
Abstract
Citizen science is often celebrated. We interrogate this position through exploration of socio-technoscientific phenomena that mirror citizen science yet are disaligned with its ideals. We term this ‘Dark Citizen Science’. We identify five conceptual dimensions of citizen science – purpose, process, perceptibility, power and public effect. Dark citizen science mirrors traditional citizen science in purpose and process but diverges in perceptibility, power and public effect. We compare two Internet-based categorisation processes, Citizen Science project Galaxy Zoo and Dark Citizen Science project Google’s reCAPTCHA. We highlight that the reader has, likely unknowingly, provided unpaid technoscientific labour to Google. We apply insights from our analysis of dark citizen science to traditional citizen science. Linking citizen science as practice and normative democratic ideal ignores how some science-citizen configurations actively pit practice against ideal. Further, failure to fully consider the implications of citizen science for science and society allows exploitative elements of citizen science to evade the sociological gaze.
1. Introduction: Defining citizen science
The term ‘citizen science’ has at least two separate origins and today has multiple competing definitions. While the term did appear in an article for the MIT Technology Review in 1989 (Kerson, 1989), in its contemporary usages ‘citizen science’ is often traced back to two independent coinages in 1995, in the United States by Rick Bonney and in the United Kingdom by Alan Irwin (see Bonney, 1996; Irwin, 1995). In the United States, the Cornell Lab of Ornithology sought to name their assortment of projects which involved large numbers of non-scientists collecting data on birds (Bonney, 1996). While Bonney labelled these activities citizen science, it is important to remember that analogous activities – non-scientists being involved in scientific data collection – have a long history (see Shuttleworth, 2015). In the United Kingdom, Irwin’s (1995) conception of citizen science drew from debates in the field of Science and Technology Studies (STS), which sought to bring science and the public closer together in a bid for more democratic scientific decision-making through dialogue and engagement. As Irwin (2015) reflected 20 years after his initial publication: citizen science is open to many definitions, and it contains more than one strand. It can be presented as a public extension to existing scientific projects. It can also be considered as one step towards greater public participation with – and democratic accountability over – the direction and creation of scientific research. (p. 30)
Bonney et al. (2016), too, have reflected on the dual nature of citizen science, suggesting that some people ‘equate citizen science with a movement to democratize science’ while others ‘equate citizen science with public participation in scientific research, in particular, with members of the public partnering with professional scientists to collectively gather, submit, or analyze large quantities of data’ (p. 3). In this article, we follow Riesch and Potter (2014) in referring to these two traditions of defining citizen science as the ‘US’ tradition, deemed to originate with Bonney and focussed on participation, and the ‘UK’ tradition, originating with Irwin, with a broader focus on democratisation.
While it is perhaps easier to understand the concept of the US definition, that of participatory science projects, the UK version of citizen science has a deeper undercurrent of both analytic and normative value. Horst et al. (2016) reflect that drawing on STS scholarship, the UK definition drew attention to how citizens could serve as knowledge generators (and not simply passive recipients) and to the ‘contextuality of all knowledge claims – whether based on close observation of everyday circumstances or formalized scientific methods’ (p. 887). As Riesch and Potter (2014: 109) argue, scholars working in the UK tradition tend to laden citizen science with their hopes of a truly two-way public engagement, a dialogue that gives an equal voice to lay experts, and demonstrates the science-public divide is not as rigid as often assumed.
In time, though, it appears that the two traditions have converged at the level of transnational policymaking. A factsheet produced to inform policymakers during a meeting of the Competitiveness Council of the European Union on 21 July 2020 defined citizen science as: the voluntary participation of non-professional scientists in research and innovation at different stages of the process and at different levels of engagement, from shaping research agendas and policies, to gathering, processing and analysing data, and assessing the outcomes of research. (European Commission, 2020)
We believe this ‘EU definition’ is itself an amalgamation of both the US and UK traditions of citizen science, which uses non-scientists instrumentally within scientific processes, and which sees citizen science as helping democratise science and create a scientific citizenry. The UK tradition’s influence on the EU conception of citizen science is apparent in the European Commission’s Science with and For Society (SWAFS) programme report, which summarises the aspirations of citizen science as follows: ‘Citizen science and science engagement more generally, is an ideal means to democratise science, build trust in science, and leverage the vast societal intelligence and capabilities to conduct excellent research and innovation’ (Warin and Delaney, 2020: 5).
