
Abstract
Missing data is a widespread issue in clinical trials, but is particularly problematic for digital health interventions where disengagement is common and outcomes are likely to be missing not at random (MNAR). Trials that use response-adaptive designs need to handle missingness online and not simply at the end of the trial. We propose a novel online imputation strategy which allows previous imputations to be re-imputed given updated estimates of success probabilities. We additionally consider: (i) truncation of deterministic algorithms to prevent extreme realised treatment imbalance and (ii) changing the random component of semi-randomised algorithms. Through a simulation study based on a trial for a digital smoking cessation intervention, we illustrate how the strategy for handling missing responses can affect the exploration-exploitation tradeoff and the bias of the estimated success probabilities at the end of the trial. In the settings explored, we found that the exploration-exploitation tradeoff is affected particularly when arms have very different rates of missingness and we identified combinations of response-adaptive designs and missingness strategies that are particularly problematic. Further, we show that estimated success probabilities at the end of the trial can be biased not only due to optimistic sampling, but potentially also due to an MNAR missingness mechanism.
Keywords
Introduction
Designs for digital health interventions
Missing data is a common issue in clinical trials and can complicate the analysis and interpretation of results. 1 In trials to evaluate digital health interventions, missing data are particularly pervasive. Digital health interventions typically promote healthy behaviors such smoking cessation or increased physical activity 2 via text messaging, mobile phone applications (apps) or other forms of digital technology. Here, missingness rates may be particularly high for treatment arms that require more engagement, as participants may find that the burden of engaging exceeds the benefits. 3 Participants may also habituate to the intervention, leading to reduced engagement. 4 Further, in these settings, outcomes are likely to be missing not at random (MNAR); for example, participants in a trial for a smoking cessation intervention may engage less if they are still smoking. 5
Trials for a digital health intervention often use some form of response-adaptive design, where treatment allocation is adapted based on the accumulating data during the trial. Recent examples that use response-adaptive designs include a trial for automated messaging to provide support and information for mental health 6 and a trial for self-guided interventions to reduce psychological stress. 7 Response-adaptive designs have a close connection with the multi-armed bandit problem (MABP), which is a framework for allocating treatments to participants in ways which balance two conflicting objectives: firstly, the objective to maximise learning about the most effective treatment and to explore the treatment space; secondly, the objective to maximise the total immediate earning and to exploit the current best treatment. There is a dilemma between exploration and exploitation or between learning and earning: allocating the treatment that is currently best performing may mean that the discovery of a better performing is never realised, on the other hand, exploring all treatments may mean that the total reward is not maximised. While response-adaptive designs for bandit problems have typically been deterministic, there has been increased interest in response-adaptive randomisation, particularly for applications to clinical trials. 8
Response-adaptive designs are particularly suited for trials for digital health interventions. Participants typically become available sequentially, and the digitalized nature of the trial delivery allows treatments to be delivered and responses to be collected in real time. 9 Further, as response-adaptive designs skew allocation towards a more effective treatment, they may help to reduce missing responses by skewing allocation to the arm that has a higher retention rate. In spite of this potential for response-adaptive designs to reduce missingness, the implementation of these designs when responses are missing is not straightforward. The responses of the current and past participants are needed to determine the allocation of the next participant. Therefore, when responses are missing, modification is required in the design and missing data is an issue for both the design and analysis stages of the trial.
Motivating example: The iCanQuit trial for smoking cessation
We focus on a two-arm, binary response setting motivated by a trial comparing two digital interventions for smoking cessation: iCanQuit, an Acceptance and Committment Therapy-based smoking cessation app (experimental arm), versus QuitGuide, a US Clinical Practice Guidelines-based app which focuses on avoiding triggers (control arm).
10
The primary outcome was self-reported 30-day point prevalence abstinence (PPA) at 12 months after randomisation. The trial recruited 2415 participants between May 2017 and September 2018. They found that iCanQuit participants had 1.49 times higher odds (with
Participants were randomised in a 1:1 ratio using permuted blocks of size 2, 4 and 6, which were stratified by demographic and smoking-related variables. We examine, through a simulation study, the potential consequences of using a response-adaptive design, which would be feasible via adaptation on a shorter-term response. For example, this could be a 7-day point prevalance abstinence after randomisation, which, for simplicity, we assume to be perfectly correlated with the primary outcome for the purpose of the simulation. Response-adaptive methods such as BRAR have been used previously in smoking cessation trials such as in Faseru et al. 11
Response-adaptive designs
We now describe the notation and framework for response-adaptive designs. When a participant
The response
There is an extensive literature on proposed designs that assign treatment to a newly enrolled participant, given the state
Fixed randomisation (FR): Permuted block randomisation (PBR): participants are randomised to treatments in blocks of size
Bayesian response adaptive randomisation (BRAR): Neyman allocation:
Gittins index (GI): Current belief (CB):
Semi-randomised versions of GI and CB perturb the index with a random component,

The indices are defined as: Randomised Gittins index (RGI) Randomised belief index (RBI):
When using response-adaptive designs, there is a risk of extreme imbalance in treatment allocation both throughout and at the end of the trial. When there are very few or no participants assigned to arm
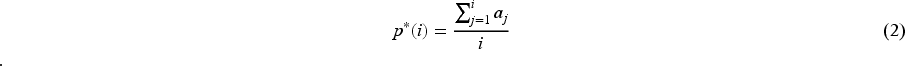
If
Fully sequential designs typically assume that the response is observed immediately. However, in trials for digital health interventions, some responses will be missing due to a variety of possible causes, such as participants declining to respond to specific questions, habituation and disengagement, loss of connectivity or technical errors. Therefore, the implementation of fully sequential designs require modification to handle missing data online as the data accrues, rather than at the end of the study. We denote by
We denote by

Analogously, we denote by
The missing data mechanism is characterised by the conditional distribution of
The missing data mechanisms are important as the validity of methods for handling missing data (i.e. whether estimators of population parameters are consistent and inferences are correct) depends on the nature of the mechanisms. There is an extensive literature on handling missing data in clinical trials, where methods can be broadly categorised as complete case analysis, likelihood-based approaches, weighting approaches such as inverse probability weighting (IPW) and imputation-based methods such as multiple imputation. We refer readers to key works such as Van Buuren,
23
Kenward and Carpenter
24
and Carpenter et al.
