
Abstract
The Part 1 prequel to this review evaluated the evolution of modelling techniques used in evaluation of fruit quality over the past three decades and noted a progression towards the use of artificial neural networks (ANNs) and convolutional neural networks (CNNs). In this review, Part 2, the use of CNNs for NIR fruit quality evaluation is explored, given the success of CNNs in various other fields, such as image, video, speech, and audio processing, and the availability of large (open source) datasets of fruit spectra and reference quality attribute, which is required for the training of CNN models. The review provides an overview of deep learning and the CNN architectures and techniques used in NIR spectroscopy for regression modelling, with advantages and disadvantages identified. Studies using CNN for NIR based fruit quality evaluation are then critically examined. Eight publications have presented on models using the same open-source mango dry matter calibration and test set, enabling inter-method comparisons. CNN models have been demonstrated to be accurate, precise and robust. Techniques of transfer learning for CNN models offer an alternative solution to model updating and calibration transfer methods applied in traditional chemometrics. The review has highlighted crucial areas that require resolution and exploration in this application through future research, including, (i) data requirements for training a CNN (ii) optimal spectral pre-processing for CNN (iii) CNN architecture and hyper-parameter selection and tuning for fruit quality evaluation (iv) CNN model interpretability and explainability. Future studies must conduct clearer comparison to partial least squares (PLS) regression and shallow ANNs to better assess the prospective benefit of using CNN, a more complex model. The potential for visualisation of spectra relevance to the CNN model using techniques such as GradCam, currently employed in visualising 2D-CNN models, remains to be explored.
Keywords
Introduction
Scope
Many industries and applications are accelerating their use of artificial intelligence, implementing machine learning over traditional statistical modelling methods. Traditionally, mechanistic models were used to predict future outcomes, with these models based on an understanding of the underlying mechanism, represented with a statistical model or specific rule set. Machine learning is different in that rather than coding the underlying knowledge, machine learning methods automatically learn patterns and relationships from provided examples. 1 This leads to a shift in focus to appropriate training of the models, such as use of sizable data sets and avoiding overfitting by selection of suitable training data.
This trend is relevant to applications involving near infrared (NIR) spectroscopy. As exemplified by the pioneering work in this discipline by Norris, 2 the traditional approach to model development involved a statistician with an underlying knowledge of chemistry and related spectroscopy of a commodity, i.e., a chemometrician, working with relatively small data sets. Improvements in computing power and availability of large data sets that span sample conditions have supported a trend to use of machine learning techniques.
The preceding review by Anderson and Walsh 3 detailed the evolution of modelling techniques employed in the field of NIR spectroscopy for fruit quality evaluation over the past three decades. A progression in modelling technique usage was noted from multiple linear regression (MLR) to the use of partial least squares (PLS) regression and more recently to techniques such as support vector machines (SVM), artificial neural networks (ANN) and convolutional neural networks (CNN). PLS regression models were noted to have dominated horticultural applications for over two decades. It was also noted that many studies used a validation set drawn from the same population (growing conditions) as the calibration set. 3 Those studies that dealt with multiple populations varying in growing condition, season, cultivar, etc., noted a need for model updating. 3
The availability of larger training datasets has enabled the development of deep learning techniques which have shown promise in their ability to generalise across seasonal differences and potentially instruments. For example, shallow (single hidden layer) ANN models have been employed in spectroscopy for over two decades. 4 ANNs have been demonstrated to outperform PLS regression models in some specific cases 5 and have been adopted into commercial use, e.g., across the FOSS Infratec instruments. 6 Additionally, several large datasets of fruit spectra and quality attributes have been publicly released7,8 which enables direct comparison of models developed by any researcher using the same training and test sets.
The current review extends the consideration of Anderson and Walsh 3 on the evolution of modelling techniques for NIR spectroscopy for fruit quality evaluation, with focus to the use of convolutional neural networks (CNNs), which is a particular form of deep learning. Given that the application of CNN is relatively new to the field of NIR spectroscopy, an introduction is provided to deep learning and the CNN architecture, followed by a consideration of the use of CNNs in NIR spectroscopy in general. For example, while spectral pre-treatment techniques have largely been developed to accentuate information specifically for PLS regression modelling, there is some suggestion that CNN models may require less pre-treatment. 9 CNN applications for the assessment of fruit quality using NIR spectroscopy are then examined, with advantages and limitations of the technique deduced and areas for refinement and improvement suggested.
Conduct of the literature survey
A systematic approach was adopted to identify relevant articles for review in the sections CNN for NIR spectroscopy and CNN-NIR in fruit quality evaluation. The searches were conducted programmatically across three popular databases, Scopus, Web of Science and Google Scholar, utilising open-source python packages, pybliometrics, wos and scholarly, available from the Python Package Index (PyPI). 10 Search queries were confined to the period from 01/01/2015 to 20/11/2022, and involved search of title, abstract and keywords of each article. Pre-prints and non-peer reviewed articles were excluded.
Slight differences were noted between the querying ability of the three databases used. Scopus provides the functionality to search across title, abstract and keywords. Web of Science, however, can only search each section separately. For example, for a search on the string “CNN” AND “NIR”, an article containing “CNN” in the title and “NIR” in the abstract but not the title will be captured by Scopus but not Web of Science. Google Scholar does not provide the functionality to limit searches to abstract or keywords, only to title or the full text. Many non-relevant results were returned when searching across the full text, so Google Scholar searches were restricted to title only.
Summary of returned results on the 20th of November 2022 for search queries during refinement.

aQuery across full text.
The topic of CNN used in context of NIR spectroscopy in general was reviewed based on query 4, (“convolutional neural network” OR “CNN”) AND (“near infrared spectroscopy” OR “NIR”) AND NOT “hyperspectral” AND NOT “fruit”, with 211 unique articles identified from the three databases. These articles were screened to remove those with the term “classification”, “discrimination”, “detection”, “recognition”, “FNIRS”, “imaging” or “images” present in the title, abstract or keywords. This step was conducted in Python on the combined results rather than the individual database searches. This resulted in 51 articles which were then individually manually screened for relevancy. A further 18 articles were removed due to not meeting the criteria after manual screening, resulting in a total of 33 articles which are reviewed in the section CNN for NIR spectroscopy. This survey method is presented in Figure 1(a). Literature survey procedure for the topic of (a) CNN used in NIR spectroscopy, and (b) CNN used in NIR spectroscopy for the application of fruit quality evaluation.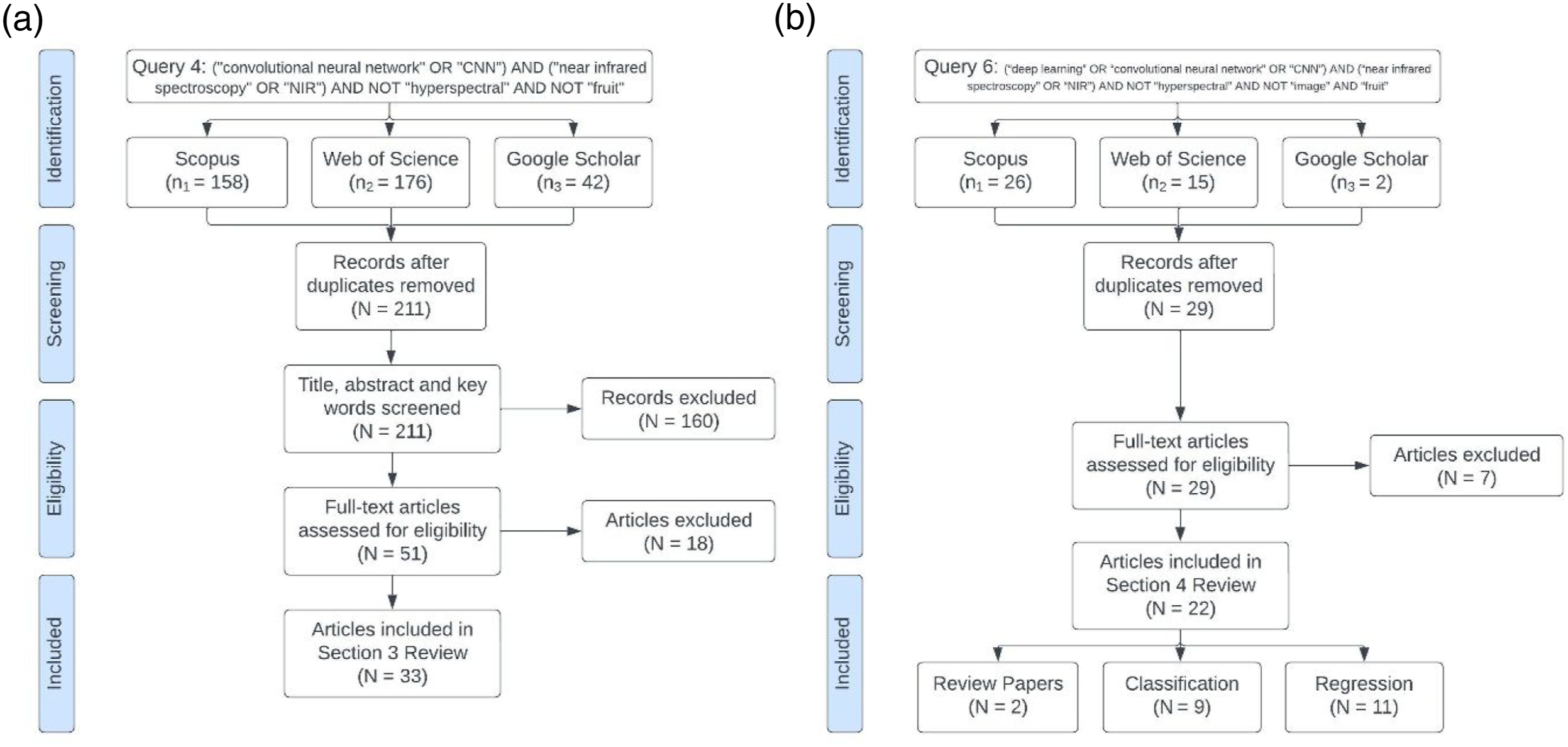
