
Abstract
Empirical claims are inevitably associated with uncertainty, and a major goal of data analysis is therefore to quantify that uncertainty. Recent work has revealed that most uncertainty may lie not in what is usually reported (e.g., p value, confidence interval, or Bayes factor) but in what is left unreported (e.g., how the experiment was designed, whether the conclusion is robust under plausible alternative analysis protocols, and how credible the authors believe their hypothesis to be). This suggests that the rigorous evaluation of an empirical claim involves an assessment of the entire empirical cycle and that scientific progress benefits from radical transparency in planning, data management, inference, and reporting. We summarize recent methodological developments in this area and conclude that the focus on a single statistical analysis is myopic. Sound statistical analysis is important, but social scientists may gain more insight by taking a broad view on uncertainty and by working to reduce the “unknown unknowns” that still plague reporting practice.
Consider the following fictitious, worst-case sequence of events in an empirical research project: A small group of researchers sets out to study a hypothesis that appears consistent with a theory that the group had promoted in earlier work. An experimental design is selected and an initial sample size is chosen based on what seems to have worked well in the past. Once the data are collected, a single data analyst applies a single statistical technique in the hope to “reject the null hypothesis,” that is, to find a p value lower than .05. If the analyst fails, additional statistical techniques are applied, the sample size is increased, other aspects of the data are explored, or—when none of these methods yield the desired outcome—the result is not reported. If the analyst is successful, the results are submitted for publication, but the data and the analysis code are not shared or shared only “upon request.” Although the researchers do not explicitly quantify their confidence in the main claim, the contents of the article title, abstract, and conclusion leave little doubt that the result is expected to replicate and generalize. The only replications that are ever reported are by the same group of researchers who published the original claim—remarkably, these replications are almost always successful.
If this worst-case scenario (described by one of the reviewers as “stone-aged”) is even remotely realistic, it is clear that the inevitable uncertainty surrounding an empirical claim cannot be gleaned from the usual statistical report that centers on the p value and the confidence interval. First, the researchers are studying their pet hypothesis, and the analysis outcome has an impact on their careers. This creates a conflict of interest that threatens the unprejudiced spirit in which the hypothesis ought to be evaluated; this is analogous to taxpayers auditing their own returns. Psychologists should be especially aware of the myriad of subtle biases that affect behavior even in the absence of any conscious effort to deceive. Second, even if researchers were perfectly unbiased, they usually present the outcome of a single analysis to test a particular hypothesis; this does not address the extent to which the outcome is fragile, that is, apparent only under a narrow set of analysis choices.
In recent years, it has become increasingly evident that there is more to data analysis and the assessment of uncertainty than the mere inspection of a confidence interval and that a truthful assessment of uncertainty requires a high degree of transparency throughout the entire research cycle. Consequently, new methods have been proposed to enhance transparency and methodological rigor, covering all stages of the empirical investigation, that is, planning an experimental study, data management, statistical inference, reporting, and publishing. In this article we provide a select overview of some of the most exciting changes to the status quo that have recently been proposed for each of these stages. Our focus is on experimental psychology, but we believe that methodological reform is also relevant for other subfields of psychology (e.g., Tackett et al., 2017 [clinical psychology]; Kapiszewski & Karcher, 2021 [qualitative psychology]; and Crüwell et al., 2019 [mathematical psychology]). We adhere to academic tradition and highlight our own contributions, if only because we know these relatively well.
Current Directions in Sample Size Planning, Restricting Analytic Freedom, and Data Management
The standard procedure in planning an experimental study concerns a statistical power analysis, which seeks to determine the sample size required to have a reasonable chance to reject the null hypothesis when it is false (e.g., when power is 80%, the Type II error rate—the probability of erroneously retaining the null hypothesis—equals 20%). A Bayesian version of power analysis is known as Bayes factor design analysis (e.g., Stefan et al., 2019), and it can be used to assess (a) the distribution of evidence for any fixed sample size and (b) the distribution of sample sizes for a fixed set of evidence thresholds in a sequential design.
