
Abstract
This brief review examines the potential to use decision science to objectively characterize depression. We provide a brief overview of the existing literature examining different domains of decision-making in depression. Because this overview highlights the specific role of reinforcement learning as an important decision process affected in the disorder, we then introduce reinforcement learning modeling and explain how this approach has identified specific reinforcement learning deficits in depression. We conclude with ideas for future research at the intersection of decision science and depression, emphasizing the potential for decision science to help uncover underlying mechanisms and targets for the treatment of depression.
Keywords
Depression is the most debilitating disease in the world according to the World Health Organization (Kessler et al., 2005). Hallmarks of depression include pessimistic and inaccurate beliefs about the self, the world, and the future, and these beliefs can influence decision processes in individuals who suffer from depression (Roepke & Seligman, 2016). Indeed, difficulty making everyday decisions, such as what to wear or what to eat, is a diagnostic criterion for major depressive disorder (MDD). In addition, MDD is associated with impaired functioning in specific brain regions—the ventromedial prefrontal cortex and ventral striatum—known to play a critical role in incentivized decision-making (Bartra et al., 2013; Kumar et al., 2018). Using the theoretical and analytical tools of decision science to investigate depression could provide a more nuanced understanding of the cognitive mechanisms affected by the disorder, shed light on the nature of heterogeneity within depression, and help bridge gaps between current research in clinical psychopathology and neuroscience. Further, identifying specific decision impairments as the targets of treatment could make more personalized help possible, as opposed to the more generic standard protocol that is currently implemented.
Decision-Making in Depression Across Domains
Though several studies have investigated decision-making in depression, a major limitation is that these studies usually include only one decision-making task. For instance, several studies have examined decision-making performance on the Iowa gambling task, which a meta-analysis has demonstrated is impaired across a number of mental health disorders, including depressive disorders (Mukherjee & Kable, 2014). Although findings of this type remain informative, we would ideally like to characterize depression across multiple decision-making domains. Such a characterization would identify whether differences in decision-making in depression are specific to particular domains as opposed to widespread. Characterizing multiple decision domains across different disorders would further identify what pattern of decision-making differences is unique to depression.