25
for an introduction to these topics. The missing data literature for clinical trials largely focuses on settings where treatment assignment does not depend on response; therefore, missing data is typically not an obstacle for treatment assignment and is a problem for the final analysis of data at the end of the trial. When data are missing in the response-adaptive setting, there are several new considerations:
Assignment of treatment for the current participant depends on the history of assigned treatments and responses. If response for participant Due to the dependence of treatment assignment on the responses, missing data can impact the realised balance between exploration and exploitation for some designs and this may depend on how missing data is handled. For example, if responses from a particular arm are mostly missing, this can impact the extent to which that arm is explored. Alternatively, if successes are likely to be mostly missing, this may impact the extent to which the allocation is skewed to the truly superior arm (as the missing successes can bias the current estimate of superior arm). Further, high rates of missing responses can make extreme imbalance in treatment assignment more likely than under complete data for some response-adaptive design. The impact on realised balance can have consequences on the operating characteristics of the trial, such as Type I error, power and the expected number of successes.
Efficient unbiased estimation in trials with response-adaptive designs is challenging as the dependence between treatment assignment and response can induce a negative bias in the estimate of treatment effect in finite sample settings due to the optimistic sampling.26–29 Unbiased estimators have been proposed
30
; when data are MNAR, there is an additional source of bias. When data are missing, analyses proceed by making an assumption about the missing data mechanism. Since it is typically not possible to verify missing data assumptions using the observed data alone, sensitivity analyses are encouraged to illustrate the robustness of results to other missing data mechanisms.
1
For response-adaptive designs, sensitivity analyses are not straightforward as considering a different missing data mechanism will have implications not only for responses but also the assigned treatments.
In this article, we focus on the first three issues outlined above. We build on recent work by Chen et al. 31 who conducted an extensive simulation study which compared complete cases versus single imputation for a number of response-adaptive designs when responses are MCAR or MAR given the treatment arm. We propose a novel imputation strategy, to be used under an MCAR or MAR assumption, specifically in the sequential allocation setting. Further, we illustrate the impact of responses that are MNAR on the balance between learning/earning and optimistic sampling bias, which has not yet been illustrated in the context of response-adaptive designs.
In Section 2, we describe the missing data strategies for response-adaptive designs. In Section 3, we outline our simulation study which compares using complete cases and three single imputation approaches for a number of response-adaptive designs when responses are MCAR, MAR given treatment arm, or MNAR. Results are presented in Section 4. In Section 5, we outline key findings from the simulation study and highlight a number of areas for future work at the intersection between response-adaptive designs and missing data.
Strategies for implementing response-adaptive designs when data are missing
We describe two general classes of methods for computing allocation probabilities/indices when responses are missing: complete cases, which ‘ignore’ the missing responses, and single imputation, which replaces the missing responses with a single value. We describe several single imputation strategies, some of which are appropriate under a MAR assumption and some of which are appropriate under an MNAR assumption. We propose a novel imputation strategy under the MAR assumption. We also consider further modifications for response-adaptive algorithms when responses are missing, which include truncation and changing the random component for semi-randomised algorithms.
When using complete cases, allocation probabilities/indices (such as those introduced in Section 1.3), are computed based on the numbers of successes
We describe three methods of imputing a missing response with a single value based on an assumed missing data mechanism. The first two approaches provide stochastic imputations, while the third involves a deterministic imputation when there is a strong assumption about an MNAR mechanism.
Single impute current (when responses are MCAR or MAR): This approach is referred to as ‘mean imputation’ in Chen et al.
31
and its performance was compared to complete cases in an extensive simulation study.
Suppose that participant We note that there may be other natural choices for imputing under a MAR mechanism, such as the posterior mode. One could also use a proper imputation, which would entail drawing from the posterior distribution of the success probability and generating an outcome (success or failure) from it. We then set the vector of responses as Single impute backward (when responses are MCAR or MAR): We note that in the single impute current approach, imputations that are generated early on in the trial are based on estimates of Suppose that participant We then set the vector of responses as If there is a missing response before an MLE can be computed, we proceed with an imputation We note that these imputations based on the MLE are used to compute the allocation indices/probabilities but are not necessarily recommended to be used in calculating the final estimates of success probabilities at the end of the trial. Single imputation with an informed choice of constant (when responses are MNAR): In some settings, an informed assumption can be made that missing values take a specific value. For example, guidance on the analysis of smoking cessation trials recommend sensitivity analyses where missing responses are imputed as smokers.5,32 In the iCanQuit trial, a sensitivity analysis showed that the effect size was similar when using complete cases versus when missing outcomes were imputed as smokers. Thus, we consider a single imputation approach where missing responses are simply imputed with a constant value We note that imputation under a MNAR assumption can take several forms and imputing missing values as smoking makes a particularly strong assumption. One may wish to impute under a weaker MNAR assumption, for example by drawing from an appropriate quantile of the posterior distribution of the success probability.



These approaches to handling missing responses online are illustrated in Figure 1.
