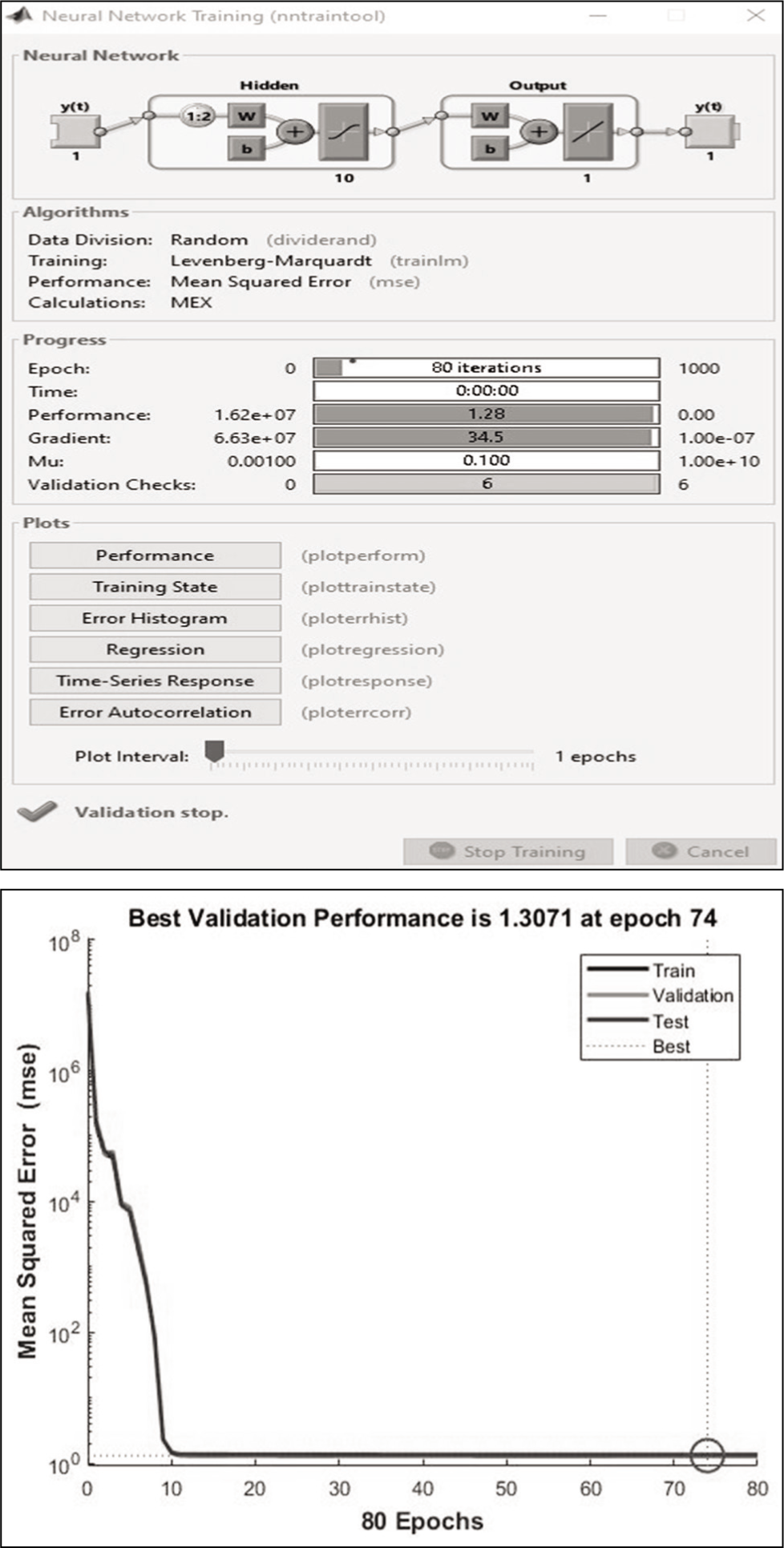
Data for this research include the closing price of the NIFTY 50 index from the NSE of India. After the network was created by MATLAB, the results were 97%, which was very encouraging for this research work. The network was trained and simulated with the Levenberg–Marquardt algorithm. Levenberg–Marquardt training is often the fastest training algorithm, as it does require more memory than other techniques and produces the output in less time. The training continued until the validation error failed to decrease for 80 iterations. Training automatically stops when generalization stops improving, as indicated by an increase in the mean square error of the validation samples. The best validation performance is equal to 01.3071 at epoch 74, as shown in the Figure 5.