As a first step toward this end, we recently conducted a study investigating a wide range of different decision processes in the same group of depressed individuals (Mukherjee, Lee, et al., 2020). We used a battery of nine tasks (yielding 10 measures; see Table 1) that spanned five different domains of choice behavior and had previously been studied only in separation. Although this is by no means an exhaustive list of the available decision-making paradigms, these specific tasks have been related to neural functioning and psychopathology in the literature.
Different Domains of Decision-Making, Decision Tasks, Performance Measures, and Task Structures Examined by Mukherjee, Lee, et al. (2020)
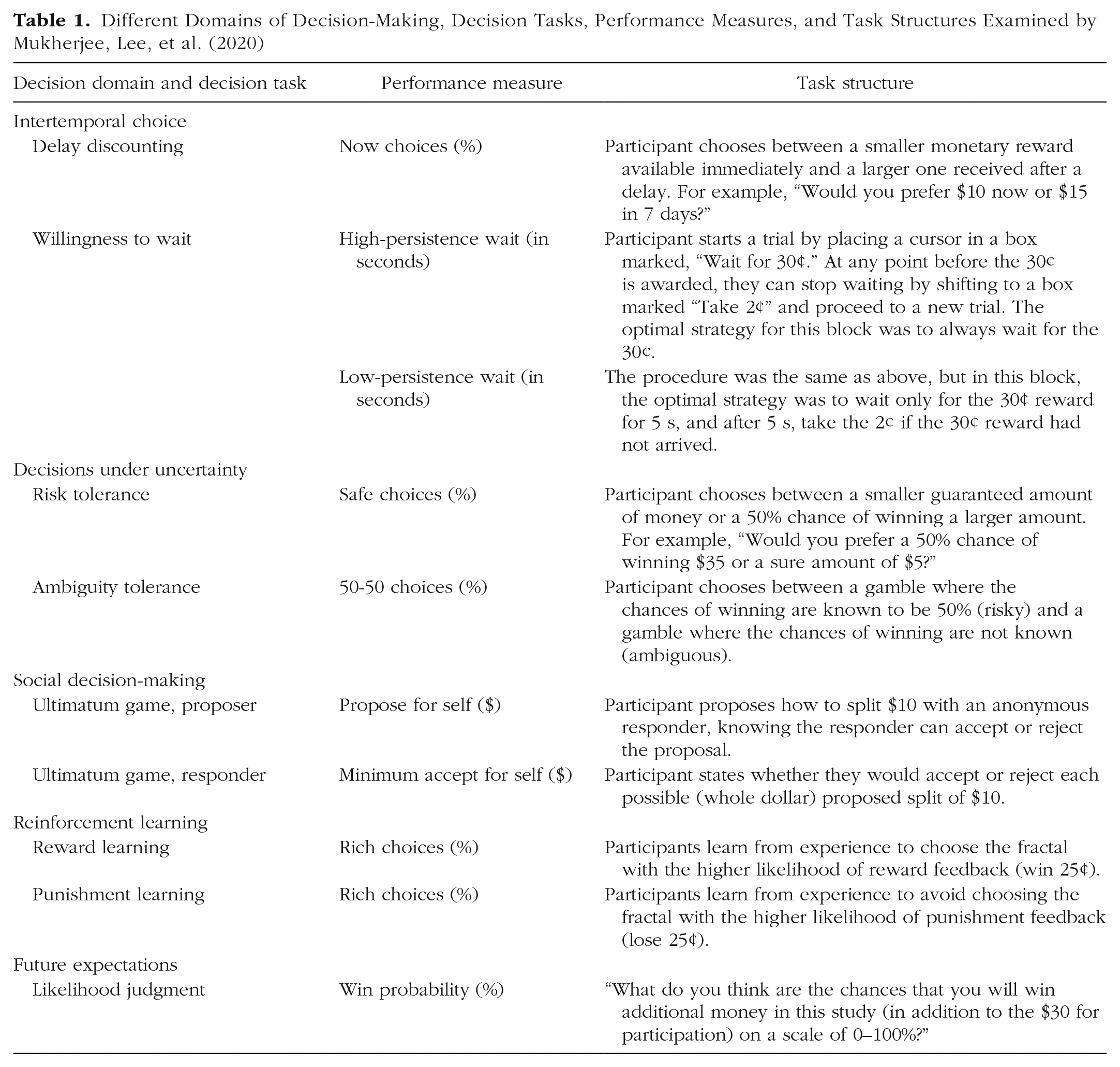
Our decision-making battery included measures of intertemporal choice, decisions under uncertainty, social decision-making, reinforcement learning, and future expectations. In intertemporal choice, individuals choose between smaller rewards that they can receive sooner and larger rewards that they will have to wait for. In one task, the delays range from weeks to months that the individual must wait after experiment (Kable & Glimcher, 2007). In another, the delays occur during the experiment (and the monetary rewards collected are correspondingly smaller), and decision-makers face the problem of optimizing persistence given the delay statistics in order to make the most money during the experiment (McGuire & Kable, 2012). In decisions under uncertainty, individuals choose between smaller rewards that are more certain and larger rewards that are more uncertain (risk- and ambiguity-tolerance tasks). Decision scientists distinguish between two different forms of uncertainty: risk and ambiguity. Under risk, the likelihood of different outcomes is known; under ambiguity, this information is unknown (Levy et al., 2010). One aspect of interpersonal interactions and social decision-making is assessed by the ultimatum game. In the ultimatum game, one player (the proposer) makes an offer to another (the responder) regarding how to split a fixed amount of money between them. The responder can either accept the offer, in which case the money will be divided on the basis of the proposer’s decision, or reject the proposal, in which case neither the proposer nor the responder will receive any of the money. Even though responders should accept any nonzero offers if they care only about maximizing their payout, they generally reject highly unequal splits, and knowing this, proposers generally offer splits that are close to equal. Reinforcement learning refers to the process by which artificial agents, humans, or other animals learn how to acquire reward in an unsupervised environment, that is, how they maximize reward and minimize loss by modifying their behavior as a consequence of experience (Rutledge et al., 2017). In our battery, participants perform two tasks in which they learn from either rewards or punishments. Participants select one of two images that are associated with rewards (or punishments) with higher or lower probability, and these probabilistic associations reversed periodically throughout the task. Finally, because negative expectations are a key mechanism in the maintenance and recurrence of depression (Roepke & Seligman, 2016), we assess future expectations by asking participants to estimate their likelihood of receiving additional money on the basis of their performance on the other decision-making tasks.