Today, there are a multitude of associations, organisations and policy institutions involved in citizen science, many offering their own definitions (see Shanley et al. (2019) for a helpful repository of 34 of these definitions). While definitions abound, we must remember that definitions are always partial and in need of renewal. This is especially true in citizen science due to the field’s heterogeneity and rapidly expanding nature. Auerbach et al. (2019) observe many citizen science professionals have attempted to define citizen science, only to discover later that their definition does not fully encompass the field. Thus, extant reifications of citizen science should always be read with caution. They can encompass not only what citizen science is, but often also reflect the normative stances and aspirations of the individuals, institutions or organisations generating them.
Given the multiple definitions offered, some researchers have called for a standard international definition of citizen science to ensure quality, uniformity of standards and values. For example, Heigl et al. (2019) believe that we must move towards a shared understanding of ‘what citizen science is, what it is not, and what criteria citizen science projects must fulfil to ensure high-quality participatory research’ (p. 8090). Believing a standard definition based on quality criteria can help ensure rigour, Heigl et al. (2019: 8090–8091) provide seven broad assessment areas to evaluate citizen science: (1) what is not citizen science, (2) scientific standards, (3) collaboration, (4) open science, (5) communication, (6) ethics and (7) data management. However, Auerbach et al. (2019: 15336) contend that the proposed international definition limits creativity and innovation, ignores inherent heterogeneity and interdisciplinarity, and ultimately argue any exclusionary approach confines rather than defines the field. Instead, Auerbach et al. (2019: 15336) advocate for a collaborative approach, emphasising informed consent about project design and transparency in data collection and handling.
In efforts to better understand what exactly citizen science is, there have also been attempts to move beyond strict definitions and criteria, instead setting out principles to which citizen science projects should adhere. Notably, the European Citizen Science Association developed the ‘10 Principles of Citizen Science’ (Figure 1), which are characteristics that underpin responsible citizen science projects (Robinson et al., 2019 [2018]). Their 10 principles have been incorporated into the EU-Citizen. Science (2021) ‘Characteristics of Citizen Science’ project, as part of the EU’s Horizon 2020 funding programmes, with the authors recommending the characteristics should be considered together with the ECSA 10 Principles of Citizen Science (Haklay et al., 2021).

The ten principles of citizen science (Robinson et al., 2019 [2018]).
Defining citizen science, then, is a contested area. From this review of the literature on definitions and boundary drawings, we can conclude that citizen science is no less of a polysemous concept now than it was deemed almost a decade ago by Riesch and Potter (2014). Despite this, we argue that across these varied attempts at defining citizen science, the following broad set of characteristics are, either tacitly or explicitly, included. These are what we term the ‘Five-Ps’ of citizen science:
While for some citizen science is simply a tool through which publics can help generate scientific knowledge, at the EU policy level it is now broader. The US and UK definitions of citizen science are entwined, and citizen science is carried out for the public good. Despite (or indeed, because of) the interpretive flexibility of the term, citizen science as a concept and practice has been incredibly successful, making its way to the very height of transnational policy making. It is reified and embedded in the EU’s research agenda, with one EU citizen science project receiving €1.5 million funding to establish citizen science hubs in European research and funding organisations (EU CORDIS, 2020).
However, we must stress that the act of definition is itself an act of power. As Eitzel et al. (2017) suggest, drawing on the foundational work of Gieryn (1999), terminology matters, and people ‘draw boundaries using language, choosing terms that include or exclude ideas, activities, and people’. The above review of the literature concerning the origins, definitions and spread of citizen science demonstrates that citizen science is not only a practice but also an evolving discourse that attempts to bind, include and exclude certain practices. This point is important for understanding the main argument of this article. Our contention is that too readily linking citizen science as practice, and citizen science as normative democratic ideal, can blind us to the ways in which some types of science-citizen configurations actively pit the US definition against the UK. That is, this linkage excludes practices which – by enrolling citizens in the collection, categorisation or analysis of data to generate knowledge – are strikingly similar, if not identical, to many self-described citizen science projects, but which happen despite the citizens who are enrolled in these projects not knowing that they are actively engaged in data analysis or knowledge production. These types of activities we label dark citizen science. In terms of our Five-Ps, dark citizen science involves citizens in activities with an identical
2. Citizen science and dark citizen science
To make sense of the concept of dark citizen science, it is best contrasted with an archetypal example of traditional citizen science. Rather than building from a normative set of assumptions about what citizen science should be, this empirical grounding opens lines of interrogation and reorientation towards citizen science as a concept. We now present two empirical cases: Galaxy Zoo, an early and prominent citizen science project, and Google’s reCAPTCHA process, which we will establish as an archetypal example of dark citizen science.
