
Abstract
Continuous-time Markov chain (CTMC) models and latent classification methods are commonly used to analyze longitudinal categorical outcomes in medical research. While CTMC models are popular for their simplicity and effectiveness, their assumption of constant transition rates presents limitations in capturing dynamic behaviors. To address this, non-homogeneous continuous-time Markov chains (NH-CTMCs) have been developed, incorporating time-varying transition rates to enhance model flexibility. In this study, we leverage closed-form transition probabilities for a fully ergodic two-state NH-CTMC model and propose a latent class clustering approach to identify heterogeneous transition rate patterns within the population. We emphasize the potential advantages of these models in health sciences, particularly for longitudinal studies where transition rates vary over time and across subgroups. Additionally, we demonstrate the practical application of our model using data from an ambulatory hypertension monitoring study.
Keywords
Introduction
A continuous-time Markov chain (CTMC) serves as a stochastic model that describes a sequence of longitudinal states with an assumption of the Markovian property, which assumes that the probability distribution of the next state depends solely on the current state, independent of past states. 1 Characterized by a state space and transition rates, CTMC facilitates the derivation of transition probabilities between observed outcomes. Markov chains find active applications across diverse fields, particularly in medical research, where they are used to analyze disease progression, treatment response, and other dynamic processes.2–6
Despite their utility, Markov models often encounter limitations, particularly due to the assumption of constant transition rates over time. In medical applications, transition behaviors often evolve dynamically, influenced by factors such as aging, disease progression, or treatment effects.7,8 To address this, several studies have explored methods for incorporating non-stationary transition rates. 9 Notable examples include modeling Alzheimer’s disease progression using non-homogeneous Markov processes to incorporate a time-dependent approach; 10 Chang et al. derived exact transition probabilities for non-homogeneous continuous-time Markov chain (NH-CTMC) models, while Ngan approximated parameter estimations using Uniform Acceleration asymptotic expansion;11–13 other works attempted to define theoretical settings or establish probability approximation methods through simulations.14–17
Another challenge in medical research is the presence of unobserved heterogeneity, where subjects exhibit different transition behaviors influenced by latent factors. Some variables may be unobserved and thus latent for various reasons, such as participants withholding information about their sexual behavior. 18 Latent class analysis provides a powerful tool to account for such hidden structures, allowing researchers to cluster subjects with similar transition patterns. 19 Applications include identifying patient subgroups from electronic health records, 20 modeling behavioral homophily in social networks, 21 and classifying individuals based on clinical characteristics. 22 In survival analysis and Markov modeling, latent classification helps differentiate subjects who may otherwise appear homogeneous. To demonstrate, Liang et al. proposed a model clustering subjects based on survival behavior, and Kuo applied latent classification to homogeneous CTMCs.23,24
NH-CTMC models offer a valuable extension for health science research, as they capture time-dependent transition behaviors more effectively than standard CTMC models. Accounting for both time-varying rates and heterogeneous transition patterns allows for a more nuanced understanding of disease progression and patient trajectories. 11 In this study, we propose a method that integrates NH-CTMC modeling with latent classification to identify distinct transition patterns among subjects. By clustering individuals based on their transition behaviors, we provide a framework for personalized modeling in longitudinal health studies. Specifically, we developed a method to classify latent subgroups based on longitudinal binary outcomes and covariates. Our approach assumes that each binary sequence follows a time-dependent CTMC, with distinct classes characterized by unique transition rate parameters. We validated the proposed method through simulations and applied it to the Dietary Approaches to Stop Hypertension (DASH) study dataset. 25 Inferences and analyses were conducted to investigate blood pressure state transitions and the impact of covariates among ambulatory patients with hypertension.
Methods
Non-homogeneous continuous-time Markov chain
Prior to model formulation, we defined key terms and variables. The model involves data with
The probability of transitioning from state
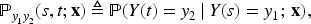
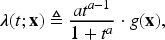
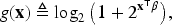
The NH-CTMC framework developed by Chang et al.