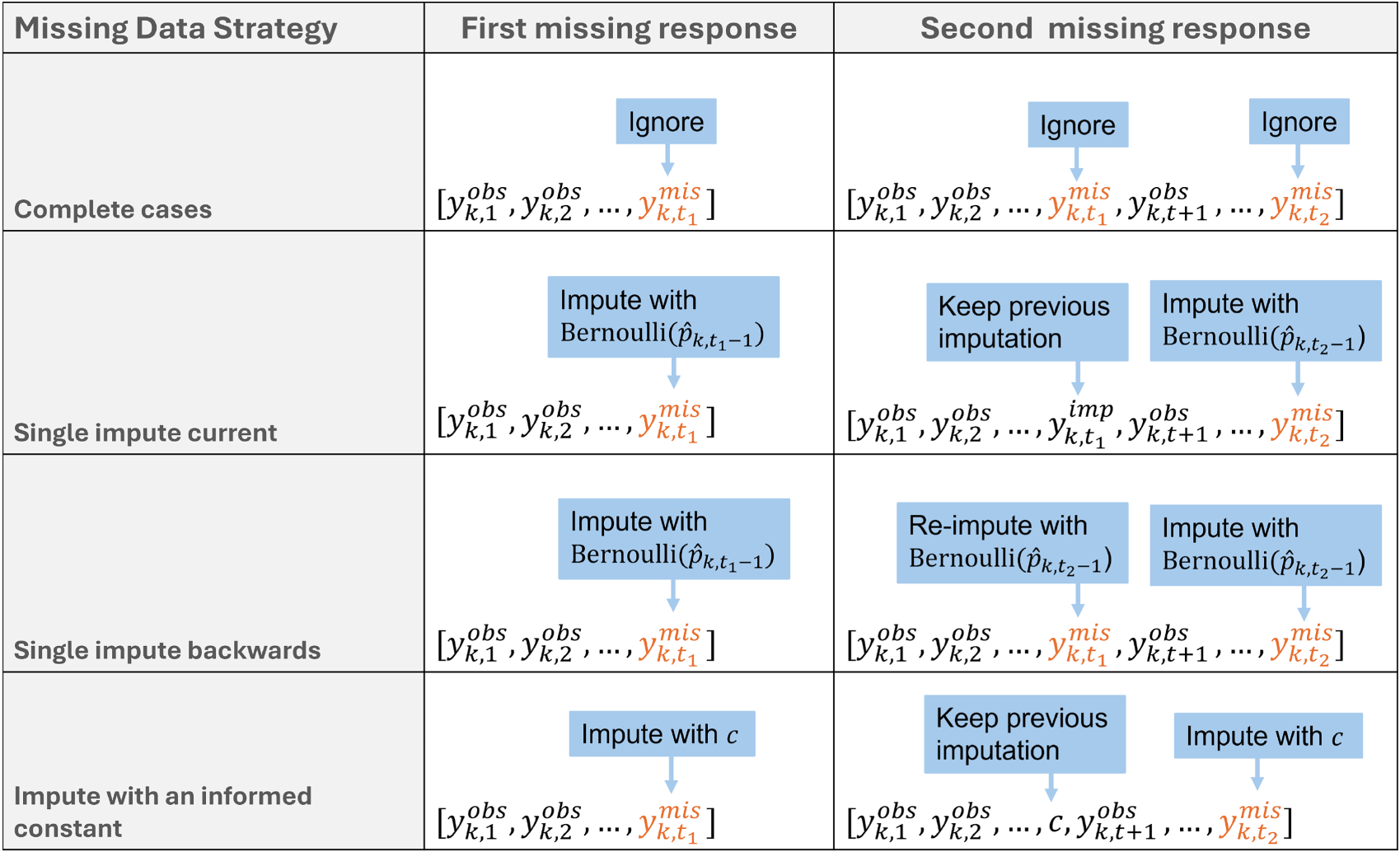
Illustration of how the first and second missing responses are handled online by different missing data strategies for response-adaptive algorithms. Note that, for single impute backward, the first missing response at time
Semi-randomised algorithms include a random component


We compare the performance of these missing data strategies for response-adaptive designs in a simulation study in the next section.
Our simulation study, motivated by the iCanQuit trial, aims to compare the performance of the missing data strategies introduced in Section 2 under combinations of (i) different data generating mechanisms for the true response, including scenarios under the null and alternative hypotheses, (ii) different missing data mechanisms, including MCAR, MAR given treatment arm and MNAR mechanisms, and (iii) different response-adaptive designs, as described in Section 1.3. In particular, we wish to assess whether the choice of online missing data strategy can impact (i) the realised balance between exploitation and exploration and (ii) the observed bias of the final estimated success probabilities.
Data generating mechanism
True response
The true binary response
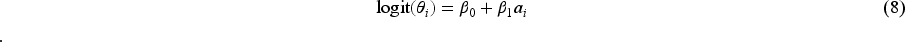
True response models in the simulation study: parameter values for equation (8) and probability of success in each treatment arm.

We simulate
Missingness mechanism
The missingness indicator 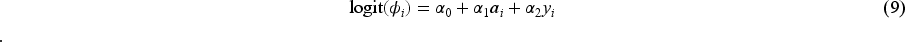
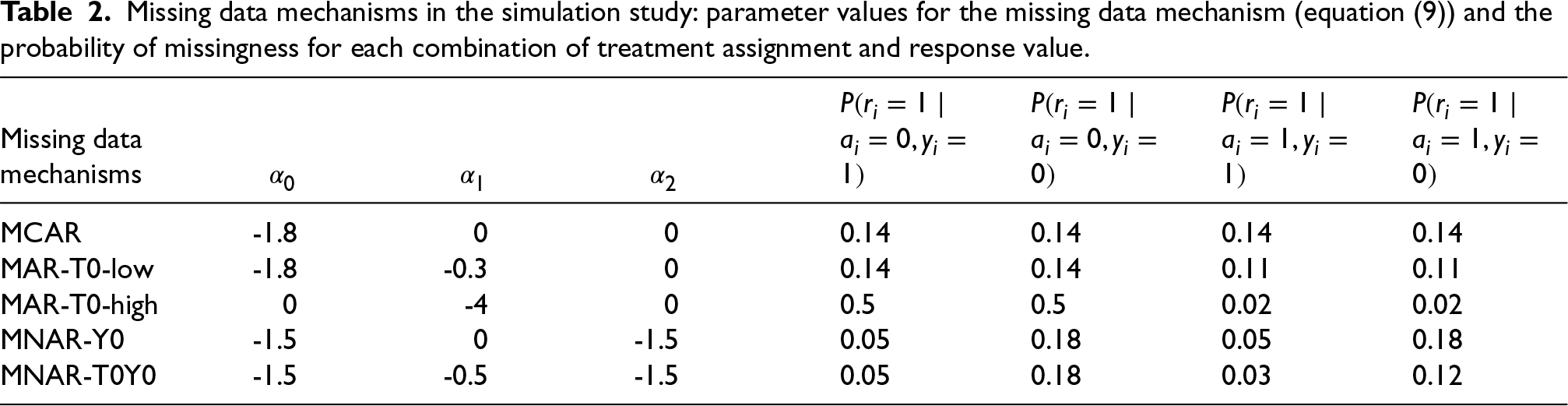
We consider the following missing data mechanisms, summarised in Table 2, to cover a range of realistic patterns and magnitudes for missing responses in the iCanQuit trial:
Missing data mechanisms in the simulation study: parameter values for the missing data mechanism (equation (9)) and the probability of missingness for each combination of treatment assignment and response value.