Traditional citizen science: Galaxy Zoo and Zooniverse
Launched in 2007 and led by astrophysicist and former co-presenter of The Sky a Night, Professor Chris Lintott, the Galaxy Zoo project is based on a classification tool for images of galaxies. It developed in the context of the so-called ‘data deluge’ or ‘information explosion’ problem, where data-generating technologies outstripped research teams’ abilities to sort, categorise, or analyse data. As Lintott reflected: ‘In many parts of science, we’re not constrained by what data we can get [. . .] We’re constrained by what we can do with the data we have. Citizen science is a very powerful way of solving that problem’ (as quoted in Pinkowski, 2010).
Galaxy Zoo is now hosted on Zooniverse, founded in 2009, which is ‘the world’s largest and most popular platform for people powered research’. 1 The platform hosts a wide variety of projects, from classifying steelpan drum vibrations to assessing monkey health, even venturing into the humanities. 2 The aims and mechanics of these different projects vary to some degree, but all essentially engage volunteers in a process of classification. In Galaxy Zoo, volunteers are shown an image of a galaxy and asked to categorise its smoothness, roundness and other characteristics (Figure 2, Bottom). In the Monkey Health Explorer project, also hosted on Zooniverse, volunteers are shown microscopic samples of monkey blood and must identify different types of blood cells. In the steelpan vibrations project, volunteers must categorise high-resolution images to reveal different kinds of vibrations in steel drums. In all three projects, the salient categories are presented via test images or tutorials, where citizen scientists can familiarise themselves with the categorisation mechanics of the Zooniverse platform.

(Top) Gems of Galaxy Zoo, collage of top-voted pictures (Keel, 2018); (Bottom) Current version of Galaxy Zoo classification tool (Zooniverse.com).
Leading up to, and throughout the
Though the citizen scientists accessing the Zooniverse platform may have limited scope to set the research agenda, it is within their power to engage in the scientific projects they choose, engage in a way that suits them, and stop engaging at any time. In this way, a balance of
Dark citizen science: Google’s reCAPTCHA
In contrast to Galaxy Zoo and the Zooniverse platform, we describe Google’s reCAPTCHA process as archetypal dark citizen science. Before making our case, we first provide a brief history of the development of CAPTCHA technology to help us understand the mechanisms underlying the process, and how and why people have been recruited to partake in distributed, unpaid, technoscientific labour for Google.
CAPTCHAs and books
CAPTCHA – an acronym that stands for ‘
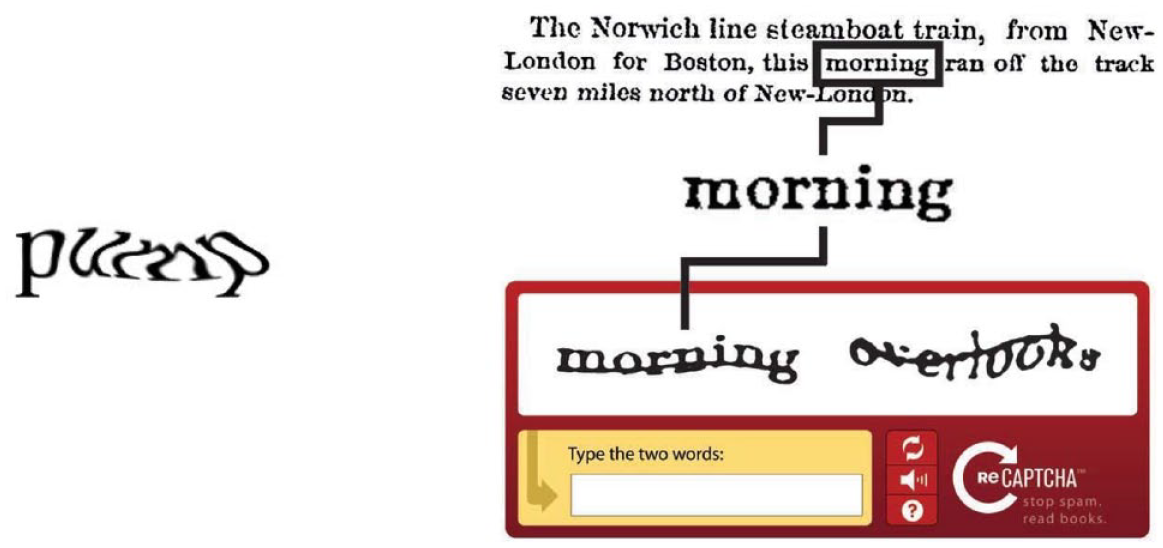
(Left) An early one-word CAPTCHA used at YahooMail (from Von Ahn et al. 2003) (Right) An early iteration of a two-word reCAPTCHA (v1). The word ‘overlooks’ is known to the program, and functions as the security protocol. The word ‘morning’ is an unknown word from the scanned text corpus, which by typing the person filling in the reCAPTCHA helps to transcribe (from Von Ahn et al., 2008).