The determination of sample size remains opaque, however, if readers are not informed about the reasoning behind the power calculations. The Samplesizeplanner application (Kovacs et al., 2022) has been developed for frequentist or Bayesian sample size determination, and it also shows what steps of the determination process need justification.
There is increasing recognition that planning an empirical project involves much more than sample size determination, and these considerations are relevant for experimental and nonexperimental studies alike. Specifically, advance measures can be taken to mitigate the deleterious impact of hindsight bias and confirmation bias. Essentially, these measures constitute a Ulysses contract: Anticipating the possibility of bias, the researcher immunizes themselves by voluntarily restricting their freedom of analysis. For instance, the researcher may choose not to analyze the original data immediately but to first develop an analysis plan on an altered version of the data (e.g., the original data but with shuffled labels). After the analysis plan is complete, the data are “unblinded” and the plan is executed on the original data as specified (e.g., Dutilh et al., 2021; Sarafoglou et al., 2023). Similarly, researchers may adopt preregistration to outline their hypothesis, method, and analysis of the study before the data are known (e.g., Hardwicke & Wagenmakers, 2021). Registered Reports, a special case of preregistration, is a relatively new publication format where prereregistration plans are peer reviewed and journals commit themselves to publishing the results independent of whether or not these turn out to be statistically significant (see Figure 1 in Chambers & Tzavella, 2022). Preregistration could serve a secondary purpose: It may force researchers to consider the methodological and practical details of their project more deeply (Sarafoglou et al., 2022).
Proper planning can prevent mistakes in the data management workflow as well. A recent survey found that for about 20% of psychology researchers, data management mistakes in the past 5 years had resulted in major adverse consequences (e.g., project failure, serious time and/or money loss, damaged professional reputation)—these mistakes were partly due to poor project preparation (Kovacs, Hoekstra, & Aczel, 2021). To prevent these mistakes, researchers should therefore carefully consider how data are collected, processed, documented, and stored.
Part of the planning phase also means formulating the research question precisely and incorporating prior literature, theory, or expert opinions into the study design (Borsboom et al., 2021; Kekecs et al., 2020). With regard to the development of an analysis plan, this may mean that such knowledge informs the specification of the model equation, the implementation of theory-based predictions as competing statistical models, and the development of appropriate parameter priors within the Bayesian framework.
A final innovation in planning is the advent of team science or “many labs” initiatives: By combining forces, a consortium of different labs is able to address an empirical question of interest conclusively while at the same time examining the extent to which the finding holds across different cultures and geographies (e.g., Forscher et al., 2022).
Current Directions in Statistical Inference
The promise of empirical science is to address substantive questions by taking a well-reasoned path from theory to design and from observation to conclusion. The step from observation to conclusion is quantified by statistical inference, usually culminating in a p value or a confidence interval. This practice has come under increasing scrutiny. Some methodologists have argued that the threshold for new discoveries should be lowered from .05 to .005 (Benjamin et al., 2018), some have argued that hypothesis testing should be replaced by parameter estimation (e.g., Cumming, 2014), and others have argued that p values ought to be supplanted or supplemented with Bayes factors (e.g., Wagenmakers et al., 2016, 2018).
This discussion tacitly assumes that there exists only a single plausible analysis path (e.g., choice of statistical model, choice of preprocessing pipeline) or—if it is admitted that multiple plausible paths may exist—that all paths lead to the same conclusion. Several large-scale projects across different fields explored the analytic space either by inviting independent teams to analyze the same data set or by having the authors conduct multiverse analyses on the data themselves (Hoogeveen et al., 2022; Wagenmakers et al., 2022). These projects demonstrate that—at least in the social and behavioral sciences—the theoretical framework does not constrain the researchers to a limited analytic path. Indeed, only rarely did two teams use the exact same analysis. More worryingly, the different paths introduce substantial variability in the conclusions; sometimes even opposing conclusions were drawn from the same data (e.g., Botvinik-Nezer et al., 2020).
The results from recent “multianalyst” projects invite the bleak view of statistical inference displayed in Figure 1: Focusing exclusively on the finer details of the statistical modeling may be likened to rearranging the deck chairs on the Titanic. The primary component of uncertainty may reside not in what is reported (the “known unknowns”—the width of a confidence interval, the strength of a Bayes factor) but in what is not reported, either because it was unflattering or because it was never explored in the first place (Donald Rumsfeld’s “unknown unknowns”).
