
Abstract
Given the importance of public engagement in governments’ adoption of artificial intelligence systems, artificial intelligence researchers and practitioners spend little time reflecting on who those publics are. Classifying publics affects assumptions and affordances attributed to the publics’ ability to contribute to policy or knowledge production. Further complicating definitions are the publics’ role in artificial intelligence production and optimization. Our structured analysis of the corpus used a mixed method, where algorithmic generation of search terms allowed us to examine approximately 2500 articles and provided the foundation to conduct an extensive systematic literature review of approximately 100 documents. Results show the multiplicity of ways publics are framed, by examining and revealing the different semantic nuances, affordances, political and expertise lenses, and, finally, a lack of definitions. We conclude that categorizing publics represents an act of power, politics, and truth-seeking in artificial intelligence.
1. Introduction
A curious problem emerged as we investigated public participation in artificial intelligence (AI). As expected, authors reported that AI was opaque, complex, and required a high degree of numeracy. Comprehension was out of reach; not only to the general public but also to the majority of researchers and policymakers (Burrell, 2016). Achieving greater public understanding of AI was important because of massive investments in AI by both the public and private sectors and because of AI’s impacts upon our daily lives. Consequently, there was considerable interest in assessing public perceptions of AI, for instance, by socio-demographics or literacy levels (Zhang and Dafoe, 2019). However, something was still missing. Were we talking about the public? The citizen? The stakeholder? All terms appeared throughout literature that spoke to participation vis-à-vis AI but terms connoted slightly different affordances, inclusions, and exclusions. The public functioned as individual citizens questioning automated decision-making or as consumers of AI services (e.g. Simonofski et al., 2017). Deployment of AI engaged members from the public in roles ranging from contributing code to analyzing model outcomes and functioning as data sources (Sloane et al., 2020). AI deployment continues to differentially affect members of the public (Benjamin, 2019). We argue that, alongside interrogations of who is left out and who is affected, we should examine the semantic, ontological, and epistemological levels of who this public, citizen, or human is in AI.
Explication of impacts, harms, and biases represents a multidisciplinary effort (Dwivedi et al., 2021; Raley and Rhee, 2023). Discourses tend to originate from computer science, philosophy, and law, but rarely social science. Diversity complicates concrete conceptions of those who are neither policymakers nor researchers who study participation and participants. Without examining the ontological or epistemological, it may be left to AI developers to interpret what is meant by citizen and those affected. Problems in identifying members of the public predates AI. Fung (2006) is well-known for his model of citizen participation vis-à-vis the state and he specifically brings the public into governance (Fung, 2015). However, a definition of the public is absent.
Concrete definitions of the participant/citizen/public in AI are important because of which characteristics of individuals are deemed important. Choosing “participant” infers some act of participation. The term participation itself is problematic; participation is “an infinitely malleable concept, [which] can be used to evoke—and to signify—almost anything that involves people” (Cornwall, 2008: 269). Calling someone a stakeholder assumes a significant interest. Use of citizen as a placeholder term infers legal rights. The AI literature, compared to prior literature on Information and Communications Technology (ICT)-related engagement, introduces a role for humans in the specific case of human-in-the-loop (HITL). A lack of grounding definitions also obscures political power. Whereas exploitation and accountability are of enhanced concern to the AI industry, researchers, and regulators; common use of abstract governance framings and vague notions of publics can entrench and obfuscate existing power structures (Whittaker, 2021). Reducing such abstractions becomes crucial to countering potential co-opting of the AI discourse.