Graph of the Best Result Achieved in Network Training of ANN of NSE Index.
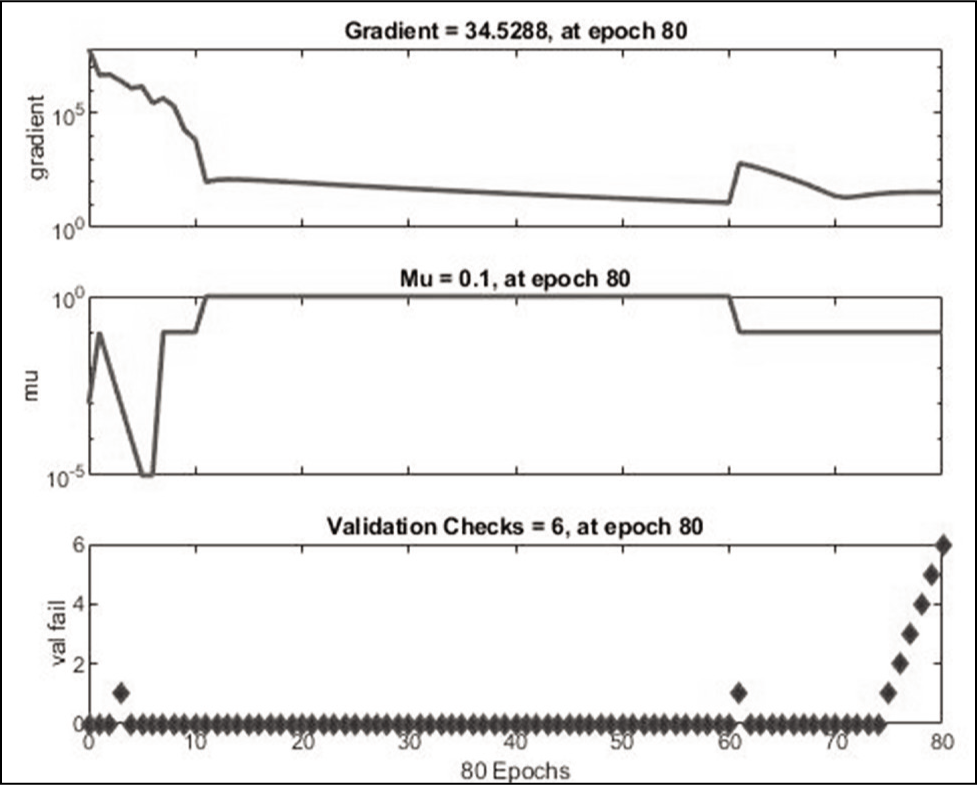
This Figures 5–7 shows that training and validation errors decrease until the highlighted epoch. It does not appear that any overfitting has occurred, because the validation error does not increase before this epoch.
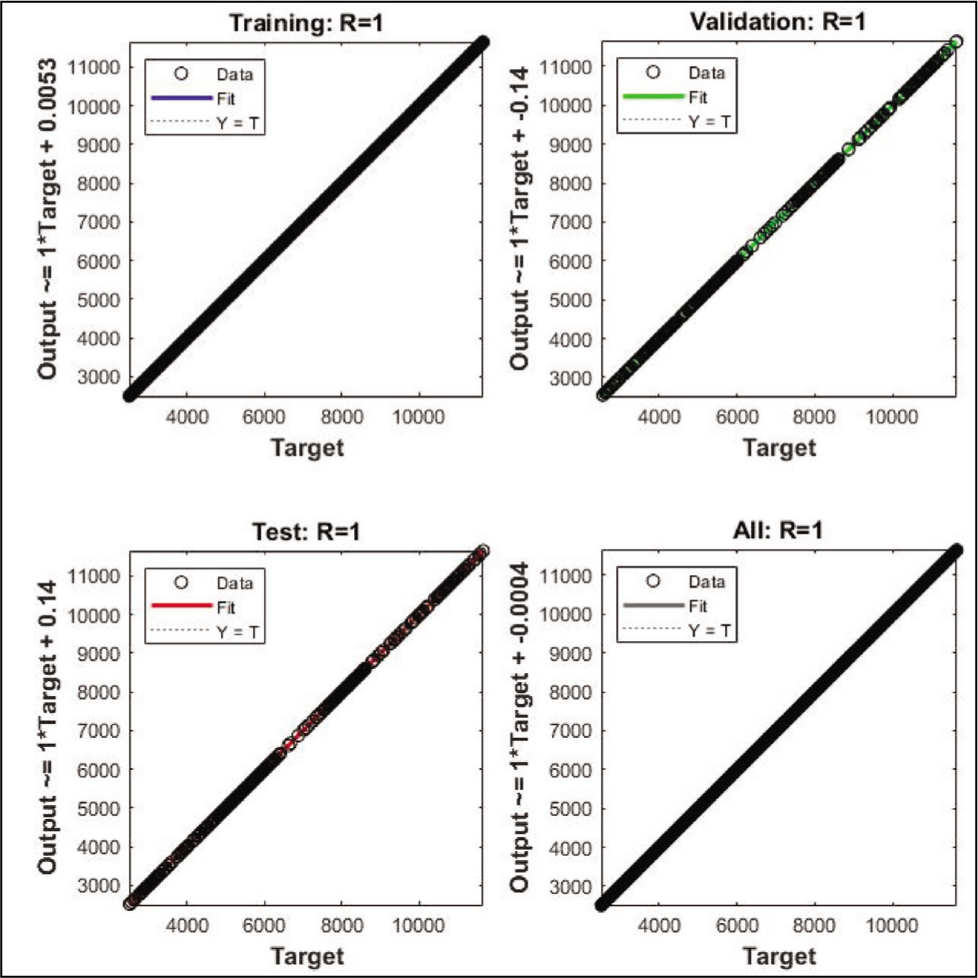
Regression Plots.
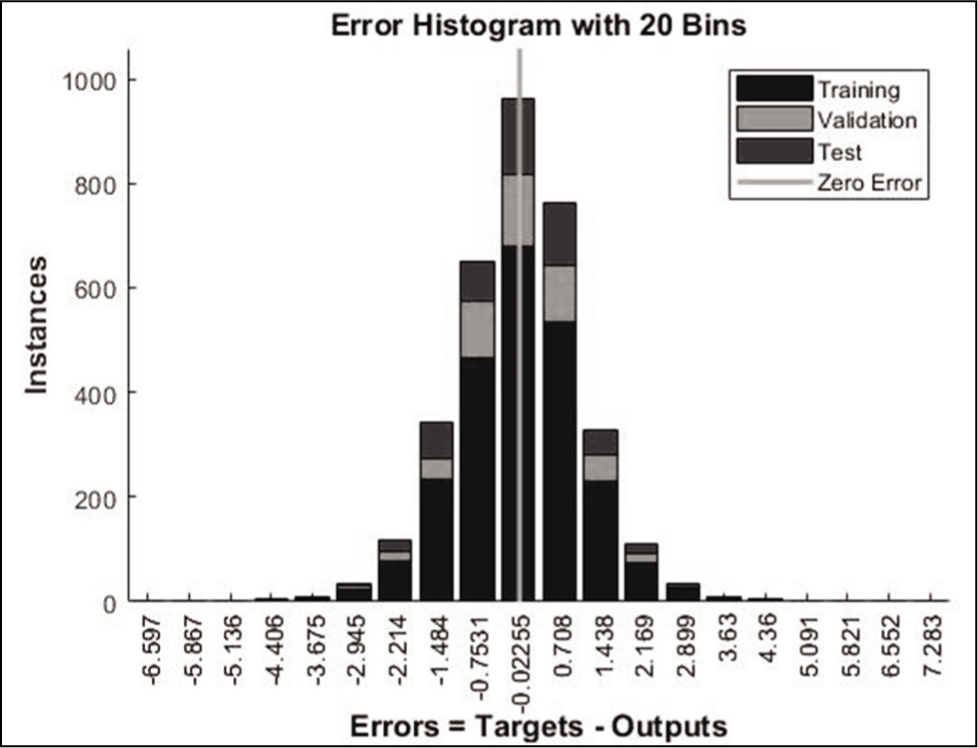
Error Histogram Plots of Predictions.
Results and Discussion
In this section, the results of the forecasting done by both ARIMA and ANN are presented.
Forecasting Results of the ARIMA Model
The forecasting is done after selecting the best value of both the parameters of the model, that is, the autoregressive part and the moving average part as indicated in Table 1. Models are selected on the basis of the least AIC and BIC values and high R2 as shown in Table 2. Hence, the model ARIMA (1, 1, 1) came out to be the best model upon the above criterion. The forecasted and actual values of the best-fit model are presented in Table 4. The forecasting performance of the selected ARIMA model can be seen in Figure 4. To calculate the forecast error, the following formula is used.