Verifying human users was a very useful service, so CAPTCHAs became more widespread. Once tens of millions were being solved each day, it was quickly realised that a vast amount of aggregate brainpower was being used to solve them. Von Ahn observed that while CAPTCHAs were effective at preventing large-scale abuse of online services, the mental effort people spent solving them – amounting, in aggregate, to hundreds of thousands of human hours per day – was otherwise wasted. Thus, he and colleagues set out to design a new process – the reCAPTCHA – that ‘made positive use of the time spent by humans solving CAPTCHAs’ (Von Ahn et al., 2008: 1465).
The difference between CAPTCHA and the new reCAPTCHA was that beyond simply functioning as a front-end security protocol, the human computation solving reCAPTCHAs was also directed at a back-end, hidden purpose. The first use case was to transcribe the vast amount of newly scanned texts from endeavours such as The New York Times Archive (Gugliotta, 2011), Google Books Project and the non-profit Internet Archive (Von Ahn et al., 2008: 1466). The automated optical character recognition (OCR) software of the time, while useful for new or clean book pages, often could not identify words in older, faded ink or on yellow pages. Professional human transcribers were reported to achieve 99% accuracy, yet were expensive, so only documents of extreme importance were manually transcribed. Figure 3 (Right) displays how the original reCAPTCHA worked. In this example, the word ‘morning’ from the scanned corpus was unrecognisable to OCR software. The word was isolated, distorted using random transformations including adding a throughline, and then presented as a reCAPTCHA challenge to the user. Because the original word (‘morning’) was not recognised by OCR software, and therefore couldn’t be used to verify ‘humanness’, another word for which the answer was known (‘overlooks’) was also presented to determine if the user entered the correct answer (Von Ahn et al., 2008: 1465). Thus, one word in the reCAPTCHA served as the front-end security protocol to prove the user was human, and the other was used to transcribe part of the scanned repository. After development and refinement, the reCAPTCHA process also reached the 99% level of accuracy achieved by professional transcribers (Von Ahn et al., 2008: 1466). Google acquired the reCAPTCHA technology in 2009 and continued this back-end use of reCAPTCHA as a transcription tool (Von Ahn and Cathcart, 2009).
This use of reCAPTCHA as an unpaid transcription service eventually led to a class action lawsuit against Google in 2015. The Plaintiff alleged that Google derived substantial profit from the transcriptions generated by users of websites that employ reCAPTCHA, that Google did not disclose to website users that Google is profiting from their time and effort, and that Google did not compensate users for such time and effort. In essence, the Plaintiff’s claimed that Google was operating a highly profitable transcription business based on free and forced labour, which it ‘deceptively and unfairly obtains from unwitting website users, unjustly enriching itself at the expense of website users responding to reCAPTCHA prompts’ (Rojas-Lozano v. Google, Inc., 2015). In 2016, US Magistrate Judge Jacqueline Scott Corley dismissed the class action lawsuit. In considering the specific legal tests needed to be met for such a claim, the judge wrote: Google’s behavior is also not immoral and oppressive because the harm – if any – of typing a single word without knowledge of how Google profits from such conduct does not outweigh the benefit. Google’s profit is not the only benefit the Court considers in this balancing test – completing the prompt also entitles users to a free Gmail account. Moreover, users’ transcriptions increase the utility of other free Google services such as Google Maps or Google Books. Plaintiff has failed to allege how these numerous benefits outweigh the few seconds it takes to transcribe one word. (Rojas-Lozano v. Google, Inc., 2016)
ReCAPTCHA: Stop a bot. Build a bot
Having laid out how reCAPTCHA works, we now justify its description as archetypal dark citizen science. This justification draws on a more recent iteration of reCAPTCHA technology (v2, which is still presently in use alongside v3). This version requires users to categorise panel images of roads and streets. These images are carved into a grid, and users are asked to select, for instance, all the panels containing ‘street signs’ or ‘bicycles’ or some other street furniture (Figure 4). Users who successfully select and categorise the target images, sometimes across multiple batteries, ‘pass’ the reCAPTCHA test and are allowed to proceed onto the site or service they are trying to access.