We found that depressed participants (n = 64) differed from healthy control participants (n = 64) most in the reinforcement learning (reward and punishment learning tasks), future expectations (likelihood judgment task), and intertemporal choice (high-persistence condition of the willingness to wait task) domains (Fig. 1). Depressed individuals made fewer optimal decisions in both the reward and punishment learning tasks, expressed more pessimistic predictions about winning money on the basis of their task performance, and were less willing to wait when persistence was optimal. The two groups did not differ significantly in performance on any of the other measures (see Fig. 1). A factor analysis of the 10 performance measures identified four factors: a learning factor, which most strongly weighted the reward and punishment learning tasks; an expectations factor, which most strongly weighted the likelihood judgment (future expectations) task; a persistence factor, which most strongly weighted the willingness-to-wait task; and an uncertainty factor, which most strongly weighted the risk and ambiguity tolerance tasks. Of these four factors, the learning and expectations factors each accounted for unique variance in predicting depressed status (Mukherjee, Lee, et al., 2020). Beyond this, however, none of the factors were uniquely correlated with specific subsets of depression symptoms.
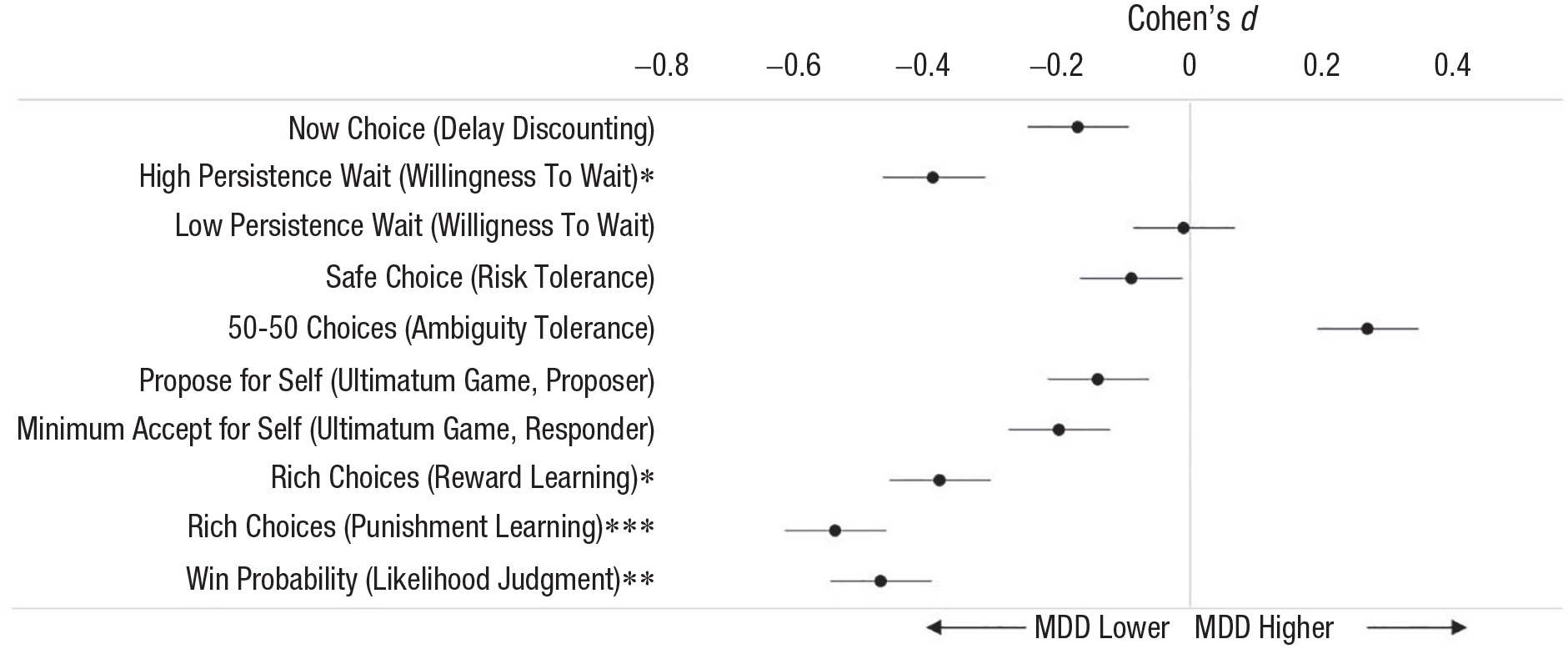
Effect size of performance difference between participants with major depressive disorder (MDD) and healthy control participants, separately for each decision task (data are from Mukherjee, Lee, et al., 2020). *p < .05, **p < .01, ***p < .001.
