
Abstract
Publicly accessible large language models like ChatGPT are emerging as novel information intermediaries, enabling easy access to a wide range of science-related information. This study presents survey data from seven countries (N = 4320) obtained in July and August 2023, focusing on the perception and use of GenAI for science-related information search. Despite the novelty of ChatGPT, a sizable proportion of respondents already reported using it to access science-related information. In addition, the study explores how these users perceive ChatGPT compared with traditional types of information intermediaries (e.g. Google Search), their knowledge of, and trust in GenAI, compared with nonusers as well as compared with those who use ChatGPT for other purposes. Overall, this study provides insights into the perception and use of GenAI at an early stage of adoption, advancing our understanding of how this emerging technology shapes public understanding of science issues as an information intermediary.
1. Introduction
Online audiences are increasingly turning to web-based tools and platforms to inform themselves about health, economics, and other science-related topics (Segev and Sharon, 2017). The advent of generative artificial intelligence (GenAI), exemplified by large language models such as ChatGPT, has the potential to further transform how audiences engage with science-related information. Although GenAI is not a search tool and faces concerns about the quality of its content, from a user perspective, interacting with GenAI through natural language, combined with the freedom to pose unlimited questions, can make GenAI a valuable source for obtaining factual and explanatory science-related information (Schäfer, 2023). Indeed, initial surveys hint at the potential of GenAI in science communication, for instance, regarding receiving answers to factual questions (Fletcher and Nielsen, 2024) or information about scientific research (Viden and Demokrati, 2023). However, our understanding of how individuals use GenAI to engage with information about science remains limited. Research so far has centered around broader applications of artificial intelligence (AI) technology, such as content creation in science journalism (e.g. Lermann Henestrosa et al., 2023; Maiden et al., 2023) or attitudes toward AI as an emerging technology (e.g. Calice et al., 2022), while tending to focus on specific countries or regions (e.g. Skjuve et al., 2023). Yet, the influence of GenAI on science communication should be considered within a cross-national perspective, taking into account the cultural, social, and economic factors that shape engagement with science communication (Gascoigne et al., 2020) and AI.
To address this need, in this study, we present results from a cross-national online survey carried out in seven countries (Ntotal = 4320): Australia, Denmark, Germany, Israel, South Korea, Taiwan, and the United States of America (USA). The purpose of this study is twofold. First, we offer a cross-country overview of the reported use of GenAI for searching science-related information, with specific focus on ChatGPT as it is the most widely recognized and used (Fletcher and Nielsen, 2024). Second, we delve into the demographics of ChatGPT users engaged in science-related information searches across countries, comparing their knowledge about and their level of trust in (Gen)AI 1 to nonusers and users who utilize ChatGPT for purposes other than science-related information searches.
To our knowledge, this is one of the first studies to explore GenAI’s role in science-information seeking in a cross-national setting. Rooted in the traditions of the technology acceptance model (Davis, 1989), the contributions of this study extend beyond providing empirical insights into an emerging channel for science communication. They capture a distinctive moment in the global adoption of GenAI, at a point in the early stages of use of a technology that has the potential to transform both the theory and practice of science communication.
2. Generative AI as a new intermediary for science-related information
GenAI sets itself apart from established information intermediaries in its ability to produce human-like content autonomously through both generalization and creativity employed by the AI itself. Unlike media that act primarily as channels for human-generated content, GenAI is designed and interpreted as a responsive message source. It steps into the role of a communicator capable of conveying original content in a manner that is socially meaningful and meets human communicative needs (Guzman and Lewis, 2020).
According to Fletcher and Nielsen (2024), ChatGPT, a large language model developed by OpenAI for conversational usage, is currently the most widely used GenAI technology. In a recent study, English-speaking ChatGPT users reported appreciating the tool for providing detailed information in response to complex inquiries, as well as for its ability to facilitate comprehension of long(er) responses through a clear structure and straightforward language (Skjuve et al., 2023). Similarly, in a nationwide survey, half of the German respondents indicated that they were satisfied with ChatGPT’s potential for explaining complicated scientific issues and for the opportunity to ask follow-up questions (Wissenschaft im Dialog, 2023). This suggests that users value ChatGPT’s capacity to convey otherwise complex and dense information in a manner that enhances comprehension. However, to better understand the potential impact of GenAI on how individuals inform themselves about science, it is necessary to assess both the extent of its use for this purpose and how users perceive its effectiveness compared with tools like Google Search—an aspect that is also highlighted in the technology acceptance model (Davis, 1989). The first set of research questions (RQ) that guide our study are as follows:
RQ1a: What proportion of people in the countries under study use ChatGPT to search for science-related information?