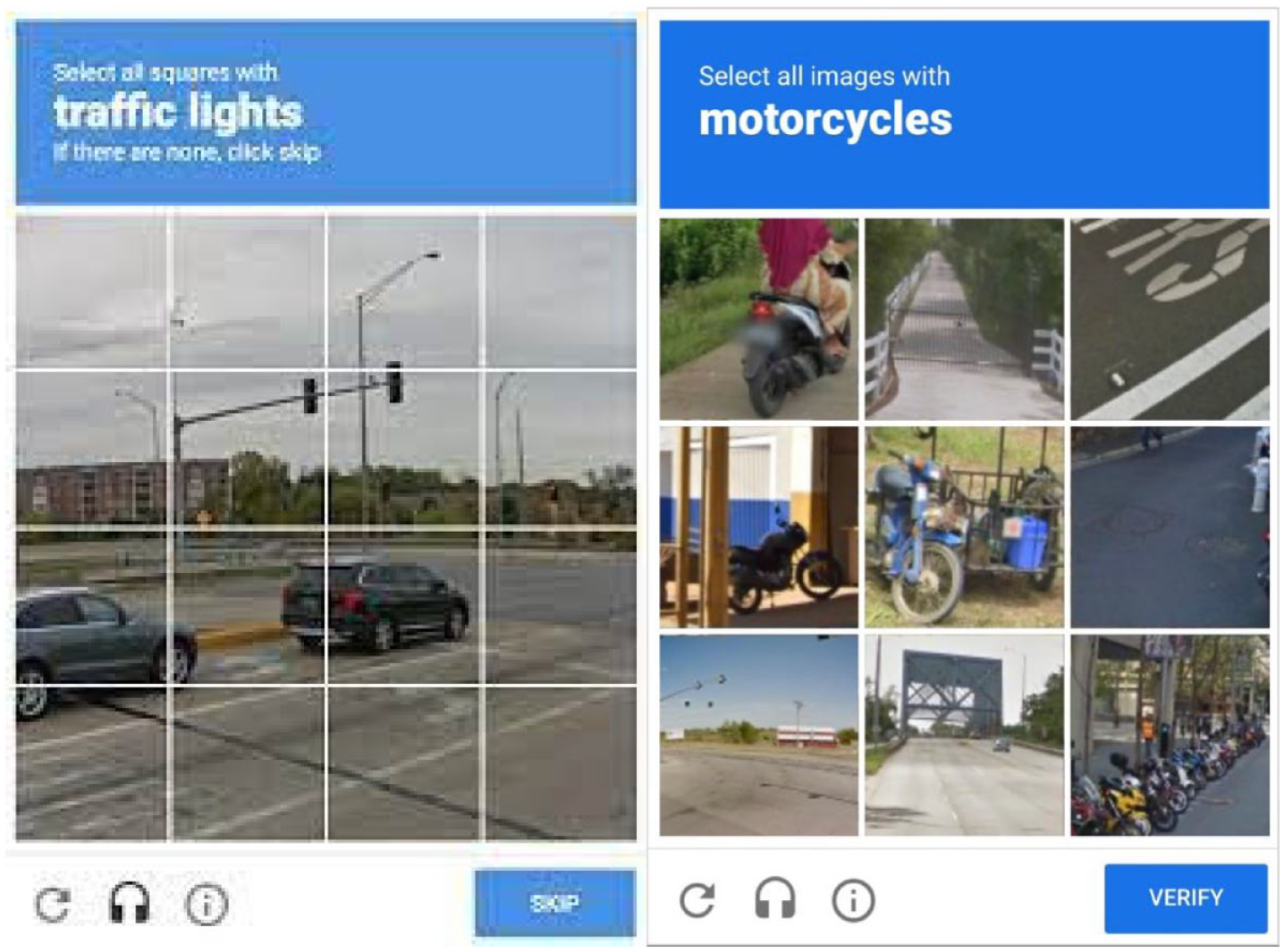
Examples from a more recent iteration reCAPTCHA (v2).
