
Abstract
Speech conveys both linguistic messages and a wealth of social and identity information about a talker. This information arrives as complex variations across many acoustic dimensions. Ultimately, speech communication depends on experience within a language community to develop shared long-term knowledge of the mapping from acoustic patterns to the category distinctions that support word recognition, emotion evaluation, and talker identification. A great deal of research has focused on the learning involved in acquiring long-term knowledge to support speech categorization. Inadvertently, this focus may give the impression of a mature learning endpoint. Instead, there seems to be no firm line between perception and learning in speech. The contributions of acoustic dimensions are malleably reweighted continuously as a function of regularities evolving in short-term input. In this way, continuous learning across speech impacts the very nature of the mapping from sensory input to perceived category. This article presents a case study in understanding how incoming sensory input—and the learning that takes place across it—interacts with existing knowledge to drive predictions that tune the system to support future behavior.
Perception allows us to interpret the present in relation to what we have experienced in the past. To take a simple example from the world of sound, consider when new acquaintances share their name. The utterance reaches our ears in the present moment and interacts with long-term representations we have built from past speech experience. The complex speech acoustics reveal their name and likewise communicate information about their gender, race, socioeconomic status, education, native language, and emotional state (see Kraus et al., 2019; Kutlu et al., 2022). Across a lifetime of listening experience, we have built representations that support the effortless mapping of complex speech acoustics to these category distinctions. Understanding how this knowledge develops across long-term experience, such as the learning necessary to acquire native- or second-language speech sounds (see Baese-Berk et al., 2022; Gervain, 2022), has been a major focus of research.
More recently, multiple lines of research have converged to highlight that the learning does not conclude after having built these representations. Instead, listeners continuously forage acoustic input, discovering patterns of statistical regularities that influence the very mapping of sensory input to speech representations. This article provides examples to make the case that speech perception illustrates a lesson general to cognitive science: There is no firm line between perception and learning. Rather, (speech) perception is (speech) learning.
Input Dimensions Carry Different Perceptual Weight
A simple utterance such as “beer” is distinguished from its near-neighbor “pier” by as many as 16 acoustic dimensions (Lisker, 1986). The expression of these dimensions varies with whether “beer” is part of a story told by Matteo or Sofia, whether the talker speaks Scottish or American English, and whether the storytelling venue is quiet or noisy. The traditional focus of research has been to wrestle with how complex and variable acoustic speech input maps to native-language representations such as phonemes, the units of sound such as [b] and [p] in “beer” versus “pier.” The immense variability would make speech comprehension difficult if the mapping between acoustic input and speech representations were fixed and unchanging, as traditional theoretical accounts had once presumed (Blumstein & Stevens, 1981; Liberman & Mattingly, 1985). But, as the next sections highlight, contemporary research demonstrates that the mapping from acoustics to speech is inherently labile, not fixed. The relationship of acoustic input to speech representations is dynamic and closely related to learning across both long- and short-term speech input.
To observe this malleability, it helps to examine a “baseline” perceptual state. Characterizing the perceptual space for even simple utterances such as “beer” and “pier” is complicated because acoustic dimensions do not necessarily contribute equivalently. Shape and color can each inform whether a fruit is a lemon or a lime, for example, but color tends to be more diagnostic—as are the acoustic dimensions of speech. Figure 1 illustrates this across two (of the at least 16) acoustic dimensions that signal “beer” versus “pier”: voice onset time (VOT; measured as the time between acoustic markers of the release of the lips to the start of vocal fold vibration) and fundamental frequency (F0; the rate of that vibration). When American English listeners categorize the utterances defined across the grid shown at the top of Figure 1 in quiet listening conditions, both VOT and F0 inform category decisions, but VOT carries more weight. This can be quantified by the normalized coefficients of regression indicating how well each dimension predicts category identity (Fig. 1, middle). On average, young adult listeners rely predominantly on VOT in quiet listening contexts, with F0 playing a secondary role. Within this aggregate data, there are individual differences (Wu & Holt, 2022) that are stable across time (Idemaru et al., 2012; Schertz et al., 2015), suggesting underlying processing differences rather than measurement fluctuation (Fig. 1, bottom).
