
Abstract
Over the past decade, there has been overwhelming interest in rapid and routine origin tracing and authentication methods, such as near infrared (NIR) spectroscopy. In a systematic and comprehensive approach, this study coupled NIR with advanced machine learning models to explore the origin classification of coffee at various scales (continental to regional level). Speciality green coffee beans were sourced from three continents, eight countries, and 22 regions. The dispersive bulk NIR spectra were used for spectral registration in the reflectance mode, and the obtained spectra were preprocessed with extended multiplicative scatter correction and mean centering. The classical linear partial least squares-discriminant analysis adequately predicted origin at the continental and country level, and showed promise at the regional level. Non-linear machine learning models improved predictions further, with the best accuracy found using random forest with accuracies up to 0.99. Discriminating wavelength regions and constituents were identified at each origin scale, with more minor wavelength regions selected by random forest. This proof of concept work demonstrated the potential of NIR spectroscopy coupled with machine learning for rapid origin classification of coffee from the continental to the regional level.
Introduction
The last decade has witnessed overwhelming interest in the use of vibrational spectroscopy methods, such as near infrared (NIR) spectroscopy, for origin traceability and authenticity of high-value agri-food products. 1 Compared to their traditional counterparts, these methods are fast, non-destructive, and affordable. They can easily be implemented into an onsite, rapid, and robust toolbox to verify the geographical origin of high-value agri-foods, such as coffee, innovating the current less effective and slow traceability system.
Coffee is one of the high-value agri-foods frequently subjected to origin fraudulent activities due to the increasing demand for single-origin speciality coffee. 2 NIR spectroscopy has thus been increasingly utilised for coffee origin verification studies. 3 NIR spectroscopy was used to classify and estimate diterpene concentrations in Ethiopian green coffee beans from different regions using high performance liquid chromatography (HPLC) as the reference 4. NIR spectroscopy has also been used to classify green coffee from different regions within Brazil,5–7 and two regions in Indonesia. 8 The spectral regions important for regional discrimination have been associated with lipids, chlorogenic acids, caffeine, trigonelline, amino acids, proteins, sugars and carbohydrates between 1400 – 2350 nm. 5 Most coffee origin studies using NIR spectroscopy have looked at classification at the regional level. Beyond regional classification, NIR spectroscopy was used to differentiate Colombian coffee from 13 other countries (two continents) (1300 – 2400 nm). 9 In a recent study, coffee samples from nine countries and two continents (America and Asia) were classified at the continental level using NIR spectroscopy. 10
Chemometric data analysis methods are commonly used to analyse NIR spectral datasets. Nonetheless, previous studies have mainly employed linear chemometrics-based classification methods such as principal components analysis (PCA), linear discriminant analysis (LDA), and partial least squares-discriminant analysis (PLS-DA). Lately, there has been a lot of enthusiasm for using non-linear machine learning models due to their ability to handle more complex data.11,12 These have not been well investigated, with limited understanding surrounding their use in coffee origin studies. Only one study has utilised a non-linear classifier, namely support vector machine (SVM), and demonstrated perfect (100%) prediction accuracy on four regions of coffee within Brazil using NIR spectra. 7
The research gaps include the lack of studies investigating coffee origin at different scales, from the continental to the regional level. There is a need for more advanced machine learning models to handle more complex classification problems with a greater range of regions and levels of classification (continent, country, region). Lastly, there is a lack of studies which have identified spectral regions and their associated compounds/groups driving the classification across various scales.
This work aims to address the research gaps by investigating the potential of NIR spectroscopy for rapid origin classification of coffee at different origin scales (continental, country, regional), and for the first time, the use of four different non-linear machine learning models to improve the performance of more complex NIR problems. These modelling techniques include k-nearest neighbours (KNN), kernel support vector machines (SVM), extreme gradient boost (XGB), and Random Forest (RF). The selection of wavelength regions important for discriminating origin at the three levels will also be identified.
Materials and methods
Samples
Green coffee beans (GCBs) and metadata were obtained from Oritain Global Limited (Dunedin, New Zealand), a traceability company. The samples included 24 GCB samples originating from three continents (Africa, Central America, and South America), eight countries (Ethiopia, Kenya, Costa Rica, Guatemala, Mexico, Nicaragua, Colombia, and Peru), and 22 regions (Gedio, Guji, Maywal, Kiajibbi, Yara, West Valley, Tarrazu, Santa Maria de Dota, El Progreso, Guatemala, Oaxaca, Puebla, Estado De Mexico, Esteli, Matagalpa, Nueva Segovia, Antioquia, Huila, Narino, Cusco, Pasco). The samples were verified with certification that they were of the arabica species (Coffea arabica L.), wet-washed, and collected between 2021 to 2022 - pooled from producers in that same region and time. These samples were selected based on their importance to the coffee industry, coming from leading coffee producing continents within the coffee belt (which include 50 countries within Africa, Central America, South America, and Asia). Each sample was ground into green coffee powder (GCP) with six replicates using a liquid nitrogen mill (Cryomill, Retsch, Germany) to a particle size of 5 μm.
NIR spectral registration
A dispersive NIR spectrometer (XDS Rapid Content Analyser, Metrohm, Herisau, Switzerland) was used for spectral acquisition in reflectance mode. Approximately 2 g of powder was packed into a quartz glass vial (17.25 mm spot size) after careful mixing, with six replicates taken per sample (technical replicates). The vial was then centered onto the sampling window area, fitted with an iris adaptor, which was rotated to collect a more representative spectrum. For each technical replicate, nine analytical replicates (spectra) were obtained for a total of 1296 observations. The measurements were taken over the spectral range 1100 to 2500 nm (data sampling interval, 0.5 nm; background, 256 scans, sample, 32 scans). An instrumental internal reference standard was used for the background scan. The Vision Air 2.0 Network software (version 66072207) was used for instrumental control and spectral acquisition.
Data analysis
The spectral data were statistically assessed with R-Studio version 4.2.0. 13 The nine analytical replicates per technical replicate were first averaged to produce six observations per sample to give a total of 144 observations.
The spectra were then preprocessed with extended multiplicative scatter correction (EMSC)
14
and mean centering, which fits a second order polynomial onto the average spectrum to correct for raw spectra curvature- due to non-linearities introduced by light scatter.
15
The preprocessed data was then saved for further analysis. Before modelling, the preprocessed spectra were split into training (80 %) and test (20 %) datasets using the caret (version 6.0-94) package in R, grouped by sample ID to prevent replicates splitting across the datasets.
16
Cross validation (CV) was performed with a k-fold 10 data splits repeated ten times. The model performance was evaluated with balanced accuracy (Acc)17,18 across the training, testing, and CV datasets (equation (1)).
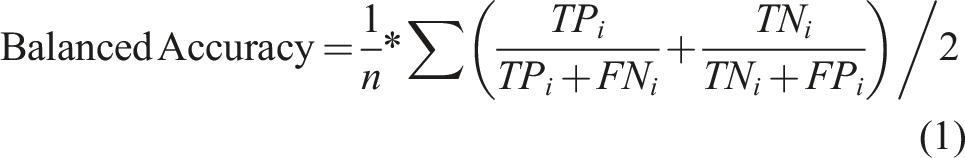
A dummy classifier also known as a random rate classifier, the no information (NR) rate, was constructed for each model to prevent overinflation of model performance using Acc. Each model was assessed to ensure its importance if Acc > NR (p-value <0.05). Compared to a random baseline, NR evaluates success in model prediction.