RQ1b: How do users perceive science-related information retrieval with ChatGPT compared with Google Search?
In sharp contrast to search engines, which provide users with diverse sources to choose from, ChatGPT gives tailored responses to each query. However, ChatGPT (in its 2023 iteration) is based on a large language model that generates these answers based on complex statistical patterns from training data and lacks an intrinsic understanding of the conveyed content. This creates a situation where non-factual content may convincingly appear as facts (Angelis et al., 2023). A study by Spitale et al. (2023) underscores that GPT models can both inform and misinform individuals on health-related issues. Although some users appear to be aware of this problem (Skjuve et al., 2023), detecting incorrect information requires knowledge that users often lack. To assess the AI knowledge of individuals who use ChatGPT for science-related information retrieval and see if they constitute a distinct segment compared with other subpopulations, we ask:
RQ2: What is the level of factual knowledge about (Gen)AI among ChatGPT users who engage the model for science-related information searches compared with nonusers and users who utilize ChatGPT for other purposes?
Furthermore, the design of AI technologies, particularly commercial GenAI models, is often non-transparent. The training data behind these models is frequently withheld from the public, and tech companies tend to guard the inner workings of their AI systems as proprietary information (Van Dis et al., 2023). In navigating the black-box nature of AI, trust emerges as a pivotal factor (Choung et al., 2023; Rheu et al., 2021). Trust has also been found to drive users’ intentions to accept such technologies (Kelly et al., 2023). Notably, survey data from Germany indicates a lack of trust in ChatGPT when disseminating science-related information (Wissenschaft im Dialog, 2023). This is attributed to concerns about misinformation, revealing a critical need to address trust in the context of AI-driven science communication. With this in mind, to further characterize individuals who use ChatGPT for science-related information retrieval, we ask:
RQ3: What is the level of trust in GenAI among ChatGPT users who engage the model for science-related information searches, and how does it compare with that of nonusers and users who utilize ChatGPT for other purposes?
3. Method
Sample
To address our RQs, we conducted an online survey gathering data in Australia, Denmark, Germany, Israel, South Korea, Taiwan, and the USA (Ntotal = 4320) between July and August, 2023. The countries examined are affluent and possess advanced technological infrastructures; however, they vary in their science communication landscapes (Gascoigne et al., 2020) and their general attitudes toward AI (Neudert et al., 2020). It is important to note that the selection of countries was not systematic but rather achieved through professional networks such as the Network for the Public Communication of Science and Technology (PCST). In each country, our samples were representative of the respective national (Internet) populations in terms of age, gender, and education. 2 We collected data on knowledge about, trust in, and use of GenAI through online access panels, with the questionnaire translated into the relevant primary languages. The numbers of respondents per country are as follows: nAUS = 552, nDEN = 504, nGER = 566, nISR = 500, nKOR = 642, nTWN = 504, nUSA = 1052. For a demographic breakdown of the sample by country, see Supplementary B (Table S1) in the Supplemental Material. The English version of the questionnaire can be found in Supplementary A. In this research note, we only present findings on a subset of all questions asked.
Measurements
Using ChatGPT for searching science-related information
This variable is based on an original questionnaire (similar to Fletcher and Nielsen, 2024), inquiring about respondents’ general experience with five AI applications—including ChatGPT—and with Google Search. Respondents were shown the list of applications they reported having used, followed by a series of questions about their use of those applications for science-related information search, including if they were confident in finding what they needed and whether they were content with the science information they found—each measured as a 5-point scale single item. To ensure shared understanding, we offered respondents a definition of science-related information search.
Knowledge about AI technology
Drawing from the literature (Long and Magerko, 2020) and in collaboration with AI experts, we developed nine statements to assess respondents’ factual understanding of (Gen)AI technology. Respondents were asked whether those statements were true or false. In addition, they could choose the option “I don’t know” if unsure. Six of the nine statements concentrate on the functioning of (Gen)AI (sum score from 0 to 6; M = 3.5, SD = 1.5), while the remaining three address the quality of the information provided (sum score from 0 to 3; M = 1.5, SD = 1.1). The two types of knowledge are weakly related (Pearson’s r = .20, p < .001); hence, we treated them as separate dimensions. In line with prior research (Calice et al., 2022), we provided respondents with definitions of both AI and GenAI.