However, just as the first version of reCAPTCHA served the back-end purpose of transcribing scanned texts, similarly the newer version serves a hidden second purpose. While not explicitly obvious to everyone completing the task, reCAPTCHA helps solve hard problems in artificial intelligence (AI). According to Google’s reCAPTCHA website: ‘high quality human labelled images are compiled into datasets that can be used to train Machine Learning systems. Research communities benefit from such efforts that help build the next generation of groundbreaking Artificial Intelligence solutions’. 3 There has been some speculation as to what type of AI exactly Google is enrolling us to build, but due to the nature of the images, some have assumed Google is using the categorised images as training sets for their autonomous vehicle programme. Google themselves have recently denied this, forcing a retraction to the claim published by Vox (Vega, 2021). Still, the very fact that we do not know specifically what type of technoscientific development Google has enrolled us all to partake in highlights the obscurity of perceptibility underlying the process and purpose of reCAPTCHA. What is clear, however, is that Google does use reCAPTCHAs – specifically, the labour of the people completing them – for the ‘creation of value’ 4 and they do so through the utilisation of data categorised by our labour every time a reCAPTCHA is completed. This back-end function of reCAPTCHA remains obscure to most people who have few options to avoid the service, as they seek to prove their ‘humanness’ online.
In completing the reCAPTCHA, Internet users are involved in a
Analytic summary: Citizen science to dark citizen science
In contrast to our earlier presentation of the Five-Ps of citizen science, we propose that dark citizen science can be understood as follows:
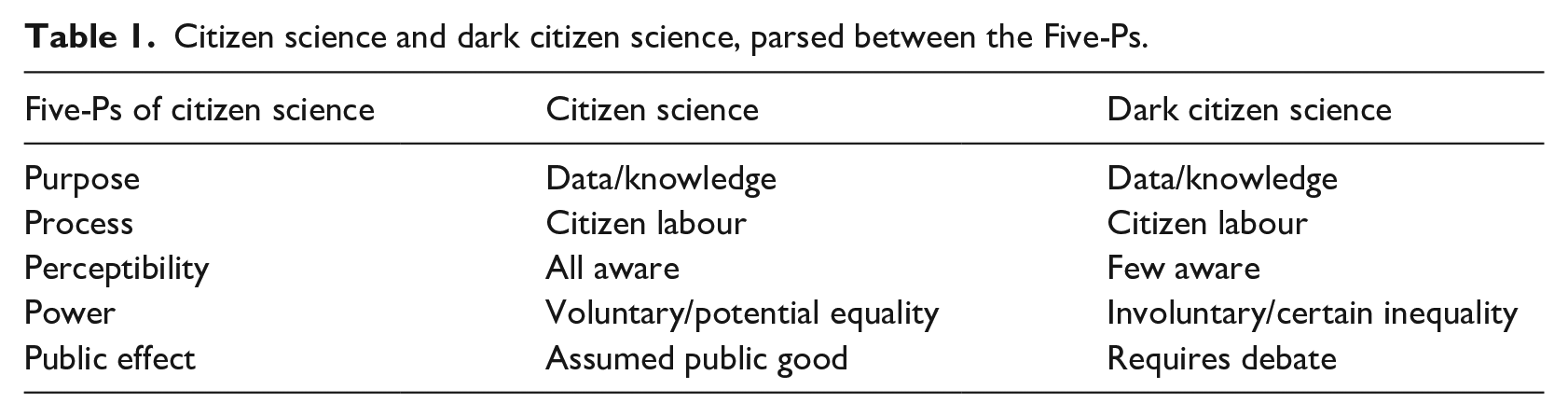
Table 1 shows a cross-comparison of how citizen science and dark citizen science can be parsed between the Five-Ps delineated above. Here then is an opportunity to consider how reCAPTCHA (and similar activities) could be transformed into citizen science projects. This would involve explicitly presenting information about the knowledge creation usages of an individual’s digital labour, gaining informed consent from users and providing opt-out options from the data collection and knowledge production processes. Thus, when prompted to fill out a reCAPTCHA, an information text box would appear stating what the (currently dark) usage of the user’s digital labour was being put towards. There would also need to be an opt-out of this kind of use and the option to carry on the purported front-end use of reCAPTCHA: the Turing Test. This, in our view, would shift reCAPTCHA from a dark to a traditional citizen science project. 5
Citizen science and dark citizen science, parsed between the Five-Ps.
3. Discussion and conclusion
Citizen science can contribute to greater engagement and increased democratic governance of science, but not all processes resembling citizen science are designed with these ideals in mind. In the digital landscapes of neoliberal late modernity, citizens are engaged in forms of technoscientific knowledge production, of which they are unaware, and for which they receive no reward. Our expanded critical framework of ‘Dark Citizen Science’ helps further illuminate these areas of concern. However, to see dark citizen science, we must first take off the rose-tinted glasses that conceptually obscure our gaze.