11
served as the basis for our model, with the following modified transition rates:
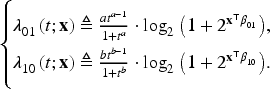
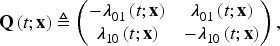
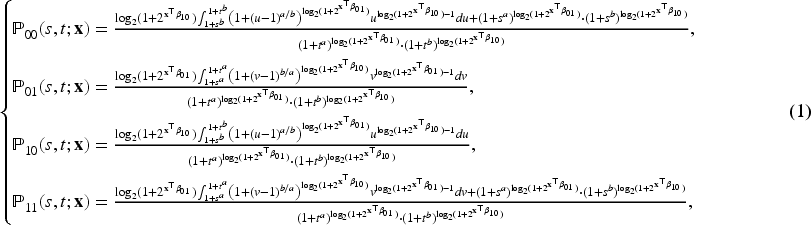
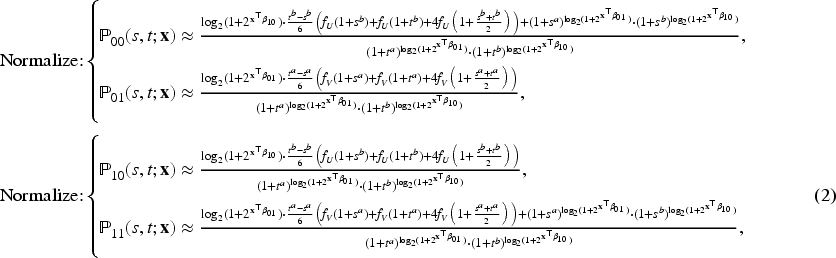

Two-state non-homogeneous continuous-time Markov chains with
The likelihood function for the observed outcome data must be formulated to estimate the parameters. Assuming we have
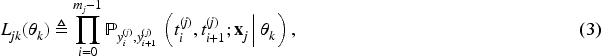
To extend the NH-CTMC framework to incorporate latent classes with class-specific transition rates, let
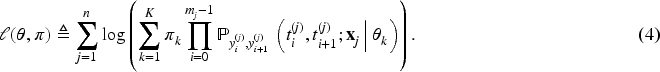
Computation of the maximum likelihood estimator (MLE) is commonly performed using the
The log-likelihood of Equation (4) served as the objective function for computing MLE of
Another computational efficiency issue is on the choice of initial value for the optimization procedure. Due to the presence of multiple latent classes, the log-likelihood of Equation (4) could exhibit several local maxima and saddle points, posing a risk of the optimization algorithm failing to converge to the desired global maximum of the objective log-likelihood function. The convergence results could be sensitive to the starting values, and hence obtaining initial values close to the true MLE values may drastically improve the convergence and optimality. We implemented Algorithm 1 to find suitable initial values, setting the upper limit for rate estimates to

Additionally, to further reduce the computation time in the optimization procedures, we also removed some constraints by transforming variables into a more amenable form. The latent class probabilities 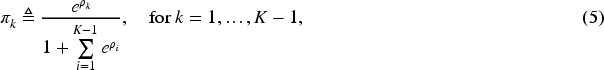

The maximum likelihood estimates 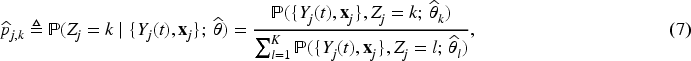
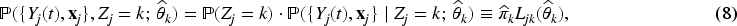

Overview
We conducted a simulation study to evaluate the performance of the proposed method under controlled conditions. We generated 1000 datasets each for sample sizes
Algorithms and propositions
The simulation algorithm for the two-state NH-CTMC model, proposed by Chang et al.,
11
involves a thinning process of a non-homogeneous Poisson process36,37 and sequentially selecting the first event as the transition event. In this paper, we present an alternative simulation algorithm, detailed in Algorithm 2. The algorithm simulates exponential random variables
Let 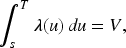
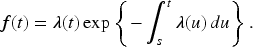
Suppose a subject is in state 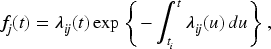
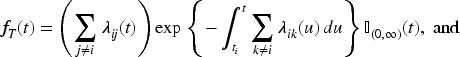

To determine the optimal number of clusters for each simulated dataset, we adapted the GIC,38,39 a generalized extension of the Akaike information criterion (AIC).40,41 The GIC is defined as the following:
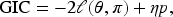
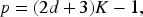
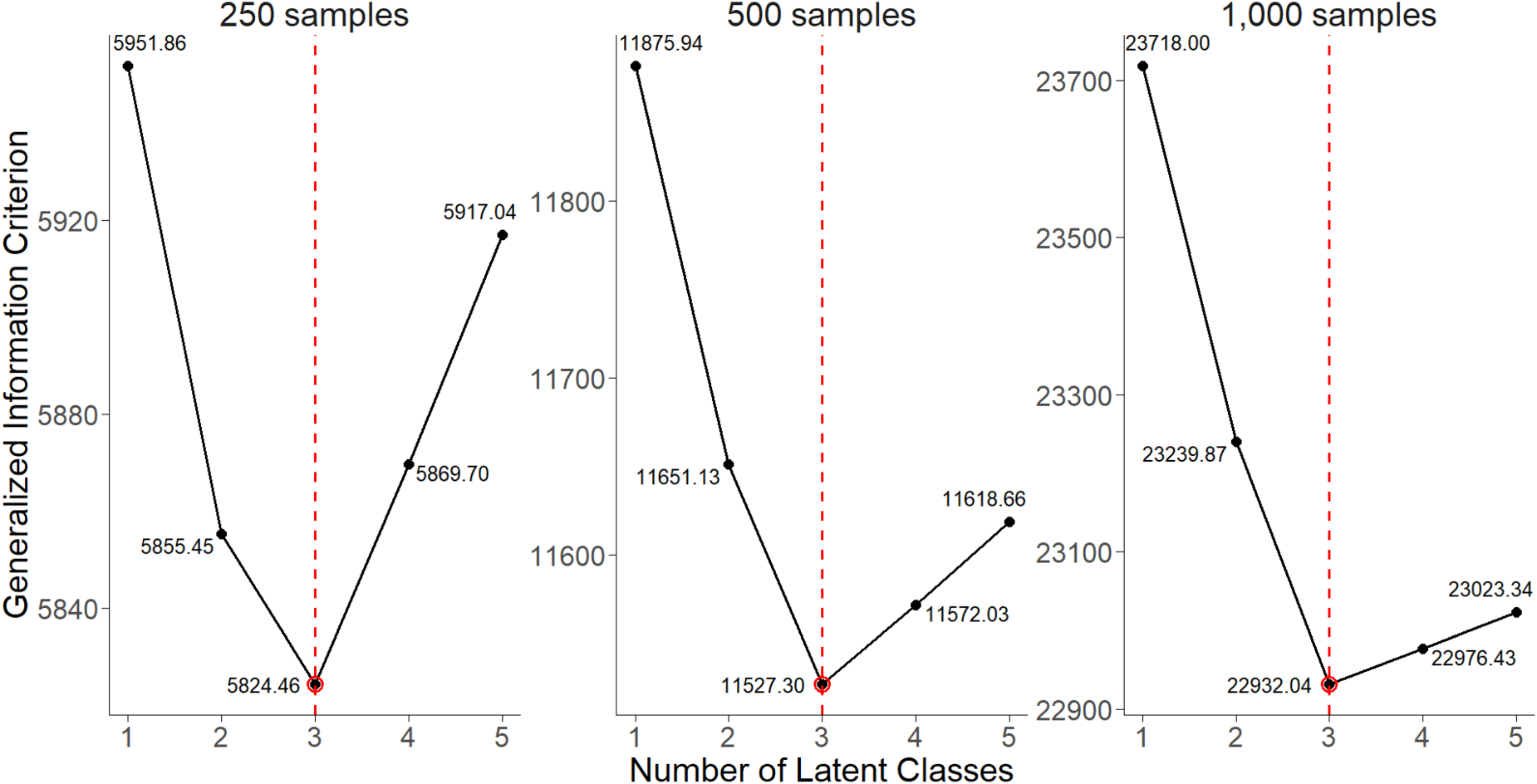
Generalized Information Criterion (GIC;
Simulation results for a single non-latent NH-CTMC model have been previously presented by Chang et al.