Trust in GenAI
Based on prior research (Choung et al., 2023; Weidmüller, 2022), we measured trust in GenAI using 15 items that encompassed aspects of both human-like trust (i.e. benevolence/helpfulness, integrity/reliability) and functionality trust (i.e. competence/functionality). In the context of science communication, we introduced dialogue and transparency as two additional dimensions deemed relevant for evaluating trust in scientists (Reif et al., 2024). The 15 items, which were measured on 5-point scales (1 = “strongly disagree,” 5 = “strongly agree”), formed a reliable scale (Cronbach’s α = .95, M = 3.4, SD = 0.8; Cronbach’s α for each dimension ranges between .76 and .80). Based on the results of an exploratory factor analysis, we used the overall score for the subsequent analyses.
4. Results
RQ1a: What proportion of people in the countries under study use ChatGPT to search for science-related information?
As displayed in Figure 1, analyzing respondents’ reported experiences with ChatGPT revealed varying usage across countries. In Australia and Denmark, 9% (95% CI = [0.06, 0.11]; 95% CI = [0.07, 0.12]) of respondents reported regular use, while Germany and the USA had 10% (95% CI = [0.08, 0.13]) and 11% (95% CI = [0.09, 0.13]) regular users, respectively. In Israel and South Korea, 16% (95% CI = [0.13, 0.19]) and 17% (95% CI = [0.14, 0.2] of respondents, respectively, reported using the chatbot on a regular basis. Taiwan had the highest proportion of regular users (26%; 95% CI = [0.22, 0.3]).
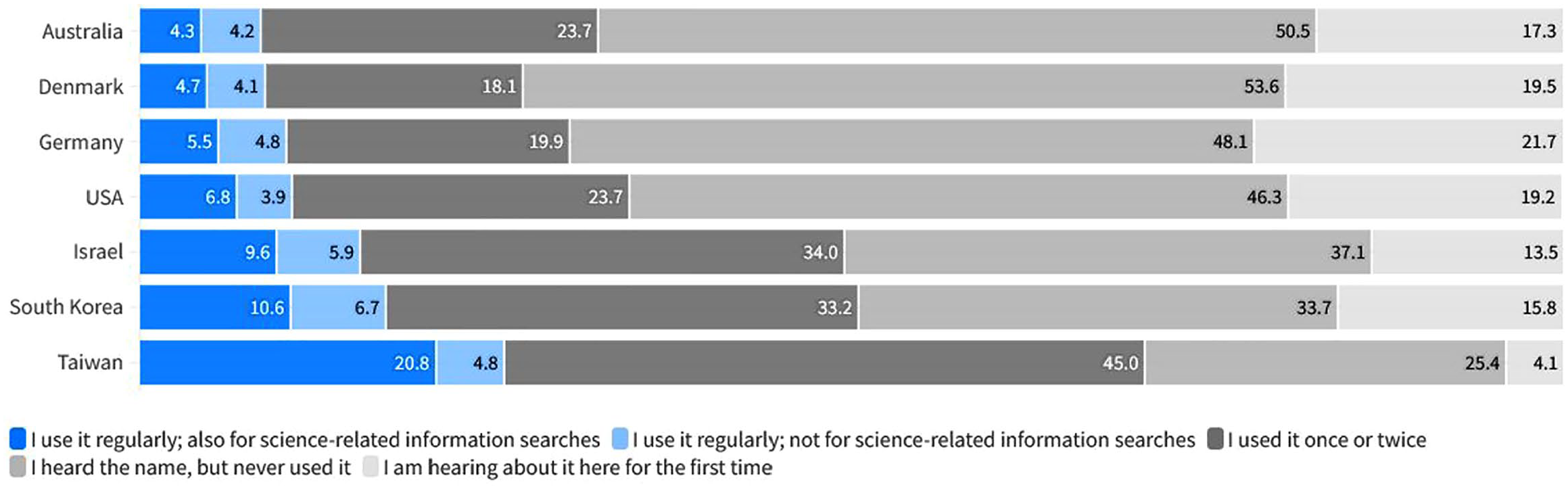
Experience with ChatGPT across countries. For color figure please see online version.
