
Abstract
Although response-adaptive randomisation (RAR) has gained substantial attention in the literature, it still has limited use in clinical trials. Amongst other reasons, the implementation of RAR in real world trials raises important practical questions, often neglected in the technical literature. Motivated by an innovative phase-II stratified RAR rare-disease trial, this paper addresses two challenges: (1) How to ensure that RAR allocations are desirable, that is, both acceptable and faithful to the intended probabilities, particularly in small samples? and (2) What adaptations to trigger after interim analyses in the presence of missing data? To answer (1), we propose a Mapping strategy that discretises the randomisation probabilities into a vector of allocation ratios, resulting in improved frequentist errors. Under the implementation of Mapping, we answer (2) by analysing the impact of missing data on operating characteristics in selected scenarios. Finally, we discuss additional concerns including: pooling data across trial strata, analysing the level of blinding in the trial, and reporting safety results.
Introduction
Well-designed randomised controlled trials (RCTs) have long been valued for their well-understood statistical properties and are recognised as the gold standard for conducting evidence-based clinical research to assess the efficacy of interventions. Yet, standard RCTs can demand substantial time and resources – both in terms of sample size and cost, and therefore can result impractical in cases such as rare diseases, where patient enrolment is slow and limited in size. Even in a common disease setting, many subtypes are increasingly being identified and may require personalised or stratified approaches to therapy, thus splitting the feasible number of patients that can be recruited for the overall trial into smaller groups for each subtype stratum trial. 1 Furthermore, conducting a trial with the main purpose of learning about treatment effectiveness (as in the traditional RCTs) may be ill suited in fatal diseases, where some have suggested that the priority should be to treat trial participants as effectively as possible.1,2 These drawbacks often prevent successful randomised experimentation and have been widely acknowledged as limiting medical innovation. 3
Adaptive trial designs have been proposed as a means of addressing some of the practical limitations of traditional RCTs. They enable the possibility of not only enhancing the likelihood of detecting the most promising treatments without substantially increasing the sample size, but also offering expected benefit to the trial participants. 4 The fundamental characteristic of an adaptive clinical trial is to allow, according to a prespecified plan, dynamic adjustments of design features while patient enrolment is ongoing 5 based on data observed at interim analysis. The first proposal of a design of this nature can be traced back to Thompson’s 6 idea of skewing the randomisation probabilities toward the most promising treatments according to their posterior probability of success. Due to this historical genesis, adaptive randomisation designs were often referred to as adaptive designs.7–9 Although the more recent use of the term applies more generally (see e.g., Bhatt and Mehta, 4 Pallmann et al. 5 for an overview), in this work, our focus will be on response-adaptive randomisation (RAR) designs, which prespecify how and when the randomisation probabilities should be adjusted based on the accumulated response data. We also explore how the randomisation probabilities can be used to inform early stopping rules for experimental arms.
RAR has received substantial attention in the biostatistical literature, contributing to a fertile area of methodological and theoretical research. Despite this and the recent encouragement of RAR adoption from government agencies and health authorities,
10
RAR uptake in clinical experimentation remains disproportionately low compared to the stream of theoretical work on this topic.11,12 The reasons behind the gap of the RAR methodology/theory versus the RAR in practice are diverse. First, the role of RAR in clinical trials has long been and still remains a subject of active debate within biostatistics due to its potential impact on statistical inference. Bias and hypothesis testing issues, among others, have been intensively studied (see e.g., Villar et al.
13
), and several solutions have emerged both from the biostatistics11,14,15 and the machine learning16–19 community. For a recent extensive review on the matter, we refer to Robertson et al.,
12
references therein, and related discussions. Second, the practical debut of RAR in clinical trials, that is, the two-armed ECMO trial,
20
resulted in a highly controversial interpretation of its results and their generalisability due to the final extreme treatment imbalance. This application of RAR to a clinical trial limited the use of RAR in clinical trials for the next 20 years. Third, the implementation phase of RAR in a real-trial context poses critical practical challenges, many of which may also apply to more traditional RCTs but which require a distinct approach when using RAR. These include, but are not limited to RAR, for example: For a given vector of theoretical randomisation probabilities, how can we minimise the chances of observing undesirable treatment allocations (that is, observed allocations diverging from their theoretical counterparts beyond an acceptable level) while taking into account the impact this may have on the design’s operating characteristics? More formally, let In case of missing response data that inform interim decisions in an RAR trial, when and to what extent should we allow deviations from balanced allocation in the following stage as dictated by a complete-case approach? Once we address problem (1), the natural progression from there is to think about what to do if we encounter missing responses at the interim analyses. A critical design decision with respect to the adaptation of the trial is whether or not to adapt the allocation towards the more promising treatment under the presence of missing responses. To the best of our knowledge, this issue has not been formally explored in the literature.
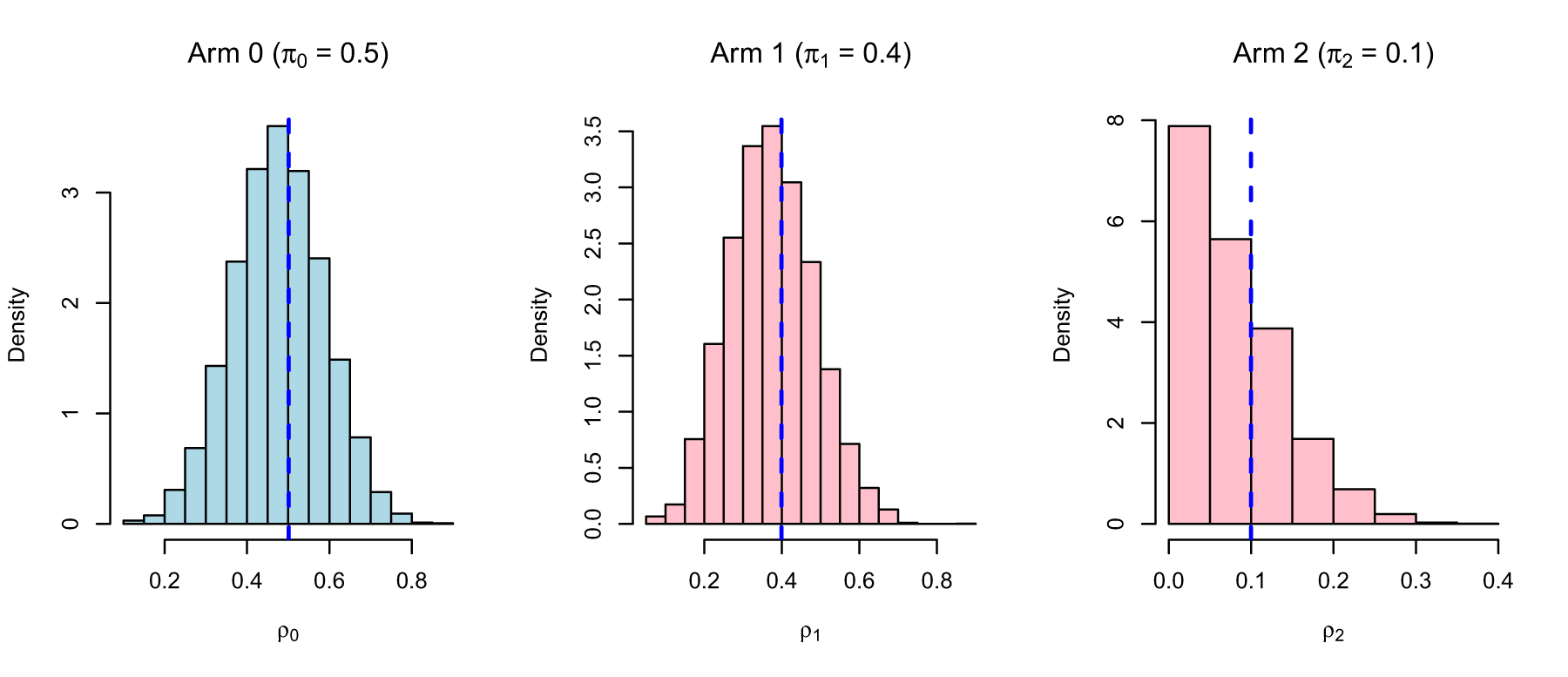
Empirical distribution of the observed allocation
In this work, we are specifically concerned with the research questions (1) and (2) as these are essential to the design and implementation of the motivating phase-II rare-disease RAR trial, StratosPHere 2. An overview of the study is presented in Section 2, with the detailed protocol given in Deliu et al. 21 For (1), we propose a Mapping rule to convert the vector of continuous target randomisation probabilities into a discrete allocation ratio object. The resulting rule preserves the randomisation properties to a chosen acceptable degree, avoids the occurrence of extreme allocation ratios by chance, and improves the operating characteristics of the original design in scenarios of interest by reducing the RAR design’s variability. For (2), we describe a procedure for handling missing data by re-evaluating the operating characteristics and taking into account the frequency of adaptations triggered in the resulting design through simulations. Other practical challenges, going from pooled analysis to safety reporting, are also surfaced.