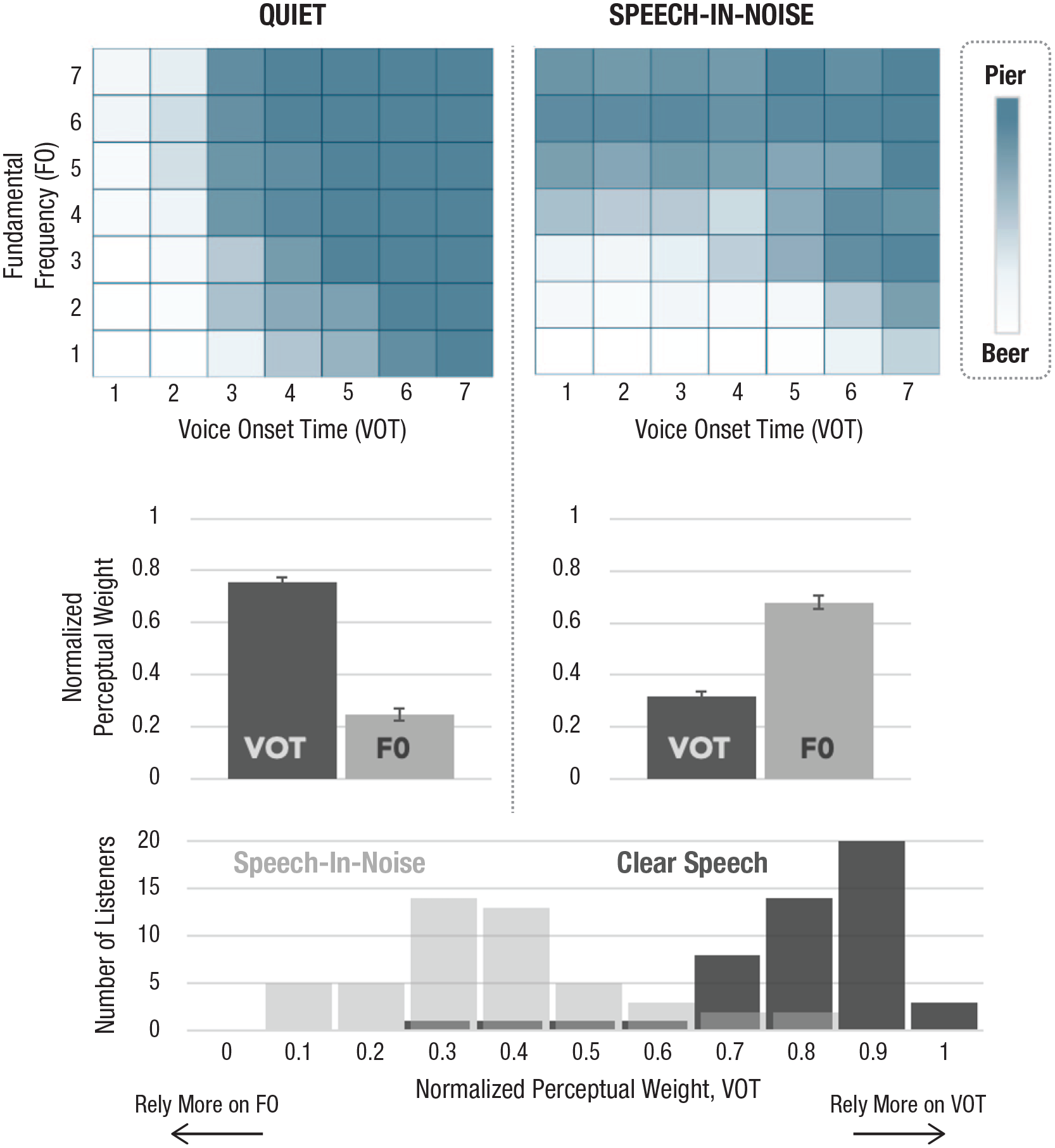
Baseline perceptual weights across two acoustic dimensions. Each square illustrates an utterance varying in F0 and VOT, with average perceptual categorization responses painted along a spectrum from blue (“pier”) to white (“beer”) in the top row. Notice the strong reliance on VOT in quiet, with secondary contribution from F0. This is quantified in the middle row as normalized perceptual weights. Perception of the same speech sounds shifts in quiet versus noisy listening contexts, with F0 more informative in perceptual categorization decisions in noise. The same listeners rely on different acoustic dimensions to categorize speech across different listening contexts. Stable individual differences in these perceptual weights exist, as shown by plotting the normalized perceptual weight of VOT according to the number of listeners exhibiting that perceptual weight (bottom row). F0 = fundamental frequency; VOT = voice onset time.