11
Therefore, in this study, we primarily focus on the results obtained from the latent model simulations. A univariate covariate
Simulation results of the latent NH-CTMC model based on 1000 simulation runs for each sample size
,
, and
(3000 runs in total), with time up to
and
latent classes, listing means of estimates, bias, PB, SD, square root of mean of squared estimated SE, and empirical CP of 95% confidence intervals.
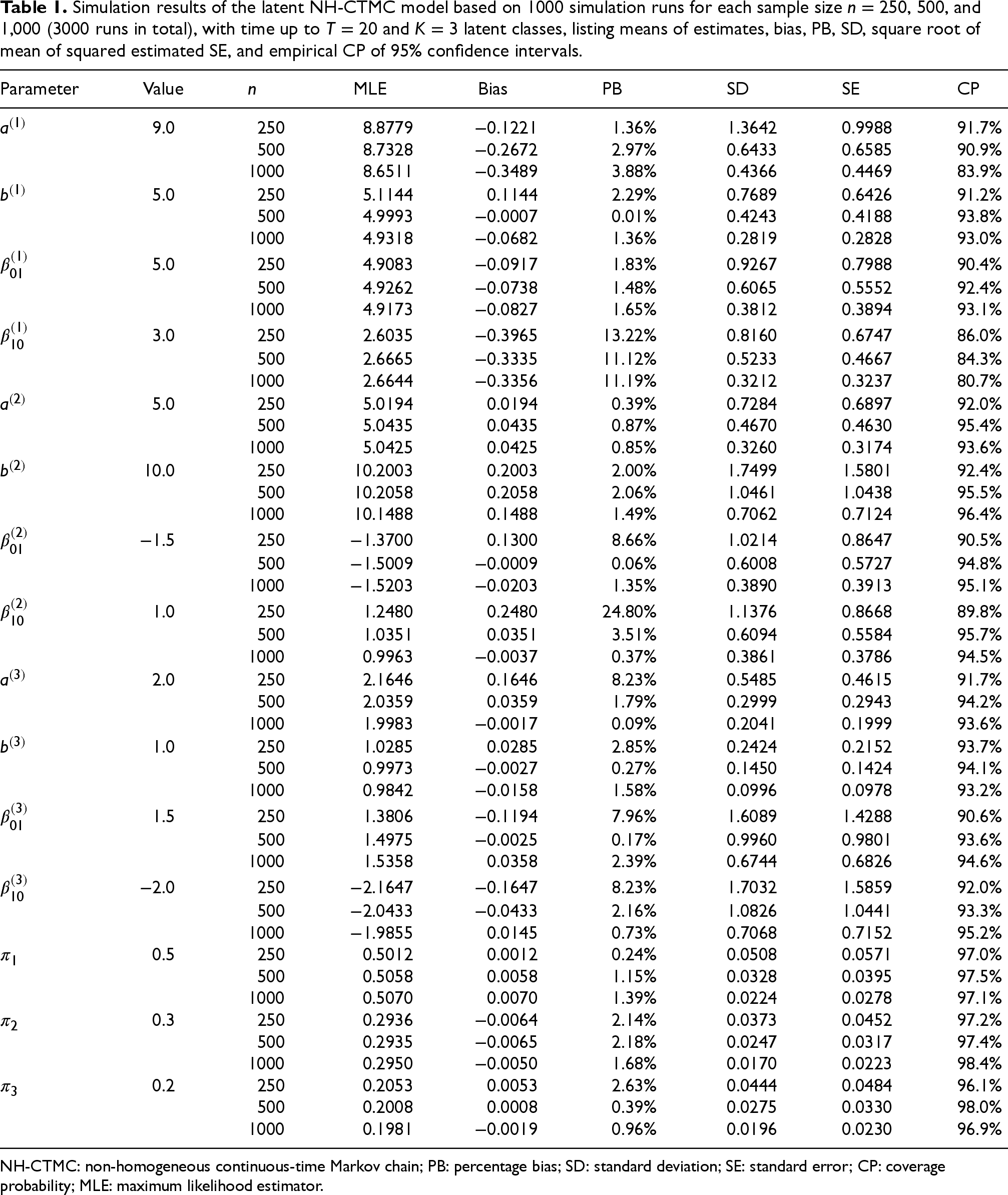
Simulation results of the latent NH-CTMC model based on 1000 simulation runs for each sample size
NH-CTMC: non-homogeneous continuous-time Markov chain; PB: percentage bias; SD: standard deviation; SE: standard error; CP: coverage probability; MLE: maximum likelihood estimator.
