
Abstract
The goal of psychological science is to discover truths about human nature, and the typical form of empirical insights is a simple statement of the form x relates to y. We suggest that such “one-liners” imply much larger x-y relationships than those we typically study. Given the multitude of factors that compete and interact to influence any human outcome, small effect sizes should not surprise us. And yet they do—as evidenced by the persistent and systematic underpowering of research studies in psychological science. We suggest an explanation. Effect size magnification is the tendency to exaggerate the importance of the variable under investigation because of the momentary neglect of others. Although problematic, this attentional focus serves a purpose akin to that of the eye’s fovea. We see a particular x-y relationship with greater acuity when it is the center of our attention. Debiasing remedies are not straightforward, but we recommend (a) recalibrating expectations about the effect sizes we study, (b) proactively exploring moderators and boundary conditions, and (c) periodically toggling our focus from the x variable we happen to study to the non-x variables we do not.
Looking across a room full of research psychologists at a professional meeting, it is possible to be struck by the thought that everyone there believes, usually with some justification, that what he or she is studying is important. (Funder & Ozer, 2019, p. 164)
The basic unit of much psychological inquiry is a statement linking a single variable x with a single outcome y. Producing such insights is a primary goal of our field’s empirical research, as evidenced by their common appearance in the abstracts of journal articles, in what we convey to journalists and the lay public, and in summaries of landmark findings for introductory psychology textbooks.
We suggest that x-y statements can be true yet misleading—and not just because of the familiar specters of reverse causality and unobserved confounds or more recently discussed problems such as mining data for statistically significant results, post hoc hypothesizing, and data faking. Our specific concern is that the implied magnitude of any x-y relationship, particularly when described without qualification or quantification, appears larger than it really is.
Why is this error so pervasive and persistent? Why, for example, is the one-liner “Grittier people are more successful” easily interpreted as an effect size larger than the observed r = .1 (Duckworth et al., 2019)? 1 Why does it disappoint policymakers to learn that the average effect size of “nudges” (such as reminding patients that a flu shot is “waiting for them”; Milkman et al., 2022) has been estimated as, at most, r = .15 (Szaszi et al., 2022)? 2 And why do we continue to power our studies as if x-y relationships were large enough to detect with just dozens of research participants?