The differences we observed echo previous research on decision-making in depression using single tasks. As discussed in more detail in the next section, impaired reinforcement learning is strongly supported in the literature (Halahakoon et al., 2020; Pike & Robinson, 2022) and can often be detected with simple measures of performance (such as we used in this study) without the use of computational modeling (e.g., Kumar et al., 2018). Pessimistic expectations are consistent with the cognitive theory of depression, which posits that depressed individuals have inaccurate, negative biases about themselves and the future, and individuals with depression make significantly more pessimistic predictions than healthy control individuals in other tasks (Strunk & Adler, 2009). The finding that depressed individuals quit significantly earlier than healthy control individuals in the high-persistence condition of the willingness-to-wait task was novel but might be related to the reductions in motivation observed in depressed individuals in effort tasks (Berwian et al., 2020; Hershenberg et al., 2016). Past studies have generally failed to find differences between depressed and healthy individuals in the ultimatum game (Zhang et al., 2019) or in risk tolerance tasks (Chung et al., 2017). Past findings regarding delay discounting tasks are mixed, with some evidence that delay discounting choices are affected by anhedonia (Lempert & Pizzagalli, 2010) or suicidality (Tsypes et al., 2022), if not depression per se.
Modeling Reinforcement Learning in Depression
Given that depressed individuals showed the largest differences from healthy individuals in reinforcement learning, in a follow-up study, we used computational models (Huys et al., 2016) to better understand the mechanism underlying these differences. Fitting computational models to the data allows us to translate choice into subject-specific parameter estimates meant to reflect high-level behavioral tendencies (Sutton & Barto, 1998).
Perhaps the most commonly used model of reinforcement learning—and the one we used here—is Q-learning, which assumes that we learn the value of choice options through a weighted average of their reward history. When an unexpected outcome is encountered (e.g., if a previously rewarded choice suddenly leads to an unfavorable outcome), people can vary in terms of how much they allow this new information to affect their expectation of the value of the choice option. To capture this source of variability, a learning rate parameter α determines the extent to which prediction error—or the difference between expected (Q) and actual (R) outcome on any given trial—leads to value updating. High estimates of α reflect greater sensitivity to the most recent choice outcome, whereas lower values indicate more gradual value updating. The standard equation to describe this process is written as follows:
Q-learning models, in their simplest formulation, also include an additional parameter: inverse temperature, or β, whose magnitude determines the impact of value on choice. Indeed, the likelihood of choosing either of the choice options is weighted by a subject-specific β such that higher inverse temperatures reflect a greater tendency toward consistently choosing the option that is estimated to have a higher Q value. Smaller βs are indicative of more stochastic, or perhaps exploratory, behavior, and people who exhibit such choice patterns can be said to be less sensitive to value in their decision-making (for equations and further information, see van Geen & Gerraty, 2021, and Mukherjee, Filipowicz, et al., 2020).
In our follow-up study (Mukherjee, Filipowicz, et al., 2020), we found that fitting Q-learning models to our data can help elucidate the differences in performance between depressed individuals and healthy control individuals (Fig. 2). Specifically, we found that depressed individuals showed lower learning rates (α) and, to a lesser extent, lower value sensitivity (β), in both the reward and punishment learning tasks. Learning rates also outperformed simple performance metrics, such as number of optimal choices made, in predicting depression status, showing that computational modeling provides additional diagnostic power. Importantly, learning rates and value sensitivity were reduced in both the reward and punishment conditions, which is consistent with the claim that depression is characterized by a hyposensitivity to positive outcomes, but goes against the belief that depression is characterized by a hypersensitivity to negative outcomes (Eshel & Roiser, 2010).