Our simulation compares the performance of each of the following designs, introduced in Section 1.3: Randomised designs which target equal treatment allocation: fixed randomisation (FR) with Randomised response-adaptive designs: Bayesian response-adaptive randomisation (BRAR); Neyman allocation, where treatment allocation is a function of estimated variances of the success probabilities. If estimated variances of Deterministic algorithms: Gittins index (GI) with discount factor 0.99 and current belief (CB). Semi-randomised algorithms: randomised Gittins index (RGI) and randomised belief index (RBI)
For each of the designs, we use four possible missing data approaches (complete cases, single impute current, single impute backward, impute zero), as described in Section 2. Further, specifically for RBI and RGI when complete cases are used, in addition to the default setting where the random component is defined as in Equation (7), we also show results when it is defined as an Equation (6), denoted Complete cases nt.
All designs begin with a permuted block of size 4 (two assignments to each arm), and we ensure that all four responses are observed. This prevents situations where missing responses at the beginning of the trial lead to extreme imbalance and prevent estimation of success probabilities. In Supplementary File 2, we provide results without this initialisation (i.e. there may be treatment imbalance in the first four participants, and they could have missing responses).
Estimands
The estimands include
Performance measures
The performance measures include the mean of 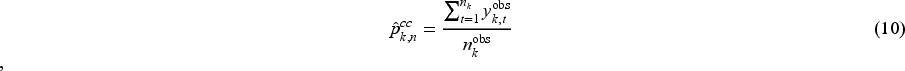
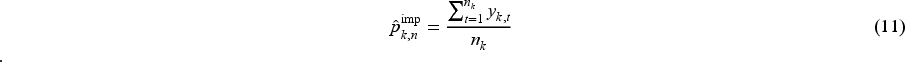
Further, when using BRAR, we additionally compute estimates of success probabilities using the inverse probability weighted (IPW) estimator.
30
This is a bias-corrected estimator, which is defined as follows when using complete cases:


Each simulation setting is repeated 10,000 times. The simulation was performed in
We focus on the results for the Null scenario, where the success probability is 0.28 for both arms, and the Alternative scenario, where the success probability for the experimental arm is 0.28 and the success probability for the control arm is 0.21. Results for other settings are provided in Supplementary file 1.