On reflection, it is obvious that any psychological outcome y is influenced by many variables other than the one we happen to be thinking about. See Figure 1. Logic further dictates that the greater the number of such non-x variables, the less important, relatively speaking, the one x we are considering at the moment. 3 For instance, human achievement is quite obviously influenced by values, goals, cognitive ability, physical health, socioeconomic advantage, years of education, social support, and personality traits other than grit. The same goes for behavioral-economics nudges. How important should we expect any given intervention to be when so many individual differences and situational factors are also at play?
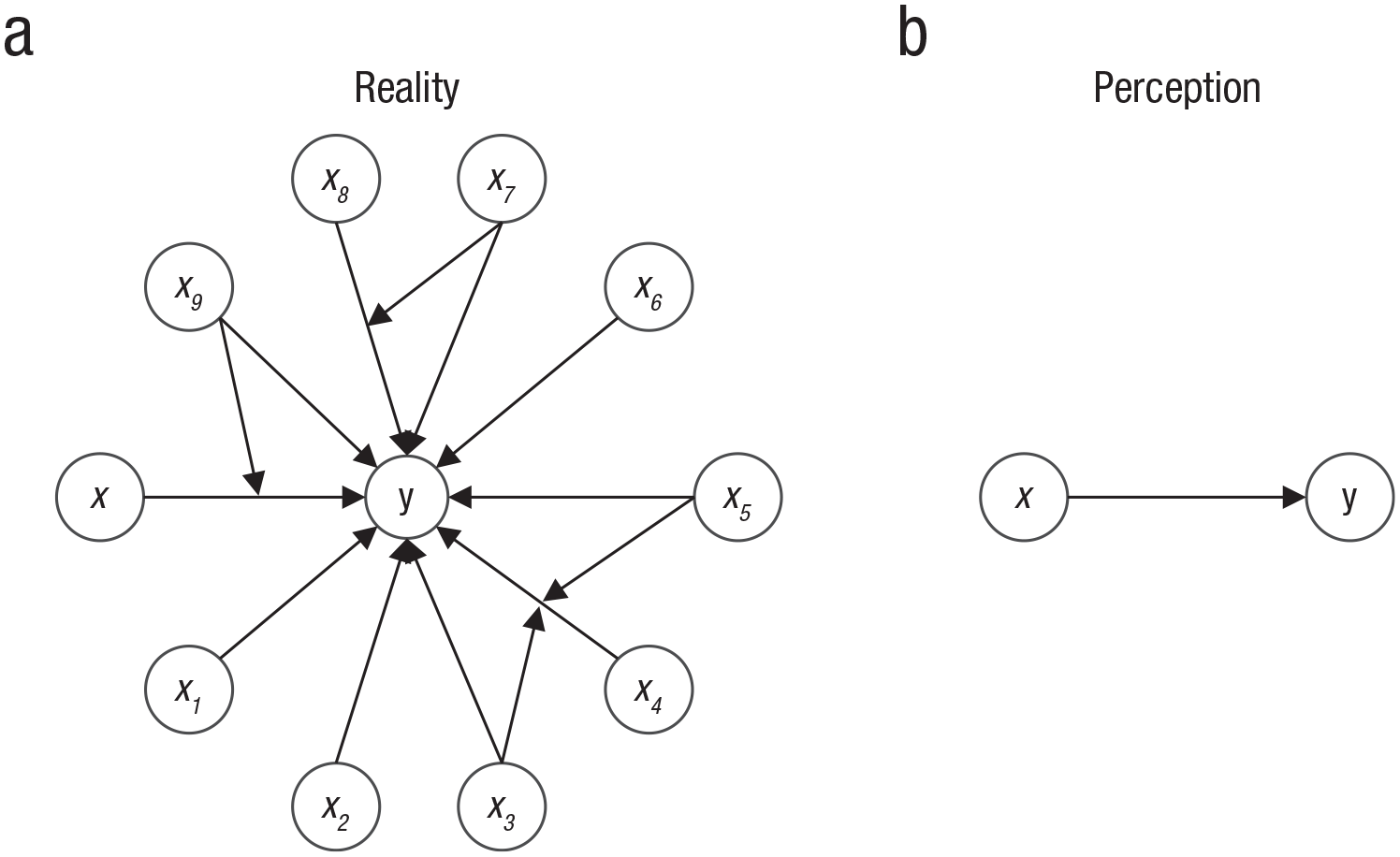
Reality versus perception. Any (a) psychological outcome y is determined by multiple influences. In this greatly simplified example, 10 variables exert main effects on y (e.g., x1, x2, . . .) and/or act as moderators (e.g., x7 and x9). When we think about (b) the influence of a particular variable x on outcome y, we tend to ignore all others (x1–x9). Omitted from this figure are the 45 pairwise correlations among the 10 independent variables that further reduce the unique variance in y explained by our focal x.
It is equally plain that any variable x interacts with others, moderating the x-y relationship. The number of possible interactions between these variables and x, and with each other, increases exponentially (Turkheimer, 2000). An absurdly oversimplified universe of only 10 independent variables yields, for example, more than a thousand possible linear interactions (45 two-way interactions, 120 three-way interactions, and so on), 4 not to mention reciprocal effects, nonlinear relationships, and the added complexity of covarying xs (Götz et al., 2024; Szaszi et al., 2024; van Tilburg & van Tilburg, 2023). As a consequence, any one x-y relationship is unlikely to apply, to the same degree, across all individuals and contexts (Bryan et al., 2021; Gelman et al., 2023; Liou et al., 2023; Tosh et al., 2024). So it is certain, for example, that even if grit is a cause of achievement, it explains only a small fraction of variation for some people and under some circumstances.
We suggest that the act of studying the relationship between x and y inadvertently leads us to ignore the multitude of factors—other than x—that also influence y. Likewise, we tend to momentarily ignore the myriad contexts or individual differences that moderate the relationship between x and y, including those rendering it weaker, nonexistent, or even reversed in sign (Bryan et al., 2021). And by extension, we tend to overestimate how well the x-y relationship generalizes—because context is nothing more than a collection of xs at varying levels. In sum, we suffer from effect size magnification, a bias in which the importance of any x-y relationship is overestimated when x is considered in isolation from other (non-x) influences.