The review was then narrowed to use of CNN in NIR spectroscopy related to fruit quality evaluation using the search term (“deep learning” OR “convolutional neural network” OR “CNN”) AND (“near infrared spectroscopy” OR “NIR”) AND NOT “hyperspectral” AND NOT “image” AND “fruit” (query 6), with 29 unique articles identified and manually screened. A total of 22 articles (2 review papers, nine classification type models and 11 regression models) were reviewed (CNN-NIR in fruit quality evaluation). The survey method for this section is presented in Figure 1(b).
Deep learning
This section provides a brief introduction to ‘deep learning’ with a specific focus on CNN architecture. ANNs are a commonly used modelling technique for non-linear systems inspired by the biological neural networks that make up animal brains. 11 Deep learning modelling techniques are classified as ANNs with more than three layers which utilise representation learning which is either supervised, semi-supervised or unsupervised.12,13 There are many ANN architectures that are classed as deep learning, including CNN, recurrent neural networks and recursive neural networks. 14
Artificial neural networks
An ANN is made from numerous interconnected nodes, known as artificial neurons, which receive and process information to signal connected neurons in the following layer.13,15 Neurons are arranged into layers of the network referred to as the input, hidden and output layers. Each hidden layer performs a transformation function on inputs, while the final output layer produces the prediction of the model. A neuron typically processes information using a non-linear function, with the exception of the output layer. The connections between neurons are weighted based on the training of the model. A bias can also be used shift the output of a neuron.
An ANN is typically trained via supervised learning using a large training data set containing the input and the desired output, known as the supervisory signal. 1 The ANN classically begins with a random set of weights for each neuron connection. The error of the processed output of the ANN compared to the supervisory signal is then computed before updating the weights based on a predefined learning rule to decrease the error. The iterative learning process is terminated based on an error criterion, upon which the final model weights are set.
ANN allows complex problems with many inputs to be modelled with relative ease with many advantages over traditional statistical models for practical applications. 14 Increasingly complex non-linear systems are being accurately modelled with deeper ANN architectures enabled by enhanced computing power and optimised training method. 16
Convolutional neural networks
A CNN is a specific feedforward ANN architecture consisting of one or more convolutional layers. 17 A convolutional layer performs a mathematical operation on the input data that can extract meaningful features while reducing the dimensionality of the data. The technology was developed in context of object recognition within images, with the LeCun et al. 18 article “Gradient-Based Learning Applied to Document Recognition” (which has over 25,000 paper citations) being a seminal study in the development of CNNs. This work proposed a method for grouping simple features into progressively more complex features for handwritten character recognition. The success of this work is seen in current use of the technique in postal sorting of handwritten postcodes on envelopes.
A typical CNN is comprised of an input and an output layer sandwiching convolution and pooling/sub-sampling layers. The training process involves the development of filters in the convolution layers that extract information (‘features’) relevant to the attribute level. Data is down-sampled with each layer, such that simpler features are learned in the early layers and more complex features are learned in deeper layers. In image analysis using CNN, a visualisation of the convolutional layer output has been used to highlight features used in the model.19,20
A CNN architecture can offer computational benefits over a fully connected ANN of the same number of neurons, while maintaining prediction accuracy. 17 Three technique advantages have been documented: (i) In a convolutional layer, a neuron is not connected to every neuron of the previous layer, reducing the number of parameters that need to be trained and increasing the speed of convergence when training. (ii) A CNN can further reduce the parameters by setting groups of neuron connections to share weights. (iii) A pooling layer within the CNN down-samples the input data while retaining useful features, which reduces the amount of data and possibly further reduces the number of model parameters.
Convolutions can be one, two or three dimensional, which refers to the number of directions the convolutional filter can move about an axis of the input data. Higher dimensional convolutions require significantly more computational power to train and implement due to their added complexities. 14
CNN applications
The LeCun et al. 18 application of CNN sparked a wide uptake of such models for a range of applications in the 2000s, but they fell by the wayside with the success of new generation machine learning techniques such as support vector machines. This can be attributed to the need for larger training datasets for a deep CNN to achieve better generalisation proficiency and the need for greater computational resources needed to train a CNN with a large dataset. However, modern graphical processing capacity allows CNN models to be trained on massive datasets by parallelising the computation. This increase in speed of training, coupled with the success of the ‘AlexNet’ model by Krizhevsky et al. 21 has made 2D CNNs the ‘go to’ method for classification and recognition in image analysis. 22 In recent years, CNN has also gained popularity with the remote sensing community in dealing with multispectral image sets, typically using visible and short wave NIR. 23
CNN architectures were originally developed for 2D data and in initial applications 1D data was represented in 2D. This approach is computationally expensive and requires large training datasets. CNN architectures have now been specifically developed for 1D data and have become widely used in many signal processing applications.24,25 The architecture for A 1D-CNN is more compact than those used for 2D data. Spectroscopy datasets are typically 1D and thus benefit computationally from use of a compact 1D-CNN. This may allow implementation on portable devices with limited computing capability.
CNN for NIR spectroscopy
In this section applications of CNN in NIR spectroscopy for regression modelling are discussed. As per the conduct of the literature survey, hyperspectral imaging applications and classification problems were excluded. The first applications of CNN models to spectroscopy 26–28 did not occur for two decades following the seminal LeCun et al. 18 work. The technique has not been widely adopted by the NIR community, although publications are increasing, as documented in the literature survey (for CNN regression models in NIR spectroscopy, excluding fruit) result of 2, 5, 7, 7 and 12 papers in each of 2018, 2019, 2020, 2021 and 2022, respectively. To the authors knowledge, however, the CNN technique has not been adopted by any NIR instrument vendor, indicating that the advantage of the technique over other methods is not yet fully demonstrated for this application.
