
Abstract
The notion of metacognitive myopia refers to a conspicuous weakness of the quality control of memory and reasoning processes. Although people are often remarkably sensitive even to complex samples of information when making evaluative judgments and decisions, their uncritical and naive tendency to take the validity of sampled information for granted constitutes a major obstacle to rational behavior. After illustrating this phenomenon with reference to prominent biases (base-rate neglect, misattribution, perseverance), we decompose metacognitive myopia into two distinct but intertwined functions, monitoring and control. We offer explanations for why effectively monitoring the biases resulting from information sampling in an uncertain world is so difficult and why the control function is severely restricted by the lack of volitional control over mental actions. Because of these and other difficulties, metacognitive myopia constitutes a major obstacle to rational judgment and decision making.
The concept of rationality is commonly related to Simon’s (1982) work on bounded rationality, to Tversky and Kahneman’s (1974) research program on heuristics and biases, or to Gigerenzer’s (2008) adaptive toolbox. Complementing these “classic” perspectives, we assign a key role to metacognition.
Our starting point is the premise that in everyday life, cognitive biases and illusions are as normal and ubiquitous as speech disfluencies, reading errors, or unskillful motor responses. Normally, however, these flaws are not consequential but rather easily noticed and corrected. One would hardly diagnose irrationality if a person sometimes exhibits spelling mistakes, mispronunciations, or clumsiness. So why should one infer irrationality from such anomalies (explained below) as anchoring biases or base-rate fallacies? What is irrational may not be the primary occurrence of biases. Rather, we reserve the term “irrational” to refer to the persistence of biases in spite of opportunities for metacognitive validity checks that can detect and enable correction of those primary biases.
Consider a cognitive reflection task (Frederick, 2005, p. 26): “A bat and a ball together cost $1.10; the bat costs $1.00 more than the ball; how much does the ball cost?” The first answer that comes to mind is 10¢, but this is wrong. The correct answer is 5¢, for $1.05 + $0.05 sums to $1.10, and $1.05 – $0.05 equals $1.00. When prompted to engage in a validity check, people easily admit the mistake and adopt the correct solution (5¢). A mistake should be considered irrational only when it persists despite a validity check. Going beyond the Kahneman-Tversky approach, we propose that a useful definition of rationality should not be based on initial slips or preliminary inferences; rather, it must take metacognition into account.
Granting that nominal definitions are matters of convention, we cannot prescribe the ultimate definition of rationality. Still, though definitions are not true or false, the growth of science depends on the usefulness and theoretical fertility of definitions. For a comprehensive account of the rationality of human intellect to be useful and to achieve explanatory power, it must explain why anomalies go undetected and uncorrected despite metacognitive monitoring and attempts at control (Nelson, 1990). The monitoring function assesses accuracy and mistakes in memory and reasoning, providing the input to the control function, which administrates corrections and decisions to use valid and discard invalid information. 1
Metacognitive Myopia
Indeed, many anomalies in judgment and decision making reflect conspicuous deficits in metacognitive validity checking that we have come to call metacognitive myopia (MM). 2 The term “myopia” refers to situations in which the immediate information is processed correctly, but the layer below the immediate information—its source, or context—is neglected and “out of focus.” Rationality and metacognition are commonly considered to be primarily restricted by excessive task demands and working memory constraints; in contrast, MM is not contingent on capacity constraints. Although, or exactly because, people are often remarkably sensitive to even complex stimulus arrays, they take the content of such samples for granted, processing it accurately but uncritically and naively ignoring validity constraints. In the absence of excessive demands, a key feature of MM is naive sampling (Juslin et al., 2007) and uncritical trust in the validity of the information given. MM is not caused by lack of motivation or of intelligence. Ironically, participants who are most prone to MM are often highly motivated (to accurately assess the information given) rather than careless or overburdened. We illustrate the phenomenon next, before we decompose MM into distinct monitoring versus control deficits.
Illustrative Examples
Perseverance
A prototypical example of MM as a missed opportunity to engage in critical validity checking is perseverance. In a classic experiment, Ross et al. (1975) unequivocally debriefed participants who had received humiliating feedback about their performance, telling them that the feedback was invalid and deceptive. Yet the psychological influence of the failure feedback persisted despite the debriefing. Naive reliance on fake feedback that persists even when a critical validity assessment is obvious reflects myopia. Participants see the superficial feedback data, but they miss the story about the feedback’s deceptive origin.