Linear supervised partial least squares-discriminant analysis (PLS-DA) was then conducted for the continental, country, and regional level classification. PLS-DA combines the dimension reducing ability of partial least squares (PLS) with the discriminatory capability of linear discriminant analysis (LDA) 19 The spectral data was set as the X predictor, while the origin class was input as the Y response variable. 20 The evolution of root mean square error of calibration/train (RMSEC) and root mean square error of cross-validation (RMSECV) was used to decide on the optimum number of latent variables (LVs) used in the model. The ropls package (version 1.26.4) was used for PLS-DA in R. PLS-DA has an embedded function to relate the distribution of scores to spectral features, which can be plotted to identify the wavelength regions important for origin discrimination for each latent variable via the loading weights.21,22
Non-linear machine learning classification models were then explored: K-nearest neighbours (KNN), radial basis function (RBF) kernel support vector machines (SVM), XGBoost (XGB), and random forest (RF). KNN measures the Euclidean distance between the observation calibration (train) and prediction (test) points. 23 K is the parameter of the nearest neighbours that is optimised based on the classification error rate and the number of observations within each class. The highest rank of the class becomes the model predicted class. The class (version 7.3-19) package in R was used to perform KNN. 24
The RBF kernel SVM captures non-linear relationships in the data using the RBF kernel. 25 The class decision boundary is optimised using the cost (C) and gamma (γ). The shape of the boundary is determined by the γ, with higher values increasing the boundary flexibility, and lower values preventing an overfit. C balances the trade-off between errors and boundary complexity, controlling the penalty for misclassification. The parameter combination was optimised with the best performance across all cross-validation rounds. Both KNN and RBF-SVM do not contain an embedded feature selection, but the genetic algorithm can be used to search for the optimum set of features that maximises classification performance in the model, but are computationally intensive. 26 RBF-SVM was performed using the package e1071 (version 1.7-13) with the “radial” kernel. 27
Both XGB and RF are ensemble decision trees which are structured like a tree where the features are the nodes, feature values are edges, and classes are leaves. 28 Beginning at the base of the tree, the tree branches are connected based on feature values, and the final node is the final prediction. Nonetheless, XGB and RF are distinct in their hyperparameter tuning, construction and residual treatment. XGB trees are shallow, with little depth, progressively constructed with each tree learning from the residuals of the trees before it. In RF however, each tree is constructed independently using a subset of features and the final prediction is based off the voting or average of all individual tree predictions. RF introduces randomness and diversity in feature selection with a bagging concept.
The XGB hyperparameter tuning includes the learning rate (eta), maximum depth (max_depth), number of trees (ntree), and regularisation parameters gamma (γ) and lambda (λ). Eta controls the contribution of each tree towards prediction, max_depth controls the maximum depth of every tree, ntree controls the number of boosting iterations, γ prevents an overfit using the requisite loss reduction, and λ helps to lessen the influence of individual features. The parameter combination is optimised using multiclass log loss (mlogloss). Gain is the improvement in model accuracy and the reduction in the loss function. XGB splits tree nodes up to the maximum tree depth and prunes the tree backward till there is no positive gain or improvement in model performance. In addition to the hyperparameters ntree and max_depth, RF has mtry which controls the quantity of features that are randomly selected with each tree node, thereby preventing an overfit through the introduction of diversity. These parameters are optimised through the out-of-bag (OOB) error rates that measures the predictions left out (one third of the data) and not included in bootstrap sampling during model training, providing an unbiased estimation of model accuracy.
XGB and RF contain an embedded feature selection opportunity to identify the wavelengths contributing most towards the models. XGB has an importance function which is calculated as the total gain from each tree node where the feature was utilised for splitting. Features with more importance have more influence on the model. RF feature selection is based on Gini impurity, a measure of uncertainty, it evaluates the importance of the feature by its ability to reduce the Gini impurity. 29 The feature with the greatest reduction in Gini impurity is most influential for class separation.
XGB was conducted using the package xgboost with the objective set to multi:softmax (version 1.6.0.1) and RF was performed with the random forest package with the tuneRF function for parameter optimisation (version 4.7-1.1). 42
While linear model scores can be plotted as a scatter plot to visualise model performance, more complex non-linear models operate in a high dimensional space with difficult to visualise decision boundary. To visualise the performance of the RF models, a dimension reduction step called a Multi-Dimensional Scaling (MDS) plot can be plotted. 30 MDS reduces the data into a two-dimensional MDS1 and MDS2 axes which perform like a conventional x and y scatter plot, providing an opportunity to estimate the underlying classification mechanisms within the model. The closer the data point is to the other, the greater their degree of similarity.
Results & discussion
Spectral features
NIR spectra are characterised by absorption bands associated with different vibrations of chemical covalent bonds. The main absorption bands are related to the composition of the bean. The mean spectra of each continent plotted after preprocessing with the associated chemical assignments are shown in Figure 1 below. The spectral pattern is in agreement with previous studies.5,7,10,31,32 Green arabica coffee beans have been known to be dominated by carbohydrates. Specifically, the components include cell wall polysaccharides (50-60 %), galactomannans and arabinogalactan-proteins, lipids (13-17 %), proteins (11-15 %), sugars (7-11 %), and chlorogenic acids (5-8 %). Carbohydrate and sugar C-H and O-H overtones are known to dominate between 1150-1250 nm, 1400-1650 nm, 2050-2150 nm, 2250 nm, and 2350 nm.
31
Cellulose C-H and O-H bonds signal at 1470 nm, 1780 nm, 1840 nm, and 2080 nm. Absorption bands of N-H overtones at 1450 nm, 1550 nm, 1740 nm, 2085 nm, and 2180 nm are associated with proteins and polyamides. The C-H overtones of fatty acids, lignin and amino acids signal around 1170-1220 nm, and between 1650-1750 nm. The C=O stretching overtones of esters signal around 2300 nm. Water O-H absorption bands are around 1430 nm and 1886-2000 nm.
33
The absorptions of C-H overtones of caffeine are at 1670 nm and 2222-2500 nm.32,34 Mean spectra plotted against wavelength constructed using EMSC preprocessed spectra for each continent (Central America, South America, Africa) with their associated chemical assignments of absorption bands.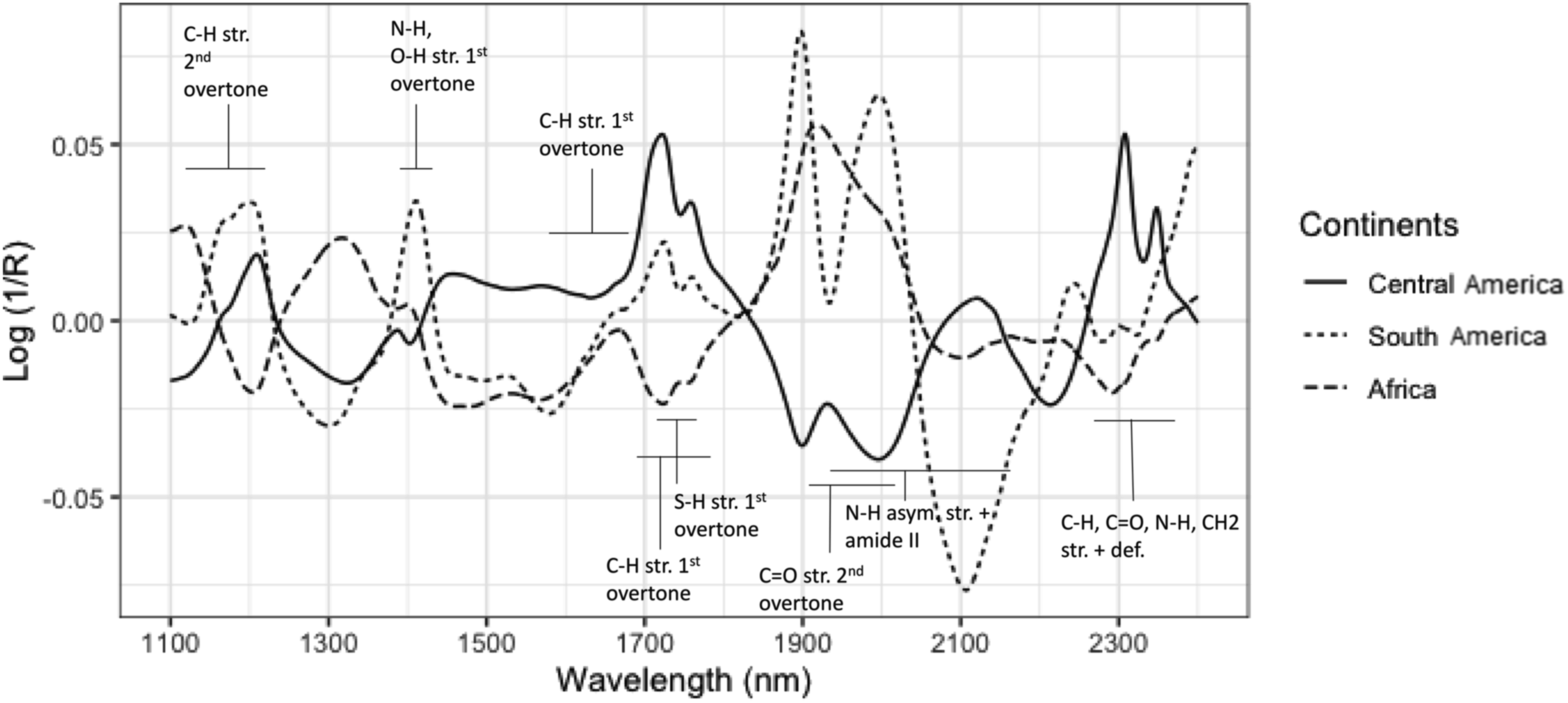
Qualifying the raw spectral data
After visual inspection of the raw spectra, preprocessing using EMSC and mean centering was applied for scatter correction. Unsupervised PCA was used for outlier detection and initial exploration. Overall, no outliers were detected and a good precision was observed among the replicates. Next, supervised classification models were then employed on the dataset, and the model classification and quality were further accessed using accuracy and a dummy classifier.