Cui and Fearn 28 used three different wheat NIR datasets to conduct systematic tests to compare CNN and PLS regression approaches. Their smallest dataset consisted of 415 training and 108 testing samples while their largest dataset had 6987 training and 618 independent test samples. The proposed CNN model, consisting of an input layer, convolutional layer, three fully connected layers and an output layer, was more accurate, less noisy, and more robust than a traditional PLS regression for their datasets. Further, they demonstrated that the output of the first layer of the trained CNN model was similar to the output of a Savitzky-Golay (first derivative) smoothing filter, i.e., the first convolutional layer of the CNN acted similarly to a commonly used spectral pre-processing technique. A method was also proposed to numerically visualise the regression coefficients of the CNN in order to quantify wavelength importance and aid in interpretation of the model. They concluded CNN model hyperparameters can be optimised and selected via cross validation and that CNN models could be used in prediction of sample attributes using NIR data. For completeness, Cui and Fearn 28 could have added comparison of a simple ANN model to the results of the CNN and PLS regression. This would have provided evidence of the value of adding additional layers, including a convolutional layer.
A general criticism of the use of CNNs and ANNs is they provide essentially black box predictions. There is an adage in the NIR scientific community that there ‘should be no prediction without interpretation, and no interpretation without prediction’, i.e., that a model tested to predict well should be interpretable in terms of the band assignments of spectral features. 29 Indeed, domain expert chemometricians can hand craft models based on the underlying chemistry of the desired attribute in each given sample by the selection of wavelengths. The ability to visualise the features extracted by the convolutions of a CNN is thus important for a general understanding of how the model is working. 28 Further work is required to adapt the visualisation approaches used in 2D-CNN, including use of GradCAM and SHAP. 30
Since the Cui and Fearn 28 initial application, CNN regression models have been tested in a range of other NIR spectroscopy applications, with the dominant application being soil related, with 17 papers found.31–47 A possible explanation for this focus is that assessing soil attributes using NIR spectra is complex, given the non-homogeneity of the medium, and likely involvement of secondary correlations. This results in researchers exploring new methods to improve NIR in this application. Other application ‘hot spots’ include grain,28,37,48–52 organic matter such as leaves, wood and beans,53–59 food powders,37,60,61 oil 62 and brain, 63 with 7, 7, 3, one and one papers, respectively.
The methodology employed by most of these papers is a comparison of the performance of the CNN model to a PLS regression model for a particular dataset. This benchmarking is laudable, however PLS regression models require operator involvement in the choice of pre-processing technique, the selection of wavelength inputs and the choice of number of latent variables. There is a risk in these comparative studies that much effort is put into optimising the CNN model while little to no effort is put into optimization of the PLS regression model. The ideal situation involves use of a publicly available data set, with a benchmark optimal PLS regression result and potentially other simpler methods such as support vector regression (SVR), Cubist, memory based learner (MBL) and shallow ANN. By providing a thorough benchmark for a particular dataset, the true value of more complex modelling techniques can be more accurately be assessed.
Due to the complexity of CNN models, it is widely accepted that large datasets are needed to effectively train the model. For example, Ng et al. 44 examined the influence of training sample size for prediction of soil properties from NIR spectra. They concluded that for their specific CNN architecture and for their soils, the CNN model was more accurate than other techniques only when the size of the training set was greater than 2000. They also reported that the performance of other models plateaued with about 5000 samples, while that of the CNN model continued to increase with more training samples up to the total size of their dataset of 9000 samples. It is expected that as more complex CNN architectures increase the number of free parameters which must be trained, more training samples will be required. However, the production of datasets with NIR spectra and reference values is typically a time consuming and expensive process. Many of the published studies identified are thus based on relatively small datasets, often involving less than 500 samples. Even given a performance benefit, the need for a large data set should temper a cost-benefit consideration of the use of CNNs.
The published studies on use of CNNS in NIR spectroscopy applications are also generally weak on documentation of the computational power and time needed to run the CNNs models in prediction. Handheld spectrometers are commonplace in NIR applications and as such information would inform assessment of the potential to use CNN models in such applications.
In summary, the potential advantages of the use of CNN’s in NIR spectroscopy identified from the literature include: (i) Multiple attribute prediction: For example, Alzubaidi et al.
64
applied a multi-task CNN model to NIR spectra of a global set of Australian wheat, barley, field pea and lentils, predicting protein, moisture, and grain type. It was concluded that the technique provides greater accuracy than PLS regression based prediction. As demonstrated by this study, CNN allows multiple attributes to be predicted using the one trained model. In contrast, PLS regression models are typically constructed for each attribute, and at most, two attributes. Einarson et al.
65
compared a multi attribute prediction from a CNN model to a PLS-2 regression model, also finding the CNN model to be more accurate for global modelling. In general, PLS-2 regression should only be employed where the two predicted attributes are highly correlated, while multiple outputs from CNN models do not need to be correlated. (ii) Use of multiple inputs with data fusion: A CNN architecture can accept multiple sets of inputs, in so-called multi-block data input. The unique sets of input can then have their own parallel layers, such as convolutional layers, before the data is fused internally. For NIR data, this presents the opportunity to feed the neural network with the raw spectra set coupled with various pre-treatments of the data with the aim of increasing the accuracy of the model. (iii) Interpretation: In general deep learning models are largely considered black box models. Cui and Fearn
28
proposed a method to visualise the output of the convolutional layer in their CNN model, allowing for the interpretation of the effect of the convolutional layer which was found to be similar to a Savitzky-Golay first derivative treatment. Other approaches may be applied to visualisation of the regions of the spectra used by the model, e.g. GradCAM. (iv) Inbuilt pre-processing: NIR spectra frequently contain baseline offsets that vary between samples. In MLR and PLS regression, these offsets are removed using normalization or a derivative (typically first or second derivative) before modelling. Cui and Fearn
28
demonstrated that the first convolutional layer in their CNN model produced an output that approximated a first derivative and performed equally to a model developed on derivative absorbance data. (v) Improved model performance: studies indicate with large data sets CNN models can outperform traditional approaches such as PLS regression, resulting in more accurate, robust and less noise. (vi) Transfer learning: this is a deep learning technique where a pre-trained neural network model is fine-tuned for a different for a different but related tasked. This enables the knowledge gained by a neural network on a large diverse dataset to bet reused, reducing the amount of data and computational requirements needed for the new task.
CNN-NIR in fruit quality evaluation
This section focusses on the use of CNN in NIR spectroscopy in the context of fruit quality evaluation. Most attention is given to regression type applications, however a brief summary of classification application studies is also provided.
Classification applications
Classification models have been used in a range of fruit quality evaluation applications, such as variety identification and defect detection. Of 20 non-review papers addressing CNN use in fruit quality evaluation, 10 addressed classification issues, with five involving defect identification,66–70 three addressing variety identification,71–73 one the level of fruit freshness 74 and one the harvest readiness of pears. 75
Reports of CNN-NIR in fruit quality classification applications.