Perseverance effects are not confined to diffuse affective states but extend to factual information. Fake news often persists after unequivocal debriefing (Corneille et al., 2020). Debunking interventions (Chan et al., 2017) are only partially effective. Although the experienced fluency resulting from frequent repetition offers a plausible account of an initial tendency to overrate the truth of propositions (Wänke & Hansen, 2015), fluency can hardly explain why naive transitory belief in fake news persists despite subsequent validity checks or even explicit debunking. From our MM perspective, the inability to abandon blatant nontruth after explicit debunking is more diagnostic of irrationality than a transient initial truth bias (triggered by fluency). If fake news persists, people either neglect the critical monitoring of information validity in the first place or fail to correct beliefs that monitoring has shown to be obviously invalid. Analogous findings indicate that fully transparent debriefing does not eliminate misinformation in advice taking (Fiedler, Hütter, et al., 2018), evaluative conditioning (attitude formation due to pairing with positive or negative stimuli; Fiedler & Unkelbach, 2011), and group decisions (Fiedler, Hofferbert & Wöllert, 2018).
The perseverance example is ideally suited to illustrating MM: A wrong belief persists despite explicit debriefing about the belief’s invalidity. Perseverance also rules out the possibility that MM is merely due to difficulties in judging validity; it reflects a conspicuous neglect of validity. However, even in the absence of an explicit debriefing or proof of invalidity, the conditions for MM are met when people forgo an opportunity to engage in a validity check. Thus, MM is a forgone opportunity to check or double-check a mental operation. At the conceptual level, we adopt Nelson’s (1990) definition of metacognition as mental operations that serve a monitoring or control function, even though this metacognitive function may under some conditions be hard to distinguish from an ordinary reasoning function.
Base-rate neglect
Base-rate fallacies (Tversky & Kahneman, 1974) seem particularly resistant to metacognitive correction. A person interested in biographies and museums is more likely categorized as a historian than as a taxi driver, despite the fact that the base rate of taxi drivers (i.e., the percentage of taxi drivers in the population) is much higher. But why do base-rate fallacies persist when judges have time to rethink their initial guess and even when much is at stake? For instance, in legal trials with serious consequences, expert witnesses exhibit myopia for text length. As the number of linguistic truth criteria (Vrij & Mann, 2006) met by aggravating witness reports (i.e., reports that strengthen belief in the defendant’s guilt) increases, they attribute increasing credibility to the witnesses (which leads to severe verdicts), disregarding text length as a main determinant of the number of truth criteria met.
Closely related to base-rate fallacies is denominator neglect (Reyna & Brainerd, 2008) in judgments of proportions and in ratio bias (Denes-Raj et al., 1995). A lottery with 10 winning chances out of 100 is preferred to a lottery with 2 winning chances out of 20 when a short-sighted focus on the numerator (10 vs. 2 winning chances) neglects the denominator (100 vs. 20) that makes the two ratios equivalent. Dominance of numerators over denominators was observed in many experiments on sample-size biases (Price et al., 2006) and detection of change (Fiedler et al., 1996). Participants noticed increasing proportions of a focal feature only when the absolute sample size increased and noticed decreasing proportions only when the sample size decreased (e.g., they noticed that 10 wins out of 16 trials is greater than 4 out of 8, but not that 5 out of 8 is greater than 8 out of 16, although the proportional increase is the same). Likewise, the evidence that the absolute frequency of online product ratings had a stronger impact on consumer preferences than the products’ average evaluations (Powell et al., 2017) highlights the conspicuous confusion of quality and quantity.
Blatant misattribution
Judges overestimate outcomes that they themselves have oversampled. In a study concerning the perceived quality of products in different domains (computers and telecommunications), participants’ ratings were lower when they themselves had oversampled negative product experiences (instead of soliciting a representative sample), misattributing their own bias to sample negative information to the poor quality of the products (Fiedler, 2008). In a study of social hypothesis testing (Swann et al., 1982), observers misattributed acquiescent responses solicited through biased interviewer questions as manifestations of interviewees’ apparent attitudes. Observers mistook interviewee’s cooperative responses to interviewers’ leading questions focusing on extraverted behaviors as genuine evidence for extraversion and cooperative responses to leading questions focusing on introverted behaviors as genuine evidence for introversion.