This simple example extends broadly to other consonants (Idemaru & Holt, 2014) and vowels (Liu & Holt, 2015), as well as prosodic focus (as exemplified by an episode of Breaking Bad, in which Jesse says to Walt, “You don’t want a criminal lawyer. You want a criminal lawyer”; Gould & McDonough, 2009; Jasmin et al., 2023). Moreover, perceptual weights appear to emerge and develop over a rather long timeline. In category decisions such as the one described above, 4- and 6-year-old listeners rely very little on F0 compared with young adults (Bernstein, 1983). Older adults, instead, rely more on F0 than younger adults (Toscano & Lansing, 2019), perhaps because of age-related changes in hearing. Overall, the perceptual weight of acoustic dimensions is language- and dialect-specific (Escudero & Boersma, 2004), with aggregate patterns of perception reflecting global distributional patterns of speech typical of a language community and smaller, individual differences potentially reflecting idiosyncratic distinctions in experience.
Perceptual Weights Shift With Listening Contexts
Consider what happens on a slight alteration of listening context. The right column of Figure 1 shows the same listeners’ perceptual categorization of the same “beer” and “pier” utterances with a modest change in context: The speech is embedded in noise. This small change in listening context has a substantial impact on how the acoustic dimensions map to speech categories. Whereas VOT carries greater perceptual weight in quiet, F0 more effectively signals category identity in modest noise (Winn et al., 2013; Wu & Holt, 2022).
This means that everyday events such as a noisy air conditioner turning on can completely upend the information that listeners rely on to guide speech perception. The perceptual system adapts rapidly, but the changes do not overwrite the influence of long-term learning that established baseline perceptual weights in line with language community norms (Wu & Holt, 2022). When the air conditioner turns off and a quiet listening context is restored, the baseline perceptual weights are immediately reestablished. The mapping from acoustic input to speech is flexible, not fixed. As a result, understanding the representation of VOT (or any acoustic dimension) in brain or behavior only takes us part of the way in understanding how the complex acoustics of speech meet the communicative demands of everyday listening.
Learning Rapidly Changes Perceptual Weights
The rapid shift in perceptual weights arising from a noisy air conditioner might arise from lower level sensory interactions that advantage one dimension over another. For example, F0 may be more robust to noise than VOT. Yet there is an active role for learning in adjusting the mapping from acoustics to speech. Statistical learning across patterns of speech experienced over time dynamically shifts perceptual weights.
As reviewed above, baseline perceptual weights are sculpted by long-term experience in a language community. But community norms are just that—norms. They are not inviolate laws. We encounter talkers with nonnative accents, different dialects, and head colds. Each of these everyday contexts shifts how speech is realized within multidimensional acoustic space. As a concrete example, the acoustics of the vowel in the word “meet” uttered by an Australian English talker are very close to how an American English talker utters “mate,” leading to the potential for comedic misunderstanding when an Australian asks an American friend “When did you first meet?” (Wells, 1982). Speech comprehension suffers when speech departs from language community norms, but the perceptual system rapidly adapts, and comprehension improves (Bradlow & Bent, 2008). The mapping from acoustics to speech representations flexibly accommodates foreign accents, signal distortions, and even audiovisual mismatch (see Ullas et al., 2022). In a broad sense, the very acoustic dimensions that signal speech representations are dynamically—and rapidly—adjusted in online speech processing to accommodate regularities in the ambient speech environment.
A phenomenon called “dimension-based statistical learning” illustrates this accommodation. Recall the VOT × F0 acoustic space in Figure 1. Baseline perceptual weights are evident when this space is sampled equiprobably. In quiet, this results in a pattern of perceptual categorization that aligns with American English patterns of speech: Longer VOTs and higher F0s tend to signal “pier,” whereas shorter VOTs and lower F0s signal “beer.” This pattern of perception mirrors typical patterns of American English speech, reflecting an influence of long-term learning on perception.
An influence of learning is also revealed at shorter timescales. In a now well-replicated study, Idemaru and Holt (2011) selectively sampled stimuli from the VOT × F0 space to create American English-like short-term speech regularities or a reversed pattern that created a subtle accent (Fig. 2, top). In a passive exposure version of the dimension-based statistical learning paradigm (Hodson et al., 2023; Murphy et al., 2024), listeners hear a sequence of eight “beer” and “pier” utterances sampled to convey one of the distributional regularities shown in yellow in Figure 2. The final stimulus is always one of two F0-differentiated test stimuli. With only F0 available to convey category identity, test-stimuli categorization indexes listeners’ reliance on F0 in speech categorization (i.e., its perceptual weight).