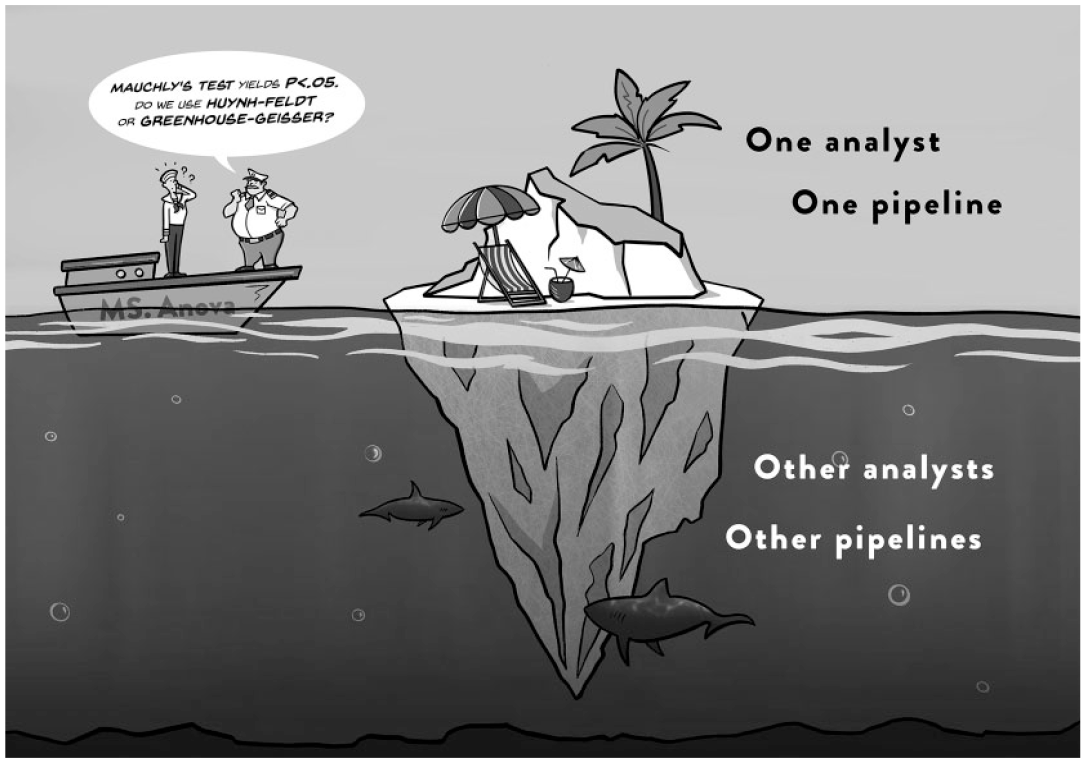
The traditional data analysis framework wherein a single data analyst reports the outcome of a single statistical analysis procedure. The first problem with this framework is the risk of bias, that is, the danger that the analyst has (perhaps unwittingly) cherry-picked a procedure that yields a relatively flattering outcome. The second problem is overconfidence, that is, the fact that by ignoring alternative plausible analysis procedures, much of the uncertainty that accompanies an empirical claim remains hidden beneath the surface. See also Wagenmakers et al. (2022). Figure available under a CC-BY license from BayesianSpectacles.org. Design by Viktor Beekman; concept by Eric-Jan Wagenmakers.
In order to obtain a more realistic impression of the uncertainty of an empirical claim, it is therefore important to assess the extent to which the conclusion is robust to plausible changes in the analytic path. Such changes can involve different preprocessing pipelines (e.g., Steegen et al., 2016), different dependent and independent variables, different models, and of course, also different outcome metrics (e.g., intervals, p values, and Bayes factors). Guidelines for conducting and reporting many-analysts studies are provided by Aczel, Szaszi, Nilsonne, et al. (2021). In Wagenmakers et al. (2021), we outline seven general recommendations for more transparency in statistical inference that will result in a fairer acknowledgement of uncertainty: (a) visualizing data, (b) quantifying inferential uncertainty, (c) assessing data preprocessing choices, (d) reporting multiple models, (e) involving multiple analysts, (f) interpreting results modestly, and (g) sharing data and code. In that article, we provide explanations and guidance for each of these recommendations.