Summary
Typical of all the MM examples discussed so far is biases’ persistent evasion of monitoring and control. Uncritical monitoring often overlooks invalidity or misattributes it to wrong sources; poor control functions fail to discard or correct for information that monitoring (or debriefing) has diagnosed as invalid. Although monitoring and control are not independent but rather are coordinated functions, decomposing MM is instructive and helpful for understanding the double function of metacognition. We first consider three difficulties that afflict the monitoring function, before we elaborate on pitfalls of control.
Metacognitive Monitoring Functions
Monitoring biased samples
Effective monitoring must be sensitive to sampling biases, whether in group discussions, newspaper coverage, or lists of search engine results. Although this requirement appears to be self-evident, sampling biases can be hard to deal with. Monitoring the validity of real samples, which are rarely random or unbiased, is often flawed.
For example, participants in the “ultimate sampling dilemma” (Fiedler, 2008) evaluate positive and negative experiences with three providers (P1, P2, P3) in two product domains, computers and telecommunications. In the universe from which they sample information (upper left chart in Fig. 1), the same 2:1 distribution of positive to negative evaluations holds for both product classes (computers and telecommunications, distributed 2:1) and across all three providers (P1, P2, and P3, distributed 4:2:1). Thus, all contingencies are set to zero. Yet, depending on the focus of information search, samples drawn from this universe can lead to markedly different judgments. Thus, when participants focus on P3 (vs. P1 and P2), this oversampling of P3 creates a pattern like the one shown in the upper right chart of Figure 1. In contrast, when sampling from the same universe focuses on negative outcomes (i.e., product deficits), the resulting pattern resembles the chart in the lower left chart. Subsequent myopic judgments accurately reflect the sampled proportions, but fail to take the sampling bias (on P3 or on negative outcomes) into account.
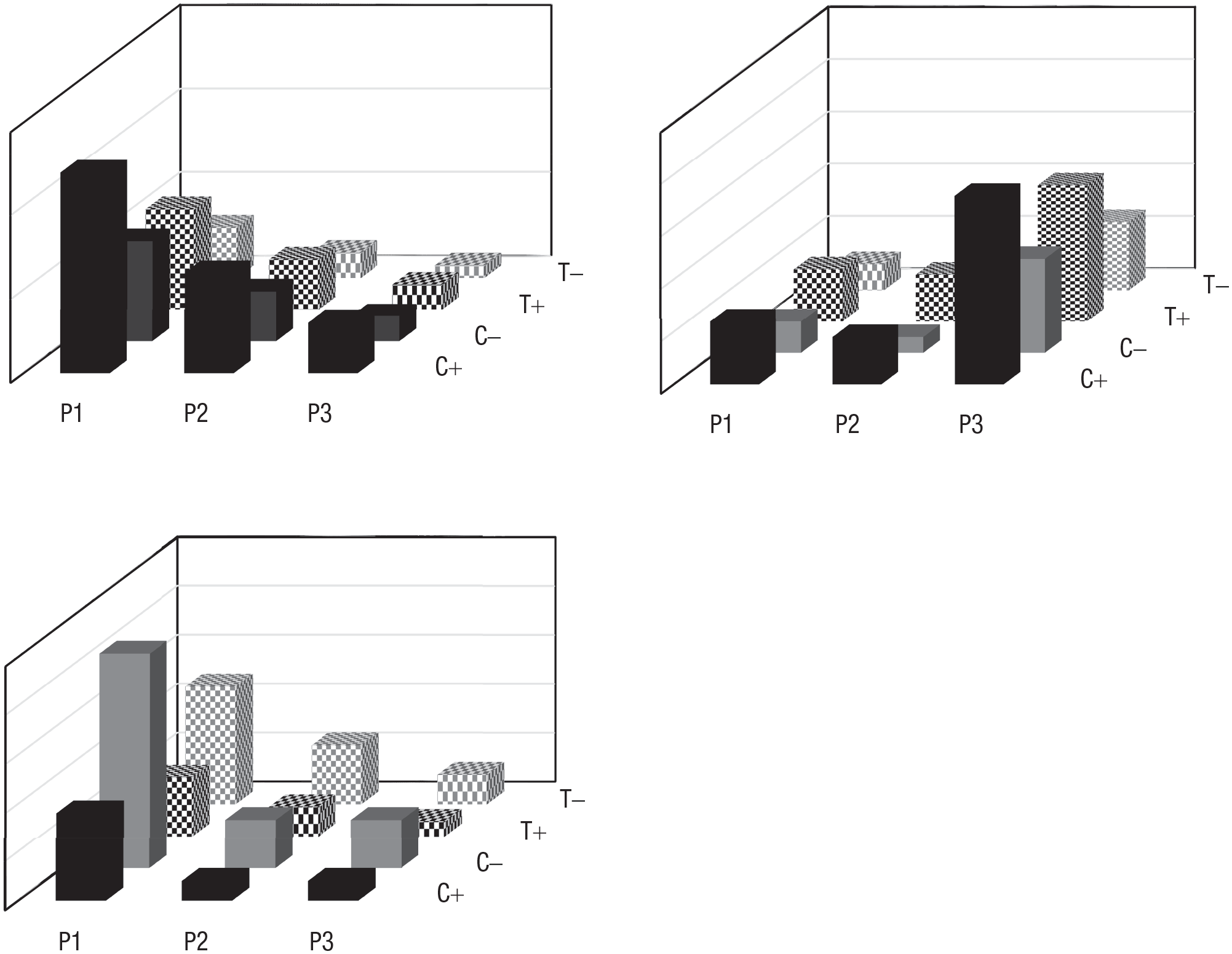
Illustration of failure in monitoring sampling bias. Given the same skewed (2:1) distribution of positive (+) to negative (–) outcomes for three providers (P1, P2, P3) in two product domains (C = computers, T = telecommunications) in the upper left chart, completely different patterns emerge when sampling draws heavily on P3 (upper right chart) or on negative outcomes (bottom left chart), as demonstrated in Fiedler (2008).
Denominator neglect in monitoring numerators