Overall, with this work, we aim to discuss a set of critical practical problems along with potential solutions and recommendations, guided by our experience and collaboration with the clinical team in designing and conducting StratosPHere 2. Our research questions are directly inspired by addressing the practical needs and the well-known difficulties of a rare disease community. We emphasise that our proposals are not meant to be regarded as universal solutions, but rather to inspire and encourage greater synergy between methodological and practical research. We hope our work contributes to stimulating research to increase the adequate adoption and implementation of adaptive designs such as RAR into clinical practice.
The remainder of this paper is structured as follows. In Section 2, we provide an overview of the motivating RAR trial, StratosPHere 2, and present the preliminary notation and design setup (Section 2.1). In Section 3, we discuss the research question (1). We explore the research question (2) in Section 4. In Section 5, we discuss additional challenges that are of central interest in the final analysis of our motivating trial, and, potentially, other stratified RAR trials. Final considerations and concluding remarks are given in Section 6.
This work is motivated by practical challenges we encountered while planning the implementation of a rare-disease trial in pulmonary arterial hypertension (PAH): StratosPHere 2. 21 PAH is a life-threatening, progressive disorder characterised by high blood pressure in the arteries of the lungs. It affects between 15 and 50 people per million in the US and Europe and, although treatable, there is currently no cure. In this context, StratosPHere 2 represents the first-ever precision-medicine trial specifically designed to treat the causes of PAH rather than its symptoms. Importantly, it seeks to directly address devastating causes given by genetic mutations in the bone morphogenetic protein receptor type-2 (BMPR2), the most common genetic cause of familial PAH. 22
StratosPHere 2 is a three-armed, placebo-controlled phase-II stratified RAR trial. The primary objective is to explore the efficacy of two repurposed therapies as genetic modulators of BMPR2 signalling: hydroxychloroquine and phenylbutyrate. Patients are stratified according to two specific classes of BMPR2 mutations, namely haploinsufficient (herein, Stratum A) and missense (herein, Stratum B) mutations. More formally, denoted by
Primary versus adaptation endpoint
The primary endpoint of the study,

Overall, for both strata, an expected number of
Eligible subjects will be randomly assigned to one of the three arms (

Schematic of the StratosPHere 2 trial design for one stratum. Threshold
Bayesian response-adaptive randomisation
The design of StratosPHere 2 builds on the RAR allocation rule proposed in Trippa et al.
24
and further discussed in Wason and Trippa.
25
It adopts a Bayesian framework for adjusting the randomisation probabilities at each interim analysis based on the accumulated response data up to that point. Let
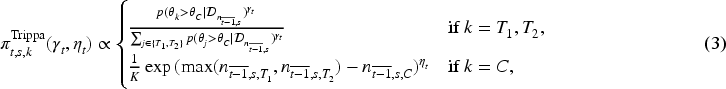
Note that Trippa-BRAR
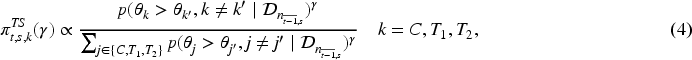
Being a Bayesian framework, we make use of prior distributions on the unknown parameters
We evaluated by extensive simulations the frequentist properties (type-I error and power) as well as the probability of patients receiving a superior arm when this exists. As detailed in Deliu et al.,
21
all evaluations for final analysis, were implemented using a fully non-parametric approach based on a bootstrap resampling technique applied on response data – corresponding to cases (patients) but with standard of care treatment, available from a preliminary phase (StratosPHere 1; Jones et al.
23
) and using a one-sided Wilcoxon test. The non-parametric approach is motivated by the small sample and the non-normally distributed data. As illustrated in Table 1, satisfactory results are expected with the proposed sample size. Simulation studies resulted in almost
Operating characteristics of the evaluated Bayesian response-adaptive randomisation (BRAR) designs.
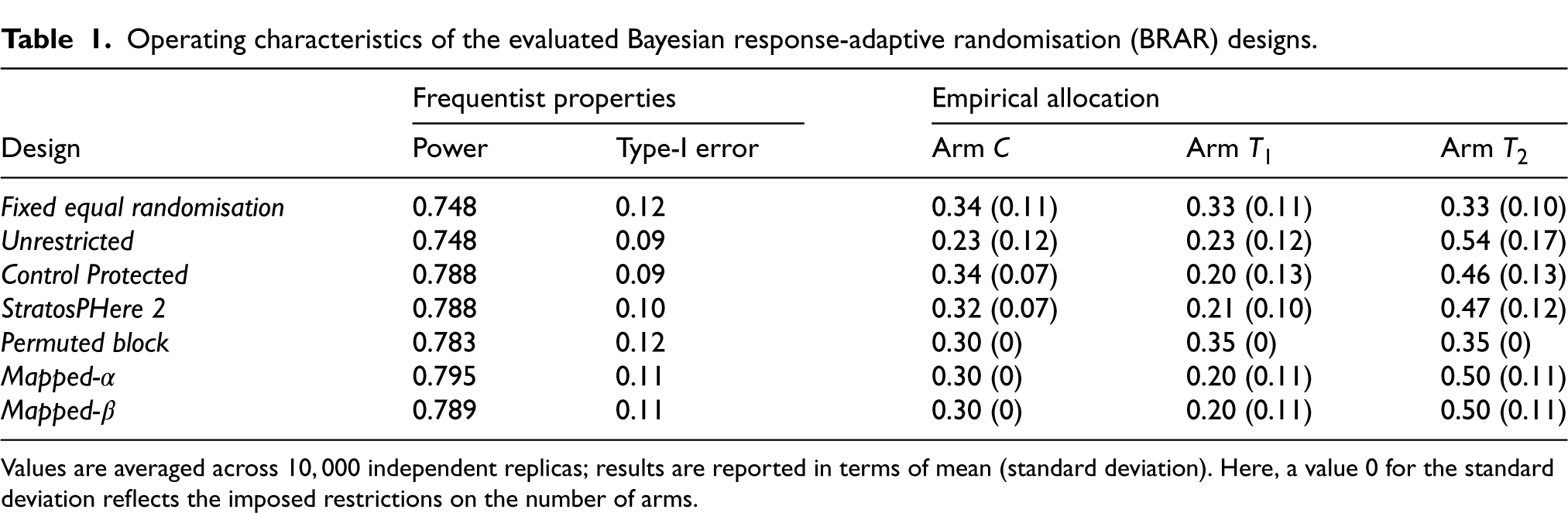
Operating characteristics of the evaluated Bayesian response-adaptive randomisation (BRAR) designs.