In order to explore the significance of ChatGPT as a search tool for science-related information, we centered our analysis on regular users of ChatGPT (n = 555; 13% of the total sample). In total, 67% of regular users reported using ChatGPT for science-related information searches (n = 371; 9% of the total sample). The highest usage rate was again observed in Taiwan, with 84% of regular users employing ChatGPT for science-related searches. Across the remaining countries, the proportions were as follows: 69% of regular ChatGPT users in the USA, 65% in South Korea, 64% in Israel, 54% in Denmark and Germany, and 53% in Australia (see Table 1).
Use for science-related information searches among regular users of ChatGPT.
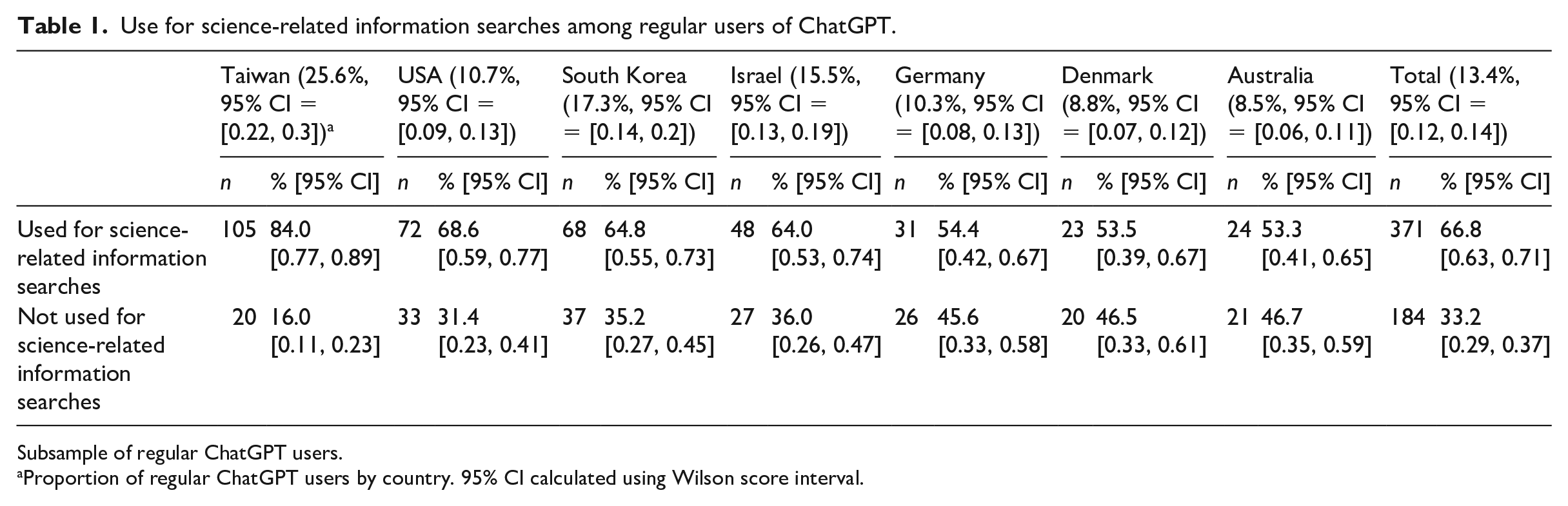
Subsample of regular ChatGPT users.
Proportion of regular ChatGPT users by country. 95% CI calculated using Wilson score interval.
RQ1b: How do users perceive science-related information retrieval with ChatGPT compared with Google Search?
Across the seven countries, we found that users who employed ChatGPT for science-related information expressed contentment with the information provided (M = 4.0, SD = 0.9) and felt confident in their ability to find the necessary information (M = 3.6, SD = 1.0). Comparing ChatGPT with Google Search, there was a small significant difference in user satisfaction with the information provided (t(263) = −2.038, p = .043). Also, a significant difference emerged in users’ confidence in finding the information they sought (t(276) = −3.798, p < .001), with higher scores for Google Search in both cases. At the country level, however, a significant difference was particularly evident in Germany and Israel, where respondents reported significantly higher confidence in finding information using Google Search (see Table 2).
Confidence and contentment the last time ChatGPT and Google Search were used for science-related information searches.