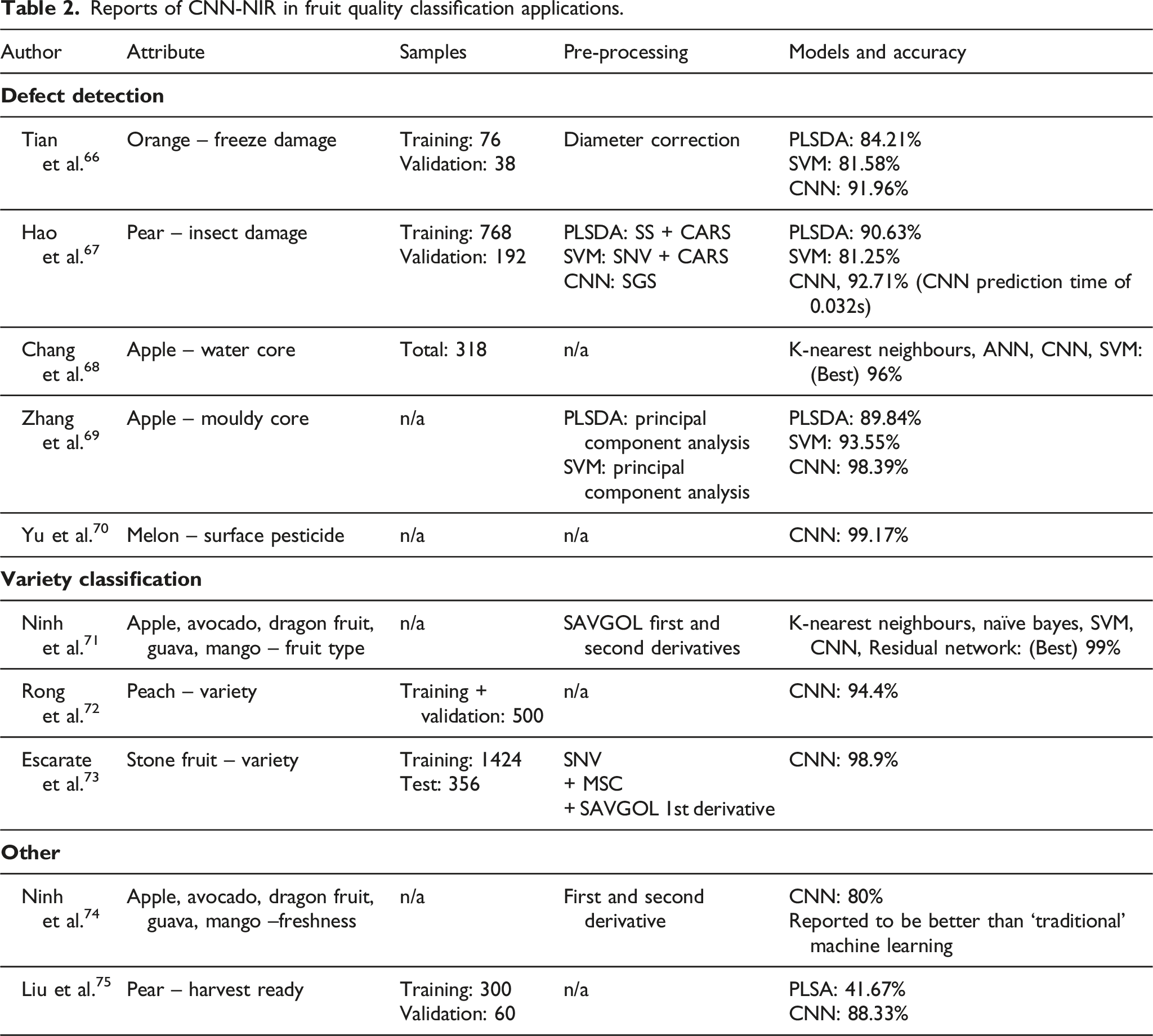
Hao et al. 67 presented a methodology for testing the combination of pre-processing techniques with specific model types, such as PLSDA, SVM and CNN. They compared Savitzky-Golay Smoothing (SAVGOL), spectral standardization (SS), max-min normalization (MMN) and standard normal variate transformation (SNV) in combination with competitive adaptive reweighted sampling (CARS) for the optimal selection of features. The optimal pre-processing technique was determined for each model type using the calibration set before testing on the validation set. Their results demonstrated that optimal pre-processing technique can be different for each model type.
Many reports incorporate the use of spectral pre-processing with use of a CNN model (Table 2). For classification of fruit, Ninh et al. 71 reported that using first and second Savitzky-Golay derivative of spectra as inputs improved the accuracy for both CNN and CNN Residual Network models by more than 8%. Hao, Zhang et al. 67 also reported improvement in CNN model performance with input of spectra derivatives for predicting insect damage in pears.
The need to test for model performance in prediction of fruit from a range of growing conditions and seasons is as valid for classification applications as for regression applications. For classification of pear harvest readiness, Liu et al. 75 found that accuracy for a model tested on samples from the same year as the training set was 100% for both PLSDA and CNN models. However, when the models were tested on data from the next season, accuracy dropped to 42% and 88% respectively. This demonstrates the importance of using new data for testing models and calls into question the accuracy of models such as Yu et al., 70 for which a 99.17% accuracy was reported for samples from the same harvest season and location. The generalisation of the models to fruit from a new harvest event and growing condition cannot be deduced.
Escarate et al. 73 report use of a combination of a classification and a regression model. A CNN classification model was used to classify the stone fruit type (peach, yellow pulp nectarine, white pulp nectarine, red plums, black plums and plumcots), with cultivar specific ANN regression models then applied to predict fruit soluble solid content (SSC). An accuracy of 98.9% was reported for the classification task, however again the test set was randomly selected from the total of 1780 fruit.
Regression
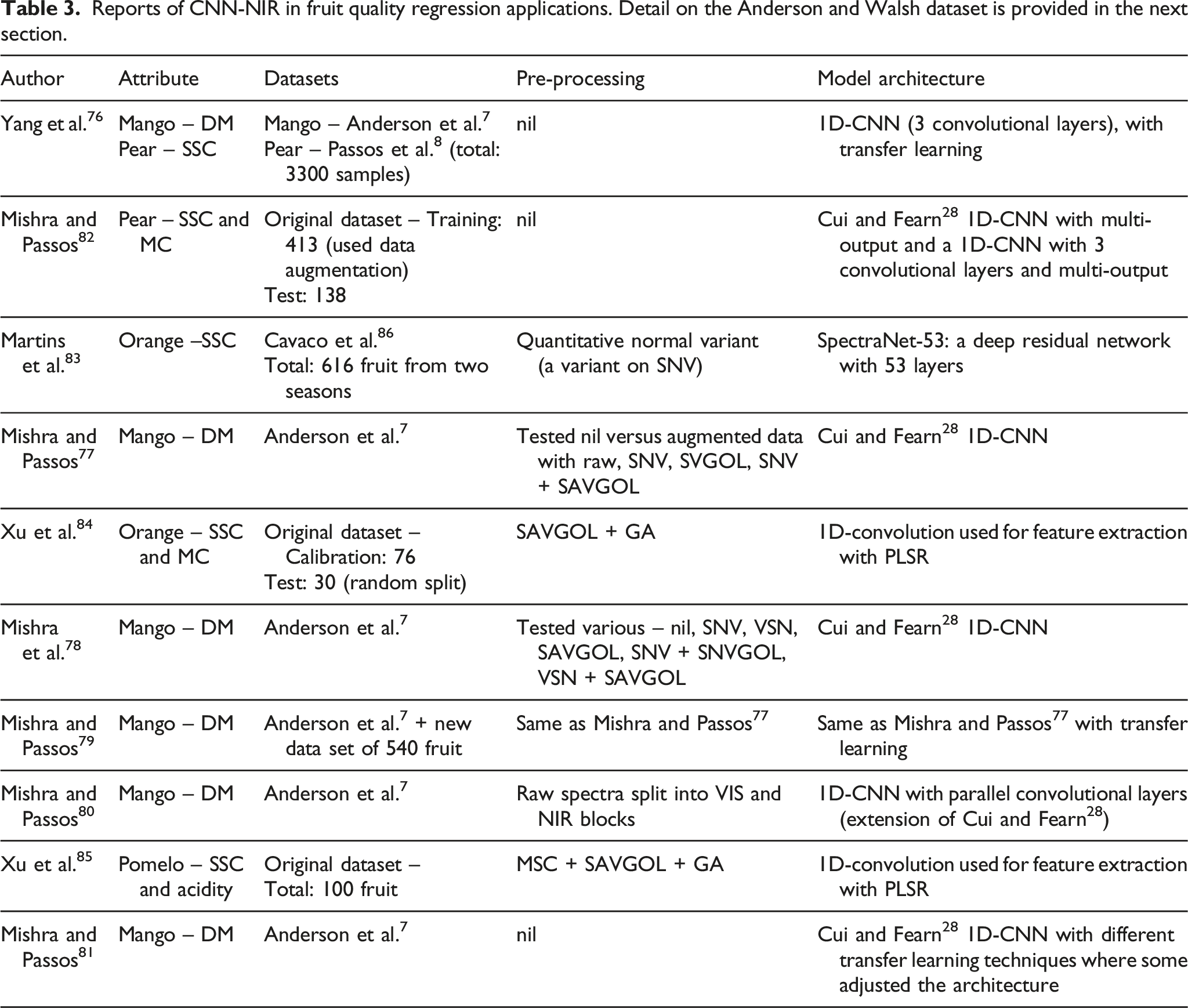
Reports of CNN-NIR in fruit quality regression applications. Detail on the Anderson and Walsh dataset is provided in the next section.