Current Directions in Transparency, Communication, and Publishing
The credibility of an empirical claim hinges on the transparency with which the results are reported. The practical challenge, however, is to know what and how to report. Some scientific subfields have already developed their own standards for reporting (e.g., START, PRISMA, and CONSORT; see https://www.equator-network.org). To assist researchers in the behavioral and social sciences, we recently developed a comprehensive transparency checklist to improve and document the transparency of their research (Aczel et al., 2020). The transparency checklist and accompanying online application allow researchers to obtain an overview of the transparency-related aspects of their work (e.g., preregistration; data, code, and materials availability) and communicate these aspects to the journal at the time of submission. 1
Another challenge in the reporting stage is to avoid overconfidence when statistical outcomes are translated to substantive conclusions (e.g., Hoekstra & Vazire, 2021; Van Doorn et al., 2021). For instance, van Doorn et al. (2021) surveyed authors who had published a strong claim in Nature Human Behaviour (NHB). As shown in Figure 2, all 31 respondents indicated that the data reported in the NHB article made their claim more plausible than it was before. However, the size of the increase is relatively modest, and the final confidence was considerably lower than the article title suggests. The prior plausibility assessment centers around 50 (median = 56), and the posterior plausibility assessment centers around 75 (median = 80). It is not unlikely that the implicit demands of the traditional academic publishing system frustrate a modest interpretation of the results, as authors are generally expected to present compelling data that warrant strong claims.
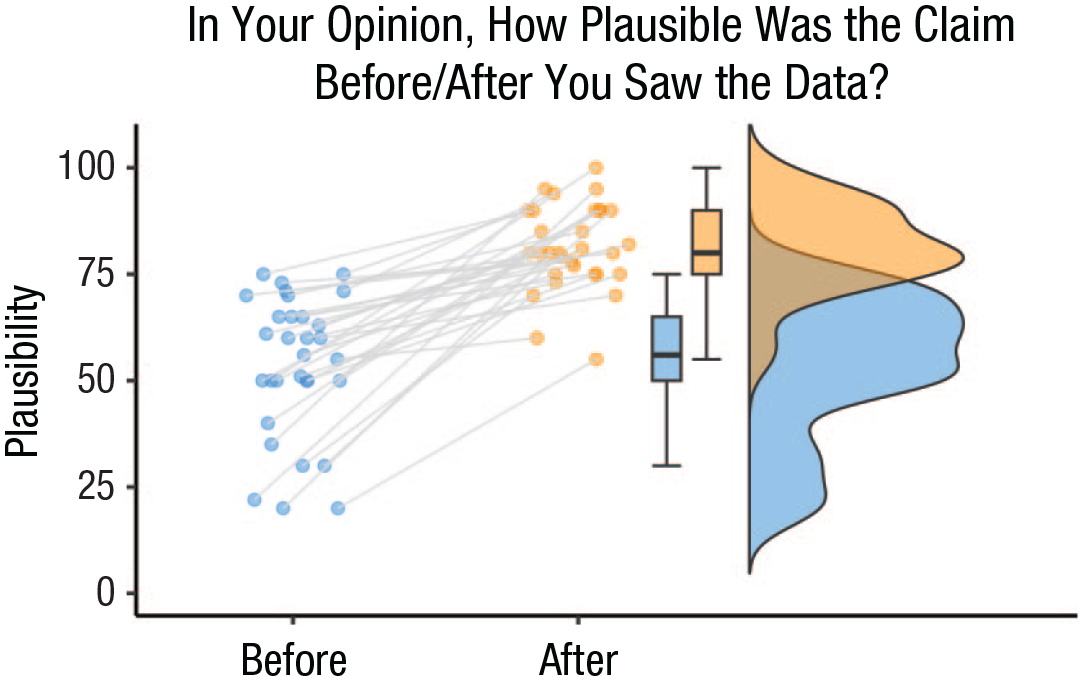
Results from van Doorn and colleagues (2021). The gray lines connect the responses for each respondent. See text for details. Figure from preprint available at https://psyarxiv.com/pc4ad.