No term fully encompasses participant/citizen/public. We choose the term publics to capture various ways they are considered in the AI literature from these diverse disciplines. Our object of study therefore is the characterization of actor and not the act within this broad literature scan. We first examine past literature reviews of public participation 1 in AI, where researchers and practitioners likely describe publics. Next, we outline a mixed methodology for a structured literature analysis on publics in AI. We present our findings on 12 types of publics. We conclude by discussing the epistemological and ontological implications of these varied terms.
2. Past literature reviews on publics in public engagement in AI
No literature directly examines the subject of publics regarding AI. We assumed that, of all the literature concerned about AI impacts, literature considering AI-related participation would contain the most refined conceptualizations of various publics. Table 1 summarizes the key focus of past literature reviews and any mentions of publics.
Instances of definitions and characterizations of “publics” in key literature reviews on the use of AI for public participation.
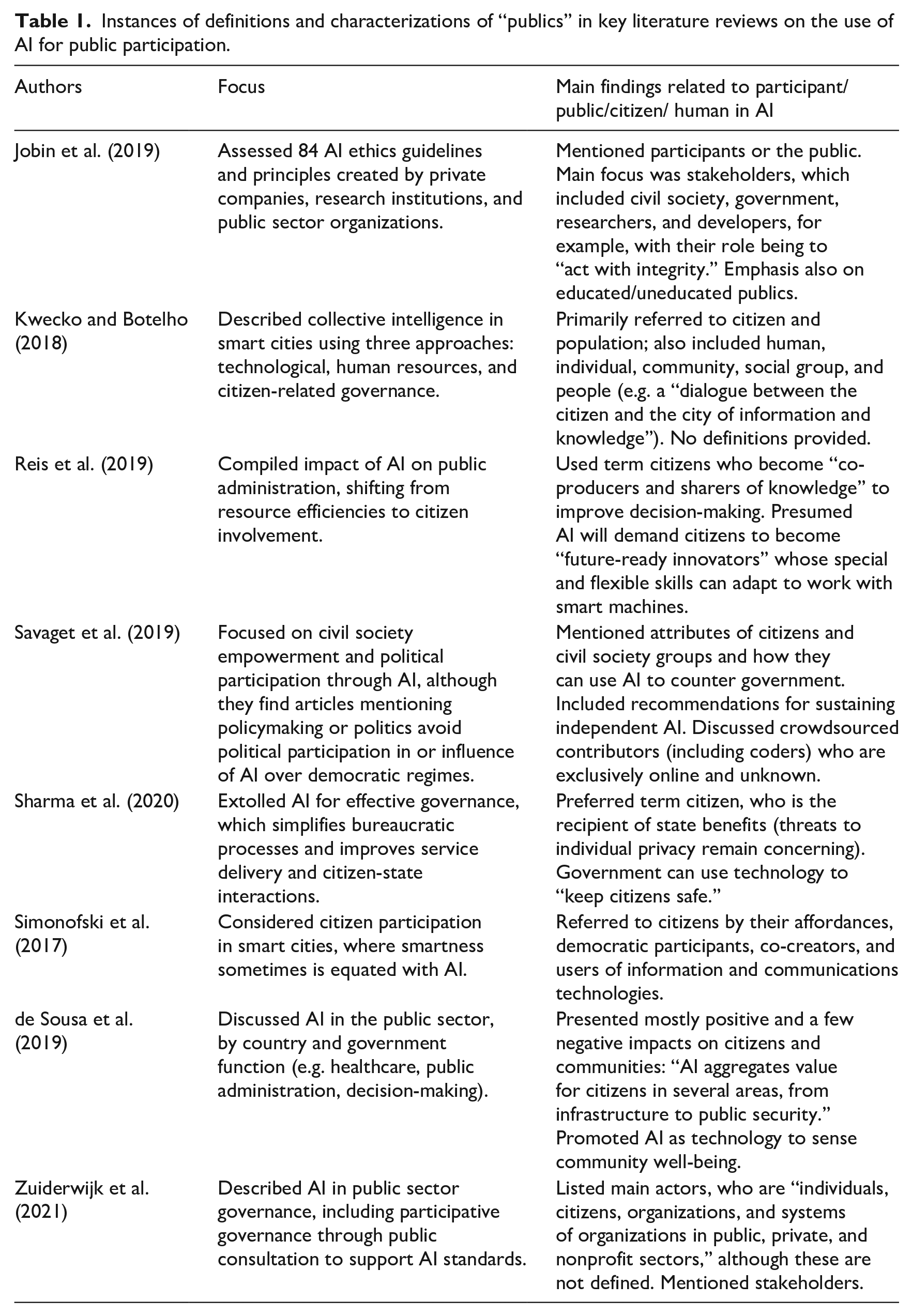
These literature reviews identified participation as integral to a fair, transparent, and inclusive AI; however, authors rarely defined publics beyond generic terms such as public and citizen. Participation could be services based with individuals as beneficiaries or victims (de Sousa et al., 2019); transaction-based, where individuals engaged in dialogue with government (Zuiderwijk et al., 2021); or “maker”-based, with citizens as contributors who could optimize AI processes (Reis et al., 2019; Savaget et al., 2019). Articles such as Vanolo (2016) emphasized a rights-based approach, where publics should have the right of access to information or a right to privacy (European Union, 2022). Simonofski et al. (2017) provided among the few reviews that identified a broad range of publics, for example democratic participants and knowledge co-creators.
Reviews focused on AI applied in the public sector (e.g. Simonofski et al., 2017), citizen participation in smart cities since smartness is associated with technologies like AI (e.g. Kwecko and Botelho, 2018), distillations of AI ethics (Jobin et al., 2019), implications of AI in governance (Zuiderwijk et al., 2021), and political empowerment through AI (Savaget et al., 2019). Characterization of publics appeared to vary by object of study. For example those conducting smart city research conceived of publics as individual citizens interacting with a technologically enabled locality. Jobin et al.’s (2019) analysis of 84 guidelines of ethical AI drew on national or global entities. These large-scale entities conceived of publics as stakeholders who could include almost everyone: private sector actors, government employees, and AI designers. Those who study AI governance (e.g. Zuiderwijk et al., 2021), Gurumurthy and Chami (2019) argued, tended to depoliticize the role of the publics. This could incentivize policy makers to seek out publics without political agendas and or knowledge of AI. One missing voice is the computer/data scientist, the builder of AI (e.g. Zuiderwijk et al., 2021 explicitly excluded them). AI developers may invoke various publics but receive little guidance from these literature reviews.
Gurumurthy and Chami’s (2019) critique also implies that political orientation affects choice of publics, for instance, framing publics as part of neoliberalism or a participatory democracy. In the first, a co-producer or “future-ready innovator” invokes an AI that aggregates value for and from citizens (Reis et al. 2019). In a participatory democracy, citizens actively participate in decision-making processes and have the potential to influence policy outcomes. We unpack the implications in the choice of representations.
3. Methods
A literature analysis encompassing AI and all references to various publics generated millions of potential articles, especially when the goal was a cross-disciplinary overview. To accommodate this breadth, we conducted a structured literature analysis using a combination of automated keyword querying and manual review, following Sacha et al. (2016). We outline this process in Figure 1. The process comprised the following seven steps: (1) determine the essential reading list, (2) create initial filter keywords, (3) develop search strings, (4) collect a corpus of articles (e.g. input search strings to collect articles), (5) classify the corpus, (6) refine the corpus (https://osf.io/6tjb8/) and identify articles to include and exclude, and (7) interpret a refined corpus.
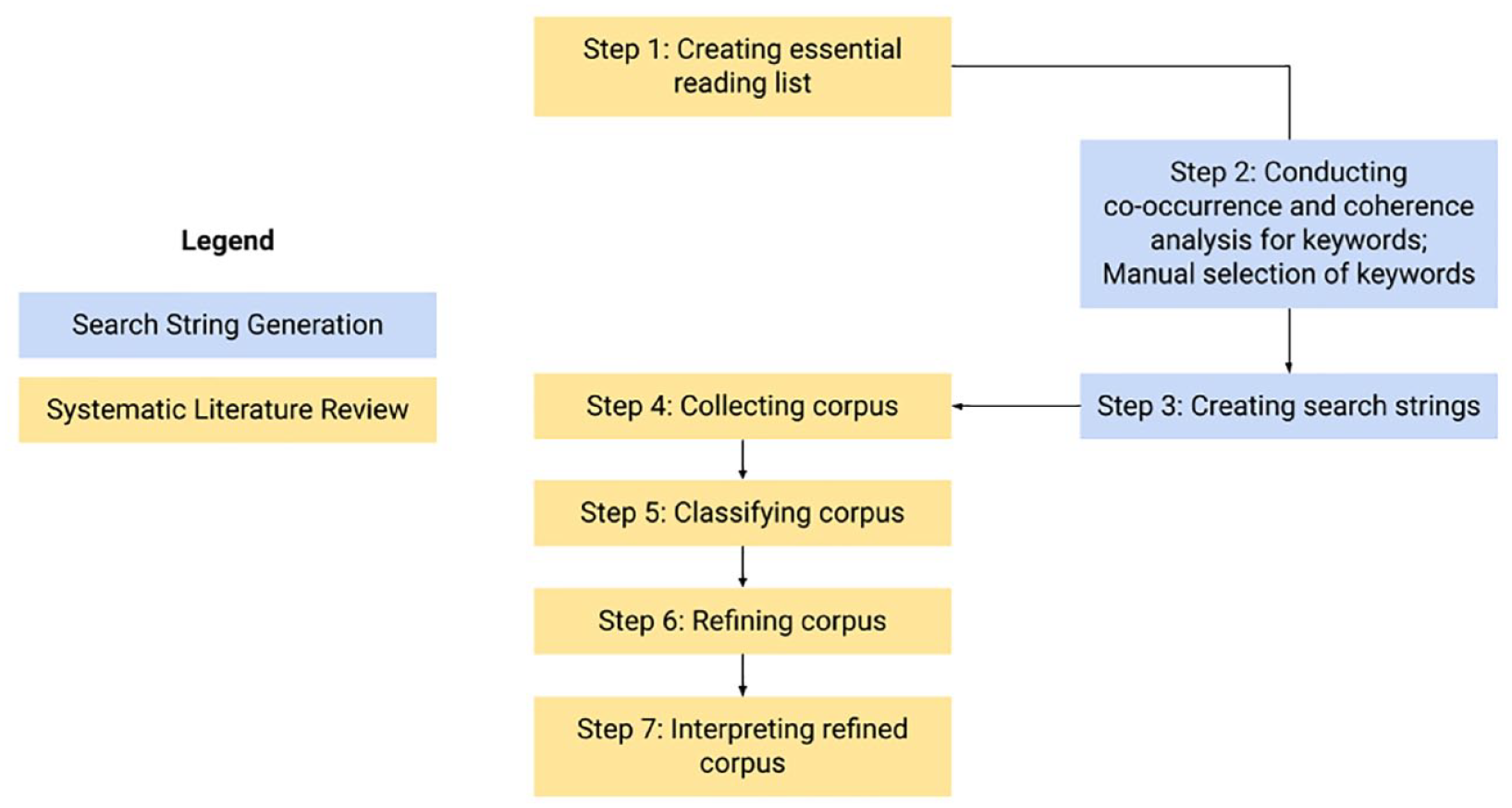
Overview of the structured literature analysis for corpus processing and interpretation.