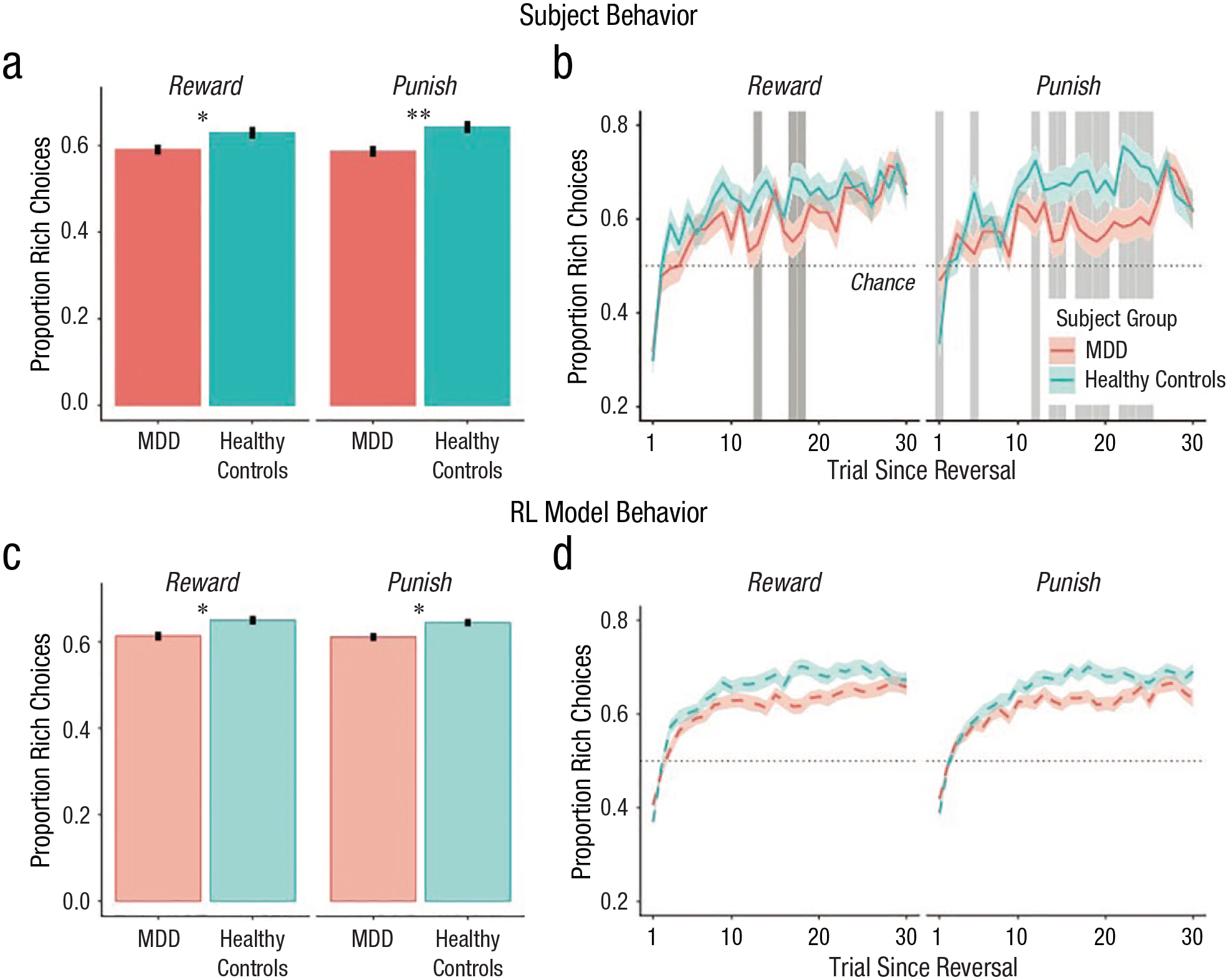
Differences between participants with major depressive disorder (MDD) and control participants. Individuals with MDD (red) made fewer rich choices than control participants (blue) in both the reward and punishment conditions. (a) Mean proportion of rich choices in MDD and healthy control participants across all trials in the reward and punishment conditions. (b) Mean proportion of rich responses as a function of trial since the last reversal. (c) and (d) Identical statistics reported in (a) and (b), respectively, computed from simulations of subject behavior from reinforcement learning model fits (100 independent simulations per subject using their fit parameter estimates). Error bars in (a) and (c) and shaded regions in (b) and (d) correspond to ±1 SEM. Asterisks indicate significant between-group differences (*p < .05, **p < .01). Gray areas in (b) indicate trials after reversal on which signed-rank tests were significant (p < .05). Figure reprinted with permission from Mukherjee, Filipowicz, et al. (2020).