Linear partial least squares-discriminant analysis classification model
The classical and linear partial least squares-discriminant analysis (PLS-DA) was applied to understand the origin classification performance of NIR spectra at different scales, from the continental to the country and up to the regional level. At the continental level, five latent variables (LVs) were selected as optimum based on cross-validation, and explained 93.60 % and 38.80 % of X and Y variances, respectively (see Figure 2). There is no clear separation between the continents on LV1. On LV2, Africa was partially differentiated from the South American samples. There is a relatively good prediction balanced accuracy (Acc) of 0.77 which was more than the no information rate (NR) (p-value <0.05) at the continental level. It is evident from Figure 2 that there are high variations within each continent, indicating the potential country and/or regional level differences. To better investigate these variations, independent PLS-DA models were built for each continent. Partial least squares-discriminant analysis (PLS-DA) 3D scores plots at the continental level (Africa, Central America, South America).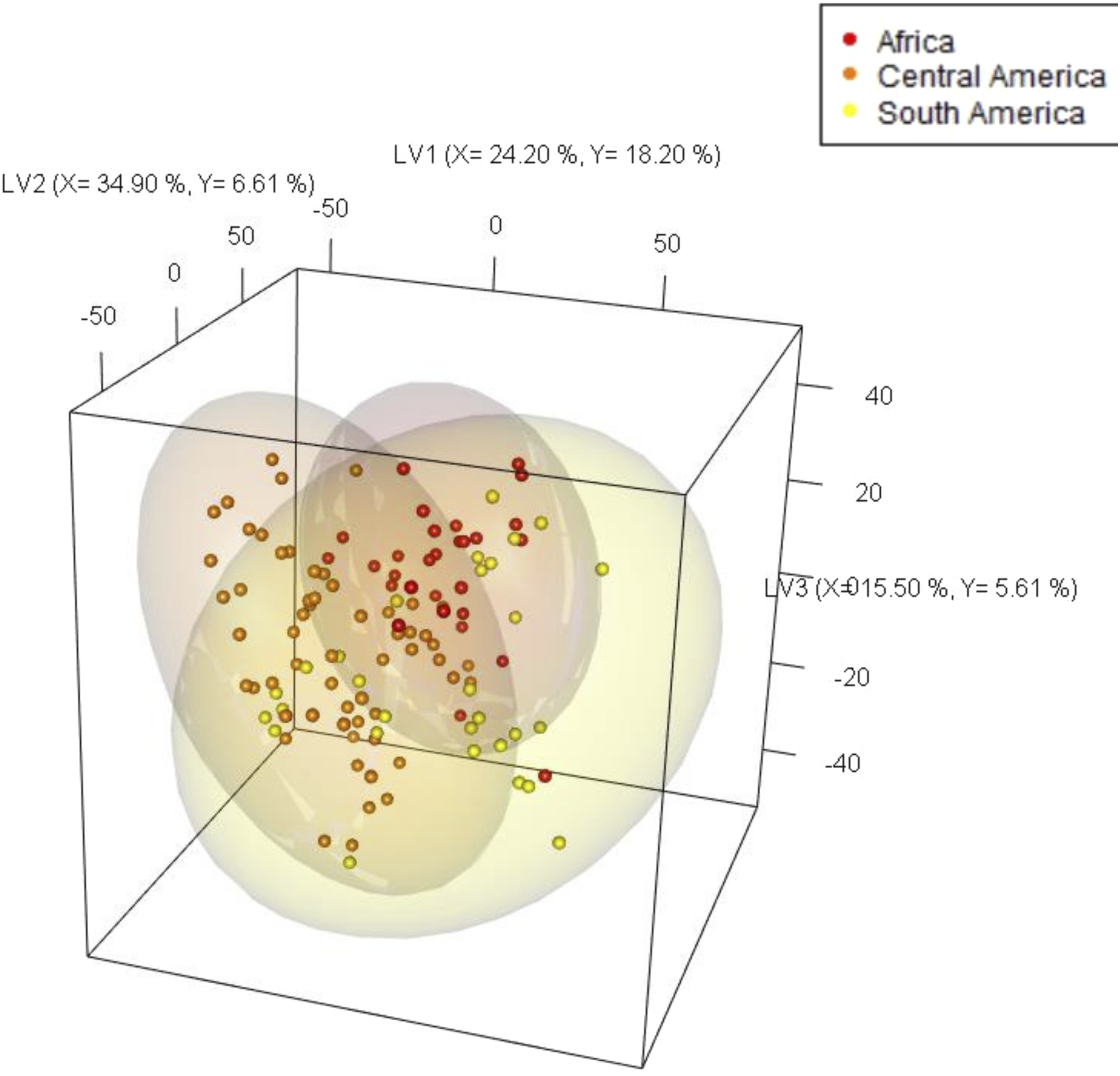
The African samples were explored using PLS-DA with Ethiopia and Kenya as the two classes (Y-variables) (Figure 3a). The model explained 87.20 % and 93.80 % of the X and Y variances, respectively. The two African country samples were differentiated on LV1, with Ethiopian coffee samples positioned on the negative loading and Kenyan samples on the positive loading. There were also variations observed within each country on LV2. The distribution of scores to spectral features can be understood through the loading weights plot, which indicates the wavelength regions important for origin discrimination from each LV. Loading weights for LV1 (Figure 3bi), have the highest contribution from carbohydrates at about 1500-1650 nm, and 2250 nm on the positive loading, cellulose at 1780 nm and the water peaks on the negative loading at around 1430 nm and 1900 nm. These results indicate that Kenyan samples could have higher carbohydrate and cellulose contents, while Ethiopian samples could contain higher levels of water. There might also be differences in the water holding capacity of the beans from the two countries. Further studies are warranted since the samples were prepared and stored the same way to control for moisture. The LV2 loading weights (Figure 3bii) show a dominance of cellulose on the positive loading at around 2080 nm, and negative loadings of proteins at around 1550 nm. These components may help explain the variations observed within each country. All the samples were predicted accurately at the country level (Acc = 1 > NR) (p-value <0.05). Partial least squares-discriminant analysis (PLS-DA) (a) 3D scores plots for Africa at the country level, (b) loading weights plot for (i) LV1, and (ii) LV2.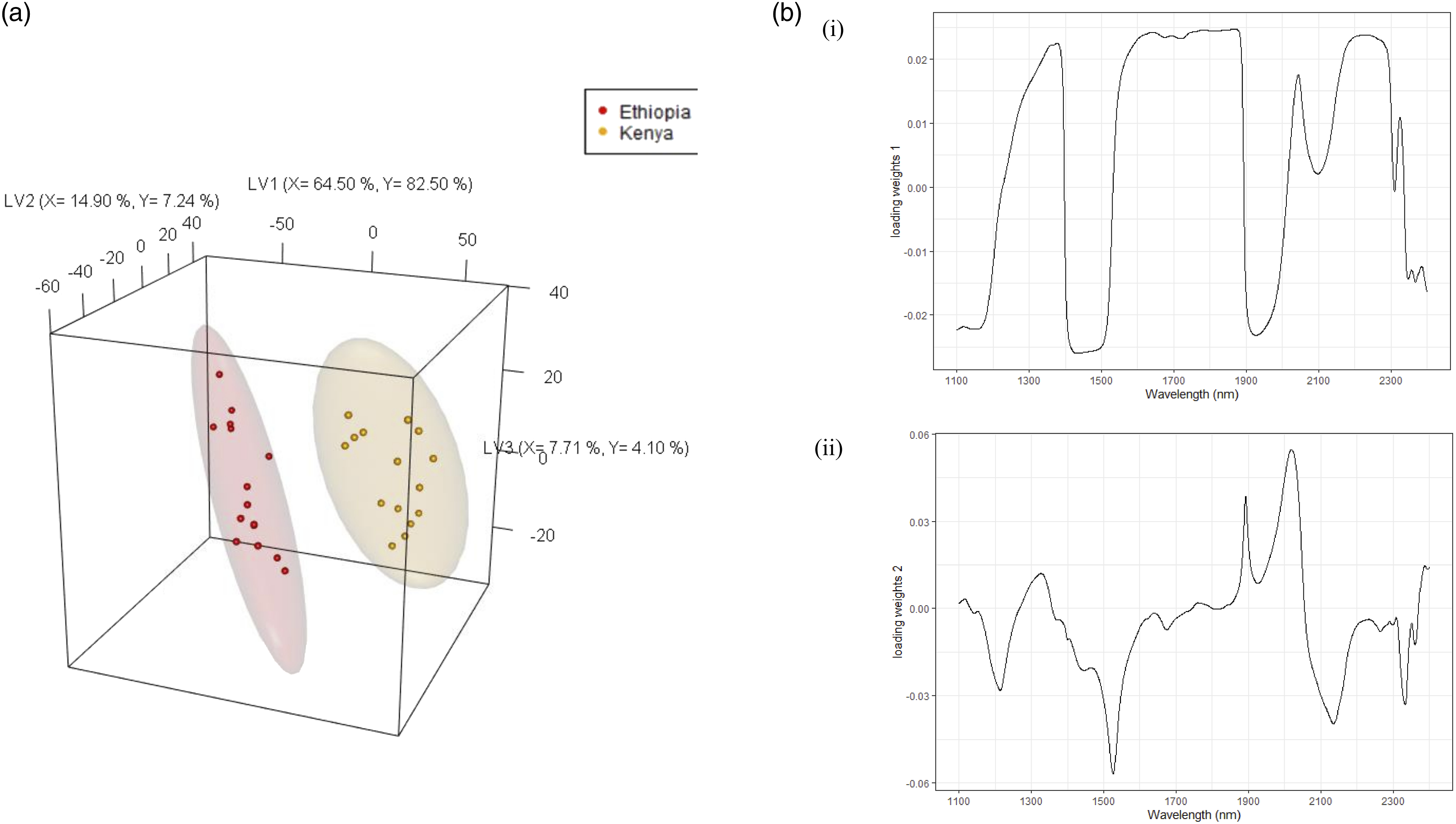