Most Effect Sizes in Psychological Science Are Surprisingly Small
Cohen (1992) suggested that an effect of r = .3 is both “visible to the naked eye of a careful observer” and “the average size of observed effects in various fields” (p. 156). More recently, the benchmarks of r = .1, .3, and .5 for small, medium, and large effects, respectively, have been recognized as overly optimistic (Funder & Ozer, 2019; Götz et al., 2024). 5 Our field’s historical miscalibration is immediately evident in Table 1, which summarizes median published effect size estimates ranging from r = .13 to .19 from four large-scale reviews.
Meta-Analytic Estimates of Typical Published Effect Sizes in Psychological Science

Note: Where necessary, we converted between correlation and effect size using the following:
There is good reason to believe that unpublished effect sizes (i.e., results hidden in the proverbial file drawer) may be even smaller. For example, Polanin et al. (2016) estimated the average difference in effect size between published and unpublished studies in meta-analyses to be r = .09 (d = 0.18). When the Open Science Collaboration replicated 100 studies from three high-impact journals, the average replication effect size was r = .20—half that of the original (r = .40; Open Science Collaboration, 2015). Similarly, 11 years of student replication projects found effects (r = .14) that were half the size of those originally published (r = .30; Boyce et al., 2023). Multiple-lab replications of 15 meta-analyses yielded effects (r = .08) that were one-third the size of the originally published estimates (r = .21; Kvarven et al., 2020). 6 And recent reviews have estimated the effect of nudges in practitioner reports to be about one-sixth the size of corresponding effects in the published literature (Dellavigna & Linos, 2022). 7
After accounting for publication bias, the evidence suggests that the median effect size of a finding in psychological science may be no larger than r = .1. Of course, the distribution contains larger and smaller effects. Effect sizes depend on idiosyncratic researcher decisions around which x-y relationship to study, particularities of the study design, specifications of the statistical analyses, and more—such that even their central tendencies may be misleading (Simonsohn et al., 2022). Regardless, we contend that the typical x-y relationship studied by psychological scientists is likely so slight that to detect it at all requires a tightly controlled research design—one that effectively minimizes the influence of non-x variables.
To be clear, our point is not that effect sizes need to be gigantic to matter. Effects on the order of r = .1, or even smaller, can be consequential when the x-y relationship is repeated many times, applied to many people, or low-cost to implement (on nudges, see Benartzi et al., 2017; on wise interventions, see Walton, 2014), or when y is especially important (Funder & Ozer, 2019). On the contrary, we are increasingly skeptical of eye-popping effect sizes, particularly when produced by subtle and brief manipulations.
What concerns us is that if effect sizes in psychological science are typically as small as we surmise, then simple x-y statements (e.g., “Grittier people are more successful,” “Nudges encourage healthy choices”), by failing to highlight the de minimis nature of the relationship, can inadvertently mislead their audience.
What’s more, we suspect that as researchers, we may also be misleading ourselves. The primary evidence for researcher overconfidence in x-y effects is the persistent norm of underpowering studies. More than 60 years ago, Cohen (1962) lamented that the typical study was underpowered. As shown in Table 2, subsequent surveys of statistical power do not suggest much progress. From Cohen’s day to the present, the median study in psychological science continues to have only a one in six chance of detecting an effect of r = .1. Although we tend to recruit dozens of subjects for a given study, what is required are samples in the hundreds or more (e.g., N > 780 to detect r = .1 using a two-tailed t test with a threshold of p < .05 with 80% power). 8
Median Statistical Power of Studies in Psychological Science Across Four Reviews

Note: Each numeric column represents the percentage of studies in the cited review that were powered to detect a small, medium, and large effect, respectively. The definition of each category varied slightly across reviews and is specified in the first column. When necessary, we transformed effect sizes into Pearson correlations.
Cohen (1962) chose small, medium, and large values for d (the standardized difference between two groups) that differ slightly from conversions to Pearson’s r. Cohen’s d values of 0.2, 0.5, and 0.8 convert to Pearson’s r values of approximately .100, .243, and .371, respectively. Cohen explained that the larger rules of thumb chosen for Pearson r correlations reflected a variety of considerations, including differences in the expected effects in correlational (e.g., validity coefficients) versus experimental research.