Values are averaged across
Randomisation is an essential component of a trial design. In complex trial settings, careful considerations are required from the implementation side to choose an appropriate randomisation procedure (be this adaptive or not). For example, in small trials, particular emphasis is placed on avoiding undesirable allocations, which can occur when targeting a particular allocation ratio. Furthermore, with the spread of adaptive designs, there is an increasing need for randomisation methods that allow unequal allocations. The rationale for using unequal allocation is provided by Peckham et al. 27 and Dumville et al., 28 underlining factors such as cost considerations or ethical concerns. However, methodological challenges of randomisation in small samples remain; see, for example, Berger et al. 29 and van der Pas, 30 who discuss the permuted-block design and put forward merged-block designs to lower predictability. To achieve a target allocation ratio, 31 propose a truncated multinomial design where participants are randomised to treatments according to a multinomial distribution until the target allocation number is reached for each treatment. Kuznetsova and Tymofyeyev 32 also point out the importance for robust randomisation methods to preserve the targeted allocation ratio, discussing and calling for alternative allocation procedures, such as biased coin randomisation, that better approximate the allocation ratio in small samples, while reducing the selection bias in open-label studies. Designs such as the big-stick design, 33 the block-urn design, 34 the maximal procedure, 35 or the brick-tunnel design, 36 among others, are some of the randomisation methods that effectively achieve unequal treatment allocations, once the allocation ratio has already been determined. In parallel, one also faces the problem of determining these practical allocation ratios, by which we mean the allocation ratios are desirable given the allocation probabilities and they adhere to the constraints of the trial design. Existing proposals, for example, Tymofyeyev et al., 37 discuss how allocations can be optimised in order to maximise power; however, resulting values are typically defined on a continuous range and their translation in practice is underdeveloped. Therefore, there is gap between methods to define ideal allocation ratios reflecting the underlying design’s goal and the existing procedures to best implementing resulting ratios into a feasible the randomisation system. This is particularly true for BRAR settings, which is the most used RAR in practice so far. 38
To summarise, managing unequal allocation ratios with small sample sizes is a challenge within itself (even outside of RAR designs). Particularly, BRAR designs pose additional challenges since instead of working with whole number ratio allocation weights, it primarily returns (continuous) allocation probabilities. This makes it more challenging to achieve the desired allocation, as described within the research problem 1 in the introduction.
In this paper, we aim to fill the aforementioned gap. Specifically, we propose a method to map the (continuous) allocation probabilities derived according to the design’s allocation rule, for example, Thompson sampling or Trippa’s rule, to a suitable ratio using probability thresholds which act as boundaries for decision making for the adaptive design. We call this method Mapping. As a result, the randomisation process preserves its adaptability and operating characteristics up to the level of avoiding pre-established undesirable allocations. Furthermore, Mapping simultaneously covers both the both the determination of the target ratio and its implementation. This guarantees that the randomised sequence (randomised list) adheres to the constraints of the design and maintains the expected allocation ratios.
This section focuses on research problem (1) as outlined in the Introduction. First, we provide a comparison amongst selected designs considered for StratosPHere 2 differing in their degree of constraints on the allocation probabilities. We will refer to them as the Unmapped RAR design, since their continuous randomisation probabilities are directly used to determine the allocations. Then, we consider the baseline design to be StratosPHere 2 (as illustrated in Figure 2 and discussed in the study protocol 21 and statistical analysis plan). 39 Finally, we present Mapped designs which includes Permuted Block Design and our proposed designs that translate the continuous allocation probabilities to discrete target allocations. A preliminary summary of the comparators is given in Table 2.
Taxonomy of the evaluated BRAR designs, with corresponding allocation rule and restrictions per stage.
indicates the exact number of controls allocated.
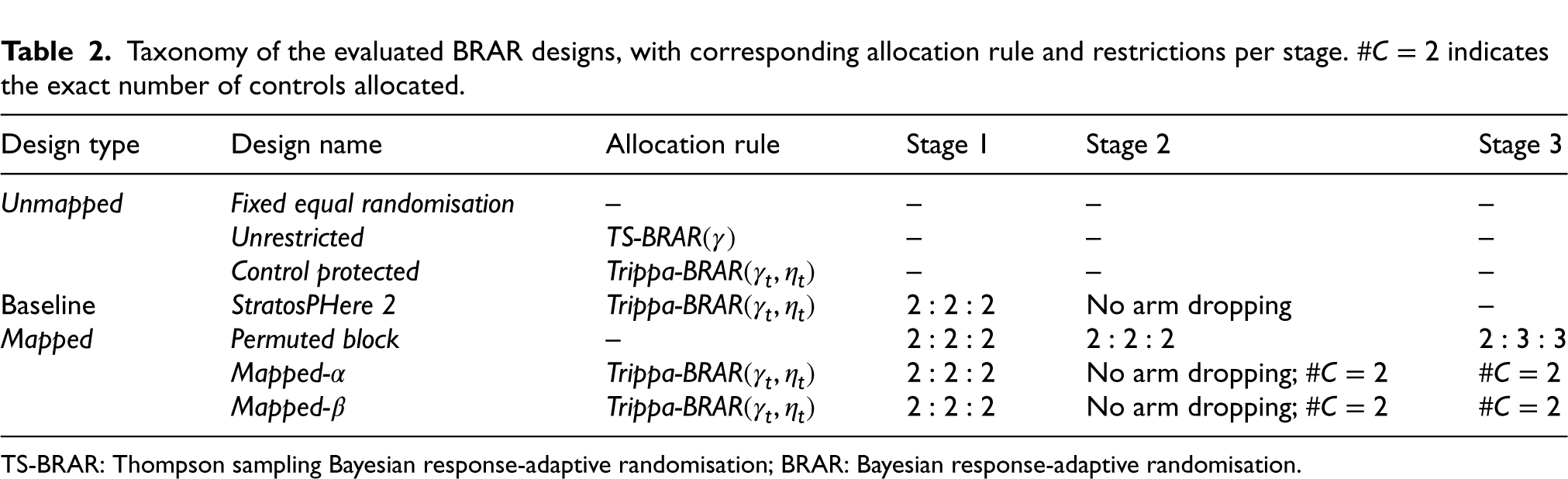
Taxonomy of the evaluated BRAR designs, with corresponding allocation rule and restrictions per stage.
TS-BRAR: Thompson sampling Bayesian response-adaptive randomisation; BRAR: Bayesian response-adaptive randomisation.
Since each design is implemented independently within each stratum, we outline our proposal with reference to a single stratum. The same approach can be replicated for the other stratum. We recall that each stratum is structured in three stages
We consider three types of Unmapped designs – first one is Fixed Equal Randomisation where there is a
These designs include direct implementation according to the continuous randomisation probabilities estimated at each interim analysis (end of stages 1 and 2; see Figure 2) with no guaranteed properties of the resulting allocation sequences. As an example, think of assigning the second stage of 6 patients to the three treatment arms by rolling a fair 3-sided die, that is, with probability of 1/3 each. Since the allocation is determined randomly only once, there is no guarantee that the assignments will result in a 2:2:2 allocation across the treatments due to the stochastic nature of the process; thus, the resulting sequence (randomisation list) of treatments may deviate from the expected or desired allocation.