Search string generation
We implemented a series of filters to arrive at our final corpus. We first developed a set of keywords that would form the search strings. This was the search string generation portion of the structured literature analysis (Figure 1). To achieve these keywords, we analyzed an essential reading list of 77 articles, which represented core debates on participation and AI (Step 1). Using these articles to seed the keywords, and ultimately search strings, gave us confidence that our searches would return results representative of similar discourses across the broader literature. The 77 articles were analyzed algorithmically using a bigram model, which approximates the probability of a word given all the previous words by using only the conditional probability of one preceding word. After filtering out frequent low-value words (e.g. “and”), we selected the 100 most frequent words. These 100 keywords were manually classified into the following two categories: technology keywords and participation keywords. We employed VOSviewer 1.6.16 2 to visually inspect word co-occurrence and find word clusters, especially frequent phrases. Manual classification resulted in 16 technology keywords (e.g. “machine learning”), 27 participation keywords (e.g. “democratic participation”), and eight mixed keywords (e.g. “data governance”; Step 2). From these keywords, we developed 36 search strings (Step 3).
Search strings combined technology phrases including “Artificial Intelligence,” “Machine Learning,” “Algorithmic/Algorithm(s),” “Automated Decision(s).” Participation phrases included “Public Participation,” “Citizen(s)/Civic Participation,” “Political Participation,” “Public Engagement,” “Citizen(s)/Civic Engagement,” “Political Engagement,” “Democracy/Democratic,” “Governance/government,” and “Data Governance.” Searches returned both peer-reviewed articles and gray literature. We retained gray literature (e.g. reports and non-peer-reviewed articles) due to their popularity as a medium among both academic and non-academic authors. Search strings were used to query Google Scholar, which returned 3533 articles (step 4).
Systematic literature review
Step 5 (Figure 1) consisted of classifying our corpus. We chose to classify articles (Statistics Canada, 2005) to provide an overview of the multidisciplinarity of our corpus (Figure 2). The two dominant categories were computer science (452 articles) and public administration and public policy (483 articles). Law contributed 245 articles. Articles offering technical methodologies and applications to multiple sectors and fields also are included (primarily health/medicine, communication/media studies, political science, sociology). Overall our corpus contained articles from 1969 to 2022, noting that the majority of the articles were published from 2010 to present (2467 of 2656 articles).
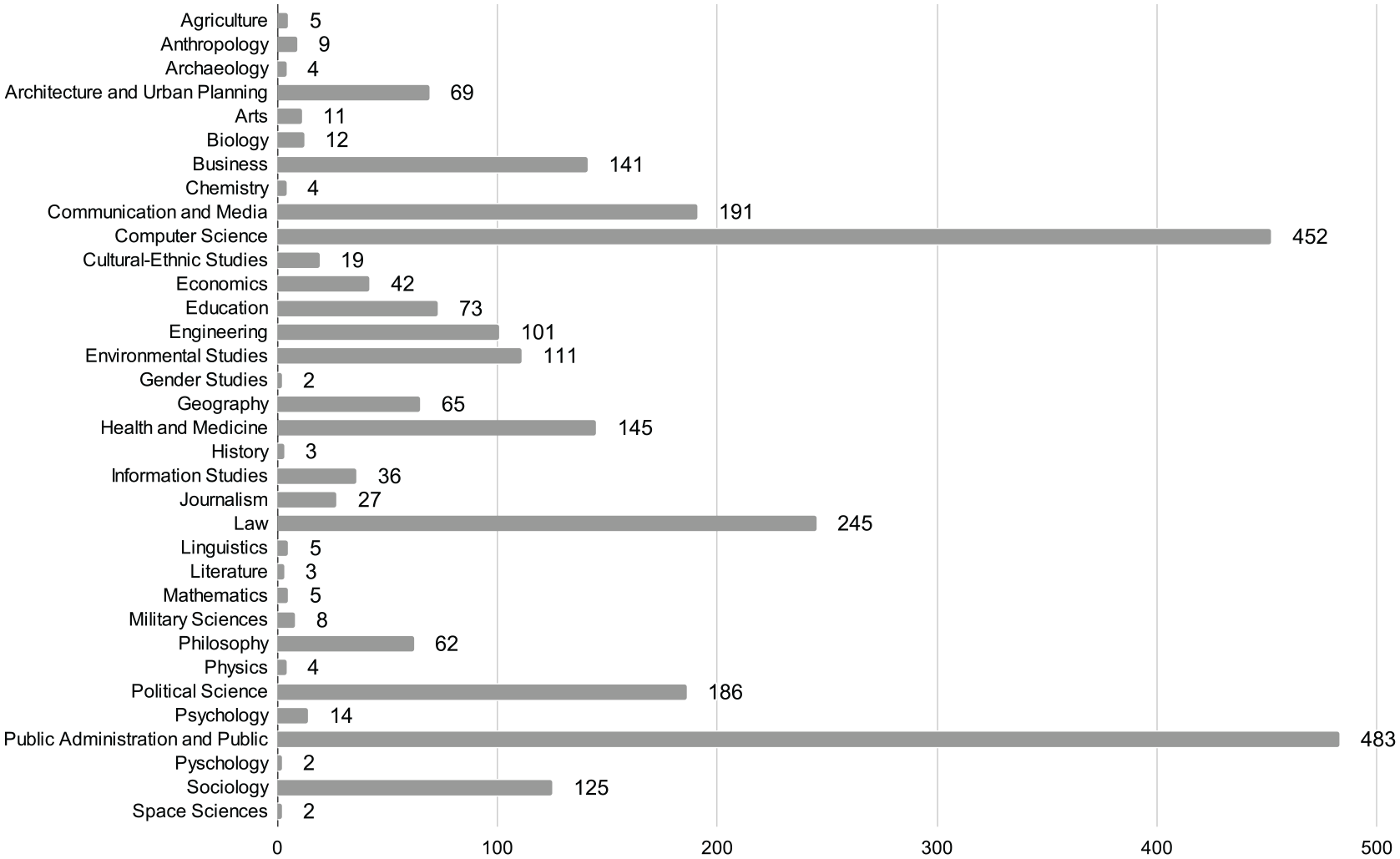
Diversity of corpus. Classification count of articles per Classification of Instructional Programs (CIP) Canada 2000 categorization. The X-axis corresponds to the count of articles and the Y-axis to the classification categories.