To further validate the proposed method, we compared its ability to classify latent classes against other well-known longitudinal clustering models. Specifically, we compared with the following four algorithms: Two-step clustering using a linear model and Finite Gaussian mixture model (GMM):
44
A model-based clustering technique that assumes data arise from a mixture of Gaussian distributions, offering a probabilistic framework for clustering. Latent class mixed model (LCMM):45,46 A flexible longitudinal model that accommodates heterogeneity within latent classes and allows inclusion of covariates through mixed-effects modeling. Latent continuous-time Markov chain (LCTMC):
24
A model-based clustering approach using CTMCs with latent class structure.
We utilized the
Table 2 presents the latent class prediction performance metrics: precision, sensitivity, specificity, and 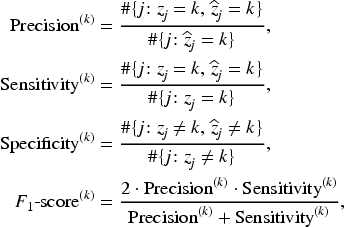
Latent class prediction analysis based on 1000 simulation runs for each sample size (
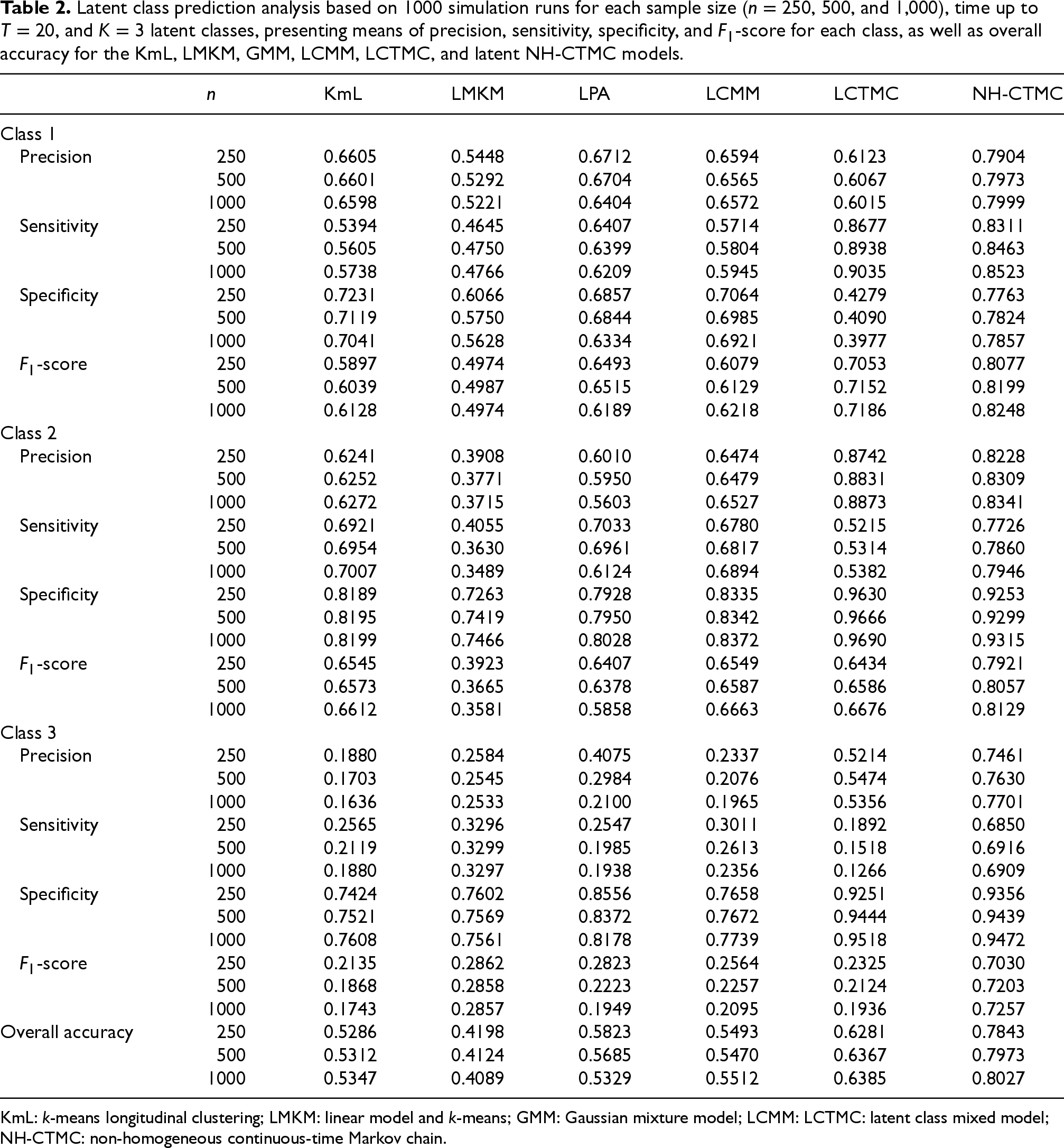
KmL:
We applied our latent NH-CTMC model to an ambulatory blood pressure dataset for a comprehensive analysis of hypertension. Hypertension is a major risk factor for various health issues, including heart disease and stroke. Approximately 78 million people in the United States are affected by high blood pressure, significantly increasing the risk of cardiovascular diseases.48–50 Around 48.1% of adults are expected to develop hypertension,
51
and its national and global prevalences continue to rise.52,53 Research has highlighted links between hypertension and factors such as diet, age, and body mass index (BMI).25,54,55 To better understand the dynamics of hypertension, we applied our model to the DASH study, a multicenter randomized controlled trial aimed at determining the effects of dietary patterns on reducing blood pressure.