Response of Output with Reference to Time.
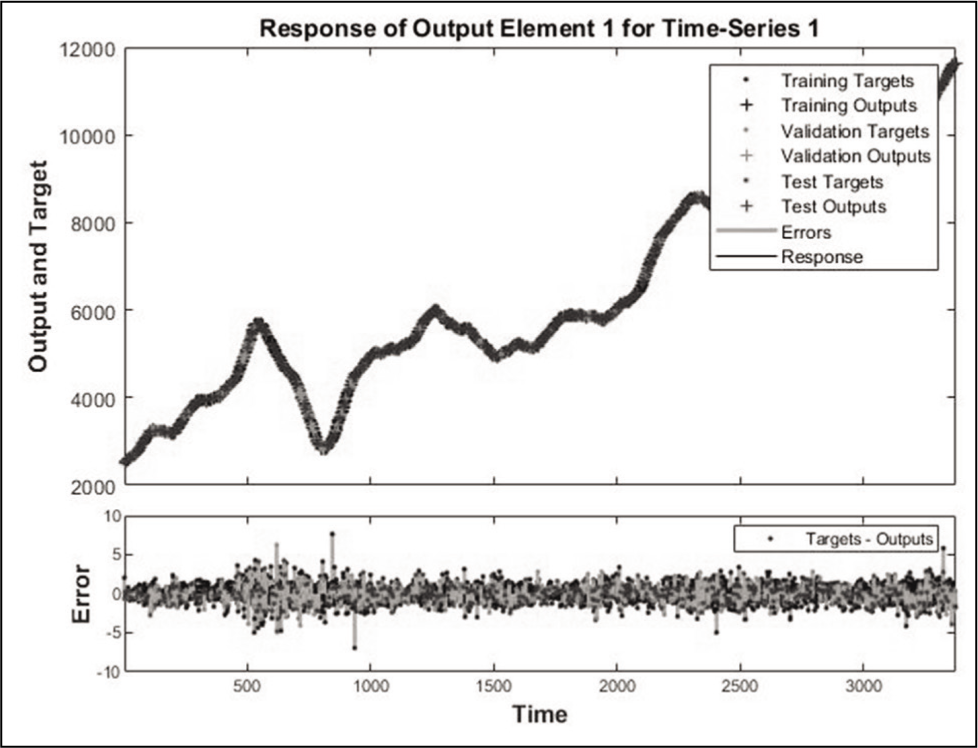
Errors in the Forecasted Models.

Forecasting Results of the ARIMA (1, 1, 1) Model for the NSE.
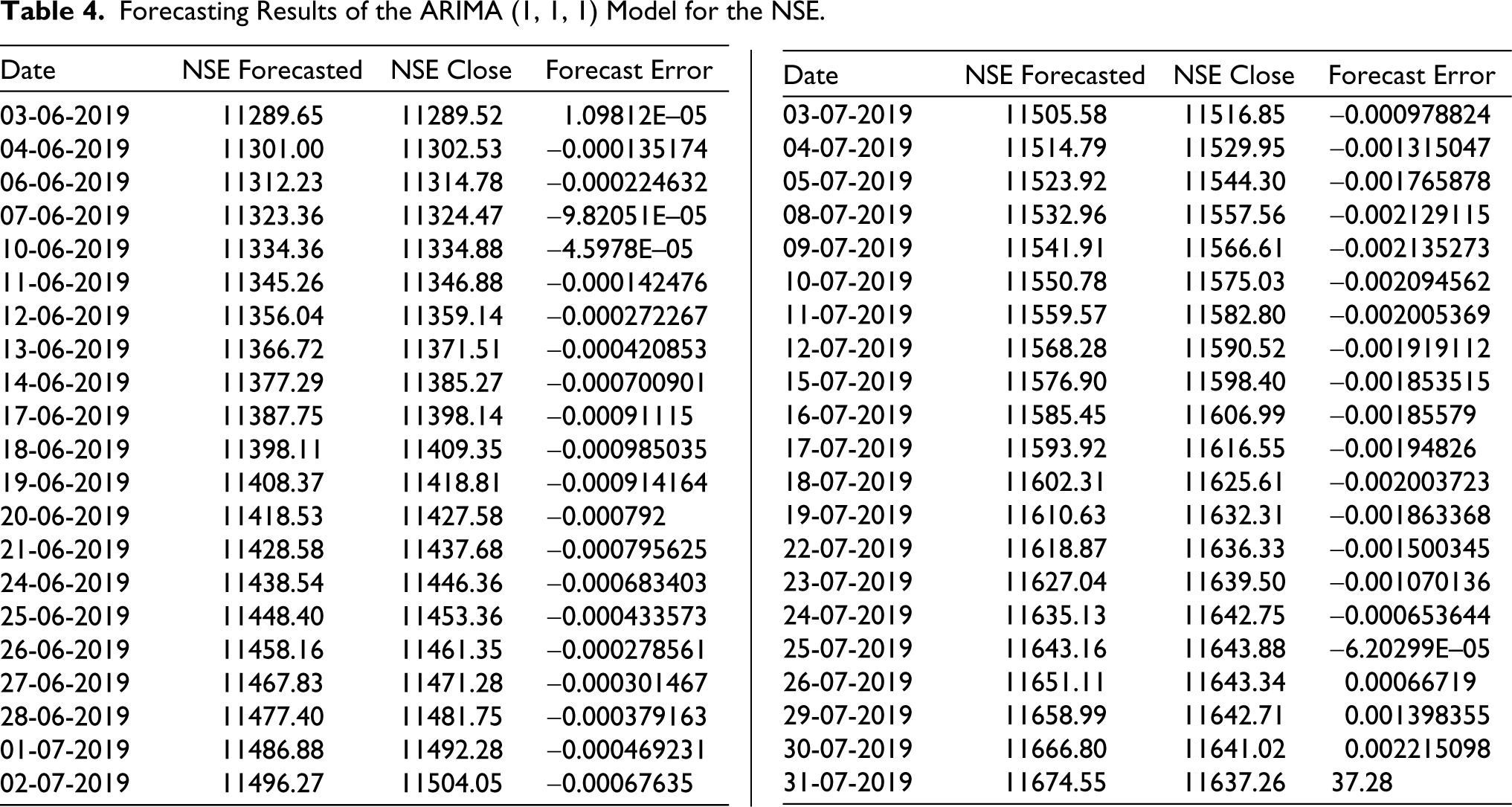
Forecast error = (actual - predicted)/actual.