Figure 3 shows an apparent variation (mainly represented by LV3) within each African country. To investigate these variations, and to test the sensitivity of NIR with PLS-DA to classify at the regional level, the African samples were modelled using the five regions as the Y-variables. The model explained 98.50 % and 84.80 % of the X and Y variances, respectively. The Ethiopian regions (Gedio and Guji) were grouped on the positive loading of LV1, separated from the Kenyan samples (Kiajibbi, Maywal, and Yara), which were positioned on the negative loading. Loading weights for LV1 (Figure 4b) show similar results as the loading weights for LV1 for the country level model, but flipped. Water was dominant on the positive loading at around 1900 nm, with Ethiopian regional samples showing higher levels of water. Carbohydrates and cellulose again show dominance in the Kenyan regional samples. LV1 also differentiated Kiajibbi from the other Kenyan samples. Within each country, there were overlaps with Gedio and Guji from Ethiopia, and Maywal with Yara on LV1. These overlapped regions were differentiated on LV2, which showed a dominance of proteins, cellulose, and carbohydrates on the positive loading at around 2100 nm. The predictive accuracy for the African samples at the regional level was Acc of 1 > NR (p-value <0.05). This is the first study on the origin classification of African arabica coffee. Previous research on Ugandan robusta coffee showed poor differentiation from other regions.
9
Partial least squares-discriminant analysis (PLS-DA) (a) 3D scores plots for Africa at regional level, (b) loading weights plot for (i) LV1, and (ii) LV2.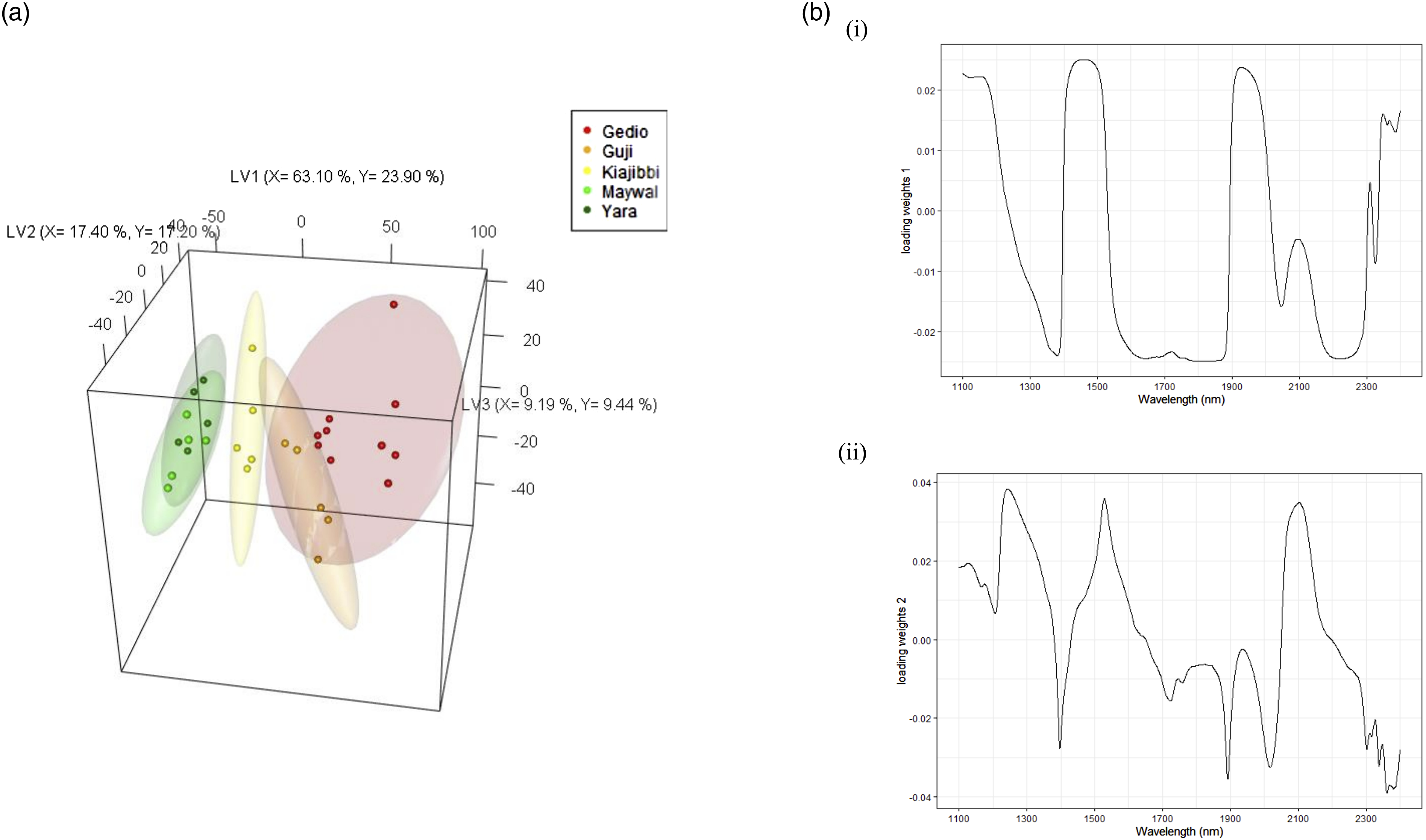
The South American samples were then modelled to study country level differences. The model explained 86.40 % and 88.10 % of the X and Y variances, respectively. The two country samples were differentiated on LV1, with Colombian samples on the negative loading and Peruvian samples on the positive loading (see Figure 5a). The loading weights in Figure 5bi show a dominance of proteins, cellulose, and carbohydrates on the positive loading and water on the negative loading. Colombian samples were characterised by lower levels of carbohydrates and proteins, while Peruvian samples had high water contents. On LV2 and LV3, differences are observed within each country, especially for samples from Colombia. The Loading weights for LV2 in Figure 5bii show a dominance of lignin and cellulose at 1700 nm and 2300 nm peaks associated with caffeine and esters.