25
The DASH dataset contains 24-hour ambulatory blood pressure measurements for 341 patients, recorded approximately every 30 minutes. Each record includes values for systolic blood pressure (SBP), observation time, and covariate information such as dietary plan, age, and BMI, with data extracted starting from the time
Hypertension states, measurement times, and additional covariates were derived from the dataset. Hypertension states were determined based on SBP measures, classified into two states: (0) normal and (1) hypertensive, corresponding to SBP levels less than 130 mmHg and greater than or equal to 130 mmHg, respectively. 56 Measurement time was calculated as the elapsed time from the patient waking up, recorded in hours. Three covariates were considered: dietary plan, age, and BMI. Patients were initially categorized into three dietary interventions: the control diet, an intermediate diet, and a reduced diet with lower fat content and higher intake of vegetables, fruits, proteins, and dairy products. The patients with an intermediate diet had a dietary plan similar to the control diet group overall, except for higher intakes of fruits and vegetables. The dietary intervention was treated as a binary covariate, with the first group (0) consisting of control and intermediate diet groups, and the second group (1) assigned to the reduced diet group. Age was a continuous covariate directly extracted from the dataset, while BMI was calculated from weight and height.
Prior to conducting a detailed analysis, we determined the optimal number of latent classes using the GIC with a penalty weight parameter of
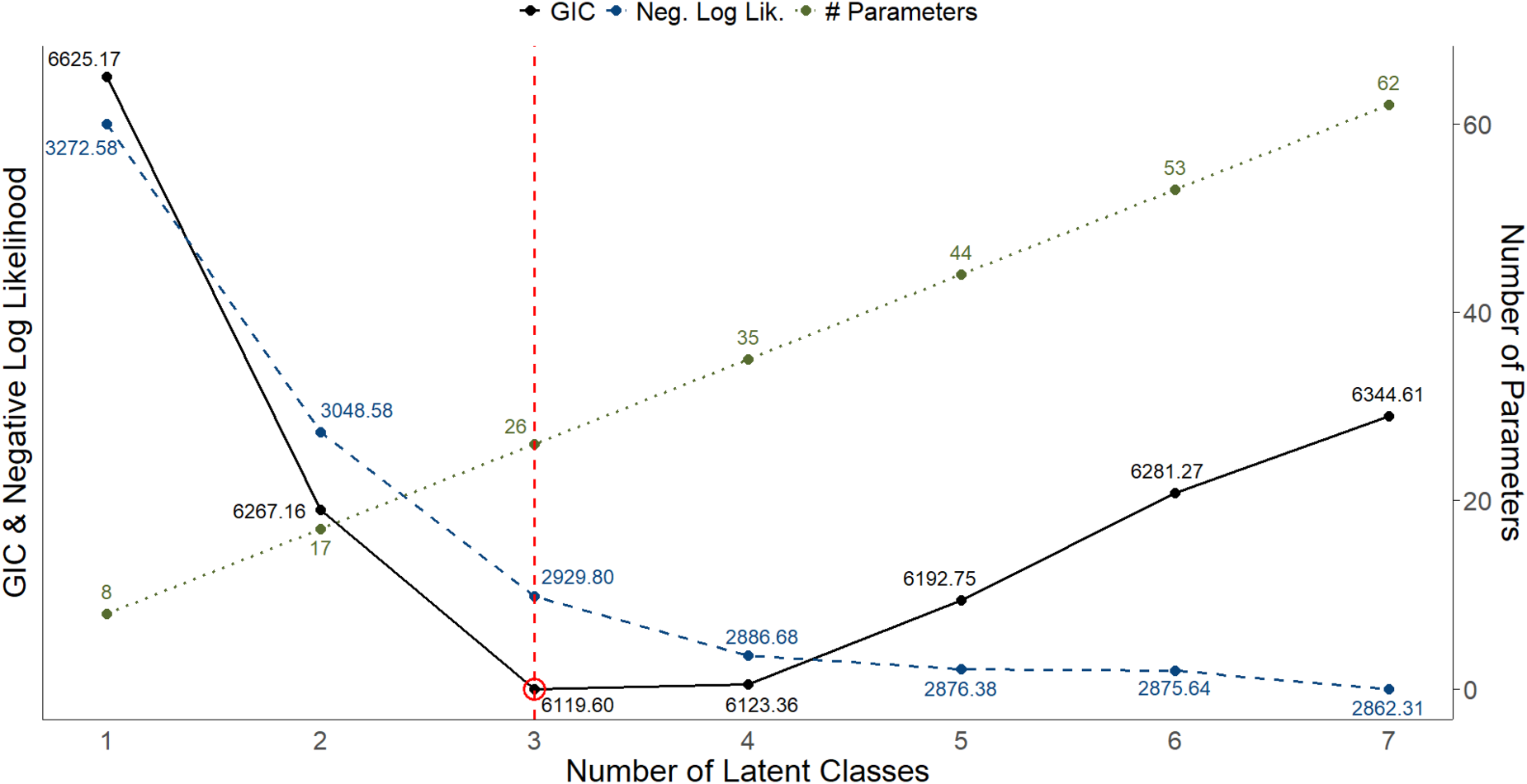
GIC (
The rate parameters
Estimated coefficients values of the latent NH-CTMC model with 3 latent classes on the DASH dataset, with standard error (SE) values enclosed in parentheses.