A transparent report also contains the contributions of the authors. As the number of authors on journal articles increases, it becomes more and more difficult to know who did what. Tenzing (Holcombe et al., 2020; Kovacs, Holcombe, et al., 2021) is a tool that aims to assist researchers to document the roles each author played in the project. This online application makes it easy to create a list of authors, to report each author’s contribution, and to provide funding information. 2
The reform of scientific publishing concerns not just the authors’ reporting practices but also the whole publication system. Current reform initiatives concern open review (in which the reviews are publicly accessible; Ross-Hellauer, 2017), double-blind review (in which the reviewers do not know the identity of the authors; Snodgrass, 2006), or noncommercial peer review that is independent from journals. 3 In addition, there is increasing realization that reviewing is mostly done by researchers without any compensation or recognition. Aczel, Szaszi, and Holcombe (2021) estimated that in 2020 alone, this service totaled more than 100 million hours, equivalent to 15,000 years. The fact that much published research is subsequently hidden behind a publisher’s paywall suggests that the research community and all stakeholders of science should invest more effort into developing alternative models for the peer-review process and the entire publication system.
It is clear that science can progress even in the absence of publishers and academic journals. For instance, in data science and engineering, considerable prestige is associated with conference proceedings; in physics, preprints on ArXiv communicate key results well before they are ultimately published in a journal. It remains an open question how exactly such alternatives can be made normative and rewarding for researchers in other fields. However, we speculate that in order to change the status quo, two elements are critical: (a) The alternative to the current publishing system needs to be noncommercial, that is, open access for the reader and with near-zero article processing fees for the authors (e.g., https://scipost.org/); (b) funders need to demand that researchers publish only in these noncommercial outlets. In other words, funders need to prohibit publication in commercial outlets. Unless funders prohibit commercial publication, individual researchers will too easily succumb to the lure of the prestige associated with a high-impact journal, propagating a practice that in other walks of life would be considered racketeering.
Concluding Comments
Recent methodological work in psychological science has revealed that there is more to statistical uncertainty than meets the eye. Specifically, the uncertainty as routinely reported through confidence intervals, p values, and Bayes factors represents only the tip of an iceberg of uncertainty. In order to obtain a more realistic impression of the uncertainty that accompanies an empirical claim, it is necessary to know much more than the final outcome of a single statistical analysis. As Figure 3 illustrates, an ideal empirical report is freely available and features (a) assurance against cherry-picking (e.g., through preregistration or other Ulysses contracts), (b) publicly shared and properly anonymized data and code, (c) an assessment of inferential robustness (e.g., through a multiverse analysis or a multianalyst effort), (d) a modest interpretation of the outcome, and (e) a transparent description of the research.