31
The loading weights for LV3 (Figure 5biii) showed a dominance of peaks at 2300 nm on the positive loading. All the samples were predicted accurately at the country level with Acc = 1 > NR (p-value <.05). Partial least squares-discriminant analysis (PLS-DA) (a) 3D scores plots for South America at the country level, (b) loading weights plot for (i) LV1, and (ii) LV2, (iii) LV3.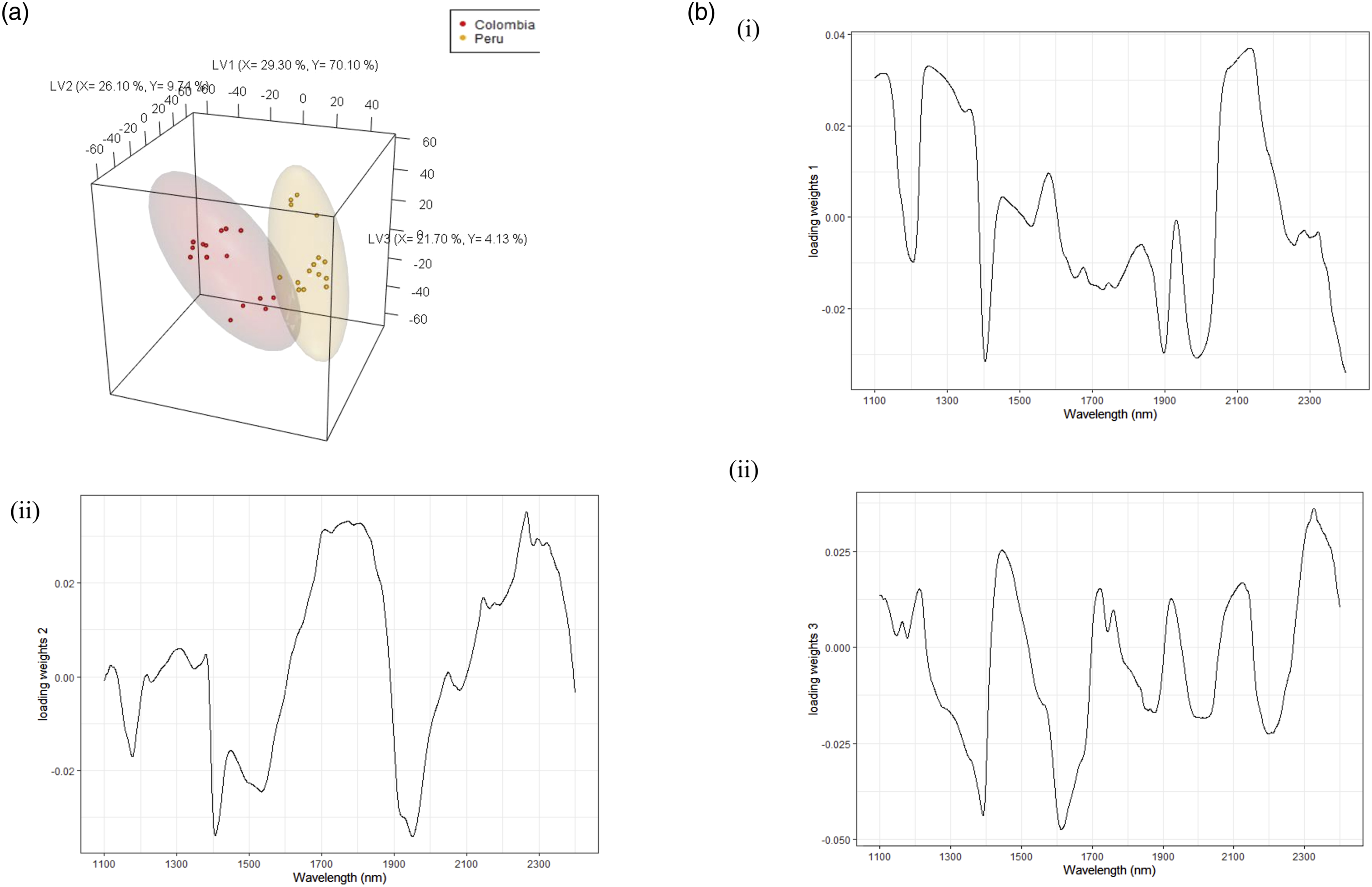
To understand regional differences within country samples on LV2 and LV3 in Figure 5, the PLS-DA model was constructed with the five South American regions as the Y- variable. The model explained 96.60 % and 77.00 % of the X and Y variances, respectively. On LV1, the Colombian (Antioquia, Huila, and Narino) regional samples were grouped on the negative loading and separated from the Peruvian (Cusco and Pasco) samples, which were grouped on the positive loading (see Figure 6a). The loading weights for LV1 (Figure 6bi) show a dominance of carbohydrates on the positive loading at 1500 nm, with Peruvian samples having higher carbohydrate contents, and Narino in Colombia having the lowest levels. These loading weights follow the similar trend as the country level model. On LV2 and LV3, regional separation was observed for both countries. The loading weights for LV2 show a dominance of carbohydrates in the positive loading, and proteins on the negative loading. The loading weights for LV3 show a dominance of cellulose on the positive loading and esters on the negative loading. The South American model also performed well at the regional level with an Acc = 1 > NR (p-value <0.05). Partial least squares-discriminant analysis (PLS-DA) (a) 3D scores plots for South America at regional level, (b) loading weights plot for (i) LV1, (ii) LV2, and (iii) LV3.