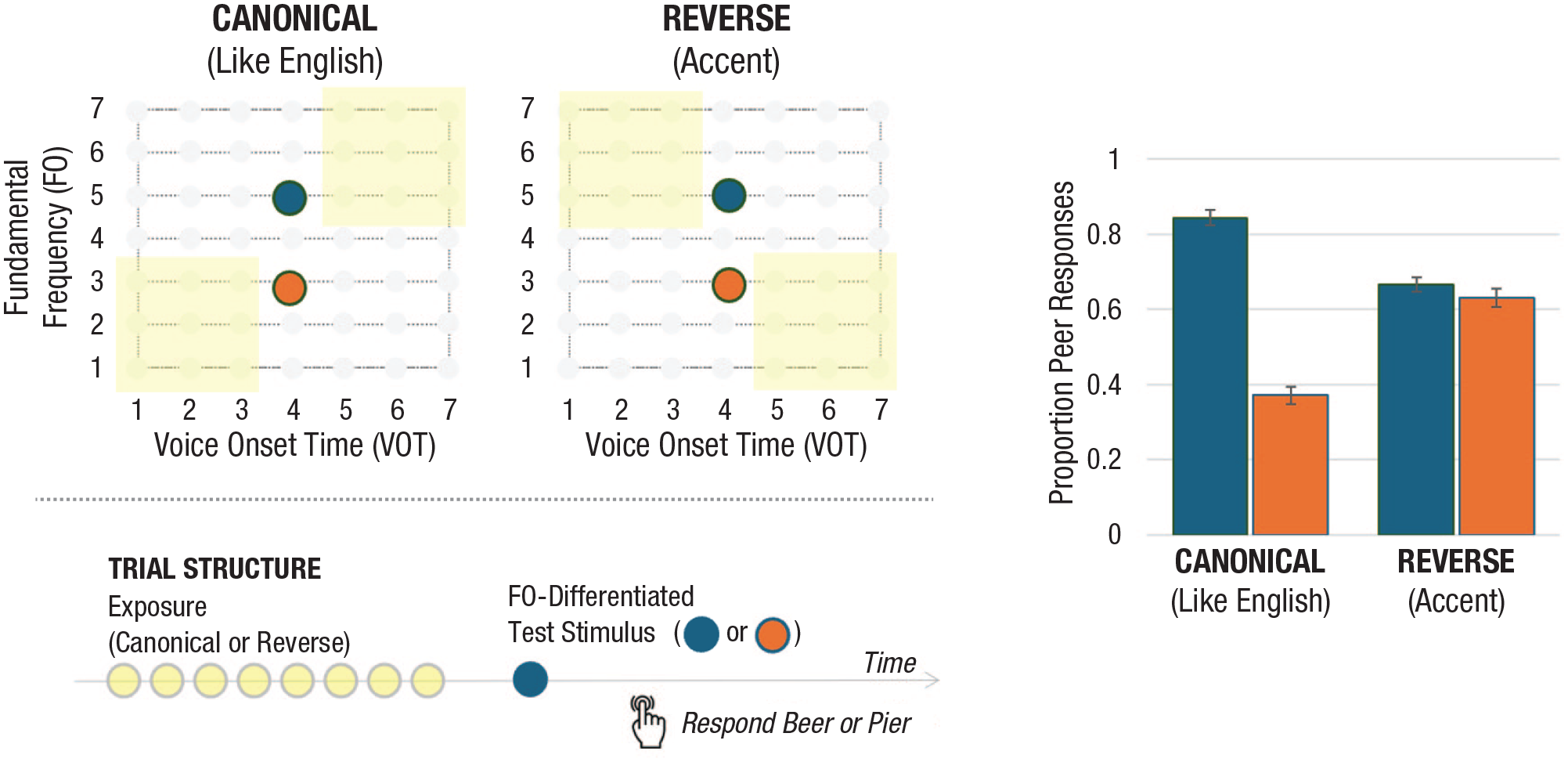
Dimension-based statistical learning. The top left shows the same VOT × F0 stimulus space plotted in Figure 1. The yellow highlighted regions indicate selective sampling of the space to create short-term speech regularities that match American English norms (canonical) or violate them to create an accent (reverse). Each trial passive listening across eight of these exposure stimuli (yellow) is followed by one of two F0-differentiated test stimuli (blue, orange). Participants categorize the final test stimulus as “beer” or “pier.” The data on the right illustrate the influence of statistical learning across passive exposure on the effectiveness of F0 in signaling “beer” versus “pier.” In the context of the accent, F0 is not a reliable cue to category identity (see Hodson et al., 2023; Idemaru & Holt, 2011). VOT = voice onset time; F0 = fundamental frequency.