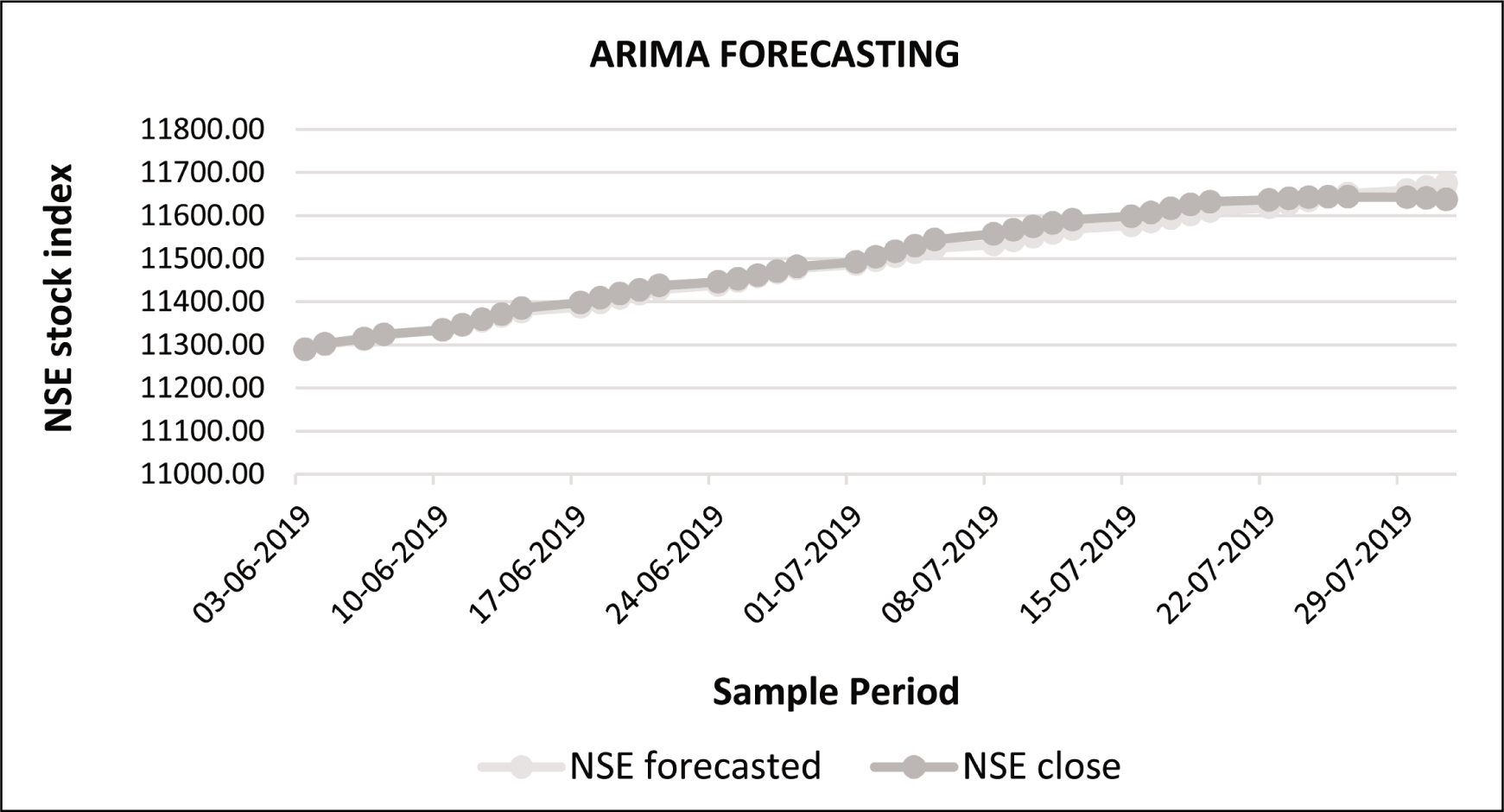
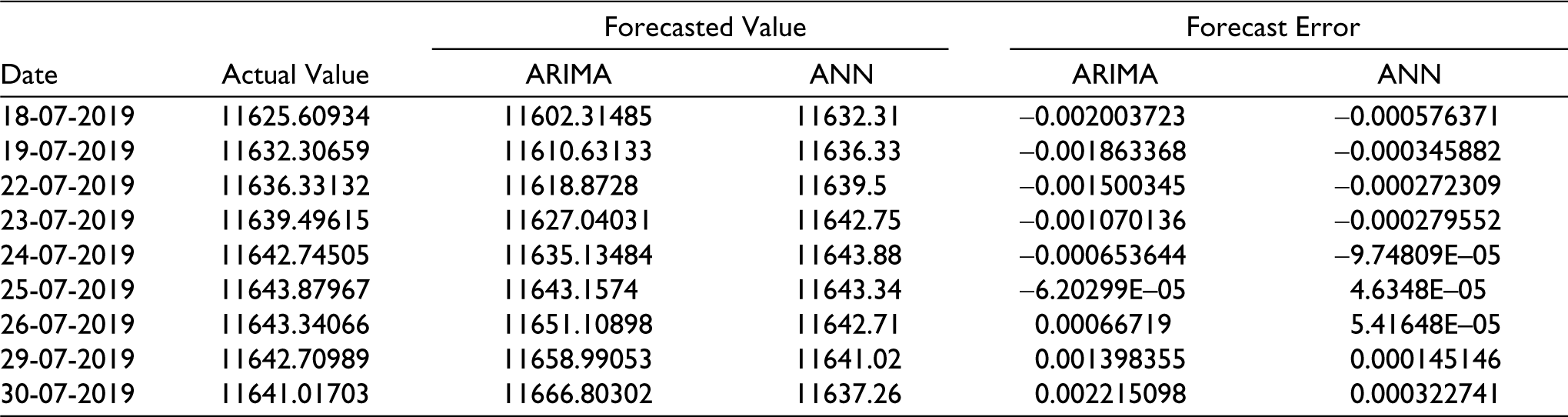
Tables 3 and 4 shows that actual and predicted values vary by a very small ratio. RMSE is the gap between the actual variable and the forecasted variable, which is low and hence denotes that the predicted values are very close to the actual values. Both the values have the same direction which describes the level of precision as quite high which can be seen in Figure 4–9.
The Graph for ARIMA Model Showing Actual Price Against the Predicted Values.