Datasets
Many publications have made use of open access data (Table 3). The publicly-available dataset from Anderson et al. 7 consists of over 11,000 spectra of mango fruit, with related metadata. Of the four publications not involving this data set, the maximum number of samples used in any one study is 616. For example, a study of total soluble solid content and acidity in pomelo fruit (a large thick-skinned citrus) was based on only 100 samples. 85 The CNN model was reported to deliver an inferior performance to PLS regression for prediction of acidity, but nonetheless increased performance in prediction of the total soluble solid content, relative to PLS regression models. The validity of such studies on such small datasets is questionable.
Pre-processing
Various combinations of pre-processed spectra have been recommended as input to CNN models, including standard normal variant (SNV), multiplicative scattering correction (MSC), Savitzky-Golay derivatives (SAVGOL) and genetic algorithms (GA). Mishra and Passos 77 reported that augmentation of the raw mango spectra with several pre-processed data sets resulted in increased accuracy of a CNN model compared to use of the raw spectra only.
In contrast, working with the same Anderson et al. 7 mango dataset, Mishra et al. 78 reported that the use of spectra pre-processed using scatter correction techniques reduced the prediction performance of both a PLS regression and CNN model. On the hold-out fourth season, an RMSEP of 0.87 and 0.76% FW was achieved for PLS regression and CNN, respectively, using only the raw absorbance. The best pre-processing for PLS regression was found to be a second derivative, with and RMSEP of 0.88% FW, while standard normal variant (SNV) worked best for CNN (RMSEP of 0.81% FW). The decrease in model performance with input of pre-processed spectra contradicts the general experience of researchers using PLS regression e.g., Anderson et al. 87 The issue of the value of derivative pre-processing for the fruit application requires resolution.
As noted earlier, Cui and Fearn 28 reported that the first convolutional layer a CNN model developed for estimation of wheat attributes from NIR spectra acted to produce an output equivalent to a first derivative. Bai et al. 88 attempted to employ an ANN architecture with an input of pre-processed spectra instead of a convolutional layer to develop a model for predicting the soluble solid content of apple fruit. A deep ANN was used with a random forest algorithm used to pre-process the spectra. However, this study was based on only 208 apple samples, and it is recommended that the technique be tested with a larger training set and compared with a CNN with no pre-processing.
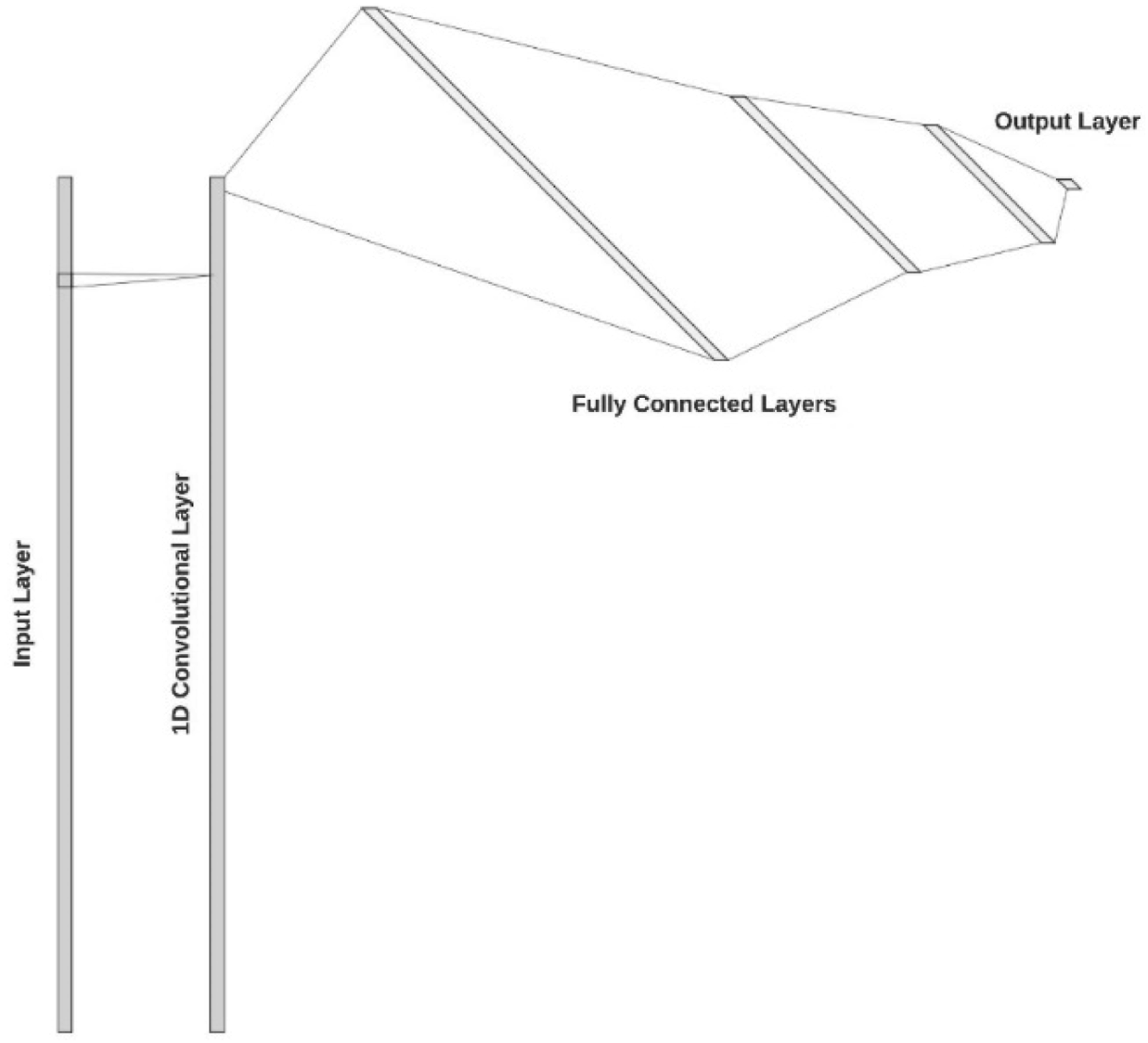
CNN architecture
Mishra and co-workers adopted a 1D-CNN architecture to develop a mango dry matter content model using the Anderson et al.
7
data set. The CNN architecture of Cui and Fearn
28
was adopted, being comprised of an input layer, one convolution layer, three fully connected layers and an output layer (Figure 2). However, no justification was given for the choice of this architecture beyond its use in other (non-spectroscopy) applications. The CNN model improved the prediction error from the previous best reported RMSEP (achieved by Anderson et al.
89
with an ensemble of multiple non-linear models) of 0.84 to 0.79% FW.
77
However, the authors raised the concern that the CNN model might be overfitted to the data set, with a new CNN model proposed in a subsequent paper based on testing on fruit from a new season, cultivar and scanned with a new instrument.
79
The results of Mishra and co-workers has yet to be replicated by other research groups. The 1D-CNN architecture first implemented to NIR spectroscopy by Cui and Fearn.