Implementation of Unmapped versus Mapped designs
Unmapped procedures require the randomisation system to use probabilistic assignment methodology that is, utilise probabilities derived from the BRAR algorithm along with some type of random number generator and logic to perform patient assignments. Implementing this within a randomisation system is complex and requires advanced software/coding by randomisation system providers. This level of complexity can limit the number of providers capable of supporting such systems. Whereas for Mapped designs, the derived discrete allocations can be implemented within the standard randomisation schedules (e.g., randomisation list with permuted blocks containing the included treatments and allocations). These standard randomisation schedules can be used in any randomisation system.
Mapped designs
Now, we describe our proposal for the Mapped versions of the Unmapped designs. In practice, Mapping can be viewed as an intermediate step to link the adaptive design’s definition to its implementation in a concrete trial setting. As such, Mapping involves a decision rule to translate the continuous randomisation probabilities derived in the Unmapped designs at the interim analyses into a target vector of discrete allocation ratios of the form
In Table 2, we have listed three designs as Mapped – first of which is the Permuted Block Design where the allocation ratio is fixed to maintain balance in the three different stages. The other two designs, which are discussed in the rest of the section, allow more room to deviate from the balanced allocations if needed.
Definition of the discrete allocation ratio space
The allocation ratio is directly driven by the allocation probabilities dictated by the underlying Unmapped design. Given its practical relevance, we will focus on the baseline design StratosPHere 2 where we are interested in the
Specifically, in our implementation, we consider the following five decision categories depending on the stage of the trial and the data observed: Drop, Disfavour, Balance, Favour, and Keep. The first two categories refer to a situation in which an active treatment arm shows unpromising results relative to the other active arm, as opposed to the last two categories; category Balance indicates a case of relative indifference between the two active treatment arms. Note that, for a given arm, these categories are mutually exclusive – if an arm is determined as Drop and it is the only arm in this category, it will be excluded from further allocation and the Disfavour allocation ratios will not apply. To resemble the design of StratosPHere 2 (which has a protection on the control treatment), we start by fixing the number of allocations to control
Guided by the StratosPHere 2 design, in Table 3, we present possible decisions that can be made regarding the allocation ratios for
Possible options for the allocation ratios for
at each stage of the trial based on the categories of the active treatment arms.

Possible options for the allocation ratios for
“never” refers to a situation in which that category is not an option (e.g., at stage 1, we always choose balance, with arms allocated based on a
Given the categories per interim stage, one can define multiple types of Mapped designs depending on the number of thresholds that are considered per stage on the continuous probability space. In this paper, we discuss two types of such designs which we will call Mapped-
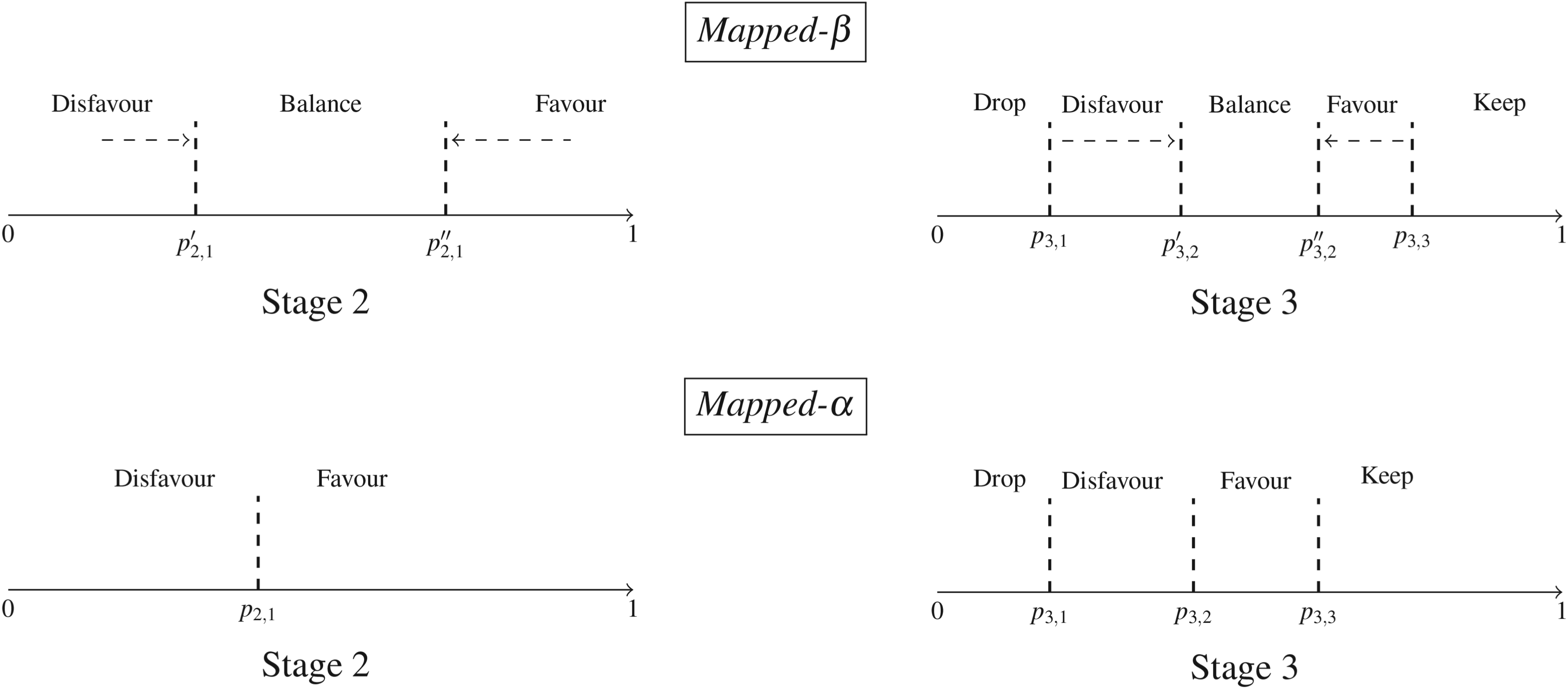
Schematic of the proposed Mapped designs. Closing the Balance region in the top-row design Mapped-
Thus, to summarise, Mapped designs implement the usage of thresholds
Once a category for an active arm has been chosen based on the thresholds by the Mapped design (threshold selection is discussed later), the corresponding discrete allocation ratio is selected from the options listed in Table 3. If two active arms fall in the same category, say Disfavour, then we opt for the balanced allocation of that stage. If the category has two possible allocation ratios, then either of them is chosen at random with equal probability.
Definition of the Mapping functions
We now give a formal description of our proposed approach, encompassing both the decision rule and the allocation strategy. At the end of stage 1 and 2, we observe some interim data and obtain a vector of allocation probabilities
For example, the representation of Figure 3 can be formalised through a mapping function 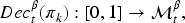
Once the mapping rule outputs an adaptation category for each active treatment arm, we can finalise the allocation ratio based on the number of arms in each category. This is defined using an auxiliary function 
Determination of the Mapping thresholds
The implementation of Mapping requires fixing the set of probability thresholds
Thresholds are selected per stage using simulations, with calibration of an additional parameter that captures the level of adaptability achieved across simulations at each stage. With adaptability we refer to decisions for “Favouring” or “Dropping” an active arm, thereby deviating from a balanced allocation between the two active treatment arms. In our motivating trial, this occurs when the allocation ratios in stage 2 and stage 3 deviate from the initial 2:2:2 and 2:3:3 due to an active arm being favoured or dropped. Our goal is to determine thresholds such that adaptations are less often triggered under the null hypothesis (no difference in treatment arms) while also resulting in good operating characteristics, particularly in terms of power (under the alternative hypothesis: superiority of an active arm).