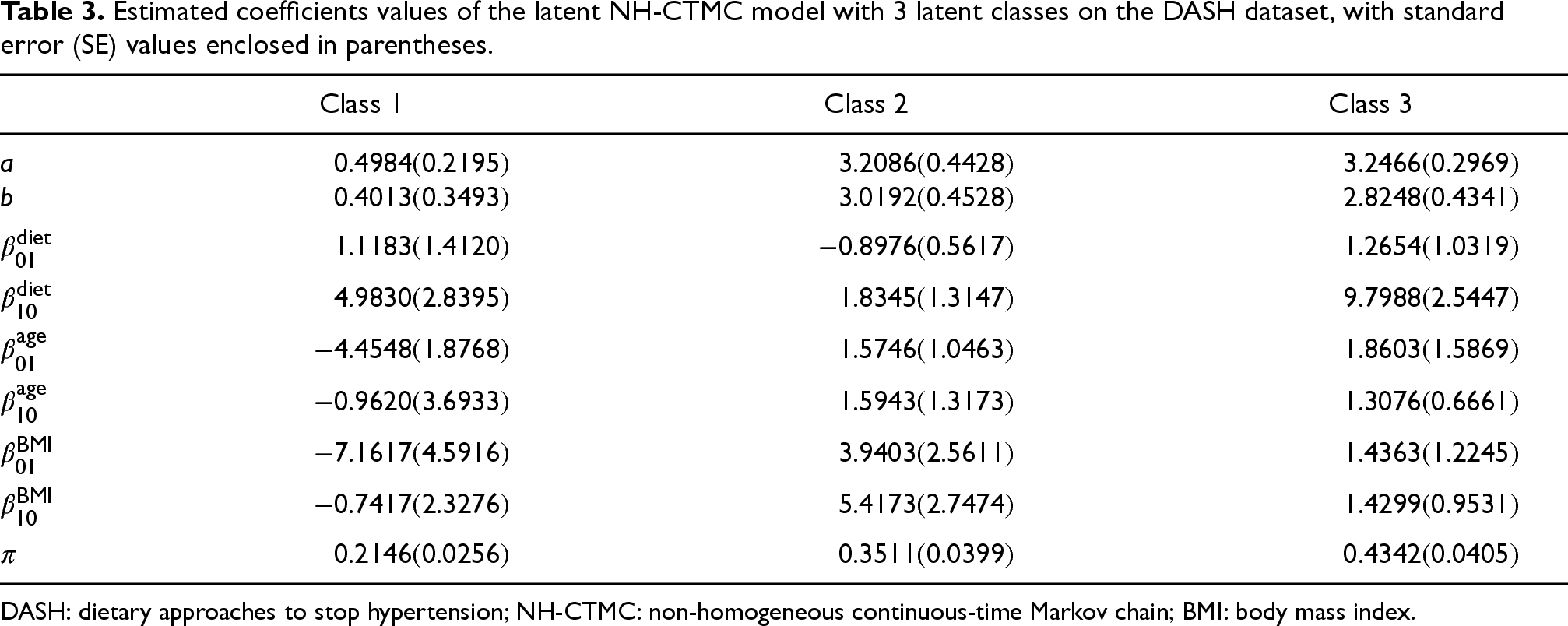
DASH: dietary approaches to stop hypertension; NH-CTMC: non-homogeneous continuous-time Markov chain; BMI: body mass index.
Demographic information of three latent classes of DASH dataset, stratified by predicted latent classes.