When passive exposure conveys a short-term regularity that conforms to their language community, American English listeners use F0 to inform category decisions when VOT is ambiguous: The higher F0 test stimulus is more often labeled “pier,” and the lower F0 test stimulus is more often labeled “beer,” consistent with long-term language community norms. But these same listeners’ reliance on F0 in speech categorization rapidly shifts when passive listening conveys a subtle accent, resulting in listeners relying very little on F0 as a signal of category identity (Fig. 2). Rapid learning across the reversal in the VOT × F0 correlation conveyed by the accent has an immediate influence on how F0 contributes to speech categorization. The very same test stimuli are perceived differently as a function of the input regularities that came before them. Learning across a brief period of passive listening is sufficient to shift how acoustics map to speech.
Although this accent is subtle, occurs across a single voice, and is largely unbeknownst to listeners, its influence is fast (emerging in a few trials) and evident for vowels and prosodic contrasts and for both words and nonwords (Jasmin et al., 2023; Lehet & Holt, 2020; Liu & Holt, 2015). Listeners can even juggle competing statistics evolving across two voices, adjusting the mapping from acoustics to speech for each according to the regularities of the specific voice (Zhang & Holt, 2018). These findings demonstrate reliable perceptual changes in how speech maps to categories as a function of brief exposure to subtle shifts in the statistical properties of acoustic speech input.
There would seem to be an obvious benefit to this flexibility in accommodating accented speech, but at what cost? As in all cognitive systems, there is inherent tension in flexibility and stability: It would be undesirable to have a lifetime of speech learning overwritten by a conversation. Indeed, the fingerprints of long-term learning persist, even as the system flexibly adjusts to the accent. Five consecutive days of experience with the accent produces persistent F0 downweighting but not a complete remapping to mirror the statistics of the accent (Idemaru & Holt, 2011).
Liu and Holt (2015) proposed that the basis for this persistence arises from the interaction of existing speech representations with input—such as an accent—that mismatches the predictions they generate. Imagine basic perceptual representations of VOT and F0 capable of activating a speech-category representation for /b/ or /p/ that will inform the “beer” versus “pier” perception. The connections between these representations are “weighted” in the sense that they are more—or less—efficient. This provides a proxy for the baseline perceptual weights illustrated in Figure 1. Among most English listeners hearing “beer” and “pier” in quiet, the VOT will carry greater weight. This bottom-up sensory information will be highly effective in selectively activating /b/ versus /p/.
The proposal is that this activation drives corresponding predictions about the nature of weights that other acoustic dimensions typically carry in the native language community. In the case of an accent, bottom-up VOT information is as unambiguous as it is in the case of English-consistent speech. But, for the accent, F0 is discrepant. Liu and Holt proposed that this discrepancy between actual and expected input generates an error signal that drives adaptive adjustments to the F0 connection weight, effectively rendering it less efficient in activating /b/ versus /p/ categories. Adjusting the effectiveness of input in activating existing category representations would allow the system to balance flexibility (through connection weight change) even as it maintains stability in speech representations. In this way, short-term flexibility may be “reweighting” rather than “remapping” perceptual space.
Several lines of evidence support this possibility. The magnitude of downweighting is closely related to successful category activation by stimuli that convey the accent, as measured by overt categorization decisions (Wu & Holt, 2022). Further, context manipulations that shift baseline perceptual weights—such as the noise of an air conditioner—change the direction of perceptual downweighting. In noise, F0 is the more robust signal of category identity providing a route to category activation and driving VOT to be downweighted with a reversal in VOT × F0 statistics. In quiet, as in the examples above, VOT drives activation, and F0 is downweighted (Wu & Holt, 2022). In more natural contexts, this is observed in Korean, in which modern-era language change—driven largely by young women—is shifting baseline Seoul Korean perceptual weights away from VOT and toward F0 (Kang & Guion, 2008). Correspondingly, patterns of adjustment to shifting speech statistics can be predicted on the basis of listeners’ baseline perceptual cue weights (Schertz et al., 2015).