28
A novel development is the use of multi-block parallel inputs. Mishra and Passos
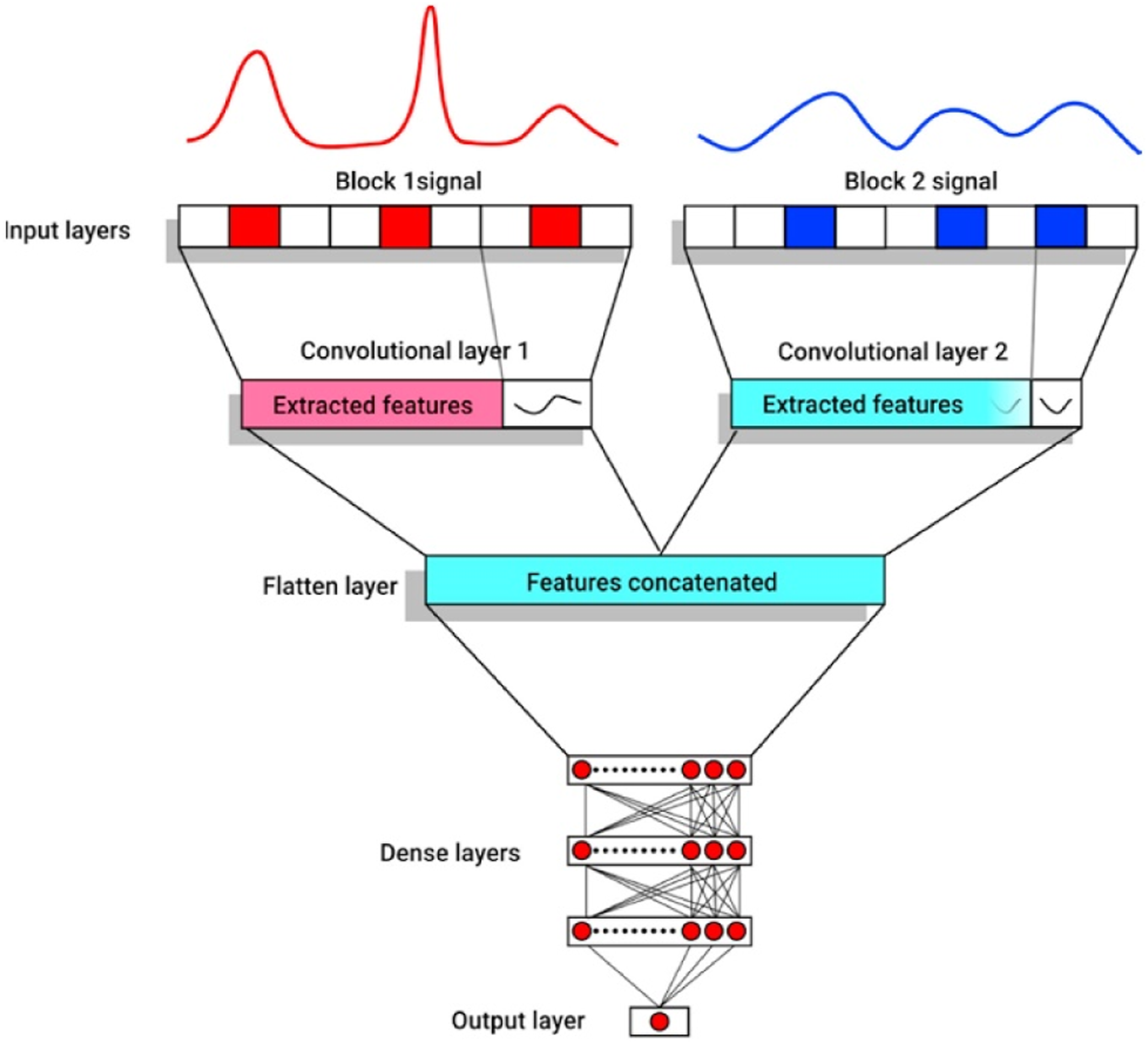
80
split the visible and near-infrared spectra of mango fruit collected from one instrument to feed into parallel convolutional layers (Figure 3). This technique can also be used to fuse results from two different instruments to improve the prediction accuracy by removing bias from each instrument.
90
Using a multi-output architecture, a recent study demonstrated simultaneous prediction of moisture content and soluble solids content in pear using one CNN model. 82 Two 1D CNNs were tested, one with one convolutional layer and the other with three. The 3-layer model slightly outperformed the one convolutional layer network. Only 551 samples were collected, but a data augmentation was performed to assist in training the model. Again, such techniques should be validated on a larger set.
Transfer learning
A common issue for chemometric models is their inability to generalise for variance in the spectra, for example, for spectra from different instruments or from samples from different growing or storage conditions. Various approaches have been used with PLS regression models, including (i) development of a new model following addition of a small amount of new data of samples from the new condition to the calibration set, or corrected for some bias with a (ii) use of a calibration transfer function to make samples from one condition look like samples from another condition, and (iii) removal from spectra the effect of a given influence, e.g., temperature. 91
Using transfer learning, a CNN model which is initially trained on a large common data set can be localised by tweaking the model to generate new weights with the same architecture based on small sample relevant to the new population. This has been demonstrated for the new season mango fruit crop and across instruments.81,92
Platforms – cloud and portable
In recent years, cloud based machine learning resources have become available. Solihin et al. 93 investigated using one such software platform (Orange data mining; orangedatamining.com), in different NIR spectroscopy applications, including the prediction of mango soluble solids content. However, the platform did not have a PLS regression or CNN toolkit. Anderson et al. 89 evaluated the DataRobot and Hone cloud chemometric platforms in the context of the mango dry matter data set used by Mishra and Passos. 77 Again, neither platform provided a CNN resource. However, considerable work is being put into the development of these user-friendly machine learning platforms by both the open-source community and private companies, e.g., Amazon Sagemaker (Amazon Web Services; aws.amazon.com/sagemaker/) and Azure Machine Learning (Microsoft Azure; azure.microsoft.com/services/machine-learning/). There are currently no reports in literature of their use by the NIR spectroscopy community. Further investigation of these platforms as they develop is warranted for NIR spectroscopy applications as they allow method evaluation with little to no programming knowledge.
Technique comparison involving publicly available data
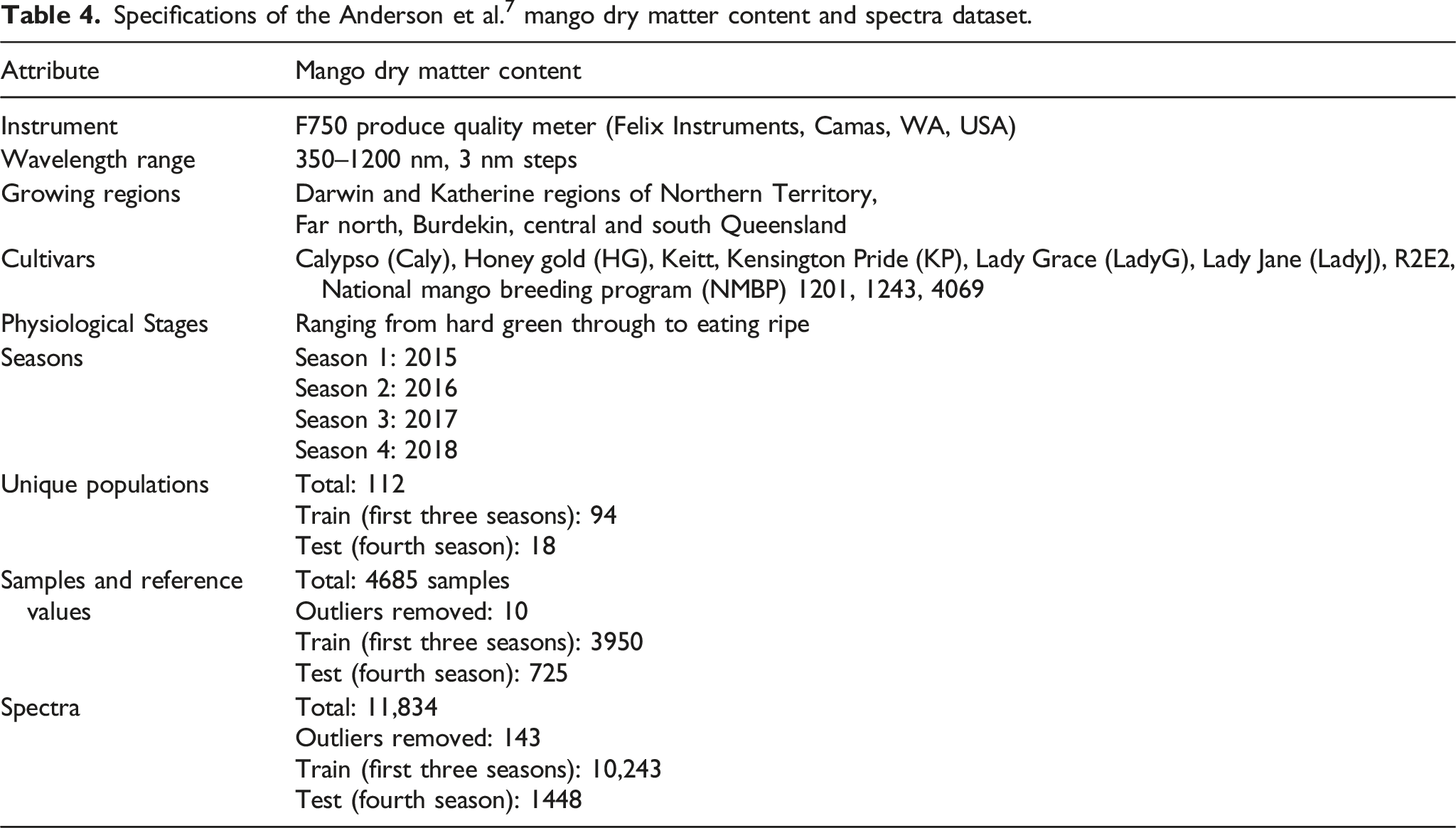
Specifications of the Anderson et al. 7 mango dry matter content and spectra dataset.