Like a good pair of glasses, good concepts focus sight. In creating the term dark citizen science, we hope to focus the sociological gaze on socio-technoscientific interactions that undermine the normative ideals of traditional citizen science. The example of reCAPTCHA explored in this article represents an archetypical example, but others no doubt exist. As private digital industries are most likely to generate these hidden processes, they are by definition harder to identify than transparent citizen science projects that are upfront about their aims. Indeed, this is partly why we designate them ‘dark’ – just as the dark matter of the universe is in a sense hidden, but contributes greatly to the universe’s mass, the same may be said for dark citizen science. It is there without one seeing it. Indeed, we believe the number of citizens engaged in dark citizen science activities – be they active or passive – far outstrips those engaged in traditional citizen science by orders of magnitude. 6 We urge scholars of citizen science to turn their critical skills towards this hidden socio-technoscientific phenomenon.
In its original conception, reCAPTCHA was a technology that not only helped keep sites safe from malicious programs but also served a second hidden use. In presenting snippets of a large, scanned corpus of texts to the millions of users accessing web services, the process of translating these texts into machine-readable formats was automated and outsourced, creating a searchable digital repository through the hidden labour of people completing reCAPTCHAs. In concluding their original Science article on the technology, reCAPTCHA’s developers Dr Von Ahn et al. (2008) state: ‘[w]e hope that reCAPTCHA continues to have a positive impact on modern society by helping to digitize human knowledge’ (p. 1468). Indeed, Von Ahn seemed already to understand potential future pitfalls of the process he had created and hoped back in 2009 that the pursuit of ‘public goods’ would deflect any resentment from the people marshalled to conduct this unpaid labour. ‘We could do other things, like digitizing cheques’, he noted in an interview, ‘[b]ut banks already make enough money’ (quoted in Hutchinson, 2009). Since then Google has acquired reCAPTCHA, and this unsuspecting labour has been marshalled in service of technoscientific development – the creation of training sets for the development of machine learning/AI for one of the world’s richest companies. We suspect that most people who have filled out a reCAPTCHA are unaware that every time they actively complete a reCAPTCHA they are doing unpaid technoscientific work for Google.
Drawing upon literature defining citizen science and its shared characteristics, we have delineated the Five-Ps of citizen science:
In designating these activities ‘Dark Citizen Science’, we in part hope to renew a critical turn among scholars of citizen science and science and society. As detailed in the introduction, much literature in the area of citizen science either seeks to define, evaluate or strictly advocate for how citizen science projects should run. As an example, the 10 Principles of Citizen Science (Robinson et al., 2019 [2018]) engage with citizen science in an ideal world. Instead, our focus on dark citizen science seeks to understand and critique the world as it is. It draws focus to citizen-science configurations that have until now been beyond our conceptual horizon.
Our highlighting of dark citizen science may seem to imply that we view those activities currently designated citizen science as wholly ‘light’, and thus ‘good’. This is not the case. Even idealised forms of citizen science can create issues of displaced labour and exploitation. Citizen science is often celebrated for the distributed nature of the labour involved and as a result its ‘value for money’. This is the case with Galaxy Zoo, where the tasks that citizen scientists carry out are not only analogous with but are promoted as serving to replace traditional scientific labour. Indeed, a (somewhat light-hearted) 2009 blog post on the Galaxy Zoo website celebrates the measurements of distributed data classification tasks among volunteers. The unit of measurement was called a ‘Kevin-week’, that is the equivalent amount of galaxy classifications a PhD student called Kevin could do in one week (The Zooniverse, 2009). 7 Though seemingly flippant, this issue of displaced labour brings to the fore further similarities between Galaxy Zoo and Google’s reCAPTCHA and what results once millions of people complete a task that a programme initially found difficult. The Galaxy Zoo team has recently built a machine learning algorithm based on training sets from 7.5 million volunteer classifications of over 314,000 galaxies to accurately measure detailed galaxy morphology. The affectionately named ‘Zoobot’ is now 99% accurate compared with expert human classifiers (Lintott, 2021; Walmsley et al., 2022). This mirrored process across citizen science and dark citizen science: technoscientific work outsourced to unpaid volunteers, then volunteer work being used to train machine learning algorithms that can replace both the initial paid work and the volunteer work, suggests that when projects are coupled with AI, citizen scientists may be clicking their active roles into the grave.