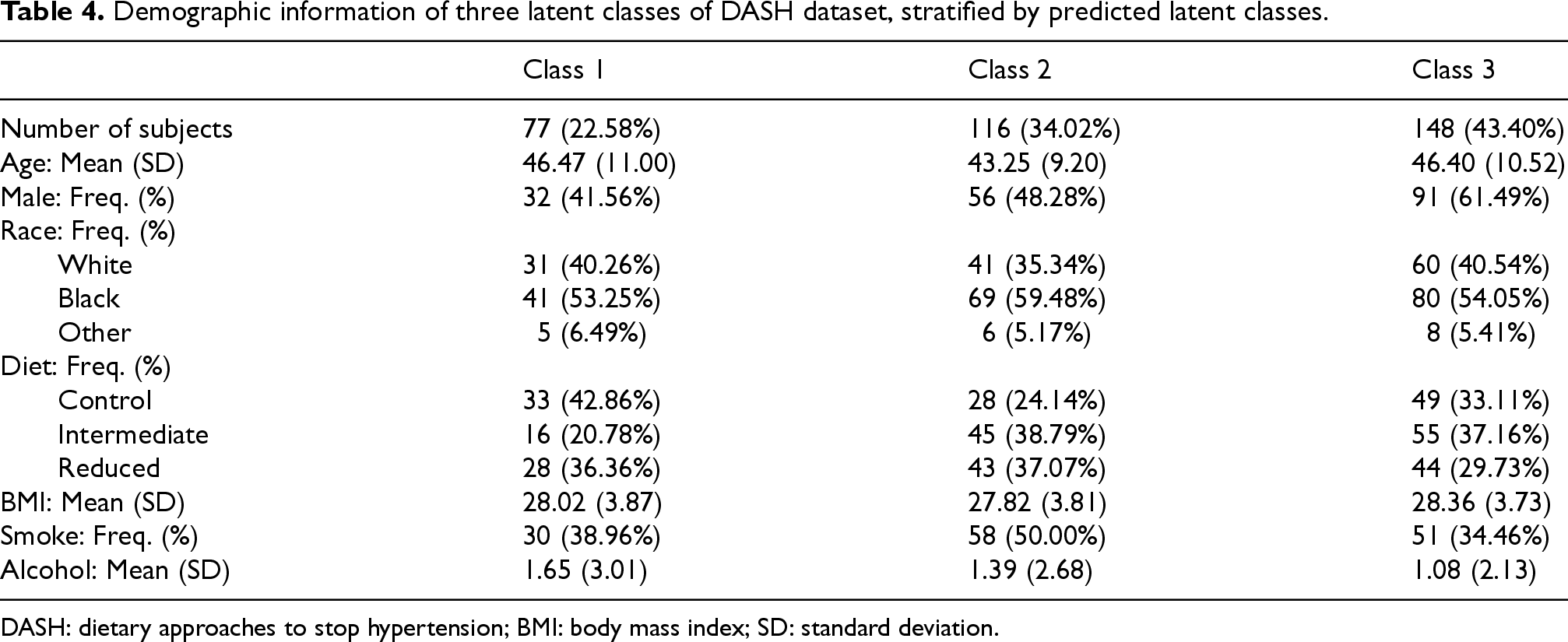
DASH: dietary approaches to stop hypertension; BMI: body mass index; SD: standard deviation.
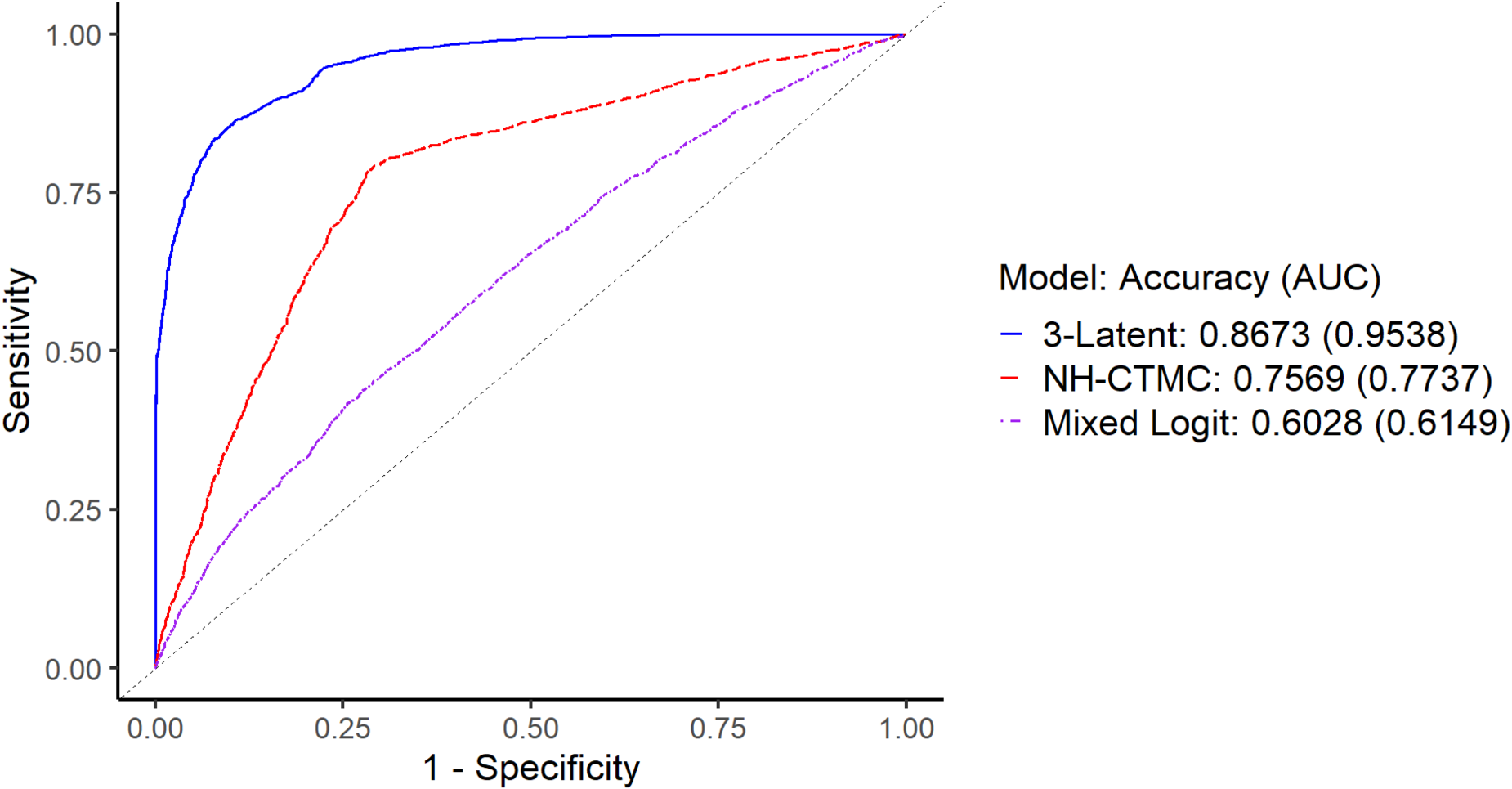
10-fold cross-validated ROC curves for the 3-latent class NH-CTMC model, single NH-CTMC model, and longitudinal logistic regression model applied to DASH data for predicting hypertensive states, presenting accuracy and AUC metrics. DASH: dietary approaches to stop hypertension; NH-CTMC: non-homogeneous continuous-time Markov chain; ROC: receiver operating characteristic curve; AUC: area under the curve.