A comparison of published models based on the three season training set and fourth test set of Anderson, Walsh et al. 7 Models predict intact mango dry matter content.
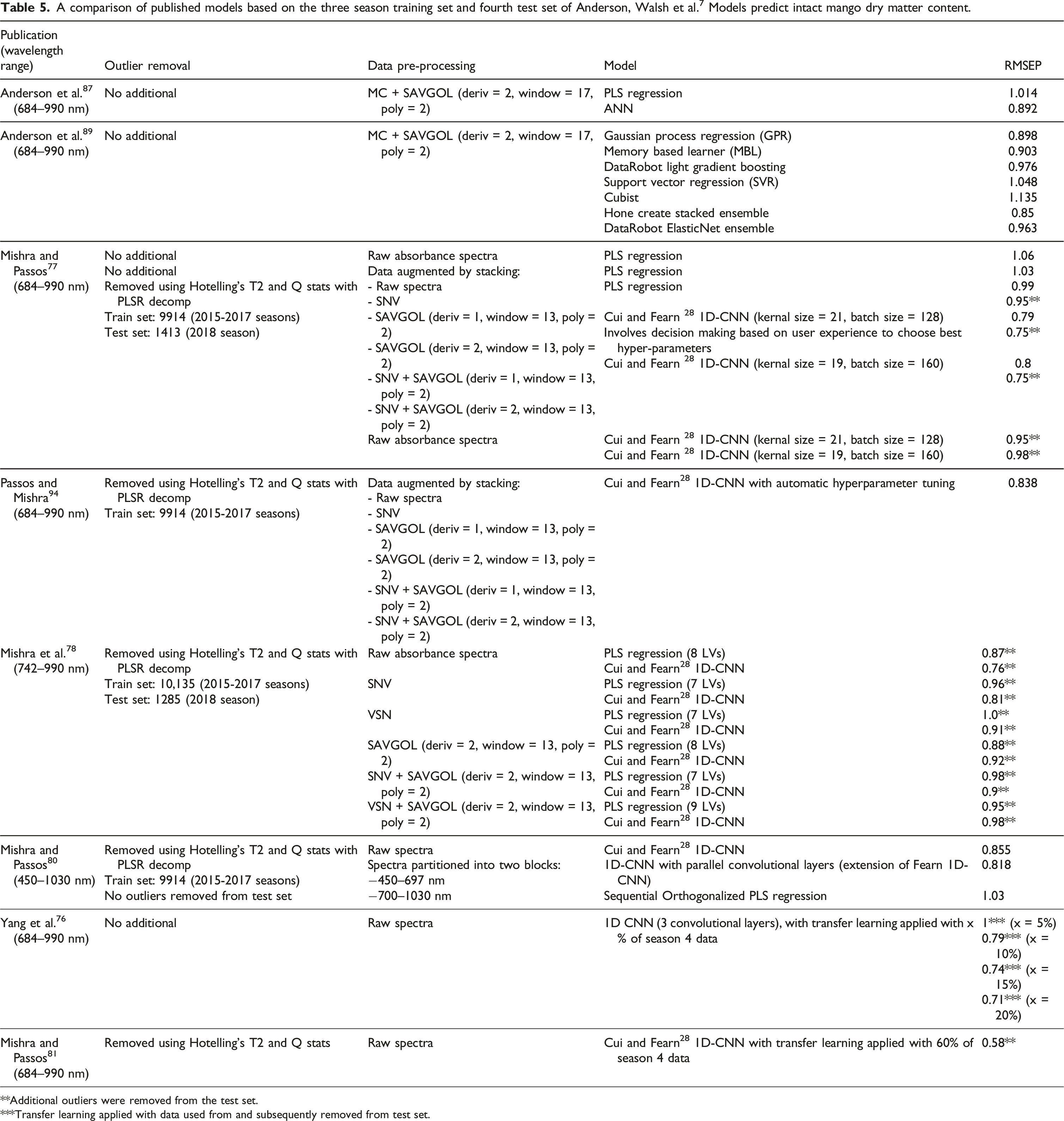
**Additional outliers were removed from the test set.
***Transfer learning applied with data used from and subsequently removed from test set.
Model comparisons
The lowest RMSEP on the independent fourth season was achieved by Mishra and Passos 77 using the Cui and Fearn 28 1D-CNN model architecture with augmented data utilising various pre-processing techniques. A similar result, although not directly comparable due to different outliers being removed from the test set, was achieved by Mishra et al. (2021) with the same CNN architecture but using only the raw absorbance spectra on a slightly narrower wavelength range. Using a wider wavelength range including the visible spectra, as in Mishra and Passos, 80 was less successful.
The outlier removal process is an area of contention. The published Anderson et al. 7 dataset, already has a number of samples removed as outliers. Further outlier removal, (Table 2), prevent direct comparison of model results between the published papers. Additionally, the outlier removal process described by some studies, such as Mishra and Passos, 77 is not replicable due to their manual nature. It is however evident that implementation of an improved outlier removal process over that originally used by Anderson et al. 7 can achieve more accurate model predictions.
Mishra et al. 78 provide no reasoning or justification for using the slightly narrower wavelength range of 742–990 nm compared with 684–990 nm as used by Anderson et al. 87 Utilising a multi-block CNN model with the visible wavelength range of 450–697 nm is an interesting proposition; however, its rationale is questionable in terms of relationship to dry matter content of the fruit. Anderson et al. 87 justifies the wavelength range used it terms of the underlying chemistry of the fruit, noting the spectral feature peaking around 680 but stretching out to 720 nm to be associated with chlorophyll. Fruit left on the tree longer than commercial harvest timing will have higher dry matter content and lower carbohydrate, but the relationship between chlorophyll content and dry matter content will vary with fruit maturity and growing condition. In contrast, absorbance features at 840 and 960 can be associated with O-H. 87 Justification can be made for narrowing the wavelength range to remove wavelengths that offer no correlation for dry matter.
Similarly, various data pre-treatments have been proposed (Table 5). As Cui and Fearn 28 discussed, the convolutional layer of a CNN model may remove the need for data-pre-treatment for these models. This is partially supported by the findings of Mishra et al. 78 who achieved similar results to Mishra and Passos 77 with augmented pre-treated data using the same CNN architecture. However, further work should be conducted to ensure that results are directly comparable and undertaking evaluation of other pre-treatments.