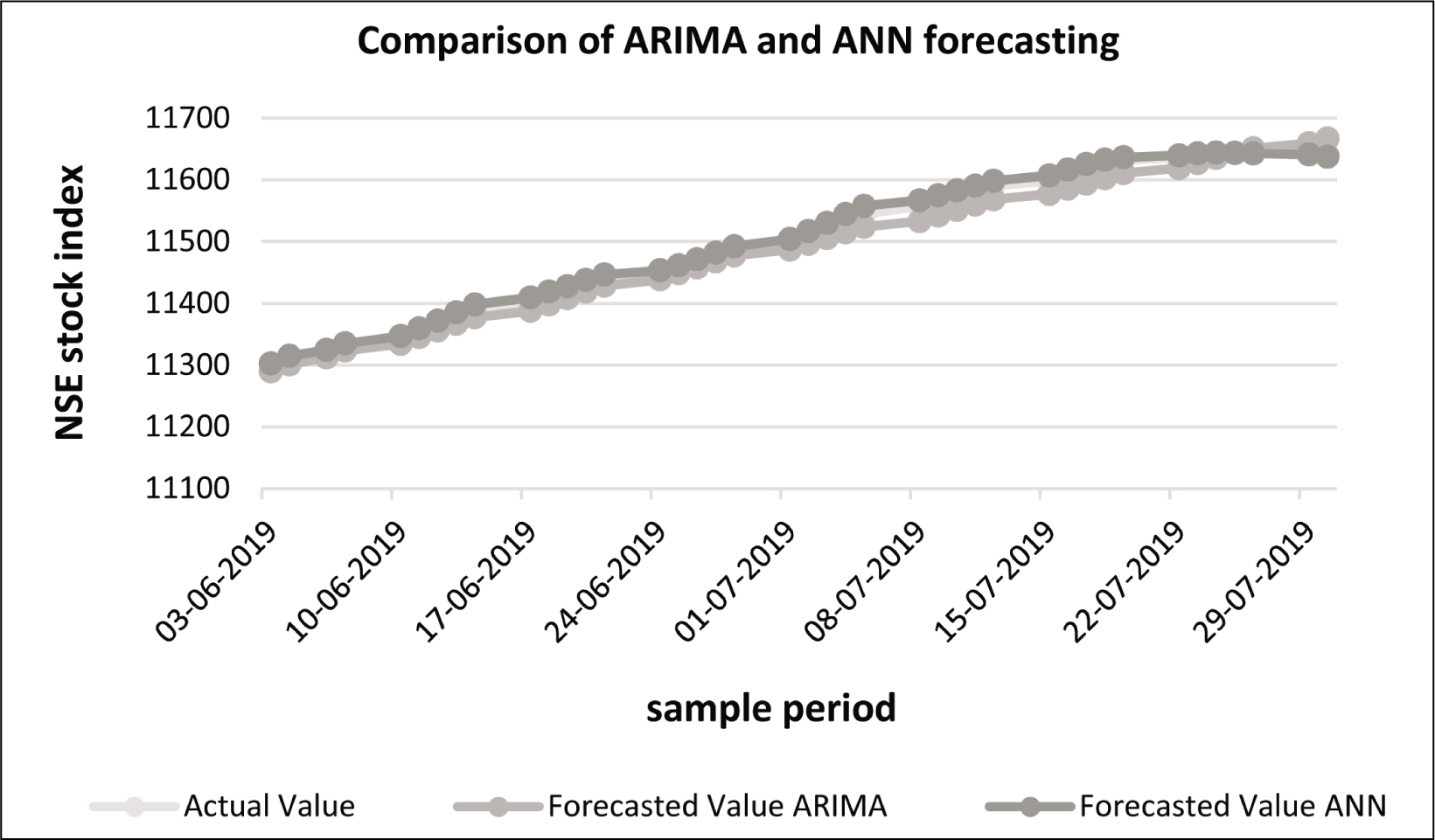
Comparison of ARIMA and ANN Model
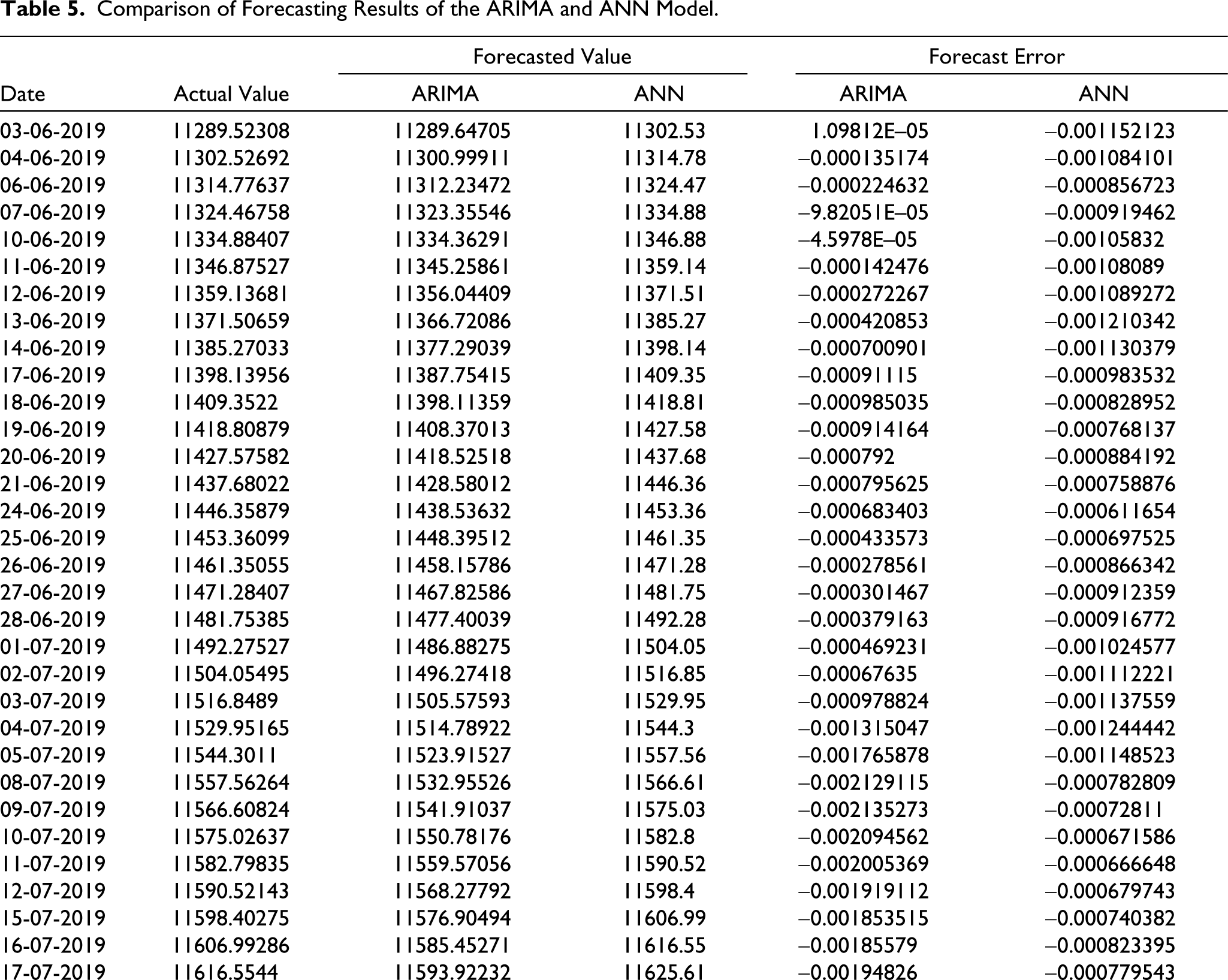
Figure 10 and Table 5 show the empirical results, and while analysing it is found that the comparison of prediction can be done by both the models. This can be clearly interpreted that these two models achieved almost near forecast performance as the forecast error resulting from them is quite low. These findings are similar to the work of Adebiyi et al. (2014). However, the prediction of ANN results is better than ARIMA results which can be seen in Figure 10. The forecasting line of the ANN model almost overlaps the actual values of the NSE index. Whereas the forecasting of the ARIMA model can be seen not exactly overlapping but with a difference. The results of ARIMA show more deviation as we reach the end of the study period. The results of the ARIMA model show a linear pattern in Figure 9; therefore, it is directional. However, the pattern followed by the ANN results in Figure 10 shows value forecasting because they almost overlap the actual values of NIFTY 50.
The Graph for ARIMA and ANN Forecasting Comparison Showing Actual Price Against the Predicted Values.
Comparison of Forecasting Results of the ARIMA and ANN Model.
Conclusion
The study focuses on the forecasting capabilities of two models, ANN and ARIMA, for the NIFTY 50 stock index . The conventional ARIMA model which is widely used for the prediction purpose is compared with the predictive ANN model in this study. The results show that both models can achieve good forecasting results and can be used for the prediction of share prices. The forecasting values of both the forecasting models are quite close to the actual values, but the performance of the ANN model is found to be superior to the prediction done by the ARIMA model. In future studies, a hybrid model of both models can be used to find improved results from various stock indices and share prices.
In the present work, data from 2005 to 2019 were taken. Future studies can be done on a more extensive data set comprising various commodities across the stock markets.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.