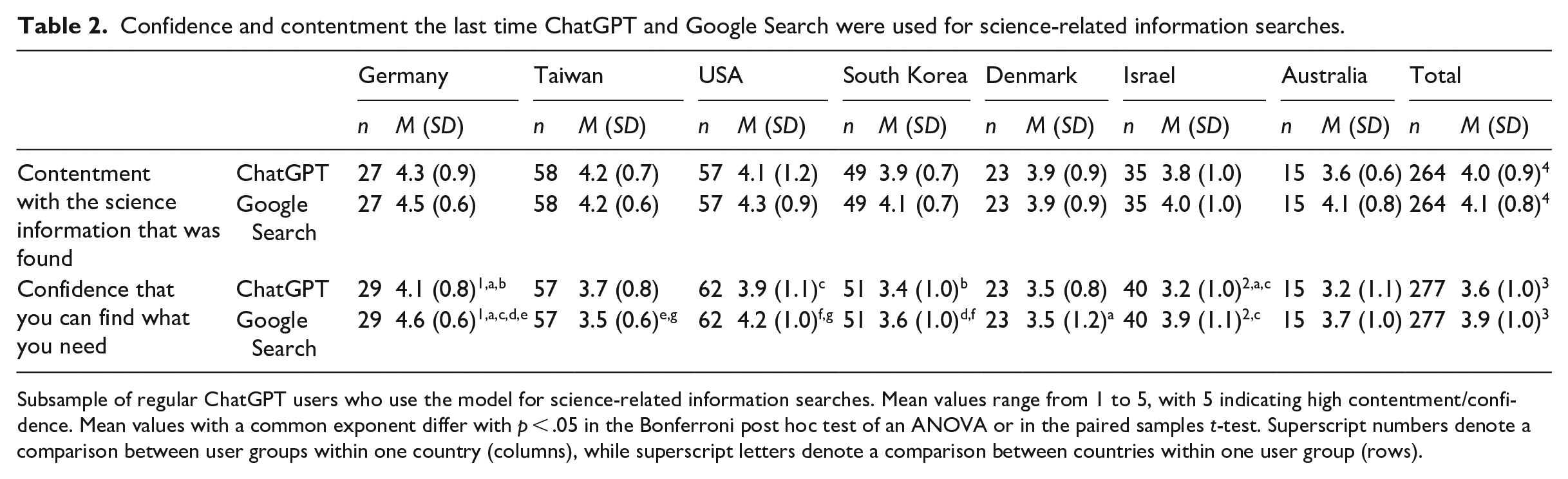
Subsample of regular ChatGPT users who use the model for science-related information searches. Mean values range from 1 to 5, with 5 indicating high contentment/confidence. Mean values with a common exponent differ with p < .05 in the Bonferroni post hoc test of an ANOVA or in the paired samples t-test. Superscript numbers denote a comparison between user groups within one country (columns), while superscript letters denote a comparison between countries within one user group (rows).
RQ2: What is the level of factual knowledge about (Gen)AI among ChatGPT users who engage the model for science-related information searches, compared with nonusers and users who utilize ChatGPT for other purposes?
As given in Table 3, knowledge about the functioning of (Gen)AI varies among science-information seekers: The six-point sum score ranges from M = 3.5 (SD = 1.3) in Australia to M = 4.6 (SD = 0.9) in Taiwan. Across the seven countries studied, this group demonstrates significantly higher knowledge about how (Gen)AI functions compared with nonusers (mean difference = .7, p < .001) (F(2, 4316) = 36.66, p < .001). However, there is no significant difference between the two groups of ChatGPT users, nor are there any significant group differences in Australia and Taiwan. Regarding knowledge about the quality of information provided, among science-information seekers, the three-point sum score ranges from M = 1.0 (SD = 0.9) in Taiwan to M = 2.2 in Israel (SD = 0.9). Significant differences are only observed in Israel, where users engaging ChatGPT for science-related searches know more about the epistemic limitations of (Gen)AI than nonusers (F(2, 497) = 7.45, p < .001; mean difference = .5). Notably, across all countries, there is a prevalent use of “I don’t know” responses (see Supplementary B, Table S2).
Factual knowledge about AI among different user groups.