Still, enrolling citizens in scientific knowledge creation may be viewed unproblematically. Expanding the range of legitimate actors involved in scientific knowledge creation, and thus decoupling science and elite institutions – a process that has been described as ‘democratising’ (e.g. Collins et al., 2022) – has been a key goal of much scholarship concerned with citizen science (e.g. Strasser and Haklay, 2018). However, we contend that there are potentially pernicious impacts of this process for both scientific institutions and society, and we urge scholars to attend to these more overlooked processes. Although Vohland et al. (2019) argue that in the context of neoliberalisation, citizen science is ambivalent, that it can ‘either strengthen or challenge’ (p. 1) the neoliberalisation of science, we observe that under pressure from, responding to, and therefore recreating wider neoliberal economic conditions, academic work, where much scientific research takes place, is increasingly precarious. Though of course not solely responsible for these wider socio-economic shifts, citizen science, in its celebration of distributing labour away from professional scientists, can be seen as a further line of attack in neoliberalism’s undermining of the material and professional conditions of science. To return to the quotation offered previously, Zooniverse claims to facilitate work that would not be ‘practical’ otherwise. This invocation of ‘practicality’ here can be viewed in terms of Gramsci’s critique of common sense; a taken-for-granted set of understandings which limit the imagination of other economic and social modes. What is ‘practical’, then, is that which serves and aligns with hegemonic material and cultural relations (see Crehan, 2011).
This line of critique of citizen science may appear to be motivated by instrumental concerns – to be clear, in some important ways it is. Both authors of this piece are precariously employed researchers who have a very real stake in the maintenance (or re-establishment) of academic research as a viable career choice. Yet this critique is also motivated by a wider and more fundamental concern with the role that science as an institution should play in democracy – that is as a normative model for democratic values, and a vital check and balance in pluralist democracies against increasingly resurgent populist and authoritarian tendencies (e.g. Collins et al., 2020, 2022; Collins and Evans, 2017). For the institutions of science to play this role, the material conditions which maintain science as a career must also be maintained. Neoliberal economic orthodoxy is in real and serious ways undermining this role, and citizen science may be viewed in a similar light. Dark citizen science processes compound this issue further, due to their hidden nature and compelled technoscientific labour. The appellation ‘Dark’, then, stresses both the invisibility and potentially nefarious impacts of these processes.
Considering citizen science and dark citizen science in this way can prompt reflection on the wider socio-economic conditions experienced under the most recent iteration of neoliberal capitalism. The concept of ‘shadow work’ (Lambert, 2015) is helpful to recognise the increasing encroachment of practices which resemble labour into all areas of our lives – such as scanning your own groceries through the tills, or serving as your own bank teller, or travel agent. Both traditional citizen science and dark citizen science require labour-like activities from those engaged with them, but in neither case does this labour receive traditional monetary recompense. In the dark citizen science case of Google’s reCAPTCHA, this labour is ultimately appropriated for techno-capitalist gain, as Google, one of the richest companies in the world, uses it to create and improve their machine learning and AI. This type of unrecompensed AI training is an increasingly common phenomenon, and at least one which – with the rise of movements, for example, protesting against profiteering from AI-generated art trained on human artwork with no attribution nor recompense for the original artists (e.g. Xiang, 2022) – is being actively and currently resisted. Perhaps more insidiously, traditional citizen science activities, though more open about their goals, still chiefly reward the citizen with a sense of ‘a job well done’. A full discussion of the implications for individuals in a society of the drive to find ‘meaning in work’ or work-like activities is beyond the scope of this article, but it is increasingly the focus of academic critique in a wide variety of fields (e.g. Johnson, 2015 identifies this phenomenon in a care-work setting). Nevertheless, these wider-ranging social consequences must be held in view if we are to fully grasp the implications of citizen science in its various forms. For it is increasingly apparent that in our distributed, technological world, whether we know it or not, we are all on the production line, and the production line is never silent.
Footnotes
Acknowledgements
The authors would like to thank Dr Venessa Heggie for organising a one-day workshop, ‘The Citizen in Citizen Science’ in 2019, with the support of the Institute of Advanced Studies, University of Birmingham, UK, where the ideas underlying this paper were first discussed. Furthermore, we thank Dr Ernesto Schwartz-Marin for his early and helpful conversations. A version of this paper was presented at PCST 23, Rotterdam, and the authors thank the organisers, chair, participants and audience for their comments. Finally, the authors thank Dr Alexander Hall for his insightful comments on a draft of this article.
Funding
The author(s) regretfully received no specific financial support for the research, authorship and/or publication of this article.