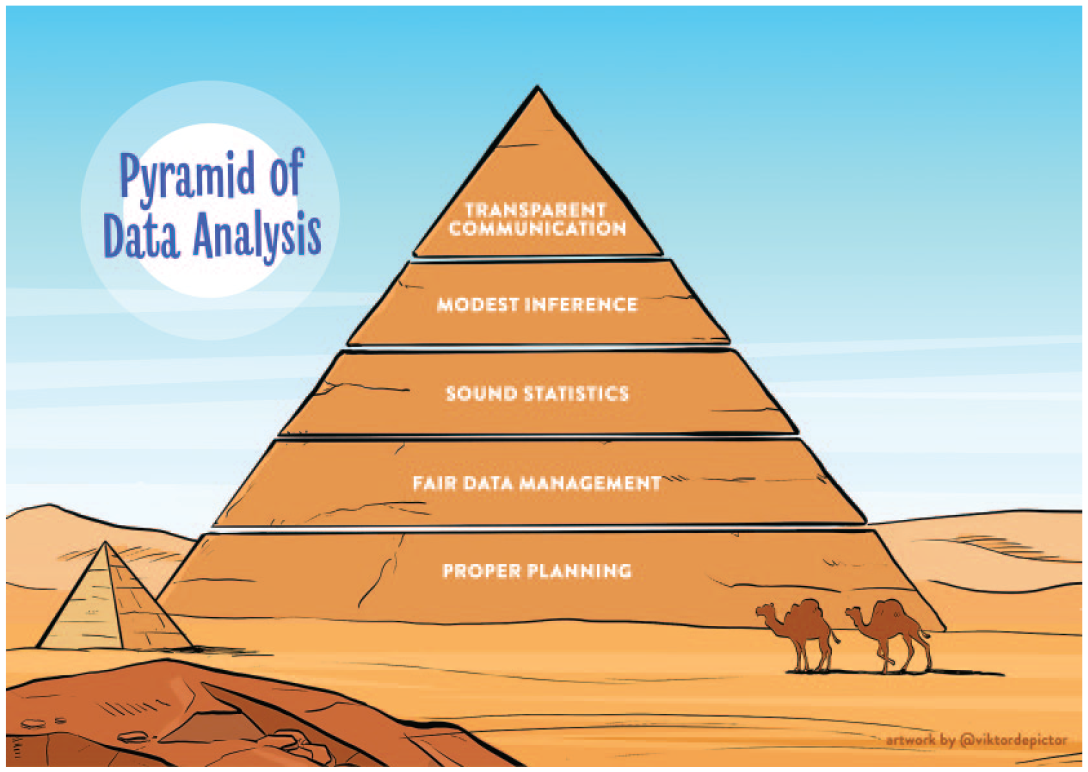
A pyramid of data analysis. The figure highlights five stages of the empirical cycle (i.e., planning, data management, statistics, inference, communication) in which researchers can improve the assessment of uncertainty. The validity of higher stages relies on the validity of the underlying stages. Figure available under a CC-BY license from BayesianSpectacles.org. Design by Viktor Beekman; concept by Balazs Aczel, Alexandra Sarafoglou, and Eric-Jan Wagenmakers.
A proper assessment of uncertainty therefore demands transparency across much of the empirical cycle, and this implies a radical departure from standard practice. Psychology has been at the forefront of these methodological developments, but for some other disciplines (e.g., medicine, neuroscience, biology, economics), it is mostly still business as usual. This is bound to change. Finally, these insights are also relevant to statistics proper. Especially for applied statisticians, it is important to realize they have a role to play from the conception of a project to its final report.
Recommended Reading
Hoekstra, R., & Vazire, S. (2021). (See References). Proposes that researchers emphasize the statistical uncertainty of their results, stress the limitations of their studies, and provide alternative interpretations of their findings.
Hoffmann, S., Schönbrodt, F., Elsas, R., Wilson, R., Strasser, U., & Boulesteix, A. L. (2021). The multiplicity of analysis strategies jeopardizes replicability: Lessons learned across disciplines. Royal Society Open Science, 8(4), 201925. Summarizes common sources of uncertainty of analysis strategies and describes how different disciplines deal with them.
MacCoun, R., & Perlmutter, S. (2015). Blind analysis: Hide results to seek the truth. Nature, 526(7572), 187–189. Outlines the method of analysis blinding and shows that this Ulysses contract benefits even researchers who work in a theory-strong discipline, such as physics.
Nosek, B. A., Hardwicke, T. E., Moshontz, H., Allard, A., Corker, K. S., Dreber, A., Fidler, F., Hilgard, J., Kline Struhl, M., Nuijten, M. B., Rohrer, Romero, F., Scheel, A. M., Scherer, L. D., Schönbrodt, F. D., & Vazire, S. (2022). Replicability, robustness, and reproducibility in psychological science. Annual Review of Psychology, 73(1), 719–748. Discusses the importance of replication studies and summarizes the recent advances on this topic in psychological science.
Silberzahn, R., & Uhlmann, E. L. (2015). Crowdsourced research: Many hands make tight work. Nature, 526(7572), 189–191. https://doi.org/10.1038/526189a. One of the first articles to promote a multianalyst approach in psychological science.