Our finding that depressed individuals exhibited lower learning rates is consistent with results of some previous studies. For instance, Chase et al. (2010) found that participants with MDD had lower learning rates for both punishments and reward in the initial training phase of a reward-learning paradigm. They also showed a negative correlation between learning rate and anhedonia, one of the primary symptoms of depression. Similarly, Dombrovski et al. (2010) found decreased learning rates in a probabilistic reversal learning task among suicide attempters. However, not all studies have found reduced learning rates in depression (Moutoussis et al., 2018). Combining evidence across studies, a recent meta-analysis concluded that there was evidence for lower reward learning rates in individuals with mood and anxiety disorders (Pike & Robinson, 2022).
Other work has also shown that depressed individuals exhibit decreased value sensitivity. For instance, one study found that patients with depression are more exploratory when they decide which of two differentially rewarding options to choose (Blanco et al., 2013). Using computational modeling, one study (Rupprechter et al., 2018), found both reduced memory for and sensitivity to past values in in their paradigm. In an adapted Q-learning model, Huys et al. (2013) further demonstrated that both MDD and anhedonia are correlated with lower reward sensitivity, meaning that patients’ choices are less deterministically guided by value. In this meta-analysis, however, the researchers did not find any association between depressive symptoms and learning rate. This suggests that more evidence is needed in order to parse the separate contributions of prediction-error updating and reward sensitivity to learning, as well as how they may be differentially affected by depression.
One critical reason there may be inconsistency across studies is that, as a field, we have not paid sufficient attention to the reliability and generalizability of parameter estimates derived from computational models. Indeed, a recent analysis (Eckstein et al., 2022) suggests that although estimates of reward sensitivity across different tasks are fairly reliable within participants, learning rates do not show evidence of generalization. As a consequence, two recommendations emerge. First, it is crucial to fit computational models using techniques that have been shown to provide the greatest out-of-sample reliability (e.g., using group-level priors, as suggested by van Geen & Gerraty, 2021). Second, it is necessary to consider the context of the experimental task when assessing how parameters may differ from optimality. For example, depending on the experimental paradigm, having a higher learning rate is not always better. If characteristics of different experiments make faster learning more optimal in one context and slower learning more optimal in another, a high-performing participant may demonstrate learning rates that differ greatly from one context to the next. In a similar vein, Vandendriessche et al. (2023) have recently shown that individuals with depression learn less accurately when the overall expected value of an environment is negative but not when it is positive. In cases such as this one, considering characteristics of the specific experimental context is necessary if we hope to identify biases in behavior that correlate with depressive symptoms. Moving forward, such considerations will be crucial if we hope to achieve a coherent understanding of how depression affects reinforcement learning.
An association between depression and parameters of reinforcement learning is broadly consistent with neurobiological ideas that link depression with alterations in dopamine and/or serotonin systems (Lan & Browning, 2022). Given how closely prediction errors track with dopamine release in the brain, reductions in the behavioral effect of prediction errors are in line with the hypothesis that depression is associated with reduced dopamine functioning (Delgado, 2000; Gradin et al., 2011). These findings could help explain the efficacy of antidepressants that increase dopamine availability. Serotonin, on the other hand, has been linked to reward and punishment signaling (Lan & Browning, 2022), and sustained intake of serotonin reuptake inhibitors leads to changes in reinforcement learning parameters (Michely et al., 2022). Beyond suggesting potential neurobiological mechanisms of depression, these ideas can also help reconcile some of the inconsistencies in the literature noted above. For example, though not all studies have found reduced learning rates in depression, some have nonetheless been able to leverage parameter estimates from reinforcement learning models to identify a widespread hyposensitivity to prediction error across the brain’s reward system (Gradin et al., 2011).
These links between reinforcement learning processes and dopamine and serotonin systems highlight the need to investigate potential medication-related confounds in studies of reinforcement learning in depression. For example, the Mukherjee, Filipowicz, et al. (2020) study systematically examined the effect of different forms of treatment in the MDD group. Individuals treated with medication only tended to have lower learning rates than those not on medication in the reward condition (medication only: M = 0.54, SD = 0.17, no medication: M = 0.69, SD = 0.17; signed-rank test, p = .041) but not in the punishment condition (p = .419). No other parameters in either condition differed between individuals being treated with medication only and no medication, between individuals undergoing therapy only and no therapy, or between individuals under any treatment (therapy and/or medication) and no treatment (no medication or therapy; all signed-rank ps > .05). These analyses show that the association between MDD and reinforcement learning parameters in Mukherjee, Filipowicz, et al. (2020) are unlikely to be confounded by MDD treatment, though prospective investigation of the effects of medication treatment on reinforcement learning parameters in depressed individuals is needed (Lan & Browning, 2022).