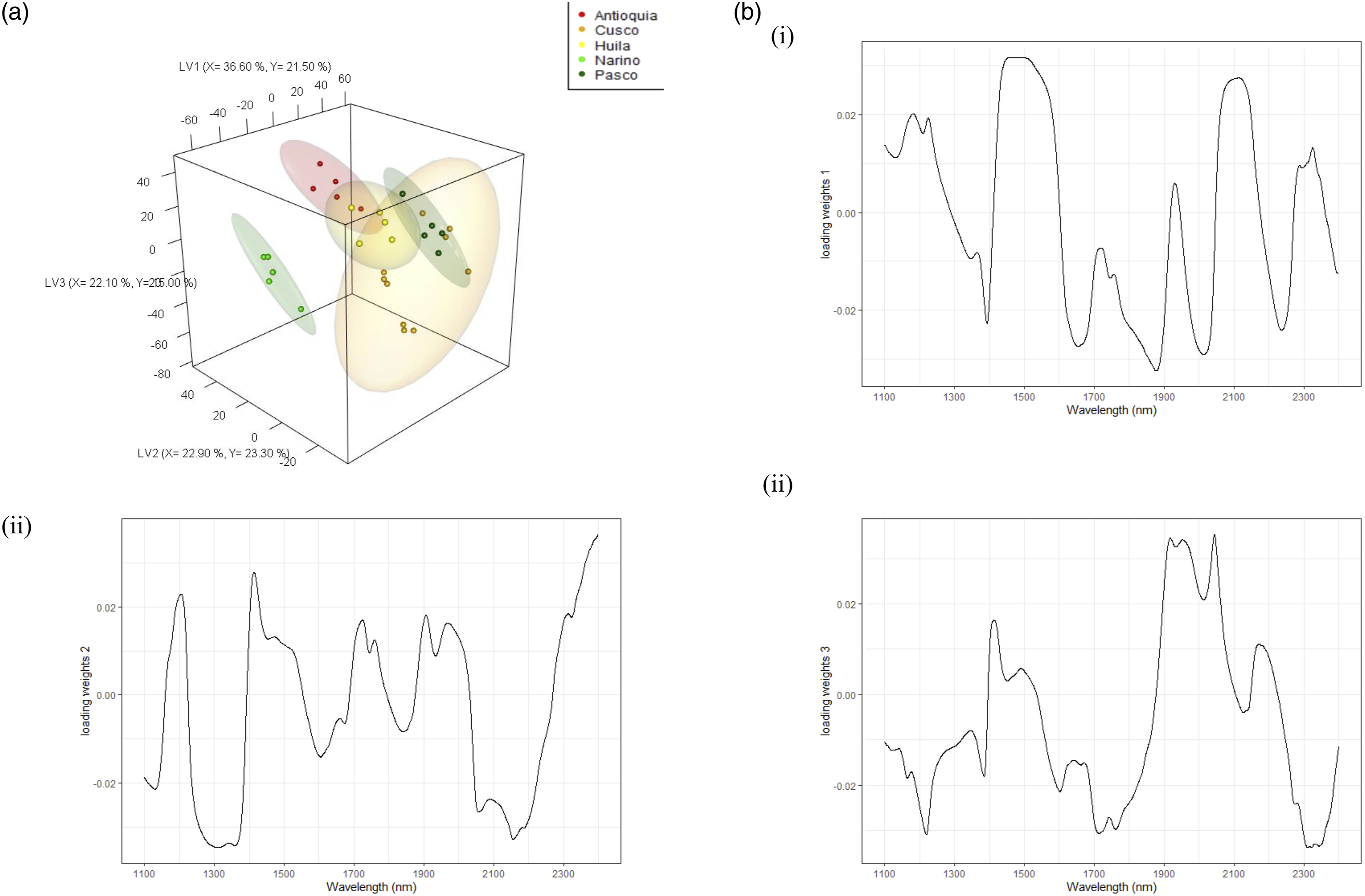
For the Central American samples, PLS-DA was employed on the four countries (Costa Rica, Guatemala, Mexico, and Nicaragua) to investigate country level differences. On LV1, Nicaragua was partially separated on the negative loading, with overlaps of the other three countries on the positive loading (see Figure 7a). The loading weights 1 (Figure 7b) show a dominance of positive loadings of lignin and cellulose around 1700 nm, and esters and caffeine around 2300 nm. These suggest that Nicaraguan samples are lower in lignin, cellulose and esters, and some regional samples in Costa Rica and Mexico have the highest amounts of these constituents. Partial least squares-discriminant analysis (PLS-DA) (a) 3D scores plots for Central America at the country level, (b) loading weights plot for (i) LV1, (ii) LV2.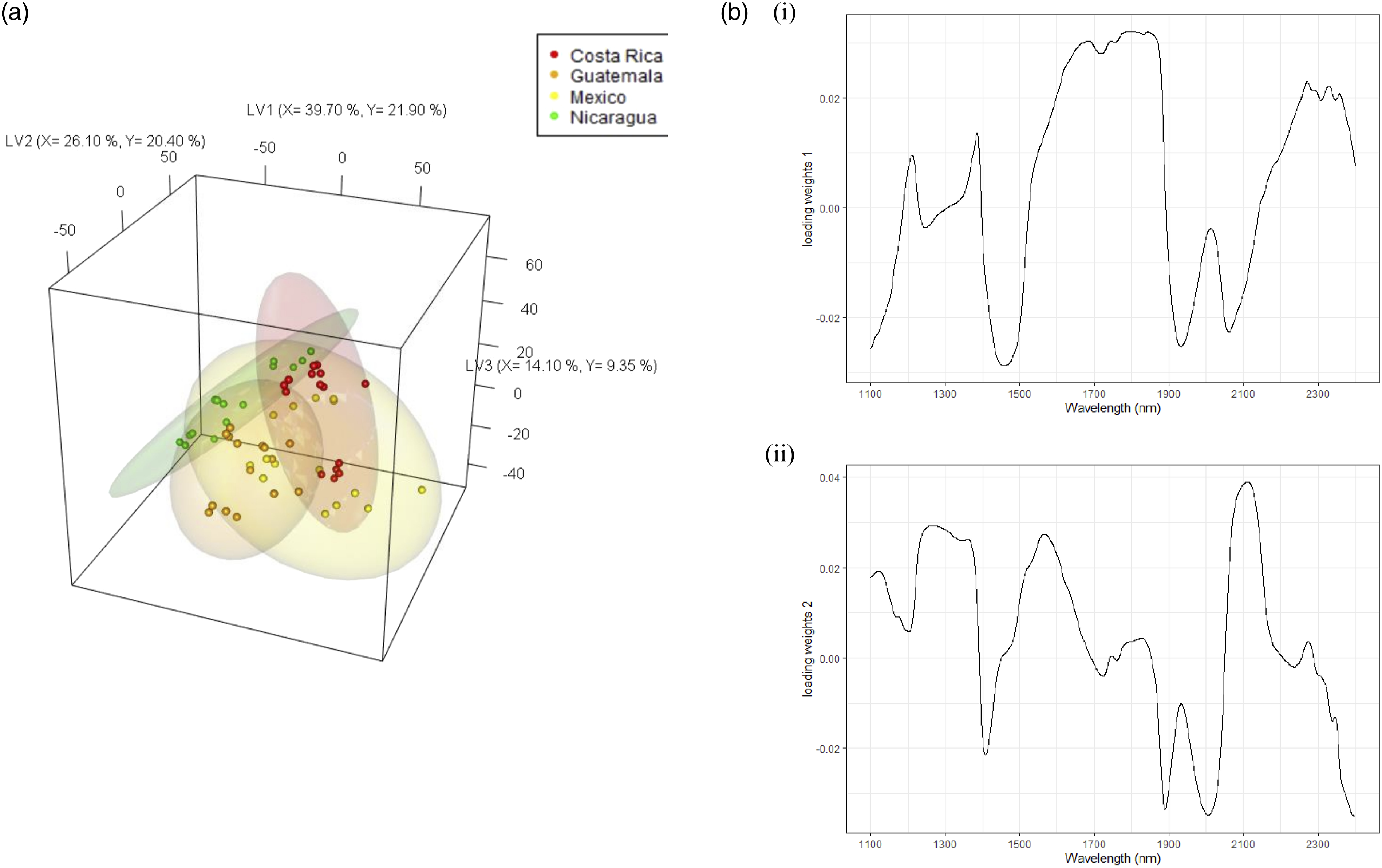
On LV2, Nicaragua and Costa Rica were partially differentiated. The loading weights (LV2) show a dominance of water on the negative loading and carbohydrates and proteins on the positive loading. Nicaraguan samples have the highest water contents, with Costa Rican samples differentiated by their higher carbohydrate and protein contents. The Central American model performed relatively well with an Acc = 0.83 > NR (p-value <0.05) at the country level.