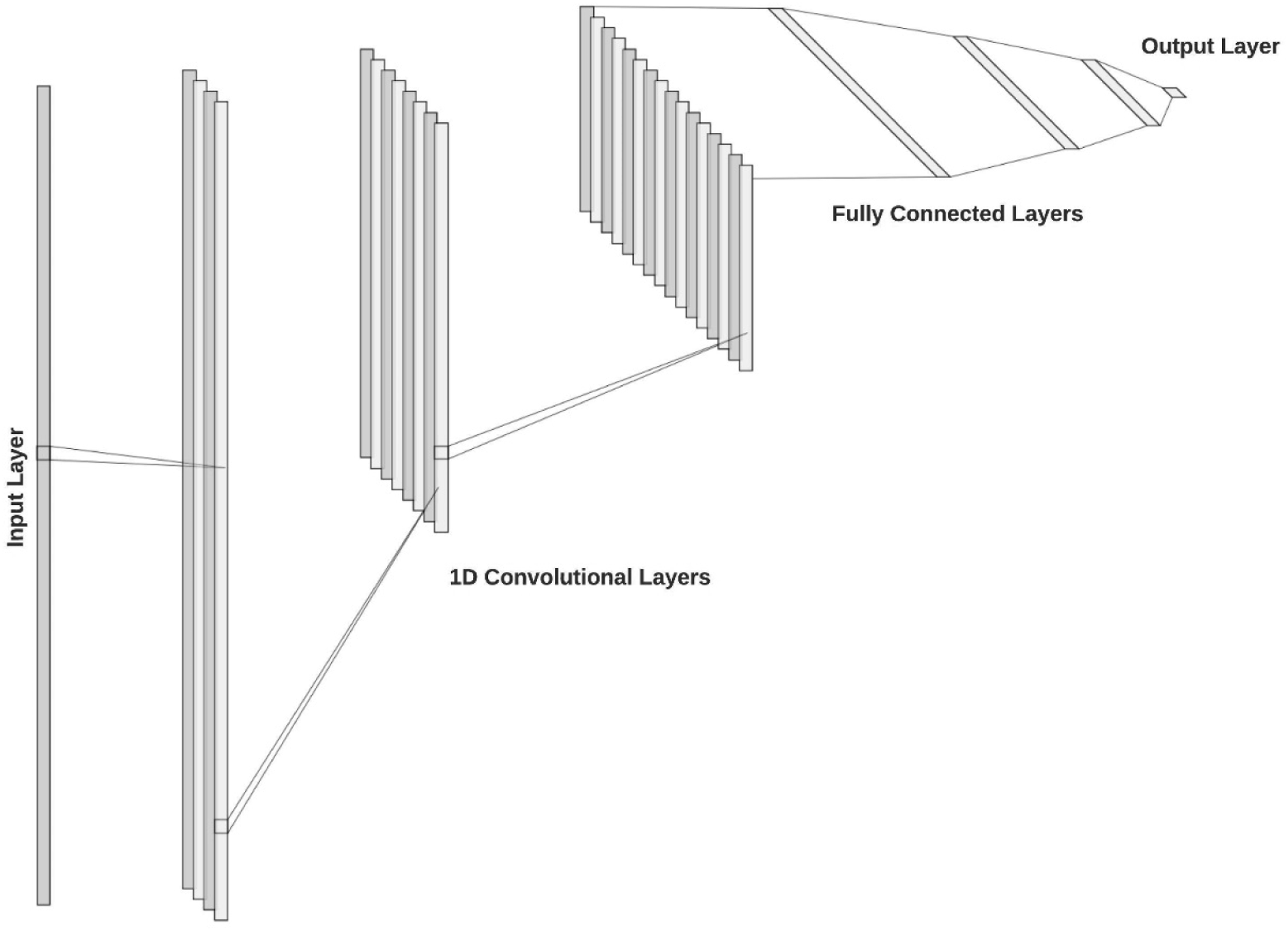
Yang et al.
76
experimented with a CNN architecture with three convolutional layers as opposed to the Cui and Fearn
28
architecture implemented by Mishra and Passos
77
which employs only one convolutional layer (Figures 2 and 4). Although the results are not directly comparable, as Yang et al.
76
used up to 20% of the fourth season dataset to train the model, it can be inferred that the Yang et al.
76
CNN architecture is much less successful for the mango dry matter application. Yang et al.
76
could have easily produced a directly comparable result by keeping the fourth season as the independent test set, as per the previous publications. 1D-CNN architecture proposed by Yang et al.
76
Data set issues
There is a broad push in the scientific community for the publication of data sets. The Anderson et al. 7 dataset is an early example of a large open access data set in the NIR-fruit quality space. This resource facilities experimentation with deep learning, given the need for large training data sets, and, with discipline in use of training and test sets, allows for across literature comparison of results. Hopefully this open data set will be expanded, e.g., with the additional data collected in Mishra and Passos. 79
The slow adoption of newer techniques like CNNs in NIR spectroscopy for fruit quality evaluation may be due to the divide between those proficient in CNN techniques, such as computer scientists and mathematicians, and those with access and domain understanding of large data sets such as chemometrics. This disparity can result in a “siloed” approach and missed opportunities for collaboration between computer science and mathematics on one side and chemometrics on the other. Sharing large public datasets is critical to advancing this field, as it bridges the gap between modalities and encourages interdisciplinary collaboration. This will drive scientific progress in the NIR field.
It is important to exercise caution when selecting the test set from the overall dataset for fruit quality evaluation using NIR spectroscopy. In real-world applications, a model is trained on historical data and applied to new data. Similarly, when evaluating a model for publication purposes, it is recommended to use the same logic. Use of random splits to create training and test sets is not advised if all future variability is not captured in the existing data. Also, prediction results from different studies will not be directly comparable if researchers have altered the test set.
The comparison of techniques across studies using the same dataset in this section highlights the importance of clear and fair benchmarking when presenting new techniques. When utilizing publicly available datasets, authors are encouraged to employ quantitative and repeatable methods. The use of subjective techniques for outlier removal is discouraged as they cannot be reliably replicated in other studies.
Conclusion
CNNs have been demonstrated to be appropriate for use in fruit quality evaluation using NIR. With the increased availability of large open-source datasets and the widespread success of CNNs in other applications, such as image and speech processing, it is likely that this technique will continue to gain popularity and be applied to a wider range of NIR applications in the future.
For future studies is crucial to conduct a thorough comparison of CNN models to traditional chemometric techniques, such as PLS regression, to fully appreciate the benefits of using complex models in this context. While PLS regression operates under the assumption of a linear relationship between the spectra and the attribute of interest, this assumption may not hold true with larger datasets. Furthermore, simply comparing a CNN model to PLS regression is not always sufficient, especially if the PLS regression results have not been optimized through traditional chemometric techniques. To provide a clearer understanding of the advantages of using deep learning techniques such as CNN, a comparison to a shallow ANN should also be performed.
The publication of data sets and open-source code plays a crucial role in facilitating the reproducibility of research results and advancing the field. Open access datasets, provide a valuable resource for experimentation with deep learning and allow for across-literature comparison of results. The tutorial and code repository provided by Passos and Mishra 94 serve as an excellent example for the NIR community, demonstrating the benefits of open and accessible resources in advancing the field.
The highly encouraging results achieved by Mishra and co-workers in predicting mango dry matter using a 1D-CNN architecture are a significant step towards wider adoption of CNNs in fruit quality evaluation using NIR spectroscopy. So far, most implementations in this application have been based on the CNN architecture proposed by Cui and Fearn, 28 which consists of an input layer, one convolution layer, three fully connected layers, and an output layer. Further investigation is necessary to optimize the CNN models for this specific use case and other fruit applications, including exploring different model architectures, hyper-parameter tuning, and data pre-processing.
To the authors knowledge, CNNs are not currently used in any commercial applications of fruit quality evaluation with NIR. At the present, caution should be exercised before utilising them in commercial applications due the lingering issues that require resolution by further research. It cannot be said that CNNs outperform traditional techniques such as PLS regression in all cases, but rather that they outperform PLS in certain scenarios, depending on the instrument and the attribute. It is crucial to consider the context of the application, available resources, and expertise to achieve the “best result” for the application. The best model should not solely be judged by an RMSEP value, as a simpler model may be easier to implement and maintain.
In summary, the rise of CNNs for fruit quality evaluation using NIR spectroscopy is a promising development. Further work is necessary to fully understand the benefits of using complex models in this context and to optimize the models for this specific application. The publication of data sets and open-source code will play a crucial role in advancing the field and facilitating the reproducibility of research results.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the Central Queensland University (Master of Research Part Scholarship).