How gloomy is the prospect of effects so small that they can be detected only with very large samples? It may help to recall that a common measure of effects, Pearson’s r, is a ratio: The numerator describes the covariance of x and y, and the denominator describes the variability (SD) of x and y. Likewise, Cohen’s d is a ratio: The numerator describes how y changes in response to a given change in x, and the denominator describes the variability of y. Small effect sizes in psychological science are not a symptom of small numerators so much as enormous denominators. In the form of a one-liner: People are complicated.
A Special Case of the Focusing Illusion
So why do small effects still surprise us? We suggest that effect size magnification is, in part, driven by a special case of the focusing illusion, a concept first introduced with an aphorism: “Nothing in life is as important as you think it is when you are thinking about it” (Kahneman, 2011, p. 402).
To date, happiness has been a primary outcome of interest in empirical demonstrations of the focusing illusion (Schkade & Kahneman, 1998). Like success, happiness depends on a multitude of factors, each of which can move happiness up or down and surely interact in uncountable ways—as shown in Figure 1a. Yet as suggested in Figure 1b, narrowing our attention to consider one particular factor—focusing in on it—momentarily isolates and magnifies its importance.
Consider whether someone would be happier living in the Midwest or Southern California. Their happiness would be driven by the weather, cost of living, industry mix, cultural influences, and more. Schkade and Kahneman (1998) found that self-reported overall life satisfaction was quite similar in the two regions, but—focusing on the salient factor of the weather—participants from both regions predicted that Midwesterners would be less happy than Californians. 9 When we zoom out to consider the myriad determinants of how satisfied a person is with their life overall, it seems foolish to put much weight on the weather. And yet, to examine the potential influence of weather on happiness, we must, by necessity, zoom in.
What underlies the focusing illusion is the highly selective nature of attention. By analogy, the human eye has only one fovea, covering only about one degree of the visual field—approximately the size of your thumb when held at arm’s length. We see whatever is in our fovea more clearly than anything in the periphery. Such acuity is made possible by a far greater density of photoreceptors in the fovea compared with the rest of the retina—a prioritization necessitated by the fact that dramatically more visual information enters the retina than could possibly be processed by the brain (Luck & Ford, 1998). In other words, rather than see everything with equal acuity, we prioritize what is central.
We conjecture that simple x-y statements focus attention in a similar way. When we use a simple x-y statement to specify our hypotheses ex ante or to summarize our results ex post, what unfolds is a kind of mental movie. In the mind’s eye, we conjure an image of x changing y against an empty backdrop—or, at most, a backdrop of other non-x variables optimally favorable for this effect. What we tend not to do, either before or after collecting data, is conjure a messier yet more realistic narrative.
Are we wrong not to do so? Try telling or recalling a story without spotlighting the protagonist and the plotline, instead describing every ancillary detail of the setting, all minor characters, and every subplot. “Writing is selection,” says the writer John McPhee (2015). So, too, is thinking—and perhaps especially so for scientists. From our one-liners to our carefully controlled research designs, to make sense of x as it relates to y, we must only have eyes for x.
Implications
Experts learn more and more about less and less, goes the old joke, until they know everything about nothing. We likewise suggest an inherent tradeoff between depth and breadth that renders effect size magnification something of a “necessary evil.”
On one hand, it is a serious error to repeatedly expect dramatically larger x-y relationships than what we typically find. This bias introduces problems from the very beginning of a research program, when we decide how many participants to recruit, to the end, when we communicate our findings to fellow scientists and the public. Further, it compounds more systemic problems, such as the pressure to publish novel and counterintuitive findings at a galloping pace. When we expect implausibly large effects, we may find ourselves publishing spurious findings from underpowered studies (Gelman & Carlin, 2014)—exacerbating the already thorny collective-action challenges that pervade social science (Hoekstra & Vazire, 2021).
On the other hand, overestimating the importance of a given variable while we are thinking about it may be the only way we can think about it in the first place. Put differently, the mental acuity afforded by zooming in on one x-y relationship may be possible only while ignoring myriad other causes and moderators that likely diminish this relationship. In fact, the exogenous minimizing of confounds is the very essence of the experimental method. There is a seemingly inescapable tradeoff between ecological validity (real-world relevance) and internal validity (clean causal inference) embedded in our scientific methods (Campbell & Stanley, 1963/2015, p. 5).