We chose to group articles based on title, not author(s)’ disciplines. For instance, articles from the conferences on Fairness, Accountability and Transparency in Socio-Technical Systems were categorized as computer science because proceedings were published by the Association for Computing Machinery. We argue that those articles will invariably be guided by the ontologies and epistemologies of the association. We acknowledge the limitations of assigning publications to specific fields.
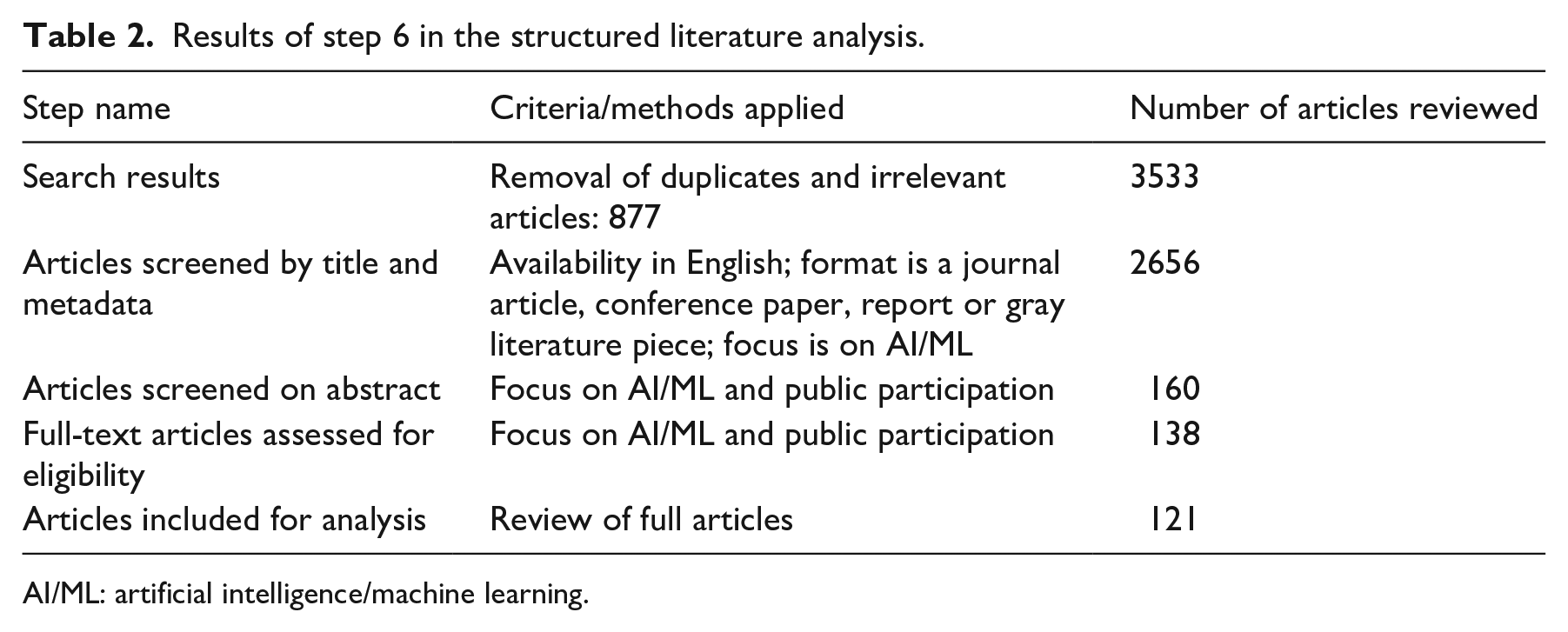
In Step 6 (Figure 1), we refined our corpus. After removing duplicates and irrelevant articles, we conducted manual expert filtering (Sacha et al., 2016) of 2656 article titles and abstracts. We made judgment calls to filter articles based on the level of relevance to some form of AI and participation (with cross-validation of each choice done by two of the authors). Table 2 shows the substeps of manual filtering conducted in Step 6, which resulted in a final corpus of 121 articles. Table 3 shows some examples of titles we included or excluded.
Results of step 6 in the structured literature analysis.
AI/ML: artificial intelligence/machine learning.
Examples of included and excluded articles based on their titles.