Future Directions
The findings above regarding reinforcement learning and depression are promising, but several gaps in our understanding remain. We see three particularly important directions that merit further investigation. First, future research should use more advanced reinforcement learning models to characterize how depression impacts reward and punishment learning. Simple reinforcement learning models such as the ones we have discussed so far posit that learning occurs exclusively through direct feedback and are often referred to as model-free reinforcement learning. On the other hand, model-based reinforcement learning assumes that we accumulate knowledge about the general structure of the environment and use this knowledge flexibly to infer value when planning and selecting actions. The relative contribution of model-free and model-based learning is often thought of as a marker of cognitive complexity, and some evidence suggests that depression may bias people toward more model-free learning strategies (Blanco et al., 2013). However, another study, using a large-scale online assessment of psychiatric symptoms, found that obsessive compulsive disorder symptomology is more predictive of a decrease in model-based behavior than depression is (Gillan et al., 2016). Other researchers have proposed that depression may be associated specifically with avoidance biases in model-based planning (Lally et al., 2017). Beyond the model-based versus model-free distinction, another idea is that mood, including depressed mood, is a representation of recent trends in the environment, referred to as momentum, which can be used to improve learning in more sophisticated reinforcement learning algorithms (Bennett et al., 2022). Thus, an important question for computational psychiatry going forward is how people’s mental models of the world may be affected by depression and how this could impact how depressed people learn.
Second, further research should better parse the relationship between reinforcement learning deficits and specific symptoms. Some of the work above suggests that decreased learning rate or decreased feedback sensitivity is associated with specific symptom dimensions of depression, such as high levels of anhedonia (Huys et al., 2013). Other work suggests that reinforcement learning processes are affected by symptoms of anxiety, which are highly comorbid with depression (Gillan et al., 2016). Thus, another important question is the sensitivity and specificity of reinforcement learning deficits across symptoms. Addressing this question might shed light on the heterogeneity of depression—two people may be diagnosed with MDD and not have a single overlapping clinical symptom—and reinforcement learning may prove useful to characterize subtypes of depression.
A third area for future investigation is targeting reinforcement learning processes for treatment. If depression symptoms are associated with features of reinforcement learning, then treatment-related symptom changes should be associated with changes in learning rate and reward sensitivity. In a recent mixed cross-sectional cohort study, participants with MDD completed a probabilistic learning task during functional MRI before and after cognitive behavioral therapy (CBT). Computational models applied to the data uncovered associations between parameter estimates and depression symptoms, but importantly, symptom improvement following CBT was associated with the normalization of learning parameters (Brown et al., 2021). This is exciting because the association of reinforcement learning parameters to symptoms of depression suggests novel therapeutic interventions could be developed that target and improve reinforcement learning processes to treat depression.
These areas for future research will help to determine the extent to which decision science advances our characterization of depression in two related yet distinct senses. It is possible that decision science could ultimately contribute to better measures of depression, or aspects of depression, that avoid key biases in self-reports, even if the theoretical implications of these measures for understanding depression remain unclear. It also possible that decision science could become an extremely useful theoretical framework for understanding depression, even if the psychometric properties of the most theoretically insightful paradigms are modest. Only future research can fully resolve whether one or both of these twin potentials of decision science—for better measurement and for better theoretical understanding of depression—is fulfilled.
Recommended Reading
Brown et al. (2021). (See References). Describes how treatment-related symptom change is associated with learning changes for depressed individuals following cognitive behavioral therapy.
Halahakoon, D. C., Kieslich, K., O’Driscoll, C., Nair, A., Lewis, G., & Roiser, J. P. (2020). (See References). Meta-analyses on overall reward processing depression, including reinforcement learning deficits.
Huys, Q. J., Maia, T. V., & Frank, M. J. (2016). (See References). A more comprehensive review of computational psychiatry.
Pike, A. C., & Robinson, O. J. (2022). (See References). A review of reinforcement learning modeling in both mood and anxiety disorders.
van Geen, C. & Gerraty, R. T. (2021). (See References). An overview of reinforcement learning models.