Results for
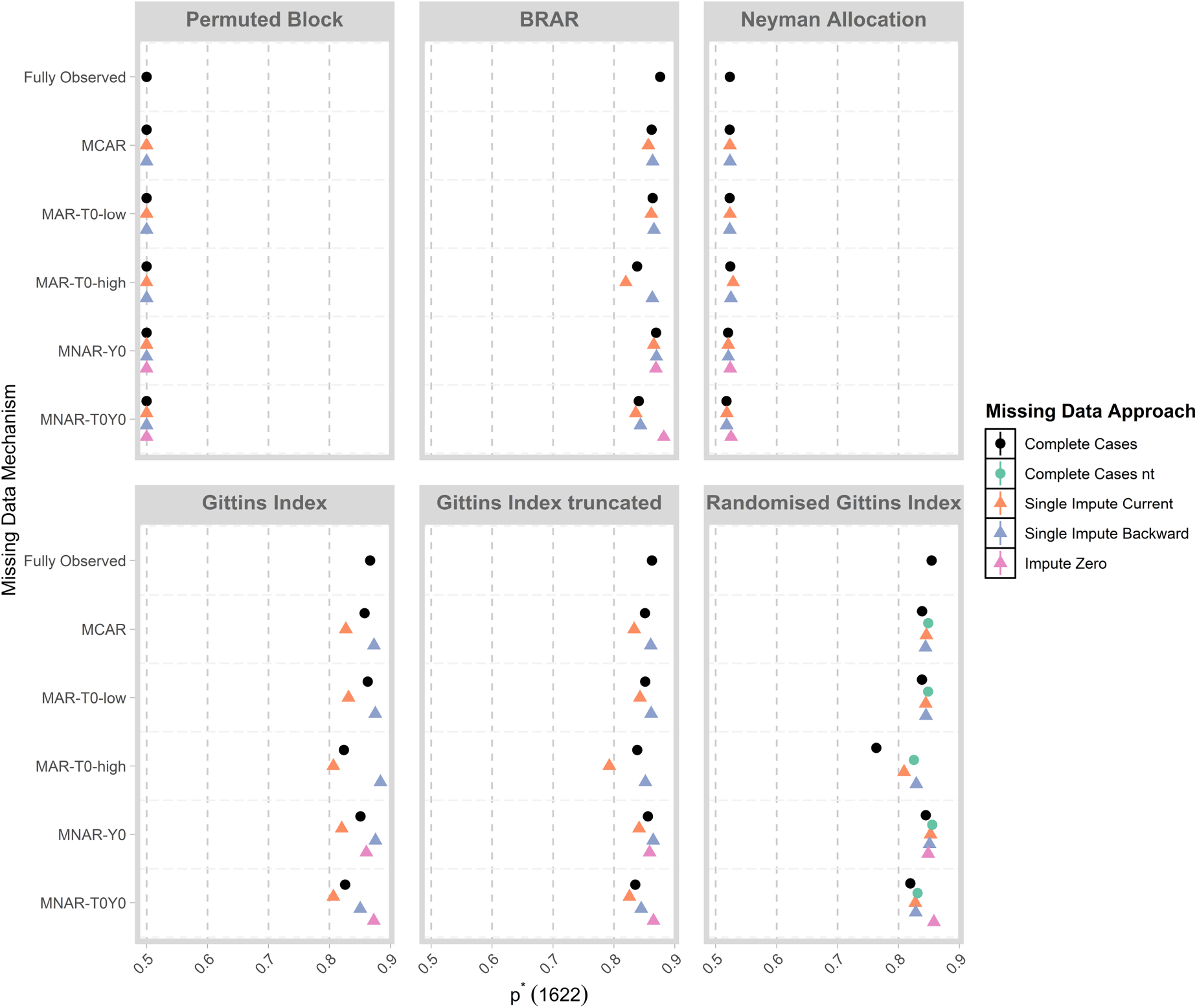
Figure 2 displays
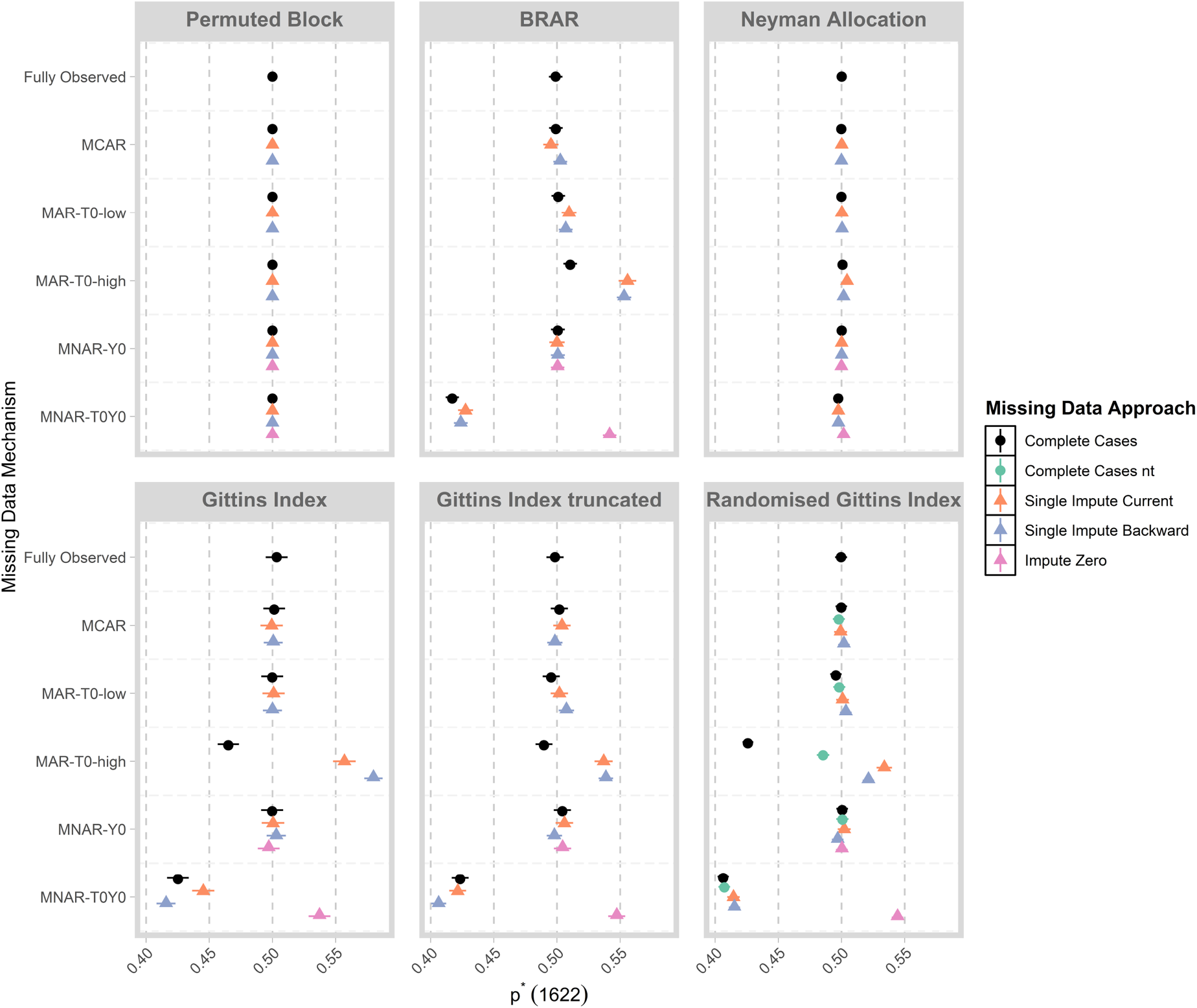
Mean of
Under the Null, when data are fully observed, all designs lead to equal allocation as expected, as neither arm is superior. The permuted block design and Neyman allocation lead to equal allocation under all missing data mechanisms and missing data strategies. For all other designs, when the missing data mechanism is the same in each arm (i.e. MCAR, MNAR-Y0), or the quantity of missing data is low (i.e. MAR-T0-low), we observe that the value
Specifically, for MAR-T0-high, we observe that when complete cases are used in conjunction with designs that are geared towards exploration (e.g. GI, GI-truncated, RGI) more patients are assigned to the control arm. The tendency for these algorithms to favour the arm with more missing responses was noted by Chen et al.
31
The extent of the selection can be reduced by using the truncated version of GI. Changing the random component to Equation (6) when using complete cases for RGI can also mitigate the selection of the control arm. Further, for BRAR, GI, GI-trunced and RGI, we observe that using single impute current and single impute backward leads to the selection of the experimental arm under MAR-T0-high. Some intuition can be gained by visualising the estimated values of
For MNAR-T0Y0, failures have a higher rate of missingness in for the control arm. Although the control arm has a greater rate of missingness, the MNAR mechanism means that the estimated success probability is greater for the control arm and it is selected for BRAR, GI, GI-truncated and RGI when used with complete cases, single impute current or single impute backward. When missing outcomes are imputed with zero, the experimental arm is favoured instead. This is because a small proportion of successes can be missing in the MNAR-T0Y0 setting, but impute-zero will impute all missing outcomes as failures, leading to selection in the opposite direction.