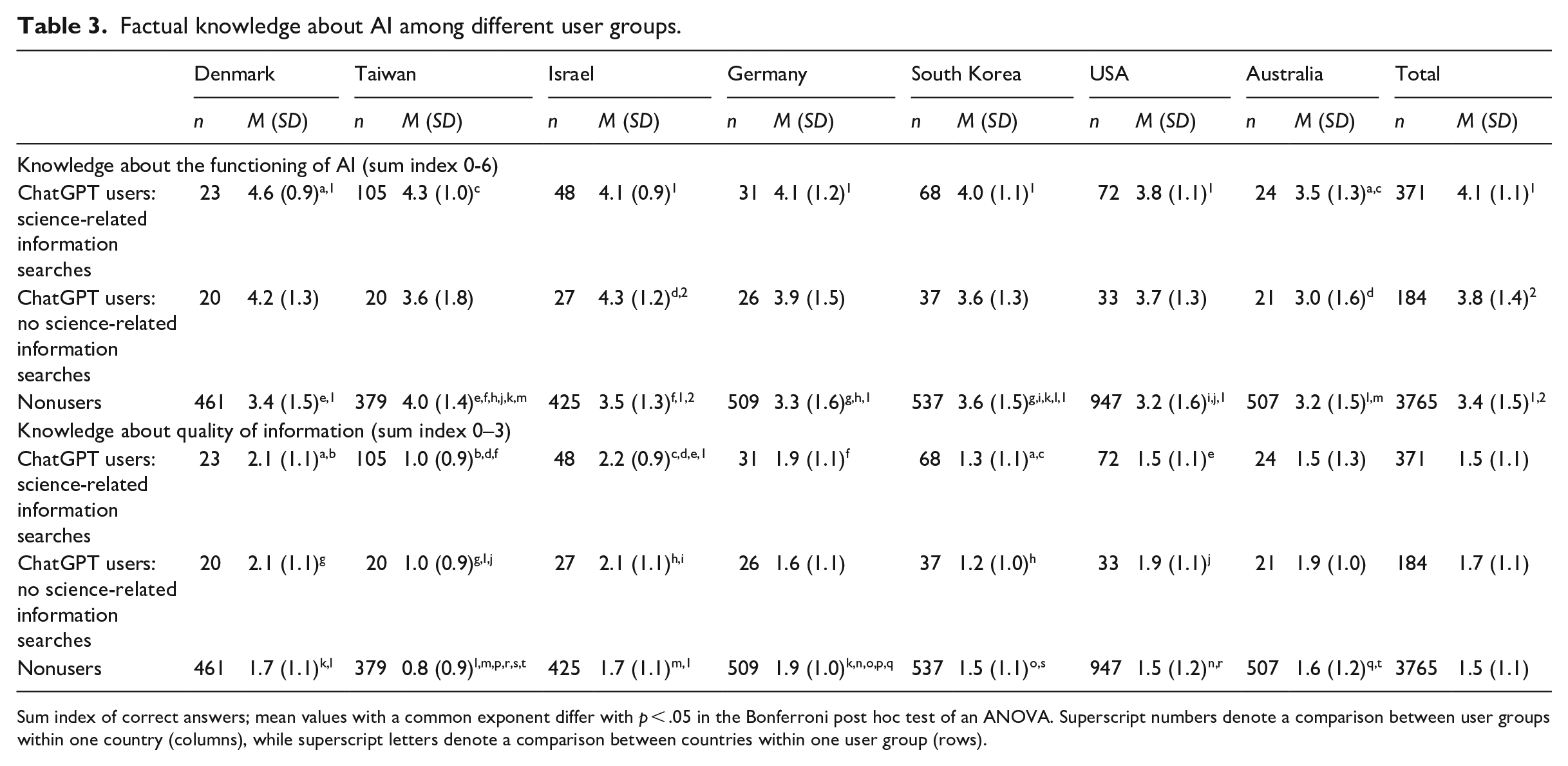
Sum index of correct answers; mean values with a common exponent differ with p < .05 in the Bonferroni post hoc test of an ANOVA. Superscript numbers denote a comparison between user groups within one country (columns), while superscript letters denote a comparison between countries within one user group (rows).
RQ3: What is the level of trust in GenAI among ChatGPT users who engage the model for science-related information searches, compared with nonusers and users who utilize ChatGPT for other purposes?
Among ChatGPT’s regular users who employed the tool for science-related information searches, the levels of trust in GenAI ranged from M = 3.4 (SD = 06. and SD = 0.5, respectively) in Denmark and Israel to M = 4.1 (SD = 0.5) in Taiwan (see Table 4). Across all countries (F(2, 2935) = 69.34, p < .001), trust in GenAI was higher for ChatGPT users who engage the model in science-related information search than for nonusers (p < .001); but no significant difference was observed for ChatGPT users who did not engage in science-related searches (p = .06). At the country level, the significant difference, however, was not evident in Israel (F(2, 286) = 0.1, p = .90). In all subpopulations, a substantial proportion found themselves unable to provide responses to items related to trust in GenAI, reflected in the prevalent occurrence of “I don’t know” responses.