We express adaptability as a percentage: at each stage, we replicate the Mapped-
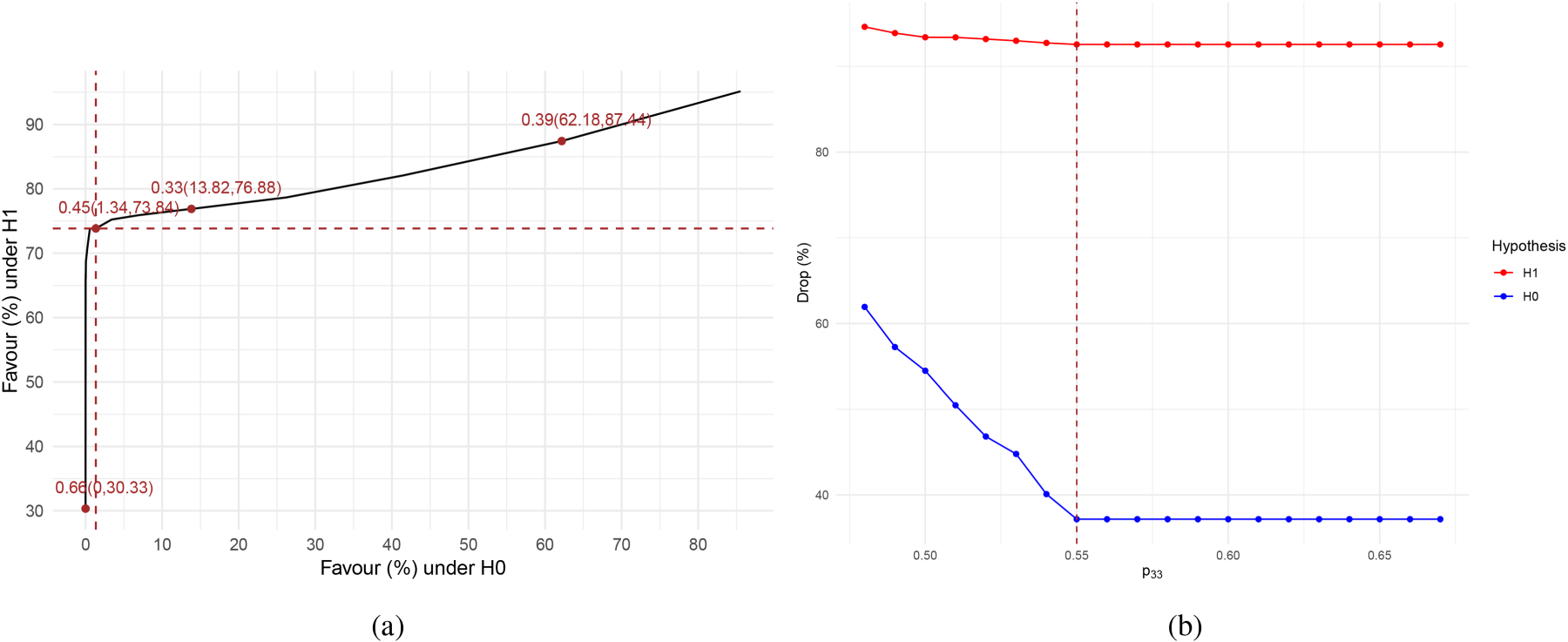
Selecting probability thresholds for Mapped-
For Mapped-
Operating characteristics of the Mapped versus Unmapped designs
A final part of addressing our research question (1) is to investigate: How do the operating characteristics of the original StratosPHere 2 design and other variants, including the Mapped versions for our selected thresholds, compare against each other? Results corresponding to the BRAR designs outlined in Table 2 are presented in Table 1. The operating characteristics are reported in terms of power, type-I error, and expected allocation probabilities under the alternative hypothesis of an optimal arm (see also Section 2). These are computed following a bootstrap approach (based on real data from a pilot StratosPHere 1 phase; see Jones et al.
23
), and by replicating the design a number of
In this section, we address research problem (2) as outlined in the Introduction. Specifically, we discuss here how to handle the occurrence of missing response data during the conduct of the StratosPHere 2 trial to effectively implement the (adaptive) Mapped-
All simulations are carried out under a missing-at-random framework assuming all the components of the biomarker panel for a patient’s primary endpoint are missing. We focus on the case where a maximum of 2 patients, that is, 10% drop out of the study in the listed missing data cases. If the rate of missing data exceeds 10%, we assume that no adaptations can be safely triggered. We also assume that when a data point is missing we will refrain from imputing it as this is a small-sized trial. Imputation will be discussed later in this section. The following cases are considered and compared with a scenario with no missing data denoted as Case 0, that is, when the response data is available for (6, 6, 8) patients in each stage respectively.
Case 1 One patient’s data is missing at random from stage 1 of a stratum, that is, the composition of the stratum is (5, 6, 8) for the sample sizes of the first, second and third stages respectively.
Case 2 Two patients’ data are missing at random from stage 1 of a stratum, that is, the composition of the stratum is (4, 6, 8) for the first, second and third stages respectively.
Case 3 One patient’s data is missing at random from stage 2 of a stratum, that is, the composition of the stratum is (6, 5, 8) for the first, second and third stages respectively.
Case 4 Two patients’ data are missing at random from stage 2 of a stratum, that is, the composition of the stratum is (6, 4, 8) for the first, second and third stages respectively.
Case 5 One patient’s data is missing at random from each of stages 1 and 2 of a stratum, that is, the composition of the stratum is (5, 5, 8) for the first, second and third stages respectively.
Results, in terms of the operating characteristics of the Mapped-
We note that with more missing data points, more power is reduced but overall, the operating characteristics remain reasonable allowing us to not interfere with the design.