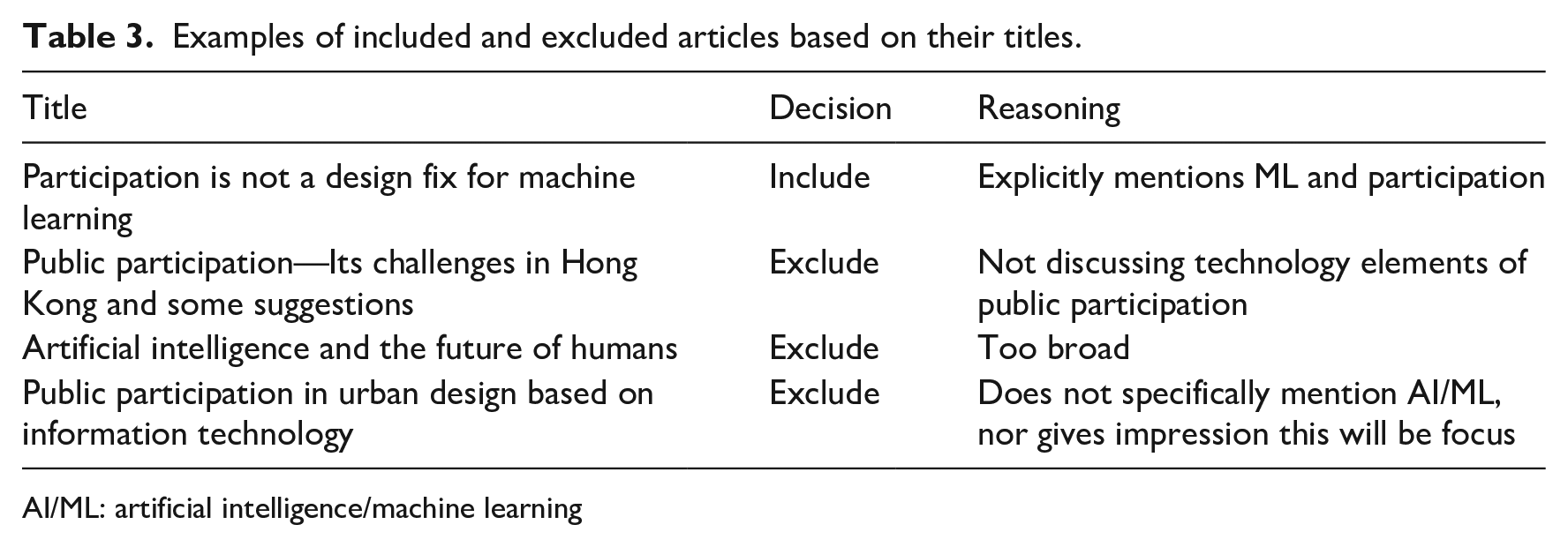
AI/ML: artificial intelligence/machine learning
To analyze the 121 articles (Step 7), we coded articles according to words related to publics (e.g. stakeholder, citizen, consumer). We collectively inferred definitions and affordances of what constituted publics. We compared instances across the corpus and compared corpus definitions of publics to definitions found in our essential reading list. Each substep was cross-validated by at least two authors.
4. Results
We draw on our methods to uncover the numerous ways that publics were discussed in our corpus. Our object of study is the actor, not the act. We follow DiSalvo (2009), who argued that we cannot identify or understand the publics’ actions until they are first constituted as a public. In our results, we seek to explicate the blurriness of publics and implied affordances of their “publicness.”
Table 4 shows the wide variety in how publics were described in our corpus. In the aggregate, they could be the public or community. As individuals, they included citizens (unarticulated, although presumably of a state/jurisdiction), consumers of public services, or residents of a smart city.
Differences in how publics are perceived as engaged in AI.
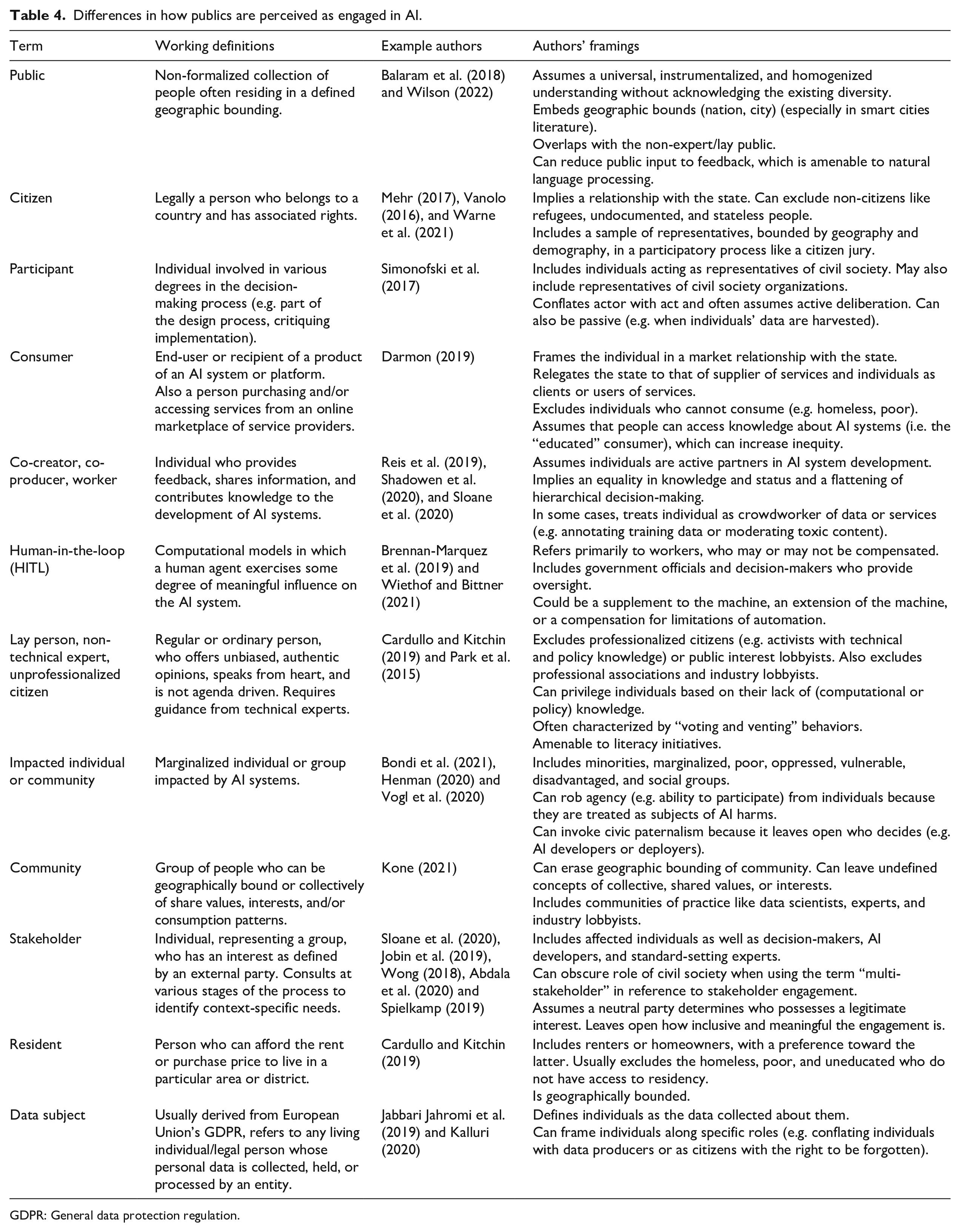
GDPR: General data protection regulation.