Trust in generative AI among different user groups.
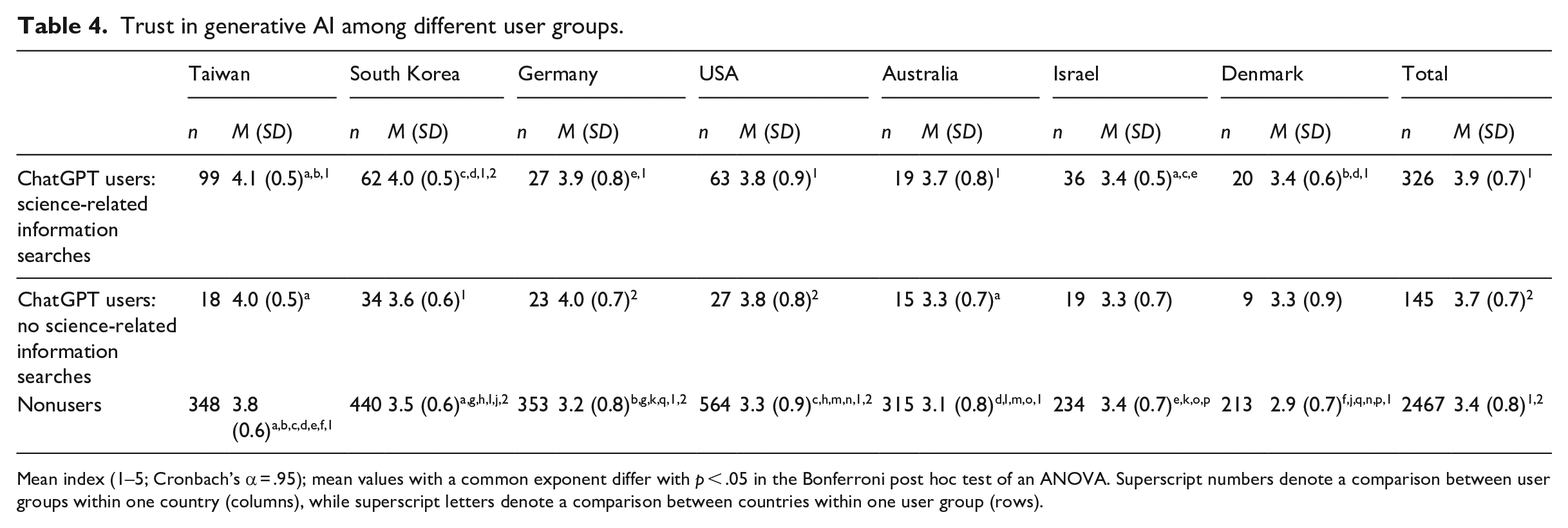
Mean index (1–5; Cronbach’s α = .95); mean values with a common exponent differ with p < .05 in the Bonferroni post hoc test of an ANOVA. Superscript numbers denote a comparison between user groups within one country (columns), while superscript letters denote a comparison between countries within one user group (rows).
5. Discussion
This research note explores the evolving landscape of new intermediaries for science-related information searches, by providing insights into the cross-national use of GenAI, exemplified by ChatGPT. 9% of the total sample reported actively using this tool for information retrieval in scientific domains, which may highlight the start of a potentially transformative role of AI in shaping how individuals access and engage with scientific knowledge (Schäfer, 2023). Although differences across countries must be interpreted with caution due to the small sample sizes and the resulting sampling variability, ChatGPT users in Taiwan, the USA, South Korea, and Israel seem to display a keen interest in leveraging ChatGPT for science-related information searches. Taiwan, South Korea, and Israel are known for having a receptive environment for AI adoption (Getz et al., 2020; Johnson and Tyson, 2020). In addition, while there is widespread belief in science and technology for national prosperity in these countries, their science communication landscapes are still developing (Baram-Tsabari et al., 2020; Huang et al., 2020; Kim, 2020), potentially creating an opportunity for new intermediaries like ChatGPT to fill a gap. In the USA, however, while there is evident interest in using AI tools like ChatGPT (Fletcher and Nielsen, 2024), concerns about their impact on daily life and privacy remain prominent (Tyson and Kikuchi, 2023).