Closer reflection on denominator neglect (Reyna & Brainerd, 2008) offers a plausible mechanistic account of MM in proportional reasoning. To assess a proportion (or average), one needs to assess both the frequency (sum) of a focal outcome (the numerator) and the sample size (n) by which it is divided (the denominator). The increment or decrement coded for each observation depends on n; it is ½ if n = 2, 1/10 if n = 10, and so forth. Yet, as sample size (all ongoing samples’ n) is rarely known beforehand, the increment or decrement is unknown, which makes denominator size indeterminate, even when n is known. Participants may thus learn to make do without n, resorting to (numerator) summation strategies that value the same relative proportion higher when observations are summed over a large n rather than a small n (Fiedler et al., 2016; Price et al., 2006). As a consequence, the tendency to underestimate the same proportion in a small sample (e.g., 2/10) relative to a large sample (e.g., 20/100) may prevent people from recognizing the preciousness of scarce goods (Pleskac & Hertwig, 2014). Conversely, an adaptive consequence of denominator neglect may be to ameliorate disappointment (i.e., the difference between obtained and forgone outcomes), which decision affect theory predicts to be most severe for small samples (Mellers et al., 1999).
Evaluability constrains monitoring of value
Monitoring of value depends on evaluability (Hsee & Zhang, 2010). Highly evaluable attributes (e.g., the design of a new car) can be evaluated regardless of the context, whereas low-evaluability attributes (e.g., density of a car’s service network) can be evaluated only in comparison with other options. Recent experiments (Fiedler et al., 2020) using a speed-accuracy trade-off task illustrate strong evaluability constraints. In a sequential investment game, participants’ total payoff was the product of the average payoff (i.e., positive for correct choices and negative for incorrect choices between two investment funds) multiplied by the number of choices completed in a given time period. Increasing the number of observations about the prior success of both funds increased accuracy in choosing successful funds but at the same time decreased speed (the number of completed choices). Because speed decreased at a higher rate than accuracy increased with increasing sample size, a profitable strategy called for increasing speed and sacrificing accuracy. Yet participants failed to exploit the speed advantage and therefore obtained a much lower total payoff than possible, because accuracy’s greater evaluability induced dramatic overweighting of it. Correct or incorrect choices are easy to evaluate, but it is hard to evaluate strategies as either fast or slow. In any case, variation in evaluability can render monitoring functions difficult and tricky.