Tellingly, bottom-up information from sensory input need not be the driver of category activation. Zhang et al. (2021) neutralized the dominant VOT dimension and capitalized on well-established top-down effects of word knowledge to internally activate /b/ versus /p/ (Ganong, 1980). They created a “phantom” accent with constant and ambiguous VOT stimuli. Lower F0 stimuli were presented in the context of __eace (“peace” is a word but “beace” is not, resulting in /p/ activation from top-down word knowledge) and high F0 stimuli conveyed by __eef (“beef” vs. “peef”; greater /b/ activation). This phantom accent was not present in the sensory input; VOT × F0 distributions were identical, and only the word frame was varied to create English-consistent or accented phantom distributions from word knowledge. This top-down activation of speech categories results in F0 downweighting for the phantom accent.
Thus, the detailed nature of existing, long-term speech representations is crucial to how learning across short-term input regularities plays out, with category activation a driving force in the reweighting of acoustic input dimensions in speech categorization. This may allow short-term changes to coexist as connection weight changes, even as long-lasting representations persist, thus contributing to the balance of flexibility with stability.
Summary
Results such as these demonstrate that the mapping of acoustic input to speech representations is dynamically altered by online statistical learning about the patterns of speech that have recently preceded the current input. How we interpret the sounds arriving at our ears right now is a compromise among input, long-term experience (such as with our native language norms), and short-term experience evolving across a much more rapid timescale (see Gwilliams & Davis, 2022). Listeners actively forage the acoustic environment for regularities that support online adjustments in the mapping of acoustics to speech, presenting an inherent interdependency of perception and learning that blurs the artificial lines we traditionally draw in cognitive science.
Along with other research examining recalibration, perceptual learning, and adaptation effects in speech perception (for review, see Ullas et al., 2022), this makes the case that there is no single mapping from acoustics to speech to be discovered and no firm line between perception and learning. In speech perception (and likely other perceptual domains), the “learning is always on.” Simply learning a probabilistic mapping from acoustics to a phoneme such as /b/ or a name such as Sofia is not enough to account for the richness of speech perception. The relative contributions of acoustic dimensions are continuously and dynamically reweighted.
This has important implications. If the mapping of acoustic dimensions to speech representations is not rigidly fixed by long-term experience, as these results suggest, the hunt for the neural code for speech features may end empty-handed, or at least incomplete: We can expect the code to shift and change according to context. Research has traditionally focused on how learning establishes long-term speech representations, but results such as these make clear that ongoing learning continuously tunes how information interacts with existing representations, comingling speech perception and learning and requiring more dynamic models. Further, although this short-term learning can develop across passive exposure, it depends on interaction with existing speech representations and, presumably, the predictions they can generate. This likely requires learning mechanisms distinct from both those that have been traditionally considered “statistical” learning over passive listening and those proposed to drive the acquisition of categories over long-term learning. Learning across speech will likely drive multiple learning mechanisms.
Ultimately, a better understanding of the dynamic, flexible nature of speech processing will advance understanding of communication in listening conditions that are more typical of natural environments. This will be especially important for understanding listeners with hearing loss and communication disorders, for whom baseline perceptual weights often differ from healthy listeners. Even more broadly, speech provides a rich and ecologically significant test bed for understanding how incoming sensory input—and the learning that takes place across it—interacts with existing knowledge to drive predictions that tune the system to support future behavior.
Recommended Reading
Gwilliams, L., & Davis, M. H. (2022). (See References). Summarizes a growing body of work demonstrating that speech processing is influenced by statistical properties of the information conveyed and introduces a modeling approach to understanding these influences.
Ullas, S., Bonte, M., Formisano, E., & Vroomen, J. (2022). (See References). Reviews how word knowledge and audiovisual correspondences can influence speech categorization, connecting with theories and neurobiological evidence to advance understanding of this perceptual plasticity.
Van Hedger, S. C., & Johnsrude, I. S. (2022). Speech perception under adverse listening conditions. In L. L. Holt, J. E. Peelle, A. B. Coffin, A. N. Popper, & R. R. Fay (Eds.), Speech perception (pp. 141–171). Springer. Reviews how challenging listening contexts impact speech processing and the cognitive and neurobiological processes that help listeners cope with adverse listening environments.