To understand the regional differences observed in Figure 7, the model was built with the 12 regions as the Y- variable. There was no clear separation of regional samples. The predictive accuracy of the regional samples for Central America was poor at an Acc of 0.25 > NR (p-value <0.05). 5
In summary, NIR showed sensitivity for continental classification. The variations observed within each continent were modelled to identify discriminant wavelengths for country and regional level models. The African and South American samples were most easily differentiated, with the Central American samples performing well at the country level, and poorly at the regional level. Overall, the linear PLS-DA model appeared to struggle at the Central American regional level. Non-linear machine learning modelling techniques were subsequently investigated across all origin scales to determine if classification improvement was possible even for well performing models.
Non-linear machine learning classification models
Accuracy for the train, cross-validation (cv), and test set for NIR spectral datasets across the origin scales (continental. Country, regional) using five different modelling techniques [partial least squares-discriminant analysis (PLS-DA), k-nearest neighbours (KNN), support vector machine (SVM), extreme gradient boost (XGB), random forest (RF)].
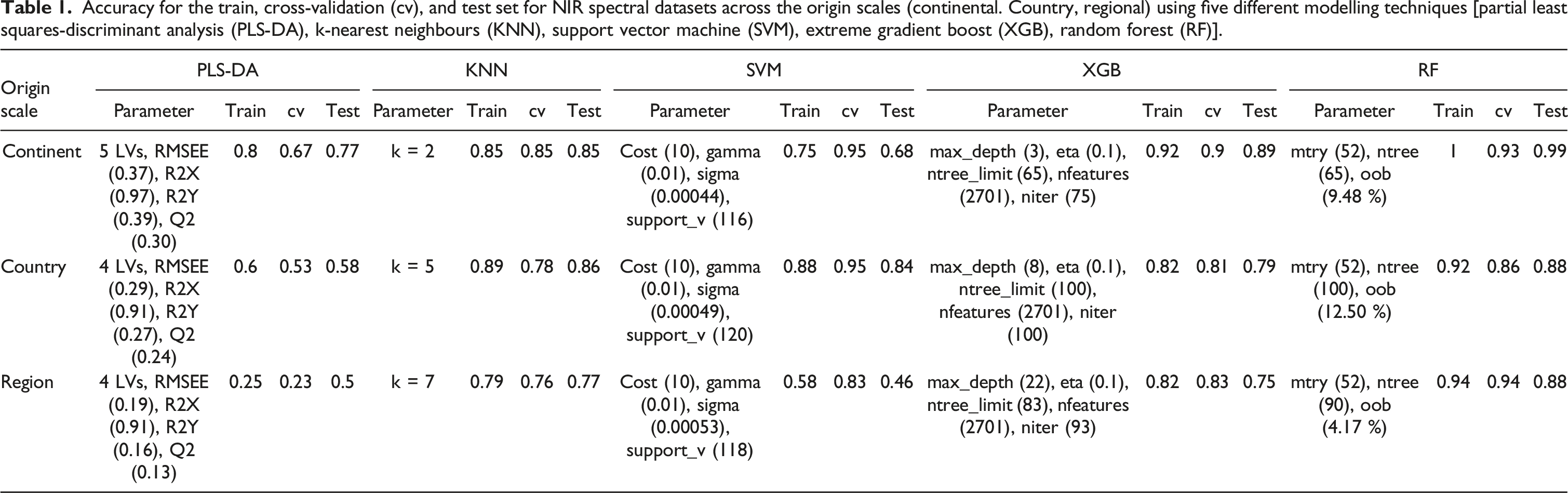
In Table 1, the continental level classification using PLS-DA achieved a relatively good performance with an Acc of 0.77. Non-linear models KNN, SVM, XGB, and RF all appeared to improve the model performance further, with the best model performance from XGB and RF, the two ensemble decision trees. At the country level, with all 8 countries set as Y, the performance was poor at an Acc of 0.58. Non-linear models increased the performance to a moderate Acc of 0.76 (KNN) and 0. 74 (SVM), and up to a good performance of 0.79 (XGB) and 0.88 (RF). Lastly at the regional level with all 22 regions in the model, the model predicted at a level of chance with poor performance even across the training and cv sets. Non-linear models again improved the performance, with XGB and RF consistently performing the best with an improved Acc of 0.80 and 0.88 respectively.
Overall, all the non-linear models have demonstrated potential in dealing with more complicated NIR spectral datasets. The results comparing the best non-linear model agree with a previous study. A bioinformatic classification study comparing 13 machine learning models also found RF and XGB to be exceptional in contrast to SVM and KNN. 35
Non-linear models, however, tend to be black boxes in which the innerworkings of the model is not well understood, and variable identification is lacking. While XGB appears to perform well, the mechanisms for classification are not well understood. RF on the other hand includes a built-in feature selection parameter called the Gini impurity which decides the feature (wavelength) that is more important- based on how well the decision tree was split. The features that are more important towards the prediction model show a larger mean decrease in Gini impurity. In addition, the interpretability and graphical visualisation of machine learning algorithms are important for researchers to understand predictive models qualitatively. 36 A proximity matrix can be calculated in RF to build a MDS (multidimensional scaling) plot - a visual representation of class similarities via a scatter plot. Proximity is the proportion of time that two classes end up in the same tree node out of all the trees in the forest.