Metacognitive Control Functions
Monitoring and control functions can be mapped onto each other; monitoring results provides instructions for control. Thus, when monitoring entails feedback about what choice in a binary choice task was correct, one might assume that control reduces to following the instruction inherent in the feedback. In fact, however, control is much more intricate; imperative control instructions may not work. People cannot deliberately turn control functions on or off.
The myth of volitional control
Nobody would expect that participants who were given an imperative to stop learning from the pairing of stimuli and electrical shocks in a conditioning experiment would be successful in doing so. Yet an elusive myth assumes that one can turn learning on and off in an epistemic task, so that it is possible not to learn from stimulus exposure. Contrary to this myth, alerting participants to the fact that a piece of information is invalid or fully redundant does not prevent them from learning that information, and telling them that an anchor (e.g., an arbitrarily selected numerical value) is irrelevant does not prevent that anchor from influencing the learning process. For instance, when experimental participants were asked to estimate how often different stocks were among the daily winners on the stock market, they were as sensitive to mere repetitions of winning outcomes as to independent winning outcomes, even after an explicit warning not to be fooled by repetitions (Unkelbach et al., 2007). Similarly, in another study, group decision makers could hardly distinguish novel arguments from repeated old arguments (Fiedler, Hofferbert, & Wöllert, 2018). In a study of acceptance of advice, participants’ risk estimates were biased toward incontestably invalid advice (Fiedler, Hütter, et al., 2018), just as arbitrary numerical anchors have often been shown to bias quantitative judgments. Thus, voluntary control over the inclusion and exclusion of unequivocally valid and invalid information, respectively, can be harder than expected.
Feedback vicissitudes
A distinct control domain concerns utilization of feedback. It appears to be self-evident that feedback simply has to be translated into action, but in fact, using feedback is not at all easy. It is a long way from unambiguous feedback to an effective change in a corresponding action or performance. Just as mere failure feedback hardly enables a tennis player to improve a backhand stroke, feedback may not suffice to improve performance on epistemic tasks. Conversely, if no explicit feedback is provided in a paired-associates task or in a binary prediction task, participants may mistake their own self-generated expectations for explicit feedback. Their self-generated expectation that A, rather than B, will win can influence their learning about as much as does explicit outcome feedback that A actually won (Elwin et al., 2007). Ignoring self-constructed feedback in the absence of explicit feedback can be very hard for the control function.
Misattribution
To use feedback effectively, the control function must be sensitive to causality. To learn from wrong responses on a test, students must causally attribute their mistakes to their own behavior rather than blame teachers or classroom stress. Metacognition must avoid misattributions to unwarranted sources (Johnson et al., 1993).
Blends of Monitoring and Control Difficulties
Because monitoring and control are intertwined in the quality checks performed during cognitive tasks, many MM findings entail blends of both metacognitive functions. For instance, Hütter et al.’s (2022) recent research on evaluative conditioning revealed a combination of myopia for stimulus monitoring and feedback control. Unlike in traditional designs but in line with real life, participants could themselves sample conditioned-stimulus faces that were paired with positive or negative pictures as unconditioned stimuli, according to an experimental feedback plan. They exhibited a marked bias in their control of information search, sampling more rewarding faces paired with positive pictures than disappointing faces paired with negative pictures. In the monitoring function, the experience of sampling a face was as positive and reinforcing as experiencing a face paired with a positive picture.