Reliance on the most common terms
Similar to the section “Past literature reviews on publics in public engagement in AI,” authors in our corpus utilized the terms citizen or public generically to describe individuals or groups outside the public and private sectors. The challenge of finding exact definitions in the corpus suggests that authors either assumed that terms required no definition because they were universally understood or definitions were left to AI practitioners (e.g. AI developers or policymakers) to operationalize.
The term public vis-à-vis AI often appeared in polls, which gauge attitudes, expectations, opinions, and levels of support of the technology (Ipsos, 2022; Zhang and Dafoe, 2019). Polls have offered insight into socio-demographic differences in reactions to AI (Zhang and Dafoe, 2019). Contrary to being purely descriptive, the public has frequently functioned as a consenting or dissenting body, serving as a foundation for affirming the trustworthiness of AI (Ipsos, 2022). The public also could prioritize aspects of AI ethics. Kieslich et al. (2022) conducted a survey to rank public perception of AI ethical design principles, with accountability as the most important of the AI design principles, closely followed by fairness, security, privacy, accuracy, and explainability. The public as supplier of feedback offers a way for governments to manage trade-offs in AI ethics principles, yet public polling has limits. Cowls (2020) argued that pollsters’ attempts to “strive for overall representativeness” (p. 108) in assessing perceptions of AI, may homogenize the public into a single entity and further what he called a democratic deficit.
Far more effort in the literature is devoted to characterizations of individuals (i.e. citizen, public, resident, democratic participant, and also civil society). Where a definition of citizen occurred, it was largely drawn from what publics afford AI deployment (Mehr, 2017). Characterizations could evoke aspects of citizenship, those civil, political, and social rights and responsibilities that accompany membership in a national community (Vanolo, 2016). Instead of a static definition derived from legal status, Vanolo (2016) preferred a cosmopolitan definition where citizenship would recognize “membership in all cross-cutting political communities, from the local to the global” (p. 8). Conversely, Cardullo (2020) expressed citizenship in socio-technical systems as digital rights “expressed, inhibited, or enhanced through digital platforms or electronic voting; civic rights shaped and regulated deeply through algorithmic processing” (p. 62). The concern with a rights-based approach was the inability to keep pace with technical disruptions and private sector power (Fukuda-Parr and Gibbons, 2021).
Predominance of the neoliberal
Figure 2 shows the importance of the disciplines of public administration and public policy in our corpus. Unsurprisingly, many of those authors situated citizens in relation to the speed and efficiency that AI promises for public sector service delivery (Battina, 2017; Mehr, 2017). We found that, reinforced by Cardullo and Kitchin (2019), AI could easily remake citizens who have rights and are entitled to receive services, into consumers who select government services through a market. In a market-based framing, public engagement becomes transactional and expressed through individual actions like purchases, feedback, or boycotts (Wilson, 2022). As governments adopt AI systems for service delivery, the citizen transitions into an impersonalized user, with government-to-citizen interactions focused on “resolving inquiries,” “trouble-shooting network inactivity,” and “enabling a better customer experience” (Darmon, 2019: n.p.). A market-based framing extends to citizens as co-creator and co-producer in AI deployment and policymaking (Shadowen et al., 2020). Neologisms like co-producers often conceal demotions of publics from democratic participants engaged, for instance, in social justice, to participants-as-worker (Sloane et al., 2020).
Publics also may be valued for their ability to contribute to collective intelligence (Verhulst et al., 2019), a networked zeitgeist of productive knowledge. These buzzwords envisage individuals as “future-ready innovators who uniquely combine specialization and flexibility” (Reis et al., 2019: 242), which suggests ideal participants will embody entrepreneurial values contained in an innovation discourse. Collective intelligence is emblematic of the inevitable overlaps in any discrete definitions of publics. For Simonofski et al. (2017), a participant could manifest neoliberalism (consumer, co-producer) as well as a participatory democracy (citizen, resident, community). There are inevitable limits to making definitions of terms discrete, that can obscure power differentials, including resources and skills like literacy. HITL is one such example.
STEM confidence in human-in-the-loop
In contrast to prior reviews (e.g. Zuiderwijk et al., 2021), we included articles from core disciplines such as computer science and engineering, which play a central role in dictating the AI discourse. When opening up the corpus to AI developers, one primary concept emerges, HITL.
HITL arose from human factors and human-computer interfaces research and was originally described as “a decision-making system in which the initial triage or categorization of cases is performed by a machine, but a human agent exercises some degree of meaningful influence” (Brennan-Marquez et al., 2019: 749). HITL positions publics as essential components of AI systems, a form of human–computer interaction in which the system is not fully automated.
Generic terms like human in HITL can be disciplinarily dependent. To policymakers, the human is a decision-maker who ensures a degree of oversight over the AI’s results (Kuziemski and Misuraca, 2020). For Binns (2022), “each [human] is situated in widely varying social and structural conditions with different powers, pressures, motivations, and agendas affecting how they exercise judgment in ways which are unlikely to conform to expectations of the algorithm’s designers” (p. 9).
Despite this reference to publics, HITL models can misrepresent human oversight, where a person appears to be in the loop but actually is not. Such was the case in Poland, where an AI profiling system was found to have less than 1% of AI-made decisions questioned by human clerks, despite instituting an HITL advisory body. In addition, the system was found to be unconstitutional for its potential to discriminate, despite being subject to the law (Kuziemski and Misuraca, 2020). A misalignment between appearance and actuality of human involvement could create a false sense of public trust. The human’s role is potentially marginal in most decisions but we are reassured by the appearance of human oversight.
We found science, technology, engineering, and mathematics (STEM) professionals to conceive of the human as a worker, given microtasks in platforms like Mechanical Turk, or an uncompensated contributor, for instance, in answering reCaptcha. The work tends toward the mechanical, distanced in a crowdsourcing platform with anonymous contributors who collectively train, classify, and refine data in AI systems. The humans may not be acknowledged or adequately compensated. They are not overseers (Binns, 2022) but can be reduced to dehumanized ghost workers, for instance, labeling social media content to train classification systems (Gray and Suri, 2019; Roberts, 2019). The complication is that approaches like HITL can become conflated with participatory and inclusionary discourses and enable a kind of “participation-washing” (Sloane et al., 2020), for instance, with content moderators.
Notwithstanding these concerns, researchers have found utility in expanding HITL to community-in-the-loop (Häußermann and Lütge, 2022) or society-in-the-loop (Rahwan, 2018). These authors suggested we move beyond the origins of HITL, which employ individuals’ input to optimize AI systems and toward embedding societal values and stakeholder deliberations into AI systems. Similar to crowdsourcing and its inception as anonymous outsourcing (Howe, 2008), unacknowledged implications and assumptions can linger. These definitions continue to frame humans within a system, where humans are prone to exploitation as labor. What of humans outside the loop?