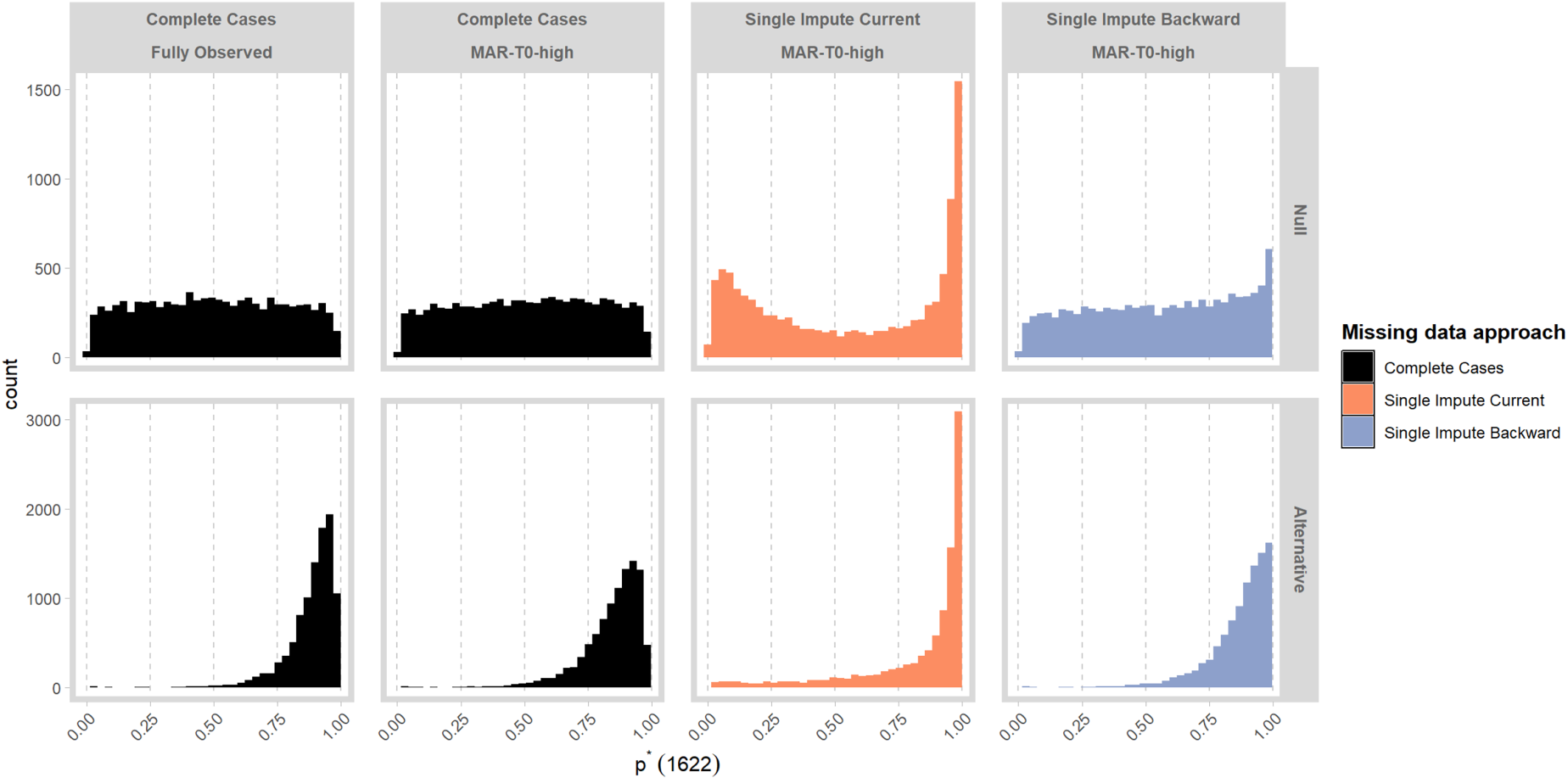
Figure 3 displays
Distribution of
Specifically, for BRAR, GI and GI-truncated, using single impute current can lead to a reduced value of
In Supplementary File 2, we display results when the design does not begin with a permuted block of size 4 with all responses observed. Here, we see that results for single impute current are very sensitive to specification of the initial part of the design.
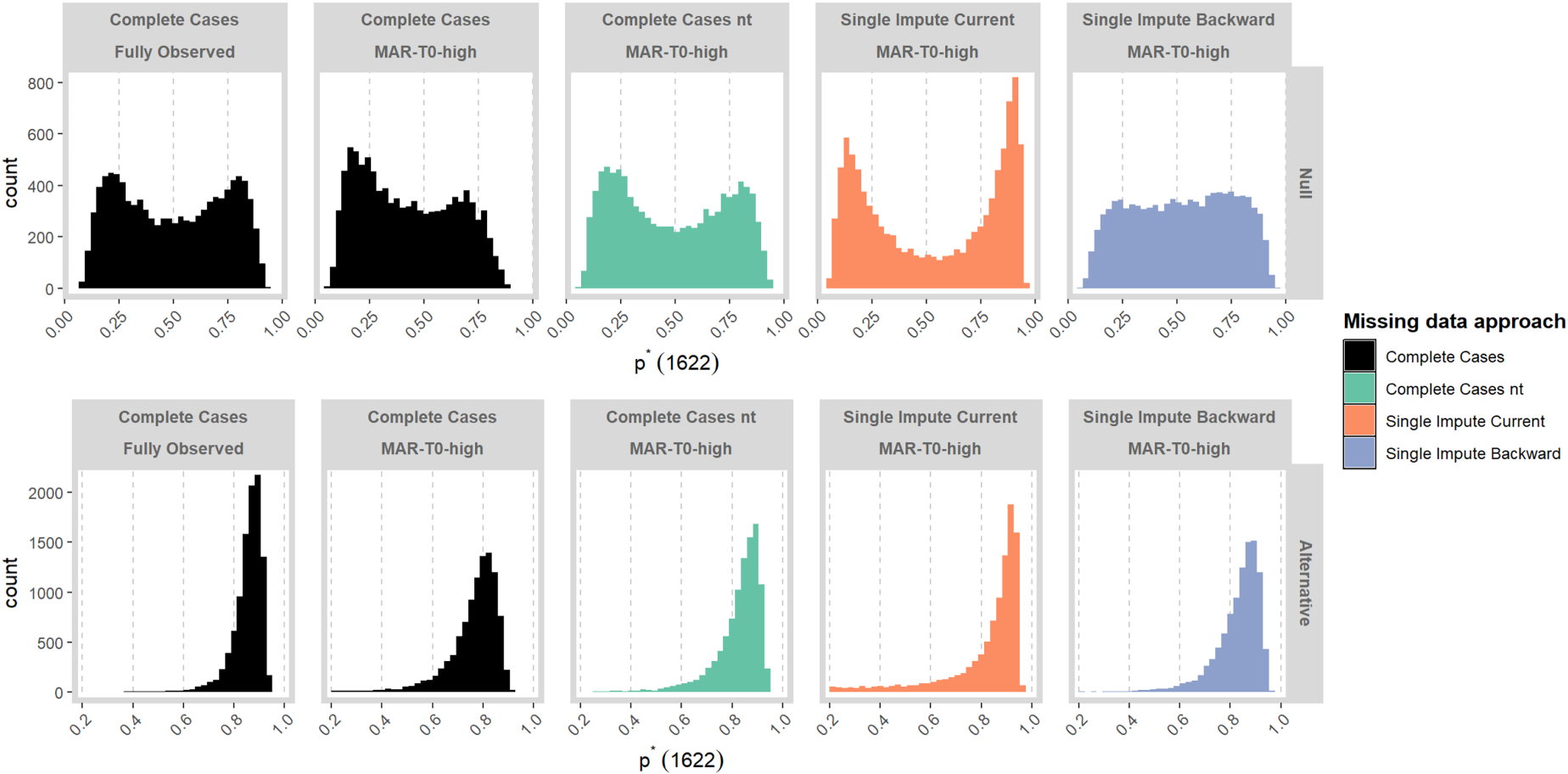
We examine more closely the distribution of
In Figure 4, we compare the distribution of
Distribution of
In Figure 5, we compare the distribution of
Distribution of
In Figure 6, we display the mean of MLEs of
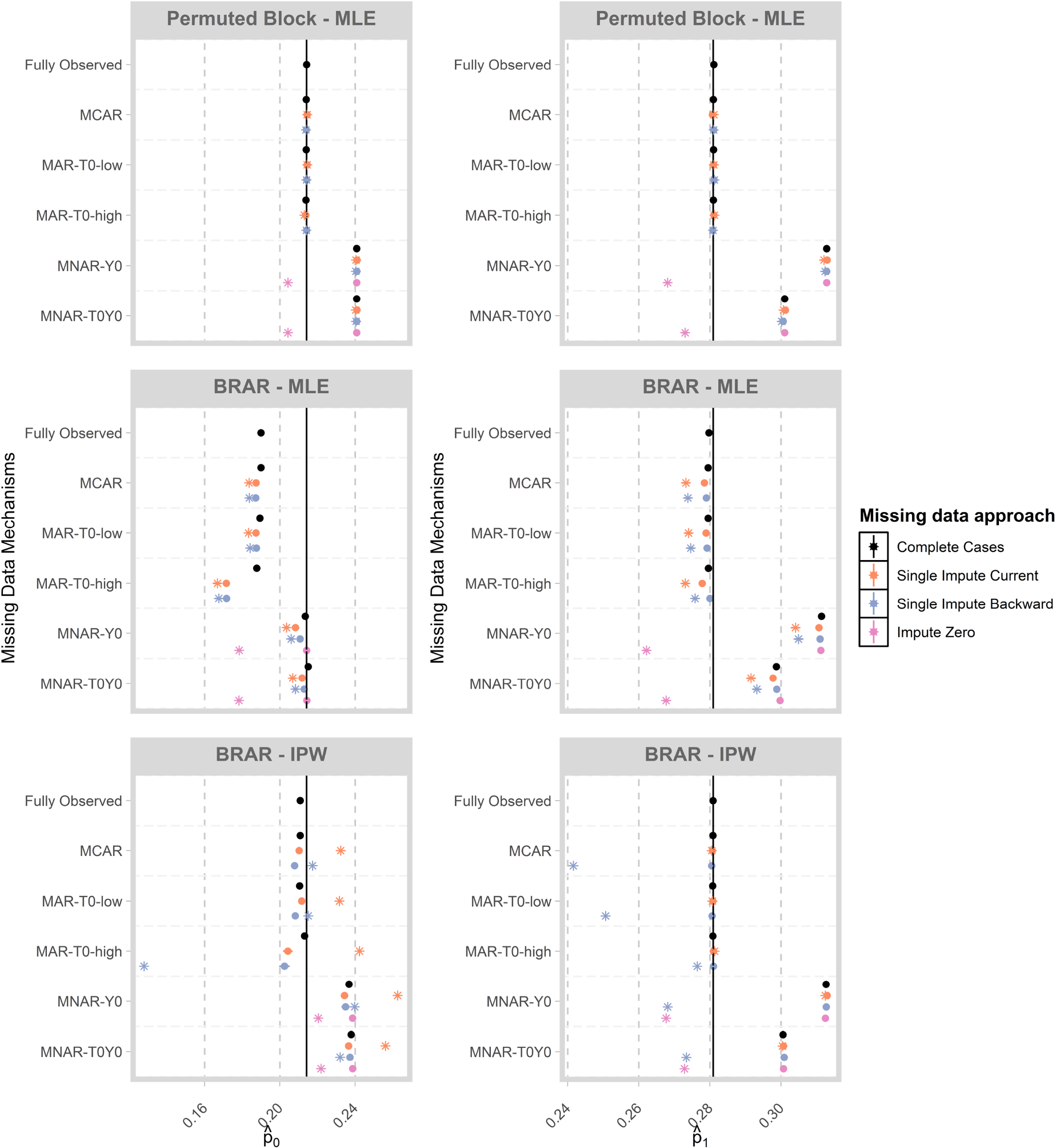
Mean of estimates of
For the permuted block design, we observe that estimates are generally unbiased when data are fully observed or missing under the MCAR, MAR-T0-low or MAR-T0-high mechanisms. Since we are estimating the success probabilities for each treatment, the MAR-T0-low and MAR-T0-high scenarios can be considered as MCAR within each treatment group. Under MNAR, we observe an upward bias unless missing outcomes are imputed as zero, in which case we observe a slight downward bias.
For BRAR, we observe negative bias in the MLE for
When the IPW-estimator is used for BRAR, we observe that the downward bias due to optimistic sampling is corrected when using estimates from complete cases under the MCAR, MAR-T0-low and MAR-T0-high mechanisms. Using the IPW-estimator in combination with imputed values can lead to bias, as the imputations are based on MLEs which are biased for adaptive designs. Further, we observe upward bias under the MNAR mechanism which is alleviated to some extent when imputing missing outcomes as zero. These results illustrate that, for response-adaptive designs, imputations based on the MLE can lead to biased results. Further, biases can be considerable when data are MNAR and analysis proceeds with complete cases or imputation with the MLE.