Earlier research (reviewed in Fiedler, 2012) revealed a combination of base-rate neglect in monitoring and misattribution in control. Given a breast-cancer base rate of 1% in a universe of 1,000 women, a hit rate of 80%, and a false alarm rate of 9.6%, it follows that a positive mammogram should be obtained in 8 out of 10 women with breast cancer (i.e., 80%), as well as in 95 of 990 women without breast cancer (i.e., 9.6%). When sampling from an index-card file in which cards for women with and without breast cancer were separated, participants sampled roughly the same number of cases in the two categories. Thus, the roughly 50% rate of breast cancer in the sample overrepresented the true rate by a factor of 50. Because participants’ control function did not attribute the inflated breast-cancer rate to their own lopsided information search, their conditional probability judgments of breast cancer being present when a mammogram was positive were also highly inflated. Their monitoring function fell prey to denominator neglect, given a sample with 50% breast-cancer cases to estimate the rate in a reference set with 1% breast cancer.
Another study (Fiedler et al., 1996) demonstrated that judges exhibited systematic biases toward wrong propositions that they themselves had correctly denied. After seeing a video-recorded group discussion, participants were asked to verify whether the discussion leader had shown either 12 negative or 12 positive social behaviors. Even those actions that they correctly denied as having occurred in the video had a strong impact on subsequent judgments. Merely considering fictitious positive actions, whether or not they were denied as invalid, led to enhanced positive ratings on semantically related trait dimensions, and merely considering fictitious negative actions led to enhanced negative ratings.
Conclusions: Remedies and Debiasing Training
Closer analyses of the judgment-and-decision-making literature testify to MM as a major obstacle on the way to rationality. Whereas optimistic views of human rationality are typically based on tasks that call for accurate assessment of sample contents, pessimistic conclusions refer to situations that call for metacognitive assessment of sampling bias and validity. People are quite sensitive to assessing even complex and fine-grained information on consumer products, student achievement, or sports records. However, they are naive and uncritical regarding the validity of evidence.
Nevertheless, seemingly disastrous deficits in monitoring and control resulting in countless flaws in memory and reasoning (Fiedler, 2012) need not be attributed to a lack of intelligence or motivation (Connor Desai et al., 2020). Deeper reflection shows that quality control can be intrinsically difficult, sometimes facing problems for which no proper solutions exist at all. It is hardly possible to reconstruct a parent population from a biased sample, to give a weight of 1/n to each observation in a sample of size n when n is unknown, to render all attributes equally evaluable, or to instruct the cognitive system not to learn from invalid advice, an irrelevant anchor, or fake news.
Because a best normative solution does not exist for many inference tasks, it is but one step further to admit that there can be no generally applicable remedy or debiasing training to overcome MM. It is no wonder that feedback cannot be effective in wicked environments (in which feedback is absent or misleading; Hogarth et al., 2015). Training in Bayesian probability calculus also does not afford an effective remedy, when Bayesian mathematics does not offer a solution to correct for sampling biases. Likewise, nudging, sensitivity training, or implementation-intentions training cannot strengthen optimal strategies if no such strategies exist.
Although it may be possible to sensitize decision makers, influencers, teachers, and scientists to MM-prone task settings—and this is one of the purposes of the present article—we do not believe that the core problems of MM can be tackled by educating people to understand all vicissitudes of sampling biases, base-rate neglect, evaluability effects, attribution, feedback, and volitional control of one’s mental activities. A more modest but also more realistic strategy would be to improve people’s ability to recognize tricky MM settings in which no best solution or foolproof method for quality control exists. Diagnosing (and educating people about) task contexts leading to perseverance, sampling biases, base-rate neglect, or misattribution constitutes a more realistic goal for applied cognitive work than does trying to cure MM at its core. It is important to learn under which conditions one should refrain from premature inferences, use the opportunity to consider the opposite, or consult an expert in logical inference (much as one should consult an optometrist to treat myopia). Awareness of the problem may often provide the key to avoiding costly mistakes and downstream consequences of imperfect monitoring and control functions.
Recommended Reading
Ackerman, R., & Thompson, V. A. (2017). (See References). Presents good reasons why the scope of metacognition should be broadened to include reasoning.
Fiedler, K. (2012). (See References). Provides a comprehensive overview of the phenomenon of metacognitive myopia.
Hogarth, R. M., Lejarraga, T., & Soyer, E. (2015). (See References). Explains the notion of wicked environments.
Hsee, C. K., & Zhang, J. (2010). (See References). Offers a scholarly presentation of evaluability theory.