Those left out
Even though expansions to HITL promise greater inclusion of actors, there are still publics who are excluded. This finding cuts across our categories.
An overreliance on the uncomplicated member of the public reflects what Cardullo (2020) termed the “general citizen.” For Cardullo (2020), the general citizen “is largely framed as white, male, heterosexual, ablebodied and middle class” (p. 65). This general usage of citizen invokes and is in direct contrast with an “‘absent citizen’, referring to all those diverse communities that hold identities, values, concerns, and experiences.” To counter the generic use of citizen, Vanolo (2016) recommended the inclusion of the marginalized, minoritarian or even subaltern, who are deprived of credibility and agency. Benjamin (2019), referred to Our Data Bodies project (https://www.odbproject.org) and termed the left out “[t]hose who are typically watched but not seen” (p. 189). Molnar and Gill (2018: 7) classified some who are subject to AI surveillance as “people on the move,” where “even well-intentioned policymakers are sometimes too eager to see new technologies as a quick solution to what are otherwise tremendously complex and intractable policy issues.” These policy decisions are seen in how refugees, for example, are being used as testing subjects for biometric systems.
Sieber and Brandusescu (2021) conducted a workshop during which AI ethics researchers and data scientists had difficulty establishing a common definition for the citizen, while noting many terms to be exclusionary, especially when people affected by the system fell outside the description bracket or jurisdiction. Workshop attendees suggested expansions beyond a traditional demographic, for instance, to include youth and the elderly, and to incorporate those who function to counter the state or big tech (e.g. journalists, whistleblowers). To the term citizen, attendees suggested the addition of the formerly incarcerated, undocumented, stateless, disabled, and wards of the state. Arguably, these publics should have a stake, which leads us to the term stakeholder.
Sheer breadth of actors
We found a significant variety of actors in our corpus, among them stakeholders. Stakeholders were ubiquitous in the literature on AI ethics but similarly lacked definition. The category has long been argued to have power due to its conceptual breadth (Phillips et al., 2003). Phillips et al. (2003) continued that “The term means different things to different people and hence evokes praise or scorn from a wide variety of scholars and practitioners” (p. 479).
For many AI researchers, the term stakeholder was a catch-all for publics, including nearly anyone who expressed an interest in the AI decision-making process (Jobin et al., 2019). Stakeholders included those with political power: decision-makers, government officials and industry lobbyists. Stakeholders also included the disempowered: impacted groups, vulnerable, victims, targets, the profiled, or those who were discriminated against (e.g. Fukuda-Parr and Gibbons, 2021). Individuals afforded stakeholder status functioned as stand-ins for their identity group, which could reinforce a performative check-box action on the part of a facilitator. Designating who did and did not have an official stake could diminish the role of community organizations, who themselves could provide representatives (Bondi et al., 2021). Definitional breadth diluted the influence of affected individuals and hid significant imbalances in resources (Sambuli, 2021).
Part of the breadth of actors stems from jurisdictionally dependent terms like resident, although people outside particular jurisdictions might still be affected or implicated. Publics could be labeled as subjects of AI systems (Jabbari Jahromi et al., 2019). In data protection and privacy laws, the data subject is any individual, for example, under the European Union’s General Data Protection Regulation (EU GDPR, 2016). Anyone is potentially subject to AI harm, not just the marginalized. As with stakeholders, this generalization could render the concept relatively meaningless and exploitable by those with power and knowledge (Cofone, 2020). The concept of data subjects results in a datafication of publics (Micheli et al., 2020; Posada et al., 2021). Ultimately, individuals could become a series of pixels that are everywhere (i.e. data is repurposable and shareable) and nowhere (i.e. publics are dematerialized). The data subject suggests a position of vulnerability (“we are subject to”); however, authors also noted possibilities for empowerment (Kalluri, 2020), including the ability to contest decisions (Almada, 2019) and gain expertise.
Affordances of expertise
The most detailed explication of publics in the corpus referenced levels of expertise, which acknowledged the important affordance of knowledge and skill development. Unlike other definitions of publics (e.g. public, consumer), researchers like Havrda (2020: 440) provided detailed characterizations of relevant expert stakeholders: governments, well-being researchers, AI developers, communication experts, video game developers, practitioners and local decision-makers, and activists. These technical experts, “create efficiencies and use accreted knowledge to tackle issues in which citizens may have little experience or knowledge” (Cardullo and Kitchin, 2019: 4). Expertise creates a binary of experts and non-experts, which is prevalent in knowledge-heavy AI. In this formulation, technical experts and facilitators control who is the expert and which expertise is valued. Those without technical expertise may find the value of their lived experiences diminished and their role lessened.
Contrast the above with labels of the public such as non-professionalized, non-technical, or lay persons. Labels align with sentiment in the AI ethics and the human–computer interaction research community, where a fundamental predicate for public engagement in AI is an increase in technical literacy. This includes skills and competencies required for the “learner” (who ranges from a school student to the broader public; Long and Magerko, 2020; Ng et al., 2021; Ylipulli and Luusua, 2019) and the role that public spaces and libraries play in developing public AI literacy (Watkins, 2020). Finland’s highly ambitious public education program on AI targets a public whose affordance can shift from uneducated to varying levels of expertise. The temptation of these literacy efforts can be the formation of an AI-ready workforce (Wilson, 2022), where humans educated under national training programs may be viewed as economic agents more than democratic actors. Occasionally, an educated public is not always desired by the state. Policymakers may want a lay public: individuals who provide authentic feedback (Verhulst et al., 2019) without preconceived positions or political agendas. The lay public can simultaneously imply a characterization of which types of expertise are and are not valued as well as strategies to ameliorate deficits.
5. Discussion
Our corpus uncovered numerous terms to describe publics. Rather than focus on only one term, we considered the diversity and changing dynamics of these terms, especially since a diverse corpus introduced new terms. What is revealed is that those who write in the AI literature present fundamental ontological shifts and epistemological shapings in what we consider to be publics in AI.
Ontological shifts
How do we define the public vis-à-vis AI ontologically? Concepts are intertwined with affordances (e.g. a participant is one who participates). Avoiding explication of terms by shifting to different terms only introduces new challenges. Relying on the term citizen embeds complex and potentially unarticulated associations to citizenship, which can create whole categories of absent citizens (Cardullo, 2020). We are left with assumptions of homogeneity, representation, identity, or (economic) value generation. Not only do we see a flattening within categories but across categories, for instance, creating equivalencies between human and public. Flattening blurs power dimensions and elides movement from one category to another (e.g. from consumer to citizen or from local citizen to global citizen).