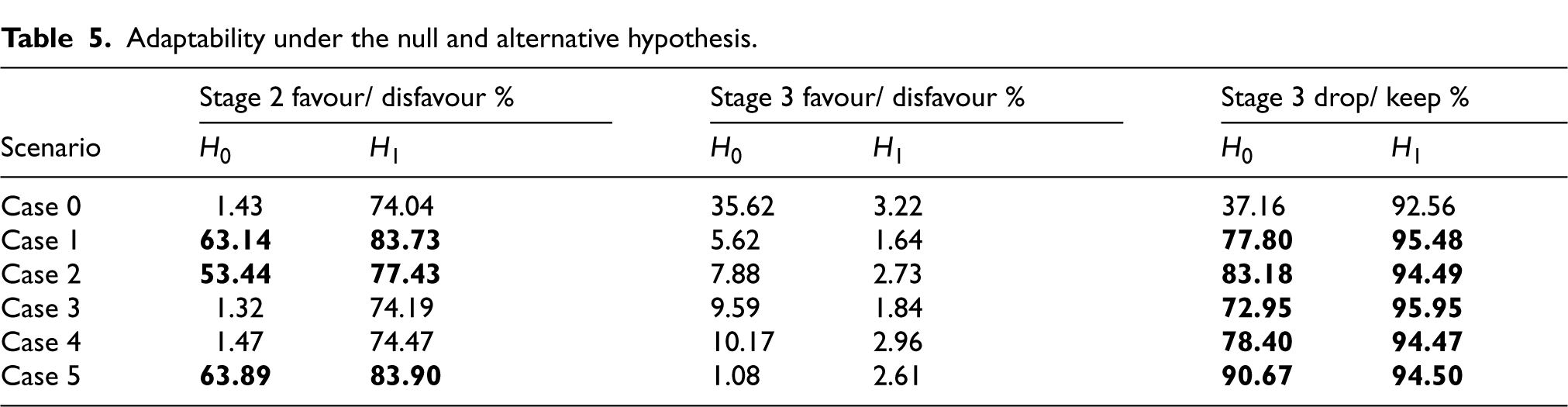
Now, we want to address the key question at the design stage – whether to allow adaptation or not, when recommended by the BRAR design using the observed outcome data while ignoring any missing data. To investigate this, we utilise the parameter adaptability to observe the extent to which the design deviates from a balanced allocation in the simulations. Table 5 illustrates how adaptability varies in the cases considered in this work. Since the data size is small, we wish to see lesser adaptability under the Null hypothesis so that under the Alternative, we can expect lesser adaptability and just let the trial design decide whether to adapt or not even during missingness without any interference. To decide whether to adapt or not during the interim analysis, we examine the situations one by one. During the first interim that is, at the end of stage 1, we aim to understand how the adaptability varies for stage 2 when we have missing data points in stage 1 that is, cases 1, 2 and 5 are possible. Referring to Table 5, we find that for these specific cases, adaptability under the the Null is very high (highlighted in bold in the table). Therefore, we are inclined to not adapt away from balanced allocation in the stage 2 if there is any missing datapoint in stage 1. Moving on to Interim 2, with a similar rationality, we have cases 3, 4 and 5 to consider and we note that the Drop/ Keep % is very high under the Null. This leads us to not permit dropping either of the active treatment arms in stage 3 if missingness is found in stage 2. However, we may allow adaptation towards favouring an arm if need be. The final decisions on missing data handling in the ongoing trial are provided in the statistical analysis plan of the trial StratosPHere 2.
Operating characteristics of the Mapped-
design evaluated under different cases of missingness.
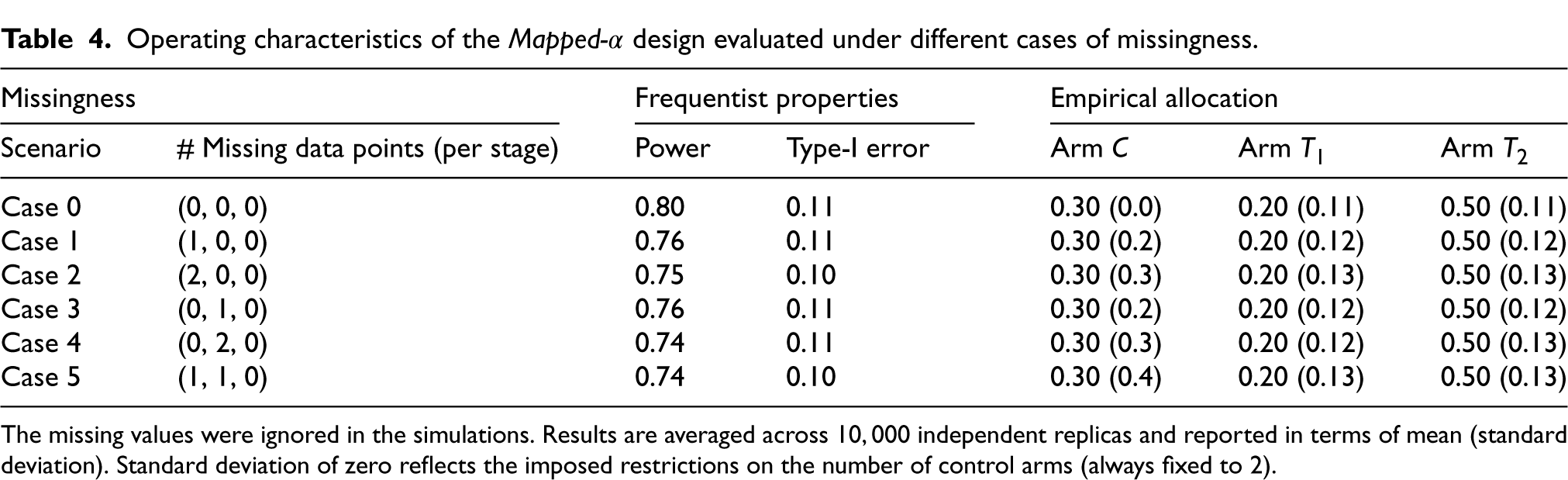
Operating characteristics of the Mapped-
The missing values were ignored in the simulations. Results are averaged across
Adaptability under the null and alternative hypothesis.
Finally, we also review how the operating characteristics, particularly Power, would look like at the end of the study depending on our decision to adapt or not. This is illustrated in Figure 5 representing Power under different scenarios of adaptability. We can see that, when data is complete (Case 0), adapting gives maximum power as expected. Note that some of these scenarios are redundant for example, for missing case 3 where stage 1 has no missingness, it is pointless to consider the possibility of allowing favour in stage 2 as till that point data is complete and we do not interfere or interrupt. But, the plot helps us to understand how Power can get affected depending on what action we take.
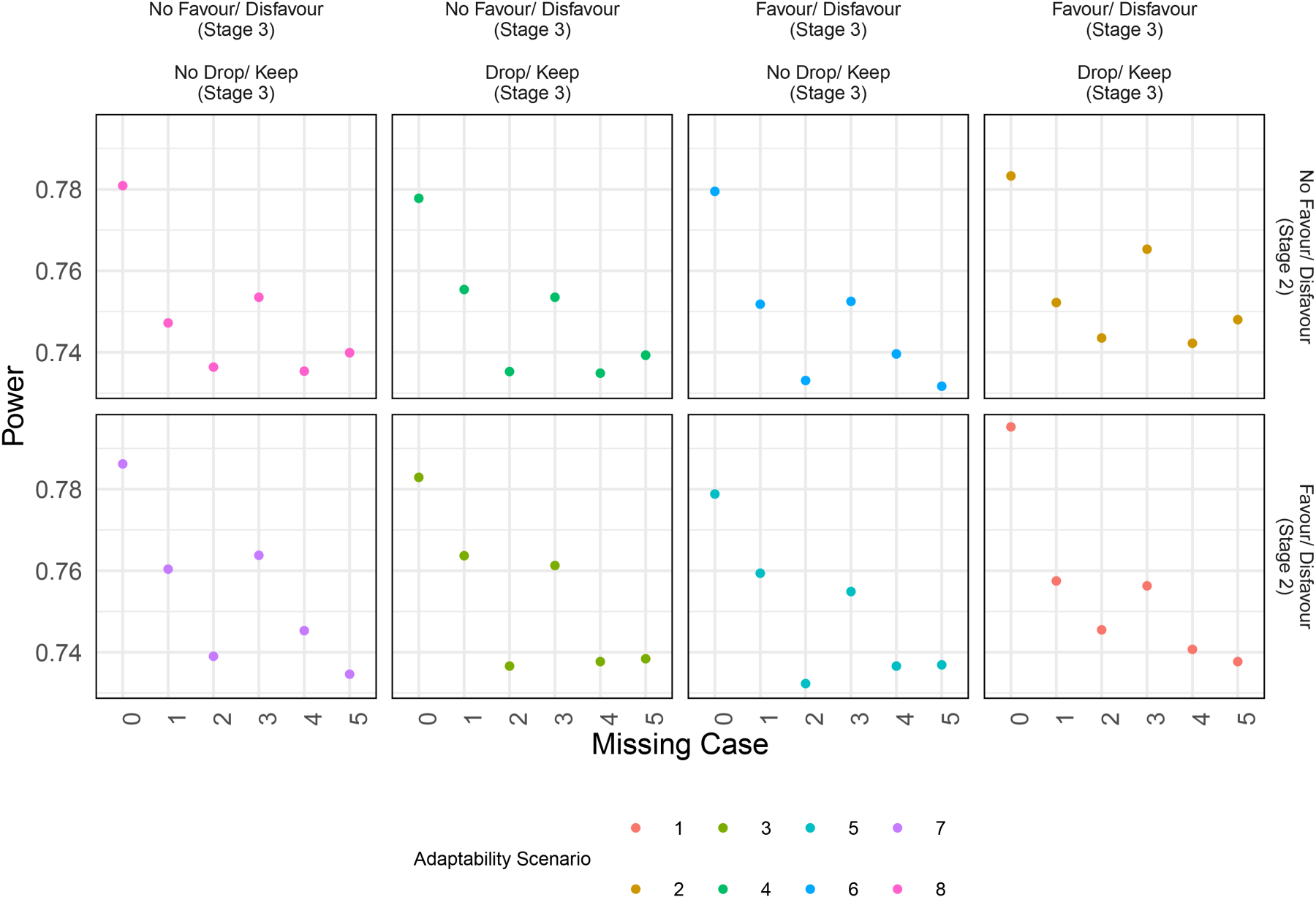
Power under different scenarios of adapting in the stage.