According to the technology acceptance model, the perceived ease of use and usefulness of a technology drives its adoption (Davis, 1989). Our data indicate that ChatGPT users in Germany and Israel have higher confidence in finding the desired information via Google Search, representing an established science-information search tool. However, at the country level, users evaluate ChatGPT and Google Search comparably in terms of satisfaction with the information provided. This is noteworthy because, while GenAI technologies can aid in information retrieval, they clearly distinguish themselves from traditional intermediaries such as search engines—particularly regarding the quality of factual information (Angelis et al., 2023).
For science communication research, the tension between the probabilistic nature of AI outputs—where answers are generated by predicting the most likely next words or sequences based on data patterns rather than directly retrieving facts—and the public’s need for accurate scientific information for quality decision-making is of significant theoretical importance. Our study contributes to this by showing that, in all seven countries surveyed, ChatGPT users seeking science-related information are at least as informed about the functioning and epistemic limitations of AI and GenAI as nonusers. In most countries, knowledge about how AI technology works is higher among users compared with nonusers. Moreover, apart from Israel where no significant differences were found, the level of trust in AI is significantly higher among ChatGPT users compared with nonusers. This alignment of characteristics among users potentially suggests a specific subpopulation that actively seeks out AI-powered solutions for scientific information retrieval (Bao et al., 2022). However, given the substantial proportion of respondents answering “I don’t know” in all subpopulations of our study, it appears that many people do not feel adequately informed—at least, at this stage of the adoption of GenAI tools for daily use—to express definitive opinions on trust in AI systems or to report whether a statement about (Gen)AI is true or false. Also, there were no significant differences between users employing ChatGPT for science versus other purposes, raising questions about whether science-related information is treated just like any other type of information in this context. This underscores the need for ongoing research in this area, also taking into account country-specific engagement with science and AI and additional variables; for instance, we also found that respondents who use ChatGPT for science-related information searches were on average younger, often male, and tended to have higher levels of education (see Supplementary B, Table S1).
Acknowledging both the novelty of the technology and the resulting small sample sizes within regular users of ChatGPT seeking science-related information, we refrained from further characterizing this subpopulation at a country-level. Furthermore, in the absence of established scales for GenAI, we relied on self-created items, which need to be further validated in future studies. Our selection of countries also extends beyond the traditionally well-researched areas of Europe and the USA, albeit with a continued emphasis on Western-oriented countries. As mentioned, the selection process was not guided by a systematic approach. Consequently, the findings of this study should not be generalized globally. Future research would benefit from adopting a more rigorous sampling strategy, assembling cross-national samples based on a systematic variation of criteria such as the pace of digital adoption, the presence of AI policies, or the status of the science communication landscape.
Despite these limitations, our cross-national survey provides empirical insights at an early stage of an emerging technology’s integration into everyday life, focusing on users’ science-related searches. As such, it paves the way for future research to delve more deeply into the global changes in science communication practices resulting from GenAI.
Supplemental Material
sj-docx-1-pus-10.1177_09636625241308493 – Supplemental material for The perception and use of generative AI for science-related information search: Insights from a cross-national study
Supplemental material, sj-docx-1-pus-10.1177_09636625241308493 for The perception and use of generative AI for science-related information search: Insights from a cross-national study by Esther Greussing, Lars Guenther, Ayelet Baram-Tsabari, Shakked Dabran-Zivan, Evelyn Jonas, Inbal Klein-Avraham, Monika Taddicken, Torben Esbo Agergaard, Becca Beets, Dominique Brossard, Anwesha Chakraborty, Antoinette Fage-Butler, Chun-Ju Huang, Siddharth Kankaria, Yin-Yueh Lo, Kristian H. Nielsen, Michelle Riedlinger and Hyunjin Song in Public Understanding of Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Niedersächsisches Vorab, Research Cooperation Lower Saxony—Israel and Lower Saxony Ministry for Science and Culture (MWK), Germany [Grant No. 11-76251-2345/2021 (ZN 3854)]; Aarhus University Research Foundation, Grant No. AUFF-E-2019-9-13; Morgridge Institute for Research & Wisconsin Alumni Research Foundation (WARF); National Science and Technology Council, Taiwan (Grant No. MOST 110-2511-H-194-003-MY3 and Grant No. NSTC 112-2628-H-128-001-MY3); and Yonsei University Research Grant (Funding no: 2024-22-0385).
ORCID iDs
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.