The estimated coefficients and demographic distributions provide valuable insights into the differences between the three latent classes identified in the DASH dataset. As shown in Table 3, Class 1 is characterized by relatively low transition rate parameters (
Demographically, Table 4 shows that Class 3 had the largest proportion of subjects (43.40%), followed by Class 2 (34.02%) and Class 1 (22.58%). The classes exhibited subtle variations in age, with Class 1 and Class 3 participants being slightly older on average (46.47 and 46.40 years, respectively) compared to Class 2 (43.25 years). Gender composition varied across classes, with Class 3 having a higher proportion of male subjects (61.49%) compared to Class 1 (41.56%). Racial distributions were relatively similar, with Black participants representing the majority in all classes (53.25%, 59.48%, and 54.05% for Classes 1, 2, and 3, respectively).
The data analysis highlighted distinct transition dynamics and behavioral influences across the three latent classes identified by the NH-CTMC model. Class 1, characterized by older individuals with more stable health states, showed slower transition rates. In contrast, Class 2 exhibited the most dynamic transitions, potentially driven by higher smoking prevalence and BMI. Class 3 demonstrated a balanced but responsive transition pattern, with significant dietary effects. These findings underscore the value of latent class modeling in revealing the nuanced relationship between demographic characteristics, behavioral factors, and transition dynamics within the NH-CTMC model framework, offering a coherent explanation for the observed differences in transition rates and covariate effects.
CTMCs with finite state spaces find broad applications in modeling dynamic processes across diverse medical domains.3–5,10 This study derived closely approximated closed-form transition probability functions for a two-state NH-CTMC and extended the framework to cluster subjects into latent groups with varying transition rates. For parameter estimation, we constructed a log-likelihood function, estimated the initial values for the optimization procedure using Algorithm 1, and utilized the L-BFGS-B method implemented in
The latent NH-CTMC model offers several advantages compared to other conventional longitudinal models. Unlike traditional CTMC models, the latent NH-CTMC captures varying rates of state transition events and monitors their trends. In contrast to longitudinal logistic regression models, the NH-CTMC maintains the transitioning nature of the process through its Markovian property. Moreover, compared to NH-CTMC models without latent classes, the latent model categorizes subjects into groups with different transition rates, enabling the capture of varying behaviors within each group and facilitating more accurate predictions based on the estimated latent class. The ability to cluster subjects provides inferences on time-varying transitions and supports demographic analysis, revealing behavioral and demographic factors influencing state transitions.
Our findings highlighted the computational efficiency of the proposed latent NH-CTMC model. While Kuo et al.
24
employed a latent CTMC framework and required simulations with 10,000 samples to obtain stable results for CPs and latent class prediction, our method incorporated the non-homogeneous nature of the Markov chain and achieved comparable stability even with a sample size as low as
The application of the latent NH-CTMC model to the DASH study dataset underscores its ability to perform latent class analysis, identifying distinct patterns of health state transitions and exploring how various demographic and behavioral factors influence these transitions. Through latent class modeling, we identified three distinct classes of subjects, each exhibiting unique transition dynamics based on factors such as age, BMI, and dietary intervention status. The model successfully categorized individuals into latent classes, offering insights into the relationship between covariates and the rates of transitions between normal and hypertensive states. This demonstrates the latent NH-CTMC model’s potential in both state prediction and latent class analysis, providing a powerful framework for uncovering hidden structures in longitudinal health data like the DASH study.
Despite its advantages, the latent NH-CTMC model presents certain limitations. First, the transition rate is defined by a fixed form of log-logistic function, while general longitudinal studies may involve various forms of transition rates. Second, the maximum likelihood estimation process can become computationally intensive and may yield inaccurate results when the number of latent classes increases, due to the rapid growth in the number of parameters that can lead to suboptimal MLE outcomes. Future research directions for this work include the following: (a) Exploring more general forms of transition rates and deriving the corresponding general transition probabilities, (b) reducing computational burden by investigating optimal parameter estimation methods, and (c) simplifying transition probabilities by reducing the number of parameters as the number of latent classes increases. By addressing these limitations, the latent NH-CTMC framework can further enhance its utility and applicability for modeling complex longitudinal processes in healthcare research.
Footnotes
Acknowledgments
The authors would like to acknowledge the support and resources provided by the University of Texas Health Science Center at Houston and Louisiana State University Health Sciences Center.
Ethical approval
We obtained ethical approval for this study from the Institutional Review Board (IRB) at the University of Texas Health Science Center at Houston.
Informed consent
All participants provided informed consent prior to inclusion in the study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data and code availability statement
The dataset used in this study was obtained from the Biologic Specimen and Data Repository Information Coordinating Center (BioLINCC). The Dietary Approaches to Stop Hypertension (DASH) study aimed to evaluate the impact of dietary patterns on lowering hypertension. To access data from the DASH study, visit https://biolincc.nhlbi.nih.gov/studies/dash/. A sample R script for simulating and estimating the latent NH-CTMC model is publicly available at the following GitHub repository: ![]() .
.