Imputation
Biswas and Rao 40 reports that based on simulations under the assumption of missing at random, statistical power improves when imputing missing data responses using the sample mean in their adaptive design as compared to not imputing. Here we assess how imputation affects the operating characteristics of the design.
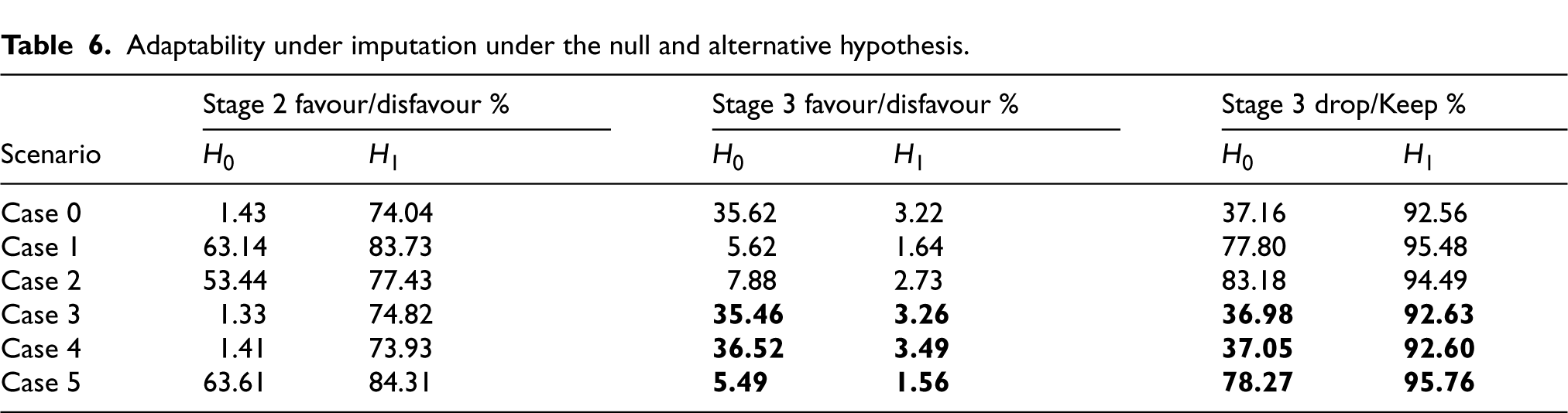
Given the specified trial design and the implementation of Mapped-
In Table 6, the bold text cells show the updated values reporting adaptability when missing data points are imputed only in stage 2. Other slight changes in the non-bold values are due to the variability of results due to simulations. We note that when missing data points are imputed, then under the Null hypothesis, the adaptability values for the cases 3 and 4 are similar to the complete case (Case 0) as expected as there is no missingness anymore. However, the same values for Case 5 are dissimilar to Case 0 since there still exists an unimputed missing point which is from stage 1. The updated values for cases 3 and 4 show the chances of dropping an active treatment arm under the null have decreased which is a favourable outcome suggesting that imputation can be recommended. These results show that when we want to be conservative with respect to the extent of adapting in case of missingness in the data, then imputing can also lower the scope of extreme adapting such as Drop/ Keep % in stage 3. This observation is specific to our motivating trial but we believe it can be generalised to other studies highlighting the importance of checking levels of adaptability through simulations. However, the choice of imputation method will require a rigorous approach and expert advice.
Adaptability under imputation under the null and alternative hypothesis.
Informative missing data
In Section 4, we addressed the issue of missing data from a design point of view. However, once the trial concludes, we will need to revisit the handling of missing data from an analysis perspective. First of all, the number of missing data cases to consider will increase as the missing data cases listed in Section 4 do not account for missingness in stage 3 due to their lack of impact on adaptive decisions. Secondly, the pattern of missingness needs to be examined. In our simulations, we assumed that missing data occurred at random. This makes sense in our trial because of the nature of the endpoint. However, in other settings there is the possibility of missingness not at random, where missing data may disproportionately occur in a specific treatment arm, signalling a non-random pattern. If this occurs, the risk of biased estimates increases, potentially compromising the trial’s operating characteristics. Therefore, identifying and understanding the missingness pattern is crucial. Finally, we will need to re-evaluate our imputation strategies and techniques, as those used previously may no longer be appropriate for the analysis stage of the trial. Before, in the design stage, we did not perform imputation in stage 1, and in stage 2 we imputed using historical data from the trial. However, after the conclusion of the study, if imputation is required, we can impute missing data in stage 1 also, as we now have more data points available to do so. A Bayesian imputation can be done to impute the missing data points.
Pooling strata versus independent analysis
In stratified designs or master protocols such as “umbrella”, platform or basket designs, which are differentiated into multiple parallel sub-studies, 41 investigators are often faced with the dilemma of pooling data from subgroups, borrowing some information, or simply following a set of parallel analyses. In fact, while conducting independent or stand-alone analyses (such as the primary one in StratosPHere 2) perfectly fit into the tailored paradigm of precision medicine, there are a number of concerns with this approach (see e.g., Berger et al., 42 Berry 43 ), including the issue of multiple testing and the lack of sufficient power. This is particularly relevant in rare disease trials, where the sample size is inherently low for detecting significant effects. One of the secondary analyses pre-planned in StratosPHere 2 is, in fact, a final analysis based on a pooled sample from the two mutation strata. Nonetheless, this may conflict with the potential heterogeneity of the treatment effects in the two strata, especially when the primary analysis (per strata) does not reach a decisive conclusion about the treatment effect(s) due to low power. Dedicated analyses should be conducted to assess when and to what extent a pooled analysis would be suitable and superior compared to independent stand-alone type of analyses: we report some preliminary exploration in Appendix A.1. Then, information borrowing principles, as done in for example, Zheng and Wason, 44 may be included to enhance the informative content of a stratum. In alternative, a decision rule could be identified to guide a “Pool vs. Don’t Pool” analysis, for example, using a “Test and Pool” approach as discussed in Li et al. 45 Such a decision rule may have several benefits in clinical research, starting from enhancing power and/or minimising the risk of incorrect conclusions (under strata and treatment heterogeneity) for the current trial, and ending with informing the design of future phases of the trial. In StratosPHere 2, for example, it may suggest whether to keep a stratified approach in a future phase-2b or phase-3 trial.