Of course, effect size magnification is not a peccadillo unique to psychological scientists. No one can see or think about everything everywhere all at once. As a profession, however, we are responsible for reckoning with it.
Although remedies are not straightforward, as a start, a serious recalibration of expectations is in order (cf. Götz et al., 2022). There is simply no reason to expect effects large enough, as Cohen (1992) put it, to be “visible to the naked eye,” and no reason to be embarrassed about effects that are not. After all, the modest size of the typical x-y relationship in psychology does not undermine causal inference per se. Certainly, no one would doubt the causal influence of genes on behavior—but because outcomes are typically influenced by hundreds of genes, it is not surprising that a relevant single-nucleotide polymorphism x usually explains far less than 0.1% (an r of approximately .03; Chabris et al., 2015) of the variance in a given phenotype y (O’Connor, 2021). Further, just as polygenic scores, which aggregate the effects of numerous genes, often correlate higher with phenotypes than any single gene (Plomin & von Stumm, 2022), it may be that structural influences (e.g., growing up in Texas vs. Tunisia; the combined effects of cigarette taxes, antismoking media campaigns, and prohibitions against smoking in public spaces) that represent many, many x variables in concert exert a larger influence on our focal y outcomes than any single variable x (Chater & Loewenstein, 2023). Unfortunately, these complex influences are not easily studied using the scientific method.
Second, we can search for and report the moderating and boundary conditions of the x-y relationships we study (Götz et al., 2024; Krefeld-Schwalb et al., 2024), predicting effects out of sample (Salganik et al., 2020) and explicitly recognizing limits to generalizability (Simons et al., 2017).
Third, just as the eye rapidly shifts from one fixation point to another, we can periodically wrest attention away from the x variable we most often think about and instead consider a non-x influence on outcome y, and then another, and so on. We might even center our research on a given y rather than on a given x (Watts, 2017). And every so often, we might zoom out, take stock of the empirical x-y one-liners that we and other psychological scientists have accumulated, and weave them together into more holistic theories of the phenomenon of interest (e.g., Lewin, 1938).
We may not be able to escape the tendency to exaggerate the effect we’re thinking about while we’re thinking about it—but we can shift what we’re thinking about. Doing so may be our only hope of glimpsing the big picture.
Recommended Reading
Ahadi, S., & Diener, E. (1989). Multiple determinants and effect size. Journal of Personality and Social Psychology, 56(3), 398–406. Demonstrates the statistical implications of accepting that psychological outcomes are driven by multiple interacting factors.
Bryan, C. J., Tipton, E., & Yeager, D. S. (2021). (See References). Argues for more systematic investigation into how psychological interventions can have smaller or larger effects as a result of heterogeneous populations and contexts.
Funder, D. C., & Ozer, D. J. (2019). (See References). Proposes best practices on how to interpret, evaluate, and report effect sizes in psychological research.
Götz, F. M., Gosling, S. D., & Rentfrow, P. J. (2022). (See References). Discusses the prevalence of small effects in psychological science and how they can be harnessed to further the field.
Schkade, D. A., & Kahneman, D. (1998). (See References). Provides the classic empirical demonstration of the “focusing illusion” as a cognitive bias.
Footnotes
Acknowledgements
We are deeply grateful to the late Daniel Kahneman for his extensive contributions to the conceptualization and refinement of this argument, as well as his seemingly boundless patience, humility, and good humor. We hope this article would make him proud. We also appreciate the thoughtful feedback we received from colleagues, including Abdullah Almaatouq, Frank Bosco, David Brainard, Christopher Bryan, Francisco Ceballos, Christopher Chabris, Stefano Dellavigna, David Funder, Andrew Gelman, Gilles Gignac, Samuel Gosling, Friedrich Götz, Elizabeth Linos, Brian Nosek, Daniel Ozer, Peter Rentfrow, Dan Richard, David Schkade, Daniel Simons, Barnabás Szászi, Elizabeth Tipton, Eric Turkheimer, Simine Vazire, Duncan Watts, and two reviewers.
Transparency
Action Editor: Robert L. Goldstone
Editor: Robert L. Goldstone