The estimates of
We explored a number of strategies to handle missing data in the implementation of response-adaptive designs in a two-arm, binary response setting based on the iCanQuit trial. These included online imputation strategies, as well as modifications to algorithms such as truncation and changing the random component. We demonstrated the impact of the missing data mechanism and proportion of missing responses on (i) the realised balance between exploration and exploitation and (ii) the estimated success probabilities at the end of the trial. We summarise the findings below, with key considerations outlined in Table 3 and provide directions for future work.
Design, implementation, and analysis considerations for response-adaptive designs with missing data from the icanQuit simulation study.

Design, implementation, and analysis considerations for response-adaptive designs with missing data from the icanQuit simulation study.
When there are substantially different rates of missing data in the two arms, there can be a greater chance of realised imbalance in treatment allocation. In the iCanQuit trial, the experimental and control arms had using complete cases together with algorithms that favour exploration can lead to the selection of the arm with greater missingness; using single impute current and single impute backwards when there are differential rates of missingness can lead to differential bias of the success probability of the two arms, which can drive selection of one arm; Single impute current is more prone to extreme imbalance in treatment allocation and is more sensitive to the initialisation of the design (see Supplementary File 2 for simulation results where there is no burn-in and initial responses can be missing).
We have shown that truncation can mitigate the impact of missing data on the imbalance for GI and CB by reducing the tendency of these designs to favour an arm early on, and further, changing the random component of the semi-randomised algorithms can improve the realised balance when complete cases are used.
A general recommendation at the design stage is to consider whether missingness rates may be different in the two arms to explore the potential impact on operating characteristics of the design through simulations. If differential missingness rates are suspected, we recommend complete cases together with RBI and RGI. This can lead to lead to realised treatment imbalance under the Null as well as reduced proportion of participants allocated to the superior arm under the Alternative. Single impute current with BRAR, GI-truncated and CB-truncated, as this can lead to selection Under the Null as well as reduced values of
When does missing data induce additional bias in the MLE (i.e. beyond the optimistic sampling bias) at the end of the study?
The MLE at the end of the study for an adaptive design can have a small negative bias due to optimistic sampling, even when data are complete. Missing responses can change the direction and magnitude and bias of the MLE. In particular, when data are MNAR, we demonstrated that there is additional (upward or downward) bias in addition to the downward bias due to optimistic sampling.
When IPW estimator is used for BRAR, we note that the bias due to optimistic bias is generally corrected if outcomes are MCAR or MAR, but imputations generated from an MLE should generally not be used to compute the estimate. When data are MNAR, we note bias can be considerable for both the MLE and IPW estimators, unless imputations are correctly specified.
Future work
There are several important areas for future work. First, our simulations showed that different forms of regularisation can be helpful in reducing imbalance when there is risk of missing outcomes. We explored truncation for deterministic designs, where the proportion of participants allocated to the experimental arm are constrained between 0.1 and 0.9. Exploring other choices of thresholds for this truncation and their impact on operating characteristics is an area of future work.
Second, our simulations showed that differential rates of missingness in the two arms can have large implications for the realised balance between exploitation and exploration. Further, we showed that imputations generated from an MLE may not be ideal as they are generally biased due to optimistic sampling. Future work could investigate testing of differential rates of missing outcomes in arms and selecting an appropriate missing data strategy based on results of this test. This missing data strategy may involve an online imputation strategy which employs bias-corrected methods. 35
Third, further work is needed in statistical inference when response-adaptive designs are used and outcomes are missing. For example, Type I error and power have been explored for the analysis of trials that use response-adaptive designs,12,36,37 but the impact of missing data on these operating characteristics require further exploration. An additional area of inference is assessing robustness of estimates to missing data assumptions. Sensitivity analyses are encouraged when responses are missing in clinical trials. 38 When response-adaptive algorithms are used, sensitivity analyses are not straightforward as the consideration of an alternative missing data mechanism to the one actually assumed when designing the trial opens up different trajectories for how treatment allocations and subsequent responses could have unfolded. Thus, an approach to assessing robustness of missing data assumptions offline when response-adaptive designs are used is an important avenue of future work.
Fourth, exploration of missing data strategies for more complex settings which are characteristic of trials for digital health interventions are needed. In these settings, participants’ baseline characteristics or contextual information such as the time of day when the user is engaging with the intervention may be available. Such covariates may be predictive both of the response and the probability that the response is missing, in which case their inclusion in an imputation model will lead to improved imputations. Thus, incorporating covariates in imputation for response-adaptive procedures, as well as handling missing responses in covariate-adaptive randomisation procedures are important directions for future research. Further, exploration of more complex outcomes, such as longitudinal outcomes, categorical outcomes (e.g. questionnaire outcomes) or continuous outcomes (e.g. step count), as well as more complex treatment structures such as factorial designs, are much needed areas for further investigation due to their relevance for digital health interventions.
We focused on a selection of response-adaptive designs applied to the setting of digital health interventions. This investigation has shed light on the potential impact of missing data for other response-adaptive designs and applications to other types of interventions, and also highlighted several open questions and remaining challenges in this area.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802251366843 - Supplemental material for Implementing response-adaptive designs when responses are missing: Impute or ignore?
Supplemental material, sj-pdf-1-smm-10.1177_09622802251366843 for Implementing response-adaptive designs when responses are missing: Impute or ignore? by Mia S Tackney and Sofía S Villar in Statistical Methods in Medical Research
Supplemental Material
sj-pdf-2-smm-10.1177_09622802251366843 - Supplemental material for Implementing response-adaptive designs when responses are missing: Impute or ignore?
Supplemental material, sj-pdf-2-smm-10.1177_09622802251366843 for Implementing response-adaptive designs when responses are missing: Impute or ignore? by Mia S Tackney and Sofía S Villar in Statistical Methods in Medical Research
Footnotes
Acknowledgements
Authors would like to thank Dr. Elinor Curnow and three anonymous reviewers for very helpful comments on an earlier draft of this manuscript.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship and/or publication of this article: SSV is on the advisory board for PhaseV (unrelated to this work).
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: Mia Tackney, Advanced Fellow, NIHR305417, is funded by the NIHR for this research project. The views expressed are those of the authors and not necessarily those of the NIHR or the Department of Health and Social Care.
Supplemental material
Supplemental material for this article is available online.
Appendix II: Additional results
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.