Blinded versus veiled analysis
In placebo-controlled trials with multiple treatments that are noticeably different in terms of their drug's physical appearance or mode of administration, to ensure complete blinding (of both patients and physicians), a double-dummy approach must be implemented. That is, if we denote the two drug kits of the active treatments by A and B and the drug kits of their corresponding placebos by PA and PB, then each patient should receive two treatments having one of the following forms: (i) active A treatment arm patients receive drug kits A, PB, (ii) active B treatment arm patients receive drug kits B, PA, and (iii) placebo arm patients receive drug kits PA, PB. In this way, neither patients nor physicians can be informed about the drug kits they are given or, most importantly, about the drug kits they are not receiving (as would occur in a standard placebo-controlled trial). This double-dummy technique is recommended by FDA
46
for (confirmatory) platform trials but it can increase costs and place additional burdens on patients, potentially reducing compliance. An alternative approach is based on having different placebos matching all the active treatments and administering a single drug kit from the following set: (i) active A treatment arm patients receive drug kit A, (ii) active B treatment arm patients receive drug kit B, (iii) placebo A treatment arm patients receive drug kit PA, and (iv) placebo B treatment arm patients receive drug kit PB. In this way, the patients remain unaware of whether they are receiving an active treatment or a placebo, but they do know which active treatment they have not been given. This partial blinding is termed Veiled in Senn.
47
The level of blinding ultimately leads to a re-definition of the hypothesis in equation (1): that is, should we compare the active treatment, say A, to the combined placebo control arm (i.e., both PA and PB), or only to the corresponding placebo arm PA? In StratosPHere 2, we adopted a veiled approach and the control arm is represented by the combination of the two control arms (i.e., they are not differentiated). If we were to follow a double-dummy approach, we would need to differentiate between
Safety reports
In many trials, including adaptive trials, it is important to account for the differential nature of exposure to treatments. The patients will not have the same duration of taking treatments during the trial and these differences in follow-up times are not recorded in the commonly reported incidence proportion of an adverse event – thus, introducing biases in estimating the adverse events by not accounting for time in treatment or follow-up. One way to address this is by updating the incidence proportions such that the duration of the treatment until an adverse event is factored in as suggested by Allignol et al. 48 More methods are provided by Unkel et al. 49 In this trial StratosPHere 2, the drugs are repurposed, therefore, their safety information is already known to an extent. However, further work needs to be done while reporting safety analyses especially for adaptive trials where the follow-up times are bound to vary thereby, adding biases.
Discussion
In this article, we present research directly motivated by our involvement in conducting a stratified BRAR trial for a rare disease. We have explored methodological solutions to practical problems that limit the wider adoption of RAR in clinical trials. These specific challenges have been poorly addressed in the literature and continue to be a barrier to implementation. These specific challenges have been poorly addressed in the literature and continue to be a barrier to implementation in practice. In particular, we focus on two implementation issues that play a fundamental role in small-sample trials: (1) How can we minimise the chance of undesirable empirical treatment allocations while reflecting the theoretical allocation probabilities dictated by the RAR design and preserving an adequate level of the design’s operating characteristics; and (2) how should we handle the occurrence of missing data in an RAR trial when decisions regarding adaptations need to be made at the interims?
In addressing (1), we have provided a general Mapping procedure that converts the vector of continuous allocation probabilities into a discrete allocation ratio. We have evaluated two instances of the proposed rule accounting for two levels of granularity for the final discrete set according to a different number of probability thresholds. We would like to emphasise that the evaluation was driven by the design characteristics of our motivating study, StratosPHere 2. To decide the probability thresholds, we introduced an adaptability parameter recording deviations from the balanced allocation of the treatments. The thresholds have been appropriately selected in simulation studies by optimising the trade-off of the adaptability parameter under the Null and Alternative hypotheses. Note that the number of probability thresholds and their respective values can be adjusted with other practical considerations, for example, based on statistical summaries of the allocation distribution or other specific constraints dictated by the unique requirements of the trial in hand. The implemented Mapping rule also resulted in useful improvements in the operating characteristics of the trial, both in terms of frequentist errors and participants allocated to the most promising arms, when compared to the original StratosPHere 2 design.
Additionally, we examined the impact of missing data on the operating characteristics of the trial and the newly introduced adaptability parameters. This analysis suggested the potential to adapt probability thresholds based on the extent of missingness, with a primary goal, for example, of minimising extreme adaptations such as the dropping of a treatment arm during stage 3 under the Null hypothesis (i.e., when all treatment are equivalent). However, for the purpose of the ongoing trial, we have opted to keep the probability thresholds as constant across the different scenarios of missing data. Further, the possibility of imputation is introduced and its impact on the trial design characteristics.
In conclusion, our solutions provide a way to conduct a safe trial (avoiding undesirable allocations and minimising wrong decisions in case of missing data) while serving as a strategy to enhance the frequentist properties of a small-sample trials and also keeping the essence of an RAR design. This procedure of Mapping is also amenable to a straightforward implementation for any type of randomisation system. To illustrate, Sealed Envelope 50 is a randomisation system commonly used by Clinical Trial Units that randomises patients to the treatment groups by utilising blocked randomisation list(s). In the StratosPHere 2 trial, the unblinded statistician is responsible for generating the final randomisation list(s) that includes permuted blocks containing treatments and allocation ratios that match the Mapped design for BRAR. The unblinded statistician then provides the generated randomisation list(s) for the utilisation in the Sealed Envelope for patient assignments. Our experience with this trial shows that the Mapping procedure can address the challenges of achieving the allocation ratio within small sample sizes while also simplifying the implementation for the randomisation system. Moreover, our findings suggest that relying solely on operating characteristics for handling missing data in an RAR design, especially at the design stage, could be insufficient. Incorporating additional parameters, such as the frequency of adaptations triggered during the trial, could provide deeper insights, ultimately leading to a more informed decision-making.
Finally, we highlighted four statistical problems for post-trial (final) analyses. We would have more missing data patterns, requiring an understanding of the missingness pattern and then the decision for the imputation method, if needed. Then, we raised the question of whether to pool data from different strata or not, which is especially relevant for rare disease early-phase trials. Next, we consider the impact of the level of blinding on the hypothesis testing. As a last point, we emphasise the importance of carefully thinking of how to best report adverse events by factoring in the varying follow-up times in adaptive trials.
Directly motivated by our concrete experience in a stratified RAR trial for a rare disease, our proposals may warrant evaluation in broader contexts. This could include other trial designs or RAR rules. Further extensions could involve larger sample sizes or modifications to the number and size of trial stages. Another area for practical RAR exploration is missing data, particularly non-random missingness. While our analyses primarily focussed on design and practical implementation, this work can be extended to the final analysis stage; crucially, the final analysis stage warrants exploration of additional imputation methods. The overall goal of this article was to describe practical challenges often neglected in technical literature and offer potential solutions for addressing them. We hope this inspires greater synergy between practical and methodological research, which is crucial for translating RAR’s benefits into clinical practice.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article: This research was supported by the UK Medical Research Council
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: SSV is member of the advisory board for PhaseV. MRT received support from NIHR Cambridge BRC and MRC. He received consulting fees for advisory roles by Jansen, Apollo Therapeutics and Merck, and travel support from GSK and Jansen. He has been member of the ComCov and FluCov data safety monitoring/ advisory boards. This research is independent of these links.