As discussed in the previous section, the Central American regional model had a higher classification challenge with more countries sampled compared to the African and the South American model. This led to the poor predictive Acc of 0.25. Mexico is a large country by land area. This may have led to the overlap of macro and micro climates across regions, resulting in a broad range of constituent concentrations in the coffee bean.37–41 The Central American regional dataset was thus used as an example to demonstrate the potential of non-linear RF, to see if improvements could be made to the performance, and to identify RF selected features compared to the loading weights from the linear PLS-DA model (Figure 8b). Partial least squares-discriminant analysis (PLS-DA) (a) 3D scores plots for Central America at regional level, (b) loading weights plot for (i) LV1, and (ii) LV2.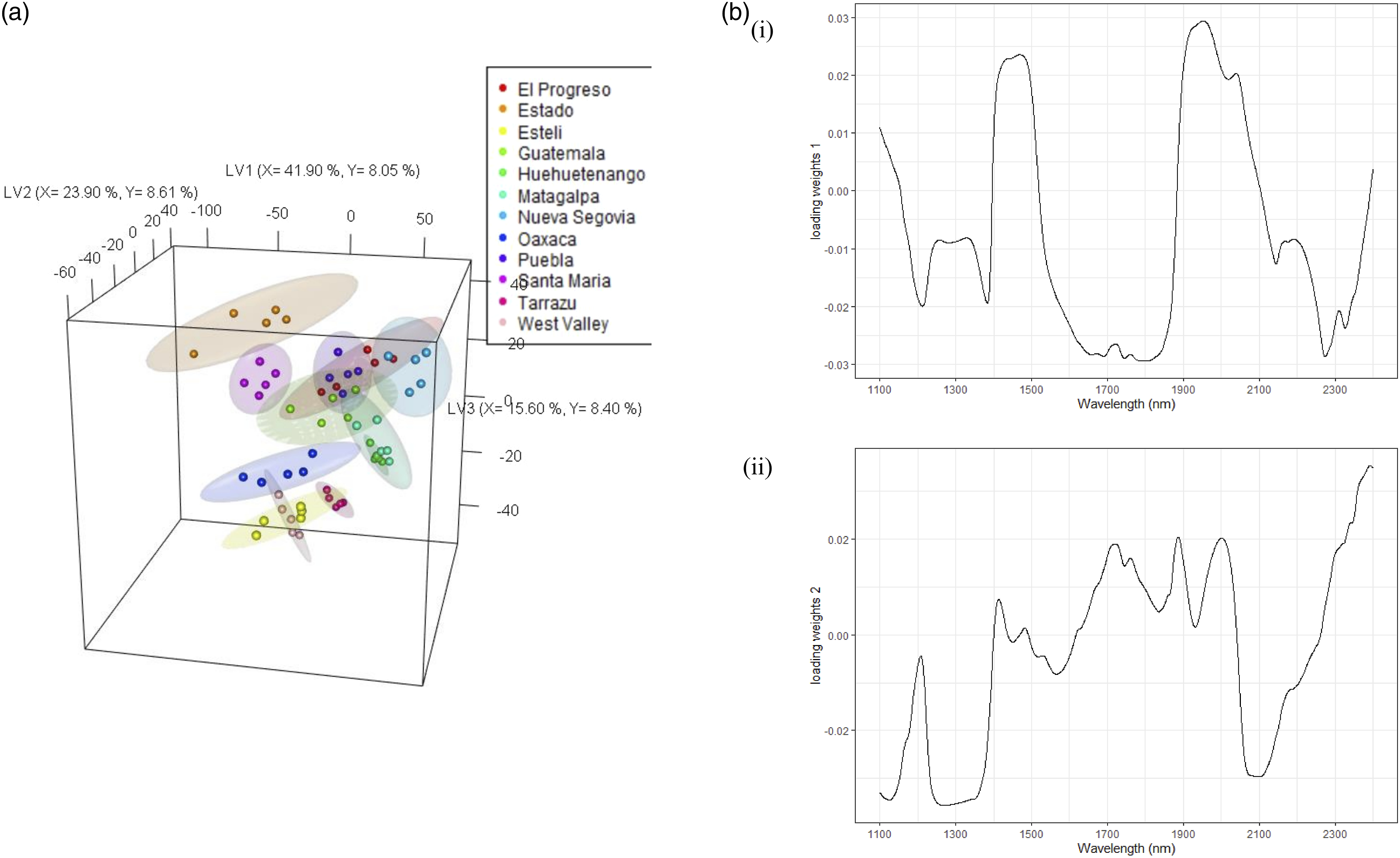
The RF MDS plot and feature selection plots in Figure 9 show some improvements visually – the regions are more distinguished. The RF feature selection plot (Figure 9b) demonstrate the wavelengths most important towards reducing the Gini impurity and thus overall model accuracy. Modelling the Central American data at regional level led to a significant increase in Acc to 0.98. Random forest (RF) (a) MDS (multi-dimensional scaling) plot, and (b) feature selection plot with the most important wavelengths indicated the Central American regional model.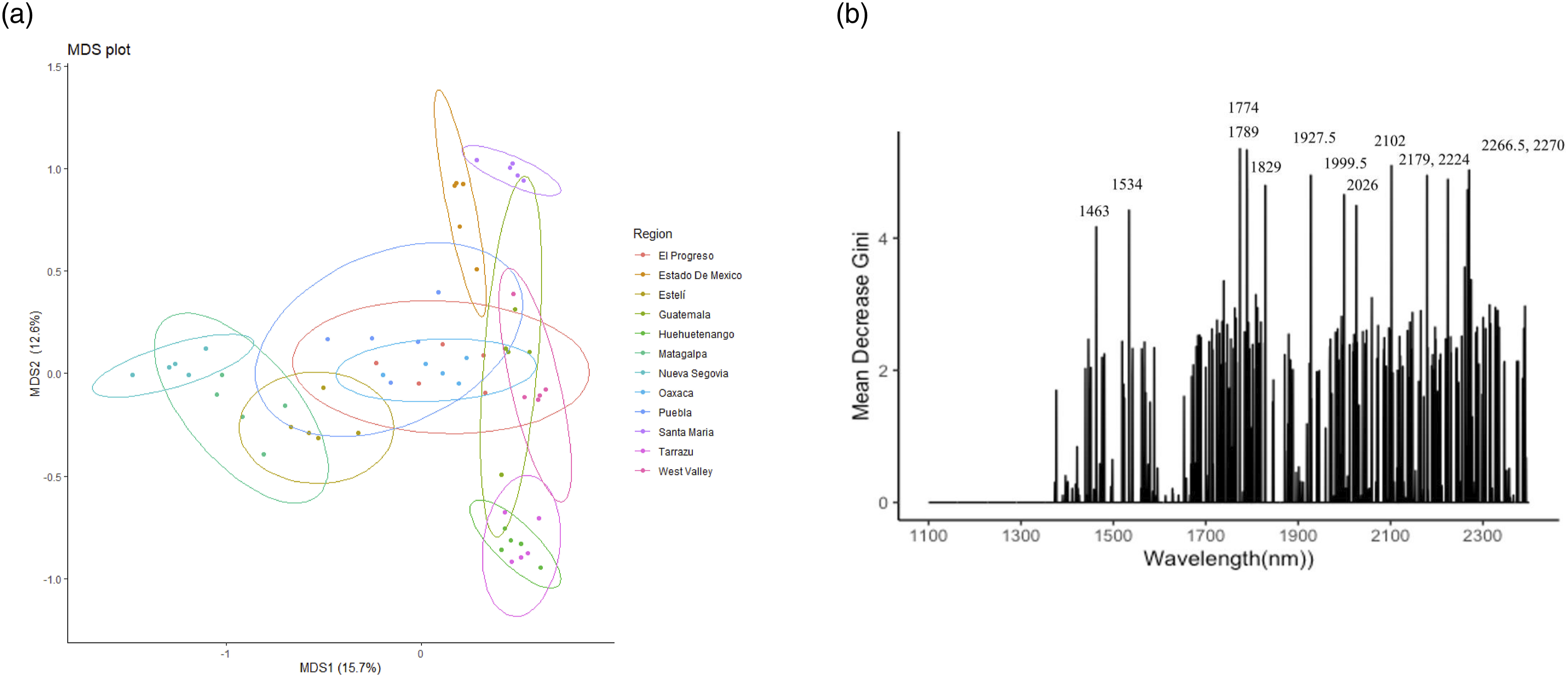
However, the visualisation (Figure 9a) does not appear to be an accurate representation of the excellent performance by the RF model given that there were overlaps across classes. To circumvent this limitation, there is growing interest in Explainable Artificial Intelligence (XAI) which aims to reveal the inner workings and mechanisms behind these complex models. 42 More effort is needed to make machine learning models more understandable to increase transparency and veracity of predictions.
A broader range of feature selected wavelengths can be observed from the Central American regional RF model (Figure 9b). The RF selected top wavelengths were similar to the ones identified in the linear PLS-DA loading weights (see Figure 8b). Minor peaks appear to become more important when using non-linear RF machine learning models.
Conclusions
The present work demonstrated the potential of NIR spectroscopy coupled with machine learning for rapid and cost-effective origin classification of coffee from the continental to the regional level. NIR spectroscopy coupled with PLS-DA appears to be sensitive at the continent and country level, with promise at the regional level. Overall, this study is the first to indicate the potential of a variety of non-linear machine learning models to improve model performance for authentication of coffee origin. The non-linear models can better deal with complicated classification challenges compared to the linear PLS-DA model. Random forest was found to be superior to other non-linear models for their added visual illustration of the underlying discriminatory mechanisms and variable identification opportunity. Additional effort needs to be put in to enable machine learning models to be more interpretable. However, the choice of an appropriate model depends on the classification problem at hand, and for more straightforward problems, the linear models appear good enough for their simplicity. This is a preliminary study which serves as a proof of a concept demonstrating the potential of NIR spectroscopy coupled with machine learning. Each location was represented by a small number of samples, future studies will require an extended sample set with precise geographical metadata to ensure more representative sampling. The model can be extended and made robust with external validation and by considering natural variations with samples from different years, seasons, batches, and genetics. Targeted analyses can be performed to confirm the identification of the discriminative wavelength regions. There is potential for NIR spectroscopy coupled with machine learning to monitor the authenticity of coffee beans of labelled origins on a global scale, and to expand it to the verification of bean species.
Footnotes
Acknowledgements
We would like to acknowledge Oritain Global Limited for providing the green coffee bean samples, equipment, and metadata.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.