What definitively is a citizen? A citizen may or may not be linked with human and digital rights. Reliance on human rights frameworks like GDPR remains problematic because frameworks are frequently vague and aspirational, presume universality, and display the unevenness of legally binding compliance with those rights (focusing on process as opposed to outcome, cf., Miller and Redhead, 2019). Smuha (2021) found rights-based frameworks to be too Western and individualistic and to impose a narrow unit of analysis. For example, an American or European approach emphasizes individual rights to privacy, resulting in individuals as the primary data subjects who receive and benefit from governance and regulatory regimes, as opposed to communities and collective rights to privacy (e.g. First Nations Information Governance Centre, 2020). Relying on Western frameworks can be too narrow because they position rights in relation to the state instead of the private sector, the latter being the primary developer of AI systems (Smuha, 2021). Viewing the connection of public with properties and affordances as inexorable can render members of the public always in the service of external forces, whether these forces manifest in the AI developer, government convener, or the algorithm itself.
We cannot easily determine definitions because categories we assign to publics blur, which creates significant implications for affordances. Numerous articles (e.g. Darmon, 2019) conflated citizens with customers. Under a neoliberal framing, publics shift toward consumers of government services made more efficient by AI and the government as a business focused on optimization. In this shift, objections to AI are articulated, for example, through consumer boycotts instead of political elections. In an effort to label publics as co-producers or co-creators of the state, these roles can underestimate the potential for exploitation, particularly of marginalized participants (cf. Tõnurist and Surva, 2017). The term data subjects obscures the fact that we are talking about data contributors, digitizing their lives. In this commodification of human as data, publics are as much suppliers as they are victims (e.g. of privacy violations). Neither can we ignore ghost workers when the emphasis shifts from citizen to consumer (Gray and Suri, 2019). These unacknowledged workers comprise the invisible members of the public constructing AI’s training data and shielding our eyes from harmful content (Roberts, 2019). HITL is implicated in this shift and cannot be separated from discussions of publics as AI aids in this neoliberal shift.
Epistemological shapings
Categorizing publics represents an act of power, politics, and truth-seeking. Here, we examine which new terms are introduced in disciplines and how organizations leverage categories of publics to shift the boundaries of what is accepted as truth. In certain cases, technologies socially shape those notions. For instance, who decides that important publics are those with a stake in a technology or that all publics are humans in HITL? HITL is an interesting example of how classification systems interweave people and technology.
Classifications are not merely neutral organizational tools but have profound consequences for individuals and communities (Bowker and Star, 2000). Through acts of defining, sorting, and ranking (Suchman, 1993), classification systems can both differentiate and discard people (Liboiron and Lepawsky, 2022). Such systems embody motivations of control and disciplinary action (Suchman, 1993), while disguising their provenance by removing identifiers of things and people (Latour, 2005). AI expresses this power and control dimension with techniques like unsupervised classification, which offers a prime tool for large-scale passive harvesting of participants. The method appears objective due to automation but obscures the direct role of developers in removing words and topics and controlling selection of labels. In this, developers can use AI to influence which voices are heard and prioritized.
Researchers in our corpus appeared to normalize certain categories, such as the public, as naturally occurring entities or as the only way to define individuals or groupings of individuals. The notion of a naturally occurring public has long been revealed as socially constructed, which arises from social relations as opposed to containing inherent, immutable qualities. One hundred years ago, philosopher John Dewey and journalist Walter Lippman debated the ability of the public to engage in decision-making; however they largely agreed that the public “emerges once its members are affected by a problem . . . (the public) can never exist in the abstract, but must be thought of as entangled with an issue” (Monsees, 2019: 45). In this way, the public is not simply a set of characteristics of a group, but rather the result of relations between and within groups working on a common issue. As mentioned earlier, publics must be formalized before their actions can be understood and analyzed (DiSalvo, 2009). In addition to the rejection of the public as a natural entity, science and technology studies researchers have rejected the public as a homogeneous entity. A lack of a single public generated calls for “hybrid forums” (Callon et al., 2011), composed of actors with diverse interests, perspectives, and forms of expertise. Here, instruments like AI-driven platforms could be used to facilitate public interactions, although those technologies also can nudge publics toward outcomes that align with powerful interests (Monsees, 2019).
Categories like citizen or the public existed before AI but they can be shaped by AI. For instance, AI decenters geography as a natural way to understand publics by disrupting the notion of a public as an aggregation of citizens delineated by jurisdiction. A jurisdiction aggregates individuals that achieve an identity as a physical community. A spatial logic remains relevant as long as publics are jurisdictionally bound (e.g. electoral districts and political representation). However, AI and its impacts often transcend such boundaries.
AI can enable the passive and unbounded enrollment of publics into systems (e.g. through crowdwork or passive harvesting of data subjects). Publics are not distinct from the technological processes in which they are involved—they are mutable cyborgs (Haraway, 1991). Automated systems increasingly intervene in social relations and individuals, such as the (conscious and unconscious) use of filtering algorithms in online searches and social networks, and prevalence of personal assistants. Gillespie (2014) argued that we risk a “calculated public,” a positive feedback loop in which algorithms present publics back to themselves and in turn shape publics’ view of themselves. For us, AI may constantly shape and reshape who is affected. Lippmann’s and Dewey’s points are therefore amplified by AI where innovations in AI create new publics.
6. Conclusion
We conducted a structured literature analysis to create a diverse corpus that revealed twelve categories of publics used by researchers and practitioners in AI. Most authors used the terms citizen and the public uncritically. A diverse corpus introduced new terms like HITL, although even authors could not agree on whether the human was a worker or decision-maker. We saw affordances of expertise and properties of politics, which cut across terms. We also examined who is included and excluded, with the implication that those without the resources or status to participate are left out. Efforts toward broader and inclusive categorizations like data subjects can elide differentials in power. Our goal was to make the implicit explicit.
Precise definitions and affordances are more than semantic exercises. Without precision, interpretations are left to readers who will apply terms to their own domain and culturally specific contexts. Definitions may be outsourced to more powerful external authorities. Impactful decisions will be made as to who, for example, is constituted as a stakeholder and whose voices are acknowledged. Uncovering the affordances remains crucial as AI delivers new promises and problems that recalculate publics.
Footnotes
Acknowledgements
The authors are grateful for the early work of Sam Lumley, who did some of the initial bibliographic work and Zhibin Zhang who provided technical support for the search string generation.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Social Sciences and Humanities Council of Canada, SSHRC 430-2020-00564.